
ARIADNE: Final Report on Data Mining
88
D16.3: Final Report on Data Mining Authors: W.X.Wilcke, VU University Amsterdam H. Dimitropoulos, ATHENA RC Ariadne is funded by the European Commission’s 7th Framework Programme.
-
Upload
ariadnenetwork -
Category
Data & Analytics
-
view
132 -
download
1
Transcript of ARIADNE: Final Report on Data Mining

D16.3: Final Report on Data Mining
Authors: W.X.Wilcke, VU University AmsterdamH. Dimitropoulos, ATHENA RC
Ariadne is funded by the European Commission’s 7th Framework Programme.

Theviewsandopinionsexpressedinthisreportarethesoleresponsibilityoftheauthor(s)anddonotnecessarilyreflecttheviewsoftheEuropeanCommission.
ARIADNED16.3:FinalReportonDataMining(Public)
Version:1.1(final) 20thJanuary2017
Authors: W.X.Wilcke,VUUniversityAmsterdam
H.Dimitropoulos,ATHENARCContributingPartners
V.deBoer,VUUniversityAmsterdam
F.A.HvanHarmelen,VUUniversityAmsterdam
M.T.MdeKleijn,VUUniversityAmsterdam
R.vanhetVeer,VUUniversityAmsterdam
M.Wansleeben,LeidenUniversity
I.Foufoulas,ATHENARC
A.Giannakopoulos,ATHENARC
Qualityreview: HollyWright,ADS

ARIADNED16.3Public
2
TableofContents
ListofAbbreviations...............................................................................................................3
ExecutiveSummary.............................................................................................................4
1 IntroductionandObjectives............................................................................................61.1. SummaryofPreviousFindings...................................................................................................71.2. Continuation...............................................................................................................................91.3. StructureofReport..................................................................................................................10
2. RevisitingSemanticWebMining....................................................................................12
2.1. LinkedDataasaGraph.............................................................................................................132.2. ChallengesInvolved..................................................................................................................14
3. CaseStudies..................................................................................................................163.1. ARIADNERegistry.....................................................................................................................183.2. OPTIMA....................................................................................................................................223.3. SIKBDutchArchaeologicalProtocol0102................................................................................38
4. Conclusion.....................................................................................................................51
4.1. Recommendations...................................................................................................................53
AppendixA SIKBProtocol0102ConversiontoRDF............................................................54A.1 ProtocolDescription.................................................................................................................54A.2 ProtocolConversion.................................................................................................................55A.2.1 ProtocolEnrichment.................................................................................................................62A.3 ThesauriConversion.................................................................................................................64A.4 DataConversionandPublication.............................................................................................66
AppendixB PipelineVUA/LU............................................................................................67
B.1 DataPreparation......................................................................................................................68B.2 HypothesisGenerator..............................................................................................................70B.3 PatternEvaluatorandKnowledgeConsolidator......................................................................71
AppendixC PipelineATHENARC.......................................................................................72
C.1 PipelineComponents...............................................................................................................72
AppendixD ExpertEvaluation...........................................................................................77D.1 OPTIMACaseEvaluations........................................................................................................77D.2 SIKBProtocolCaseEvaluations...............................................................................................81

ARIADNED16.3Public
3
ListofAbbreviationsThefollowingabbreviationswillbeusedinthisreport.
Abbreviation FullTermACDM ARIADNECatalogueDataModelADS ArchaeologicalDataServiceAPI ApplicationProgrammingInterfaceARIADNE AdvancedResearchInfrastructureforArchaeologicalDataset
NetworkinginEuropeARM AssociationRuleMiningBGV BasicGeoVocabularyDM DataMiningGIS GeographicInformationSystemKG KnowledgeGraphLAD LinkedArchaeologicalDataLD LinkedDataLOD LinkedOpenDataML MachineLearningNLP NaturalLanguageProcessingOWL WebOntologyLanguageRDF ResourceDescriptionFrameworkRDFS ResourceDescriptionFrameworkSchemaSIKB DutchFoundationInfrastructureforQualityAssuranceofSoil
ManagementSKOS SimpleKnowledgeOrganizationSystemSW SemanticWebSWM SemanticWebMiningUI UserInterfaceURI UniversalResourceIndicatorW3C WorldWideWebConsortiumWGS WorldGeodeticSystemWP WorkPackage

ARIADNED16.3Public
4
ExecutiveSummaryARIADNE,theAdvancedResearchInfrastructureforArchaeologicalDatasetNetworking inEurope,facilitates a central web portal that provides access to archaeological data from various sources.PartsofthesedataarebeingprovidedasLinkedData.Userscanexplorethesedatausingtraditionalmethodssuchas facetedbrowsingandkeywordsearch,aswellas themore-advancedcapabilitiesthat come with Linked Data such as semantic queries. A shared characteristic amongst thesemethodsisthattheyallowuserstoexploreexplicitinformationpresentinthedata.However,sincethedataisavailable instructuredandexplicitform,wecanadditionallyuseMachineLearningandDataMining techniques to identify implicitpatterns thatexistwithin thisexplicit information.Theworkinthisreportaimstofacilitatethis.
Thisreport(D16.3)isadirectcontinuationofD16.1,FirstreportonDataMining.D16.1presentedadetailedstudyintothetheoreticalbackgroundofbothLinkedData,DataMining,andonthenovelareaofresearchwherebothdomainsmeet,knownasSemanticWebMining(SWM).ItadditionallydiscussestheapplicationofSWMwithinthearchaeologicalcommunityfromtheperspectiveofbothuser needs anddata characteristics. Finally, the report concludes by recommending severalData-Miningtasksthatcouldbeofusetothearchaeologicalresearcher.Wehaveselectedoneofthesetasks,namelyHypothesisGeneration,astheprimaryfocusofthisreport:
Hypothesis Generation involves detecting interesting and potentially relevant patterns thatcan be presented to users as starting blocks for forming new research hypotheses. Theresearchermightalreadyhaveahypothesis,inwhichcasefoundpatternsmaystrengthenhisorherbelief inthehypothesis.Alternatively, thepatternsmayrevealsomethingnewtotheresearcher that he or she is interested in exploring further. The support and confidence ofpatterns will be generated algorithmically on the basis of predefined criteria and userfeedback.
TheHypothesisGenerationtaskhasbeenimplementedintoanexperimentalpipelinenamedMinoS(MiningonSemantics).ThispipelinehasbeenintegratedintoasimpleinfrastructureconsistingofaData-Miningbackend,runningonahigh-performanceserver,withaccesstotheLinkedOpenData(LOD) cloud. A subset of the LOD's data is retrieved via a SPARQL querywhichwill be generatedsemi-automatically based on a certain task, and a set of provided constraints. Both the task andconstraintswillbeprovidedbytheuserthroughasimpleUserInterface(UI).
Inaddition toHypothesisGeneration,wehavealsoappliedmore traditionaldataminingmethodsduringtheexperiments.Thesemethodswill involve1)SemanticContentMiningtodetermineandcompare project connotations, 2) relationship discovery among the authors of OpenAIRE andARIADNEReports,3) thecreationandanalysisofARIADNE’sauthornetworks,and4)performingtext mining on OpenAIRE publications to link them with ARIADNE metadata or other extractedobjectsfromtheARIADNEreports.
To investigate the effectiveness of the pipeline with respect to the selected task, we have beenrunningmultipleexperimentson threedifferentdata sets.Theseconstitute1)project-widemeta-dataasavailableintheARIADNERegistry,2)projectreportsthathavebeensemanticallyannotatedusing the OPTIMA pipeline developed for Semantic Technologies for Archaeological Resources

ARIADNED16.3Public
5
(STAR)1,and3)richdatabaseextractions (SIKBProtocol0102) fromentireprojects thathavebeenconverted by us into Linked Data. These three data sets have been specifically chosen for theseexperimentsaseachonedifferssignificantlyinitslevelofinformationgranularity.Thisallowedustotesttheeffectsofinformationgranularityontherelevanceoftheresultsproducedbythepipeline.
Eachofthethreedatasetshavebeentreatedasseparateandparallelcasestudies,totestthegoalof producing results relevant to the archaeological community. Here, the first use case (ARIADNERegistry)differsfromtheothertwointhatithasbeeninvestigatedbytheATHENARC,whereastheother two have been investigated by the collaboration of the Vrije Universiteit Amsterdam andLeidenUniversity (VUA/LU). Therefore, the first use case has used the pipeline developed by theUoA,whereastheremainderhasusedthepipelinedevelopedbytheVUA/LU.
Overall,thecombinedresultsofallthreecasestudiescanbeseenasamildlypromisingbeginninginthe use of Data Mining for Linked Archaeological Data. Moreover, the domain experts weresurprisedbytherangeofpatternsdiscovered,despitemostpatternsdescribingeithertrivialitiesortautologies.Nevertheless,therearestillchallengestoovercomeforthefieldofSWMtomature,andto be of actual use to the archaeological community. Until that time arrives, it may be best toemploy traditional Data Mining techniques that have been perfected over several decades, andwhichhaveproventoproducereliableandusefulresults.
1Seehttp://hypermedia.research.southwales.ac.uk/kos/star/2 Bizer, C, T Heath, and T Berners-Lee. "Linked data-the story so far." Semantic Services,
InteroperabilityandWebApplications:EmergingConcepts,2009:205-227.

ARIADNED16.3Public
6
1 IntroductionandObjectivesARIADNE,theAdvancedResearchInfrastructureforArchaeologicalDatasetNetworking inEurope,facilitates a central web portal that provides access to archaeological data from various sources.SomeofthesedataarebeingprovidedasLinkedData(LD):anopenformatthatiswellestablishedand a World Wide Web Consortium (W3C) standard. As such, it aims to propel the creation,management, anduseofdata towardsahigher levelof interoperability2.Users canexplore thesedata using traditional methods, such as faceted browsing and keyword search, as well as more-advancedcapabilitiesthatcomewithLinkedDatasuchassemanticqueries.Asharedcharacteristicamongstthesemethodsisthattheyallowuserstoexploreexplicitinformationpresentinthedata.However, since thedata isavailable instructuredandexplicit form,wecanuseMachineLearningandDataMiningtechniquestoidentifyimplicitpatternsinthisexplicitinformation3.
Data Mining (DM) provides tools and techniques to identify valid, novel, potentially useful, andultimately understandable patterns in data4. These patterns represent implicit regularities withinthesedata, andoftenpoint to someyet-unknowncharacteristic that isbeing sharedamongst thedifferentdatapoints. Someof these characteristicsmaybeof relevance to theusersof thedata,whomay infer new theories from them. These theories can consequently be used to draw newconclusions,ortoconfirmorfalsifyexistingones.Ultimately,thismayresultinaddition,removal,orcorrectionofdatapointsthateitherdoordonotadheretothediscoveredpatterns.
Discovering patterns by conventional Data Mining requires data to be stored in tables, whereindividual entities are represented by the rows in such a table. In the Linked Data paradigm,information is not represented using tables, but rather in graphs, consisting of entities linkedthroughRDFtriples.DataMiningongraphdataingeneral(LinkedData)isconsideredstate-of-the-art research. This report (D16.3) will present the final work on our continuing effort as part ofWP16.1toexplorethechallengesandopportunitiesforDataMiningonarcheologicalLinkedData.We build on lessons learned and the recommendationsmade within D16.1, First report on DataMining5.andpresentthreecasesofDataMiningusingdifferenttechniquesandondifferenttypesofarcheological Linked Data. We first summarize the previous findings and provide background onSemanticWebMining.
2 Bizer, C, T Heath, and T Berners-Lee. "Linked data-the story so far." Semantic Services,
InteroperabilityandWebApplications:EmergingConcepts,2009:205-227.3Hastie,T,RTibshirani,JFriedman,THastie,JFriedman,andRTibshirani.Theelementsofstatistical
learning.NewYork:Springer,2009.4Fayyad,UM."Dataminingandknowledgediscovery:Makingsenseoutofdata." IEEE Intelligent
Systems11,no.5(1996):20-25.5Wilcke,WX,VdeBoer,MTMdeKleijn, FAHvanHarmelen, andMWansleeben.D16.1: First
ReportonDataMining.Deliverable,ARIADNE,2015.

ARIADNED16.3Public
7
1.1. SummaryofPreviousFindings
First reportonDataMining (D16.1)presentedadetailed study into the theoreticalbackgroundofbothLinkedData,DataMining,andthenovelareaofresearchwherebothdomainsmeet,knownasSemanticWebMining.
Semantic Web Mining is a young area of research of which many aspects are still uncertain orunexplored,bothfromatechnicalandpracticalperspective.Tothisend,thestudyfocussedonthemore-prominentmovementsasseen in recent literature. Inaddition, thestudyanalysedexpectedusage-patternsinordertodetermineusers’needsandwisheswithrespecttoDataMining(1.1.1),aswell as conducting a thorough exploration of the expected data’s characteristics (1.1.2). Theoutcomesofthesestudiesleadtotheselectionoftworecommendationsforpotentially-interestingData-MiningTasks(1.1.3),namelyHypothesisGenerationandDataQualityAnalysis.Wewillprovideaconcisesummarisationofthesesectionsnext.
1.1.1. DomainUnderstanding
The user-requirement study involved an analysis of the questionnaires and interviews that wereconductedbyworkpackage2.16 and13.17, respectively.Whileproviding valuable insight into thestakeholders of ARIADNE, both work packages only touched on the possibility of Data Mining.Therefore, several additional interview sessions with stakeholders were held, during which thepossibilityofDataMiningwasmore-activelyexplored.Regardless,ofallthetopicsdiscussed,onlyafewwererelevantwithrespecttoDataMining.
In its entirety, the requirement study indicated that the majority of difficulties experienced bystakeholderscouldbemitigatedbytheuseoftheexplicitinformationintheLinkedDataalone(forexample,throughdirectlyqueryingthisdata).However,severaloftheseissuescouldadditionallybeimprovedwiththehelpofDataMining.Theseissuesinvolvedknowingwhichdataareavailable,howto locate relevant data, and how to distil the results. In addition, the quality of the data wasmentioned prominently, thereby emphasising their (lack of) completeness and the (lack of)confidence in how trusted the data should be. Together, these were amongst the prime areasconsideredtowhichaData-Miningsolutioncouldbeapplied.
1.1.2. DataUnderstanding
Exploring the data is an important early step within any Data-Mining process, during which thedata’s characteristics, quality, and abnormalities are inspected. Generally, a generous amount ofdata is provided from which conclusions can be drawn that influence choices made during thedevelopment of the eventual Data-Mining solution. Unfortunately, theminimal amount of LinkedDatathathasbeenmadeavailablethroughARIADNEwereinsufficient,therefore,LinkedDatafrom
6Selhofer,H,andGuntramGeser.D2.1:Firstreportonusers'needs.Deliverable,ARIADNE,2014.7Hollander,H,andMHoogerwerf.D13.1:ServiceDesign.Deliverable,ARIADNE,2014.

ARIADNED16.3Public
8
several different archaeological repositories around the globewere inspected instead. Thesedatawerechosenfortheiralmost-disjointcharacteristics,thushopefullyprovidinggoodrepresentationsof thedifferent facets thatARIADNEwouldproduce.Theanalysis resulted inseveralobservations.Mostprominent,apart for thegenerallyexpecteddifferences inontologiesandstructure,wastheLinked Archaeological Data examined were found to strongly depend on descriptive values.Moreover, all data sets were found to consist largely of relatively ‘flat’ data structures, whereinformationrelevanttoanodeinthegraphisrelativelyfewstepsawayinthatgraph.Thisislikelytohaveitsoriginindirectconversionfromtabulardata.TheseaspectsofthedatahadtobeconsideredduringthedevelopmentoftheData-Miningsolution.
1.1.3. RecommendationsMade
Basedonthestudyofbothdomainanddata,aswellasonpracticalconstraintswithrespecttotimeandresources, twoData-Miningsolutionswerechosenwhichweredeemedthemost feasibleandsuitable for implementationwithin theARIADNE infrastructure. These constitute 1) the ability forusers to generate potentially-relevant hypotheses, and 2) analysing the quality of data aswell ashelpingtoimproveit.Wewillbrieflytouchonthesetwosolutionsnext:
HypothesisGenerationThe official project proposal of ARIADNE mentions the ability to detect patterns inarchaeologicaldataorrelateddata,andapplicationswithintheARIADNEinfrastructure.Data-Miningmethodsarecapableofdetectingsuchpatterns. Interestingandpotentially relevantsubsetsof thesepatternscanthenbepresentedtousersasstartingpoints for formingnewresearch hypotheses. The researchermight already have a hypothesis, or the patternsmayreveal something the researcher is interested in exploring further. The interestingness ofpatterns will be generated algorithmically on the basis of predefined criteria and userfeedback.
DataQualityAnalysisTwoaspectsthatreflectpoorlyonthequalityofdataaretheoccurrenceofgapsanderrorsintheknowledgecontainedtherein.Incaseoftheformer,fillingthesevoidsinvolvespredictingthe most-likely resource, link, or literal. In the latter case, these errors typically containanomalies within the data, which cannot be explained by any of the discovered patternsalone. Depending on the likelihood of them being erroneous, the detected errors could besuggested for removal or tagged as dubious. Alternatively, they could be replaced by apredictiononthecorrectvalue.

ARIADNED16.3Public
9
1.2. Continuation
This report discusses the technical feasibility and practical usability of Data-Mining on LinkedArchaeological Data. As such, this report emphasises 1) data preparation, 2) implementation, 3)experimentation,and4)evaluation:
DataPreparationTheworkinthisreportwilldiscusstherelevancyofminingLinkedArchaeologicalDataforthearchaeological community. This relevancy can only be measured meaningfully when it isreflected in the results produced by aData-Mining experiment. For these results to possessuch relevant characteristics, they must be mined from data that possesses thesecharacteristicsaswell.Unfortunately,FirstreportonDataMining(D16.1)concludedwiththeobservation that very little of this data exists at present. Therefore, part of this work willinvolve thecreationofadedicatedLinkedArchaeologicalDatacloud filledwith fine-grainedinformation.
ImplementationA considerable part of the work in this report will involve the development andimplementation of two pipelines: ATHENA and VUA/LU. Both pipelines will facilitate Data-Mining on Linked Archaeological Data, with the sole difference being the approach. Moreprecisely, the ATHENA pipeline specifically aimed to find correlations within and betweendifferent sets of coarse-grained information,whereas the VUA/LU pipeline aimed to detectdomain-relevantregularitieswithinfine-grainedinformation.Bothpipelineswereusedduringthesubsequentexperimentation.
ExperimentationThe experimental design covered three case studies with distinctly different levels ofinformationgranularity.Assuch,itwaspossibletoascertaintheeffectofthesedifferencesonthe resulting output, aswell as on the relevancy of this output towards the archaeologicalcommunity.Thethreecasestudiesencompassmeta-data(coarsegrained),annotatedreports(‘finer’grained),andrichdatabaseextracts(finegrained).
EvaluationAll output from the experimentations were evaluated algorithmically to ascertain aquantitativemeasureofrelevancy.Forthispurpose,standardgraphstatisticswereemployedand ontological background knowledge was utilised. This evaluation step will result in asmaller output, ofwhich its reduction ratewill be dependent on the input constraints. Thereduced output was subsequently evaluated qualitatively together with domain experts toascertaintherelevancyforthearchaeologicalcommunity.
1.1.1 TaskSelection
TheARIADNEdeliverableFirstreportonDataMining(D16.1)concludedwiththerecommendationoftwoDataMiningtasks:HypothesisGenerationandDataQualityAnalysis.Forthepurposeofthisdeliverable effortswere focussed onHypothesisGeneration only. This decisionwasmade for thefollowingreasons:

ARIADNED16.3Public
10
1) Hypothesis Generation constitutes a novelmethod to detect domain-relevant regularitieswithin data sets. To the best of our knowledge, this has never before been applied toarchaeological data. In contrast, Data Quality Analysis has a long history with manyapplications in many different domains. If fact, most off-the-shelf statistical softwarepackagesalreadyprovidethisformofautomaticcuration.
2) Hypothesis Generation allows exploitation of the relational structure within data sets, aswell as their semantics. Hence, it is more likely that complex patterns that span overmultiplerelatedentitieswillbediscovered.Incontrast,DataQualityAnalysiswouldlargelyfocusonsetsofvalues,hencegaining littlebenefit fromLinkedData’s relational structureand semantics. Differently put, Data Quality Analysis is likely to perform equally well onLinkedDataasontabulardata,andthushaslessacademicvalue.
3) HypothesisGeneration is likely to yield archaeologically-interesting patterns that, if foundrelevant,may add to the knowledgebaseof the archaeological community. As such, newinsights may be created that form the starting point of new research endeavours. Incontrast, Data Quality analysis will, at best, result in the improvement of a data set’scorrectness.While valuable, this doesnotmeetour goal of accentuating the relevancyofminingLinkedArchaeologicalDatatothearchaeologicalcommunity
4) HypothesisGenerationproducesresultsthatareeasilyinterpretablebyindividualswithoutabackground in Data Mining or similar. The importance of this aspect became apparentfollowingtheuser-requirementanalysisofD16.1.Moreprecisely,archaeologicalresearchershave the need to clearly understand the generated hypotheses themselves, instead ofneeding to decipher a symbolic representation. Only if this criterion holds, will theresearchersevenconsiderthem.Incontrast,mostmethodscapableofDataQualityAnalysisapplyaformofstatisticalanalysis.Assuch,theyaremorelikelytoproducetheirresultsasasymbolicrepresentation.
As postulated above, it is unlikely data sets with coarse-grained information will yieldarchaeologically-interestingresults.Therefore,weadditionallyappliedmoretraditionaldataminingmethods during the corresponding experiments. More precisely, these methods involved 1)SemanticContentMiningtodetermineandcompareprojectconnotations,2)relationshipdiscoveryamong theauthorsofOpenAIREandARIADNEReports, 3) the creationandanalysisofARIADNE’sauthor networks, and 4) performing text mining on OpenAIRE publications to link them withARIADNEmetadataorotherextractedobjectsfromtheARIADNEreports.
1.3. StructureofReport
Followingthissection,aconcisesummaryofthefieldofSemanticWebMiningandthechallengesinvolved will be given in Section 2. Next, we will discuss three case studies with increasinggranularityofknowledgerepresentationinSection3. Ineachofthesethreecases,wewillstartbygoingthroughtherespectivedatasetandtaskdescription, followedbyadiscussionofthedesign,results, and evaluation of their respective experiments. Section 4 will continue by looking at theaggregated results and their evaluation, followed by final remarks and several concludingrecommendations. Finally, for those interested,AppendicesA throughCwilldiscuss thedetailsofthe pipelines in more detail, whereas Appendix D will list the evaluation reports. A schematicvisualisationofthisstructureisprovidedinFigure1.

ARIADNED16.3Public
11
Figure1:Structureofthisreport.

