Building Recommendation Engines Using Lambda Architecture
13
Building ngines Recommendation using Lambda rchitecture
-
Upload
datamatics-global-services-limited -
Category
Data & Analytics
-
view
828 -
download
1
Transcript of Building Recommendation Engines Using Lambda Architecture

Building
ngines
Recommendation using Lambda rchitecture
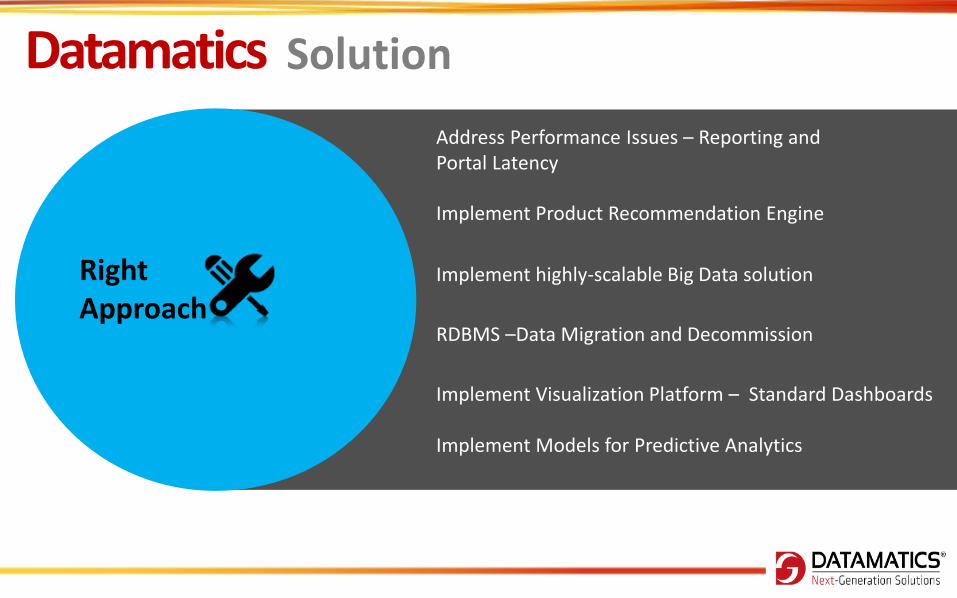
Address Performance Issues – Reporting and Portal Latency
Implement Product Recommendation Engine
Implement highly-scalable Big Data solution
RDBMS –Data Migration and Decommission
Implement Models for Predictive Analytics
Implement Visualization Platform – Standard Dashboards
Right Approach
Datamatics Solution
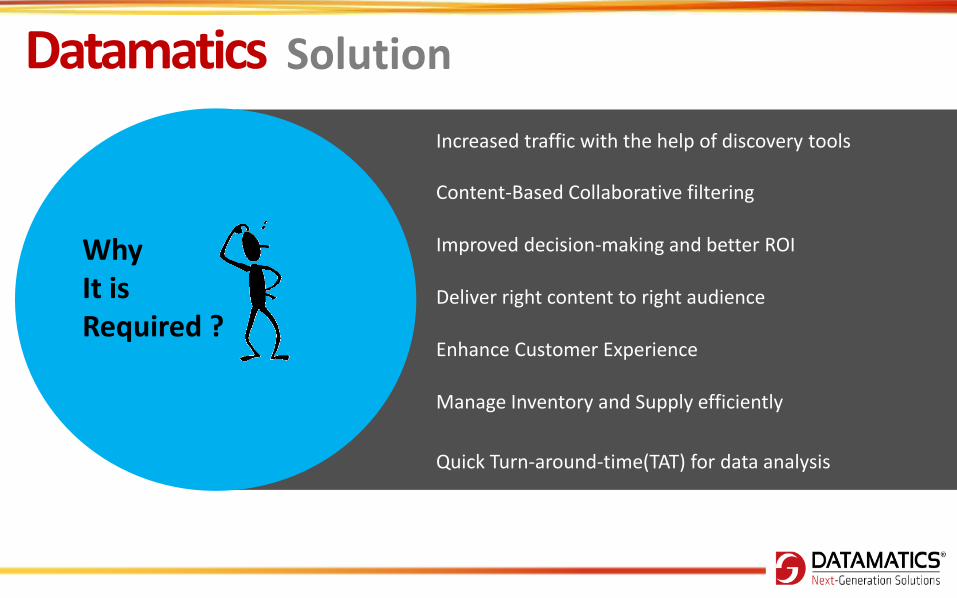
Why It is Required ?
