

Apache Lucene for Java EE Developers
77
APACHE LUCENE FOR JAVAEE DEVELOPERS VIRTUAL:JBUG by @SanneGrinovero
-
Upload
virtual-jboss-user-group -
Category
Technology
-
view
321 -
download
11
Transcript of Apache Lucene for Java EE Developers

A QUICK INTRODUCTION
HIBERNATE TEAM
Hibernate Search project lead
Hibernate OGM team, occasionally Hibernate ORM

INFINISPAN TEAM
The Lucene guy: Infinispan Query, Infinispan Lucene Directory

OTHER PROJECTS I HELP WITH...
WildFly, JGroups, Apache Lucene, ...

SUPPORTED BY
Red Hat and a lot of passion for OSS

AGENDAWhat is and how can it help youIntegrations with a JPA application via How does this all relate with and Lucene index managementPlans and wishlist for the future
Apache LuceneHibernate Search
Infinispan WildFly
THE SEARCH PROBLEM
Hello, I'm looking for a book in your onlineshop having primary key #2342


SQL CAN HANDLE TEXT
The LIKE operator?
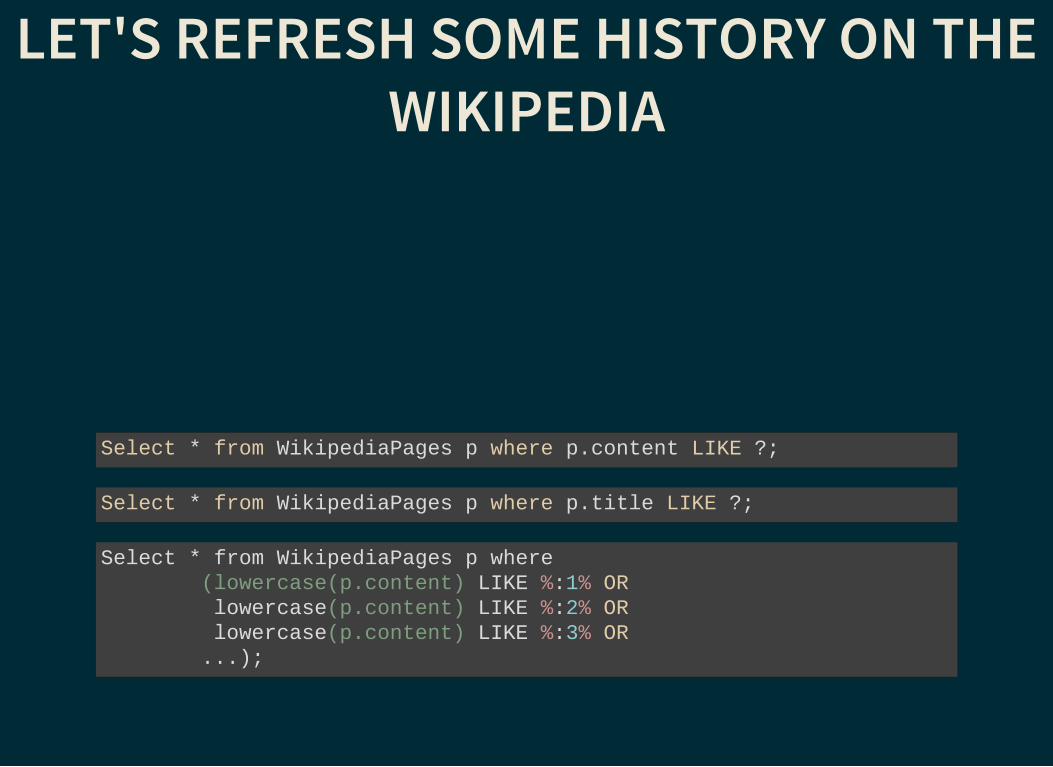
LET'S REFRESH SOME HISTORY ON THEWIKIPEDIA
Select * from WikipediaPages p where p.content LIKE ?;
Select * from WikipediaPages p where p.title LIKE ?;
Select * from WikipediaPages p where (lowercase(p.content) LIKE %:1% OR lowercase(p.content) LIKE %:2% OR lowercase(p.content) LIKE %:3% OR ...);



AM I CHEATING?
I'm quoting some very successfull web companies.
How many can you list which do not provide an effectivesearch engine?
Why is that?

REQUIREMENTS FOR A SEARCH ENGINE
Need to guess what you want w/o you typing all of thecontent
We all hate forms
We want the results in the blink of an eye
We want the right result on top: Relevance


SOME MORE THINGS TO CONSIDER:
Approximate word matches
Stemming / Language specific analysis
Typos
Synonyms, Abbreviations, Technical Languagespecializations

BASICS: KEYWORD EXTRACTIONOn how to improve running by Scott
1. Tokenization & Analysis:howimprovrunscott
2. Scoring

APACHE LUCENEOpen source Apache™ top level projectPrimarily Java, ported to many other languages andplatformsExtremely popular, it's everywhere!High pace of improvement, excellent teamMost impressive testing

