
MongoDB Days UK: Using MongoDB and Python for Data Analysis Pipelines
Upload
james-blackburnCategory
view
659download
1
© Man 2015
Arctic: High-performance IoT and financial data storage
the Python + MongoDB TimeSeries store
July 2015
@ManAHLTech
@jimmybbJames Blackburn

2
1. Overview: Data @ AHL
2. Arctic: a fast Python library for TimeSeries (and anything else)
3. Demo
4. Performance
Overview

3
Love
© Man 2015
… we

4
More love
© Man 2015
…and we data...

5
AHL’s Data Pipeline

Quant researchers
• Interactive work – latency sensitive• Batch jobs run on a cluster – total throughput• Historical data• New data• ... want control of storing their own data
Trading system
• Auditable – SVN for data• Stable
6
Users
Data sizes we deal with…
• ~1MB x 1000s 1x a day price data 10k rows (30 years)• ~0.5GB x 1000s 1-minute data 4M rows (20 years)• ~1GB x 1000s 10k x 10k data matrices 100M cells (30 years)• ~30TB Tick data 100k msgs/s
800M msgs/day
… and different shapes
• Time series of prices• Event data• News data• Metadata• What’s next?
7
Data sizes
8
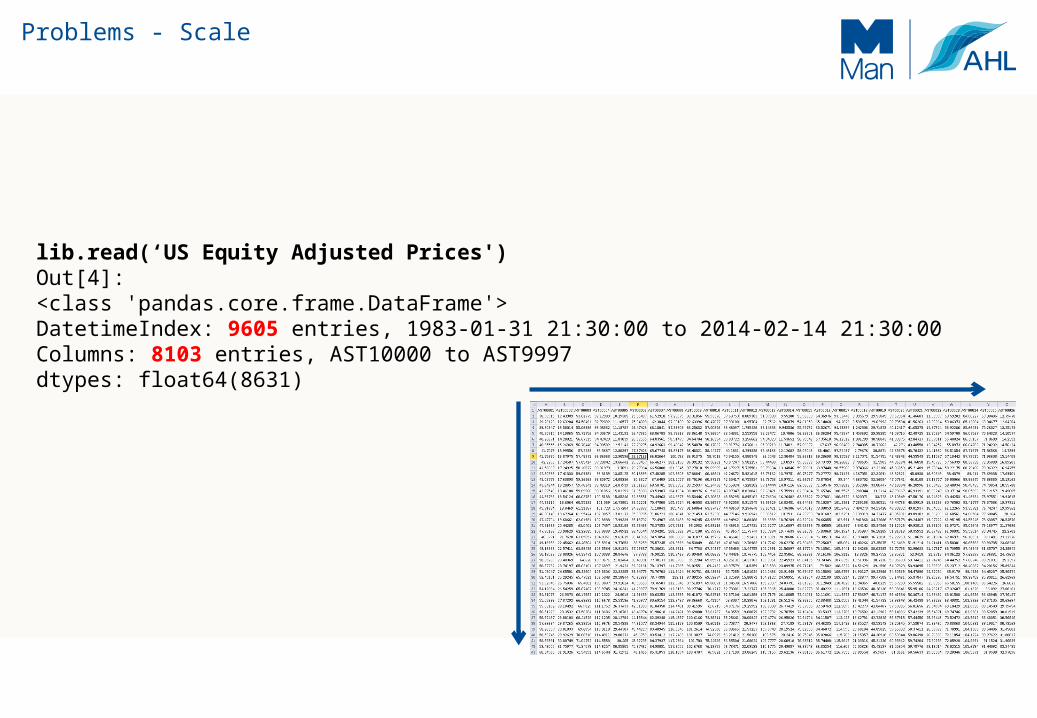
lib.read(‘US Equity Adjusted Prices')Out[4]: <class 'pandas.core.frame.DataFrame'>DatetimeIndex: 9605 entries, 1983-01-31 21:30:00 to 2014-02-14 21:30:00Columns: 8103 entries, AST10000 to AST9997dtypes: float64(8631)
Problems - Scale

9
lib.read(‘US Equity Adjusted Prices')Out[4]: <class 'pandas.core.frame.DataFrame'>DatetimeIndex: 9605 entries, 1983-01-31 21:30:00 to 2014-02-14 21:30:00Columns: 8103 entries, AST10000 to AST9997dtypes: float64(8631)
Equity Prices: 77M float64s 600MB of data ~= 5Gbits!
600 MB
Problems - Scale

