
Architecture Design for Low Power - University of Texas at...
26
The University of Texas at Austin EE382M VLSI-II Class Notes Foil # 1 Architecture Design for Low Power Peter Hofstee, IBM Systems & Technology Group Kevin Nowka, IBM Austin Research Laboratory EE-382M VLSI–II
Transcript of Architecture Design for Low Power - University of Texas at...

The University of Texas at AustinEE382M VLSI-II Class Notes Foil # 1
Architecture Design for Low Power
Peter Hofstee, IBM Systems & Technology Group Kevin Nowka, IBM Austin Research Laboratory
EE-382M
VLSI–II

The University of Texas at AustinEE382M VLSI-II Class Notes Foil # 2
Agenda
• System limitations/constraints
• Efficiency and metrics
• Designing for energy efficiency
– Instruction Set Architecture
– Microarchitecture/Organization
– Circuits (next lecture)

The University of Texas at AustinEE382M VLSI-II Class Notes Foil # 3
Designing within limits: power & energy
• Thermal limits (for most parts self-heating is a substantial thermal issue)
- package cost (4-5W limit for cheap plastic package, 50-100W/sq-cm air cooled limit, 5k-7.5kW 19” rack)
- Device reliability (junction temp > 125C quickly reduces reliability)- Performance (25C -> 105C loss of 30% of performance)
- Distribution limits- Substantial portion of wiring resource, area for power dist.- Higher current => lower R, greater dI/dt => more wire, decap- Package capable of low impedance distribution
- Energy capacity limits- AA battery ~1000mA.hr => limits power, function, or lifetime
- Energy cost - Energy for IT equipment large fraction of total cost of ownership

The University of Texas at AustinEE382M VLSI-II Class Notes Foil # 4
Efficiency
• Efficient design is all about managing tradeoffs• Within power/energy constrained designs, there are many ways
to achieve higher processor performance:– Higher supply voltage– Deeper pipelines– Increased ILP– Bigger transistors– Lower temperature– …

The University of Texas at AustinEE382M VLSI-II Class Notes Foil # 5
Efficiency Problem Statement
How do we make sure all power-performance tradeoffs in a design are made in a consistent and optimal manner?
What is the right metric?

The University of Texas at AustinEE382M VLSI-II Class Notes Foil # 6
Common Metrics for Energy-Efficiency
Metric CMOS 1st order scaling
Energy, PDPE
~ CV2
Energy-delayEτ
~ CV
Energy-delay2
Eτ2~ C

The University of Texas at AustinEE382M VLSI-II Class Notes Foil # 7
Each of These Metrics Makes Sense
• Energy– Lowest energy per operation, appropriate when there is no
performance constraint• Energy-delay
– Appropriate metric when application is assumed to be concurrent (twice as fast is only twice as good)
• Energy-delay2
– Appropriate metric under (old) voltage scaling assumptions– Matches AT2 notion of cost-performance

The University of Texas at AustinEE382M VLSI-II Class Notes Foil # 8
Example application of metrics:Sizing Gates versus Wires
Ctr Cw Delay (Ctr + Cw) / Ctr
Energy Ctr + Cw
Optimize assuming fixed wire load:
-Optimal Energy: Ctr = min-Optimal Energy-Delay: Ctr = Cw-Optimal Energy-Delay2: Ctr = 2 Cw-Optimal Energy-Delayn: Ctr = n Cw-Optimal Delay: Ctr =
Ctr

