
An Adaptive Parallel Algorithm for Computing Connectivity
29
An Adaptive Parallel Algorithm for Computing Connectivity Chirag Jain, Patrick Flick, Tony Pan, Oded Green, Srinivas Aluru 1 SIAM Workshop on Combinatorial Scientific Computing (CSC16) October 10, 2016
Transcript of An Adaptive Parallel Algorithm for Computing Connectivity

An Adaptive Parallel Algorithm for Computing Connectivity
Chirag Jain, Patrick Flick, Tony Pan, Oded Green, Srinivas Aluru
1
SIAM Workshop on Combinatorial Scientific Computing (CSC16) October 10, 2016
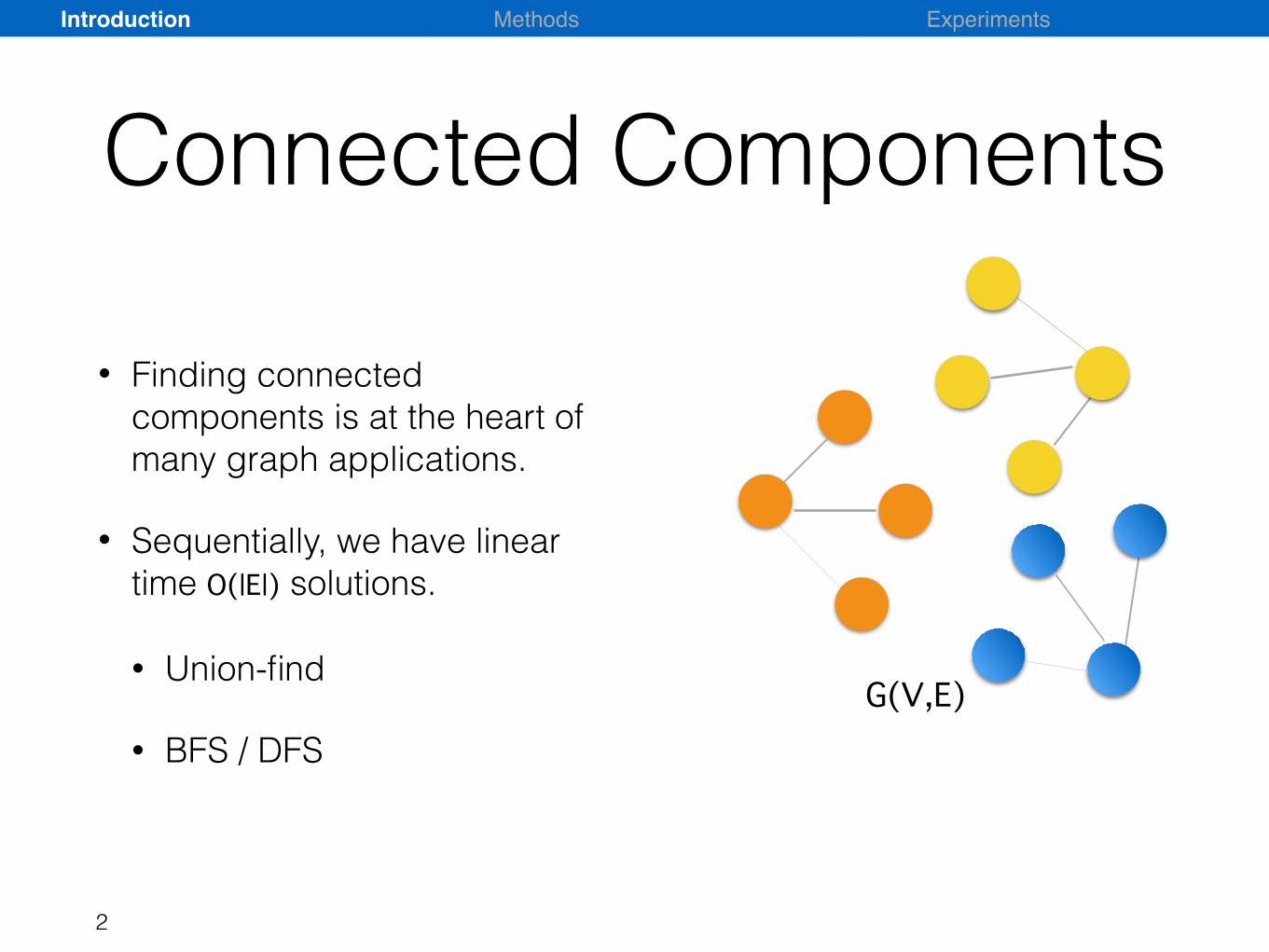
Connected Components
