
MAPLD Reconfigurable Computing Birds-of-a-Feather Programming Tools

Aggarwal #198 MAPLD 2004
Design and Analysis of Parallel N-Queens on Reconfigurable Hardware with Handel-C and MPI
Vikas Aggarwal, Ian Troxel, and Alan D. George
High-performance Computing and Simulation (HCS) Research Lab
Department of Electrical and Computer EngineeringUniversity of Florida
Gainesville, FL

#198 MAPLD 2004Aggarwal 2
Outline
Introduction N-Queens Solutions Backtracking Approach N-Queens Parallelization Experimental Setup Handel-C and Lessons Learned Results and Analysis Conclusions Future Work and Acknowledgements References

#198 MAPLD 2004Aggarwal 3
Introduction
N-Queens dates back to the 19th century
(studied by Gauss)
Classical combinatorial problem, widely used
as a benchmark because of its simple and regular structure
Problem involves placing N queens on an N N chessboard such that no queen can attack any other
Benchmark code versions include finding the first solution and finding all solutions

#198 MAPLD 2004Aggarwal 4
Introduction
Mathematically stated:Find a permutation of the BOARD() vector containing numbers 1:N, such that
for any i != j
Board( i ) - i != Board( j ) - j Board( i ) + i != Board( j ) + j
42531BOARD [ ]i = 1 2 3 4 5
Q
Q
Q
Q
Q

#198 MAPLD 2004Aggarwal 5
N-Queens Solutions
Various approaches to the problem Brute force[2]
Local search algorithms[4]
Backtracking[2], [7] , [11], [12], [13]
Divide and conquer approach[1]
Permutation generation[2]
Mathematical solutions[6]
Graph theory concepts[2]
Heuristics and AI[4], [14]

#198 MAPLD 2004Aggarwal 6
Backtracking Approach
One of the only approaches that guarantees a solution, though it can be slow
Can be seen as a form of intelligent depth-first search Complexity of backtracking typically rises exponentially
with problem size Good test case for performance analysis of RC systems,
as the problem is complex even for small data size* Traditional processors provide a suboptimal platform for this
iterative application due to serial nature of their processing pipelines
Tremendous speedups achieved by adding parallelism at the logic level via RC
* For an 8x8 board, 981 moves (876 tests + 105 backtracks) are required for first solution alone

#198 MAPLD 2004Aggarwal 7
Backtracking Approach
Tables provide an estimate of the backtracking approach’s complexity Problem can be made to find
first solution or the total number of solutions
Total number of solutions is obviously a more challenging problem
Interesting observation: 1st solution’s complexity (i.e. number of operations) does not increase monotonically with board size
# of operations for 1st solution [7] Number of solutions [8]

#198 MAPLD 2004Aggarwal 8
N-Queens Parallelization Different levels of parallelism added to improve
performance Functional Unit replication Parallel column check Parallel row check Q
Q
Q
Q
Q
Q
Sequential : 11 cycles
Parallel column check: 3 cycles
Multiple row check appended:1 cycles
11x speedup over sequential operation
Note: Assume first four queens have been placed and the fifth queen starts from the 1st row
Parallelization Comparison

#198 MAPLD 2004Aggarwal 9
Experimental setup
Experiments conducted using RC1000 boards from Celoxica, Inc., and Tarari RC boards from Tarari, Inc.
Each RC1000 board features a Xilinx Virtex-2000 FPGA, 8 MB of on-card SRAM, and PCI Mezzanine Card (PMC) sockets for connecting two daughter cards
Each Tarari board features two user-programmable Xilinx Virtex-II FPGAs in addition to a controller FPGA, 256 MB of DDR SDRAM
Configurations designed in Handel-C using Celoxica’s application mapping tool DK-2, along with Xilinx ISE for place and route
Performance compared against 2.4 GHz Xeon server and 1.33 GHz Athlon server

#198 MAPLD 2004Aggarwal 10
Celoxica RC1000
* Figure courtesy of Celoxica RC1000 manual
PCI-based card having one Xilinx FPGA and four memory banks FPGA configured from the host processor over the PCI bus Four memory banks, each of 2MB, accessible to both the FPGA and any other device
on the PCI bus Data transfers: The RC1000
provides 3 methods of transferring data over PCI bus betweenhost processor and FPGA: Bulk data transfers performed via
memory banks Two unidirectional 8 bit ports, called
control and status ports, for direct comm.between FPGA and PCI bus(note: this method used in our experiments)
User I/O pins USER1 and USERO for single bit communication with FPGA
API-layer calls from host to configure and communicate with RC board

