
Automatic Cache and Local Memory Optimization for Multicores · Automatic Cache and Local Memory...
28
Automatic Cache and Local Memory Optimization for Multicores Hironori Kasahara Professor, Dept. of Computer Science & Engineering Director, Advanced Multicore Processor Research Institute Waseda University, Tokyo, Japan IEEE Computer Society President Elect 2017, President 2018 URL: http://www.kasahara.cs.waseda.ac.jp/ Waseda Univ. GCSC
Transcript of Automatic Cache and Local Memory Optimization for Multicores · Automatic Cache and Local Memory...

Automatic Cache and Local Memory Optimization for Multicores
Hironori KasaharaProfessor, Dept. of Computer Science & Engineering
Director, Advanced Multicore Processor Research InstituteWaseda University, Tokyo, Japan
IEEE Computer Society President Elect 2017, President 2018 URL: http://www.kasahara.cs.waseda.ac.jp/
Waseda Univ. GCSC

Core#2 Core#3
Core#1
Core#4 Core#5
Core#6 Core#7
SNC
0SN
C1
DBSC
DDRPADGCPGC
SM
LB
SC
SHWY
URAMDLRAM
Core#0ILRAM
D$
I$
VSWC
Multicores for Performance and Low Power
IEEE ISSCC08: Paper No. 4.5, M.ITO, … and H. Kasahara,
“An 8640 MIPS SoC with Independent Power-off Control of 8 CPUs and 8 RAMs by an Automatic
Parallelizing Compiler”
Power ∝ Frequency * Voltage2
(Voltage ∝ Frequency)Power ∝ Frequency3
If Frequency is reduced to 1/4(Ex. 4GHz1GHz),
Power is reduced to 1/64 and Performance falls down to 1/4 .<Multicores>If 8cores are integrated on a chip,Power is still 1/8 and Performance becomes 2 times.
2
Power consumption is one of the biggest problems for performance scaling from smartphones to cloud servers and supercomputers (“K” more than 10MW) .

Core #3
I$16K
D$16K
CPU FPU
User RAM 64K
Local memoryI:8K, D:32K
Core #2
I$16K
D$16K
CPU FPU
User RAM 64K
Local memoryI:8K, D:32K
Core #1
I$16K
D$16K
CPU FPU
User RAM 64K
Local memoryI:8K, D:32K
Core #0
I$16K
D$16K
CPU FPU
URAM 64K
Local memoryI:8K, D:32K
CCNBAR
8 Core RP2 Chip Block Diagram
On-chip system bus (SuperHyway)
DDR2LCPG: Local clock pulse generatorPCR: Power Control RegisterCCN/BAR:Cache controller/Barrier RegisterURAM: User RAM (Distributed Shared Memory)
Snoo
p co
ntro
ller
1
Snoo
p co
ntro
ller
0
LCPG0
Cluster #0 Cluster #1
PCR3
PCR2
PCR1
PCR0
LCPG1
PCR7
PCR6
PCR5
PCR4
controlSRAM
controlDMA
control
Core #7
I$16K
D$16K
CPUFPU
User RAM 64K
I:8K, D:32K
Core #6
I$16K
D$16K
CPUFPU
User RAM 64K
I:8K, D:32K
Core #5
I$16K
D$16K
CPUFPU
User RAM 64K
I:8K, D:32K
Core #4
I$16K
D$16K
CPUFPU
URAM 64K
Local memoryI:8K, D:32K
CCNBAR
Barrier Sync. Lines

With 128 cores, OSCAR compiler gave us 100 times speedup against 1 core execution and 211 times speedup against 1 core using Sun (Oracle) Studio compiler. 4
Earthquake Simulation “GMS” on Fujitsu M9000 Sparc CC-NUMA Server

To improve effective performance, cost-performance and software productivity and reduce power
OSCAR Parallelizing Compiler
Multigrain Parallelizationcoarse-grain parallelism among loops and subroutines, near fine grain parallelism among statements in addition to loop parallelism
Data LocalizationAutomatic data management fordistributed shared memory, cacheand local memory
Data Transfer OverlappingData transfer overlapping using DataTransfer Controllers (DMAs)
Power ReductionReduction of consumed power bycompiler control DVFS and Powergating with hardware supports.
1
23 45
6 7 8910 1112
1314 15 16
1718 19 2021 22
2324 25 26
2728 29 3031 32
33Data Localization Group
dlg0dlg3dlg1 dlg2

