

Administrando VMware Site Recovery Manager 1.0 Actualización 1_SRM_Guide_1.4_-_Spanish
332
1 Administrando VMware™ Site Recovery Manager™ 1.1 Por Mike Laverick © RTFM Education Traducido por © José María González Por favor, contacta con errores o correcciones a: mailto:[email protected]
-
Upload
arturo-de-lira-delgado -
Category
Documents
-
view
196 -
download
7
Transcript of Administrando VMware Site Recovery Manager 1.0 Actualización 1_SRM_Guide_1.4_-_Spanish

1
Administrando VMware™ Site Recovery Manager™ 1.1
Por Mike Laverick © RTFM Education
Traducido por © José María González
Por favor, contacta con errores o correcciones a: mailto:[email protected]

2
Administrando VMware Site Recovery Manager Copyright © 2008 Mike Laverick y Jose Maria Gonzalez Todos los derechos reservados. Ninguna parte de este libro deberá ser reproducida, almacenada en un sistema de recuperación, o transmitida por cualquier medio, sea electrónico, mecánico, o de otro tipo, sin el permiso escrito de la editorial. No se asume responsabilidad con respecto a la utilización de la información aquí contenida. Aunque se han tomado todas las precauciones en la preparación de este libro, el editor y el autor no asume ninguna responsabilidad por errores u omisiones. Tampoco se asume ninguna responsabilidad por daños y perjuicios derivados de la utilización de la información aquí contenida. Mike Laverick y Jose Maria Gonzalez ofrecen descuentos de este libro cuando se compran a granel. LULU ofrecerá descuentos en los pedidos de 25 ejemplares o más.

3
Tabla de contenido Capítulo 1: Introducción ............................................................................................................................ 8
Agradecimientos .................................................................................................................................... 9
Sobre este libro ..................................................................................................................................... 9
Sobre usted - El lector ........................................................................................................................... 9
Sobre los Hipervínculos ....................................................................................................................... 10
Exención de responsabilidad ............................................................................................................... 10
Sobre la historia de la vida - antes de VMware SRM .......................................................................... 10
Qué es VMware SRM? ......................................................................................................................... 12
¿Qué es la coherencia a nivel de archivo? .......................................................................................... 14
Principios de la administración del almacenamiento y la replicación ................................................. 14
Guías de los proveedores de almacenamiento ................................................................................... 21
Capítulo 2: Primeros pasos con Virtual Appliance VSA Lefthand Networks ........................................... 24
Algunas preguntas frecuentes sobre VSA Lefthand Networks ............................................................ 26
Descargar e instalar el VSA .................................................................................................................. 27
Modificar la Configuración del VSA ..................................................................................................... 28
Licenciar por dirección Virtual MAC .................................................................................................... 29
Instalar el cliente de Gestión ............................................................................................................... 32
Configurar el VSA (gestión de grupos, clusters y volúmenes) ............................................................. 33
Configurar el VSA para la replicación .................................................................................................. 40
Monitorizar la replicación/instantáneas ............................................................................................. 43
Crear las listas de volúmenes y grupos de autenticación .................................................................... 45
Configurando el software iSCSI en el ESX ............................................................................................ 49
Licenciar el VSA .................................................................................................................................... 55
Apagar el VSA ...................................................................................................................................... 56
Conclusión ........................................................................................................................................... 56
Capítulo 3: Instalando VMware SRM ....................................................................................................... 57
La arquitectura de VMware SRM ........................................................................................................ 58
Limitaciones del producto VMware SRM y erratas ............................................................................. 67

4
Licenciar VMware SRM ........................................................................................................................ 74
Configurando la conectividad de la base de datos de VMware SRM .................................................. 76
Instalación del servidor de VMware SRM ........................................................................................... 80
Instalación del plug-in SRM en el cliente Vi ........................................................................................ 87
No es posible conectar con el servidor de SRM .................................................................................. 90
Conclusión ........................................................................................................................................... 91
Capítulo 4: Configuración del Sitio de Protección ................................................................................... 93
La vinculación de SRM del sitio de protección con el sitio de recuperación ....................................... 94
Configuración de los Array Managers ............................................................................................... 100
Configuración de los Array Managers – LeftHand Networks SRA ..................................................... 105
Configurar las asignaciones de Inventario......................................................................................... 112
Creación de grupos de protección .................................................................................................... 116
Fallos al proteger una máquina virtual .............................................................................................. 125
Conclusión ......................................................................................................................................... 127
Capítulo 5: Configuración del sitio de Recuperación ............................................................................ 130
Creación de un plan de recuperación completo de sitio básico ....................................................... 131
Pruebas de configuración de almacenamiento en el sitio de recuperación ..................................... 136
Descripción: Primer Plan de Recuperación de prueba ...................................................................... 145
Practica: Primer Plan de Recuperación de prueba ............................................................................ 151
Controlando & Solución de problemas en planes de recuperación .................................................. 153
Escenarios de ciclos de replicación del almacenamiento.................................................................. 160
Conclusión ......................................................................................................................................... 164
Capítulo 6: Planes Personalizados de Recuperación ............................................................................. 166
Configurar el apagado de las máquinas virtuales protegidas en el sitio protegido .......................... 168
Configurar la prioridad/orden de las máquinas virtuales en el sitio de recuperación ...................... 173
Orden de puesta en marca paralelo y Normal/Baja .......................................................................... 174
Adición de Mensajes.......................................................................................................................... 174
Adición de comandos ........................................................................................................................ 177
Configure la dirección IP de configuración de las máquinas virtuales de recuperación ................... 179
Asignaciones personalizadas de VM.................................................................................................. 185
Gestión de cambios en el sitio de protección ................................................................................... 188
Gestión de cambios en el sitio de recuperación ............................................................................... 197
Creación de nuevas redes y nuevas máquinas virtuales en almacenamiento nuevo ....................... 200

5
Storage VMotion y grupos de protección ......................................................................................... 207
Máquinas virtuales almacenadas en múltiples Datastores VMFS ..................................................... 210
Máquinas virtuales con dispositivos en bruto/ asignaciones de disco ............................................. 214
Múltiples grupos de protección y múltiples planes de recuperación ............................................... 218
El botón reparación del Array Manager ............................................................................................ 224
Conclusión ......................................................................................................................................... 225
Capítulo 7: Alarmas, Exportando el Histórico y el Control de Acceso ................................................... 227
Descripción alarmas .......................................................................................................................... 228
Exportando & Historia ....................................................................................................................... 235
Control de Acceso .............................................................................................................................. 238
Probando sus permisos ..................................................................................................................... 244
Algunas limitaciones en los permisos ................................................................................................ 246
Los archivos de registro de VMware SRM ......................................................................................... 247
Conclusiones ...................................................................................................................................... 248
Capítulo 8: Configuraciones Bi-direccionales ........................................................................................ 250
Configuración del Array Manager ..................................................................................................... 254
Configurando las asignaciones de inventario .................................................................................... 258
Creación del grupo de protección ..................................................................................................... 259
Crear el plan de recuperación ........................................................................................................... 259
Conclusiones ...................................................................................................................................... 260
Capítulo 9: Failover and Failback ........................................................................................................... 262
Consideraciones antes de failover y recuperación ............................................................................ 264
Failover previsto - El sitio protegido está disponible ........................................................................ 264
Failback planeado - El sitio de protegido está disponible ................................................................. 268
Limpieza del plan de recuperación .................................................................................................... 285
Errores de limpieza ............................................................................................................................ 295
Failover imprevisto - El sitio protegido está MUERTO ...................................................................... 298
Failback planeado - El sitio protegido ha vuelto! y está funcionando .............................................. 301
Resolviendo problemas con RDM - Failover ...................................................................................... 303
Resolviendo problemas RDM - Failback ............................................................................................ 311
Conclusiones ...................................................................................................................................... 313
Capítulo 10: La recuperación del sitio, sin VMware SRM ...................................................................... 315
Reconocimiento especial ................................................................................................................... 316

6
Introducción ...................................................................................................................................... 316
Para una recuperación no planificada ............................................................................................... 317
Gestionar el almacenamiento ........................................................................................................... 317
VMware PowerShell Toolkit .............................................................................................................. 318
Escanear las HBAs de cada servidor ESX ........................................................................................... 320
Crear una red interna para las pruebas ............................................................................................. 321
Añadir máquinas virtuales en el Inventario ...................................................................................... 322
Arreglar los archivos VMX ................................................................................................................. 326
Conclusiones ...................................................................................................................................... 327
Fin - Conclusiones finales .................................................................................................................. 327
Index ...................................................................................................................................................... 330

7

8
Capítulo 1: Introducción

9
Agradecimientos Antes de comenzar este libro quiero dar las gracias a muchas personas que me han ayudado durante la creación de este libro. En primer lugar, quiero dar las gracias a mi compañero Carmel Edwards. Siempre me ha aguantado cuando me pongo a “deliberar” sobre VMware y la virtualización en general. Carmel es la primera en leer mis obras y es quien hizo la primera lectura de prueba del libro. En segundo lugar, quiero dar las gracias a Adam Carter, el técnico de producto para Lefthand Networks. Adam fue de inestimable ayuda al permitirme discutir con él mis ideas, y peguntarle preguntas de novato con referencia a Lefthand Networks. Si sueno como una especie de gurú de almacenamiento en este libro, le tendré que agradecer a Adam por ello. En realidad, no soy un gurú en absoluto, incluso en productos de VMware. No soporto el uso de la palabra “gurú”. En tercer lugar, quiero dar las gracias a Daniel Crider de VMware y la comunidad “VMware Certified Instructor”. Daniel es miembro del equipo de desarrollo de cursos en VMware, y hemos trabajado estrechamente en lo que me gustaría pensar fue un mutuo acuerdo recíproco en el que ambos hemos discutido ideas y experiencias en torno a SRM. Por último, quisiera agradecer personalmente a Mornay Van Der Walt de VMware y al equipo de SRM en general. Mornay es Managing Architect for Enterprise & Technical Marketing. Yo conocí por primera vez a Mornay en Cannes en el año 2008. Mornay me ayudo a conocer a Adam de Lefthand Networks. También fue muy útil ayudándome a resolver mis más oscuras cuestiones técnicas que rodean el producto SRM.
Sobre este libro Esta es una guía completa para el uso de VMware Site Recovery Manager (SRM). La versión de ESX y vCenter utilizada es la 3.5 y 2.5 Update 1 respectivamente. Este libro no ha sido probado sobre la versión ESXi, sin embargo, debería de funcionar igualmente.
Sobre usted - El lector Tengo una idea muy clara de la clase de persona que lee este libro. Preferentemente, usted ha trabajando con VMware Vi3 por algún tiempo. Tal vez usted ha asistido a un curso autorizado Vi3 como el "Install & Configure" o incluso el "Deploy, Secure and Analyse". Además tal vez usted sea ya VMware Certified Professional (VCP). Bien, ¿A dónde quiero llegar?. Este libro no es una guía de SRM para principiantes. Usted va a necesitar algunos conocimientos base, o al menos leer otras de mis guías o libros para ponerse al día. Pero seré amable con usted - asumiendo que usted ya se ha olvidado de algunos de los conceptos de los cursos, tales como los metadata VMFS, UUID y VMFS Resignaturing, pues usted tiene que entender también la replicación del almacenamiento. Por último, si usted es un instructor certificado de VMware puede encontrar este libro muy útil. Esto se debe a que este libro está basado ampliamente en VSA Lefthand Networks (Virtual SAN Appliance) ya que también se utiliza en los cursos
oficiales de VMware. La utilización de VSA Lefthand Networks no debería tomarse

10
como una recomendación hacia sus productos. Conocí a los chicos de Lefthand Networks en VMworld Europa 2008 en Cannes y fueron muy amables al ofrecerme dos licencias NFR (Non for Resellers) de su tecnología de almacenamiento. Los otros proveedores de almacenamiento también me han ayudado a escribir este libro. Es sólo que Lefthand Networks llego primero.
Sobre los Hipervínculos Internet es un recurso fantástico como todos sabemos. Sin embargo, los hipervínculos impresos son a menudo bastante largos, difíciles de escribir correctamente y cambian con frecuencia. He creado una página web muy simple que contiene todas las URL incluidas en este libro. Me esforzaré por mantener esta página actualizada para haceros la vida más fácil para todos los interesados. El URL único que necesitas para todos los enlaces y contenidos en línea está aquí: http://www.josemariagonzalez.es/srm.html
Exención de responsabilidad Ningún libro sobre un producto informático estaría completo sin una cláusula de exención de responsabilidad. Aquí está la mía: Aunque todas las precauciones se han tomado en la preparación de este libro, el editor y el autor no asumen ninguna responsabilidad por errores u omisiones. Tampoco se asume ninguna responsabilidad por daños y perjuicios derivados de la utilización de la información aquí contenida.
Sobre la historia de la vida - antes de VMware SRM Para apreciar realmente el impacto de VMware SRM, quizás valga la pena hacer una pausa por un momento y pensar cómo era la vida antes de que la virtualización y VMware SRM fueran inventados. Antes de que la virtualización se hiciera popular, tener entornos DR (Disater Recovery a partir de ahora) convencionales, significaba dedicar equipos físicos en el sitio DR en una relación uno-a-uno. Por lo tanto, en todas las empresas con servicios críticos había un duplicado (servidor) en el sitio remoto o DR. Por su naturaleza, este modelo es caro y difícil de mantener y gestionar. Los servidores estaban configurados en modo “standby”, a la espera de ser utilizados en caso de un desastre del sitio principal. Para aquellas empresas que carecían de los recursos internos, esto significaba tener que alquilar espacio de “servidores en rack” en un lugar comercial, y si además esto incluía la compra de mas servidores, muy a menudo significaba que el hardware que tenían que comprar era completamente diferente al del sitio de producción. Aunque implementar un plan de contingencias es probable que sea costoso de gestionar, la virtualización ayuda enormemente a reducir los costes financieros y los costes de planificación. Primero, las máquinas virtuales son más baratas que las máquinas físicas. Podemos tener muchas instancias de software, por ejemplo Windows, ejecutándose en el mismo hardware o servidor, reduciendo así el espacio en rack necesario para una ubicación DR. Ya no tiene que preocuparse de que el hardware en la ubicación primaria sea diferente al hardware de la ubicación DR, siempre y cuando el hardware en la ubicación DR soporte VMware ESX. Así nuestro tiempo puede ser dedicado a lograr que los

11
servicios que mantenemos se pongan en marcha y entren en funcionando en el menor tiempo posible. Una de las cosas más comunes que he escuchado en mis cursos y conferencias a personas que son nuevas en la virtualización son, entre otras cosas: "Vamos a tratar de virtualizar nuestro sitio DR , antes de instalarlo en nuestro sitio primario o de producción" Esto se utiliza a menudo como una “excusa prudente” por parte de las empresas que están adoptando tecnologías de virtualización por primera vez. Cuando me dicen esto yo siempre les respondo - pensar en las consecuencias de lo que estás diciendo. En mi opinión, una vez que adapta el camino de la virtualización en su sitio DR, es casi inevitable desear virtualizar también sus sistemas de producción por dos razones principales. En primer lugar, usted estará tan impresionado y convencido de las ventajas de la virtualización, que también querrá virtualizar el sitio de producción. Y en segundo lugar, y más importante para el contexto de este libro, si su entorno de producción no está ya virtualizado, entonces, ¿cómo va a mantener el sito DR sincronizado con la ubicación principal o sitio de Producción? Hay un par de maneras de lograr este objetivo. Primero, se puede confiar únicamente en las copias de seguridad convencional y la restauración, aunque esto no va a ser muy rápido. Segundo, y esta es una mejor alternativa, podría utilizar algún tipo de tecnología P2V (En Ingles Physical to Virtual – Conversión de Físico a Virtual). En los últimos años muchos de los proveedores de estas herramientas de conversión P2V como PlateSpin y LeoStream, han re-posicionado sus productos hacia "herramientas de disponibilidad". La idea es que usted utiliza el software P2V para mantener también el entorno de producción sincronizado con el sitio DR. Hoy en día, estas tecnologías funcionan, y habrá algunas ventajas en la adopción de esta estrategia, por ejemplo, hay aplicaciones/servicios que por alguna razón deben permanecer en un servidor físico en el sitio primario. Pero en general soy escéptico sobre el uso de este método. Me suscribo a la opinión de que se debe utilizar las herramientas adecuadas para el trabajo adecuado. Nunca use una llave inglesa para hacer el trabajo de un martillo. Usted descubrirá defectos y problemas, porque está utilizando una herramienta con un fin para el que nunca fue diseñada. Para mí P2V es P2V, y no se trata de una herramienta DR, aunque puede ser re-diseñada para hacer este tipo de tareas. Otra forma de atajar este problema ha sido la de virtualizar los sistemas de producción antes de virtualizar los sistemas en el sitio DR. Al hacer esto usted sólo tendrá que usar la tecnología de su proveedor de almacenamiento para “replicar” una fotografía o snapshot de los archivos de datos que componen una máquina virtual (VMX, vmdk, nvram, log, snapshot, fichero swap) al sitio o ubicación DR. Aunque este método es mucho más “limpio”, esto en sí mismo introduce una serie de problemas – entender la tecnología de replicación de almacenamiento de su proveedor y asegurar que hay suficiente ancho de banda disponible entre el sitio de producción y la ubicación DR para que este método sea viable. Además, esto introduce una pregunta de gestión. Los chicos que manejan la capa de virtualización y prueban el plan de recuperación no son los mismos chicos que gestionan la capa de almacenamiento. Por lo tanto, tiene que existir una gran colaboración entre estos dos equipos para que interactúen entre sí de manera eficaz. Pero dejemos a un lado por el momento estas consideraciones importantes de almacenamiento - aún habría mucho trabajo por hacer en la capa de virtualización

12
antes de entra en esta capa. Las máquinas virtuales “replicadas” tienen que ser "registradas" en un ESX del sitio de recuperación, y asociadas a la carpeta correcta, la red y al resource pool en el lugar de destino. Deben estar contenidas dentro de algún tipo de sistema de gestión como vCenter para poder ser encendidas y, además, para poder arrancar las máquina virtual, todos los "metadatos" almacenados en el fichero VMX de todas las maquinas virtuales podrían tener que ser modificados. Una vez encendidas (en el orden correcto), es muy probable que se necesite modificar su configuración IP. Aunque algunos de estos pasos podrían automatizarse vía secuencia de comandos, nos llevaría mucho tiempo crear y comprobar las secuencias de comandos. Además, como su entorno de producción empezó a evolucionar y a cambiar, las secuencias de comandos necesitan un mantenimiento y una revisión constante. Para las organizaciones que crean cientos de máquinas virtuales a la semana, esto puede convertirse rápidamente en algo “inmanejable”. Vale la pena decir que si su organización ya ha invertido mucho tiempo en este proceso de secuencias de comandos para una solución a medida, es muy probable que SRM no cubra todas sus necesidades específicas. Esta es una especie de tópico pero es cierto. Cualquier sistema a medida creado internamente siempre va a estar más ajustado a las necesidades de la empresa. El problema está en su mantenimiento, en las pruebas y en demostrar a los auditores que funciona con fiabilidad. Es en este contexto en el que los ingenieros de VMware comenzaron a trabajar en la primera versión de SRM, con un objetivo muy noble, crear un sistema automatizado DR accionable mediante un “botón” para simplificar considerablemente el proceso. Personalmente estoy convencido que de todos los instrumentos de gestión que VMware ha añadido durante los últimos años, VMware SRM es el más importante. Las personas más o menos entienden y aprecian su significación e importancia. Por fin podemos finalmente usar el término "virtualización del sitio DR", sin que en realidad esto sea un término de marketing. Si desea obtener más información acerca de este manual DR, VMware ha escrito un libro sobre la virtualización DR que se llama "Guía práctica para la Continuidad empresarial y recuperación de desastres con VMware Infrastructure". Es gratuito y está disponible en línea aquí: http://www.vmware.com/files/pdf/practical_guide_bcdr_vmb.pdf
Qué es VMware SRM? Sencillamente SRM es un instrumento de automatización. Automatiza la prueba y la invocación de la "recuperación de desastres (en Ingles DR) o como ahora se prefiere llamar, la “continuidad del negocio "(en Ingles BC-Business Continuity) de las máquinas virtuales. En realidad, es más complicado de lo que para muchos es solo un procedimiento o evento DR. Cuando se produce un desastre se requieren medidas y procedimientos destinados a “levantar” el negocio de nuevo. Por otra parte la continuidad del negocio es más un evento estratégico relacionado con las perspectivas a largo plazo de la empresa después de un desastre, y debe incluir un plan sobre cómo el negocio un día podría volver al sitio de producción o moverlo a otro lugar totalmente distinto. Alguien podría escribir un libro entero sobre este tema. De hecho hay libros que han sido escritos sobre este tema. Así que no tengo la intención de explicar que es el objetivo de tiempo de recuperación, objetivo de punto de recuperación o parada máxima tolerable. Eso no es realmente el tema de este libro. En pocas palabras VMware SRM no es una herramienta para DR o BC que soluciona todos los problemas, sino es una herramienta que facilita los procesos de

13
toma de decisiones previstas antes de la catástrofe. Este libro se centrara sobre cómo poner en marcha VMware SRM. Con VMware SRM, si pierde su sitio primario o "sitio protegido", el objetivo es poder ir al sitio secundario o "sitio recuperación", y hacer clic en un botón para ver como sus máquinas virtuales se encienden en el sitio de recuperación. Para lograr este objetivo, su proveedor de almacenamiento debe proporcionar un motor para replicar sus máquinas virtuales desde el sitio protegido al sitio se recuperación. Su proveedor de almacenamiento también le proporcionará un "Adaptador Recuperación de Sitio " (en Ingles SRA – Site Recovery Adapter), el cual está instalado en su servidor SRM. Actualmente, VMware SRM está solo soportado para redes de área local (en Ingles Storage Area Network – SAN) de fibra y iSCSI. No hay soporte todavía para NFS. Como la replicación o las instantáneas son un requisito absoluto para que SRM funcione, pensé que era una buena idea comenzar cubriendo un par de diferentes tipos de dispositivos de almacenamiento desde la perspectiva de SRM. Esto dará a los lectores una base sobre cómo conseguir que la replicación o las instantáneas del almacenamiento funcionen, especialmente para aquellos lectores como yo que no se consideran expertos en el área del almacenamiento. Recuerde que VMware SRM no hace la réplica o la instantánea. Este libro no constituye un sustituto para una buena formación en estas tecnologías de replicación, a ser posible directamente del vendedor. Si ya está familiarizado con la funcionalidad del software de replicación e instantáneas de su proveedor de almacenamiento puede decidir pasar al Capítulo 3: Instalación de VMware SRM. Tuve la suerte de conocer al personal de gerencia del producto de SRM a través de Lefthand Networks en el VMworld Europa 2008 en Cannes. Desde el momento en que los conocí, me ofrecieron dos licencias NFR (Non For Resellers) del Virtual Appliance Lefthand Networks para redes SAN iSCSI, mayormente conocido por el nombre de VSA, con fines de prueba. Más tarde me presentaron a los dos chicos de EMC y NetApp y me interese mucho por estas tecnologías de almacenamiento, tanto desde una perspectiva de SRM como de VDI(Virtual Desktop Infrastructure). En términos de configuración, voy a empezar con una configuración muy simple - una única LUN/volumen replicándose al emplazamiento remoto. Sin embargo, más adelante voy a cambiar la configuración de modo que tendremos múltiples LUNs/Volúmenes con los discos virtuales de las máquinas virtuales en las LUNs. Evidentemente, la gestión en la frecuencia de las replicas será importante. Si tenemos una archivo boot.VMDK en una LUN/Volumen y ficheros de base de datos almacenados en un archivo data.VDMK en otra LUN/Volumen, los dos archivos que formar parte de la máquina virtual podría fácilmente des-sincronizarse, lo que podría corromper los datos. Si utilizamos los “extents” VMFS en VMware ESX , y olvidamos incluir todas las LUNs/volúmenes que componen el extent, estaríamos provocando que el “extent” se rompiera en la ubicación remota y los archivos que componen la máquina virtual estarían dañados. Entonces, la pregunta sobre cómo utilizar las LUN y donde puede guardar sus máquinas virtuales, puede llegar a ser más complicado que este simple ejemplo de los extents. Nuestra atención se

14
centrara en VMware SRM, no en el almacenamiento. Sin embargo, la estructura de almacenamiento y replicación es fundamental para la implementación de SRM.
¿Qué es la coherencia a nivel de archivo? Una de las preocupaciones o preguntas que usted puede tener es, cual es el nivel de coherencia de la copia en el sitio de recuperación?. Esta pregunta es muy fácil de responder - el mismo nivel de coherencia que si no hubiera virtualizado su sito DR. A través de la capa de almacenamiento se podrán replicar las máquinas virtuales de un sitio a otro de manera síncrona. Esto significa que los datos almacenados en ambos sitios van a ser de una “calidad” muy alta. Sin embargo, lo que no se sincroniza es el estado de la memoria de sus servidores en el sitio de producción. Lo que esto significa es que si se produce un verdadero desastre, el estado de la memoria se pierde. Así, pase lo que pase, habrá algún tipo de pérdida de datos a menos que su proveedor de almacenamiento tenga una manera de “parar” las aplicaciones y servicios dentro de su máquina virtual. Este nivel de consistencia a nivel de la máquina virtual se limita normalmente a su software de copia de seguridad. Así que aunque usted pueda ser capaz de poder encender las máquinas virtuales en un sitio de recuperación, puede que aún sea necesario usar herramientas de terceros para la reparación de estos sistemas a partir del estado “crash consistent". De hecho, si estas herramientas fallan, usted puede verse obligado a reparar los sistemas mediante la restauración de una copia de seguridad. Con aplicaciones como Microsoft SQL y Exchange esto podría llevar mucho tiempo dependiendo de si los datos son inconsistentes y de la cantidad del dato. Usted debe realmente incluir este factor en la variable “objetivo tiempo de recuperación”. Lo primero que hay que garantizar en su plan de DR es tener una estrategia de seguridad y de restauración efectiva que trate con la posibilidad de corrupción de los datos y los ataques de virus.
Principios de la administración del almacenamiento y la replicación En mi próximo capítulo voy a exponer en detalle un sistema de almacenamiento especial – VSA Lefthand Networks. Pero antes me gustaría decir muy brevemente y de una forma muy genérica cómo es la gestión del almacenamiento de otros proveedores, y la forma en que gestionan la duplicación de los datos de una ubicación a otra. Debido a esta necesidad, esta sección va a ser muy general y no especifica a un proveedor, de modo que para abordar un problema particular con la capa de almacenamiento, terminare con toda una serie de enlaces de la web donde muchos de estos proveedores de almacenamiento tienen documentación específica relacionada con los requisitos y configuración de VMware Site Recovery Manager. Cuando empecé a escribir este libro tuve ambiciosas, yo diría incluso extravagantes esperanzas, de que sería capaz de cubrir la configuración básica de todas las cabinas de los proveedores de almacenamiento y de cómo conseguir comunicación entre VMware SRM y las cabinas. Sin embargo, después de un corto período de tiempo reconocí que esta ambición era irrealista!. Espero por consiguiente ofrecer

15
este contenido a las personas de las comunidades de VMware/Almacenamiento mediante la liberación de este material como archivos PDF, como un “acompañante” de este libro. Después de todo este libro trata de VMware SRM y no de almacenamiento. Sin embargo, el almacenamiento y la duplicación es un requisito primordial para que VMware SRM funcione, por lo que considero negligente de mi parte no esbozar al menos algunos conceptos básicos y advertencias para aquellos lectores a los que el almacenamiento no sea algo con lo que “jueguen” todos los días. Advertencia número 1: En esencia todos los sistemas de gestión de almacenamiento son los "mismos", es sólo que los proveedores de almacenamiento tratan de confundir a todos (y mí en particular) con el uso de sus propios términos específicos. Los proveedores de almacenamiento no llegaron a un acuerdo sobre los términos a usar. Por lo tanto, para algunos vendedores un "storage group" es un "device group", mientras que otros lo llaman "volumen group". Para otros un volumen es una LUN, pero para otros proveedores de almacenamiento un volumen es una colección LUNs. De hecho, algunos proveedores de almacenamiento piensan que la palabra “LUN” es una especie de palabra "mala". En resumen, descárguese la documentación de su proveedor de almacenamiento y sumérjase en sus términos y su idioma. Esto evitara que se sienta confundido. Advertencia número 2: Todos los proveedores de almacenamiento “re-venden” la replicación. De hecho, pueden muy bien soportar hasta tres o cuatro tipos diferentes de replicación. Algunos vendedores no implementan o soportan todos los tipos de replicación con VMware SRM. Así que puede que tenga una licencia para la replicación de tipo A, pero su proveedor sólo admite replicación de tipo B, C y D, lo cual esto puede obligarle a que actualice sus licencias, el firmware, y los sistemas de gestión para soportar el tipo B, C o D. De hecho, en algunos casos usted puede necesitar una combinación de funcionalidades obligándole así a comprar el tipo B y C o C y D. En pocas palabras, le podría costar un “buen” dinero hacer el cambio al tipo de replicación correcto. Alternativamente, usted podría encontrarse con que aunque el tipo de replicación que tiene cuenta con el soporte necesario, este no sea el más eficiente desde el punto de vista de E/S. Un buen ejemplo de esta situación son los sistemas de EMC Clarrion. En los sistemas Clarrion usted puede utilizar una tecnología de replicación llamada MirrorView. La tecnología MirrorView de EMC cuenta con el soporte de VMware SRM, pero inicialmente sólo soportaba el modo asincrónico. A finales del año 2008, el soporte ha cambiado y MirrorView ya soporta el modo síncrono. Aunque la replicación síncrona es altamente recomendable, se ve frecuentemente limitada por la distancia entre el sitio protegido y el sitio de recuperación o DR. A un nivel superior de la replicación síncrona esta la distancia máxima de replicación que se sitúa en un rango de 400-450 kilómetros. Sin embargo, en la práctica y en el mundo real, estas distancias suelen estar en un rango de 50-60 kilómetros. La distancia es relativa, y así se ha demostrado en los EE.UU. donde estas limitaciones han sido especialmente importantes en los

16
recientes huracanes, pero en mi país que tiene el de tamaño de un sello de correos, tal vez sea menos importante!. Otro ejemplo en las diferencias específicas de soporte de los proveedores de almacenamiento es el caso de HP. Las cabinas de HP (EVA) son compatibles con VMware SRM. Sin embargo, deben tener las licencias de "Business Copy” y "Continuous Access" para que puedan funcionar correctamente. La licencia de “Business Copy” sólo se utiliza cuando se crean las instantáneas o snapshots durante un test de “Plan de Recuperación” con VMware SRM. La licencia “Continuous Access”, permite la replicación de lo HP llamada "vdisks" en un storage group. Advertencia número 3: Los sistemas de gestión de almacenamiento tienen decenas de contenedores que a su vez contienen decenas de otros contenedores o containers. Esto significa que el sistema puede ser administrado de una forma muy flexible. Un ejemplo típico de esto es Microsoft con sus múltiples opciones en la estructura de Active Directory. Tenga en cuenta que a veces esto significa que la replicación de almacenamiento se limita a un determinado tipo de contenedor o de nivel. Esto significa que usted, o su equipo de almacenamiento, tienen que sentarse y pensar muy bien cómo van agrupar sus LUNs para asegurarse de que sólo replican las LUNs que sean necesarias, y que el proceso de replicación en sí, no sea la causa de la corrupción de los datos porque los horarios de replicación no coincidieron. Ciertamente, muchos proveedores de almacenamiento tienen requisitos muy específicos acerca de las relaciones entre los diferentes contenedores cuando se utilizan con VMware SRM. Además, algunos proveedores de almacenamiento “imponen” requisitos sobre estos objetos y shapshots o instantáneas. Si no cumple con estas recomendaciones, puede encontrarse en la situación en que VMware SRM no podrá incluso comunicarse con su almacenamiento correctamente. En pocas palabras, es una combinación del tipo correcto de replicación junto con las estructuras de gestión correctas que harán que todo funcione y sólo se puede saber consultando la documentación que viene con su proveedor de almacenamiento. En resumen - RTFM! (Read the Fun Manual) Ahora que hemos desglosado estas advertencias, me gustaría trazar las estructuras de cómo la mayoría de los proveedores de sistemas de almacenamiento funcionan, para esbozar después algunas consideraciones sobre la planificación de almacenamiento. A continuación, se muestra un diagrama de una cabina de almacenamiento la cual contiene muchas unidades.

