
Big Data Architectural Patterns and Best Practices on AWS
56
© 2016, Amazon Web Services, Inc. or its Affiliates. All rights reserved. Ian Meyers, Principal Solutions Architect July 7 th , 2016 Big Data Architectural Patterns and Best Practices on AWS
-
Upload
amazon-web-services -
Category
Technology
-
view
6.168 -
download
2
Transcript of Big Data Architectural Patterns and Best Practices on AWS

© 2016, Amazon Web Services, Inc. or its Affiliates. All rights reserved.
Ian Meyers, Principal Solutions Architect
July 7th, 2016
Big Data Architectural Patterns and Best Practices on AWS

Big Data Evolution
Batch processing
Streamprocessing
Machinelearning

Powerful Services, Open Ecosystem
Amazon Glacier
S3 DynamoDB
RDS
EMR
Amazon Redshift
Data PipelineAmazon Kinesis
Kinesis-enabled app
Lambda ML
SQS
ElastiCache
DynamoDBStreams
Amazon ElasticsearchService
Amazon Web Services Open Source & Commercial Ecosystem

Separation of compute & storage• Event driven, loose coupling, independent scaling & sizing
“Data Sympathy” - use the right tool for the jobData structure, latency, throughput, access patterns
Managed services, open technologiesScalable/elastic, available, reliable, secure, no/low adminFocus on the data, and your business, not undifferentiated tasks
Architectural Principles

Big Data != Big Cost
Aim to reduce the cost of experimentation to near 0

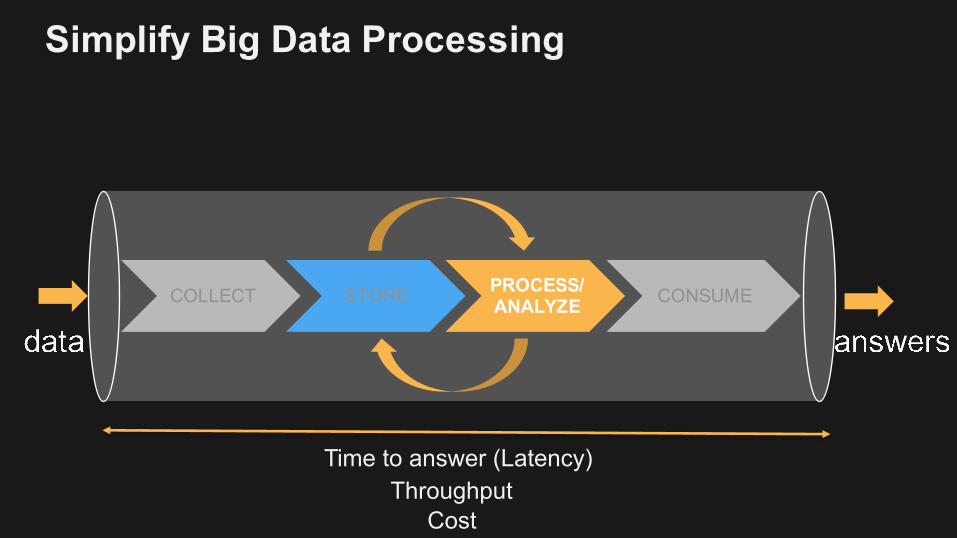
Simplify Big Data Processing
COLLECT STORE PROCESS/ANALYZE CONSUME
Time to answer (Latency)Throughput
Cost

Devices
Sensors & IoT platforms
AWS IoT STREAMS
IoT
Appl
icat
ions
AWS Import/ExportSnowball
Logging
Amazon CloudWatch
AWSCloudTrail
DOCUMENTS
FILES
Logg
ing
Tran
spor
t
MessagingMessage MESSAGES
Mes
sagi
ngCOLLECT
Mobile apps
Web apps
Data centers AWS Direct Connect
RECORDS
AWS Mobile SDK
AWS IoT
Amazon CloudWatchLogs Agent
Amazon CognitoSync
AWS Mobile Analytics
Easily Capture Mobile Data through Sync and Server Logging
File based integration to Streaming Storage
API Integration via SDK’s and Ecosystem Tools
Amazon Kinesis Producer LibraryAmazon Kinesis Agent

Principles for Collection Architecture
• Should be easy to install, manage, and understand
• Meet requirements for data durability & recovery• Ensure ability to meet latency & performance
requirements• Data handling should be sympathetic to the type
of data

