
Basic Molecular Biology Structures of biomolecules How does DNA function? What is a gene? Computer...
83
Basic Molecular Biology
-
Upload
magdalen-boone -
Category
Documents
-
view
215 -
download
0
Transcript of Basic Molecular Biology Structures of biomolecules How does DNA function? What is a gene? Computer...

Basic Molecular Biology

Basic Molecular Biology
Structures of biomolecules How does DNA function? What is a gene? Computer scientists vs Biologists

Bioinformatics schematic of a cell
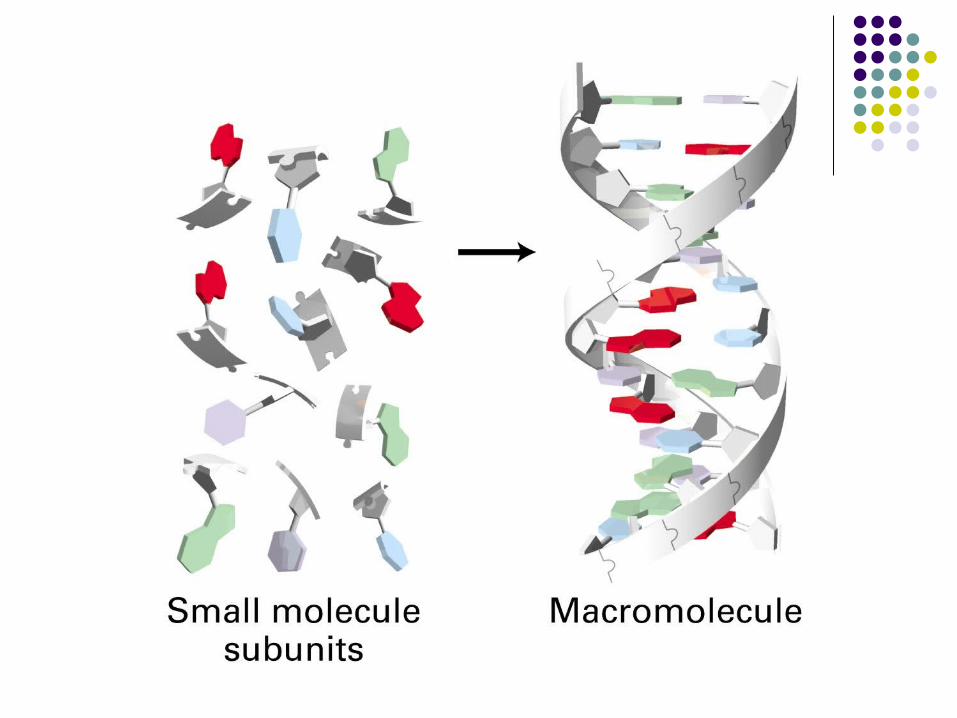
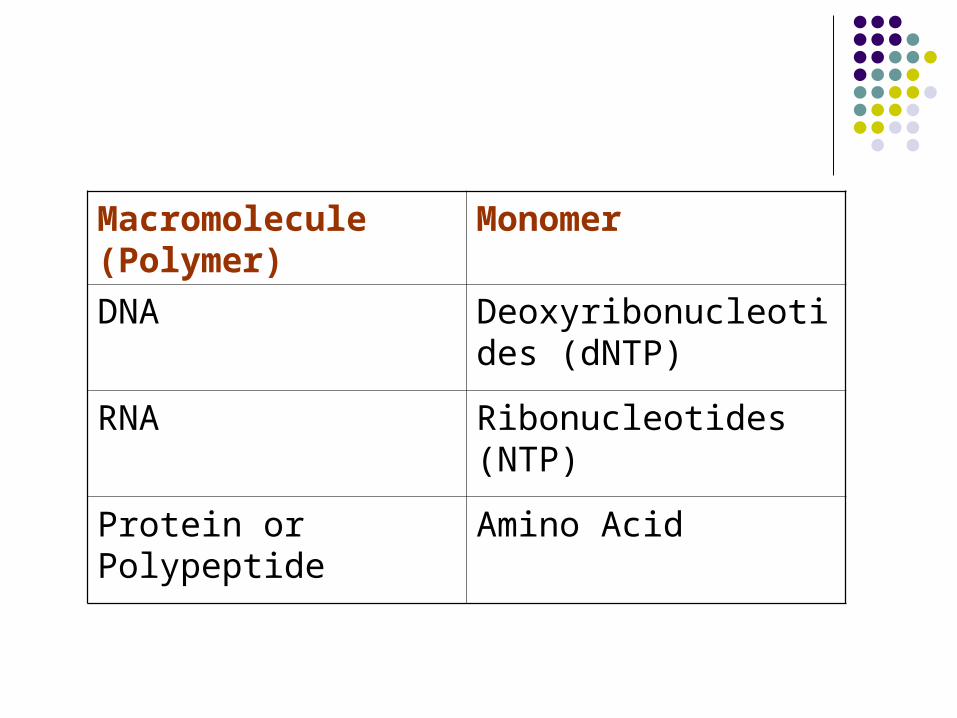
Macromolecule (Polymer)
Monomer
DNA Deoxyribonucleotides (dNTP)
RNA Ribonucleotides (NTP)
Protein or Polypeptide Amino Acid

Nucleic acids (DNA and RNA)
Form the genetic material of all living organisms.
Found mainly in the nucleus of a cell (hence “nucleic”)
Contain phosphoric acid as a component (hence “acid”)
They are made up of nucleotides.
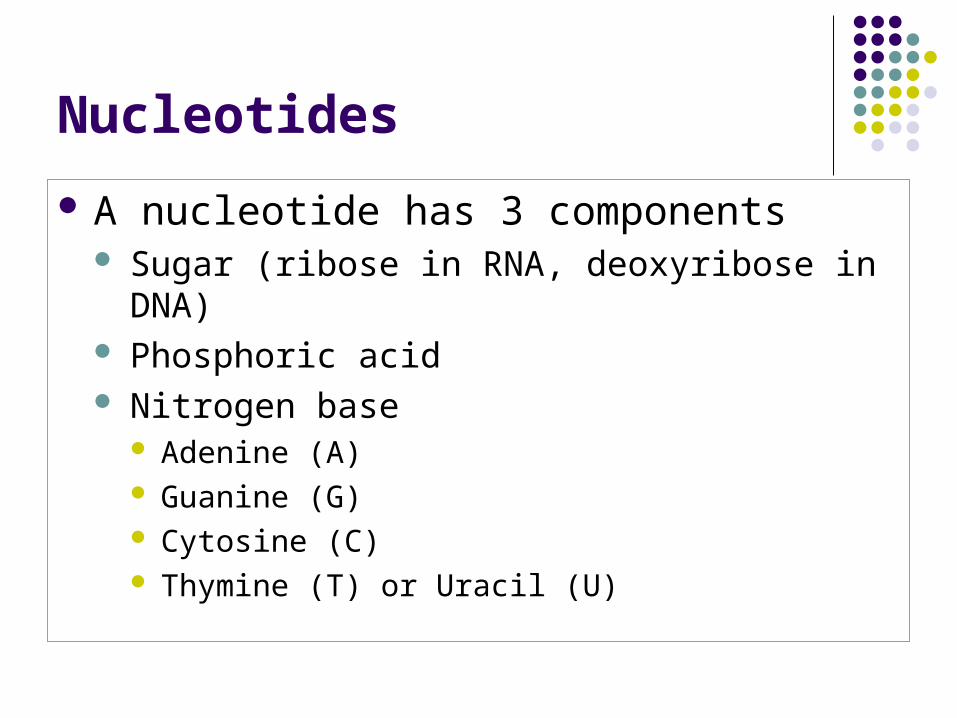
Nucleotides
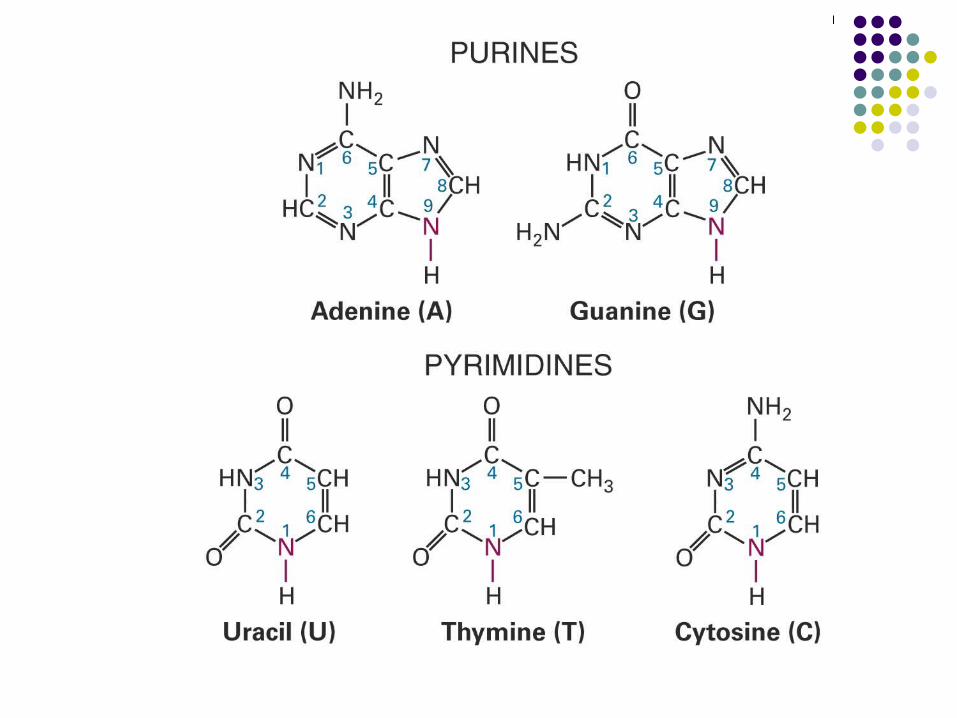
A nucleotide has 3 components Sugar (ribose in RNA, deoxyribose in DNA) Phosphoric acid Nitrogen base
Adenine (A) Guanine (G) Cytosine (C) Thymine (T) or Uracil (U)
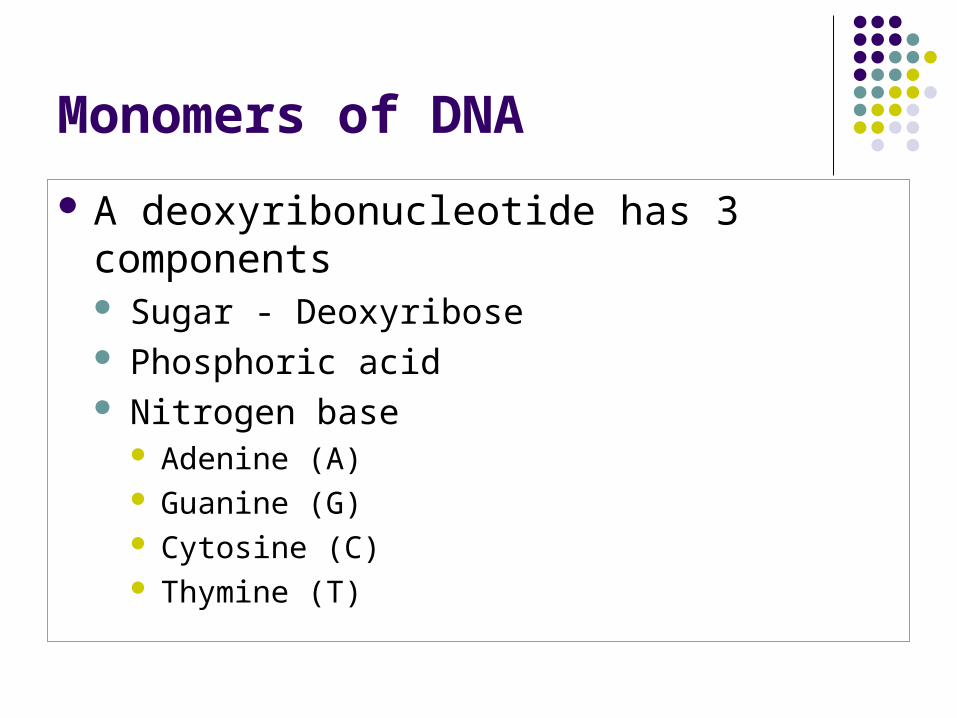
Monomers of DNA
A deoxyribonucleotide has 3 components Sugar - Deoxyribose Phosphoric acid Nitrogen base
Adenine (A) Guanine (G) Cytosine (C) Thymine (T)

