
(C) 2000, The University of Michigan 1 Language and Information Handout #5 November 30, 2000.
68
(C) 2000, The Univ ersity of Michigan 1 Language and Information Handout #5 November 30, 2000
-
Upload
clement-gallagher -
Category
Documents
-
view
218 -
download
0
Transcript of (C) 2000, The University of Michigan 1 Language and Information Handout #5 November 30, 2000.

(C) 2000, The University of Michigan
1
Language and Information
Handout #5
November 30, 2000

(C) 2000, The University of Michigan
2
Course Information
• Instructor: Dragomir R. Radev ([email protected])
• Office: 305A, West Hall
• Phone: (734) 615-5225
• Office hours: TTh 3-4
• Course page: http://www.si.umich.edu/~radev/760
• Class meets on Thursdays, 5-8 PM in 311 West Hall

(C) 2000, The University of Michigan
3
Clustering (Cont’d)

(C) 2000, The University of Michigan
4
Using similarity in visualization
• Dendrograms (see Figure 14.1 of M&S, page 496)

(C) 2000, The University of Michigan
5
Types of clustering
• Hierarchical: agglomerative, divisive• Soft & hard• Similarity functions:
– Single link: most similar members– Complete link: least similar members– Group-average: average similarity
• Applications:– improving language models– etc.

(C) 2000, The University of Michigan
6
HITS-type algorithms

(C) 2000, The University of Michigan
7
Hyperlinks and resource communities
• Jon Kleinberg (Almaden, Cornell)
• authoritative sources
• www.harvard.edu --> Harvard
• conferring authority via links
• global properties of authority pages

(C) 2000, The University of Michigan
8
Hubs and authoritieshubs authorities unrelated pages

(C) 2000, The University of Michigan
9
Authorities
• Java: www.gamelan.com, java.sun.com, sunsite.unc.edu/javafaq/javafaq.html
• Censorship: www.eff.org, www.eff.org/blueribbon.html, www.aclu.org
• Search engines: www.yahoo.com, www.excite.com, www.mckinley.com, www.lycos.com

(C) 2000, The University of Michigan
10
Related pages
• www.honda.com: www.ford.com, www.toyota.com, www.yahoo.com
• www.nyse.com: www.amex.com, www.liffe.com, update.wsj.com

(C) 2000, The University of Michigan
11
Collocations

(C) 2000, The University of Michigan
12
Collocations
• Idioms
• Free word combinations
• Know a word by the company that it keeps (Firth)
• Common use
• No general syntactic or semantic rules
• Important for non-native speakers

(C) 2000, The University of Michigan
13
Examples
Idioms
To kick the bucketDead endTo catch up
Collocations
To trade activelyTable of contentsOrthogonal projection
Free-word combinations
To take the busThe end of the roadTo buy a house

(C) 2000, The University of Michigan
14
Uses
• Disambiguation (e.g, “bank”/”loan”,”river”)
• Translation
• Generation

(C) 2000, The University of Michigan
15
Properties
• Arbitrariness
• Language- and dialect-specific
• Common in technical language
• Recurrent in context
• (see Smadja 83)

(C) 2000, The University of Michigan
16
Arbitrariness
• Make an effort vs. *make an exertion
• Running commentary vs. *running discussion
• Commit treason vs. *commit treachery

(C) 2000, The University of Michigan
17
Cross-lingual properties
• Régler la circulation = direct traffic
• Russian, German, Serbo-Croatian: direct translation is used
• AE: set the table, make a decision
• BE: lay the table, take a decision
• “semer le désarroi” - “to sow disarray” - “to wreak havoc”

(C) 2000, The University of Michigan
18
Types of collocations
• Grammatical: come to, put on; afraid that, fond of, by accident, witness to
• Semantic (only certain synonyms)
• Flexible: find/discover/notice by chance

(C) 2000, The University of Michigan
19
Base/collocator pairs
Base
NounNounVerbAdjectiveVerb
Collocator
verbadjectiveadverbadverbpreposition
Example
Set the tableWarm greetingsStruggle desperatelySound asleepPut on

(C) 2000, The University of Michigan
20
Extracting collocations• Mutual information
• What if I(x;y) = 0?• What if I(x;y) < 0?
P(x,y)
P(x)P(y)I (x;y) = log2