En este caso: A. Es la cabina que usted estimportante en este caso. B. Muestra que incluso antesalmacenamiento permitir agagrupación como un disco codonde tenemos la primera op C. Es otro grupo – esto es malmacenamiento (storage grovolúmenes (volumen group) D. Dentro de estos grupos tede los vendedores llaman a este punto, y la replicación ela flecha E. En este caso cadaremota y si esto no estuvierareplicadas en la sitio de recu F. Algunos proveedores de adenominan a veces grupos d(protected groups), grupos d
17
tá utilizando, si se trata de canal de fibra o i
s de permitir el acceso a disco, muchos provgrupar los discos. Por ejemplo NetApp se refonjunto o “disk aggregate”, y es aquí muy a portunidad de establecer un nivel de RAID p
mencionado por algunos vendedores como goup), grupo de dispositivo (device group) o .
enemos los bloques de almacenamiento, y laestos grupos LUNs. Algunos proveedores se
es habilitada para el Grupo C como se indicaa LUN dentro de este grupo se replica a la ca bien planificado nos podemos encontrar LUperación que no eran necesarias replicarlas.
lmacenamiento permiten otros subgrupos. Ee recuperación (recovery groups), grupos p
de contingencia (contingency groups) o grup
iSCSI no es
veedores de fiere a esta menudo
por defecto.
rupo de grupos de
a mayoría e “paran” en mediante
cabina UNs .
Estos se rotegidos
pos de

coherencia (consistency grouGrupo E se replican a la otrano se replican. Para entendeexcepción a esa regla. G. El último grupo es G. Esteacceso tanto al Grupo C o Gralmacenamiento soporte. Estde fibra WWN (World Wide Nproveedores que desarrollan Adapter (VRA) es el softwarealmacenamiento -, a menudocreación de estas agrupaciongrupo E puede ser miembro no presentar todas las LUNs Esta estructura de agrupacióejemplo de esto es cuando ses una recomendación de VMque esto permite adoptar difno está bien planificado, pod
En el ejemplo anterior, los do(SCSI 0:0 y SCSI 0:1) se haciclo de replicación de un gruotro no tiene ninguna latencicorrupción de archivos de regdisco del sistema operativo destado que el disco de los da
18
ups). En este caso sólo las LUNs que figuran cabina remota. Las LUNs no incluidas en el rlo mejor, el grupo C es la regla, siendo el g
e es un grupo de servidores ESX, que permitrupo E, dependiendo de lo que cabina de tos servidores ESX se añadirán al Grupo G,
Name) o iSCSI IQN(iSCSI qualified Name). Lsu adaptador para VMware SRM - Site Reco
e que permite a VMware SRM comunicar coo tienen sus propias normas y reglamentos nes. Por ejemplo, pueden estipular que ningdel grupo C. Esto puede resultar en un falloque los servidores ESX necesitan.
ón puede tener importantes consecuencias. Ue colocan las máquinas virtuales en múltiple
Mware, generalmente por razones de rendimferentes niveles de RAID en diferentes discodría causar la corrupción de las máquinas vir
os discos virtuales que componen la máquinn dividido en dos LUNs y en dos grupos difeupo tiene una latencia de 15 minutos, mientia en absoluto. En este caso, podríamos lleggistro, “date stamps”, y creación de archivode las máquinas virtual no se recupero en elatos.
en el subgrupo E
grupo E una
ten el
vía canal Los overy n la capa de sobre la ún disco del del VRA al
Un buen es LUN. Esto
miento, ya s. Si esto rtuales.
na virtual erentes. El tras que el ar a la os, pues el mismo

Podemos ver otro ejemplo deESX tiene la posibilidad de añcapacidad o porque quiera roúnico volumen VMFS. Esto setravés de múltiples bloques d
En este caso el problema estdos LUNs separadas en dos gque la máquina virtual esta auno no mire muy de cerca copuede ser que usted no noteabarcando dos LUNs en dos gla máquina virtual, sino lo qudel “extent VMFS”. Dicho estla comunidad de VMware en “cura temporal” para solucio Mi único mensaje es que prosituaciones catastróficas. La “consciente” de la estructuraque usted podría crear un “eEl resultado sería un volume También habrá ocasiones en direcciones diferentes. Para upermita controlar los ciclos dsi usted tiene la intención deexpandir los archivos de máextents” porque los diferenteTenga en cuenta que la mayo
19
e esto si usted elige utilizar “VMFS extents”.ñadir espacio a un volumen VMFS que este fomper la limitación de 2TB del tamaño máxie logra expandiendo (extents) un volumen de almacenamiento o LUNs.
tá siendo causado por almacenar la máquinagrupos separados. Lo peor es que el cliente almacenada en un solo VMFS DataStore. A mon el cliente Vi en la sección de almacenamiee que el archivo de las máquinas virtuales esgrupos diferentes. Esto no sólo causa un proue es más importante, pude comprometer lato, los “extent VMFS” son generalmente mageneral, aunque en ocasiones se utilizan conar un problema a corto plazo.
oceda con cautela, de lo contrario podrían prinfraestructura virtual de VMware no es mu
a subyacente, por eso esta falta de “conciencxtent” que incluya una LUN que no se esté rn VMFS dañado en el sitio de destino.
las que usted se sienta “arrastrado” hacia duna máxima flexibilidad, un grupo con una sde replicación de una forma más clara. En pre aprovechar esta estrategia tenga cuidado dáquina virtual a través de múltiples LUNs y “es ciclos de replicación pueden causar la cororía de la gente que utiliza la infraestructura
. Como sabe falto de mo de un VMFS a
a virtual en Vi pensara
menos que ento, sta oblema con a integridad al vistos por omo una
roducirse y cia” significa replicando.
dos sola LUN le rimer lugar, de no VMFS rupción. a Vi3,

20
pueden tener poco conocimiento sobre la estructura de la replicación que está por debajo. En segundo lugar, si usted decide poner muchas LUNs contenidas en un solo grupo, tenga encuentra que esto ofrece menos flexibilidad. Si no se tiene cuidado, podría incluir LUNs que no son necesarias replicar o limitar la capacidad necesaria de la frecuencia de las replicas. Estas cuestiones sobre la gestión del almacenamiento van a ser “complicadas” de resolver, porque no se ajustan a una estrategia general. Pero me gustaría imaginar que algunas organizaciones tendrán tres grupos, los cuales estarán diseñados con la replicación en mete. Uno se podría utilizar para la replicación síncrona, y los otros dos puede tener intervalos de replicación de 30 y 60 minutos respectivamente. Depende mucho de cuál sea su "objetivo de punto de recuperación" (en Ingles, Recovery Point Objectives - RPO). Esta configuración creara máquinas virtuales en los volúmenes VMFS correctos, los cuales se está replicando con una frecuencia adecuada a sus necesidades de recuperación, aunque pienso que implantar esta estrategia sería difícil. ¿Cómo sabrá nuestro administrador de máquinas virtuales cual es la configuración correcta de los volúmenes VMFS para crear las máquinas virtuales? Un método mucho mejor sería crear grupos de almacenamiento con el software de gestión de la cabina y mapear estos a las máquinas virtuales dependiendo de su funcionalidad. Los nombres de los volúmenes VMFS reflejaran sus diferentes objetivos. Además, en VMware SRM podemos crear lo que se llama "grupos de protección". Estos grupos de protección podrían mapear directamente los volúmenes VMFS y los grupos de almacenamiento de la cabina. El diagrama de abajo ilustra este enfoque que propongo.

En este caso tendría dos "gruuno para el arranque y datosAsimismo, esto permitiría trede recuperación en caso de fde fallos sólo para SQL y un máquinas virtuales. Ahora que he expuesto los pgustaría darle la dirección dealmacenamiento de varios prque puedo yo en este libro, lnecesidades de sus tecnologRecovery Adapter” cuando lo
Guías de los proveLeftHand Networks SRA for VMwhttp://resources.lefthandnetwor HP disaster tolerant solutions uVirtual Array in a VMware Infra[Document ID: 4AA1-0820ENW]http://h71028.www7.hp.com/ER VMware Site Recovery Manage
21
upos de protección" en VMware Site Recoves de Exchange, y otro para el arranque y dates tipos de planes de recuperación con SRM fallos sólo Exchange, un plan de recuperacióplan de recuperación en caso de fallos para
rincipios en la administración del almacename algunos archivos PDF de gran importancia roveedores, los cuales exponen en más detaa replicación de almacenamiento y gestión días. Algunas de estas guías están incluidas eo descargue desde el sitio Web de VMware.
eedores de almacenamiento ware Site Recovery Manager rks.com/forms/VMware-LeftHand-SRA-Download
sing Continuous Access for HP StorageWorks Entstructure 3 environment ] RC/downloads/4AA1-0820ENW.pdf
r in a NetApp Environment
ry Manager, tos de SQL. - un plan
ón en caso todas las
miento me sobre el
alle de lo de las en el “Site
d
terprise

22
[Document ID: TR-3671] http://media.netapp.com/documents/tr-3671.pdf Disaster Recovery Using Dell Equallogic Ps Series Storage And VMware Site Recovery Manager [Document ID: TR1039] http://www.equallogic.com/uploadedFiles/Resources/Tech_Reports/TR1039-Dell-EqualLogic-PS-Series-SAN-and-VMware-SRM.pdf Improving VMware Disaster Recovery with EMC RecoverPoint [Document ID: H5582] http://powerlink.emc.com/km/live1/en_US/Offering_Technical/Technical_Documentation/H5582-VMware_Site_Recovery_Manager_with_EMC_RecoverPoint_Implementation_Guide.pdf Using EMC SRDF Adapter VMware Site Recovery Manager [Document ID: H5511] http://powerlink.emc.com/km/live1/en_US/Offering_Technical/White_Paper/H5511-using-emc-srdf-adapter-vmware-site-rcvry-mgr-wp.pdf VMware Site Recovery Manager with EMC Celerra NS Series and Celerra Replicator Implementation Guide [Document ID: H5581] http://powerlink.emc.com/km/live1/en_US/Offering_Technical/Technical_Documentation/H5581-VMware_Site_Recovery_Manager_with_EMC_Celerra_NS_Series_and_Celerra_Replicator_Implementation_Guide.pdf VMware Site Recovery Manager with EMC CLARiiON CX3 and MirrorView Implementation Guide [Document ID: H5583] http://powerlink.emc.com/km/live1/en_US/Offering_Technical/Technical_Documentation/H5583-VMware_Site_Recovery_Manager_with_EMC_CLARiiON_CX3_and_MirrorViewS_Implementation_Guide.pdf

23

24
Capítulo 2: Primeros pasos con Virtual Appliance VSA Lefthand Networks

25
Lefthand Networks es una empresa que proporcionan dispositivos de almacenamiento tanto físicos como virtuales basados en IP y en el mercado SAN iSCSI. En particular, tienen un dispositivo virtual denominado VSA (Virtual SAN Appliance), que se puede descargar desde su sitio web para evaluarlo por un período de 30 días. En este sentido, es ideal para “tipos” como yo a los que les gustar jugar con esta tecnología y VMware SRM. Si sigue este libro punto por punto, debería terminar con una estructura igual a la que adjunto, con los nombres adaptados a su propia normativa.
Esta pantalla muestra la consola de administración de Lefhand Networks, en la cual se puede ver que tengo dos VSAs (vsa1 y vsa2), cada uno en su propio grupo de gestión (ProtectedManagementGroup y RecoveryManagementGroup). Como puede ver, tengo un volumen llamado "virtualmachines" que esta replicando los datos de vsa1 al volumen llamado "replica_of_virtualmachines" en vsa2. Es una configuración muy simple, pero es suficiente para comenzar con el producto SRM.

26
Algunas preguntas frecuentes sobre VSA Lefthand Networks
1. ¿Cuál es la memoria y CPU mínima recomendable? 1GB de RAM, 1 vCPU con acceso a 2GHz de CPU o más. La suma de nuevas vCPUs no mejorará significativamente el rendimiento
2. ¿El VSA debe ser almacenado en un volumen local VMFS o en un volumen VMFS compartido? Depende totalmente de la calidad de la cabina de almacenamiento. Si su almacenamiento local es más rápido y ofrece más redundancia que cualquier otro almacenamiento remoto, entonces debería utilizar el almacenamiento local. En algunos entornos es posible que prefiera utilizar almacenamiento compartido para facilitar la copia de seguridad, el despliegue, y para permitir alta disponibilidad con VMware HA
3. VSA se licencia por la dirección MAC. ¿Debería usar una dirección MAC fija? Si usted decide comprar el VSA, se recomienda el uso de una dirección MAC fija. Si solo lo está evaluando, la dirección MAC fija no es requerida, aunque si es recomendada.
4. ¿Se puede usar la funcionalidad de “cloning” en vCenter para crear múltiples VSAs? Sí. Sin embargo, el VSA no debe ser configurado en un grupo de gestión. Si ha adquirido una versión de VSA con licencia, tenga en cuenta que al generar un clone con vCenter se genera una nueva dirección MAC para la máquina virtual, y como tal tendrá que licenciar de nuevo este clone de VSA.
5. La creación de dos VSAs en un grupo de gestión con todos los ajustes adecuados lleva algún tiempo. ¿Se puede utilizar la característica de clon en vCenter para restaurar los entornos de laboratorio? Sí. Configure los dos VSAs al nivel deseado. Después simplemente haga clic con el botón derecho sobre el grupo de gestión y elija la opción de apagado del grupo de gestión. Después, podrá clonar, borrar y volver a clonar. No obstante debe tener cuidado en el proceso de clonación ya que este cambia la dirección MAC, al igual que el proceso de clonación mediante plantilla. Una alternativa puede ser aprender el CLI (Command Line Interface) de Lefthand Networks el cual le permite crear una secuencia de comandos con el procedimiento. Esto no será cubierto en este libro.
6. ¿Se puede capturar la configuración de VSA y restaurarla? Sí y no. Usted puede capturar la configuración con el propósito de recibir soporte, pero no con el propósito de guardar la configuración. Es muy posible que las futuras versiones de este Appliance tenga esta opción y se pueda capturar la configuración en un archivo XML para que se permita su “recarga”. Esto pondría fin a la necesidad de clonar o crear un script para el proceso de configuración de alto nivel que se produce en la Consola de Administración.

27
Descargar e instalar el VSA El VSA está disponible para la descargar en formato OVF "Open Virtual Machine Format" en la página de VMware Virtual Appliance. También puede descargar la versión "ESX" del VSA Lefthand Network desde su sitio web en un archivo zip o en formato OVF. Verá que hay una versión ESX y una versión que se puede ejecutar en un ordenador portátil con VMware Workstation o Server. Yo estoy usando la versión de ESX en este libro.
http://www.lefthandnetworks.com/vsa_eval.aspx
También hay un blog, un foro y una guía PDF disponible en el sitio.
La forma de “subir” el VSA a tu servidor ESX depende mucho de la versión de ESX que usted esté utilizando. Si está utilizando ESX 3.5.0 y el servicio de consola, es muy probable que sea más fácil y más rápido subir el archivo ZIP sin extraerlo, y después descomprimirlo en el servicio de consola con el comando tar. Si, por otra parte, usted está utilizando la versión ESX3i, quizás le resulte más sencillo extraer el fichero en Windows primero para después subir los archivos al servidor ESX usando la utilidad de navegador de DataStore, o la función de importación, si usted ha decidido bajarse el Appliance en formato OVF.
Una vez extraído el archivo adecuadamente, este puede ser añadido al inventario del vCenter simplemente haciendo clic con el botón derecho del ratón sobre el archivo VMX del VSA:

28
Modificar la Configuración del VSA Modifique la configuración de red de las máquinas virtuales Por defecto, el VSA será conectado a la red "VM Network". Esta es el “port group” creado por defecto en una instalación de ESX. Sin embargo, si usted quiere administrar el VSA, este debe ser conectado a una red accesible por el servidor ESX con LUNs iSCSI presentadas por el VSA.
Añada el tercer disco virtual
1. Pulse “next” para añadir un tercer y último disco. Este disco será presentado a su servidor ESX y se utilizara para almacenar las máquinas virtuales protegidas por SRM. Como tal, tendrá que hacerlo tan grande como sea posible ya que crearemos máquinas virtuales en este disco. Además este debe ser configurado en SCSI 1:0

29
Nota: Más tarde, cuando creamos los volúmenes en el VSA, usare "thin provisioning" para presentar este disco a una LUN de 1TB. En la actualidad el VSA sólo puede contener tres discos virtuales. Las futuras versiones del VSA permitirán agregar más discos virtuales.
Licenciar por dirección Virtual MAC Antes de encender por primera vez el VSA, es posible que desee considerar la forma en que el producto se licencia en caso de que desee utilizar VSA más allá de los 30 días del período de evaluación. VSA está licenciado por la dirección virtual MAC de la máquina virtual cuando VMware enciende la maquina virtual. Este proceso de arrancado genera automáticamente la dirección MAC y por lo tanto no debe cambiar, aunque esta MAC podría cambiar en algunos casos en los que tengamos que registrar manualmente una máquina virtual de un servidor ESX a otro. Además, si no hace una copia de seguridad del fichero VMX, podría perder esta configuración para siempre. Por último, si por la razón que sea, usted decido hacer un clon del VSA con vCenter y la funcionalidad de clonar plantillas, se generaría una nueva dirección MAC. Para estar 100% seguros de que la dirección MAC no cambiara, podría establecer y registrar una dirección MAC para su VSA. Si lo desea, puede configurar esta dirección MAC dentro del rango previsto por VMware. Con VMware 3.5, ya es posible establecer una dirección MAC desde la GUI de vCenter por lo que ya no es necesario editar el archivo VMX directamente.

30
Independientemente de que usted elija una dirección MAC estática o dinámica, asegúrese de apuntar esta dirección MAC en caso de tener que reconstruir el VSA completamente desde cero. Lefthand Networks recomienda una dirección MAC estática.
Configuración primaria del servidor VSA Antes de encender el VSA y llevar a cabo la configuración, es posible que desee considerar la opción de crear un segundo VSA. Para crear rápidamente un segundo VSA, puede hacer otro del primero usando vCenter. Es posible hacer el clon incluso si la máquina virtual se encuentra en un almacenamiento local como en el caso de mi VSA1. La configuración inicial consiste en establecer la configuración IP y el nombre del host VSA desde el “VMware Remote Console”. Usted puede navegar por esta utilidad mediante una combinación de teclas, con las teclas del cursor, con las teclas de tabulación, y la barra espaciadora o la tecla “enter”. Es muy sencillo de utilizar.
1. Encienda ambas máquinas virtuales VSA 2. Abra una consola remota de VMware (“VMware Remote Console”) 3. En el símbolo de inicio de sesión, escriba start y pulse [Intro]
Nota:

31
El color de las imágenes se ha invertido para facilitar la impresión. El VSA presenta un fondo negro y texto blanco.
4. Pulse [Intro] en el símbolo de inicio de sesión
5. En el menú, seleccione “Network TCP/IP Settings” y pulse [Intro]
6 Suba el cursor hacia arriba para seleccionar < eth0 > and pulse [Intro]
7. Cambie el hostname y configure una dirección IP estática

32
8. Pulse [Intro] para confirmar la advertencia sobre el reinicio de la creación de redes 9. Use “Back options” para volver al menú principales de acceso Nota: Repita este proceso para los demás VSA. En mi caso he usado la dirección IP 172.168.3.98 para el segundo VSA SUGERENCIA: Es posible que quiera actualizar su configuración de DNS para reflejar estos nombres de host y direcciones IP para que pueda utilizar el FQDN en diversas herramientas de gestión.
Instalar el cliente de Gestión La configuración avanzada se realiza a través de la consola de administración centralizada de Lefthand Networks. Esta es una aplicación muy simple que se utiliza para configurar el VSA. También hay una versión para Linux. Su PC debe tener una dirección IP valida o enrutable para comunicarse con los dos VSAs. La consola de administración centralizada de Lefthand Networks se puede descargar gratis desde la página web de descargas de Lefthand Networks http://www.lefthandnetworks.com/vsa_eval.aspx En este libro, voy a usar la versión para Windows “Windows CMC” (.exe) La instalación de la consola de administración es muy simple, y no tiene mucho sentido documentar dicha instalación. Una instalación típica debería ser suficiente para el propósito de este libro.
33
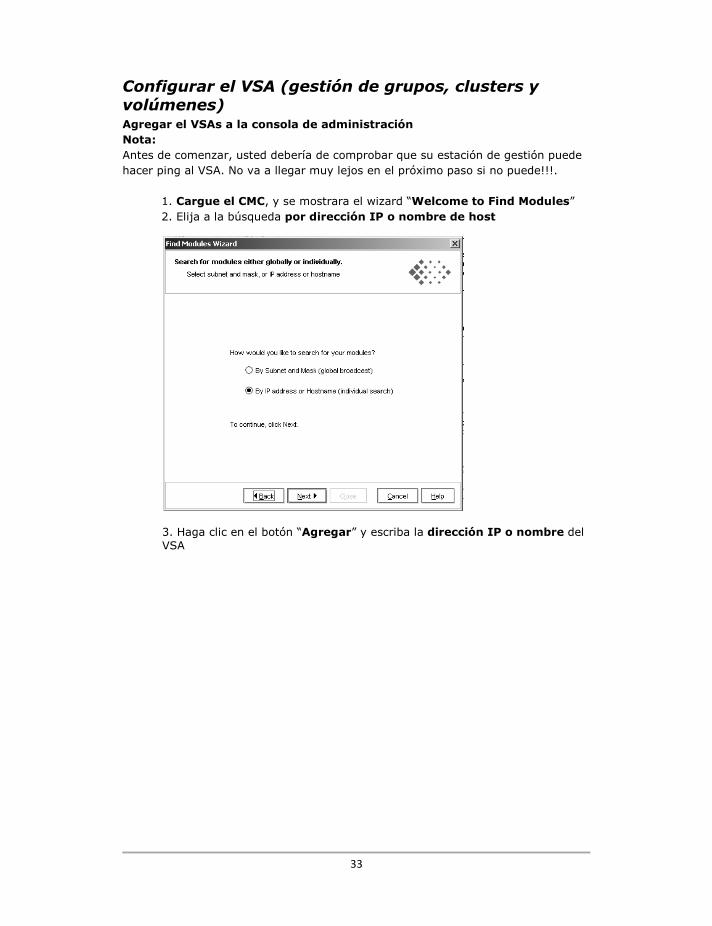
Configurar el VSA (gestión de grupos, clusters y volúmenes) Agregar el VSAs a la consola de administración Nota: Antes de comenzar, usted debería de comprobar que su estación de gestión puede hacer ping al VSA. No va a llegar muy lejos en el próximo paso si no puede!!!. 1. Cargue el CMC, y se mostrara el wizard “Welcome to Find Modules” 2. Elija a la búsqueda por dirección IP o nombre de host
3. Haga clic en el botón “Agregar” y escriba la dirección IP o nombre del VSA

34
Nota: En este cuadro de diálogo podría verse un estado de “unknown" hasta que haga clic en Finalizar. 4. Haga clic en Finalizar
5. Haga clic en Close
Agregar los VSAs a los grupos de gestión Cada VSA estará en su propio grupo de gestión. Durante este proceso usted será capaz de establecer nombres descriptivos para los grupos y los volúmenes. Claramente tiene sentido utilizar nombres que reflejen un significado tales como:
• ProtectedManagementGroup y RecoveryManagementGroup

35
• Protected_Cluster y Recovery_Cluster • Virtual_Machines Volume • Replica_Of_Virtual_Machines Volume • Alternativamente si lo prefiere, usted puede indicar que los dos VSAs estén
en dos lugares diferentes como Londres y Reading o Chicago y Nueva York. Por supuesto, usted decide que proceso de nombre adopta. Solo tenga en cuenta que estos nombres no pueden incluir ningún espacio. 1. En el menú “Getting Started Node”, haga clic en 2. Management Groups, Cluster and Volumes” y luego haga clic en Next en la página de Bienvenida 2. Elija “New Management Group” 3. Para el nombre “management group” ponga algo significativo como ProtectedManagementGroup y seleccione el VSA que desee añadir, en mi caso es vsa1.rtfm ed.co.uk
Nota: En un entorno de producción teóricamente usted podría tener hasta 5 VSAs en el sitio protegido, todos replicándose entre ellos de forma asíncrona, y otros 5 VSAs en el sitio de recuperación replicándose de forma asíncrona contra el sitio de protección. No se permiten espacios en el “Management Group Name”.
4. Seleccione un “username” y una “password”.

36
Nota: Este nombre de usuario y contraseña se almacena en una base de datos interna en el VSA. La base de datos está en un formato binario propietario y se copiara a todos los VSAs en el mismo grupo de gestión. Este usuario es diferente a los inicios de sesión de vCenter o directorio activo.
5. Elija manualmente el “set time”
Nota: Como el VSA es un dispositivo (Appliance) virtual debería recibir actualizaciones de “tiempo” vía el servidor de ESX, que es a su vez configurado para NTP. Para habilitar esto, yo he editado el archivo VMX de mis dos VSAs y he añadido esta línea: tools.syncTime = "TRUE"
Crear un Cluster La siguiente fase del asistente es la creación de un clúster. En nuestro caso tendremos un VSA en un grupo de gestión dentro de un grupo, y otro VSA en otro grupo de gestión dentro de un grupo Cluster. El Cluster está destinado para múltiples VSA dentro de un grupo de gestión, sin embargo, no podemos configurar la replicación o instantáneas entre dos VSA en diferentes ubicaciones con solo un sitio.
1. Elija Standard Cluster 2. Escriba un nombre de clúster como “Protected_Cluster” 3. Siguiente, configure una IP virtual. Esta IP es utilizada principalmente por el clúster cuando se tienen dos VSAs dentro del mismo grupo de gestión. En mi caso he usado el siguiente IP 172.168.3.97

37
Crear un Volumen El siguiente paso es la creación de un volumen. Un volumen es otra palabra para describir una LUN. Sea cual sea la palabra con la que usted esté familiarizado, lo que estamos creando es un bloque de almacenamiento sin formato, el cual pueda ser accesible por otro sistema (en nuestro caso un servidor ESX) y una vez formateado, se podrían crear archivos sobre este. Algunos proveedores de almacenamiento se refieren a este proceso como la creación de un "sistema de archivos". Esto puede ser un poco confuso ya que muchas personas asocian esto con el uso de EXT3, VMFS o NTFS. Un volumen o sistema de archivos es otra capa de abstracción entre el almacenamiento físico y el acceso por el servidor. Esto permite funciones avanzadas tales como el “thin provisioning” o almacenamiento virtual.
Un volumen puede estar parcialmente o totalmente “aprovisionado”. Con el aprovisionamiento parcial, los volúmenes presentados a un servidor o sistema operativo pueden ser incluso mayor en tamaño que del almacenamiento real físico disponible. Por lo tanto, el volumen puede ser de 1TB en tamaño, aunque sólo haya 512GB de espacio de disco real. Usted puede conocer este concepto como “virtual storage” por el cual usted adquiere espacio en disco según lo requiera, en lugar de por adelantado. El inconveniente es que debemos monitorizar la utilización actual del almacenamiento muy cuidadosamente.

38
1. Escriba un nombre de volumen, por ejemplo: virtualmachines 2. Ajuste el tamaño de volumen, por ejemplo: 1TB 3. Elija Thin para el aprovisionamiento
Nota: En este caso, he creado un volumen llamado virtualmachines que se utilizara para almacenar máquinas virtuales. El tamaño del disco "físico" es 48GB, pero con “thin-provisioning” voy a presentar este almacenamiento como si fuera un volumen/LUN de 1TB. La opción de nivel de replicación, se utilizaría si estuviera replicando dentro en un grupo de gestión. En el caso de esta configuración esto es irrelevante porque estamos replicando entre grupos de gestión.
Puede cambiar la configuración de “Thin” a “Full” en cualquier momento que usted desee. Después de esperar algún tiempo, el grupo y el volumen se habrán creado.

