
Applying Artificial Neural Networks to problems in Geology · •Artificial neural networks: a...
28
Applying Artificial Neural Networks to problems in Geology Ben MacDonell
Transcript of Applying Artificial Neural Networks to problems in Geology · •Artificial neural networks: a...

Applying Artificial Neural Networks to problems in Geology
Ben MacDonell

• Artificial neural networks: a new method for mineral prospectivity mapping
• Training an ANN on geological data to predict parts of an area that are most likely to contain minerals
• Detection of hydrocarbon reservoir boundaries using neural network analysis of surface geochemical data
• Training an ANN to detect a hydrocarbon reservoir from data collected from soil samples
• An artificial neural network-based approach to identifying mammalian fossil localities in the Great Divide Basin, Wyoming
• Training an ANN to detect locations that may contain fossils from a data set of known fossil locations

Why use an ANN?
• Relationships are often not well understood
• Data is often not independent
• Data can be noisy
• Collecting data is expensive (need to generalize)

What is grade estimation?
Given data collected from geological tests, determine where the best place to mine is.
Testing can range from satellite imaging, analyzing magnetic fields, to drilling holes.

Why do we need computers to do this?
The amount of data generated by mineral exploration techniques is already far too vast for a human to analyze.
The amount of data we need to analyze is continually increasing as new technologies become available.

