
Apache Flink vs Apache Spark - Reproducible experiments on cloud.
30
Reproducible distributed experiments on cloud vs Shelan Perera Ashansa Perera Kamal Hakimzadeh
-
Upload
shelan-perera -
Category
Technology
-
view
2.252 -
download
0
Transcript of Apache Flink vs Apache Spark - Reproducible experiments on cloud.

Reproducible distributed experiments on cloud
vs
Shelan PereraAshansa Perera Kamal Hakimzadeh

“Reproducing experiments
with
minimal effort

Spark and Flink
▷ Batch Processing vs. Stream Processing
▷ Micro Batching vs. Natural Data Flow
▷ Good fit for scalable deployment in the cloud

Motivation
▷ Validate Performance claims
▷ Take off deployment overhead
▷ Design reproducible experiments

Karamel =>“Framework for reproducible distributed experiments”

Benchmark - Batch
Teragen - To generate data (Hadoop)
Terasort - Benchmarking Algorithm(Spark, Flink)

To make Dongwon Kim’s comparison reproducible.
http://www.slideshare.net/ssuser6bb12d/a-comparative-performance-evaluation-of-apache-flink
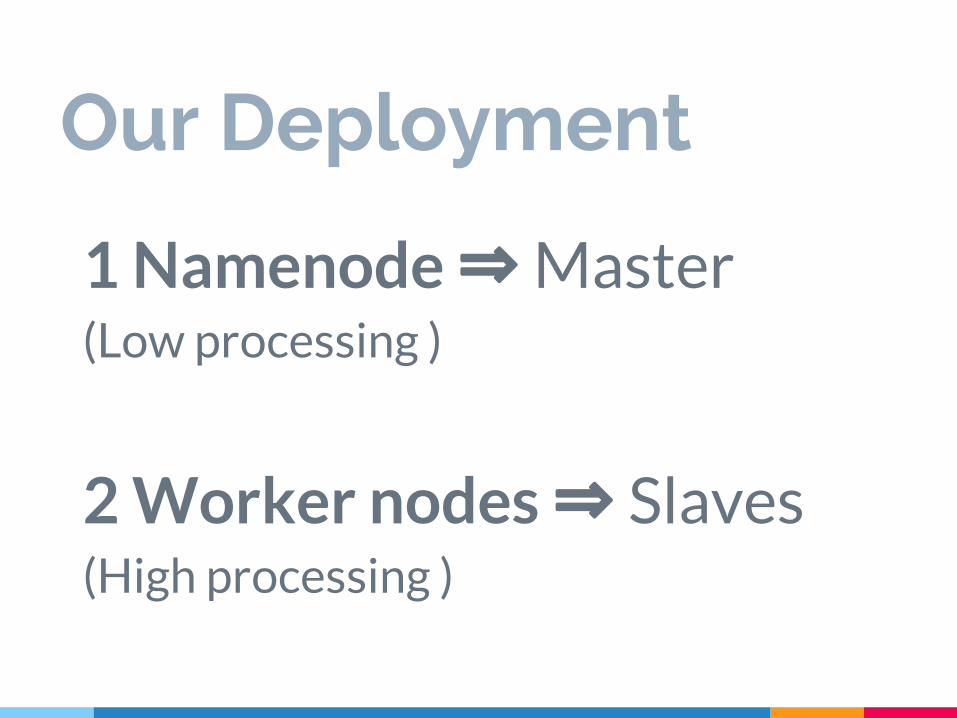
1 Namenode ⇒ Master(Low processing )
