
Boston Spark Meetup event Slides Update
42
© 2015 IBM Corporation IBM Analytics for Apache Spark Rich Tarro & Virender Thakur IBM Big Data Technical Specialists WeWork (South Station) 745 Atlantic Ave, Boston, MA November 19, 2015
Transcript of Boston Spark Meetup event Slides Update
© 2015 IBM Corporation
IBM Analytics for Apache Spark
Rich Tarro & Virender Thakur
IBM Big Data Technical Specialists
WeWork (South Station)
745 Atlantic Ave, Boston, MA
November 19, 2015

© 2015 IBM Corporation2
Analytics and Development Today …. on Spark
complex | disparate | limited flexible | unified | unlimited
What is Spark

© 2015 IBM Corporation3
What Spark isn’t
A data store – Spark attaches to other data stores but does not
provide its own
Only for Hadoop – Spark can work with Hadoop (especially
HDFS), but Spark is a separate, standalone system
Only for machine learning – Spark includes machine learning
and does it very well, but it can handle much broader tasks
equally well
A replacement for Real Time Streaming Applications – Spark
Streaming employs micro-batching, not true streaming
© 2015 IBM Corporation4
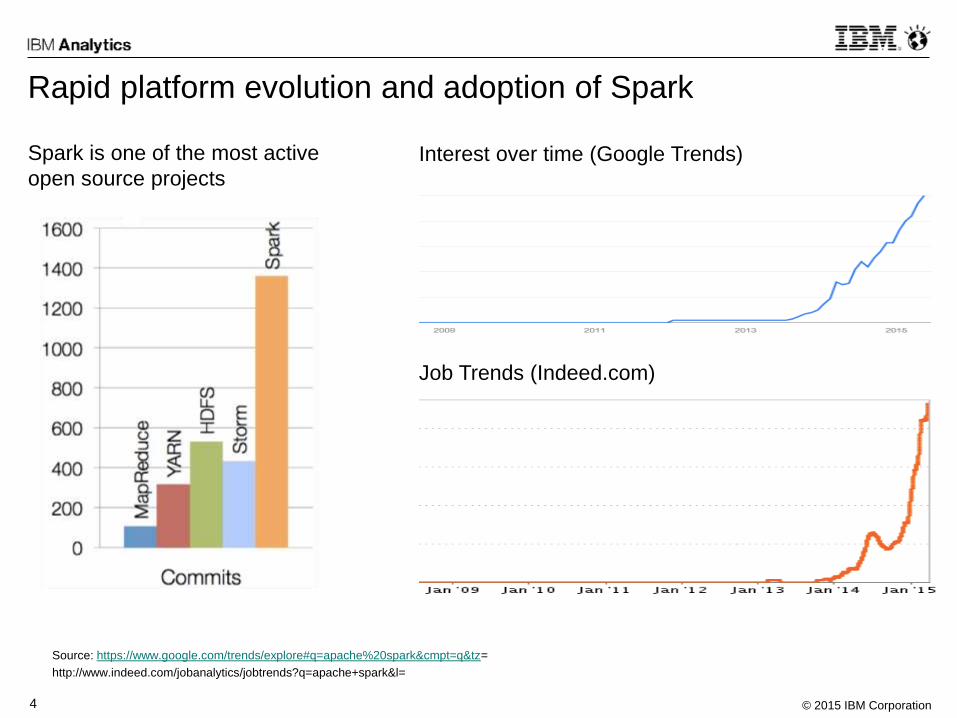
Rapid platform evolution and adoption of Spark
Spark is one of the most active
open source projects Interest over time (Google Trends)
Source: https://www.google.com/trends/explore#q=apache%20spark&cmpt=q&tz=
http://www.indeed.com/jobanalytics/jobtrends?q=apache+spark&l=
Job Trends (Indeed.com)
© 2015 IBM Corporation5
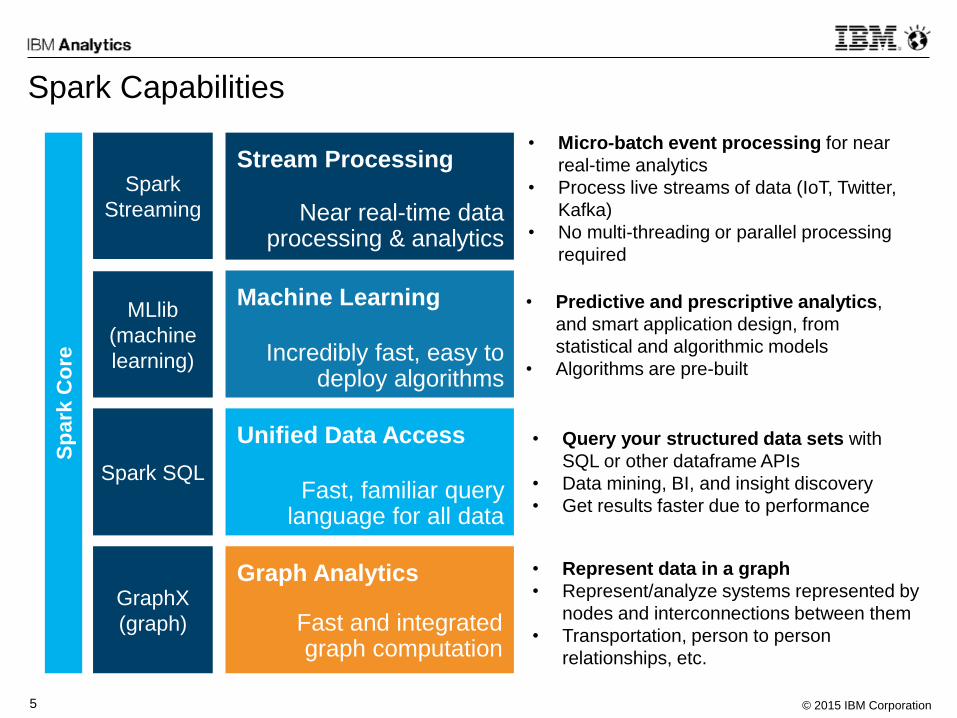
Spark Capabilities
Log processing TBD
Graph Analytics
Fast and integrated graph computation
Stream Processing
Near real-time data processing & analytics
Machine Learning
Incredibly fast, easy to deploy algorithms
Unified Data Access
Fast, familiar query language for all data
• Micro-batch event processing for near
real-time analytics
• Process live streams of data (IoT, Twitter,
Kafka)
• No multi-threading or parallel processing
required
• Predictive and prescriptive analytics,
and smart application design, from
statistical and algorithmic models
• Algorithms are pre-built
• Query your structured data sets with
SQL or other dataframe APIs
• Data mining, BI, and insight discovery
• Get results faster due to performance
• Represent data in a graph
• Represent/analyze systems represented by
nodes and interconnections between them
• Transportation, person to person
relationships, etc.
Sp
ark
Co
re
Spark SQL
Spark
Streaming
MLlib
(machine
learning)
GraphX
(graph)
© 2015 IBM Corporation6
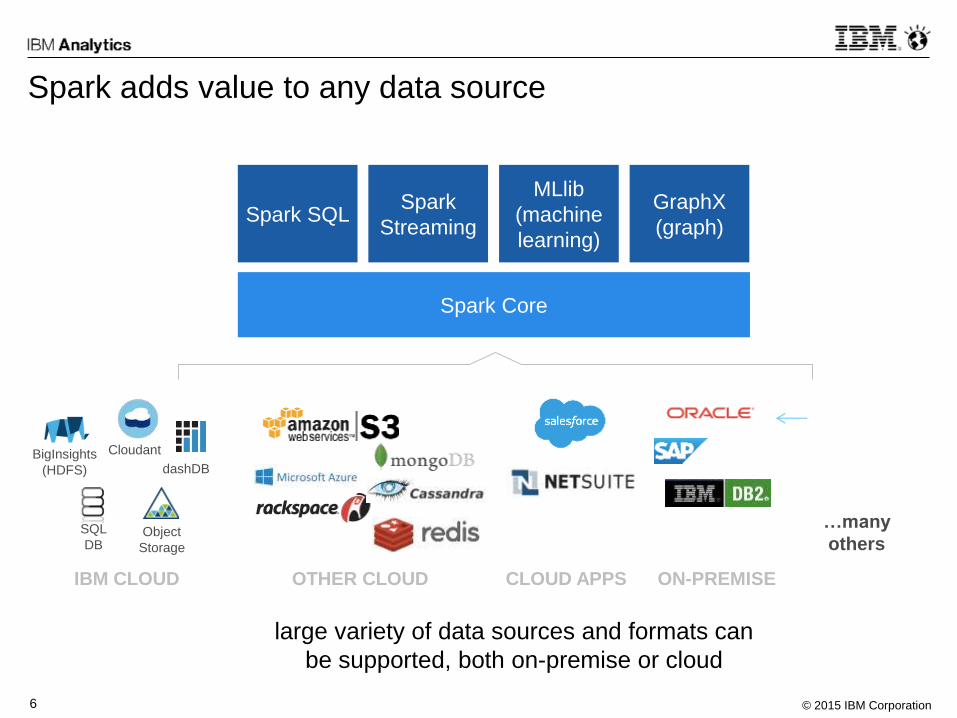
Spark adds value to any data source
Spark Core
Spark SQLSpark
Streaming
MLlib
(machine
learning)
GraphX
(graph)
large variety of data sources and formats can
be supported, both on-premise or cloud
BigInsights
(HDFS)
Cloudant
dashDB
Object
Storage
SQL
DB
…many
others
IBM CLOUD OTHER CLOUD CLOUD APPS ON-PREMISE

