
Architectures for LDPC Decoders - Lab-STICCboutillon/ldpc/LDPC_CWT05.pdf · Regular (3,6) LDPC code...
39
Architectures for LDPC Decoders Frédéric Guilloud, ENST Bretagne Emmanuel Boutillon, University of South Britany
Transcript of Architectures for LDPC Decoders - Lab-STICCboutillon/ldpc/LDPC_CWT05.pdf · Regular (3,6) LDPC code...

Architectures for LDPC Decoders
Frédéric Guilloud, ENST BretagneEmmanuel Boutillon, University ofSouth Britany

CTW’05 2
Contents
Part 1 : Main Bottlenecks in LDPC DecoderDesign
Design flowImplementation costs
Part 2 : Case studyAd hoc implementation for shuffle-BP scheduling
Decoding SchedulesGeneric Node UnitsArchitectural study

Part 1 : Main bottlenecks in LDPCdecoders designs

CTW’05 4
Design Flows
Design code withgood performance
Implement it inhardware
Classical
Design code underimplementationconstraints
Design an efficientarchitecture
Reverse
Joint Design

CTW’05 5
Implementation costs
An efficient LDPC code is a good thing …The opportunity to implement it in a small areachip is even better !
Processing power
Exchange power
Memorization power
Implementationcosts

CTW’05 6
Processing power (1/2)Check update:
For all edges (m,n) connecting the mth check to the nth
variable: 2 additions and 2 LUT (f ) per edges.
Variable update:For all edges (n,m) connecting the nth variable to the mth
check : 2 additions per edges.
NB : We define also
Complexity proportionnal to the number of edges
( )
=
= ∑∏
∈
−
∈
−
nmNnmn
nmNnmnnm TTE
\)(','
1
\)(','
1, ff
21tanhtanh2
nmnmnMm
nmnmn ETEIT ,\)('
,', −=+= ∑∈
( )( )2tanhln)( xxf −=
)( and )( ,,,,1
mnmnnmnm TfQERf ==−

CTW’05 7
Processing power (2/2)
Specifications:Information size: K bitsInformation throughput: Db bit/sThe maximum number of iterations: imax
The clock frequency: fclk
Number of edges to be processed:
E being the number of non zero entries in the matrix
cyclek edges/cloc clk
max
KfDEiR b
e =

