
BIRS Workshop, Banff, Canada Jan 22, 2014 © 2014 IBM Corporation Resolution and Parallelizability:...
18
BIRS Workshop, Banff, Canada Jan 22, 2014 © 2014 IBM Corporation Resolution and Parallelizability: Barriers to the Efficient Parallelization of SAT Solvers George Katsirelos MIAT, INRA, Toulouse, France Ashish Sabharwal IBM Watson, USA Horst Samulowitz IBM Watson, USA Laurent Simon Univ. Paris-Sud, LRI/CNRS, Orsay, France [published at AAAI-2013]
-
Upload
augustus-harper -
Category
Documents
-
view
217 -
download
2
Transcript of BIRS Workshop, Banff, Canada Jan 22, 2014 © 2014 IBM Corporation Resolution and Parallelizability:...

BIRS Workshop, Banff, Canada
Jan 22, 2014 © 2014 IBM Corporation
Resolution and Parallelizability:Barriers to the Efficient Parallelization of SAT Solvers
George Katsirelos MIAT, INRA, Toulouse, FranceAshish Sabharwal IBM Watson, USAHorst Samulowitz IBM Watson, USALaurent Simon Univ. Paris-Sud, LRI/CNRS, Orsay, France
[published at AAAI-2013]

Resolution and Parallelizability
© 2014 IBM Corporation
Trend Towards Parallelization
Focus Shifting From Single-Thread Performanceto Multi-Processor Performance
– 100s and even 1000s of compute cores easily accessible
– Classical Algorithm Parallelization, e.g., parallel sort, shortest path,PRAM model, AC circuits
– Significant Advances in Data Parallelisme.g., MapReduce, Hadoop, SystemML, R statistics
Challenge: Search and Optimization on 1000s of Processors
– Tremendous advances in the Sequential case of Combinatorial Search E.g., SAT solvers can tackle instances with ~2M variables, 10M constraints!
– Exponential search appears to be an “obvious” candidate to parallelize!
– In fact, many SAT/CSP/MIP solvers already do support multi-core andmulti-machine runs
2 Banff Workshop on SAT, 2014 | Katsirelos, Samulowitz, Sabharwal, Simon

Resolution and Parallelizability
© 2014 IBM Corporation
Parallelization of Combinatorial Search
Fact: State-of-the-Art Search Engines Do NOT Parallelize Well
– Brute Force exponential search is, of course, trivial to parallelize
– But sophisticated search engines that adapt (through e.g. clause learning, variable impact aggregation, etc.) have inherent sequential aspects
– Modern SAT/MIP/”adapting”-CP solvers do not parallelize well• Supporting data: next slide
AAAI 2012 Challenge Paper on the topic [Hamadi & Wintersteiger 2012]
– P-completeness of Unit Propagation a key barrier (solvers spend ~80% of the time Unit Propagating and we don’t know how to parallelize P well)
– Our result: barriers exist even if Unit Propagation came for free!
3 Banff Workshop on SAT, 2014 | Katsirelos, Samulowitz, Sabharwal, Simon

Resolution and Parallelizability
© 2014 IBM Corporation
Parallelization of Combinatorial Search: SAT
Rather Disappointing Performance at SAT Competitions – e.g., in 2011:
– Average speedup on 8 cores only ~1.8x, on 32 cores only ~3x
– Top performing parallel solvers were based on little to no communication(CryptoMinisat-MT [Soos 2012], Plingeling [Biere 2012])
– Winners were “simple” Portfolio solvers (ppfolio [Roussel], pfolioUZK [Wotzlaw et al])
Plingeling-ats-587[Dec 2013]
– Single machine with 128 coresand 128 GB memory
– Benchmark set used in thiswork, restricted to the 142instances solved by 1 core in[10,5000) seconds
4 Banff Workshop on SAT, 2014 | Katsirelos, Samulowitz, Sabharwal, Simon
1 6 640.50
5.00
1.00
1.25
1.90
2.57 2.69
1.63
Plingeling ats 587
Number of Cores
Sp
ee
du
p(g
eo
me
tric
av
era
ge
)

Resolution and Parallelizability
© 2014 IBM Corporation5 Banff Workshop on SAT, 2014 | Katsirelos, Samulowitz, Sabharwal, Simon
What makes parallelization of SAT solvers hard?
Can we obtain insights into their behaviorbeyond eventual wall-clock performance?

