
Building Symbiotic Relationships Between Formal Verification and High Performance Computing Mike...
42
Building Symbiotic Relationships Between Formal Verification and High Performance Computing Mike Kirby School of Computing and Scientific Computing and Imaging Institute University of Utah Salt Lake City, UT, USA
-
date post
21-Dec-2015 -
Category
Documents
-
view
217 -
download
1
Transcript of Building Symbiotic Relationships Between Formal Verification and High Performance Computing Mike...

Building Symbiotic Relationships Between
Formal Verification and High Performance Computing
Mike KirbySchool of Computing and
Scientific Computing and Imaging InstituteUniversity of Utah
Salt Lake City, UT, USA

Scientific Computing and Imaging Institute, University of Utah
Faculty• Ganesh Gopalakrishnan• Mike Kirby
Post-Docs and Students• Dr. Igor Melatti (postdoc)• Robert Palmer (PhD)• Yu Yang (PhD) • Salman Pervez (PhD)• Steve Barrus (BS/MS)• Sonjong Hwang (BS/MS)• Jeffrey Sawaya (BS)
Funding Acknowledgements: • NSF (CSR–SMA: Toward Reliable and Efficient Message Passing Software Through Formal Analysis)• Microsoft (Formal Analysis and Code Generation Support for MPI)
Gauss Group

Scientific Computing and Imaging Institute, University of Utah
• Motivation• Connection Between Formal Methods and HPC• Three Applications
• Example 1: Modeling of the MPI Library• Example 2: Verifying One-Sided MPI Constructs• Example 3: Parallel Model Checking
Outline

Scientific Computing and Imaging Institute, University of Utah
Motivation
$10k/week on Blue Gene (180 GFLOPS)at IBM’s Deep Computing Lab
136,800 GFLOPS Max

Scientific Computing and Imaging Institute, University of Utah
Motivation
• 50% of development of parallel scientific codes spent in debugging [Vetter and deSupinski 2000]
• Programmers from a variety of backgrounds—often not computer science

Scientific Computing and Imaging Institute, University of Utah
Needs of an HPC programmer
• Typical HPC program development cycle consists of:
* Understand what is being simulated (the physics, biology, etc).
* Develop a mathematical model of relevant "features" of interest
* Generate a numerical discretization of the mathematical model
* Solve numerical problem• Usually begins as serial code• Later the numerical problem – not the serial code – is parallelized
* Often best to develop numerical model that’s amenable for parallelization
* At every step, check consistency (e.g. conservation of energy)
* Tune for load-balancing ; make code adaptive ; …

Scientific Computing and Imaging Institute, University of Utah
Challenges in producing Dependable and Fast MPI / Threads programs
• Threads style : - Deal with Locks, Condition Variables, Re-entrancy, Thread Cancellation, …
• MPI :
- Deal with the complexity of * Single-program Multiple Data (SPMD) programming
* Performance optimizations to reduce communication costs
* Deal with the complexity of MPI (MPI-1.has 130 calls ; MPI-2 has 180 ; various flavors of sends / receives) • Threads and MPI are often used together
• MPI libraries are threaded

Scientific Computing and Imaging Institute, University of Utah
Solved and Unsolved Problems in MPI/Thread programming
• Solved Problems : (Avrunin and Siegel (MPI) as well as our group)
- Modeling MPI library in Promela
- Model-checking simple MPI programs
• Unsolved Problems: a rather long list, with some being:
- Model-extraction
- Handling Mixed-paradigm programs
- Formal Methods to find / justify optimizations
- Verifying Reactive aspects / Computational aspects

Scientific Computing and Imaging Institute, University of Utah
Example 1: Modeling of the MPI Library

Scientific Computing and Imaging Institute, University of Utah
Variety of bugs that are common in parallel scientific
programs• Deadlock• Communication Race Conditions• Misunderstanding the semantics of
MPI procedures• Resource related assumptions• Incorrectly matched send/receives

Scientific Computing and Imaging Institute, University of Utah
State of the art in Debugging
• TotalView– Parallel debugger – trace visualization
• Parallel DBX• gdb• MPICHECK
– Does some deadlock checking – Uses trace analysis

Scientific Computing and Imaging Institute, University of Utah
Related work
• Verification of wildcard free models [Siegel, Avrunin, 2005]
– Deadlock free with length zero buffers ==> deadlock free with length > zero buffers
• SPIN models of MPI programs [Avrunin, Seigel, Seigel, 2005] and [Seigel, Mironova, Avrunin, Clarke, 2005]
– Compare serial and parallel versions of numerical computations for numerical equivelnace