#198 MAPLD 2004Aggarwal 11
Tarari Content Processing Platform PCI-based board having 3 FPGAs and a 256 MB memory bank Two Xilinx Virtex-II FPGAs available for user to load configuration files from host over the
PCI bus Each Content Processing Engine or CPE (User FPGA)
configured with one or two agents Third FPGA acts as controller providing high-bandwidth
access to memory and configuration of CPP
with agents 256 MB of DDR SDRAM for data sharing between
CPEs and the host application Configuration files first uploaded into the
memory slots and used to configure each FPGA Both single-word transfers and DMA transfers supported between the host and the CPP
* Figure courtesy of Tarari CP-DK manual

#198 MAPLD 2004Aggarwal 12
Handel-C Programming Paradigm Handel-C acts as a bridge between VHDL and “C”
Comparison with conventional C More explicit provisioning of parallelism within the code Variables declared to have the exact bit-lengths to save space Provides more bit-level manipulations beyond shifts and logic operations Limited support for many ANSI C standards and extensions
Comparison with VHDL Application porting is much faster for experienced coders Similar to VHDL behavioral models Lacks VHDL concurrent signal assignments which can be suspended
until changes on input triggers (Handel-C requires polling) Provides more higher-level routines

#198 MAPLD 2004Aggarwal 13
Handel-C Design Specifics
Design makes use of the following two approaches
Approach 1 Use of an array of binary numbers to hold a ‘1’ at a particular bit position to indicate the
location of queen in the column A 32 x 32 board will require an array of 32 elements of 32 bits each Correspondingly use bit-shift operations and logical-and operations to check diagonal
and row conditions More closely corresponds to the way the operations will take place on the RC fabric
Approach 2 Use of an array of integers instead of binary numbers Correspondingly use the mathematical model of the problem to check the validation
conditions Smaller variables yield better device utilization; slices occupied reduce from about 75%
to about 15% for similar performance and parallelism
Approach 2 found to be more amenable for Handel-C designs

#198 MAPLD 2004Aggarwal 14
Lessons Learned with Handel-CSome interesting observations: Code for which place and route did not work, finally worked when
the function parameters were replaced by global variables Less control at lower level with place and route being a consistent
problem even with designs using up only 40% of total slices Self-referenced operations (e.g. a=a+x) affect the design
adversely, so use intermediate variables Order of operations and conditional statements can affect design Useful to reduce wider-bit operations into a sequence of narrower-
bit operations Balancing “if” with “else” branches leads to better designs Comments in the main program sometimes affected the synthesis,
leading to place and route errors in fully commented code We are still learning more everyday!

#198 MAPLD 2004Aggarwal 15
Sequential First-Solution Results
Sequential version does not perform well versus the Xeon and Athlon CPUs
Algorithm needs an efficient design to minimize resource utilization
The results do not include the one-time configuration overhead of ~150 ms
RC1000 clock speed @ 40 MHz
RC1000 clock speed @ 40 MHz
Algorithm type Bit manipulation Integer manipulation
Parallel column checks
19% 3%
Parallel row and column checks
78% 15%
Performance Comparison of Sequential Version with Host
0
2000
4000
6000
8000
10000
1 5 4 7 6 9 11 8 10 13 12 15 14 19 17 16 21 23 18 25 20 24
Board Size
Tim
e (m
s)
RC1000 Dual Xeon Server Athlon Server
Performance Comparison of Similar Version of Bit and Integer Algorithms
0
100
200
300
400
500
1 5 4 7 6 9 11 8 10 13 12 15 14 19 17 16 18 20
Board Size
Tim
e (m
s)
RC1000 (Bit Version) RC1000 (Integer Version)

#198 MAPLD 2004Aggarwal 16
Performance Comparison of Different Versions with Host
0
100200
300
400
500600
700
1 5 4 7 6 9 11 8 10 13 12 15 14 19 17 16 18 20
Board Size
Tim
e (
ms
)
RC1000(Parallel column check) RC1000(2 Row check appended)
RC1000(6 Row check appended) Dual Xeon Server
Athlon Server
Parallel First-Solution Results Version Slices Occupied
With parallel column check (for all columns)
3%
With two row check appended
5%
With six row check appended
15%
RC1000 clock speed @ 25 MHz
The most parallel algorithm runs about 20x faster than sequential algorithm on RC fabric Parallel algorithm with two row checks almost duplicates behavior of 2.4 GHz Xeon server, while 6-row check outperforms it by 74% Further increasing the number of rows checked is likely to further improve performance for larger problem sizes
Version Speedup
With parallel column check (for columns)
0.18
With 2-row check appended
0.83
With 6-row check appended
1.74
Performance Comparison of Parallel Algorithm
0
100
200
300
400
500
600
700
17 16 18 20
Board Size
Tim
e (
ms
)