Current methods
• Statistical method - fails when region is poorly explored.
• Fuzzy logic method - requires an expert to analyze the results.
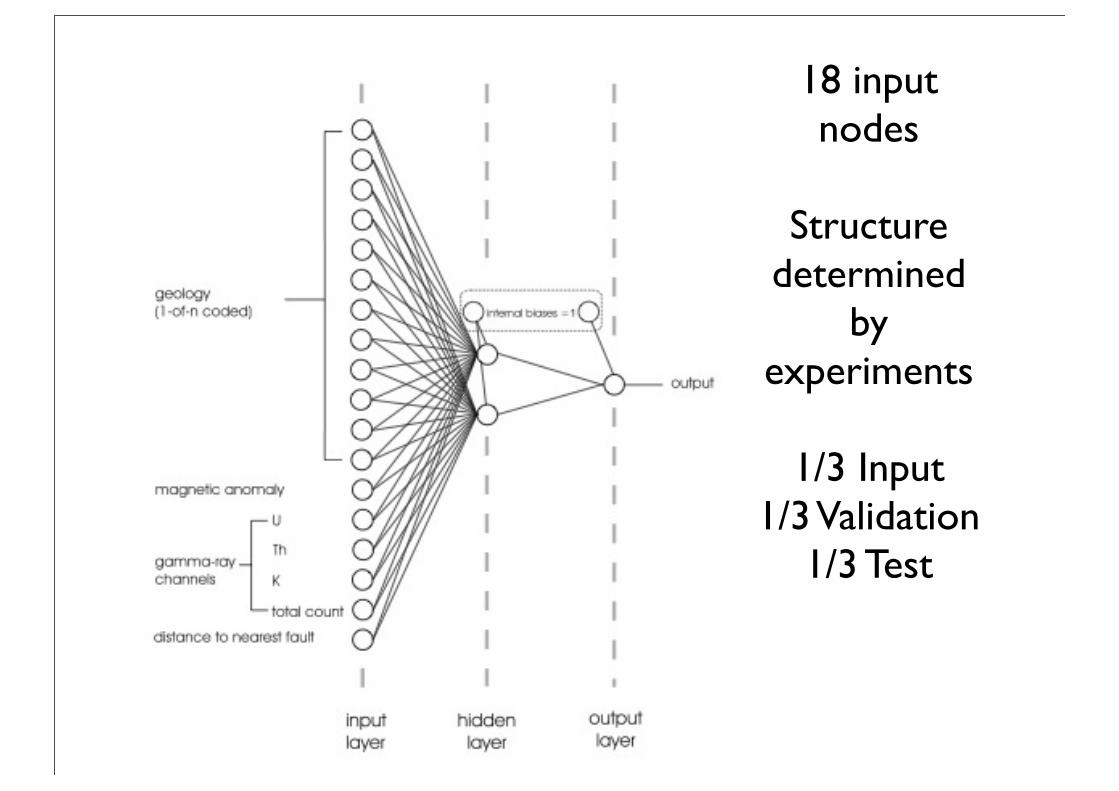
18 input nodes
Structure determined
by experiments
1/3 Input1/3 Validation
1/3 Test
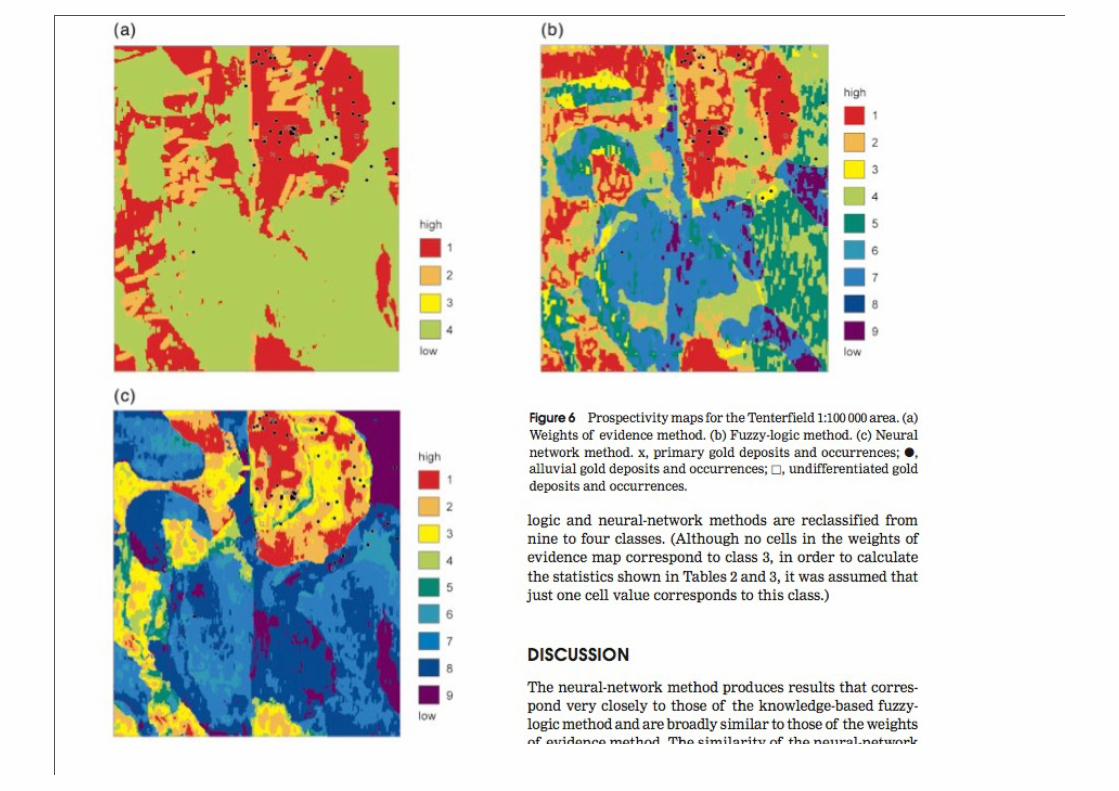

Results
• More accurate than the statistical method.
• Similar to fuzzy logic method (but used 2/3 of the data).
• The authors suggested this was because the ANN is able to respond to critical combinations of parameters, rather than the statistical and fuzzy logic methods which can only increase the prospectivity value.