The University of Texas at AustinEE382M VLSI-II Class Notes Foil # 9
Energy-Delayn vs. Energy/Performancen
• Energy/Perf n is the more general metric– Energy-Delayn is a special case more appropriate for lower
level analysis– There are more ways to increase performance than just
increasing frequency!• Examples
– Multiprocessing– ILP
What n to choose for a Metric?
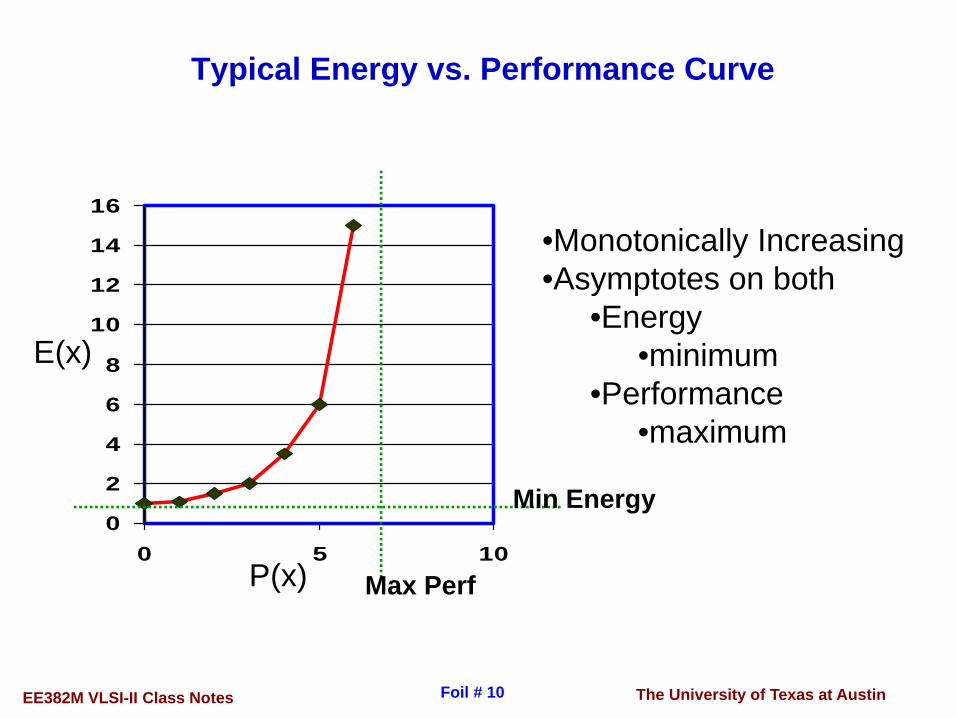
The University of Texas at AustinEE382M VLSI-II Class Notes Foil # 10
Typical Energy vs. Performance Curve
0
2
4
6
8
10
12
14
16
0 5 10
•Monotonically Increasing•Asymptotes on both
•Energy•minimum
•Performance•maximum
Min Energy
Max Perf
E(x)
P(x)
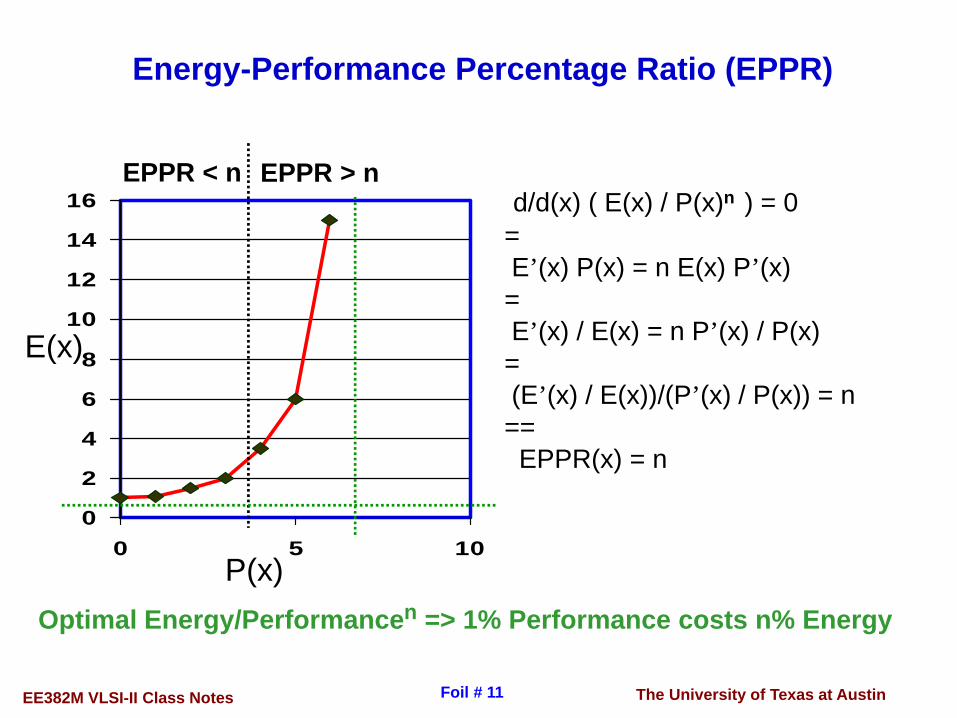
The University of Texas at AustinEE382M VLSI-II Class Notes Foil # 11
