
Biomedical Clusters, Clouds and Commons - DePaul Colloquium Oct 24, 2014
47
Biomedical Clusters, Clouds and Commons Robert Grossman University of Chicago Open Cloud Consor=um October 24, 2014 DePaul CDM Research Colloquium
-
Upload
robert-grossman -
Category
Data & Analytics
-
view
26 -
download
0
Transcript of Biomedical Clusters, Clouds and Commons - DePaul Colloquium Oct 24, 2014

Biomedical Clusters, Clouds and Commons
Robert Grossman University of Chicago
Open Cloud Consor=um
October 24, 2014 DePaul CDM Research Colloquium

Part 1: Biomedical discovery is being disrupted by big data

Genomic Data • DNA sequence • RNA expression • etc.
Phenotype Data • Biology • Disease • etc.
Environmental Data • Environmental exposures • Microbial environment • etc.
data driven discovery

We can produce lots of data, but why do we need so much?

The Dark MaQer of Genomic Associa=ons with Complex Diseases: Explaining the Unexplained Heritability from Genome-‐Wide Associa=ons Studies (NHGRI Workshop held in Feb 2-‐3, 2009)
Genome Wide Associa=on Studies Were Disappoin=ng Where is the missing inheritability?

What is the Gene=c Origin of Common Diseases?
allele frequency HIGH LOW
effect size
WEAK
STRONG Rare alleles
causing Mendelian diseases
Common variants implicated in
common diseases with GWAS
?
Current hypothesis: common diseases result from the combina=on of many rare variants. This requires lots of data.
Missing inheritability – GWAS by and large failed to
find the genetic origin of common diseases

One Million Genome Challenge
• Sequencing a million genomes would likely change the way we understand genomic varia=on.
• The genomic data for a pa=ent is about 1 TB (including samples from both tumor and normal =ssue).
• One million genomes is about 1000 PB or 1 EB • With compression, it may be about 100 PB • At $1000/genome, the sequencing would cost about $1B
• Think of this as one hundred studies with 10,000 pa=ents each over three years.

Four Ques=ons
1. What is the same and what is different about big biomedical data vs big science data and vs big commercial data?
2. What instrument should we use to make discoveries over big biomedical data?
3. Do we need new types of mathema=cal and sta=s=cal models for big biomedical data?
4. How do we organize large biomedical datasets and the community to maximize the discoveries we make and their impact on health care?

The standard model of biomedical compu=ng is also be disrupted by big data. What instrument do we use to make biomedical discoveries?

Standard Model of Biomedical Compu=ng
Public data repositories
Private local storage & compute
Network download
Local data ($1K)
Community socware
Socware & sweat and tears ($100K)

Instruments are dropping in cost, devices are prolifera=ng, and pa=ents are dona=ng data.

We have a problem …
Image: A large-‐scale sequencing center at the Broad Ins=tute of MIT and Harvard.
Explosive growth of data
New types of data
It takes over three weeks to download the TCGA data at 10 Gbps and requires $M’s to harmonize
Analyzing the data is more expensive than producing it
Not enough money