Problems
• They found that the networks performance degrades when they use more than 18 input nodes but they didn’t try to increase the number of hidden nodes.
• Their experiments showed that the network trained the fastest with a momentum constant of 0. Maybe they didn’t do enough tests per value?
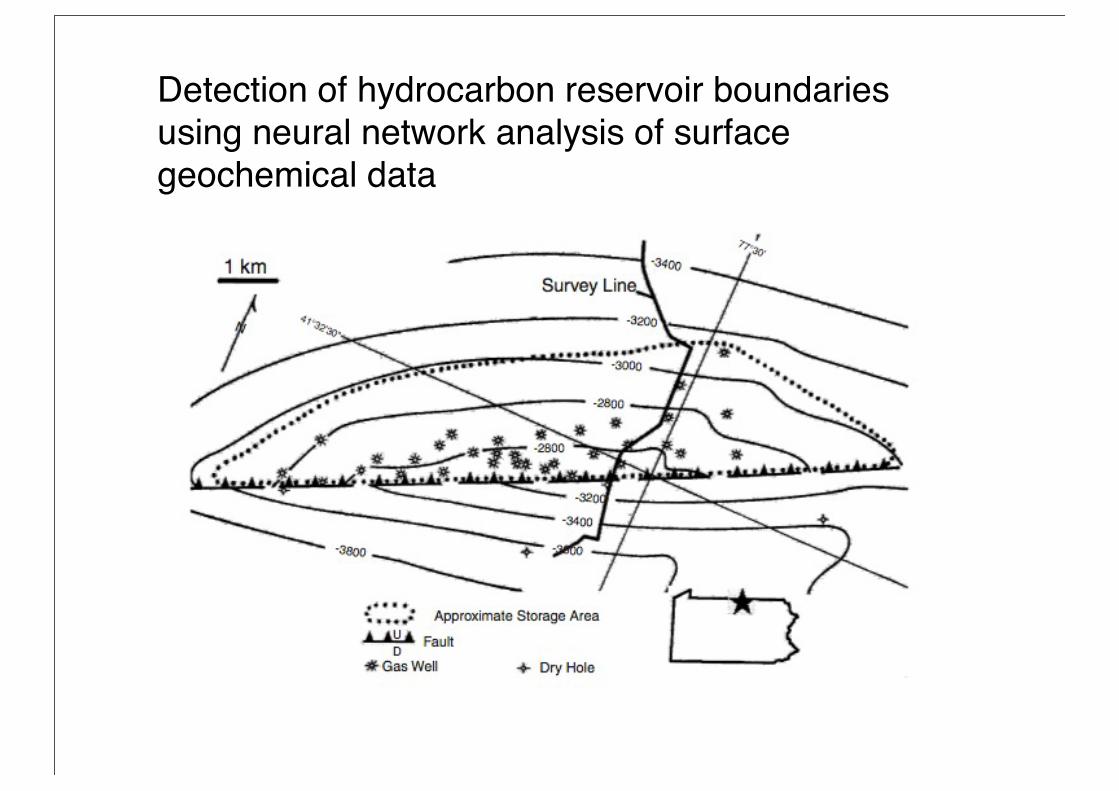
Detection of hydrocarbon reservoir boundaries using neural network analysis of surface geochemical data

Why use an ANN?
• The relationship between soil chemistry and a reservoir is not well understood.
• Collecting data the traditional way is expensive, you have to drill holes.

8:10:1 network
Used three parameters to represent ethane content. The current position, and the values of two neighbours

Results
• Network successfully categorized 15/16 test patterns

ProblemsThe network was trained using data collected in November 1996. When it was tested on data collected in July 1996 it categorized only 1/3 of the input patterns.Added an extra input parameter to represent the season. When trained on data from both seasons with the extra parameter the network performed well again.
Could have fixed this by having the seasonal parameters represent a difference from a control some distance from the reservoir.

We would expect the moisture value to vary between seasons so if a control soil sample is taken from a position that is probably not over the reservoir and is subtracted from all samples we might be able to remove the seasonal variation.
However, the ethane concentration is also likely to vary between seasons because the reservoir is now used as storage. But this wouldn’t be a problem when exploring a new reservoir.

The whole paper relies on the network being able to generalize but:
Arbitrary choice of 10 hidden nodes (no experiments were performed).
Didn’t use a validation set.
Could have improved generalization by: creating a validation set, implementing network pruning, or implementing weight decay.