Simplify Big Data Processing
COLLECT STORE PROCESS/ANALYZE CONSUME
Time to answer (Latency)Throughput
Cost
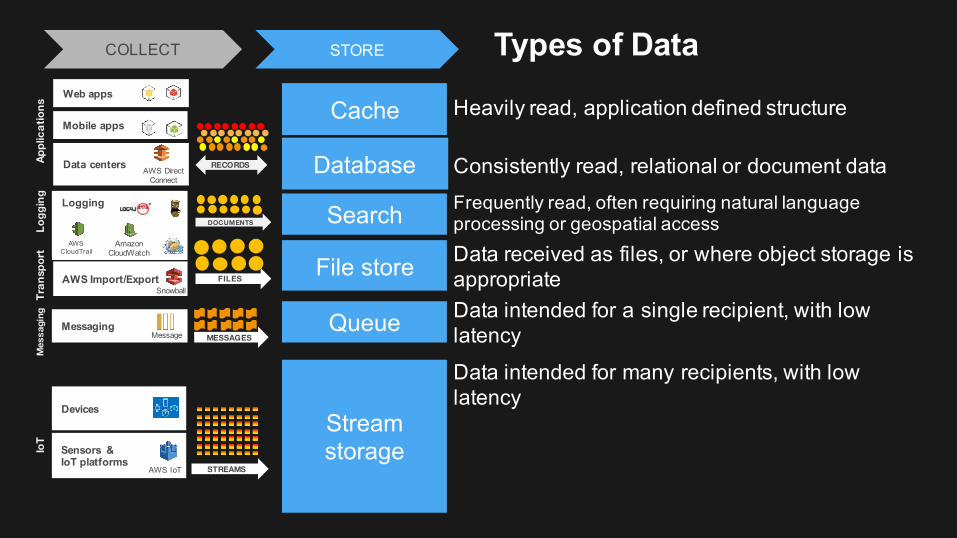
Types of Data
Devices
Sensors & IoT platforms
AWS IoT STREAMS
IoT
Appl
icat
ions
AWS Import/ExportSnowball
Logging
Amazon CloudWatch
AWSCloudTrail
DOCUMENTS
FILES
Logg
ing
Tran
spor
t
MessagingMessage MESSAGES
Mes
sagi
ngCOLLECT
Mobile apps
Web apps
Data centers AWS Direct Connect
RECORDS Database
STORE
Search
File store
Queue
Streamstorage
Cache Heavily read, application defined structure
Consistently read, relational or document dataFrequently read, often requiring natural language processing or geospatial accessData received as files, or where object storage is appropriateData intended for a single recipient, with low latency
Data intended for many recipients, with low latency

