
Automatic Storage Management The New Best Practice Steve Adams Ixora Rich Long Oracle Corporation...
56
-
Upload
felicity-dalton -
Category
Documents
-
view
221 -
download
2
Transcript of Automatic Storage Management The New Best Practice Steve Adams Ixora Rich Long Oracle Corporation...


Automatic Storage ManagementAutomatic Storage ManagementThe New Best PracticeThe New Best Practice
Steve AdamsIxora
Rich LongOracle Corporation
Session id: 40288

The Challenge
Today’s databases– large– growing
Storage requirements– acceptable performance– expandable and scalable– high availability– low maintenance

Outline
Introduction– get excited about ASM
Current best practices– complex, demanding, but achievable
Automatic storage management– simple, easy, better
Conclusion

Current Best Practices
General principles to follow– direct I/O– asynchronous I/O– striping– mirroring– load balancing
Reduced expertise and analysis required– avoids all the worst mistakes

FileSystemCache
Database Cache
SGA
PGA
Buffered I/O
Reads– stat: physical reads– read from cache– may require
physical read
Writes– written to cache– synchronously
(Oracle waits until the data is safely on disk too)

FileSystemCache
Direct I/O
I/O– bypasses file
system cache
Memory– file system cache
does not contain database blocks(so it’s smaller)
– database cache can be larger
Database Cache
SGA
PGA

Buffered I/O – Cache Usage
FileSystemCache
Database Cache
Legend:
hot data
recent warm data
older warm data
recent cold data
o/s data

Direct I/O – Cache Usage
FileSystemCache
Database Cache
Legend:
hot data
recent warm data
older warm data
recent cold data
o/s data

Cache Effectiveness
Buffered I/O– overlap wastes memory– caches single use data– simple LRU policy– file system cache hits
are relatively expensive– extra physical read and
write overheads – floods file system
cache with Oracle data
Direct I/O– no overlap– no single use data– segmented LRU policy– all cached data is found
in the database cache– no physical I/O
overheads – non-Oracle data
cached more effectively

Buffered Log Writes
Most redo log writes address part of a file system block
File system reads the target block first
– then copies the data
Oracle waits for both the read and the write
– a full disk rotation is needed in between
FileSystemCache
Log BufferSGA

I/O Efficiency
Buffered I/O– small writes
must wait for preliminary read
– large reads & writes performed as a
series of single block operations
– tablespace block size must match file system block size exactly
Direct I/O– small writes
no need to re-write adjacent data
– large reads & writes passed down the
stack without any fragmentation
– may use any tablespace block size without penalty

Direct I/O – How To
May need to– set filesystemio_options parameter– set file system mount options– configure using operating system commands
Depends on– operating system platform– file system type

Synchronous I/O
Processes wait for I/O completion and results
A process can only use one disk at a time
For a series of I/Os to the same disk
– the hardware cannot service the requests in the optimal order
– scheduling latencies
DBWn write batch

Asynchronous I/O
Can perform other tasks while waiting for I/O
Can use many disks at once
For a batch of I/Os to the same disk
– the hardware can service the requests in the optimal order
– no scheduling latencies
DBWn write batch

Asynchronous I/O – How To
Threaded asynchronous I/O simulation– multiple threads perform synchronous I/O– high CPU cost if intensively used– only available on some platforms
Kernelized asynchronous I/O– must use raw devices
or a pseudo device driver product eg: Veritas Quick I/O, Oracle Disk Manager, etc

Striping – Benefits
Concurrency– hot spots are spread over multiple disks which
can service concurrent requests in parallel
Transfer rate– large reads & writes use multiple disk in parallel
I/O spread– full utilization of hardware investment
important for systems relatively few large disks

Striping – Fine or Coarse
Concurrency – coarse grain– most I/Os should be serviced by a single disk– caching ensures that disk hot spots are not small– 1 Mb is a reasonable stripe element size
Transfer rate – fine grain– large I/Os should be serviced by multiple disks– but very fine striping increases rotational latency
and reduces concurrency– 128 Kb is commonly optimal

Striping – Breadth
Comprehensive (SAME)– all disks in one stripe– ensures even utilization
of all disks– needs reconfiguration
to increase capacity– without a disk cache
log write performance may be unacceptable
Broad (SAME sets)– two or more stripe sets– one sets may be busy
while another is idle– can increase capacity
by adding a new set– can use a separate disk
set to isolate log files from I/O interference

Striping – How To
Stripe breadth– broad (SAME sets)
to allow for growth to isolate log file I/O
– comprehensive (SAME) otherwise
Stripe grain– choose coarse for high concurrency applications– choose fine for low concurrency applications

Data Protection
Mirroring– only half the raw disk
capacity is usable– can read from either
side of the mirror– must write to both
sides of the mirror
Half the data capacity Maximum I/O capacity
RAID-5– parity data use the
capacity of one disk– only one image from
which to read– must read and write
both the data and parity
Nearly full data capacity Less than half I/O ability
“Data capacity is much cheaper than I/O capacity.”