CTW’05 8
Generic Message Passing Architecture(Regular (j,k) code)
……
……Control
Variable NodeUnit
Check NodeUnit
SpatialPermutations
βv jd =
…
vdvd
…cd αc kd = cd
CNU 1 CNU P
VNU 1 VNU V
Number of edges to be processed:so P=Re/k check nodes per clock cycle
(if α=1)
(CNU)
(VNU)
cyclek edges/cloc αkPRe =
• dv,dc: number of input/outputports of the node units
• α,β : number of clock cyclesrequired to process all the j/knode output messages. Inverse
InterleavingDirect Interleaving
CTW’05 9
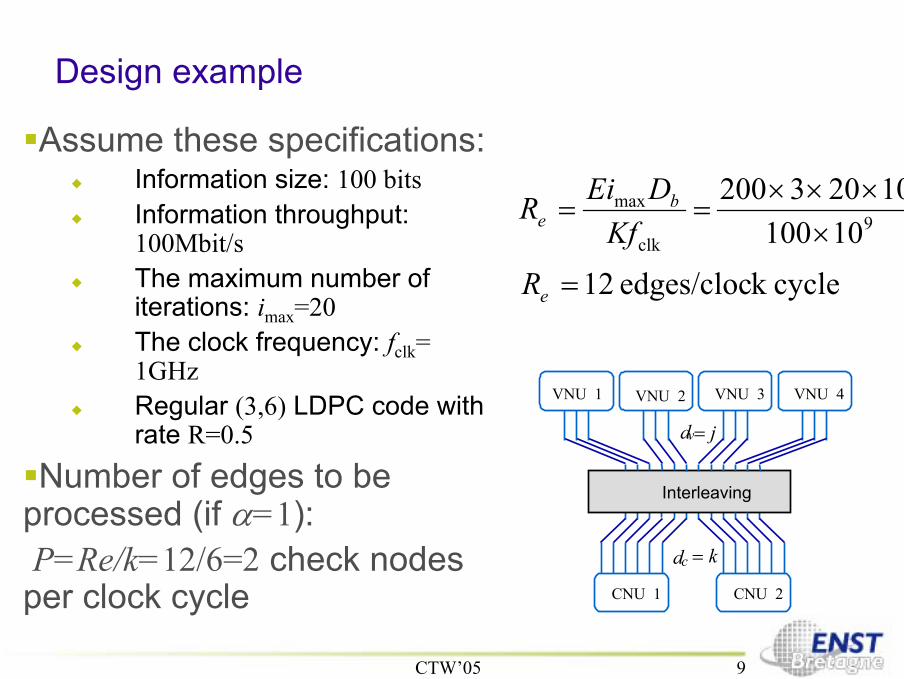
Design example
Assume these specifications:Information size: 100 bitsInformation throughput:100Mbit/sThe maximum number ofiterations: imax=20The clock frequency: fclk=1GHzRegular (3,6) LDPC code withrate R=0.5
Number of edges to beprocessed (if α=1): P=Re/k=12/6=2 check nodesper clock cycle
9
8
clk
max
1010010203200
××××
==Kf
DEiR be
vd = j
cd = k
CNU 1
VNU 1 VNU 2
Interleaving
CNU 2
VNU 3 VNU 4
cyclek edges/cloc 12=eR

CTW’05 10
Memorization power
The parity check matrix has to be saved insidethe chip.
Exchange memory against processing(addresses processing)
value_1
value_2
value _x
counter
clock
address value
clock
Logic value
Memory
CTW’05 11
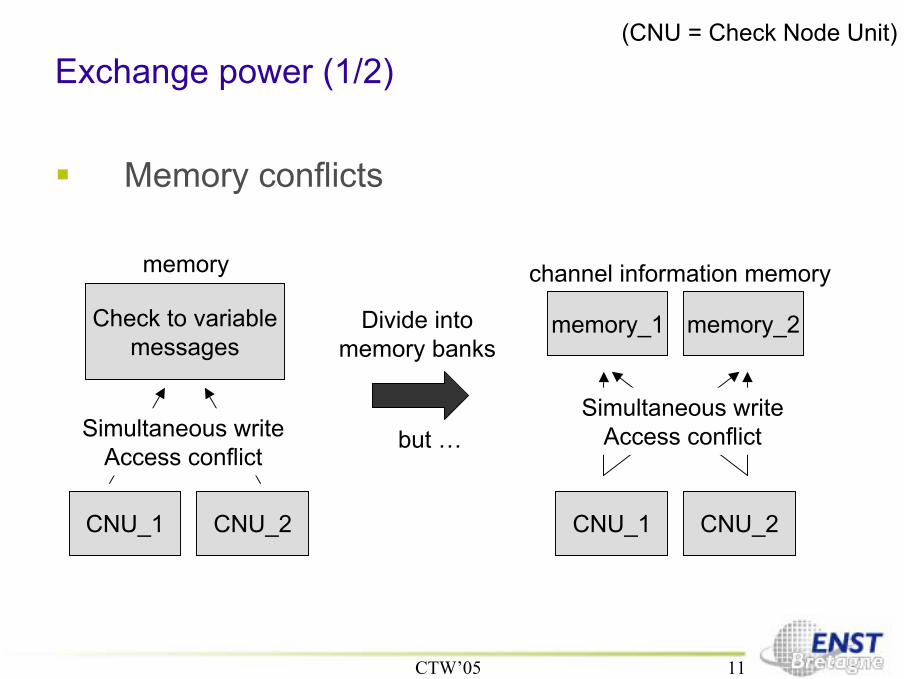
Exchange power (1/2)
Memory conflicts
CNU_1 CNU_2
Check to variablemessages
memory
Simultaneous writeAccess conflict
Divide intomemory banks
but …
CNU_1 CNU_2
memory_1 memory_2
Simultaneous writeAccess conflict
channel information memory
(CNU = Check Node Unit)

