
Audio-Visual Graphical Models Matthew Beal Gatsby Unit University College London Nebojsa Jojic...
29
Audio-Visual Graphical Audio-Visual Graphical Models Models Matthew Beal Gatsby Unit University College London Nebojsa Jojic Microsoft Research Redmond, Washington Hagai Attias Microsoft Research Redmond, Washington
-
date post
20-Dec-2015 -
Category
Documents
-
view
221 -
download
0
Transcript of Audio-Visual Graphical Models Matthew Beal Gatsby Unit University College London Nebojsa Jojic...

Audio-Visual Graphical ModelsAudio-Visual Graphical Models
Matthew Beal
Gatsby Unit
University College London
Nebojsa Jojic
Microsoft Research
Redmond, Washington
Hagai Attias
Microsoft Research
Redmond, Washington

Beal, Jojic and Attias, ICASSP’02
OverviewOverview
Some background to the problem A simple video model A simple audio model Combining these in a principled manner Results of tracking experiments Further work and thoughts.
Beal, Jojic and Attias, ICASSP’02
Motivation – applicationsMotivation – applications
Teleconferencing– We need speaker’s identity, position, and individual speech.– The case of multiple speakers.
Denoising– Speech enhancement using video cues (at different scales).– Video enhancement using audio cues.
Multimedia editing– Isolating/removing/adding objects, visually and aurally.
Multimedia retrieval– Efficient multimedia searching.

Beal, Jojic and Attias, ICASSP’02
Motivation – current state of artMotivation – current state of art Video models and Audio models
– Abundance of work on object tracking, image stabilization…– Large amount in speech recognition, ICA (blind source separation),
microphone array processing…
Very little work on combining these– We desire a principled combination.– Robust learning of environments using multiple modalities.– Various past approaches:
• Information theory: Hershey & Movellan (NIPS 12)• SVD-esque: (FaceSync) Slaney & Covell (NIPS 13)• Subspace stats.: Fisher et al. (NIPS 13).• Periodicity analysis: Ross Cutler• Particle filters: Vermaak and Blake et al (ICASSP 2001).• System engineering: Yong Rui (CVPR 2001).
Our approach: Graphical Models, Bayes nets.
Beal, Jojic and Attias, ICASSP’02
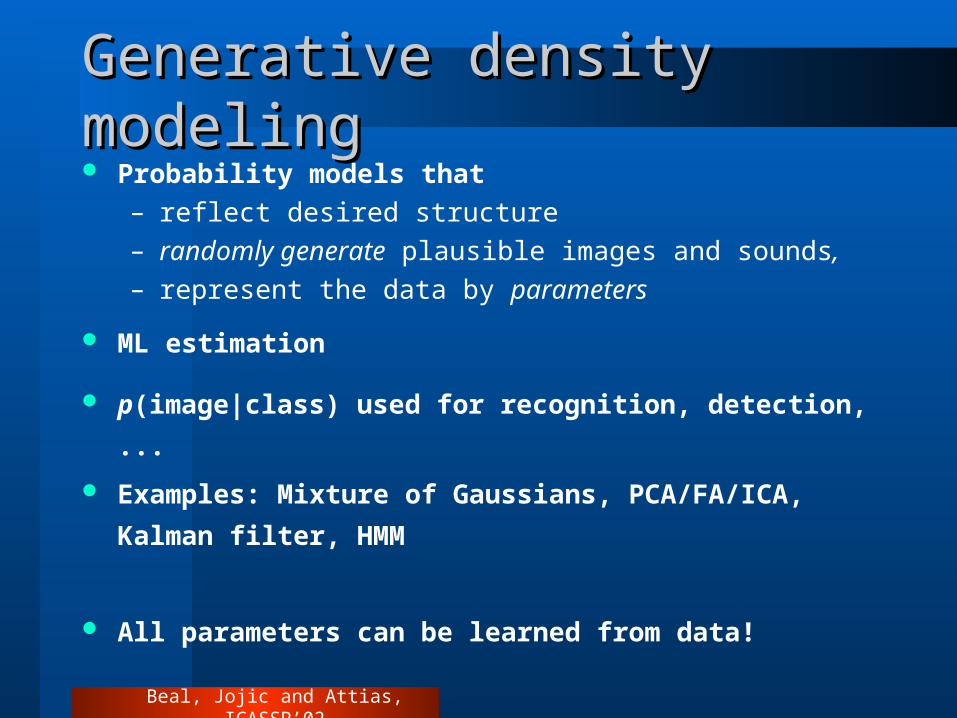
Generative density modelingGenerative density modeling Probability models that
– reflect desired structure– randomly generate plausible images and sounds, – represent the data by parameters
ML estimation
p(image|class) used for recognition, detection, ...
Examples: Mixture of Gaussians, PCA/FA/ICA, Kalman
filter, HMM
All parameters can be learned from data!