Resolution and Parallelizability
© 2014 IBM Corporation
Contributions of the Work
A New Systematic Study of Parallelism in the Context of Searchthrough the Lens of Proof Complexity
– Focus on understanding rather than on engineering
– Are there inherent bottlenecks that may hinder parallelization,irrespective of which heuristics are used to share information?
1. A Practical Study: Interesting properties of Actual Proofs
– Proofs generated by state-of-the-art SAT solvers contain narrow bottlenecks
2. Proof-Based Measures that capture Best-Case Parallelizability
– Coarse measure: “Depth” of the proof graph
– Refined measure: Makespan of a resource constrained scheduling problem
3. Empirical Findings: Correlations and Parallelization Limits
– Typical sequential proofs are not very parallelizable even in the best case!
– “Schedule speedup” / makespan correlates with observed speedup
6 Banff Workshop on SAT, 2014 | Katsirelos, Samulowitz, Sabharwal, Simon

Resolution and Parallelizability
© 2014 IBM Corporation
Approach: Proof Complexity (applied here to Typically Generated Proofs)
Proof Complexity [Cook & Reckhov, 1979]: Study of the nature (e.g., size, width, space, depth, “shape”, etc.) of Proofs of Unsatisfiability
– Resolution Graph of Conflict-Directed-Clause-Learning (CDCL) SAT Solvers
Runtime(any SAT solver, F) minproofs Size(Resolution proof of F)
– Note: Insights applicable also to Satisfiable instances!• Solvers prove a lot of sub-formulas to be unsatisfiable before hitting the first solution• Formal characterization [Achlioptas et al, 2001 & 2004]
Study of Proofs has provided strong insights into CDCL SAT solvers
– What does “clause learning” bring?
– What do “restarts” add?
[Beame et al, 2004; Buss et al, 2008, 2012; Hertel et al, 2008; Pipatsrisawat et al, 2011]
7 Banff Workshop on SAT, 2014 | Katsirelos, Samulowitz, Sabharwal, Simon
Worst case / Best case results

Resolution and Parallelizability
© 2014 IBM Corporation8
Underlying Inference Principle: Resolution
CDCL SAT solvers produce Resolution Derivations
Proof Graph and Depth:
– Each initial and derived constraint is a node, annotated with its proof depth
– proofdepth(initial clause C) = 0
– proofdepth(derived clause C) = 1 + maxparents proofdepth(parent(C))
C1 0 C2 0 C3 0 C4 0 C5 0 C6 0
C7 1
C8 2
C9 1
C10 3
C11 2
C12 3
C13 4
Banff Workshop on SAT, 2014 | Katsirelos, Samulowitz, Sabharwal, Simon
Constraint ID Depth
F :

Resolution and Parallelizability
© 2014 IBM Corporation9
How Parallelizable are Resolution Refutations?
Refutation(F) = Resolution Proof that derives the empty (“false”) clause
Depth of the proof clearly limits the amount of potential parallelization
– Chain of dependencies
– Theorem: All Resolution Proof Graphs of certain “pebbling” style instances have large depth; also holds for all Conflict Resolution Graphs (XOR substitution trick)
However, proofdepth bound on parallelization is very crude
– Does not explain poor performance with small k (e.g., 8, 32, … processors)
How does a typical sequential SAT solver proof look like?
– Setup for Experiments:• Sequential Glucose 2.1 extended with proof output• GluSatX10: using SatX10 to run a k-processor version of Sequential Glucose
– Working Assumption: Proofs produced by GluSatX10 on k cores look “similar”to proofs produced by Sequential Glucose
Banff Workshop on SAT, 2014 | Katsirelos, Samulowitz, Sabharwal, Simon
http://x10-lang.org/satx10 [IBM Teams: X10 and SAT/CSP]
** simplified statements; see paper for more formal notions

Resolution and Parallelizability
© 2014 IBM Corporation10
Proof Graph Example: Very Complex Structure
Banff Workshop on SAT, 2014 | Katsirelos, Samulowitz, Sabharwal, Simon
[Easy sequential case, solved in ~30 seconds]