CTW’05 12
Exchange power (2/2)
Routing conflicts
CNU_1 CNU_2 CNU_3 CNU_4
VNU_1 VNU_2 VNU_3 VNU_4
(VNU = Variable Node Unit)(CNU = Check Node Unit)
permutation network
Simple permutationnetworks :
Rotations,Protographs, …

CTW’05 13
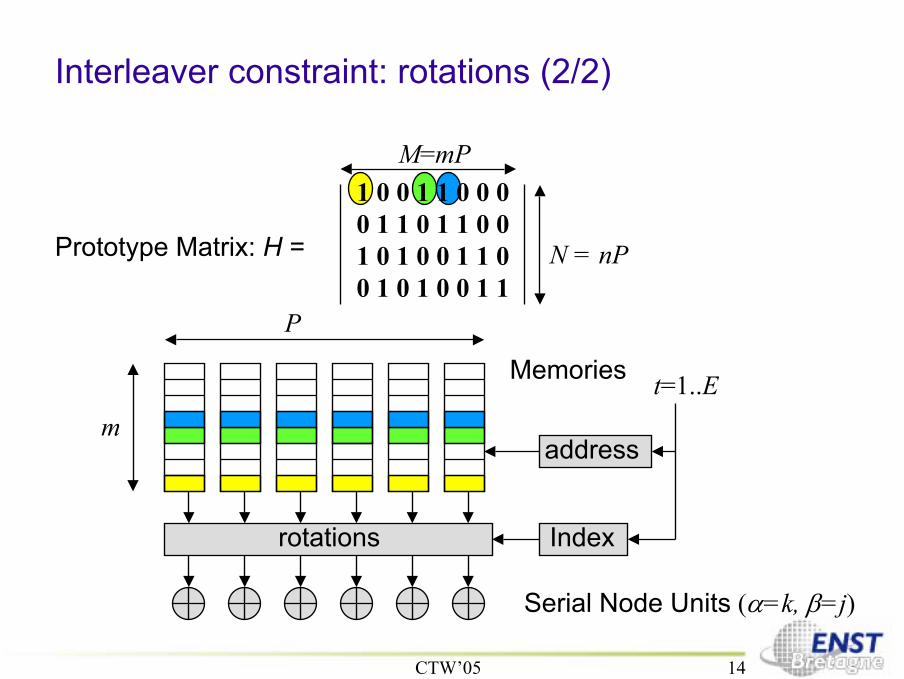
1 0 0 1 1 0 0 00 1 1 0 1 1 0 01 0 1 0 0 1 1 00 1 0 1 0 0 1 1
Interleaver constraint: rotations (1/2)
Prototype Matrix: H =
Πi,j(Ip ) =
0 0 1 0 0 00 0 0 1 0 00 0 0 0 1 00 0 0 0 0 11 0 0 0 0 00 1 0 0 0 0
0 0 0 0 0 00 0 0 0 0 00 0 0 0 0 00 0 0 0 0 00 0 0 0 0 00 0 0 0 0 0
P
P
N = nP
M=mP
Moreover : Small memory requirements for parity check matrix
[Hocevar 2003][Sridhara, Fuja, Tanner 2001]
CTW’05 14
Interleaver constraint: rotations (2/2)
Prototype Matrix: H =
1 0 0 1 1 0 0 00 1 1 0 1 1 0 01 0 1 0 0 1 1 00 1 0 1 0 0 1 1
N = nP
M=mP
rotations
m
P
t=1..E
Index
Serial Node Units (α=k, β=j)
address
Memories