Source: Interior of one of Google’s Data Center, www.google.com/about/datacenters/
A possible solu=on: create large “commons” of community data and compute. (Think of this as our instrument for big data discovery)
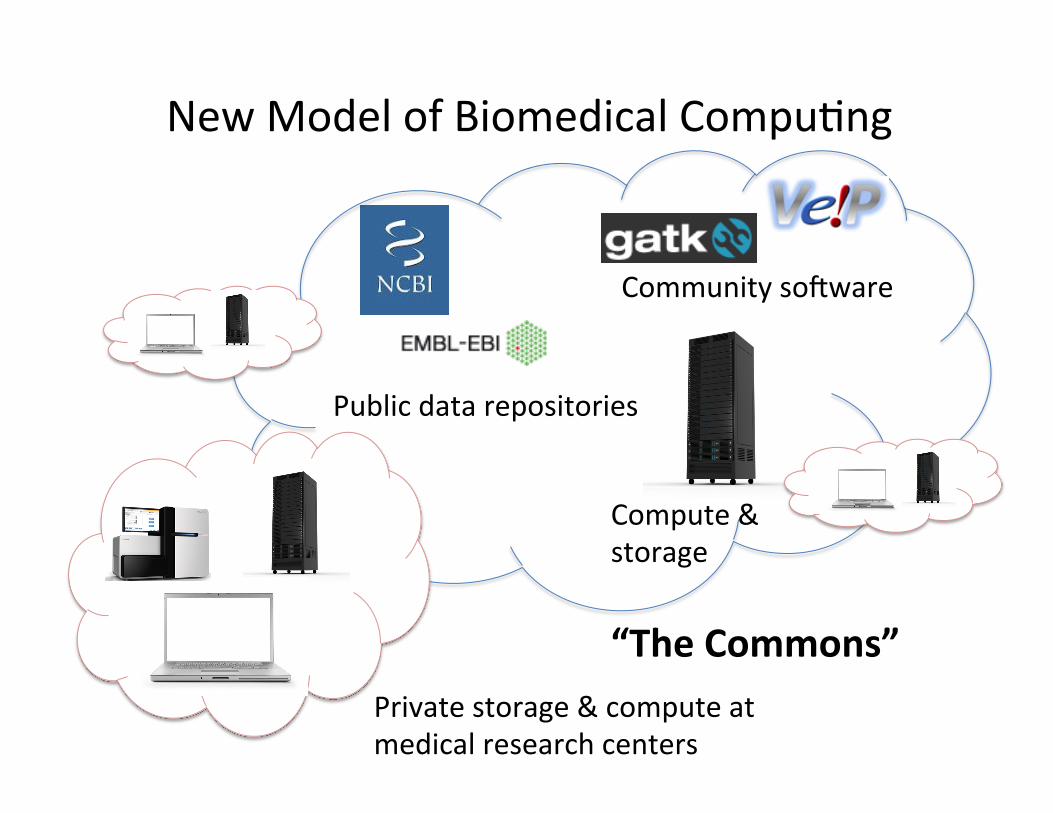
New Model of Biomedical Compu=ng
Public data repositories
Private storage & compute at medical research centers
Community socware
Compute & storage
“The Commons”

Solution: The Power of the Commons
Data
The Long Tail
Core Facilities/HS Centers
Clinical /Patient
The Why: Data Sharing Plans
The Commons
Government
The How:
Data Discovery Index
Sustainable Storage
Quality
Scientific Discovery
Usability
Security/ Privacy
Commons == Extramural NCBI == Research Object Sandbox == Collaborative Environment
The End Game:
Knowledge NIH Awardees
Private Sector
Metrics/ Standards
Rest of Academia
So2ware Standards Index
BD2K Centers
Cloud, Research Objects, Business Models Source: Philip Bourne, NIH

Part 2: Biomedical Clouds and Commons

• The Cancer Genome Atlas (TCGA) is a large scale NIH funded project that is collec=ng and sequencing disease and normal =ssue from 500 or more pa=ents x 20 cancers.
• Currently about 12,000 pa=ents are available. • There is about 4 PB of research data today and growing.

TCGA Analysis of Lung Cancer
• 178 cases of SQCC (lung cancer)
• Matched tumor & normal
• Mean of 360 exonic muta=ons, 323 CNV, & 165 rearrangements per tumor
• Tumors also vary spa=ally and temporally. Source: The Cancer Genome Atlas Research Network, Comprehensive genomic
characteriza=on of squamous cell lung cancers, Nature, 2012, doi:10.1038/nature11404.

Clonal Evolu=on of Tumors
Tumors evolve temporally and spa=ally.
Source: Mel Greaves & Carlo C. Maley, Clonal evolu=on in cancer, Nature, Volume 241, pages 306-‐312, 2012.

TNBC
ER+
Source: White Lab, University of Chicago.
Tumors have genomic signatures that can stra=fy diseases so we can treat each stratum differently.

