


Apache Hadoop & Friends - blog.cloudera.com · Outline Why should you care? (Intro) Challenging...
53
Transcript of Apache Hadoop & Friends - blog.cloudera.com · Outline Why should you care? (Intro) Challenging...

Hi there!
Software Engineer
Worked at
And, oh, I ski (though mostly in Tahoe)
2

@cloudera, I work on...
Cloudera Desktop
Apache Avro
3

Outline
Why should you care? (Intro)
Challenging yesteryear’s assumptions
The MapReduce Model
HDFS, Hadoop Map/Reduce
The Hadoop Ecosystem
Questions
4

Data is everywhere.
Data is important.
5

6

7

8

“I keep saying that the sexy job in the next 10 years will be
statisticians, and I’m not kidding.”
Hal Varian (Google’s chief economist)
9

Are you throwing away data?
Data comes in many shapes and sizes: relational tuples, log files, semistructured textual data (e.g., e-mail), … .
Are you throwing it away because it doesn’t ‘fit’?
10

So, what’s Hadoop?
The Little Prince, Antoine de Saint-Exupéry, Irene Testot-Ferry
11

Apache Hadoop is an open-source system (written in Java!) to reliably
store and process
gobs of dataacross many commodity computers.
The Little Prince, Antoine de Saint-Exupéry, Irene Testot-Ferry
12

Two Big Components
HDFS Map/Reduce
Self-healing high-bandwidth
clustered storage.
Fault-tolerant distributed computing.
13

Challenging some of yesteryear’s
assumptions...
14

Assumption 1: Machines can be reliable...
Image: MadMan the Mighty CC BY-NC-SA
15

Hadoop Goal:
Separate distributed system fault-tolerance
code from application logic.
Systems Programmers Statisticians
16

Assumption 2: Machines have identities...
Image:Laughing Squid CC BY-NC-SA
17

Hadoop Goal:
Users should interact with clusters, not machines.
18

Assumption 3: A data set fits on one machine...Image: Matthew J. Stinson CC-BY-NC
19

Hadoop Goal:
System should scale linearly (or better) with
data size.
20

The M/R Programming Model
21

You specify map() and reduce() functions.
The framework does the rest.
22

fault-tolerance
(that’s what’s important)(and that’s why Hadoop)
23

map()
map: K!,V!"list K#,V#
public class Mapper<KEYIN, VALUEIN, KEYOUT, VALUEOUT> {
/**
* Called once for each key/value pair in the input split. Most applications
* should override this, but the default is the identity function.
*/
protected void map(KEYIN key, VALUEIN value,
Context context) throws IOException,
InterruptedException {
// context.write() can be called many times
// this is default “identity mapper” implementation
context.write((KEYOUT) key, (VALUEOUT) value);
}
}
24

(the shuffle)
map output is assigned to a “reducer”
map output is sorted by key
25

