
Association Rules
30
1 Association Rules Apriori Algorithm
-
Upload
xanthus-fox -
Category
Documents
-
view
72 -
download
3
description
Association Rules. Apriori Algorithm. Item. Item. Basket 1. Item. Item. Item. Item. Basket 2. Item. Item. Item. Item. Basket 3. Item. Item. Etc. Computation Model. Typically, data is kept in a flat file rather than a database system. Stored on disk. Stored basket-by-basket. - PowerPoint PPT Presentation
Transcript of Association Rules

1
Association Rules
Apriori Algorithm

2
Computation Model Typically, data is kept in a flat file
rather than a database system. Stored on disk. Stored basket-by-basket.
The true cost of mining disk-resident data is usually the number of disk I/O’s.
In practice, association-rule algorithms read the data in passes – all baskets read in turn.
Thus, we measure the cost by the number of passes an algorithm takes.
Item
Item
Item
Item
Item
Item
Item
Item
Item
Item
Item
Item
Basket 1
Basket 2
Basket 3
Etc.

3
Main-Memory Bottleneck
For many frequent-itemset algorithms, main memory is the critical resource. As we read baskets, we need to count
something, e.g., occurrences of pairs. The number of different things we can
count is limited by main memory. Swapping counts in/out is a disaster.

4
Finding Frequent Pairs
The hardest problem often turns out to be finding the frequent pairs.
We’ll concentrate on how to do that, then discuss extensions to finding frequent triples, etc.

5
Naïve Algorithm
Read file once, counting in main memory the occurrences of each pair. From each basket of n items, generate
its n (n -1)/2 pairs by two nested loops.
Fails if (#items)2 exceeds main memory. Remember: #items can be 100K (Wal-
Mart) or 10B (Web pages).

6
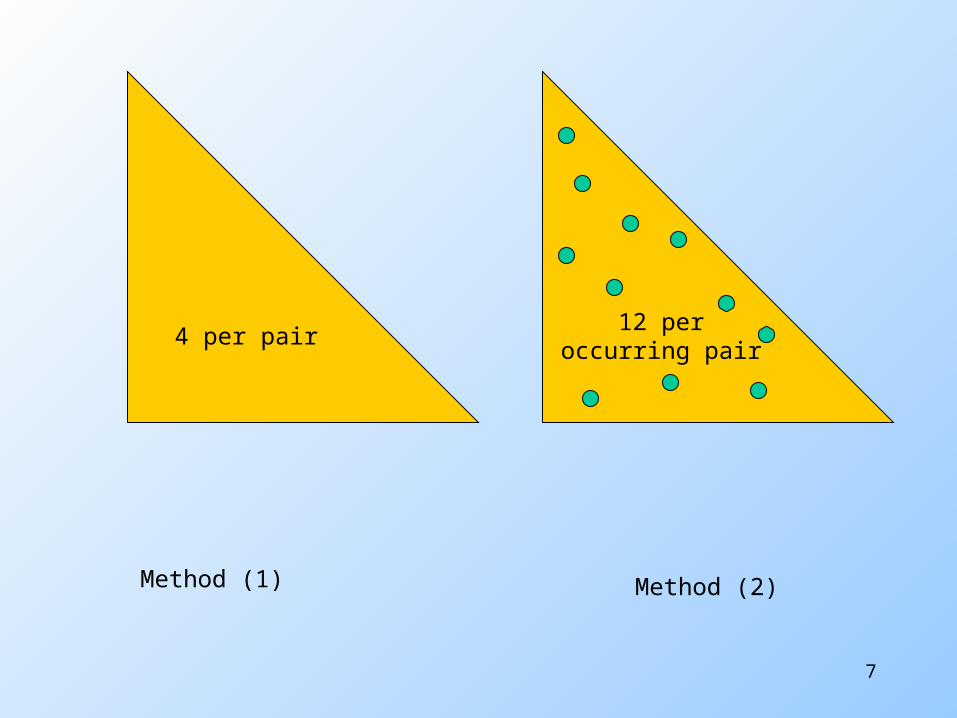
Details of Main-Memory Counting
Two approaches:1. Count all pairs, using a triangular
matrix.2. Keep a table of triples [i, j, c] = the
count of the pair of items {i,j } is c. (1) requires only 4 bytes/pair.
Note: assume integers are 4 bytes. (2) requires 12 bytes, but only for
those pairs with count > 0.
7
4 per pair
Method (1) Method (2)
12 peroccurring pair

