
Benchmarks for Parallel Systems Sources/Credits: “Performance of Various Computers Using Standard...
25
Benchmarks for Parallel Systems Sources/Credits: “Performance of Various Computers Using Standard Linear Equations Software”, Jack Dongarra, University of Tennessee, Knoxville TN, 37996, Computer Science Technical Report Number CS - 89 – 85, April 8, 2004, url:http://www.netlib.org/benchmark/performance.ps http://www.top500.org FAQ: http://www.netlib.org/utk/people/JackDongarra/faq-linpack.ht ml Courtesy: Jack Dongarra (Top500) http://www.top500.org The LINPACK Benchmark: Past, Present, and Future, Jack Dongarra, Piotr Luszczek, and Antoine Petitet NAS Parallel Benchmarks. http://www.nas.nasa.gov/Software/NPB/
-
Upload
william-little -
Category
Documents
-
view
217 -
download
0
Transcript of Benchmarks for Parallel Systems Sources/Credits: “Performance of Various Computers Using Standard...

Benchmarks for Parallel Systems
Sources/Credits:“Performance of Various Computers Using Standard Linear Equations Software”, Jack Dongarra, University of Tennessee, Knoxville TN, 37996, Computer Science Technical Report Number CS - 89 – 85, April 8, 2004, url:http://www.netlib.org/benchmark/performance.pshttp://www.top500.orgFAQ: http://www.netlib.org/utk/people/JackDongarra/faq-linpack.htmlCourtesy: Jack Dongarra (Top500)http://www.top500.orgThe LINPACK Benchmark: Past, Present, and Future, Jack Dongarra, Piotr Luszczek, and Antoine Petitet NAS Parallel Benchmarks. http://www.nas.nasa.gov/Software/NPB/

LINPACK (Dongarra: 1979)
Dense system of linear equations Initially used as a user’s guide for
LINPACK package LINPACK – 1979 N=100 benchmark, N=1000
benchmark, Highly Parallel Computing benchmark

LINPACK benchmark Implemented on top of BLAS1 2 main operations – DGEFA(Gaussian
elimination - O(n3)) and DGESL(Ax = b – O(n2))
Major operation (97%) – DAXPY: y = y + α.x
Called n3/3 + n2 times. Hence 2n3/3 + 2n2 flops (approx.)
64-bit floating point arithmetic

LINPACK N=100, 100x100 system of equations. No change in
code. User asked to give a timing routine called SECOND, no compiler optimizations
N=1000, 1000x1000 – user can implement any code, should provide the required accuracy: Towards Peak Performance (TPP). Driver program always uses 2n3/3 +2n2
“Highly Parallel Computing” benchmark – any software, matrix size can be chosen. Used in Top500
Based on 64-bit floating point arithmetic

LINPACK
100x100 – inner loop optimization 1000x1000 – three-loop/whole
program optimization Scalable parallel program – Largest
problem that can fit in memory

HPL (High Performance LINPACK)

HPL Algorithm
• 2-D block-cyclic data distribution
•Right-looking LU
•Panel factorization: various options
- Crout, left or right-looking recursive variants based on matrix multiply
- Number of sub-panels
- recursive stopping criteria
- pivot search and broadcast by binary-exchange

HPL algorithm Panel broadcast: -
Update of trailing matrix:
- look-ahead pipeline
Validity check - should be O(1)

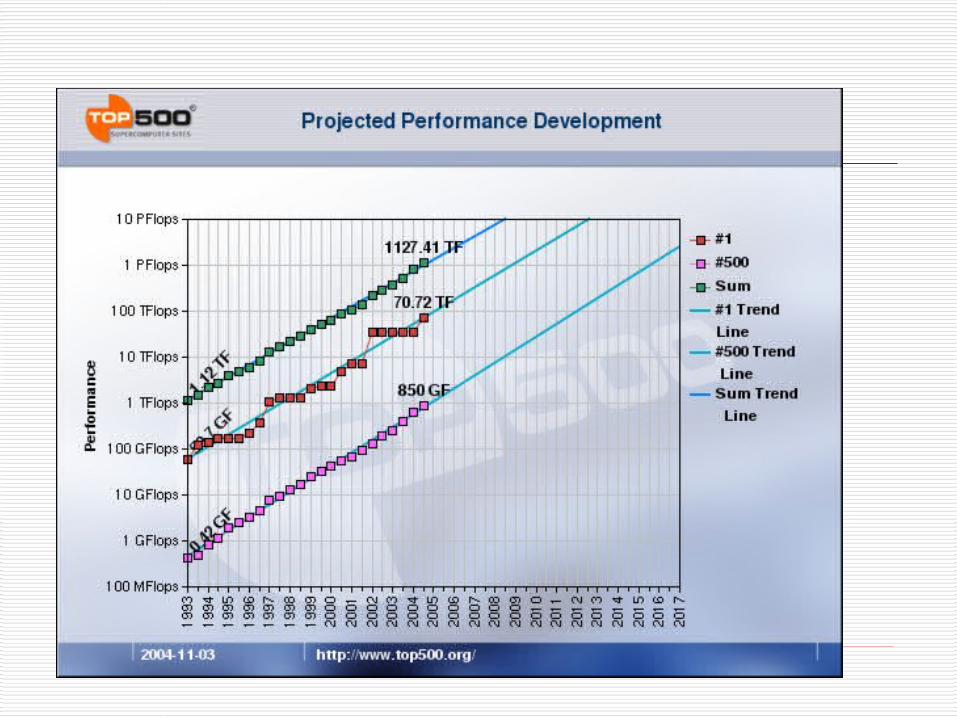
Top500 (www.top500.org)
Top500 – 1993 Twice a year – June and November Top500 gives Nmax, Rmax, N1/2,
Rpeak