39
Nota: Ahora tenemos que repetir este mismo proceso para VSA2 pero con diferentes nombres y direcciones IP
Management Group Name: RecoveryManagementGroup Cluster Name: Recovery_Cluster Volume Name: replica_of_virtualmachines Nota: Al final de este proceso usted debería tener una de vista similar a esta:

40
Configurar el VSA para la replicación Es muy fácil de configurar la replicación o una instantánea entre dos VSAs en dos grupos diferentes de gestión. Con el VSA Lefthand Networks usamos una "Lista de instantáneas a distancia – Schedule Remote Snapshot". Esto permite la replicación asíncrona entre dos VSAs con un intervalo de replicación de su elección - en intervalos de 30 minutos o más. Un ciclo de replicación más pequeño entre dos VSAs en el mismo grupo de gestión es soportado, pero no funciona con SRM ya que estos ciclos de replicación más pequeños no fueron diseñados para ser utilizados a través de dos sitios.
En VSA Lefthand Networks el proceso de la instantánea comienza con una instantánea en el lugar protegido, y una vez completado, esta instantánea es copiada al sitio de recuperación. Después de la primera copia, los únicos datos que se transfieren son los cambios o deltas. Tenemos una opción para controlar la retención de estos datos. Podemos controlar el tiempo que queremos mantener las instantáneas de datos tanto en el grupo gestión de protección como en el de recuperación.
1. En el ProtectedManagementGroup, Protected Cluster, Volumes 2. Haga clic con el botón derecho y seleccione New Schedule Remote Snapshot

41
3. Configure el “Recur Every” para 30 minutos 4. En la sección "Primary Snaphot Setup" habilite la opción Retained for a maximun de 3 snapshots. Nota: Usted decide por cuánto tiempo quiere mantener sus instantáneas. En esta configuración, a mi me gustaría hacer 3 instantánea en 180 minutos y cuando la cuarta instantánea se haga, las más antigua sería sobrescrita. Cuanto más tiempo mantenga sus instantáneas y mayor sea la frecuencia de las instantáneas, existirán más opciones para la recuperación de los datos. En el entorno de prueba que estamos configurando probablemente no tiene sentido guardar los datos durante demasiado tiempo. Cuanto mayor sea la frecuencia en la toma de las instantáneas y más tiempo conserve estas, será necesario más espacio de almacenamiento. Para fines de pruebas, la frecuencia de las instantáneas deberá ser mucho menor, así el espacio necesario para mantener estas será menor. 5. En la sección "Remote Snapshot Setup", seleccione RecoveryManagementGroup y 6. En la sección Volume name, asegúrese de que ha seleccionado replica_of_virtualmachines
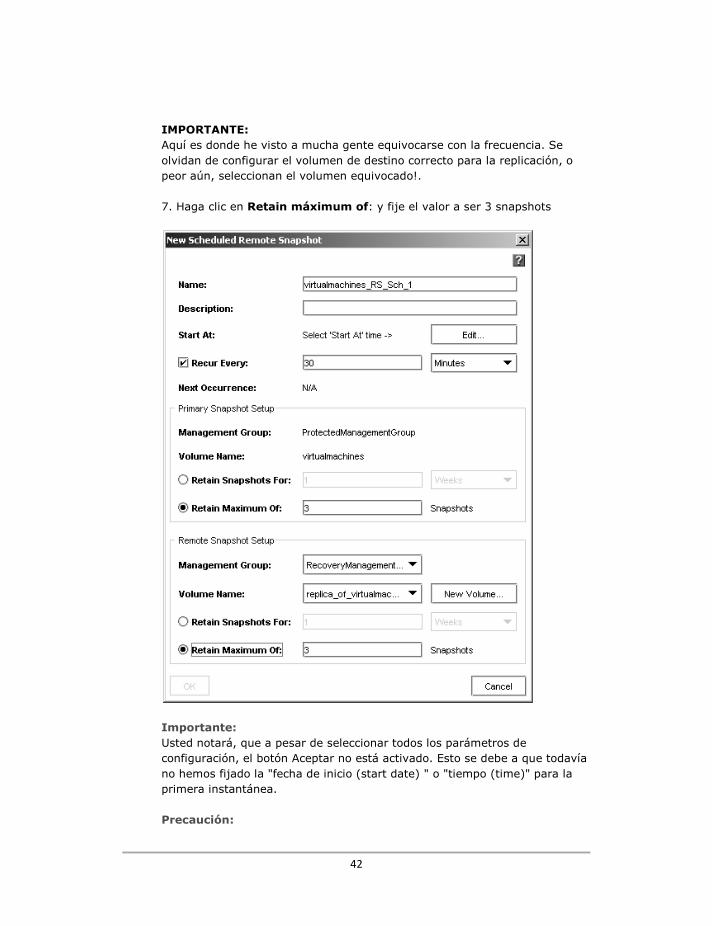
42
IMPORTANTE: Aquí es donde he visto a mucha gente equivocarse con la frecuencia. Se olvidan de configurar el volumen de destino correcto para la replicación, o peor aún, seleccionan el volumen equivocado!. 7. Haga clic en Retain máximum of: y fije el valor a ser 3 snapshots
Importante: Usted notará, que a pesar de seleccionar todos los parámetros de configuración, el botón Aceptar no está activado. Esto se debe a que todavía no hemos fijado la "fecha de inicio (start date) " o "tiempo (time)" para la primera instantánea. Precaución:

43
Los valores en la frecuencia de la instantánea y tiempo de retención, son valores importantes. Si crea ciclos de replicación demasiado cortos, como yo he hecho aquí, puede ser que a medio camino en una prueba de plan de recuperación encuentre que la imagen con la que está trabajando actualmente está siendo sobrescrita. Al final, por falta de almacenamiento (yo he configurado la frecuencia en una hora), me quede sin espacio en el almacenamiento a medio camino cuando estaba escribiendo este libro, y eso que mi entorno de pruebas no generaba muchos archivos nuevos o borraba muchos archivos antiguos. 8. Junto a Select `Start At´ time, haga clic en el botón Edit y utilizando el interfaz de la fecha y la hora, configure cuando desea que el proceso de la replicación/instantánea comience. 9. Haga clic en OK 10. Haga clic en OK en la cuadro de diálogo de advertencia "Make Volume Remote"
Nota: Este cuadro de diálogo se refiere al volumen de destino (aquí llamado replica_of_virtualmachines) y que puede ya contener datos. El proceso de la replicación/instantánea sobrescribirá este volumen. Para evitar la pérdida de datos, el VSA hace una instantánea también de este volumen. Nota: Esta funcionalidad estará disponible por sólo 30 días, si usted no tiene licencia para el VSA. También puede que reciba advertencias de que usted está trabajando con una versión del VSA de evaluación.
Monitorizar la replicación/instantáneas

44
Dentro del VSA Por supuesto, usted se preguntara si las replicas/instantáneas están funcionando. Hay dos maneras de confirmarlo. Si expande los volúmenes dentro de cada grupo de gestión, se verán las instantáneas. Usted puede ver el proceso de replicación con iconos animados en la pantalla como se muestra a continuación:
Después de seleccionar la instantánea remota, verá una pestaña en la parte derecha denominada "Remote Shanpshots". Esto le dirá la cantidad de datos que han sido transferidos y el tiempo que se tardó en completar la operación.
La frecuencia de replicación El VSA Lefthand Networks ofrece un método de replicación por niveles de "deshacer". Y hasta cierto punto esto es cierto ya que si tenemos tres instantáneas (SS1, SS2, SS3), separados por una hora, tenemos la capacidad de volver a la última imagen y a la que se creó una hora antes. Sin embargo, y en primer lugar, la mayoría de los SRAs utilizan la instantánea más reciente o crean una instantánea sobre la marcha, por lo que si quisiera utilizar estos niveles de “deshacer" (undo), tendría que conocer las herramientas de administración de su almacenamiento lo suficientemente bien como para replicar una imagen antigua a la parte superior de la pila de las replicas. En otras palabras, SS1 se convertiría en SS4.

45
Por último, vale la pena añadir y siempre que sea posible, muchas organizaciones querrán utilizar la replicación sincrónica, siempre que el ancho de banda y la tecnología lo permita. La replicación sincrónica ofrece el nivel más alto de integridad ya que constantemente y en tiempo real, mantiene el estado de los discos del sitio de protección y recuperación sincronizados. También, esta forma de replicación es menos restrictiva en cuanto al tiempo donde podemos revertir (rollback) los datos. Usted debe saber, sin embargo, que esta funcionalidad no está automatizada o expuesta al producto VMware SRM y nunca fue parte del diseño. Como tal es una funcionalidad que sólo puede lograrse mediante la gestión manual de la capa del almacenamiento. Un buen ejemplo de un proveedor de almacenamiento que ofrece este nivel de control granular sería EMC con su tecnología "Recovery Point", la cual le permite revertir una réplica segundo por segundo. También, recuerde que la replicación síncrona está restringida por la distancia, de manera que este método puede ser inviable, según sus necesidades, para la creación de un plan de contingencias.
Crear las listas de volúmenes y grupos de autenticación Evidentemente, habría poca seguridad si solo tuviésemos que darle una dirección IP y la ruta de almacenamiento al servidor ESX. Para permitir el acceso de los servidores ESX al almacenamiento, tenemos que completar tres pasos
• Crear lista de volumen
Literalmente, esta es una lista de volúmenes a los que los servidores ESX pueden acceder. En nuestra configuración, esta contendrá un solo volumen, aunque podría contener muchos más volúmenes.
• Autenticación de Grupo Este contiene el servidor ESX al que desea conceder acceso. En nuestro caso tendremos un servidor ESX. Los grupos de autenticación contienen un único host, y a estos “grupos" se les permite el acceso a los volúmenes. Los grupos de autenticación pueden estar basados en CHAP (Challenge Handshake Authentication Protocol), además del valor de la configuración del IQN (iSCSI Qualified Name). Algo que resulta, cuando menos extraño, es el hecho de que estos grupos sólo contienen un objeto - una referencia a un único host ESX. • IQN (iSCSI Qualified Name) A cada servidor ESX se le asignará un nombre IQN. El nombre IQN se utiliza en el grupo de autenticación para identificar al servidor ESX. El nombre IQN es una convención de nombre estándar en lugar de un código de nombre único, y tiene el formato de iqn-fecha-inversa- fqdn: alias. Como nombre de dominio sólo pueden ser registrados una vez en una fecha determinada (si bien este puede ser transferido o vendido a otra organización). Un ejemplo de IQN sería:

46
iqn.2001-09.uk.co.rtfm-ed:esx1
En esta configuración de seguridad sencilla, mis servidores ESX están en el sitio protegido, y se llaman esx1.rtfm-ed.co.uk y esx2.rtfm-ed.co.uk. Mis otros dos servidores ESX (sí, adivinaste - esx3 y esx4) se encuentran en el sitio de recuperación y no necesitan acceso al volumen en el grupo de gestión protegido. Antes de iniciar un test de DR/BC con VMware SRM ,el SRA de Lefthand Networks necesita conceder acceso a la última instantánea de replica_of_virtual_machines. Por el momento ESX3 y ESX4 no necesitan acceso al VSA.
Creación de una lista de Volumen
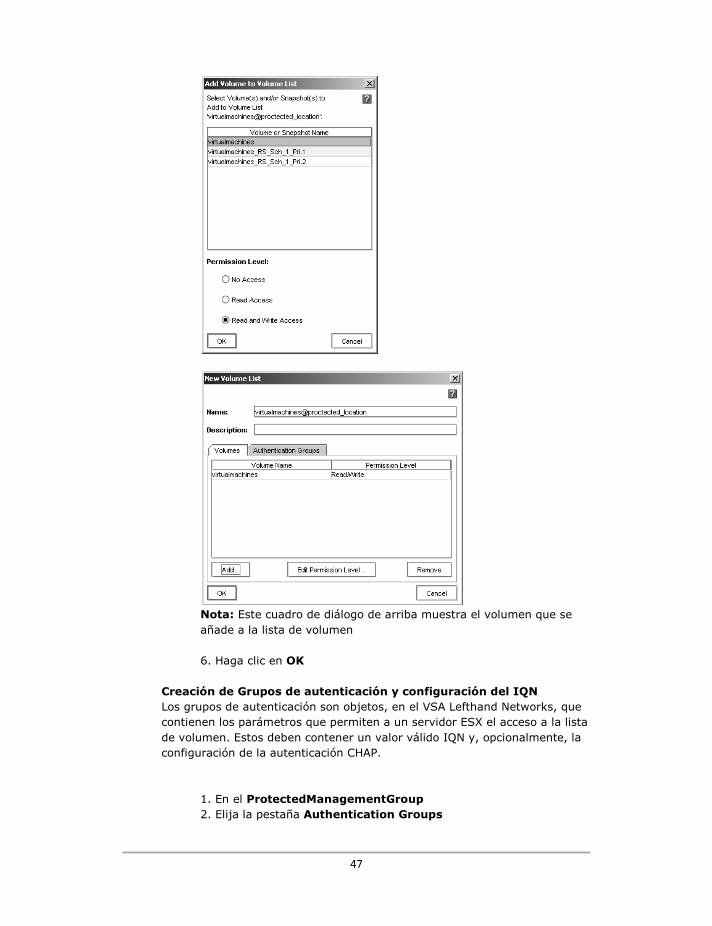
1. En el ProtectedManagementGroup 2. Elija la pestaña Volume List 3. Haga clic en Volume List Tasks, y seleccione New Volume List
4. Escriba un nombre como virtualmachines@protected_location 5. A continuación, haga clic en el botón Add y seleccione el volumen virtualmachines y asegure que los permisos son acceso de lectura/escritura
47
Nota: Este cuadro de diálogo de arriba muestra el volumen que se añade a la lista de volumen
6. Haga clic en OK
Creación de Grupos de autenticación y configuración del IQN Los grupos de autenticación son objetos, en el VSA Lefthand Networks, que contienen los parámetros que permiten a un servidor ESX el acceso a la lista de volumen. Estos deben contener un valor válido IQN y, opcionalmente, la configuración de la autenticación CHAP.
1. En el ProtectedManagementGroup 2. Elija la pestaña Authentication Groups

48
3. Haga click en Authentication Group Tasks, y New Authentication Group 4. Establezca un nombre descriptivo para el Authentication Group como por ejemplo: esx1.rtfm-ed.co.uk 5. Seleccione, de la lista desplegable, el volumen de la lista que ha creado anteriormente - en mi caso virtualmachines@ protected_location 6. En "autenticación", haga clic en Initiator Node Name y escriba su IQN, como iqn.2001-09.uk.co.rtfm-ed: esx1

49
Advertencia: No es necesaria la autenticación CHAP para que el VSA funcione con VMware SRM, aunque este ofrece una capa adicional de seguridad. También, y si utiliza la autenticación CHAP específicamente con el SRA de Lefthand Networks, recibirá un mensaje de error indicando que no pudo encontrar un grupo de autentificación CHAP. 7. Haga clic en OK Nota: Repita este proceso para los otros servidores ESX que necesiten tener acceso al mismo volumen/LUN en su sitio protegido.
Conclusión Por ahora, esto completaría la configuración del VSA. Ahora, todo lo que tenemos que hacer es configurar la conexión del servidor ESX al VSA. Actualmente, nuestros servidores ESX, en la ubicación de recuperación, no tienen acceso al VSA pero no lo necesitan hasta que muestre la prueba del plan DR/BC.
Configurando el software iSCSI en el ESX Si usted tiene un adaptador de hardware iSCSI, puede configurar su IP e IQN directamente en la tarjeta. La gran ventaja de esto es que si usted re-instala su servidor ESX, la configuración iSCSI permanecer en la tarjeta. En la actualidad hay solo dos iniciadores hardware iSCSI soportados por ESX (QLA 4050C y QLA 4052C) pero es posible también utilizar el iniciador software iSCSI, localizado en el propio servidor ESX. Las siguientes instrucciones explican cómo configurarlo para que hable con el VSA.
Antes de habilitar el iniciador software iSCSI en el servidor ESX, usted necesitara crear un servicio de “VMkernel” y “puerto de consola” con una dirección IP correcta para comunicarse con el VSA. La razón por la que necesita el servicio de consola es porque la parte del descubrimiento de volúmenes/LUN (SendTargets) y la autenticación CHAP se hacen vía el servicio de consola. Por lo tanto, ambos, el VMkernel y el kernel del puerto de consola necesitan tener acceso. Esto no aplica en el caso de ESX3i, donde sólo un puerto VMkernel es necesario.
El siguiente diagrama muestra la configuración de mi esx1 y esx2. Observe que el vSwitch tiene dos tarjetas para la tolerancia a fallos.

50
Antes de proceder a la configuración del iniciador software de VMware, usted quizás desea confirmar que puede comunicarse con el VSA mediante una simple prueba con ping y vmkping.
Habilitar el Iniciador iSCSI Nota: Dependiendo de la versión de ESX 3.x.x que esté utilizando, puede o no, tener que abrir manualmente el puerto software iSCSI TCP en el ESX. Siempre he habilitado el iniciador iSCSI manualmente para asegurarme al 100% de que la comunicación entre los servidores ESX y el destino iSCSI existe.
1. Seleccione el servidor ESX y la pestaña de Configuration 2. Seleccione Security Profile en la pestaña Software 3. Haga clic en Properties 4. En el cuadro de diálogo, abra el puerto TCP (3260) para el Software de Cliente iSCSI
5. Siguiente, haga clic en Storage Adapter y seleccione iSCSI software adapter 6. Seleccione Propiedades ... 7. En el cuadro de diálogo, haga clic en el botón Configure 8. Habilite la opción como se muestra a continuación
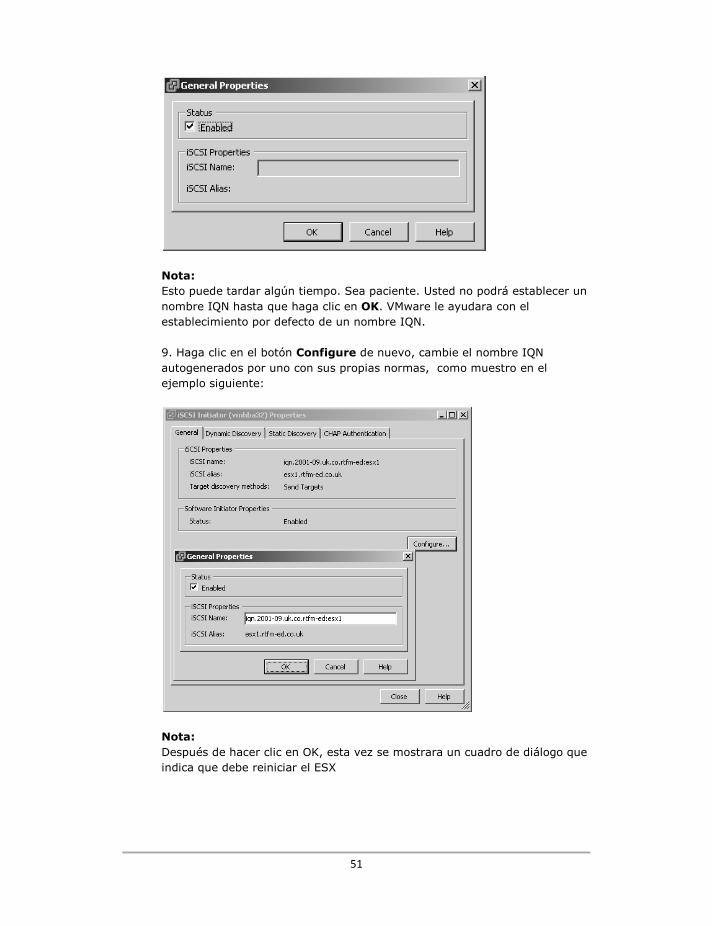
51
Nota: Esto puede tardar algún tiempo. Sea paciente. Usted no podrá establecer un nombre IQN hasta que haga clic en OK. VMware le ayudara con el establecimiento por defecto de un nombre IQN.
9. Haga clic en el botón Configure de nuevo, cambie el nombre IQN autogenerados por uno con sus propias normas, como muestro en el ejemplo siguiente:
Nota: Después de hacer clic en OK, esta vez se mostrara un cuadro de diálogo que indica que debe reiniciar el ESX
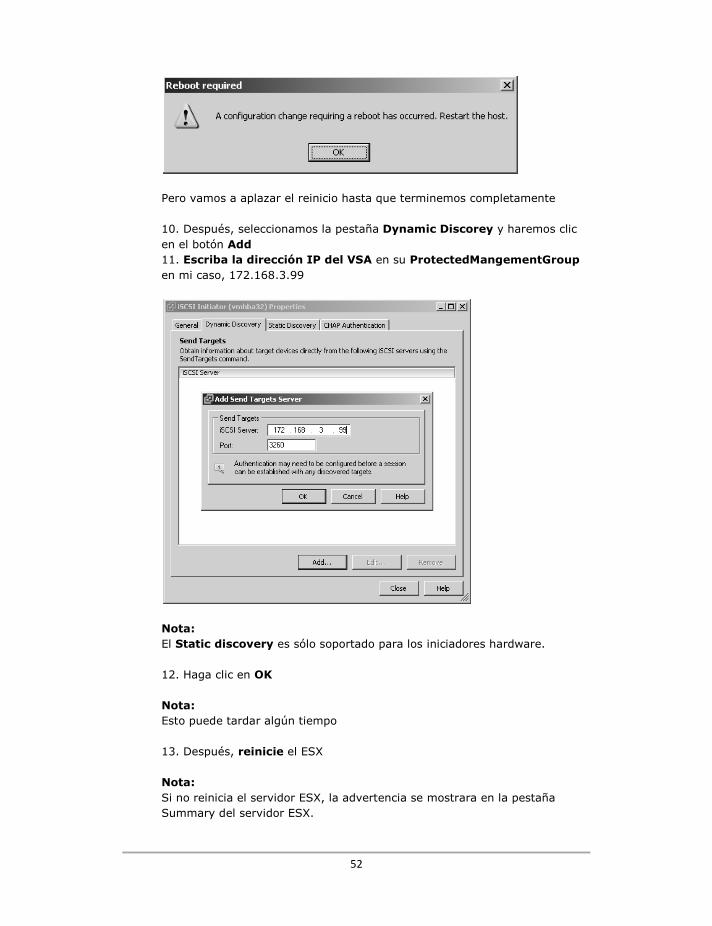
52
Pero vamos a aplazar el reinicio hasta que terminemos completamente
10. Después, seleccionamos la pestaña Dynamic Discorey y haremos clic en el botón Add 11. Escriba la dirección IP del VSA en su ProtectedMangementGroup en mi caso, 172.168.3.99
Nota: El Static discovery es sólo soportado para los iniciadores hardware.
12. Haga clic en OK
Nota: Esto puede tardar algún tiempo
13. Después, reinicie el ESX
Nota: Si no reinicia el servidor ESX, la advertencia se mostrara en la pestaña Summary del servidor ESX.

53
Monitorizando sus conexiones iSCSI Hay muchos sitios en donde puede confirmar que hay una conexión iSCSI válida. Usted debe ser capaz de ver el volumen/LUN con en el cliente Vi al seleccionar el HBA iSCSI virtual en los adaptadores de almacenamiento:
Nota: En las propiedades de la HBA "virtual", vemos como diferentes versiones de ESX 3.x.x muestran diferentes números de HBA virtual (vmhba32 o vmhba40), en nuestro caso es vmhba32.
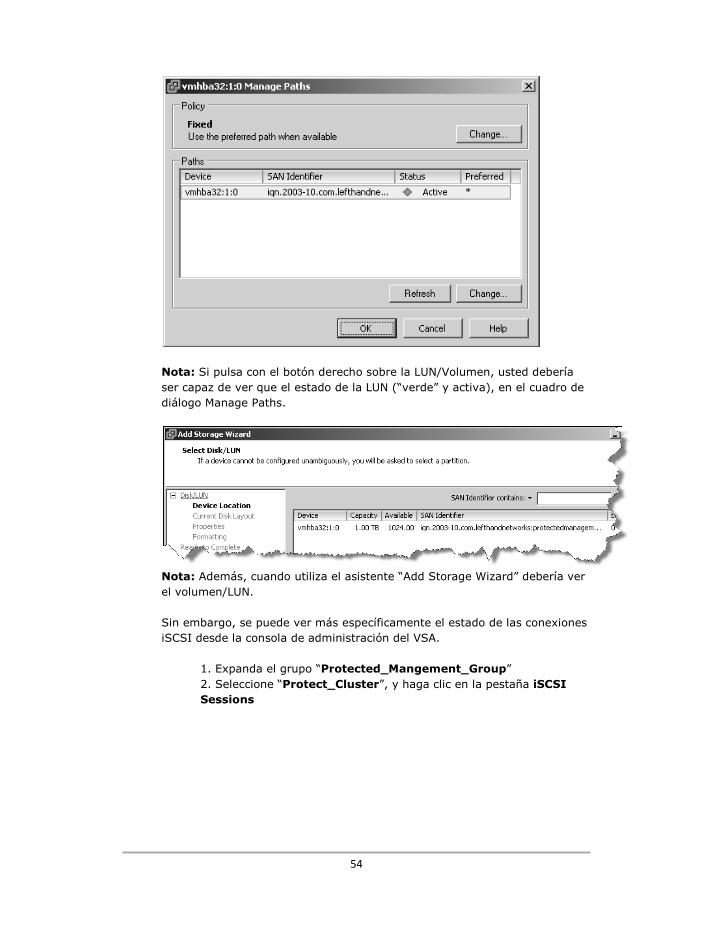
54
Nota: Si pulsa con el botón derecho sobre la LUN/Volumen, usted debería ser capaz de ver que el estado de la LUN (“verde” y activa), en el cuadro de diálogo Manage Paths.
Nota: Además, cuando utiliza el asistente “Add Storage Wizard” debería ver el volumen/LUN. Sin embargo, se puede ver más específicamente el estado de las conexiones iSCSI desde la consola de administración del VSA.
1. Expanda el grupo “Protected_Mangement_Group” 2. Seleccione “Protect_Cluster”, y haga clic en la pestaña iSCSI Sessions

55
Nota: En este caso, usted puede ver hay 3 sesiones pero una ha fallado. Esto fue causado porque borre la configuración iSCSI en el ESX3 mientras estaba conectado al VSA.
Licenciar el VSA Si usted decide adquirir el VSA, sepa que se licencia por servidor VSA. Como mencioné anteriormente, la licencia es emitida por la dirección MAC del VSA. Una vez que ha registrado su MAC con Lefthand Networks, usted obtendrá el código de licencia necesario. Para introducir el número de su licencia, es necesario el siguiente procedimiento
1. Expanda “ProtectedManagementGroup”, “Protect_Cluster”, “Modules” 2. Seleccione su VSA, y haga clic en la pestaña Feature Registration
Aviso: La interfaz de usuario, muestra la dirección MAC del VSA. De bajo, está el espacio para la clave de licencia. 3. Seleccione Feature Registration Task y seleccione Edit License Key 4. Para terminar, corte y pegue el código de su clave de licencia

56
Apagar el VSA Para apagar el VSA, se recomienda el uso de la consola de administración del VSA.
1. Haga clic con el botón derecho en el Management Group 2. Elija Shutdown Management Group
Conclusión En esta sección, he demostrado cómo configurar una copia de evaluación de 30 días del appliance VSA, el cual es compatible con el uso de VMware SRM. Configuramos dos VSAs Lefthand Networks y luego los configuramos para la replicación y las instantáneas. Por último, conectamos el VRA a un servidor ESX. A partir de este momento, le recomendaría formatear el volumen/LUN con VMFS para la creación de máquinas virtuales. De esta forma, usted podría utilizar estas máquinas virtuales para hacer pruebas con VMware SRM. SRM sólo funciona con LUN/volúmenes que estén formateados con VMFS y que contengan máquinas virtuales. Si usted tiene un volumen VMFS que no contiene ninguna maquina virtual, esta no se mostrará en el asistente de configuración “SRM Manager”. Este es, aparentemente, un error muy popular entre la gente que configura SRM. Desde ESX 3.5 y VirtualCenter 2.5, es posible re-alocar el archivo de intercambio (.vswp) de la máquina virtual, a otros datastores diferentes, en lugar de dejarlo en la ubicación predeterminada. Es un buen consejo re-alocar este fichero de intercambio de las máquinas virtuales en LUNs compartidas en el almacenamiento, pero no replicarlas. Esto reducirá la cantidad de ancho de banda necesaria en la replicación. Esto no reduce la cantidad de espacio en disco utilizado en el sitio de recuperación, ya que este será generado automáticamente en el almacenamiento del sitio de recuperación. La versión 1.0.1 de VMware SRM, ya soporta discos en formato RDM (Raw Device Maping ). Cubriremos RDMs unos capítulos más tarde en este libro porque es una característica muy popular de VMware. En el siguiente capítulo instalaremos VMware Site Recovery Manager (SRM).