#198 MAPLD 2004Aggarwal 17
Total Number of Solutions Method Employ divide-and-conquer approach Seen as a parallel depth-first search Solutions obtained with queen positioned in any row
in the first column are independent from solutions with queens in other positions
Technique allows for high
degree of parallelism (DoP)

#198 MAPLD 2004Aggarwal 18
One-Board Total-Solutions Results
Designs on hardware perform around 1.7x faster than Xeon server Performance on both RC platforms similar for same clock rates RC1000 performs a notch better for smaller chess board sizes while
Tarari CPP’s performance improves with chess board sizes Almost entire Virtex–II chip on the Tarari is occupied for one FU
RC1000 and Tarari clock speed @ 33 MHz
Target Platform Area (slices)
RC1000 (Virtex 2000e) 10%
Tarari CPP (Virtex–II) 94%
Comparison of Tarari CPP vs. RC1000
0
2000000
4000000
6000000
8000000
10000000
12000000
14000000
16000000
18000000
20000000
4 5 6 7 8 9 10 11 12 13 14 15 16 17
Board Size
Tim
e (m
s)
Tarari 1FU RC1000 1FU Xeon Server Athlon Server

#198 MAPLD 2004Aggarwal 19
Multiple Functional Units (FUs)
Used additional FUs per chip to increase parallelism per chip
Each FU searches for the number of solutions corresponding to a subset of rows in the first column
The controller Handles communication with the host Invokes all FUs in parallel Combines all results
Co
ntr
olle
r
Host processor
fu1
fu2
fu6
fu7
fu8
fu9
fu1
0
fu3
fu4
fu5
On
bo
ard
FP
GA
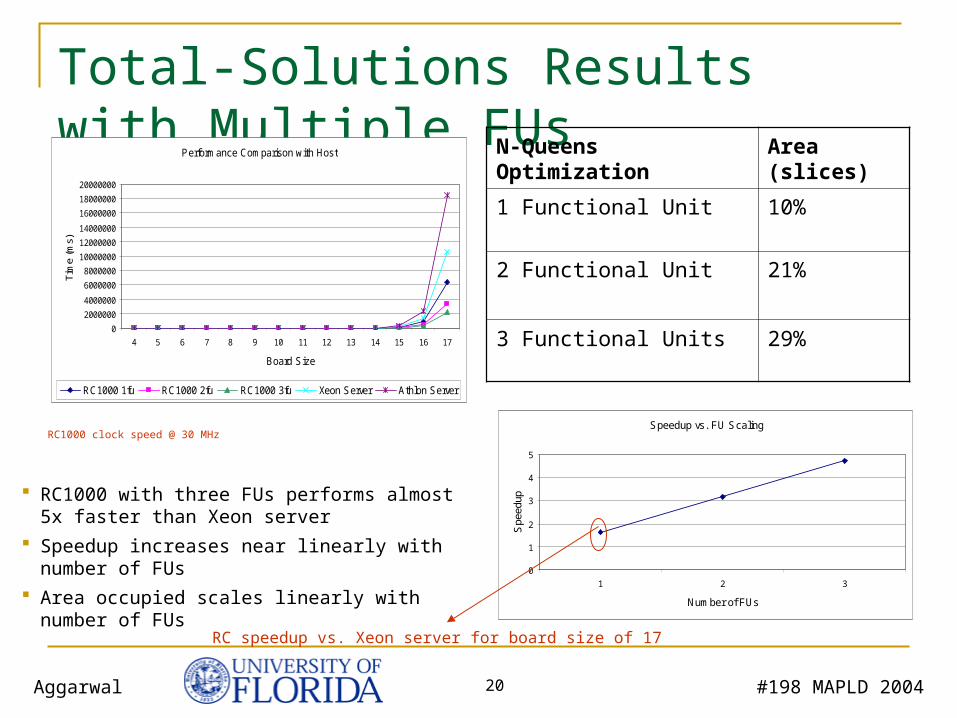
#198 MAPLD 2004Aggarwal 20
Speedup vs. FU Scaling
0
1
2
3
4
5
1 2 3
Number of FUs
Spe
edup
Total-Solutions Results with Multiple FUs N-Queens Optimization Area (slices)
1 Functional Unit 10%
2 Functional Unit 21%
3 Functional Units 29%
RC1000 with three FUs performs almost 5x faster than Xeon server
Speedup increases near linearly with number of FUs
Area occupied scales linearly with number of FUs
RC1000 clock speed @ 30 MHz
RC speedup vs. Xeon server for board size of 17
Performance Comparison with Host
0
2000000
4000000
6000000
8000000
10000000
12000000
14000000
16000000
18000000
20000000
4 5 6 7 8 9 10 11 12 13 14 15 16 17
Board Size
Tim
e (m
s)
RC1000 1fu RC1000 2fu RC1000 3fu Xeon Server Athlon Server