COLLECT STORE
Mobile apps
Web apps
Data centers AWS Direct Connect
RECORDS
AWS Import/ExportSnowball
Logging
Amazon CloudWatch
AWSCloudTrail
DOCUMENTS
FILES
MessagingMessage MESSAGES
Devices
Sensors & IoT platforms
AWS IoT STREAMS
Stre
am
Amazon SQS
Mes
sage
Amazon Elasticsearch Service
Amazon DynamoDB
Amazon S3
Amazon ElastiCache
Amazon RDS
Sea
rch
S
QL
N
oSQ
L
Cac
heFi
le
Logg
ing
IoT
Appl
icat
ions
Tran
spor
tM
essa
ging
File store
Queue
Amazon Kinesis Firehose
Amazon KinesisStreams
Amazon DynamoDB Streams
Streamstorage
Cache, Database,
Search
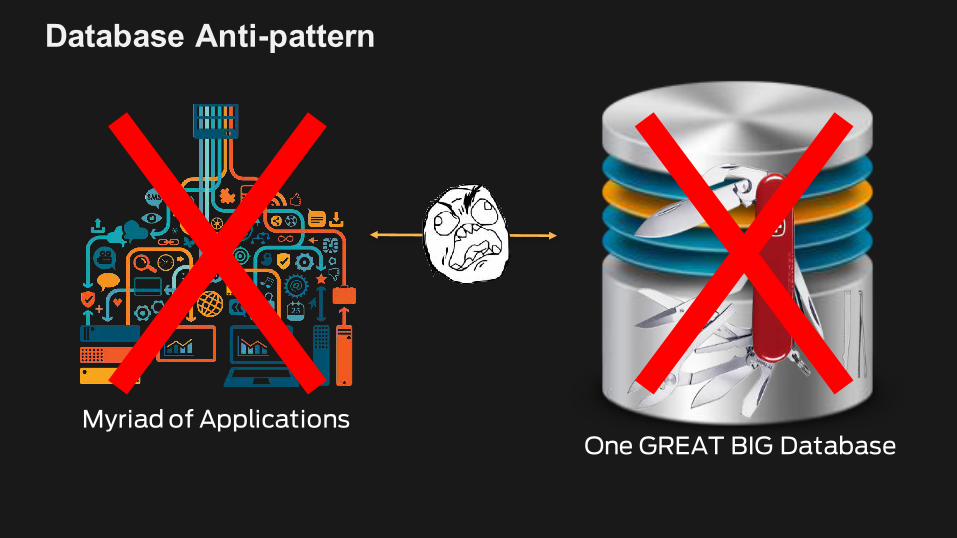
Database Anti-pattern
Myriad of ApplicationsOne GREAT BIG Database
Myriad of Applications
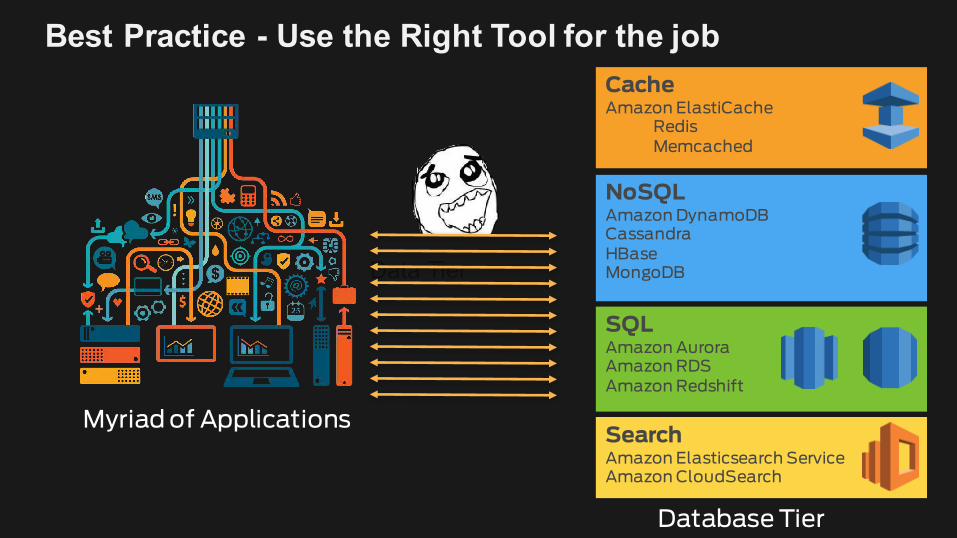
Best Practice - Use the Right Tool for the job
Data Tier
SearchAmazon Elasticsearch ServiceAmazon CloudSearch
CacheAmazon ElastiCache
RedisMemcached
SQLAmazon AuroraAmazon RDSAmazon Redshift
NoSQLAmazon DynamoDBCassandraHBaseMongoDB
Database Tier
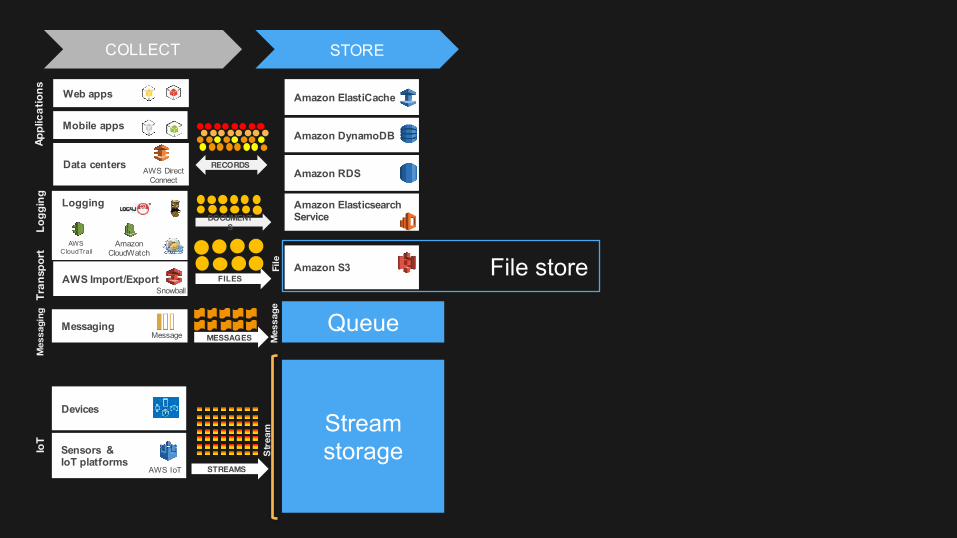
COLLECT STORE
Mobile apps
Web apps
Data centers AWS Direct Connect
RECORDS
AWS Import/ExportSnowball
Logging
Amazon CloudWatch
AWSCloudTrail
DOCUMENTS
FILES
MessagingMessage MESSAGES
Devices
Sensors & IoT platforms
AWS IoT STREAMS
Stre
am
Amazon SQS
Mes
sage
Amazon S3File
Logg
ing
IoT
Appl
icat
ions
Tran
spor
tM
essa
ging
Amazon Kinesis Firehose
Amazon KinesisStreams
Amazon DynamoDB Streams
Queue
Streamstorage
Amazon Elasticsearch Service
Amazon DynamoDB
Amazon ElastiCache
Amazon RDS
File store

Why is Amazon S3 Good for Big Data?
• Virtually unlimited storage, unlimited object count• Very high bandwidth – no aggregate throughput limit• Highly available – can tolerate AZ failure• Designed for 99.999999999% durability• Tired-storage (Standard, IA, Amazon Glacier) via life-cycle
policies• Native support for Versioning• Secure – SSL, client/server-side encryption at rest• Low cost