• Finding connected components is at the heart of many graph applications.
• Sequentially, we have linear time O(|E|) solutions.
• Union-find
• BFS / DFSG(V,E)
2
Introduction Methods Experiments
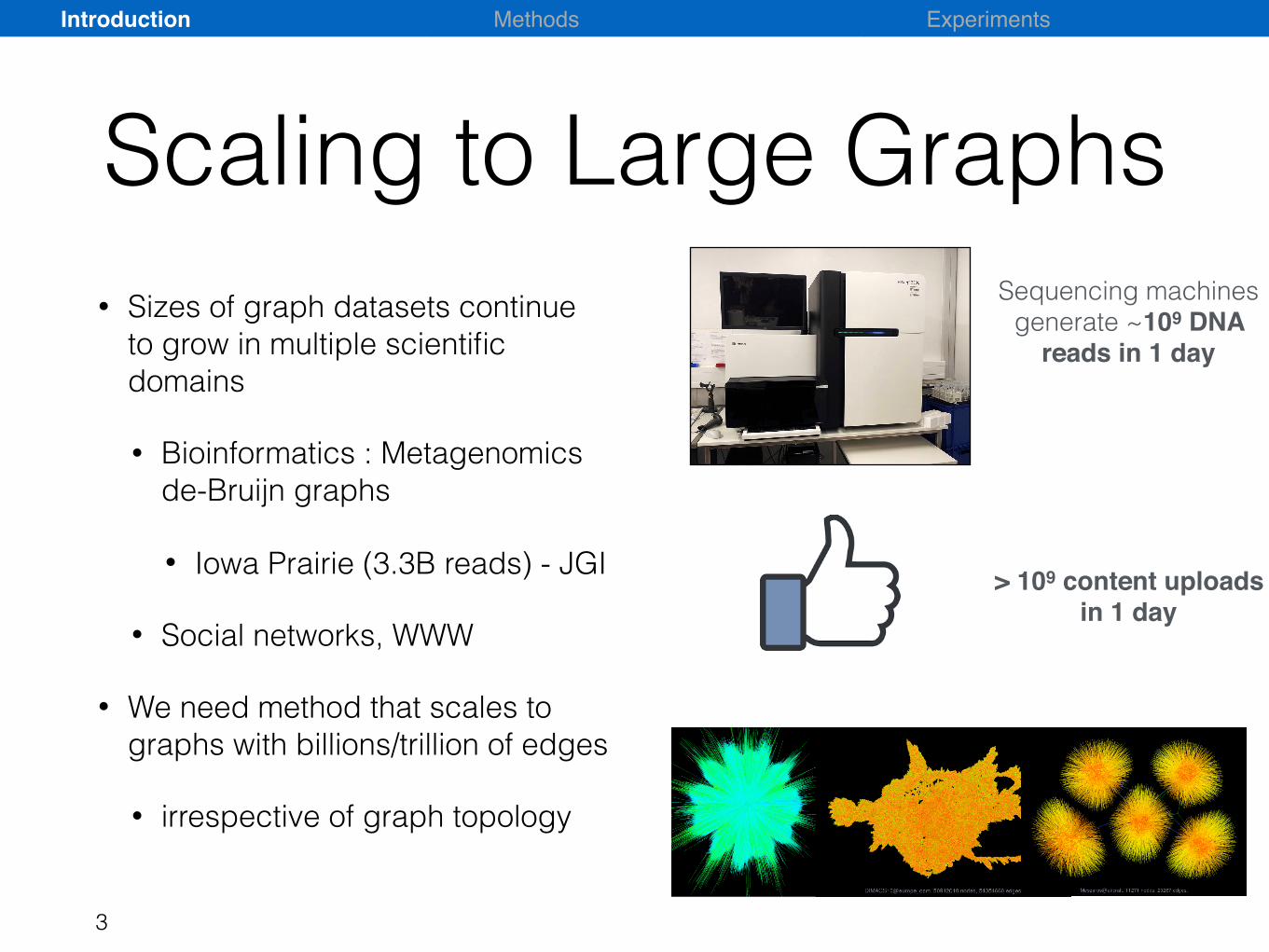
Scaling to Large Graphs• Sizes of graph datasets continue
to grow in multiple scientific domains
• Bioinformatics : Metagenomics de-Bruijn graphs
• Iowa Prairie (3.3B reads) - JGI
• Social networks, WWW
• We need method that scales to graphs with billions/trillion of edges
• irrespective of graph topology
Sequencing machines generate ~109 DNA
reads in 1 day
> 109 content uploads in 1 day
3
Introduction Methods Experiments

