
Bill Cochran Oak Ridge National Laboratory [email protected] The AMP Backplane Discreet Management...
18
Bill Cochran Oak Ridge National Laboratory [email protected] The AMP Backplane Discreet Management of Numerical Libraries and Multiphysics Data
-
Upload
henry-mathews -
Category
Documents
-
view
221 -
download
3
Transcript of Bill Cochran Oak Ridge National Laboratory [email protected] The AMP Backplane Discreet Management...

Bill CochranOak Ridge National [email protected]
The AMP BackplaneDiscreet Management of Numerical Libraries and Multiphysics Data

The AMP BackplaneDiscreet Management of Numerical Libraries and Multiphysics Data
Oak Ridge National LabKevin ClarnoBobby PhilipBill CochranSrdjan SimunovicRahul SampathSrikanth AlluGokan YesilyurtJung Ho LeeJames BanfieldPallab Barai
Los Alamos National LabGary DiltsBogdan Mihaila
Idaho National LabRichard MartineauGlen HansenSamet KadiogluRay Berry
Oak Ridge National LabSreekanth PannalaPhani NukalaLarry OttJay Billings
Los AlamosNational LabMike Rogers
Argonne National LabAbdellatif Yacout
Los Alamos National LabCetin UnalSteven Lee
Oak Ridge National LabLarry OttJohn Turner
Argonne National LabMarius Stan
Developers: Collaborators: Advisors:

Epetra_Vector x;Vec y;N_Vector z;
VecAXPBYPCZ ( z , alpha , 1 , 0 , x , y );
The AMP Backplane
Vectors

Why So Many Libraries?
AMP uses:
Moertel and ML
SNES and KSP
IDA
ContactPreconditioning
JFNK
Time integration
Epetra_CrsMatrix P;Mat A;N_Vector x, y, z;
P.Multiply ( false , x , y );MatMult ( A , y , z );
Vec multiPhysicsSolution;Vec tempPellet, displacementPellet;Vec thermoMechanicsPellet;
SolveThermoMechanics ( thermoMechanicsPellet );
Epetra_Vector x;Vec y;N_Vector z;
VecAXPBYPCZ ( z , alpha , 1 , 0 , x , y );
The AMP Backplane
VectorsMatricesMeshes
MechanicsTemperature
Oxygen DiffusionBurn UpNeutronicsEtc.stk::mesh::Entity curElement;
libMesh::FE integrator;
integrator.reinit ( &curElement );

How Does It Work?
Virtual methods
Polymorphism
Templates
Iterators
Standard template library
TheLessYouKnow

How Do I Use It?
Master six classes
AMP::Vector
AMP::Matrix
AMP::MeshManager
AMP::MeshManager::Adapter
AMP::Variable
AMP::DOFMap
Linear combinations,Norms,Get/Setetc.
Matrix-Vector productsScalingetc.
Multiple domainsParallel managementI/OSpace allocationetc.
Entity iterationBoundary conditionsMemory managementVector indexingetc.
Mapping meshentities to indices invectors and matrices
Describe desiredmemory layoutIndex individual physics

In Parallel
How Do I Use It?
Step 1: makeConsistent()
Step 2: ???
Step 3: Profit!
MulticoreMulti-multicore

AMP::Vector::shared_ptr thermalResidual;AMP::Vector::shared_ptr thermalSolution;
thermalResidual = residual->subsetVectorForVariable ( temperatureVar );thermalSolution = solution->subsetVectorForVariable ( temperatureVar );
AMP::Vector::shared_ptr epetraView; epetraView = AMP::EpetraVector::view ( vector );
Epetra_Vector &epetraVec = epetraView->castTo<AMP::EpetraVector>().getEpetra_Vector();
AMP::Vector::shared_ptr sundialsView; sundialsView = AMP::SundialsVector::view ( vector );
N_Vector sundialsVec;sundialsVec = sundialsView->castTo<AMP::SundialsVector>().getNVector();
How Discreet Is It?
AMP::Vector::shared_ptr petscView; petscView = AMP::PetscVector::view ( vector );
Vec petscVec;petscVec = petscView->castTo<AMP::PetscVector>().getVec();
-Most vector functionality-Enough matrix functionality-Works with SNES and KSP
-Most vector functionality-Works with IDA-Single domain/single physics-Default linear algebra engine-Hopefully, limitation eased by Tpetra
-Variables describe- Memory layout- Physics- Discretization