Cyber Pods • New data centers are some=mes divided into “pods,” which can be built out as needed.
• A reasonable scale for what is needed for a commons is one of these pods.
• Let’s use the term “cyber pod” for a por=on of a data center whose cyber infrastructure is dedicated to a par=cular project.
Pod A Pod B

The Bionimbus Protected Data Cloud

Analyzing Data From The Cancer Genome Atlas (TCGA)
1. Apply for access to data (using dbGaP).
2. Hire staff, set up and operate secure compliant compu=ng environment to mange 10 – 100+ TB of data.
3. Get environment approved by your research center.
4. Setup analysis pipelines. 5. Download data from CG-‐
Hub (takes days to weeks). 6. Begin analysis.
Current Prac2ce With Bionimbus Protected Data Cloud (PDC) 1. Apply for access to data
(using dbGaP). 2. Use your exis=ng NIH grant
creden=als to login to the PDC, select the data that you want to analyze, and the pipelines that you want to use.
3. Begin analysis.

Open Science Data Cloud
• 500 users use OSDC resources • 150 ac=ve each month • Users u=lize between 1000 – 100,000+
core hours per month for compu=ng over PB scale commons of data

Goals of the OSDC Commons
• Build a commons to store, harmonize and analyze exis=ng biomedical data that scales to 5-‐100+ PB
• The commons must support “permanent” genomic data, clinical data, environmental data, social media data, donated data, etc.
• The commons must provide an interac=ve system for researchers and eventually pa=ents to upload their data.
• Researchers should be able to “pay for compute.” • Pa=ents should be able to use the commons to inform their treatment.

The Tragedy of the Commons
Source: GarreQ Hardin, The Tragedy of the Commons, Science, Volume 162, Number 3859, pages 1243-‐1248, 13 December 1968.
Individuals when they act independently following their self interests can deplete a deplete a common resource, contrary to a whole group's long-‐term best interests.
GarreQ Hardin

Cloud 1 Cloud 3
Data Commons 1 Commons provide data to other commons and to clouds
Research projects producing data
Research scien=sts at medical research center B
Research scien=sts at medical research center C
Research scien=sts at medical research center A downloading data
Community develops open source socware stacks for commons and clouds
Cloud 2 Data
Commons 2

Cloud 1
Data Commons 1
Data Commons 2
Data Peering
• Tier 1 Commons exchange data for the research community at no charge.

OSDC Commons Architecture
Object storage (permanent)
Scalable light weight workflow
Community data products (data harmoniza=on)
Data submission portal
Open APIs for data access and data access portal
Co-‐located “pay for compute”
“Permanent” Digital ID Service & Metadata Service
Devops suppor=ng virtualized environments

Part 3: Analyzing Data at the Scale of a Cyber Pod (the need for a new data science)
Source: Jon Kleinberg, Cornell University, www.cs.cornell.edu/home/kleinber/networks-‐book/

Complex models over small data that are highly manual.
Simpler models over large data that are highly automated.
Small data Medium data
GB TB PB
W KW MW
Big data
Cyber pods