Generation of Coarse Grain TasksMacro-tasks (MTs) Block of Pseudo Assignments (BPA): Basic Block (BB) Repetition Block (RB) : natural loop Subroutine Block (SB): subroutine
Program
BPA
RB
SB
Near fine grain parallelization
Loop level parallelizationNear fine grain of loop bodyCoarse grainparallelizationCoarse grainparallelization
BPARBSB
BPARBSB
BPARBSBBPARBSBBPARBSBBPARBSB
1st. Layer 2nd. Layer 3rd. LayerTotalSystem
6

Earliest Executable Condition Analysis for Coarse Grain Tasks (Macro-tasks)
BPA
BPA
1 BPA
3 BPA2 BPA
4 BPA
5 BPA
6 RB
7 RB15 BPA
8 BPA
9 BPA 10 RB
11 BPA
12 BPA
13 RB
14 RB
END
RB
RB
BPA
RB
Data Dependency
Control flow
Conditional branch
Repetition Block
RB
BPA
Block of PsuedoAssignment Statements
7
11
14
1
2 3
4
5 6
15 7
8
9 10
12
13
Data dependency
Extended control dependencyConditional branch
6
ORAND
Original control flowA Macro Flow GraphA Macro Task Graph
7

PRIORITY DETERMINATION IN DYNAMIC CP METHOD
8

Earliest Executable Conditions
9
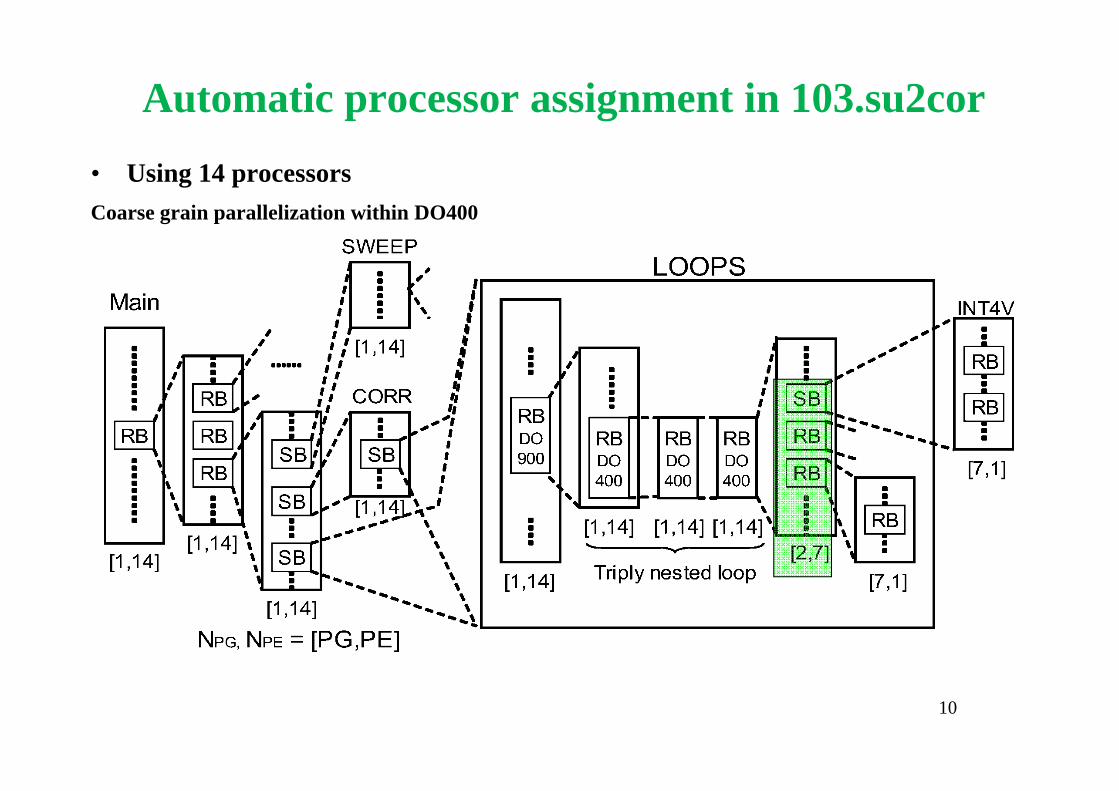
Automatic processor assignment in 103.su2cor
• Using 14 processorsCoarse grain parallelization within DO400
10

