BB30055: Genes and genomes Genomes - Dr. MV Hejmadi ([email protected])
30
BB30055: Genes and genomes Genomes - Dr. MV Hejmadi ([email protected])
-
Upload
anastasia-black -
Category
Documents
-
view
221 -
download
0
Transcript of BB30055: Genes and genomes Genomes - Dr. MV Hejmadi ([email protected])

BB30055: Genes and genomesGenomes - Dr. MV Hejmadi ([email protected])

BB30055: Genomes - MVH3 broad areas
(A) Genomes
(B)Applications genome projects
(C) Genome evolution

Why sequence the genome?3 main reasons
• description of sequence of every gene valuable. Includes regulatory regions which help in understanding not only the molecular activities of the cell but also ways in which they are controlled.
• identify & characterise important inheritable disease genes or bacterial genes (for industrial use)
• Role of intergenic sequences e.g. satellites,
intronic regions etc

History of Human Genome Project (HGP)
1953 – DNA structure (Watson & Crick)1972 – Recombinant DNA (Paul Berg)1977 – DNA sequencing (Maxam, Gilbert and Sanger)1985 – PCR technology (Kary Mullis)1986 – automated sequencing (Leroy Hood & Lloyd
Smith1988 – IHGSC established (NIH, DOE) Watson leads1990 – IHGSC scaled up, BLAST published
(Lipman+Myers)1992 – Watson quits, Venter sets up TIGR1993 – F Collins heads IHGSC, Sanger Centre (Sulston)1995 – cDNA microarray1998 – Celera genomics (J Craig Venter)2001 – Working draft of human genome sequence
published2003 – Finished sequence announced
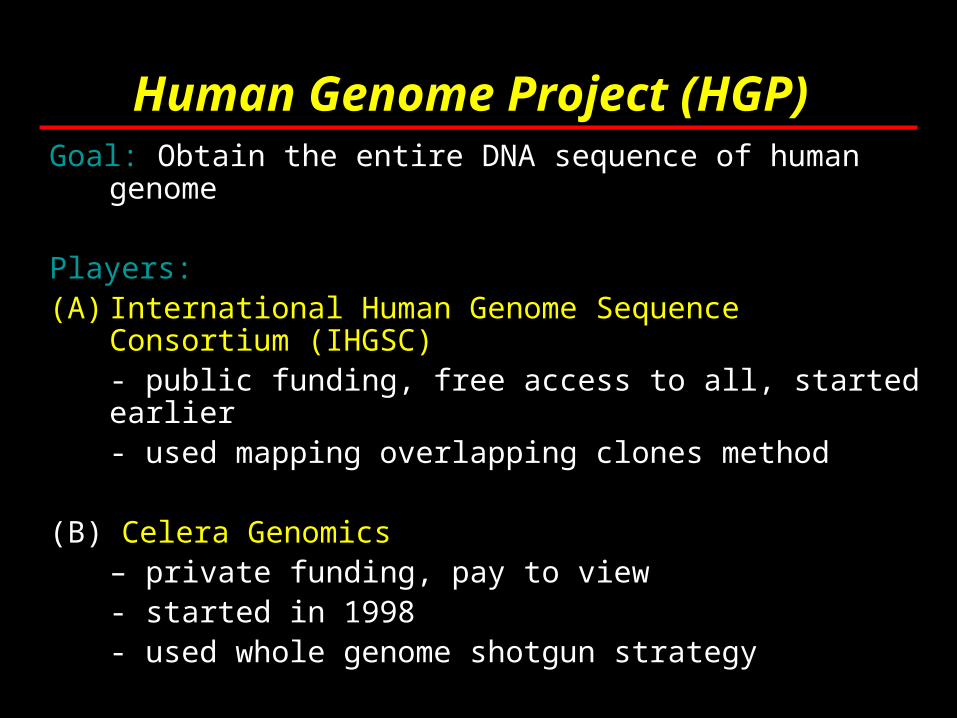
Human Genome Project (HGP)
Goal: Obtain the entire DNA sequence of human genome
Players:(A) International Human Genome Sequence
Consortium (IHGSC)- public funding, free access to all, started
earlier- used mapping overlapping clones method
(B) Celera Genomics – private funding, pay to view- started in 1998- used whole genome shotgun strategy

Whose genome is it anyway?
(A) International Human Genome Sequence Consortium (IHGSC)- composite from several different people generated from 10-20 primary samples taken from numerous anonymous donors across racial and ethnic groups
(B) Celera Genomics – 5 different donors (one of whom was J
Craig Venter himself !!!)