AS A JAVAEE DEVELOPER:
You are familiar with JPA
But Lucene is much better than a relational database toaddress this problem
Easy integration with the platform is a requirement
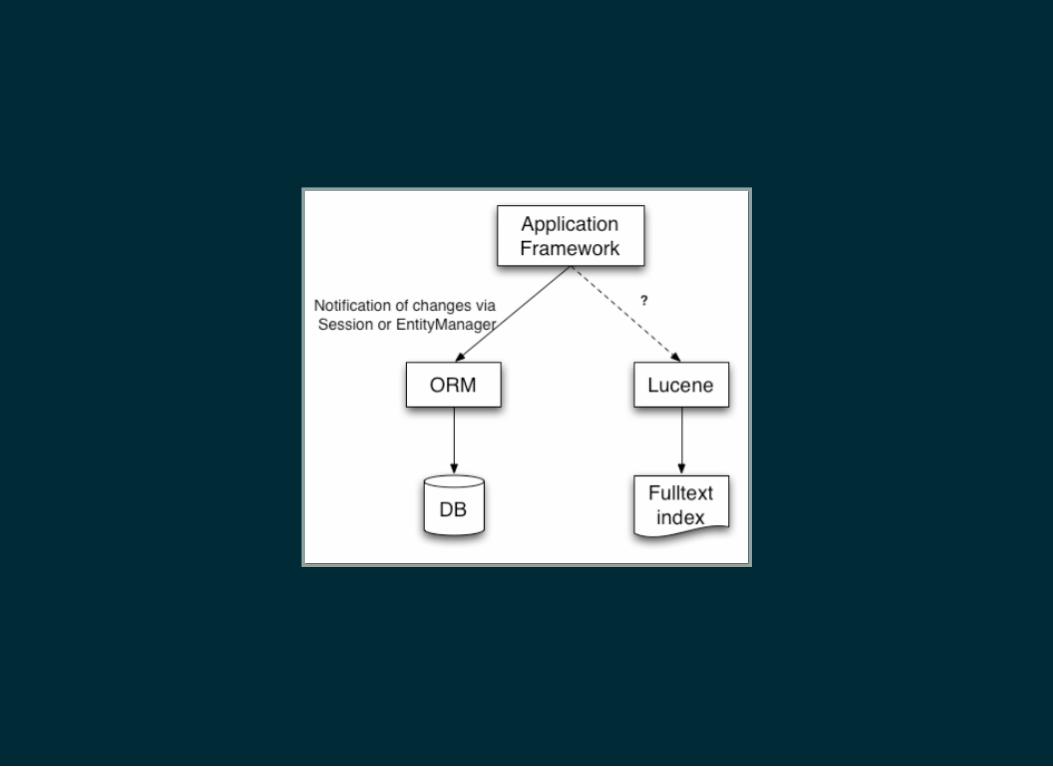

LET'S INTRODUCE APACHE LUCENE VIAHIBERNATE SEARCH
Deeply but transparently integrated with Hibernate's

Deeply but transparently integrated with Hibernate'sEntityManager
Internally uses advanced Apache Lucene features, butprotects your deadlines from the lower level detailsGets great performance out of itSimple annotations, yet many flexible override options

Does not prevent you to perform any form of advanced /native Lucene query

Transparent index state synchronizationTransaction integrationsOptions to rebuild the index efficientlyFailover and clustering integration pointsFlexible Error handling

HIBERNATE SEARCH QUICKSTART<dependency> <groupid>org.hibernate</groupid> <artifactid>hibernatesearchorm</artifactid> <version>5.4.0.CR1</version></dependency><dependency> <groupid>org.hibernate</groupid> <artifactid>hibernatecore</artifactid> <version>5.0.0.CR2</version></dependency><dependency> <groupid>org.hibernate</groupid> <artifactid>hibernateentitymanager</artifactid> <version>5.0.0.CR2</version></dependency>