Bigger problems3/8 input parameters are ethane concentration values.
The authors admit that the experiment relies on the false assumption that ethane will travel vertically up from the reservoir when in reality it will travel the path of least resistance.
So it is unlikely to work in practice.

An artificial neural network-based approach to identifying mammalian fossil localities in the Great Divide Basin, Wyoming
• Identifying fossil-bearing rock requires expert knowledge of anatomy and geology
• Authors attempt to train a network to identify fossil-bearing rock by training it on data collected from 110 fossil locations

6:12:20:10 network
• Structure decided after testing 16 different network configurations.
• Input patterns created from Landsat images. Used the pixel value at each fossil location.
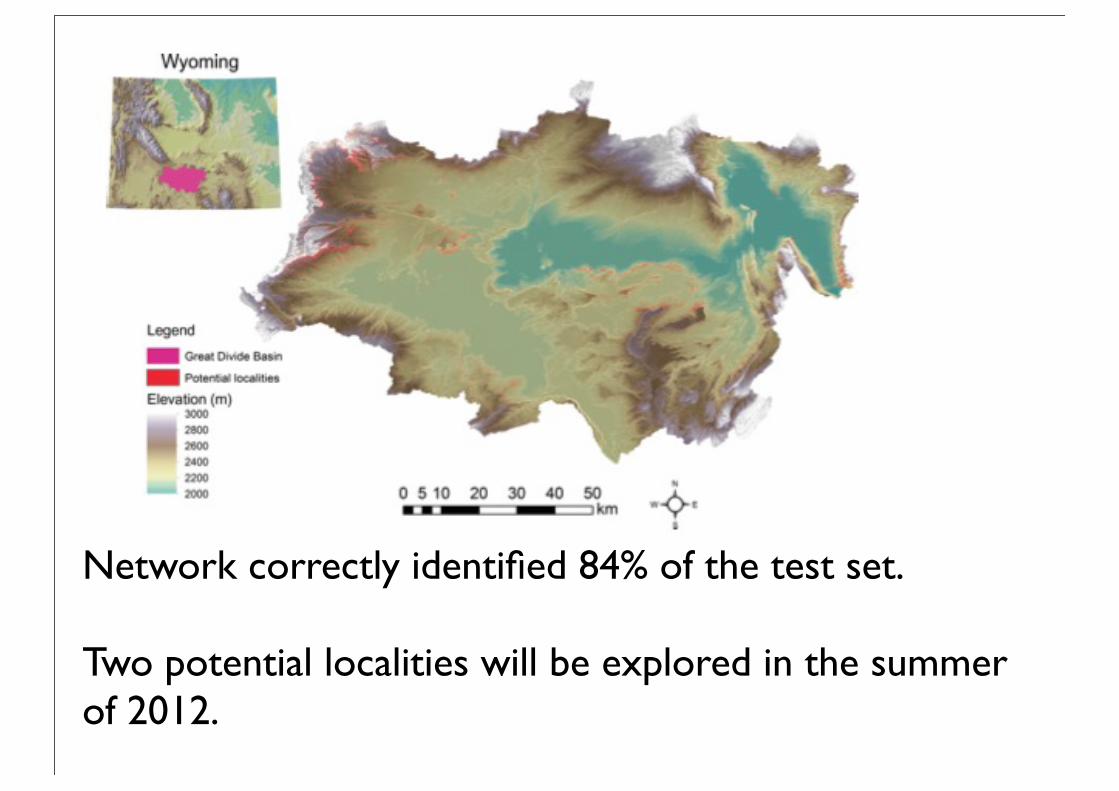
Network correctly identified 84% of the test set.
Two potential localities will be explored in the summer of 2012.

Problems
The authors didn’t say what the output nodes represent. Why do they need 10?
Chose the structure after 16 tests. Could have used a script to test hundreds of combinations of network parameters. Or used a network pruning technique.