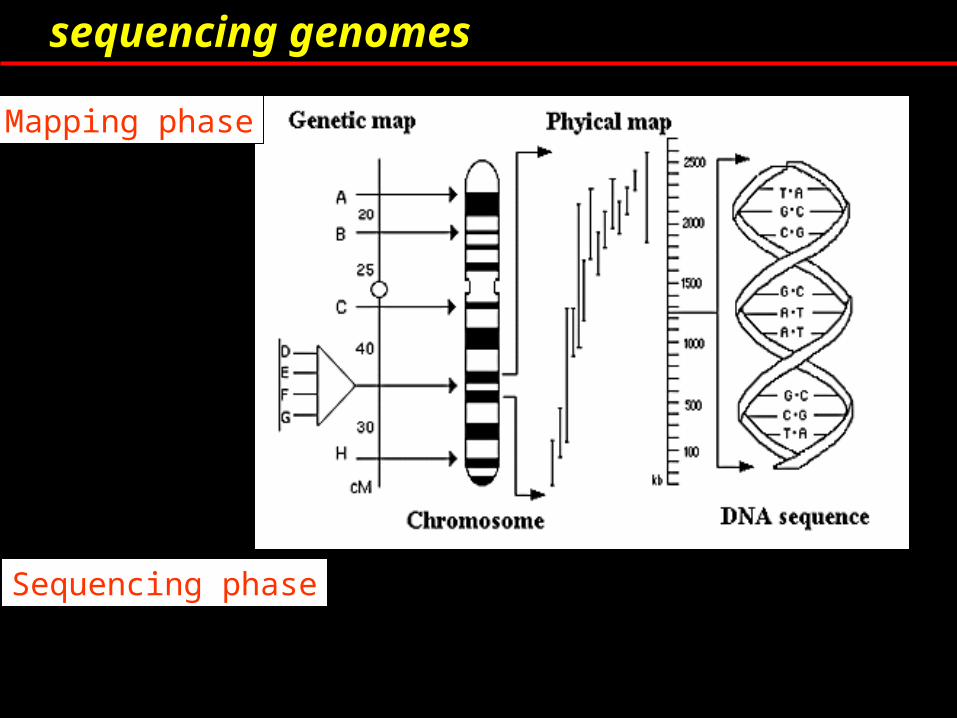
sequencing genomes
Mapping phase
Sequencing phase
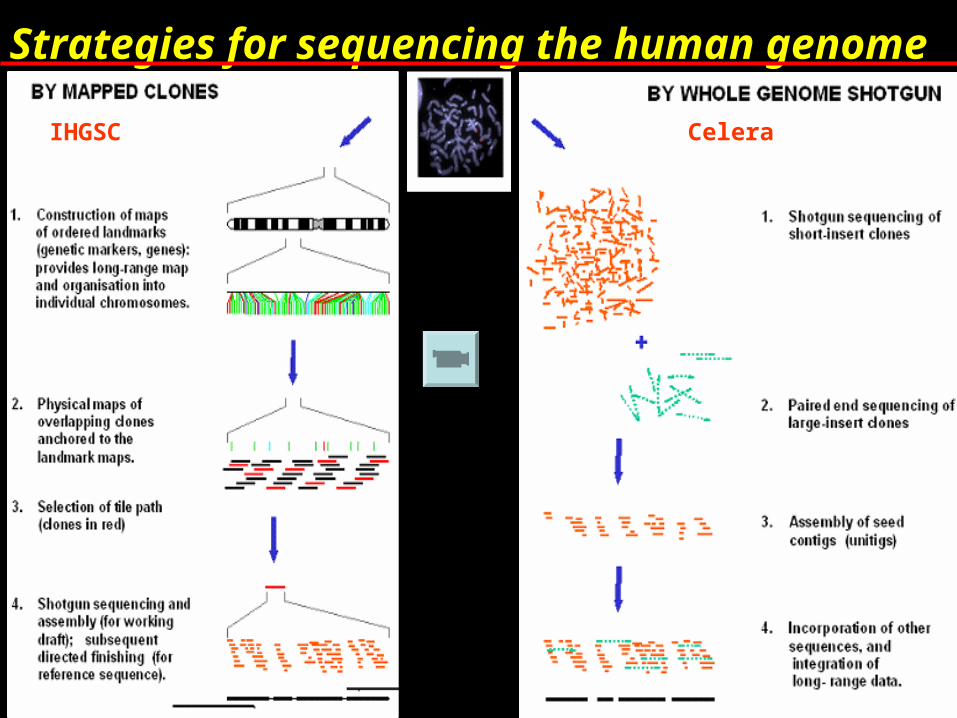
Strategies for sequencing the human genome
IHGSC Celera
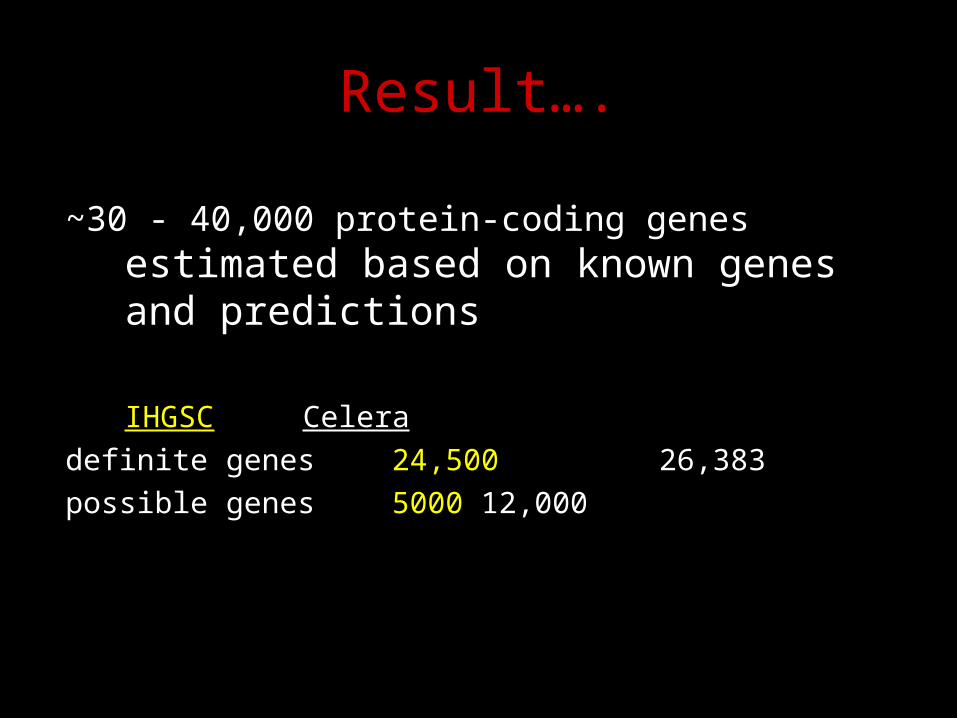
Result….