10
SQL
© Man 2015
cx_Oracle
~ 200us per Row.
10k rows => 2.2s

11
SQL
© Man 2015
cx_Oracle
~ 200us per Row.
10k rows => 2.2s
How do we query 4 million rows?

12
Local files
© Man 2015
Fast!

13
Local files
© Man 2015
Fast!
Multi-machine access?Versioning?Non-timeseries data?
Using all the technology:
• Relational databases• Tick databases• Flat files • HDF5 files• Caches
14
Databases

Using all the technology:
• Relational databases• Tick databases• Flat files • HDF5 files• Caches
15
Can we build one system to rule them all?
Databases

16
Arctic

Requirements
• Scalable – unbounded in data-size and number of clients
• Agile – any data shape; new shapes; iterative development
• Fast – as fast as local files
• Easy to use – and we mean easy
17
Project Requirements

Goals
• 20 years of 1 minute data in <1s
• 200 instruments x all history x once a day data <1s
• Single data store for all data types• 1x day data Tick data
• Data versioning + Audit
18
Project Goals

Data bucketed into named Libraries
• One minute
• Daily
• User-data: jbloggs.EOD
• Metadata Index
Pluggable Library types:
• VersionStore
• TickStore
• Pickle Store
• … pluggable …
https://github.com/manahl/arctic/blob/master/howtos/how_to_custom_arctic_library.py
19
Arctic Libraries

20© Man 2015

Document ~= Python Dictionary
Flexible schema Rapid prototyping
OpenSource database
Great support
#1 NoSQL DB (#3 overall) http://db-engines.com/en/ranking
21
Why MongoDB

22© Man 2015
Demo
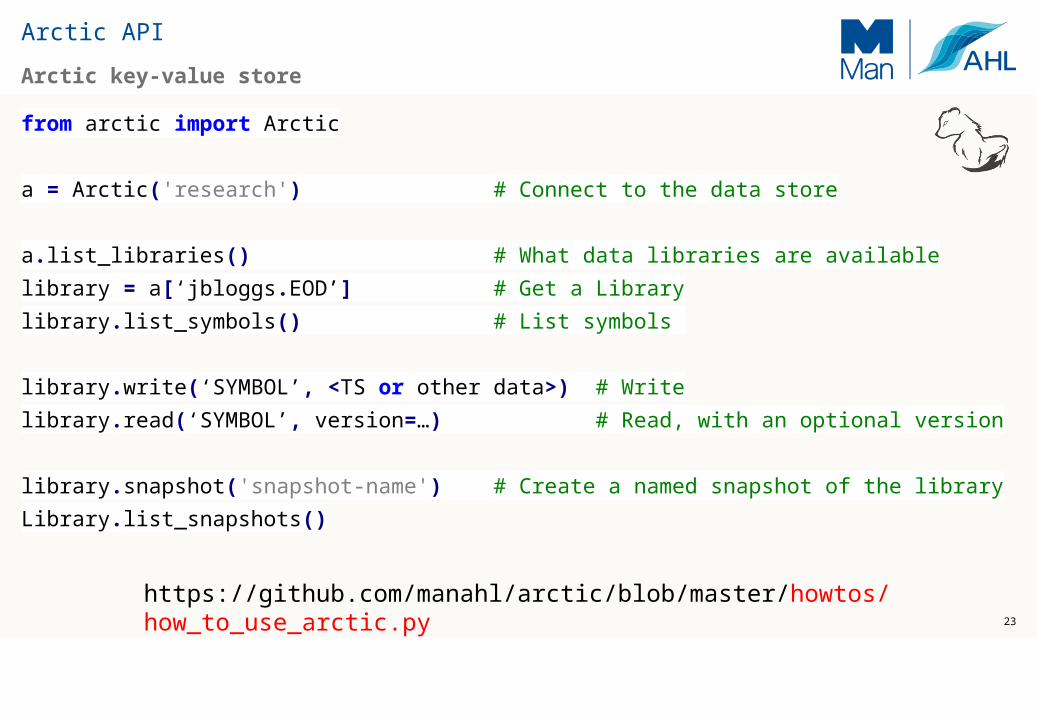
Arctic key-value store
23
from arctic import Arctic
a = Arctic('research') # Connect to the data store
a.list_libraries() # What data libraries are available
library = a[‘jbloggs.EOD’] # Get a Library
library.list_symbols() # List symbols
library.write(‘SYMBOL’, <TS or other data>) # Write
library.read(‘SYMBOL’, version=…) # Read, with an optional version
library.snapshot('snapshot-name') # Create a named snapshot of the library
Library.list_snapshots()
https://github.com/manahl/arctic/blob/master/howtos/how_to_use_arctic.py
Arctic API