HOW TO INDEX A TRIVIAL DOMAINMODEL
@Entitypublic class Actor @Id Integer id; String name;
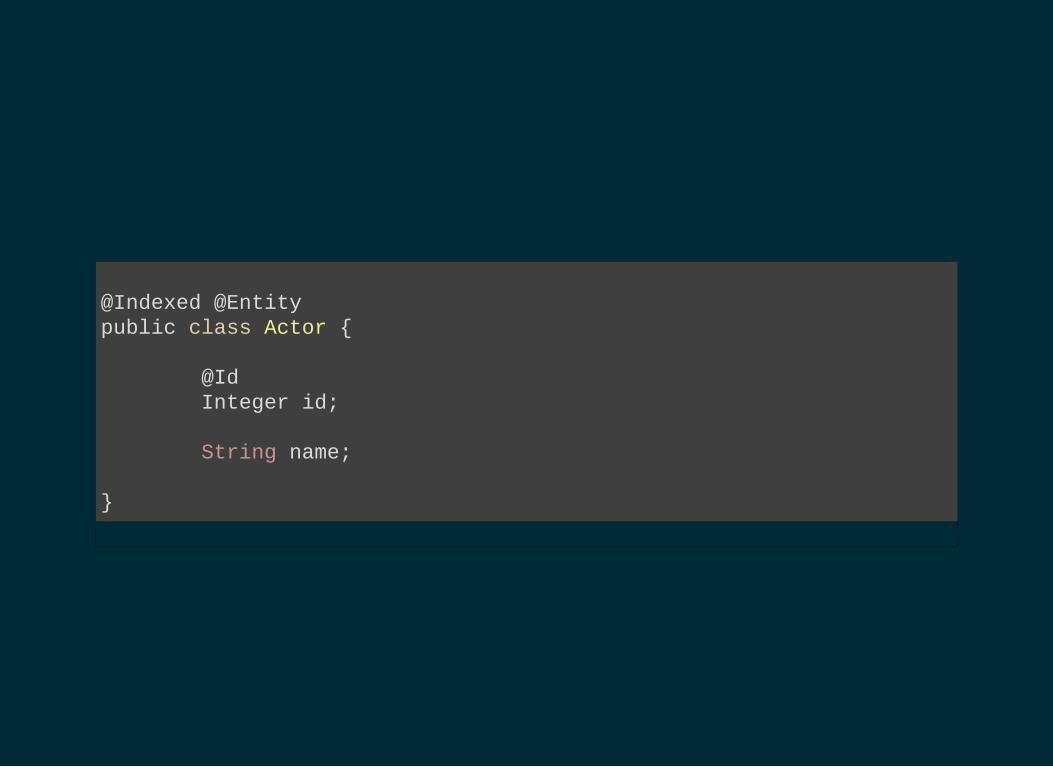
@Indexed @Entitypublic class Actor @Id Integer id; String name;

@Indexed @Entitypublic class Actor @Id Integer id; @Field String name;

LET'S INTRODUCE RELATIONS
@Entitypublic class DVD
@Id Integer id;
String title;
@ManyToMany Set<Actor> actors = new HashSet<>();

@Indexed @Entitypublic class DVD
@Id Integer id;
@Field String title;
@ManyToMany @IndexedEmbedded Set<Actor> actors = new HashSet<>();

INDEX FIELDS FOR ACTOR
id name
1 Harrison Ford
2 Kirsten Dunst
INDEX FIELDS FOR DVD
id title actors.name *
1 Melancholia Kirsten Dunst, Charlotte Gainsbourg,Kiefer Sutherland
2 The ForceAwakens
Harrison Ford, Mark Hamill, CarrieFisher

RUN A LUCENE QUERY BUT GET JPAMANAGED RESULTS
String[] productFields = "title", "actors.name" ;
org.apache.lucene.search.Query luceneQuery = // ...
FullTextEntityManager ftEm = Search.getFullTextEntityManager( entityManager );
FullTextQuery query = // extends javax.persistence.Query ftEm.createFullTextQuery( luceneQuery, DVD.class );
List dvds = // Managed entities! query.setMaxResults(100).getResultList();
int totalNbrOfResults = query.getResultSize();