Background
4
A. Parallel connectivity algorithms
1. Parallel BFS
2. Shiloach-Vishkin PRAM algorithm (SV)
B. Recent prior work
BuluçandMadduri“Parallelbreadth-firstsearch…”SC11Beameret.al."Distributedmemorybreadth-firstsearchrevisited…”IPDPSW13
source
Introduction Methods Experiments

Background
5
A. Parallel connectivity algorithms
1. Parallel BFS
2. Shiloach-Vishkin PRAM algorithm (SV)
B. Recent prior work
ShiloachandVishkin“AnO(logn)parallelconnecLvityalgorithm”1982
Introduction Methods Experiments

Background
ShiloachandVishkin“AnO(logn)parallelconnecLvityalgorithm”19826
Pointer jumping for faster convergence
O(log |V|) iterations → O(|E| log |V|) work
A. Parallel connectivity algorithms
1. Parallel BFS
2. Shiloach-Vishkin PRAM algorithm (SV)
B. Recent prior work
Introduction Methods Experiments
O(|V|) iterations
→ O(|E|.|V|) work
LabelPropagaLon Shiloach-Vishkin

Background
7
A. Parallel connectivity algorithms
1. Parallel BFS
2. Shiloach-Vishkin PRAM algorithm (SV)
B. Recent prior work
G(V,E)
Multistep algorithm
Part of popular graph analysis frameworks : GraphX, PowerLyra, PowerGraph
1 Parallel BFS iteration
Parallel Label Propagation
Slotaet.al.“ACaseStudyofComplexGraphAnalysis…”IPDPS2016Slotaetal.“BFSandcoloring-basedparallel…IPDPS2014
Introduction Methods Experiments

Flicket.al.“AparallelconnecLvityalgorithm…”SC15
Contributions1. Novel edge-based adaptation of Shiloach-Vishkin
algorithm for distributed memory parallel systems.
2. Fast heuristic to guide algorithm selection at run-time.
8
G(V,E)
Parallel SV
Parallel BFS
1
2
Introduction Methods Experiments

Parallel SV algorithm
9
Current partition id
Vertex ids
• Initialization
• We work with an array of tuples (call it A) to keep partition id of each vertex.
• O(|V|) partitions at beginning
• Size of A : O(|V| + |E|)
Introduction Methods Experiments
u
v1
v2
uv1 v2 u
v1 v2
v2v1u
v2uv1 u
v2v1u
v2uv1 u

Parallel SV algorithm
10 < ,
• Initialization
• We work with an array of tuples (call it A) to keep partition id of each vertex.
• O(|V|) partitions at beginning
• Size of A : O(|V| + |E|)
Introduction Methods Experiments
u
v1
v2
uv1 v2 u
v1 v2
v2v1u
v2uv1 u
v2v1u
v2uv1 u
Current partition id
Vertex ids

Parallel SV algorithm
11
u
u u u
Current partition id
Vertex ids
• vertex ‘u’ is member of which all partition ids?
• Sort A by ‘vertex id’ layer
Introduction Methods Experiments
u

Parallel SV algorithm
12
u
u u u
Current partition id
u
v w
u v w
• Which all vertices are member of partition ?
• Sort A by ‘partition id’ layer
Current partition id
Introduction Methods Experiments
Vertex ids
• vertex ‘u’ is member of which all partition ids?
• Sort A by ‘vertex id’ layer
u
v w

Parallel SV algorithm
13
u
u u u
Current partition id
u
v w
u v w
• Which all vertices are member of partition ?
• Sort A by ‘partition id’ layer
Current partition id
Introduction Methods Experiments
Vertex ids
• vertex ‘u’ is member of which all partition ids?
• Sort A by ‘vertex id’ layer
u
v w

Parallel SV algorithm
14
• In our implementation, we use parallel sample sort.
• Custom reduction operations to efficiently compute minimums.
• Additional details:
• pointer jumping
• detect convergence of small components early, load balance
• Runtime :
Introduction Methods Experiments
Check our preprint

Flicket.al.“AparallelconnecLvityalgorithm…”SC15
Contributions1. Novel edge-based adaptation of Shiloach-Vishkin
algorithm for distributed memory parallel systems.
2. Fast heuristic to guide algorithm selection at run-time.
15
G(V,E)
Parallel SV
Parallel BFS
1
2
Introduction Methods Experiments