24© Man 2015

25
Arctic - TickStore
Arctic(‘localhost’).initialize_library(‘tickdb’, ‘TickStoreV3’)
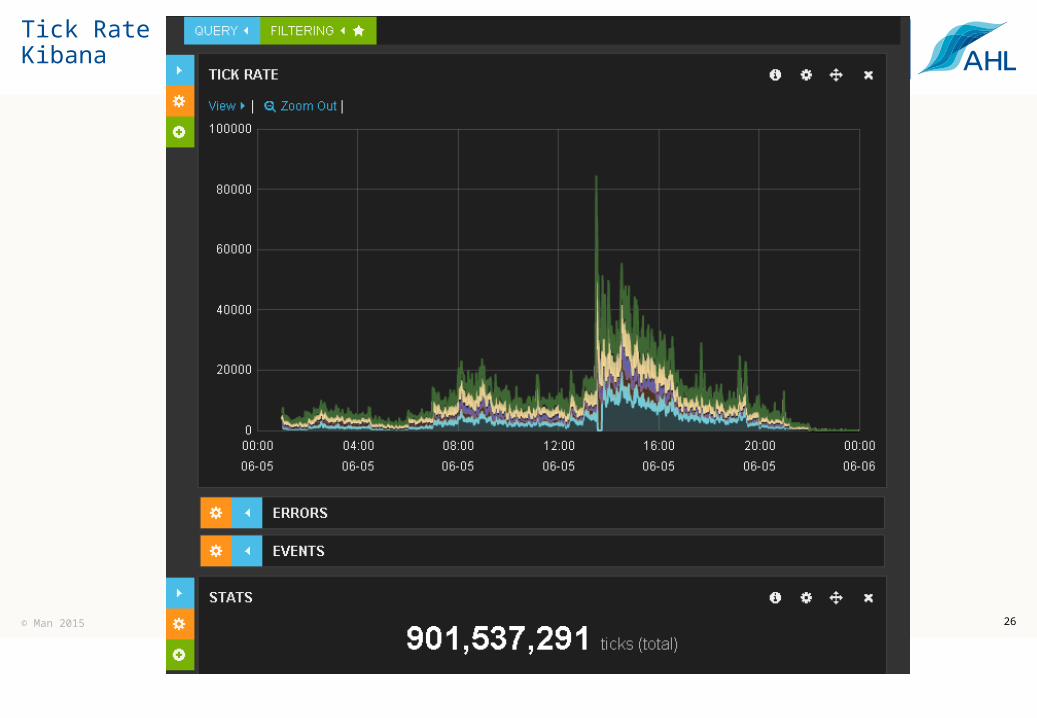
26
Tick Rate – Kibana
© Man 2015

27
Implementation – TickStore
Sym1
Sym2

28
Implementation – a chunk
{ ID: ObjectId('52b1d39eed5066ab5e87a56d'), SYMBOL: 'symbol' INDEX: Binary('...', 0), COLUMNS: { ASK: { DATA: Binary('...', 0), DTYPE: '<f8', ROWMASK: Binary('...', 0) }, ... } START: DateTime(...), END: DateTime(...), SEGMENT: 1386933906826L, SHA: 1386933906826L, VERSION: 3,}