HIBERNATE SEARCH: BASICS DEMO

LUCENE & TEXT ANALYSIS@Indexed(index = "tweets")@Analyzer(definition = "english")@AnalyzerDef(name = "english", tokenizer = @TokenizerDef( factory = StandardTokenizerFactory.class), filters = @TokenFilterDef(factory = ASCIIFoldingFilterFactory.class), @TokenFilterDef(factory = LowerCaseFilterFactory.class), @TokenFilterDef(factory = StopFilterFactory.class, params = @Parameter(name = "words", value = "stoplist.properties"), @Parameter(name = "ignoreCase", value = "false") ))@Entitypublic class Tweet
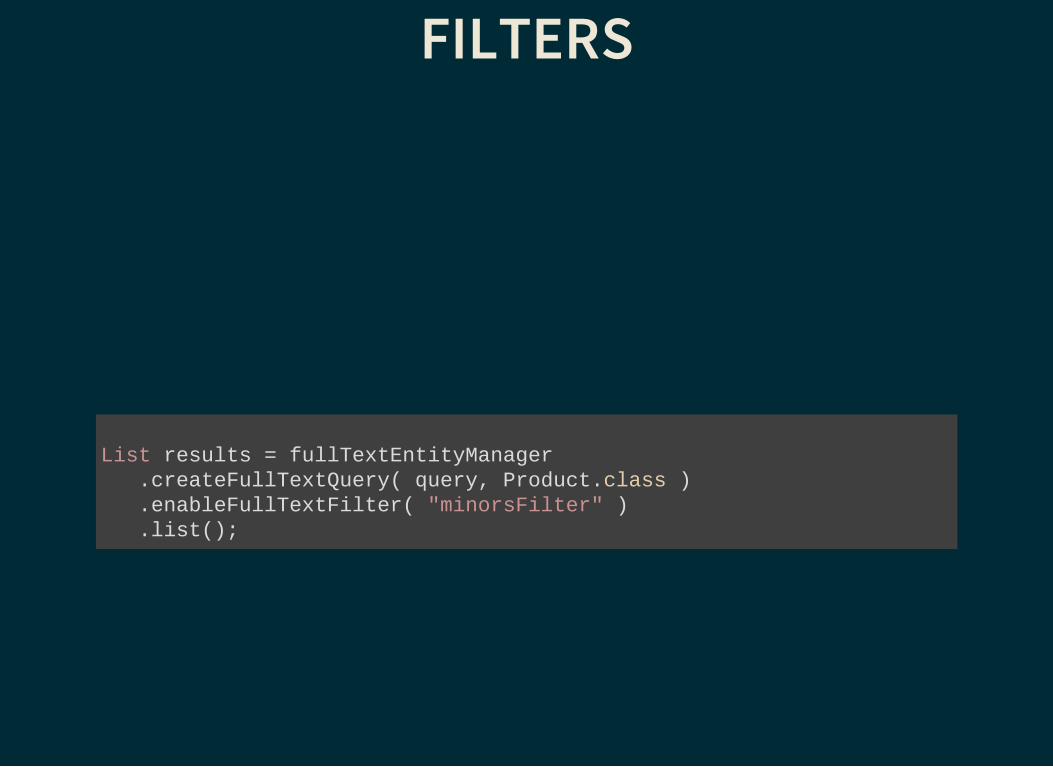
FILTERS
List results = fullTextEntityManager .createFullTextQuery( query, Product.class ) .enableFullTextFilter( "minorsFilter" ) .list();
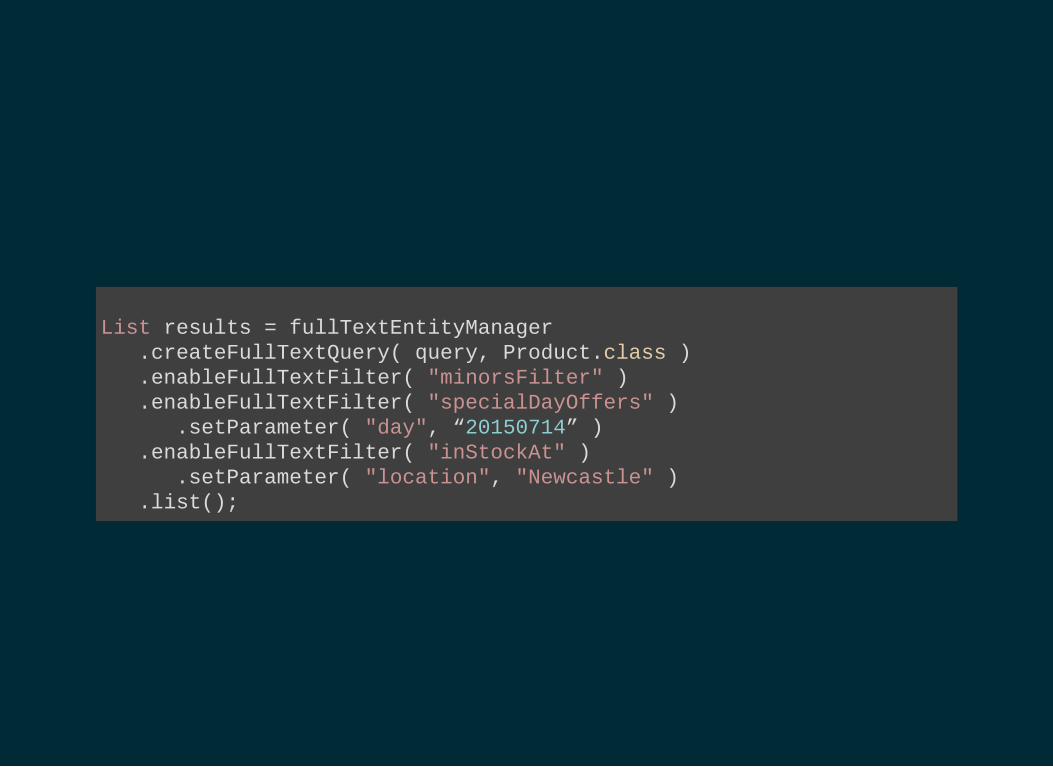
List results = fullTextEntityManager .createFullTextQuery( query, Product.class ) .enableFullTextFilter( "minorsFilter" ) .enableFullTextFilter( "specialDayOffers" ) .setParameter( "day", “20150714” ) .enableFullTextFilter( "inStockAt" ) .setParameter( "location", "Newcastle" ) .list();


FACETING

"MORE LIKE THIS"Coffee decaffInstance = ... // you already have oneQueryBuilder qb = getCoffeeQueryBuilder();Query mltQuery = qb .moreLikeThis() .comparingAllFields() .toEntityWithId( decaffInstance.getId() ) .createQuery();List results = fullTextEntityManager .createFullTextQuery( mltQuery, Coffee.class ) .list();

SPATIAL FILTERING

HOW TO RUN THIS ON WILDFLY?

ARCHITECTURE & INDEX MANAGEMENT
ah, the catch!

Indexes need to be stored, updated and read from.
You can have many indexes, managed independentlyAn index can be written by an exclusive writer onlyBackends can be configured differently per indexIndex storage - the Directory - can also be configured perindex



THE INFINISPAN / LUCENEINTEGRATIONS

WHAT IS INFINISPAN?In Memory Key/Value StoreASL v2 LicenseScalableJTA TransactionsPersistence (File/JDBC/LevelDB/...)Local/ClusteredEmbedded/Server...