57
Capítulo 3: Instalando VMware SRM

La arquitectura deAntes de comenzar el proceses importante comprender la
Uno de los principales desafíque el servidor SRM resida salmacenamiento, muy posiblpalabras, hay cuatro vías difeSRM:
• A/Desde la base de • A/Desde la cabina d(SRA) escrito por su• A/Desde el servidor • A/Desde el servidor se comunica con el secomo un servidor "pro Nota: Por supuesto es posib(base de datos, SRM,
58
e VMware SRM so de creación y configuración de SRM por pa estructura del producto y sus requisitos bá
os de esta arquitectura es que, es muy pocoolo en una red. Y sin embargo, la cabina de lemente será “parcheada” a una red diferenterentes de comunicación hacia y desde el se
datos backend del SRM (SQL u Oracle) de almacenamiento a través del Site Recover proveedor de almacenamiento de vCenter y el servidor de licencias de vCenter en el sitio de recuperación, el q
ervidor SRM del sitio de recuperación. El vCeoxy" para sus respectivos servidores SRM
ble tener todos los roles en un único ServidovCenter, servidor de licencias). En el diagra
rimera vez, ásicos.
o probable
te. En otras ervidor de
ry Adapter
ue a su vez enter actúa
r Windows ama

59
anterior, los roles han sido representados, por claridad, de forma independiente y mostrando los números de puerto utilizados.
Le adjunto una lista de los números de puerto y los caminos de comunicación utilizados en el diagrama:
1. El servidor SRM se comunica con el servidor de base de datos de Microsoft SQL u Oracle. 2. SRM se comunica con el servidor de licencias por el puerto TCP 22000 y 20001. 2/4 SRM se comunica con los dos vCenters, en el sitio protegido y en el sitio de recuperación por el puerto TCP 443. El vCenter actúa como un servidor “proxy” entre los dos servidores SRM. El servidor SRM “escucha” en el puerto TCP 8095 basado en SOAP. Los usuarios del cliente Vi, se descargan el plug-in de SRM por un puerto HTTP personalizado, puerto 8096. Si decide utilizar la API, la comunicación iría por el puerto TCP 9007 y 9008 (SOAP y HTTP personalizado respectivamente). 3. El SRM, a través del SRA (Site Recovery Adapter), se comunica por una serie de puertos de almacenamiento "dictados" por el vendedor. Por favor, consulte la documentación específica del proveedor.
Durante la configuración del SRM "Array Manager", el SRM utiliza un software especial escrito por su proveedor de almacenamiento ( Storage Array Adapter) para descubrir las LUNs/Volúmenes que se están replicando. Esta comunicación será a través de la red, vía enlaces UTP de la cabina de almacenamiento de fibra, o directamente a un objeto iSCSI. En un entorno de producción, tendrá que configurar el enrutamiento o la comunicación intra-VLAN para permitir que el adaptador de SRM pueda comunicarse con su “Array Manager”. Otro desafío de red es asegurarse de que los servidores de seguridad permiten la comunicación de un vCenter al otro y de un servidor SRM al. Finalmente, el último desafío es conseguir que las dos cabinas de almacenamiento se comuniquen entre ellas con el fin de replicar y crear instantáneas. Componentes de replicación del almacenamiento SRM asume que usted tiene dos o más ubicaciones geográficamente dispersas. La primera es su "sitio protegido". Usted puede conocer este como el “sitio donde corren todas las funciones críticas de su negocio. Si pierde este sitio, su negocio no puede funcionar, por lo que se realiza el cambio a un "sitio de recuperación", el cual puede ser usado en el caso de fallos en el sitio principal. Usted puede conocer mejor este sitio como el “sitito secundario” o como el sitio DR/BC. Hay ya muchas empresas que alquilan “espacio en rack” por tarifas comerciales, para proveer un sitio de recuperación a otras empresas. En mi caso, voy a comenzar con el uso de nombres muy claros para el sitio primario y el secundario. Voy a asumir que tenemos un lugar dedicado para la recuperación - quizás hemos contratado “espacio en rack” para esto - y la tolerancia a fallos es unidireccional. Es decir, el sitio principal siempre “falla” hacia

60
el sitio secundario. Hay otra configuración diferente, la cual llamamos bidireccional. En este caso, la ubicación secundaria DR es el sitio principal y, el sitio principal DR, es la ubicación del sitio secundario. Este enfoque bidireccional se utiliza mucho en grandes empresa donde la ubicación del sitio Londres DR podría ser las oficinas en Edimburgo y, la ubicación de las oficinas de Edimburgo DR, sería Londres. Voy a tratar la configuración bidireccional DR de SRM en el Capítulo 8. Otra forma de describir la diferencia entre una configuración unidireccional y bidireccional, es utilizando los términos más convencionales como “activo/standy” o “activo/activo”. Voy a seguir con los términos unidireccional y bidireccional porque son también los términos que encontrará en la documentación oficial de VMware. En alguno de estos dos sitios hay servidores ESX con máquinas virtuales que necesitan protección. Las máquinas virtuales del "sitio protegido", se han replicado con una cierta frecuencia determinada, la cual será un equilibrio entre su ancho de banda y su tolerancia a la pérdida de datos. Cuanto mayor sea el ancho de banda entre el sitio protegido y el sitio de recuperación, mayor será la frecuencia con la que podremos replicar los dos sitios. Las grandes empresas pueden y, muchas veces tienen, una mezcla de tecnologías y ciclos de replicación para facilitar el desplazamiento de los datos fuera del espacio protegido. Quizás tienen un canal de fibra de alta velocidad entre el SitioA y SitioB, pero luego usan una red más lenta entre SitioB y SitioC. En esta configuración, la replicación entre SitioA y SitioB podría ser sincrónica y sin latencia. Así, cuando un disco “escribe” en el SitioA, este dato ya se ha escrito en un disco del SitioB. Esa frecuencia de replicación ofrece una probabilidad muy baja de pérdida de datos. La replicación de SitioB a SitioC tendrá una mayor latencia, pero este tipo es con frecuencia seleccionado como el mejor método para replicar los datos a una distancia considerable y fuera de la zona protegida de una forma económica. Actualmente, SRM está limitado a crear solo una relación de sitios “uno-a-uno”. En la actualidad, no es posible crear una relación de replicación “spoke-and-hub”. Es de esperar que en el futuro, este tipo de configuración sea posible. Componentes VMware Dejando las consideraciones de almacenamiento a un lado, hay una serie de componentes VMware que necesitan ser configurados. Es posible que ya tenga algunos de estos componentes configurados, si usted ha estado utilizando VMware Vi3 durante algún tiempo. Tanto en el sitio de protección, como en el sitio de recuperación usted necesita:
• ESX 3.0.x, 3.5 o 3i Update 1 • vCenter 2.5 Update 1 • Una base de datos para el servidor de SRM en el sitio de protección y otra en el sitio recuperación. VMware soporta SQL 2000 Standard (SQL Express funciona también) o superior y Oracle 9i Release 2 Standard o superior • SRM en el sitio de protección y otro SRM en el sitio de recuperación (SRM está disponible para Windows XP SP2 Professional, Windows 2003 R2, Windows 2003 Server SP1, Windows 2000 Server SP4 con Update Rollup 1, solo en la versión de 32bits) • Adaptador SRM de su proveedor de almacenamiento instalados en ambos servidores SRM. • SRM Vi plug-in • Enmascaramiento LUN – Los servidores ESX en el sitio protegido ven las LUNs “reales” pero los servidores ESX en el sitio de recuperación sólo ven las "replicas" o instantáneas. Esto permite, que en las pruebas, no se

61
interrumpan las operaciones normales y tampoco se interrumpe el ciclo normal de la replicación entre los dos sitios • La resolución de nombres DNS. Al igual que con Vi3, se recomienda probar todos los métodos de resolución de nombres - nombre de host, corto, largo FQDN, e inverso.
Una pregunta muy común, es si es posible replicar la base de datos en vCenter en el sitio protegido al sitio de recuperación. La respuesta es NO, si usted tiene intención de usar SRM. SRM asume que las dos bases de datos de vCenter se están ejecutando de forma independiente la una de la otra. De hecho, una de las tareas de gestión necesarias durante la configuración de los dos SRM es la "vinculación" del SRM en el sitio de protección con el SRM del sitio de recuperación. Después, se mapean los objetos del vCenter (carpetas, resource pools, redes) en el sitio protegido con el sitio de recuperación. Actualmente, la estructura de la base de datos de vCenter no permite el uso de la replicación de SQL u Oracle para duplicar esta en el sitio de recuperación. A efectos de brevedad, voy a asumir que usted sabe cómo configurar ESX y vCenter para que pueda centrarse más específicamente en la parte del proceso de instalación y configuración de SRM. En mi caso, he usado los siguientes nombres para mis componentes: protectedvc.rtfm-ed.co.uk protectedsrm.rtfm-ed.co.uk protectedsql.rtfm-ed.co.uk recoveryvc.rtfm-ed.co.uk recoverysrm.rtfm-ed.co.uk recoverysql.rtfm-ed.co.uk La captura de pantalla siguiente muestra la configuración completa de mis servidores ESX, VMware DRS / HA Clusters vCenter y otros objetos, incluido carpetas y resource pools, antes de iniciar la instalación de SRM. Si usted está siguiendo este libro, no tiene necesariamente que adoptar mi estructura y convenciones de nombres, aunque estas son las que voy a utilizar a lo largo de este libro. Por supuesto, ninguna de estas máquinas virtuales se están ejecutando en un entorno de producción. Esto es simplemente un entorno de demo para "jugar" con SRM y demostrar la funcionalidad del producto. Por razones obvias, yo recomendaría este enfoque de “demo” antes de instalar SRM en un entorno de producción. Como puede ver, estoy ejecutando el VSA Lefthand Networks y los componentes necesarios para que funcione SRM.

62
Nota: Usted puede considerar todas las maquinas virtuales de la carpeta/resource pool “infrastructrure”, como maquinas virtuales “locales”, las cuales no se replicaran al sitio de recuperación. Además, mi Test & Dev resource pools, representa máquinas virtuales que no son críticas para el negocio, con lo que no forman parte de mi plan de recuperación.
Información más detallada acerca de los requerimientos hardware y software Como usted sabe, los requisitos de software y nivel de parches, cambian muy a menudo. Por lo menos usted querrá saber si su almacenamiento se ha probado con SRM y es compatible. No me parece muy lógico listar estos requisitos en detalle en

63
este libro. Así que en su lugar, le dejo con esta URL, donde encontrará todo tipo de información útil - PDFs, white papers, guías, webcasts, etc. http://www.vmware.com/products/srm/ En esta otra página, usted encontrará la guía oficial de administración de SRM http://www.vmware.com/support/pubs/srm_pubs.html y algunas otras guías, incluyendo: VMware Site Recovery Manager 1.0 Release Notes (HTML) Getting Started with Site Recovery Manager (PDF) Site Recovery Manager Administration Guide (PDF) Site Recovery Manager Compatibility Matrixes (PDF) Site Recovery Manager API (PDF) La matriz de compatibilidad de SRM, le dirá todo lo que necesita saber acerca de lo que está o no esta soportado, como por ejemplo:
• ¿Qué versión de ESX y vCenter estas soportados y que parches se necesitan? • ¿Qué sistemas operativos Windows y Service Packs son necesarios? • ¿Qué Base de datos están soportadas por SRM? • ¿Qué Sistemas Operativos podemos proteger con SRM? • ¿Qué sistema operativo permite la personalización (permite el cambio de la dirección IP)?, Por ejemplo, Solaris no está en la lista. • ¿Qué cabina de almacenamiento esta soportada por SRM?
Trate a esta matriz de compatibilidad de la misma forma que trata a la lista de compatibilidad de VMware ESX. Si tu configuración no está en la lista, no está soportada. Su configuración puede funcionar, pero si se “rompe” o no funciona bien, no espere que el soporte de VMware le ayude mucho. En cuanto a los requisitos de hardware (físico o virtual), VMware actualmente recomienda estos mínimos, como un punto de partida: Procesador - Intel 2.0GHz o superior o procesador AMD x86. Memoria - 2GB Disco - 2 GB Red - Gigabit recomendado La escalabilidad de VMware SRM Otra de las preocupaciones que tenemos sobre VMware SRM, es si tiene algún límite en cuanto al número de servidores ESX y máquinas virtuales que puede proteger y, cuántos planes de recuperación se pueden crear y ejecutar. Hace un momento hablábamos de los mínimos, pero vale la pena mencionar los máximos actuales de SRM. SRM ha sido probado para proteger hasta un máximo de 500 máquinas virtuales por sitio. Puede crear un máximo de 150 grupos de protección que a su vez están vinculados a 150 LUNs/Volúmenes replicadas. Puede ejecutar hasta tres planes de recuperación simultáneos. Como con todos los productos, usted puede esperar a que estas cifras aumenten en versiones posteriores. Diseñado tanto para el “failover” como para el “failback” (recuperación)?

64
Como puede ver, SRM fue diseñó desde el primer día para automatizar el failover desde el sitio protegido, hacia el sitio de recuperación. Tal vez le sorprenderá saber, que nunca fue parte de la estrategia de diseño, automatizar la recuperación del sitio de protección (failback). En teoría, el proceso de failback debería de ser tan sencillo como el proceso de failover, pero siento decir que no es tan sencillo. Ejecutar un proceso de failover o failback es una gran decisión, con o sin software de virtualización. Vamos a ver de una forma muy amplia, cómo funciona la versión actual de SRM y lo que se puede lograr con el software en su forma actual. De mis conversaciones con los clientes de VMware, el hecho de no haber un botón grande en SRM que diga "failback”, a veces, es visto o considerado como algo positivo y no negativo. Aunque también es cierto que hay otros clientes que dicen; donde está el botón de “failback”? Hay algunas razones del por qué no hay un botón de failback. El “failback”, en muchos aspectos, es más peligroso que el failover. Con el failover realmente no hay otra opción que la de pulsar el botón rojo grande y empezar el proceso. Después de todo, si un incendio, inundación, o un ataque terrorista ha destruido total o parcialmente su sitio principal, usted no tendrá más remedio que iniciar el proceso de failover al sitio de recuperación. Digamos que el proceso ya concluido con éxito, y ahora está en el sitio de recuperación. Si usted está funcionando sin problemas en el sitio de recuperación, que es lo que le llevara a hacer un failback?. En primer lugar, su personal de ventas están creando nuevos pedidos y sus financieros están procesamiento las facturas. Ellos están generando beneficios para la organización. En segundo lugar, los propietarios de las aplicaciones están contentos porque estas aplicaciones sobrevivieron a la catástrofe y sus servicios/servidores están online. Debido a estas circunstancias, es más probable que desee poco a poco y con cuidado volver al sitio principal (si puede). Usted seguramente no desea que el failback sea tan sencillo, como presionar un botón. El hecho mismo de llevar a cabo una recuperación de esta forma, podría llevar a cabo males mayores. Después de todo, si su sitio principal se vio gravemente destruido durante un desastre, puede que nunca quiera regresar a ese lugar. Lo que espero que vea, es un proceso de failback más sencillo y fácil de hacer, con menos pasos y etapas que en la actualiza, especialmente en el área de la cabina de almacenamiento, para que podamos concentrarnos en lo que realmente importa. Para muchas empresas, el cumplimiento, la auditoría y la seguridad es importante. Por eso, el ser capaz de pulsar un botón de "prueba de failover", es por lo que realmente compran VMware SRM. Esto significa que puedo decir a mi empresa, directivos y auditores, “mira” tenemos un plan de contingencia que ha sido probado y funciona. Sin embargo, para probar realmente un plan de recuperación o failover, la única prueba real es la de ejecutar un plan de failback de verdad. En algunos entornos corporativos, la prueba de su plan de recuperación es cada dos años. Para estas organizaciones, la falta de una opción fácil de recuperación o failback, les resulta un gran inconveniente. No estoy diciendo que el failback no es posible con SRM, es sólo que es mucho más un proceso manual que simplemente presionar el botón de prueba que se ve en el producto de SRM. MUY IMPORTANTE: Algo sobre los volúmenes VMFS y el Resignaturing Esta sección es para aquellas personas que no han asistido a los cursos oficiales de VMware “Depoy, Secure and Analyse” o para los que han olvidado rápidamente la mayoría de lo que se les dice en este curso.

65
Es importante que usted entienda, cual es el concepto de resignaturing y por qué SRM hace esto automáticamente. Esto le ayudará a entender algunos de los mensajes raros que a veces SRM nos muestra. En primer lugar, vamos a empezar con una revisión sobre las propiedades de los volúmenes VMFS. Antes y después de formatear un volumen VMFS, el almacenamiento se puede abordar de muchas maneras diferentes:
• Mediante su nombre de dispositivo Linux: /dev /sdk • Mediante su nombre de dispositivo VMkernel: vmhba1: 0:15 • Mediante su nombre de volumen, el cual tiene que ser único en el servidor ESX: myvmfs • Mediante su nombre de DataStore, que tiene que ser único en vCenter: myvmfs • Mediante su UUID: 47877284-77d8f66b-fc04-001560ace43f
Es importante saber que el valor UUID debe ser único y que un ESX no puede tener dos UUID iguales al mismo tiempo. Los UUID son generados por medio de tres variables básicas; la fecha, la hora y el número de LUN, con el fin de garantizar que el valor UUID es absolutamente único. Esto puede causar desagradables consecuencias si no son coherentes en su numeración LUN. Es decir, los problemas pueden ocurrir si ESX1 cree que una LUN/Volumen tiene un número 15, y otro hosts ESX cree que el mismo bloque de almacenamiento LUN/Volumen tiene el numero 20. También vale la pena decir que en la actualidad, las máquinas virtuales no encuentran sus archivos VMDK y VSWP mediante el nombre de volumen o datastore. Si examina el contenido de un archivo .VMX, verá referencias al valor UUID.
Como se puede ver, los números UUID son muy importantes. El requisito de UUID únicos, presenta retos interesantes para el DR. Por definición, cualquier imagen o proceso de replicación configurado en el sistema de almacenamiento está destinado a crear un duplicado exacto del volumen VMFS que, por definición, incluye el valor UUID. En condiciones normales, un servidor ESX en el sitio protegido, no debe llegar a ver la LUN original y la LUN/instantánea replicada al mismo tiempo. Si esto pasara, ESX suprimiría la segunda LUN/Volumen. Si a un ESX se le permitió ver ambas LUNs/ volúmenes al mismo tiempo, este estaría muy confuso y no muy feliz. No sabrá en qué LUN/Volumen podrá leer y escribir. Por consiguiente, ESX imprime un mensaje de error en la consola que sugiere que es posible que tenga que hacer un “resignature” del volumen VMFS.

66
Nota: Soy consciente de que esta imagen es difícil de leer en blanco y negro y que el contraste de color azul sobre fondo negro puede que no se reproduzca muy bien cuando se imprima el libro. La impresión en color tiene un coste prohibitivo para un libro de este tipo y aumentaría sus costes por un factor de un tercio. Para su información el texto afirma que para la instantánea con numero: "1c6953435349344 se ha desactivado el acceso. Vea la sección resignaturing de la Guía de administración de SAN. Si esta LUN fuese una LUN replicada o una instantánea, entonces la forma de resolverlo sería, modificando la configuración avanzada en el ESX para permitir la resignature y forzar un re-escaneo de la HBA. Esto podría tener algunas consecuencias indeseables. El nombre de volumen/DataStore se cambiaria y se generaría un nuevo valor UUID. Si hubiese máquinas virtuales registradas en ese volumen VMFS, tendríamos un problema en el que todos los archivos de los equipos virtuales .VMX, apuntarían al valor antiguo UUID, en lugar del nuevo. La buena noticia es que SRM automáticamente hace el resignatures de los volúmenes para usted, pero sólo en el sitio de recuperación y, automáticamente corrige cualquier problema con el archivo .VMX, usando una técnica llamada "placeholder" o "shadow". Estos archivos temporales ayudan a resolver estas cuestiones de almacenamiento así como se aseguran de que todos los ajustes importantes del archivo original .VMX, como la asignación de memoria y de CPU, se mantienen. Como el servidor ESX en el sitio de recuperación podría haber presentado diferentes instantáneas tomadas en diferentes momentos, SRM automáticamente y por defecto, re-firma o “resignaturing” el volumen VMFS y cambia el nombre del volumen/DataStore VMFS a su nombre original. Después, corrige los archivos .VMX de las máquinas virtuales en el sitio de recuperación para asegurar que se pueden encender sin errores. El cambio de nombre de este volumen, a su nombre original, se puede habilitar editando el archivo vmware-dr.xml. Mostrare esto más adelante cuando lleguemos a ejecutar nuestra primera prueba de un plan de recuperación.

67
Esto podría ser considerado por algunos como algo "más prudente" por parte de VMware, pero esto garantiza menos errores en el servidor ESX, eliminando así el potencial de presentar el mismo UUID más de una vez. Si dicho resignaturing no se produjo y se presentó al ESX los dos LUN/volúmenes VMFS con el mismo volumen VMFS, DataStore y valores UUID, el administrador recibirá un error en la consola del ESX. Algunas personas prefieren evitar por completo este tipo de problemas de replicación, en lugar de tomar riesgos innecesarios con los datos o tener que lidiar con una capa innecesaria de configuración manual. Quizás valga la pena mencionar que existen productos de almacenamiento por los que un servidor ESX podría ver la LUN original y su instantánea al mismo tiempo. Estoy pensando en los productos como HP Crosslink/Continuous Access y TimeFinder de EMC. Estas tecnologías están diseñadas para proteger su sistema en caso de pérdida de su SAN. Con estas tecnologías, el ESX tendría conectividad a dos cabinas de almacenamiento, las cuales estarían replicándose constantemente de una cabina a otra. La idea es que si toda una cabina de almacenamiento fallase, sería aún posible acceder a la LUN en la otra cabina. Es probablemente por esta razón, que por defecto, VMware SRM haga un resignaturing de las LUNs para poner fin a la posible corrupción de los datos. El Gran Plan Nuestro plan maestro será el poder ser capaces de “tirar” todos los servidores ESX en el sitio protegido, simulando la pérdida de todos los componentes de nuestra infraestructura, y poder invocar una prueba DR/BC en el sitio de recuperación.
Limitaciones del producto VMware SRM y erratas Lo que sigue a continuación es un “cortar y pegar” de las notas de la versión de SRM. Lea las notas de la versión de SRM. Detectar problemas potenciales, antes de pasar una semana tratando de resolver un problema que, es muy probable que se mencione en las notas de la versión.
Database
Mixed mode SQL Server Authentication When configuring a database connection to a SQL Server database that is not on the same host as the SRM Server, select mixed mode rather than Windows authentication.
Installation
VirtualCenter Database Must Not be Overwritten if VirtualCenter is Updated SRM is a VirtualCenter extension. If you update the VirtualCenter installation that SRM extends, you must not overwrite the Virtual Center database during the update. Doing so removes information that SRM has stored in that database and invalidates the current installation of SRM.
Update Servers First To avoid various problems with the SRM plug-in when updating SRM, update the SRM servers before you update the plug-in.
Before Updating, Uninstall SRM 1.0 Plug-In Before you can update the SRM plug-in in a VI Client to version 1.0 Update 1, you must use the Windows "Add and remove Software" tool to uninstall the SRM 1.0 plug-in from that client host.

68
Recovering Overwritten Versions of vmware-dr.xml and Other Configuration Files An update of SRM overwrites vmware-dr.xml and other configuration files, including certGenUtil.xml and extension.xml. If you have made any changes to these files, you can recover them from the backup files created by the update (for example, vmware-dr.xml.BAK).
Length and Character Set Requirements for Passwords. SRM passwords cannot be more than 31 characters long and must consist entirely of ASCII characters.
SRM Service Does Not Start After Reinstallation in a Different Directory. If you uninstall SRM and then reinstall it in a different directory on the same host but re-use the database connection created by the previous installation, the SRM service fails to start.
Non ASCII Characters are Not Supported in Some Fields SRM supports entry of non-ASCII characters in most fields during installation. If you enter a non-ASCII character into a field that does not support it, the installer warns you and requires you to re-type the entry in an acceptable character set.
Enabling and Disabling the SRM Plug-in The VI Client fails to display the SRM user interface if the SRM plug-in is disabled and then enabled. Workaround: Close and reopen the VI Client after you enable the SRM plug-in.
SRM Server Installation Fails and Reports the Error: "Failed to Register Extension" During the SRM Server installation, the installation fails and reports the error message: "failed to register extension." SRM reports this error if VirtualCenter Server has license issues. For example, if the VirtualCenter Server isn't licensed, or it lost connection to its license server, registration of the extension fails during installation.
Installation fails if DSN has trailing space During SRM installation, if you specify a DSN that has a trailing space character (for example, "SRM DB "), the installation fails.
A Non-Specific Error Message Displays if the SRM Server is Down During SRM Plug-in Installation If the SRM Server is down or unreachable when you try to install the SRM plug-in in the VI Client, the VI Client displays the message "The remote server returned an error: (503) Server Unavailable."
Role and Permissions
Recovery Plan Administrator Must Have Read Permission for All Recovery Plans A user who has administrator permission for any recovery plan must be granted read permission for all recovery plans. Assigning read permission for all recovery plans enables the user to access hidden metadata that must be read when an administrator role accesses a specific recovery plan
SRM Role Assignments and VirtualCenter When you assign a role to an SRM inventory object such as a protection group or recovery plan, that role assignment is not visible in the VirtualCenter Administration Roles pane. You can see it by viewing the properties of the SRM object.
SRM Service Failure
SRM Service Fails to Start if SRA is Corrupted or Not Found The SRM service will fail to start if an SRA it has been configured to use is uninstalled, becomes corrupted, or is reinstalled in a different directory.

69
SRM Service Fails to Start if VirtualCenter is not Running The SRM will not start unless the VirtualCenter one which it depends is running. Workaround: Ensure that VirtualCenter is running before trying to start SRM.
VI Client and SRM Plug-in
Display Refresh Issues When Using Multiple Virtual Infrastructure Clients If you are using more than one Virtual Infrastructure Client to manage SRM, changes initiated by one client may not be reflected in the displays of the the other clients.
Certificate Warnings when Connecting to SRM The SRM plug-in may report a certificate problem warning about a host name mismatch when you connect to a local or remote SRM server. Unless there are other problems with the certificate, you can accept it for this connection.
VI Client Does Not Display Current Information if the SRM Service Fails If the SRM service fails and then reconnects to the SRM Server, the VI Client does not display current information for Site Recovery. Workaround: Restart the SRM Service and then restart the VI Client.
VI Client Must Be Restarted if it Loses Connection with SRM Site connection is not updated if the local SRM server loses connectivity with the remote SRM server. Workaround: Restart the VI Client after the recovery SRM Server restarts.
Unauthorized operations can sometimes be selected Some operations for which the user does not have privileges appear to be available in the user interface and can be selected. If they are selected, the operation fails due to an authorization failure.
SRM Plug-in is Still Present After the VI Client is Uninstalled The SRM plug-in is not uninstalled when the VI Client is uninstalled. After reinstalling the VI Client, the SRM plug-in is still present. Workaround: Using the VI Client, uninstall the SRM plug-in before uninstalling the VI Client.
Site Pairing
Invalid ESX Server Certificate Causes Errors During Customization Server certificates created by the default ESX installation may appear invalid to SRM and cause errors indicating problems with the server certificate to be logged during customization. Workaround: If you cannot install an acceptable certificate on the ESX host, you can disable certificate checking by setting the value of the <disableNFCServerCertificateChecks> parameter in vmware-dr.xml to true. This forces all ESX server certificates to be accepted, and therefore creates a security risk that could potentially compromise the user name and password for any ESX server involved in customization.
SRM Reports Error Messages When Breaking Site Connection After attempting to break the protected and recovery site connection, SRM reports the errors: "Unable to break the connection with remote site because it is currently user by other users" and "The request refers to an object that no longer exists or has never existed." These errors appear if the recovery user permissions are changed to "No Access" when the VI client is connected to the protected site. Workaround: Do not change user permissions to "No Access" from the recovery site while protected site VI Client is connected to remote site with this user. If you receive these errors, restart the protected site's SRM service and the VI Client.
Accepting Thumbprints for Secondary Servers During Site Pairing Reports "Incompatible Authentication Method" Error During site pairing, SRM suggests to accept thumbprints for the secondary server.

70
Thumbprint certificate validation during pairing is not a valid option if SRM and VirtualCenter authentication is using trusted certificates.
VI Client Displays "Loading..." in the SRM Tab if the SRM Server is Unavailable If the SRM Server is not installed or available, the "Connect To VMware SRM Server" button displays and the SRM tab displays "Loading..." for the status of each SRM component. Workaround: Start the SRM service if it is not running.
Configure Array Managers Display is Not Refreshed After Connecting the Protected and Recovery Sites After reconnecting the protected and recovery sites, the Configure Array Managers summary information in the VI Client is not refreshed and the information is out of sync. Workaround: Restart VI Client then launch Site Recovery Manager.
Protected Sites Shows "Unable to Connect" After Successful Connection After successful connection between protected and recovery sites, the protected site reports "Unable to Connect" and eventually reports the error: "Low Resources on Pair..." Workaround: 1. Restart the SRM Service. 2. Close the VI Client for the recovery site. 3. Break the connection and configure connection from the protected Summary
page. 4. Start the VI Client and log in to the recovery site. 5. Select Site Recovery and configure the connection from the remote site.
During Site Connection, an SSL Exception error reports: "The host certificate chain is not complete" When trying to connect protected and recovery sites, a SSL Exception error reports: "The host certificate chain is not complete." This error occurs if the certificate on the protected site is changed before pairing with the recovery site. Workaround: Restart the SRM service on the protected site before pairing with the recovery site.
Error Message Displays While Breaking Recovery Site Connection Breaking the connection from the protected site to the recovery site displays the error: "Object reference not set to an instance of an object" after the sites are disconnected. Workaround: Acknowledge the error message.
Cannot Break Connection After the VI Client Process is Terminated Abnormally You cannot break the connection with the recovery site from the protected site if the vpxClient.exe process is not running. The error message: "Unable to break the connection with the remote site because it is currently used by other users" is reported. Workaround: Restart both SRM Servers then break the connection between the recovery site and the protected site.
Inventory Mappings Information is Incorrect After breaking and reconnecting site pairing, the VI Client at the protection site might not display correct information in Inventory Mappings. Workaround: Refresh the Inventory Mappings to display the actual mappings. Click the Refresh button from the Inventory Mappings tab.
Pairing Site to Itself Doesn't Fail in the Correct Step If you select Site Recovery > Configure and enter the local VirtualCenter Server IP address, SRM continues to the next connection step and asks for user credentials. The connection should fail when the local VirtualCenter Server's IP address is entered. Workaround: Do not attempt to pair with the local VirtualCenter Server.
When Pairing Sites, Use Trusted Certificates When pairing sites and the certificates of the recovery-site VirtualCenter Server and SRM Server are not trusted by the protection-site SRM server, yellow warning triangles, rather than green check boxes, appear to the left of the Certificate

71
Validation steps. The yellow warning triangles warn the user that the given certificates did not pass the validation requirements that the certificates be signed by a trusted Certificate Authority (CA) and have a DNS value matching the address of the server. During the pairing, the user indicated that the certificates should be accepted based on their SHA-1 thumb-prints. It is a serious security violation to accept certificates based on their thumb-prints without verifying that the thumb-prints are correct. Workaround: Ensure that both VirtualCenter Servers and both SRM Servers use trusted certificates.
Protection Group
VM Name Column Must be Populated When Using Batch IP Customization Tool If you use the batch IP customization tool to customize IP properties, you must copy the VM Name (column 2 of the row for Adapter ID 0) into column 2 of each row that you add for a virtual machine.
Protected Virtual Machine Converted to Template Loses Protection If you convert a protected virtual machine to a template, the protection on that virtual machine becomes invalid and must be reconfigured. Otherwise subsequent recoveries of that VM will fail. Workaround:Remove protection from the virtual machine at the protected site, and then reprotect it.
No Support for Customization of Debian and Ubuntu Guests Linux guests based on the Debian and Ubuntu distributions (and related ones) cannot be customized. Placeholder virtual machines for these guests are recovered running the configuration that they have at the protected site.
Customization Specification Manager Does Not Reflect Changes Made by Batch IP Customization Tool If you use the batch IP customization tool to customize IP properties in a recovery group, the Customization Specification Manager window does not reflect those changes even after you refresh the display. Workaround Close and re-open the Customization Specification Manager window.
VI Client Inventory Reports the Error: "The request refers to an object that no longer exists or has never existed" After removing a protection group, the VI Client Inventory view on the recovery site is not refreshed. Attempting to select an object from the Inventory reports the error: "The request refers to an object that no longer exists or has never existed." Workaround: Restart the VI Client.
Protection Groups Display is Not Refreshed After Connecting the Protected and Recovery Sites After reconnecting the protected and recovery sites, the Protection Groups display in the VI Client is not refreshed and the information is out of sync. Workaround: Restart the VI Client.
Recovery Plan
Curly Braces Not Allowed in Recovery Plan Name You cannot use the { or } characters ("curly braces") in the name of a recovery plan.
Inaccurate Description of Normal and Low Priority Virtual Machine Startup in Administrator's Guide When a recovery plan includes virtual machines hosted on more than one ESX host, virtual machines that have a recovery priority of normal or low are started in parallel. Because they are started sequentially on each ESX host, the amount of parallelism is determined by the number of ESX hosts.