Energy-Performance Percentage Ratio (EPPR)
0
2
4
6
8
10
12
14
16
0 5 10
Optimal Energy/Performancen => 1% Performance costs n% Energy
d/d(x) ( E(x) / P(x)n ) = 0=E’(x) P(x) = n E(x) P’(x)=E’(x) / E(x) = n P’(x) / P(x)=(E’(x) / E(x))/(P’(x) / P(x)) = n==EPPR(x) = n
P(x)
E(x)
EPPR < n EPPR > n
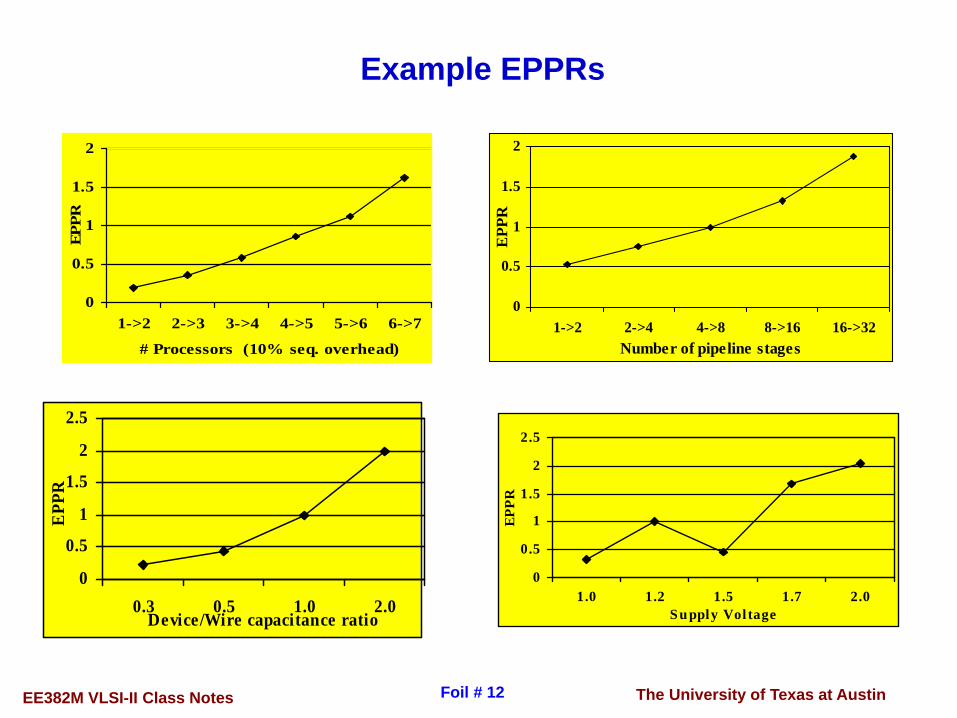
The University of Texas at AustinEE382M VLSI-II Class Notes Foil # 12
Example EPPRs
0
0.5
1
1.5
2
1->2 2->3 3->4 4->5 5->6 6->7
# Processors (10% seq. overhead)
EPPR
0
0.5
1
1.5
2
1->2 2->4 4->8 8->16 16->32Number of pipeline stages
EPP
R
0
0.5
1
1.5
2
2.5
0.3 0.5 1.0 2.0Device/Wire capacitance ratio
EPP
R
0
0.5
1
1.5
2
2.5
1.0 1.2 1.5 1.7 2.0Supply Vol tage
EPPR