8
Triangular-Matrix Approach – (1)
Number items 1, 2, …,n Requires table of size O(n). Count {i, j } only if i < j. Keep pairs in the order
{1,2}, {1,3},…, {1,n}, {2,3}, {2,4},…,{2,n}, {3,4},…, {3, n}, … {n -1,n}.

9
Triangular-Matrix Approach – (2)
Let n be the number of items. Find pair {i, j } at the position
(i-1)n-i(i+1)/2+j
{1,2}, {1,3}, {1,4}, {2,3}, {2,4} {3,4}
Total number of pairs n (n –1)/2; total bytes about 2n 2.

10
Details of Approach #2
Total bytes used is about 12p, where p is the number of pairs that actually occur. Beats triangular matrix if at most 1/3 of
possible pairs actually occur. May require extra space for retrieval
structure, e.g., a hash table.

11
Apriori Algorithm for pairs– (1)
A two-pass approach called a-priori limits the need for main memory.
Key idea: monotonicity : if a set of items appears at least s times, so does every subset. Contrapositive for pairs: if item i does
not appear in s baskets, then no pair including i can appear in s baskets.

12
Apriori Algorithm for pairs– (2)
Pass 1: Read baskets and count in main memory the occurrences of each item. Requires only memory
proportional to #items.
Pass 2: Read baskets again and count in main memory only those pairs whose both elements were found in Pass 1 to be frequent. Requires memory
proportional to square of frequent items only.
Item counts
Pass 1 Pass 2
Frequent items
Counts ofcandidate pairs