Dynamic hybrid method
16
• Parallel BFS is close to work efficient for a giant small world graph component.
• Efficiency is lost when :
• Large number of small components
• Large diameter of a graph component
• How to decide which algorithm to choose at runtime?
Introduction Methods Experiments
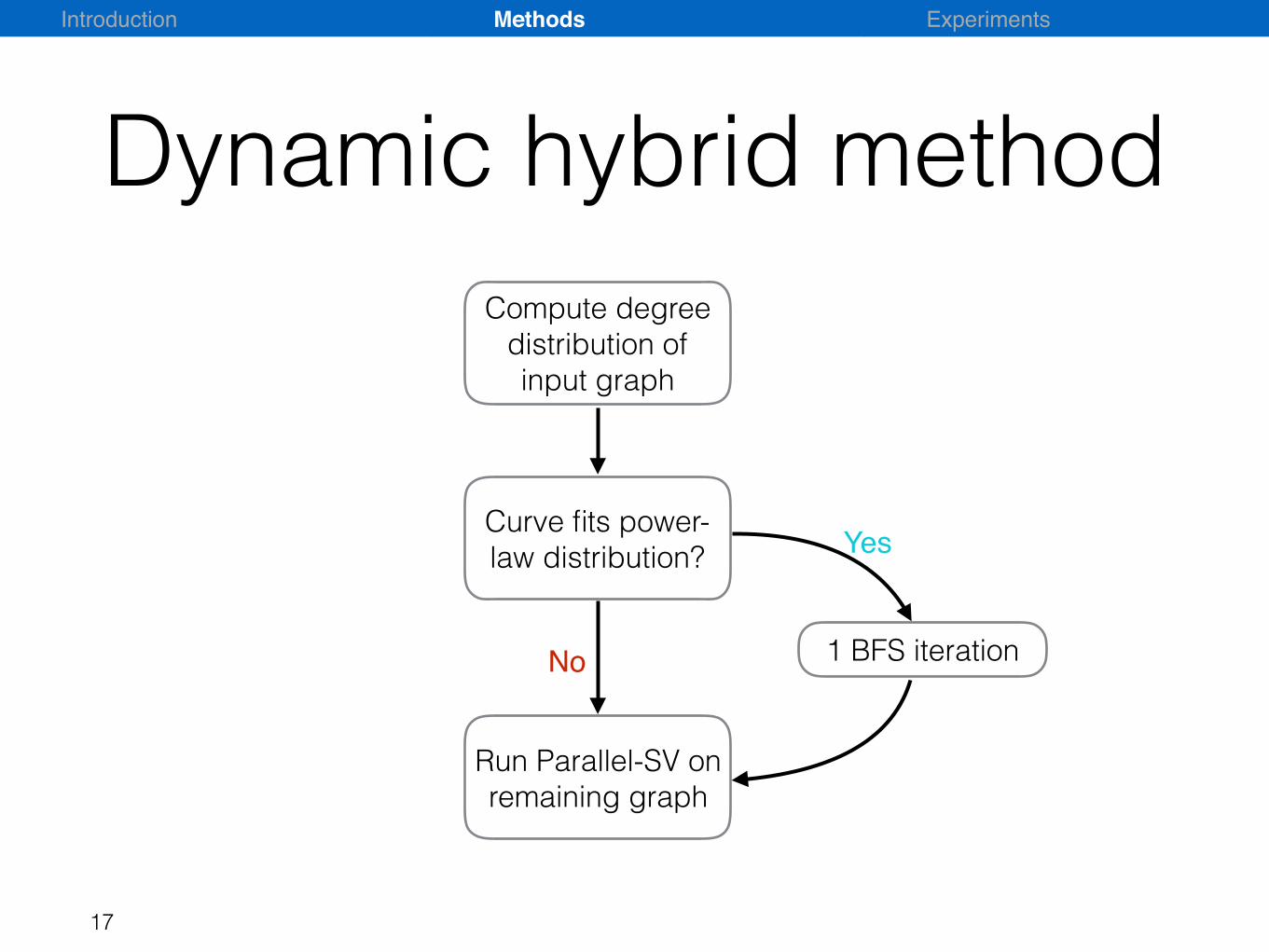
Dynamic hybrid method
17
Introduction Methods Experiments
Run Parallel-SV on remaining graph
Curve fits power-law distribution?
Compute degree distribution of input graph
1 BFS iteration
Yes
No

Experimental Setup• Software : C++14, MPI, CombBLAS library for parallel BFS
• Hardware : Cray XC30 (Edison) at Lawrence Berkeley National Laboratory
• 5,576 nodes, each with 2 x 12-core Intel Ivy processors and 64 GB RAM
• 1 MPI process per physical core
• Timing :
• Exclude graph construction and I/O time
• Profiling starts after having block-distributed list of edges in memory
18 BuluçandGilbert“TheCombinatorialBLAS:Design…”IJHPCA2011
Introduction Methods Experiments
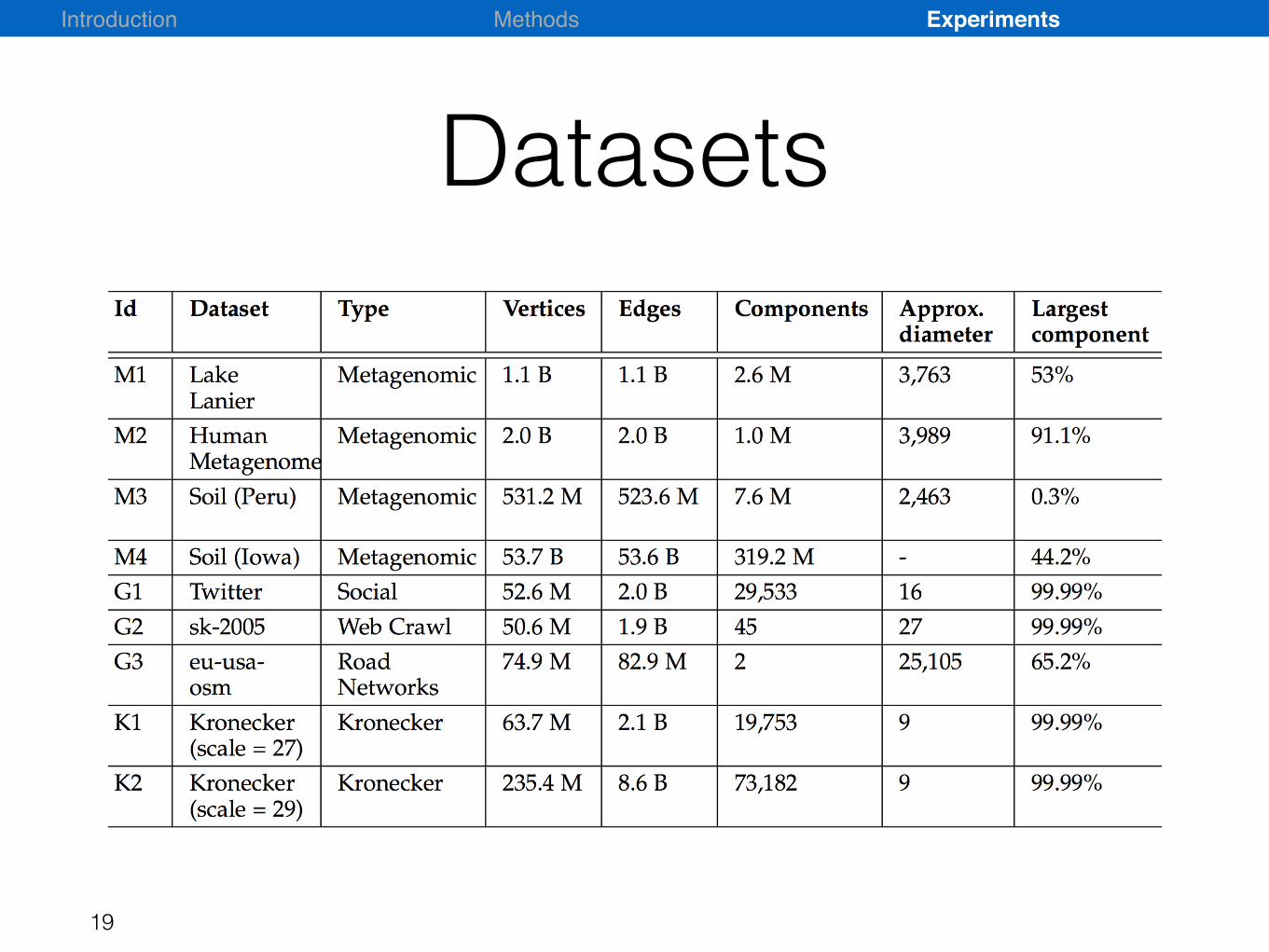
Datasets
19
Introduction Methods Experiments