Scientific Computing and Imaging Institute, University of Utah
The Big Picture
Model Generator
MC Server
MC ClientMC Client
MC ClientMC Client
MC ClientMC Client
MC ClientMC Client
MC Client…
#include <mpi.h>#include <stdio.h>#include <stdlib.h>
int main(int argc, char** argv){
int myid; int numprocs;
MPI_Init(&argc, &argv); MPI_Comm_size(MPI_COMM_WORLD, &numprocs); MPI_Comm_rank(MPI_COMM_WORLD, &myid);
if(myid == 0){ int i; for(i = 1; i < numprocs; ++i){ MPI_Send(&i, 1, MPI_INT, i, 0, MPI_COMM_WORLD); } printf("%d Value: %d\n", myid, myid); } else { int val; MPI_Status s; MPI_Recv(&val, 1, MPI_INT, 0, 0, MPI_COMM_WORLD, &s); printf("%d Value: %d\n", myid, val); }
MPI_Finalize(); return 0;}
MPI Program int y;active proctype T1(){ int x; x = 1; if :: x = 0; :: x = 2; fi; y = x;}active proctype T2(){ int x; x = 2; if :: y = x + 1; :: y = 0; fi; assert( y == 0 );}
ProgramModel
Compiler
10010101000101010001010100101010010111001001001110101011011010010010010011001001110010010000111100101100111100011110010101000101010001010100101010010111001001001110101011011010010010010011001001110010010000111100101100111100011110010101000101010001010100101010010111001001001110101011011010010010010011001001110010010000111100101100111100011110010101000101010001010100101010010111001001001110101011011010010010010011001001110010010000111100101100111100011110010101000101010001010100101010010111001001001110101011011010010010010011001001110010010000111100101100111100011110010101000101010001010100101010010111001001001110101011011010010010010011001001110010010000111100101100111100011100100100111010101101101001001001001100
MPI Binary
Error Simulator
Result Analyzer
Refinement
OK
proctype MPI_Send(chan out, int c){ out!c;}proctype MPI_Bsend(chan out, int c){ out!c;}proctype MPI_Isend(chan out, int c){ out!c;}typedef MPI_Status{ int MPI_SOURCE; int MPI_TAG; int MPI_ERROR;}…
MPI LibraryModel
+
Zing
Abstractor
EnvironmentModel
+

Scientific Computing and Imaging Institute, University of Utah
Goal
• Verification / Transformation of MPI programs– “that is nice that you may be able to
show my program does not deadlock but can you make it faster?”
– Verification of safety properties…– Automatic optimization through
“verifiably safe” transformation (Send with ISend/Wait, etc.)

Scientific Computing and Imaging Institute, University of Utah
Example 2: Verifying One-Sided MPI Constructs

Scientific Computing and Imaging Institute, University of Utah
Byte-Range lockingusing MPI one-sided
communication• One process makes its memory space available
for communication• Global state is stored in this memory space• Each process is associated with a flag, start and
end values stored in array A• Pi’s flag value is in A[3 * i] for all i
Flag Flag Start FlagStart StartEnd EndEnd

Scientific Computing and Imaging Institute, University of Utah
Lock Acquirelock_acquire (strat, end) {1 val[0] = 1; /* flag */ val[1] = start; val[2] = end;2 while(1) {3 lock_win4 place val in win5 get values of other processes from win6 unlock_win7 for all i, if (Pi conflicts with my range)8 conflict = 1;
9 if(conflict) {10 val[0] = 011 lock_win12 place val in win13 unlock_win14 MPI_Recv(ANY_SOURCE)15 }16 else17 /* lock is acquire */18 break;19 }

Scientific Computing and Imaging Institute, University of Utah
Lock Release
lock_release (strat, end) { val[0] = 0; /* flag */ val[1] = -1; val[2] = -1;
lock_win place val in win get values of other processes from win unlock_win
for all i, if (Pi conflicts with my range) MPI_Send(Pi);}

Scientific Computing and Imaging Institute, University of Utah
Error Trace
P1 P2 P3
Try lock for range (3, 5)
Try lock for range (6, 8)
Try lock for range (5, 6)
Lock acquired BlockedLock acquired
Lock releasedLock released
MPI_Send(P3) MPI_Send(P3) MPI_Recv(P1)
Error - no matching MPI_Recv

Scientific Computing and Imaging Institute, University of Utah
Error Discussion
• Problem: too many Send’s, not enough Recv’s• Not really a problem
– Messages are 0 bytes only– Send’s could be made non-blocking
• Maybe a problem– Even 0 byte messages cause unknown memory
leaks, not desirable– More importantly, if there are unused Send’s in the
system, processes that were supposed to be blocked may wake up by consuming these. This ties up processor resources and hurts performance!