CTW’05 15
Conclusion : LDPC decoder design from thearchitecture point of view
Code performanceCode itself ☺Decoding algorithm
CNUBP,BP-Based, λ-min, A-min*
VNUPrecisionScheduling
Flooding, shuffled
Low costNode unit complexityStructured parity check matrix
VersatilitySizeRate
High throughputImprove Hardware
Utilization efficiency: Qhard x activity rate / processing xclock frequency

Part 2 : Case study
Scheduling implementation

CTW’05 17
mnT ,
011110101101110101
Flooding scheduling(classical one)
0 1 2 3 4 5
LDPC paritycheck matrix
0
nmE ,

CTW’05 18
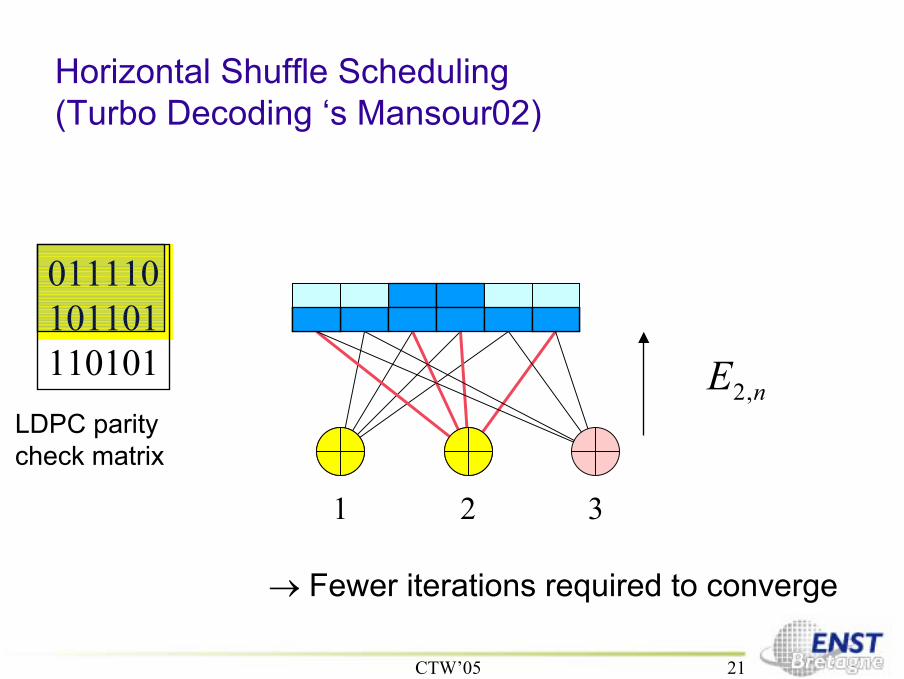
Horizontal Shuffle Scheduling(Turbo Decoding ‘s Mansour02)
011110101101110101
1 2 3
1,nTLDPC paritycheck matrix

CTW’05 19
Horizontal Shuffle Scheduling(Turbo Decoding ‘s Mansour02)
011110101101110101
nE ,1
1 2 3
LDPC paritycheck matrix