Why is Amazon S3 Good for Big Data?
• Natively supported by big data frameworks (Spark, Hive, Presto, etc.)
• No need to run compute clusters for storage (unlike HDFS)• No need to pay for data replication• Can run transient Hadoop clusters & Amazon EC2 Spot
Instances• Multiple & heterogenous analysis clusters can use the same
data

What about HDFS & Data Tiering (S3 IA & Amazon Glacier)?
• Use HDFS for very frequently accessed (hot) data
• Use Amazon S3 Standard as system of record for durability
• Use Amazon S3 Standard – IA for near line archive data
• Use Amazon Glacier for cold/offline archive data

Amazon Kinesis Firehose
Amazon KinesisStreams
Amazon DynamoDB Streams
Amazon SQS
Amazon SQSManaged message queue service
Amazon Kinesis StreamsManaged stream storage + processing
Amazon Kinesis FirehoseManaged data delivery
Amazon DynamoDB Streams
Managed NoSQL databaseTables can be stream-enabled
Message & Stream Data
Devices
Sensors & IoT platforms
AWS IoT STREAMS
IoT
COLLECT STORE
Mobile apps
Web apps
Data centers AWS Direct Connect
RECORDSAppl
icat
ions
AWS Import/ExportSnowball
Logging
Amazon CloudWatch
AWSCloudTrail
DOCUMENTS
FILES
Logg
ing
Tran
spor
t
MessagingMessage MESSAGES
Mes
sagi
ng
Que
ueS
tream
Amazon Elasticsearch Service
Amazon DynamoDB
Amazon ElastiCache
Amazon RDS
Amazon S3
Queue
Streamstorage
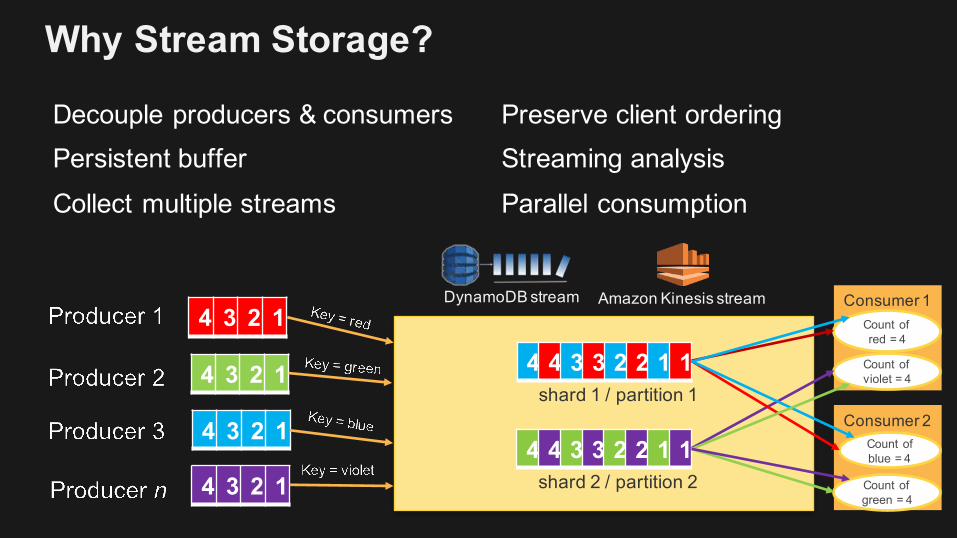
Why Stream Storage?
Decouple producers & consumersPersistent bufferCollect multiple streams
Preserve client orderingStreaming analysisParallel consumption
4 4 3 3 2 2 1 14 3 2 1
4 3 2 1
4 3 2 1
4 3 2 14 4 3 3 2 2 1 1
shard 1 / partition 1
shard 2 / partition 2
Consumer 1Count of red = 4
Count of violet = 4
Consumer 2Count of blue = 4
Count of green = 4
DynamoDB stream Amazon Kinesis stream

What Data Store Should I Use?
Data structure → Fixed schema, JSON, key-value
Access patterns → Store data in the format you will access it
Data / access characteristics → Hot, warm, cold
Cost → Right cost

Data Structure and Access Patterns
Access Patterns What to use?Put/Get (key, value) Cache, NoSQLSimple relationships → 1:N, M:N NoSQLCross table joins, transaction, SQL SQLFaceting, natural language, geo Search
Data Structure What to use?Fixed schema SQL, NoSQLSchema-free (JSON) NoSQL, Search(Key, value) Cache, NoSQL

What Is the Temperature of Your Data / Access ?