72
Problems Customizing Certain Linux Guest Configurations During Recovery Linux guests that are not running an ext2, ext3, or ReiserFS file system may experience customization failures when recovered.
Error reported when running recovery plans simultaneously Certain array managers do not support simultaneous execution of recovery plans and report an error when such recoveries are attempted.
SRM Reports the Error: "Cannot execute scripts" When Customizing Windows Virtual Machines During Recovery During test recovery or recovery, when Windows guests are customized, occasionally the virtual machines attempt to shut down gracefully and SRM reports the error "Cannot execute scripts." This results in a hard shut down after customization is complete and the virtual machine remains powered off regardless of its recovery plan priority. Workaround: Manually power on the Windows virtual machines that report this error.
Test Recovery
Failure to Power Down Virtual Machine at Protected Site Causes Spurious Report of Recovery Failure If a recovery plan includes a step that powers down one or more virtual machines at the protected site and does not receive confirmation that the requested power-down completed, the recovery plan is reported as failed even though all other steps may have succeeded.
A Stop Button Appears After Starting a Recovery Plan Test Occasionally, after you start recovery test for the first time, a "Stop" button appears with the message: "Stop Recovery. Are you sure you want to stop this recovery plan? This process may take several minutes." Workaround: Click "No." The test proceeds and completes successfully.
Recovery Plan Test Status is "Running Test" After the Test is Canceled Canceling a recovery plan test from the task list cancels the recovery plan test, but the VI Client displays the status as "Running Test" under Recovery Plans.
Converting a Template During a Test Leaves the Virtual Machine Unprotected If you test a recovery plan containing a virtual machine template, and during the test you convert the template to a virtual machine and then power it on, the test cleanup steps do not unregister the virtual machine correctly and its protection is lost. Workaround: To restore protection, manually power-off and unregister the placeholder virtual machine and then reconfigure protection.
Miscellaneous Issues
Refresh Inventory Mappings Can Make Display Unresponsive at Sites That Support Large Numbers of ESX Hosts When you are connected to a site that supports more than 7 ESX hosts and refresh inventory mappings, the display becomes unresponsive for up to ten minutes. Workaround: A patch that corrects this problem is available on the SRM Download Site
Some Arrays May Present Too Many iSCSI Targets When using the ESX software iSCSI stack, SRM can manage up to 23 iSCSI targets per host. Arrays that present each LUN as a separate iSCSI target may exceed this limit.
Some Arrays Might Require a Second Rescan. Some storage arrays might require a second rescan to discover LUNs. HP arrays have been identified as having this requirement. To enable the additional rescan, edit the vmware-dr.xml file at both the protected and recovery sites to add a <hostRescanRepeatCnt> element within the <SanProvider> element. Set the value of <hostRescanRepeatCnt> to 2, as shown in the following example:

73
<SanProvider> . . . <hostRescanRepeatCnt>2</hostRescanRepeatCnt> </SanProvider>
Incorrect Step in Specify a Nonreplicated Datastore for Swapfiles Procedure. The first line of step 3 of the "Specify a Nonreplicated Datastore for Swapfiles" procedure in Appendix D of the Administration Guide should read "For each host in the cluster:"
Long Timeouts for Misconfigured or Corrupted Virtual Machine. If a recovered virtual machine does not power on within the specified timeout period, either because it has been improperly configured or has become corrupted during data replication, the recovery plan will wait considerably longer for that virtual machine to timeout than the interval specified by "Change Network Settings" in the recovery plan. This type of abnormally long timeout typically occurs only when applying a customization specification to the virtual machine." Workaround: During a test recovery, verify that the virtual machine image is not corrupted (will boot successfully) and has VMware Tools installed before customizing it.
SRM is Not Compatible With DPM (Distributed Power Management) SRM recovery plans cannot power-on a host that is in standby mode. If a recovery plan specifies that a host at the recovery site exit standby mode, the host will remain in standby mode, and the virtual machines assigned to that host will not start.
Log Collector Does Not Support non-ASCII Encodings The log collector does not support use of non-ASCII encodings when writing log files.
Japanese Characters in SRM Log Files Use Shift-JIS Encoding To read these log files, use a browser, viewer, or editor that can interpret Shift-JIS.
Cannot Specify RDM Devices for Templates You cannot specify an RDM device in a virtual machine template.
Problems When a LUN in a Consistency Groups is Not Part of a Datastore Group If a consistency group contains a LUN that is not used as a datastore or as an RDM device, SRM may not be able to recover that consistency group. Workaround Add a virtual machine without an OS that has the LUN mapped as an RDM device.
VirtualCenter 2.5 Simultaneous Boot Limit VirtualCenter 2.5 does not allow you to boot more than 16 virtual machines simultaneously.
"Unexpected MethodFault" error when using VC 2.5 Update 1 When you are using SRM in conjunction with Virtual Center 2.5 Update 1, attempts to connect to the recovery site sometimes fail and log an error message of the form "DR: Unexpected MethodFault". Workaround: Upgrade to Virtual Center 2.5 Update 2 or later, or re-start the VirtualCenter server at the recovery site.
SRM is Incompatible with DRS Clusters That Mix ESX 3.5 and ESX 3.0.x Hosts SRM does not support using ESX 3.5 and ESX 3.0.x versions of ESX Server in DRS clusters. Virtual machines fail and report errors during customization and resource pool configuration fails. Workaround: Create DRS clusters using ESX hosts of the same version.
SRM Alarms Appear in the VI Client After SRM is Uninstalled SRM Alarm Status (if any) is kept after SRM is uninstalled. If the VirtualCenter Server is not reinstalled and you install SRM again, the previous SRM Alarm Status is applied.
The srm-config Tool Exits and Reports the Error: "Error [2]: OSERROR [0x80090016] Failed to open crypto key container for certificate" During the SRM certificate replacement process, a Windows API can fail with the

74
error message: "Failed to open crypto key container for certificate." This is caused by one of the following: A missing operating system internal file in the following folder:
C:\Documents and Settings\All Users\Application Data\Microsoft\Crypto\RSA\MachineKeys
Incorrect permissions of one of the following folders: C:\Documents and Settings\All Users\Application Data\Microsoft\Crypto C:\Documents and Settings\All Users\Application Data\Microsoft\Crypto\RSA\S-1-5-18 C:\Documents and Settings\All Users\Application Data\Microsoft\Crypto\RSA\MachineKeys
Workaround: Run the command again or fix the permissions.
Licenciar VMware SRM SRM se licencia usando el servidor de licencias estándar de VMware. No es necesario modificar sus archivos de licencia. Se trata simplemente de copiar su archivo de licencia SRM.LIC en el directorio de licencias, para que después y, utilizando el administrador de licencias de VMware, pulsemos al botón de “re-read license file”. En este punto tal vez valga la pena explicar que, VMware SRM tiene dos diferentes modelos de concesión de licencias, ya que este puede ser configurado de dos modos, unidireccional (activo/standby) y bidireccional (activo/activo). Con la configuración unidireccional, usted sólo necesita una licencia de SRM para las máquinas virtuales que quiere cubrir con SRM. No tenemos que tener una licencia en el sitio de recuperación para SRM. Esto no significa que usted pueda ejecutar Vi3 en el sitio de recuperación de forma gratuita. Si usted está ejecutando ESX 3.5 y vCenter en el sitio de recuperación, necesitará licencias para estos productos. Si está ejecutando ESX3i actualización 2, el cual fue lanzado en agosto de 2008, debe de saber que el producto ha sido liberado de forma gratuita. Sin embargo, el sistema de gestión de vCenter, el cual es necesario para la aplicación de SRM, no es gratuito. Si activa su plan de recuperación de una forma real y, al hacerlo, usted hace un failover hacia el sitio de recuperación, entonces es necesario tener licencias CPU Socket para que se ejecute en ese sitio durante cualquier periodo de tiempo. Cuando utilice en SRM, la opción de failback, se le permitirá usar temporalmente su licencia de SRM del sitio protegido en el sitio de recuperación para comenzar el proceso. Esto es legal y está dentro de los términos y condiciones de VMware SRM EULA. Si está instalando una configuración bidireccional tendrá que tener una licencia de SRM en ambos lugares. Posteriormente, en este libro también enseñare una configuración bidireccional. Dada la complejidad actual en torno a la concesión de licencias de SRM, algunos clientes han propuesto posibles escenarios donde el modelo de licencias por “socket” falla. Aquí va un buen ejemplo. Digamos que tengo un clúster DRS/HA con 32 nodos, donde cada servidor ESX tiene 4 sockets y 4 núcleos por socket, con un total de 16 núcleos por servidor ESX. Eso significa 128 licencias socket que tendría

75
que comprar en el sitio de protección. Pero qué pasa si sólo tenemos 5 máquinas virtuales que necesitan protección? Esto ha llevado a algunos expertos a sugerir que el modelo de licencia por cada máquina virtual que queremos proteger habría sido mejor para SRM. De esta forma sólo pagara por lo que quiere protección. En primer lugar, y siendo consciente de este punto de vista (después de todo, es un intento de ahorrar dinero en licencias,) es muy poco realista pensar que, una organización con este número de servidores ESX, tendrá un número tan pequeño de máquinas virtuales que necesitan protección. En segundo lugar, sería muy difícil que VMware implemente este cambio rápidamente ya que la principal herramienta para la concesión de licencias sigue siendo FLEXnet, la cual cuenta el número de sockets, en lugar del número de vCPUs en uso. Un cambio en Flexnet requeriría un cambio en la arquitectura del sistema de concesión de licencias de VMware. Mi última palabra sobre este debate, es que creo que esto ilustra, que el contar los sockets para la concesión de licencias de productos, se ha convertido algo desfasado, sobre todo porque el mismo hecho de virtualizar ha hecho del licenciado de CPUs sea algo cada vez más misterioso . Creo que es muy revelador el hecho de que uno de los competidores de VMware, Citrix XenServer, optó por un modelo de licencia por servidor físico en lugar del modelo por socket. En los últimos meses, VMware ha “desplazado” el objeto de la conversación diciendo que no importa el número de socket que su servidor pueda tener, si usted tiene el hipervisor libre como es el caso de ESX3i. Pero el problema es que la gestión de alto nivel de productos como VMware SRM, todavía están ligados al antiguo modelo de por socket. De todos modos, la concesión de licencias puede ser un tema muy confuso y a menudo es comparable con comparar tarifas telefónicas de un proveedor con otro. Así que, aquí va un simple consejo, por el momento, para el licenciamiento de VMware SRM: Cuando usted crea un grupo de protección (para proteger máquinas virtuales), usted necesita una licencia. IMPORTANTE: Tanto la licencia de los servidores de protección, como los servidores del sitio de recuperación, deben ser correctamente licenciados.
1. Descargue su archivo SRM.LIC 2. Copie el archivo .lic en C: \Progam Files\Vmware \VMware License Server\Licenses en su servidor de licencias - en la mayoría de los casos este también es su servidor de vCenter Nota: Su archivo de licencia debe tener la extensión .lic 3. Abra la herramienta VMware License Manager 4. Seleccione la pestaña Start/Stop/Re-Read 5. Haga clic en el botón ReRead License File

76
Nota: Esto deberá actualizar la información de la licencia, en la pestaña de Administración de Licencias:
Configurando la conectividad de la base de datos de VMware SRM SRM requiere dos bases de datos, una instancia de SQL u Oracle en el sitio de protección y otra instancia de SQL u Oracle en el sitio de recuperación. Usted puede utilizar la autenticación de Windows o la autenticación de SQL, para tener el servidor de Base de Datos separado del servidor de SRM. Sin embargo, ambos servidores, tanto el servidor de SQL como el servidor de SRM, deben ser parte del mismo dominio. Para el servidor SQL, el usuario de la base de datos de SRM no necesita los permisos DB_OWNER, como es el caso en la base de datos del vCenter. Por último, la cuenta que utilizara para acceder a la base de datos de SRM, debe tener privilegios de administrador. SRM es compatible con toda una serie de base de datos como SQL 2005 con SP1 o superior y SQL 2000 con SP4. Para los usuarios de Oracle, Oracle 91 Release 2 Standard y superior son compatibles. Por último, recordar que con SQL 2005, usted

77
tendrá que instalar el SQL Native Client en los servidores SRMs del sitio de protección y recuperación respectivamente. Si está usando un servidor de Oracle 9i, la funcionalidad “SRM Bulk Insert” debe desactivarse. Además, después de la instalación de SRM, usted debe editar el archivo de configuración vmware-dr.xml en su servidor SRM y cambiar la configuración de “EnableBulkInsert” a falso. La ubicación predeterminada de este archivo es: C:\Program Files\VMware\VMware Site Recovery Manager\config Después de cambiar el archivo de configuración, reinicie el servicio de Site Recovery Manager de VMware en los servidores SRM que estén utilizando esta base de datos, para que esta configuración surta efecto. Lo que sigue, es una guía paso a paso sobre la creación de la base de datos en SQL 2005, utilizando la autenticación de SQL con un servidor SQL externo. La guía oficial de la administración de SRM no incluye una guía detallada paso a paso de la configuración de SQL. El curso de formación oficial de SRM dice que debe utilizarse los permisos de DB_OWNER sobre la base de datos de SQL. Los permisos expuestos a continuación puede ser excesivos, pero SRM he estado funcionando por algún tiempo sin ningún error. Personalmente, espero que muy pronto VMware publique, en la próxima guía de administración o en un artículo KB, los permisos que son necesarios para la base de datos, con una guía paso a paso de cómo hacerlo para que los administradores de VMware, que dicen no ser expertos en SQL y no tienen un equipo DBA dedicado, puedan consultar esta cuando necesitan ayuda. Creación de la base de datos y configuración de permisos
1. Cree un usuario local en el servidor SQL 2. Abra Microsoft SQL Server Management Studio 3. Inicie sesión en el servidor SQL, y haga clic con el botón derecho en Databases 4. Elija New Database y en el campo elegir el nombre de base de datos escriba: srmprotected-db(o algo parecido que corresponda) y seleccione OK
78
5. Expanda la ficha Security y haga clic derecho en Logins y seleccione New Login 6. Escriba el nombre de la cuenta de usuario creado para la base de datos de SRM protegido, en mi caso llamé a mi usuario srmprotected-db 7. Establezca la base de datos predeterminada que sea la base de datos creada en el punto 2
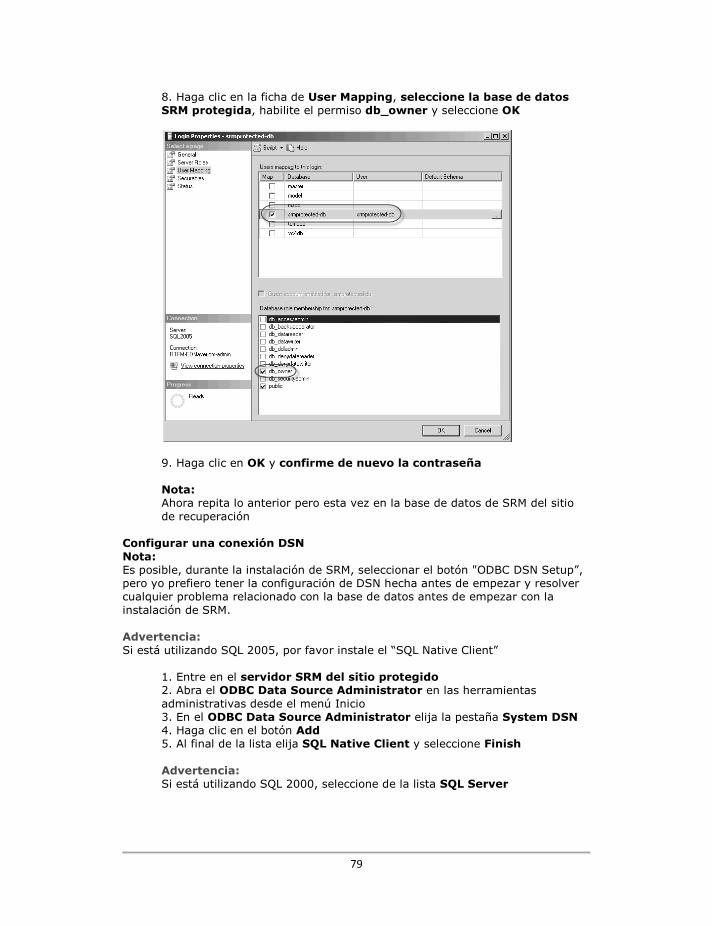
79
8. Haga clic en la ficha de User Mapping, seleccione la base de datos SRM protegida, habilite el permiso db_owner y seleccione OK
9. Haga clic en OK y confirme de nuevo la contraseña Nota: Ahora repita lo anterior pero esta vez en la base de datos de SRM del sitio de recuperación
Configurar una conexión DSN Nota: Es posible, durante la instalación de SRM, seleccionar el botón "ODBC DSN Setup”, pero yo prefiero tener la configuración de DSN hecha antes de empezar y resolver cualquier problema relacionado con la base de datos antes de empezar con la instalación de SRM. Advertencia: Si está utilizando SQL 2005, por favor instale el “SQL Native Client”
1. Entre en el servidor SRM del sitio protegido 2. Abra el ODBC Data Source Administrator en las herramientas administrativas desde el menú Inicio 3. En el ODBC Data Source Administrator elija la pestaña System DSN 4. Haga clic en el botón Add 5. Al final de la lista elija SQL Native Client y seleccione Finish Advertencia: Si está utilizando SQL 2000, seleccione de la lista SQL Server

80
6. En el campo nombre de Create a New Data Source to SQL Server, escriba VMware SRM 7. De la lista desplegable, seleccione su servidor SQL Protegido y haga clic en Next
8. Seleccione "With SQL Authentication…" y escriba la cuenta de usuario y la contraseña de la base de datos creada en SQL y haga clic en Next 9. Habilite "Change the default database to" y seleccione la base de datos de SRM protegida que creó anteriormente 10. Haga clic en Next y Finish Nota: Debería ahora estar en condiciones de confirmar todos los cuadros de diálogo relacionados con la configuración del ODBC. Pruebe también que tiene conectividad con el servidor de base de datos. Nota: Repita esta configuración del DSN para el servidor SRM del sito de recuperación.
Instalación del servidor de VMware SRM Instalación del software SRM La instalación de SRM es la misma tanto para el servidor del sitio protegido como para el servidor del sitio de recuperación. Durante la instalación se necesitan los siguientes datos:
• vCenter FQDN • Un nombre de usuario y contraseña válidos para autenticarnos con vCenter • Aceptar un certificado por defecto o generar uno propio • Valores de identificación de sitio como el nombre del sitio, información de contacto y correo electrónico • Credenciales de SQL/Oracle DSN para la base de datos correcta 1. Entre en el servidor SRM del sitio protegido
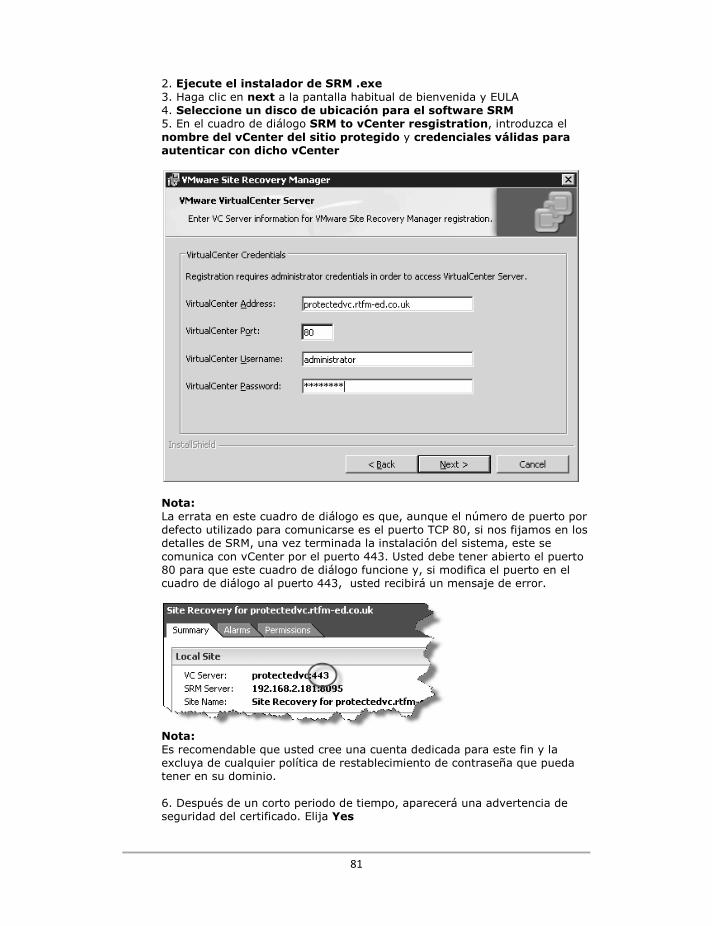
81
2. Ejecute el instalador de SRM .exe 3. Haga clic en next a la pantalla habitual de bienvenida y EULA 4. Seleccione un disco de ubicación para el software SRM 5. En el cuadro de diálogo SRM to vCenter resgistration, introduzca el nombre del vCenter del sitio protegido y credenciales válidas para autenticar con dicho vCenter
Nota: La errata en este cuadro de diálogo es que, aunque el número de puerto por defecto utilizado para comunicarse es el puerto TCP 80, si nos fijamos en los detalles de SRM, una vez terminada la instalación del sistema, este se comunica con vCenter por el puerto 443. Usted debe tener abierto el puerto 80 para que este cuadro de diálogo funcione y, si modifica el puerto en el cuadro de diálogo al puerto 443, usted recibirá un mensaje de error.
Nota: Es recomendable que usted cree una cuenta dedicada para este fin y la excluya de cualquier política de restablecimiento de contraseña que pueda tener en su dominio. 6. Después de un corto periodo de tiempo, aparecerá una advertencia de seguridad del certificado. Elija Yes

82
Nota: Como mencione hace un momento, a pesar de que el cuadro de diálogo utiliza por defecto el puerto 80, se produce un intercambio de detalles de los certificados. Esto es hecho así, para confirmar que el sitio SRM de protección "confía" en el servidor de vCenter. Esta advertencia se produce al usar los certificados auto-generados del servidor vCenter, los cuales no coincide con el FQDN del servidor vCenter. Para eliminar este mensaje que aparece, tendría que generar certificados de confianza para el vCenter en el sitio de protección y recuperación.
7. El siguiente cuadro de diálogo también se refiere a la seguridad. También es posible que la instalación de SRM pueda generar un certificado para demostrar la identidad del servidor de SRM. Alternativamente usted puede también crear sus propios certificados. Seleccione Automatically generate a certifícate y haga clic en Next

83
8. Como parte de la auto-generación del certificado SRM, debe indicar su organización y unidad de organización
Advertencia: Espacios, comas, puntos y caracteres Alfanuméricos son todos válidos. Caracteres no válidos incluyen el guión y el subrayado

84
9. Siguiente, introduzca la información del sitio. En este caso, yo he aceptado el nombre por defecto del sitio. Añada la dirección de correo electrónico
Nota: Los puertos SOAP/HTTP (9007/9008) sólo se utilizan, si decide utilizar el kit de desarrollo de software (SDK), para crear aplicaciones o scripts que automaticen aún más SRM. El puerto de escucha SOAP (8095) se utiliza para enviar y recibir peticiones del servicio SRM. El puerto de escucha HTTP (8096) se utiliza en el proceso de descargar del plug-in del SRM. La configuración del correo electrónico se puede encontrar en el archivo extension.xml, situado en el servidor SRM. 10. Luego, complete la información de la conexión de la base de datos
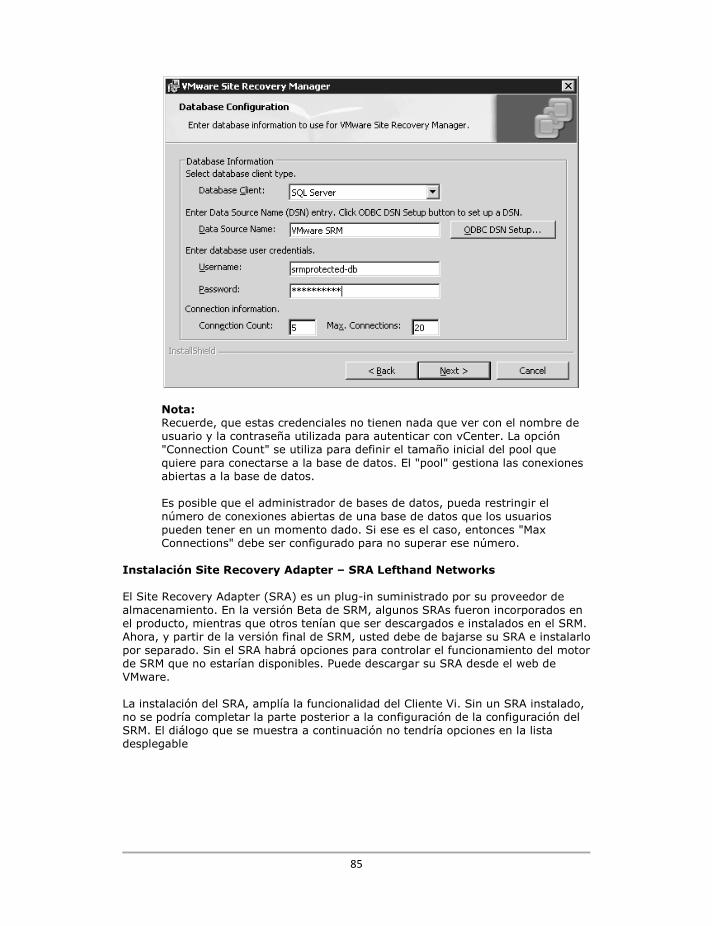
85
Nota: Recuerde, que estas credenciales no tienen nada que ver con el nombre de usuario y la contraseña utilizada para autenticar con vCenter. La opción "Connection Count" se utiliza para definir el tamaño inicial del pool que quiere para conectarse a la base de datos. El "pool" gestiona las conexiones abiertas a la base de datos. Es posible que el administrador de bases de datos, pueda restringir el número de conexiones abiertas de una base de datos que los usuarios pueden tener en un momento dado. Si ese es el caso, entonces "Max Connections" debe ser configurado para no superar ese número.
Instalación Site Recovery Adapter – SRA Lefthand Networks El Site Recovery Adapter (SRA) es un plug-in suministrado por su proveedor de almacenamiento. En la versión Beta de SRM, algunos SRAs fueron incorporados en el producto, mientras que otros tenían que ser descargados e instalados en el SRM. Ahora, y partir de la versión final de SRM, usted debe de bajarse su SRA e instalarlo por separado. Sin el SRA habrá opciones para controlar el funcionamiento del motor de SRM que no estarían disponibles. Puede descargar su SRA desde el web de VMware. La instalación del SRA, amplía la funcionalidad del Cliente Vi. Sin un SRA instalado, no se podría completar la parte posterior a la configuración de la configuración del SRM. El diálogo que se muestra a continuación no tendría opciones en la lista desplegable

86
Esto permitirá a VMware SRM, una vez que el SRA ha sido instalado, pueda descubrir las LUNs/Volúmenes en los sitios de protección y recuperación. También encuentra que LUNs/Volúmenes se están replicando. La verdadera idea de esto es permitir que el administrador del sitio de recuperación pueda ejecutar planes de recuperación sin tener que gestionar la capa de almacenamiento directamente. El SRA automatizará el proceso de presentación de las LUNs replicadas o instantáneas correctas a los servidores ESX en el sitio de recuperación cuando estas se necesiten. En mi ejemplo, yo estoy usando un appliance virtual (VSA) de Lefthand Networks por lo que necesito descargar e instalar el SRA de Lefthand Networks. La instalación del SRA es muy simple y en la mayoría de los casos es, siguiente-siguiente-y-finalizar junto con el reinicio de los servicios de VMware SRM.
1. Descargue el SRA de Lefthand Networks desde su web 2. Haga doble clic en el ejecutable 3. Después del proceso de extracción, usted verá una pantalla de bienvenida

87
4. Haga clic en Next 5. Acepte el acuerdo de licencia 6. Abra la consola de Servicios y reinicie el servicio de VMware Site Recovery. Alternativamente usted puede reiniciar el servicio de SRM desde la línea de comandos con net stop vmware-dr net start vmware-dr Nota: Repita esta instalación en el servidor SRM del sitio de recuperación
Instalación del plug-in SRM en el cliente Vi Al igual que con la instalación de VMware Update Manager o VMware Converter, la instalación del "plug-in" para SRM, "extiende" el cliente Vi con funcionalidad de gestión adicional. Después de la instalación correcta de los SRMs usted debe ver el plug-in “Recovery Manager plug-in” disponible en el menú de plug-ins. Este plug-in necesita ser instalado para llevar a cabo la primera configuración y posterior configuración del servicio SRM.
1. Inicie sesión con el cliente Vi en el vCenter del sitio de protección o recuperación 2. En el menú elija Plug-ins y Manage plug-ins 3. Haga clic en el botón Download and Install
88
Nota: No hay nada de especial en la instalación de un plug-in, aparte de aceptar el EULA y hacer clic en siguiente 4. Luego seleccione la pestaña “Installed” en el Plug-in Manager y active el plug-in. Esto debería añadir un icono “Site Recovery” en la barra de botones principales
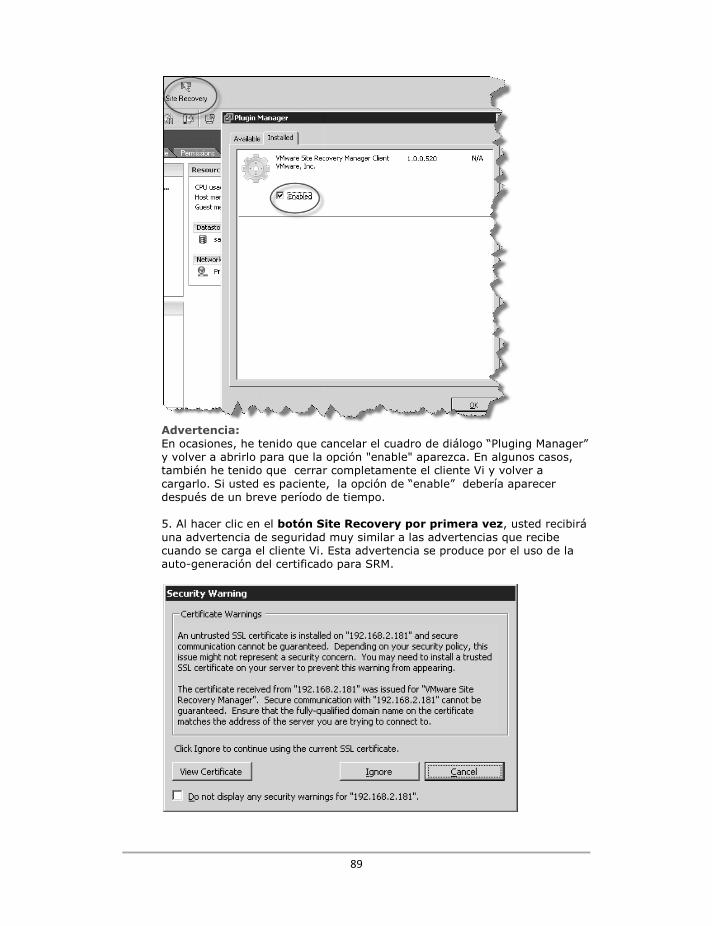
89
Advertencia: En ocasiones, he tenido que cancelar el cuadro de diálogo “Pluging Manager” y volver a abrirlo para que la opción "enable" aparezca. En algunos casos, también he tenido que cerrar completamente el cliente Vi y volver a cargarlo. Si usted es paciente, la opción de “enable” debería aparecer después de un breve período de tiempo. 5. Al hacer clic en el botón Site Recovery por primera vez, usted recibirá una advertencia de seguridad muy similar a las advertencias que recibe cuando se carga el cliente Vi. Esta advertencia se produce por el uso de la auto-generación del certificado para SRM.