CTW’05 20
Horizontal Shuffle Scheduling(Turbo Decoding ‘s Mansour02)
011110101101110101
2,nT
1 2 3
LDPC paritycheck matrix
CTW’05 21
Horizontal Shuffle Scheduling(Turbo Decoding ‘s Mansour02)
011110101101110101
→ Fewer iterations required to converge
nE ,2
1 2 3
LDPC paritycheck matrix
CTW’05 22
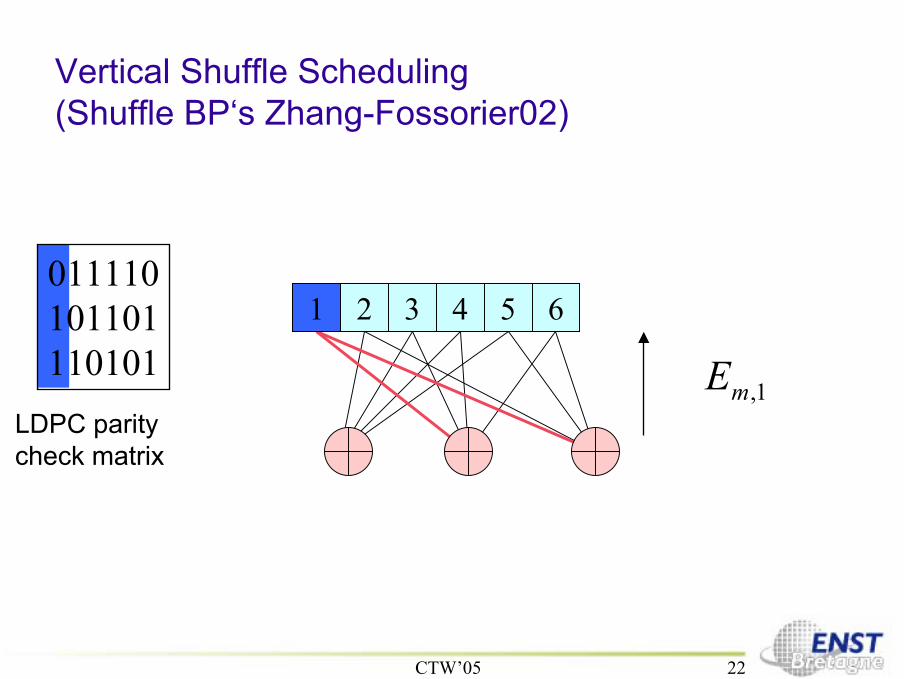
Vertical Shuffle Scheduling(Shuffle BP‘s Zhang-Fossorier02)
1 2 3 4 5 6011110101101110101
1,mELDPC paritycheck matrix
CTW’05 23
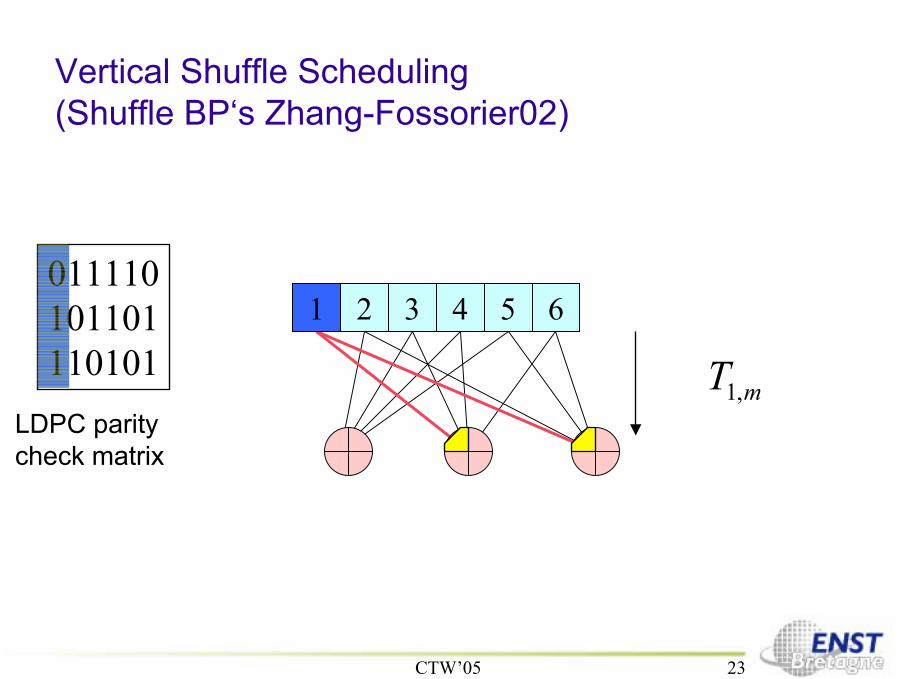
Vertical Shuffle Scheduling(Shuffle BP‘s Zhang-Fossorier02)
1 2 3 4 5 6011110101101110101
mT ,1LDPC paritycheck matrix