Is More Different? Do New Phenomena Emerge at Scale in Biomedical Data?
Source: P. W. Anderson, More is Different, Science, Volume 177, Number 4047, 4 August 1972, pages 393-‐396.
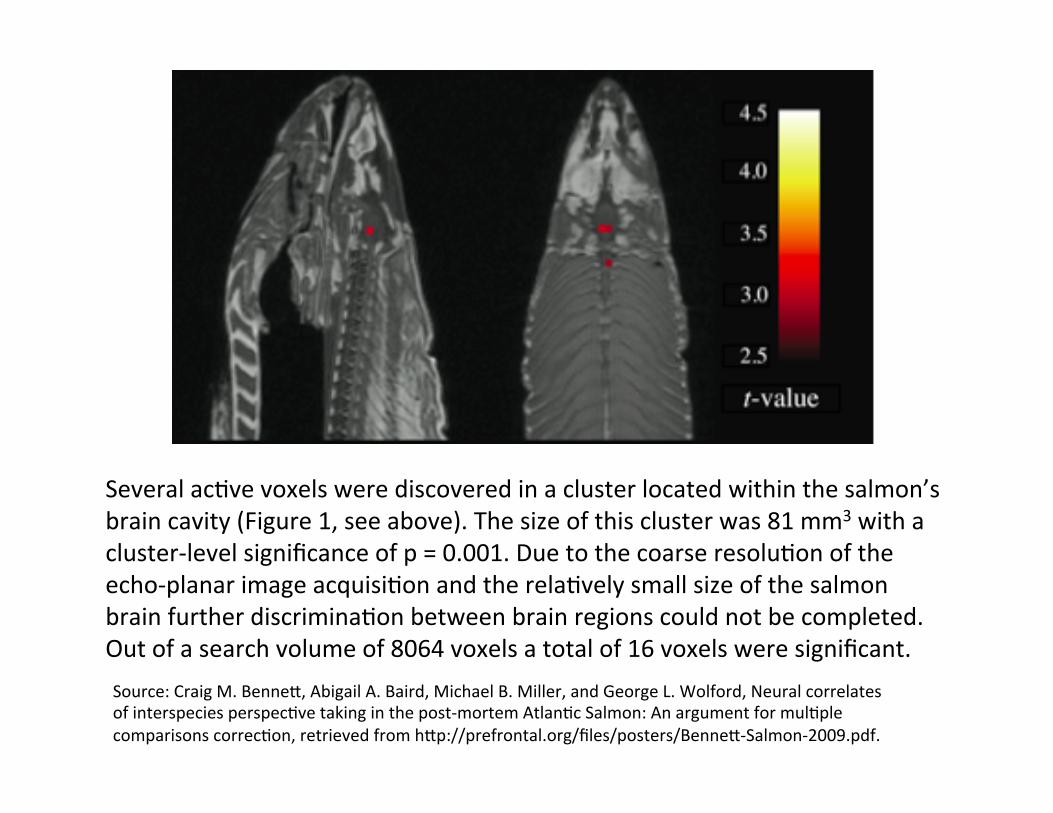
Several ac=ve voxels were discovered in a cluster located within the salmon’s brain cavity (Figure 1, see above). The size of this cluster was 81 mm3 with a cluster-‐level significance of p = 0.001. Due to the coarse resolu=on of the echo-‐planar image acquisi=on and the rela=vely small size of the salmon brain further discrimina=on between brain regions could not be completed. Out of a search volume of 8064 voxels a total of 16 voxels were significant. Source: Craig M. BenneQ, Abigail A. Baird, Michael B. Miller, and George L. Wolford, Neural correlates of interspecies perspec=ve taking in the post-‐mortem Atlan=c Salmon: An argument for mul=ple comparisons correc=on, retrieved from hQp://prefrontal.org/files/posters/BenneQ-‐Salmon-‐2009.pdf.

4. Center for Data Intensive Science at the University of Chicago

Center for Data Intensive Science • New center whose mission is data science and the data
intensive compu=ng that is required to support it. • Focus on applica=ons in biology, medicine and health care,
but interested in all of data science. • CDIS is organizing around some challenge problems and
building an open data and open source ecosystem to support big data science.
• Leveraging “instruments” such as the Protected Data Cloud and the Open Science Data Cloud.
• Building data commons for the research community, star=ng with a data commons for genomic data.
• POV: “more is different.”

Data Science
Data Intensive Applica=ons
Data center scale compu=ng (“cyber pods”)
Data driven discoveries
Data driven diagnosis
Data driven therapeu=cs
We are developing a socware stack that scales to a cyber pod and cura=ng “commons of data” that we can use as an “instrument” for data driven discoveries

Biomedical Commons Clouds (BCC)
• The not-‐for-‐profit Open Cloud Consor=um is developing and opera=ng a biomedical commons and cloud called the Biomedical Commons Cloud or BCC
• BCC is a global consor=um that includes universi=es, companies and medical research centers
• Please let me know if you are interested

