
Apache Apex (Next Gen Hadoop) vs. Storm - Comparison and Migration Outline
40
Devendra Tagare <[email protected]> Software Engineer @ DataTorrent Inc Committer @ Apache Software Foundation for Apex @devtagare Feb 1, 2017 Introduction to Apache Apex Storm Comparison & Migration Outline
-
Upload
datatorrent -
Category
Technology
-
view
167 -
download
0
Transcript of Apache Apex (Next Gen Hadoop) vs. Storm - Comparison and Migration Outline

Devendra Tagare <[email protected]>
Software Engineer @ DataTorrent Inc
Committer @ Apache Software Foundation for Apex
@devtagare
Feb 1, 2017
Introduction to Apache Apex
Storm Comparison & Migration Outline

What is Apex
2
✓ Platform and Runtime Engine - enables development of scalable and fault-tolerant
distributed applications for processing streaming and batch data
✓ Highly Scalable - Scales linearly to billions of events per second with statically defined or
dynamic partitioning, advanced locality & affinity
✓ Highly Performant - In memory computations.Can reach single digit millisecond
end-to-end latency
✓ Fault Tolerant - Automatically recovers from failures - without manual intervention
✓ Stateful - Guarantees that no state will be lost
✓ YARN Native - Uses Hadoop YARN framework for resource negotiation
✓ Developer Friendly - Exposes an easy API for developing Operators, which can include
any custom business logic written in Java, and provides a Malhar library of many popular
operators and application examples.High level API for data scientists/ analysts.
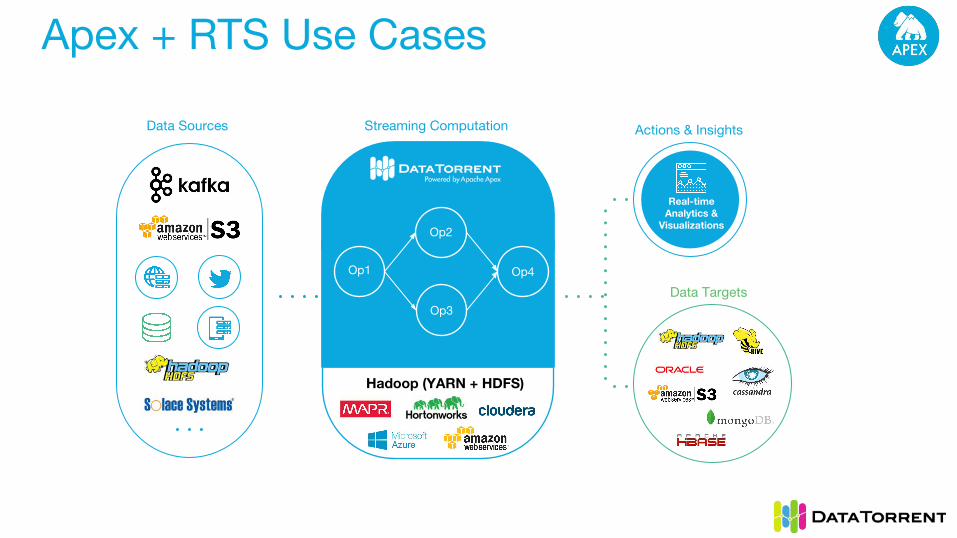
Apex + RTS Use Cases
Data Sources
Op1
Hadoop (YARN + HDFS)
Real-time Analytics &
Visualizations
Op3
Op2
Op4
Streaming Computation Actions & Insights
Data Targets

44
DataTorrent Platform
Solutions for Business
Ingestion & Data Prep ETL Pipelines
Ease of Use Tools Real-Time Data VisualizationManagement & MonitoringGUI Application Assembly
Application Templates
Apex-Malhar Operator Library
Big Data Infrastructure Hadoop 2.x – YARN + HDFS – On Prem & Cloud
Core
High-level APITransformation ML & Score SQL Analytics
FileSync
Dev Framework Batch Support
Apache Apex Core
Kafka-to-HDFS JDBC-to-HDFS HDFS-to-HDFS S3-to-HDFS