CTW’05 24
Vertical Shuffle Scheduling(Shuffle BP‘s Zhang-Fossorier02)
1 2 3 4 5 6011110101101110101
2,mELDPC paritycheck matrix
CTW’05 25
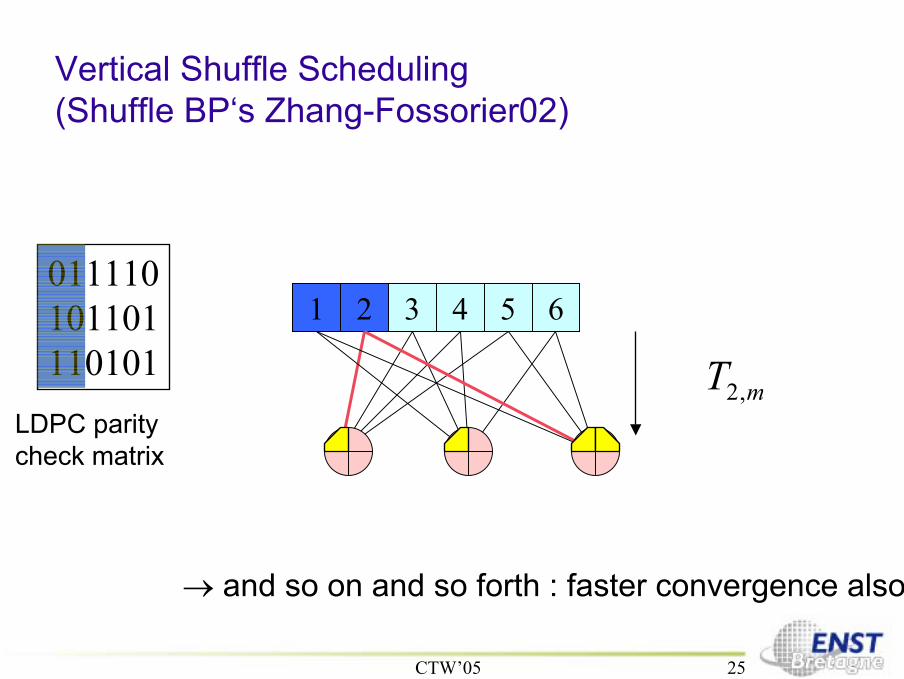
1 2 3 4 5 6011110101101110101
Vertical Shuffle Scheduling(Shuffle BP‘s Zhang-Fossorier02)
mT ,2
→ and so on and so forth : faster convergence also
LDPC paritycheck matrix

CTW’05 26
Generic Node Units
Classical Node Unit processing:
Flooding / Horizontal Schedules : CNUs controland VNUs save informationVertical Schedule : Reverse !Solution : use the symmetry
Implementation Issue for schedulings
( )xf
Σ
( )xf 1−
Σ
VNU
CNU

CTW’05 27
Generic Node Units (exclude the f function)
How to manage inputs & outputs for node units?
d inputs em and d outputs sn(d=j or k) Input / output law:
NB: replace Σ by × for signprocessing
Generic Node unitMemories + processing
∑≠
=nm
mn es

CTW’05 28
Generic Node Unit implementations:a) Compact mode («no memories »)
compact mode and parallelimplementation
(α or β = 1 → dc=k or dv=j)
compact mode and serialimplementation
(α = k or β = j → dv = dc = 1)dee L1 dss L1
b)
1e
me
de
FIFO
FIFO
FIFO
1s
me
ds
FIFO