29
Arctic - VersionStore
Arctic(‘localhost’).initialize_library(‘library’)

30© Man 2015

31
Implementation – VersionStore
Snap A
Snap B
Sym1, v1
Sym2, v3
Sym2, v4
Sym2, v5
Sym2, v6
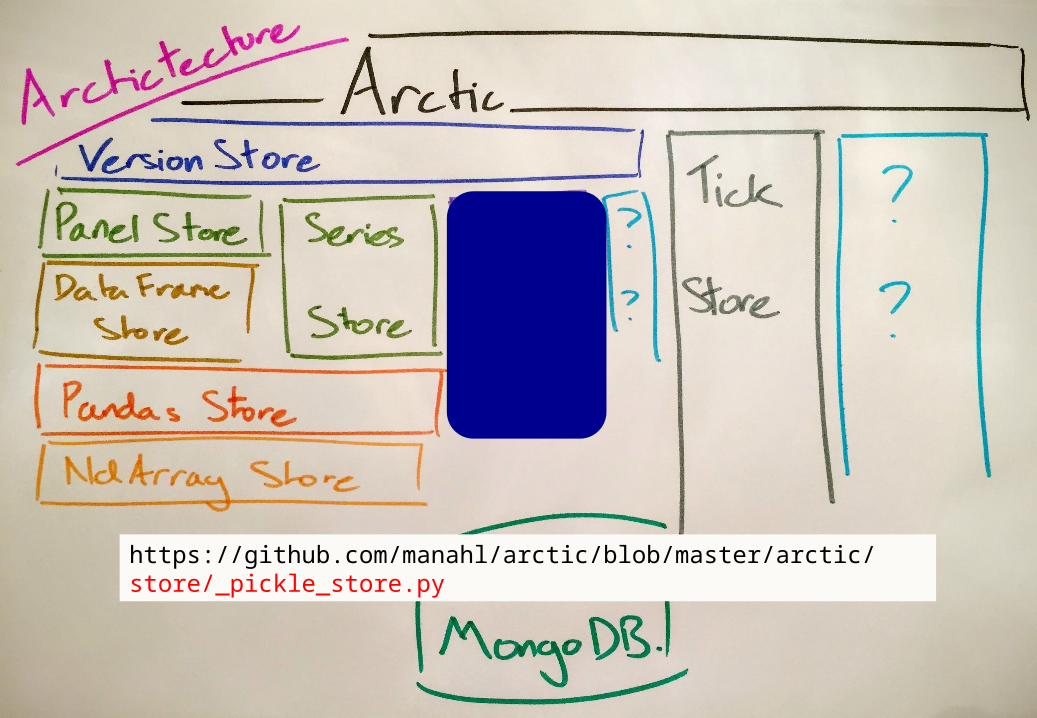
32© Man 2015
https://github.com/manahl/arctic/blob/master/arctic/store/_pickle_store.py

33
Performance
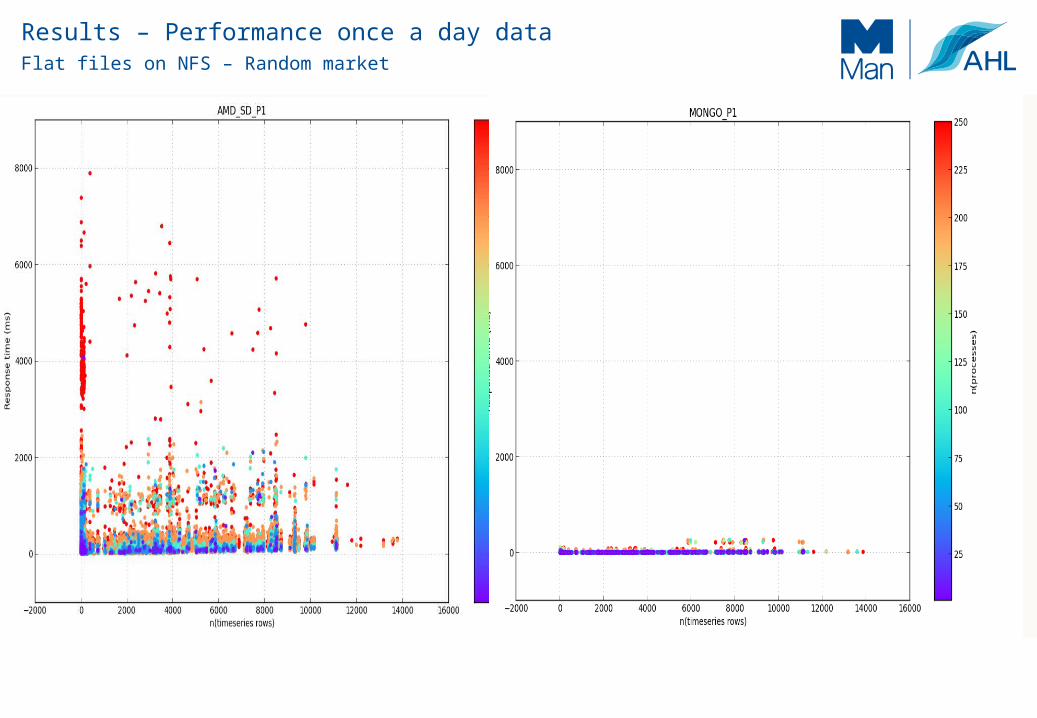
Flat files on NFS – Random market
34
Results – Performance once a day data