13
Detail for A-Priori
You can use the triangular matrix method with n = number of frequent items. Saves space compared with storing
triples.
Trick: number frequent items 1,2,… and keep a table relating new numbers to original item numbers.
14
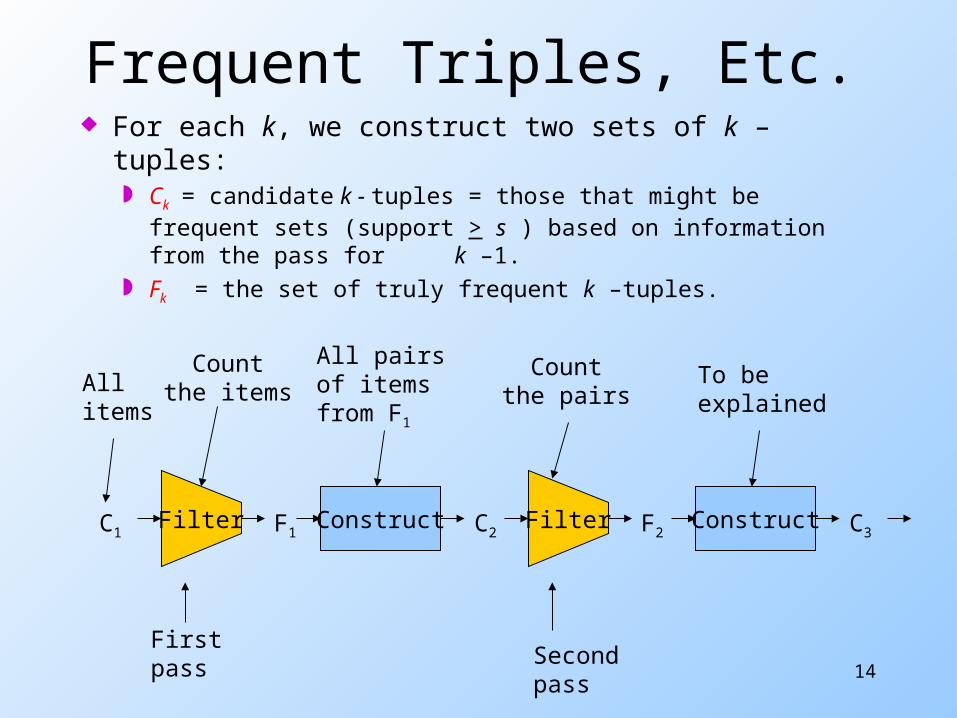
Frequent Triples, Etc. For each k, we construct two sets of k –tuples:
Ck = candidate k - tuples = those that might be frequent sets (support > s ) based on information from the pass for k –1.
Fk = the set of truly frequent k –tuples.
C1 F1 C2 F2 C3Filter Filter ConstructConstruct
Firstpass Second
pass
Allitems
All pairsof itemsfrom F1
Countthe pairs
To beexplained
Countthe items
15
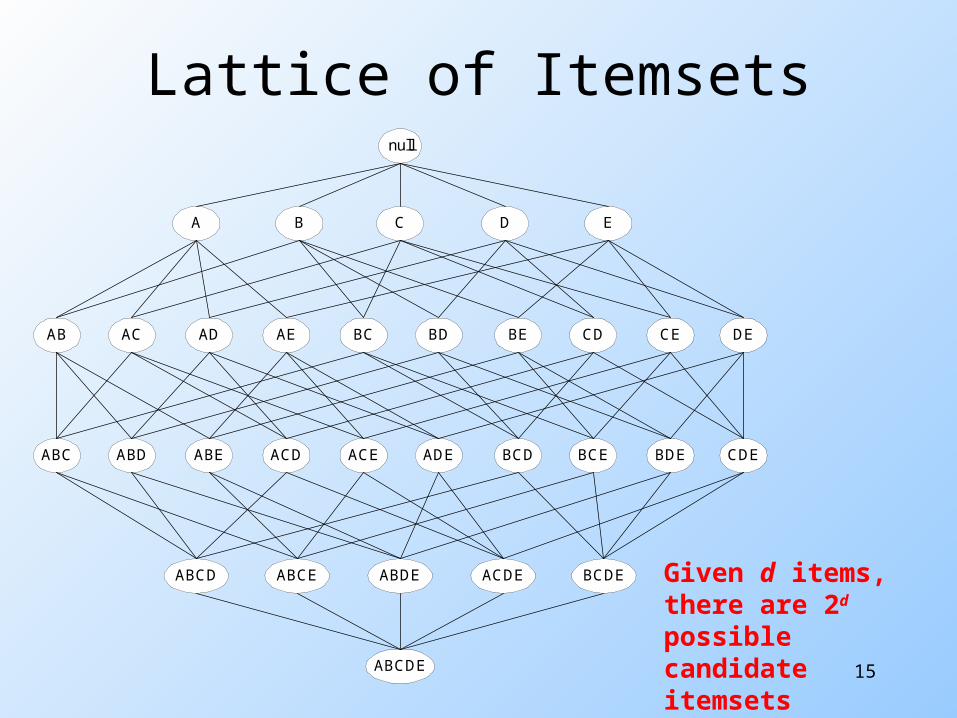
Lattice of Itemsetsnull
AB AC AD AE BC BD BE CD CE DE
A B C D E
ABC ABD ABE ACD ACE ADE BCD BCE BDE CDE
ABCD ABCE ABDE ACDE BCDE
ABCDE
Given d items, there are 2d possible candidate itemsets
16
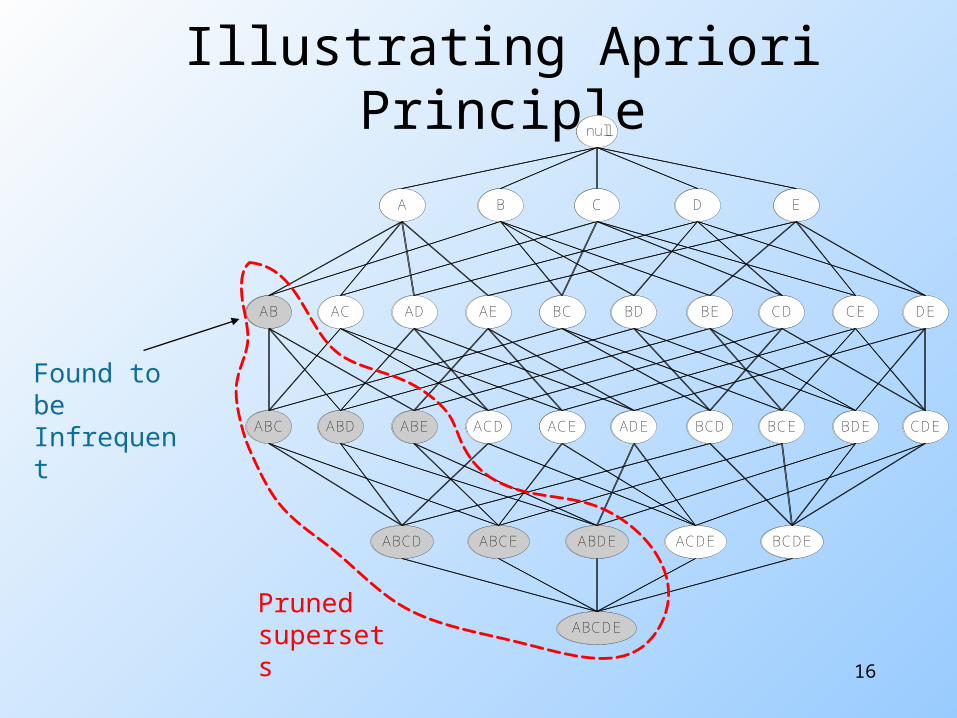
Found to be Infrequent
null
AB AC AD AE BC BD BE CD CE DE
A B C D E
ABC ABD ABE ACD ACE ADE BCD BCE BDE CDE
ABCD ABCE ABDE ACDE BCDE
ABCDE
Illustrating Apriori Principlenull
AB AC AD AE BC BD BE CD CE DE
A B C D E
ABC ABD ABE ACD ACE ADE BCD BCE BDE CDE
ABCD ABCE ABDE ACDE BCDE
ABCDEPruned supersets