CTW’05 29
Generic Node Unit implementations:b) Distributed Mode with slow update (Serial)
)()(2
)(1
)( ... id
iii eeet +++=Previousiteration
Currentiteration
)(ins
)(ine
)(it )1( +it
Permutation network
-
EdgeMemory
)1()1(1
)1( ... +++ ++= in
ii eet
)1( +ine
)1( +ine

CTW’05 30
)1( +ine
)1( +ine
)()1()1(1
)1(1
)1( ... id
in
in
iin eeeet ++++= ++
−++-
)1( +it is changing allalong the iteration
Permutation network
Currentiteration
Generic operator implementation:c) Distributed Mode with fast update
)()()1(1
)1(1
)1(1 ... i
di
ni
nii
n eeeet ++++= +−
++−
)(ins
)(ine
)1(1+
−i
nt
CTW’05 31
VerticalShuffle
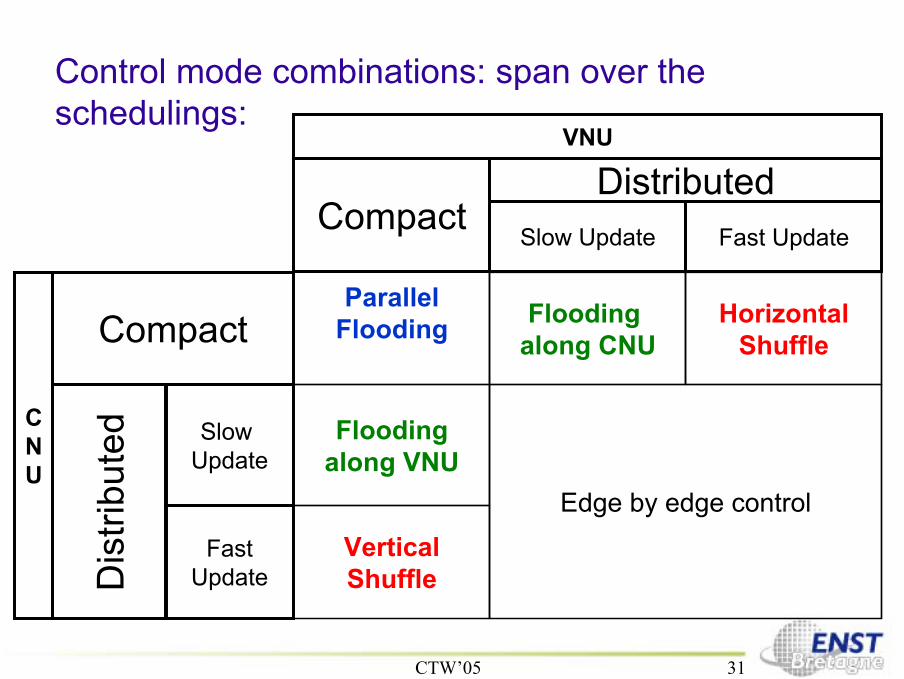
Control mode combinations: span over theschedulings:
ParallelFlooding Flooding
along CNU
Floodingalong VNU
HorizontalShuffle
Edge by edge control
CompactDistributed
Slow Update Fast Update
VNU
CNU
Compact
Dis
tribu
ted Slow
Update
FastUpdate

CTW’05 32
Example: Vertical Shuffle ad-hoc architecture (1)
Originally proposed as Shuffle-BP (Zhang &Fossorier, 2002)
Combination of:Compact Mode for VNUDistributed Mode with fast update for CNU

CTW’05 33
Example: Vertical Shuffle ad-hoc architecture (2)
Compact VNU (serial)
nISerialGNU
CompactMode
)1(,−inmE
∑∈
−
mnMm
inmE
\)('
)1(,
)(,imnT )1(
,1
−inmE
)1(,3
−inmE
nI
)(, 2
imnT
)1(,2
−inmE
)(, 3
imnT)(
, 1
imnT