Monomers of RNA
A ribonucleotide has 3 components Sugar - Ribose Phosphoric acid Nitrogen base
Adenine (A) Guanine (G) Cytosine (C) Uracil (U)


Nucleotides
Phosphate Group
Sugar
NitrogenousBase
Phosphate Group
Sugar
NitrogenousBase
T
C
A
C
T
G
G
C
G
A
G
T
C
A
G
C
G
A
G
U
C
A
G
C
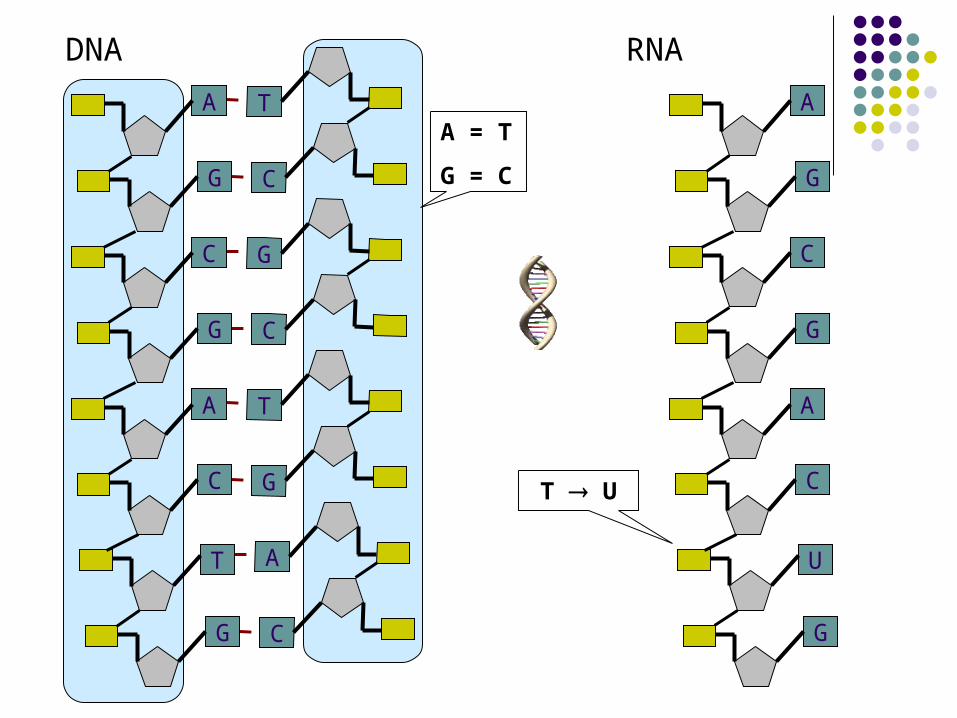
DNA RNA
A = T
G = C
T U
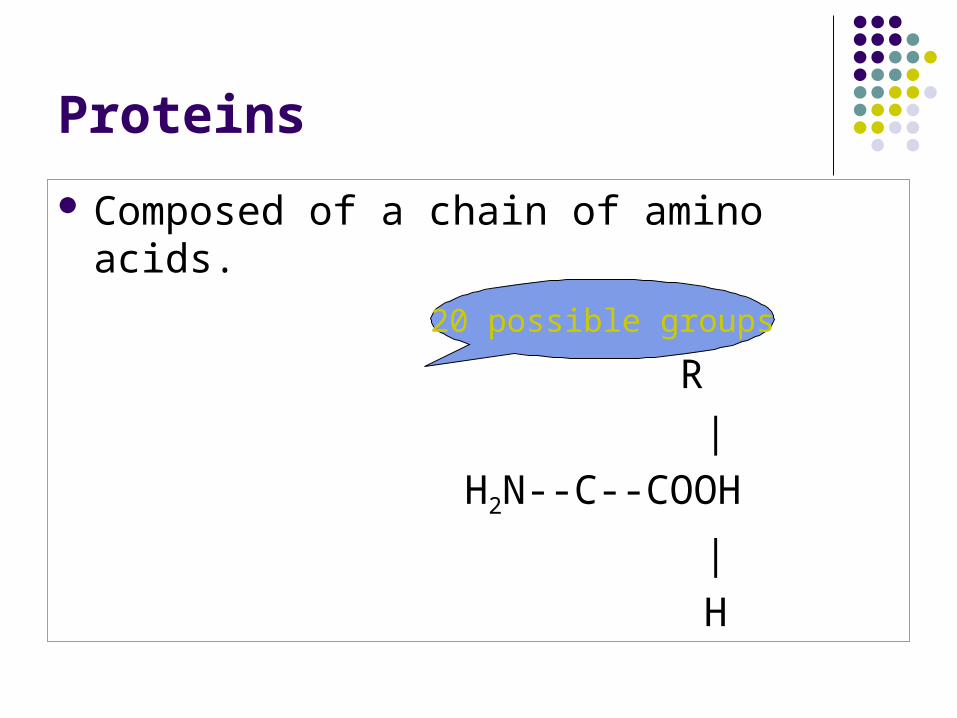
Composed of a chain of amino acids.
R
|
H2N--C--COOH
|
H
Proteins
20 possible groups
R R | | H2N--C--COOH H2N--C--COOH | | H H
Proteins
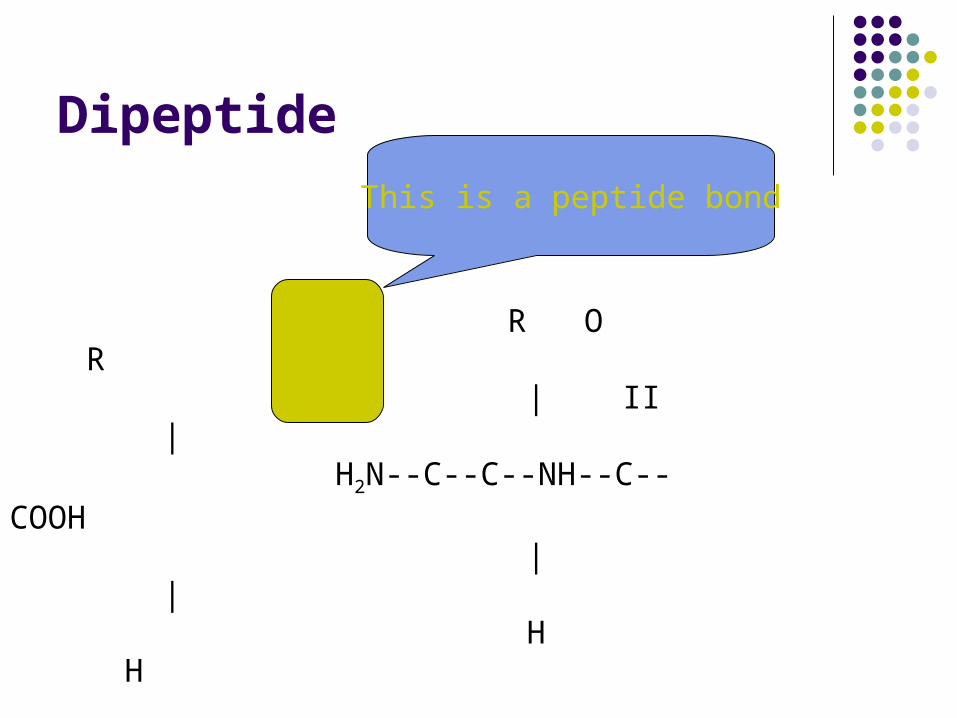
Dipeptide
R O R | II | H2N--C--C--NH--C--COOH | | H H
This is a peptide bond