ARIADNED16.3Public
12
2. RevisitingSemanticWebMiningSemantic-Web Mining (SWM) is an umbrella term which denotes the area of Data Mining thatfocusesonminingLinkedDatafoundontheSemanticWeb.Itisarelativelynewareaofresearchofwhich many aspects are still uncertain or left unexplored, from both a technical and practicalperspective.Iffact,manytasksandlearningmethodsarestillunderheavydevelopment,withfewofthemhavingprogressedoutsidetheconfinesofacademicresearch.
TherearetwoprominentapproachestoSWM,namelypropositionallearningandrelationallearning.Propositional, or “traditional”, learning solely concerns propositional data formats such as tables(Figure2-1Left).Here,thegraphstructureofLinkedDataisfirstconvertedtoatabularstructure.Assuch, this approach makes several assumptions about the data that do not necessarily hold forLinkedData.Forexample,theassumptionthateachdatapointisindependentofanyarbitraryotherdatapointinthedataset.Incontrast,relationallearningdoesassumethatsuchadependencymayexist.
Given the graph structure of Linked Data (Figure 2-1 Right), it would seem natural to focus onrelational learning. A considerable disadvantage of this approach is that where propositionallearning is a mature and established field of work, relational learning has hardly been appliedoutside of experimental research. Therefore, propositional learning is often still preferred whenlearning from Linked Data. This work’s decision to employ such propositional methods is largelymotivatedbythisaspect.
Figure 2-1: Two different datamodels. Left) Propositional (tabular data). Right) Relational (graphdata).
Additional steps are neededwhen applying propositional learning to relational structures such asLinked Data, namely context sampling and propositionalisation. Context sampling involves thecreation of individual units that represent instances (e.g. rows in a table) overwhichwewant tolearn. These individual units do not explicitly exist in LinkedData, and thus should be created bysmartlysamplingrelatedconcepts(i.e.directlyand indirectlyconnectednodes).Onceall instanceshave been sampled, they can be translated to a propositional format (e.g. a table) by a processknownaspropositionalisation.Thiswillresultinadatasetthatissuitableforpropositionallearning.

ARIADNED16.3Public
13
2.1. LinkedDataasaGraph
LDdata sets are representedusing theResourceDescription Format (RDF). InRDF, information isrepresentedusingtriples(subject,predicate,object),whichtogetherformgraphs.ThesegraphsaresometimesreferredtoasKnowledgeGraphs(KGs).InaKG,bothsubjectsandobjectsareencodedasvertices, whereas the predicates are encoded as edges. Differently put, each triple (subject,predicate,object)inthedatasetisrepresentedbyanuniqueanddirectededgebetweenexactlytwovertices. Finally, to map the semantics of the edges and vertices in the resulting graph, theseelementsarelabelledwiththeiridentifier(forLinkedDatathisisaURI)orasimplelabel.
Dependingonitspurpose,aKGmaydifferentiatebetweentheinstancelevelandtheschemalevelofagivendataset.Thelattercontainsallinformationonclassesandproperties,whereastheformerconcerns all information on the instantiations of those classes and properties. This distinction isillustratedinFigure2-2,whichdepictsasimpleinstanceandschemagraphontheleftandrightside,respectively.
Figure2-2:Agraph representationof LinkedData. Left)An instancegraphwithnumbersdenotingresources and with letters denoting predicates. Right) A schema graph, projected over a triple ingraph form, with Roman numbers denoting resource classes and with capital letters denotingpredicateclasses.
Whileintuitiveandeasilyinterpretable,thegraphrepresentationofLinkedDataisasimplificationoftheactualdata.Nevertheless, itoffersasuitableapproximationfordataminingpurposes inwhichonegeneralisesoverthedata.Therefore, it isbyfarthemostcommonrepresentationusedintherelatedliterature.TheremainderofthisworkwillfollowthisviewandthusrefertoaLinkedDatasetasaKnowledgeGraph.

ARIADNED16.3Public
14
2.2. ChallengesInvolved
Previousresearchdone inD16.1 indicatedanumberofchallengesthatariseat the intersectionofDataMiningandLinkedData.Aconcisedescriptionofthesechallengesisgivennext.
DifferentontologiesDifferentKGsmayemployverydifferentontologiestorepresentsemantics(forexample,inoneKG, a person might be represented using the Friend-of-a-Friend ontology (FOAF)8, while inanother,personsarerepresentedusingaCIDOCCRMclass9).Similarly, someKGsmayemploydifferentversionsofthesameontologies.Eithersituationposesasignificantchallengeforanylearning task that tries to exploit semantical relations. That is, patterns found to fit semanticconstructsofontologyAcannotbeusedtoderivenewinsightsfromaKGthatemploysontologyB.
StructuralvariationKGs from different sourcesmay vary considerably in their structure. Thismay be due to theontologyusedorsimplyduetothecreator’sdiscretion.Alternatively,anystructuralpeculiaritymaybeinheritedfromtheoriginaldatasetitwasderivedfrom.Irrespectiveofthecause,thesevariations pose a challenge when trying to generalize over KGs with different origins. Morespecifically, patterns found to describe certain substructures, e.g. a subgraph of a KG, areunlikelytoperformwellonKGswithatotallydifferentstructure.
DescriptivevaluesArchaeologicaldatasetstendtohaveafrequentuseofdescriptivevalues(forexample infreetext).Often,thesevaluesprovidecrucialinformationandthuscannotsimplybeignoredwithoutasignificant lossof information. IncludingthesevaluesposesaconsiderablechallengeasDataMiningisincapableofnaturallyprocessingfreetext.Thatis,anynon-numericalvalueshouldbeconvertedtoaninternalnumericalrepresentationpriortolearning.
ConceptambiguityIn a KG, concepts are defined by their directly and indirectly related vertices. This becomesevident when viewing directly related vertices as the attributes of a concept, and whenconsidering indirectly related vertices as attributes of attributes thatmight contribute to thisconcept. For instance, knowing the colour of a certain material is likely meaningful to thesemanticrepresentationofafindcomposedofsaidmaterial. Incontrast,knowingthenumberof atoms in that material’s element is hardly relevant. This example already illustrates thechallenge of choosing the subset of related vertices that most accurately define a certainconcept.
8http://xmlns.com/foaf/spec/9http://www.cidoc-crm.org/Entity/e21-person/version-6.2

ARIADNED16.3Public
15
DatamodelincompatibilityPropositional Data Mining is unable to process any data which does not conform to apropositional data model. Among those data models that do not conform is that of a KG.Therefore,tolearnoveraKG,theymustfirstbetranslatedtofitapropositionaldatamodel.Anunfortunatesideeffectofthisprocessisthatcomplexrelationalstructuresarereplacedbymoresimple propositional structures. Differently put, we lose potentially-relevant information bypropositionalisingaKG.Tominimisethisloss,asuitablestrategymustbeselected.

ARIADNED16.3Public
16
3. CaseStudiesThe informativeness of patterns found in Knowledge Graphs depends heavily on the contents ofthosegraphsaswellasonthestructuralfeaturesofthesegraphs.Toincreasethescopeoftheworkinthistask,threeseparatecasestudiesinSemanticWebDataMiningonarchaeologicaldatawereconducted. Each of the three studies used different types of Linked Data, produced within theARIADNEproject.Theseare:
1. DatafromtheARIADNERegistry,2. Grey literature that has been semantically-annotated using the OPTIMA text-mining
pipeline,3. RichLinkedDatadatabaseextractionsthatfollowtheSIKBProtocol0102specification.
Onehelpfulwayoforganizingthethreecasesistoorderthemby`granularity'ofknowledge.Morefine-graineddatasetshavemorespecificinformationaboutarchaeologicalfindsandtheircontexts,whereasmorecoarse-graineddatasetsdescribeinformationatahigherlevel(metadata).Figure3-1showsthethreedatasetsonthiscontinuum.
Figure 3-1: Relative differences between the granularity of knowledge seenwith various formsofdata.
Thefirstcasewill involvetheARIADNERegistry(Section3.1),whichcanberegardedasrichmeta-data thathasbeenextendedwithdomain-specificelements.Assuch, thesedatahold informationaboutdocuments,ratherthanaboutarchaeologicalknowledgewithinthosedocuments.Therefore,weexpectitunlikelytoyieldresultsthatareofinteresttoanarchaeologist.
The second casewill concern the combined output of the OPTIMA pipeline on a large corpus ofBritish archaeological reports (Section 3.2). In contrastwith the ARIADNE Registry, these data docontain archaeological knowledge in the form of semantic annotations. However, the context ofthese annotations is rather limited, spanning a paragraph at most. Therefore, the span of anypotentialpatternisalsolimited.

ARIADNED16.3Public
17
ThethirdandfinalcasewillinvolveacloudofSIKBProtocol0102instances(Section3.3).Thesedataconcernmanyofaproject’selements,rangingfromreportsanddatabaseextractstomedia,finds,andthecontextofthesefinds.Assuch,theseinstancesincludemeta-datathatissimilartothatoftheARIADNERegistry,aswellasholdingarchaeologicalknowledgethat isbothdeeperandbetterconnected than that producedby theOPTIMApipeline. Therefore,weexpect thesedata likely toyieldresultsthatareofinteresttoanarchaeologicalresearcher.
Eachofthethreedatasetswillbetreatedasseparateandparallelcasestudies.Here,thefirstusecase(ARIADNERegistry)differsfromtheothertwointhatitwillbeinvestigatedbytheATHENARC,whereas theother twowill be investigatedby theVrijeUniversiteitAmsterdam (VUA). Therefore,thefirstusecaseusedthepipelinedevelopedbyATHENARC,whereastheremainderwillusethepipelinedevelopedbytheVUA.
Eachofthesethreecasesandtheirpotentialusewillnowbediscussedinmoredetail.

ARIADNED16.3Public
18
3.1. ARIADNERegistry
TheARIADNEregistrydescribedinthisreportusestheARIADNECatalogueDataModel(ACDM)andCataloguesystemdesignedandcreatedbyATHENARCandCNR.TheARIADNECatalogueiscentredon the model of individual data sets, but as many of the partners hold data in the form ofcollections, the Catalogue has also been extended to handle collections. The Catalogue is also ametadataregistry(foradiscussionofmetadataregistriesandstandards,alongwiththetechnologiesusedtodevelopthemetadataregistrywithintheCatalogue,followedbyadescriptionoftheACDMandCataloguesystemitselfpleaserefertodeliverableD3.1: Initialreportonstandardsandontheprojectregistry10.
3.1.1. DataDescription
This“SpecificationoftheARIADNECatalogueDataModel(ACDM)”documentdescribesindetailthedata model underlying the catalogue developed by the ARIADNE project for describing thearchaeologicalresourcesthataremadeavailablebythepartnersoftheprojectforthepurposesofdiscovery,accessandintegration.Theseresourcesinclude:
• dataresources,suchasdatasetsandcollections;• services;and• languageresources,suchasmetadataformats,vocabulariesandmappings.
Themodelisaddressedtoculturalinstitutions,privateorpublic,whichwishtodescribetheirassetsinordertomakethemknowntoe-infrastructures.
OneoftheaimsofT16.1istoexplorelinkagesbetweendataandpublications.Anexamplegiveninthe DoW suggests that ARIADNE provide metadata from the integrated data sets to OpenAIRE,which would then return back links to possibly relevant publications. Building a bridge betweenARIADNE and OpenAIRE would be a positive step towards exploring the possibility of linkingarchaeologicaldatawithresearchpublications.
Forsuchause-case,theDataResourcesmetadataoftheACDMarerelevant,andmorespecificallythefollowingclasses:
CollectionThisclassisaspecialisationoftheclassDataResource,andhasasinstancescollectionsinthearchaeological domain. In order to be as general as possible, archaeological collections aredefined as an aggregation of resources, and named the items in the collection. Beingaggregations, collectionsareakin todata sets,butwith the following, importantdifference:
10Papatheodorou,C,etal.D3.1:Initialreportonstandardsandontheprojectregistry.Deliverable,ARIADNE,2013.

ARIADNED16.3Public
19
the items in a data set are data records of the same structure (see definition of Data setbelow). In contrast, the items ina collectionare individualobjectswhicharedifferent fromrecords(e.g.,images,texts,videos,etc.)orarethemselvesdataresourcessuchascollections,datasets,databasesorGIS;forinstance,acollectionmayincludeatextualdocument,asetofimages,oneormoredatasetsandothercollections.
DatabaseThisclassisaspecialisationoftheclassDataResource,andhasasinstancesdatabases,definedas a set of homogeneously structured records managed through a Database ManagementSystem,suchasMySQL.
DatasetThis class is a specialisation of the classes DataResource. It has archaeological data sets asinstances. An archaeological data set is defined as a set of homogeneously structured datarecords,consistingoffieldscarryingdatavalues.
GISThis class is a specialisation of the class DataResource, and has as instances data records,consisting of fields carrying data values, which are not managed through a GeographicalInformationSystems(GISs).
ItwasdecidedtofocusonDatabasesandDatasetsfromtheARIADNEcatalogue,asagoodstartingpointforinvestigatingrelevantlinkstoOpenAIREpublications.
3.1.2. TaskDescription
AsstatedinSection1.2that,inadditiontoHypothesisGeneration,itwasalsoplannedtoapplymoretraditional data mining methods during the experiments. These methods involve 1) SemanticContentMining to determine and compareproject connotations, 2) relationship discovery amongthe authors and the citations of OpenAIRE and ARIADNE Reports, 3) the creation and analysis ofARIADNE’sauthornetworks,and4)performingtextminingonOpenAIREpublicationsto linkthemwithARIADNEmetadataorotherextractedobjectsfromtheARIADNEreports.Apartfromthefirstmethod(seeSection3.2forSemanticContentMining)theremainingmethodsaredealtwithinthissection.
3.1.3. ExperimentalDesign
An algorithm for citation extraction and algorithm data setmatchingwas implemented first. TheimplementationdetailscanbefoundinAppendixC.
As a first experiment, arXiv open access publicationswere used and textmining techniqueswereappliedtofindreferencestoARIADNEcollectionsordatasets.ItwashopedthatwitharXiv,linkstoARIADNE’sdendrochronologydatasetrecordscouldbefound,butunfortunatelytheywerenot.
Forthesecondexperiment,PubMed/ePMCpublicationswereused,asARIADNEcontainssomedatasetsrelevanttothebiomedicaldomain(mitochondrialDNAsequence,SNPdata,datingtechniques,

ARIADNED16.3Public
20
etc.).However, this setalsodidnotproduceanysignificant findings.TestingwithotherOpenAIRErepositories with PDF/full-text collections of their publications will continue (although note thatarXivandePMCaretwoofthelargestsuchcollections).
Meanwhile,linkagesbetweenARIADNEandOpenAIREintheoppositedirectionarebeingexplored.Forexample,startingwiththeADSgreyliteraturereports,citationextractionalgorithmlookingforhookstoOpenAIREpublicationswasrun.AlthoughnolinkstoarXivpublicationswerefound,whenrunning the algorithm on ePMC publications, promising results were returned. The results aredescribedinsection3.1.4,followedbytheirevaluationbyanarchaeologistinsection3.1.5.
Similarexperimentsonotherrepositoriesarenowbeingrun, includingexperimentsusingtheADSgreyliteraturemetadata,inorderto:
(i) discoverrelationshipsamongtheauthorsofOpenAIREandARIADNEReports,(ii) createandanalyseauthornetworks,(iii) dofurthertextminingonOpenAIREpublicationstolinkthemwithARIADNEmetadata
orotherextractedobjectsfromtheARIADNEreports.
So far, (i) above has been pursued, finding thousands of single author links between ADS greyliterature andOpenAIRE authors. The set of results is too large tomanually evaluate and a largenumberoflinksareexpectedtobefalsematches,i.e.differentpeoplethathappentohavethesamesurnameandinitials(somenamesarequitecommon).Tomakethismoremanageable,two-authorlinks between ADS reports and OpenAIRE publications were looked for (see Appendix C for thealgorithm), resulting in 131 ADS-OpenAIRE links of 54 distinct author-pair names. This set willcontinuetobeevaluateduntiltheendoftheARIADNEproject,sotheresultsarenotpresentedinthisdeliverable.AnyfurtherfindingsbeforetheendoftheARIADNEprojectwillbeincludedinthefinalreporting.
Inparallel,clustersofsimilarrecordswithintheARIADNEdatabasearealsobeinglookedfor.Forthispurpose,thekeywordsgeneratedbytextminingtheabstractsandtitlesofARIADNE’srecordswereextractedandsimilarityalgorithmsinordertogenerateclustersofrelatedrecordswererun.Afirstsetofresultswereproduced(e.g.~250Κsimilarpairswithjaccard>0.3),butkeywordextractionisbeingmodified to improve results, as there aremany “automated” descriptions in the data thatsharecommonexpressionswithonlyoneworddiffering,etc.Theabovealgorithmwillbeusedtofindsimilaritiesbetweenthe16M+publicationsinOpenAIREandARIADNErecords,usingtitlesandabstracts.
3.1.4. Results
Asdescribedintheprevioussection,itwasnotpossibletofindreferencestoARIADNEcollectionsordatasetswhenusing thecitationextractionandalgorithmdatasetmatchingalgorithmon twoofthelargestPDF/full-textcorporainOpenAIRE,theArXiVandPubMed/ePMCrepositories.
However,whenexploring linkagebetweenARIADNEandOpenAIRE in theopposite direction, andspecifically, when running the citation extraction algorithm on the ADS grey literature reportslookingforhookstoOpenAIREpublications,theresultswerepositive,asdescribedbelow.

ARIADNED16.3Public
21
A large subset of the ePMC corpus was used and 216 direct citation links from ADR reports toPubMed publications were found, as well as 83 indirect links. The direct links were all highconfidence links, the indirect linksweregenerallymediumconfidence,andtherewere seven falsepositiveswhichwerealllowconfidenceandwereremovedaftermanualcuration.Thefalsepositivescanbeeliminatedinfuturerunsbeselectinganappropriateconfidencecut-offvalue.
In total, 299 valid citation links from ADS grey literature reports to PubMedwere found,mostlyreferencestopublicationsinmedicalhistoryjournals/epidemiology(e.g.yellowfeverinthe1790s),geochronology,paleopathology,dentalanthropology,anatomy,DNAstudies,andsoon.
IndirectlinksareusuallylinksfromanADSreporttoareviewofthecitedworkinOpenAIRE.So,notadirectcitationmatch,butvery relevant. Inotherwords,anADSreport is linkedtoanOpenAIREpublicationwhichdiscusses,presentsorreviewsthepublicationcitedbyADS,butisnottheactualpublication.
All linksfoundweregivenforfurtherassessmenttoanarchaeologisttoconfirmtheirrelevancetothisproject.Thearchaeologist’sevaluationispresentedinsection3.1.5below.
Regarding theutilisationof theADSgrey literaturemetadata todiscover relationshipsamongADSandOpenAIREauthorsandtocreateandanalyseauthornetworks,etc.,sinceatthetimeofwritingtheminingexperimentsarestillbeingrunandresultsarenotcompleteorfullyevaluatedyet,anyfurtherfindingsbeforetheendoftheARIADNEprojectwillbeincludedinthefinalreporting.
3.1.5. Evaluation
The299citationlinksfromADSgrey literaturereportstoPubMed/ePCMpublications inOpenAIREmentionedintheprevioussectionwereevaluatedbyanarchaeologist.
Accordingtothesummaryevaluationreport,“thevastmajorityofrecordsareabsolutelyusefulandrelevant”. The archaeologist also noted that topics were related to fields such as anthropology,biology,palaeontology,pottery,andalsooutsidetheUK,suchasOceania.Withtheexceptionofafewrecords,theywereuseable.
Theonlyproblemmentionedwasafewmultiple/duplicateentries.Uponfurtherinvestigation,thisappearstobecausedbyasmallsetofADSreportsthatappeartohavemorethanone(verysimilarintext)version.
Inmoredetail,292ofthelinkswerejudgedasrelevant,sixlinksaspossiblyrelevant,andeightlinksasirrelevant.Thisisinlinewiththeinternalevaluation(insection3.1.4).

ARIADNED16.3Public
22
3.2. OPTIMA
Archaeologicalreportsholdawealthofinformationwhichsoftwareagentsareunabletointerpret.This can be partially solved by processing reports through a Natural Language Processing (NLP)pipeline.Suchapipeline,calledOPTIMA,wasdevelopedbyAndreasVlachidis11inthecontextoftheSemantic Technologies forArchaeologicalResources (STAR) 12project. For this purpose, it employsboththeCIDOCCRMandCIDOCCRM-EHontologies.
3.2.1. DataDescription
Since itsdevelopment,OPTIMAhasprocessednumerousarchaeological reportswritten inEnglish.Thishasresultedinseveralthousandfilesfulloftripleswhichassignsemanticannotationstotheirrespectivereports.Theseannotationsmayinvolvethefollowingconcepts:
• Physicalobjectsandfinds,aswellasthematerialsofwhichtheyconsistandthecontextsinwhichtheywerediscovered.
• Temporalinformationsuchasarchaeologicalperiodappellationsandtimespans,aswellastheeventsorobjectstowhichtheyareassigned.
• Varioustypesofeventsrelatedtotheproductionanddepositionoffinds,aswellastotheirplaceandtimeofoccurrence.
Asmallexcerpt,representativeofallofOPTIMA’soutput, isshowninExcerpt3-1.There,acertainfindisdeclaredasbeingofthetype‘naturalclay’,therebyincludingareferencetoavocabulary.Theoccurrenceof that type’snamewithin theaccompanyingsentence is listedasanotebelongingtothis find. Inaddition,thefind isdeclaredasbeingmovedtoacontextoftype ‘linearfeature’byacertaindepositionevent.
SeveralobservationscanbemadethatinfluencethedesignoftheData-Miningpipeline.Firstly,thelimitsofOPTIMA’scapabilities largelyprevent inferencesbeingmadebeyondthelinguisticcontextofaterm.Asaresult,thereishardlyanycross-linkingbetweentheannotatedconceptsbeyondtheirdirectly related attributes.Moreover, it is very likely for the same concept to be annotatedmorethan once andwith different attribute values if the corresponding term ismentionedmore thanonce as well. Consequently, per processed document, the result is multiple small and possiblyconflictinggraphs.
Arelatedobservationisthesesmallgraphstranslatetoindividualswithrelativelyfewattributes.Forinstance, the find listed in Excerpt 3-1 has only has three potentially-relevant attributes. Theseconcern the find’sdepositionevent,aswellas its typeandcontext.Allotherattributesareeitherirrelevant,e.g.notesandtypeappellations,orhavethesamevaluethroughoutthefile,e.g.sources.Consequently, a Data-Mining pipeline is only able to compare individuals using a handful ofcharacteristics.Assuch,itmaylimitthepredictivepowerofthispipeline.
11Seehttp://www.andronikos.co.uk/12Seehttp://hypermedia.research.southwales.ac.uk/kos/star/

ARIADNED16.3Public
23
:contextFind_Aacrmeh:EHE0009.ContextFind;crm:P2F.has_typetype_C;crm:P3F.has_note“...alignment.2.13Linearfeature[101]wasobservedcuttingintothenaturalclay,orientatedNE-SWtowardsthesouth-eastendofthetrench.Thisfeature...”^^xsd:string;dc:sourcesource_X,source_Y.:contextFindDepositionEvent_Aacrmeh:EHE1004.ContextFindDepositionEvent;crm:P3F.has_note“13Linearfeature[101]wasobservedcuttingintothenaturalclay”^^xsd:string;crm:P25F.movedcontextFind_A;crm:P25F.moved_tocontext_A;dc:sourcesource_X,source_Y.:context_Aacrmeh:EHE0007.Context;crm:P2F.has_typetype_D;crm:P3F.has_note“...acrosstheverysouth-eastendofthetrenchonaNE-SWalignment.2.13Linearfeature[101]wasobservedcuttingintothenaturalclay,orientatedNE-SWtowar...”^^xsd:string;dc:sourcesource_X,source_Y.:type_Cacrm:E55.Type;rdf:value“naturalclay”;crmeh:EXP10F.is_represented_byconcept_C;dc:sourcesource_X,source_Y.:type_Dacrm:E55.Type;rdf:value“LinearFeature”;crmeh:EXP10F.is_represented_byconcept_D;dc:sourcesource_X,source_Y.
Excerpt3-1:Anannotatedcontextfind(naturalclay)anditslinkedresources.
A final observation is the total absence of continuous numerical attributes. Rather, all possibleattributesholdnominalorfreetextvalues.Data-Miningonlyworkswithnumericalvalues.Forthisreason, nominal or free text values are often represented by such numerical values. While thisappears to nullify the initial observation, the now numerical values are simply a differentrepresentationofthenominalandfreetextvalues,andthusdifferfrom‘real’numericalvalues.Asaresult,learningtasksthatrelyon‘real’numericalvalues,suchasregression,cannotbeused.