Beal, Jojic and Attias, ICASSP’02
Speaker detection & tracking problemSpeaker detection & tracking problem
mic.1 mic.2
source at lx
camera
lx
ly
Video scenario Audio scenario

Beal, Jojic and Attias, ICASSP’02
Bayes Nets for MultimediaBayes Nets for Multimedia
Video models– Models such as Jojic & Frey (NIPS’99, CVPR’99’00’01).
Audio models– Work of: Attias (Neural Comp’98); Attias, Platt, Deng & Acero
(NIPS’00,EuroSpeech’01).

Beal, Jojic and Attias, ICASSP’02
A generative video model for scenesA generative video model for scenes(see Frey&Jojic, CVPR’99, NIPS’01)(see Frey&Jojic, CVPR’99, NIPS’01)
Mean s
Class s
Latent image z
Transformed image z
Generated/observed image y
Shift
(lx,ly)

Beal, Jojic and Attias, ICASSP’02
ExampleExample
Hand-held camera Moving subject Cluttered background
DATA
Mean
One class summary
Variance5 classes

Beal, Jojic and Attias, ICASSP’02
A generative video model for scenesA generative video model for scenes(see Frey&Jojic, CVPR’99, NIPS’01)(see Frey&Jojic, CVPR’99, NIPS’01)
Mean s
Class s
Latent image z
Transformed image z
Generated/observed image y
Shift
(lx,ly)

Beal, Jojic and Attias, ICASSP’02
A failure mode of this modelA failure mode of this model

Beal, Jojic and Attias, ICASSP’02
Modeling scenes - the audio partModeling scenes - the audio part
mic.1 mic.2
source at lx
camera
mic.1 mic.2

Beal, Jojic and Attias, ICASSP’02
Unaided audio modelUnaided audio model
audio waveform
+15
-15
video frames
+15
-15
Posterior probability over , the time delay.
Periods of quiet cause uncertainty in – (grey blurring).
Occasionally reverberations / noise corrupt inference on – and we become certain of a false time delay.
time

Beal, Jojic and Attias, ICASSP’02
Limit of this simple audio modelLimit of this simple audio model