Increased traffic with the help of discovery tools
Improved decision-making and better ROI
Deliver right content to right audience
Manage Inventory and Supply efficiently
Enhance Customer Experience
Quick Turn-around-time(TAT) for data analysis
Content-Based Collaborative filtering
Datamatics Solution
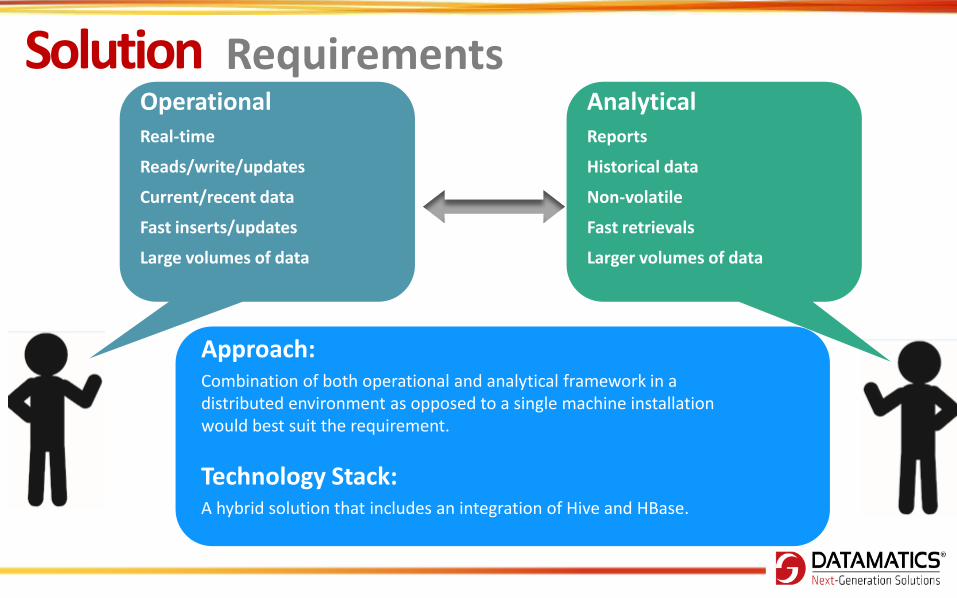
Analytical Reports
Historical data
Non-volatile
Fast retrievals
Larger volumes of data
Operational Real-time
Reads/write/updates
Current/recent data
Fast inserts/updates
Large volumes of data
Approach: Combination of both operational and analytical framework in a distributed environment as opposed to a single machine installation would best suit the requirement.
Technology Stack: A hybrid solution that includes an integration of Hive and HBase.
Solution Requirements
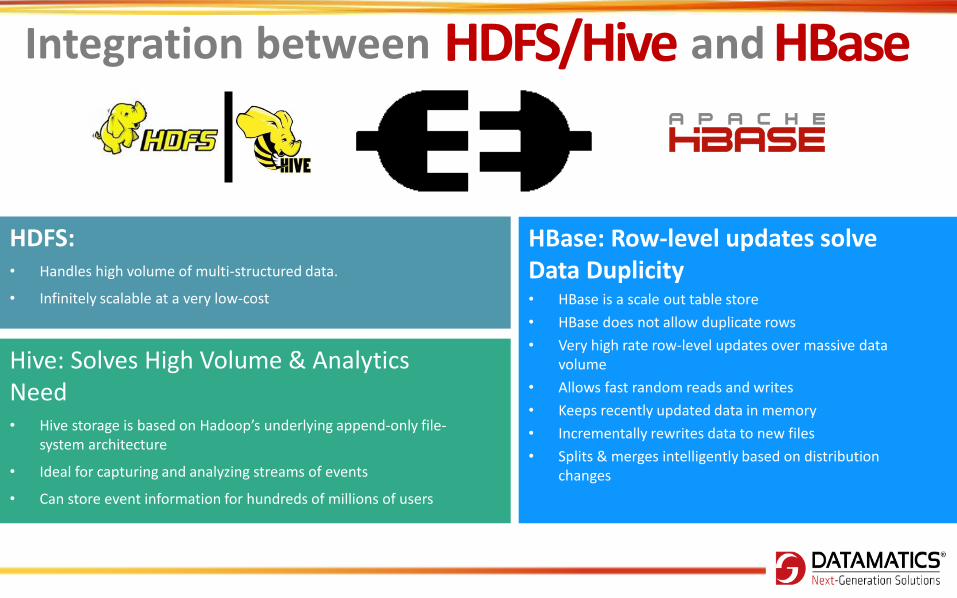
Integration between HDFS/Hive and HBase
HBase: Row-level updates solve Data Duplicity • HBase is a scale out table store
• HBase does not allow duplicate rows
• Very high rate row-level updates over massive data volume
• Allows fast random reads and writes
• Keeps recently updated data in memory
• Incrementally rewrites data to new files
• Splits & merges intelligently based on distribution changes
Hive: Solves High Volume & Analytics Need • Hive storage is based on Hadoop’s underlying append-only file-
system architecture
• Ideal for capturing and analyzing streams of events
• Can store event information for hundreds of millions of users
HDFS: • Handles high volume of multi-structured data.