ARIADNED16.3Public
24
3.2.2. TaskDescription
RecallfromSection1.2thatHypothesisGenerationandSemanticContentMiningwaschosenasthepreferredtask for the followingexperiments.HypothesisGeneration involvesdetecting interestingandpotentiallyrelevantpatternsthatcanbepresentedtousersasstartingblocksforformingnewresearchhypotheses.Theresearchermightalreadyhaveahypothesis,inwhichcasefoundpatternsmaystrengthentheirbeliefinthehypothesis.Alternatively,thepatternsmayrevealsomethingnewtotheresearcherthattheyareinterestedinexploringfurther.Thesupportandconfidencepatternswillbegeneratedalgorithmicallyonthebasisofpredefinedcriteriaanduserfeedback.
Semantic Content Mining involves determining the optimal connotation of a data set by itssemantics.Inthecaseofasinglesemantically-annotatedreport,theresultwilllikelybelimited.Thisstemsmainlyfromthelownumberofrelevantattributespergraph.Adifferentapproachistomineover more than one semantically-annotated report. For this purpose, the whole output of aprocessedreportcouldfunctionasasemanticbagofwords.Thiswould,forexample,allowformoreaccurate clustering or classifying of reports. Consequently, it could minimize the time thatresearchers have to spend searching for relevant documents. In addition, it would allow for thecategorisationofreportsindifferenttypesofhierarchies,e.g.,byperiodorbylocation.Yetanotherpossibilityistorankreportsbasedonhowwelltheircontentsfitsacertaincriterion.
3.2.3. ExperimentalDesign
The tasks discussed abovewere investigated usingmultiple experiments. Each experiment testedvarious sets of constraints on different subsets of the entire data set. To acquire these subsets,archaeological searches on topics of interestwere translated into SPARQL queries. These queriesweresubsequentlyexecutedonadataset.Togetherwiththeremainingconstraints, thesubsetofdatawasofferedasinputtothepipelinedescribedinAppendixB.TheresultsandevaluationofthisspecificcaseareprovidedinSection3.2.4and3.2.5,respectively.
HypothesisGeneration
The following experiments involved the generation of hypotheses using ARM. Each of theexperiment’s runsusedasubsetof thedatasetdescribed inSection3.2.1.Textualdescriptionsofthese subset’s criteria are provided in Table 3-1, as well as additional constraints. Note that adetailedexplanationofhowthesecriteriacomeintoplayhasbeendocumentedinAppendixB.
Table3-1:ConfigurationsoftheHypothesisGenerationExperimentID
DatasetSelectionCriteria
Variation
SamplingMethod GeneralizationFactor
A Allfactsrelatedtoartefacts(EHE0009_ContextFind)
1 ContextSpecificationA⁰ 0.1
2 ContextSpecificationA⁰ 0.6
3 ContextSpecificationA⁰ 0.9
B Allfactsrelatedtoartefactdepositevents 1 ContextSpecificationB† 0.1
ARIADNED16.3Public
25
(EHE1004_ContextFindDepositionEvent)2 ContextSpecificationB† 0.6
3 ContextSpecificationB† 0.9
C Allfactsrelatedtocontextevents(EHE1001_ContextEvent)
1 ContextSpecificationC‡ 0.1
2 ContextSpecificationC‡ 0.6
3 ContextSpecificationC‡ 0.9
D Allfactsrelatedtoartefactdepositevents(EHE1002_ContextFindProductionEvent)
1 ContextSpecificationD• 0.1
2 ContextSpecificationD• 0.6
3 ContextSpecificationD• 0.9
ThenextfourtablesdenotethecontextdefinitionsusedbyexperimentsAthroughD.Thesedefinitionsdescribeoneormorepredicatepathsthatconstituteanindividualcontext.Assuch,they
contributerelevantinformationtoanindividualwhichisexploitedinthepipeline.Forinstance,thecontextdefinitionlistedinTable3-2willresultinindividualsofclassEHE0009_ContextFindwitheachhavingasmanyattributesastherearerows(i.e.3).Thecorrespondingattributevalueswereretrievedbyrequestingthevaluesattheendofthedefinedpredicatepaths.Notethatthesecontextdefinitionswerecreatedwiththehelpofadomainexpert.
Table3-2:ContextdefinitionforinstancesoftypeEHE0009_ContextFind,asusedinexperimentA.
ID PredicatePath1 http://purl.org/dc/elements/1.1/source2 http://www.cidoc-crm.org/cidoc-crm/P4F_has_time-span,
http://www.cidoc-crm.org/cidoc-crm/P1F_is_identified_by,http://www.cidoc-crm.org/cidoc-crm/P2F_has_type,http://www.w3.org/1999/02/22-rdf-syntax-ns#value
3 http://www.cidoc-crm.org/cidoc-crm/P108F_has_produced,http://www.cidoc-crm.org/cidoc-crm/P2F_has_type,http://www.w3.org/1999/02/22-rdf-syntax-ns#value
Legend
ID Identifierofexperiment.Thisistiedtotheselectedsubset.Variation Variationonexperimentwithadifferentsetofconstraints.DatasetSelectionCriteria Criteriausedtogenerateasubsetoftheentiredatacloud.SamplingMethod Methodtosampleindividualswithinthesubset.GeneralizationFactor Howwellrulesgeneralize.Highervaluesimplylessgeneralization.

ARIADNED16.3Public
26
Table3-3:ContextdefinitionforinstancesoftypeEHE1004_ContextFindDepositionEvent,asusedinexperimentB.
ID PredicatePath1 http://purl.org/dc/elements/1.1/source2 http://www.cidoc-crm.org/cidoc-crm/P25F_moved,
http://www.cidoc-crm.org/cidoc-crm/P2F_has_type,http://www.w3.org/1999/02/22-rdf-syntax-ns#value
3 http://www.cidoc-crm.org/cidoc-crm/P25F_moved,http://www.cidoc-crm.org/cidoc-crm/P45F_consists_of,http://www.w3.org/1999/02/22-rdf-syntax-ns#value
4 http://www.cidoc-crm.org/cidoc-crm/P26F_moved_to,http://www.cidoc-crm.org/cidoc-crm/P2F_has_type,http://www.w3.org/1999/02/22-rdf-syntax-ns#value
5 http://www.cidoc-crm.org/cidoc-crm/P26F_moved_to,http://www.cidoc-crm.org/cidoc-crm/P45F_consists_of,http://www.w3.org/1999/02/22-rdf-syntax-ns#value
Table3-4:ContextdefinitionforinstancesoftypeEHE1001_ContextEvent,asusedinexperimentC.
ID PredicatePath1 http://purl.org/dc/elements/1.1/source2 http://www.cidoc-crm.org/cidoc-crm/P4F_has_time-span,
http://www.cidoc-crm.org/cidoc-crm/P1F_is_identified_by,http://www.cidoc-crm.org/cidoc-crm/P2F_has_type,http://www.w3.org/1999/02/22-rdf-syntax-ns#value
3 http://www.cidoc-crm.org/cidoc-crm/P7F_witnessed,http://www.cidoc-crm.org/cidoc-crm/P2F_has_type,http://www.w3.org/1999/02/22-rdf-syntax-ns#value
Table3-5:ContextdefinitionforinstancesoftypeEHE1002_ContextFindProductionEvent,asusedinexperimentD.
ID PredicatePath1 http://purl.org/dc/elements/1.1/source2 http://www.cidoc-crm.org/cidoc-crm/P4F_has_time-span,
http://www.cidoc-crm.org/cidoc-crm/P1F_is_identified_by,http://www.cidoc-crm.org/cidoc-crm/P2F_has_type,http://www.w3.org/1999/02/22-rdf-syntax-ns#value
3 http://www.cidoc-crm.org/cidoc-crm/P108F_has_produced,http://www.cidoc-crm.org/cidoc-crm/P2F_has_type,http://www.w3.org/1999/02/22-rdf-syntax-ns#value
SemanticContentMining
The following three experiments – A, B, and C – involved Semantic ContentMining. Each of theexperiment’s runs will use the data set described in Section 3.2.1. Experiment A concerned theaggregateddataofmore than50annotated reports. Toexemplify thedifferencebetweenminingwithinandminingbetweenreports,experimentsBandCconcernedonearbitrarily-selectedreporteach.Whiletheremainingreportswereminedaswell,theyareomittedthosefromthisdocument

ARIADNED16.3Public
27
for clarity. Note however, that the selected reports are a representive samples of all availablereports.AnoverviewoftheseexperimentalconfigurationsisprovidedinTable3-6.
Allresourcesinthedatasetwereofatypethathasbeendefinedwithastringliteral(Excerpt3-1).Thisstringliteralequalstherawannotatedtermfromthecorrespondingreport.Hence,isitlikelytohavedifferenttypesdefinedforvariousversionsofthesameterm,forinstance,duetosingularorpluralforms,duetoqualifiers,orduetootherlinguisticsymbols(e.g.adash).Therefore,topreparetheannotateddataformining,wehavefirstalignedalltermswiththehelpoftextminingtools.Inaddition,textcleaningtoolswereusedtoremovemosterroneousterms.
Table3-6:ConfigurationsofexperimentsforSemanticContentMining
ID DatasetSelectionCriteria #Contexts #Finds #Periods
A EntireDatasetconsistingofmorethan50aggregatedannotatedreports.
26675 20984 32755
B AnnotatedreportonLincolnshireproject† 2906 1903 3401
C AnnotatedreportonEssexproject‡ 3005 2119 3788
†ARCHAEOLOGICALEVALUATIONONLANDATMANORFARM,SUDBROOK,LINCOLNSHIRE(SUMF06)WorkUndertakenForHPCHomesLtd.September2006
‡ARCHAEOLOGICALEXCAVATIONANDMONITORING,DAGNETSFARM,M.LANE,BRAINTREE,ESSEX.September2005
Legend(Table3-6)
ID Identifierofexperiment.Thisistiedtotheselectedsubset.#Contexts Numberofsemanticannotationsoncontexts.#Finds Numberofsemanticannotationsonfinds.#Periods Numberofsemanticannotationsonperiods.
3.2.4. Results
In this section, the results of the two selected Data Mining tasks are presented: HypothesisGenerationandSemanticContentMining.TheseresultsareevaluatedinSection3.2.5.
HypothesisGeneration
ThissectionwillpresenttheoutputoftheHypothesisGenerationexperimentsdescribedabove. Intotal,thecombinedrawresultsholdmorethantenthousandpotentialhypotheses.Toreducethistoamore-manageableamount,therawresultswerefirstpassedthroughanalgorithmicfilter.Thisfilter(Table3-7)applies ‘commonsense’heuristicstonarrowthesearch.For instance,hypotheseswith a minimal support apply only to a single resource and are therefore unsuitable forgeneralisationoverotherresources.Inaddition,hypotheseswithamaximumconfidenceapplytoallresourcesofacertaintype,andcanthusberegardedastrivial.Omittingthesehypotheseswillthusleadtoacleanerresultwithlessnoise.

ARIADNED16.3Public
28
Table3-7:Tablelistingtheconditionsusedtofiltertherawoutputoftheexperiments.
FILTER Condition1 Hypothesismustnotbetoocommon,forelseitdescribescommonknowledgethatdoesnotcontributetotheentity’s
semantics.Valuedependsonclassfrequencyindataset.2 Hypothesismustnotbetoorare,forelseitdescribesapeculiarityofafewdistinctcases.Valuedependsonclassfrequencyin
dataset.3 Hypothesismustnotholdforonlyasingleentity,forelseitdescribesauniquecharacteristicofthatentity.Valuedependson
classfrequencyindataset.4 Hypothesismustnotbeaboutanyofthefollowingirrelevantproperties:
- RDFlabel- OWLsameAs- SKOSprefLabel- SKOSnote- SKOSscopeNote- SKOSinScheme- SKOStopConceptOf- DCTERMSissued- DCTERMSmedium- PRISMversionIndentifier- CIDOCCRMpreferred_identifier- CIDOCCRMidentified_by- CIDOCCRMnote- CIDOCCRMdocuments- GEOSPARQLasGML
Unfortunately,noneofthehypothesesgeneratedinanyofthefourexperimentspassedthecriteriadefined by the algorithmic filter. Specifically, the large majority of the hypotheses described apattern of a single resource and its attributes, thus failing the third criterion. The remaininghypothesesdescribedpatternsthatweretoorare,thusfailingthesecondcriterion.AnexampleofsuchahypothesesisonethatdescribesthataterminreportX isfoundtobeoftypeY,anddatesfrom period Z. Here,X, Y, and Z represent variables, specifically URIs. Therefore, this hypothesis,whilstcorrect,doesnotteachusanythingwhichhasnotalreadybeendescribedinthedataitself.
Toallowustoanalysethegeneratedhypotheses,wehavererunthealgorithmicevaluationwithoutupholdingcriteriatwoandthree.Thisresultedinseveralthousandpotentialhypothesesforeveryoneofthefourexperiments.Foreachofthese,wehaverandomlysampledfivehypothesesforexpositionalpurposes.ThesehypothesesarelistedintablesTable3-8,
Table3-9,
Table3-10,andTable3-11 forexperimentsAthroughD, respectively.All samplehypotheseshavebeenmanuallytranscribedtofacilitateeasyinterpretation.Pleasenotethatthedatasetislenientinitsuseofsemantics.Hence,whilesometranscriptionsmightappeartoextendtheimplicationofahypothesis,theyareinfactanaccuratedescription.
ARIADNED16.3Public
29
Table3-8:FiverepresentableresultsofexperimentA(archaeologicalfinds(EHE0009_ContextFind).Ex. HypothesisA1 [crmeh#EHE0009_ContextFind]
IF('P2F_has_type',‘torc’)THEN('DC:source',‘Suffolk')Support:<0.001Confidence:1.000Foreveryfindholdsthat,iftheyareofmaterialtype‘torc’,thentheyoriginatewithinthereportsonSuffolk.
A2 [crmeh#EHE0009_ContextFind]IF('P2F_has_type','sherds')THEN('P45F_consists_of',‘pottery’)Support:<0.001Confidence:1.000Foreveryfindholdsthat,iftheyareoftype‘sherds’,thentheyconsistof‘pottery’.
A3 [crmeh#EHE0009_ContextFind]IF('P2F_has_type',‘ironstone’)THEN('P45F_consists_of',‘pottery’)Support:<0.001Confidence:1.000Foreveryfindholdsthat,iftheyareoftype‘ironstone’,thentheyconsistof‘pottery’.
A4 [crmeh#EHE0009_ContextFind]IF('P2F_has_type',‘datableartefacts’)THEN('DC:source','Suffolk')Support:<0.001Confidence:1.000Foreveryfindholdsthat,iftheyareoftype‘datableartefacts’,thentheyoriginatewithinthereportsonSuffolk.
A5 [crmeh#EHE0009_ContextFind]IF('P2F_has_type','whitewashedbricks’)THEN('P45F_consists_of',‘building’)Support:<0.001Confidence:1.000Foreveryfindholdsthat,iftheyareoftype‘whitewashedbricks’,thentheyconsistofa‘building’.
Table 3-8 lists five representable results of experiment A (archaeological finds(EHE0009_ContextFind). Three of these results indicate a correlation between the material andcategoryofafind.For instance,sampleA2statesthatfindsof ‘material’sherdsconsistofpottery.Notethat,inthisexample,theproperty‘material’isusedinitsbroadestsense.Theremainingthreehypothesesindicateacorrelationbetweencertaintypesoffindsandthereporttheyarefrom.Forinstance, hypothesis A4 states that all ‘datable artefacts’ have been documented in reports onSuffolk. It is easy to see, evenwithout the help of domain experts, that this cannot be true. Thereason that this hypothesis has been generated stems from the use of the joined term ‘datableartefacts’inonereport,whereasthatjoinedtermisnotpresentinanyoftheotherreports.

ARIADNED16.3Public
30
Table3-9:FiverepresentableresultsofexperimentBonartefactdepositevents(EHE1004_ContextFindDepositionEvent).
Ex. HypothesisB1 [crmeh#EHE1004_ContextFindDepositionEvent]
IF('P25F_moved',‘bowl’)THEN('DC:source','Lincolnshire')Support:<0.001Confidence:1.000Foreverydepositioneventholdsthat,ifitinvolvedmovinga‘bowl’,thenitoriginatesfromreportsonLinconshire.
B2 [crmeh#EHE1004_ContextFindDepositionEvent]IF('P25F_moved','iron’)THEN('P26F_moved_to','internalwell)Support:<0.001Confidence:1.000Foreverydepositioneventholdsthat,ifitinvolvedmoving‘iron’,thenitmovedthatfindtoan‘internalwell’.
B3 [crmeh#EHE1004_ContextFindDepositionEvent]IF('P25F_moved',‘pottery’)THEN('P26F_moved_to','rubbishpit’)Support:<0.001Confidence:1.000Foreverydepositioneventholdsthat,ifitinvolvedmoving‘pottery’,thenitmovedthatfindtoa’rubbishpit’.
B4 [crmeh#EHE1004_ContextFindDepositionEvent]IF('P25F_moved','clay’)THEN('P26F_moved_to',‘greydeposit’)Support:<0.001Confidence:1.000Foreverydepositioneventholdsthat,ifitinvolvedmoving‘clay,thenitmovedthatfindtoa‘greydeposit’.
B5 [crmeh#EHE1004_ContextFindDepositionEvent]IF('P26F_moved_to',‘wall’)THEN('DC:source',‘Headland’)Support:<0.001Confidence:1.000Foreverydepositioneventholdsthat,ifitinvolvedmovinga‘wall’,thenitoriginatesfromreportsonHeadland.
Table 3-9 lists five representable results of experiment B on artefact deposit events(EHE1004_ContextFindDepositionEvent).AsinthesampleofexperimentA,twohypothesesindicateacorrelationbetweenaresourceandthereport inwhich it isdocumented.Here, theseresourcesinvolvemovementoffinds,ratherthantheirtypeofmaterial.Forinstance,hypothesisB1statesthatonly reports on Lincolnshire mention bowls that have been deposited. All remaining hypothesescorrelatethemovingofafindwiththecontextitwasmovedtobymeansofadepositionevent.Forinstance,hypothesisB3statesthatpotterywasfoundmovedtoa‘rubbishpit’.

ARIADNED16.3Public
31
Table3-10:FiverepresentableresultsofexperimentConcontextevents(EHE1001_ContextEvent).
Ex. HypothesisC1 [crmeh#EHE1001_ContextEvent]
IF('DC:source',‘Thames’)THEN('P4F_has_time-span',‘ironage’)Support:<0.001Confidence:1.000 Foreverycontexteventholdsthat,ifitoriginatesfromreportsonThames,thenitdatesfromthe‘ironage’.
C2 [crmeh#EHE1001_ContextEvent]IF('P7F_witnessed','structureX')THEN('P4F_has_time-span','17thcentury')Support:<0.001Confidence:1.000Foreverycontexteventholdsthat,ifitwitnessedcontext‘structureX’,thenitdatesfromthe‘17thcentury’.Here,Xrepresentsaspecificresource.
C3 [crmeh#EHE1001_ContextEvent]IF('P7F_witnessed','enclosureX')THEN('P4F_has_time-span',‘ironage')Support:<0.001Confidence:1.000Foreverycontexteventholdsthat, if itwitnessedcontext ‘enclosureX’, then itdates fromthe ‘ironage’.Here,Xrepresentsaspecificresource.
C4 [crmeh#EHE1001_ContextEvent]IF('P7F_witnessed','townX’)THEN('P4F_has_time-span',‘medieval’)Support:<0.001Confidence:1.000Foreverycontexteventholdsthat,ifitwitnessedcontext‘townX’,thenitdatesfromthe‘medieval’.Here,Xrepresentsaspecificresource.
C5 [crmeh#EHE1001_ContextEvent]IF('P7F_witnessed','streetX')THEN('P4F_has_time-span',‘medieval’)Support:<0.001Confidence:1.000Foreverycontexteventholdsthat, if itwitnessedcontext ‘streetX’, then itdates fromthe ‘17thcentury’.Here,Xrepresentsaspecificresource.
Table 3-10 lists five representable results of experiment C on context events(EHE1001_ContextEvent).Onceagain,wecanobserveahypothesis thatcorrelatesaresourcetoareport.Inthissample,thatresourceinvolvescontextswithtimespans.Forinstance,hypothesisC1

ARIADNED16.3Public
32
states thatall contextsdocumented in reportsonThamesdate fromthe IronAge.The fourotherhypothesescorrelatethefindingofacontextwithacertaintimespan.Forinstance,hypothesisC2statesthatacertainstructuredatesfromthe17thcentury.Notethat,inthissample,contextlacksaspecific context type. Hence, each context instance (variable X) is unique and thus prevents thehypothesisfromgeneralisingtoothercontexts.
Table3-11:FiverepresentableresultsofexperimentDonartefactdepositevents(EHE1002_ContextFindProductionEvent)
Ex. HypothesisD1 [crmeh#EHE1002_ContextFindProductionEvent]
IF('P108F_has_produced','brooches’)THEN('P4F_has_time-span',‘RomanPeriod’)Support:<0.001Confidence:1.000Foreverycontextproductioneventholdsthat,ifithasproduced‘brooches’,thenitdatesfromthe‘RomanPeriod’.
D2 [crmeh#EHE1002_ContextFindProductionEvent]IF('P108F_has_produced','temperedsherds’)THEN('P4F_has_time-span','14thto15thcentury')Support:<0.001Confidence:1.000Foreverycontextproductioneventholdsthat,ifithasproduced‘temperedsherds’,thenitdatesfromthe‘14thto15thcentury’.
D3 [crmeh#EHE1002_ContextFindProductionEvent]IF('P108F_has_produced','brick’)THEN('P4F_has_time-span','modern')Support:<0.001Confidence:1.000Foreverycontextproductioneventholdsthat,ifithasproduced‘bricks’,thenitdatesfrom‘modern’times.
D4 [crmeh#EHE1002_ContextFindProductionEvent]IF('P108F_has_produced','pottery')THEN('P4F_has_time-span','latemedieval')Support:<0.001Confidence:1.000Foreverycontextproductioneventholdsthat,ifithasproduced‘pottery’,thenitdatesfrom‘latemedieval’times.
D5 [crmeh#EHE1002_ContextFindProductionEvent]IF('P108F_has_produced','romanpottery’)THEN('P4F_has_time-span',‘Romanage’)Support:<0.001Confidence:1.000Foreverycontextproductioneventholdsthat,ifithasproduced‘romanpottery’,thenitdatesfrom‘Romanage’.
Table 3-10 lists five representable results of experiment D on artefact deposition events(EHE1002_ContextFindProductionEvent). In contrastwith the results of the other experiments, allgenerated hypotheses are of similar structure. That is, all hypotheses in the sample correlate theproductionof finds toa time span. For instance,hypothesisD2 states that tempered sherdshave