Apex Operator Library - Malhar
5
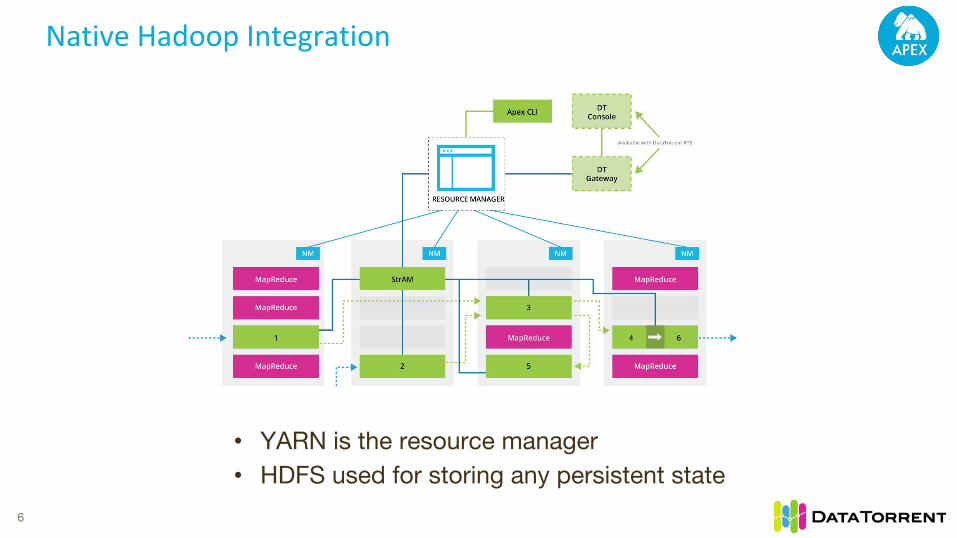
Native Hadoop Integration
6
• YARN is the resource manager• HDFS used for storing any persistent state

Application Development Model
7
●A Stream is a sequence of data tuples●A typical Operator takes one or more input streams, performs computations & emits one or more output streams
• Each Operator is YOUR custom business logic in java, or built-in operator from our open source library• Operator has many instances that run in parallel and each instance is single-threaded
●Directed Acyclic Graph (DAG) is made up of operators and streams
Directed Acyclic Graph (DAG)
Filtered
Stream
Output StreamTuple Tuple
Filtered Stream
Enriched Stream
Enriched
Stream
er
Operator
er
Operator
er
Operator
er
Operator
er
Operator
er
Operator

Advanced Windowing Support
8
● Application window ● Sliding window and tumbling window● Checkpoint window● No artificial latency

Application in Java
9

Operators
10

Operators (contd)
11

Partitioning and unification
12
NxM Partitions
Unifier
0 1 2 3
Logical DAG
0 1 2
1
1 Unifier
1
20
Logical Diagram
Physical Diagram with operator 1 with 3 partitions
0
Unifier
1a
1b
1c
2a
2b
Unifier 3
Physical DAG with (1a, 1b, 1c) and (2a, 2b): No bottleneck
Unifier
Unifier0
1a
1b
1c
2a
2b
Unifier 3
Physical DAG with (1a, 1b, 1c) and (2a, 2b): Bottleneck on intermediate Unifier