17
Full Apriori Algorithm Let k=1 Generate frequent itemsets of length 1 Repeat until no new frequent itemsets are found
k=k+11. Generate length-k candidate itemsets from length-k-1
frequent itemsets2. Prune candidate itemsets containing subsets of length k-1 that
are infrequent 3. Count the support of each candidate by scanning the DB and
eliminate candidates that are infrequent, leaving only those that are frequent

18
Candidate generationAn effective candidate generation procedure: 1. Should avoid generating too many
unnecessary candidates.
2. Must ensure that the candidate set is complete,
3. Should not generate the same candidate itemset more than once.

19
Data Set Example
TID Items
1 Bread, Milk
2 Bread, Diaper, Beer, Eggs
3 Milk, Diaper, Beer, Coke
4 Bread, Milk, Diaper, Beer
5 Bread, Milk, Diaper, Coke
s=3

20
Fk-1F1 Method Extend each frequent (k - 1)
itemset with a frequent 1-itemset.
Is it complete? Yes, because every frequent k
itemset is composed of a frequent (k-1) itemset and a frequent 1 itemset.
However, it doesn’t prevent the same candidate itemset from being generated more than once. E.g., {Bread, Diapers, Milk} can
be generated by merging {Bread, Diapers} with {Milk}, {Bread, Milk} with {Diapers}, or {Diapers, Milk} with {Bread}.

21
Lexicographic Order Avoid generating duplicate candidates by ensuring
that the items in each frequent itemset are kept sorted in their lexicographic order.
Each frequent (k-1) itemset X is then extended with frequent items that are lexicographically larger than the items in X.
For example, the itemset {Bread, Diapers} can be augmented with {Milk} since Milk is lexicographically larger than Bread and Diapers.
However, we don’t augment {Diapers, Milk} with {Bread} nor {Bread, Milk} with {Diapers} because they violate the lexicographic ordering condition.
Why is it complete?