ARIADNED16.3Public
33
beenproducedinthe14thto15thcentury.Notehowever,thattheterm“14thto15thcentury”isseenasdifferent in thedata set from synonyms such as “14th - 15th century” and “14th century to 15thcentury”.
SemanticContentMining
ThissectionwillpresenttheoutputoftheSemanticContentMiningexperimentsdescribedabove.Foreachexperiment,theresultswereorderedonthenormalisedfrequencyoftheirsemantictags.For expositional purposes, these tags were separated into three categories: contexts, finds, andperiods.Furthermore,theresultsforeachofthesethreecategorieshavebeenlimitedtotheirtop-tentags.
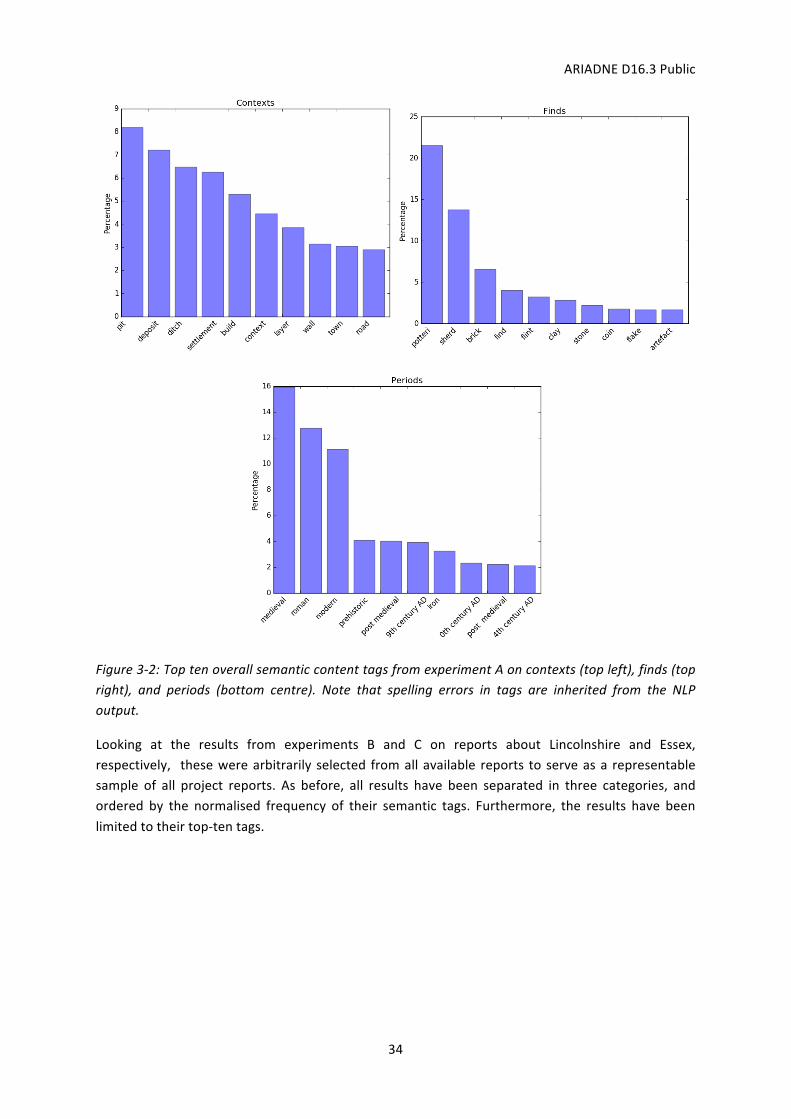
Experiment Amined the aggregated data frommore than 50 reports. The top-ten semantic tagsoccurring in its results are shown in Figure 3-2 for contexts, finds, and periods. In the case ofcontexts, a gradual decrease in percentages can be observed from the most frequent to leastfrequentcontext.Moreover,wecanobservethepercentagerange israther limited, fromthreetoeightpercent.Bothobservationsseemtoindicatethatnoneofthecontextsoccursignificantlymorethanothercontexts.
In thecaseof finds,wecanobserveasteepdecrease inpercentagesover the fourmost-frequenttags.Inthesefoursteps,thepercentagedecreasesfrom22tofourpercent,thuslosingclosetoone-fifthinfrequency.Together,thesetwoobservationsmayindicatethatpottery,sherds,andbrickarementionedfarmorefrequentthanothertypesoffinds.
Finally, in the case of periods, a sudden and strong decreasewas observed after the thirdmost-frequenttag.This isfollowedbyaslowlydecreasingrighttaildistribution.Bothobservationsseemtoindicatethatthethreemost-frequentperiods;medieval,Roman,andmodern,arementionedfarmoreoftenthananyoftheotherperiods.
ARIADNED16.3Public
34
Figure3-2:ToptenoverallsemanticcontenttagsfromexperimentAoncontexts(topleft),finds(topright), and periods (bottom centre). Note that spelling errors in tags are inherited from the NLPoutput.
Looking at the results from experiments B and C on reports about Lincolnshire and Essex,respectively, thesewerearbitrarily selected fromallavailable reports toserveasa representablesample of all project reports. As before, all results have been separated in three categories, andordered by the normalised frequency of their semantic tags. Furthermore, the results have beenlimitedtotheirtop-tentags.

ARIADNED16.3Public
35
Figure3-3:ToptensemanticcontenttagsfromexperimentBoncontexts(topleft),finds(topright),andperiods (bottomcentre) fromLincolnshireproject reports.Note that spellingerrors in tagsareinheritedfromtheNLPoutput.
ExperimentBminedthedatafromareportonLincolnshire.Thetop-tensemantictagsoccurringinitsresultsareshowninFigure3-3forcontexts,finds,andperiods.Inthecaseofcontexts,asteadydecreasecanbeobservedthatislargelysimilartotheresultsfromexperimentA.Thesoleexceptioninvolves‘settlements’,whichoccurthreepercentmorefrequentlythanthesecondcontext‘pit’. Inaddition,theterm‘village’appearstooccurmorefrequentlyinthisreportthanonaverageoverallreports.
Inthecaseoffinds,both‘pottery’and‘sherds’occurconsiderablymorefrequentlythananyoftheotherfinds.Nevertheless,thetopfourmost-frequenttermsfollowtheaveragefinddistributionoverallreports.However,itcanadditionallybeobservedthatthetrendofthedistributionislesssmooththantheaveragedistribution.
Finally, in the case of periods, three periods can be observed –medieval,modern, and Roman –roughly share the position of most-prominent term. These three pose a stark contrast to the

ARIADNED16.3Public
36
remainingperiods,which forma slowlydecreasing right tail.A similar tail canbeobserved in theaveragedistribution.
Figure3-4:ToptensemanticcontenttagsfromexperimentConcontexts(topleft),finds(topright),andperiods(bottomcentre)fromEssexprojectreports.NotethatspellingerrorsintagsareinheritedfromtheNLPoutput.
Experiment Cmined the data from a report on Essex. The top-ten semantic tags occurring in itsresults are shown in Figure3-4 for contexts, finds, andperiods. In the caseof contexts, it canbeobservedthatboth ‘pit’and ‘ditch’are featuredmostprominently in reports fromEssex,whereasthe remainingcontextsoccurconsiderably less frequent followingaslowlydecreasing right tail. Infact,itcanbeobservedthatthepercentagescalehasamaximumvaluethatisseveralpercentageshigher than those in the results of both experiment A and B, hence amplifying the previousobservation.
Inthecaseoffinds,wecanobservethatpotteryoccursconsiderablymorefrequentthananyoftheotherterms.Infact,itoccursalmosttwiceasoftenasonaverageoverallreports.Itcanadditionally

ARIADNED16.3Public
37
beobservedthattheremainingfindsdroprelativelyquicklyintoafrequencypercentageoftwotothreepercent.Thisisroughlysimilartotherighttaildistributionoverallreports
Finally, in the case of periods, it can be observed that ‘medieval’ is by far themost-prominentlyfeaturedterminthereports,withitsvalueexceedingthenumberoneperiodinthedistributionoverallreports.Inaddition,theterms‘postmedieval’occursrelativelyfrequentcomparedtotheresultsofbothexperimentAandB.
3.2.5. Evaluation
Thissectionwill involveanevaluationontheresultsof theexperiments.For thispurpose,wewillfirstdiscussthetaskofHypothesisGeneration,followedbythetaskofSemanticContentMining.
HypothesisGeneration
In total, the combined raw results contained more than ten thousand potential hypotheses.However,noneofthesewereabletopassthecriteriadefinedbythealgorithmicfilter.Specifically,the large majority of the hypotheses describe a pattern of a single resource and its attributes,whereastheremaininghypothesesdescribepatternsthat,whilelarger,werestilltoorare.Analysisindicatedthatthestructure,quality,andsizeofthedatasetisthelikelyreasonfortheunsatisfyingresultsofthisexperiment.
Asdiscussedinsection3.2.1,theOPTIMAdatasetusedintheexperimentsisstructurallyratherflat.This is caused by OPTIMA’s limitations in making inferences that go beyond the local linguisticcontext of a term. Therefore, there is hardly any cross-linking between the annotated conceptsbeyondtheirdirectlyrelatedattributes.Consequently,perprocesseddocument,therearemultiplesmallanddisconnectedgraphs,ratherthanonelargeandstronglyinterconnectedgraph.
Discovering patterns within multiple disconnected graphs proved to be difficult, as there is noexplicitreferencebetweentwoormoregraphsthatindicatetheexistenceofapossiblepattern.Thisproblem is reflected in theresultinghypotheses,whichbarelyspansbeyonddescribinganentity’sownattributes.Asaresult,thesehypothesesareunlikelytodescribepatternsthatareunknownorrelevant todomainexperts.Moreover, it additionally results inhypotheseswith very low supportvalues.Thisgreatlydecreasestheeffectivenessofanyalgorithmicevaluationwhich,inturn,leadstoan explosive increase in the number of generated hypotheses. Often, as was the case in all fourexperiments,thiswillmakemanualevaluationinfeasible.
Thisproblemisfurther increasedbythesuboptimalqualityofthedata,ascausedbythetechnicallimitationsofNLP.Morespecifically,itisverylikelyforthesameconcepttobeannotatedmorethanonceandwithdifferentattributevaluesifthecorrespondingtermismentionedmorethanonceaswell.Moreover, variations on terms (e.g. singular or plural form, quantifiers, and other linguisticconstructs)areseenasentirelydifferentconcepts.EachofthesetermsissubsequentlyassigneditsownURIwithoutreference(e.g.owl:sameAs)asitsencounteredvariation.
Afinalremarkconcernsthedimensionalityofthedataset. Intotal,thedatasetwascomprisedofmorethan50annotatedarchaeologicalreports.Afterconversion,thisresultedinnearlyonemilliontriples describingnearly 21,000 findswith 27,000 contexts.Despite thesenumbers, these entities

ARIADNED16.3Public
38
varied widely, partly due to term inconsistency. Therefore, the pipeline had trouble discoveringpatternsthatcanbegeneralisedovertheentiredata,andinsteadbeganoverfittingthedata.
Toascertaintheusefulnessoftheresultinghypothesesandofthemethodusedtogeneratethem,severaldomainexpertswereaskedtoevaluatetheresultslistedinTable3-8,
Table3-9,
Table 3-10, and Table 3-11 on both their plausibility and their relevancy. The reports on thisevaluationarelistedinAppendixD Expert Evaluation. A shared opinion amongst the evaluationgroupwas that themethodproducedmostlynonsense,and thatnoneof thehypotheseswereofactualuse.Thissupportstheoutcomeofourinitialalgorithmicevaluation,aswellasconfirmingthetheoryabouttheusefulnessofminingcoarse-graineddata.
SemanticContentMining
The results of the experiments on Semantic ContextMining demonstrated a differentmethod ofvisualising the semantics of one or more archaeological reports. Using statistical metrics, it waspossible to compare the differences in connotation between and within the reports. Morespecifically,itwaspossibletoanalysethetermfrequencydistributionoffinds,contexts,andperiods,aswellascomparethemtothoseofotherreports,ortotheglobalaverage.
Whilecontentminingitselfisnotnovel,exploitingsemanticannotationsforthispurposeis,andgivetheaddedpossibilitytoclassifytermsbytheirtypehierarchy,aswellasretrievetermstowhichtheyhavebeen linked.However,any imperfection intheNLPtechniquewillbepresent intheresultingdata.Whenleftuncurated,asisthecaseintheOPTIMAdataset,theseimperfectionsmayresultinincorrect or inaccurate semantic associations. Therefore, drawing conclusions during subsequentanalysismustbehandledwithcare.
Content mining itself has limited use for archaeological research. It can, however, be used tofacilitate more accurate clustering or classifying of reports. This could minimise the time thatresearchershave to spend searching for relevantdocuments. Furthermore, itwould allow for thecategorisation of reports in different types of hierarchies, e.g., by find, context, or period. Yetanotherpossibilityisrankingreportsbasedonhowwelltheircontentsfitsacertaincriterion.
3.3. SIKBDutchArchaeologicalProtocol0102
Inaneffort tostandardiseandsmooth informationexchangebetweendataproducers (excavatingorganisations) and receivers (physical andelectronic depots), theDutch Foundation Infrastructure

ARIADNED16.3Public
39
for Quality Assurance of Soil Management13 (SIKB) has, in strong collaboration with thearchaeological community, and has been developing the Archaeological Protocol 0102. Thisprotocol, often referred to as pakbon (package slip), provides a formalised means to summarisemanyprojectelements–reports,databases,media,findsandtheircontext,etcetera–intoasinglesemi-structured file suitable for automated processing. As such, instances of this protocol offer arichandvariedsourceofarchaeologicalknowledge.
SIKB Protocol 0102 specifies XML as the recommendeddata serialisation format. For instances ofthis protocol tobe applicable to this research, first theprotocol and its already-existing instanceshad tobe translated,and its referenced thesauri transfored intoLinkedData. For this reason, theprotocol’s relatively flat-structured schema has been converted to a more interconnected graphstructurewiththehelpofdomainexperts.Inaddition,referencedthesaurihavebeentranslatedtotheirSKOSequivalent,andaparserhasbeenwrittento facilitateautomaticconversionofexistingprotocol instances.Asetof fortyofthese instanceshavesincebeenconvertedandarehostedviathe ClioPatria triple store14. Note that a full account of this conversion process is documented inAppendixA.
3.3.1. DataDescription
Eachconvertedprotocolinstance,whichwillnowbereferredtoasaninstancegraph,consistsofthecompletecontentsoftheoriginalfile.Assuch,thefollowinghigh-levelgroupscanbedistinguished:
• General information about the entire archaeological project, including people, companiesandorganisationsinvolved,aswellasthegenerallocationwheretheresearchtookplace.
• Finalandintermediatereportsmadeduringtheproject,aswellasdifferentformsofmediasuchasphotos,drawings,andvideostogetherwiththeirmeta-dataand(cross)referencestotheirrespectivefilesandsubjects.
• Detailed information about the finds discovered during the project, as well as their(geospatialandstratigraphic)relationstoeachotherandthearchaeologicalcontextinwhichtheywerefound.
• Accurate information about the locations and geometry where finds were discovered,archaeologicalcontextswereobserved,andmediawascreated.
AsmallexcerpthasbeengiveninExcerpt3-2.ToemphasisethedifferenceinthelevelofknowledgerepresentationwithExcerpt3-1,thefocushasbeenplacedonceagainonanarbitraryfind.Thisfindcanbeseentoholdarelativelylargenumberofattributes,mostofwhichareresourcesthemselves.Twoof these are listed aswell.Directly linked to the find is the groupof findswithwhich itwasdiscovered.Thearchaeologicalcontextinwhichthisdiscoveryhasbeenmadecanbeseenlistedastheformerlocationofsaidgroup,andiscomposedofyetanothercontext.
13StichtingInfrastructuurKwaliteitsborgingBodembeheerinDutch.14Currentlyhostedatpakbon-ld.spider.d2s.labs.vu.nl.

ARIADNED16.3Public
40
Several observations can be made that influence the design of the Data-Mining pipeline. Firstly,manyelementshavebeendefinedusingacustomontologywhichutilisedDutchURIsfollowingtheprotocol’s naming scheme. The resources and properties to which these URIs belong have beendefined as subclasses and subproperties of equivalent CIDOC CRM and CIDOC CRM-EH elements.Thisheritagemayinfluencethenumberofsteps(i.e.triples)requiredtostateafact.Forexample,when using the aforementioned ontologies, four triples are needed to assign a range of periods(“fromP1 toP2”) toa find.Asaresult, ratherthan lookingonestepaheadfordirectattributes,aData-Miningpipelineshouldlookatseveral.
Anothernoteworthycharacteristicof the instance graphs is theirconsiderableportionof free textattributes.Theseattributesinvolvegeneralcomments,descriptions,variousnotes,aswellasnames,labels, and identifiers. A Data-Mining pipeline is, by default, unable to process these textualattributes.Apossiblesolutionistoincorporateamethodtotransformthesetonumericalattributes.However, as including the free-text attributes listed above is unlikely to increase the overallpredictiveperformance,itmightbemoreeffectivetosimplyignorethem.
:contextFind_Aacrmeh:EHE0009_ContextFind;rdfs:label"Vondst(TDS1431:V00960AML)"@nl;:SIKB0102S_aantalnumberOfPartsMeasurement_A;:SIKB0102S_artefacttypeSIKB_Code_Artefacttype_AWG;:SIKB0102S_geconserveerdfalse;:SIKB0102S_gedeselecteerdfalse;:SIKB0102S_gewichtweightMeasurement_A;:SIKB0102S_materiaalcategorieSIKB_Code_Materiaalcategorie_KER;crm:P140i_was_attributed_bydatingEvent_A;crm:P1_is_identified_by"TDS1431:V00960AML"^^xsd:ID;crm:P46i_forms_part_ofbulkFind_X,collection_Y;crm:P48_has_preferred_identifier"contextFind_A"^^xsd:ID.:collection_Yacrm:E78_Collection;rdfs:label"Veldvondst(TDS1431:413)"@nl;:SIKB0102S_verzamelwijzeSIKB_Code_Verzamelwijze_SCHA;crm:P1_is_identified_by"TDS1431:413"^^xsd:ID;crm:P46_is_composed_ofcontextFind_A,contextFind_B;crm:P48_has_preferred_identifier"collection_Y"^^xsd:ID;crm:P53_has_former_or_current_locationcontext_Y.:context_Yacrmeh:EHE0007_Context;rdfs:label"Vondstcontext(typeSPOOR,vanSpoor(TDS1431:762))"@nl;:SIKB0102S_contexttype:SIKB_Code_Contexttype_SPOOR;crm:P48_has_preferred_identifier"context_Y"^^xsd:ID;crm:P53_is_former_or_current_location_ofcollection_Y;crm:P89i_containssubContext_Y.
Excerpt3-2:Smallexampleofacontextfindand(partof)itscontext.Forreadability,bothidentifiersandURIshavebeenreplacedbyhuman-interpretablealternatives.Notethatpropertiesstartingwith“SIKB0102S”aresubpropertiesoftheirCIDOCCRMequivalent.

ARIADNED16.3Public
41
3.3.2. TaskDescription
Recall from Section 1.2 that Hypothesis Generation was chosen as the preferred task for thefollowing experiments. Hypothesis Generation involves detecting interesting and potentiallyrelevant patterns that can be presented to users as starting points for forming new researchhypotheses. The researcher might already have a hypothesis; in which case found patterns maystrengthentheirbelief in thehypothesis.Alternatively, thepatternsmayreveal somethingnewtotheresearcherthattheyareinterestedinexploringfurther.Thesupportandconfidenceofpatternswillbegeneratedalgorithmicallyonthebasisofpredefinedcriteriaanduserfeedback.
3.3.3. ExperimentalDesign
Thetaskdiscussedabovewillbeinvestigatedusingmultipleexperiments.Eachexperimentwilltestvarioussetsofconstraintsondifferentsubsetsof theentiredatacloud.Toacquire thesesubsets,archaeological topics of interest will be translated into SPARQL queries. These queries willsubsequentlysenttotheendpointofthedatacloud.Togetherwiththeremainingconstraints,thesubsetofdatawillbeofferedasinputtothepipelinedescribedinAppendixB.NotethattheresultsandevaluationofthisspecificcasewillbeprovidedinSection3.3.4and3.3.5,respectively.
The following experiments will involve the generation of hypotheses using ARM. Each of theexperiment’srunswilluseasubsetofthedataclouddescribedinSection3.3.1.Textualdescriptionsof these subset’s criteriaareprovided inTable3-12,aswellasadditional constraints.Note thatadetailedexplanationofhowthesecriteriacomeintoplayhasbeendocumentedinAppendixB.
Table3-12:ConfigurationsoftheHypothesisGenerationExperimentID
DatasetSelectionCriteria
Variation
SamplingMethod Generalization
Factor
A15 Allfactsrelatedtoarchaeologicalcontexts(EHE0007_Context).
1 L.Neighbourhood(depth=2) 0.6
2 L.Neighbourhood(depth=2) 0.9
3 L.Neighbourhood(depth=3) 0.6
4 L.Neighbourhood(depth=3) 0.9
B Allfactsrelatedtoarchaeologicalcuts(EHE0007_ContextwithcontexttypeCut)
1 ContextSpecificationB† 0.1
2 ContextSpecificationB† 0.6
3 ContextSpecificationB† 0.9
C Allfactsrelatedtoartefacts(EHE0009_ContextFind)
1 ContextSpecificationC‡ 0.1
2 ContextSpecificationC‡ 0.6
15ExperimentAistheonlyexperimentinwhichLocal-Neighbourhoodsamplingwillbeusedbecauseitsdataset selection criterion for archaeological contexts (EHE0007_Context) includes several subclasses, eachwithverydifferentattributesets.Hence,nosinglecontextdefinitionwouldsuffice.

