
Big Data & Hadoop
39
Big Data & Hadoop Hannah Jones presents
description
Hannah Jones presents. Big Data & Hadoop. Agenda. What is BigData ? What is Hadoop? Hadoop vs. Traditional Database Who uses Hadoop? Brief History How does Hadoop work ? Storage Processing Other Projects Presentation Layer. What is Big Data?. - PowerPoint PPT Presentation
Transcript of Big Data & Hadoop

Big Data & HadoopHannah Jones presents

Agenda
What is BigData? What is Hadoop? Hadoop vs. Traditional Database Who uses Hadoop? Brief History How does Hadoop work?
Storage Processing
Other Projects Presentation Layer

What is Big Data?
Collections of large and complex data sets
Difficult to process
Challenges to capture, store, search, share, transfer, analyze and visualization
Volume, Velocity, Variety

New types of Data
Structured Unstructured
Tweets Images Audio Text Messages Click Trails

Big Data = Big ROI
Healthcare: 20% decrease in patient mortality by analyzing streaming patient data
Telco: 92% decrease in processing time by analyzing networking and call data
Utilities: 99% improved accuracy in placing power generation resources by analyzing 2.8 petabytes of untapped data

Software Available
Amazon DynamoDB
Couchbase 2.0
Apache Cassandra
Apache Hadoop

Hadoop

HADOOP! The… Database…?
Massively scalable storage and batch data processing system
Replace some functions of DBs Simultaneously ingesting, processing
and delivering/exporting large volumes of data
Absorb any type of data from any source

Traditional DB
Databases (MySQL, SQL Server, Oracle, etc..) Transactional systems, reporting, and
archiving Reads & Writes for “reasonable” data
sets (< 1B rows) Real time or batch processing

Hadoop
Overcomes the traditional limitations of storage and computing
Provides linear scalability from 1 to 4000 servers
Low cost, open source software Leverage inexpensive, commodity
hardware as platform

Hadoop
Analysis of highly granular data Structured and Unstructured data Fast integration of multiple data sources Responds well to rapidly changing
business requirements

Hadoop vs. Databases
Scale-Out instead of Scale-Up Key/value pairs instead of relational
tables Functional programming
(MapReduce) instead of declarative queries (SQL)
Offline batch processing instead of online transactions
More complex security

Who uses Hadoop?
History

Hadoop in Detail
2 Main pieces HDFS▪ Storage▪ Files and directories▪ Provides high bandwidth access to the data
MapReduce▪ Processing – Manages Jobs

Hadoop in Detail
2 Main pieces
HDFS▪ Storage▪ Files and directories▪ Provides high bandwidth access to the data
MapReduce▪ Processing – Manages Jobs