Protein structure
Linear sequence of amino acids folds to form a complex 3-D structure.
The structure of a protein is intimately connected to its function.

Structure -> Function
It is the 3-D shape of proteins that gives them their working ability – generally speaking, the ability to bind with other molecules in very specific ways.
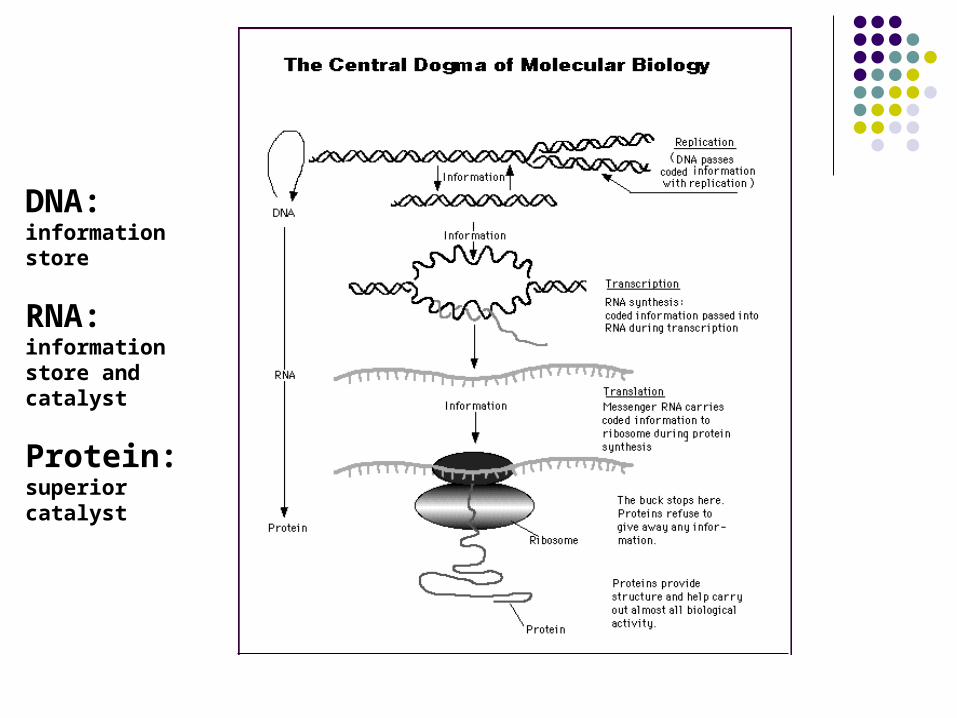
DNA: information store
RNA:information store and catalyst
Protein: superior catalyst
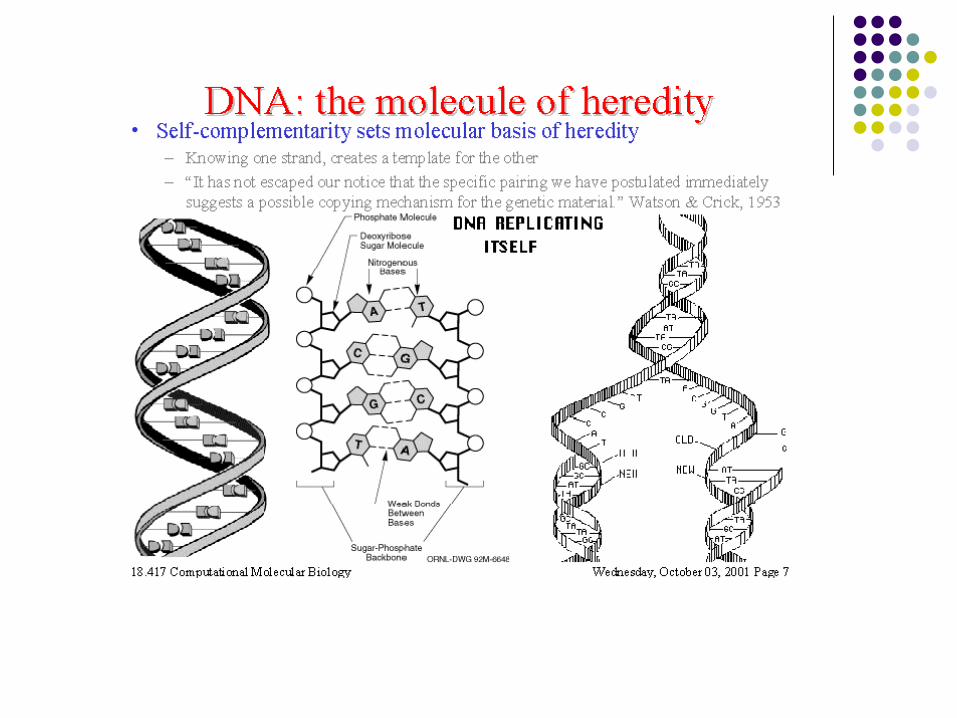

DNA in action
Questions about DNA as the carrier of genetic information: What is the information? How is the information stored in DNA? How is the stored information used ?
Answers: Information = gene → phenotype Information is stored as nucleotide sequences. .. and used in protein synthesis.

How does the series of chemical bases along a DNA strand (A/T/G/C) come to specify the series of amino acids making up the protein?

The need for an intermediary
Fact 1 : Ribosomes are the sites of protein synthesis.
Fact 2 : Ribosomes are found in the cytoplasm.
Question : How does information ‘flow’ from DNA to protein?

The Intermediary
Ribonucleic acid (RNA) is the “messenger”. The “messenger RNA” (mRNA) can be
synthesized on a DNA template. Information is copied (transcribed) from DNA
to mRNA. (TRANSCRIPTION)

Biological functions of RNA
• Mediate of the protein synthesis
• Messenger RNA (nRNA)
• Transfer RNA (tRNA)
• Ribosomal RNA (rRNA)
• Structural molecule: Ribosomal RNA
• Catalytic molecule: ribozyme
• Guide molecule: primer of DNA replication, protein degradation (tm RNA)…
• Ribonucleoprotein (complex of RNA and protein): mRAN edition, mRAN spicing, protein transport…
DNA
TRANSCRIPTION
rRNA mRNA tRNA
ribosome
TRADUCTION
PROTEINE