© 2015 IBM Corporation77
Similar divide-and-conquer architecture
of breaking large jobs into smaller
pieces
General data processing platform
suitable for batch analysis
Can coexist within existing Hadoop
environments and use Hadoop
components such as HDFS
Open source with extensive community
support
How is Spark SIMILAR to
Hadoop?
Spark vs. Hadoop
How is Spark DIFFERENT
from Hadoop?
In-memory architecture vs. file-based for
Hadoop, generates up to 100x speed
improvements
Faster speed enables new use cases such
as interactive or iterative analysis
Simpler programming model, up to 5x less
code
Multiple programming languages
supported, vs. only Java for Hadoop
Single modular platform enables extension
via libraries, not separate applications
Specialized machine learning algorithms
available
© 2015 IBM Corporation8
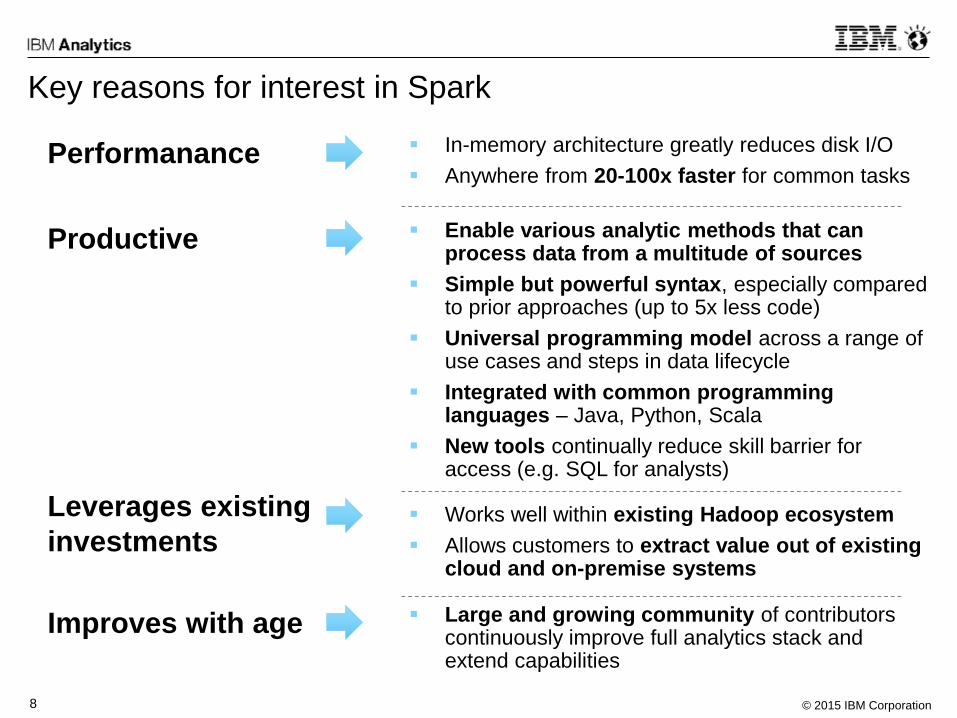
Key reasons for interest in Spark
Performanance In-memory architecture greatly reduces disk I/O
Anywhere from 20-100x faster for common tasks
Productive Enable various analytic methods that can process data from a multitude of sources
Simple but powerful syntax, especially compared to prior approaches (up to 5x less code)
Universal programming model across a range of use cases and steps in data lifecycle
Integrated with common programming languages – Java, Python, Scala
New tools continually reduce skill barrier for access (e.g. SQL for analysts)
Leverages existing
investments Works well within existing Hadoop ecosystem
Allows customers to extract value out of existing cloud and on-premise systems
Improves with age Large and growing community of contributors continuously improve full analytics stack and extend capabilities