Beal, Jojic and Attias, ICASSP’02
Multimodal localizationMultimodal localization Time delay is approximately linear in
horizontal position lx
Define a stochastic mapping from spatial location to temporal shift:
Beal, Jojic and Attias, ICASSP’02
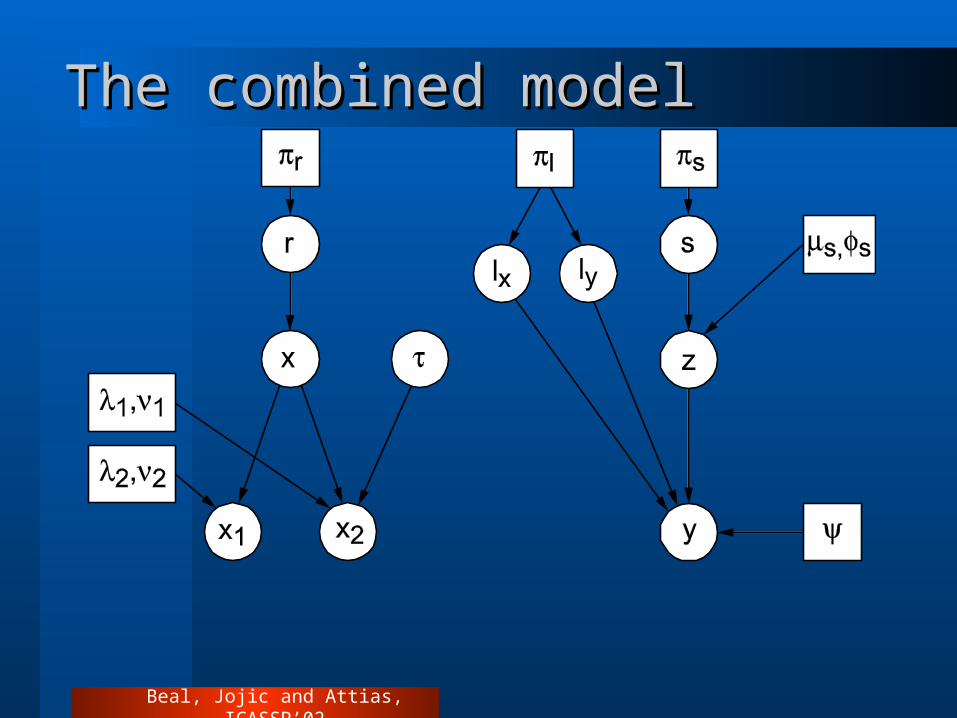
The combined modelThe combined model
Beal, Jojic and Attias, ICASSP’02
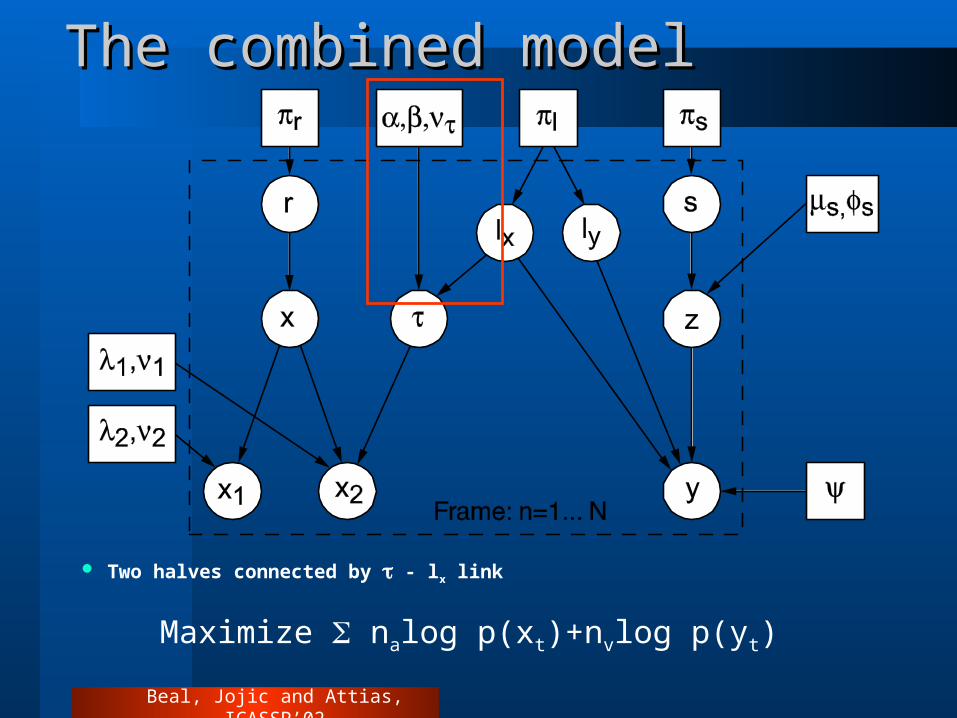
The combined modelThe combined model
Two halves connected by - lx link
Maximize nalog p(xt)+nvlog p(yt)

Beal, Jojic and Attias, ICASSP’02
Learning using EM: E-StepLearning using EM: E-StepDistribution Q over hidden variables is inferred given the
current setting of all model parameters.

Beal, Jojic and Attias, ICASSP’02
Learning using EM: M-StepLearning using EM: M-Step
Audio:– Relative microphone
attenuations 1,2 and noise levels 12
AV Calibration between modalities– , ,
Video:– object templates s and precisions s
– camera noise
Given the distribution over hidden variables, the parameters are set to maximize the data likelihood.

Beal, Jojic and Attias, ICASSP’02
Efficient inference and integration over all shifts Efficient inference and integration over all shifts (Frey and Jojic, NIPS’01)(Frey and Jojic, NIPS’01)
E Estimating posterior Q(lx,ly,) involves computing Mahalanobis distances for all possible shifts in the image
M Estimating model parameters involves integrating over all possible shifts taking into account the probability map Q(lx,ly,)
E reduces to correlation, M reduces to convolution
Efficiently done using FFTs

Beal, Jojic and Attias, ICASSP’02
Demonstration of trackingDemonstration of tracking
A
AV
V
na/nv