• Infinitely scalable at a very low-cost

Challenges with HDFS/Hive and HBase HBase: Row-level updates solve Data Duplicity
• Right Design: To ensure high throughput and low latency the schema has to be designed right
Other challenges include • Data model
• Designing based on derived query patterns
• Row key design
• Manual splitting
• Monitoring Compactions
Hive: Solves High Volume & Analytics Need
• Keeping the warehouse up to date
• Has append-only constraint
• Impossible to directly apply individual updates to warehouse tables
• Optionally allows to p`eriodically pull snapshots of live data and dump them to new Hive partition which this is a costly operation.
• Can be done utmost daily once, and leaves the data to be stale.
HDFS:
• Cannot handle high velocity of random reads and writes
• Fast random reads require the data to be stored structured(ordered)
• Unable to change a file without completely writing it
• Only way to a modify file stored without rewriting is appending
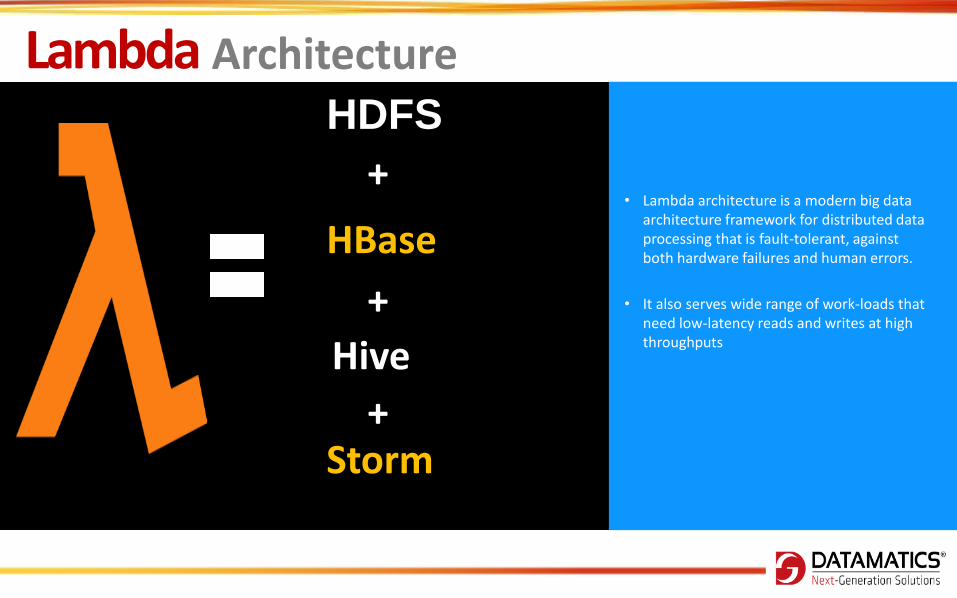
Hive
Storm
+
HBase
HDFS
+
+
Lambda Architecture
• Lambda architecture is a modern big data architecture framework for distributed data processing that is fault-tolerant, against both hardware failures and human errors.
• It also serves wide range of work-loads that need low-latency reads and writes at high throughputs

SERVING
QUERY
Serving layer is used to index batch views. • Ad-hoc batch views can be queried with low-latency • Hive is used for Batch views • HBase is used for Real-time views. • Hive and HBase integration happens in this layer.