~30 - 40,000 protein-coding genes estimated based on known genes and predictions
IHGSC Celeradefinite genes 24,500 26,383 possible genes 5000 12,000

Other genomes sequenced
200236,000 genes
Sept 200318,473human orthologs
19974,200 genes
199819,099 genes
200238,000 genes
Science (26 Sep 2003)Vol301(5641)pp1854-1855
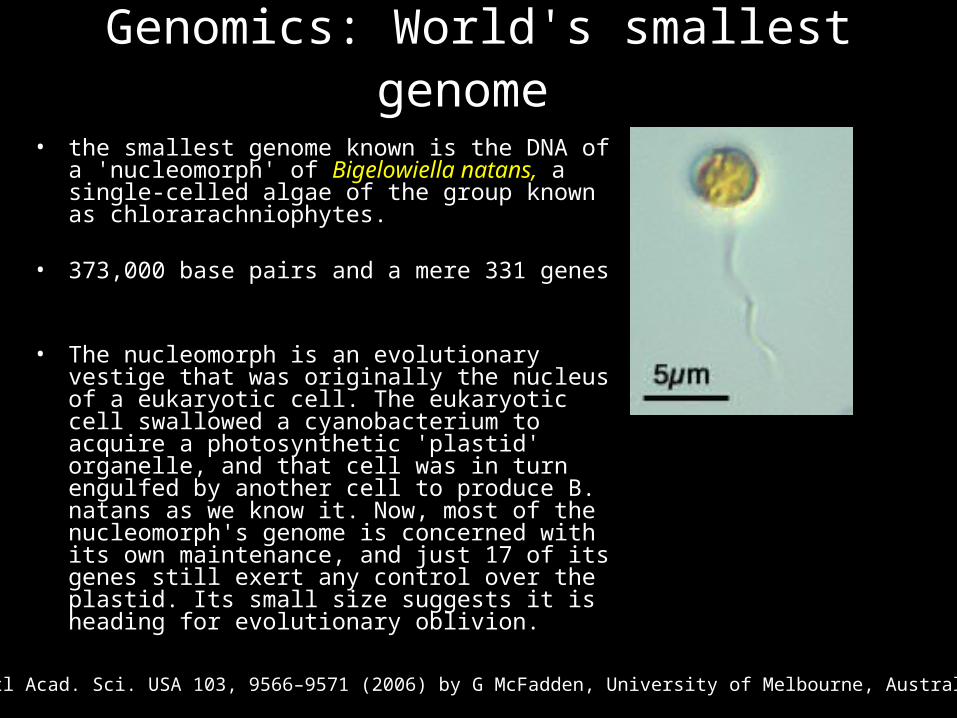
Genomics: World's smallest genome
• the smallest genome known is the DNA of a 'nucleomorph' of Bigelowiella natans, a single-celled algae of the group known as chlorarachniophytes.
• 373,000 base pairs and a mere 331 genes
• The nucleomorph is an evolutionary vestige that was originally the nucleus of a eukaryotic cell. The eukaryotic cell swallowed a cyanobacterium to acquire a photosynthetic 'plastid' organelle, and that cell was in turn engulfed by another cell to produce B. natans as we know it. Now, most of the nucleomorph's genome is concerned with its own maintenance, and just 17 of its genes still exert any control over the plastid. Its small size suggests it is heading for evolutionary oblivion.