Transcription
The DNA is contained in the nucleus of the cell.
A stretch of it unwinds there, and its message (or sequence) is copied onto a molecule of mRNA.
The mRNA then exits from the cell nucleus. Its destination is a molecular workbench in
the cytoplasm, a structure called a ribosome.
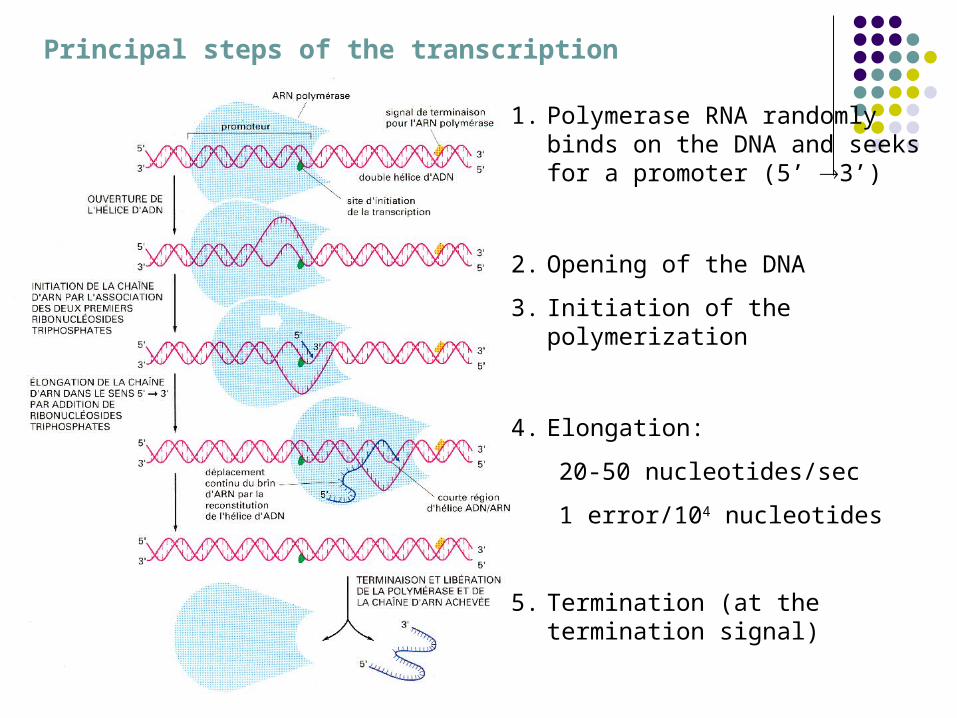
Principal steps of the transcription
1. Polymerase RNA randomly binds on the DNA and seeks for a promoter (5’ 3’)
2. Opening of the DNA
3. Initiation of the polymerization
4. Elongation:
20-50 nucleotides/sec
1 error/104 nucleotides
5. Termination (at the termination signal)

RNA polymerase
It is the enzyme that brings about transcription by going down the line, pairing mRNA nucleotides with their DNA counterparts.

Promoters
Promoters are sequences in the DNA just upstream of transcripts that define the sites of initiation.
The role of the promoter is to attract RNA polymerase to the correct start site so transcription can be initiated.
5’Promoter 3’

Promoters
Promoters are sequences in the DNA just upstream of transcripts that define the sites of initiation.
The role of the promoter is to attract RNA polymerase to the correct start site so transcription can be initiated.
5’Promoter 3’

Promoter
So a promoter sequence is the site on a segment of DNA at which transcription of a gene begins – it is the binding site for RNA polymerase.
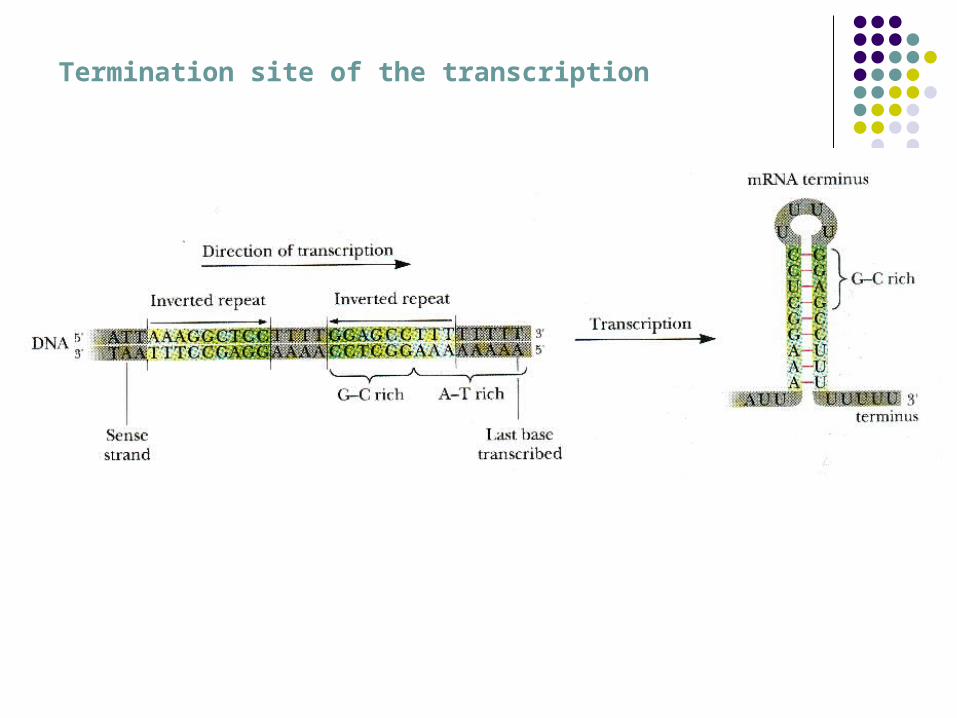
Termination site of the transcription
Next question…
How do I interpret the information carried by mRNA?
Think of the sequence as a sequence of “triplets”.
Think of AUGCCGGGAGUAUAG as AUG-CCG-GGA-GUA-UAG.
Each triplet (codon) maps to an amino acid.
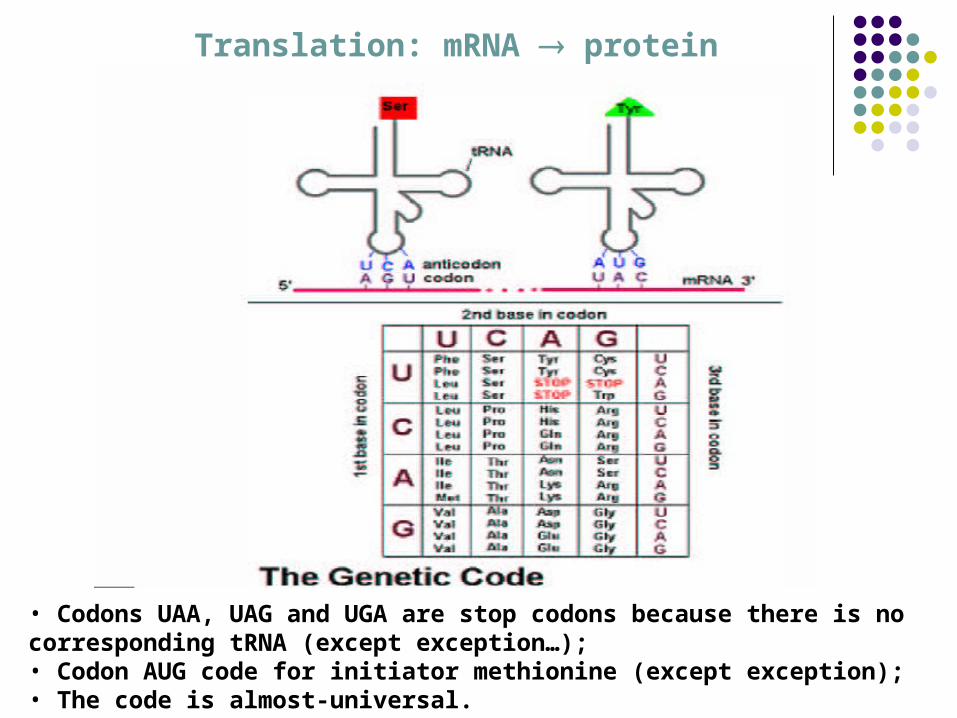
Translation: mRNA protein
• Codons UAA, UAG and UGA are stop codons because there is no corresponding tRNA (except exception…);• Codon AUG code for initiator methionine (except exception); • The code is almost-universal.

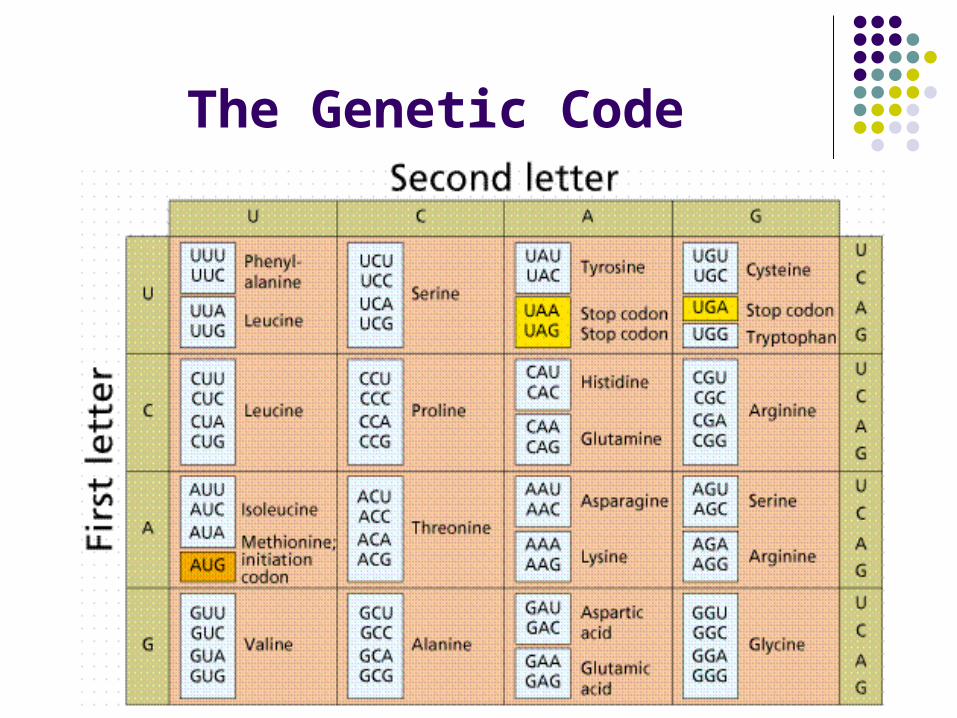
The Genetic Code

Translation
At the ribosome, both the message (mRNA) and raw materials (amino acids) come together to make the product (a protein).