22
Prunning E.g. merging {Beer, Diapers} with {Milk} is
unnecessary because one of its subsets, {Beer, Milk}, is infrequent.
Solution: Prune! How?
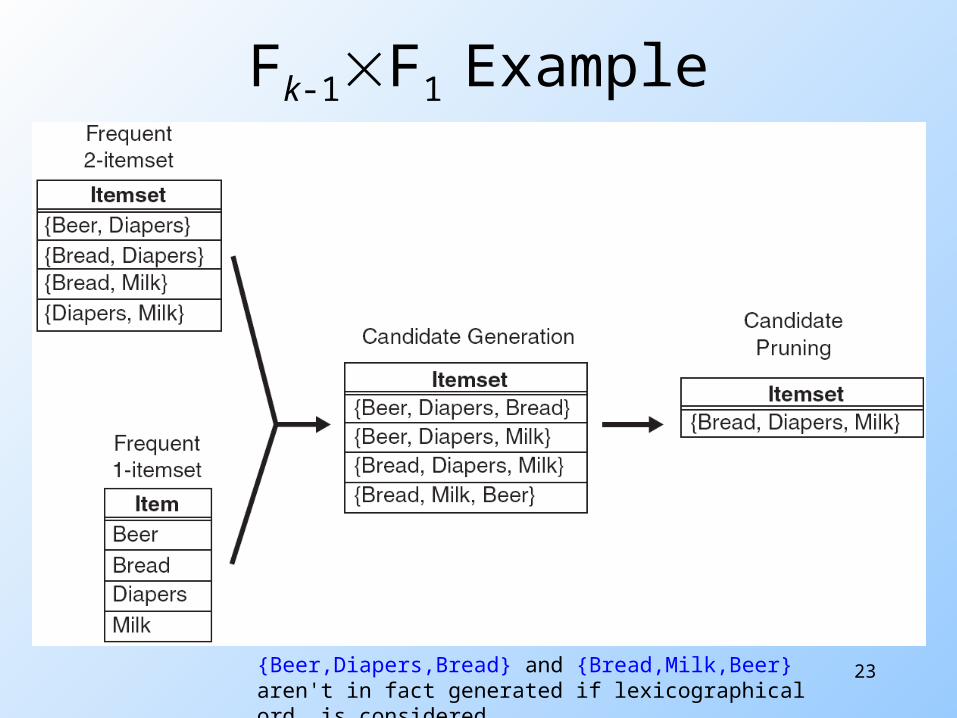
23
Fk-1F1 Example
{Beer,Diapers,Bread} and {Bread,Milk,Beer} aren't in fact generated if lexicographical ord. is considered.

24
Fk-1Fk-1 Method Merge a pair of frequent (k-1) itemsets only if their
first k-2 items are identical.
E.g. frequent itemsets {Bread, Diapers} and {Bread, Milk} are merged to form a candidate 3 itemset {Bread, Diapers, Milk}.