Hot Warm ColdVolume MB–GB GB–TB PBItem size B–KB KB–MB KB–TBLatency ms ms, sec min, hrsDurability Low – high High Very highRequest rate Very high High-Med LowCost/GB $$-$ $-¢¢ ¢
Hot data Warm data Cold data
Data / Access Characteristics: Hot, Warm, Cold
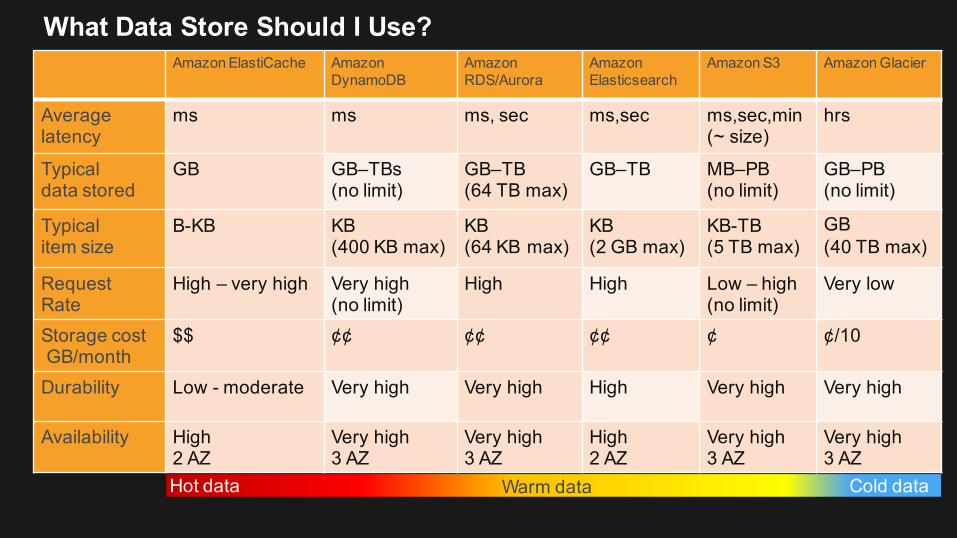
Amazon ElastiCache AmazonDynamoDB
AmazonRDS/Aurora
AmazonElasticsearch
Amazon S3 Amazon Glacier
Average latency
ms ms ms, sec ms,sec ms,sec,min(~ size)
hrs
Typicaldata stored
GB GB–TBs(no limit)
GB–TB(64 TB max)
GB–TB MB–PB(no limit)
GB–PB(no limit)
Typicalitem size
B-KB KB(400 KB max)
KB(64 KB max)
KB(2 GB max)
KB-TB(5 TB max)
GB(40 TB max)
Request Rate
High – very high Very high(no limit)
High High Low – high(no limit)
Very low
Storage costGB/month
$$ ¢¢ ¢¢ ¢¢ ¢ ¢/10
Durability Low - moderate Very high Very high High Very high Very high
Availability High2 AZ
Very high 3 AZ
Very high3 AZ
High2 AZ
Very high3 AZ
Very high3 AZ
Hot data Warm data Cold data
What Data Store Should I Use?
Simplify Big Data Processing
COLLECT STORE PROCESS/ANALYZE CONSUME
Time to answer (Latency)Throughput
Cost

COLLECT STORE PROCESS / ANALYZE
Amazon Elasticsearch Service
Amazon SQS
Amazon DynamoDB
Amazon S3
Amazon ElastiCache
Amazon RDS
Hot
War
m
Sea
rch
S
QL
N
oSQ
L
Cac
heFi
leM
essa
geS
tream
Mobile apps
Web apps
Devices
MessagingMessage
Sensors & IoT platforms
AWS IoT
Data centers AWS Direct Connect
AWS Import/ExportSnowball
Logging
Amazon CloudWatch
AWSCloudTrail
RECORDS
DOCUMENTS
FILES
MESSAGES
STREAMS
Logg
ing
IoT
Appl
icat
ions
Tran
spor
tM
essa
ging
Amazon Kinesis Firehose
Amazon KinesisStreams
Amazon DynamoDB Streams
Hot

Tools and Frameworks
Amazon SQS apps
Streaming
Amazon Kinesis Analytics
Amazon KCLapps
AWS Lambda
Amazon Redshift
PROCESS / ANALYZE
Amazon Machine Learning
Presto
AmazonEMR
Fast
Slow
Fast
Bat
chM
essa
geIn
tera
ctiv
eS
tream
ML
Amazon EC2
Amazon EC2
Batch - Minutes or hours on cold dataDaily/weekly/monthly reports
Interactive – Seconds on warm/cold dataSelf-service dashboards
Messaging – Milliseconds or seconds on hot data Message/event buffering
Streaming - Milliseconds or seconds on hot dataBilling/fraud alerts, 1 minute metrics