Translation
The sequence of codons is translated to a sequence of amino acids.
How do amino acids get to the ribosomes? They are brought there by a second type of RNA,
transfer RNA (tRNA).

Translation
Transfer RNA (tRNA) – a different type of RNA. Freely float in the cytoplasm. Every amino acid has its own type of tRNA that
binds to it alone. Anti-codon – codon binding crucial.

tRNA

tRNAOne end of the tRNA links with a specific amino acid, which it finds floating free in
the cytoplasm.
It employs its opposite end to form base pairs with
nucleic acids – with a codon on the mRNA tape that is
being read inside the ribosome.
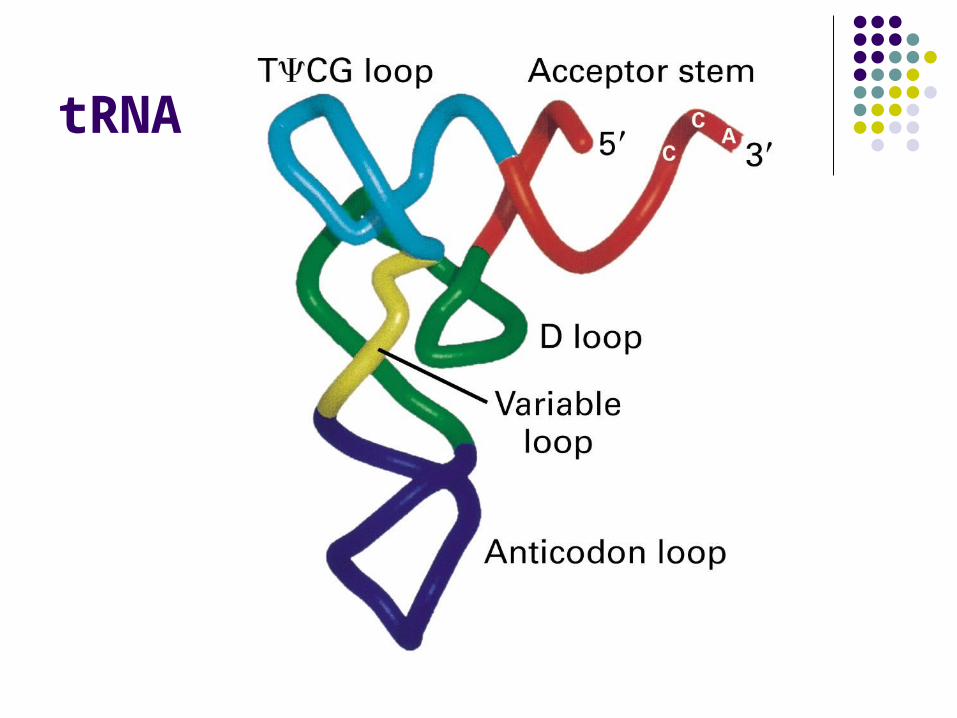
tRNA

Transfer RNA
• 61 different tRAN, composed of from 75 to 95 nucleotides
• Recognition of a codon and binding to the corresponding amino acid

Elongation of the translation
The ribosome move by 3 nucleotides toward 3’ (elongation); in 1 second a Bacteria ribosome adds 20 amino acids!Eucaryote: 2 amino acids/second !
A stop codon stop (UAA, UAG, AGA) In the same reading frame, end the process; the ribosome break away from the mRNA.
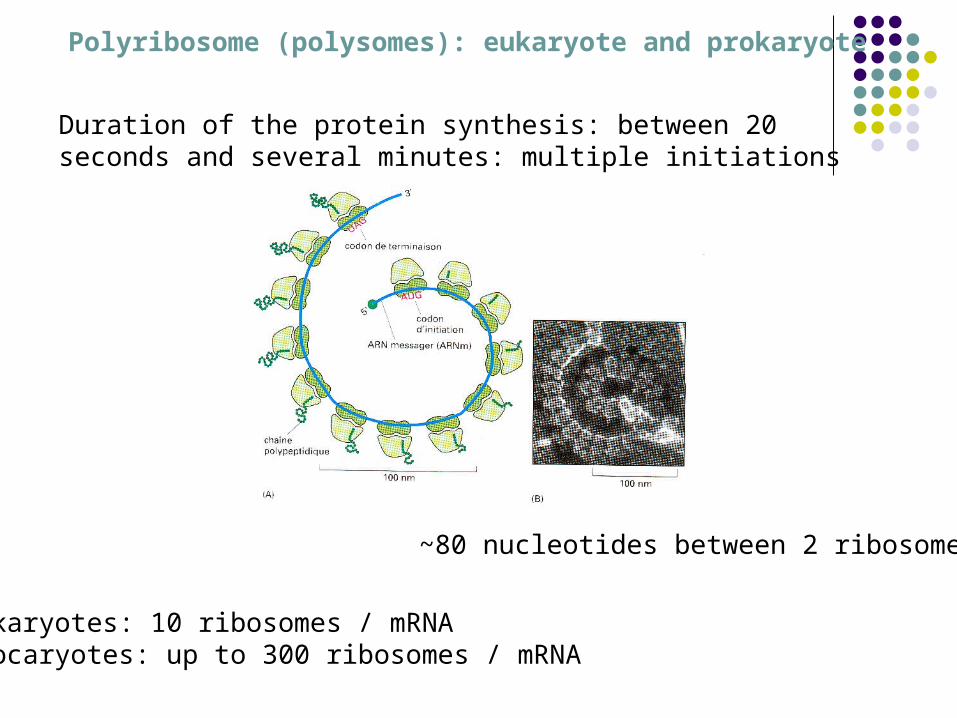
Polyribosome (polysomes): eukaryote and prokaryote
Duration of the protein synthesis: between 20 seconds and several minutes: multiple initiations
~80 nucleotides between 2 ribosomes
Eukaryotes: 10 ribosomes / mRNAProcaryotes: up to 300 ribosomes / mRNA

The gene and the genome
A gene is a length of DNA that codes for a protein.
Genome = The entire DNA sequence within the nucleus.
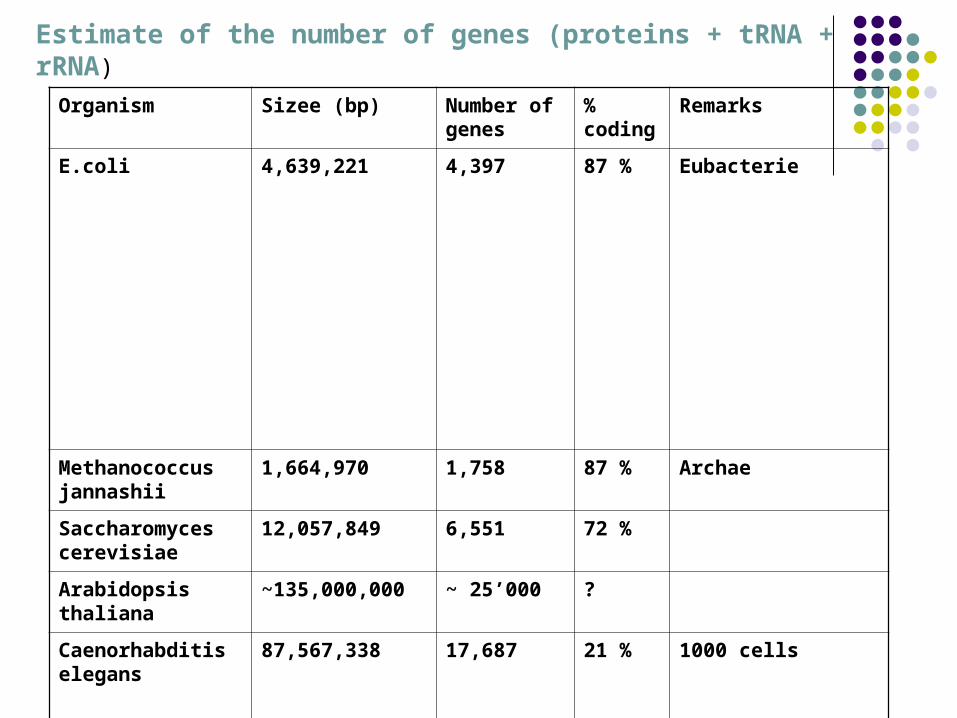
Organism Sizee (bp) Number of genes
% coding
Remarks
E.coli 4,639,221 4,397
87 % Eubacterie
Methanococcus jannashii
1,664,970 1,758 87 % Archae
Saccharomyces cerevisiae
12,057,849 6,551 72 %
Arabidopsis thaliana
~135,000,000 ~ 25’000 ?
Caenorhabditis elegans
87,567,338 17,687
21 % 1000 cells
Drosophila melanogaster
~180,000,000 ~13,600 20 % Core proteome: 8,000 (families)
Human ~3,000,000,000 20,000-25,000
4-7 % (?)
Estimate of the number of genes (proteins + tRNA + rRNA)

Genome coding regions
Gene definition
• Nucleic acid sequence required for the synthesis of:
• a functional polypeptide
• a functional RNA (tRNA, rRNA,…)
• A gene coding for a protein generally contains:
• a coding sequence (CDS)
• control regions for transcription and translation (promoter, enhancer, poly A site…)
A gene contains coding and non-coding regions

More complexity
The RNA message is sometimes “edited”. Exons are nucleotide segments whose
codons will be expressed. Introns are intervening segments (genetic
gibberish) that are snipped out. Exons are spliced together to form mRNA.