CTW’05 34
Example: Vertical Shuffle ad-hoc architecture (3)
Go through the f functions and the interleaver
nISerialGNU
CompactMode
)1(,−inmE
∑∈
−
mnMm
inmE
\)('
)1(,
)(,imnT
inte
rleav
er
f)(
,imnQ

CTW’05 35
Example: Vertical Shuffle ad-hoc architecture (4)
Save new message Qn,m and update theaccumulation Rm (fast update)
nISerialGNU
CompactMode
)1(,−inmE
∑∈
−
mnMm
inmE
\)('
)1(,
)(,imnT f
)(,imnQ
)(imR
)1(,−imnQ
)1(,
)(,
−− imn
imn QQ
inte
rleav
er
CTW’05 36
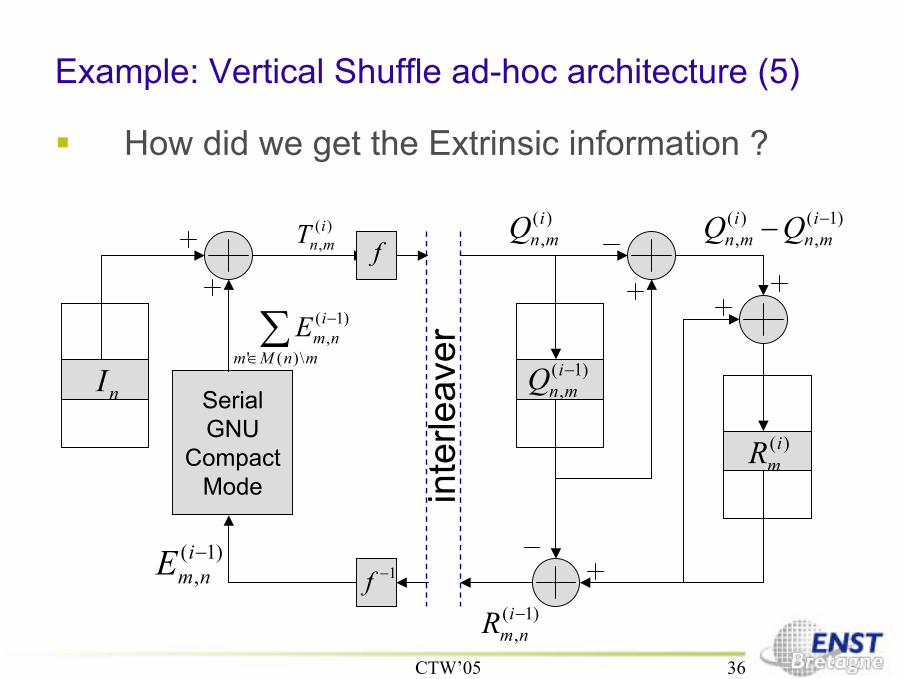
Example: Vertical Shuffle ad-hoc architecture (5)
How did we get the Extrinsic information ?
nISerialGNU
CompactMode
)1(,−inmE
∑∈
−
mnMm
inmE
\)('
)1(,
)(,imnT
inte
rleav
er
f
1−f
)(,imnQ
)(imR
)1(,−imnQ
)1(,−inmR
)1(,
)(,
−− imn
imn QQ

CTW’05 37
Example: Vertical Shuffle ad-hoc architecture (6)
NB : Qn,m messages can be moved to VNU:
nISerialGNU
CompactMode
)1(,−inmE
∑∈
−
mnMm
inmE
\)('
)1(,
)(,imnT f
1−f
)(,imnQ
)(imR
)1(,−imnQ
)1(,−inmR
)1(,
)(,
−− imn
imn QQ
inte
rleav
erN+E+M memory words

CTW’05 38
Conclusion
Investigations on high level design allowed usto propose a new and memory efficientarchitecture for the shuffled-BP schedule
Channel information still available (turboequalization for example)
Characterization of LDPC decoders by somegeneric parameters (interconnection networkposition, node unit architecture, node unitcontrol mode, parallelism parameters)

Thank you for your attention !


