HDF5 files – Random instrument
35
Results – Performance One Minute
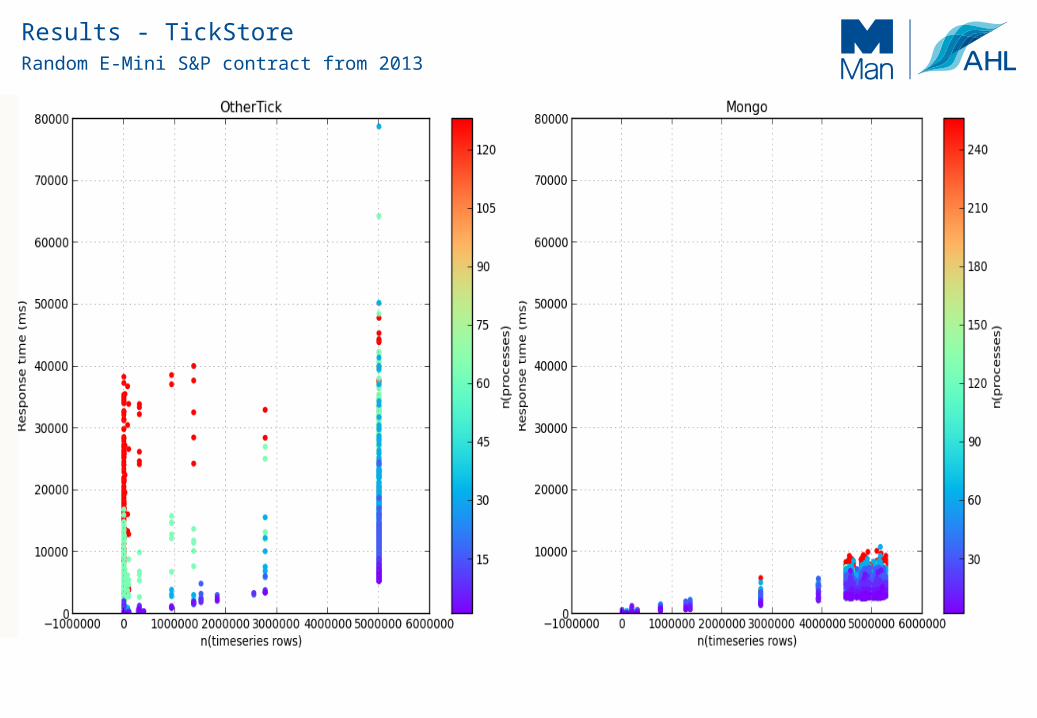
Random E-Mini S&P contract from 2013
© Man 2013 36
Results - TickStore

Random E-Mini S&P contract from 2013
© Man 2013 37
Results – TickStore Throughput
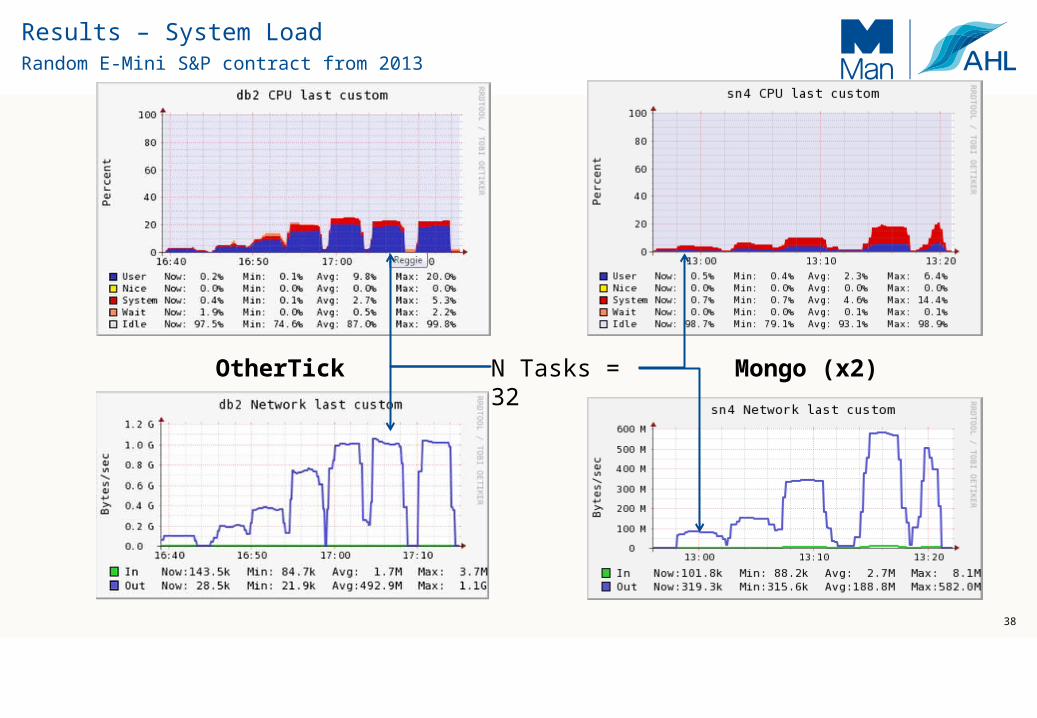
Random E-Mini S&P contract from 2013
38
OtherTick Mongo (x2)N Tasks = 32
Results – System Load