Tools and Frameworks
BatchAmazon EMR (MapReduce, Hive, Pig, Spark)
InteractiveAmazon Redshift, Amazon EMR (Presto, Spark)
MessagingAmazon SQS application on Amazon EC2
StreamingMicro-batch: Spark Streaming, KCLReal-time: Amazon Kinesis Analytics, Storm, AWS Lambda, KCL
Amazon SQS apps
Streaming
Amazon Kinesis Analytics
Amazon KCLapps
AWS Lambda
Amazon Redshift
PROCESS / ANALYZE
Amazon Machine Learning
Presto
AmazonEMR
Fast
Slow
Fast
Bat
chM
essa
geIn
tera
ctiv
eS
tream
ML
Amazon EC2
Amazon EC2

What Analytics Technology Should I Use?Amazon Redshift
Amazon EMR
Presto Spark Hive
Query latency
Low Low Low High
Durability High High High High
Data volume 1.6 PB max ~Nodes ~Nodes ~Nodes
AWS managed
Yes Yes Yes Yes
Storage Native HDFS / S3 HDFS / S3 HDFS / S3
SQL compatibility
High High Low (SparkSQL) Medium (HQL)
Slow
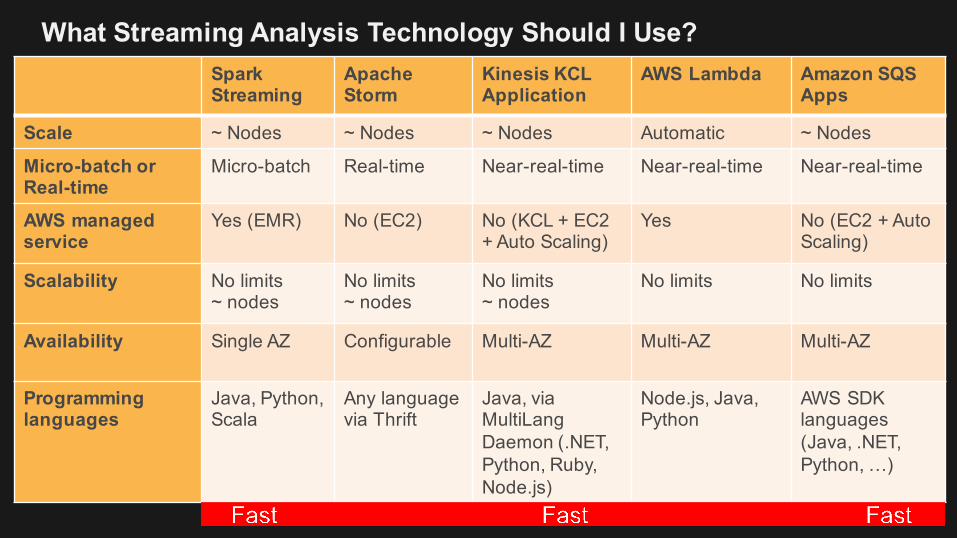
What Streaming Analysis Technology Should I Use?Spark Streaming
Apache Storm
Kinesis KCL Application
AWS Lambda Amazon SQS Apps
Scale ~ Nodes ~ Nodes ~ Nodes Automatic ~ Nodes
Micro-batch or Real-time
Micro-batch Real-time Near-real-time Near-real-time Near-real-time
AWS managed service
Yes (EMR) No (EC2) No (KCL + EC2 + Auto Scaling)
Yes No (EC2 + AutoScaling)
Scalability No limits ~ nodes
No limits~ nodes
No limits~ nodes
No limits No limits
Availability Single AZ Configurable Multi-AZ Multi-AZ Multi-AZ
Programminglanguages
Java, Python, Scala
Any language via Thrift
Java, via MultiLangDaemon (.NET,Python, Ruby, Node.js)
Node.js, Java, Python
AWS SDK languages (Java, .NET, Python, …)

Simplify Big Data Processing
COLLECT STORE PROCESS/ANALYZE CONSUME
Time to answer (Latency)Throughput
Cost

Amazon SQS apps
Streaming
Amazon Kinesis Analytics
Amazon KCLapps
AWS Lambda
Amazon Redshift
COLLECT STORE CONSUMEPROCESS / ANALYZE
Amazon Machine Learning
Presto
AmazonEMR
Amazon Elasticsearch Service
Amazon SQS
Amazon DynamoDB
Amazon S3
Amazon ElastiCache
Amazon RDS
Hot
Hot
War
m
Fast
Slow
Fast
Bat
chM
essa
geIn
tera
ctiv
eS
tream
ML
Sea
rch
S
QL
N
oSQ
L
Cac
heFi
leM
essa
geS
tream
Amazon EC2
Amazon EC2
Mobile apps
Web apps
Devices
MessagingMessage
Sensors & IoT platforms
AWS IoT
Data centers AWS Direct Connect
AWS Import/ExportSnowball
Logging
Amazon CloudWatch
AWSCloudTrail
RECORDS
DOCUMENTS
FILES
MESSAGES
STREAMS
Logg
ing
IoT
Appl
icat
ions
Tran
spor
tM
essa
ging
ETL
Amazon Kinesis Firehose
Amazon KinesisStreams
Amazon DynamoDB Streams