INFINISPAN / JAVAEE?JavaEE: JCache implementationA core component of WildFly"Embedded" mode does not depend on WildFlyHibernate 2n level cache

INFINISPAN / APACHE LUCENE?Lucene integrations for Querying the datagrid!Lucene integrations to store the index!Hibernate Search integrations!

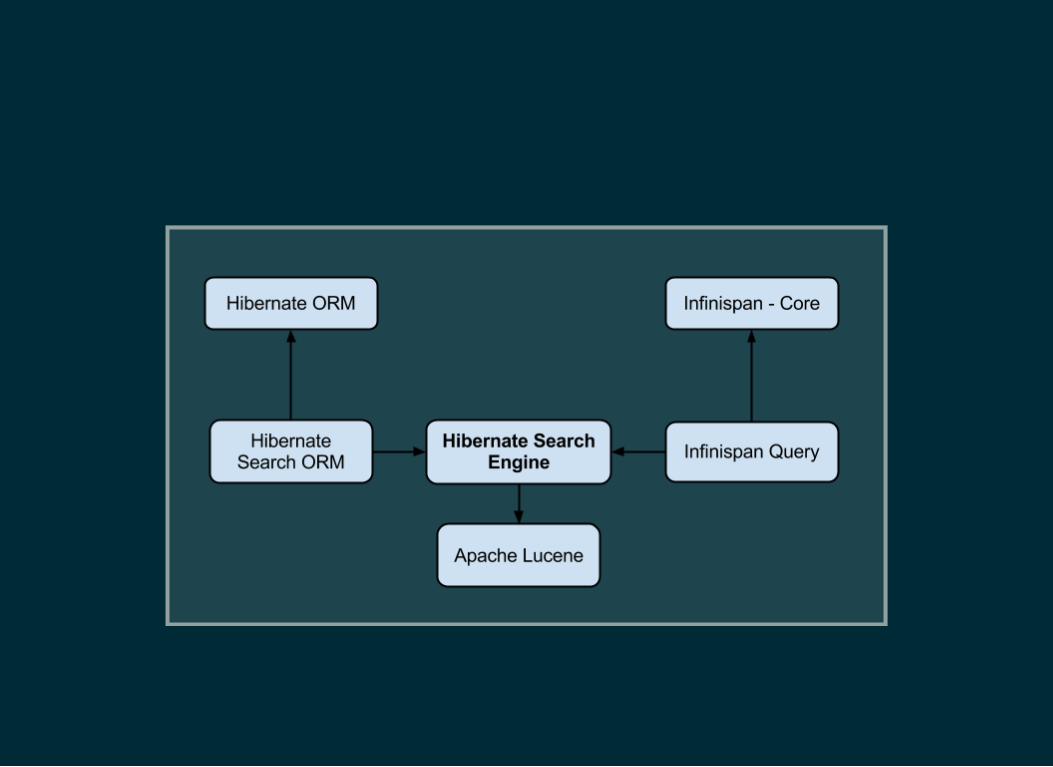
HIBERNATE SEARCH & INFINISPANQUERY
Same underlying technologySame API to learnSame indexing configuration options
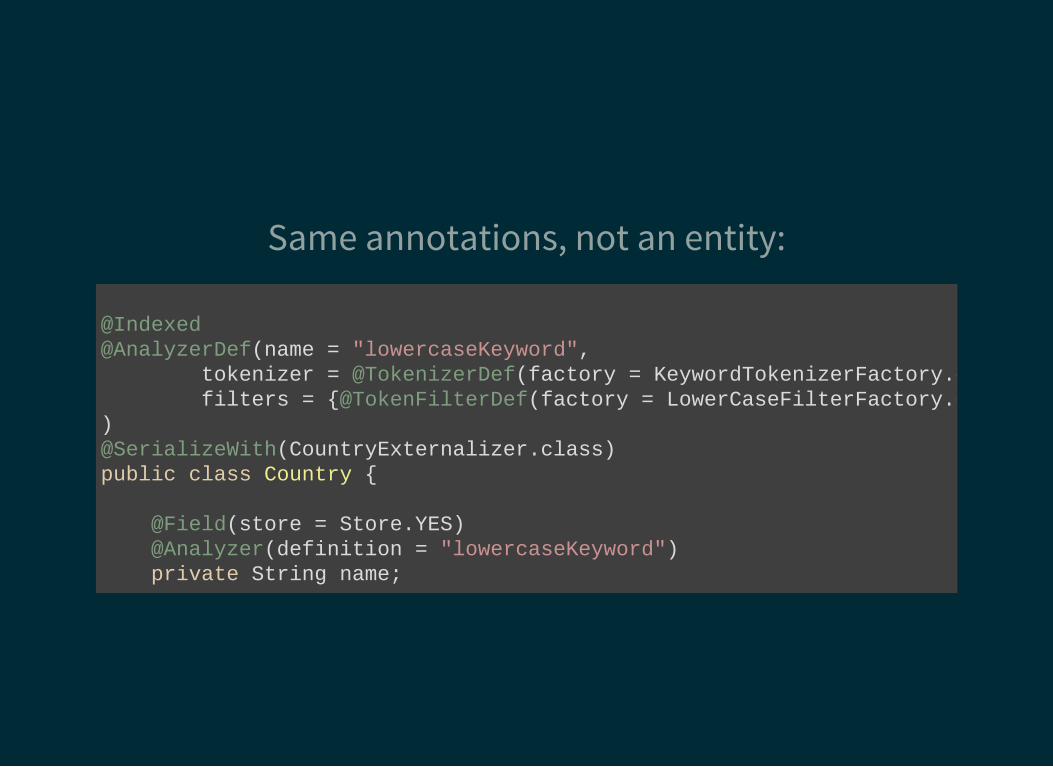
Same annotations, not an entity:
@Indexed@AnalyzerDef(name = "lowercaseKeyword", tokenizer = @TokenizerDef(factory = KeywordTokenizerFactory.class), filters = @TokenFilterDef(factory = LowerCaseFilterFactory.class))@SerializeWith(CountryExternalizer.class)public class Country
@Field(store = Store.YES) @Analyzer(definition = "lowercaseKeyword") private String name;