ProblemsThe whole point of the paper is to tell the difference between rocks that contain fossils and rocks that don’t contain fossils.
They didn’t have any input patterns that don’t contain fossils. So the network could have simply learned to output “highly prospective” for any input pattern.
Could easily have invented input patterns for non-fossiliferous rocks since only a few specific types of rock can harbor fossils.

Problems
Since the entire data set consists only of fossiliferous rocks and the test set is a subset of the data set. Then the network is obviously going to output “highly prospective” for most of the test set. So the results don’t tell us anything about the networks ability to predict fossil locations.

ProblemsThe previous map shows the network locating potentially fossiliferous rock. But after training the network, the authors decided they weren’t interested in fossils found on ground that wasn’t sloped.
So they decided that only data with a slope greater than 5 degrees would be input into the network. This constraint would make a network that generally outputs “highly prospective” appear to be more discerning than it is, when deciding if a location is likely to contain fossiliferous rock.
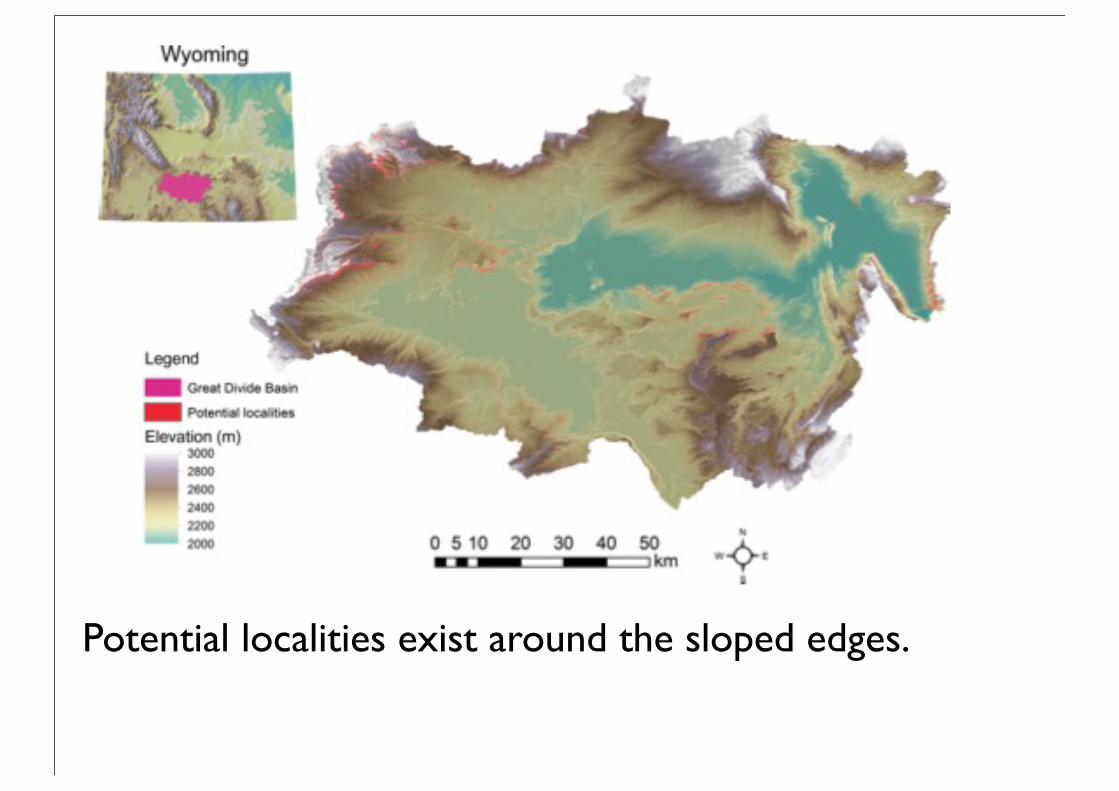
Potential localities exist around the sloped edges.

Problems with all the papers
• All rely on the network generalizing. But none made any attempt to improve generalization except for a few experiments with structure.
• All could benefit from implementing network pruning, weight decay, or more experimenting with the number of hidden nodes.
• Could have used a small learning constant since time to train is not an issue.

Questions


