90
Si no desea que aparezca este mensaje de nuevo, active la opción de no mostrar ninguna de las advertencias de seguridad y haga clic en el botón Ignore
No es posible conectar con el servidor de SRM Si usted pierde la conectividad o reinicia el servicio de SRM en cualquiera de los sitios protegidas o de recuperación y tiene el cliente de Vi abierto, recibirá un cuadro de diálogo de error come este:
Si se produce un fallo al conectarse al servidor de SRM verá esto cuando usted haga clic en el icono del sitio de recuperación
Si esto ocurre, confirme que el servicio SRM esta arrancado. Si SRM no se iniciará, confirme la conectividad con la base de datos SQL y otras dependencias como la IP y la resolución de nombres DNS. Además, si el sitio protegido no se puede conectar al sitio de recuperación (tal vez ha perdido la conectividad con el sitio de recuperación), verá este mensaje de error en la ventana “Site Recovery Manager”
Si esto le sucede a usted, compruebe las cosas sospechosos habituales, tales como un fallo del servicio en el sitio recuperación y, a continuación, haga clic en el enlace Configure para el reabastecimiento de las credenciales del vCenter en el sitio de recuperación.

91
Conclusión En este capítulo, he intentado ponerle en marcha a través de las principales etapas, sobre como configurar e instalar el servicio de SRM. Básicamente, si usted puede crear una base de datos y “apuntar” a esa base de datos, usted entonces puede instalar SRM. A este respecto, es muy similar a la instalación de VMware Update Manager. Recuerde que su mayor desafío con SRM está en, conseguir ver a través de la red de comunicaciones, el sitio de protección con el sitio recuperación y esto no solo se trata de una cuestión de IP y DNS. Existen posibles consideraciones de seguridad (firewall) que deben tenerse en cuenta también. Es ahí donde vamos en el próximo capítulo, las fases posteriores al período de configuración del producto SRM, que se inician en el vCenter del sitio protegido. En el siguiente capítulo veremos la configuración de “vinculación” de los dos sitios así como el mapeo de los inventarios y grupos de protección.

92

93
Capítulo 4: Configuración del Sitio de Protección

94
La vinculación de SRM del sitio de protección con el sitio de recuperación Una de las principales tareas llevadas a cabo en la primera configuración de los servidores SRM, es la vinculación del servidor SRM del sitio protegido con el servidor SRM del sitio de recuperación. Aquí es donde se configura una relación entre los dos sitios, y en realidad esta es la primera vez que indicamos quien es el sitio protegido y el sitio de recuperación. Al hacer esta configuración por primera, yo personalmente prefiero tener dos ventanas del cliente Vi abiertas, una para el vCenter del sitio de protección y otra para el vCenter del sitio de recuperación. De esta manera consigo controlar mejor el proceso de emparejamiento. Así se podrá ver, en tiempo real, el efecto del cambio en el sitio de protección sobre el sitio de recuperación.
Como usted puedo sospechar, el proceso de emparejamiento significa poner en comunicación el servidor de SRM del sitio de protección con el servidor SRM del sitio de recuperación para que así estos puedan compartir información. Si se fija detenidamente vera las direcciones IP de mis servidores SRM. Uno tiene la dirección IP 192.168.2.182 y el otro tiene la dirección IP 192.168.2.181. Las dos direcciones IP, están dentro de mi red de entorno de pruebas, pero en realidad sería más probable que los servidores SRM estuvieran en dos redes totalmente diferentes y dos lugares físicos totalmente diferentes. Después de todo, este es el significado de un plan DR/BC, verdad? Aunque, también es posible tener el mismo rango de IPs en diferentes ubicaciones geográficas. El concepto de estas redes se llama "stretched VLAN". Si se implementa este concepto de red puede llegar a simplificar, en gran medida, el proceso de emparejamiento, así como simplificar enormemente la configuración de

95
red de las máquinas virtuales cuando se ejecutan pruebas de planes de recuperación con SRM. Si usted nunca ha oído hablar del concepto de “stretched VLANs”, vale la pena que lo repase, ya que su uso facilita los planes DR/BC. Este tipo de configuración - stretched VLAN - como veremos más adelante, puede realmente reducir la carga administrativa al ejecutar planes de prueba o planes reales de DR. Este proceso de vinculación, a veces se le denomina "establecimiento de la reciprocidad"(Establishing Reciprocity). Actualmente, el proceso de emparejamiento es de uno-a-uno. Todavía no es posible crear emparejamientos con más de dos SRM y más de dos sitios. La estructura del producto actualmente impide vinculación de relaciones de muchos-a-muchos. La instalación del software SRM y vCenter sobre la misma instancia de Windows puede ahorrarle una licencia de Windows. Sin embargo, algunas personas podrían considerar este enfoque como un aumento en la dependencia del sistema de gestión de vCenter. Ciertamente hay una preocupación o ansiedad acerca de la creación de un escenario donde todos los "huevos están en una canasta". Si sigue este razonamiento a su extremo lógico, su servidor de administración tendrá que hacer de muchos roles, tales como:
• Servidor vCenter • Servidor Web Access • Servidor de Consolidación Guiadas • Servidor de Conversión (Converter Server) • Servidor de Actualizaciones (Update Manager Server)
Cuando conecte los dos sitios juntos, siempre inicie sesión en sitio protegido y desde aquí conéctese al sitio de recuperación. Este orden de conexión dictara la relación entre los dos servidores SRM.
1. Inicie sesión con el cliente Vi en el vCenter del servidor del sitio protegido 2. Haga clic en el icono Site Recovery 3. En la pestaña Summary del panel de Configuración de protección - haga clic en Configure al lado de Connetion Option

96
4. En el cuadro de diálogo, escriba el nombre del vCenter del sitio de recuperación
Advertencia: Al introducir el nombre del servidor de vCenter, utilice minúsculas. El nombre del servidor de vCenter debe ser exactamente igual al nombre que uso durante la instalación inicial del vCenter Además, aunque usted puede usar el nombre o la dirección IP durante el proceso de emparejamiento, sea coherente. No mezcle direcciones IP y nombres de dominio completo, ya que esto sólo confunde al SRM. Nota:

97
Como vimos anteriormente durante la instalación, a pesar de escribir el puerto 80 para conectarse al vCenter, parece ser que la comunicación es a través del puerto 443
Nota: De nuevo, si usted está usando uno de los certificados auto-generados que vienen con la instalación por defecto de vCenter, recibirá un cuadro de diálogo de advertencia sobre el certificado de seguridad
5. A continuación, especifique el nombre de usuario y contraseña del servidor vCenter del sitio de recuperación Nota: De nuevo, si usted está usando uno de los certificados auto-generados que vienen con la instalación por defecto de vCenter, recibirá un cuadro de diálogo de advertencia sobre el certificado de seguridad
Advertencia: Aunque estos dos cuadros de diálogo de advertencia parecen el mismo, son advertencias sobre servidores completamente diferentes – el servidor vCenter y el servidor SRM del sitio de recuperación.

98
6. En este punto, el asistente de SRM intentará completar las conexiones y un cuadro de diálogo le mostrará el progreso de dicha tarea
También verá una barra de progreso sobre la barra de tareas en el vCenter del sitio protegido
Al final del proceso, se le pedirá que se autentifique el cliente Vi del sitio de protección contra el sitio de recuperación. Si tiene dos clientes Vi abiertos al mismo tiempo en ambas sitos (protegido y recuperación), usted recibirá dos cuadros de diálogo
Una vez más, puede recibir una advertencia de seguridad si ha utilizado un certificado auto-generado por el vCenter

99
Nota: Al final de esta primera etapa debe comprobar que los dos sitios están marcados como conectados. La información tanto para el sitio local como para el sitio remoto, deberían aparecer en la pestaña Summary. Además podrás ver que hay una opción para romper el vínculo entre los dos servidores SRM.
Nota: El botón break es lo contrario al proceso de emparejamiento. Es difícil pensar en un caso de uso útil de esta opción. Supongo que quizás quiera en un futuro, romper el emparejamiento para crear una relación diferente. En un caso extremo, si ha tenido un verdadero desastre el sitio protegido, puede que se haya perdido irremediablemente. SUGERENCIA: Esta ventana también le pueden dar información útil acerca del estado de la falta de recursos entre la “pareja”. Esto puede significar también que tenga que modificar los parámetros por defecto que controla esta alerta, en el archivo vmware-dr.xml

100
Nota: A partir de ese momento cada vez que cargue el cliente Vi por primera vez, y haga clic en el icono Site Recovery Manager, se le pedirá un nombre de usuario y contraseña para el vCenter remoto. El mismo cuadro de diálogo aparece en el sitio de recuperación de SRM.
Configuración de los Array Managers El siguiente elemento esencial en la etapa posterior a la configuración de SRM, es habilitar el software de gestión de la cabina de almacenamiento. El Array Manager, que a menudo es sólo un front-end gráfico, proporcionara las variables al SRA. El SRA es a menudo sólo una colección de scripts que llevan a cabo tres tareas principales
• Comunicarse y autenticarse con el Array (Cabina de almacenamiento) • Descubrir que LUN se está replicando y seleccionar/crear una instantánea antes del ejecutar el test o failover • Trabajar con SRM para iniciar las pruebas, la “limpieza” después de la prueba, y desencadenar un failover verdadero
Es en esta parte, done usted informa al SRM que motor está utilizando para replicar sus máquinas virtuales desde el sitio de protección hacia el sitio de recuperación. En este proceso, el SRA “interroga” la cabina para descubrir las LUNs que se está replicando y habilita al SRM del sitio de recuperación hacer el “espejo" (mirror) de sus máquinas virtuales a la cabina del sitio de recuperación. Evidentemente, la configuración de cada cabina de almacenamiento varía según el proveedor. Aunque me gustaría mucho ser neutro en todo momento, no me es posible validar la configuración de cada cabina ya que sería muy costoso y llevaría mucho tiempo. Sin embargo, con el tiempo espero conseguir appliance virtuales o sistemas reales de almacenamiento para documentar el proceso. Como puede ver en pantalla, las tres interfaz de usuario son diferentes para cada proveedor de SRA.

101
Vale la pena señalar que algunos SRA tienen otros requerimientos de software o de licencias, por ejemplo:
• Falconstor SRA actualmente exige introducir una cadena de licencia durante la instalación • EMC SRDF requiere instalar la solución de “EMC Enabler” software antes de instalar el SRDF SRA • EMC MirrorView SRA necesita .NET 2.0, aunque el SRA MirrorView instalará este si usted no lo tiene instalado • 3Par SRA requiere instalar el “Infrom CLI” para Windows antes de instalar su SRA
Además, si nos fijamos en las imágenes de cada SRA que he incluido en esta guía, se puede ver que todos comparten dos cosas en común. En primer lugar, usted debe proporcionar una dirección IP o URL para comunicarse con el array o cabina de almacenamiento, y en segundo lugar, usted debe proporcionar las credenciales de usuario para autenticarse con esta. La mayoría de los SRA tendrá dos campos para dos direcciones IP, que normalmente se utilizan para el 1ª y 2ª controlador redundantes de almacenamiento, ya sea canal de fibra o iSCSI. Los proveedores de almacenamiento llaman a estos controladores de almacenamiento de una forma diferente. Así, si usted está familiarizado con NetApp, quizás el término "Storage Heads" es el que está acostumbrado o, si se trata de EMC Clarrion, usted este acostumbrado a usar el término "Storage Processor". Es evidente que para que el SRA funcione debe haber una dirección IP configurada en estos controladores de almacenamiento y debe ser accesible por el servidor SRM. Lefthand Networks SRA
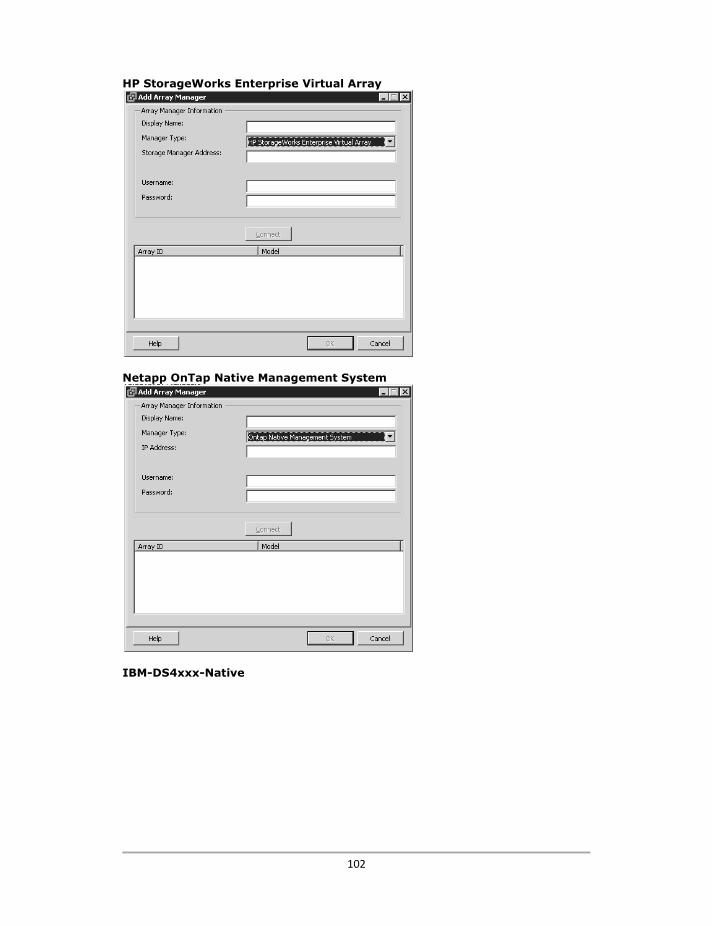
102
HP StorageWorks Enterprise Virtual Array
Netapp OnTap Native Management System
IBM-DS4xxx-Native

103
Dell Equallogics PS Series SRA
EMC Celerra iSCSI Native

104
EMC MirrorView
EMC Symmetrics Native SRA

105
Configuración de los Array Managers – LeftHand Networks SRA En este ejemplo, voy a explicarle la configuración de Lefthand Networks SRA. Con un sistema iSCSI el servidor SRM se comunicará con un iSCSI Target en el sitio protegido para recuperar la información de los DataStore y LUNs. Es necesario, por tanto, configurar una dirección IP válida para el servidor SRM o permitir el enrutamiento/ intra-VLAN si su servidor SRM y el VSA residen en diferentes redes. Este es uno de los retos al instalar el SRM y el vCenter sobre la misma instancia de Windows. Otra solución es configurar su servidor SRM con dos tarjetas de red, una para la comunicación general y la otra específicamente para la comunicación con el VSA. Si no tiene comunicación entre el SRA y el VSA, recibirá este mensaje de error.
Advertencia: Confirme que puede hacer ping a su destino o iSCSI Target desde el SRA en el sito protegido antes de comenzar esta parte de la configuración
1. Inicie sesión con el cliente Vi en el vCenter del sitio protegido 2. Haga clic en el icono Site Recovery 3. En la pestaña Summary, en el panel de configuración de protección, haga clic en el Configure al lado de Array Managers Option

106
4. En el cuadro de diálogo Protection Side Array Managers, haga clic en el botón Add
5. En el cuadro de diálogo Array Manager, escriba un nombre para este gestor como “Array Manager para el sitio Protegido” 6. Seleccione Lefthand Network SAN / iQ como el tipo de administrado 7. Escriba la dirección IP del VSA del sitio protegido en el campo SAN/iQ Manager IP1, en mi caso este es mi sistema vsa1.rtfm-ed.co.uk con la dirección IP 172.168.3.99

107
Nota: Si sólo tiene un manager en el sitio protegido (como es mi caso), escriba de nuevo el mismo nombre de host o dirección IP. Usted debe completar los dos campos, SAN/iQ Manager IP 1 y SAN/iQ Manager IP 2. 8. Introduzca el nombre de usuario y contraseña 9. Haga clic en el botón Connect Nota: Esto deberá conectar el servidor SRM con el VSA Manager y mostrar el nombre del grupo de gestión creado en el VSA
Nota: Utilizando una “coma” como separador, se pueden especificar más de dos SAN/iQ Managers 10. Haga clic en OK.

108
Nota: SRM comenzar a descubrir la cabina y los DataStore
Nota: En el cuadro de diálogo anterior se puede ver como el Array Manager ha descubierto mi única LUN/Volumen creada en VSA Lefthand Networks. Con fines de prueba, he creado una única LUN/volumen con formato VMFS donde alojare las máquinas virtuales. 11. Haga clic en Next IMPORTANTE: En la próxima etapa vamos a decir al SRA del sitio de recuperación, cual es la dirección IP/FQDN del Array Manager para el Target iSCSI del sitio de recuperación. Una vez más, el SRA del sitio de recuperación necesitará una dirección IP válida para conectarse a su target iSCSI al igual que el servidor SRA en el sitio protegido necesita una dirección IP válida para conectarse a su Target iSCSI. La configuración del cuadro de diálogo “Add Array Manager” para el SRA del sitio de recuperación es prácticamente el mismo.

109
Nota: A pesar de que estamos ejecutando el asistente del Array Manager desde el sitio protegido, en este momento en realidad estamos configurando el SRM del sitio de recuperación. 12. Haga clic en OK

110
Nota: Nota que el valor de LUN cont es 1. Esto es el valor que el VSA Lefthand Networks a dado a mi volumen llamado "virtualmachines". Si creara nuevos volúmenes replicados y los usara con VMware ESX, este contador incrementaría en consecuencia. Para ello tendría que usar el botón Rescan Arrays que vera al final de este asistente. 13. Haga clic en Next, revise la información del DataStore y haga clic en Finish

111
Nota: En cualquier momento que desee, puede volver a ejecutar este asistente para añadir nuevos arrays o para volver a re-escanear el array existente para forzar descubrir nuevos LUNs/volúmenes, haciendo clic en la opción de configuración en la consola de administración. Nota: Recuerde que para que los datastores aparezcan, estos deben estar en uso por una o más máquinas virtuales. Importante: Si se configuran los detalles de las direcciones IP en el sitio de protección así como la autentificación, se permitirá a los servidores SRM automatizar el proceso, el cual normalmente requiere la interacción del equipo de gestión de almacenamiento. Esto se utiliza específicamente en SRM cuando un plan de recuperación es probado. Como las HBAs de los ESX en el sitio de recuperación son re-escaneadas, el SRA permitirá de forma automática el acceso a los LUNs/volúmenes replicados para que la prueba se ejecute. Sin embargo, esta funcionalidad varía de una cabina de almacenamiento a otra. Por ejemplo con privilegios en una cabina de NetApp, permitirá la creación dinámica y destrucción de “FlexClones” (re-instantáneas). Sin embargo, alguien del equipo de almacenamiento ha de conceder acceso al grupo de volumen para que esto tenga éxito. Se podría pensar que este nivel de acceso a la capa de almacenamiento es algo más bien “político”. Sin embargo, en mis conversaciones con VMware y con personas que fueron los primeros en probar SRM, esto no siempre ha sido el caso. De hecho, muchos administradores de los equipos de almacenamiento estarían encantados de renunciar a este control de gestión de la capa de almacenamiento, si esto significa que tendrán menos

112
solicitudes de intervención desde los departamentos de servidores y virtualización. Verá muchos administradores de almacenamiento que comprensiblemente se irritan si la gente como nosotros les llama a todas horas para pedirles que lleven a cabo tareas rutinarias, como la creación de una instantánea y la inclusión de esta a un número de servidores ESX. El hecho de que nosotros, como los administradores de SRM, podamos hacerlo con seguridad, automáticamente y sin su ayuda, liberaría muchísimo al equipo de almacenamiento, los cuales dedicarían este tiempo a otras tareas quizás más importantes. Lamentablemente, algunas empresas, todavía no lo llegan a entender este sin explicarles antes cual es la plena competencia del SRA. Si hemos molestado al equipo de almacenamiento, ha sido debido, en gran medida, a la dificultad en encontrar “buenos” manuales de administración de las cabinas de los proveedores de almacenamiento. Esto ha dejado a muchos administradores de SRM y de almacenamiento “luchando” día y noche para encontrar los parámetros y requisitos necesarios para que el SRA funcione correctamente.
Configurar las asignaciones de Inventario La próxima parte en la configuración, es la configuración de asignaciones de inventario. Esto implica la asignación de resource pool, carpetas y redes virtuales del sitio de protección al sitio de recuperación. Esto es necesario ya que tenemos dos instalaciones de vCenter que no comparten una misma base de datos en común. Cuando su plan de recuperación se ejecute para la prueba o para un caso real, el servidor SRM en el sitio de recuperación tiene que saber sus preferencias acerca de cómo quiere que se “levanten” las maquinas virtuales que se están replicando. A pesar de que el sitio de recuperación tiene los archivos de las máquinas virtuales por medio de la replicación por cabina, los "metadatos" que constituyen el inventario del vCenter no se replican. Corresponde al administrador de SRM decidir cómo se manejan estos datos del vCenter. El administrador de SRM debe ser capaz de indicar qué resource pool, redes y carpetas van a utilizar las máquinas virtuales replicadas. Este proceso de asignación es opcional. Si lo desea, puede mapear manualmente cada máquina virtual al resource pool, carpeta y red, al crear los llamados "grupos de protección" (protección groups). El asistente para la "asignaciones de inventario ", sólo acelera este proceso y le permite configurar sus preferencias por defecto. Es posible hacer esta asignación máquina virtual por máquina virtual, sin embargo, esta es desde el punto de vista “administrativo”, una tarea laboriosa. Al tener que configurar manualmente cada máquina virtual a que red, carpeta y resource pool, debe utilizar en el sitio de recuperación, se tardaría mucho tiempo, incluso en un entorno con pocas máquinas virtuales. Más adelante en este libro, veremos la asignación de inventario manual como una forma de hacer frente a las máquinas virtuales que tienen una configuración más singular o complicada. En pocas palabras, vea las "asignaciones de inventario" como un método de tratar con la configuración de las máquinas virtuales como si fueran grupos, y los otros métodos, como si estuviéramos haciendo una asignación de usuarios individuales. Es perfectamente aceptable que las "asignaciones de inventarios" tengan este icono al lado de algunos de los objetos del inventario.

113
Después de todo, puede haber resource pools, carpetas y redes que necesitan ser incluidas en su plan de recuperación. Por ejemplo, máquinas virtuales de prueba y desarrollo no deberían de ser replicadas, y por tanto, el inventario de objetos que se utilizan para la gestión de estas maquinas no estarán configurados. Del mismo modo, es posible que usted tenga máquinas virtuales "locales" que no necesitan ser configuradas. Un buen ejemplo podría ser que su vCenter y su instancia de SQL podrían estar virtual izados. Por definición, estas máquinas virtuales de "infraestructura" no se replican al sitio de recuperación, porque ya tenemos duplicados estos servicios, ya que es parte de la arquitectura de SRM. Otros servicios específicos locales pueden ser los sistemas anti-virus, DNS, DHCP, Proxy, Servidores de impresión y, dependiendo de su estructura de servicios de directorio, los controladores de dominio de Active Directory. Por último, es posible que máquinas virtuales con servicios de despliegue - en mi caso UDA, no necesiten ser replicados en el sitio de recuperación, ya que no son muy críticos para el negocio. Aunque yo le sugeriría que considerara la dependencia que tiene de estas máquinas virtuales “auxiliares” en las operaciones de su día a día. En este punto, no vamos a indicar que máquinas virtuales se van a incluir en nuestro procedimiento de recuperación. Esto se hace en una etapa posterior, al crear en SRM los grupos de "protección". Nota: SRM emplea el término "Cálculo de Recursos" (compute rezurces) para referirse a clusters de servidores ESX y a los resource pools dentro de estos clusters
1. Inicie sesión con el cliente Vi en el vCenter del sitio protegido 2. Haga clic en el icono de Site Recovery 3. En la pestaña de Summary, en el panel de configuración de protección - haga clic Configure al lado de las opciones de Inventory Mappings

114
Nota: Esto sólo le llevará a la pestaña de Protection Groups nodo e Inventory Mappings. La columna llamada "Recovery Site Resource" la cual contiene "None Selected" simplemente significa que no hay aún ningún mapeo por defecto.
4. Haga doble clic en su preferencia de red virtual (en mi caso es el portgroup con nombre vlan11). En el subsiguiente cuadro de diálogo seleccione la red virtual en el sitio de recuperación
Nota:

115
Cuando usted ejecuta una prueba de "plan de recuperación", SRM mueve automáticamente las máquinas virtuales replicadas a una red "burbuja”, la cual las aísla completamente de la red interna utilizando un vSwitch. Esto evita posibles conflictos de direccionamiento IP y NetBIOS. Trate de ver esta "red burbuja” como un valor de seguridad que le permite que usted lleve a cabo planes de prueba con una garantía, para no generar así conflictos entre el sitio protegido y el sitio de recuperación. La configuración anterior sólo se utilizan en el caso de la activación de su plan de recuperación real. Si yo asigno la red de "producción" a la red "Interna” los usuarios no podrán conectarse a las máquinas virtuales en el sitio de recuperación. Nota: El tema de la red y DR puede ser más complejo de lo que usted piensa y depende mucho de cómo haya creado la red. Cuando usted empieza a arrancar máquinas virtuales en el sitio de recuperación, estas pueden estar en una red totalmente diferente y pueden requerir direcciones IP y DNS diferentes para permitir que los usuarios se conecten. La buena noticia es que SRM pueden controlar y automatizar este proceso. Una manera muy fácil de simplificar esto es mediante SRM y “strectched VLANs”, donde dos redes de dos lugares geográficamente diferentes “aparecen” en la misma VLAN o subred. Sin embargo, puede que no tenga la posibilidad de implementar “stretched VLANs” y amenos que esta técnica no está ya implantada, sería un cambio importante el tener que cambiar su configuración física. Vale la pena dejar claro que incluso si implementa stretched VLANs, es posible que se aún tenga que crear inventory mappings a causa de las diferencias de los port groups. Por ejemplo, puede haber una VLAN ID 101 en Nueva York y otra VLAN ID 101 en Chicago. Pero si el equipo administrativo en Nueva York, llama a los port groups en el switch virtual “NYC-101”, y el equipo administrativo en Chicago, llama a sus port groups “CHIC-101”, todavía usted tendrá que necesitar hacer el mapeo de port groups en la pestaña Inventory Mappings. Por último, en la esquina superior derecha de la pestaña “Inventory Mappings” hay dos opciones Refresh … y Remove… El uso de estas dos opciones en gran medida se explican por sí mismo. Nota: Una vez que usted entiende el principio de las asignaciones de inventario (inventory mappings), se convierte en una tarea muy tediosa de corregir manualmente el mapeo de los objetos en el vCenter del sitio protegido, con los objetos en el vCenter del sitio de recuperación, como por ejemplo:

116
Como puede ver, no he configurado ninguna asignación para mi red de prueba. Del mismo modo, no he creado ninguna relación entre mi red de infraestructuras (vlan10, resource pool o carpeta de máquinas virtuales. Además, en lugar de tener carpetas de máquinas virtuales llamadas “Primary & Secondary” en ambos sitios, voy a coger todas las máquinas virtuales del sitio de protección, y las volcare en una carpeta llamada "Recovery VMs" en el vCenter del sitio de recuperación. Aunque he hecho esto en este ejemplo, en realidad yo no lo recomendaría. Yo recomendaría la duplicación de la carpeta de recursos y estructura de grupos en el sitio de recuperación, de modo que coincida exactamente con el sitio protegido. Esto ofrece un mayor control y flexibilidad, sobre todo cuando usted comienza el proceso de recuperación o failback.
Creación de grupos de protección Los grupos de protección se utilizan cada vez que usted realiza una prueba de su plan de recuperación, o cuando se invoca un DR real. Los grupos de protección contienen una colección de máquinas virtuales que harán failover desde el sitio de protección hasta el sitio de recuperación. La relación de los grupos de protección con volúmenes VMFS, puede ser de uno a uno, es decir, un grupo de protección puede contener o apuntar a un volumen VMFS. Alternativamente, es posible que un grupo de protección pueda contener muchos volúmenes VMFS. Esto puede suceder cuando los archivos de una máquina virtual se distribuyen a través de muchos volúmenes VMFS para el rendimiento del disco o, cuando por razones de optimización de una máquina virtual, tiene una mezcla de discos virtuales y discos RDM asignados . En algunos aspectos, los grupo de protección de SRM podría estar estrechamente alineados con los grupos que cree en su cabina de almacenamiento. De hecho, si usted hace esto, estaría simplificando las capas de software en uso. Sin embargo, lo que realmente determina la pertenencia de un VMFS a un grupo de protección, es la forma en que los volúmenes VMFS son utilizados por las máquinas virtuales. Una parte importante del asistente para la creación de grupos de protección, es la selección de un destino "de posición" o placeholder en el sitio de recuperación – se trata de un volumen VMFS en el sitio de recuperación. Después de que el asistente