Proc. Natl Acad. Sci. USA 103, 9566–9571 (2006) by G McFadden, University of Melbourne, Australia
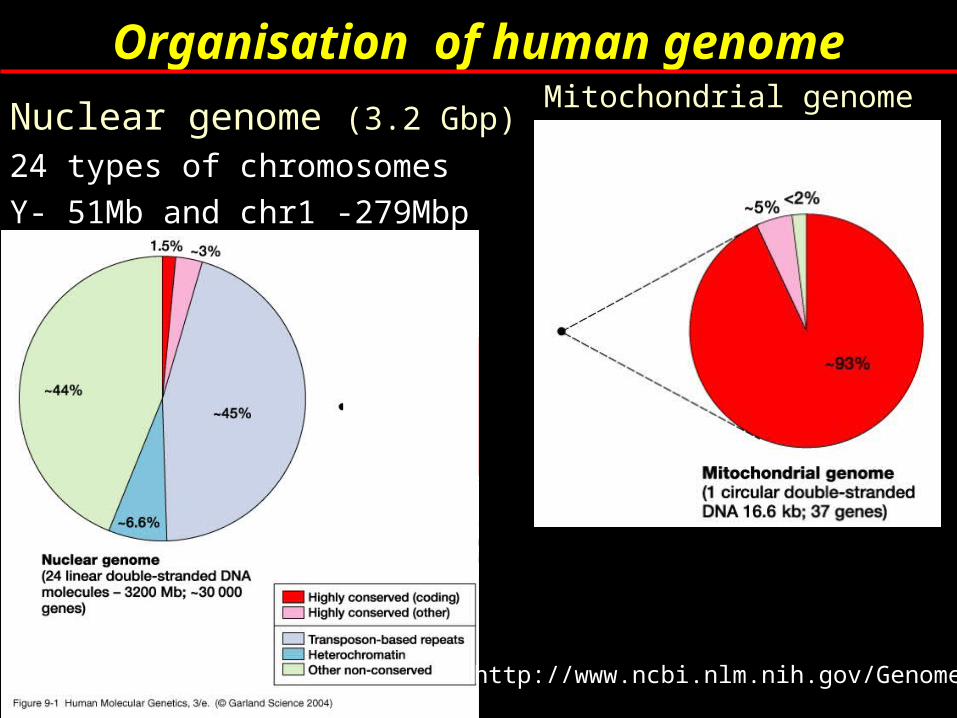
Organisation of human genome
Nuclear genome (3.2 Gbp) 24 types of chromosomes Y- 51Mb and chr1 -279Mbp
Mitochondrial genome
http://www.ncbi.nlm.nih.gov/Genomes/
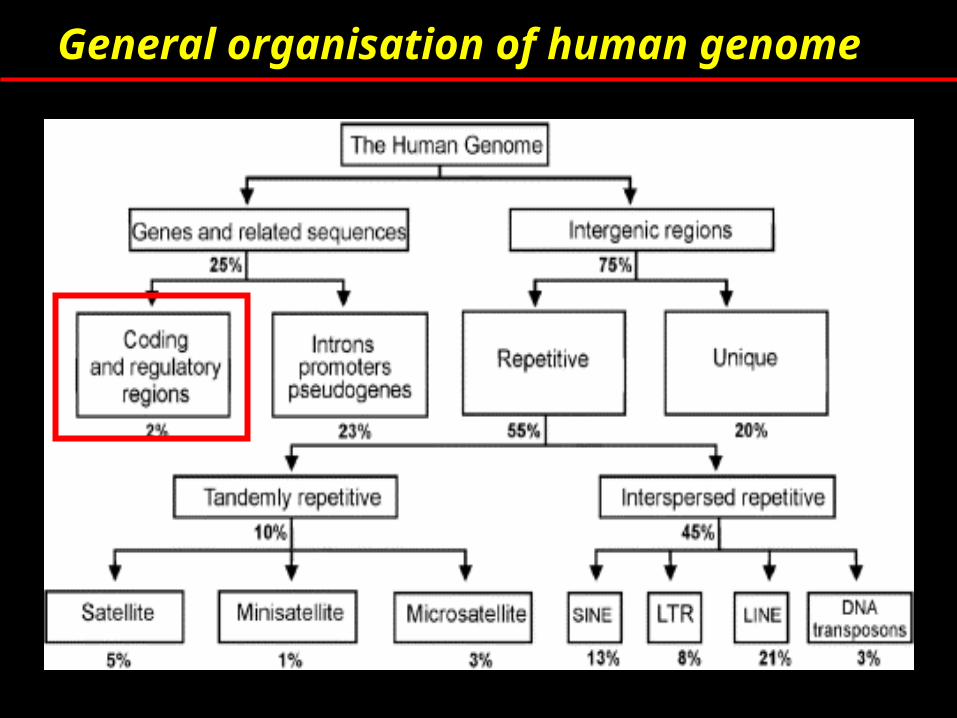