25
Fk-1Fk-1 Method We don’t merge {Beer, Diapers} with {Diapers, Milk}
because the first item in both itemsets is different.
But, is this "don't merge" decision Ok? Indeed, if {Beer, Diapers, Milk} is a viable candidate, it
would have been obtained by merging {Beer, Diapers} with {Beer, Milk} instead.
Pruning However, because each candidate is obtained by
merging a pair of frequent (k-1) itemsets, an additional candidate pruning step is needed to ensure that the remaining k-2 subsets of k-1 elements are frequent.
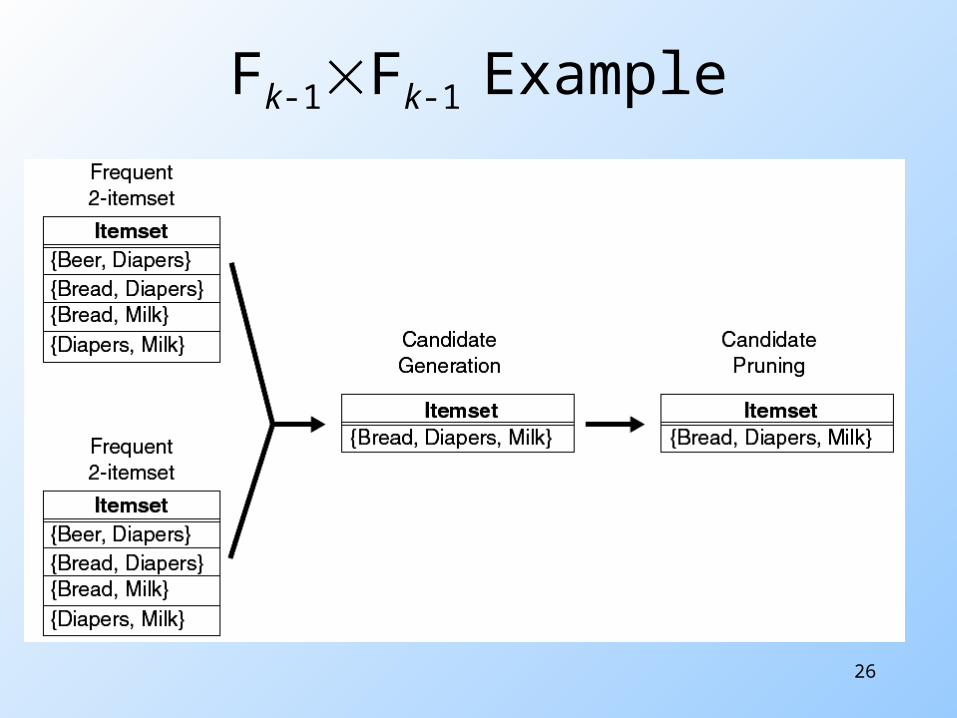
26
Fk-1Fk-1 Example
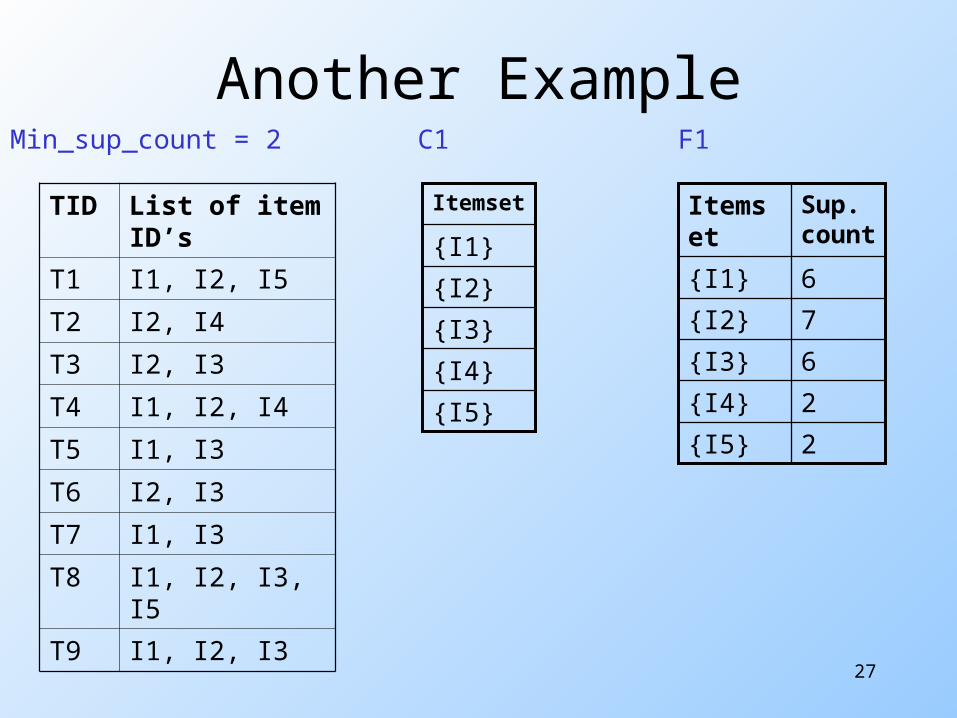
27
Another Example
TID List of item ID’s
T1 I1, I2, I5