Advanced Partitioning
13
0
1a
1b
2 3 4Unifier
Physical DAG
0 4
3a2a1a
1b 2b 3b
Unifier
Physical DAG with Parallel Partition
Parallel Partition
Container
uopr
uopr1
uopr2
uopr3
uopr4
uopr1
uopr2
uopr3
uopr4
dopr
dopr
doprunifier
unifier
unifier
unifier
Container
Container
NIC
NIC
NIC
NIC
NIC
Container
NIC
Logical Plan
Execution Plan, for N = 4; M = 1
Execution Plan, for N = 4; M = 1, K = 2 with cascading unifiers
Cascading Unifiers
0 1 2 3 4
Logical DAG
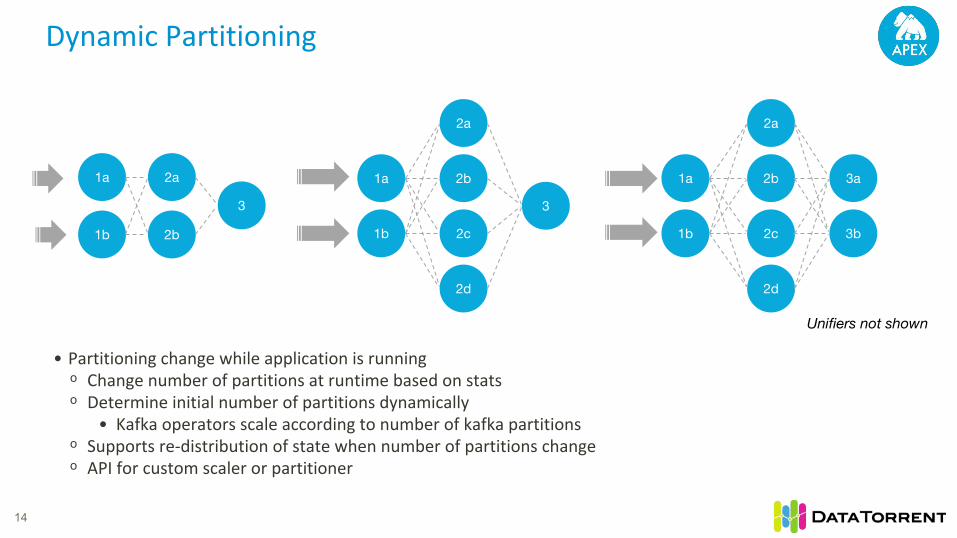
Dynamic Partitioning
14
• Partitioning change while application is runningᵒ Change number of partitions at runtime based on statsᵒ Determine initial number of partitions dynamically
• Kafka operators scale according to number of kafka partitionsᵒ Supports re-distribution of state when number of partitions changeᵒ API for custom scaler or partitioner
2b
2c
3
2a
2d
1b
1a1a 2a
1b 2b
3
1a 2b
1b 2c 3b
2a
2d
3a
Unifiers not shown
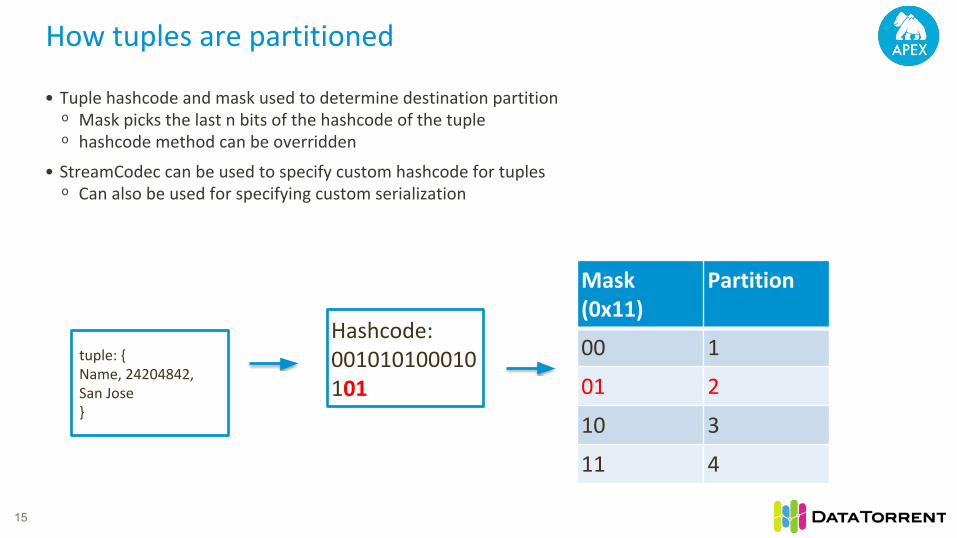
How tuples are partitioned
15
• Tuple hashcode and mask used to determine destination partitionᵒ Mask picks the last n bits of the hashcode of the tupleᵒ hashcode method can be overridden
• StreamCodec can be used to specify custom hashcode for tuplesᵒ Can also be used for specifying custom serialization
tuple: {Name, 24204842, San Jose}
Hashcode: 001010100010101
Mask (0x11)
Partition
00 1
01 2
10 3
11 4
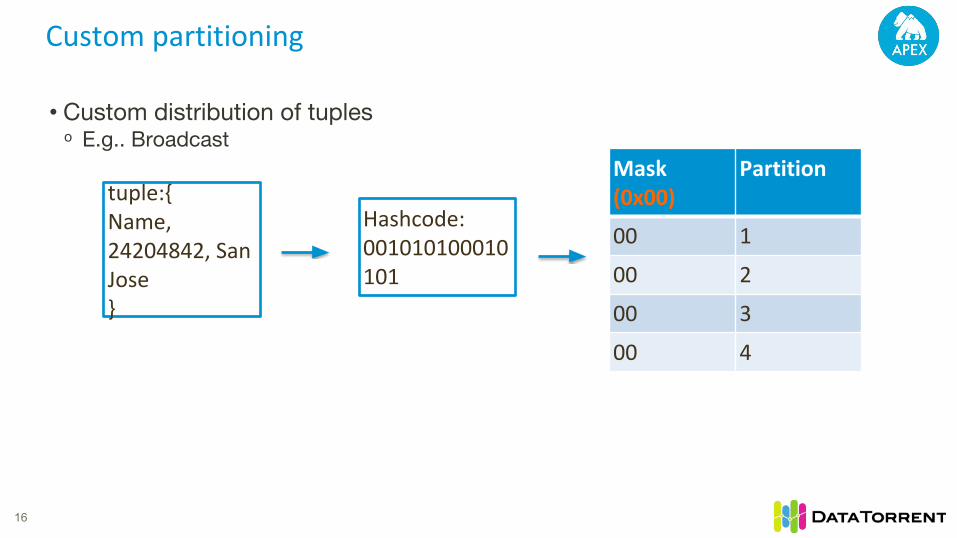
Custom partitioning
16
• Custom distribution of tuples ᵒ E.g.. Broadcast
tuple:{Name, 24204842, San Jose}
Hashcode: 001010100010101
Mask (0x00)
Partition
00 1
00 2
00 3
00 4