ARIADNED16.3Public
42
3 ContextSpecificationC‡ 0.9
D Allfactsrelatedtoarchaeologicalprojects(EHE0001_EHProject)
1 ContextSpecificationD• 0.1
2 ContextSpecificationD• 0.6
3 ContextSpecificationD• 0.9
ThenextthreetablesdenotethecontextdefinitionsusedbyexperimentB,C,andD.Thesedefinitionsdescribeoneormorepredicatepathsthatconstituteanindividual’scontext.Assuch,theycontributerelevantinformationtoanindividualwhichweexploitinourpipeline.Forinstance,thecontextdefinitionlistedinTable3-13willresultinindividualsofclassEHE0007_Contextwitheachhavingasmanyattributesastherearerows(i.e.12).Thecorrespondingattributevalueswillberetrievedbyrequestingthevaluesattheendofthedefinedpredicatepaths.Notethatthesecontextdefinitionswerecreatedwiththehelpofdomainexperts.
Table3-13:ContextdefinitionforinstancesoftypeEHE0007_Context,asusedinexperimentB.
ID PredicatePath1 http://pakbon-ld.spider.d2s.labs.vu.nl/ont/SIKB0102S_grondspoortype2 http://www.cidoc-crm.org/cidoc-crm/P53i_is_former_or_current_location_of3 http://www.cidoc-crm.org/cidoc-crm/P89_falls_within,
http://pakbon-ld.spider.d2s.labs.vu.nl/ont/SIKB0102S_contexttype4 http://purl.org/crmeh#EHP3i,
http://pakbon-ld.spider.d2s.labs.vu.nl/ont/SIKB0102S_kleur5 http://purl.org/crmeh#EHP3i,
http://pakbon-ld.spider.d2s.labs.vu.nl/ont/SIKB0102S_textuur6 http://www.cidoc-crm.org/cidoc-crm/P53i_is_former_or_current_location_of,
http://pakbon-ld.spider.d2s.labs.vu.nl/ont/SIKB0102S_structuurtype7 http://pakbon-ld.spider.d2s.labs.vu.nl/ont/SIKB0102S_diepte,
http://www.cidoc-crm.org/cidoc-crm/P40_observed_dimension,http://www.cidoc-crm.org/cidoc-crm/P90_has_value
8 http://pakbon-ld.spider.d2s.labs.vu.nl/ont/SIKB0102S_diepte,http://www.cidoc-crm.org/cidoc-crm/P40_observed_dimension,http://www.cidoc-crm.org/cidoc-crm/P91_has_unit
9 http://www.cidoc-crm.org/cidoc-crm/P140i_was_attributed_by,http://www.cidoc-crm.org/cidoc-crm/P141_assigned,http://pakbon-ld.spider.d2s.labs.vu.nl/ont/SIKB0102S_beginperiode
10 http://www.cidoc-crm.org/cidoc-crm/P140i_was_attributed_by,http://www.cidoc-crm.org/cidoc-crm/P141_assigned,http://pakbon-ld.spider.d2s.labs.vu.nl/ont/SIKB0102S_eindperiode
11 http://www.cidoc-crm.org/cidoc-crm/P53i_is_former_or_current_location_of,http://www.cidoc-crm.org/cidoc-crm/P140i_was_attributed_by,http://www.cidoc-crm.org/cidoc-crm/P141_assigned,http://pakbon-ld.spider.d2s.labs.vu.nl/ont/SIKB0102S_beginperiode
12 http://www.cidoc-crm.org/cidoc-crm/P53i_is_former_or_current_location_of,http://www.cidoc-crm.org/cidoc-crm/P140i_was_attributed_by,http://www.cidoc-crm.org/cidoc-crm/P141_assigned,http://pakbon-ld.spider.d2s.labs.vu.nl/ont/SIKB0102S_eindperiode
Legend
ID Identifierofexperiment.Thisistiedtotheselectedsubset.Variation Variationonexperimentwithadifferentsetofconstraints.DatasetSelectionCriteria Criteriausedtogenerateasubsetoftheentiredatacloud.SamplingMethod Methodtosampleindividualswithinthesubset.GeneralisationFactor Howwellrulesgeneralise.Highervaluesimplylessgeneralisation.
ARIADNED16.3Public
43
Table3-14:ContextdefinitionforinstancesoftypeEHE0009_ContextFind,asusedinexperimentC.
ID PredicatePath1 http://pakbon-ld.spider.d2s.labs.vu.nl/ont/SIKB0102S_artefacttype2 http://pakbon-ld.spider.d2s.labs.vu.nl/ont/SIKB0102S_exposabel3 http://pakbon-ld.spider.d2s.labs.vu.nl/ont/SIKB0102S_geconserveerd4 http://pakbon-ld.spider.d2s.labs.vu.nl/ont/SIKB0102S_gedeselecteerd5 http://pakbon-ld.spider.d2s.labs.vu.nl/ont/SIKB0102S_materiaalcategorie6 http://www.cidoc-crm.org/cidoc-crm/P3_has_note7 http://pakbon-ld.spider.d2s.labs.vu.nl/ont/SIKB0102S_gewicht,
http://www.cidoc-crm.org/cidoc-crm/P90_has_value8 http://pakbon-ld.spider.d2s.labs.vu.nl/ont/SIKB0102S_gewicht,
http://www.cidoc-crm.org/cidoc-crm/P91_has_unit9 http://pakbon-ld.spider.d2s.labs.vu.nl/ont/SIKB0102S_aantal,
http://www.cidoc-crm.org/cidoc-crm/P90_has_value10 http://pakbon-ld.spider.d2s.labs.vu.nl/ont/SIKB0102S_aantal,
http://www.cidoc-crm.org/cidoc-crm/P91_has_unit11 http://www.cidoc-crm.org/cidoc-crm/P46i_forms_part_of,
http://pakbon-ld.spider.d2s.labs.vu.nl/ont/SIKB0102S_verzamelwijze12 http://www.cidoc-crm.org/cidoc-crm/P140i_was_attributed_by,
http://www.cidoc-crm.org/cidoc-crm/P141_assigned,http://pakbon-ld.spider.d2s.labs.vu.nl/ont/SIKB0102S_beginperiode
13 http://www.cidoc-crm.org/cidoc-crm/P140i_was_attributed_by,http://www.cidoc-crm.org/cidoc-crm/P141_assigned,http://pakbon-ld.spider.d2s.labs.vu.nl/ont/SIKB0102S_eindperiode
14 http://www.cidoc-crm.org/cidoc-crm/P46i_forms_part_of,http://www.cidoc-crm.org/cidoc-crm/P46i_forms_part_of,http://pakbon-ld.spider.d2s.labs.vu.nl/ont/SIKB0102S_bewaarTemperatuur
15 http://www.cidoc-crm.org/cidoc-crm/P46i_forms_part_of,http://www.cidoc-crm.org/cidoc-crm/P46i_forms_part_of,http://pakbon-ld.spider.d2s.labs.vu.nl/ont/SIKB0102S_bewaarVochtigheid
16 http://www.cidoc-crm.org/cidoc-crm/P46i_forms_part_of,http://www.cidoc-crm.org/cidoc-crm/P46i_forms_part_of,http://pakbon-ld.spider.d2s.labs.vu.nl/ont/SIKB0102S_breekbaar
17 http://www.cidoc-crm.org/cidoc-crm/P46i_forms_part_of,http://www.cidoc-crm.org/cidoc-crm/P46i_forms_part_of,http://pakbon-ld.spider.d2s.labs.vu.nl/ont/SIKB0102S_lichtgevoelig

ARIADNED16.3Public
44
Table3-15:ContextdefinitionforinstancesoftypeEHE0001_EHProject,asusedinexperimentD.
ID PredicatePath1 http://pakbon-ld.spider.d2s.labs.vu.nl/ont/SIKB0102S_onderzoektype2 http://www.cidoc-crm.org/cidoc-crm/P7_took_place_at,
http://pakbon-ld.spider.d2s.labs.vu.nl/ont/SIKB0102S_gemeentecode3 http://www.cidoc-crm.org/cidoc-crm/P7_took_place_at,
http://pakbon-ld.spider.d2s.labs.vu.nl/ont/SIKB0102S_plaatscode4 http://www.cidoc-crm.org/cidoc-crm/P7_took_place_at,
http://pakbon-ld.spider.d2s.labs.vu.nl/ont/SIKB0102S_provinciecode5 http://www.cidoc-crm.org/cidoc-crm/P7_took_place_at,
http://pakbon-ld.spider.d2s.labs.vu.nl/ont/SIKB0102S_toponiem6 http://www.cidoc-crm.org/cidoc-crm/P7_took_place_at,
http://pakbon-ld.spider.d2s.labs.vu.nl/ont/SIKB0102S_vindplaatstype7 http://www.cidoc-crm.org/cidoc-crm/P7_took_place_at,
http://www.cidoc-crm.org/cidoc-crm/P4_has_time-span,http://pakbon-ld.spider.d2s.labs.vu.nl/ont/SIKB0102S_beginperiode
8 http://www.cidoc-crm.org/cidoc-crm/P7_took_place_at,http://www.cidoc-crm.org/cidoc-crm/P4_has_time-span,http://pakbon-ld.spider.d2s.labs.vu.nl/ont/SIKB0102S_eindperiode
9 http://www.cidoc-crm.org/cidoc-crm/P9_consists_of,http://www.cidoc-crm.org/cidoc-crm/P108_has_produced,http://www.cidoc-crm.org/cidoc-crm/P46_is_composed_of,http://www.cidoc-crm.org/cidoc-crm/P46_is_composed_of,http://pakbon-ld.spider.d2s.labs.vu.nl/ont/SIKB0102S_artefacttype
10 http://www.cidoc-crm.org/cidoc-crm/P9_consists_of,http://www.cidoc-crm.org/cidoc-crm/P108_has_produced,http://www.cidoc-crm.org/cidoc-crm/P46_is_composed_of,http://www.cidoc-crm.org/cidoc-crm/P46_is_composed_of,http://pakbon-ld.spider.d2s.labs.vu.nl/ont/SIKB0102S_materiaalcategorie
11 http://www.cidoc-crm.org/cidoc-crm/P9_consists_of,http://www.cidoc-crm.org/cidoc-crm/P108_has_produced,http://www.cidoc-crm.org/cidoc-crm/P46_is_composed_of,http://www.cidoc-crm.org/cidoc-crm/P46_is_composed_of,http://www.cidoc-crm.org/cidoc-crm/P46i_forms_part_of,http://pakbon-ld.spider.d2s.labs.vu.nl/ont/SIKB0102S_verzamelwijze
12 http://www.cidoc-crm.org/cidoc-crm/P9_consists_of,http://www.cidoc-crm.org/cidoc-crm/P108_has_produced,http://www.cidoc-crm.org/cidoc-crm/P46_is_composed_of,http://www.cidoc-crm.org/cidoc-crm/P46_is_composed_of,http://www.cidoc-crm.org/cidoc-crm/P46i_forms_part_of,http://www.cidoc-crm.org/cidoc-crm/P53_has_former_or_current_location,http://pakbon-ld.spider.d2s.labs.vu.nl/ont/SIKB0102S_contexttype
3.3.4. Results
Thissectionwillpresenttheoutputoftheexperimentsdescribedabove.Intotal,thecombinedrawresults hold more than hundred thousand potential hypotheses. To reduce this to a more-manageablenumber,therawresultswerefirstpassedthroughanalgorithmicfilter.Thisfilter(Table3-16) applies ‘common sense’ heuristics to narrow the results. For instance, hypotheses withminimalsupportapplyonlytoasingleresourceandarethereforeunsuitableforgeneralisationoverother resources. In addition, hypotheses with amaximum confidence apply to all resources of acertain type, and can thus be regarded as trivial. Omitting these hypotheses will thus lead to acleanerresultwithlessnoise.

ARIADNED16.3Public
45
Table3-16:Tablelistingtheconditionsusedtofiltertherawoutputoftheexperiments.
FILTER Condition1 Hypothesismustnotbetoocommon,orelseitdescribescommonknowledgethatdoesnotcontributetotheentity’s
semantics.Valuedependsonclassfrequencyindataset.2 Hypothesismustnotbetoorare,orelseitdescribesapeculiarityofafewdistinctcases.Valuedependsonclassfrequencyin
dataset.3 Hypothesismustnotholdforonlyasingleentity,orelseitdescribesauniquecharacteristicofthatentity.Valuedependson
classfrequencyindataset.4 Hypothesismustnotbeaboutanyofthefollowingirrelevantproperties:
- RDFlabel- OWLsameAs- SKOSprefLabel- SKOSnote- SKOSscopeNote- SKOSinScheme- SKOStopConceptOf- DCTERMSissued- DCTERMSmedium- PRISMversionIndentifier- CIDOCCRMpreferred_identifier- CIDOCCRMidentified_by- CIDOCCRMnote- CIDOCCRMdocuments- GEOSPARQLasGML
Afirstpassthroughthealgorithmicfilterreducedthenumberofpotentialhypothesestoseveralthousands.Foreveryhypothesis,bothits(relative)supportand(relative)confidencewascalculated.Thesemetricswereusedtorankthehypothesesbyquantitativerelevancyforeachofthefourexperiments:A,B,C,andD.Wehavesemi-randomlysampledfivehypothesesfromthetophundredhypothesesforexpositionalpurposes.ThesehypothesesarelistedintablesTable3-17,Table3-18,Table3-19,andTable3-20forexperimentsAthroughD,respectively.Allsamplehypotheseshavebeenmanuallytranscribedtofacilitateeasyinterpretation.
Table3-17:FiverepresentableresultsofexperimentAonarchaeologicalcontexts(EHE0007_Context).
Ex. Hypothesis
A1[crmeh#EHE0008_ContextStuff]IF(SIKB0102S_kleur,'lichtgeel')THEN(SIKB0102S_grondspoortype,SIKB_Code_Grondspoortype_GRAF.DIER)Support:0.001Confidence:1.000Foreverycontextstuffholdsthat,iftheyhaveabrightyellowcolour,thentheyareofspecifictypeANIMALGRAVE.
A2[crmeh#EHE0004_SiteSubDivision]IF(SIKB0102S_vindplaatstype,SIKB_Code_Complextype_NBAS)THEN(P4_has_time-span,"Tijdspanne(vanperiodeNEOVtotperiodeNTL)")Support:0.077Confidence:1.000Foreverysiteholdsthat,iftheyareofspecifictypeBASECAMP,thentheyaredatedfromtheNEOVtoNTLperiod.
A3[crmeh#EHE0004_SiteSubDivision]IF(SIKB0102S_vindplaatstype,SIKB_Code_Complextype_GVX)THEN(P4_has_time-span,"Tijdspanne(vanperiodeROMtotperiodeNT)”)Support:0.077Confidence:1.000

ARIADNED16.3Public
46
Foreverysiteholdsthat,iftheyareofspecifictypeGRAVEYARD,thentheyaredatedfromtheROMtoNTperiod.
A4[crmeh#EHE0004_SiteSubDivision]IF(SIKB0102S_vindplaatstype,SIKB_Code_Complextype_EIVB)THEN(P4_has_time-span,"Tijdspanne(vanperiodeMESOtotperiodeNEO)”)Support:0.077Confidence:1.000Foreverysiteholdsthat,iftheyareofspecifictypeFLINTCARVING,thentheyaredatedfromtheMESOtoNEOperiod.
A5[crmeh#EHE0004_SiteSubDivision]IF(SIKB0102S_vindplaatstype,SIKB_Code_Complextype_GVC)THEN(P4_has_time-span,"Tijdspanne(vanperiodeBRONSMtotperiodeIJZL)”)Support:0.077Confidence:1.000Foreverysiteholdsthat,iftheyareofspecifictypeCREMATION,thentheyaredatedfromtheMIDDLEBRONStoIRONperiod.
Table 3-1 lists five representable results of experiment A on all types of archaeological contexts(EHE0007_Context). Interestingly, none of the generated hypotheses apply to this class itself, butrather to a subclasses thereof. This is caused by the chosen sampling method (i.e. localneighbourhood). Irrespectiveofthis,onlyoneofthepotentialhypothesesappliestocontextstuff.Specifically,itpositivelycorrelatesthecolourofthestuffwiththepurposeofthecontext’scontents.Thelowsupportofthishypothesisseemstoindicatethatthispatternhasonlybeenfoundtoholdinfrequently.
Additionally,allfourremaininghypothesesareofsimilarform.Thatis,eachonecorrelateswiththecategory of the site where the context was found to the likely time span of that context. Forinstance,hypothesisA4statesthatsitesatwhichflintcarvingsoccurredlikelydatetotheMesolithicto Neolithic period. Finally, note that each support has the same value. This may indicate thatcertainclustersinthedatasetexistwhereallcontextsareoffromthesamelocation.
Table3-18:FiverepresentableresultsofexperimentBonarchaeologicalfinds(EHE0009_ContextFinds).
Ex. HypothesisB1 [crmeh#EHE0009_ContextFind]
IF(SIKB0102S_artefacttype,SIKB_Code_Artefacttype_HOUTSKL')THEN(SIKB0102S_materiaalcategorie,SIKB_Code_Materiaalcategorie_OPHK')Support:0.009Confidence:0.958Foreveryfindholdsthat,iftheyareofspecifictypeCHARCOAL,thentheyareofmaterialtypeCHARCOAL.
B2 [crmeh#EHE0009_ContextFind]IF(SIKB0102S_materiaalcategorie,SIKB_Code_Materiaalcategorie_STU')THEN(P4_has_time-span,"Tijdspanne(vanperiodePALEOVtotperiodeNTL)"@nl)Support:<0.001Confidence:1.000Foreveryfindholdsthat,iftheyareofspecifictypeTUFF,thentheyaredatedfromEARLYPALEOtoLATENT.
B3 [crmeh#EHE0009_ContextFind]IF(SIKB0102S_artefacttype,SIKB_Code_Artefacttype_RUWNIJM')THEN(P4_has_time-span,"Tijdspanne(vanperiodeROMVtotperiodeROML)"@nl)Support:0.002Confidence:1.000Foreveryfindholdsthat,iftheyareofspecifictypeRAWEARTHENWARE(Nimeguen),thentheyaredatedfromEARLYROMANtoLATEROMAN.

ARIADNED16.3Public
47
B4 [crmeh#EHE0009_ContextFind]IF(P4_has_time-span,"Tijdspanne(vanperiodeNEOMtotperiodeNEOL)"@nl)THEN(SIKB0102S_materiaalcategorie,SIKB_Code_Materiaalcategorie_SDI')AND(SIKB0102S_artefacttype,SIKB_Code_Artefacttype_HAMERBL')Support:0.001Confidence:1.000 Forevery findholds that, if theyaredated fromMIDDLENEO toLATENEO, then theyareof specific typeHAMMERAXEandofmaterialtypeDOLERITE.
B5 [crmeh#EHE0009_ContextFind]IF(SIKB0102S_artefacttype,SIKB_Code_Artefacttype_DISSEL')THEN(P4_has_time-span,"Tijdspanne(vanperiodeNEOtotperiodeBRONS)"@nl)Support:0.001Confidence:1.000Foreveryfindholdsthat,iftheyareofspecifictypeADZE,thentheyaredatedfromNEOtoBRONS.
Table 3-18 lists five representable results of experiment B on archaeological finds(EHE0009_ContextFinds).Threehypothesescorrelatethecategoricalormaterialtypeofafindtothetimespanitdatesto.Forinstance,hypothesisB3statesthatrawNimegeunearthenwarelikelydatessomewhere between early and late roman times. The two remaining hypotheses correlate thecategoryofafindtoitsmaterial.Itisnoteworthytoobservethat,ifwefocuspurelyontheirform,thesehypotheses–B1andB4–aretheinverseofeachother.Thatis,B1appliestofindsofacertaincategory,whereasB4appliestofindsofacertainmaterial.
Table3-19:FiverepresentableresultsofexperimentConarchaeologicalcuts(EHE0007_Context).
Ex. HypothesisC1 [crmeh#EHE0007_Context]
IF(SIKB0102S_grondspoortype,SIKB_Code_Grondspoortype_HUTKOM') THEN(P4_has_time-span,"Tijdspanne(vanperiodeROMtotperiodeMEV)"@nl) AND(SIKB0102S_structuurtype,SIKB_Code_Structuurtype_PLATTEGR')Support:0.001Confidence:1.000Foreverycontextholdsthat,iftheyareofspecifictypeDWELLING,thentheyaredatedfromROMANtoMIDDLEDARKAGES,andhavestructureFLOORPLAN.
C2 [crmeh#EHE0007_Context]IF(SIKB0102S_grondspoortype,SIKB_Code_Grondspoortype_GREPPEL.HUISGREP') THEN(P4_has_time-span,"Tijdspanne(vanperiodeIJZVtotperiodeIJZV)"@nl) AND(SIKB0102S_structuurtype,SIKB_Code_Structuurtype_HUIS')Support:0.001Confidence:1.000Foreverycontextholdsthat,iftheyareofspecifictypeHOUSEDITCH,thentheyaredatedfromEARLYIRONAGE,andhavestructureHOUSE.
C3 [crmeh#EHE0007_Context]IF(SIKB0102S_grondspoortype,SIKB_Code_Grondspoortype_WATERPUT') THEN(P4_has_time-span,"Tijdspanne(vanperiodeBRONStotperiodeIJZ)"@nl) AND(SIKB0102S_structuurtype,SIKB_Code_Structuurtype_WATERPUT')Support:0.001Confidence:1.000Foreverycontextholdsthat,iftheyareofspecifictypeWELL,thentheyaredatedfromBRONStoIRONAGE,andhavestructureWELL.
C4 [crmeh#EHE0007_Context]IF(SIKB0102S_grondspoortype,SIKB_Code_Grondspoortype_GRAF.INHUMGRF) THEN(P4_has_time-span,"Tijdspanne(vanperiodePREHtotperiodePREH)"@nl) AND(SIKB0102S_structuurtype,rdflib.term.URIRef('SIKB_Code_Structuurtype_GRAF)Support:0.001

ARIADNED16.3Public
48
Confidence:1.000Foreverycontextholdsthat,iftheyareofspecifictypeBURIAL,thentheyaredatedfromPREH,andhavestructureGRAVE.
C5 [crmeh#EHE0007_Context]IF (SIKB0102S_diepte,"21cm") AND(P4_has_time-span,"Tijdspanne(vanperiodePREHtotperiodePREH)"@nl) THEN(SIKB0102S_grondspoortype,SIKB_Code_Grondspoortype_GREPPEL.STANDGRP')Support:<0.001Confidence:1.000Foreverycontextholdsthat,iftheyare21cmdeep,thentheyaredatedfromPREH,andhavespecifictypeDITCH.
Table 3-19 lists five representable results of experiment C on archaeological cuts(EHE0007_Context).Incontrasttotheresultsfromallotherexperiments,thegeneratedhypothesescontainanadditionalelement ineithertheirantecedent(C5)ortheirconsequent(C1throughC4).Thisislikelytheresultofhavingthesamesupportandconfidenceastheirfragments–ifA→B&Cholds,thenitsfragmentsA→BandA→Choldaswell–butarefavouredbythealgorithmicfilterduetotheirbroaderapplicability.
Four of the generated hypotheses correlate the type of cut of a certain context to its type ofstructure and its likely time span. For instance, hypothesis C1 states that floor plans of dwellingslikelydate somewherebetweenRoman timesandmiddleDarkages.WecanadditionallyobservethathypothesisC5 correlatesa certaindepthand likely time spanofa context to the categoryofthatcontext.Itisnoteworthytoremarkthefixedvaluefordepthof“21cm”asantecedent.Asthecurrent method used to generate hypotheses is unable to compare literals, it is also unable todifferentiatebetweencloselyrelatedliterals.Hence,avalueof“21”isseenasdifferentfrom“20”asitisfrom“100”,“1000”,andevenfromnon-numericalliteralssuchas“posthole”.
Table3-20:FiverepresentableresultsofexperimentDonarchaeologicalProjects(EHE0001_EHProject).
Ex. HypothesisD1 [crmeh#EHE0001_EHProject]
IF(SIKB0102S_onderzoektype,SIKB_Code_Verwerving_AOP)THEN(SIKB0102S_vindplaatstype,SIKB_Code_Complextype_BEWV.X)Support:0.014Confidence:1.000Foreveryprojectsholdsthat, iftheyareofspecifictype‘destructiveexcavation’,thentheyhavelocationtype‘settlementwithdefences’.
D2 [crmeh#EHE0001_EHProject]IF(SIKB0102S_onderzoektype,SIKB_Code_Verwerving_AVE)THEN(SIKB0102S_vindplaatstype,SIKB_Code_Complextype_BEWV.X)Support:0.014Confidence:1.000Foreveryprojectholds that, if theyareof specific type ‘destructivemapping’, then theyareof location type ‘settlementwithdefences’.
D3 [crmeh#EHE0001_EHProject]IF(P7_took_place_at,locationX)THEN(P7_took_place_at,locationY)Support:0.029Confidence:0.500Foreveryprojectholdsthat,iftheytookplaceatlocationX,thentheyalsotooplaceatlocationY.Here,XandYarevariablesandYlieswithinX.