STORE CONSUMEPROCESS / ANALYZE
Amazon QuickSight
Anal
ysis
& v
isua
lizat
ion
Not
eboo
ksID
E
Apps & Services API
Applications & API
Reporting, Exploratory and Ad-Hoc Analysis and Data Visualization
Notebooks
Data Science
Business users
Data scientist, developers
COLLECT ETL


Design Patterns

Primitive: Batch Analysis & Enhancement
process store
Amazon S3
Amazon DynamoDB
Amazon EMR
Presto
Spark SQL
Amazon Redshift Amazon
Quicksight
AWS Marketplace

Primitive: Event Processing “Data Bus”
Multiple stagesStorage raises events to decouple processing stages
Store Process Store Process
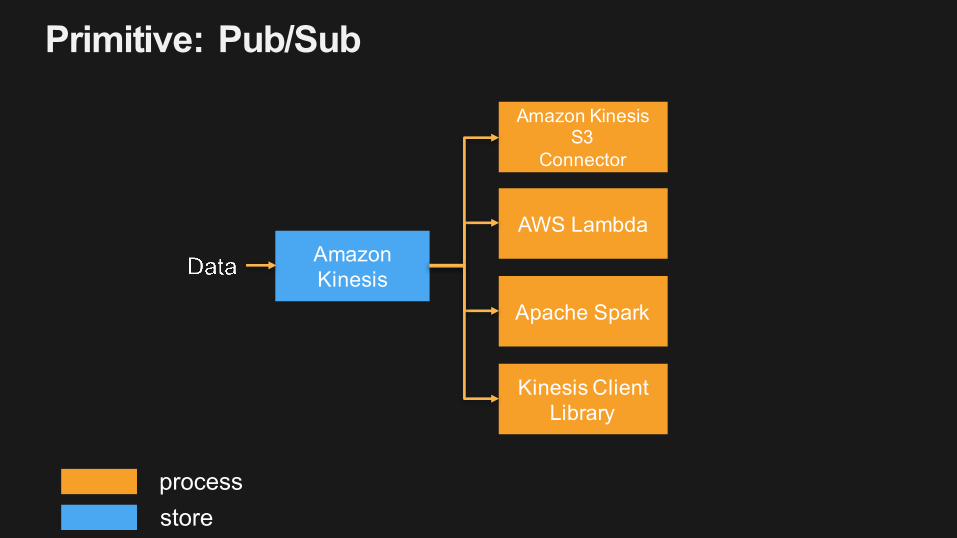
Primitive: Pub/Sub
processstore
Amazon Kinesis
AWS Lambda
Amazon Kinesis S3
Connector
Apache Spark
Kinesis Client Library

Combining Primitives: Event Processing Network
Combines data bus and pub/sub patterns to create asynchronous, continuously executing transformations
Store Process Store Process
Process Store Process
Process
Process
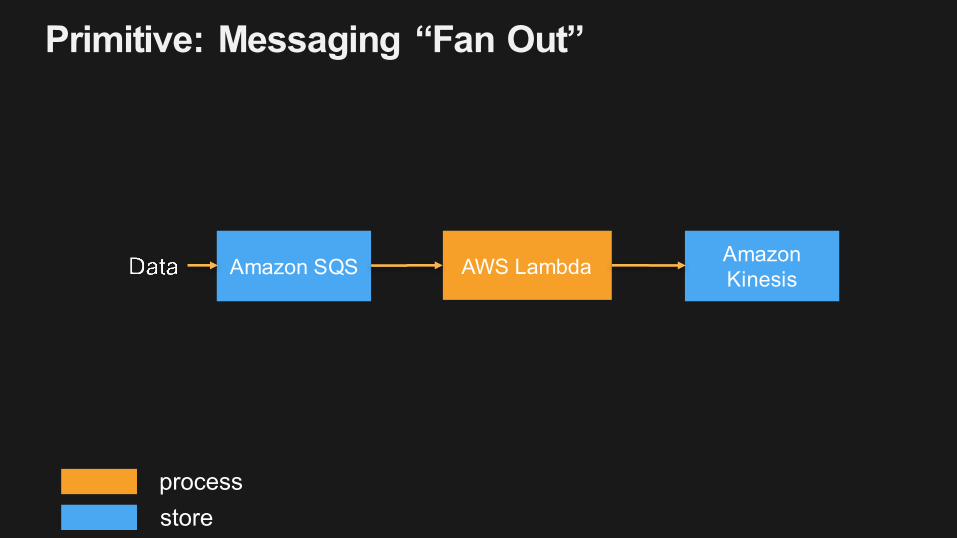
Primitive: Messaging “Fan Out”
processstore
Amazon SQS AWS Lambda Amazon Kinesis
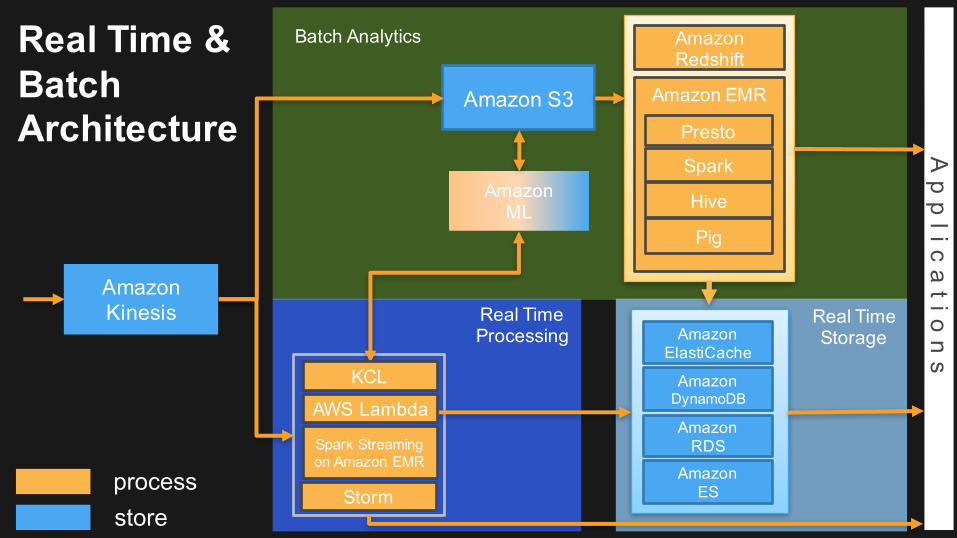
Real Time Processing
Batch Analytics
processstore
Amazon S3
Amazon Redshift
Amazon EMR
Presto
Hive
Pig
Spark
Real Time StorageAmazon
ElastiCache
AmazonDynamoDB
AmazonRDS
AmazonES
AmazonML
KCL
AWS Lambda
Storm
Real Time & Batch Architecture
Spark Streaming on Amazon EMR
Ap
plic
atio
ns
Amazon Kinesis