Resolution and Parallelizability
© 2014 IBM Corporation11
Bottlenecks in Typical SAT Proofs
Banff Workshop on SAT, 2014 | Katsirelos, Samulowitz, Sabharwal, Simon
Proofs Generated by SAT Solvers Exhibit Surprisingly Narrow “Bottlenecks”, i.e., Depths with Very Few (~1) Clauses!
– Nothing deeper can be derived before bottleneck clauses Sequentiality
Depth in the proof
Nu
mb
er o
f C
lau
ses
(lo
g-sc
ale)
Der
ived
at
that
Dep
th

Resolution and Parallelizability
© 2014 IBM Corporation12
Best-Case Parallelization with k Processors
Given Proof P and k Processors, Best-Case Parallelization of P = Resource Constrained Scheduling Problem with Precedences
Let Mk(P) = makespan of the optimal schedule of P on k processors
– Even approximating Mk(P) within 4/3 is NP-hard, but (2 – 1/k) approx. is easy
Best-Case k processor speedup on P: Sk(P) = M1(P) / Mk(P)
Banff Workshop on SAT, 2014 | Katsirelos, Samulowitz, Sabharwal, Simon
C1 0 C2 0 C3 0 C4 0 C5 0 C6 0
C7 1
C8 2
C9 1
C10 3
C11 2
C12 3
C13 4Constraint ID Depth
C’9 1Example:M1(P) = 8M2(P) = 5M3(P) = 4M4(P) = 4…depth = 4
1 1 2
2 3
3 4
5

Resolution and Parallelizability
© 2014 IBM Corporation13
Makespan vs. Proof Depth
Schedule Makespan yields a finer grained lower bound, Sk(P),on best-case parallelization than proof depth
– proofdepth(P) : limit of parallelization of P with “infinite” processors
– Mk(P) proofdepth(P)
– Mk(P) proofdepth(P) as k
Banff Workshop on SAT, 2014 | Katsirelos, Samulowitz, Sabharwal, Simon

Resolution and Parallelizability
© 2014 IBM Corporation14 Banff Workshop on SAT, 2014 | Katsirelos, Samulowitz, Sabharwal, Simon
Empirical Findings