MTG of Su2cor-LOOPS-DO400
DOALL Sequential LOOP BBSB
Coarse grain parallelism PARA_ALD = 4.3
11

Data-Localization: Loop Aligned Decomposition• Decompose multiple loop (Doall and Seq) into CARs and LRs
considering inter-loop data dependence.– Most data in LR can be passed through LM.– LR: Localizable Region, CAR: Commonly Accessed Region
DO I=69,101DO I=67,68DO I=36,66DO I=34,35DO I=1,33
DO I=1,33
DO I=2,34
DO I=68,100
DO I=67,67
DO I=35,66
DO I=34,34
DO I=68,100DO I=35,67
LR CAR CARLR LR
C RB2(Doseq)DO I=1,100
B(I)=B(I-1)+A(I)+A(I+1)
ENDDO
C RB1(Doall)DO I=1,101A(I)=2*I
ENDDO
RB3(Doall)DO I=2,100
C(I)=B(I)+B(I-1)ENDDO
C
12
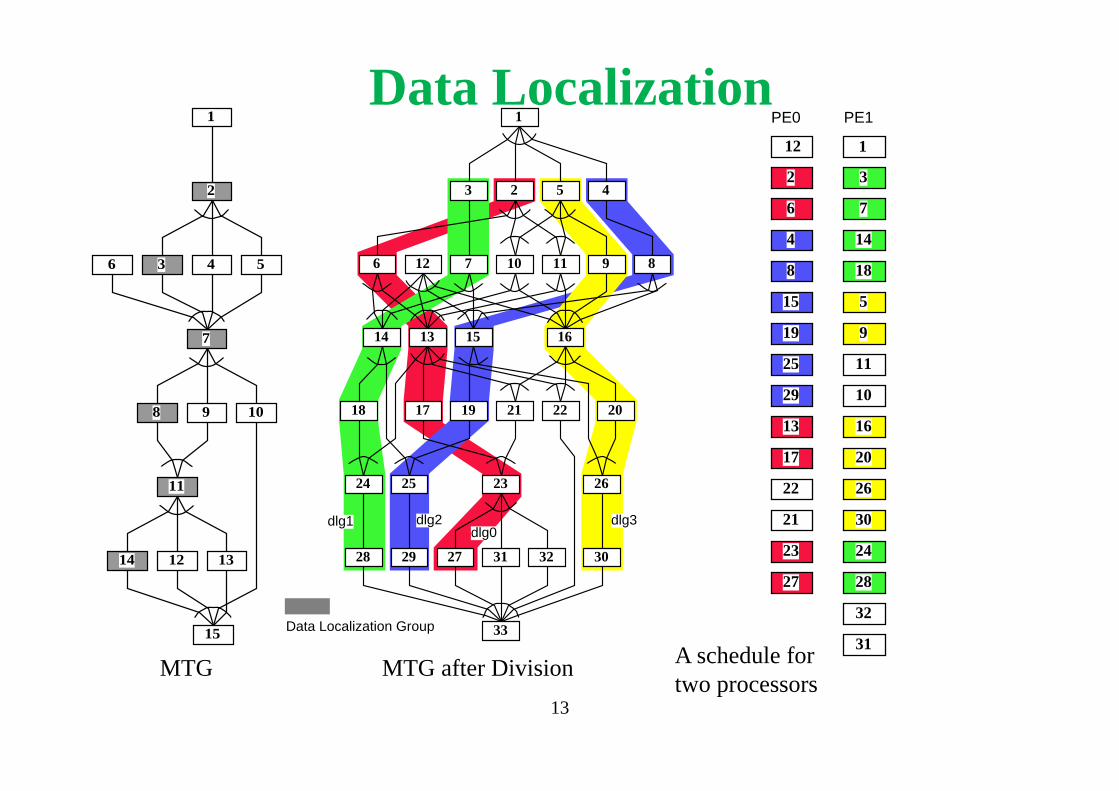
Data Localization
MTG MTG after Division
1
2
3 4 56
7
8 9 10
11
12 1314
15
1
23 45
6 7 8910 1112
1314 15 16
1718 19 2021 22
2324 25 26
2728 29 3031 32
33Data Localization Group
dlg0dlg3dlg1 dlg2
3
4
2
5
6 7
8
9
10
11
13
14
15
16
17
18
19
20
21
22
23 24
25
26
27 28
29
30
31
32
PE0 PE1
12 1
A schedule for two processors
13