What About Performance?
1) C++2) Virtual methods Clever compiler
optimizations
Iterative access: L2Norm(), dot(), min(), axpy(), scale(), …
Non-iterative access:for ( i = 0 ; i != numElems ; i++ ) for ( j = 0 ; j != 8 ; j++ ) vector->addValue ( elem[8*i+j] , phi );
FORTRAN-esque speed

Digression
Time to perform dot product 2 vectors:
Virtual method penalty: Time to perform tight loop virtual methoddot product: Dot product # floating point ops:
Dot product FLOPS (FORTRAN style):
Similar sized matvec w.r.t. FLOPS:
matvec cache penalty:
0.05 secs50%
0.075 secs2n-1
40n-20
24n-12
40%

What About Performance?
1) C++2) Virtual methods Clever compiler
optimizations
Iterative access:
Non-iterative access:for ( i = 0 ; i != numElems ; i++ ) for ( j = 0 ; j != 8 ; j++ ) vector->addValue ( elem[8*i+j] , phi[j] );
FORTRAN-esque speed
for ( i = 0 ; i != numElems ; i++ ) vector->addValues ( 8 , elem + 8*i , phi );

Does it work?
100,000+ unit tests:
AMP interfaceAMP interface vs PETScAMP interface vs EpetraPETSc wrappersSUNDIALS wrappersEpetra vs PETScVarious bugs found in
development
Single physics, single domainMultiple physics, single domainSingle physics, multiple domainsMultiple physics, multiple domainsMultiple linear algebra engines
ViewsClonesClones of viewsViews of clones
AMP vectorsPETSc viewsSundials views
SerialParallel

SUNDIALS IDA time integration
PETSc SNES JFNKquasi-static
Trilinos ML preconditioning
What Can It Do?
What Can It Do?Ti
me
(s)
Number of cores
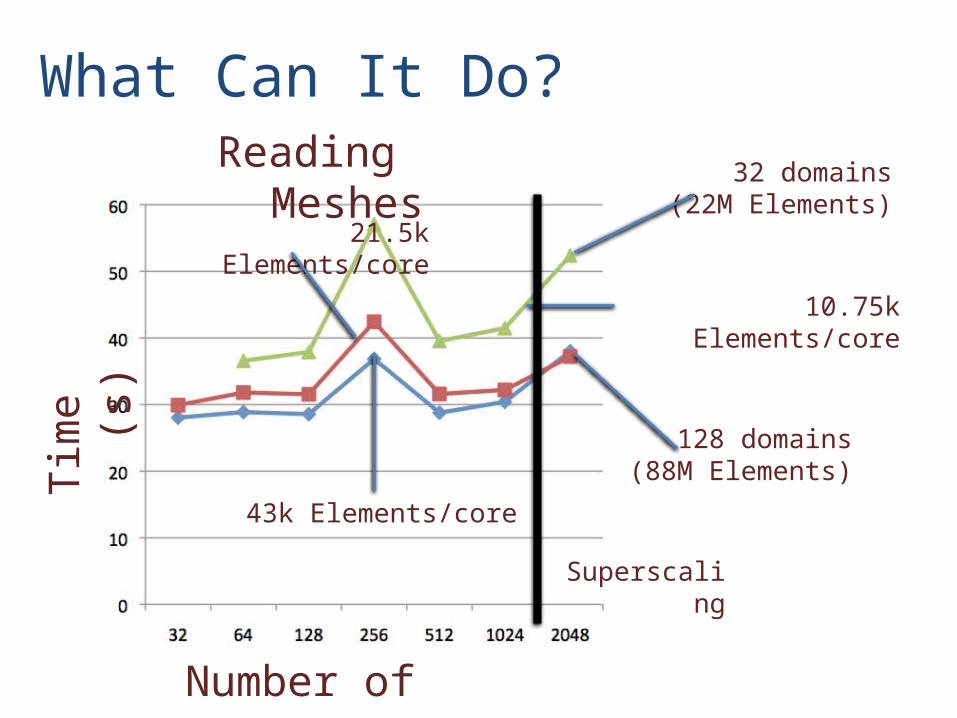
10.75k Elements/core
21.5k Elements/core
43k Elements/core
Reading Meshes
128 domains(88M Elements)
32 domains(22M Elements)
Superscaling

What Can It Do?
Multiphysics
Multidomain
Multicore

What’s On The Horizon?
“PMPIO” check pointing and restart
Rudimentary contact search
On-the-fly d.o.f. extraction
Hot swap linear algebra engines
Better interface for multi* data

What’s Left To Do?
Performance testing and tuning
More libraries
Generalized discretizations
Bringing everything together


