© 2015 IBM Corporation9
Common Spark use cases
Interactive querying of very large data sets (e.g. BI)
Running large data processing batch jobs (e.g. nightly ETL from production systems, primary Hadoop use case)
Complex analytics and data mining across various types of data
Building and deploying rich analytics models (e.g. risk metrics)
Implementing near-real time stream event processing (e.g. fraud / security detection)
1
2
3
4
5

© 2015 IBM Corporation10
An RDD is a distributed collection of Scala/Python/Java objects of the same type:
RDD of strings, integers, (key, value) pairs, RDD of class Java/Python/Scala objects
An RDD is physically distributed across the cluster, but manipulated as one logical entity.
Suppose we want to know the number of names in the RDD “Names”
User simply requests: Names.count()
Spark will “distribute” count processing to all partitions so as to obtain:
• Partition 1: Mokhtar(1), Jacques (1), Dirk (1) 3
• Partition 2: Cindy (1), Dan (1), Susan (1) 3
• Partition 3: Dirk (1), Frank (1), Jacques (1) 3
Local counts are subsequently aggregated: 3+3+3=9
To lookup the first element in the RDD: Names.first()
To display all elements of the RDD: Names.collect() (careful with this)
Resilient Distributed Dataset: (Spark’s basic unit of data)
Mokhtar
Jacques
Dirk
Cindy
Dan
Susan
Dirk
Frank
Jacques
Partition 1 Partition 2 Partition 3Names

© 2015 IBM Corporation11
Resilient Distributed Datasets: Creation and Manipulation
Three methods for creation
Distributing a collection of objects from the driver program (using the parallelize method of
the spark context)
val rddNumbers = sc.parallelize(1 to 10)
val rddLetters = sc.parallelize (List(“a”, “b”, “c”, “d”))
Loading an external dataset (file)
val quotes = sc.textFile("hdfs:/sparkdata/sparkQuotes.txt")
Transformation from another existing RDD
val rddNumbers2 = rddNumbers.map(x=> x+1)
Dataset from any storage supported by Hadoop
HDFS, Cassandra, Hbase, Amazon S3, DashDB, Cloudant
Others
File types supported
Text files
SequenceFiles
Hadoop InputFormat