Store the Java POJO classes in the cache directly:
Country uk = ...cache.put("UK", uk );

USING LUCENE QUERY PARSERQueryParser qp = new QueryParser("default", new StandardAnalyzer()); Query luceneQ = qp .parse("+station.name:airport +year:2014 +month:12 +(avgTemp < 0)");
CacheQuery cq = Search.getSearchManager(cache) .getQuery(luceneQ, DaySummary.class); List<Object> results = query.list();

COUNT ENTITIESimport org.apache.lucene.search.MatchAllDocsQuery;
MatchAllDocsQuery allDocsQuery = new MatchAllDocsQuery(); CacheQuery query = Search.getSearchManager(cache) .getQuery(allDocsQuery, DaySummary.class); int count = query.getResultSize();

USING LUCENE INDEXREADERDIRECTLY
SearchIntegrator searchFactory = Search.getSearchManager(cache) .getSearchFactory(); IndexReader indexReader = searchFactory .getIndexReaderAccessor().open(DaySummary.class); IndexSearcher searcher = new IndexSearcher(indexReader);

GETTING STARTED WITH INFINISPAN<dependency> <groupId>org.infinispan</groupId> <artifactId>infinispanembedded</artifactId> <version>7.2.3.Final</version></dependency>
EmbeddedCacheManager cacheManager = new DefaultCacheManager();Cache<String,String> cache = cacheManager.getCache();
cache.put("key", "data goes here");

ADD PERSISTENCE (XML)<infinispan> <cachecontainer> <localcache name="testCache"> <persistence> <leveldbstore path="/tmp/folder"/> </persistence> </localcache> </cachecontainer></infinispan>
DefaultCacheManager cm = new DefaultCacheManager("infinispan.xml");Cache<Integer, String> cache = cacheManager.getCache("testCache");

ADD PERSISTENCE(PROGRAMMATIC)
Configuration configuration = new ConfigurationBuilder() .persistence() .addStore(LevelDBStoreConfigurationBuilder.class) .build();
DefaultCacheManager cm = new DefaultCacheManager(configuration);Cache<Integer, String> cache = cm.getCache();

CLUSTERING - REPLICATEDGlobalConfiguration globalCfg = new GlobalConfigurationBuilder() .transport().defaultTransport() .build(); Configuration cfg = new ConfigurationBuilder() .clustering().cacheMode(CacheMode.REPL_SYNC) .build(); EmbeddedCacheManager cm = new DefaultCacheManager(globalCfg, cfg);Cache<Integer, String> cache = cm.getCache();

CLUSTERING - DISTRIBUTEDGlobalConfiguration globalCfg = new GlobalConfigurationBuilder() .transport().defaultTransport() .build(); Configuration configuration = new ConfigurationBuilder() .clustering().cacheMode(CacheMode.DIST_SYNC) .hash().numOwners(2).numSegments(100) .build();
EmbeddedCacheManager cm = new DefaultCacheManager(globalConfiguration, configuration);Cache<Integer, String> cache = cm.getCache();

QUERYINGApache Lucene IndexNative Map ReduceIndex-lessHadoop and Spark (coming)

INDEXING - CONFIGURATIONConfiguration configuration = new ConfigurationBuilder() .indexing().index(Index.ALL) .build();
EmbeddedCacheManager cm = new DefaultCacheManager(configuration);Cache<Integer, DaySummary> cache = cm.getCache();

QUERY - SYNC/ASYNCConfiguration configuration = new ConfigurationBuilder() .indexing().index(Index.LOCAL) .addProperty("default.worker.execution", "async") .build();
EmbeddedCacheManager cm = new DefaultCacheManager(configuration);Cache<Integer, DaySummary> cache = cm.getCache();

QUERY - RAM STORAGEConfiguration configuration = new ConfigurationBuilder() .indexing().index(Index.LOCAL) .addProperty("default.worker.execution", "async") .addProperty("default.directory_provider", "ram") .build();
EmbeddedCacheManager cm = new DefaultCacheManager(configuration);Cache<Integer, DaySummary> cache = cm.getCache();