HDFS – Gettysburg Address Example

HDFS – Gettysburg Address Example

HDFS – Gettysburg Address Example

HDFS – Gettysburg Address Example
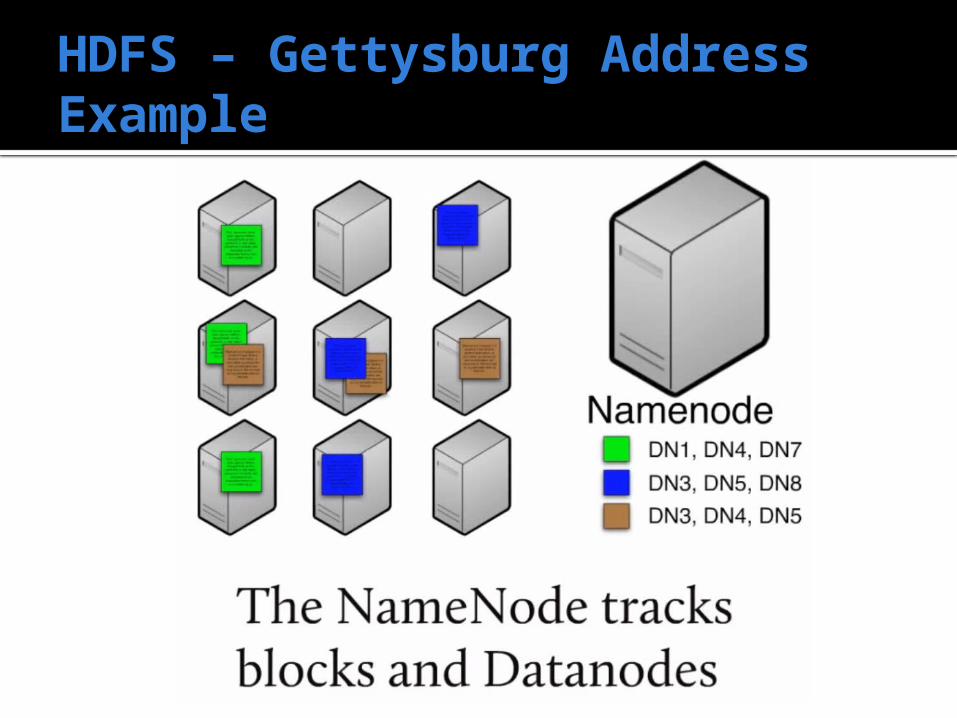
HDFS – Gettysburg Address Example
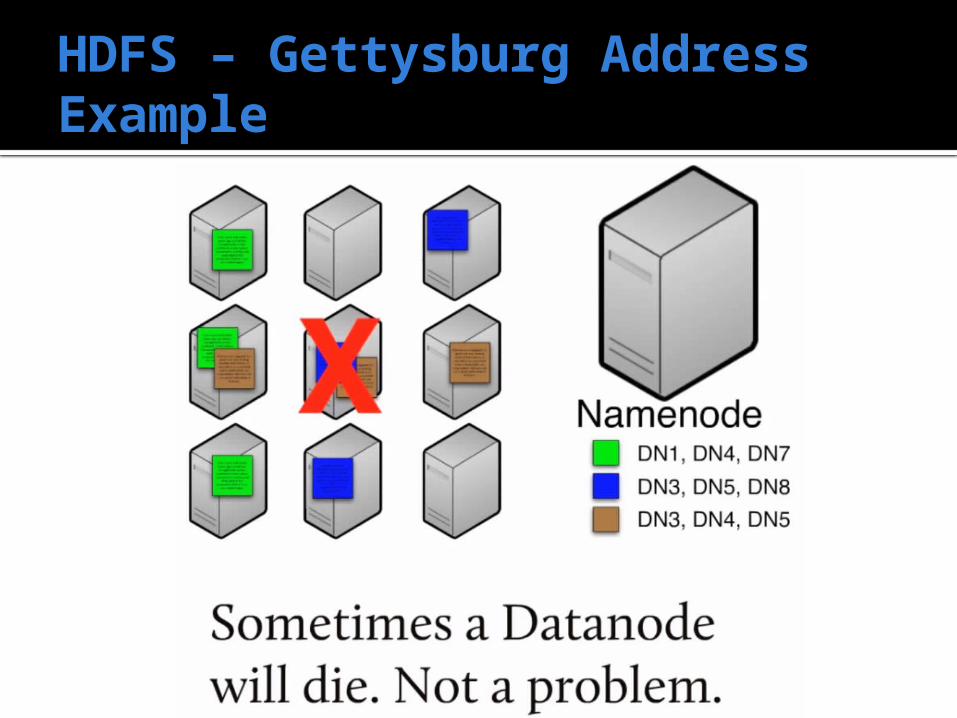
HDFS – Gettysburg Address Example

NameNode Disabilities
Loose all 3 machines => Lose all of the data Very Rare
Single Point of Failure Doesn’t fail very often Secondary NameNode▪ A backup▪ Not automatic