The University of Texas at AustinEE382M VLSI-II Class Notes Foil # 13
Optimal Design => EPPR(x) = EPPR(y)
Poor man’s proof:Assume EPPR(x) = n , EPPR(y) = m , m > n
(e.g. x = Vdd, y = Pipeline Depth)
Increase x a little to gain performance (at a cost of n% Energy per 1% performance)
while decreasing y to hold performance constant(at a cost of m% Energy per 1% performance)
Net (if “little” is small enough to maintain m>n):ENERGY DECREASE at SAME PERFORMANCE, and thus
Optimal => EPPR(x) = EPPR(y)

The University of Texas at AustinEE382M VLSI-II Class Notes Foil # 14
A Characterization of Microprocessor Designs
• Power Optimized: EPPR < 1– Run at low Vdd– Mostly small devices– Shallow pipeline
• Power – Performance: 1<= EPPR <= 2– Run at nominal Vdd– Moderate pipeline depth, moderate ILP
• Performance optimized: EPPR > 2– Run at max. Vdd– Little concurrency in application– Deep pipelines

The University of Texas at AustinEE382M VLSI-II Class Notes Foil # 15
Metrics conclusions
• Energy-optimal designs have consistent EPPRs– Or EPPRs that have reached fundamental max. or min.
• Which EPPR is appropriate depends on the goals of the project– No one size fits all
• EPPRs provide a quantitative approach to Energy-efficient design– Many rules of thumb once EPPR is set

The University of Texas at AustinEE382M VLSI-II Class Notes Foil # 16
ISA Design for Efficiency
Instruction Set Architecture design for power efficiency (not a
focus of VLSI-II, nor of this lecture) involves:
1) Specifying what is (more efficiently w.r.t. perf, power)
implemented in
a) direct-mapped hardware,
b) general purpose instructions, or
c) in instruction sequences,
2) Encoding the instructions in such a way that they:
• Can be efficiently stored, moved, and decoded.

The University of Texas at AustinEE382M VLSI-II Class Notes Foil # 17
ISA Techniques
• Memory accessing model (RR vs RM)
– Reuse is especially profitable for power!
• Instruction encodings (variable length, short-fixed)
– Clear tradeoff between bandwidth & decode complexity
• I-Stream decompression (e.g. Codepack)
– Ditto, can save >½ the I/O switching, but costs time in reload.
• Dedicated ISA extensions (mmx, 3Dnow, Altivec), accelerators &
dedicated pipes(crypto, voice reco, dsp, graphics pipes)

The University of Texas at AustinEE382M VLSI-II Class Notes Foil # 18
Accelerators, direct-mapped implementations
“Direct mapped, hardware implementations can be up to 4-orders-magnitude less power for the same function as a general purpose processor”*
Hardware acceleration is particularly effective when combined in an SOC environment (avoid off-chip access penalty),
…especially when the processor and core can be operated at minimum voltages required to achieve computational throughput. E.g. PowerPC 405LP crypto accelerator, compression engine, speech reco accelerator.
* Allan, et. al., “2001 Tech. Roadmap for Semiconductors”,IEEE Computer Jan. 2002

The University of Texas at AustinEE382M VLSI-II Class Notes Foil # 19
uArchitecture / Organization for efficiency
uArchitecture design for power efficiency (more of a focus
for VLSI-II) involves:
– Specifying how architecture can be implemented to achieve
most performance under constraints
– Controlling how major resources will be partitioned, placed,
and interconnected

The University of Texas at AustinEE382M VLSI-II Class Notes Foil # 20
uArchitecture Techniques
• Partitioning of design – resource integration
• Parallelism:
– Execution: multiple issue, out-of-order execution,
speculation, branch prediction…
– Organization: set assoc caches, parallel execution with late
select
• Pipelining and super-pipelining
• Hardware/Software tradeoff – interlocks, dep. checking