Datasets
Small world graphs20
Introduction Methods Experiments

Datasets
21Small world graphsLarge diameter graph
Introduction Methods Experiments
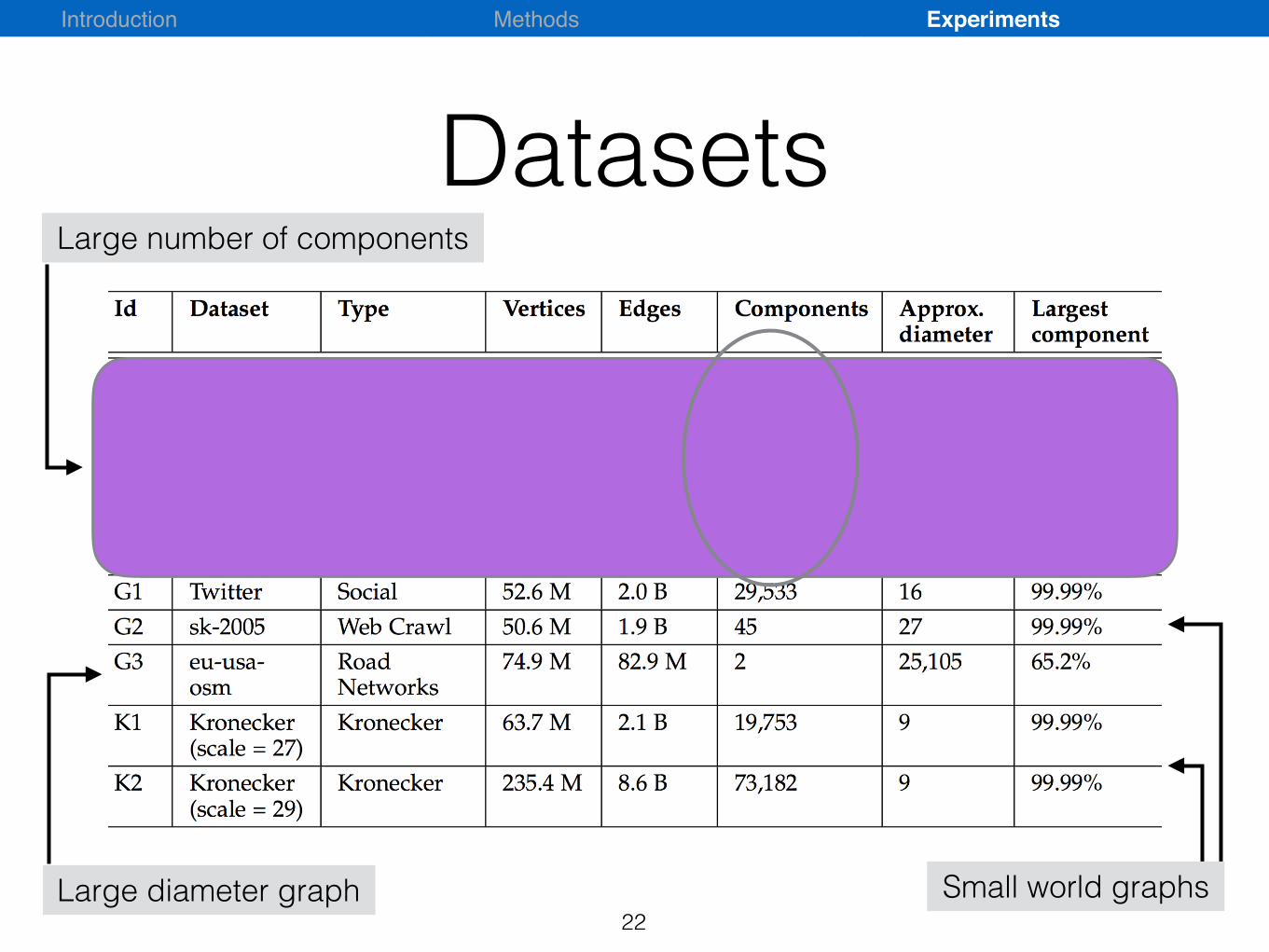
Datasets
22Small world graphsLarge diameter graph
Large number of components
Introduction Methods Experiments