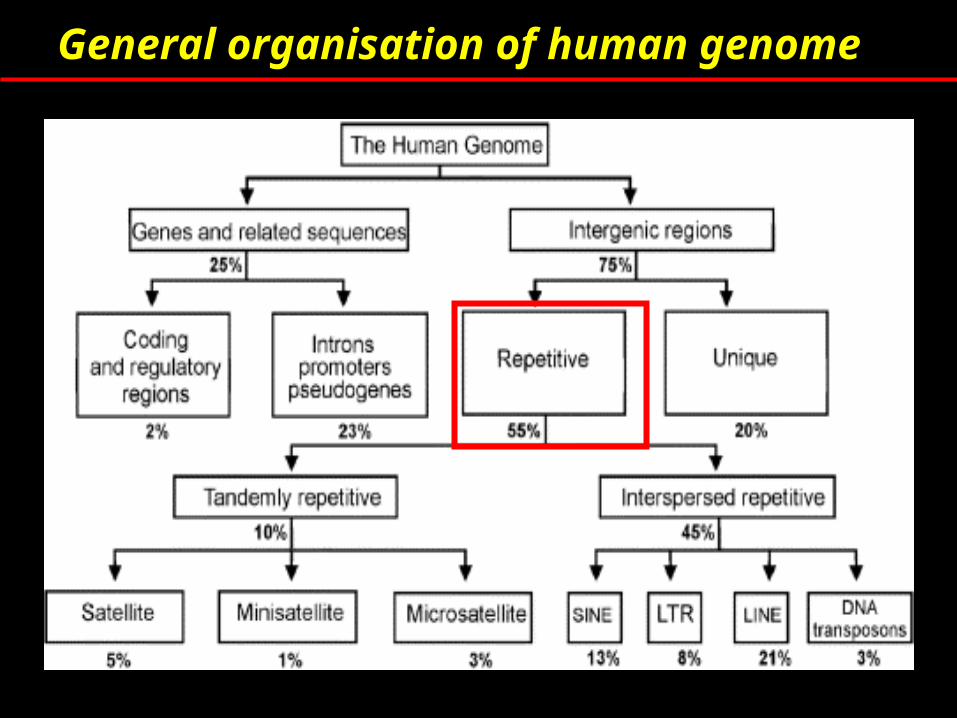
General organisation of human genome
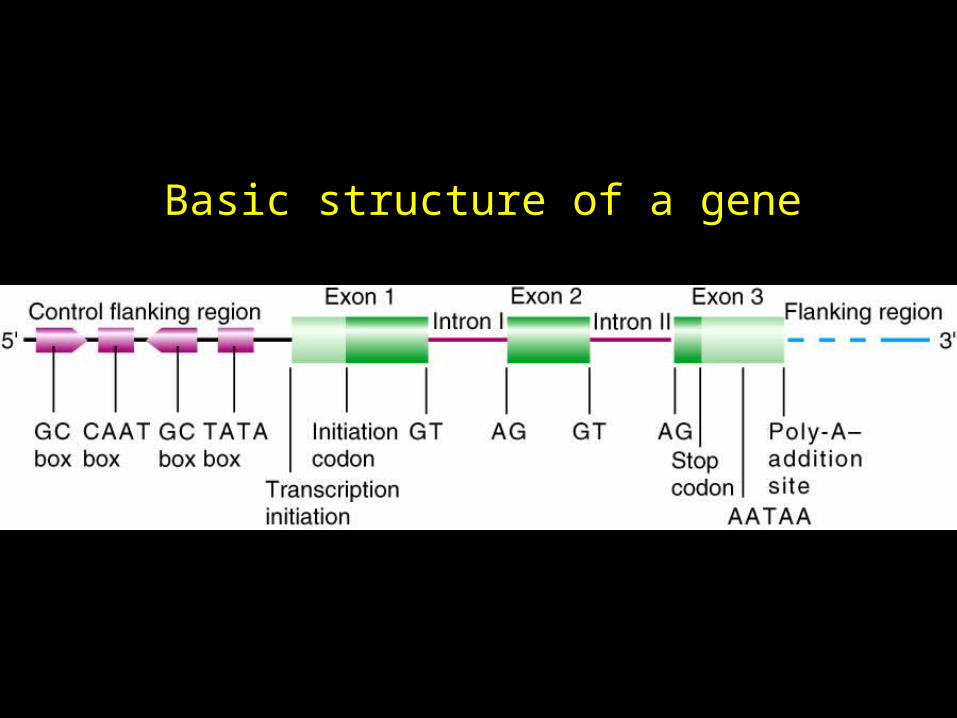
Basic structure of a gene
Fig. 21.11
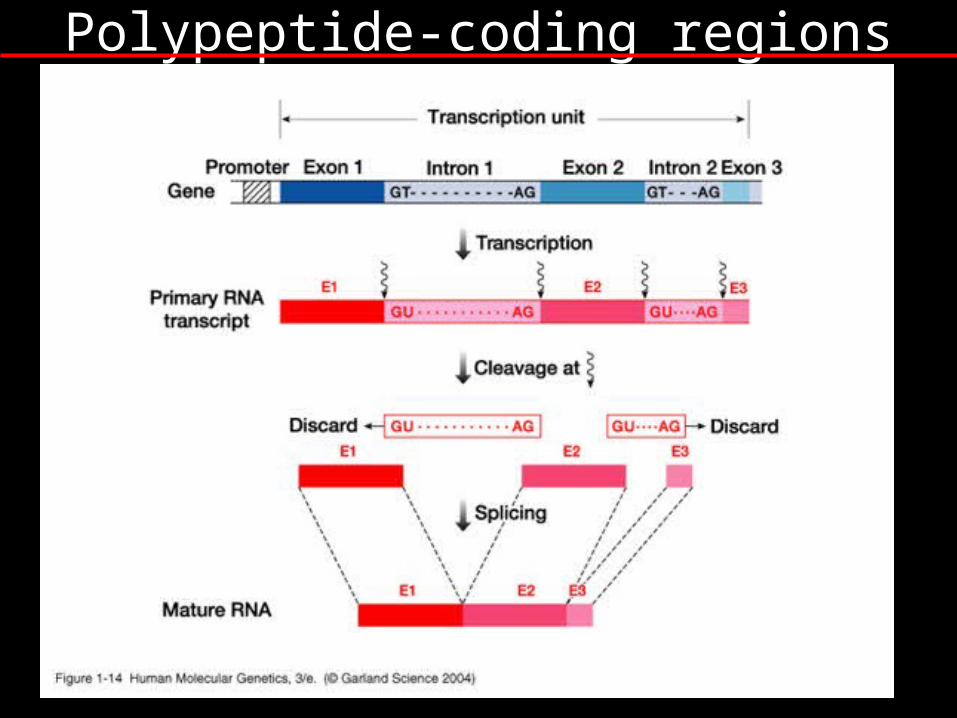
Polypeptide-coding regions

Gene organisation
Rare bicistronic transcription units E.g. UBA52 transcription generates ubiquitin
and a ribosomal protein S27a
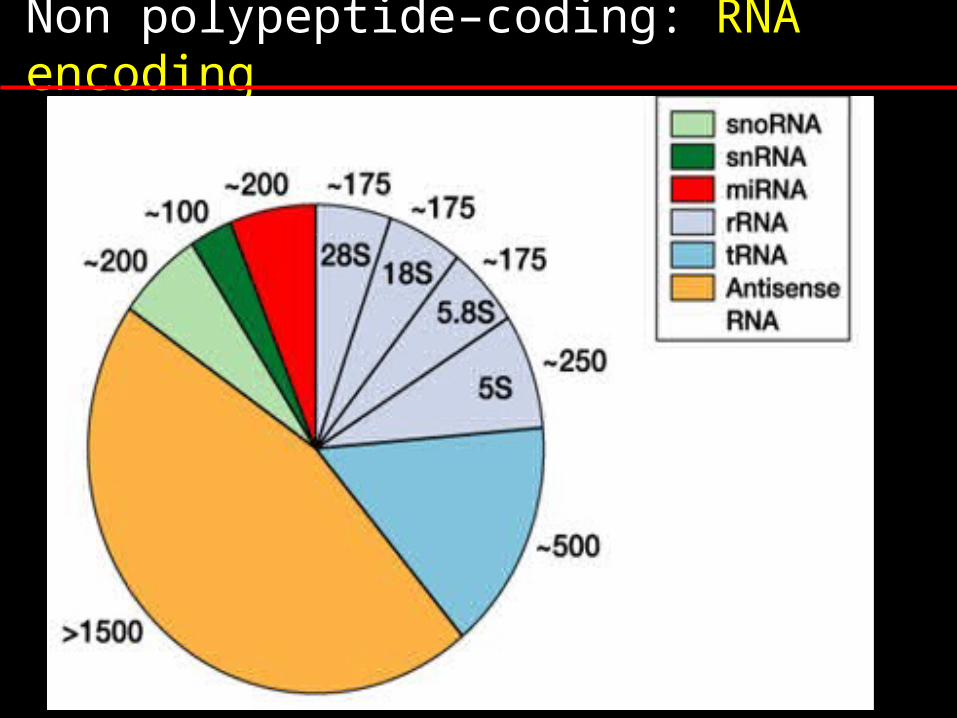