• Batch views and Real-time views are merged in this layer.
• Merged views are implemented using HBase
Majorly handles two functions • Managing master dataset. (append-only set of raw data). • Pre-compute arbitrary query functions (batch views) • Hadoop’s HDFS is used in this layer
SPEED
DATA STREAM
BATCH
Majorly handles two functions • Managing master dataset. (append-only set of raw data). • Pre-compute arbitrary query functions (batch views) • Hadoop’s HDFS is used in this layer
• Speed layer deals with recent data only.
• High latency of updates due to the batch layer in the serving layer are addressed in the Speed Layer.
• Storm is used in this layer.
Proposed Architecture – Option 1 - Open Source
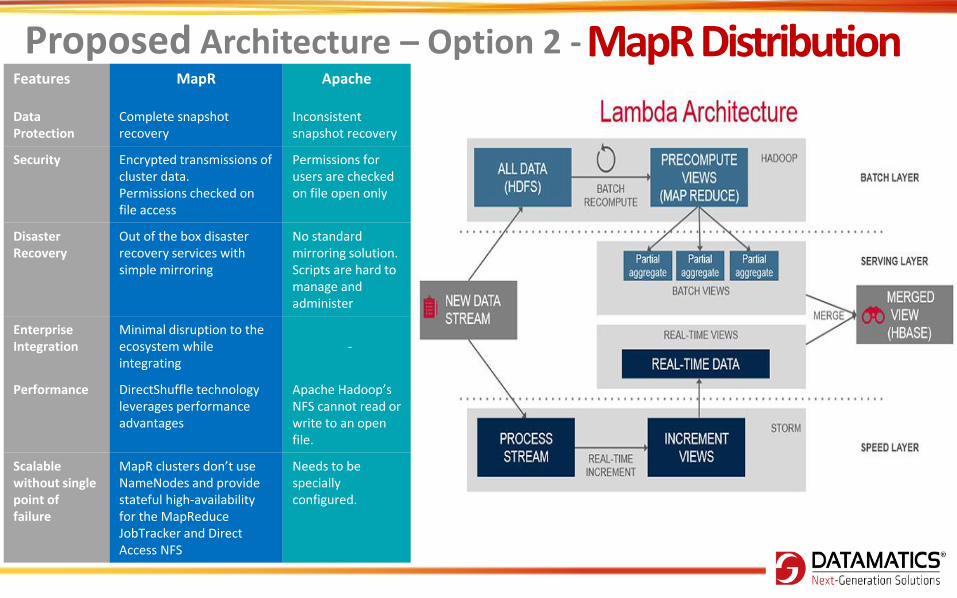
Features MapR Apache
Data Protection
Complete snapshot recovery
Inconsistent snapshot recovery
Security Encrypted transmissions of cluster data. Permissions checked on file access
Permissions for users are checked on file open only
Disaster Recovery
Out of the box disaster recovery services with simple mirroring
No standard mirroring solution. Scripts are hard to manage and administer
Enterprise Integration
Minimal disruption to the ecosystem while integrating
-
Performance DirectShuffle technology leverages performance advantages
Apache Hadoop’s NFS cannot read or write to an open file.
Scalable without single point of failure
MapR clusters don’t use NameNodes and provide stateful high-availability for the MapReduce JobTracker and Direct Access NFS
Needs to be specially configured.