0
20
40
60
M1 M2 M3 G1 G2 G3 K1 K2Datasets
Tim
e (s
ec)
Method
Dynamic
Static (Opp. Choice)
Time (sec)
Graphs
Dynamic Approach
23Run BFS?
1.2x
0.9x
1.2x4.1x
3.7x4.7x
3.6x
4.0x
Timings against opposite choice, using 2K cores
Introduction Methods Experiments

0
20
40
60
M1 M2 M3 G1 G2 G3 K1 K2Datasets
Tim
e (s
ec)
Method
Dynamic
Static (Opp. Choice)
Time (sec)
Graphs
Dynamic Approach
24
Proportion of time spent in prediction (using 2K cores)
Proportion of time
Introduction Methods Experiments
Run BFS?
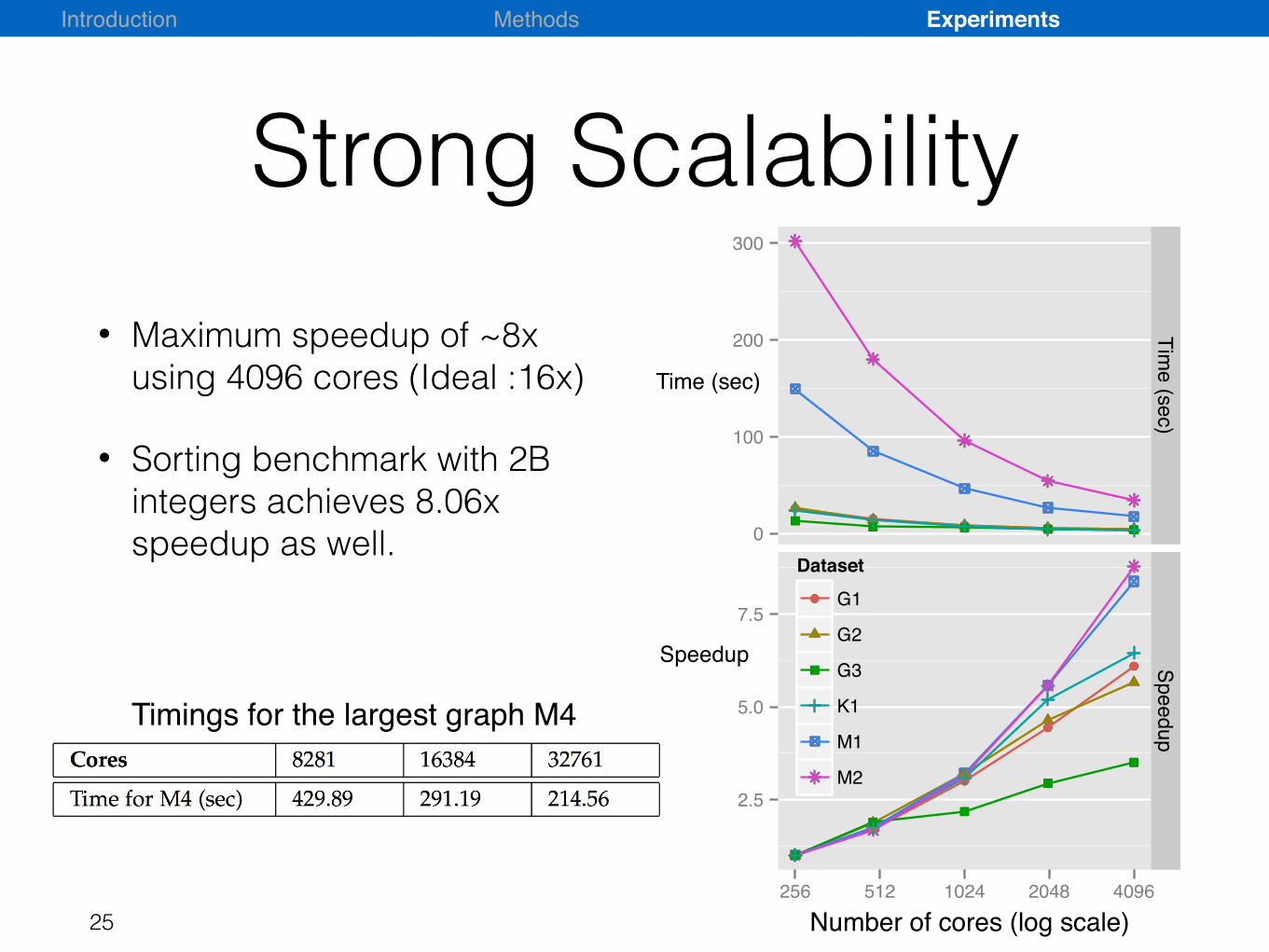
• Maximum speedup of ~8x using 4096 cores (Ideal :16x)
• Sorting benchmark with 2B integers achieves 8.06x speedup as well.