2 Worker nodes ⇒ Slaves(High processing )
Our Deployment
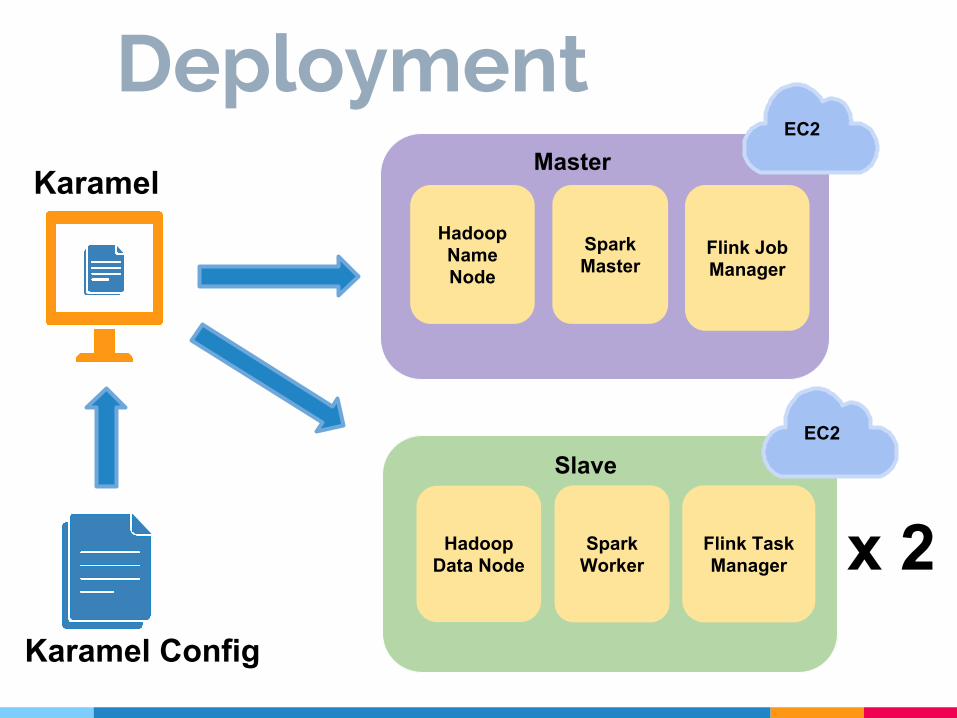
EC2
Slave
EC2
Master
Deployment
HadoopName Node
SparkMaster
Flink JobManager
SparkWorker
Flink TaskManager
HadoopData Node
Karamel
x 2Karamel Config
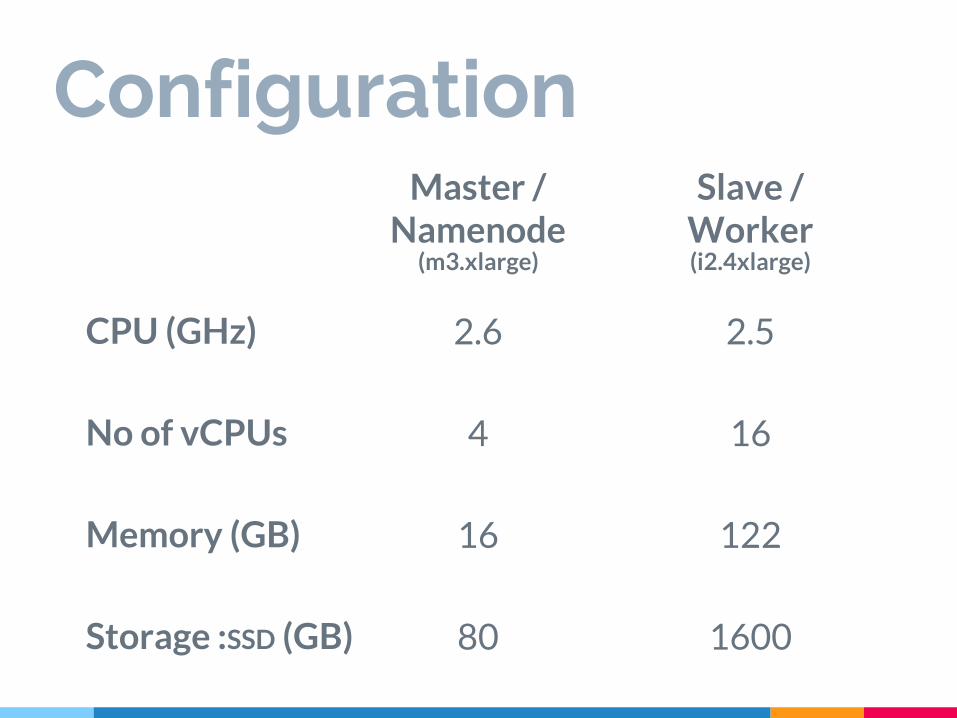
ConfigurationMaster /
Namenode
2.6
4
16
80
Slave / Worker
2.5
16
122
1600
CPU (GHz)
No of vCPUs
Memory (GB)
Storage :SSD (GB)
(m3.xlarge) (i2.4xlarge)
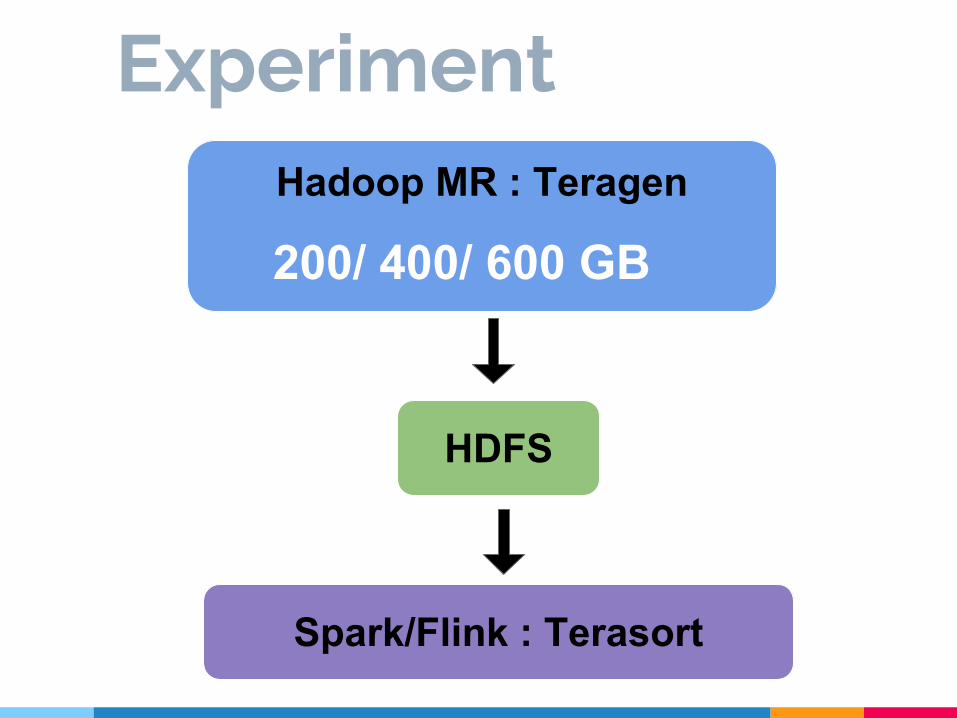
ExperimentHadoop MR : Teragen
HDFS
Spark/Flink : Terasort
200/ 400/ 600 GB