Resolution and Parallelizability
© 2014 IBM Corporation15
Even Best-Case Parallelization Efficiency is Low Beyond 100 Processors
Banff Workshop on SAT, 2014 | Katsirelos, Samulowitz, Sabharwal, Simon
Best-Case Efficiency of parallelizing P with k processors = 100 * (Sk(P) / k)
E.g., 100% = full utilization of k processors speedup = k
Resolution and Parallelizability
© 2014 IBM Corporation16
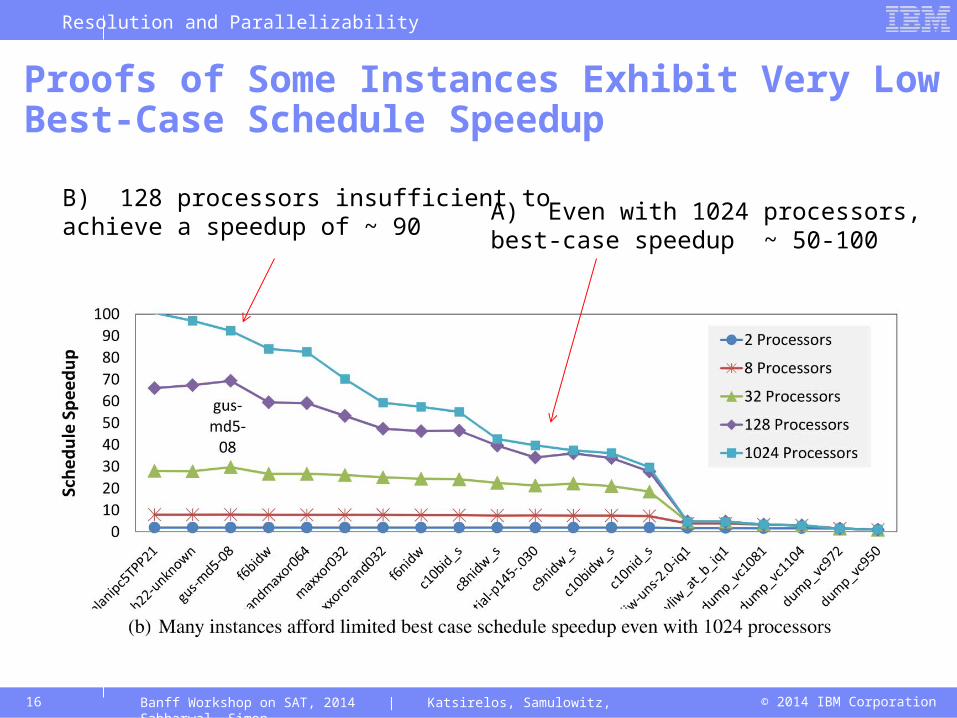
Proofs of Some Instances Exhibit Very LowBest-Case Schedule Speedup
Banff Workshop on SAT, 2014 | Katsirelos, Samulowitz, Sabharwal, Simon
A) Even with 1024 processors,best-case speedup ~ 50-100
B) 128 processors insufficient toachieve a speedup of ~ 90
Resolution and Parallelizability
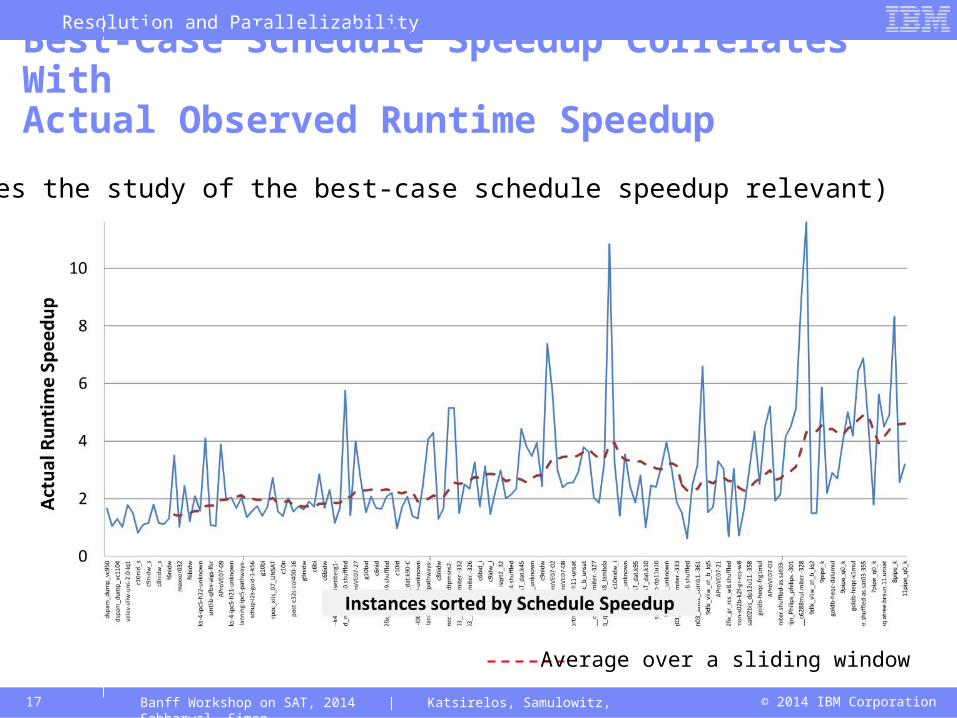
© 2014 IBM Corporation17
Best-Case Schedule Speedup Correlates WithActual Observed Runtime Speedup
Banff Workshop on SAT, 2014 | Katsirelos, Samulowitz, Sabharwal, Simon
Average over a sliding window
(Makes the study of the best-case schedule speedup relevant)

Resolution and Parallelizability
© 2014 IBM Corporation
Summary
A New Systematic Study of Parallelism in the Context of Searchthrough the Lens of Proof Complexity
– Focus on understanding rather than on engineering
Main Findings:
A. Typical Sequential Refutations Contain Surprisingly Narrow Bottlenecks
B. Typical Sequential Refutations are Not Parallelizable Beyond a Few Processors, even in the best case of offline ‘schedule speedup’ produced in hindsight
C. Observed Runtime Speedup with k processors weakly correlates withBest-Case Schedule Speedup of a Sequential Proof produced in hindsight
Open Question: Can we design SAT solvers that generate Proofs that are inherently More Parallelizable?
Caveat: assumption that proofs generated by GluSatX10 on k cores look “similar” to proofs generated by Sequential Glucose
18 Banff Workshop on SAT, 2014 | Katsirelos, Samulowitz, Sabharwal, Simon


