QUERY - INFINISPAN STORAGEConfiguration configuration = new ConfigurationBuilder() .indexing().index(Index.LOCAL) .addProperty("default.worker.execution", "async") .addProperty("default.directory_provider", "infinispan") .build();
EmbeddedCacheManager cm = new DefaultCacheManager(configuration);Cache<Integer, DaySummary> cache = cm.getCache();

QUERY - FILESYSTEM STORAGEConfiguration configuration = new ConfigurationBuilder() .indexing().index(Index.LOCAL) .addProperty("default.directory_provider", "filesystem") .addProperty("default.indexBase", "/path/to/index);.build();
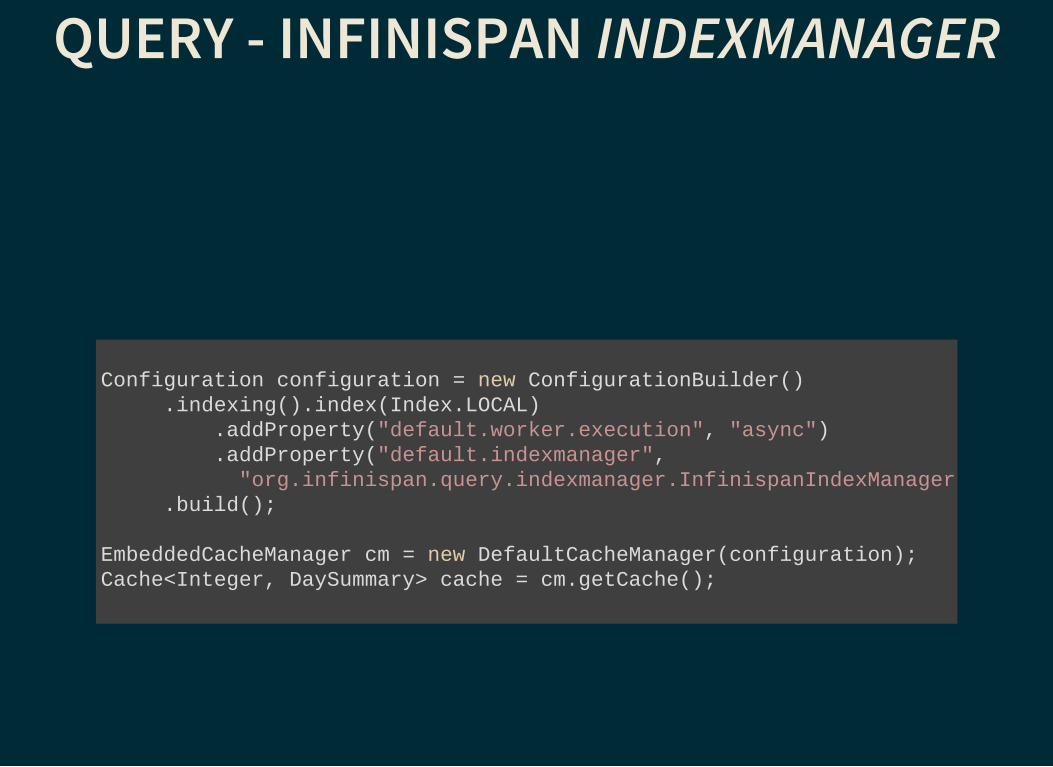
QUERY - INFINISPAN INDEXMANAGER
Configuration configuration = new ConfigurationBuilder() .indexing().index(Index.LOCAL) .addProperty("default.worker.execution", "async") .addProperty("default.indexmanager", "org.infinispan.query.indexmanager.InfinispanIndexManager" .build();
EmbeddedCacheManager cm = new DefaultCacheManager(configuration);Cache<Integer, DaySummary> cache = cm.getCache();
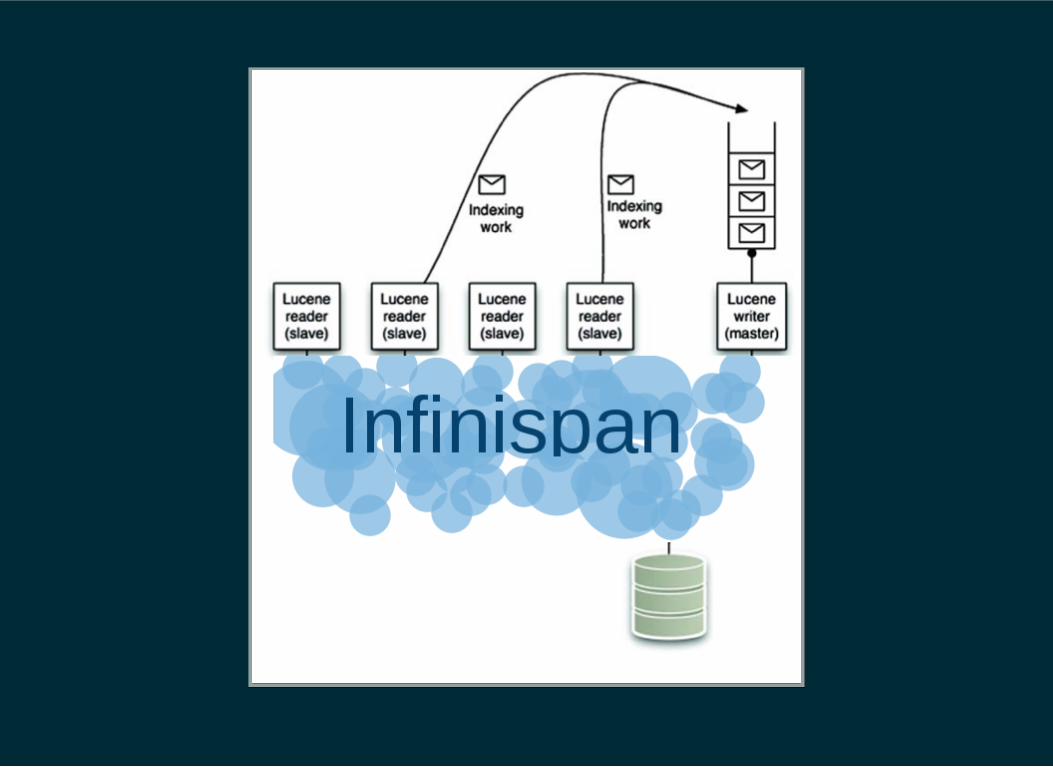