Low latency:
- 1xDay data: 4ms for 10,000 rows (vs. 2,210ms from SQL)
- OneMinute / Tick data: 1s for 3.5M rows Python (vs. 15s – 40s+ from OtherTick)
- 1s for 15M rows Java
Parallel Access:
- Cluster with 256+ concurrent data access
- Consistent throughput – little load on the Mongo server
Efficient:
- 10-15x reduction in network load
- Negligible decompression cost (lz4: 1.8Gb/s)
39
Conclusions

Like data? We’re [email protected]
40
Questions?
@ManAHLTech
https://github.com/manahl/arctic
@jimmybbJames Blackburn

41© Man 2015
Bonus

_CHUNK_SIZE = 15 * 1024 * 1024 # 15MB
class PickleStore(object):
def write(collection, version, symbol, item):
# Try to pickle it. This is best effort
pickled = lz4.compressHC(cPickle.dumps(item))
for i in xrange(len(pickled) / _CHUNK_SIZE + 1):
segment = {'data': Binary(pickled[i * _CHUNK_SIZE : (i + 1) * _CHUNK_SIZE])}
segment['segment'] = i
sha = checksum(symbol, segment)
collection.update({'symbol': symbol, 'sha': sha},
{'$set': segment,
'$addToSet': {'parent': version['_id']}},
upsert=True)
42
Implementation – PickleStore

_CHUNK_SIZE = 15 * 1024 * 1024 # 15MB
class PickleStore(object):
def write(collection, version, symbol, item):
# Try to pickle it. This is best effort
pickled = lz4.compressHC(cPickle.dumps(item))
for i in xrange(len(pickled) / _CHUNK_SIZE + 1):
segment = {'data': Binary(pickled[i * _CHUNK_SIZE : (i + 1) * _CHUNK_SIZE])}
segment['segment'] = i
sha = checksum(symbol, segment)
collection.update({'symbol': symbol, 'sha': sha},
{'$set': segment,
'$addToSet': {'parent': version['_id']}},
upsert=True)
43
Implementation – PickleStore

_CHUNK_SIZE = 15 * 1024 * 1024 # 15MB
class PickleStore(object):
def write(collection, version, symbol, item):
# Try to pickle it. This is best effort
pickled = lz4.compressHC(cPickle.dumps(item))
for i in xrange(len(pickled) / _CHUNK_SIZE + 1):
segment = {'data': Binary(pickled[i * _CHUNK_SIZE : (i + 1) * _CHUNK_SIZE])}
segment['segment'] = i
sha = checksum(symbol, segment)
collection.update({'symbol': symbol, 'sha': sha},
{'$set': segment,
'$addToSet': {'parent': version['_id']}},
upsert=True)
44
Implementation – PickleStore

class PickleStore(object):
def read(self, collection, version, symbol):
data = ''.join([x['data'] for x in collection.find({'symbol': symbol,
'parent': version['_id']},
sort=[('segment', pymongo.ASCENDING)])])
return cPickle.loads(lz4.decompress(data))
45
https://github.com/manahl/arctic/blob/master/arctic/store/_pickle_store.py
Implementation – PickleStore


















