
CCGrid 2014 Improving I/O Throughput of Scientific Applications using Transparent Parallel...
23
CCGrid 2014 Improving I/O Throughput of Scientific Applications using Transparent Parallel Compression Tekin Bicer, Jian Yin and Gagan Agrawal Ohio State University Pacific Northwest National Laboratories 1 ‡ ‡
-
Upload
marcia-barnett -
Category
Documents
-
view
214 -
download
0
Transcript of CCGrid 2014 Improving I/O Throughput of Scientific Applications using Transparent Parallel...

CCGrid 2014
Improving I/O Throughput of Scientific Applications using Transparent Parallel
Compression
Tekin Bicer, Jian Yin and Gagan Agrawal
Ohio State UniversityPacific Northwest National Laboratories
1
‡
‡

CCGrid 2014
Introduction• Increasing parallelism in HPC systems
– Large-scale scientific simulations and instruments– NOT so scalable I/O
• Example:– PRACE-UPSCALE:
• Decrease in mesh sizes. i.e. more computation and data• 2 TB per day; expectation:10-100PB per day
– Management of data limits the performance• “Big Compute” Opportunities → “Big Data” Problems
– Output of large-scale applications slowdown simulation– Storage, management, and transfer issues of “Big Data”– Reading large data and analysis performance
• Compression
2

CCGrid 2014
Introduction (cont.)• Community focus
– Storing, managing and moving scientific dataset• Compression can further help
– Decreased amount of data• Increased I/O throughput• Better data transfer performance
– Increased data analysis and simulation performance• But…
– Can it really benefit the application execution?• Tradeoff between CPU utilization and I/O idle time
– What about integration with scientific applications?• Effort required by scientists to adopt their application
3

CCGrid 2014
Scientific Data Management Libs.
• Widely used by the community– PnetCDF (NetCDF), HDF5…
• NetCDF Format– Portable, self-describing,
space-efficient• High Performance Parallel I/O
– MPI-IO• Optimizations: Collective
and Independent calls• Hints about file system
• No Support for Compression
4

CCGrid 2014
Parallel and Transparent Compression for PnetCDF
• Parallel write operations– Size of data types and variables– Data item locations
• Parallel write operations with compression– Variable-size chunks– No priori knowledge about the locations– Many processes write at once
5

CCGrid 2014
Parallel and Transparent Compression for PnetCDF
Desired features while enabling compression:• Parallel Compression and Write
– Sparse and Dense Storage• Transparency
– Minimum effort from application developer– Integration with PnetCDF
• Performance– Different variable may require different compression– Domain specific compression algorithm
6

CCGrid 2014
Outline
• Introduction• Scientific Data Management Libraries• PnetCDF• Compression Approaches• A Compression Methodology• System Design• Experimental Result• Conclusion
7

CCGrid 2014
Compression: Sparse Storage
• Chunks/splits are created• Compression layer applies
user provided algs.• Compressed splits are
written w/ orig. offset addr.• Still can benefit I/O
– Only compressed data• No benefit for storage
space
8

CCGrid 2014
Compression: Dense Storage
• Generated compressed splits are appended locally
• Net offset addresses are calculated– Requires metadata
exchange• All compressed data blocks
written using collective call• Generated file is smaller
– Advantages: I/O + storage space
9

CCGrid 2014
Compression: Hybrid Method
• Developer provides:– Compression ratio– Error ratio
• Does not require metadata exchange
• Error padding can be used for overflowed data
• Generated file is smaller• Relies on user inputs
10
Off’ = Off x (1/(comp_ratio-err_ratio)

CCGrid 2014
Compression Methodology• Common properties of scientific datasets
– Consist of floating point numbers– Relationship between neighboring values
• Generic compression cannot perform well• Domain specific solutions can help• Approach:
– Differential compression• Predict the values of neighboring cells• Store the difference
11

CCGrid 2014
Example: GCRM Temperature Variable Compression
• E.g.: Temperature record• The values of neighboring cells
are highly related• X’ table (after prediction):
• X’’ compressed values– 5bits for prediction +
difference• Lossless and lossy comp.• Fast and good compression
ratios
12

CCGrid 2014
PnetCDF Data Flow
1. Generated data is passed to PnetCDF lib.
2. Variable info. gathered from NetCDF header
3. Splits are compressed1. User defined comp. alg.
4. Metadata info. exchanged
5. Parallel write ops.
6. Synch. and global view1. Update NetCDF header
13

CCGrid 2014
Outline
• Introduction• Scientific Data Management Libraries• PnetCDF• Compression Approaches• A Compression Methodology• System Design• Experimental Result• Conclusion
14