Source: David R. Blair, Christopher S. LyQle, Jonathan M. Mortensen, Charles F. Bearden, Anders Boeck Jensen, Hossein Khiabanian, Rachel Melamed, Raul Rabadan, Elmer V. Bernstam, Søren Brunak, Lars Juhl Jensen, Dan Nicolae, Nigam H. Shah, Robert L. Grossman, Nancy J. Cox, Kevin P. White, Andrey Rzhetsky, A Non-‐Degenerate Code of Deleterious Variants in Mendelian Loci Contributes to Complex Disease Risk, Cell, September, 2013
5. Challenges

The 5P Challenges
• Permanent objects
• Cyber Pods that scale • Data Peering • Portable data • Support Pay for compute

Challenge 1: Permanent Secure Objects
• How do I assign Digital IDs and key metadata to “controlled access” data objects and collec=ons of data objects to support distributed computa=on of large datasets by communi=es of researchers? – Metadata may be both public and controlled access – Objects must be secure
• Think of this as a “dns for data.” • The test: One Commons serving the cancer community can transfer 1 PB of BAM files to another Commons and no bioinforma=cians need to change their code

Challenge 2: Cyber Pods
• How can I add a rack of compu=ng/storage/networking equipment to a cyber pod (that has a manifest) so that – Acer aQaching to power – Acer aQaching to network – No other manual configura=on is required – The data services can make use of the addi=onal infrastructure
– The compute services can make use of the addi=onal infrastructure
• In other words, we need an open source socware stack that scales to cyber pods.

Challenge 3: Data Peering
• How can a cri=cal mass of data commons support data peering so that a research at one of the commons can transparently access data managed by one of the other commons – We need to access data independent of where it is stored
– “Tier 1 data commons” need to pass community managed data at no cost
– We need to be able to transport large data efficiently “end to end” between commons

Challenge 4: Biomedical Data Portability
• We need an “Indigo BuQon” to safely and compliantly move our biomedical data between Commons.
• Similar to the HHS “Blue BuQon.”

Challenge 5: Pay for Compute Challenges – Low Cost Data Integra=on
• Today, we by and large integrate data with graduate students and technical staff
• How can two datasets from two different commons be “joined” at “low cost” – Linked data – Controlled Vocabularies – Dataspaces – Universal Correla=on Keys – Sta=s=cal methods

2005 -‐ 2015 Bioinforma2cs tools & their integra2on. Examples: Galaxy, GenomeSpace, workflow systems, portals, etc.
2010 -‐ 2020 Data center scale science. Interoperability and preserva=on/peering/portability of large biomedical datasets. Examples: Bionimbus/OSDC, CG Hub, Cancer Collaboratory, GenomeBridge, etc.
2015 -‐ 2025 New modeling techniques. The discovery of new & emergent behavior at scale. Examples: What are the founda=ons? Is more different?

Ques=ons?
46

Major funding and support for the Open Science Data Cloud (OSDC) is provided by the Gordon and BeQy Moore Founda=on. This funding is used to support the OSDC-‐Adler, Sullivan and Root facili=es. Addi=onal funding for the OSDC has been provided by the following sponsors: • The Bionimbus Protected Data Cloud is supported in by part by NIH/NCI through NIH/SAIC Contract
13XS021 / HHSN261200800001E. • The OCC-‐Y Hadoop Cluster (approximately 1000 cores and 1 PB of storage) was donated by Yahoo!
in 2011. • Cisco provides the OSDC access to the Cisco C-‐Wave, which connects OSDC data centers with 10
Gbps wide area networks. • The OSDC is supported by a 5-‐year (2010-‐2016) PIRE award (OISE – 1129076) to train scien=sts to
use the OSDC and to further develop the underlying technology. • OSDC technology for high performance data transport is support in part by NSF Award 1127316. • The StarLight Facility in Chicago enables the OSDC to connect to over 30 high performance
research networks around the world at 10 Gbps or higher. • Any opinions, findings, and conclusions or recommenda=ons expressed in this material are those
of the author(s) and do not necessarily reflect the views of the Na=onal Science Founda=on, NIH or other funders of this research.
The OSDC is managed by the Open Cloud Consor=um, a 501(c)(3) not-‐for-‐profit corpora=on. If you are interested in providing funding or dona=ng equipment or services, please contact us at [email protected].


