© 2015 IBM Corporation12
Resilient Distributed Datasets: Properties Two types of operations
Transformations ~ DDL (Create View V2 as…)
• val rddNumbers = sc.parallelize(1 to 10): Numbers from 1 to 10
• val rddNumbers2 = rddNumbers.map (x => x+1): Numbers from 2 to 11
• The LINEAGE on how to obtain rddNumbers2 from rddNumber is recorded in DAG
(Direct Acyclic Graph)
• No actual data processing does take place Lazy evaluations
Actions ~ DML (Select * From V2…)
• rddNumbers2.collect(): Array [2, 3, 4, 5, 6, 7, 8, 9, 10, 11]
• Performs transformations and action
• Returns a value (or write to a file)
Immutable
Fault tolerance
If data in memory is lost it will be recreated from lineage
Caching, persistence (memory, spilling, disk) and check-pointing
© 2015 IBM Corporation13
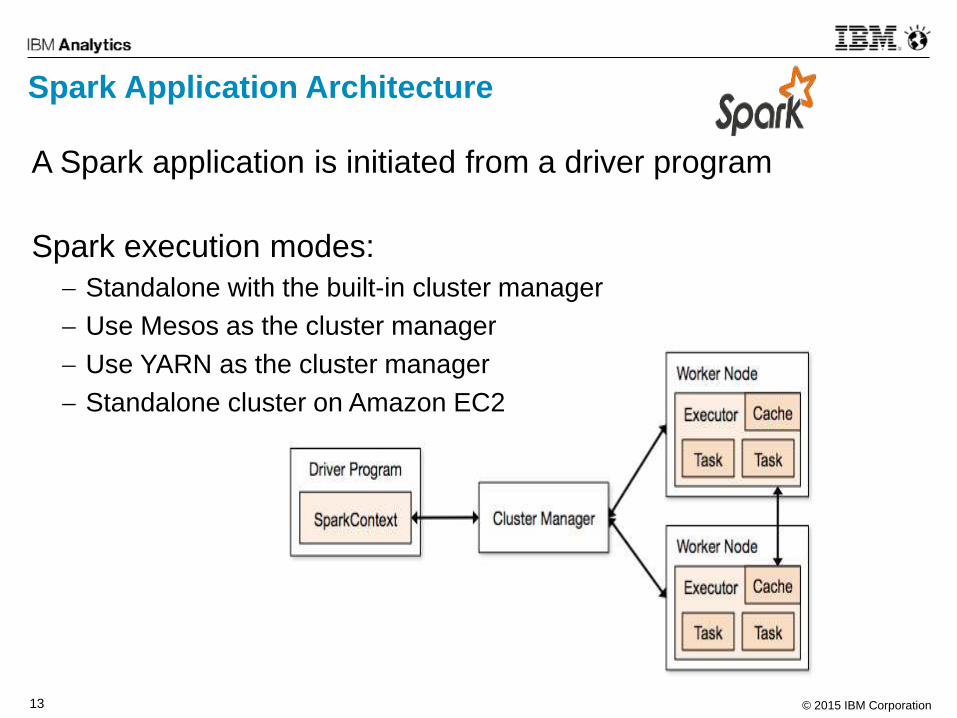
Spark Application Architecture
A Spark application is initiated from a driver program
Spark execution modes:
Standalone with the built-in cluster manager
Use Mesos as the cluster manager
Use YARN as the cluster manager
Standalone cluster on Amazon EC2
© 2015 IBM Corporation14
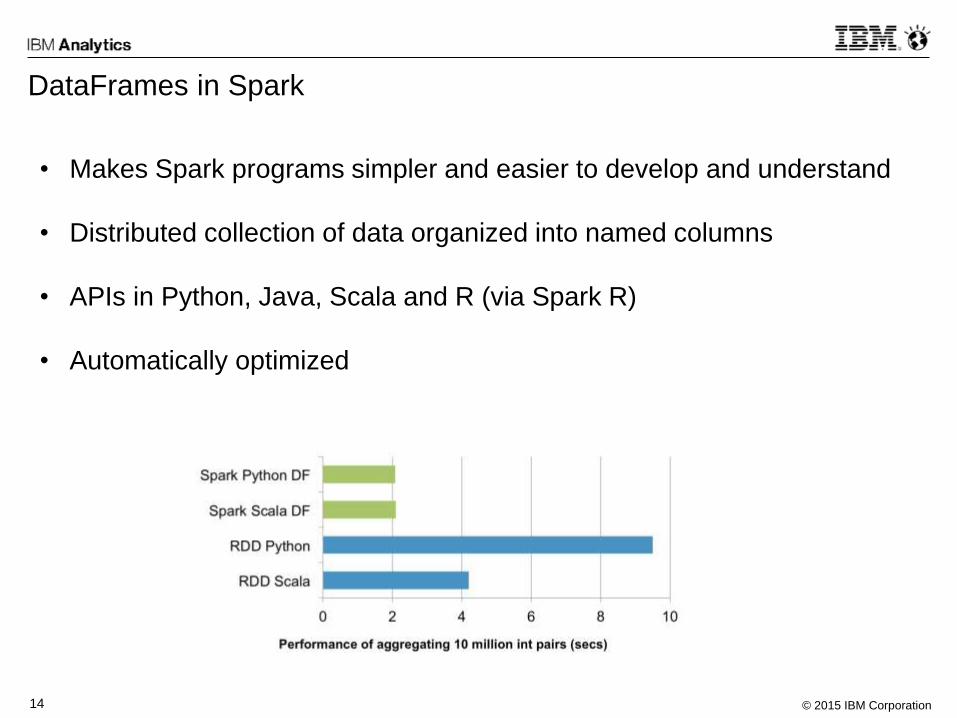
DataFrames in Spark
• Makes Spark programs simpler and easier to develop and understand
• Distributed collection of data organized into named columns
• APIs in Python, Java, Scala and R (via Spark R)
• Automatically optimized
© 2015 IBM Corporation15
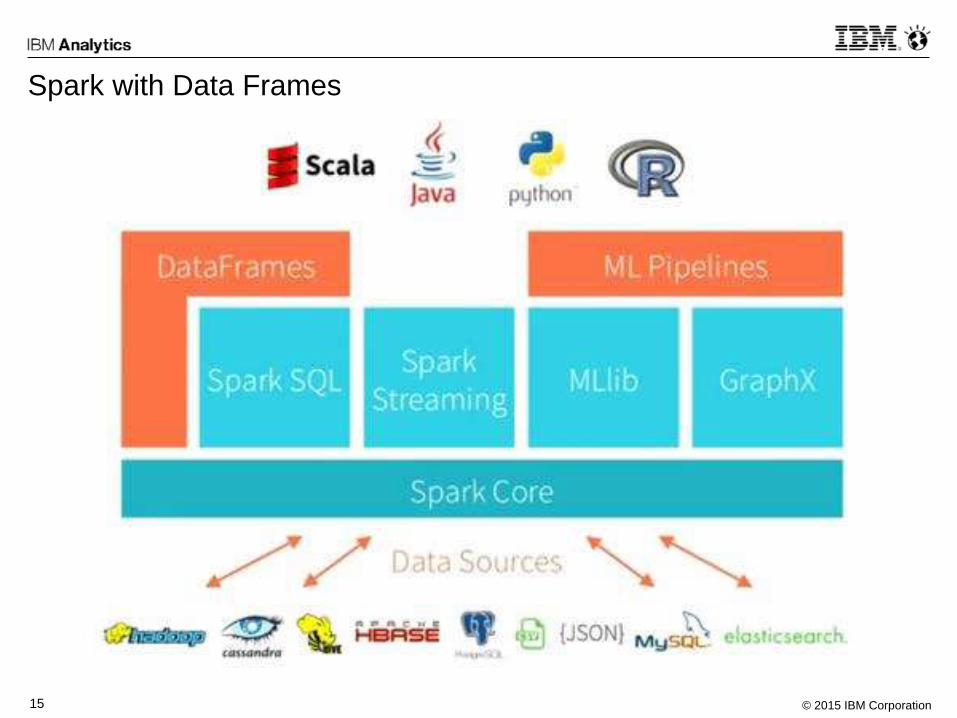
Spark with Data Frames
© 2015 IBM Corporation16
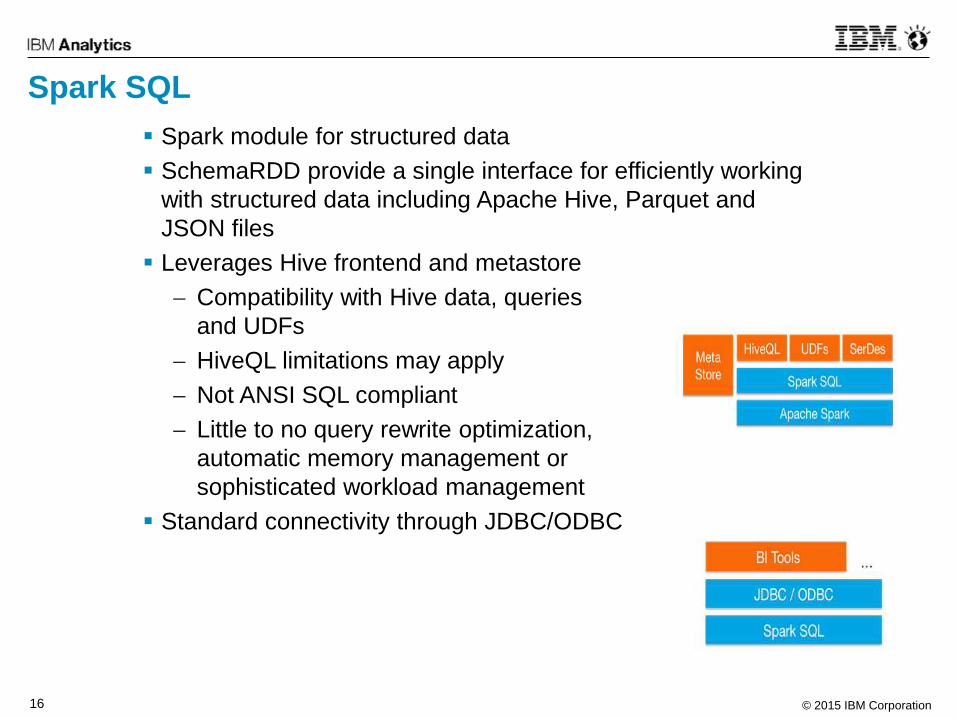
Spark SQL
Spark module for structured data
SchemaRDD provide a single interface for efficiently working
with structured data including Apache Hive, Parquet and
JSON files
Leverages Hive frontend and metastore
Compatibility with Hive data, queries
and UDFs
HiveQL limitations may apply
Not ANSI SQL compliant
Little to no query rewrite optimization,
automatic memory management or
sophisticated workload management
Standard connectivity through JDBC/ODBC