#198 MAPLD 2004Aggarwal 21
MPI for Inter-Board Communication
On-board FPGA(with one or multiple FU’s)
MPI
Host server
Host server
On-board FPGA(with one or multiple FU’s)
To further increase system speedup (having more functional units), multiple boards employed
Each FU programmed to search a subset of the solution space
Servers communicate using the Message Passing Interface (MPI) to start search in parallel and obtain the final result
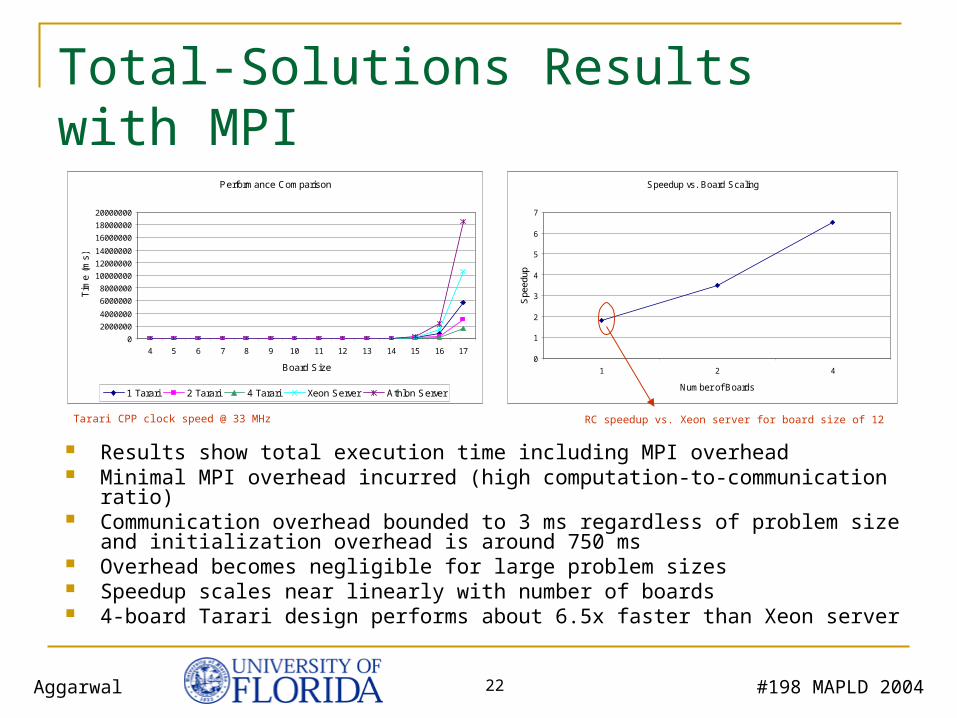
#198 MAPLD 2004Aggarwal 22
Speedup vs. Board Scaling
0
1
2
3
4
5
6
7
1 2 4
Number of Boards
Spe
edup
Total-Solutions Results with MPI
Results show total execution time including MPI overhead Minimal MPI overhead incurred (high computation-to-communication ratio) Communication overhead bounded to 3 ms regardless of problem size and
initialization overhead is around 750 ms Overhead becomes negligible for large problem sizes Speedup scales near linearly with number of boards 4-board Tarari design performs about 6.5x faster than Xeon server
Tarari CPP clock speed @ 33 MHz RC speedup vs. Xeon server for board size of 12
Performance Comparison
0
2000000
4000000
6000000
8000000
10000000
12000000
14000000
16000000
18000000
20000000
4 5 6 7 8 9 10 11 12 13 14 15 16 17
Board Size
Tim
e (m
s)
1 Tarari 2 Tarari 4 Tarari Xeon Server Athlon Server

#198 MAPLD 2004Aggarwal 23
Speedup vs. Board Scaling
0
2
4
6
8
10
12
14
1 2 4
Number of Boards
Spe
edup
Total-Solutions Results with MPI
RC speedup vs. Xeon server for board size of 12RC1000 clock speed @ 30 MHz
Results show total execution time including MPI overhead Minimal MPI overhead incurred (high computation-to-communication ratio) Communication overhead bounded to 3 ms regardless of problem size and
initialization overhead is around 750 ms Overhead becomes negligible for large problem sizes Speedup scales near linearly with number of boards 4-board RC1000 design performs about 12x faster than Xeon server
Performance Comparison with Host
0
500000
1000000
1500000
2000000
2500000
8 9 10 11 12 13 14 15 16
Board size
Tim
e (
ms)
1 RC1000 2 RC1000 4 RC1000 Xeon Server Athlon Server

