
Aspiration Noise during Phonation: Synthesis,...
15
HST-SHBT 1 Aspiration Noise during Phonation: Synthesis, Analysis, and Pitch-Scale Modification Daryush Mehta SHBT ‘03 Research Advisor: Thomas F. Quatieri Speech and Hearing Biosciences and Technology
-
Upload
hoangthuan -
Category
Documents
-
view
216 -
download
1
Transcript of Aspiration Noise during Phonation: Synthesis,...

HST-SHBT1
Aspiration Noise during Phonation: Synthesis, Analysis, and Pitch-Scale Modification
Daryush MehtaSHBT ‘03
Research Advisor: Thomas F. QuatieriSpeech and Hearing Biosciences and Technology

HST-SHBT2
Summary
Studied the problem of high-quality speech synthesis and pitch-scale modification in the context of vocalic speech sounds containing an aspiration noise component.
Developed a vowel production model and corresponding vowel synthesizer, in which periodic and noise speech sources are coupled by temporally modulating the noise by the periodic gating of turbulent airflow by the vocal fold vibrations.
Investigated a periodic/noise signal separation algorithm, revealing aspiration noise characteristics in normal and pathological speech.
Inspired by our observation of natural modulations in the aspiration noise source, we designed an alternate approach to pitch-scale modification.
The modified speech signal is perceived to be natural-sounding and generally reduces artifacts that are typically heard in current modification techniques.

HST-SHBT3
Motivation
Clinical assessment of vocal pathology: Noninvasive diagnostic procedures are desired to efficiently assess the quality of a patient’s vocal apparatus during therapy of post-surgery.
Speech modification: Current modification methods have difficulty with the presence of a significant aspiration noise component.
Text-to-speech synthesis: Desires high quality and naturalness, requiring an accurate representation of the aperiodic speech component.
Speaker identification: Uses distinct traits in different speakers, with the noise characteristics of speech perhaps being unique to different speakers.
Many applications would benefit from a better understanding of inherent characteristics of the aspiration component

HST-SHBT4
Definitions
Noise
t
Impulse
Periodic Puffs
tNoise
NasalCavity
OralCavity
PowerSupply
PharynxModulator
Adapted from (Quatieri)
OralCavity
NasalCavity
PharynxFrication and Aspiration Noise Sources Vibrating Vocal Folds
Lungs
The phonation source is due to mechanisms that cause the vocal folds to vibrate. The closed phase refers tovocal fold closure, contrastingwith the open phase.
The aspiration noise sourcerefers to turbulent airflow that is generated in the vicinity of the vocal folds, while frication sources are noises generated farther downstream in other cavities.
Relying on the lungs for primary air supply, these sources propagate through the pharynx, the nasal cavity, and (most importantly) the oral cavity to produce the acoustic speech signal that we can hear and record using a microphone.
Phonation Source
Open Phase
Closed Phase

HST-SHBT5
Additive Modulation ModelBased on Voice Production
RadiationCharacteristic
RadiationCharacteristic
Vocal TractFilter
Noise Component
Periodic Component
+
Modulation
Vocal TractFilter
Phonation Source
Aspiration NoiseSource
2 source model
Voiced Speech Sound
A model for vocalic speech sounds in which the aspiration noise source is modulated by the phonation source before acoustically exciting the resonant vocal tract cavities.

HST-SHBT6
The separation algorithm has limitations due to spectral leakage and robustness to shimmer and jitter in speech, but it has proved useful as an initial tool.
The pitch-scaled harmonic filter technique (Jackson and Shadle) for the separation of harmonic and noise contributions aims at preserving the temporal and spectral characteristics inherent in the noise component.
Speech AnalysisHarmonic/Noise Separation
0 50 100 150 200 25010
-1
100
101
102
0 50 100 150 200 25010
-1
100
101
102
0 50 100 150 200 25010
-2
10-1
100
101
Original spectrum
Harmonic estimate
Noise estimate
Frequency
Log
mag
nitu
deSpoken vowel “ah”