T2 I2, I4
T3 I2, I3
T4 I1, I2, I4
T5 I1, I3
T6 I2, I3
T7 I1, I3
T8 I1, I2, I3, I5
T9 I1, I2, I3
Min_sup_count = 2
Itemset
{I5}
{I4}
{I3}
{I2}
{I1}
C1
Sup. count
Itemset
2{I5}
2{I4}
6{I3}
7{I2}
6{I1}
F1
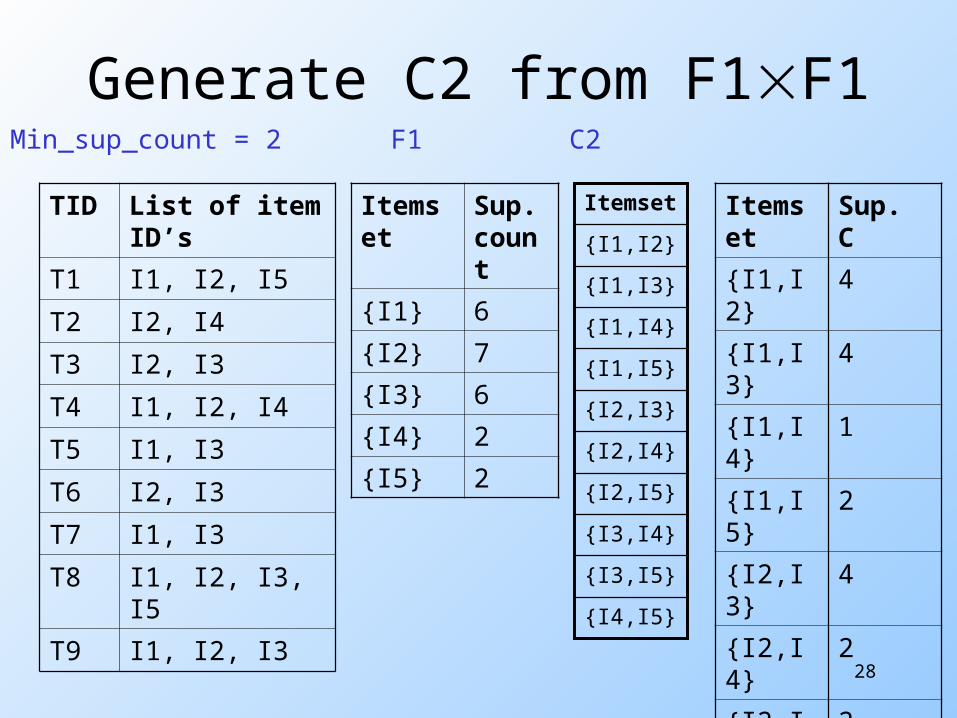
28
Generate C2 from F1F1
TID List of item ID’s
T1 I1, I2, I5
T2 I2, I4
T3 I2, I3
T4 I1, I2, I4
T5 I1, I3
T6 I2, I3
T7 I1, I3
T8 I1, I2, I3, I5
T9 I1, I2, I3
Min_sup_count = 2
Itemset Sup. count
{I1} 6
{I2} 7
{I3} 6
{I4} 2
{I5} 2
F1
{I4,I5}
{I3,I5}
{I3,I4}
{I2,I5}
{I2,I4}
Itemset
{I2,I3}
{I1,I5}
{I1,I4}
{I1,I3}
{I1,I2}
C2
Itemset Sup. C
{I1,I2} 4
{I1,I3} 4
{I1,I4} 1
{I1,I5} 2
{I2,I3} 4
{I2,I4} 2
{I2,I5} 2
{I3,I4} 0
{I3,I5} 1
{I4,I5} 0