The University of Texas at AustinEE382M VLSI-II Class Notes Foil # 21
Integration for energy efficiency
-- Fundamental issue: Technology scaling efficiencies have applied to on-chip only. I/O and packaging have not kept pace. Thus, the on-die capacity for FETs increases and the relative cost of off-chip increases => greater degree of integration.
-- For example, a 3.3V off-chip driver, with 10pF (driver, wire, pad, pin, package) consumes about 54pJ each time it is switched. Switching one NFET in a 100nm technology consumes about 0.2fJ. One 24b-address, 32b-data off-chip write > switching 15,000,000 FETs
-- uArch design to manage this discrepancy
-- Resulting challenges: yield; leakage; coexistance of heterogeneous technologies; analog in noisy, low-voltage digital environment;
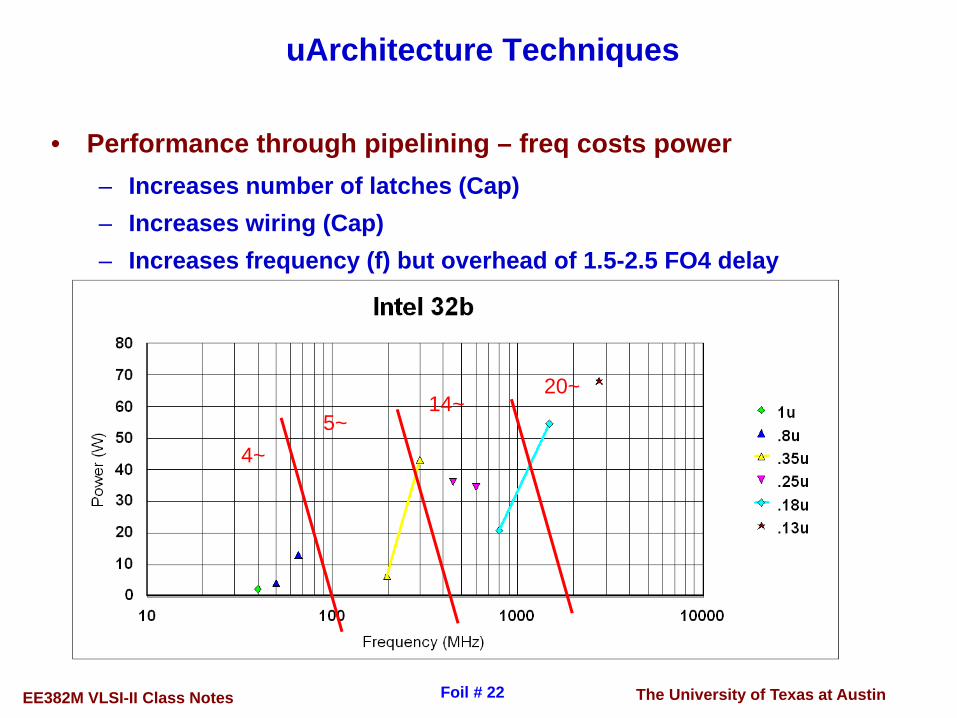
The University of Texas at AustinEE382M VLSI-II Class Notes Foil # 22
uArchitecture Techniques
• Performance through pipelining – freq costs power– Increases number of latches (Cap)– Increases wiring (Cap)– Increases frequency (f) but overhead of 1.5-2.5 FO4 delay
4~5~
14~20~

The University of Texas at AustinEE382M VLSI-II Class Notes Foil # 23
0.40.60.8
11.21.41.61.8
22.22.4
0.8 0.85 0.9 0.95 1 1.05 1.1 1.15 1.2 1.25 1.3
Relative Time per Instruction
Rel
ativ
e Po
wer
Optimal BIPS^3/W
Performance
Tradeoff via changing VddTradeoff via frequency
Impact on Design
Tradeoff via pipeline depth12FO4
18FO423FO4
14FO4
Maximum Power Budget
Zyuban, et. al., Transactions onComputer’ 04