24th List: The TOP 5Rank
SiteCountry/Year
Computer / ProcessorsManufacturer
Rmax
Rpeak
1 IBM/DOEUnited States/2004
BlueGene/L beta-SystemBlueGene/L DD2 beta-System (0.7 GHz PowerPC 440) / 32768IBM
7072091750
2 NASA/Ames Research Center/NAS
United States/2004
ColumbiaSGI Altix 1.5 GHz, Voltaire Infiniband / 10160SGI
5187060960
3 The Earth Simulator CenterJapan/2002
Earth-Simulator / 5120NEC
3586040960
4 Barcelona Supercomputer Center
Spain/2004
MareNostrumeServer BladeCenter JS20 (PowerPC970 2.2 GHz), Myrinet / 3564IBM
2053031363
5 Lawrence Livermore National Laboratory
United States/2004
ThunderIntel Itanium2 Tiger4 1.4GHz - Quadrics / 4096California Digital Corporation
1994022938

24th List: IndiaRank Site
Country/YearComputer / Processors
ManufacturerRmax
Rpeak
267 Tech Pacific Exports CIndia/2004
Integrity Superdome, 1.5 GHz, HPlex / 288HP
12101728
289 Semiconductor Company (F)India/2003
xSeries Cluster Xeon 2.4 GHz - Gig-E / 574IBM
1196.412755.2
435 Geoscience (C)India/2004
xSeries Xeon 3.06 GHz - Gig-E / 256IBM
961.281566.72
438 Institute of Mathematical Sciences, C.I.T CampusIndia/2004
KABRUPentium Xeon Cluster 2.4 GHz - SCI 3D / 288IMSc-Netweb-Summation
9591382.4
445 Geoscience (B)India/2004
BladeCenter Xeon 3.06 GHz, Gig-Ethernet / 252IBM
946.261542.24
446 Geoscience (B)India/2004
BladeCenter Xeon 3.06 GHz, Gig-Ethernet / 252IBM
946.261542.24
447 Geoscience (B)India/2004
BladeCenter Xeon 3.06 GHz, Gig-Ethernet / 252IBM
946.261542.24
448 Geoscience (B)India/2004
BladeCenter Xeon 3.06 GHz, Gig-Ethernet / 252IBM
946.261542.24


Manufacturer

Architecture

Processor Generation

System Processor Count

NAS Parallel Benchmarks - NPB Also for evaluation of Supercomputers A set of 8 programs from CFD 5 kernels, 3 pseudo applications NPB 1 – Original benchmarks NPB 2 – NAS’s MPI implementation. NPB 2.4
Class D has more work and more I/O NPB 3 – based on OpenMP, HPF, Java GridNPB3 – for computational grids NPB 3 multi-zone – for hybrid parallelism

NPB 1.0 (March 1994)
Defines class A and class B versions “Paper and pencil” algorithmic
specifications Generic benchmarks as compared to
MPI-based LinPack General rules for implementations –
Fortran90 or C, 64-bit arithmetic etc. Sample implementations provided

Kernel Benchmarks EP – embarrassingly parallel MG – multigrid. Regular communication CG – conjugate gradient. Irregular long distance
communication FT – a 3-D PDE using FFT. Rigorous test of long distance
communication IS – large integer sort Detailed rules regarding - brief statement of the problem - algorithm to be practiced - validation of results - where to insert timing calls - method for generating random numbers - submission of results

Pseudo applications / Synthetic CFDs
Benchmark 1 – perform few iterations of the approximate factorization algorithm (SP)
Benchmark 2 - perform few iterations of diagonal form of the approximate factorization algorithm (BT)
Benchmark 3 - perform few iterations of SSOR (LU)

Class A and Class B
Sample Code
Class A
Class B

NPB 2.0 (1995) MPI and Fortran 77
implementations 2 parallel kernels (MG,
FT) and 3 simulated applications (LU, SP, BT)
Class C – bigger size Benchmark rules – 0%,
5%, >5% change in source code

NPB 2.2 (1996), 2.4 (2002), 2.4 I/O (Jan 2003)
EP and IS added FT rewritten NPB 2.4 – class D and rationale for class D
sizes 2.4 I/O – a new benchmark problem based
on BT (BTIO) to test the output capabilities A MPI implementation of the same (MPI-IO)
– different options using collective buffering or not etc.



