© 2015 IBM Corporation17
FYI: Some RDD Transformations
Transformations are lazy evaluations
Returns a pointer to the transformed RDDTransformation Meaning
map(func) Return a new dataset formed by passing each element of the source through a function
func.
filter(func) Return a new dataset formed by selecting those elements of the source on which func
returns true.
flatMap(func) Similar to map, but each input item can be mapped to 0 or more output items. So func
should return a Seq rather than a single item
join(otherDataset,
[numTasks])
When called on datasets of type (K, V) and (K, W), returns a dataset of (K, (V, W)) pairs
with all pairs of elements for each key.
reduceByKey(func) When called on a dataset of (K, V) pairs, returns a dataset of (K,V) pairs where the
values for each key are aggregated using the given reduce function func
sortByKey([ascending],[nu
mTasks])
When called on a dataset of (K, V) pairs where K implements Ordered, returns a dataset
of (K,V) pairs sorted by keys in ascending or descending order.
Full documentation at http://spark.apache.org/docs/1.4.1/api/scala/index.html#org.apache.spark.package
© 2015 IBM Corporation18
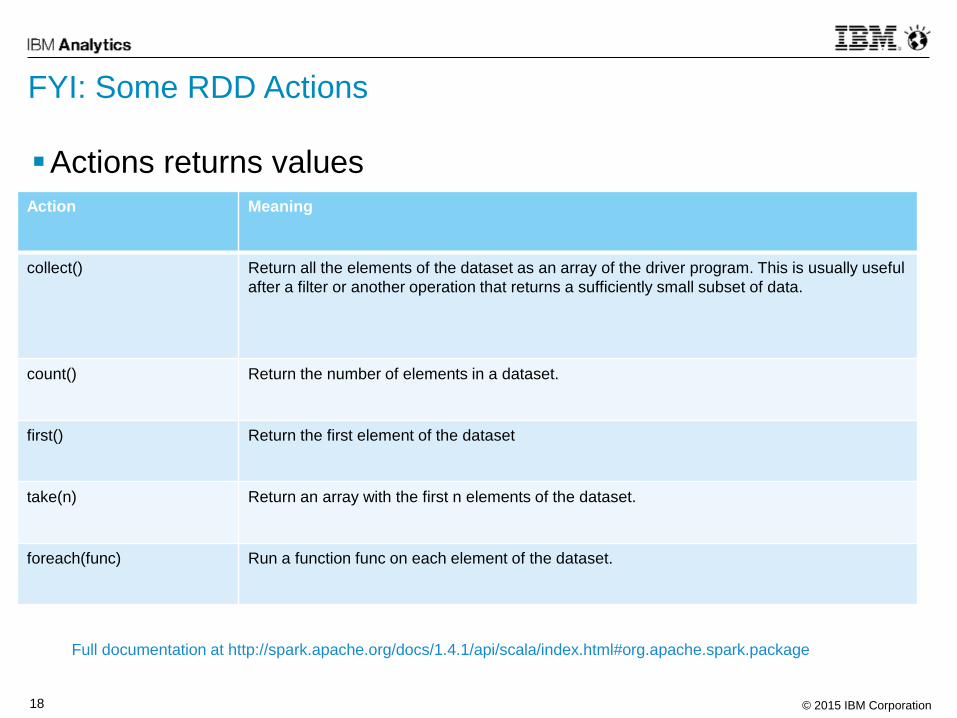
FYI: Some RDD Actions
Actions returns values
Action Meaning
collect() Return all the elements of the dataset as an array of the driver program. This is usually useful
after a filter or another operation that returns a sufficiently small subset of data.
count() Return the number of elements in a dataset.
first() Return the first element of the dataset
take(n) Return an array with the first n elements of the dataset.
foreach(func) Run a function func on each element of the dataset.
Full documentation at http://spark.apache.org/docs/1.4.1/api/scala/index.html#org.apache.spark.package

© 2015 IBM Corporation19
IBM Announces Major Commitment
to Advance Apache® Spark™

© 2015 IBM Corporation20
Announcing
Open Source SystemML
Educate One Million Data Professionals
Establish Spark Technology Center
Founding Member of AMPLab
Contributing to the Core
Our commitment to Spark

© 2015 IBM Corporation21
Big Data University MOOC
Spark Fundamentals I and II
Advanced Spark Development series
Foundational Methodology for Data Science
Partnerships with Databricks, AMPLab, DataCamp and MetiStream
Educate 1 Million Data Scientists and Data Engineers
Our investment to grow skills

© 2015 IBM Corporation22
Our goal is to be the #1 Spark contributor and adopter
Inspire the use of Spark to solve business problems
Encourage adoption through open and free educational assets
Demonstrate real world solutions to identify opportunities
Use the learning to improve Spark and its application
Spark Technology Center

© 2015 IBM Corporation23
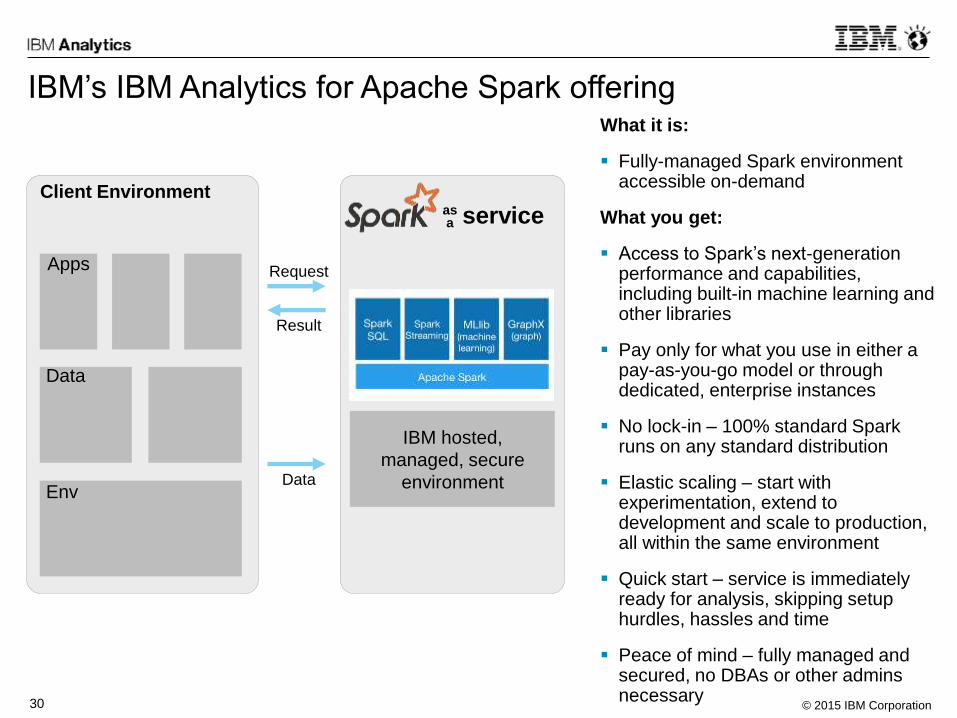
IBM’s IBM Analytics for Apache Spark offeringWhat it is:
Fully-managed Spark environment accessible on-demand
What you get:
Access to Spark’s next-generation performance and capabilities, including built-in machine learning and other libraries
Pay only for what you use in either a pay-as-you-go model or through dedicated, enterprise instances
No lock-in – 100% standard Spark runs on any standard distribution
Elastic scaling – start with experimentation, extend to development and scale to production, all within the same environment
Quick start – service is immediately ready for analysis, skipping setup hurdles, hassles and time
Peace of mind – fully managed and secured, no DBAs or other admins necessary
as aservice
IBM hosted, managed,
secure environment