(C) 2000, The University of Michigan
21
Yule’s coefficient
A - frequency of lemma pairs involving both Li and Lj
B - frequency of pairs involving Li only
C - frequency of pairs involving Lk only
D - frequency of pairs involving neither
YUL = AD - BC
AD + BC -1 YUL 1

(C) 2000, The University of Michigan
22
Specific mutual information
• Used in extracting bilingual collocations
I (e,f) = p (e,f)
p(e) p(f)
• p(e,f) - probability of finding both e and f in aligned sentences
• p(e), p(f) - probabilities of finding the word in one of the languages

(C) 2000, The University of Michigan
23
Example from the Hansard corpus (Brown, Lai, and Mercer)
French word Mutual information
sein 5.63
bureau 5.63
trudeau 5.34
premier 5.25
résidence 5.12
intention 4.57
no 4.53
session 4.34

(C) 2000, The University of Michigan
24
Total p-5 p-4 p-3 p-2 p-1 p+1 p+2 p+3 p+4 p+5
8031 7 6 13 5 7918 0 12 20 26 24
Flexible and rigid collocations
• Example (from Smadja): “free” and “trade”

(C) 2000, The University of Michigan
25
Xtract (Smadja)
• The Dow Jones Industrial Average
• The NYSE’s composite index of all its listed common stocks fell *NUMBER* to *NUMBER*

(C) 2000, The University of Michigan
26
Translating Collocations
• Brush up a lesson, repasser une leçon
• Bring about/осуществлять
• Hansards: late spring: fin du printemps, Atlantic Canada Opportunities Agency, Agence de promotion économique du Canada atlantique

(C) 2000, The University of Michigan
27
The eSseNSe system

(C) 2000, The University of Michigan
28
…
Offline processing Online processing
…
cluster 1 cluster 2 cluster 3 cluster n
summary 1 summary 2 summary 3 summary n
cached documents
hitlist
…user query
summary

(C) 2000, The University of Michigan
29

(C) 2000, The University of Michigan
30

(C) 2000, The University of Michigan
31
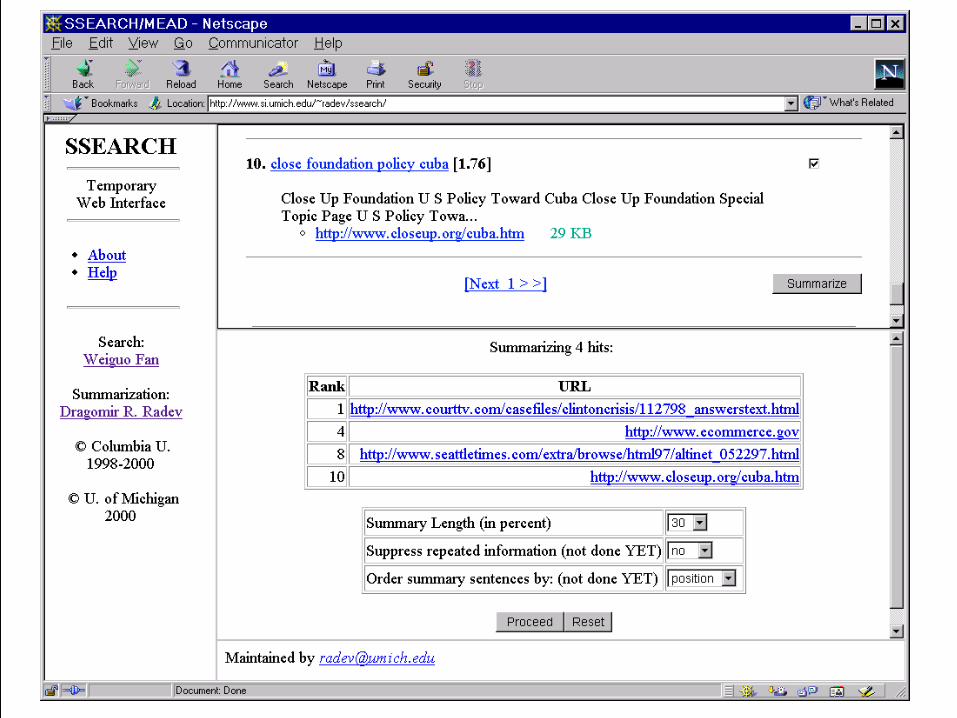
(C) 2000, The University of Michigan
32