Standard structure of a gene for vertebrate
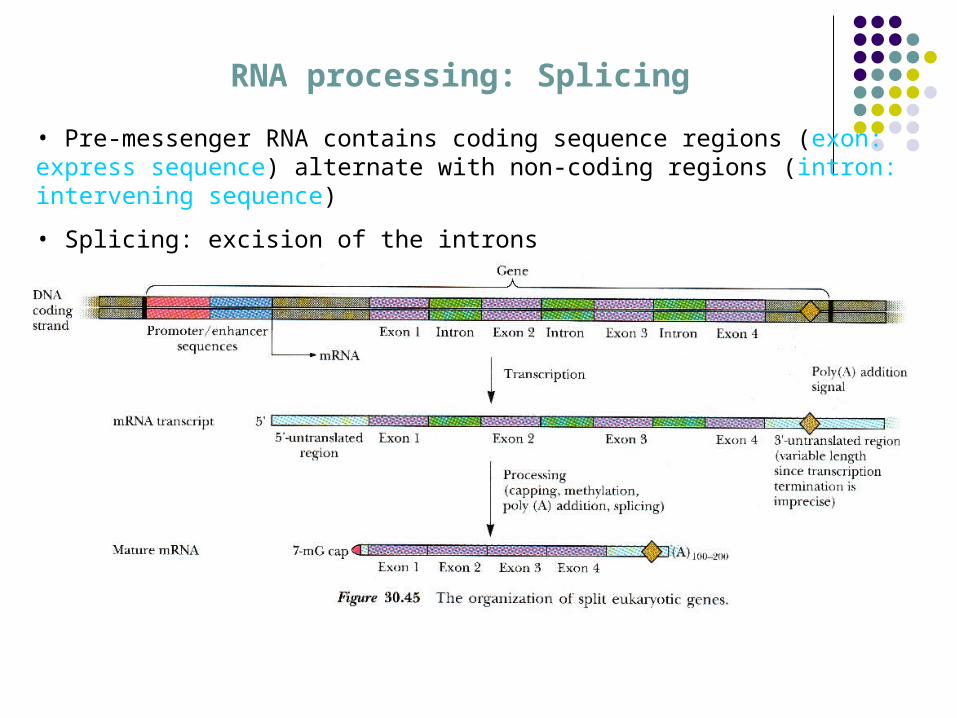
RNA processing: Splicing
• Pre-messenger RNA contains coding sequence regions (exon: express sequence) alternate with non-coding regions (intron: intervening sequence)
• Splicing: excision of the introns

• High variability of the number of intron between genes in a given specieEx: human: from 2 introns (insulin) to more than 100 introns (117 introns collagen type VII)
• High variability of the number of intron between species : Ex: yeast gene has few introns (max 2 introns / gene).
• High variability of the size of the introns (min 18 nucleotides; to 300 kb);
• High variability of the size of the exons (min 8 coding nucleotides);
• Mitochondrial human genes do not contain introns, but mitochondrial vegetal and fungus (yeast include) contain introns; chloroplast’s genes contain introns; there exists introns for some prokaryotes !
• Importance in evolution; facilitate genetic recombination; linked with the notion of domains in proteins
• Human: average: 7kb intron / 1 kb exon;
Splicing: generalities
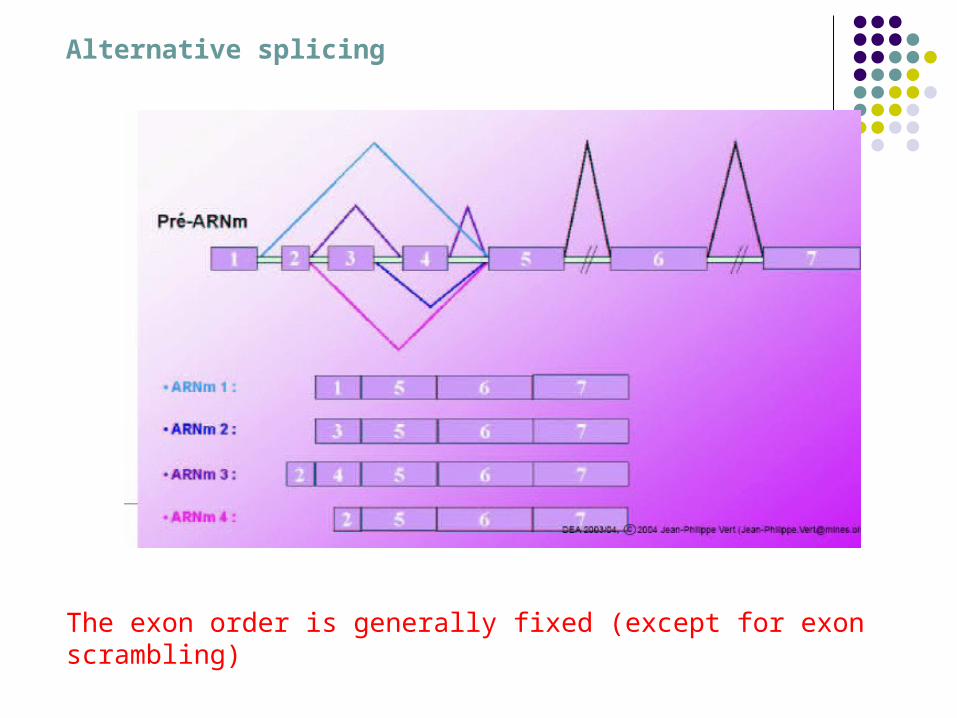
Alternative splicing
The exon order is generally fixed (except for exon scrambling)
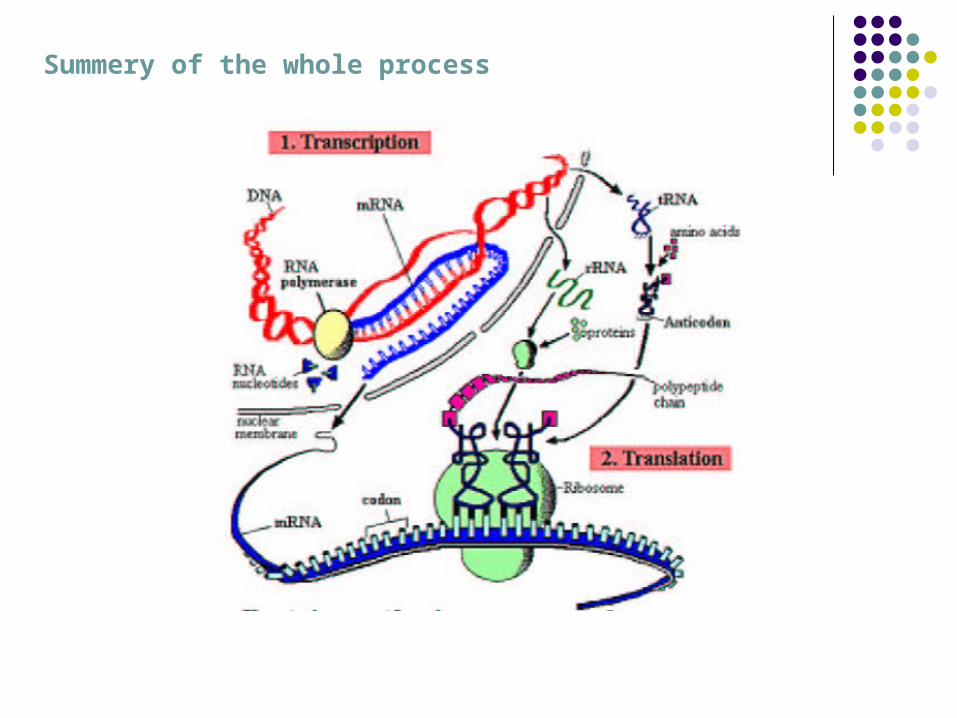
Summery of the whole process