Fault Tolerance
17
● Operator state is check-pointed to a persistent store
○ Automatically performed by engine, no additional work needed by operator
○ In case of failure operators are restarted from checkpoint state
○ Frequency configurable per operator
○ Asynchronous and distributed by default
○ Default store is HDFS
● Automatic detection and recovery of failed operators
○ Heartbeat mechanism
● Buffering mechanism to ensure replay of data from recovered point so that there is no loss of data
● Application master state check-pointed
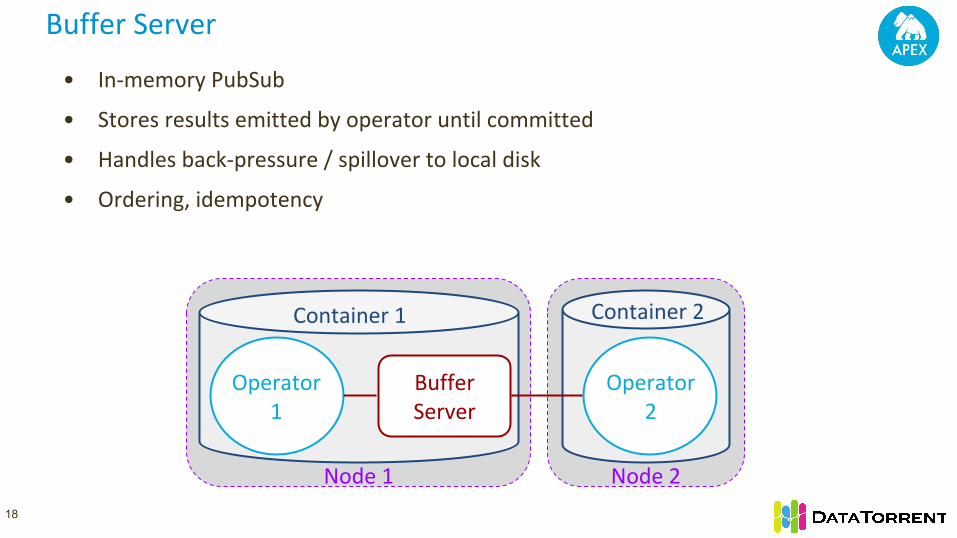
• In-memory PubSub
• Stores results emitted by operator until committed
• Handles back-pressure / spillover to local disk
• Ordering, idempotency
Operator 1
Container 1
BufferServer
Node 1
Operator 2
Container 2
Node 2
Buffer Server
18
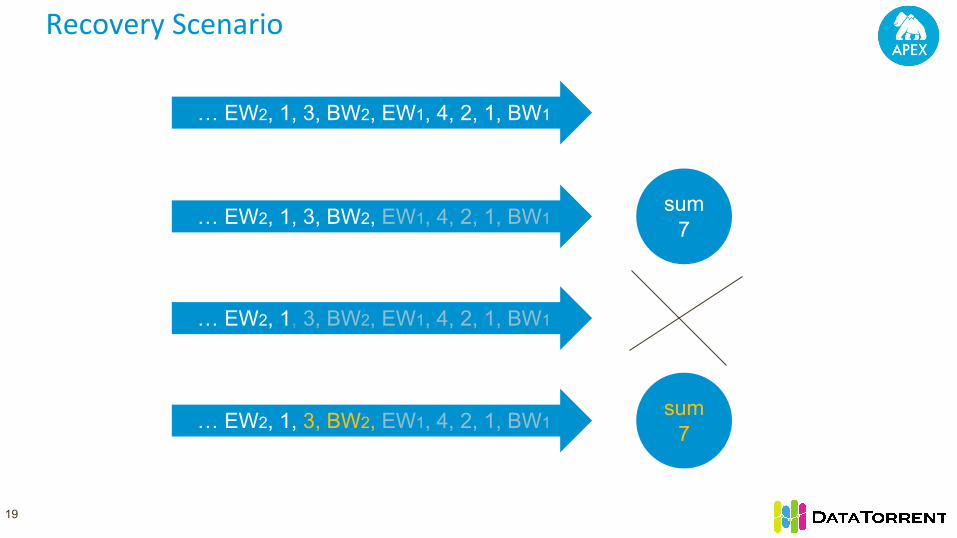
Recovery Scenario
… EW2, 1, 3, BW2, EW1, 4, 2, 1, BW1sum
0
… EW2, 1, 3, BW2, EW1, 4, 2, 1, BW1sum
7
… EW2, 1, 3, BW2, EW1, 4, 2, 1, BW1sum10
… EW2, 1, 3, BW2, EW1, 4, 2, 1, BW1sum
7
19