(C) 2000, The University of Michigan
33

(C) 2000, The University of Michigan
34
Sample summary
500.80Data mining on the other hand through the use of specific algorithms or search engines attempts to source out discernable patterns and trends in the data and infers rules from these patterns
520.53Data mining versus traditional database queries Traditional database queries contrasts with data mining since these are typified by the simple question such as what were the sales of orange juice in January 1995 for the Boston area
486.92Intense competition in an increasing saturated marketplace the ability to custom manufacture market and advertise to small market segments and individuals 4 and the market for data mining products is estimated at about 500 million in early 1994 12 Data mining technologies are characterized by intensive computations on large volumes of data
576.60These are : -the untapped value in large databases consolidation of database records tending towards a single customer view concept of an information or data warehouse from the consolidation of databases dramatic drop in the cost/performance ratio of hardware systems - for data storage and processing
487.92This term data mining has been used by statisticians data analyst and the MIS management information systems community whereas KDD has been mostly used by artificial intelligence and machine learning researchers
509.11The term data mining is then this high-level application techniques / tools used to present and analyze data for decision makers
494.92The idea behind data mining then is the non-trivial process of identifying valid novel potentially useful and ultimately understandable patterns in data 18 2 The term knowledge discovery in databases KDD was formalized in 1989 in reference to the general concept of being broad and 'high level' in the pursuit of seeking knowledge from data
Score Sentence
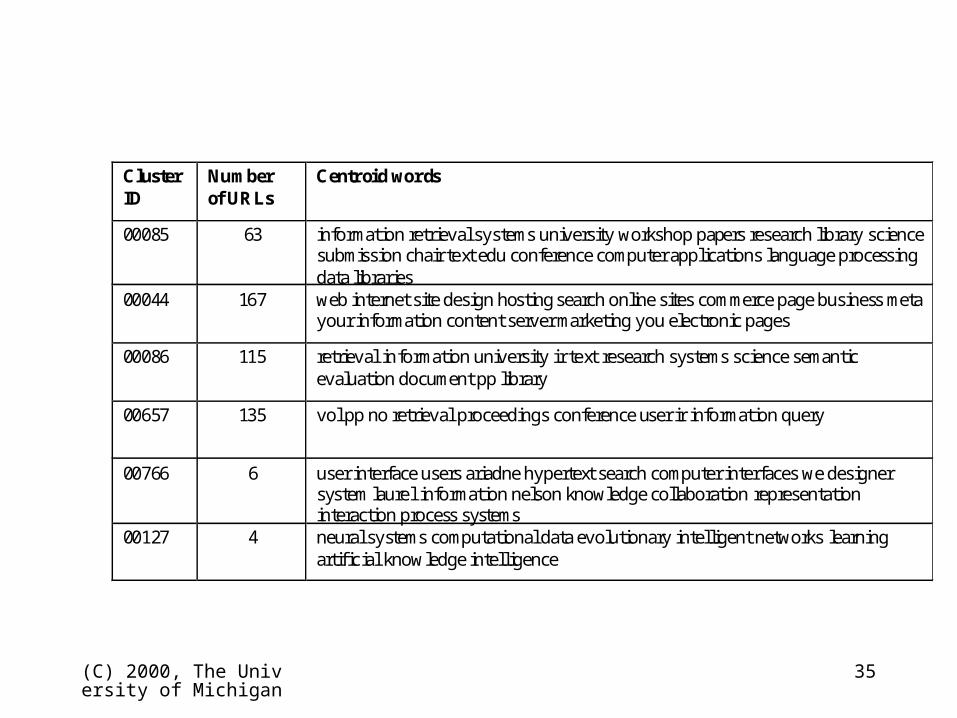
(C) 2000, The University of Michigan
35
ClusterID
Numberof URLs
Centroid words
00085 63 informat ion retrieval systems university workshop papers research library sciencesubmission chair text edu conference computer applications language processingdata libraries
00044 167 web internet site design hosting search online sites commerce page business metayour information content server marketing you electronic pages
00086 115 retrieval in formation university ir text research systems science semanticevaluation document pp library
00657 135 vol pp no retrieval proceedings conference user ir informat ion query
00766 6 user interface users ariadne hypertext search computer interfaces we designersystem laurel informat ion nelson knowledge collaboration representationinteraction process systems
00127 4 neural systems computational data evolutionary intelligent networks learningartificial knowledge intelligence