Scientific Computing and Imaging Institute, University of Utah
Example 3: Parallel Model CheckingThe Eddy-Murphi Model Checker

Scientific Computing and Imaging Institute, University of Utah
Parallel Model Checking
• Each computation node “owns” a portion of the state space– Each node locally stores and analyzes its
own states– Newly generated states which do not
belong to the current node are sent to the owner node
• Standard distributed algorithm may be chosen for termination

Scientific Computing and Imaging Institute, University of Utah
Eddy Algorithm
• For each node, two threads are used– Worker thread: analyzes, generates and
partitions states• If there are no states to be visited, it sleeps
– Communication thread: repeatedly sends/receives states to/from the other nodes• It also handles termination
• Communication between the two threads– Via shared memory– Via mutex signals primitives
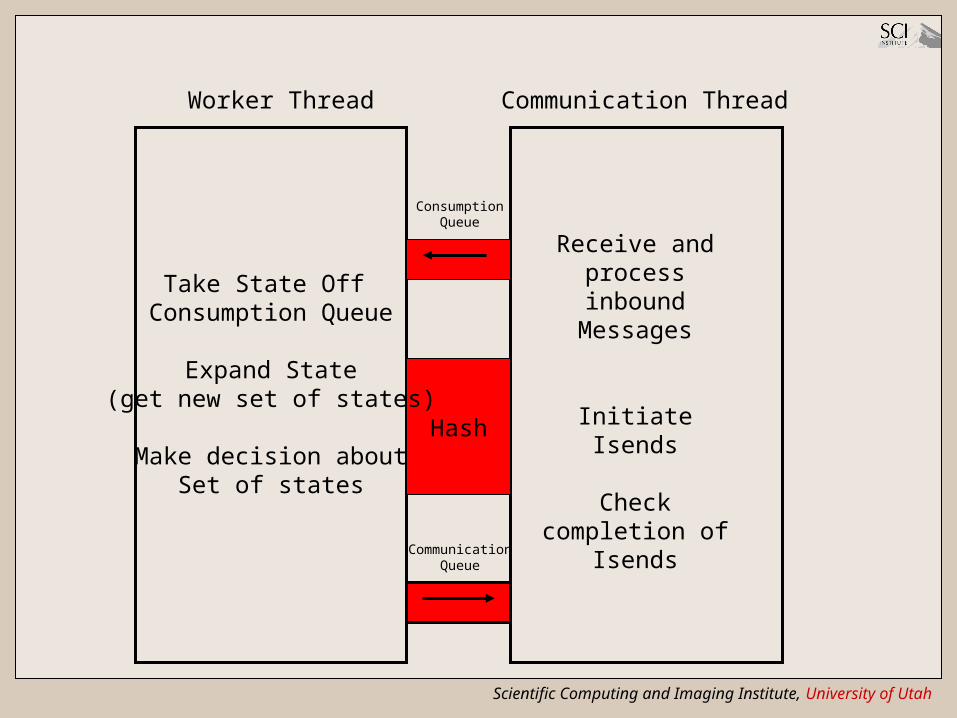
Scientific Computing and Imaging Institute, University of Utah
Worker Thread Communication Thread
Hash
ConsumptionQueue
CommunicationQueue
Take State Off Consumption Queue
Expand State(get new set of states)
Make decision aboutSet of states
Receive and process inbound
Messages
Initiate Isends
Check completion of Isends

Scientific Computing and Imaging Institute, University of Utah
The Communication Queue
• There is one communication queue for each node
• Each communication queue has N lines and M states per line
• States additions are made (by the worker thread) only on one active line
• The other lines may be already full or empty

Scientific Computing and Imaging Institute, University of Utah
The Communication Queue
• Summing up, this is the evolution of a line status:
WTBA Active WTBS CBS

Scientific Computing and Imaging Institute, University of Utah
Eddy-Murphi Performance
• Tuning of the communication queuing mechanism– High number of states per line is
required• Much better sending many states at a
time
– Not too few number of lines• Or the worker will not be able to submit
new states