29
Generate C3 from F2F2
TID List of item ID’s
T1 I1, I2, I5
T2 I2, I4
T3 I2, I3
T4 I1, I2, I4
T5 I1, I3
T6 I2, I3
T7 I1, I3
T8 I1, I2, I3, I5
T9 I1, I2, I3
Min_sup_count = 2
Itemset Sup. C
{I1,I2} 4
{I1,I3} 4
{I1,I5} 2
{I2,I3} 4
{I2,I4} 2
{I2,I5} 2
F2
Itemset
{I1,I2,I3}
{I1,I2,I5}
{I1,I3,I5}
{I2,I3,I4}
{I2,I3,I5}
{I2,I4,I5}
Prune
Itemset
{I1,I2,I3}
{I1,I2,I5}
{I1,I3,I5}
{I2,I3,I4}
{I2,I3,I5}
{I2,I4,I5}
Itemset Sup. C
{I1,I2,I3} 2
{I1,I2,I5} 2
F3
30
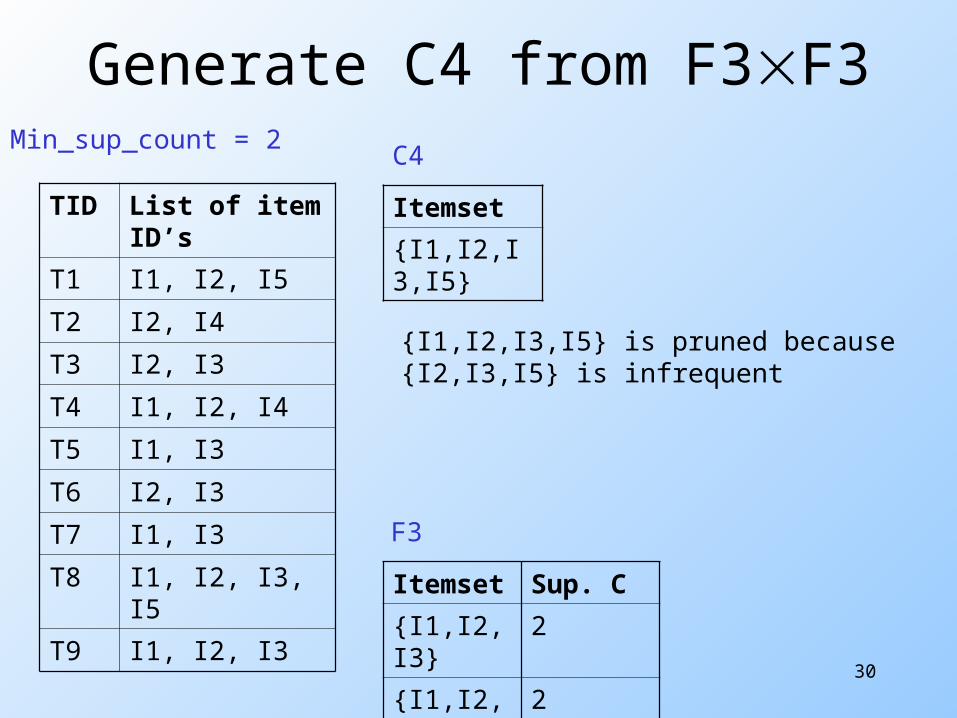
Generate C4 from F3F3
TID List of item ID’s
T1 I1, I2, I5
T2 I2, I4
T3 I2, I3
T4 I1, I2, I4
T5 I1, I3
T6 I2, I3
T7 I1, I3
T8 I1, I2, I3, I5
T9 I1, I2, I3
Min_sup_count = 2
Itemset
{I1,I2,I3,I5}
C4
{I1,I2,I3,I5} is pruned because {I2,I3,I5} is infrequent
Itemset Sup. C
{I1,I2,I3} 2
{I1,I2,I5} 2
F3







![Association Rules Dm[2]](https://static.fdocuments.us/doc/165x107/577d38671a28ab3a6b97c249/association-rules-dm2.jpg)