The University of Texas at AustinEE382M VLSI-II Class Notes Foil # 24
uArchitecture Techniques
• Performance through parallelism – processor complexityhas high power cost
0.1 0.2 0.3 0.4 0.5 0.6 0.7ISPEC/MHz
20
30
40
50
60
70
80
90
100
Pow
er (W
) .68u.5u.35u.25u
DEC Alpha
064
164
264
remaps newuArch
‘064 2 issue,‘164 4 issue, ‘264 4 issue out-of-order
The University of Texas at AustinEE382M VLSI-II Class Notes Foil # 25
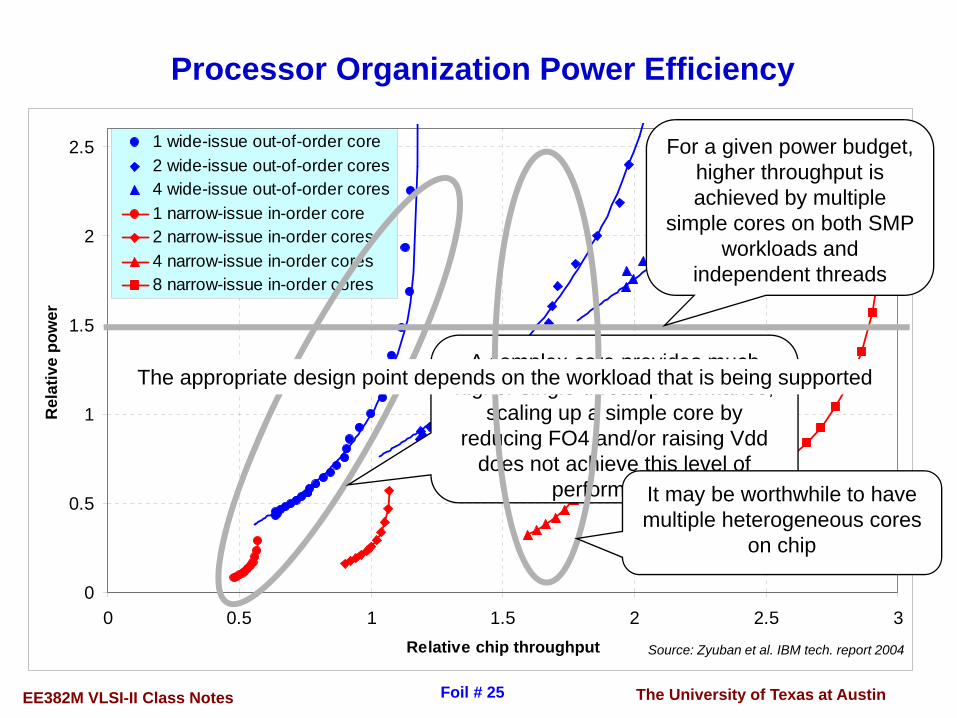
Processor Organization Power Efficiency
0
0.5
1
1.5
2
2.5
0 0.5 1 1.5 2 2.5 3Relative chip throughput
Rel
ativ
e po
wer
1 wide-issue out-of-order core2 wide-issue out-of-order cores4 wide-issue out-of-order cores1 narrow-issue in-order core2 narrow-issue in-order cores4 narrow-issue in-order cores8 narrow-issue in-order cores
For a given power budget, higher throughput is achieved by multiple
simple cores on both SMP workloads and
independent threads
A complex core provides much higher single-thread performance;
scaling up a simple core by reducing FO4 and/or raising Vdd
does not achieve this level of performance.It may be worthwhile to have
multiple heterogeneous cores on chip
The appropriate design point depends on the workload that is being supported
Source: Zyuban et al. IBM tech. report 2004

The University of Texas at AustinEE382M VLSI-II Class Notes Foil # 26
uArchitecture Summary
• Power efficient design means optimizing to the correct metric
• ISA design
• Custom hardware, accelerators – can be power efficient
• Integration – saves offchip power, can cost leakage
• Performance thru complexity – expensive in power
• Performance thru pipeline depth – expensive in power


