Proteins
• Several levels from primary to quaternary structure
• Composed of amino acids
0
1
2
3
4
5
6
7
8
9
10
% frequency
L A S G V E T K I R D P N Q F Y M H C W
Amino acid
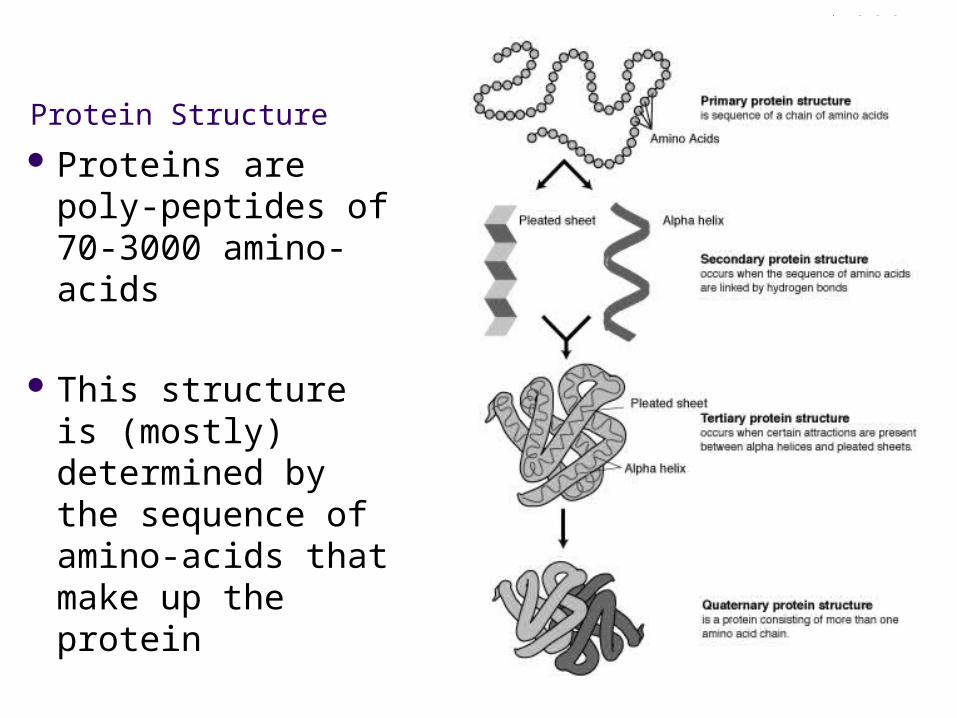
Protein Structure
Proteins are poly-peptides of 70-3000 amino-acids
This structure is (mostly) determined by the sequence of amino-acids that make up the protein
USER
למצוא קצת יותר מידע על תמונה זו

Functional categories Enzymes Kinase, Protéase Transport Hemoglobin, Regulation Insuline, Répresseur lac Storage Caséine, Ovalbumine Structure Protéoglycan, Collagène Contraction Actine, Myosine Protection Immunoglobulines, Toxines Scaffold proteins Grb 2, crk Exotics Resiline, protéines adhésives

Number of proteins in various organisms
Organism Number
Bacteria 500-6’000Yeast 6’000C. elegans 19’000 Drosophila 15’000 Human 30’000-1’000’000
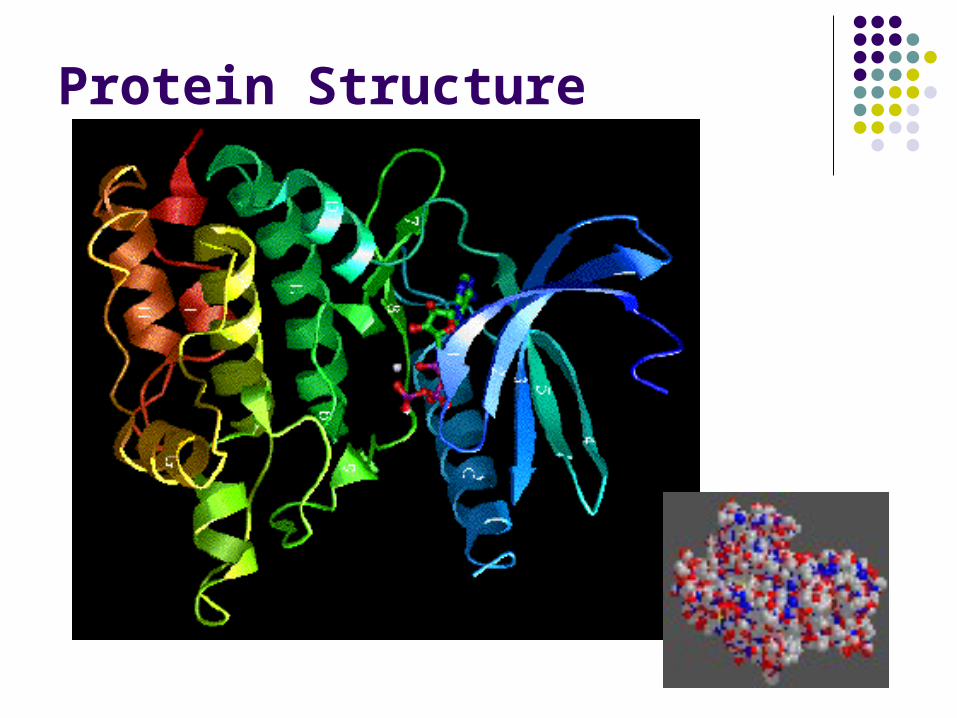
Protein Structure

Example of structural motif: HTH
• Helix – Turn – Helix (HTH) motif very common (prokaryotes et eukaryotes)
• DNA binding site for procaryotes:
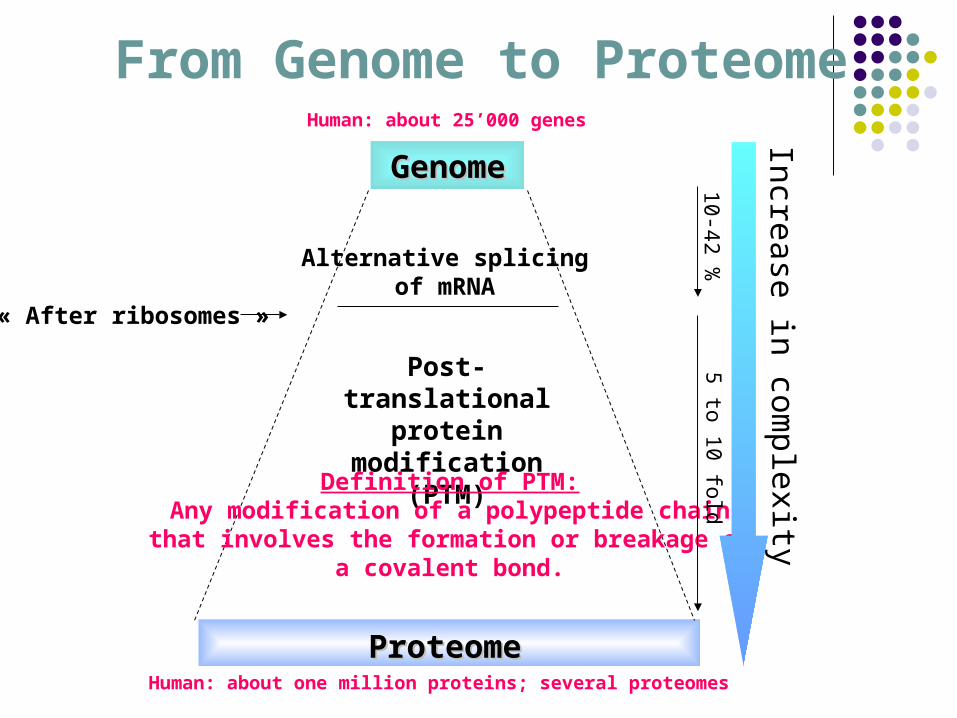
From Genome to Proteome
ProteomeProteome
Alternative splicingof mRNA
Post-translational protein
modification (PTM)
Definition of PTM:Any modification of a polypeptide chain
that involves the formation or breakage ofa covalent bond.
Increase in complexity
10 -42 %5 to 10 fold
GenomeGenome
Human: about 25’000 genes
Human: about one million proteins; several proteomes
« After ribosomes »

Evolution
Related organisms have similar DNA Similarity in sequences of proteins Similarity in organization of genes along the
chromosomesEvolution plays a major role in biology
Many mechanisms are shared across a wide range of organisms
During the course of evolution existing components are adapted for new functions

Evolution
Evolution of new organisms is driven byDiversity
Different individuals carry different variants of the same basic blue print
Mutations The DNA sequence can be changed due to
single base changes, deletion/insertion of DNA segments, etc.
Selection bias