Hadoop in Detail
2 Main pieces HDFS▪ Storage▪ Files and directories▪ Provides high bandwidth access to the data
MapReduce▪ Processing – Manages Jobs
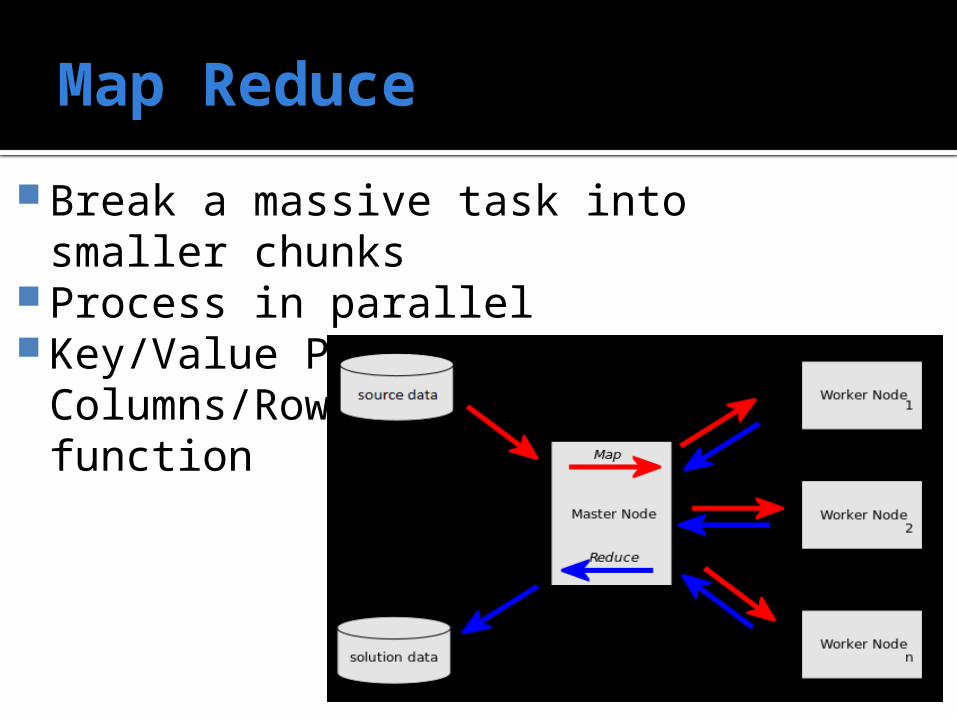
Map Reduce
Break a massive task into smaller chunks
Process in parallel Key/Value Pairs vs. Columns/Rows
-> map() function

Steps to understanding MapReduce
1. Think in terms of keys and values
2. Write a Mapper3. Write a Reducer

Job and Task Trackers
Job Tracker MapReduce Coordinator 1 JobTracker for an entire cluster Accepts user’s jobs Divides it into tasks Assign to individual TaskTracker▪ TaskTracker reports statuses as it runs
Notice if a TaskTracker disappears if failure▪ Assign the things running on that Tasktracker to
another task tracker

MapReduce – Gettysburg Address Example Hello World :: Regular Programming
Word Count :: Map Reduce Programming

Word Count Example
Map

Word Count Example

Word Count Example
Shuffle<Four, [1, 1]>
<Score, [1, 1, 1]><and, [1, 1, 1, 1, 1, 1, 1]><seven, [1, 1, 1, 1]><years, [1]><ago, [1, 1, 1]><our, [1, 1, 1, 1, 1]><fathers, [1]><brought, [1]>

Word Count Example
<Four, 2><Score, 3><and, 7><seven, 4><years, 1><ago, 3><our, 5><fathers, 1><brought, 1>
Reduce

MapReduce jobs can be tedious to write…

MapReduce jobs can be tedious to write…

But wait… there’s more

Zoo Keeper

New Projects
Hcatalog Store meta data
Oozie Scheduling System
Sqoop Transfer data
Mahout Machine learning w/ MapReduce
BigTop Integrates all of these projects

Getting Data Out
Databases
Datameer
Tableau

Summary
BigData is the new trend in businesses
Hadoop is a way to store and process the data Made up of many projects
Presentation tools are a great way to visualize the data


