reduce()
K#, iter(V#)"list(K$,V$)
public class Reducer<KEYIN,VALUEIN,KEYOUT,VALUEOUT> {
/**
* This method is called once for each key. Most applications will define
* their reduce class by overriding this method. The default implementation
* is an identity function.
*/
@SuppressWarnings("unchecked")
protected void reduce(KEYIN key, Iterable<VALUEIN> values, Context context
) throws IOException, InterruptedException {
for(VALUEIN value: values) {
context.write((KEYOUT) key, (VALUEOUT) value);
}
}
}
26
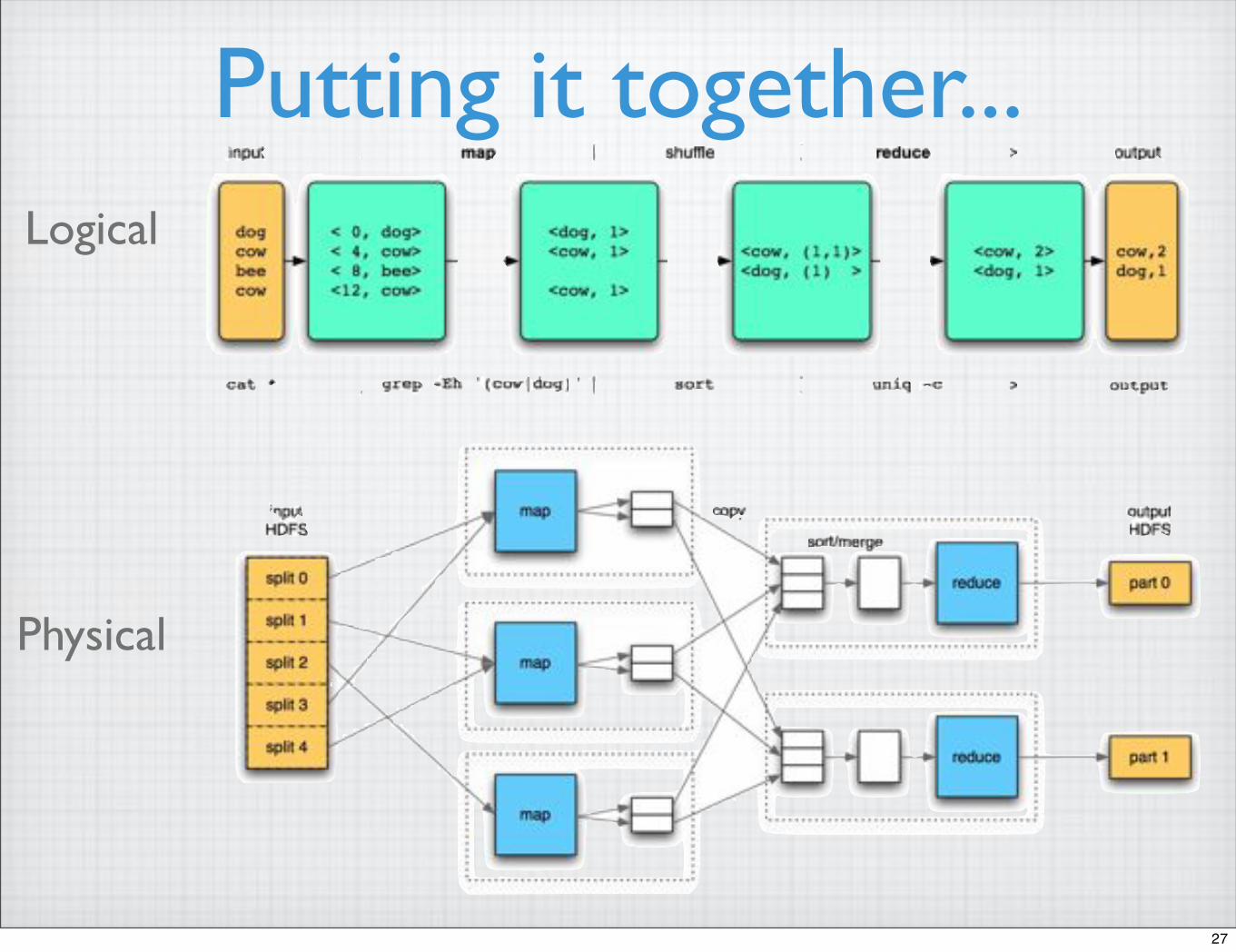
Physical Flow
Putting it together...
Logical Flow
Logical
Physical
27

Some samples...Build an inverted index.
Summarize data grouped by a key.
Build map tiles from geographic data.
OCRing many images.
Learning ML models. (e.g., Naive Bayes for text classification)
Augment traditional BI/DW technologies (by archiving raw data).
28

There’s more than the Java API
perl, python, ruby, whatever.
stdin/stdout/stderr
Higher-level dataflow language for easy ad-hoc analysis.
Developed at Yahoo!
SQL interface.
Great for analysts.
Developed at Facebook
Streaming Pig
Many tasks actually require a series of M/R jobs; that’s ok!
Hive
29

A Typical Look...
Commodity servers (8-core, 8-16GB RAM, 4-12 TB, 2x1 gE NIC)
2-level network architecture
20-40 nodes per rack
30

So, how does it all work?
31

dramatis personae
NameNode (metadata server and database)
SecondaryNameNode (assistant to NameNode)
JobTracker (scheduler)
DataNodes (block storage)
TaskTrackers (task execution)
Thanks to Zak Stone for earmuff image!
Starring...
The Chorus…
32

HDFS(fs metadata)
Namenode
Datanodes
One Rack A Different Rack
3x64MB file, 3 rep
4x64MB file, 3 rep
Small file, 7 rep
33