HST-SHBT7
Maintaining the time-domain patterns of the source waveforms
To estimate the aspiration source, linear prediction analysis was used to remove vocal tract resonances in the signal. In the figure below, we show that source estimate of the separated aspiration component contains modulations with peaks during the open phase of the known phonation source waveform. The processing was performed on the vowel “ah” synthesized using our additive modulation model to allow for direct comparison between known and separated source waveforms.
Speech AnalysisHarmonic/Noise Separation
0.2 0.21 0.22 0.23 0.24 0.25-0.04
-0.02
0
0.02
0.04
0.06
0.08
Time (s)
Am
plitu
de
Aspiration noise source estimate
Known phonation source waveform
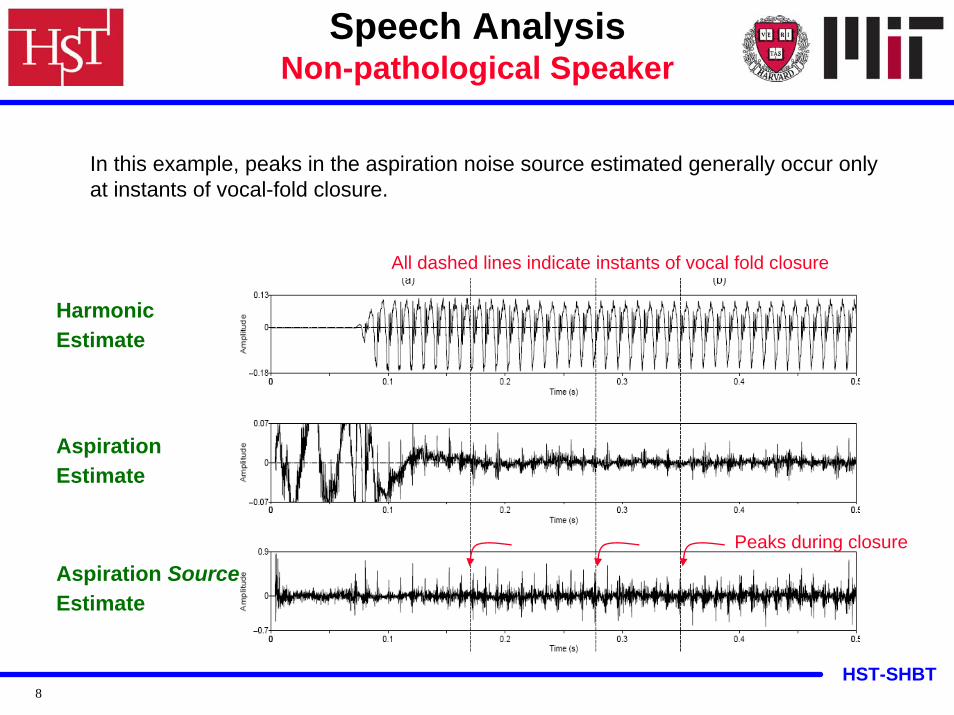
HST-SHBT8
In this example, peaks in the aspiration noise source estimated generally occur only at instants of vocal-fold closure.
Speech AnalysisNon-pathological Speaker
HarmonicEstimate
AspirationEstimate
Aspiration SourceEstimate
All dashed lines indicate instants of vocal fold closure
Peaks during closure

HST-SHBT9
Speech AnalysisSpeaker with Vocal Pathology
Cysts can obstruct the airflow from the lungs and act as an additional source of air turbulence to normal aspiration noise sources.
Peaks in the aspiration source estimate are observed to occur regularly at the instants of excitation as well as other phases within the phonation source.
HarmonicEstimate
AspirationEstimate
Aspiration SourceEstimate
Peak during open phase Peak during closure
Dashed line indicates open phase Dotted line indicates vocal fold closure instant

HST-SHBT10
Speech ModificationAlgorithm based on Physiology
Harmonic Component f1 to f2
Modified SpeechSeparationSeparation
Pitch Modification
Noise Component
Pitch Modification of Aspiration Noise Component
f1 to f2
SourceEstimation
Vocal TractFiltering
SourceModification
+Speech
Design strategy to take into account the observed patterns of modulation and temporal synchrony between the harmonic and noise components in a voiced speech. The stages of our algorithm reverse-engineer the additive modulation model to modify the modulation rate of the aspiration noise source.
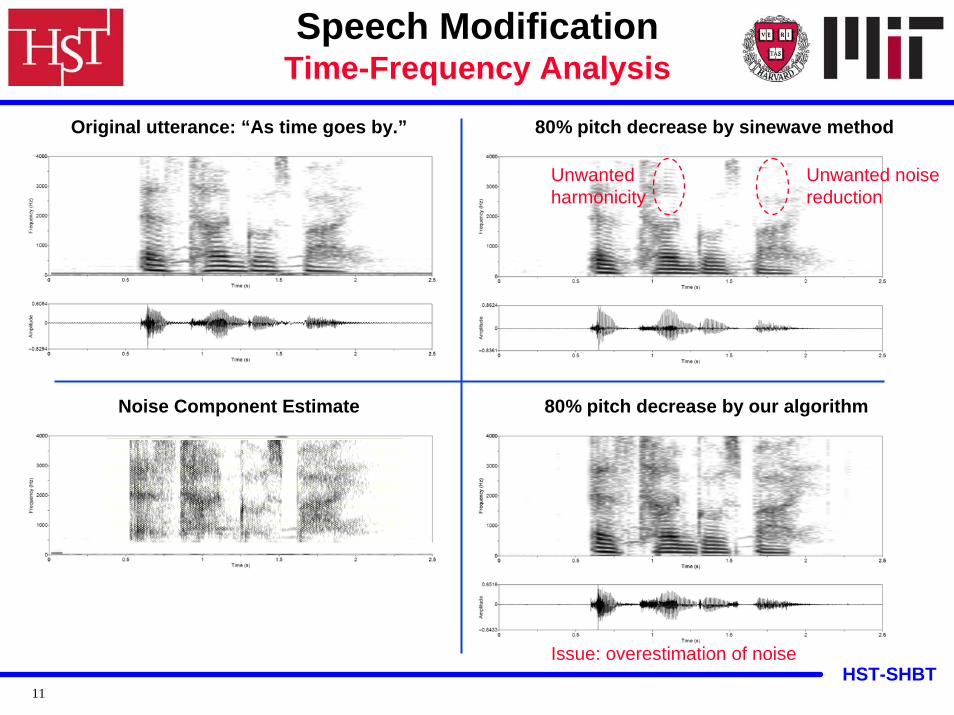
HST-SHBT11
Original utterance: “As time goes by.” 80% pitch decrease by sinewave method
Unwanted noise reduction
Unwanted harmonicity
80% pitch decrease by our algorithm
Issue: overestimation of noise
Noise Component Estimate
Speech ModificationTime-Frequency Analysis