Inter-loop data dependence analysis in TLG
• Define exit-RB in TLG as Standard-Loop
• Find iterations on which a iteration of Standard-Loop is data dependent– e.g. Kth of RB3 is data-dep
on K-1th,Kth of RB2,on K-1th,Kth,K+1th of RB1
C RB2(Doseq)DO I=1,100B(I)=B(I-1)
+A(I)+A(I+1)ENDDO
C RB1(Doall)DO I=1,101A(I)=2*I
ENDDO
C RB3(Doall)DO I=2,100C(I)=B(I)+B(I-1)
ENDDO
Example of TLG
I(RB1)
I(RB2)
I(RB3)K
K
K K+1K-1
K-1
14

Target Loop Group Creation and Inter-Loop Dependence Analysis
Target Loop Groups grouped loops that access
the same array baseline loop chosen for
each group the largest estimated time
loop Inter-Loop Dependency
Analysis data dependencies
between loops within the TLGs
detects relevant iterations of those loops that have dependence with the iterations of the baseline loop
15
DO I=1,100B(I)=B(I-1)+A(I)+A(I+1)
ENDDO
DO I=1,101A(I)=2*I
ENDDO
DO I=2,100C(I)=B(I)*B(I-1)
ENDDO
Inter‐Loop dependence
i‐1 i i+1
i

Decomposition of RBs in TLG
• Decompose GCIR into DGCIRp(1≦p≦n)– n: (multiple) num of PCs, DGCIR: Decomposed GCIR
• Generate CAR on which DGCIRp&DGCIRp+1 are data-dep.• Generate LR on which DGCIRp is data-dep.
GCIR
I(RB2)
I(RB3)
I(RB1)101
100
99 100
10099
2
2
2 31
1
66 67
6766
34
33 34
3433
68
67
36
35
35
35 66
65
65RB11 RB12 RB13RB1<1,2> RB1<2,3>
RB21
RB31 RB32
RB22 RB23
RB33
RB2<1,2> RB2<2,3>
DGCIR1 DGCIR2 DGCIR3
16

Automatic Parallelization of Still Image Encoding Using JPEG-XR for the Next Generation Cameras and Drinkable Inner Camera
Waseda U. & Olympus 17
TILEPro64
Ds
t0X4)
rt 1
al)
nal)
X4)
1.00 1.96 3.95 7.86
15.82
30.79
55.11
0.00
10.00
20.00
30.00
40.00
50.00
60.00
1 2 4 8 16 32 64
Speed up
コア数
Speed‐ups on TILEPro64 Manycore0.18[s]
1コア10.0[s]
55 times speedup with 64 coresagainst 1 core

18
Road Tracking, Image Compression : http://www.mathworks.co.jp/jp/help/vision/examplesBuoy Detection : http://www.mathworks.co.jp/matlabcentral/fileexchange/44706‐buoy‐detection‐using‐simulinkColor Edge Detection : http://www.mathworks.co.jp/matlabcentral/fileexchange/28114‐fast‐edges‐of‐a‐color‐image‐‐actual‐color‐‐not‐converting‐to‐grayscale‐/Vessel Detection : http://www.mathworks.co.jp/matlabcentral/fileexchange/24990‐retinal‐blood‐vessel‐extraction/
Speedups of MATLAB/Simulink Image Processing on Various 4core Multicores
(Intel Xeon, ARM Cortex A15 and Renesas SH4A)