THE INFINISPAN LUCENE DIRECTORY
Storing the Apache Lucene index in an high-performance inmemory data grid
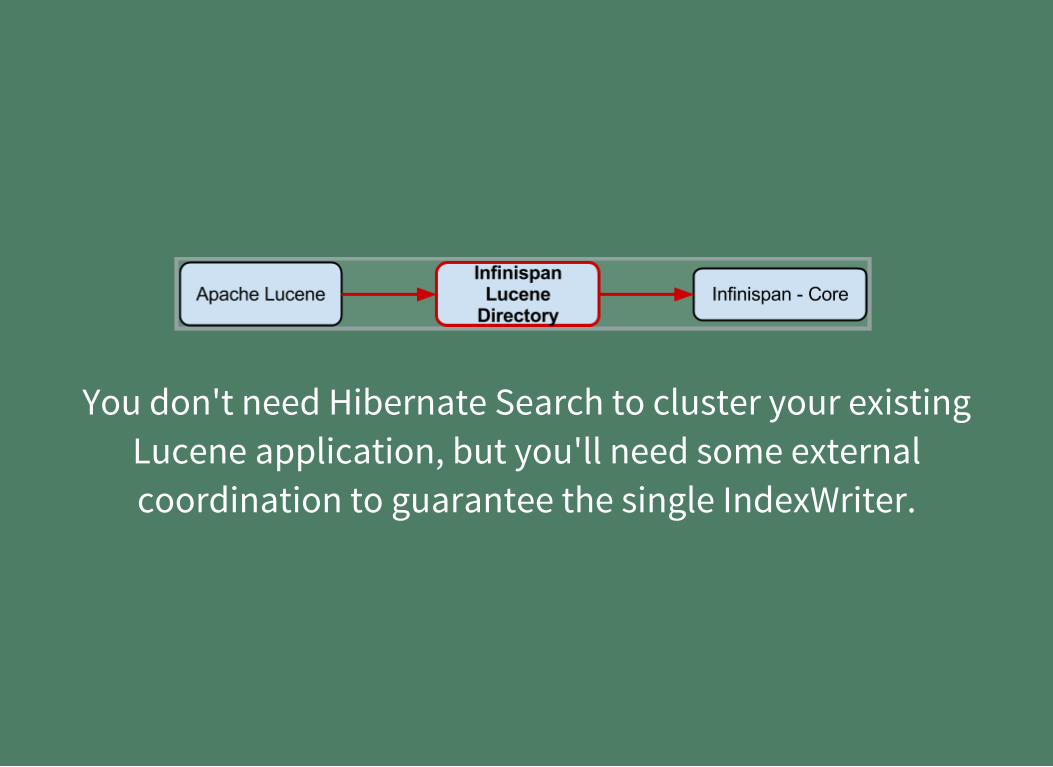
You don't need Hibernate Search to cluster your existingLucene application, but you'll need some externalcoordination to guarantee the single IndexWriter.

INFINISPAN QUERY AND THE LUCENEDIRECTORY IN ACTION
Weather Demo by Gustavo Nalle Fernandes
DEMO
Indexed
NOAA.gov data from 1901 to 2014~10M summariesYearly country max recorded temperature by month
Cache<Integer, DaySummary>

WHAT'S ON THE HORIZON FORINFINISPAN
Improvements in indexing performanceHadoop and Spark integration experimentsCombining indexed & non-indexed query capabilities,including remote queries

WHAT'S COMING FOR HIBERNATESEARCH
Upgrading to Lucene 5Experiment integrations with REST based Lucene servers(Solr, ElasticSearch)Improved backends to simplify clustering setupGSOC: generic JPA support and improved developertoolingA lot more! See also the roadmap

THANK YOU!Some references:
, the super simple , the
The website, the by
The websiteOur team's blog
(requires Chrome)
Apache Lucene websiteHibernate Search website HibernateSearch JPA demo WildFly integration tests
Infinispan Weather Demo@gustavonalle
WildFlyin.relation.to
Export these slides to PDF


















