
C-Store: A Column-oriented DBMS Speaker: Zhu Xinjie Supervisor: Ben Kao.
24
C-Store: A Column- C-Store: A Column- oriented DBMS oriented DBMS Speaker: Zhu Xinjie Supervisor: Ben Kao
-
Upload
bennett-dennis -
Category
Documents
-
view
218 -
download
0
Transcript of C-Store: A Column-oriented DBMS Speaker: Zhu Xinjie Supervisor: Ben Kao.

C-Store: A Column-oriented C-Store: A Column-oriented DBMSDBMS
Speaker: Zhu Xinjie
Supervisor: Ben Kao

C-Store: A Column-oriented DBMS
• Introduction• Data model• RS (read-optimized store)• WS (writeable store)• Tuple mover• Performance comparison

Introduction
• Most existing DBMS are record-oriented (row-oriented) storage systems, whose major features consist of:
• Store complete tuples of tabular data along with auxiliary B-tree indexes on attributes in the table
• store values in their native data format
• Effective on OLTP-style applications

Introduction
Deficiencies of row-oriented store:
• Bring into memory irrelative attributes for processing a given query
• Ineffective in read-mostly (ad hoc query) environment, i.e., not support read-optimized
• Shifting data values onto byte or word boundaries in main memory is expensive

Introduction
• C-Store physically stores a collection of column-oriented overlapping projections, each sorted on some attributes.
• Code data elements into a more compact form
• Query executor operates on the compressed representation to avoid the cost of decompression.

Introduction
• C-Store is implemented as a grid environment where there are G nodes with private disk and private memory.
• Redundant objects to be stored in different sort-orders provide higher retrieval performance and high availability (K-safe)
• Simultaneously achieve very high performance on queries and reasonable speed on OLTP-style transactions
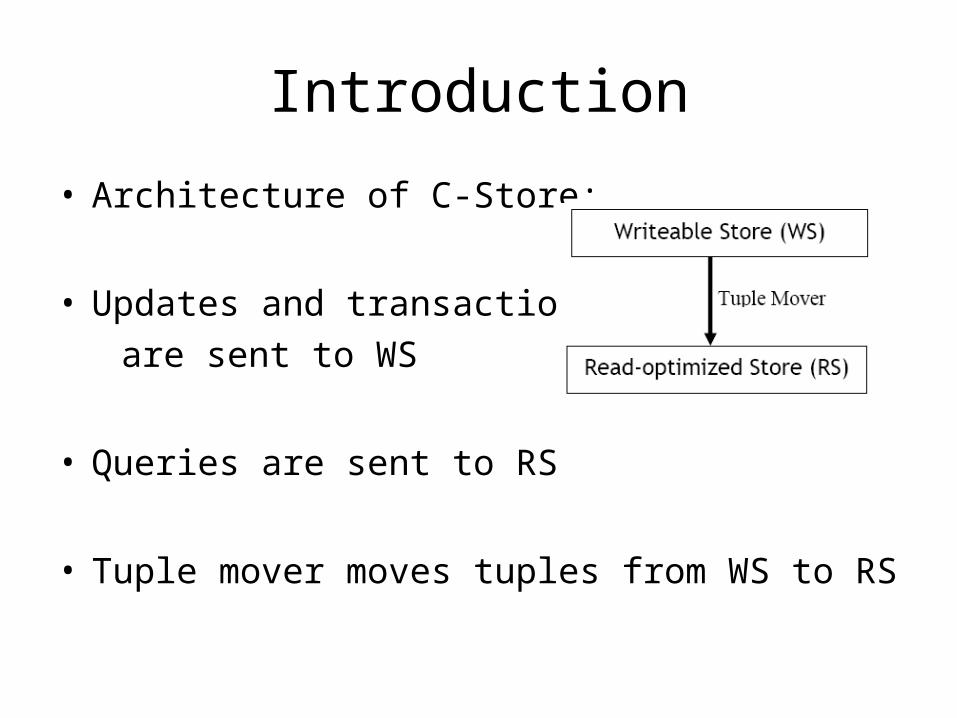
Introduction
• Architecture of C-Store:
• Updates and transactions
are sent to WS
• Queries are sent to RS
• Tuple mover moves tuples from WS to RS

Data Model
• C-Store implements only projections.
• Each projection is anchored on a given logical table T, and contains one or more attributes from T.
• In addition, a projection may also contain other attributes from other non-anchored table.