Processing Guarantees - Recovery
20
At-least once
• On recovery data will be replayed from a previous checkpointᵒ Messages will not be lostᵒ Default mechanism and is suitable for most applications
• Can be used in conjunction with following mechanisms to achieve exactly-once behavior in fault recovery scenariosᵒ Transactions with meta information, Rewinding output, Feedback from external
entity, Idempotent operations
At-most once
• On recovery the latest data is made available to operatorᵒ Useful in use cases where some data loss is acceptable and latest data is sufficient
Exactly once
• At least once + state recovery + operator logic to achieve end-to-end exactly once

Stream Locality
21
• By default operators are deployed in containers (processes) randomly on
different nodes across the Hadoop cluster
• Custom locality for streams
ᵒ Rack local: Data does not traverse network switches
ᵒ Node local: Data is passed via loopback interface and frees up network bandwidth
ᵒ Container local: Messages are passed via in memory queues between operators and
does not require serialization
ᵒ Thread local: Messages are passed between operators in a same thread equivalent to
calling a subsequent function on the message
Native Streaming
Credit: Gyula Fóra & Márton Balassi: Large-Scale Stream Processing in the Hadoop Ecosystem
22

Storm - Key ConceptsNimbus : Master node responsible for distributing data among all the worker nodes, assign tasks to worker nodes and
monitoring failures.
Supervisor : Runs worker processes on each node and governs worker processes to complete the tasks assigned by the
nimbus
Topologies : The logic for a realtime application is packaged into a Storm topology.
A topology is a graph of spouts and bolts that are connected with stream groupings
Streams : The stream is the core abstraction in Storm. A stream is an unbounded sequence of tuples that is processed
and created in parallel in a distributed fashion.
Spout is a source of streams in a topology.
Bolts - All processing in topologies is done in Bolts.
Bolts can do anything from filtering, functions, aggregations, joins, talking to databases
ZooKeeper helps the supervisor to interact with the nimbus. It is responsible to maintain the state of nimbus and
supervisor along-with keeping track of shared data.23