Parallel Processing of Face Detection on Manycore, Highend and PC Server
19
OSCAR compiler gives us 11.55 times speedup for 16 cores against 1 core on SR16000 Power7 highend server.
1.00 1.72
3.01
5.74
9.30
1.00 1.93
3.57
6.46
11.55
1.00 1.93
3.67
6.46
10.92
0.00
2.00
4.00
6.00
8.00
10.00
12.00
14.00
1 2 4 8 16
速度
向上
率
コア数
速度向上率tilepro64 gcc
SR16k(Power7 8core*4cpu*4node) xlc
rs440(Intel Xeon 8core*4cpu) icc
Automatic Parallelization of Face Detection

Data Localization: Loop Aligned Decomposition• Decomposed loop into LRs and CARs
– LR ( Localizable Region): Data can be passed through LDM– CAR (Commonly Accessed Region): Data transfers are
required among processors
20
Single dimension DecompositionMulti-dimension Decomposition

Adjustable Blocks
Handling a suitable block size for each application different from a fixed block size in cache each block can be divided into smaller blocks
with integer divisible size to handle small arrays and scalar variables
21

Multi-dimensional Template Arrays for Improving Readability
• a mapping technique for arrays with varying dimensions– each block on LDM corresponds to
multiple empty arrays with varying dimensions
– these arrays have an additional dimension to store the corresponding block number
• TA[Block#][] for single dimension• TA[Block#][][] for double dimension• TA[Block#][][][] for triple dimension• ...
• LDM are represented as a one dimensional array– without Template Arrays, multi-
dimensional arrays have complex index calculations
• A[i][j][k] -> TA[offset + i’ * L + j’ * M + k’]– Template Arrays provide readability
• A[i][j][k] -> TA[Block#][i’][j’][k’] 22
LDM

Block Replacement Policy Compiler Control Memory block
Replacement using live, dead and reuse information of each
variable from the scheduled result different from LRU in cache that does not use
data dependence information Block Eviction Priority Policy
1. (Dead) Variables that will not be accessed later in the program
2. Variables that are accessed only by other processor cores
3. Variables that will be later accessed by the current processor core
4. Variables that will immediately be accessed by the current processor core
23

Code Compaction by Strip MiningPrevious approach produces
duplicate code generates multiple copies of the
loop body which leads to code bloat
Proposed method adopts code compaction based on strip mining multi-dimensional loop can be
restructured
24
Code Duplication
Strip Mining

Evaluation Environment Implemented on the OSCAR
compiler
Tested on RP2 SH4A with 600MHz processor
based 8 core homogeneous multicore
processor each processor core has 16KB
LDMwith a 1 clock cycle latency
equipped with 128MB DDR2 off-chip CSM (Central Shared Memory) with a 55 clock cycle latency
25
On‐chipCSM128K
Off‐chipCSM128M
Architecture of the RP2 Multicore Pro

Applications for EvaluationSequential C Applications
Example code in explanation of code compaction AACenc (provided by Renesas Technology)
AAC encoder, input: a 30 second audio file Mpeg2enc (part of the MediaBench benchmark suite)
MPEG2 encoder, input: a 30 frame video with a resolution of 352 by 256 pixels
SPEC95 Tomcatv loop fusion and variable renaming were applied
SPEC95 Swim loop distribution and loop peeling were performed
26

Speedups by the Proposed Local Memory Management Compared with Utilizing Shared Memory on
Benchmarks Application using RP2
27
20.12 times speedup for 8cores execution using local memory against sequential execution using off‐chip shared memory of RP2 for the AACenc

Conclusions This talk introduced automatic cache and local memory management
method using data localization with hierarchical loop aligned decomposition, adjustable block tailored for each application, and block replace considering block reuse distance .
The local memory management method was implemented on the OSCAR parallelization compiler.
The performance on the RP2 8 core multicore gave us for example,
20.12 times speedup on 8cores using local memory against sequential execution using off‐chip shared memory for the AAC encoder though the 8 core execution using
shared memory gave us 7.14 times speedup. 11.30 times speedup on 8cores execution using local memory against sequential execution using off‐chip shared memory for the SPEC95 swim though the 8 core execution using shared memory gave us 7.40 times speedup.
28


