ARIADNED16.3Public
49
D4 [crmeh#EHE0001_EHProject]IF(SIKB0102S_onderzoektype,typeX)THEN(P9_consists_of,documentY)Support:0.043Confidence:0.333Foreveryprojectholdsthat,iftheyareofspecifictypeX,thenisconsistsof(documentation)Y.Here,XandYarevariables.
D5 [crmeh#EHE0001_EHProject]IF(P9_consists_of,documentX)THEN(P9_consists_of,containerY)Support:0.014Confidence:1.000Foreveryprojectholdsthat,iftheyaredocumentedindocumentX,thentheyconsistofcontainerY.Here,XandYarevariables.
Table 3-20 lists five representable results of experiment D on archaeological projects(EHE0001_EHProject).Twoofthesehypotheses–D1andD2–correlatethetypeofprojecttothetype of its location. For instance, hypothesis D1 states that destructive excavations occur atsettlements with defences. It is unlikely that this hypothesis can be generalised over other, yetunseen,datasets.Thisisalsoindicatedbythelowsupportithas,andisprobablycausedbyseveralprotocolinstancesdocumentingdifferentfacetsofthesameproject.
The three remaininghypothesescanbebestviewedas templatesofpossiblehypotheses.For thispurpose, individual URIswith variablesX and Y have been replaced. For instance, hypotheses D3states that projects occurring at a certain location (i.e. area) has sites within that location. Notehowever,thatthishypothesishasaconfidenceof0.5,thusindicatingitwasfoundtobetrueinhalfthecases.Similarly,hypothesisD4wasfoundtobetrueinonlyonethirdofthecases.
3.3.5. Evaluation
In its entirety, the combined raw results contained more than a hundred thousand potentialhypotheses.Wewereabletobringthisdowntoseveralthousandsbypassingtheseresultsthroughanalgorithmicfilter.Theremaininghypothesesweresubsequentlyassignedsupportandconfidencevalues. These valueswereused to rank thehypothesesbyquantitative relevancy, afterwhichwesemi-randomlysampledfivehypothesesfromthetophundredforeachofthefourexperiments.
Overall,itwasobservedthatthegeneratedhypotheseswereabletocorrectlyreflectpatternswithinthe data set. However, the relevancy of these patterns, aswell as their ability to generalise, hasprovendifficult todeterminewithoutmanualevaluation.Sifting throughcandidatehypothesesbyhandtakesconsiderabletime,andthemetrics,thepurposeofwhichistoguidethisprocessmoreintelligently, were found to be inadequate. More specifically, both confidence and support arestrongly influenced by the size, variety, and quirks of a data set. For instance, the uniqueness ofentitiesinLinkedDatacanquicklyleadtohighconfidenceandlowsupport.
Fromadataperspective,weobserveddifficultieswithboththeinstanceandontologygraph.Inthecase of the latter, it appears that the path length between related entities makes it difficult todiscoverover.ThisislargelyacharacteristicinheritedfromtheCIDOCCRMontology,whichisknownfor its verbosity. Regardless, shorter paths (i.e. more local patterns) were computationally lesscostly,andwere thereforepreferredby themethodemployed. Lookingat the instancegraph,wecouldobserve that commonandomnipresentattributes clutter results. In this case, LinkedData’s

ARIADNED16.3Public
50
characteristicofreusingpropertiesamplifiedthis issue. Inaddition,manyofthe interestingvaluesfor these properties consisted of textual or numerical literals. As the method used to generatehypotheseswasunabletocompareliterals,itisalsounabletodifferentiatebetweencloselyrelatedliterals.Thisbecameespeciallyapparentincasesofgeometries(WKTliteral)andmetrics.
Toascertain theusefulnessof the resultinghypothesesandof themethod thathasbeenused togeneratethem,wehaveaskedseveraldomainexpertstoevaluatetheresults listed inTable3-17,Table3-18,Table3-19,andTable3-20onboththeirplausibilityandtheirrelevancy.ThereportsonthisevaluationarelistedinAppendixD Expert Evaluation. A shared opinion amongst theevaluation group was that the method produced mostly plausible hypotheses, with a handfulpotentiallybeingof actualuse. Themain criticismwas that fewhypotheses yieldednovel insightsintothedataorweregeneralisabletootherdatasets. Insteadmosthypotheseswerefoundtobeeithertrivial,tautologies,orspecifictoasingleprojectorarea.Nevertheless,allexpertswereoftheopinionthatthemethodyieldedpromise,andthat,withsufficientimprovements,itmayeventuallyresultinatoolthatisofactualusetothearchaeologicalcommunity.

ARIADNED16.3Public
51
4. ConclusionThis work set out to investigate the technical feasibility and practical usability of therecommendations made at the end of deliverable D16.1: First Report on Data Mining. For thepurpose of this report, efforts were focussed primarily on one of these recommendations,specifically Hypothesis Generation, due to this task’s novelty and potential usefulness to thearchaeologicalcommunity.Asthistaskwasnotfoundsuitableforalldatasets,moretraditionaldataminingmethodswere additionally applied aswell. These involved 1) Semantic ContentMining todetermine and compare project connotations, 2) relationship discovery among the authors ofOpenAIREandARIADNEReports,3)thecreationandanalysisofARIADNE’sauthornetworks,and4)performing textmining on OpenAIRE publications to link themwith ARIADNEmetadata or otherextractedobjectsfromtheARIADNEreports.
To increase the scope of our work in this task, three separate case studies in Data Mining onarchaeologicaldatawereconducted.Theseare1)datafromtheARIADNERegistry,2)greyliteraturethat has been semantically-annotated using the OPTIMA text-mining pipeline, and 3) rich LinkedData database extractions that follow the SIKB Protocol 0102 specification. Each of these threestudies has a different granularity of knowledge.More fine-grained data sets havemore specificinformation about archaeological findings and their contexts, whereas more coarse-grained datasetsdescribeinformationatahigherlevel.
Overall, the combined resultsof all three case studies canbe seenas amildlypromising forDataMining for Linked Archaeological Data. From the results of the ARIADNE Registry case study, themost encouraging were the citation links found in ADS grey literature reports to PubMed/ePCMpublicationsinOpenAIRE.Evaluationoftheselinksbyadomainexpertindicatedthataconsiderablenumberofthemwereindeedrelevant.Notethattheselinkscoveredvarioustopics,includingtopicsofthebroaderarchaeologicalfieldsuchasanthropology,biology,paleontology,pottery,aswellasoutsidetheUK,e.g.Oceania.
From the results of the case studies on both semantically-annotated reports (OPTIMA) and richLinked Data database extractions (SIKB Protocol 0102), the generated hypotheses were able tocorrectly reflectpatternswithinthedataset.However, therelevancyof thesepatterns,aswellastheirabilitytogeneralise,hasproventobeverydependentonboththestructureandqualityofthedataset.IntheOPTIMAcasestudy,thedatasetwasofinsufficientquality(uncuratedNLPoutput)and structurally flat. Therefore, the generated hypotheses barely spanned beyond describing anentity’sownattributesand,consequently,werefoundtobeoflittleusetoourevaluationgroup.Incontrast,asharedopinionamongsttheevaluationgroupwasthattheresultsof theSIKBProtocolcase study were nearly all plausible, with only a handful potentially being of actual use. This, incombination with the results from the OPTIMA case study, supports the initial theory about theinfluenceofadataset’sgranularityofknowledgeontheusefulnessofpatternmining.
TherearenumerouschallengesstilltoovercomeforHypothesisGenerationtomatureandbeofusetothearchaeologicalcommunity.Forinstance,siftingthroughcandidatehypothesesbyhandtakesconsiderabletime,andthemetrics,thepurposeofwhichistoguidethisprocessmoreintelligently,

ARIADNED16.3Public
52
were found tobe inadequate.Moreover, themain criticism from theevaluationgroupconcernedthefactthatfewhypothesesyieldednovelinsightsintothedataorweregeneralisabletootherdatasets. Insteadmost hypotheses were found to be either trivial, tautologies, or specific to a singleproject. Nevertheless, all expertswere responded positively to the range of patterns themethodwasabletogenerate.
At present, Data Mining for Linked Data still has a long way to go before it will transcend theacademic stadium. Eventually, with sufficient improvements, continuing researchmay result in atoolthatisofactualusetothearchaeologicalcommunity.Untilthattimearrives,itmaybebesttoemploytraditionalDataMiningtechniquesthathavematuredoverseveraldecades,andwhichhaveproventoproducereliableandusefulresults.

ARIADNED16.3Public
53
4.1. Recommendations
Basedupontheresearchdoneandtheexperiencegainedoverthepastyearsworkingonthisdeliverable,aseriesofrecommendationscanbemade.
GranularityofknowledgeTheusefulnessofdataminingtodomainexpertsdependsheavilyonthedata’sgranularityofknowledge. More fine-grained data have more-specific information, whereas more coarse-grained data describes information at a higher level (e.g. collection level metadata).Discovering domain-relevant patterns within coarse-grained data proves to be difficult, asthese data simply do not contain such patterns, neither explicitly nor implicitly. Therefore,miningcoarse-graineddatawillatbest,result inhigh-levelconstructs,ratherthanyieldnewinsight that can help further archaeological research. Hence, the creation and use of fine-graineddatashouldbestimulated.
ChoiceofontologyTheinformativenessofpatternsdependsheavilyonthestructuralfeaturesofthedata.Thesefeatures are often inherited from the ontologies used to describe the data. More verboseontologies, such as CIDOC CRM, require more steps (i.e. triples) to describe the sameinformation. Discovering patterns over a larger number of steps is computational moredifficult than if the number of steps are less. As a result, local patterns are preferred (lesscostly), thus potentially leading to more trivial and less complex patterns. Therefore, todiscover more useful patterns, either an ontology with low verbosity should be used, orimplementapenaltyforlocalpatternssothatmorecomplexpatternswillbefavoured.
DatasetqualityDiscoveringplausiblepatternsfromdatarequiresthesedatatobeofasufficientquality.Therefore,alldatashouldbecuratedbeforeaDataMiningmethodisapplied.Ifthisisnotthecase,asobservedwiththeresultsoftheuncuratedOPTIMAtextminingcasestudy,thennoneofthepatternsfoundwillbearchaeologicallycorrect.Thisisaknownweaknessofmanytextminingefforts.Therefore,itisrecommendedtonotusetheiroutput,exceptwhenitiscurated.
LiteralsupportMostarchaeologicaldatasetsconsistoftextualornumericalvaluesthatcannotberepresentedbyanentryfromathesaurus.InLinkedData,thesevaluesbecomeliteralsholdingacertaindatatype.Assuch,theydifferfromresourcesandarethusnotwellaccountedforinthegraphrepresentationofadataset.MostDataMiningmethodsthatcanbeappliedtoLinkedDataexploitthisgraphrepresentation,asdoestheoneemployedinthiswork,andthusoftenignoreliterals.However,theseliteralstypicallycontainveryinterestingvalues,suchasgeometriesandmetrics(e.g.depthanddimensions).Westronglyrecommendtakingthesevaluesintoconsideration.

ARIADNED16.3Public
54
AppendixA SIKBProtocol0102ConversiontoRDFThe SIKB Archaeological Protocol 0102, often referred to as pakbon (package slip), provides aformalised means to summarise many of a project’s elements into a single semi-structured filesuitable for sharingandautomatedprocessing.Due to theuseofXMLas the recommendeddataserialisationformat,protocol,thesauri,andalreadyexistingpakbonfileshadtobetranslatedtoLD.Thisentireprocesshasbeendocumentedinthisappendix.
A.1 ProtocolDescription
A coarse-grained viewof the SIKBArchaeological Protocol 0102 indicates the existenceof severaldistinctgroupsofinformation.Inshort,thesegroupsconcernthefollowingformsofdata:
• General information about the entire archaeological project, including people,companies and organisations involved as well as the general location where theresearchtookplace.
• Final and intermediate reportsmadeduring theproject, aswell as different formsofmediasuchasphotos,drawings,andvideostogetherwiththeirmeta-dataand(cross)referencestotheirrespectivefilesandsubject.
• Detailed information about the finds discovered during the project, as well as their(geospatialandstratigraphic) relation toeachotherand thearchaeological context inwhichtheywerefound.
• Accurateinformationaboutthelocationsandgeometryatwhichfindswerediscovered,archaeologicalcontextswereobserved,andmediawascreated.
Despite their implicit relations, the structure holding these four groups is rather flat anddisconnected(FigureA-1).Infact,allbutfiveoftheprotocol’s43elementsaredirectchildrenoftheroot element (Figure A-2). To express relations that are more complex, the protocol employsidentifiersandcrossreferencing.Theseidentifiersareonlyguaranteedtobeuniquewithinasingleinstanceoftheprotocol.
FigureA-1:Levelhierarchyof theprotocol’soriginaldatamodel.Note that the first levelhasbeendividedinmeta-data(orange)andinstancedata(purple).

ARIADNED16.3Public
55
FigureA-2:Overviewoftheprotocol’soriginaldatamodelusingtheoriginal(Dutch)labels.Verticeshavebeencolour-codedfollowingthelevelhierarchyasdepictedinFigureA-1.Notethatconnectionsbetweenverticesofthesamelevelareaccomplishedbycrossreferencingidentifiers.
A.2 ProtocolConversion
Threehigh-levelandsequentialphasescanbedistinguishedwheretheprotocolhasbeenconverted.Firstly,theoriginaldatamodelhadtobeunderstoodcompletely.Asecondphaseinvolvedanativetranslationfromthetree-basedmodeltoagraph-basedmodel.Finally,thisgraph-basedmodelwasrestructuredtomakebetteruseofitsrelationalcharacteristics.Thesestepswillnowbedescribedinmoredetail.
DataModelMappingAcompleteunderstandingoftheprotocol’soriginalmodelwasachievedbyseveralmeans.Aninitialstep involveda studyof theprotocol’s specificationand the importanceof thedesignchoices.Tothis end, several archaeological researcherswere invited to provide explanations and backgroundinformation.Additionally,itwasdiscussedwithvariouscommercialusersoftheprotocol,aswellaswithoneof thepeoplewhohelpeddevelop it.Finally, theseefforts resulted in theunderstandingthathasbeenpartiallydescribedinAppendixA.1.
NativeTranslationAnativetranslationinvolvesadirectconversionfromtheprotocol’soriginaltree-shapedmodeltoarelationalgraph-shapedmodel.Hereto,allrelationsandconceptswithinthetreewereconvertedtoedgesandvertices,respectively.That is,non-terminal leafswere linkedtotheirchildren,andleafsreferring to identifiers were linked to the items with those identifiers. In addition, the namingschemeofthetree’sleafswasusedtolabelboththeedgesandverticesofthegraphmodel.Notethat the resultingmodel would hold a structure similar to the schematic interpretation found inFigureA-2.

ARIADNED16.3Public
56
Following the naming scheme of the protocol resulted in Dutch labels without semanticalreferences.Therefore,thesesemanticswereaddedtothemodelintheformofaseparateontologybytransformingtheselabelstoURIswithapakbon-ldbase.Thisdecisionwasmadetopreventthealienation of the Dutch archaeological community,who is likely to have been accustomed to theDutch naming scheme. To maximise the compatibility with other work within ARIADNE, theresources towhich these URIs belong have beenmade subclasses of equivalent CIDOC CRM andCIDOCCRM-EHresourceswhereapplicable.Similarly,mostpropertieswithaDutchURIhavebeenmadesubpropertiesoftheaforementionedontologies.
To strengthen the translated ontology further a script was developed that automatically addedrdfs:domain and rdfs:range constraints to each predicate based on their connections within thegraph model. In addition, each resource and predicate was assigned a useful label that wasgeneratedbaseduponitsURIaswellasonconnectedvertices.Finally,descriptionswereaddedtoeachelementbyscrapingtheprotocol’sspecification.
ModelRestructuringWhiletheinitialnativetranslationallowsustobenefitfromLDfromatechnologicalperspective,itdoesnotexploititsrelationalcharacteristics’fullpotential.Thatis,thetopologyofthegraphmodelisas flatanddisconnectedasthatof theoriginal treemodel. Inaddition, it isevidentthatseveralrelations and concepts existed purely for reason of convenience. Similarly, all relations areunidirectional with some of them appearing to expect a specific workflow. For this reason, wedecidedtorestructurethemodel.
An initial step in the restructuring processwas the removal of redundant concepts and relations.Instead, a single element remained to which all related elements referred. In addition, whereapplicable,inverserelationswereaddedtofacilitateeasybrowsingandquerying.Finally,bothnewconceptsandrelationswereaddedtoaccommodatethetopologywhichtheCIDOCCRMandCIDOCCRM-EHontologies imposeonthesemanticsof thedatamodel.Examplesofaddedconcepttypesareevents,attributions,andproductions.
Anothermodificationwas the separation between the protocolmeta-data and the instance data.Differently put, rather than each instance having a protocol version, each distinct version of theprotocolholdszeroormoreinstancesmadefollowingthatversionoftheprotocol.Asanexample,consideranarbitraryversionoftheprotocoldefinedasadocument(E31)inFigureA-3.Saveforitsidentifier,theprotocolholdsaversion,atimestamp,andisspecifiedtodocument(P70)anynumberofarchaeologicalreports(EHE0001).For those interested, figures Figure A-2 through Figure A-10 provide a complete overview on allpartsofthenewdatamodel.Notethatthismodelmayalternativelybeviewedin itsentiretyasagraph(png,7mb)orasafile(.ttl).

ARIADNED16.3Public
57
FigureA-3:Partoftheprotocol’sconverteddatamodelconcerningprotocolmetadataandprojectlinking.
FigureA-4:Partoftheprotocol’sconverteddatamodelconcerninggeneralinformationonacertainproject.

ARIADNED16.3Public
58
FigureA-5:Partoftheprotocol’sconverteddatamodelconcerningorganizationsandpeople.
Figure A-6: Part of the protocol’s converted data model concerning location information andgeometries.

ARIADNED16.3Public
59
FigureA-7: Part of the protocol’s converted datamodel concerning analogue and digital files andmedia.
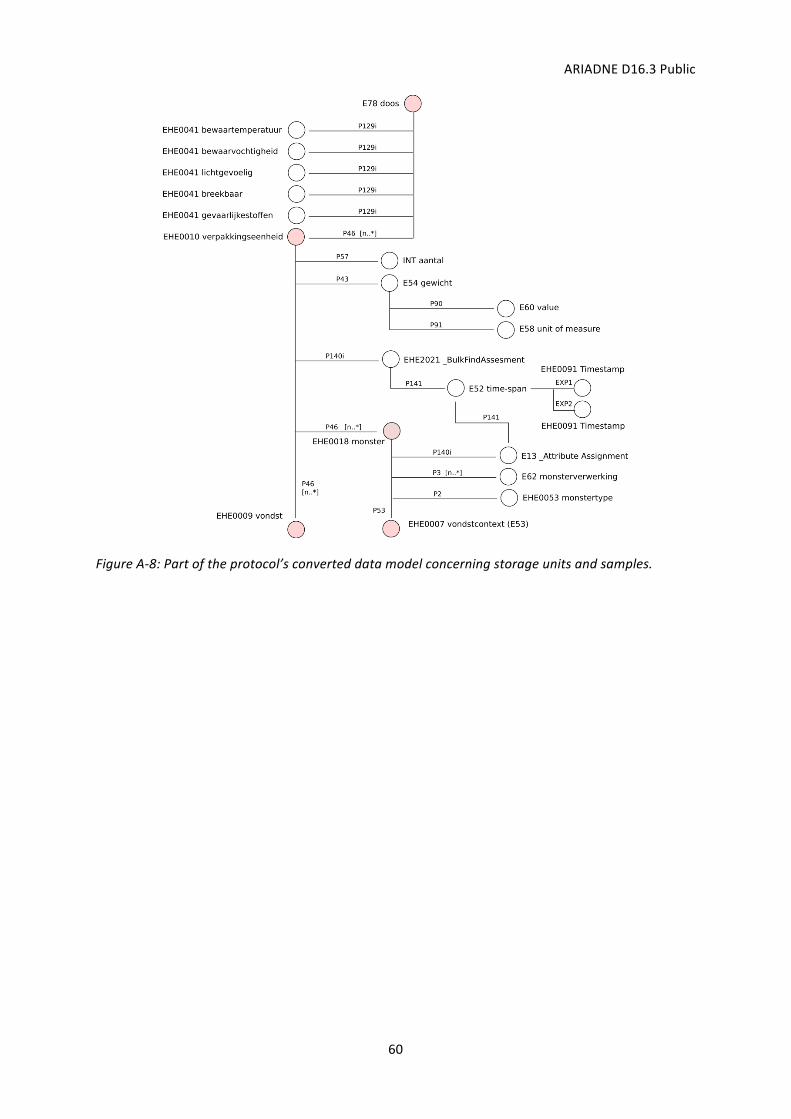
ARIADNED16.3Public
60
FigureA-8:Partoftheprotocol’sconverteddatamodelconcerningstorageunitsandsamples.

ARIADNED16.3Public
61
FigureA-9:Partoftheprotocol’sconverteddatamodelconcerningfinds.