HST-SHBT12
Sinewave transformation system (Quatieri and McAulay)The noise component is perceived as somewhat tonal and more perceptually separate from the periodic component. Harmonicity above 2500 Hz is overestimated by the STS algorithm and the perceived speech has reduced aspiration noise.
Our modification algorithm (Mehta and Quatieri)Perceived to contain a breathier quality, consistent with the quality of the original waveform. Specifically, the signal characteristics tend to preserve the fullbandaspiration noise features from the original signal. The modified signal has reduced artifacts and discontinuities that may appear in standard modification techniques.
Caveat: When performing preliminary analysis on running speech, however,the separated noise estimate sometimes contains harmonic leakage.
The time-varying nature of natural vowels, in addition to the effects of jitter and shimmer, may contribute to the suboptimal performance of the separation technique because of inaccurate pitch estimation. More advanced signal processing methods can help create perturbation-free waveforms and to better estimate the pitch contour of continuous speech.
Speech ModificationPreliminary Perceptual Results

HST-SHBT13
Future Work
Further refinementsHarmonic/noise separationEstimation and modification of noise envelope
Perceptual rating of pitch modificationFormal rating task among listenersProvide for a statistical significant way of evaluating our algorithm against baseline algorithms
Speech scienceTemporal characteristics of both aspiration and periodic sourcesAnalysis of dynamics of vocal fold vibration
Clinical evaluation of pathological voice qualityAdd to features obtained from traditional acoustic measures such as
Harmonic and noise energy levelsAerodynamic measuresElectroglottography and electromyography data
600 700 800 900 1000 1100 1200 1300 1400-0.2
-0.1
0
0.1
0.2
0.3
0.4
0.5
Blue: Inverse-filtered noise estimateDashed red: Estimated envelope

HST-SHBT14
Hermes, D. J. (1991). "Synthesis of breathy vowels - Some research methods.“ Speech Communication 10(5-6): 497-502.
Jackson, P. J. B. and C. H. Shadle (2001). "Pitch-scaled estimation of simultaneous voiced and turbulence-noise components in speech." IEEE Transactions on Speech and Audio Processing 9(7): 713-726.
Mehta, D and T. F. Quatieri (2005). “Synthesis, analysis, and pitch modification of the breathy vowel,” Proceedings of IEEE Workshop on Applications of Signal Processing to Audio and Acoustics, New Paltz, NY.
Quatieri, T. F. and R. J. McAulay (1992). "Shape invariant time-scale and pitch modification of speech." IEEE Transactions on Signal Processing 40(3): 497-510.
Quatieri, T. F. (2002). Discrete-Time Speech Signal Processing: Principles and Practice. Upper Saddle River, NJ, Prentice Hall PTR.
Stevens, K. N. (1998). Acoustic Phonetics. Cambridge, MA, MIT Press.
References

HST-SHBT15
Speech SynthesisSource Synchrony
0.2 0.21 0.22 0.23 0.24 0.25 0.26-2.5
-2
-1.5
-1
-0.5
0
0.5
1
1.5
Time (s)
Am
plitu
de
0.2 0.21 0.22 0.23 0.24 0.25 0.26-2.5
-2
-1.5
-1
-0.5
0
0.5
1
1.5
Time (s)A
mpl
itude
In-phase sources Out-of-phase sources
Speech synthesized with in phase sources are “perceptually fused,” consistent with a more natural quality than synthesis with out-of-phase sources (Hermes).


