#198 MAPLD 2004Aggarwal 24
Total-Solutions Results with MPI
Communication overheads still remain low, while MPI initialization overheads increase with number of boards (now 1316 ms for 8 boards)
Heterogeneous mixture of boards employed to solve the problem coordinating via MPI Total of 8 boards (4 RC1000 and 4 Tarari boards) allows up to 16 (43 + 41) FUs 8 boards perform about 21x faster than Xeon server for chess board size of 16
What appears to be an unfair comparison really shows how the approach scales to many more FUs per FPGA (on higher density chips)
RC1000 clock speed @ 30 MHz and Tarari clock speed @ 33MHz
Performance Comparison with Host
0
500000
1000000
1500000
2000000
2500000
8 9 10 11 12 13 14 15 16
Board Size
Tim
e (m
s)
On 8 Boards Xeon Server Athlon Server

#198 MAPLD 2004Aggarwal 25
Conclusions Parallel backtracking for solving N-Queens
problem in RC shows promise for performance N-Queens is an important benchmark in the HPC community RC devices outperform CPUs for N-Queens due to RC’s efficient
processing of fine-grained, parallel, bit-manipulation operations Previously inefficient methods for CPUs like backtracking can be
improved by reexamining their design This approach can be applied to many other applications Numerous parallel approaches developed at several levels
Handel-C lessons learned A “C-based” programming model for application mapping provides
a degree of higher-level abstraction, yet still requires programmer to code from a hardware perspective
Solutions produced to date show promise for application mapping

#198 MAPLD 2004Aggarwal 26
Future Work and Acknowledgements Compare application mappers with HDL design in terms of mapping efficiency
Develop and use direct communication between FPGAs to avoid MPI overhead Export approach featured in this talk to variety of algorithms and HPC
benchmarks for performance analysis and optimization Develop library of application and middleware kernels for RC-based HPC
We wish to thank the following for their support of this research: Department of Defense Xilinx Celoxica Tarari Key vendors of our HPC cluster resources (Intel, AMD, Cisco, Nortel)

#198 MAPLD 2004Aggarwal 27
References[1] “Divide and Conquer under Global Constraints: A Solution to the N-Queens Problem”, Bruce
Abramson and Mordechai M. Yung
[2] ”Different Perspectives Of The N-queens Problem”, Cengiz Erbas, Seyed Sarkeshikt, Murat M. Tanik, Department of Computer Science and Engineering,Southern Methodist University, Dallas
[3] “Algorithms and Complexity”, Herbert S. Wilf, University of Pennsylvania, Philadelphia
[4] “Fast search algorithms for N-Queens problem”, Rok Sausic, Jum Gu, appeared in IEEE transactions on Systems, Man, and Cybernetics, Vol 21, 6, pp 1572-76, Nov/Dec 1991
[5] http://www.cit.gu.edu.au/~sosic/nqueens.html
[6] http://bridges.canterbury.ac.nz/features/eight.html
[7] www.math.utah.edu/~alfeld/queens/queens.html
[8] www.jsomers.com/nqueen_demo/nqueens.html
[9] A polynomial time algorithm for N-queens problem
[10] remus.rutgers.edu/~rhoads/Code/code.html
[11] http://www.mactech.com/articles/mactech/Vol.13/13.12/TheEightQueensProblem/index.html
[12] http://www2.ilog.com/preview/Discovery/samples/nqueens/
[13] http://www.infosun.fmi.uni-passau.de/br/lehrstuhl/Kurse/Proseminar_ss01/backtracking_nm.pdf
[14] “From Alife Agents To A Kingdom Of N Queens”, Han Jing, Jimimg Liu, Cai Qingsheng
[15] http://www.wi.leidenuniv.nl/~kosters/nqueens.html
[16] http://www.dsitri.de/projects/NQP/






![GOVERNING COLLABORATIVE ACTIVITY: INTERDEPENDENCE …faculty.insead.edu/vikas-aggarwal/documents/[2] Aggarwal, Siggelko… · VIKAS A. AGGARWAL,1* NICOLAJ SIGGELKOW, 2and HARBIR SINGH](https://static.fdocuments.us/doc/165x107/5f086c957e708231d421f158/governing-collaborative-activity-interdependence-2-aggarwal-siggelko-vikas.jpg)