ARIADNED16.3Public
62
FigureA-10:Partoftheprotocol’sconverteddatamodelconcerningcontexts.
A.2.1 ProtocolEnrichment
Severalstepsweretakentofurtherenrichthegraph-basedmodeloftheprotocol.Mostprominentsteps involved the reconciliation of twoormore entities, and the inclusion of spatial geometries.Bothapproachesarebrieflydescribedbelow.
EntityReconciliation

ARIADNED16.3Public
63
Aconsiderablenumberofresourceswithinandbetweenprotocolinstancesarearepresentationofthe sameentity.Most frequently, these concern locations, companies and institutes, andpersonsinvolved,aswellasnumerousvocabularyitemssuchasperiodandfindclassification.Allresourcesthat are listed as vocabulary items are linked to a SKOS version of a suitable vocabulary, as isdocumented in Section A.2.1. For all remaining items, a simple form of entity reconciliation wasapplied.
Entity reconciliation isachievedbycomparing theattributesofany twoentitiesof thesametype.Whichattributesarecomparedandhowdiffersbytype.Forinstance,thenameofaninstitutemaydifferslightlybetweenentitiesaslongasitsaddressmatches.Thisaddressiscomposedofmultipleelementswithvaryinglevelsofgranularity.Toallowforimprecisions,finer-grainedlevelsaregivenlessweightinthefinalmatchresult.Thatis,housenumbersmaydifferabitaslongasthecounty,city,andstreet fullymatch.Similarly, finer-grainedelementsthataremissingfromoneofthetwoentitiesdonotautomaticallyresultinafailedmatch.
Entities that are found tomatch are linked together using the rdfs:sameAs relation (FigureA-11).This relation strongly impliesabi-directionalproperty, and should thusnormallypointbothways.However,alargenumberofduplicateentitieswerefoundtooccuroverarelativelylownumberofprotocol instances. A considerable number of duplicates were (far) less informative than thoseremaining. Finding an informative entity from a less-informative one would therefore requirecontinuously visiting a randomly-selected linked entity until one was found. To alleviate thisinconvenience, linking was only bi-directional between equally-informative entities, or otherwiselinkingsolelyfromtheless-informativetothemore-informativeentity.
FigureA-11:Tworesourcesare linkedby therdfs:sameAsrelation if they 1)areof thesametype,and2)have(nearly)similarvaluesforcertainattributes.
GeospatialExtensionSeveral formsofgeospatial referencingexist in theprotocol’sspecification.Mostprominent is thegenerallocationoftheproject,aswellasthemorespecificlocationsofexcavationsites.ThesearespecifiedasgeometriesfollowingtheGMLstandard,andtypicallyinvolvepointsorpolygons.Othergeospatial references concern location appellations and addresses that belong to the companies,institutes,andpeople involved. Incontrastwith thegeometries, thesereferencesare inplain textandregularlyincomplete.Therefore,wherepossible,thesereferencesweresupplementedbypointgeometries(FigureA-12).
GeometrieswereacquiredbyresolvingtheappellationsoraddressesviatheopenAPIprovidedbyOpenStreetMap.Oncesuccessful,thisAPIreturneda2D-coordinatefollowingtheWGS84standard.Dependingonthecompletenessandaccuracyoftheinput,thispointgeometrycanrangefromanapproximation to a perfect fit. However, to prevent the inclusion of truly erroneous geometries,referenceswereomittedtoanythingbroaderthanaplace.
Found geometries are supplemented parallel to the appellation or address of an entity. This isachievedbypointingtowardsageometry instanceusingthe locn:geometry relation.Thegeometry

ARIADNED16.3Public
64
instanceisseenasbeingindependentoftheentityreferringtoit.Hence,morethanoneentitymayrefertothesamegeometry.Inaddition,suchageometryinstanceitselfisspecifiedasbeingbothofthetypelocn:Geometryandwgs84:Point,andreferstothetwocoordinatesusingthecorrespondingrelationsfromthewgs84ontology.
FigureA-12:Resourcesthatlinktoanaddressareautomaticallyprovidedwithageometryconsistingofa2DpointcoordinateintheWGS84projectionspace.
A.3 ThesauriConversion
Aconsiderablenumberofentities linktoconceptsfromtheDutcharchaeologicalthesaurusABR16.This thesaurus is maintained by the Dutch government, and is the common standard in Dutcharchaeological research. The ABR was converted to allow the full use of this standard and itshierarchicalproperties.Thisisdiscussedbrieflybelow.
TheABRconsistsofmultiplethesauricoveringvariousarchaeologicaltopics.Thesetopicsrangefromperiod classifications to artefactmaterials, as well as place appellations andmap sections (TableA-1). In total, 24 of these topics exist,most ofwhich hold several dozen concepts. Each of theseconcepts is linked to a short code, as well as to related concepts. These involve more narrowlydefined concepts, if any, as well as alternative and deprecated versions of the current concept.Finally,eachconceptholdsashortdescriptionandanoptionalnote.
16ArchaeologischBasisRegister(ABR).Seeabr.erfgoedthesaurus.nl

ARIADNED16.3Public
65
TableA-1:A tablecontainingall code listsasan instanceof theSKOS:Conceptclass (left),and thetypeoftheirrespectiveentries(right).
Each of the ABR’s thesauri have been converted following the Simple Knowledge OrganizationSystem (SKOS) standard. As a result, the converted ABR consists of 24 entities of the typeSKOS:ConceptScheme, with each one holding several dozen members of the type SKOS:Concept.Entities of either type link to their label and description using the SKOS:prefLabel andSKOS:scopeNote relations, respectively. Finally, hierarchical properties are implemented usingSKOS:broaderandSKOS:narrowerrelations.
FigureA-13:Thestructureofasinglecodelistandthreeofitsentries(greenvertices).Forsimplicity,onlyoneentryisshownindetail.Notethatnon-SKOSpredicateshavebeenomitted.

ARIADNED16.3Public
66
A.4 DataConversionandPublication
Aconversiontool17hasbeendevelopedwhichallowsuserstoeasilyconvertanynumberofprotocolinstances. For this purpose, the tool takes two passes through the provided protocol instance.Duringthefirstpass,allentitiesareconvertedandassignedanewrandomly-generatedanduniqueidentifier. This identifier will additionally be used as the latter half of an entity’s URI. Oncecompleted,thesecondpassrestructuresthepartially-convertedprotocolinstance,aswellasenrichtheexistingdatawithadditionalresourcesandrelations.
Unique identifiers are created by generating a salted hash value based upon the attributes of anentity. Which attributes are used differs per type. For instance, the hash value generated fordocumentsdependssolelyonitsISSBincombinationwithitsassignedtype.Otherattributes,suchas its title or authors, are not guaranteed to be unique for a document, and thus may result inclashing identifierswhen used. Finally, note that identifiers of entities that belong to exactly oneparententityareprecededbytheirparentidentifier.Anexampleofsuchanentityisadatingevent,as that specificeventwillneverbeperformedagain.Acounter-example is theperiodassignedbysaidevent,asotherdatingeventsmightconcludewiththatsameperiod.
During theconversionprocess, the toolwillautomaticallyperformentity reconciliationwithinandbetween provided protocol instances, as well as with the online data cloud holding previously-convertedprotocol instances.However, each converted instancewill keep exactly one copyof allnon-thesauri entities it describes to ensure that converted instances can serve as solitary andcomplete units. Note that these instances are given the same URI as their already-existingcounterpart,hencepreventingduplicationinthedatacloud.
All currently-converted protocol instances have been made available in an experimental datacloud18. Currently, the cloud is hosted via the ClioPatria19 triple store, which is a free and open-sourceNO-SQLdatabasebuilduponthePROLOGlogicprogrammingframework.Inaddition,alldatahasbeenmadereferenceableandqueryablethroughbothawebinterfaceandaRESTAPI.Finally,pleasenotethatthedatawithinthecloudispurelyexperimental,andmayholdbugsanderrorsthatmightnotbefixedatpresent.
17Availableatgithub.com/wxwilcke/pakbon-ld18Liveatpakbon-ld.spider.d2s.labs.vu.nl19Availableatcliopatria.swi-prolog.org

ARIADNED16.3Public
67
AppendixB PipelineVUA/LUApipelinehasbeendevelopedto facilitateeasyuseof the implementedruleminingalgorithmbynon-experts. The pipeline consists of two high-level components: a backend and a frontend. Allprocessingandcomputationalstepsoccurwithintheformer,andincludesabasic interfacefortheuser.AschematicdepictionofthisstructureisprovidedinFigureB-1,whichincludesabidirectionalconnectionbetweenthebackendandtheLinkedOpenData(LOD)cloud.AspostulatedinD16.1,itisassumed that at least part of ARIADNE’s data will be included within the LOD cloud. Note that,alternatively,alocaldatasetcanbeusedaswell.
Tomakeuseof thepipeline, users should first provide a set of constraints. These constraints areused to automatically generate a suitable SPARQL query thatmatches the users’ current topic ofinterest. Thisquerywill subsequentlybeused to retrievea subsetof the LODcloud,ensuring thedatasetwillreflecttheusers’interests.Uponsuccessfulretrievalofthesubset,itsdatawillbemadesuitable for furtherprocessingby running it throughadedicatedpre-processingmodule.Thepre-processed data set will then be offered to the Hypothesis Generation module, which generatesSemantic Association Rules and their algorithmic measures of relevance. These rules are thenpresentedtotheuserforevaluation,whomayseparatenarrowthesearchbyaddingvariousfilters.Oncesatisfied,theusermaychoosetostoreanyoralloftherules.Theremainderofthissectionwillbrieflydiscusstheinnerworkingsoftheseparatemodules.

ARIADNED16.3Public
68
Figure B-1: Flowchart depicting the steps within the Rule Mining pipeline. The backend holds allprocessingandcomputationalsteps,whereasthefrontendprovidesabasicinterfacetotheuser.AlldataisacquiredfromtheLODcloud,andthebackendholdsabidirectionalconnection.
B.1 DataPreparation
Datapreparationinvolvesatwo-stepsamplingtechniquetoextractdistinctindividualsfromasetoftriples.Firstly,allentitiesinthesetthatmatchacertaininputpatternareextracted.Thispatternisintended to capture a user’s topic of interest, and is constructed prior to sampling. The resultingentities form thebasis for the individuals, andare the startingpoint of the second sampling stepknownascontextsampling.
Context sampling involves finding a set of facts, related to a specific individual that optimallycaptures thesemantic representationof that individual.Differentlyput, itconcernsdiscardinganyentity and path reachable froma certain individual that are deemed irrelevant to that individual.Hence, this step results in a set of individuals together with relevant information about theseindividuals.
As an example, consider the small KG as provided in Figure B-2: Four stages of context samplingfromasmallexampleLinkedDataset.FourstagesofcontextsamplingfromasmallexampleLinkedDataset.There,frameAdepictsasingleentitythathasbeenselectedasanindividualfollowingthe

ARIADNED16.3Public
69
firstsamplestep.Atpresent,thisindividualholdsnoinformationapartfromitsURI.InframeB,theindividualisassignedacontextoffourentities.Theyaredirectlyconnectedtotheindividualandcanthusbeviewedasanaloguestotheattributevaluesinarowofatable.Additionalentitieshavebeenadded in frame C, perhaps because all directly-connected entities were blank nodes and thatrelevant information lies behind them. Finally, frame D depicts the optional addition of externalinformationwiththehelpofotherdatasets.
Figure B-2: Four stages of context sampling froma small example LinkedData set. The dark bluenoderepresentstheentityforwhichacontextwillbesampled.Lightblue(local)andgreen(remote)nodes represent entities included in that context. In contrast,white nodes are excluded from thatcontext.
Currently, the pipeline supports two context sampling strategies; by local neighbourhood and bydefinition.Bothstrategiesareconciselydiscussedbelow.
LocalNeighbourhoodSamplingbylocalneighbourhoodmakestheassumptionthatmoredirectlyconnectedentitiesaremorerelevanttoaconceptthanthosethatareless-directlyconnected.Differentlyput,themorestepstakenawayfromacertainconcept,themoreitssemanticrepresentationdiffuses.Topreventthisrepresentationfromdiffusingtoomuch,alocalneighbourhoodapproachgeneratesanindividual’scontextbysamplingdepthfirstuptoacertaindepth.Thiscreatesashellofacertainthicknessaroundsaidindividual.
Abenefitofusingalocalneighbourhoodforsamplingisthatittypicallyprovidedgoodapproximationsduetotheintuitivecorrectnessoftheassumptionsitmakes.Additionally,itssimplicityallowsuserstoeasilyadjusttheworkingsofthesamplingmethodtofitdifferentontologies.Thatis,ontologiesthataremoreverbosemayrequireadeepersample.Nevertheless,thismethodhasthedownsidethatitisaratherbluntinstrumenttosamplewith.Forinstance,itmayreturnanynumberofentities.Thisnumberisevenlikelytovarybetweenindividualswithinthesamesample.Inaddition,itmayincludeoneormoreirrelevantorduplicateattributes,asthemethodhasnomeansofevaluatingtheirusefulness.
ContextDefinitionSampling by context definition assigns each individual with a context that is similar to or exactlyequalsthisdefinition.Thisdefinitionconstitutesasetofpredicatepathsthathavetheiroriginataspecific individual.Dependingonuser-provided constraints, either single or parallel pathsmaybeallowed.Forexample,whenastoragecontainerreferstoseveraloftheitemsitholdsviaseparatehasPart relations. Additionally, it may or may not include individuals with a partially-satisfiedcontext.

ARIADNED16.3Public
70
Usinga contextdefinitionhas theadvantageofprecise controlonhow individualsaregenerated.Hence, a domain expertmay insert their knowledge into the process by only including predicatepaths that theydeemrelevant.Thisadditionallyprevents the inclusionof irrelevantandduplicateentities. However, a self-defined context does have the disadvantage of requiring additional userinput. To ensure correctness, this user should be somewhat knowledgeable with respect to thedomainathand.
B.2 HypothesisGenerator
Importantcriteria for thehypothesisgeneratorare the interpretabilityand thebelievabilityof thegenerated hypotheses. To satisfy the former, users should be able to clearly understand thegenerated hypotheses, instead of needing to decipher a symbolic representation. To satisfy thebelievability, thereturnedhypothesesshouldadditionallyshowthereasoningbehindthem,ratherthanmerelyaconclusion.Onlyifbothcriteriahold,willtheusersconsiderthem.Thisaspectbecameapparentfollowingtheuser-requirementanalysisinD16.1.
AnaturalapproachtotackleboththeabovecriteriaistoemployAssociationRuleMining(ARM).InARM,theemphasis lies indiscoveringrulesthatexplainthepatternsandregularities inthedata20.Each of these rules is assigned a confidence scorewhich is based on the frequency of the rule’santecedent, aswell as on the number of true and false positives encountered in the data set. Adomainexpertcansubsequentlydecidewhethertheprovidedconfidencevalueissufficientlyhightodeemthecorrespondingruletrustworthy.
Asatrivialexample,considerasubsetofthedatathatconcernsdocumentedpostholeswiththeirprecise location. By running through all data points, a pattern may emerge between the localgeometry of thepostholes and the structure they are thought to be the remains of. A generatedhypothesismightthenstatethataseriesofpostholesarelikelytheremainsofahouseifandonlyiftheyareorganisedinacertainshape.
Implementation
Traditional ARM operates on tabular data and hence is unsuitable for learning rules from LD.Therefore, this pipeline employs a recent adaptation of ARM for LD, known as SWARM21. TheworkingsofSWARMarediscussedbrieflybelow.
AcorenotioninARMisthe itemset. Itemssetsaresetsof itemsthatbelongtogetherfollowingacertainpattern.SWARMextendsthisnotionwithsemanticitemsets,whicharesetsofentitiesthatshareasemanticpattern.Anexampleofsuchapatternmaystatethatseveralentitiesareallmade
20Fürnkranz, J,andTKliegr."Abriefoverviewof rule learning." InternationalSymposiumonRulesandRuleMarkupLanguagesfortheSemanticWeb,2015:54-69.
21Barati,M,BQuan,andLQing."SWARM:AnApproachforMiningSemanticAssociationRulesfromSemanticWebData."PRICAI2016:TrendsinArtificialIntelligence:14thPacificRimInternationalConferenceonArtificialIntelligence,Phuket,Thailand,August22-26,2016,Proceedings,2016:30-43.

ARIADNED16.3Public
71
usingacertainmaterial.Onceallsuchsemanticpatternshavebeenmapped,SWARMproceedsbygenerating commonbehaviour sets. These sets contain twoormore joined semantic item setsofwhich the entities are roughly equal. The rationale behind this is that patterns of similar sets ofentities are likely to be common amongst these entities. For instance, all entities made using acertainmaterialwerealsousedforthesamepurpose.
Multiplepatterns sharedamongst similarentities form thebasis togenerate rules that generalisethesepatternsoverothersimilarentities.Tothisend,SWARMexploitsthedata’ssemanticsonthelevelofRDFandRDFS.Morespecifically,classandpropertyrelationsarebeingusedtoinferamoregeneral class to which a joined pattern is attributed. For instance, patterns found to hold for aconsiderable number of finds of all subtypes, are generalised to hold for all finds independent ofsubtype.Thesegeneralisedpatternsarethenrewrittenasassociationrules.
B.3 PatternEvaluatorandKnowledgeConsolidator
Uponcompletionofallpriorprocesses,detectedpatternsarepresentedtotheuserforevaluation(FigureB-3).Hereto,thepipelineprovidesasimpleinteractiveuserinterface.Thisinterfacepresentsa candidate solution togetherwith its support and confidence values. The support indicates howcommon the antecedent is amongst entities of a certain class, whereas the confidence indicateswhatportionofthoseentitiestheconsequentsholdaswell.
CANDIDATE7/12IF hastype(RDF:type) ContextFind(CRM-EH:EHE0009)…ANDconsistsof(CRM:P54)MaterialCeramics(VOC:MatCER)
THENofsubtype(CRM:P2)Earthenware(VOC:TypeETW)
Confidence:0.86Support:0.79-SaveCandidate7?(yes/[no]/abort/verbose/addfilter)>yes-Candidate7hasbeenstored
FigureB-3:Exampleinteractionbetweentheuserandtheinterface.
Thenumberofgeneratedcandidaterulesisstronglydependentontheprovidedparametersandthesizeofthedataset.Manuallyevaluatingtheserulesbecomesunfeasiblewhentheirnumberexceedstensorhundredsofthousands.Therefore,theinterfaceoffersuserstheoptiontoaddoneormorefilters for the purpose of narrowing the search. Examples of such filters haveminimal support orconfidence, and the in-or exclusionof rules that aimat a specific classof entities.Once satisfiedwith the selection, the user may choose to store it in one or more of the provided serialisationformats.Dependingonthisformat,usersmayreusetheselectionatalatermomentorshareitwithfellowresearchers.

ARIADNED16.3Public
72
AppendixC PipelineATHENARCInthisAppendix,thedetailsandimplementationissuesregardingthevarioustextanddataminingsolutionsimplementedbyATHENAaredescribedandpresentedinsection3.1.1) Algorithmforcitationextractionandalgorithmdatasetmatching.2) Authormatchingprocedure.3) Implementationdetails(madISETL+miningsoftwaresystem).
C.1 PipelineComponents
C.1.1 Citationextractionanddatasetmatching
Themaindifficultyinextractingcitationsfromapaperarisesfromthefactthatcitationstoagivenpaper can be presented in many different formats and the publication’s text is frequentlyunstructured. Citation extraction deals with the extraction of a citation along with its metadata(authornames, journals,dates).Titleandauthormatching isalsoacomplicatedtaskastitleshavevariable lengths, and matching everything within the text is highly complex. In addition, authornamesandothermetadataareinputindifferentwaysandindifferentorder.
An algorithm that deals with two major challenges was designed which isn’t dependant on thepublication’sformat.Thismeansthatthealgorithm’sprecisionremainsthesameregardlessoftheformat or even the language of the document. This reduced the execution time and increasedscalabilityusingdatabasetechniques.
Itwasfeltthatgivenanefficientmatchingalgorithm,itwouldbepossibletomatcheverypossibletrigram of a given publication’s text with the trigrams in the publication titles. To achieve this,traditionaldatabasetechniques(executingaJOINoperatorbetweenthetexttrigramsandthetitletrigrams)wereused.
Toreducethecomputationalloadandincreasethequalityofthematchingresults,thepublication'stextwasfirstfilteredtoextractsectionswithhigherthanaveragedensityofdatesandURLs.Thesesectionsmay contain references, so theywere the only parts of the publication’s text that weremined.Onesignificantadvantageofthisapproachisthatitcanalsolocatereferencesthatappearinthebodyorfootnote(s)ofapaperandnotonlyinthereferencessection.
Wealsopreprocessed/normalisedthemetadatatoapplythecitation/datasetmatchingfaster,e.g.byreducingspacesbetweenwords,replacingpunctuationmarkswithunderscores,convertingtextin lower case, etc. The preprocessing phasemade it possible to achieve higher recall rates, as ithelped to overcome misspelling issues and other mistakes. Exactly the same preprocessingprocedurewasappliedtothepublication’sfulltext.
Afterpreprocessing,thetitlesofthedatasetswereusedandoneidentifyingtrigramforeachtitlewaskept. Identifying trigramsare trigrams thatappear inas few titlesaspossible.These trigrams

ARIADNED16.3Public
73
were matched to the extracted sections. If a trigram matched, then the full title and the othermetadata (authors, dates etc.)werematched (weutilize a trigrams-based inverted index, but thedetailsareomitted,astheyareverylowlevel).
For filtering out false matches, weighted metadata (author names, publication date, publisher,journal names) of the citation was used and a bag of words for each publication metadata wasproduced. This bag contained normalised author names, surnames, publishers, etc., alongwith aweightvalue(forexamplesurnamesweighmorethanfirstnamesorpublicationyears).Thecontextofthetitlematchwasthensearchedforwordsthatmatch.Ifawordmatched,theconfidencevaluewasincreasedbyitsweight.Thecontextusedhadafixedlengthandconsistedof60wordsbeforeand after the title string. The title lengthwas also used to calculate the confidence value. Itwasobviousthatalengthiertitlethatmatchesismorelikelytobeatruematchthanashorterone.
Thecalculationoftheweightsisaniterativeprocess.Weranthealgorithmonasetofpublications,manually curated the results and changed the weights until the algorithms worked with highprecision when processing publications from various repositories. This way, a threshold for theconfidence value that leads to themost accurate results was decided, so when a citationmatchconfidence value falls below this threshold then the corresponding link is filtered out from theresultsproduced.
Thedrawbackofthistechniqueisthatthecontextusedforcalculatingconfidencevaluehasastablelengthforspeedpurposes,so itmaycontainstrings frompreviousornextcitations.Nevertheless,manualcurationofexperimentalresultsindicatesthatlessthan1%ofmatchesarefalseduetothis.
C.1.2 AuthorMatchingProcedure
Thestepsoftheauthormatchingprocedureareasfollows:1. CreatealistofpairsofauthorsforeachpublicationinOpenAIRE.2. Create a similar author list for each ARIADNE report. For documents with a singleauthor,addtheauthortothelistonlyiftheFullNameislongerthan10characters.3. Homogeniseall thenames in theabove lists in the form [Surname,F],whereF is thefirstletteroftheFirstnameauthor.4. ReturnalllinksbetweenanARIADNEandanOpenAIREdocumentswhere:
a.eitherbothauthorsarematched(iftheARIADNEdocumenthasatleast2authors),orb.atleastoneauthormatches(iftheARIADNEdocumenthasonlyoneauthor).
Regarding step two above: for eachADS grey literature report there is a single attribute (AUTHS)containing all of the documents’ authors in one string, for example: “Sherlock, H, Pikes, P J andNewby-Vincent,J”,sotheyarefirstseparatedatthecommasandbetweenthe“and”strings.

ARIADNED16.3Public
74
C.1.3 ClusteringandSimilarityAlgorithms
AllthealgorithmswereimplementedontopofmadIS22,apowerfulextensionofarelationalDBMSwithuser-defineddataprocessingfunctionality.MadISisbuiltontopoftheSQLiteAPIwithseveralPython extensions. SQLiteAPI allows the use of differentDBMSes thatmay support it. So,madISmayworkwith SQLite or Oracle BerkeleyDB or any other DBMSwhich support this API. This APIprovides a powerful streaming interface, which is exploited in madIS via Python generators; apowerfullanguagepatternthatallowsco-routinesviaayieldstatement.
APythonprogramcanbewrittenasifitisincontrolofiteration(e.g.,iterateoveranexternaldatasource),yetyieldvaluesondemand,withcontrol transfer to theDBMSengine foreachproducedvalue.Inthisway,madIScanprocesslargeamountsofheterogeneous,externaldatainastreamingway.Moreover,madISusesPythonUDFsinthesamewayasitsnativeSQLfunctions.BothPythonandtheDBMSareexecutedinthesameprocess,greatlyreducingthecommunicationcostbetweenthem.Thisisamajorarchitecturalelementandhasapositiveimpactonjointperformance.
MadIS ishighlyscalable,easilyhandling10sofGigabytesofdataonasinglemachine.Thisbenefittransparentlycarriesovertodistributedsystems(e.g.,Hadoop23,Exareme24)whichcanusemadISineach node. The main goal of madIS is to promote the handling of data-related tasks within anextendedrelationalmodel.Indoingso,itupgradesthedatabasefromhavingasupportrole(storingandretrievingdata)tobeingafulldataprocessingsystemonitsown.
In madIS, queries are expressed in madQL: a SQL-based declarative language extended withadditional syntaxanduser-defined functions (UDFs).Oneof thegoalsofmadIS is toeliminate theeffortofcreatingandusingUDFsbymakingthemfirst-classcitizensinthequerylanguageitself.ToalloweasyUDFeditingwitha texteditor,madIS loads theUDF source code from the file system.WheneveraUDF'ssourcecodechanges,madISautomaticallyreloadstheUDFdefinition.ThisallowsrapidUDFdevelopmentiterations,whicharecommonindataexplorationandexperimentation.
TheexpressivenessandtheperformanceofmadISalongwithitsscalabilityfeatureswerecompellingreasonsforchoosingittoimplementouralgorithm.
Forexample,thequeryshowninFigureC-1 isthefinalquery(aftercalculatingalltheweightsandthresholds)used toproduce thecitation linksdescribedearlier.Thequeryextracts the referencessection, preprocesses the documents, matches them with the trigrams table, and calculates theconfidencevalue:
22 L. Stamatogiannakis, M. L. Triantafyllidi, Y. Foufoulas, M. Vayanou, andM. Kyriakidi. madIS - Extensiblerelationaldbbasedonsqlite.https://github.com/madgik/madis,(accessedJanuary10,2017).23 K. Shvachko, H. Kuang, S. Radia, and R. Chansler. The hadoop distributed file system. In Mass StorageSystemsandTechnologies(MSST),2010IEEE26thSymposiumon,pages1–10.IEEE,2010.24Y.Chronis,Y.Foufoulas,V.Nikolopoulos,A.Papadopoulos,L.Stamatogiannakis,C.Svingos,andY.Ioannidis.Arelationalapproachtocomplexdataflows.MEDAL2016.