Results
Batch Processing

Application Performance

Flink
1.5 x Faster than Spark

▷ Spark : Does not overlap stages
▷ Flink : Do pipelining
Mainly because...

Collectl- Monitor
● Tool used to collect and draw results.
● https://github.com/shelan/collectl-monitoring
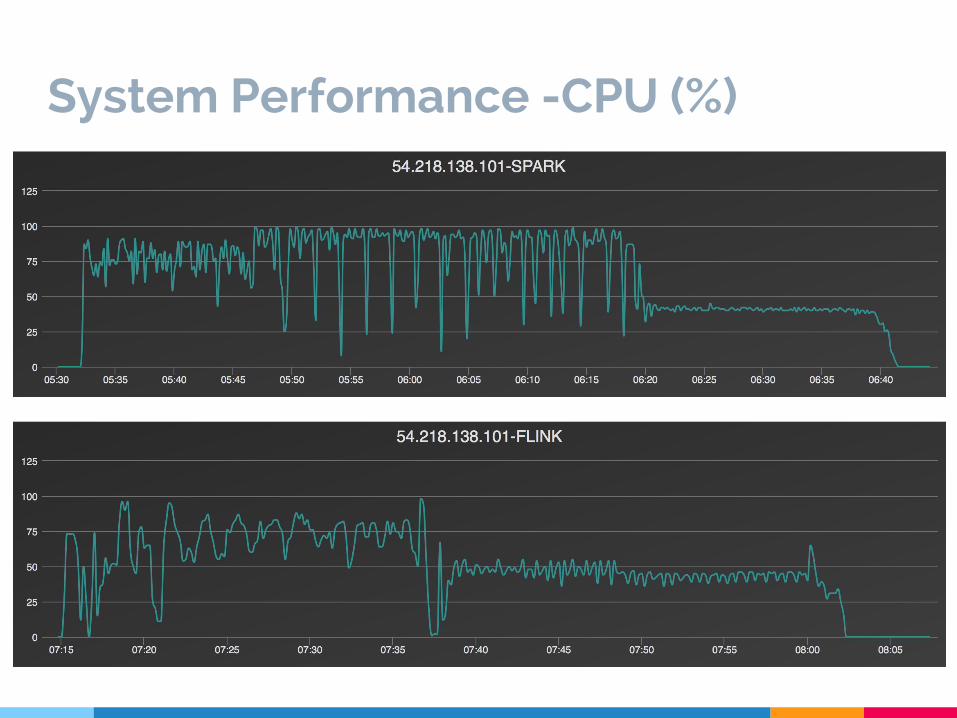
System Performance -CPU (%)
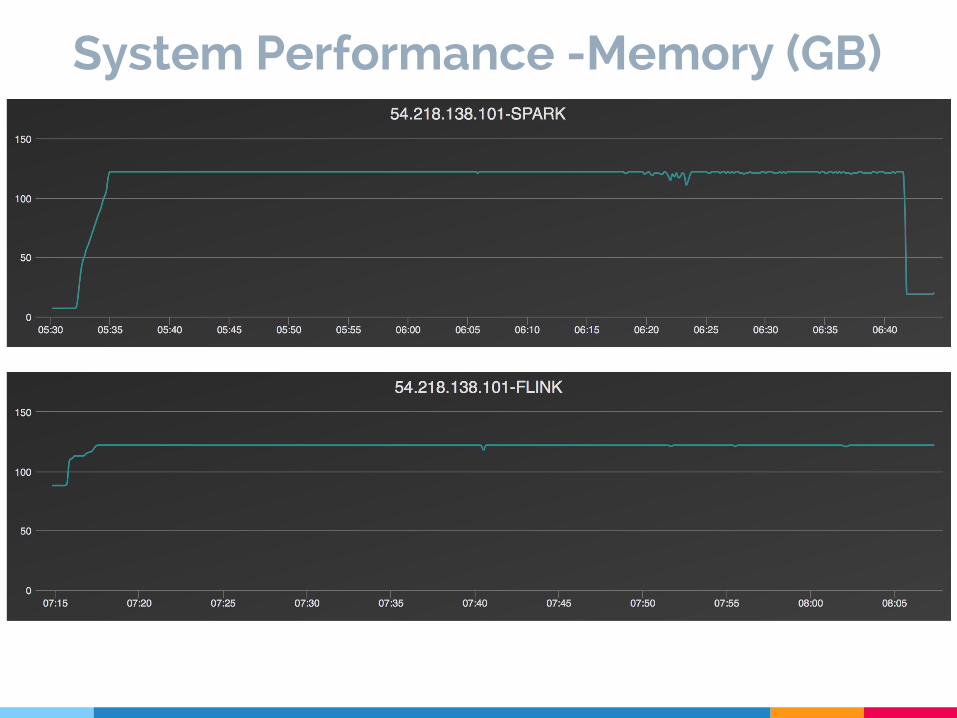
System Performance -Memory (GB)
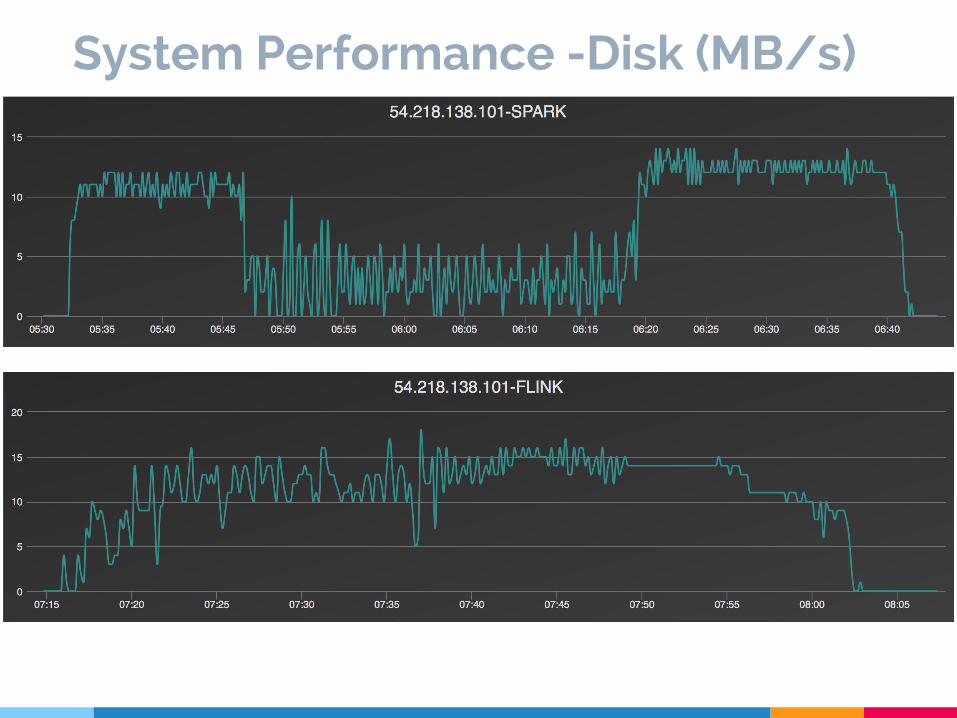
System Performance -Disk (MB/s)
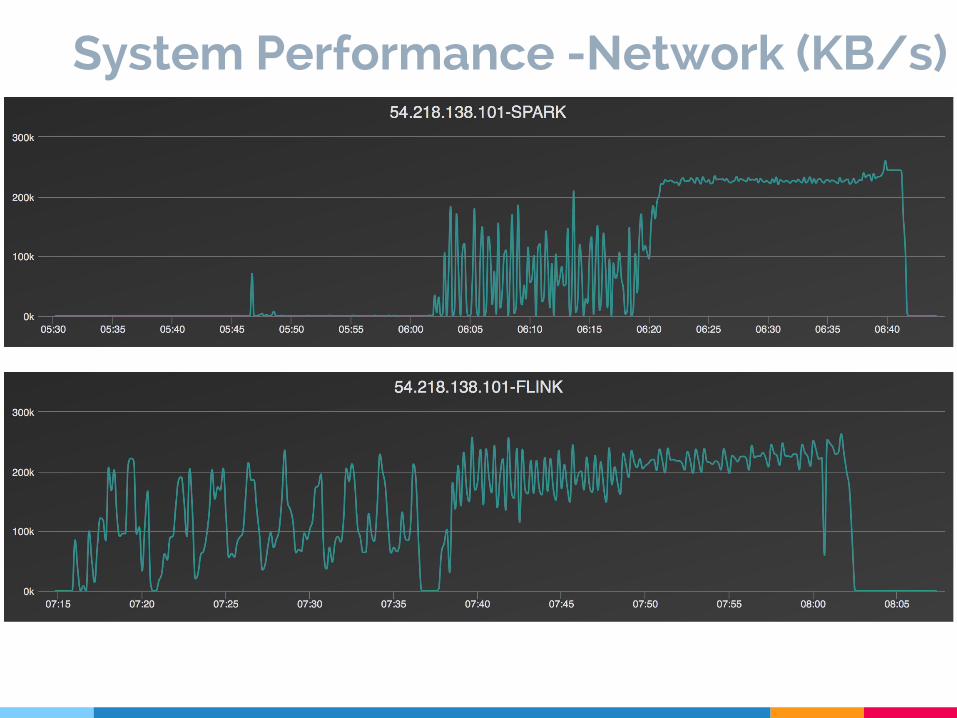
System Performance -Network (KB/s)

Load Balancing -Workers (CPU %)

Load Balancing -Workers (CPU %)

Outcome
▷ Performance Comparison Results
▷ Karamel experiments to reproduce the same results with minimal effort

How not to reproduce
“our problems”

EC2 claims 800 GB disks, But Disk File system (DF) does shows only 30GB.
If you are using I2 or R3 instances you should create a file system and partition disks manually.

Large Spark or Flink Batch applications can fail with not enough disk space
Configure Flink temp directory and Spark local directory to a partition with at least enough space to store the total input.

Reproducing experiments on EC2 may cost you a lot
Spot instances which allow to reduce the cost by 10x is also supported by Karamel

IncompatibleClassChangeError when running StreamBench built for MR2 on hadoop2.x
No explicitly defined dependencies for previous versions, but one of the dependencies (mahout) had internal references to hadoop1.x jar

Summary
▷ Introducing reproducible experiments on cloud
▷ Performance Comparison of Spark and Flink
▷ Reproducible experiments are available online (https://github.com/karamel-lab)

Thanks ..!!


