Data Model
• EMP1, EMP2 and EMP3 are anchored on Table EMP. DEPT1 is anchored on Table DEPT.
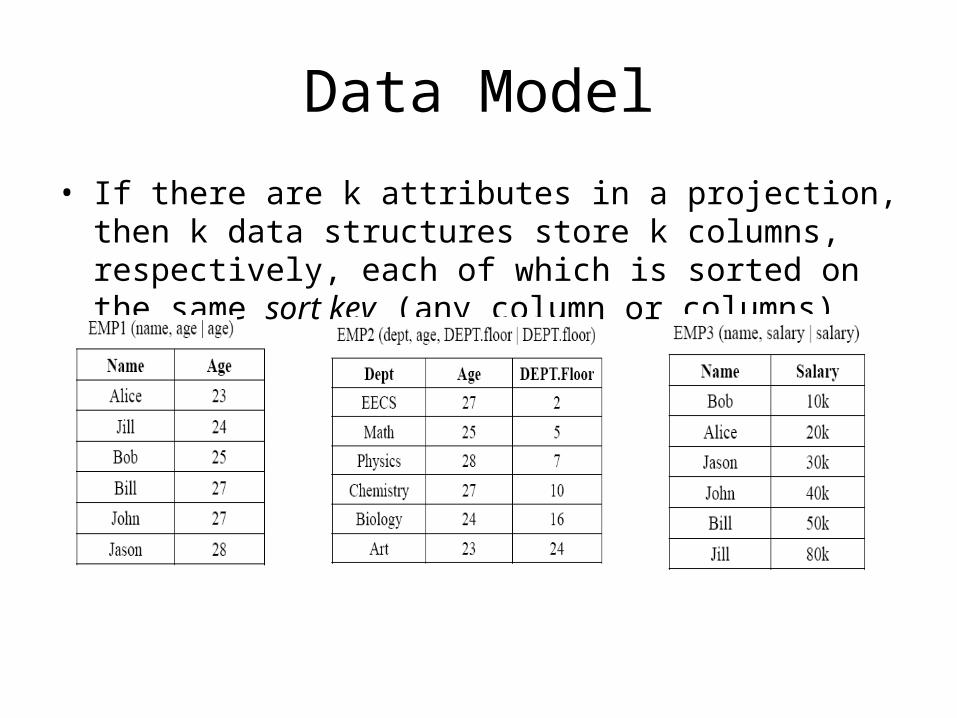
Data Model
• If there are k attributes in a projection, then k data structures store k columns, respectively, each of which is sorted on the same sort key (any column or columns).

Data Model
• Every projection is horizontally partitioned into one or more segments identified by a segment identifier Sid.

Data Model
• For every table, there must be a covering set of projections such that every column is stored in at least one projection.
• To reconstruct complete rows of tables from the stored segments needs:
• Storage Key
• Join Indices

Data Model
• Storage Key: each segment associates every data value of every column with a storage key, SK.
• Values from different column in the same segment with matching SK belongs to the same logical row.
• SK are integers and not physically stored in RS, but physically stored in WS.

Data Model
• Join Indices: if T1 and T2 are two projections anchored on a table T, a join index from T1 to T2 is logically
a collection of tables, one per segment of T1 consisting of rows of the form: (s: Sid in T2, k: SK in s)

RS
• Any segment of any projection is broken into columns, each of which is stored in order of the sort key for the projection.
• Selecting one of four encoding schemes for a column depends on its ordering (self-order or foreign order) and the proportion of distinct values it contains.

RS
• Type1 self-order, few distinct values
a column represented by a sequence of (v,f,n) such that v is the value, f is the position where v first appears and n is the number of times v appears, e.g.(4,12,7)means a group of 4’s appear in position 12,13,…18 in the column.
• Type2 foreign-order, few distinct values
a column represented by a sequence of (v,b) such that v is the value and b is a bitmap indicating the positions where v appears, e.g. 0,0,1,1,2,1,0,2 can be encoded as (0,11000010),(1,00110100),(2,00001001).

RS
• Type3 self-order, many distinct values represent every value as a delta from the previous
one,e.g.1,4,7,7,8,12 would be represented as 1,3,3,0,1,4.
• Type4 foreign-order, many distinct values just leave the values unencoded.
• Join Indexes can be stored as normal columns.

WS
• Implements the identical physical design as RS
• Each column in a WS projection is represented as a collections of pairs (v,sk) such that v is the value and sk is its corresponding storage key. Each pair is represented in a B-tree on the second field.
• “Name” is represented as (Alice,1), (Jill,2), (Bob,3)
• “Age” is represented as (23,1), (24,2), (25,3)

WS
• The sort key(s) of each projection is represented by pairs (s,sk) such that s is the sort key value and sk is the storage key describing where s first appears. Each pair is represented in a B-tree on the sort key field(s).
• To perform searches, use the latter B-tree to find the storage keys of interest, then use the former B-tree to find the other fields in the record.
• The sort key of EMP1 is “age”, so the sort key for EMP1 is represented as (23,1), (24,2), (25,3)

Tuple Mover
• Create a new RS segment named RS’
• Read in unmarked records from columns of RS segment, merges in column values from WS
• Update any join indexes
• Free disk space used by the old RS

Performance Comparison
• Performance analysis limited to read-only queries
• Report on only single-site
• Experiment data: TPC-H scale_10 totals 60,000,000 line items (1.8GB)
• Run seven queries on each system: a commercial row-store, a commercial column-store and C-Store

Performance Comparison
• Space-constrained case:

Performance Comparison
• Space-unconstrained case:

Conclusion
• A column store representation with an associated query execution engine
• A hybrid architecture allowing transactions on a column store
• A focus on economizing storage representation on disk
• A data model consisting of overlapping projections of tables


