HDFS Write Path
file in the filesystem’s namespace, with no blocks associated with it. (Step 2.) Thenamenode performs various checks to make sure the file doesn’t already exist, and thatthe client has the right permissions to create the file. If these checks pass, the namenodemakes a record of the new file, otherwise file creation fails and the client is thrown anIOException. The DistributedFileSystem returns a FSDataOutputStream for the client tostart writing data to. Just as in the read case, FSDataOutputStream wraps a DFSOutputStream, which handles communication with the datanodes and namenode.
As the client writes data (step 3.), DFSOutputStream splits it into packets, which it writesto an internal queue, called the data queue. The data queue is consumed by the DataStreamer, whose responsibility it is to ask the namenode to allocate new blocks bypicking a list of suitable datanodes to store the replicas. The list of datanodes forms apipeline—we’ll assume the replication level is three, so there are three nodes in thepipeline. The DataStreamer streams the packets to the first datanode in the pipeline,which stores the packet and forwards it to the second datanode in the pipeline. Similarlythe second datanode stores the packet and forwards it to the third (and last) datanodein the pipeline. (Step 4.)
DFSOutputStream also maintains an internal queue of packets that are waiting to beacknowledged by datanodes, called the ack queue. A packet is only removed from theack queue when it has been acknowledged by all the datanodes in the pipeline. (Step 5.)
If a datanode fails while data is being written to it, then the following actions are taken,which are transparent to the client writing the data. First the pipeline is closed, and anypackets in the ack queue are added to the front of the data queue so that datanodesthat are downstream from the failed node will not miss any packets. The current blockon the good datanodes is given a new identity, which is communicated to the name-node, so that the partial block on the failed datanode will be deleted if the failed data-node recovers later on. The failed datanode is removed from the pipeline and the re-mainder of the block’s data is written to the two good datanodes in the pipeline. Thenamenode notices that the block is under-replicated, and it arranges for a further replicato be created on another node. Subsequent blocks are then treated as normal.
It’s possible, but unlikely, that multiple datanodes fail while a block is being written.As long as dfs.replication.min replicas (default one) are written the write will succeed,and the block will be asynchronously replicated across the cluster until its target rep-lication factor is reached (dfs.replication which defaults to three).
Figure 3-3. A client writing data to HDFS
Data Flow | 61
34

HDFS Failures?
Datanode crash?
Clients read another copy
Background rebalance
Namenode crash?
uh-oh
35

M/R
Tasktrackers on the same machines as datanodes
One Rack A Different Rack
Job on starsDifferent job
Idle
36

M/R
CHAPTER 6
How MapReduce Works
In this chapter we’ll look at how MapReduce in Hadoop works in detail. This knowl-edge provides a good foundation for writing more advanced MapReduce programs,which we will cover in the following two chapters.
Anatomy of a MapReduce Job RunYou can run a MapReduce job with a single line of code: JobClient.runJob(conf). It’svery short, but it conceals a great deal of processing behind the scenes. This sectionuncovers the steps Hadoop takes to run a job.
The whole process is illustrated in Figure 6-1. At the highest level there are four inde-pendent entities:
• The client, which submits the MapReduce job.
• The jobtracker, which coordinates the job run. The jobtracker is a Java applicationwhose main class is JobTracker.
• The tasktrackers, which run the tasks that the job has been split into. Tasktrackersare Java applications whose main class is TaskTracker.
• The distributed filesystem (normally HDFS, covered in Chapter 3), which is usedfor sharing job files between the other entities.
Figure 6-1. How Hadoop runs a MapReduce job
145
37

Task fails
Try again?
Try again somewhere else?
Report failure
Retries possible because of idempotence
M/R Failures
38

Hadoop in the Wild(yes, it’s used in production)
Yahoo! Hadoop Clusters: > 82PB, >25k machines (Eric14, HadoopWorld NYC ’09)
(M-R, but not Hadoop)Google: 40 GB/s GFS read/write load (Jeff Dean, LADIS ’09) [~3,500 TB/day]
Facebook: 4TB new data per day; DW: 4800 cores, 5.5 PB (Dhruba Borthakur, HadoopWorld)
39

The Hadoop Ecosystem
HDFS(Hadoop Distributed File System)
HBase (Key-Value store)
MapReduce (Job Scheduling/Execution System)
Pig (Data Flow) Hive (SQL)
BI ReportingETL Tools
Avro
(S
erializ
ation)
Zookeepr
(Coord
ination) Sqoop
RDBMS
40

Ok, fine, what next?
Get Hadoop!
Cloudera’s Distribution for Hadoop
http://hadoop.apache.org/
Try it out! (Locally, or on EC2) Door Prize
41

Just one slide...
Software: Cloudera Distribution for Hadoop, Cloudera Desktop, more…
Training and certification…
Free on-line training materials (including video)
Support & Professional Services
@cloudera, blog, etc.42

Okay, two slides
Talk to us if you’re going to do Hadoop in your organization.
43