Scientific Computing and Imaging Institute, University of Utah
Eddy-Murphi Performances
• Comparison with previous versions of parallel Murphi– When ported to MPI, old versions of
parallel Murphi perform worse than serial Murphi
• Comparison with serial Murphi; almost linear speedup is expected

Scientific Computing and Imaging Institute, University of Utah
Eddy-Murphi Performance

Scientific Computing and Imaging Institute, University of Utah
Eddy-Murphi Performance

Scientific Computing and Imaging Institute, University of Utah
Summary
• Complex systems can benefit from formal methods
• Rich interdisciplinary ground for FM and HPC to interact
• Win-Win scenarios exist

Scientific Computing and Imaging Institute, University of Utah

Scientific Computing and Imaging Institute, University of Utah
Possible Fix - Bidding
• Main Idea: when Pi releases a lock, it bids on the right to wake up Pj– If two processes want to wake up the same process, only one
will be able to do so– Bidding array much like existing array, whoever writes first
wins.• Not Perfect!
– Performance hit due to more synchronization for bidding array.– Still possible to have too many Send’s.– Bidding array needs to be reset.– Who resets it? Doesn’t really matter. It is always possible for a
process to sneak in just at the right time and pretend it is the highest bidder!
• But not bad– Number of extra Send’s dramatically reduced. Better
performance, lesser memory leaks.

Scientific Computing and Imaging Institute, University of Utah
Better Solution - Picking
• Main Idea: The process about to be blocked picks who will wake it up and indicates so by writing to shared memory in lines 11 and 13– The process that was just picked sees this
information when it releases the lock and wakes up the blocked process
– Suppose Pi sees Pj in the critical section, it chooses Pj to wake it up. But, Pj leaves before Pi can write the information to shared memory.
– Solution: Pi will know Pj has left as it writes to shared memory. It can also read! So, instead of blocking, it must now choose Pk and retry. If it runs out of processes to choose from, it must retry.

Scientific Computing and Imaging Institute, University of Utah
Discussion on picking• Good news
– This works! Our original problem is solved. No two processes can send messages to the same blocked process.
• Bad news– Well it doesn’t ‘quite’ work!– Problem: What if Pi chooses Pj, but Pj releases the lock before it
finds out. Pi will now choose Pk, but before it can do so, Pj comes back into the critical section, sees its name in shared memory and assumes it has to wake Pi. Extra Send again!
• More good news– Number of extra sends ‘extremely’ low now.– We can fix this problem too. There are two possible fixes.
• We need to differentiate between locking cycles. Pi must not only pick Pj, but also the exact locking cycle Pj was in. Simply assign numbers whenever locking cycle is entered. So in the next locking cycle, Pj is not confused.
• Force each process to pick a different byte range each time. If you chose (m, n) in one cycle you cannot chose it in the next. This is reasonable. This gives a unique pair to each locking cycle, the byte range.
• So this solution works as far as we know! Although no formal proof has been done yet.

Scientific Computing and Imaging Institute, University of Utah
High level view of MPI model (formalization)
• All process have a local context. • MPI_COMM_WORLD is the set of all
local contexts• Communications Implemented as
operations on the local context.• MPI communicator does exchange
of messages “invisibly”

Scientific Computing and Imaging Institute, University of Utah
High level view of MPI model

Scientific Computing and Imaging Institute, University of Utah
Pros & Cons
• Elegant– All operation as sets & operations on sets.
• Too large / complicated– Can’t model check it (this is really bad!) – All semantics must be explicitly stated as set
operations– How do you implement the big “invisible”
communicator actions?– How do you maintain a handle on a given
message?

Scientific Computing and Imaging Institute, University of Utah
Another view of MPI
• Communicators (MPI_COMM_WORLD) are shared objects that has two message slots serving as contexts.
• Messages have state. • All communication actions are
implemented as state transitions on the message slots.

Scientific Computing and Imaging Institute, University of Utah
Another view of MPI

Scientific Computing and Imaging Institute, University of Utah
Pros & Cons
• Much simpler– Hope to model check this– Some semantics become implicit
• Noninterference of point to point and collective communication
• Non overtaking of messages from a particular node

Scientific Computing and Imaging Institute, University of Utah
Other projects
• Sonjong Hwang(BS/MS)– Translator from TLA+ to NuSMV– Test model checking approach to
validate sequences of MPI calls
• Geof Sawaya(BS)– Model Checker built out of Visual Studio– Verisoft style explicit state model
checker


