CCGrid 2014
Experimental Setup
• Local cluster:– Each node has 8 cores (Intel Xeon E5630, 2.53Ghz)– Memory: 12GB
• Infiniband network– Lustre file system: 8 OSTs, 4 storage nodes– 1 Metadata Sert
• Microbenchmarks: 34 GB• Two data analysis applications: 136 GB dataset
– AT, MATT• Scientific simulation application: 49 GB dataset
– Mantevo Project: MiniMD
15
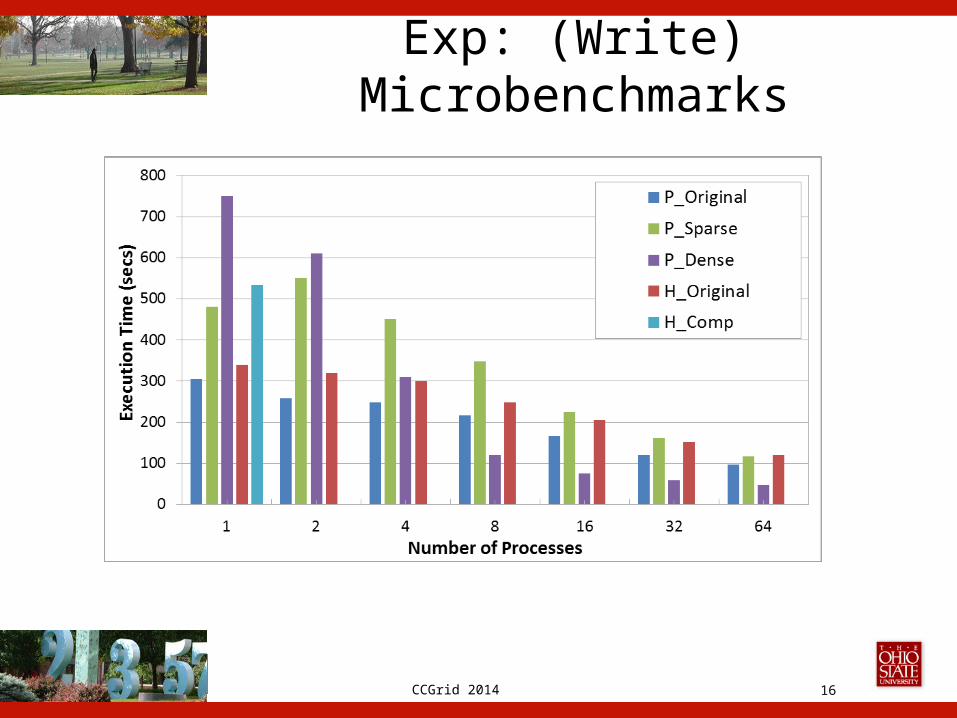
CCGrid 2014
Exp: (Write) Microbenchmarks
16
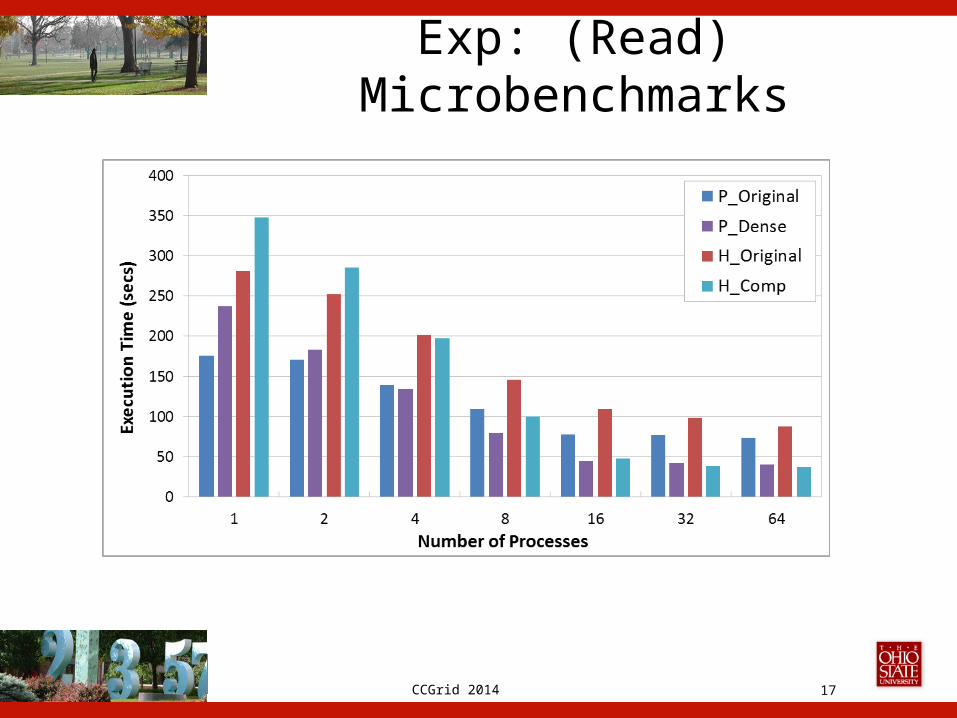
CCGrid 2014
Exp: (Read) Microbenchmarks
17