Non polypeptide–coding: RNA encoding
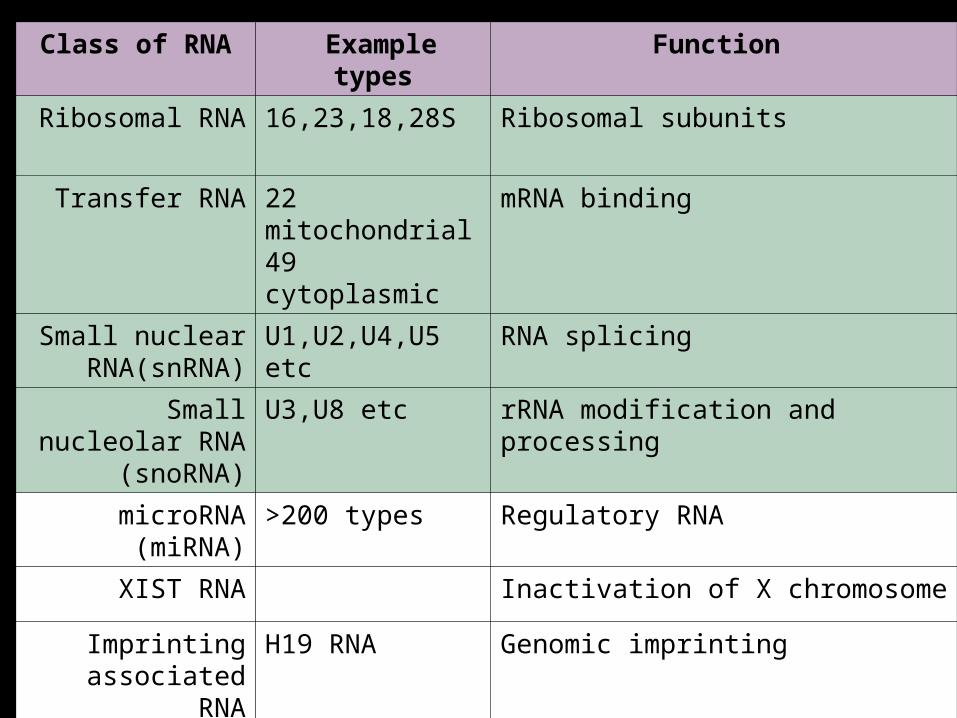
Class of RNA Example types Function
Ribosomal RNA 16,23,18,28S Ribosomal subunits
Transfer RNA 22 mitochondrial 49 cytoplasmic
mRNA binding
Small nuclear RNA(snRNA)
U1,U2,U4,U5 etc RNA splicing
Small nucleolar RNA (snoRNA)
U3,U8 etc rRNA modification and processing