Storm Parallelism
• Credits : http://storm.apache.org/releases/2.0.0-SNAPSHOT
24
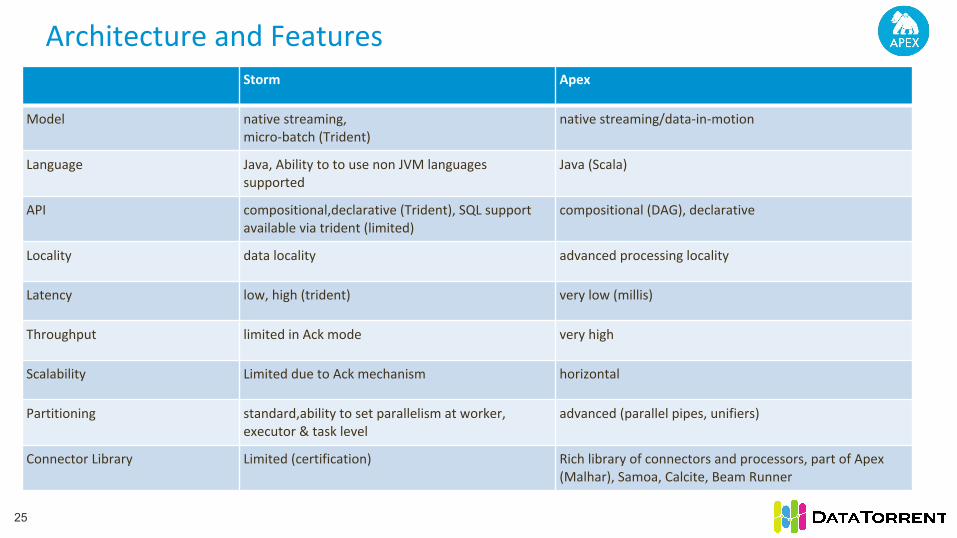
Architecture and FeaturesStorm Apex
Model native streaming,micro-batch (Trident)
native streaming/data-in-motion
Language Java, Ability to to use non JVM languages supported
Java (Scala)
API compositional,declarative (Trident), SQL support available via trident (limited)
compositional (DAG), declarative
Locality data locality advanced processing locality
Latency low, high (trident) very low (millis)
Throughput limited in Ack mode very high
Scalability Limited due to Ack mechanism horizontal
Partitioning standard,ability to set parallelism at worker, executor & task level
advanced (parallel pipes, unifiers)
Connector Library Limited (certification) Rich library of connectors and processors, part of Apex (Malhar), Samoa, Calcite, Beam Runner
25
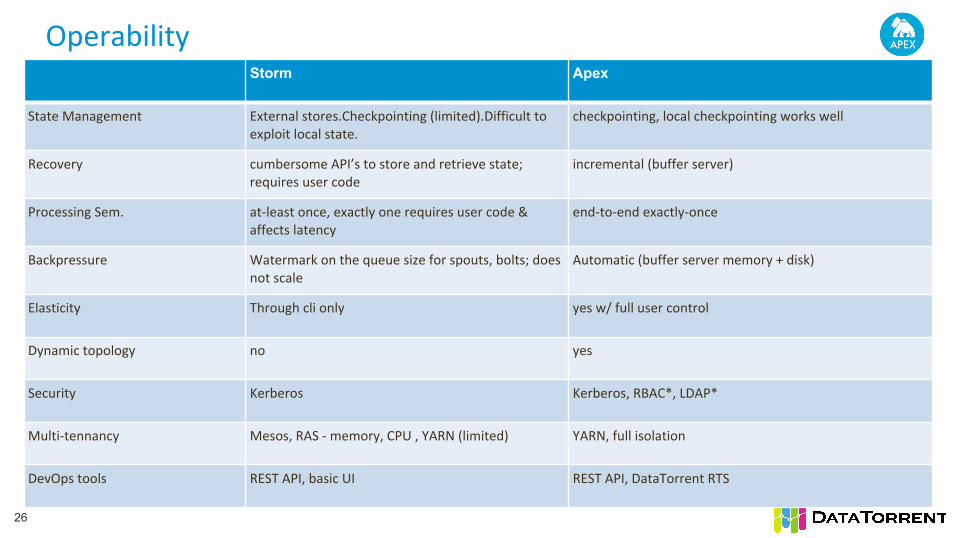
OperabilityStorm Apex
State Management External stores.Checkpointing (limited).Difficult to exploit local state.
checkpointing, local checkpointing works well
Recovery cumbersome API’s to store and retrieve state; requires user code
incremental (buffer server)
Processing Sem. at-least once, exactly one requires user code & affects latency
end-to-end exactly-once
Backpressure Watermark on the queue size for spouts, bolts; does not scale
Automatic (buffer server memory + disk)
Elasticity Through cli only yes w/ full user control
Dynamic topology no yes
Security Kerberos Kerberos, RBAC*, LDAP*
Multi-tennancy Mesos, RAS - memory, CPU , YARN (limited) YARN, full isolation
DevOps tools REST API, basic UI REST API, DataTorrent RTS
26

Mapping the terminology : Storm & Apex
● Applications running in the platform are represented by a Directed Acyclic Graph (DAG) made up of operators and streams.
DAG is the equivalent of a topology in Storm.A stream is the connection between 2 bolts or a spout and a bolt.
● All computations are done in memory on arrival of the input data, with an option to save the output to disk (HDFS) in a
non-blocking way.
● The data that flows between operators consists of atomic data elements. Each data element along with its type definition
(henceforth called schema) is called a tuple.
● Which partition of a downstream operator would get a tuple is decided based on a stream codec.This behavior is
functionally similar to stream groupings in storm minus the incremental recovery of Buffer Server.
● An application is a design of the flow of these tuples to and from the appropriate compute units to enable the computation
of the final desired results.
● A message queue (henceforth called buffer server) manages tuples streaming between compute units in different
process.This server keeps track of all consumers, publishers, partitions, and enables replay.There is no equivalent concept
for a buffer server in Storm.
● The streaming application is monitored by a decision making entity called STRAM (streaming application manager). STRAM is
designed to be a light weight controller that has minimal but sufficient interaction with the application. This is done via
periodic heartbeats. The STRAM does the initial launch and periodically analyzes the system metrics to decide if any run time
action needs to be taken.