© 2016, Amazon Web Services, Inc. or its Affiliates. All rights reserved.
Zoltan Arvai, Big Data ArchitectJuly 7th, 2016
Leveraging S3 and EMR at Adbrain

About Adbrain
• Adbrain is a market leader in providing Probabilistic Identity Solutions
• At the core of our business we build an identity graph that represents connected devices on the planet
• We enable our clients to understand and target their audience better

What does that mean?
• Ingesting large amounts of log data from different data sources
• Build a graph using statistical and machine learning algorithms
• Extract a relevant user graph for our clients

Our main scenarios
• Production graph generation and servicing our clients
• Data Science team to run computations (Spark)• R&D work with ML• Data feed evaluation• Graph analytics
• Data Engineering development workload

Our original setup
• HDFS Cluster on 18 nodes with most of our hot data• Not leveraging co-location of data• Spark clusters are separated• Spark instance type optimized according to workload
• Custom cluster provisioning solution to run Spark jobs• Built in-house• Required maintenance

challenge

What are the issues?
• “Hadoop is a cheap Big Data solution on commodity hardware” … define cheap for a startup
• Scaling Hadoop means more focus on infrastructure
• Data grows really quickly (adding a new country, data feed, etc.)

What do we need?
• Better scale
• Cheaper solution
• Less focus on infrastructure
• Reduced risk

EMR and S3 to the rescue!
• S3 is significantly cheaper compared to HDFS• We use infrequent access and Glacier storage as
well
• EMR is a fully managed solution• Up to date Spark distributions• Support of Spot instances• Managed Hadoop when / if needed
AmazonS3
Amazon EMR

The implementation challenge

Some technical challenges
• Spark 1.3.1 did not work well with S3 and Parquet files
• Writing to S3 using the default ParquetOutputComitter is slow
• Calculating output summary metadata is slow• S3 is not consistent by default (it’s not a file
system)• S3 can be slower than HDFS

Solutions
• Upgrade to Spark 1.5.1+• Using DirectParquetOutputCommitter with speculation
disabled• parquet.enable.summary-metadata = false• Enable S3 Consistent View in EMR!
• (Remember the DynamoDB tables!)• In case of a multi-step Spark workflow, utilize HDFS on
the Spark Cluster

The end result
• Decreasing costs by 70%+
• Focusing on development instead of commodities (hardware/versioning/patching)
• Eliminated risks

Thank you!aws.amazon.com/big-data

Remember to complete your evaluations!











![AWS re:Invent 2016: [JK REPEAT] Serverless Architectural Patterns and Best Practices (JKT401)](https://static.fdocuments.us/doc/165x107/586f90421a28ab54768b78e9/aws-reinvent-2016-jk-repeat-serverless-architectural-patterns-and-best.jpg)