Numerous possible effect of mutation
Neutral basic Lys -> basic Arg
ADN 3’-AAA GCT ACC TAT CGG TCT 5’5’-TTT CGA TGG ATA GCC AGA 3’N-Phe Arg Trp Ile Ala Arg-C
Missense
ADN 3’-AAT GCT ACC TAT CGG TTT 5’5’-TTA CGA TGG ATA GCC AAA 3’N-Leu Arg Trp Ile Ala Lys-C
Nonsense
ADN 3’-AAA GCT ATC TAT CGG TTT 5’5’-TTT CGA TAG ATA GCC AAA 3’N-Phe Arg Stop
Frameshift (délétion de 4 bases)
ADN 3’-AAA CCT ATC GGT TT 5’5’-TTT GGA TAG CCA AA 3’N-Phe Gly Stop
Frameshift (insertion d’une base)
ADN 3’-AAA GCT ACC ATA TCG GTT T 5’5’-TTT CGA TGG TAT AGC CAA A 3’N-Phe Arg Trp Tyr Ser Gln
Original sequence
AminoAcids N-PheArg Trp Ile Ala Lys-C
ARNm 5’-UUU CGA UGG AUA GCC AAA-3’ADN 3’-AAA GCT ACC TAT CGG TTT 5’
5’-TTT CGA TGG ATA GCC AAA 3’
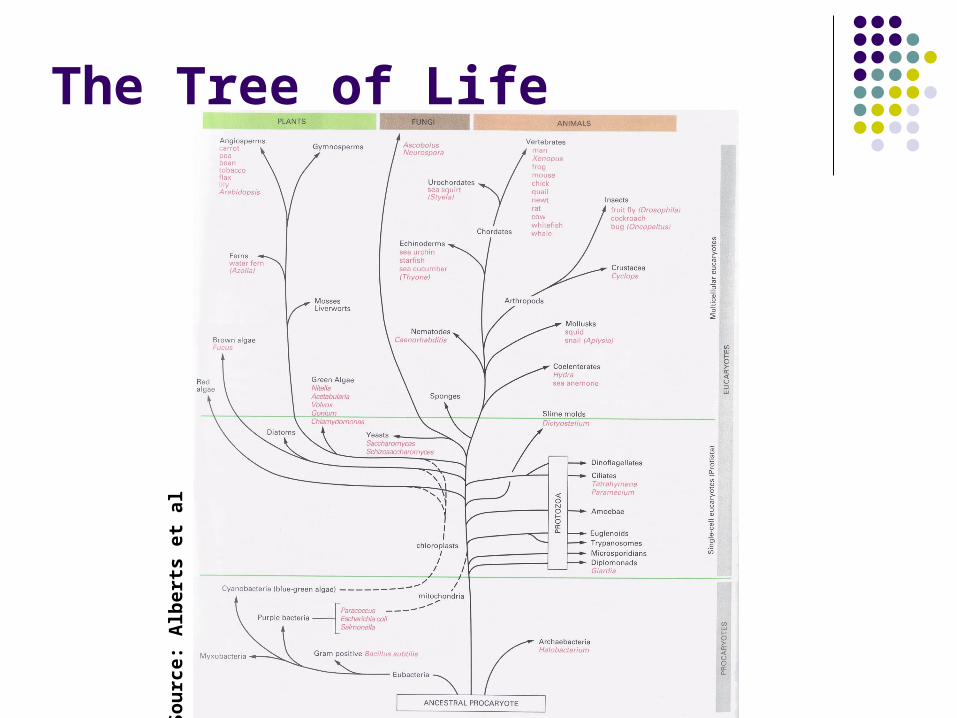
The Tree of Life
Sou
rce:
Alb
erts
et
al
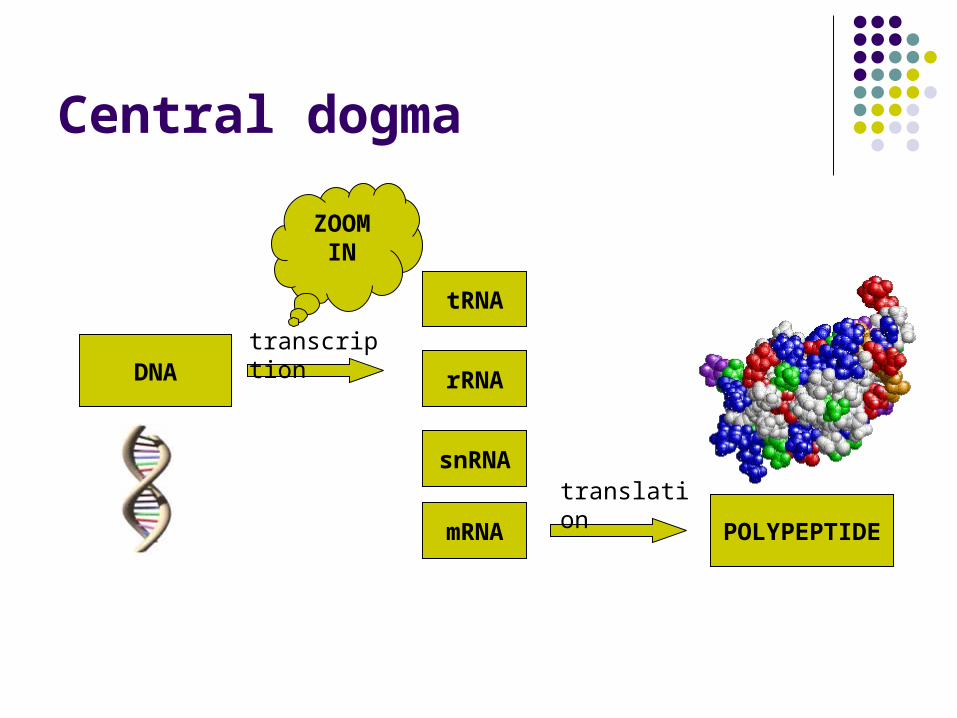
Central dogma
DNA
tRNA
rRNA
snRNA
mRNA
transcription
translation
POLYPEPTIDE
ZOOM IN

Bioinformatics Studies the flow of information in biomedicine
Information flow from genotype to phenotypeDNA → Protein → Function → Organism → Population → DNA
Experimental flow for creating and testing modelsHypothesis → Experiment → Data → Conflict → Hypothesis

Computational Biology and Bioinformatics
The systematic development and application of computing systems and computational solution techniques to the analysis of biological data obtained by experiments, modeling, database search, and experimentation
Explosion of experimental data Difficulty in interpreting data Need for new paradigms for computing with data and
extracting new knowledge from it





Brief history of early bioinformatics• Molecular sequences and data bases
Dayhoff (atlas of proteins, 1965) Zuckerkandl & Pauling (1965), Bilofsky (GenBank, 1986), Hamm & Cameron (EMBL, 1986), Bairoch (Swiss-Prot, 1986)
• Molecular sequence comparison NeedleMan & Wunsch (1970), Smith & Waterman (1981), Pearson-Lipman (Fasta, 1985), Altschul (Blast, 1990)
• Multiple alignment and automatic phylogeny Aho (common subsequence, 1976), Felsenstein (infering phylogenies, 1981-1988), Sankoff & Cedergren (multiple comparison, 1983), Feng & Doolittle (Clustal, 1987), Gusfield (inferring evolutionary trees, 1991), Thompson (ClustalW, 1994)
• Motif search and discoveryFickett (ORF, 1982), Ukkonen (approximate string matching, 1985), Jonassen (Pratt, 1995), Califano (Splash, 2000) Pevzner (WINNOVER, 2000)
• But also: RNA structure prediction, protein threading, protein foldings… Few fields and large use of combinatoric/dynamic
programming approaches

New biological data imply new bioinformatics field • Sequence
Motif search, motif discovery, alignment…
Data indexing, regular language, dynamic programming, HMM, EM, Gibbs sampling…
• Structure
RNA folding, protein threading, protein folding…
Palindrome search, context-(free, sensitive) language, dynamic programming, combinatorial optimization…
• DNA chip
Classification, clustering, feature selection, regulation network…
NN, SVM, Bayesian inference, (hierarchical, k, Gaussian)-clustering, differencial model…
• Proteomics
Spectrum analysis, image pattern matching, probabilistic model…
• Bibliographic data
Ontology, text mining…

Important source of data and information
GENEBANK: http://www.ncbi.nih.gov
Swiss-prot: http://us.expasy.org/sprot/relnotes
Protein Data Bank (PDB): http://www.rcsb.org/pdb/home/home.do
Stanford Microarray DB http://smd.stanford.edu
MedLine or PubMed http://genome.ucsc.edu or http://www.ebi.ac.uk/ensembl
Journals: Bioinformatics, BMC bioinformatics, Nucleic Acids Research, Journal of Molecular Biology, Proteomics…

Computer scientists vs Biologists
(Almost) Nothing is ever completely true or false in Biology.
Everything is either true or false in computer science.

Computer scientists vs Biologists
Biologists strive to understand the very complicated, very messy natural world.
Computer scientists seek to build their own clean and organized virtual worlds.

Computer scientists vs Biologists
Biologists are more data driven. Computer scientists are more algorithm
driven. One consequence is CS www pages have
fancier graphics while Biology www pages have more content.

Computer scientists vs Biologists
Biologists are obsessed with being the first to discover something.
Computer scientists are obsessed with being the first to invent or prove something.

Computer scientists vs Biologists
Biologists are comfortable with the idea that all data has errors.
Computer scientists are not.

Computer scientists vs Biologists
Computer scientists get high-paid jobs after graduation.
Biologists typically have to complete one or more post-docs...

Computer Science is to Biology what Mathematics
is to Physics


