© 2015 IBM Corporation24
Jupyter notebook
Browser-based document that supports code, text,
interactive visualization, math, and media.
Interactive, iterative, and collaborative work environments
for programming and analytics
Living documents that are very easy to use by both
technical and LOB users
Can take you from a concept to deploying an application in
a single environment.
© 2015 IBM Corporation25
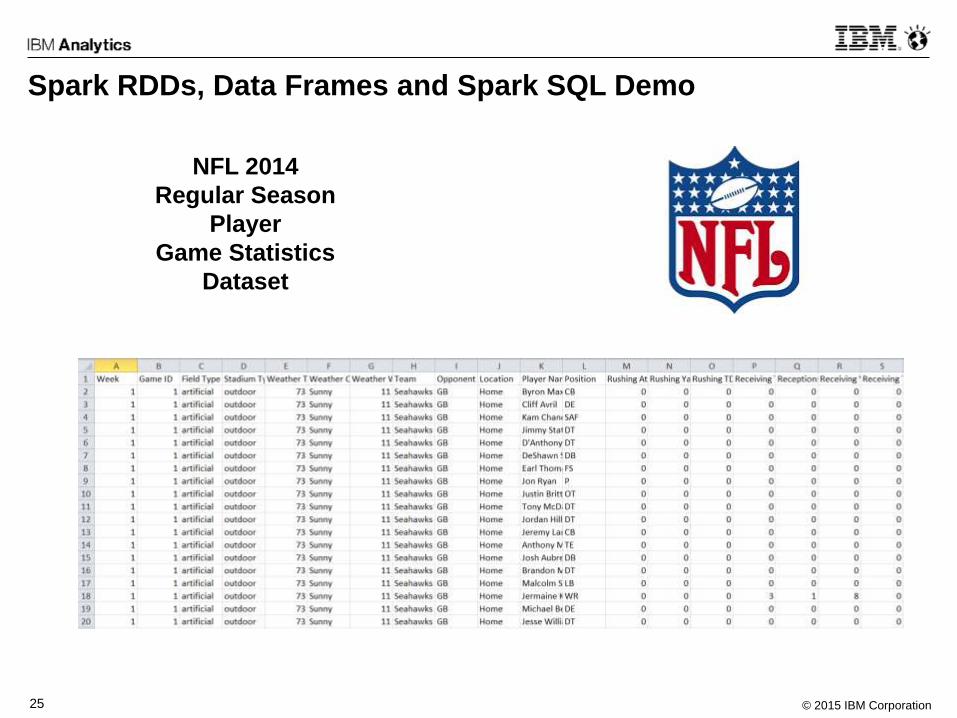
Spark RDDs, Data Frames and Spark SQL Demo
NFL 2014
Regular Season
Player
Game Statistics
Dataset

© 2015 IBM Corporation26
Demo Flow
Load data
https://community.watsonanalytics.com/analyze-nfl-data-for-the-big-
game/
Configure access to object storage
Parse data
Split CSV file lines by commas
Explore data using only RDDs
Select only WR data
Compute average WR receiving yards per game per team
List top 10 teams in descending order and plot results
Explore data using Data Frames
List top 10 teams in descending order
Explore data using Spark SQL
List top 10 teams in descending order

© 2015 IBM Corporation27
Compute average WR receiving yards per game per team (RDDs)
Data contains ‘Team’ and “Position’ and “ReceivingYards’
columns
Select only rows with WRs Position = ‘WR’
Create (key/value) pair RDD (or tuple) for each row
(Team, Receiving Yards)
Transform this tuple’s value to be sequence of values
consisting of Receiving Yards and the value “1”
(Team, (Receiving Yards, 1))
Reduce by key
(Team, (Total Receiving Yards for Team, Sum of “1”s))
Compute average for each Team
Total Receiving Yards for Team / Sum of “1”s
© 2015 IBM Corporation28
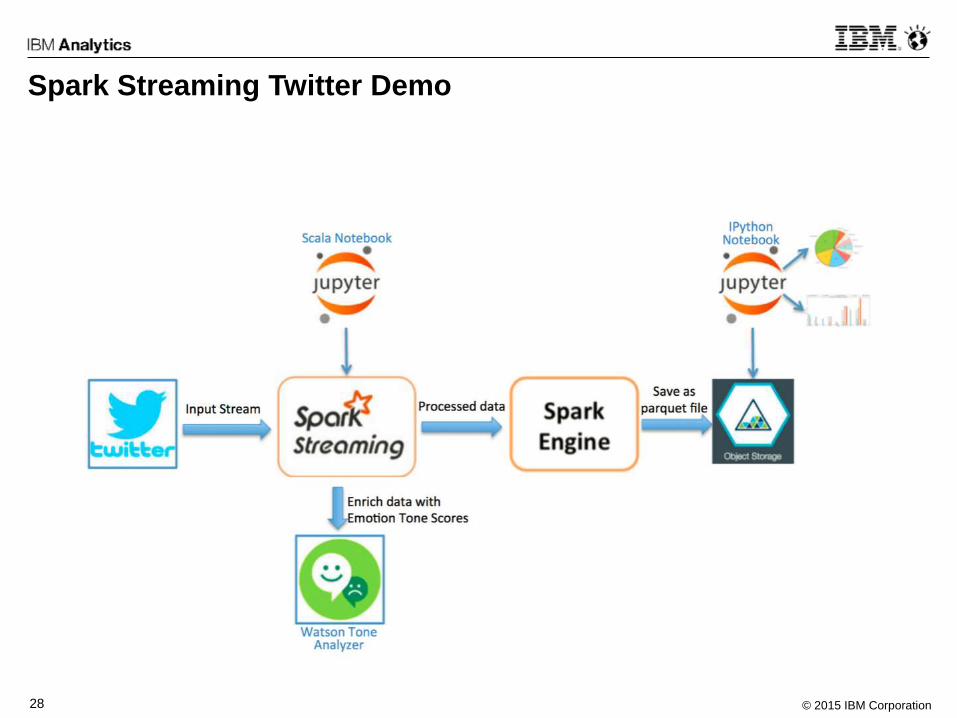
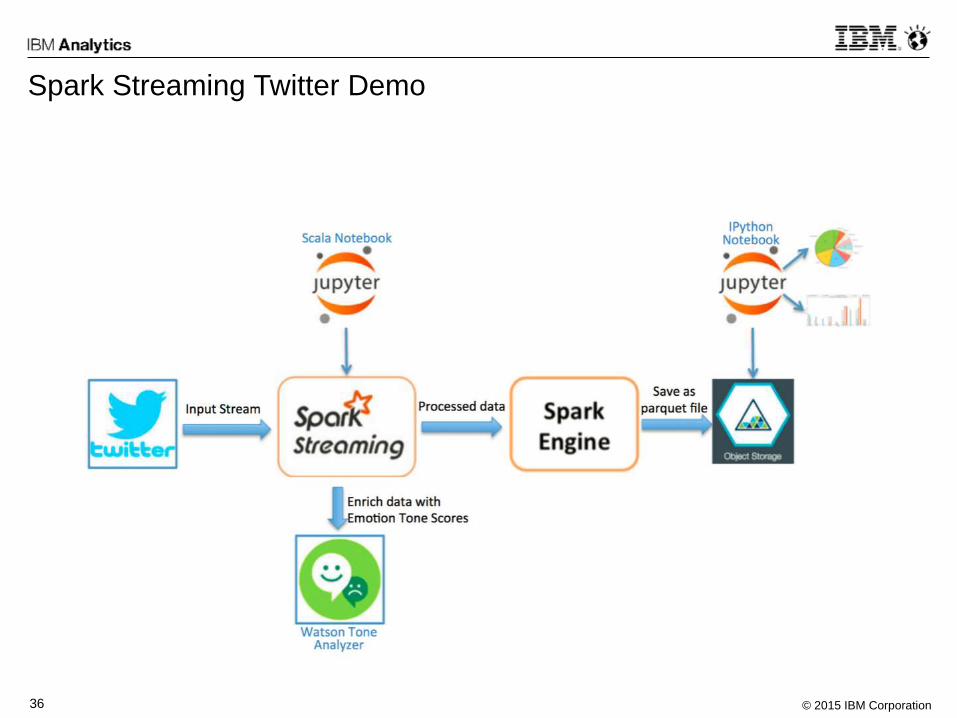
Spark Streaming Twitter Demo