microRNA (miRNA)
>200 types Regulatory RNA
XIST RNA Inactivation of X chromosome
Imprinting associated RNA
H19 RNA Genomic imprinting
Antisense RNA >1500 types Suppression of gene expression
Telomerase RNA Telomere formation
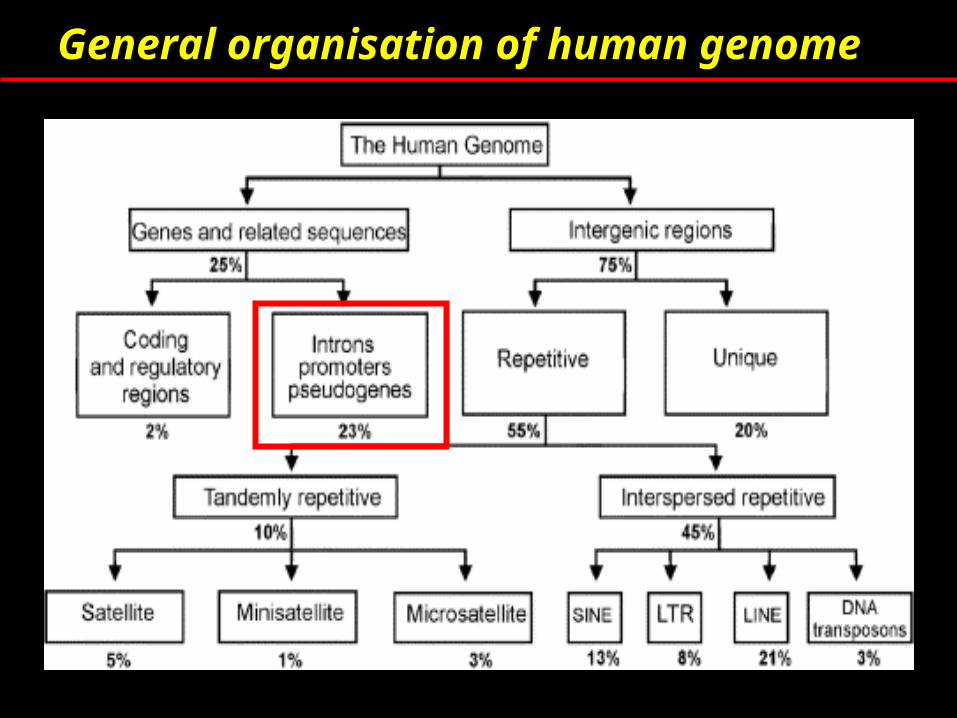
General organisation of human genome

Pseudogenes ()
non functional copies of an active gene.