Mirroring – Software or Hardware
Software mirroring– a crash can leave mirrors inconsistent– complete resilvering takes too long– so a dirty region log is normally needed
enumerates potentially inconsistent regions makes resilvering much faster but it is a major performance overhead
Hardware mirroring is best practice– hot spare disks should be maintained

Data Protection – How To
Choose mirroring, not RAID-5– disk capacity is cheap– I/O capacity is expensive
Use hardware mirroring if possible– avoid dirty region logging overheads
Keep hot spares– to re-establish mirroring quickly after a failure

Load Balancing – Triggers
Performance tuning– poor I/O performance– adequate I/O capacity– uneven workload
Workload growth– inadequate I/O capacity– new disks purchased– workload must be
redistributed
Data growth– data growth requires
more disk capacity– placing the new data on
the new disks would introduce a hot spot

Load Balancing – Reactive
Approach– monitor I/O patterns and densities– move files to spread the load out evenly
Difficulties– workload patterns may vary– file sizes may differ, thus preventing swapping– stripe sets may have different I/O characteristics

Load Balancing – How To
Be prepared– choose a small, fixed datafile size– use multiple such datafiles for each tablespace– distribute these datafiles evenly over stripe sets
When adding capacity– for each tablespace, move datafiles pro-rata from
the existing stripe sets into the new one

Automatic Storage Management
What is ASM? Disk Groups Dynamic Rebalancing ASM Architecture ASM Mirroring

Automatic Storage Management
New capability in the Oracle database kernel Provides a vertical integration of the file system and
volume manager for simplified management of database files
Spreads database files across all available storage for optimal performance
Enables simple and non-intrusive resource allocation with automatic rebalancing
Virtualizes storage resources

ASM Disk Groups
Disk Group
A pool of disks managed as a logical unit

ASM Disk Groups
Disk Group
A pool of disks managed as a logical unit
Partitions total disk space into uniform sized megabyte units

ASM Disk Groups
Disk Group
A pool of disks managed as a logical unit
Partitions total disk space into uniform sized megabyte units
ASM spreads each file evenly across all disks in a disk group

ASM Disk Groups
Disk Group
A pool of disks managed as a logical unit
Partitions total disk space into uniform sized megabyte units
ASM spreads each file evenly across all disks in a disk group
Coarse or fine grain striping based on file type

ASM Disk Groups
Disk Group
A pool of disks managed as a logical unit
Partitions total disk space into uniform sized megabyte units
ASM spreads each file evenly across all disks in a disk group
Coarse or fine grain striping based on file type
Disk groups integrated with Oracle Managed Files

ASM Dynamic Rebalancing
Disk Group
Automatic online rebalance whenever storage configuration changes

ASM Dynamic Rebalancing
Automatic online rebalance whenever storage configuration changes
Only move data proportional to storage added
Disk Group

ASM Dynamic Rebalancing
Automatic online rebalance whenever storage configuration changes
Only move data proportional to storage added
No need for manual I/O tuning
Disk Group

ASM Dynamic Rebalancing
Automatic online rebalance whenever storage configuration changes
Online migration to new storage
Disk Group

ASM Dynamic Rebalancing
Automatic online rebalance whenever storage configuration changes
Online migration to new storage
Disk Group

ASM Dynamic Rebalancing
Automatic online rebalance whenever storage configuration changes
Online migration to new storage
Disk Group

ASM Dynamic Rebalancing
Automatic online rebalance whenever storage configuration changes
Online migration to new storage
Disk Group

ASM Architecture
Pool of Storage
ASM Instance
Server
Non–RACDatabase
Oracle
DB Instance
Disk Group