Proposed Architecture – Option 2 - MapR Distribution
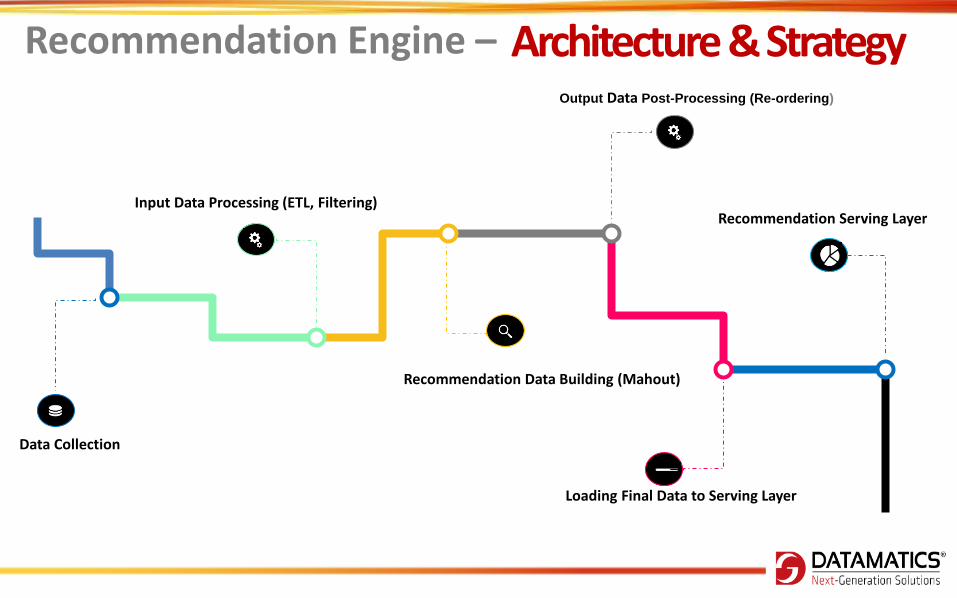
Data Collection
Input Data Processing (ETL, Filtering)
Recommendation Data Building (Mahout)
Loading Final Data to Serving Layer
Recommendation Serving Layer
Output Data Post-Processing (Re-ordering)
Recommendation Engine – Architecture & Strategy
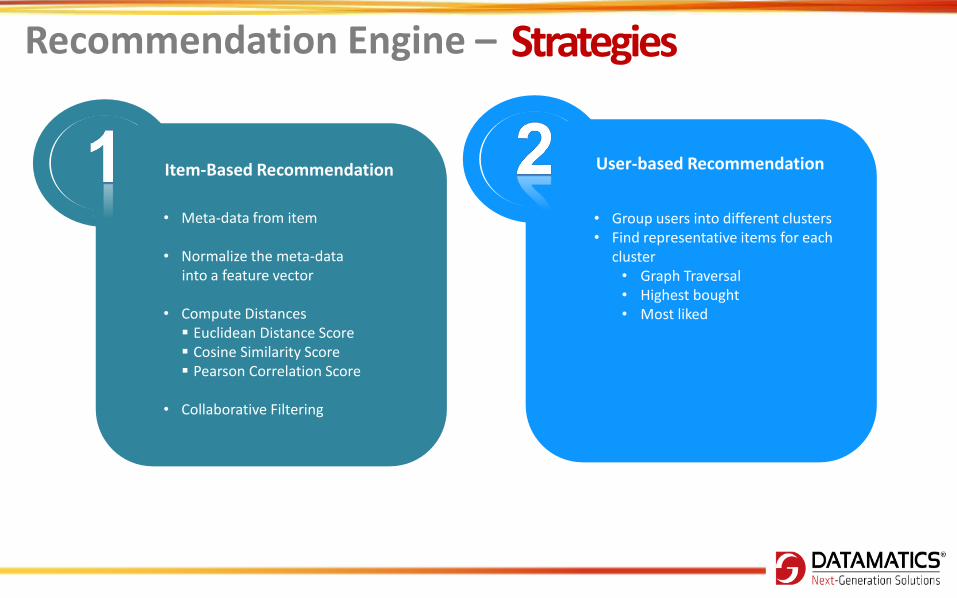
• Meta-data from item
• Normalize the meta-data into a feature vector • Compute Distances
Euclidean Distance Score Cosine Similarity Score Pearson Correlation Score
• Collaborative Filtering
Item-Based Recommendation
User-based Recommendation
• Group users into different clusters • Find representative items for each
cluster • Graph Traversal • Highest bought • Most liked
Recommendation Engine – Strategies

Construct a co-occurrence matrix (product similarity matrix), S[NxN]
Personalized Recommendation
Based on collaborative filtering
• Build preference vector
• Multiply both the matrices R = SxP
• Sort the final vector elements of R
ItemSimilarityJob
• Class to compute co-occurrence matrix
Algorithms
• Alternate Least Squares
• Singular Value Decomposition
Collaborative Filtering
RecommenderJob
• Main class to generate personalized recommendations
• Input file
• Similarities –
• CoOccurenceCountSimilarity
• TanimotoCoefficientSimilarity
• LogLikelihoodSimilarity
Role of Mahout
[ Preference matrix,S : Similarity matrix R : Recommendation matrix]