May be either
a) Nonprocessed pseudogenes
May contain exons, introns & promoters but are
inactive due to inappropriate termination
codons
Arise by gene duplication events usually in
gene clusters (e.g. and –globin gene
clusters)

Pseudogenes in globin gene cluster
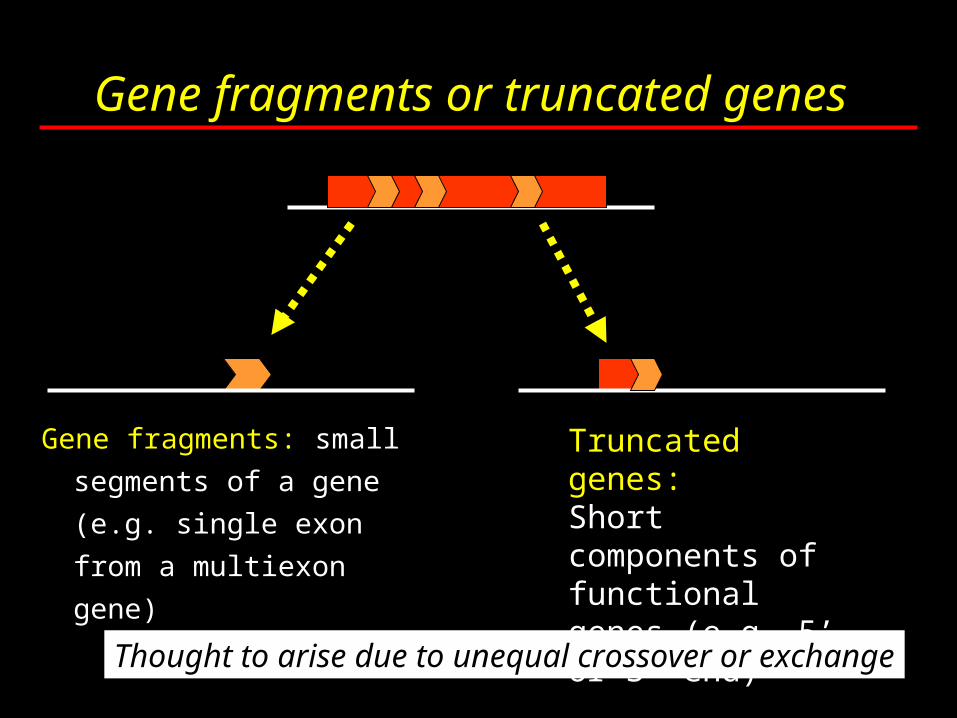
Gene fragments or truncated genes
Gene fragments: small
segments of a gene
(e.g. single exon from
a multiexon gene)
Truncated genes: Short components of functional genes (e.g. 5’ or 3’ end)
Thought to arise due to unequal crossover or exchange

b) processed pseudogenes -
Thought to arise by genomic insertion of a cDNA as a result of retrotransposition
Contributes to overall repetitive elements (<1%)
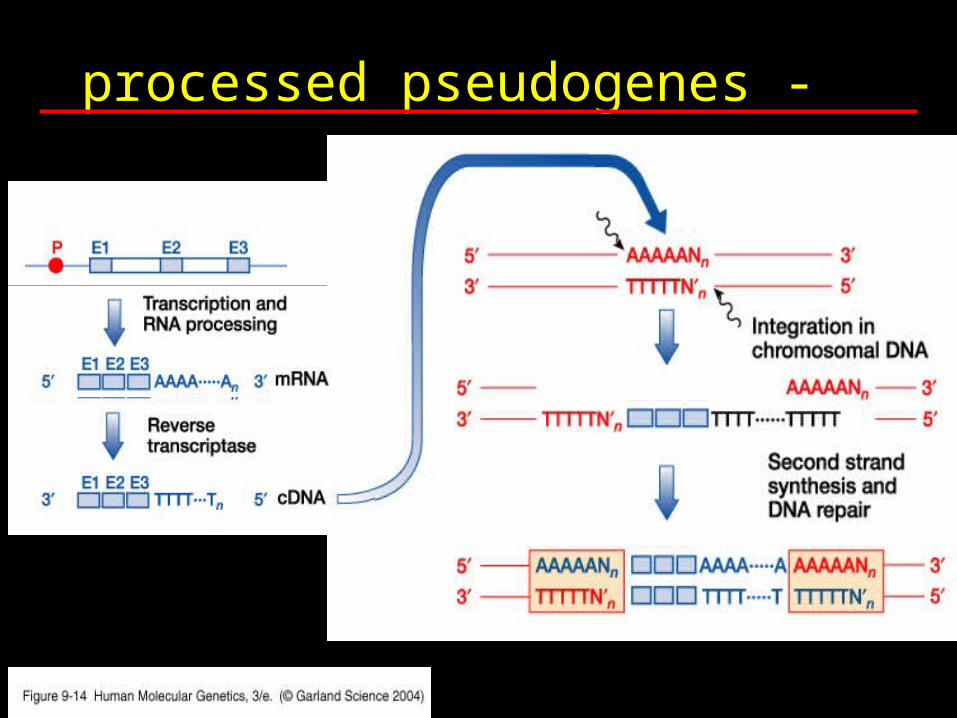
processed pseudogenes -

General organisation of human genome

Unique or low copy number sequences
Non –coding, non repetitive and single copy sequences of no known function or significance
General organisation of human genome

Repetitive elements
Main classes based on origin
Tandem repeats
Interspersed repeats
Segmental duplications

References
1) Chapter 9 pp 265-268 HMG 3 by Strachan and
Read
2) Chapter 10: pp 339-348Genetics from genes to genomes by Hartwell et al (2/e)
3) Nature (2001) 409: pp 879-891
http://www.ncbi.nlm.nih.gov/Genomes/