(C) 2000, The University of Michigan
36

(C) 2000, The University of Michigan
37
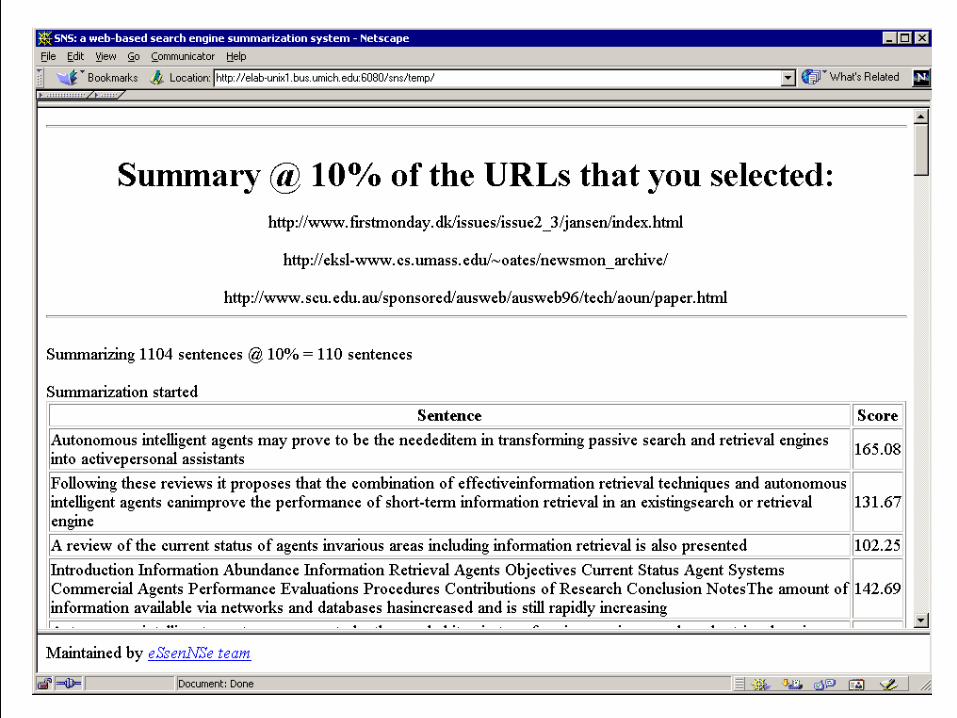
(C) 2000, The University of Michigan
38

(C) 2000, The University of Michigan
39

(C) 2000, The University of Michigan
40

(C) 2000, The University of Michigan
41
mining (84.54), data (64.13), knowledge (14.25), discovery (11.98), advertised (11.20), databases
(9.69), information (6.98), research (6.96), analysis (6.95), text (6.05), patterns (5.30), algorithms
(4.39).
Text Min ing is a new and excit ing research area that tries to solve the informat ion overloadproblem by using techniques from data mining machine learning information retrieval natural-language understanding case-based reasoning statistics and knowledge management to helppeople gain insight into large quantities of semi-structured or unstructured text
183.73
<BR> Current Projects - A ims The Data Mining Program has two projects: DMITL - DataMining in the Large Conducting practical case studies for clients involving the analysis oflarge and complex data sets ParAlg – Parallel Algorithms The main computing facility forthese projects consists of a secure multiprocessor Sun E4000
156.56
The DMITL project aims to develop knowledge and techniques relevant to the data mining oflarge and complex datasets using high performance computers
163.78
Megaputer develops software and solutions for data mining text analysis and knowledgediscovery in databases
188.96

(C) 2000, The University of Michigan
42
Cross-language information access

(C) 2000, The University of Michigan
43
English
QE
CE
DE SE
SE

(C) 2000, The University of Michigan
44
English Chinese
QE
CE
QC
DE SE
SE

(C) 2000, The University of Michigan
45
English Chinese
QE
CE CC
QC
DE SE SC DC
SE SC