© 2015 IBM Corporation29
© 2015 IBM Corporation30
IBM’s IBM Analytics for Apache Spark offeringWhat it is:
Fully-managed Spark environment accessible on-demand
What you get:
Access to Spark’s next-generation performance and capabilities, including built-in machine learning and other libraries
Pay only for what you use in either a pay-as-you-go model or through dedicated, enterprise instances
No lock-in – 100% standard Spark runs on any standard distribution
Elastic scaling – start with experimentation, extend to development and scale to production, all within the same environment
Quick start – service is immediately ready for analysis, skipping setup hurdles, hassles and time
Peace of mind – fully managed and secured, no DBAs or other admins necessary
Client Environmentas a service
IBM hosted,
managed, secure
environment
Apps
Data
EnvData
Result
Request
© 2015 IBM Corporation31
Spark RDD and Spark SQL Demos
NFL 2014
Regular Season
Player
Game Statistics
Dataset
© 2015 IBM Corporation32
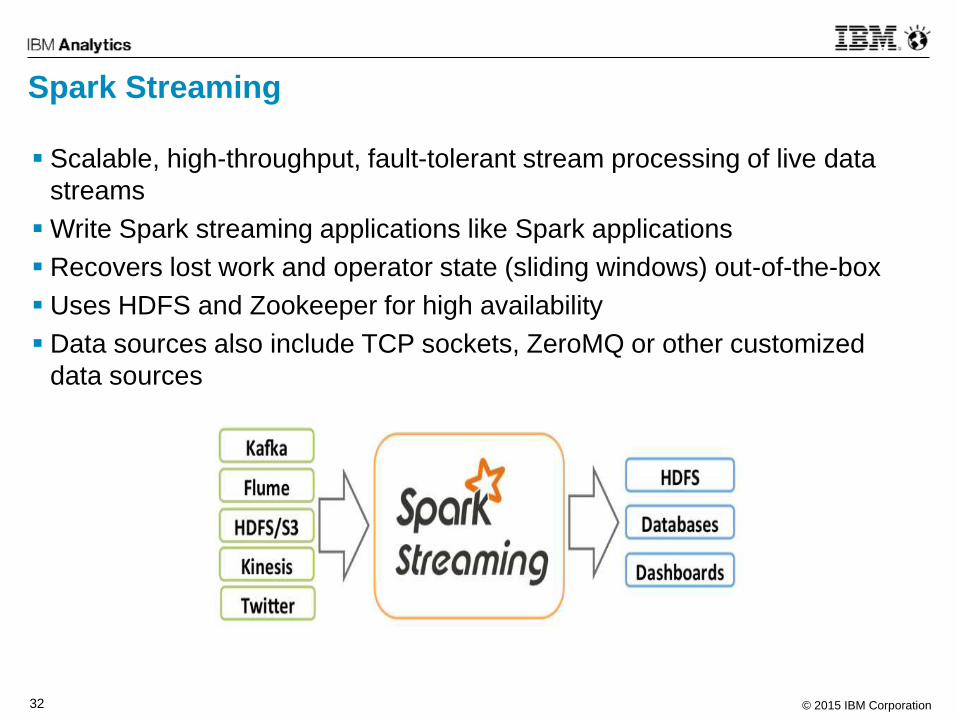
Spark Streaming
Scalable, high-throughput, fault-tolerant stream processing of live data
streams
Write Spark streaming applications like Spark applications
Recovers lost work and operator state (sliding windows) out-of-the-box
Uses HDFS and Zookeeper for high availability
Data sources also include TCP sockets, ZeroMQ or other customized
data sources
© 2015 IBM Corporation33
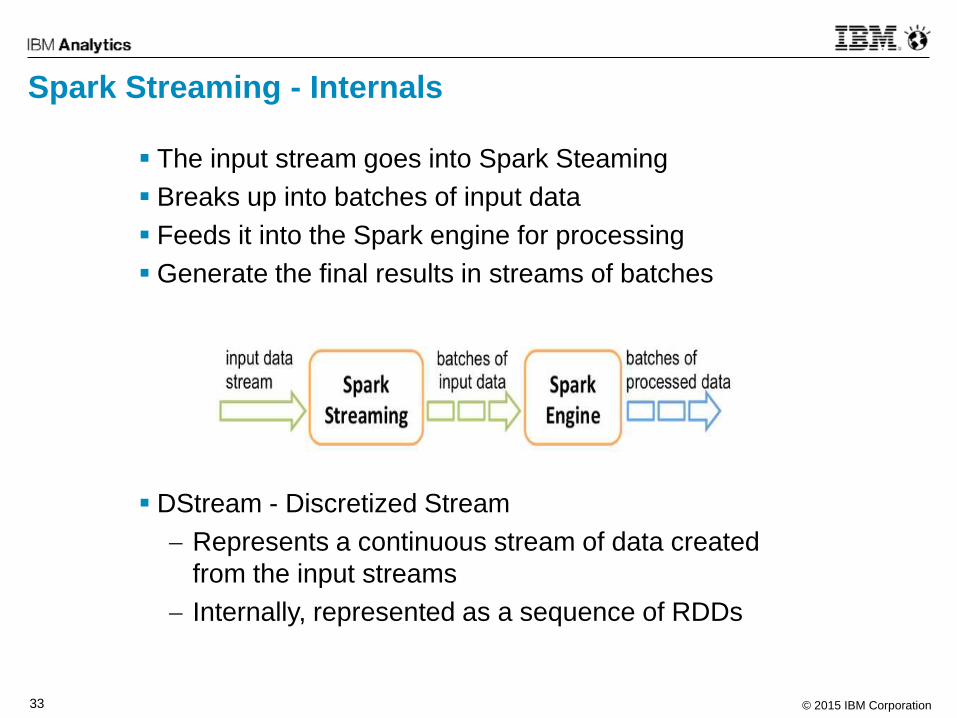
Spark Streaming - Internals
The input stream goes into Spark Steaming
Breaks up into batches of input data
Feeds it into the Spark engine for processing
Generate the final results in streams of batches
DStream - Discretized Stream
Represents a continuous stream of data created
from the input streams
Internally, represented as a sequence of RDDs
© 2015 IBM Corporation34
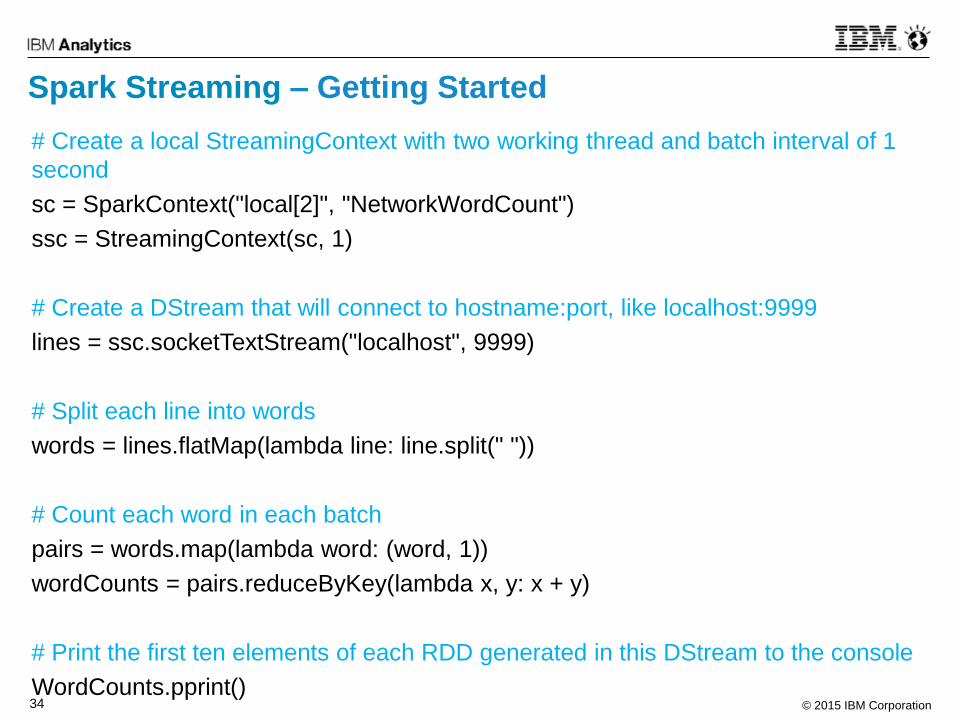
Spark Streaming – Getting Started
# Create a local StreamingContext with two working thread and batch interval of 1
second
sc = SparkContext("local[2]", "NetworkWordCount")
ssc = StreamingContext(sc, 1)
# Create a DStream that will connect to hostname:port, like localhost:9999
lines = ssc.socketTextStream("localhost", 9999)
# Split each line into words
words = lines.flatMap(lambda line: line.split(" "))
# Count each word in each batch
pairs = words.map(lambda word: (word, 1))
wordCounts = pairs.reduceByKey(lambda x, y: x + y)
# Print the first ten elements of each RDD generated in this DStream to the console
WordCounts.pprint()