Development Overview
1.Instantiate an application (DAG)
2.(Optional) Set Attributes
Assign application name
Set any other attributes as per application requirements
3.Create/re-use and instantiate operators
Assign operator name that is unique within the application
Declare schema upfront for each operator (and thereby its ports).
*** With DT RTS you can create a POJO’s from a schema on the fly and assign it to the ports.
(Optional) Set properties and attributes on the dag as per specification
Connect ports of operators via streams
Each stream connects one output port of an operator to one or more input ports of other operators.
(Optional) Set attributes on the streams
4.Test the application.

1.Getting started
Use the DataTorrent RTS Sandbox which comes packed with RTS, Hadoop & YARN for development.
Alternatively follow the instructions here for a full cluster setup.See prerequisites here.
2.Create an AppPackage
Use the Apex AppPackage archetype for creating your project in your favourite IDE.
3.Import to IDE
4.Assemble the DAG
Override the populatedDAG method and add operators to it.An operator in Apex is the equivalent of a spout or bolt in Storm.
5.Map a topology to a DAG & add operators
Input Adapter in Apex is a spout in Storm.It has no input port and only has output port(s).
Similarly, Output Adapter in Apex has one or more input ports but not output port.The rest of the operators are functionally similar to a bolt.
Several input & output operators are available from the Malhar operator library - kafka, sql, hive, FileSystem (HDFS, S3 etc) and many more.
6.Add Transformations
Add one or more transformation/intermediate operators from Malhar - here.
Migration Outline

7.Make connections
Connect the input operators to transformation operator(s) using streams.
Sample usage : dag.addStream("DimensionalData", dimensions.output, store.input);
8.Customize locality of streams
Configure the stream localities based on throughput / processing considerations.
9.Optionally Add unifiers and/or StreamCodecs
Add unifiers to merge the outputs of several upstream operators into a few downstream operators.
Sample usage :
dimensions.setUnifier(new DimensionsComputationUnifierImpl<InputEvent, Aggregate>());
10. Configure properties
Configure the operator properties externally (optionally from populateDAG).
Migration Outline .. 2/3
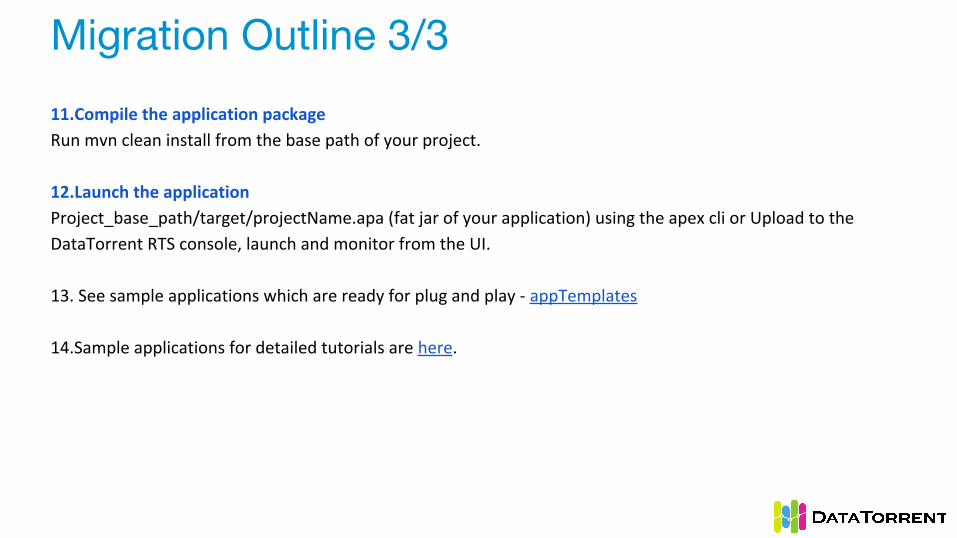
Migration Outline 3/3
11.Compile the application package
Run mvn clean install from the base path of your project.
12.Launch the application
Project_base_path/target/projectName.apa (fat jar of your application) using the apex cli or Upload to the
DataTorrent RTS console, launch and monitor from the UI.
13. See sample applications which are ready for plug and play - appTemplates
14.Sample applications for detailed tutorials are here.
Data Processing Pipeline ExampleApp Builder
32