(C) 2000, The University of Michigan
46
English Chinese
QE
CE CC
QC
DE SE SC DC
SE SC
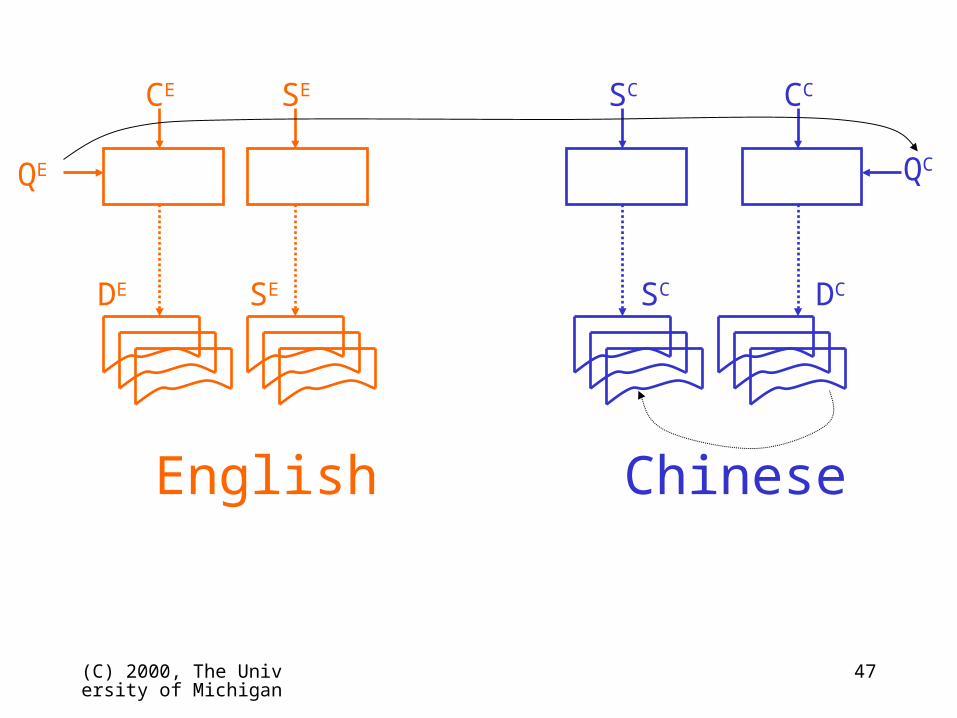
(C) 2000, The University of Michigan
47
English Chinese
QE
CE CC
QC
DE SE SC DC
SE SC

(C) 2000, The University of Michigan
48
English Chinese
QE
CE CC
QC
DE SE SC DC
SC->E
SE SC

(C) 2000, The University of Michigan
49
Objectives
• Produce summaries using multiple algorithms• evaluate summarization and translation separately• intrinsic and extrinsic language-independent
evaluation metrics• establish correlation between evaluation metrics• build parallel C-E doc+summary 9K docs (Hong
Kong news)

(C) 2000, The University of Michigan
50
Participants• Full time
– K.-L. Kwok, Queens College– Dragomir Radev, U. Michigan– Wai Lam, Chinese University of HK– Simone Teufel, Columbia
• “Consultants”– Chin-Yew Lin, ISI– Tomek Strzalkowski, Albany– Jade Goldstein, CMU– Jian-Yun Nie, U. Montréal
• Supporters– TIDES roadmap group: Ed Hovy, Daniel Marcu, Kathy McKeown

(C) 2000, The University of Michigan
51
Techniques and parameters
• Summarization:– position, TF*IDF, centroids, largest common
subsequence, keywords
• Evaluation:– intrinsic: percent agreement, relative utility,
precision/recall– extrinsic: document rank, question answering
• Length of documents/summaries

(C) 2000, The University of Michigan
52
The parallel corpus
• English and Chinese (Hong Kong News)• Already there:
– 9000 documents and their translations– list of 300 queries in English and their translations
• We will create before the workshop:– document relevance judgements
• 50 queries, 5 hrs/query, $10/hr -> $2,500
– sentence relevance judgements• 4 doc/hr, need 4000 rel. judgements -> $10,000
– optional: manual abstracts

(C) 2000, The University of Michigan
53
Creating the judgements
• For each query– submit to IR engine– discard unless it has 5-20 hits– get exhaustive document relevance judgements– consider top 100 documents
• get sentence relevance judgements for– all relevant judgements
– top 50 documents (including irrelevant ones!)