ASM Architecture
Clustered Pool of Storage
ASM Instance ASM Instance
Clustered Servers
RACDatabase
Oracle
DB Instance
Oracle
DB Instance
Disk Group
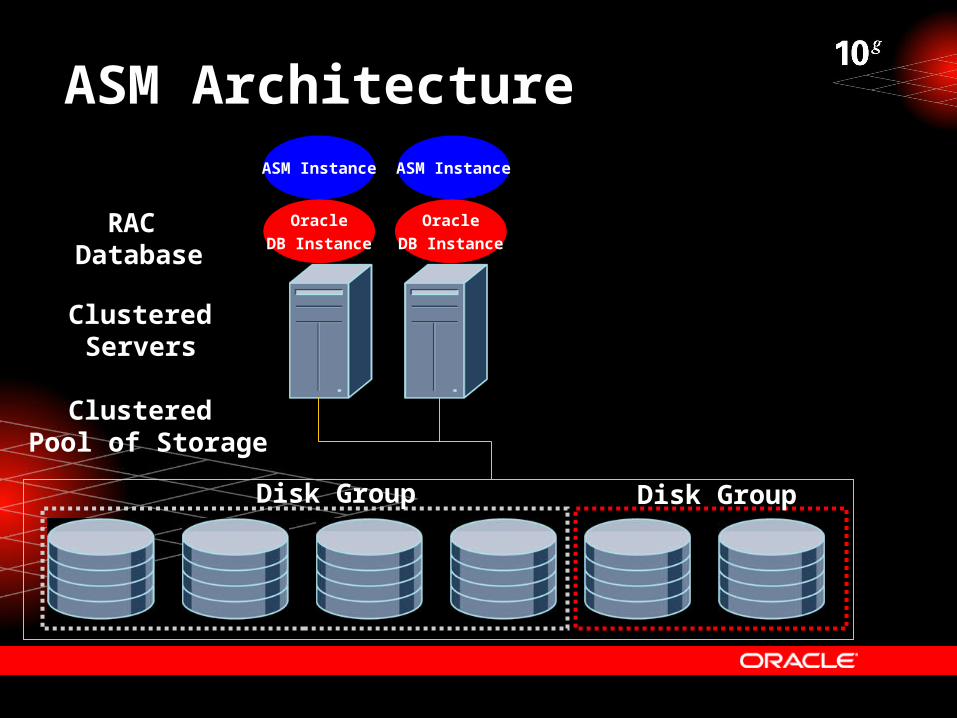
ASM Architecture
Clustered Pool of Storage
ASM Instance ASM Instance
Clustered Servers
RAC Database
Oracle
DB Instance
Oracle
DB Instance
Disk GroupDisk Group

ASM Architecture
Clustered Pool of Storage
ASM InstanceASM Instance ASM Instance ASM Instance
Clustered Servers
RAC or Non–RAC
Databases
Oracle
DB Instance
Oracle
DB Instance
Oracle
DB Instance
Oracle
DB Instance
Oracle
DB Instance
Disk GroupDisk Group

ASM Mirroring
3 choices for disk group redundancy– External: defers to hardware mirroring– Normal: 2-way mirroring– High: 3-way mirroring
Integration with database removes need for dirty region logging

ASM Mirroring
Mirror at extent level Mix primary & mirror extents on each disk

ASM Mirroring
Mirror at extent level Mix primary & mirror extents on each disk

ASM Mirroring
No hot spare disk required– Just spare capacity– Failed disk load spread among survivors– Maintains balanced I/O load

Conclusion
Best practice is built into ASM ASM is easy ASM benefits
– performance– availability– automation

Best Practice Is Built Into ASM
I/O to ASM files is direct, not buffered ASM allows kernelized asynchronous I/O ASM spreads the I/O as broadly as possible
– can have both fine and coarse grain striping ASM can provide software mirroring
– does not require dirty region logging– does not require hot spares, just spare capacity
When new disks are added ASM does load balancing automatically without downtime

ASM is Easy
You only need to answer two questions– Do you need a separate log file disk group?
intensive OLTP application with no disk cache
– Do you need ASM mirroring? storage not mirrored by the hardware
ASM will do everything else automatically Storage management is entirely automated
– using BIGFILE tablespaces, you need never name or refer to a datafile again

ASM Benefits
ASM will improve performance– very few sites follow the current best practices
ASM will improve system availability– no downtime needed for storage changes
ASM will save you time– it automates a complex DBA task entirely

AQ&Q U E S T I O N SQ U E S T I O N S
A N S W E R SA N S W E R S

Next Steps….
Automatic Storage Management Demo in the Oracle DEMOgrounds
– Pod 5DD– Pod 5QQ

Reminder – please complete the OracleWorld online session survey
Thank you.



