CCGrid 2014
Exp: Simulation (MiniMD)
18
Application Execution Times Application Write Times
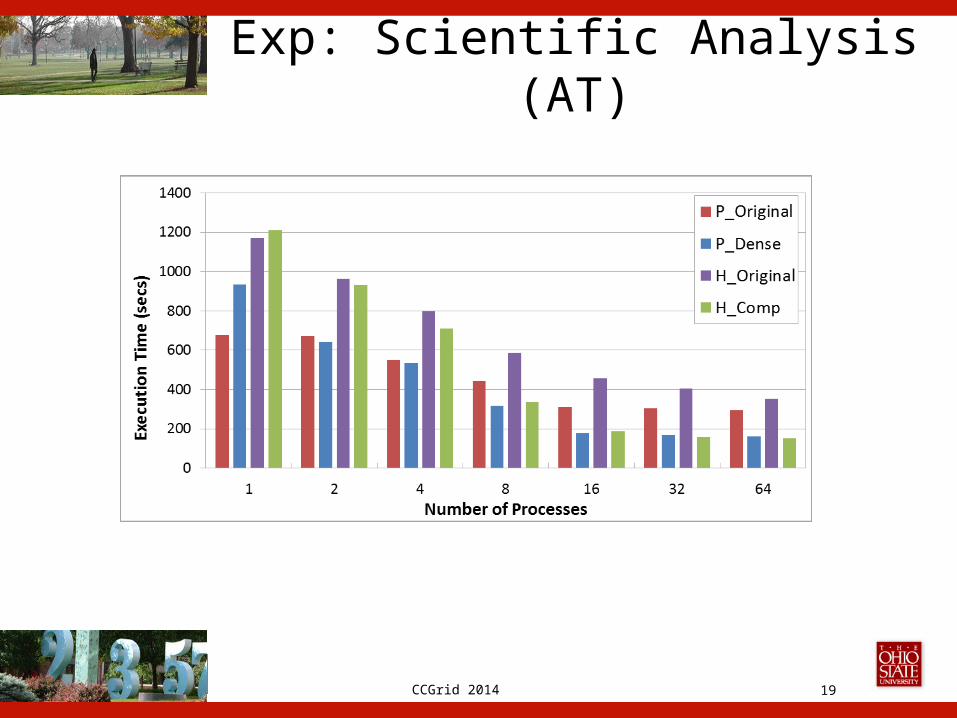
CCGrid 2014
Exp: Scientific Analysis (AT)
19

CCGrid 2014
Conclusion
• Scientific data analysis and simulation app.– Deal with massive amount of data
• Management of “Big Data”– I/O throughput affects performance– Need for transparent compression– Minimum effort during integration
• Proposed two compression methods• Implemented a compression layer in PnetCDF
– Ported our proposed methods– Scientific data compression alg.
• Evaluated our system– MiniMD: 22% performance, 25.5% storage space– AT, MATT: 45.3% performance, 47.8% storage space
20

CCGrid 2014
Thanks
21

CCGrid 2014
PnetCDF: Example Header
22
netcdf temperature_v4 {dimensions: // names and lengths
time = UNLIMITED; interface = 27;cells = 2621442;corners = 5242880 ;...
variables: // type, name and attributes double time(time) ; time:long_name = "Time" ; time:units = "days since 1901-01-01" ; ... float temperature(time, cells, interfaces) ;
// variable attributes temperature:long_name = "Potential temperature" ;
temperature:units = "K" ; ...
data: // beginning of datatime = 777600, 788400, 799200, 810000, ….;temperature =
201.2936, 217.4867, 223.3362, …..}

CCGrid 2014
Exp: Microbenchmarks
• Dataset size: 34GB– Timestep: 270MB
• Comp.: 17.7GB– Timestep: 142MB
• Chunk size: 32MB• # Processes: 64• Strip count: 8
23
Comparing Write Times with Varying Stripe Sizes


