(C) 2000, The University of Michigan
54
Experiments• Experiment 1: (Validation)
Compare preservation of ranking with other measures: judgement overlap, relative utility
• Experiment 2 & Experiment 3: – use with preservation of ranking– only possible due to new, parallel experimental design– factor out effects of
• query translation• summarization• monolingual IR
• Baseline:– leading sentence summaries vs. documents– other summarization methods vs. documents– (ideal: manual summaries vs. documents)

(C) 2000, The University of Michigan
55
• Monolingual experiments– Effect of summarization
• English Query -> English Doc (ranks)
• English Query-> English Summary (ranks)
• Chinese Query -> Chinese Doc (ranks)
• Chinese Query -> Chinese Summary (ranks)
– Baseline:• leading sentence summary vs. document
• ideal: manual summary vs. document
– Effect of language on IR• English Query -> English Doc
• Chinese Query-> Chinese Doc
• Experiment 2: crosslingual– Effect of query translation
• English Query -> English Doc
• English Query -> Chinese Query -> Chinese Doc
Experiments

(C) 2000, The University of Michigan
56
Timeline
• Pre-workshop: build corpus• Sentence segmenter, Chinese tokenizer, machine
translation, IR system, eSseNSe summarizer• Workshop: system integration, build toolkit,
summarization, evaluation, correlation, system refinement, final evaluation

(C) 2000, The University of Michigan
57
WorkshopW1
W2
W3
W4
W5
W6
Set up experimental testbedEvaluation plan laid outSelection of training/test sub-corporaAlpha version of CLIA system tested on a small number of queriesBaseline experimentRun experiment one
Run experiment twoCompute query translation qualityRun experiment threeFeedback from first three experimentsSystem improvements
Improved CLIA system readyEvaluation using unseen test dataDraft of final reportAdditional experimentsWrap-upFinal version of CLIA system released

(C) 2000, The University of Michigan
58
• Novelty: never done before, integration of CLIR and summarization
Merit criteria

(C) 2000, The University of Michigan
59
• Novelty: never done before, integration of CLIR and summarization
• Collaboration: participants wouldn’t work together otherwise
Merit criteria

(C) 2000, The University of Michigan
60
• Novelty: never done before, integration of CLIR and summarization
• Collaboration: participants wouldn’t work together otherwise• Scientific merit: much-needed evaluation metrics,
techniques for multi-document, multilingual summarization, incorporate utility, redundancy, subsumption
Merit criteria

(C) 2000, The University of Michigan
61
• Novelty: never done before, integration of CLIR and summarization
• Collaboration: participants wouldn’t work together otherwise• Scientific merit: much-needed evaluation metrics, techniques
for multi-document, multilingual summarization, incorporate utility, redundancy, subsumption
• Feasibility: uses existing work, specific plan for new work
Merit criteria

(C) 2000, The University of Michigan
62
• Novelty: never done before, integration of CLIR and summarization
• Collaboration: participants wouldn’t work together otherwise• Scientific merit: much-needed evaluation metrics, techniques
for multi-document, multilingual summarization, incorporate utility, redundancy, subsumption
• Feasibility: uses existing work, specific plan for new work• Community building: corpora, evaluation techniques, and
software (CLIR, evaluation, and summarization), builds on prior evaluations (TDT, TREC, SUMMAC, DUC)
Merit criteria

(C) 2000, The University of Michigan
63
• Novelty: never done before, integration of CLIR and summarization
• Collaboration: participants wouldn’t work together otherwise• Scientific merit: much-needed evaluation metrics, techniques
for multi-document, multilingual summarization, incorporate utility, redundancy, subsumption
• Feasibility: uses existing work, specific plan for new work• Community building: corpora, evaluation techniques, and
software (CLIR, evaluation, and summarization), builds on prior evaluations (TDT, TREC, SUMMAC, DUC)
• Funder interest: multilingual systems, large amounts of data
Merit criteria

(C) 2000, The University of Michigan
64
• Novelty: never done before, integration of CLIR and summarization
• Collaboration: participants wouldn’t work together otherwise• Scientific merit: much-needed evaluation metrics, techniques
for multi-document, multilingual summarization, incorporate utility, redundancy, subsumption
• Feasibility: uses existing work, specific plan for new work• Community building: corpora, evaluation techniques, and
software (CLIR, evaluation, and summarization), builds on prior evaluations (TDT, TREC, SUMMAC, DUC)
• Funder interest: multilingual systems, large amounts of data
Merit criteria

(C) 2000, The University of Michigan
65
What was dropped
• Interactive clustering of documents
• Evaluation of the quality of translated summaries
• Document translation
• Effects of document genre, length
• Evolving summaries

(C) 2000, The University of Michigan
66
More…

(C) 2000, The University of Michigan
67
What we didn’t talk about
• Hidden Markov models
• Part of speech tagging
• Probabilistic parsing
• Information retrieval
• Text classification
• etc.

(C) 2000, The University of Michigan
68
THE END ?
http://perun.si.umich.edu/~radev/760/job/


