ARIADNED16.3Public
75
FigureC-1::FinalmadISqueryproducingcitationlinks.
The use of the UDFs that appear in the query is shown in Table C-1. Note that due to theexpressivenessofmadIS,itisveryeasytoexperimentwiththealgorithmeitherremovingoraddingnewoperators(i.e.byremovingthetextreferencesoperatorwecansimplymakethealgorithmrunonthefullpublicationtext)orsimplychangingtheweightswhilerunningthealgorithmiterativelyinordertodecidethefinalweightsandthresholds.
TableC-1::UDFsusedincitationminingalgorithmmadISUDF’s Descriptionnormalizetext(text) Normalises text (implements preprocessing
steps.)textwindow2s(text,prev,middle,next)
Returnedschema:prev,middle,nextReturns a rolling window over the text. In ouralgorithm,thewindowincludes30wordsbeforethetrigram(3words)and30wordsafter.
textreferences(text) Implements the reference extraction phase ofthealgorithm.Itreturns thereferencessectionoftheinputtext.
normregexprmatches(pattern,arg) Thisfunctionreturnstrueifthepatternmatchesargorfalseotherwise.

ARIADNED16.3Public
76
nregexpcountuniquematches(pattern,expression)
Returns the number of unique matches ofpatterninexpression.
stripchars(str[,stripchars]) Returns *str* removing leading and trailingwhitespace characters or *stripchars*charactersifgiven.

ARIADNED16.3Public
77
AppendixD ExpertEvaluationThissectionholdstherawevaluationsreportsareprovidedbythedomainexperts.NotethatwehavetranslatedbothhypothesesandremarksfromDutchtoEnglish.
D.1 OPTIMACaseEvaluations
Person1 Hypothesis Plausible
[Y/N]Valuable[Y/N]
Relevance[0-3]
Remarks
Foreveryfindholdsthat,iftheyareofmaterialtype‘torc’,thentheyoriginatewithinthereportsonSuffolk.
N N 0 -
Foreveryfindholdsthat,iftheyareoftype‘sherds’,thentheyconsistof‘pottery’.
Y N 0 -
Foreveryfindholdsthat,iftheyareoftype‘ironstone’,thentheyconsistof‘pottery’.
Y N 0 -
Foreveryfindholdsthat,iftheyareoftype‘datableartefacts’,thentheyoriginatewithinthereportsonSuffolk.
N N 0 -
Foreveryfindholdsthat,iftheyareoftype‘whitewashedbricks’,thentheyconsistofa‘building’.
Y N 0 -
Foreverydepositioneventholdsthat,ifitinvolvedmovinga‘bowl’,thenitoriginatesfromreportsonLinconshire.
N N 0 -
Foreverydepositioneventholdsthat,ifitinvolvedmoving‘iron’,thenitmovedthatfindtoan‘internalwell’.
N N 0 -
Foreverydepositioneventholdsthat,ifitinvolvedmoving‘pottery’,thenitmovedthatfindtoa’rubbishpit’.
N N 0 -
Foreverydepositioneventholdsthat,ifitinvolvedmoving‘clay,thenitmovedthatfindtoa‘greydeposit’.
N N 0 -

ARIADNED16.3Public
78
Foreverydepositioneventholdsthat,ifitinvolvedmovinga‘wall’,thenitoriginatesfromreportsonHeadland.
N N 0 -
Foreverycontexteventholdsthat,ifitoriginatesfromreportsonThames,thenitdatesfromthe‘ironage’.
Y N 2 -
Foreverycontexteventholdsthat,ifitwitnessedcontext‘structureX’,thenitdatesfromthe‘17thcentury’.Here,Xrepresentsaspecificresource.
N N 0 -
Foreverycontexteventholdsthat,ifitwitnessedcontext‘enclosureX’,thenitdatesfromthe‘ironage’.Here,Xrepresentsaspecificresource.
N N 0 -
Foreverycontexteventholdsthat,ifitwitnessedcontext‘townX’,thenitdatesfromthe‘medieval’.Here,Xrepresentsaspecificresource.
Y N 0 -
Foreverycontexteventholdsthat,ifitwitnessedcontext‘streetX’,thenitdatesfromthe‘17thcentury’.Here,Xrepresentsaspecificresource.
N N 0 -
Foreverycontextproductioneventholdsthat,ifithasproduced‘brooches’,thenitdatesfromthe‘RomanPeriod’.
N N 0 -
Foreverycontextproductioneventholdsthat,ifithasproduced‘temperedsherds’,thenitdatesfromthe‘14thto15thcentury’.
N N 0 -
Foreverycontextproductioneventholdsthat,ifithasproduced‘bricks’,thenitdatesfrom‘modern’times.
Y N 0 -
Foreverycontextproductioneventholdsthat,ifithasproduced‘pottery’,thenitdatesfrom‘latemedieval’times.
N N 0 -

ARIADNED16.3Public
79
Foreverycontextproductioneventholdsthat,ifithasproduced‘romanpottery’,thenitdatesfrom‘Romanage’.
Y N 0 -
Person2
Hypothesis Plausible[Y/N]
Valuable[Y/N]
Relevance[0-3]
Remarks
Foreveryfindholdsthat,iftheyareoftype‘torc’,thentheyoriginatewithinthereportsonSuffolk.
n n 0 -
Foreveryfindholdsthat,iftheyareoftype‘sherds’,thentheyconsistof‘pottery’.
y n 1 -
Foreveryfindholdsthat,iftheyareoftype‘ironstone’,thentheyconsistof‘pottery’.
n n 0 -
Foreveryfindholdsthat,iftheyareoftype‘datableartefacts’,thentheyoriginatewithinthereportsonSuffolk.
y n 0 -
Foreveryfindholdsthat,iftheyareoftype‘whitewashedbricks’,thentheyconsistofa‘building’.
y n 0 -
Foreverydepositioneventholdsthat,ifitinvolvedmovinga‘bowl’,thenitoriginatesfromreportsonLinconshire.
y n 0 -
Foreverydepositioneventholdsthat,ifitinvolvedmoving‘iron’,thenitmovedthatfindtoan‘internalwell’.
n n 0 -
Foreverydepositioneventholdsthat,ifitinvolvedmoving‘pottery’,thenitmovedthatfindtoa’rubbishpit’.
n n 0 -
Foreverydepositioneventholdsthat,ifitinvolvedmoving‘clay,thenitmovedthatfindtoa‘greydeposit’.
n n 0 -
Foreverydepositioneventholdsthat,ifitinvolvedmovinga‘wall’,thenitoriginatesfromreportsonHeadland.
y n 0 -
Foreverycontexteventholdsthat,ifitoriginates
y y 1 -

ARIADNED16.3Public
80
fromreportsonThames,thenitdatesfromthe‘ironage’.Foreverycontexteventholdsthat,ifitwitnessedcontext‘structureX’,thenitdatesfromthe‘17thcentury’.Here,Xrepresentsaspecificresource.
y n 0 -
Foreverycontexteventholdsthat,ifitwitnessedcontext‘enclosureX’,thenitdatesfromthe‘ironage’.Here,Xrepresentsaspecificresource.
y n 0 -
Foreverycontexteventholdsthat,ifitwitnessedcontext‘townX’,thenitdatesfromthe‘medieval’.Here,Xrepresentsaspecificresource.
y n 0 -
Foreverycontexteventholdsthat,ifitwitnessedcontext‘streetX’,thenitdatesfromthe‘17thcentury’.Here,Xrepresentsaspecificresource.
y n 0 -
Foreverycontextproductioneventholdsthat,ifithasproduced‘brooches’,thenitdatesfromthe‘RomanPeriod’.
y y 1 -
Foreverycontextproductioneventholdsthat,ifithasproduced‘temperedsherds’,thenitdatesfromthe‘14thto15thcentury’.
n n 0 Allsherdsaretempered.
Foreverycontextproductioneventholdsthat,ifithasproduced‘bricks’,thenitdatesfrom‘modern’times.
y n 0 -
Foreverycontextproductioneventholdsthat,ifithasproduced‘pottery’,thenitdatesfrom‘latemedieval’times.
y n 0 -
Foreverycontextproductioneventholdsthat,ifithasproduced‘romanpottery’,thenitdatesfrom‘Romanage’.
n n 0 Verytrivial

ARIADNED16.3Public
81
D.2 SIKBProtocolCaseEvaluations
Person1 Hypothesis Plausible
[Y/N]Valuable[Y/N]
Relevance[0-3]
Remarks
Foreverycontextstuffholdsthat,iftheyhaveabrightyellowcolour,thentheyareofspecifictypeANIMALGRAVE.
y not 1 trivialandnotveryuseful
Foreverysiteholdsthat,iftheyareofspecifictypeBASECAMP,thentheyaredatedfromtheNEOVtoNTLperiod.
y not 1 Thisistruebutalittleroughandtrivial.Notveryuseful
Foreverysiteholdsthat,iftheyareofspecifictypeGRAVEYARD,thentheyaredatedfromtheROMtoNTperiod.
y not 1 Possiblyinterestingasthedatasetapparentlyonlyholdsgraveyardsfromthoseperiods.However,therange(+-2000years)isratherbig.
Foreverysiteholdsthat,iftheyareofspecifictypeFLINTCARVING,thentheyaredatedfromtheMESOtoNEOperiod.
y y 2 Verytrivial,butinterestingthatitcanfindsuchpatterns.
Foreverysiteholdsthat,iftheyareofspecifictypeCREMATION,thentheyaredatedfromtheMIDDLEBRONZEtoIRONperiod.
y y 2 Thisisveryinteresting,althoughtrivial.IwouldexpectalsocremationgravesintheRomanperiod.Apparently,thedatasampledoesnotcontainsuchcontexts.
Foreveryfindholdsthat,iftheyareofspecifictypeCHARCOAL,thentheyareofmaterialtypeCHARCOAL.
y not 1 Trivial,notveryrelevant.
Foreveryfindholdsthat,iftheyareofspecifictypeTUFF,thentheyaredatedfromEARLYPALEOtoLATENT.
y not 1 Periodtoobroad.Notreallyknowledge.
Foreveryfindholdsthat,iftheyareofspecifictypeRAWEARTHENWARE(Nimeguen),thentheyaredatedfromEARLYROMANtoLATEROMAN.
y not 1 Trivial.Findsaredatedaccordingtotheirartefacttype.
Foreveryfindholdsthat,iftheyaredatedfromMIDDLENEOtoLATENEO,thentheyareofspecifictypeHAMMERAXEandofmaterialtypeDOLERITE.
y y 2 Thisisinteresting.ThiswouldmeanthatfromNEOM-NEOLweonly"foundhammeraxes".Iwouldexpectthatwewouldfindalsootherfindsfromthisperiod(e.g.potteryorworkedbones)
Foreveryfindholdsthat,iftheyareofspecifictypeADZE,thentheyaredatedfromNEOto
y y 2 Thisistrue.Thisisagainarchaeologicalknowledge,verynicethatthealgorithmgotthis.

ARIADNED16.3Public
82
BRONZE.Foreverycontextholdsthat,iftheyareofspecifictypeDWELLING,thentheyaredatedfromROMANtoMIDDLEDARKAGES,andhavestructureFLOORPLAN.
y y 2 Thismeansthat"dwellings"areonlyusedfromtheRomanperiodtotheMedievalperiod.Thisisarchaeologicallycorrect.Thisistypicalspecializedarchaeologicalknowledge.Interestingthatyoufoundtheserelationships!
Foreverycontextholdsthat,iftheyareofspecifictypeHOUSEDITCH,thentheyaredatedfromEARLYIRONAGE,andhavestructureHOUSE.
y y 2 Thisisalsotrue,"houseditches"areindeedknownintheironagefortheNetherlands.Interestingthatthealgorithmgetthisinfo.Ihoweverthinkthatsuchditcheswouldalsobefoundinlaterperiods.
Foreverycontextholdsthat,iftheyareofspecifictypeWELL,thentheyaredatedfromBRONStoIRONAGE,andhavestructureWELL.
y y 2 Iwouldexpectwellsalsotobepresentinlaterperiods.Interestingknowledge,itcouldhowevermeanthatthesampleistoosmall.ButIamimpressed.
Foreverycontextholdsthat,iftheyareofspecifictypeINHUMATION,thentheyaredatedfromPREH,andhavestructureGRAVE.
y y 2 Interesting,Iwouldexpectinhumationtoalsohavehappenedinlaterperiods.Thiscouldmeanthatthearchaeologistshavedefinedthesedifferently.Ruleslikethiscouldindicatedifferencesovertimeinfunerarypractices.
Foreverycontextholdsthat,iftheyare21cmdeep,thentheyaredatedfromPREH,andhavespecifictypeDITCH.
n not 0 Thisoneisalittletoovague...Idon'tgetthisonecompletely,butisseemsabitfar-fetched.
Foreveryprojectsholdsthat,iftheyareofspecifictype‘destructiveexcavation’,thentheyhavelocationtype‘settlementwithdefenses’.
y alittle 1 Interesting!Thiscouldindicatethatsettlementsarearchaeologicallymorefindable/visiblethanforexamplegraves.However,thesamplemightbetoosmalltosaysomethinglikethis.
Foreveryprojectholdsthat,iftheyareofspecifictype‘destructivemapping’,thentheyareoflocationtype‘settlementwithdefenses’.
y alittle 1 sameasprevious
Foreveryprojectholdsthat,iftheytookplaceatlocationX,thentheyalsotooplaceatlocationY.Here,XandYarevariablesandYlieswithinX.
y not 0 notveryuseful
Foreveryprojectholdsthat,iftheyareofspecifictypeX,thenisconsistsof(documentation)Y.Here,XandYarevariables.
y not 0 same
Foreveryprojectholds y not 0 same
ARIADNED16.3Public
83
that,iftheyaredocumentedindocumentX,thentheyconsistofcontainerY.Here,XandYarevariables.
Person2 Hypothesis Plausible
[Y/N]Valuable[Y/N]
Relevance[0-3]
Remarks
Foreverycontextstuffholdsthat,iftheyhaveabrightyellowcolour,thentheyareofspecifictypeANIMALGRAVE.
No - 0 nonsense
Foreverysiteholdsthat,iftheyareofspecifictypeBASECAMP,thentheyaredatedfromtheNEOVtoNTLperiod.
Yes Yes 2 withintheavailableresources
Foreverysiteholdsthat,iftheyareofspecifictypeGRAVEYARD,thentheyaredatedfromtheROMtoNTperiod.
Yes Yes 2 withintheavailableresources
Foreverysiteholdsthat,iftheyareofspecifictypeFLINTCARVING,thentheyaredatedfromtheMESOtoNEOperiod.
Yes Yes 2 withintheavailableresources
Foreverysiteholdsthat,iftheyareofspecifictypeCREMATION,thentheyaredatedfromtheMIDDLEBRONStoIRONperiod.
Yes Yes 2 withintheavailableresources
Foreveryfindholdsthat,iftheyareofspecifictypeCHARCOAL,thentheyareofmaterialtypeCHARCOAL.
Yes No 1
Foreveryfindholdsthat,iftheyareofspecifictypeTUFF,thentheyaredatedfromEARLYPALEOtoLATENT.
Yes No 1 trivialdate,anyages…
Foreveryfindholdsthat,iftheyareofspecifictypeRAWEARTHENWARE(Nimeguen),thentheyaredatedfromEARLYROMANtoLATEROMAN.
Yes No 2 bydefault,thesaurus
Foreveryfindholdsthat,iftheyaredatedfromMIDDLENEOtoLATENEO,thentheyareofspecifictypeHAMMERAXEandofmaterialtypeDOLERITE.
Yes No 2 bydefault,thesaurus

ARIADNED16.3Public
84
Foreveryfindholdsthat,iftheyareofspecifictypeADZE,thentheyaredatedfromNEOtoBRONS.
Yes Yes 3 datebydefault=MESOL-NEOL
Foreverycontextholdsthat,iftheyareofspecifictypeDWELLING,thentheyaredatedfromROMANtoMIDDLEDARKAGES,andhavestructureFLOORPLAN.
Yes No 2 bydefault,thesaurus
Foreverycontextholdsthat,iftheyareofspecifictypeHOUSEDITCH,thentheyaredatedfromEARLYIRONAGE,andhavestructureHOUSE.
Yes No 2 withintheavailableresources
Foreverycontextholdsthat,iftheyareofspecifictypeWELL,thentheyaredatedfromBRONStoIRONAGE,andhavestructureWELL.
Yes No 2 withintheavailableresources
Foreverycontextholdsthat,iftheyareofspecifictypeINHUMATION,thentheyaredatedfromPREH,andhavestructureGRAVE.
Yes No 2
Foreverycontextholdsthat,iftheyare21cmdeep,thentheyaredatedfromPREH,andhavespecifictypeDITCH.
No No 0 nonsense
Foreveryprojectsholdsthat,iftheyareofspecifictype‘destructiveexcavation’,thentheyhavelocationtype‘settlementwithdefenses’.
Yes No 1 withintheavailableresources,toogeneral
Foreveryprojectholdsthat,iftheyareofspecifictype‘destructivemapping’,thentheyareoflocationtype‘settlementwithdefenses’.
Yes No 1 toogeneral
Foreveryprojectholdsthat,iftheytookplaceatlocationX,thentheyalsotooplaceatlocationY.Here,XandYarevariablesandYlieswithinX.
Yes - 0 trivial
Foreveryprojectholdsthat,iftheyareofspecifictypeX,thenis
Yes - 0 trivial

ARIADNED16.3Public
85
consistsof(documentation)Y.Here,XandYarevariables.Foreveryprojectholdsthat,iftheyaredocumentedindocumentX,thentheyconsistofcontainerY.Here,XandYarevariables.
Yes - 0 trivial
Person3 Hypothesis Plausible
[Y/N]Valuable[Y/N]
Relevance[0-3]
Remarks
Foreverycontextstuffholdsthat,iftheyhaveabrightyellowcolour,thentheyareofspecifictypeANIMALGRAVE.
N N 0 Thiswouldbeveryunlikelytobeheldasageneralhypothesis
Foreverysiteholdsthat,iftheyareofspecifictypeBASECAMP,thentheyaredatedfromtheNEOVtoNTLperiod.
Y N 3 Thedatingrangeisfartoowidetoholdanyvalue
Foreverysiteholdsthat,iftheyareofspecifictypeGRAVEYARD,thentheyaredatedfromtheROMtoNTperiod.
N N 2 Whatisa'graveyard'?Acemeteryoraburialsiteingeneral?
Foreverysiteholdsthat,iftheyareofspecifictypeFLINTCARVING,thentheyaredatedfromtheMESOtoNEOperiod.
N N 3 Paleolithicwouldbemissinghere
Foreverysiteholdsthat,iftheyareofspecifictypeCREMATION,thentheyaredatedfromtheMIDDLEBRONZEtoIRONperiod.
N N 2 MedievalandRomancremationswouldbemissinghere
Foreveryfindholdsthat,iftheyareofspecifictypeCHARCOAL,thentheyareofmaterialtypeCHARCOAL.
Y N 0 Thisisatautology
Foreveryfindholdsthat,iftheyareofspecifictypeTUFF,thentheyaredatedfromEARLYPALEOtoLATENT.
Y N 3 Thedatingrangeisfartoowidetoholdanyvalue
Foreveryfindholdsthat,iftheyareofspecifictypeRAWEARTHENWARE(Nimeguen),thentheyaredatedfromEARLYROMANtoLATEROMAN.
Y Y 3 Thisseemslikely,althoughIamnospecialistonthisparticulartopic
Foreveryfindholdsthat,iftheyaredatedfromMIDDLENEOtoLATE
N N 3 Thisisobviouslynottrue
ARIADNED16.3Public
86
NEO,thentheyareofspecifictypeHAMMERAXEandofmaterialtypeDOLERITE.Foreveryfindholdsthat,iftheyareofspecifictypeADZE,thentheyaredatedfromNEOtoBRONS.
Y Y 3 Thisseemslikely,althoughIamnospecialistonthisparticulartopic
Foreverycontextholdsthat,iftheyareofspecifictypeDWELLING,thentheyaredatedfromROMANtoMIDDLEDARKAGES,andhavestructureFLOORPLAN.
N N 0 Thisisobviouslynottrue
Foreverycontextholdsthat,iftheyareofspecifictypeHOUSEDITCH,thentheyaredatedfromEARLYIRONAGE,andhavestructureHOUSE.
N Y 3 ThisdoesnotaccountforhouseditchesaftertheIronAge(ofwhichthereobviouslyare)
Foreverycontextholdsthat,iftheyareofspecifictypeWELL,thentheyaredatedfromBRONStoIRONAGE,andhavestructureWELL.
N N 2 Thisisatautologyinpart
Foreverycontextholdsthat,iftheyareofspecifictypeINHUMATION,thentheyaredatedfromPREH,andhavestructureGRAVE.
N N 0 Burialsaretoogenerictomakestatementsofvalueon
Foreverycontextholdsthat,iftheyare21cmdeep,thentheyaredatedfromPREH,andhavespecifictypeDITCH.
N N 0 Thisisobviouslynottrue
Foreveryprojectsholdsthat,iftheyareofspecifictype‘destructiveexcavation’,thentheyhavelocationtype‘settlementwithdefenses’.
N N 0 Thisisobviouslynottrue
Foreveryprojectholdsthat,iftheyareofspecifictype‘destructivemapping’,thentheyareoflocationtype‘settlementwithdefenses’.
N N 0 Thisisobviouslynottrue
Foreveryprojectholdsthat,iftheytookplaceatlocationX,thentheyalsotooplaceatlocationY.Here,XandYarevariablesandYlies
N N 0 Thisholdsnovalue

ARIADNED16.3Public
87
withinX.Foreveryprojectholdsthat,iftheyareofspecifictypeX,thenisconsistsof(documentation)Y.Here,XandYarevariables.
N N 0 Thisisn'tstatinganything,asfarasIcansee
Foreveryprojectholdsthat,iftheyaredocumentedindocumentX,thentheyconsistofcontainerY.Here,XandYarevariables.
N N 0 Thisisn'tstatinganything,asfarasIcansee


