Beal, Jojic and Attias, ICASSP’02
Learning using EM: M-StepLearning using EM: M-Step
Audio:– Relative microphone
attenuations 1,2 and noise levels 12
AV Calibration between modalities– , ,
Video:– object templates s and precisions s
– camera noise
Given the distribution over hidden variables, the parameters are set to maximize the data likelihood.
Beal, Jojic and Attias, ICASSP’02
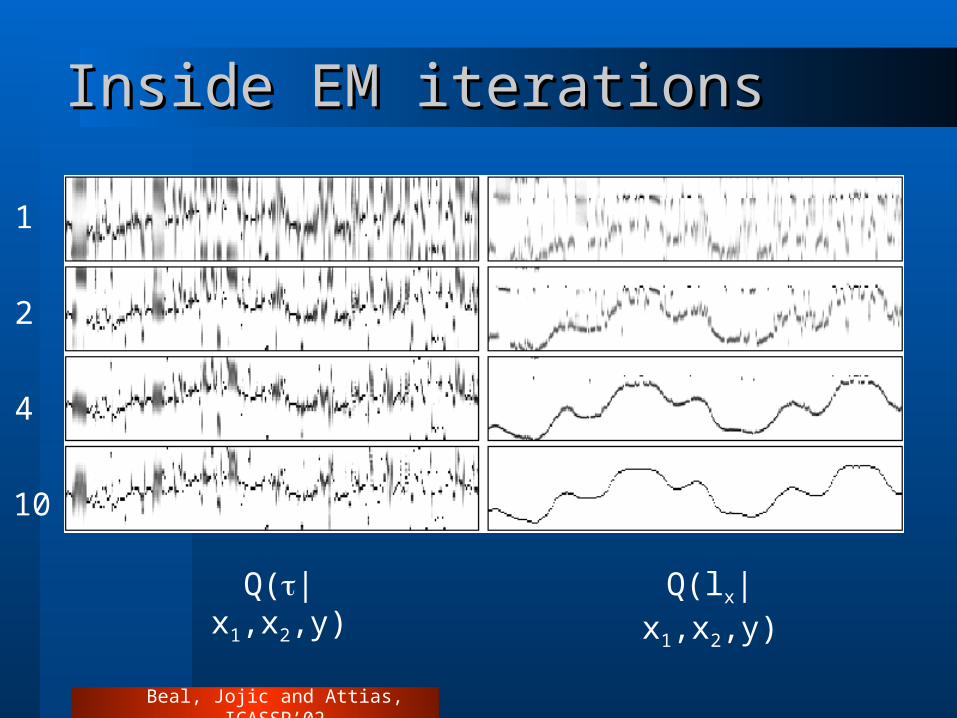
Inside EM iterationsInside EM iterations
1
2
4
10
Q(|x1,x2,y) Q(lx|x1,x2,y)

Beal, Jojic and Attias, ICASSP’02
TrackingTracking StabilizationStabilization

Beal, Jojic and Attias, ICASSP’02
Work in progress: modelsWork in progress: models Incorporating a more sophisticated speech model
– Layers of sound Reverberation filters
– Extension to y-localization is trivial.– Temporal models of speech.
Incorporating a more sophisticated video model– Layered templates (sprites) each with their own audio
(circumvents dimensionality issues).– Fine-scale correlations between pixel intensities and speech.– Hierarchical models? (Factor Analyser trees).
Tractability issues:– Variational approximations in both audio and video.

Beal, Jojic and Attias, ICASSP’02
Basic flexible layer model (CVPR’01)Basic flexible layer model (CVPR’01)

Beal, Jojic and Attias, ICASSP’02
Future work: applicationsFuture work: applications
Multimedia editing– Removing/adding objects’ appearances and associated
sounds.– With layers in both audio and video (cocktail party / danceclub).
Video-assisted speech enhancement– Improved denoising with knowledge of source location.– Exploit fine-scale correlations of video with audio. (e.g. lips)
Multimedia retrieval– Given a short clip as a query, search for similar matches in a
database.

Beal, Jojic and Attias, ICASSP’02
SummarySummary
A generative model of audio-visual data
All parameters learned from the data, including camera/microphones calibration in a few iterations of EM
Extensions to multi-object models
Real issue: the other curse of dimensionality

Beal, Jojic and Attias, ICASSP’02
Pixel-audio correlations analysisPixel-audio correlations analysis
SVD.Factor Analysis (probabilistic PCA).
Original video sequence
Inferred activation of latent variables
(factors, subspace vectors)


