Monitoring ConsoleLogical View
33

Monitoring ConsolePhysical View
34

Real-Time DashboardsReal Time Visualization
35
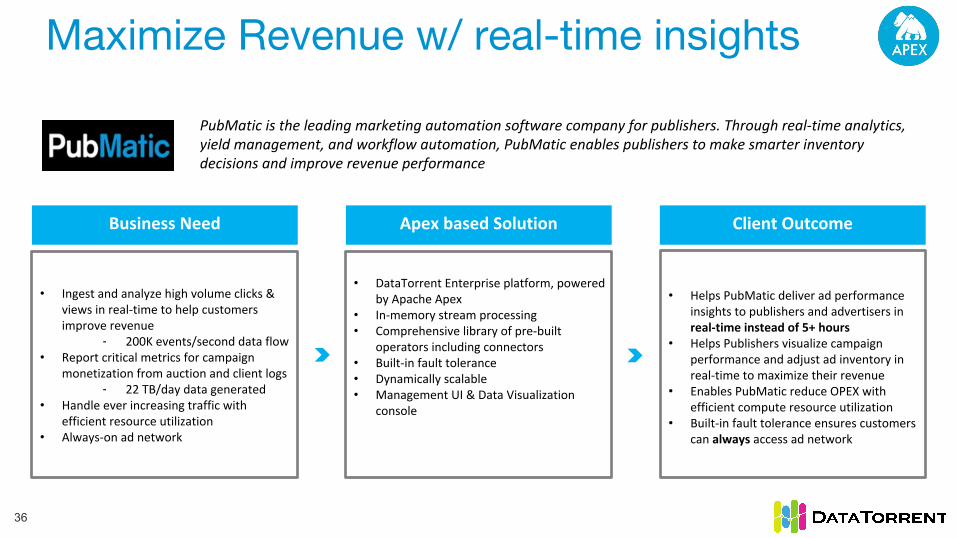
Maximize Revenue w/ real-time insights
36
PubMatic is the leading marketing automation software company for publishers. Through real-time analytics, yield management, and workflow automation, PubMatic enables publishers to make smarter inventory decisions and improve revenue performance
Business Need Apex based Solution Client Outcome
• Ingest and analyze high volume clicks & views in real-time to help customers improve revenue
- 200K events/second data flow• Report critical metrics for campaign
monetization from auction and client logs - 22 TB/day data generated
• Handle ever increasing traffic with efficient resource utilization
• Always-on ad network
• DataTorrent Enterprise platform, powered by Apache Apex
• In-memory stream processing• Comprehensive library of pre-built
operators including connectors• Built-in fault tolerance• Dynamically scalable• Management UI & Data Visualization
console
• Helps PubMatic deliver ad performance insights to publishers and advertisers in real-time instead of 5+ hours
• Helps Publishers visualize campaign performance and adjust ad inventory in real-time to maximize their revenue
• Enables PubMatic reduce OPEX with efficient compute resource utilization
• Built-in fault tolerance ensures customers can always access ad network

Industrial IoT applications
37
GE is dedicated to providing advanced IoT analytics solutions to thousands of customers who are using their devices and sensors across different verticals. GE has built a sophisticated analytics platform, Predix, to help its customers develop and execute Industrial IoT applications and gain real-time insights as well as actions.
Business Need Apex based Solution Client Outcome
• Ingest and analyze high-volume, high speed data from thousands of devices, sensors per customer in real-time without data loss
• Predictive analytics to reduce costly maintenance and improve customer service
• Unified monitoring of all connected sensors and devices to minimize disruptions
• Fast application development cycle• High scalability to meet changing business
and application workloads
• Ingestion application using DataTorrent Enterprise platform
• Powered by Apache Apex• In-memory stream processing• Built-in fault tolerance• Dynamic scalability• Comprehensive library of pre-built operators• Management UI console
• Helps GE improve performance and lower cost by enabling real-time Big Data analytics
• Helps GE detect possible failures and minimize unplanned downtimes with centralized management & monitoring of devices
• Enables faster innovation with short application development cycle
• No data loss and 24x7 availability of applications
• Helps GE adjust to scalability needs with auto-scaling

Resources• Apache Apex - http://apex.apache.org/
• Subscribe to forums
ᵒ Apex - http://apex.apache.org/community.html
ᵒ DataTorrent - https://groups.google.com/forum/#!forum/dt-users
• Download - https://datatorrent.com/download/
• Twitterᵒ @ApacheApex; Follow - https://twitter.com/apacheapexᵒ @DataTorrent; Follow – https://twitter.com/datatorrent
• Meetups - http://meetup.com/topics/apache-apex
• Webinars - https://datatorrent.com/webinars/
• Videos - https://youtube.com/user/DataTorrent
• Slides - http://slideshare.net/DataTorrent/presentations
• Startup Accelerator Program - Full featured enterprise productᵒ https://datatorrent.com/product/startup-accelerator/
• Big Data Application Templates Hub – https://datatorrent.com/apphub
38

We Are Hiring!• [email protected]
• Developers/Architects
• QA Automation Developers
• Information Developers
• Build and Release
• Community Leaders
39

www.ApexBigData.com40


