Backup Slides
(i’ve got your back)
45

Important APIsInput Format
Mapper
Reducer
Partitioner
Combiner
Out. Format
M/R
Flo
w
Oth
er
Writable
JobClient
*Context
Filesystem
K!,V!"K#,V#
data"K!,V!
K#,iter(V#)"K#,V#
K#,V#"int
K#, iter(V#)"K$,V$
K$, V$"data
! is 1:many
46

public int run(String[] args)
throws Exception {
if (args.length < 3) {
System.out.println("Grep
<inDir> <outDir> <regex>
[<group>]");
ToolRunner.printGenericCommandUsage
(System.out);
return -1;
}
Path tempDir = new Path("grep-
temp-"+Integer.toString(new
Random().nextInt(Integer.MAX_VALUE)
));
JobConf grepJob = new
JobConf(getConf(), Grep.class);
try {
grepJob.setJobName("grep-
search");
FileInputFormat.setInputPaths(grepJ
ob, args[0]);
grepJob.setMapperClass(RegexMapper.
class);
grepJob.set("mapred.mapper.regex",
args[2]);
if (args.length == 4)
grepJob.set("mapred.mapper.regex.gr
oup", args[3]);
grepJob.setCombinerClass(LongSumRed
ucer.class);
grepJob.setReducerClass(LongSumRedu
cer.class);
FileOutputFormat.setOutputPath(grep
Job, tempDir);
grepJob.setOutputFormat(SequenceFil
eOutputFormat.class);
grepJob.setOutputKeyClass(Text.clas
s);
grepJob.setOutputValueClass(LongWri
table.class);
JobClient.runJob(grepJob);
JobConf sortJob = new
JobConf(Grep.class);
sortJob.setJobName("grep-
sort");
FileInputFormat.setInputPaths(sortJ
ob, tempDir);
sortJob.setInputFormat(SequenceFile
InputFormat.class);
sortJob.setMapperClass(InverseMappe
r.class);
// write a single file
sortJob.setNumReduceTasks(1);
FileOutputFormat.setOutputPath(sort
Job, new Path(args[1]));
// sort by decreasing freq
sortJob.setOutputKeyComparatorClass
(LongWritable.DecreasingComparator.
class);
JobClient.runJob(sortJob);
} finally {
FileSystem.get(grepJob).delete(temp
Dir, true);
}
return 0;
}
the “grep” example
47

$ cat input.txt
adams dunster kirkland dunster
kirland dudley dunster
adams dunster winthrop
$ bin/hadoop jar hadoop-0.18.3-
examples.jar grep input.txt output1
'dunster|adams'
$ cat output1/part-00000
4 dunster
2 adams
48

JobConf grepJob = new JobConf(getConf(), Grep.class);
try {
grepJob.setJobName("grep-search");
FileInputFormat.setInputPaths(grepJob, args[0]);
grepJob.setMapperClass(RegexMapper.class);
grepJob.set("mapred.mapper.regex", args[2]);
if (args.length == 4)
grepJob.set("mapred.mapper.regex.group", args[3]);
grepJob.setCombinerClass(LongSumReducer.class);
grepJob.setReducerClass(LongSumReducer.class);
FileOutputFormat.setOutputPath(grepJob, tempDir);
grepJob.setOutputFormat(SequenceFileOutputFormat.class);
grepJob.setOutputKeyClass(Text.class);
grepJob.setOutputValueClass(LongWritable.class);
JobClient.runJob(grepJob);
} ...
Job1of 2
49

JobConf sortJob = new JobConf(Grep.class);
sortJob.setJobName("grep-sort");
FileInputFormat.setInputPaths(sortJob, tempDir);
sortJob.setInputFormat(SequenceFileInputFormat.class);
sortJob.setMapperClass(InverseMapper.class);
// write a single file
sortJob.setNumReduceTasks(1);
FileOutputFormat.setOutputPath(sortJob, new Path(args[1]));
// sort by decreasing freq
sortJob.setOutputKeyComparatorClass(
LongWritable.DecreasingComparator.class);
JobClient.runJob(sortJob);
} finally {
FileSystem.get(grepJob).delete(tempDir, true);
}
return 0;
}
Job2 of 2
(implicit identity reducer)
50

The types there...
?, Text
Text, Long
Long, Text
Text, list(Long)
Text, Long
51

Data Mining
Instrumentation
Collection
Storage (Raw Data)
ETL (Extraction, Transform, Load)
RDBMS (Aggregates)
BI / Reporting
Traditional DW
}
Ad-hoc Queries
52

Facebook’s DW (phase M)M > NFacebook Data Infrastructure
2008MySQL TierScribe Tier
Hadoop Tier
Oracle RAC Servers
Wednesday, April 1, 2009
53


