117
ha finalizado, SRM crea el archivo .VMX y otros archivos más pequeños que componen la máquina virtual, desde el sitio de protección al sitio de recuperación, usando el "marcador de posición" o placeholder seleccionado en el asistente. A continuación, los archivos .VMX son pre-registrados en el servidor ESX del sitio de recuperación. Este proceso de registro también asigna la máquina virtual en el resource pool por defecto y, en la carpeta y la red, tal como se establece en la sección “asignaciones de inventario”. Recuerde que sus verdaderas máquinas virtuales están en realidad siendo replicadas a un LUN/volumen en la cabina de almacenamiento del sitio de recuperación. Puede tratar estos "marcadores" o placeholders como un mero lugar de almacenamiento temporal que se utiliza sólo para completar el proceso de registro necesario de las máquinas virtuales, para que figuren en el inventario del vCenter del sitio de recuperación. A pesar de que estamos replicando nuestras máquinas virtuales desde el sitio de protección al sitio de recuperación, el archivo .VMX, contiene información específica del sitio, sobre todo en términos de creación de redes. La VLAN y la dirección IP utilizada en el sitio de recuperación, podrían diferir sustancialmente del sitio protegido. Si utilizáramos el archivo .VMX como este, en el volumen repicado, parte de su configuración sería nula (nombre del portgroup y VLAN, por ejemplo), pero algunas de sus configuraciones no cambiarían (cantidad de CPU y memoria ). El objetivo principal de marcador de posición de los archivos vmx, es que le ayudan a ver visualmente en el inventario del vCenter, donde residirán sus máquinas antes de ejecutar el plan de recuperación. Esto le permite confirmar por adelantado, si sus asignaciones de inventario son correctas. Si una máquina virtual no aparece en el inventario del sitio de recuperación, es una indicación clara de que no está siendo protegida. Esto ofrece al operador la oportunidad de corregir los problemas que haya, antes de la prueba de un plan de recuperación. Estas máquinas virtuales de posición (placeholder), a veces se denominan máquinas virtuales "sombra" (shadow). Puede que de vez en cuando vea la referencia de este término en los mensajes de error, por ejemplo, si salen mal los planes de recuperación vera: “Image for testing or recovery cannot be produced because the shadow group is currently being tested”.
SUGERENCIA:
Al crear su primer grupo de protección, quizás le gustaría tener el cliente de Vi abierto contra el vCenter del sitio de protección y también contra el vCenter del sitio de recuperación. Esto le permitirá ver, en tiempo real, “acontecimientos” que ocurren en ambos sistemas.
1. Inicie sesión con el cliente Vi en el vCenter del sitio protegido 2. Haga clic en el icono de Site Recovery 3. En la pestaña Summary, en el panel de Proctection Setup, haga clic en el enlace Create situado junto a las opciones de Protection Groups
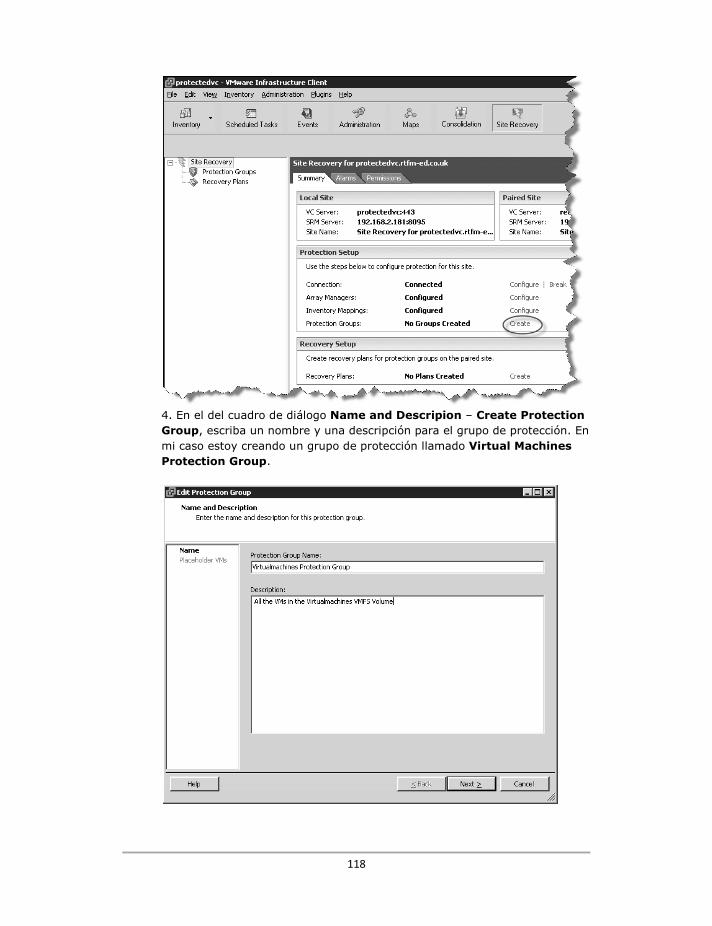
118
4. En el del cuadro de diálogo Name and Descripion – Create Protection Group, escriba un nombre y una descripción para el grupo de protección. En mi caso estoy creando un grupo de protección llamado Virtual Machines Protection Group.

119
5. Al hacer clic en Next, el Grupo de Protección del asistente le mostrará los datastores que han sido descubiertos por el Array Manager
6. A continuación, seleccione un DataStore para el "marcador de posición" o placeholder de sus máquinas virtuales. Para este placeholder puede utilizar almacenamiento local si así lo desea. También puede utilizar el almacenamiento remoto, pero si lo hace este debe ser un marcador de posición independiente, el cual no participa en ningún proceso de replicación.

120
Nota: Realmente no importa qué tipo de DataStore seleccione para el archivo .VMX placeholder. Incluso puede utilizar almacenamiento local – recuerde que sólo hay archivos "temporales" utilizados en el proceso del SRM. Sin embargo, almacenamiento local tal vez no sea una elección muy acertada. Si el servidor ESX se “cae”, este se pondrá en modo de mantenimiento o en estado desconectado, y SRM entonces no sería capaz de acceder a los archivos de posición durante la ejecución de un plan de recuperación. Sería mucho mejor utilizar una LUN/volumen de almacenamiento que este compartida entre todos los servidores ESX en el sitio de recuperación. El tamaño de esta LUN/Volumen de almacenamiento no tiene que ser grande ya que los archivos placeholder son archivos más pequeños y no contienen los discos virtuales. SUGERENCIA: Después de una prueba de un plan de recuperación, el failback o la recuperación (regresar al sitio principal) tiene una fase de limpieza manual que implica que el operador borre los archivos VMX "de posición" o placeholder. Así que podría ser útil recordar, dónde se encuentran estos archivos, o crear un lugar dedicado a ellos, en lugar de mezclarlos con los archivos verdaderos de las máquinas virtuales. Con frecuencia, a las personas les resulta difícil ver la diferencia en el vCenter entre los archivos de placeholder y los archivos reales de las máquinas virtuales. Es una buena práctica el uso de carpetas y nombres de resource pool que reflejen que estos "marcadores de posición" o placeholder de máquinas virtuales no son "reales". Sería muy útil ver en las siguientes versiones de SRM, un icono especial para indicar que son archivos de máquina virtual del SRM. Nota: Después de hacer clic en el botón Finalizar, tendrán lugar una serie de eventos. En primer lugar, en el vCenter del sitio de recuperación, verá la

121
barra de tareas indicando que el sistema está ocupado "protegiendo" a TODAS las máquinas virtuales que residen en el DataStore, incluidos en el grupo de protección
Mientras que en el vCenter del sitio de recuperación, se iniciará el proceso de registro de todas las maquinas virtuales en el lugar correcto en el inventario
También notara que estas máquinas virtuales "nuevas", están siendo colocadas en el grupo correcto de recursos y carpeta, y conectadas a la red correcta. En la pantalla siguiente vea cómo la maquina virtual ctx1, es mapeada a la red VLAN 51 en el sitio protegido, en lugar de la red VLAN11
Si “navega” por las ubicaciones de almacenamiento de estos "marcadores" o placeholder se podrá ver que son sólo archivos .VMX "ficticios". Como se puede ver en la pantalla siguiente, no hay disco virtual creado para estas máquinas virtuales "sombra".

122
En la vista de plantilla de máquinas virtuales, en el vCenter del sito de recuperación, puede ver como las Maquinas Virtuales han sido “almacenadas” en una sola carpeta.
que es lo contrario a la estructura del vCenter del sitio protegido

123
Nota: SRM sabe en qué red, carpeta y resource pool tiene que poner las maquinas virtuales de recuperación, por la configuración por defecto de las “asignaciones de inventario" que hemos especificado en la configuración anterior. Nota: Si usted crea una plantilla y la guardarla en un volumen VMFS replicado, está también será protegida. He probado esto apagando una máquina virtual y utilizando el método de “clonar a plantilla”. Después de ejecutar un plan de recuperación, he podido crear una nueva máquina virtual desde la platilla replicada. Esto aparece en el inventario del vCenter
Y en el grupo de protección

124
y también en mis planes de recuperación (que lo cubriremos en el próximo capítulo)
Observe cómo las plantillas no están encendidas cuando se ejecuta un plan de recuperación, ya que estas no pueden ser encendidas de todos modos sin que primero se conviertan de nuevo a una máquina virtual. Advertencia: La eliminación de los grupos de protección en el vCenter del sitio protegido, invierte el proceso de registro. Cuando usted elimina un grupo protegido, esto des-registra y destruye los ficheros placeholders que han sido creados en el sitio de recuperación. Esto no afecta al ciclo de replicación de las máquinas virtuales, el cual se rige por el software de replicación de su cabina. Tenga mucho cuidado con la supresión de los grupos de protección. Esta acción puede tener consecuencias imprevistas y no deseadas si están

125
"en uso" por un plan de recuperación. Este problema o peligro potencial está cubierto más adelante en este libro.
Fallos al proteger una máquina virtual Asignaciones de inventario malos? Ocasionalmente puede encontrarse con que al crear un grupo de protección, el proceso falla en registrar una o más máquinas virtuales en el sitio de recuperación. Esto es normalmente causado por un error en el proceso "Asignaciones de Inventario". El error es marcado en el sitio protegido con un signo de exclamación amarillo en el grupo de protección para las máquinas virtuales que no se registren.
Este error generalmente es causado porque, por defecto, la configuración de la máquina virtual está fuera de las "Asignaciones de Inventario " y por lo tanto, el grupo de protección no sabe cómo asignar las máquinas virtuales a la carpeta, resource pool o a la red correspondiente en el sitio de recuperación. He creado el inventario de asignaciones para la creación de redes, de la siguiente manera:
No he asignado ninguna asignación de inventario para vlan10. He considerado esta red como una red local que contiene máquinas virtuales locales que no requieren protección. Accidentalmente, la máquina virtual llamada fs-1 fue parcheada en esta red, y por lo tanto, no se configuro correctamente en el plan de recuperación. En el mundo real, esto podría haber sido un descuido, pero en mi caso el problema no fue mi máquina virtual, sino la mala configuración de las asignaciones de inventario. La máquina virtual no entra dentro del ámbito de asignaciones por defecto Otra hipótesis podría ser que el mapa de inventario se destina a manejar la configuración predeterminada cuando la regla es siempre X. Podría haber un número de máquinas virtuales dentro de un grupo de protección que tiene sus propios ajustes o configuración, después de todo, una “talla” única no sirve para todo. SRM puede permitir excepciones a dichas normas, cuando una máquina virtual tiene su propia configuración particular que se queda fuera del grupo, al igual que con los usuarios y grupos.

126
Si usted tiene este tipo de desajuste en la “asignación de inventario”, será usted quien decida el curso correcto de la acción para solucionarlo. Sólo usted puede decidir si la máquina virtual o la asignación de inventario tienen la culpa. Por lo tanto, puede resolver esto de diferentes maneras:
• Actualice la asignación de inventario, a fin de incluir los objetos que inicialmente ha pasado por alto • Corrija la configuración de la máquina virtual para que este dentro de la configuración por defecto de la asignación de inventario • Personalice la máquina virtual con su propio y única asignación de inventario. Esto no significa que usted puede tener normas (Asignación de Inventario) y excepciones a la regla (ajustes personalizados en maquinas virtuales).
La configuración de la máquina virtual previene la protección SRM no puede proteger a una máquina virtual si no pueden acceder a los dispositivos de esa máquina virtual, si no están disponibles en el sitio de recuperación. Un buen ejemplo de ello son los disquetes o las imágenes ISO No es un error, es un chico malo malo! Si usted puede perdonar a Monty Python en "Meaning of Life", puede empezar con el confuso signo de exclamación amarillo sobre un grupo de protección. Puede ser una indicación de que una nueva máquina virtual se ha creado y está cubierta por un grupo de protección. Como he dicho antes, simplemente creando una nueva máquina virtual en una LUN/volumen que se está replicando, no significa automáticamente que está este protegida e inscrita en su plan de recuperación. Voy a cubrir esto con más detalle cuando examinemos cómo SRM interactúa con un entorno de producción que está en constante cambio y evolución. Espero que con estos "errores" pueda empezar a ver el gran beneficio que ofrece la asignación de inventario. Recuerde que el mapa de inventario es opcional y si usted opta por no configurar esto en SRM al crear un grupo de protección, toda máquina virtual que no pueda ser registrada en el sito de recuperación, fallara. Esto crearía decenas o cientos de máquinas virtuales con el signo de exclamación amarillo y cada una tendría que ser re-mapeada a mano a una red, carpeta y resource pool. Y por Fin El último tipo de error tiene este aspecto en un grupo de protección
Usted se dará cuenta que las máquinas virtuales no se enumeran debajo de las máquinas virtuales en la pestaña de grupo de protección. Esto puede ocurrir si; los servidores ESX en el sitio de protección han perdido todo contacto con los

127
volúmenes VMFS cubiertos por el grupo de protección; el volumen VMFS ha sido destruido o que todas las maquinas virtuales han sido trasladadas a otro DataStore no cubierto por la replicación o por un grupo de protección de SRM.
Conclusión Como usted ha visto, una de las mayores dificultades con SRM en el período posterior a las etapas de configuración, es la “comunicación de red”. No sólo su vCenter/servidor SRM deben ser capaces de comunicarse unos con otros tanto en el sitio protegido como en el sitio de recuperación, sino que también el servidor SRM debe ser capaz de comunicarse con su Array Manager. En el mundo real, esto será un reto que sólo puede ser abordado por sofisticadas rutas de enrutamiento IP, comunicación intra-VLAN o simplemente mediante la configuración de su servidor SRM con dos tarjetas de red para hablar con ambas redes. Tal vez vale la pena decir que la comunicación que permitimos entre el SRM y la capa de almacenamiento, a través del SRA del vendedor, podría ser problemática para el “equipo de almacenamiento". Y es que, a través del Cliente Vi, estamos efectivamente gestionando la cabina de almacenamiento. Históricamente, esta ha sido una tarea puramente manual hecha por el “equipo de almacenamiento" (si es que tiene uno), y pueden reaccionar negativamente al nivel de derechos que el SRM/SRA necesita tener para que funcione, en el marco de una instalación por defecto. Esto también podría tener repercusiones negativas para los procedimientos de la gestión de cambios internos, utilizados para manejar las demandas de replicación de almacenamiento en la empresa u organización en el que usted trabaje. En mi investigación, he encontrado una gran diferencia en las actitudes de las empresas hacia este tema. Algunas empresas lo ven como obstáculos mayores. En otras empresas, pensaron que es un obstáculo pero que se puede superar siempre y cuando los administradores senior de la capa de almacenamiento acepten completamente la aplicación de SRM, en otras palabras, el equipo de almacenamiento se verá obligado a aceptar este cambio. En el extremo opuesto, las personas que tratan día a día con la administración del almacenamiento están muy agradecidas de reducir su carga de trabajo y señalaron que cuantas menos personas participen en el proceso de toma de decisiones, más rápido nuestras máquinas virtuales estarán online. La virtualización es una tecnología muy política y personalmente no veo ni creo que la automatización de sus procedimientos como DR (Desaster Recovery) sea menos política. Estamos hablando de una de las decisiones más grandes que una empresa puede tomar con su TI, la invocación de su plan de DR. Las consecuencias de que este plan falle es quizás más políticamente importante que un proyecto de virtualización vaya mal. Creo que es perfectamente posible, si usted trabaja en estrecha colaboración con su equipo de almacenamiento y su proveedor de almacenamiento, modificar los scripts del SRA para incluir la posibilidad de presentar manualmente el almacenamiento a los servidores ESX del sitio de recuperación, eludiendo así la política que esto introduce. Por supuesto, es totalmente imposible que yo pueda configurar todos y cada uno de los arrays de almacenamiento de los proveedor para mostrarle cómo se integran con VMware SRM, pero al menos espero haberte dado una idea de lo que ocurre en el nivel de almacenamiento con estas tecnologías. Lo que espero es que ahora tenga los conocimientos suficientes para comunicar sus necesidades al equipo de almacenamiento y también que comprenda mejor lo que

128
se está haciendo en la capa de almacenamiento, a todos los niveles, para que funcione. En el mundo real tendemos a vivir en “casillas”. Yo soy el especialista en servidores, yo soy el especialista de almacenamiento, yo soy el especialista de red, y con bastante frecuencia vivimos en la ignorancia de lo que cada especialista está haciendo. La ignorancia y el DR hacen una mezcla peligrosa. Por último, espero que pueda ver la importancia que el inventario de asignaciones y los grupos de protección tienen en el proceso de recuperación. Sin estos, un plan de recuperación no sabrá dónde poner sus máquinas virtuales en vCenter (carpeta, resource pool y red) y en segundo lugar tampoco sabrá en que LUN/volumen podrá encontrar los archivos de las máquinas virtuales. En el próximo capítulo vamos a ver la creación y ensayo de planes de recuperación. El capítulo 5 le pondrá en marcha y en funcionando y en el capítulo 6, trataremos los planes de recuperación a un nivel funcional. No se preocupe, cada vez está más cerca de presionar el botón que dice "prueba mi plan de recuperación"!

129

130
Capítulo 5: Configuración del sitio de Recuperación

131
Estamos muy cerca de ser capaces de ejecutar nuestra primera prueba básica de plan de contingencias. Estoy seguro de que está deseando de presionar el botón que pone a prueba la tolerancia a fallos (failover). Y quiero llegar a esa fase lo más rápidamente posible, para que pueda tener una idea clara de los componentes que conforman la lista de SRM. Me gustaría darle primero una idea general, antes de perderte con los detalles. Hasta el momento, toda nuestra atención ha estado en la configuración del vCenter del sitio de protección. Ahora vamos a cambiar el rumbo, para ver la configuración del vCetner de sitio de recuperación. La pieza fundamental es la creación de un plan de recuperación. Es probable que usted tenga múltiples planes de recuperación sobre la base de la posibilidad de diferentes desastres. Si usted pierde la totalidad de un sitio, el plan de recuperación sería muy diferente de un plan de recuperación invocado solo por la pérdida de una cabina de almacenamiento o por la pérdida de un conjunto de aplicaciones.
Creación de un plan de recuperación completo de sitio básico Nuestro primer plan va a incluir cada máquina virtual en el ámbito de nuestro grupo de protección, con poca o ninguna modificación. Una vez más, volveremos a crear un plan personalizado de recuperación en el próximo capítulo. Este es mi intento de llegar a la parte de prueba del producto tan pronto como sea posible, sin abrumarle demasiado con las personalizaciones de las máquinas virtuales. El plan de recuperación contiene muchas opciones y configuraciones:
• El grupo de protección que abarca el plan • La demora entre el encendido de una máquina virtual antes de otra basado en el servicio “Heartbeat” de las Herramientas VMware o un valor fijo en segundos • Control de la configuración de la red durante las pruebas de los planes • Suspender MV (maquinas virtuales) "locales" en el sitio de recuperación que no son criticas para el negocio, para liberar así más recursos para MV
1. Inicie sesión con el cliente Vi en el vCenter del sitio de recuperación 2. Haga clic en el icono Site Recovery 3. En la pestaña Summary, en el panel de Recovery Setup, haga clic en el enlace Create situado junto a la opción de Recovery Plans
4. En el cuadro de diálogo Create Recovery Plan – Recovery Plan Information escriba un nombre descriptivo y significativo y una descripción para el plan, como por ejemplo Complete Loss of Site Plan – Simple Test

132
5. En el cuadro de diálogo Create Recovery Plan – Protection Group, seleccione el grupo de protección, el cual está cubierto por el Plan de Recuperación

133
6. Haga clic en Next, y en el cuadro de diálogo Create Recovery Plan – Response Times, seleccione un valor en tiempo que piense es apropiado para encender las maquinas virtuales de recuperación
Nota: Estos dos valores de tiempo se unen. Por lo tanto, SRM esperara hasta que oiga la señal hearbeat desde las herramientas VMware (VMware Tools) y después añade 30 segundos de espera. El segundo valor 300 es el tiempo total que esperará por una respuesta de una máquina virtual antes de arrancar la próxima máquina virtual. Si SRM no recibe un hearbeat de las herramientas VMware, marcara esa máquina virtual como un problema en el plan, y pasara a la siguiente máquina virtual 7. Siguiente, en el cuadro de diálogo Create Recovery Plan – Configure Test Networks, establezca las opciones para manejar la creación de redes cuando se ejecute una prueba.

134
Nota: La opción llamada "auto" crea un switch "interno" (anteriormente conocido como vmnet ESX en 2.xx) llamado "burbuja". Esto asegura que no tendremos conflictos de IP o NetBIOS entre las máquinas virtuales del sitio protegido y el sitio de recuperación. Usted puede sobre-escribir esta configuración y mapear un vSwitch de su propia elección, pero tenga cuidado con la posibilidad de crear conflictos con las máquinas virtuales en producción. Nota importante sobre Auto: A simple vista, la función de auto suena como una buena idea. Evitara que ocurran conflictos basados en IP o nombre NetBIOS. Sin embargo, puede hacer parar la comunicación de dos máquinas virtuales en la prueba. He aquí un ejemplo. Digamos que tiene cuatro servidores ESX en un clúster DRS. Cuando las máquinas virtuales son encendidas, no tienen “control” sobre donde se ejecutarán esas maquinas virtuales. Estas “auto”máticamente se conectaran a un switch interno, lo que significa, que mientras las máquinas virtuales conectadas e ese vSwitch interno serán capaces de comunicarse entre sí , estas no podrá hablar con cualquier otra máquina virtual en cualquier otro servidor ESX del clúster. Las consecuencias de esto son claras. A pesar de nuestra capacidad para priorizar el encendido de las máquinas virtuales para resolver cualquier dependencia de servicio, esos servicios de red fallaran con el cumplimiento de las dependencias y, por lo tanto, las MV no se iniciaran correctamente. Actualmente no hay arreglo para este problema, excepto si se usa una estructura VLAN para aislar las máquinas virtuales de la red general. El problema puede arreglarse en futuras versiones con un concepto llamado "Cross-Host Network Fencing". Esto permitirá la comunicación cruzada entre vSwitches de un servidor ESX a otro. El concepto de network fencing

135
apareció primero hace algún tiempo en el producto de VMware Lab Manager, donde nos enfrentamos a un desafío similar a sus entornos de prueba - múltiples copias de máquinas virtuales corriendo en la misma red física. En esencia, network fencing es un despliegue muy sofisticado y automatizado de Network Address Translation (NAT) con DHCP. Esto permite que todas las máquinas virtuales puedan preservar la configuración IP original, y que aún se comuniquen unos con otros. Incluso con esta opción, aún habría algunas cuestiones por resolver, por ejemplo, algunos protocolos como DCOM no funcionan con network fencing. Otra alternativa al "Cross-Host Network Fencing" podría ser la aplicación de pVLAN o VLANs privadas. Desafortunadamente, las pVLANs están fuera del alcance de este libro. Si desea obtener más información, en este link puede encontrar más información sobre cómo funcionan: Private VLANS - A look at Cisco's implementation of Private Virtual LANs (PVLANs) http://www.cramsession.com/articles/get-article.asp?aid=12 Por el momento, la función "auto" en el asistente del plan de Recuperación, es la mejor opción a considerar como un "valor de seguridad", el cual le permite probar un plan sin temor de generar un conflicto en el IP o nombre NetBIOS en las máquinas virtuales. Nota: En ocasiones, he podido ver que el campo "DataCenter" está en blanco. Esto parece ser un error de diseño el cual ya ha sido arreglado en la versión 1.0,1 de SRM. 8. Por último, usted puede suspender la MV en el sitio de recuperación para liberar recursos de CPU y memoria en el cuadro de diálogo Create Recovery Plan – Suspend Local Virtual Machines. En mi caso, las MV bajo Test & Dev se suspenderán

136
9. Haga clic en Finish Nota: Al igual que con los grupos de protección, los planes de recuperación puede ser mucho más sofisticado que el plan que acabo de crear. Volveré con los planes de recuperación en el capítulo 8.
Pruebas de configuración de almacenamiento en el sitio de recuperación Ahora sí que estoy seguro que estará deseando de presionar el botón verde que dice "SRM Test".
Pero antes de hacerlo, si desea que sus pruebas funcionen correctamente, vale la pena confirmar que los servidores ESX, en el sitio de recuperación, pueden acceder a la cabina de almacenamiento del sitio de recuperación. Anteriormente, cuando estuvimos configurando el sitio de producción, nos centramos en asegurarnos que los servidores ESX del sitio producción tenían acceso a los volúmenes VMFS. Las mismas consideraciones también deben ser tomadas en cuenta para el sitio de recuperación . Podría ser una buena práctica asegurarse de que los servidores ESX, en el sitio de recuperación, tienen visibilidad de la cabina, especialmente si usted está utilizando una cabina iSCSI, donde una post-configuración de los servidores ESX es necesaria para permitir el acceso de estos a la cabina de almacenamiento. Usted incluso puede no ser capaz de permitir manualmente a los servidores ESX, estar en el sitio de recuperación durante la ejecución del plan de recuperación. Por ejemplo, con el

SRA de Lefthand Networks segrupos de autenticación requLefthand Networks sabe cómporque le hemos dado la direconfiguración del Array Manaotros sistemas de gestión denecesitar crear grupos de geacceso a los servidores ESX a los servidores ESX. Este nivel de automatizaciónproveedor a otro. Por ejemplnecesitar usar "enmascaramservidores ESX del sitio de re(también conocido como volurecovery group), que contienarchivo “readme” que muchafuncionalidad. Además, muchrendimiento de E/S, que creapresentan la instantánea a lola prueba, normalmente se eNetApp y su tecnología FlexCmuestra lo que ocurre en la cprueba de un plan de recupe
Lo principal aquí es que todoservidores ESX, en el sitio dealmacenamiento que incluyeSRA del vendedor del almacealmacenamiento para crear uencargara de presentar la insindica en el diagrama con unejecutan, su sistema de prodrecuperación. En definitiva, lperjudica los patrones habituservidores ESX, en el sitio deréplica de volumen marcada
137
e creará automáticamente la lista de volúmeueridos para presentar la última instantánea
mo hacerlo, ya que es uno de sus principales ección IP y las credenciales de usuario duranager en sitio protegido. Esto puede no ser ele almacenamiento de otros proveedores. Usstión en la cabina de almacenamiento y perpara que SRM presente las LUNs/Volúmenes
varía de una cabina de almacenamiento delo, con su cabina de almacenamiento usted iento LUN" (LUN masking), para conceder a ecuperación acceso al grupo de almacenamiumen group, contingency group, consistencyne la réplica o instantánea. Por eso vale la pas veces viene con el SRA para confirma su hos proveedores de almacenamiento tienen an instantáneas sobre la marcha para la pruos servidores ESX en el sitio de recuperaciónelimina esta instantánea temporal, como es Clone. A continuación se muestra un diagramcapa de almacenamiento cuando ejecutamo
eración.
o lo que se necesita configurar en la cabina ee recuperación, tienen que tener acceso a lon las LUNs replicadas. Cuando la prueba se enamiento enviará una instrucción a la cabinuna instantánea sobre la marcha. Asimismo stantánea de la cabina a los servidores ESX
na línea). Esto significa que cuando las pruebducción está todavía replicando los cambios a ejecución de las pruebas es un proceso di
uales de la replicación que ha configurado, pe recuperación, se les presenta una instantácomo read-write (lectura y escritura), mien
enes y . El VSA funciones y
nte la caso con
sted puede rmitir s replicadas
e un puede los ento y group, ena leer el
tan buen ueba y n. Al final de el caso de
ma que os una
es que los os grupos de ejecuta, el
na de el SRA se (esto se
bas se al sitio de screto y no
porque a los nea de la tras que el

138
volumen replicado es marcado como read-only (sólo lectura) y todavía sigue recibiendo bloques de actualizaciones desde la cabina de almacenamiento del sitio protegido. Nota: El VSA Lefthand Networks funciona con un programa de instantáneas y no crea instantáneas sobre la marcha. En lugar de esto, presenta a los servidores ESX, del sitio de recuperación, la última instantánea creada en el ciclo. Como he venido utilizando el VSA de Lefthand Networks a lo largo de este libro, voy a usar este como un ejemplo para la concesión de acceso a la LUN de prueba de la cabina, antes de proceder a la ejecución de una prueba. Esto es simplemente una precaución para confirmar que hemos configurado correctamente los servidores ESX para que se comuniquen con la cabina de almacenamiento. No es un requisito. Crear un volumen de prueba Antes de dar a nuestros servidores ESX, en el sitio de recuperación, acceso a mis volúmenes replicados, quiero confirmar que se pueden comunicar con mi segundo VSA. Para ello voy a crear una LUN en blanco y darles acceso. Una vez terminado, los servidores ESX verán el volumen de “prueba”. Después modificare la lista de volumen y les concederé acceso a una de las instantáneas.
1. Abra el Lefthand Networks Centralized Management Console 2. Seleccione el Recovery Management Group e inicie sesión 3. Expanda Recovery_Cluster y Volumes 4. Haga clic en Volúmenes y elija New Volumen
5. En el cuadro de diálogo New Volume, escriba un nombre como TestVolume 6. Escriba en un tamaño de volumen asegurándose que es más de 2 GB de tamaño

139
Nota: A pesar de que no vamos a formatear esta LUN, ESX no puede formatear un volumen que es inferior a los 2GB de tamaño 7. Haga clic en OK
Creando una lista de Volumen 1. Seleccione el RecoveryManagementGroup 2. En la pestaña de la parte derecha – elija la pestaña Volumen List 3. Haga clic en el Volume List Task y seleccione New Volume List 4. Escriba un nombre para la lista de volumen como por ejemplo: TestVolume@recovery_location 5. Y continuación haga clic en el botón Add, seleccione el volumen TestVolume y asegúrese que el nivel de permisos es Read/Write Access