© 2015 IBM Corporation35
Spark Streaming – Getting Started (continued)
# Start the computation
ssc.start()
# Wait for the computation to terminate
ssc.awaitTermination()
# RUNNING network_wordcount.py
$ ./bin/spark-submit examples/src/main/python/streaming/network_wordcount.py
localhost 9999
...
-------------------------------------------
Time: 2014-10-14 15:25:21
-------------------------------------------
(hello,1)
(world,1)
...
© 2015 IBM Corporation36
Spark Streaming Twitter Demo

© 2015 IBM Corporation37
Spark R
Spark R is an R package that provides a light-weight front-end to use Apache Spark from R
Spark R exposes the Spark API through the RDD class and allows users to interactively run jobs from the R shell on a cluster.
Goal
Make Spark R production ready
Integration with MLlib
Consolidations to the data frame and RDD concepts
© 2015 IBM Corporation38
Spark R Demo

© 2015 IBM Corporation39
Spark MLlib
Spark MLlib for machine learning
library
Marked as under active
development
Provides common algorithm and
utilities
• Classification
• Regression
• Clustering
• Collaborative filtering
• Dimensionality reduction
Leverages iteration and yields
better results
than one-pass approximations
sometimes
used with MapReduce

© 2015 IBM Corporation40
Spark GraphX
Flexible Graphing
GraphX unifies ETL, exploratory analysis, and iterative graph computation
You can view the same data as both graphs and collections, transform and join graphs with RDDs efficiently, and write custom iterative graph algorithms with the API
Speed
Comparable performance to the fastest specialized graph processing systems.
Algorithms
Choose from a growing library of graph algorithms
In addition to a highly flexible API, GraphX comes with a variety of graph algorithms

© 2015 IBM Corporation41
Resources
The “Learning Spark” O’Reilly book
Apache Spark at Bluemix
Workbench – Data Scientist Workbench
The following course on big data university

© 2015 IBM Corporation42


