25
●●
● ● ●
●●
● ● ●
●
●
●
●
●
●
●
●
●
●
0
100
200
300
2.5
5.0
7.5
Time (sec)
Speedup
256 512 1024 2048 4096Number of cores (log scale)
Dataset●● G1
G2
G3
K1
M1
M2
Number of cores (log scale)
Timings for the largest graph M4
Strong Scalability
Time (sec)
Speedup
Introduction Methods Experiments
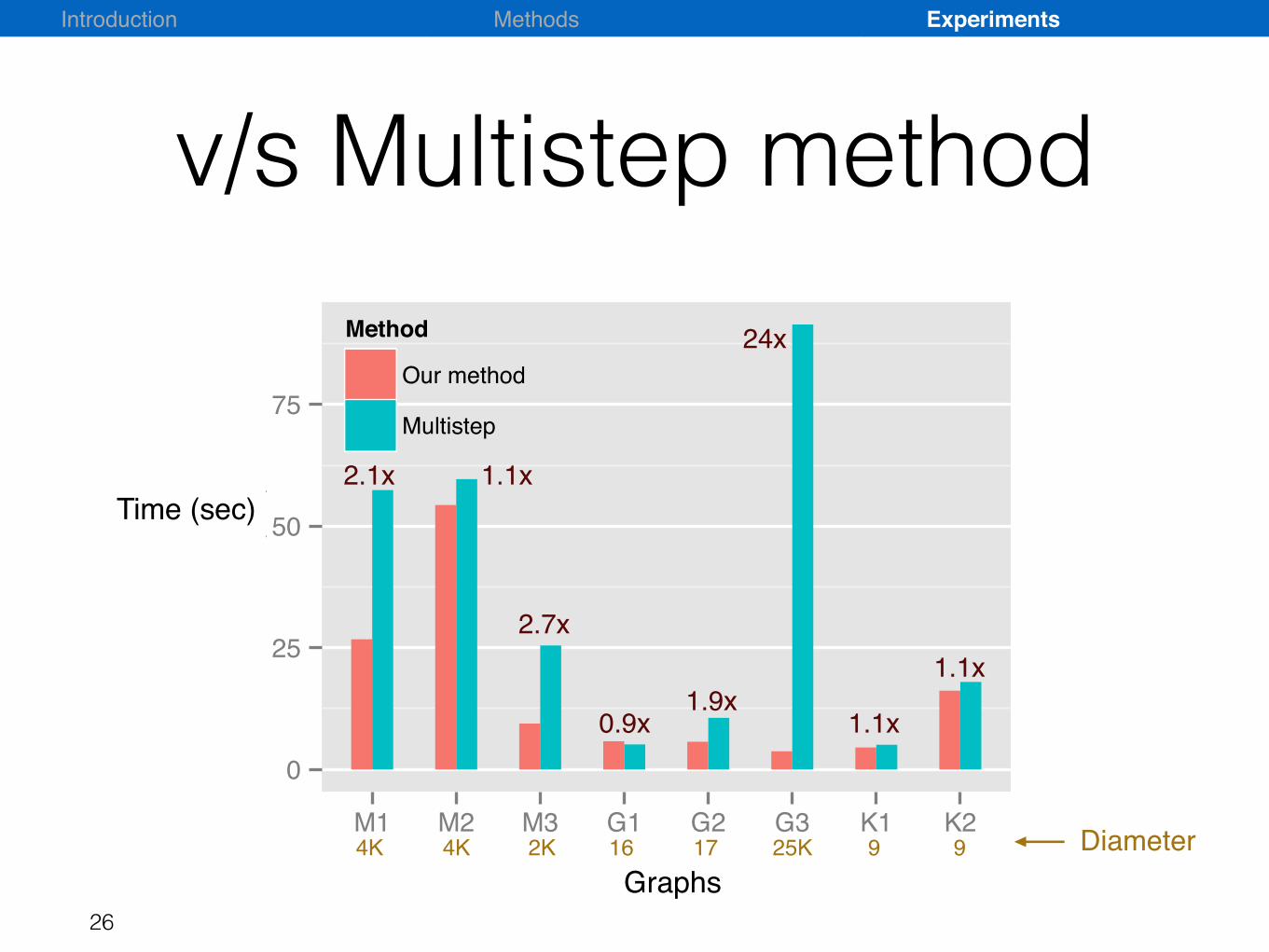
v/s Multistep method
26
0
25
50
75
M1 M2 M3 G1 G2 G3 K1 K2Datasets
Tim
e (s
ec)
Method
Our method
Multistep
Time (sec)2.1x 1.1x
2.7x
24x
0.9x 1.1x
1.1x1.9x
Diameter4K 4K 2K 25K 9 916 17Graphs
Introduction Methods Experiments
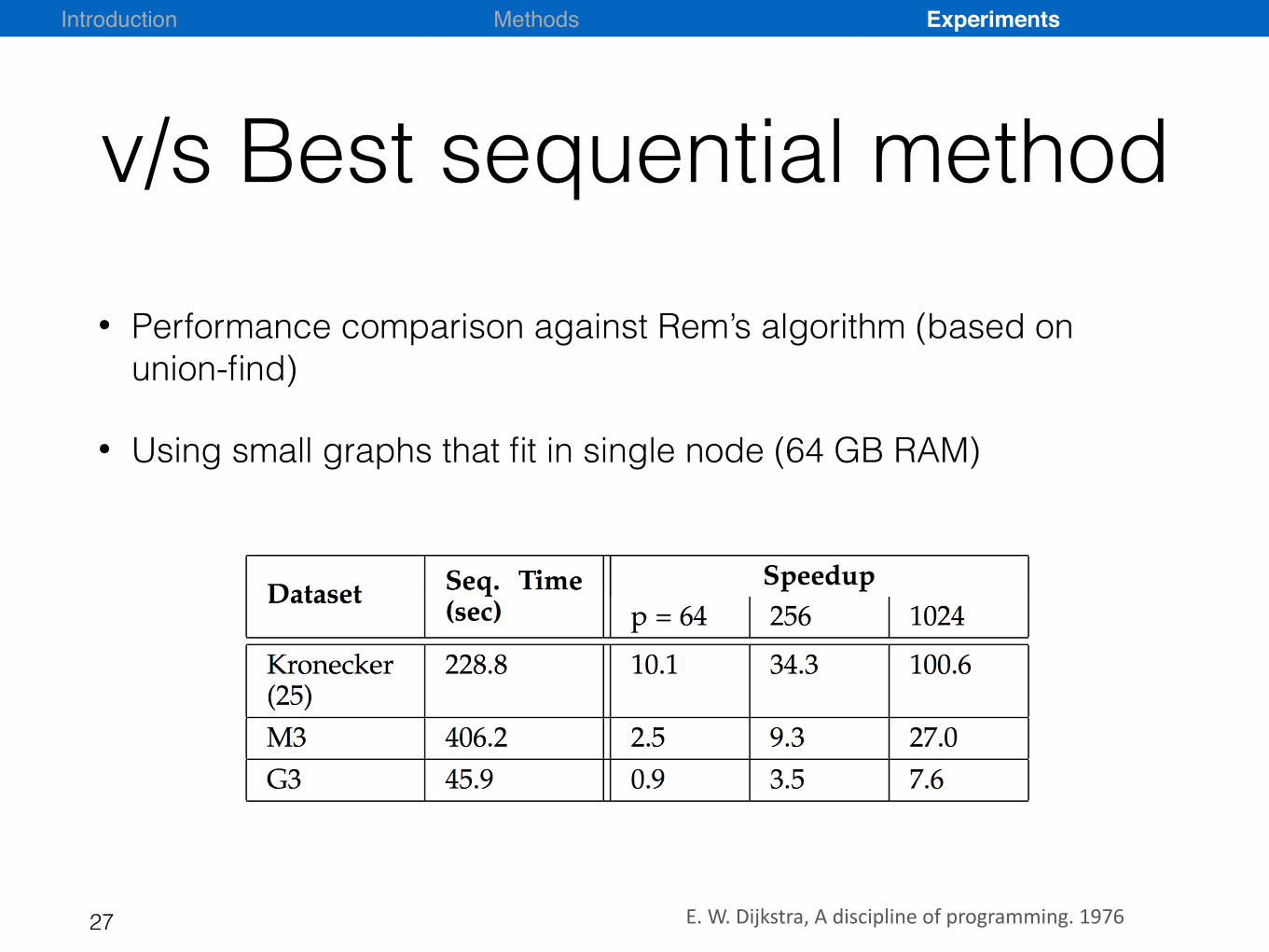
v/s Best sequential method
27
• Performance comparison against Rem’s algorithm (based on union-find)
• Using small graphs that fit in single node (64 GB RAM)
E.W.Dijkstra,Adisciplineofprogramming.1976
Introduction Methods Experiments

Conclusions1. Efficient distributed memory parallel connectivity
algorithm based on Shiloach-Vishkin approach.
2. Propose heuristic to guide algorithm selection at runtime.
3. Efficient as well as generic, scales on a variety of large graphs.
4. Significant performance gains against previous state-of-the-art, particularly in case of large diameter graphs.
28

Thank you!arxiv.org/abs/1607.06156
cjain @ gatech.edu
ReproducibilityIniLaLveAward
github.com/ParBLiSS/parconnect


