140
6. Haga clic en OK
Creación de grupos de autenticación y ajuste del IQN Los grupos de autenticación son objetos en Lefthand Networks que contienen los parámetros que permiten a un servidor ESX el acceso a la lista de volumen. Deben de contener un valor válido IQN y, opcionalmente, la configuración de la autenticación CHAP.
1. El RecoveryManagementGroup 2. En las pestañas de la parte derecha, elija la pestaña Authentication Groups 3. Haga click en Authentication Group Task, y New Authentication Group 4. Establezca un nombre descriptivo para el Authentication Group como: esx3.rtfm-ed.co.uk 5. Seleccione desde la lista desplegable de Volume List, el volumen de la lista que ha creado anteriormente, en mi caso TestVolume@recovery_location 6. Bajo "Authenticación", haga clic dentro del Initiator Node Name, y escriba su IQN como iqn.2001-09.uk.co.rtfm-ed: esx3
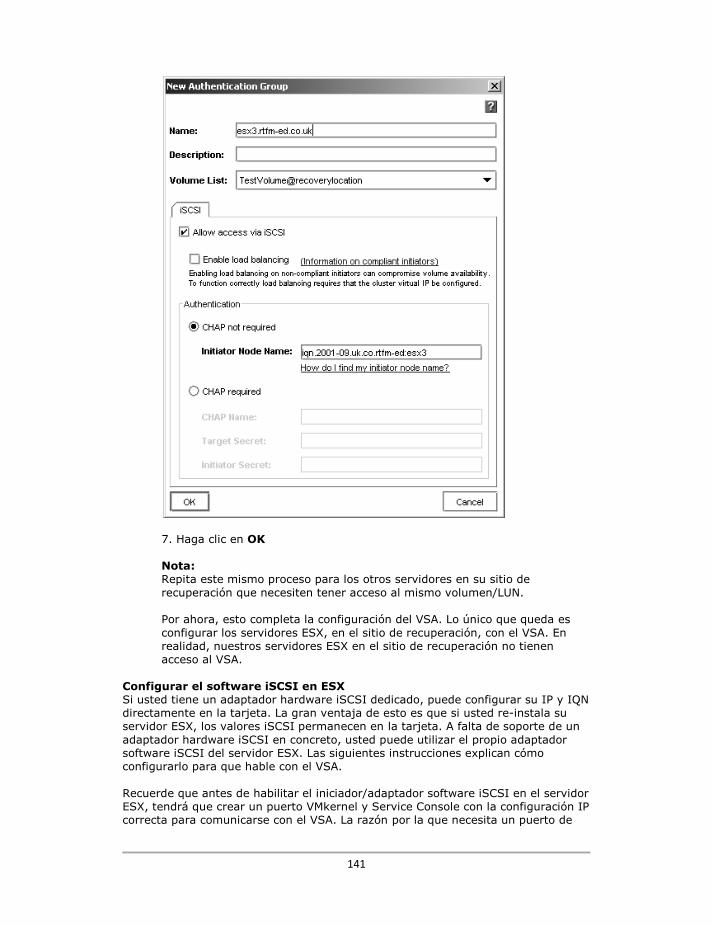
141
7. Haga clic en OK Nota: Repita este mismo proceso para los otros servidores en su sitio de recuperación que necesiten tener acceso al mismo volumen/LUN. Por ahora, esto completa la configuración del VSA. Lo único que queda es configurar los servidores ESX, en el sitio de recuperación, con el VSA. En realidad, nuestros servidores ESX en el sitio de recuperación no tienen acceso al VSA.
Configurar el software iSCSI en ESX Si usted tiene un adaptador hardware iSCSI dedicado, puede configurar su IP y IQN directamente en la tarjeta. La gran ventaja de esto es que si usted re-instala su servidor ESX, los valores iSCSI permanecen en la tarjeta. A falta de soporte de un adaptador hardware iSCSI en concreto, usted puede utilizar el propio adaptador software iSCSI del servidor ESX. Las siguientes instrucciones explican cómo configurarlo para que hable con el VSA. Recuerde que antes de habilitar el iniciador/adaptador software iSCSI en el servidor ESX, tendrá que crear un puerto VMkernel y Service Console con la configuración IP correcta para comunicarse con el VSA. La razón por la que necesita un puerto de

142
“Service Console”, es que, mientras la principal E/S es dirigida por el puerto VMkernel y su pila de configuración IP, la parte del descubrimiento de volúmenes/LUN (SendTargets) y autenticación CHAP se hace a través del puerto de Service Console. Por lo tanto el VMkernel y el Service Console necesitan tener acceso. Esto no aplica para el caso de ESX3i, donde sólo un puerto VMkernel es necesario. El siguiente diagrama muestra la configuración de mi esx1 y esx2. Observe que el vSwitch tiene dos tarjetas para la tolerancia a fallos.
Antes de proceder a la configuración del iniciador/adaptador software de VMware, confirme que puede comunicarse con el VSA mediante una simple prueba de ping. Habilitar el iniciador iSCSI
1. Seleccione el servidor ESX, y vaya a la pestaña Configuration 2. Seleccione Security Profile, en la pestaña de Software 3. Haga clic en Properties ... 4. En el cuadro de diálogo abra el puerto TCP (3260) para el Software de cliente iSCSI
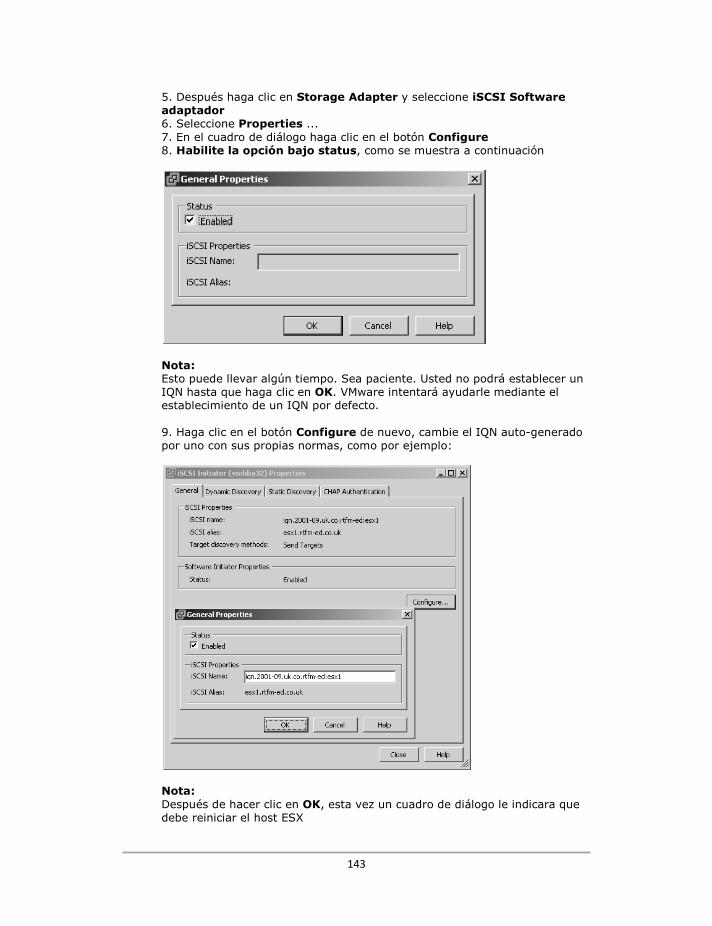
143
5. Después haga clic en Storage Adapter y seleccione iSCSI Software adaptador 6. Seleccione Properties ... 7. En el cuadro de diálogo haga clic en el botón Configure 8. Habilite la opción bajo status, como se muestra a continuación
Nota: Esto puede llevar algún tiempo. Sea paciente. Usted no podrá establecer un IQN hasta que haga clic en OK. VMware intentará ayudarle mediante el establecimiento de un IQN por defecto. 9. Haga clic en el botón Configure de nuevo, cambie el IQN auto-generado por uno con sus propias normas, como por ejemplo:
Nota: Después de hacer clic en OK, esta vez un cuadro de diálogo le indicara que debe reiniciar el host ESX

144
Aplazaremos el reinicio hasta que terminemos completamente 10. A continuación, seleccione la pestaña Dynamic Discovery y haga clic en el botón Add 11. Escriba la dirección IP del VSA en su Recovery_Mangement_Group. En mi caso es 172.168.3.98
Nota: “Static discovery” es sólo compatible con los iniciadores hardware. La autenticación CHAP es opcional y no la he configurado en este libro. 12. Haga clic en OK Nota: Esto puede llevar algún tiempo también. 13. A continuación, reinicie el servidor ESX Nota: Si no reinicia el servidor ESX, verá una advertencia en la pestaña Summary del servidor ESX.

145
Nota: Después del reinicio, usted debería ser capaz de ver que el servidor ESX puede ver el pequeño volumen “TestVolume” creado anteriormente. Si no es así, debe revisar y solucionar los problemas de su configuración hasta que pueda ver el volumen. La pantalla siguiente del servidor ESX y de la consola de gestión del VSA muestran que la conexión tuvo éxito.
Descripción: Primer Plan de Recuperación de prueba Si todo transcurre según lo planeado, usted debe ser capaz de ejecutar este plan de recuperación de base que hemos creado y ver que las maquinas virtuales en el sitio recuperación se han arrancado. Un gran número de eventos ocurren en este punto. Si tiene algún tipo de software que graba los resultados de la pantalla, como HyperCam o Camtasia, puede que incluso quiera grabar los eventos de modo que pueda reproducirlos.

146
Si desea ver un vídeo de la prueba puede ver este: http://www.josemariagonzalez.es/srm.html ¿Qué entendemos por "prueba"? Antes de que realmente "probemos" nuestro plan de recuperación, creo que debemos discutir lo que constituye realmente una prueba de su plan DR. En muchos aspectos, el botón de "prueba" en SRM está probando que el software SRM funciona y que su “SRM Plan de Recuperación” funciona como se esperaba. Para muchas organizaciones, una verdadera prueba sería una prueba “completa” del plan de recuperación, lo que significa, literalmente presionar el botón rojo y hacer un failover del sitio protegido al sitio de recuperación. Piense en esto de esta forma. Si usted tiene un sistema de SAI (sistema alimentación ininterrumpida) - UPS en Ingles - instalado en algunos de los servidores, podría hacer todo tipo de pruebas de software del sistema de gestión de energía, pero no sabrá realmente si el sistema de SAI funciona como se espera de él hasta que retire el cable de alimentación del servidor. Con lo que si tenemos en cuenta esta posibilidad, no es insólito que las grandes empresas ejecuten planes de DR completos hasta dos veces al año. Esto le permite identificar fallos en el plan para actualizar estos y, en consecuencia, mantener también al equipo encargado de controlar el plan DR al día con los procedimientos y acontecimientos inesperados que puedan aparecer y, que de hecho así ocurre. En resumen, haciendo clic en el botón de prueba de SRM, no prueba ni garantiza que las funciones de negocio de TI seguirán funcionando después de un desastre. ¿Qué sucede durante una prueba del plan de recuperación? Hay un número significativo de cambios que tienen lugar en el sitio de recuperación cuando se ejecuta una prueba. Esto es, a vista de pájaro, un resumen del proceso
• La prueba comienza • Las HBAs de los ESX hacen un re-escaneo para que puedan ver el almacenamiento replicado • Replica las MV registradas • SRM pone en modo “suspensión” las MV marcadas como no “necesarias” • Antes de que las MV son arrancadas, un switch virtual interno es creado para evitar conflictos de IP y NetBIOS • Una vez que todas las MV están arrancadas, la prueba se pausa • El administrador de SRM puede revisar las conclusiones del resultado de la prueba • El Operador hace clic en el mensaje Continue para seguir con el ensayo del plan de recuperación • Apaga y limpia las MV del sitio de recuperación • Reanuda las máquinas virtuales suspendidas • Los ESX re-escanean de nuevo el almacenamiento para eliminar las referencias a las instantáneas presentadas durante la prueba
Ahora el proceso con más detalle
• El servidor ESX ejecuta el proceso "Prepare Storage for Test" que implica
• ESX HBAs (Fibre-Channel, iSCSI, iSCSI software) son re-escaneadas • El ESX descubre el volumen VMFS que contiene las MV replicadas desde el sitio protegido al sito de recuperación • Los servidores ESX hacen un “refresh” para ver los volúmenes VMFS

147
• El volumen VMFS replicado del ESX es re-escrito con una firma (resignatured) y se le asignará un nombre de volumen como "snap- nnnnnnn-virtualmachines" donde “virtualmachines”, en mi caso, es el nombre original de volumen VMFS. A continuación, el nombre original VMFS es restaurado.
Antes ...
Después …

148
Nota: Este cambio de nombre de volúmenes VMFS ocurría por defecto en la versión Beta y versiones Release Candidate del SRM. Sin embargo, con la nueva versión esto ha cambiado. Ya no se cambia el nombre del volumen VMFS por defecto. Esto probablemente se ha cambiado para poner fin a un error que describí anteriormente en este capítulo. Si desea volver a habilitar el cambio del nombre de los volúmenes VMFS, puede hacerlo editando el archivo XML de configuración de VMware SRM en el sitio de recuperación. Busque en el directorio “C:\Program Files\Site Recovery Manager\Config” el archivo vmware-dr.xml. Modifique la línea: <fixRecoveredDatastoreNames>false</ fixRecoveredDatastoreNames> a <fixRecoveredDatastoreNames>true</ fixRecoveredDatastoreNames> • Para permitir el acceso a las LUN/Volúmenes, el SRA automáticamente permite el acceso a las LUNs/Volúmenes replicadas a los servidores ESX del sitio de recuperación. En el caso del VSA Lefthand Networks, este crea dos nuevos grupos de autenticación en el grupo de gestión de la recuperación, en este caso, llamados SRM_AG_1, y SRM_AG2 para cada uno de mis dos servidores ESX.

149
• “Registration & Unregistered” de las máquinas virtuales
• Las MVs son de-registradas del inventario del vCenter • Las MVs replicadas son registradas en el inventario • Las MVs son configuradas
• Las máquinas virtuales marcadas para la “suspensión”, son suspendidas

150
• Las máquinas virtuales son encendidas (Power on)
• Los servidores ESX crean un vSwitch llamado “testBubble-1 vswitch” • El vswitch prueba tiene un portgroup llamado “testBubble-1 group” • Las máquinas virtuales son re-configuradas para utilizar el “testBubble group”
Advertencia: Ocasionalmente, cuando la prueba se cuelga o falla por alguna razón, he visto que la fase de limpieza también falla. Este error falla

151
posteriormente al quitar el vSwitch y puerto grupo. Es recomendable eliminarlos manualmente, una vez que la prueba haya terminado. Si se deja, puede crear un mensaje de error la próxima vez que el Plan de Recuperación se pruebe.
• Siga el progreso de su plan
• Al seleccionar el plan y después Recovery Steps, usted puede ver el progreso del plan • Los errores se marca en rojo • Los “éxitos” se marcan en verde • Los procesos activos están marcados en rojo con un valor porcentual (%) de lo que se ha completado
Practica: Primer Plan de Recuperación de prueba 1. Inicie sesión con el cliente Vi en el vCenter del sitio de recuperación 2. Haga clic en el icono Site Recovery 3. Abra el icono Recovery Plans 4. Seleccione su plan, en mi caso se llama Complete Loss of Site Plan - Simple Test

152
5. Haga click en Test Recovery Plan ADVERTENCIA: No haga clic en Run Recovery Plan. Esto invocaría un plan DR completo. 6. Confirme la advertencia del cuadro de diálogo
Nota: En este punto aparece un cuadro de diálogo
y el icono de plan de recuperación cambiara, lo que indica que un plan de recuperación está en proceso.
Además, en la barra de tareas verá que los cambios ocurren
• Una vez que todos las MVs están encendidas, el proceso se detendrá en el 54% aproximadamente, y el icono Recovery Plan cambiará a un "icono de Información"
Este icono por lo general indica que un evento ha tenido lugar. Los mensajes se pueden ver en la pestaña de Recovery Step de un Plan de Recuperación. La pestaña de Recovery Steps también le permite ver el proceso que se describe en detalle al principio de esta sección

153
• Haga clic en la opción Continue, cuando usted lo desee
Controlando & Solución de problemas en planes de recuperación Pausar, reanudar y detener los planes Usted puede controlar manualmente el progreso de la prueba, con los iconos de la barra de botones.
Si decide interrumpir o detener la prueba de un Plan de Recuperación, el icono cambia en consecuencia
Una prueba puede ser cancelada por SRM si detecta un error grave como la incapacidad para acceder a la LUN/ instantánea replicada o si SRM cree que otra prueba está en marcha o se ha “colgado”. La pantalla de abajo muestra esta situación:
Nota:

154
Este error ocurre, a mí me pasa nueve de cada diez veces, al parecer por un problema con el software de la pila iSCSI en el servidor ESX. He descubierto que habilitando y deshabilitando el software iSCSI, seguido por un re-escaneado de la HBA puede arreglar este problema: esxcfg-swiscsi –d esxcfg-swiscsi –e esxcfg-rescan vmhba32 Advertencia: La cancelación de la prueba manualmente, tendrá consecuencias si no se permitir que el sistema complete la operación. Puede dejar SRM en un estado de “pendiente” con lo que creerá que la prueba aún en marcha, cuando en realidad se ha cancelado. Error: Fase de limpieza del plan La fase de limpieza y restablecimiento del plan de prueba no siempre para automáticamente el acceso a las LUN/Volúmenes replicados. Mi experiencia con el uso de SRM, es que no es inusual ver las LUN/volumen replicados en el datastores del servidor ESX después que una prueba ha terminado. Por supuesto, lo que puede suceder es que entre una prueba y otra se cree una nueva instantánea. Por defecto, la mayoría de los SRAs siempre utilizan por defecto las instantáneas más recientes. Sin embargo, algunos SRAs no deniegan el acceso a la instantánea después de que la prueba ha terminado. Esto puede conducir a una situación en la que el volumen VMFS sigue siendo visible para el ESX después de que la prueba se ha completado. Pase lo que pase, por defecto, SRM siempre prefiere utilizar la última instantánea. Esto puede causar una alerta si usted intenta ejecutar el plan de prueba varias veces. También la alerta es causada por un segundo intento de cambio de nombre del volumen y resignature. El resignature se llevara a cabo pero el cambio de nombre fallara porque puede existir un volumen VMFS con el mismo nombre de una prueba de plan anterior. Se debería de hacer un resignature de AMBOS volúmenes y cambiar el nombre del más reciente. Nota: Este error sólo puede ocurrir si habilita el proceso de cambio de nombre del DataStore en el archivo vmware-dr.xml, como he indicado anteriormente en este capítulo. Esta imagen muestra el mensaje de error:
y esta pantalla, de la vista de datastores en el ESX, muestra el efecto

155
Si esto sucede, las máquinas virtuales en el sitio de recuperación, apuntaran al volumen VMFS el cual tiene el nombre “snap-nnnnnnn-virtualmachines” que es la instantánea más reciente. En este caso, la máquina virtual llamada FS-1 esta "apuntando" al volumen de la instantánea, en lugar del volumen virtualmachines más antiguo que se creó en la prueba anterior. Cuando se complete la segunda prueba, usted encontrara que no sólo tienen el nombre de la instantánea más antigua, sino que también la segunda presentación de la instantánea ha fallado al ser renombrada.
La causa real de esto es bastante difícil de explicar, ya que depende del momento en que el plan de prueba se ha ejecutado y del ciclo de replicación adoptada por la cabina de almacenamiento. El error se produce si SRM falla manualmente a hacer un resignature de ambos volúmenes. Es fácil de solucionar este problema: cambie el nombre de su volumen VMFS antiguo a algo como "test1-virtualmachines". Esto debería permitir que la instantánea adicional se presente sin la molestia de cambiar el nombre. Error: Perdida de la configuración del grupo de protección De vez en cuando, he visto que los planes de recuperación pierden la “conciencia” de la configuración del almacenamiento. Normalmente esto es causado porque un

156
administrador de SRM borra el grupo de protección en el sitio protección. El plan de recuperación se convertirá en "orphaned" de la configuración de almacenamiento en el otro lugar y no sabrá cómo ponerse en contacto con la cabina de almacenamiento para solicitar el acceso a los Volúmenes/LUNS replicados. Lo gracioso de esto es que el Recovery Steps marca como "éxito" el resultado, pero las máquinas virtuales en el sitio de recuperación nunca se encienden. El siguiente cuadro de diálogo muestra este error - nota de cómo no hay ningún símbolo + al lado del paso 2. Prepare Storage
Mientras que un plan de recuperación, que sabe cómo comunicarse con el almacenamiento, normalmente tendría un símbolo + al lado del Paso 1, como se muestra en la pantalla de abajo.
La manera de solucionar este problema es volver a configurar el plan de recuperación y asegurarse de que puede ver los grupos de protección Haga clic derecho en cada Recovery Plan Seleccione Edit Haga clic en Next para aceptar el nombre y la descripción del plan actual Asegúrese de que marca con la protección de los grupos afectados

157
Haga clic en Next, y en el cuadro de diálogo Create Recovery Plan – Response Times, seleccione un valor de tiempo que usted cree que es apropiado para el encendido de las máquinas virtuales de recuperación Al lado del cuadro de dialogo Create Recovery Plan – Configure Test Networks, establezca las opciones para manejar la creación de redes cuando se ejecuta una prueba. Por último, usted puede suspender las máquinas virtuales en el sitio de recuperación para liberar recursos de CPU y memoria en el cuadro de diálogo Create Recovery Plan – Suspend Local Virtual Machines. En mi caso llamado Test & Dev, las MVs se suspenderán Haga clic en Finish Error: Obtener Ayuda Adicional Me he dado cuenta que si deja que pase el ratón sobre el texto de error en rojo, con frecuencia se puede ver más información del error.

158
Aquí el problema fue causado por la falta de espacio en disco para almacenar una instantánea remota y, en consecuencia, no puede encontrar la instantánea remota para volumen primario. Además, si exporta los resultados de su plan, usted puede cortar y pegar este mensaje de error y enviar la información en un correo electrónico a sus amigos de almacenamiento quienes arreglaran todos sus problemas y harán que su dolor de cabeza desaparezca. Al menos, esa es la teoría, a menos que usted sea el encargado de la capa de almacenamiento y en ese caso es su problema! Error: Non-fatal error information reported during execution of array integration script: testFailover Output: "C:\Program Files\VMware\VMware Site Recovery Manager\/scripts/SAN/LeftHand Networks/jre/bin/java" -cp "C:\Program Files\VMware\VMware Site Recovery Manager\/scripts/SAN/LeftHand Networks/UI.jar" com.lefthandnetworks.commandline.Srm.Srm < "C:\Program Files\VMware\VMware Site Recovery Manager\/scripts/SAN/LeftHand Networks/XMLinput.xml"" DELETE: The writable space on snapshot named

159
"virtualmachines_RS_Sch_1_Rmt.593" was deleted, continuing... NOTE: Had this been a real failover the remote parent volume named "replica_of_virtualmachines" would have been changed to a primary volume, continuing... ERROR: command to address 172.168.3.98 failed because could not find the matching remote schedule for primary schedule 35188AC48F2BAEBBC018AA4C3C6C6534;ProtectedManagementGroup;514;rdm_ctx1_RS_Sch_1_Pri. Error: . Después de analizar la cabina de almacenamiento más profundamente, esta indicó que se estaba empezando a quedar sin espacio
Este pequeño episodio ilustra los peligros de un seguimiento inadecuado del almacenamiento virtual o de la creación de LUN/Volúmenes muy pequeñas. La única manera para ver si está quedando sin espacio, es mediante el software de gestión de su proveedor almacenamiento. Error: Objetos eliminados en el sitio de recuperación y que aún se hacen referencia en el Plan de Recuperación Otro problema que puede ocurrir en el plan de recuperación es cuando se hace referencia a objetos del vCenter tales como máquinas virtuales que ya no existen. La pantalla de abajo muestra un error de este tipo.
Como se puede ver el mensaje de error dice “Error: The request refers to an object that no longer exists or has never existed”. Esto fue debido a que yo borre una máquina virtual de prueba, la cual fue marcada para ser suspendida durante la prueba de mi plan de recuperación. El plan de recuperación tiene una entrada huérfana a este objeto que ya no existe en el sitio de recuperación. El mismo objeto borrado crea un error más en el plan, cuando trata de reanudar la maquina virtual suspendida la cual nunca fue suspendida en primer lugar. Para corregir este error hay que editar el plan de recuperación y ejecutarlo a través del asistente, hasta llegar al cuadro de diálogo donde se puede suspender las máquinas virtuales

160
Simplemente ejecutando el asistente, este actualizara el plan de recuperación y eliminara la referencia a la máquina virtual pérdida.
Escenarios de ciclos de replicación del almacenamiento Quiero dedicar algún tiempo para ver diferentes ejemplos o escenarios de ciclos de replicación/instantánea, para explicar algunas de las "extrañezas" que de vez en cuando se pueden ver dentro de SRM. Tomemos el ejemplo de un ciclo de mantenimiento de tres instantáneas, haciendo una instantánea cada hora. Esto generará una situación en la que usted tiene un volumen con tres instantáneas, Snapshot1, Snapshot2, Snapshot3. Dependiendo del proveedor de almacenamiento, usted a veces puede ver hasta cuatro instantáneas ya que la mayoría de las cabinas no eliminan el Snapshot1, la instantánea más antigua, hasta que no se haga hecho el último shapshot. Durante este tiempo usted tendrá Snapshot1, Snapshot2, Snapshot3 y Snapshot4. Una vez que se ha hecho Snapshot4, usted vería que Snapshot1 será purgado y el asistente le mostrara Snapshot2, Snapshot3 y Snapshot4. Esto nos deja con dos escenarios diferentes: Escenario 1: LUN/Volumen, S3, S2, S1 Escenario 2: LUN/Volumen, S4, S3, S2, S1 En el escenario 2, S4 (snapshot4) está en proceso de ser creado o bien S1 se encuentra en el proceso de ser purgado de la serie. Por ejemplo, esto es como el VSA Lefthand Networks vería la serie en el escenario 2:

161
La forma en la que VMware SRM y el SRA de su proveedor de almacenamiento se comportan, depende de cuando un plan de recuperación se prueba o se ejecuta y de cómo este interactúe con el ciclo de replicación. Ejemplo 1: Si SRM se ejecuta en el escenario 1, por ejemplo, a las 3:30 (S3 + 30 minutos), el SRA se comunicará con la cabina para, en primer lugar encontrar el volumen, después completara la instantánea más reciente (S3) y por ultimo configurara la autenticación para permitir a los ESX el acceso a esa instantánea. Cuando la prueba termina, muchas de las cabinas borran el espacio temporal que fue utilizado por el SRM durante la toma de la instantánea. Las cabinas hacen esto para ahorrar espacio en la SAN de recuperación. El SRA no des-autentifica un servidor ESX de la instantánea. SRM no da la información al SRA para hacer esto. Ejemplo 2: En este ejemplo, son las 4:01 (S4 + 1 minuto) y usted ejecuta de nuevo su plan de recuperación de prueba. Una vez más, SRA se comunicará con la cabina, en primer lugar, para encontrar el volumen, después completara la instantánea más reciente (S3), la cuan todavía resulta ser S3 porque S4 esta aun siendo copiada. En este caso, el SRA no cambiará nada. S3 ya está autenticada y SRM procederá a repetir la última prueba que se corrió. Una vez más, cuando se detenga, no des-autentificara la instantánea del servidor ESX. Usted debe ser capaz de ejecutar pruebas de SRM en sucesiones rápidas, tantas veces como lo desee. Muchas de las veces, usted en realidad no estará cambiando el estado de la SAN si el ciclo de replicación no se ha movido todavía.

162
Ejemplo 3: En este ejemplo, son ahora las 4:10 (S4 +1 min) y usted ejecuta otra vez su plan de recuperación de prueba. Una vez más, el SRA encontrara la instantánea más reciente, que en este caso es S4 y esta vez autenticada, ya que la instantánea se ha completado. El servidor ESX ahora tiene montadas S3 y S4. Ambas fueron resignatured y los nombres deberían de ser "snap-NNNNN". SRM no encuentra datastores basado en nombres, sino que este encuentra los datastores por el nombre de dispositivo que la SRA pasa al SRM. Por lo tanto, independientemente del nombre del dataStore, SRM utilizará el dataStore que montamos para la prueba S4, y este ignorara los demás, sin importar cómo de similares sean en el nombre o el contenido, incluido S3. Esta captura de pantalla, muestra cómo el ESX puede ver dos imágenes al mismo tiempo, pero renombra el volumen VMFS del más reciente para denominarlo "virtualmachines"
Nota: Recuerde que desde la última versión, el proceso de cambio de nombre ya no es el comportamiento por defecto, pero se puede habilitar de nuevo editando el archivo vmware-dr.xml Aquí puedo decir que el VMFS llamado "virtualmachines" es la más reciente ya que el VSA Lefthand Networks presenta la nueva imagen con un número mayor de "objetivo", vmhba32: 32 en lugar de vmhba32: 31:0:1. Al final de la prueba y, durante la fase de "limpieza", el SRM debe hacer de nuevo un resignature al volumen. Esto es, lo que de vez en cuando he visto fallar. Esta captura de pantalla muestra el éxito de un resignature
Ejemplo 4: En este ejemplo, han pasado dos horas más y es exactamente una hora en punto. En este caso tenemos un nuevo escenario. Escenario 3: LUN/Volumen, S6, S5, S4, S3 S6 casi ha terminado de copiarse mientras que S3 y S4 siguen montadas en el servidor ESX. Pero tan pronto como S6 haya completado el proceso de instantánea, S3 será borrada por el schedule. Como parte del proceso de borrado, esta será eliminada de la lista de autenticación para el servidor ESX y el acceso iSCSI a la

163
misma no se permitirá más. Aquí es cuando la fase de limpieza realmente ocurre y esta fase de limpieza es realizada por su cabina de almacenamiento y no por el SRM o el SRA. Después de todo, la cabina no puede ofrecer al ESX una instantánea que ya no existe. Usted podría ver por un corto período de tiempo, que la autenticación se ha eliminado de la cabina de almacenamiento y que el servidor ESX ya no ve S3. Si usted llega a una conclusión lógica, el dejar un espacio de tiempo bastante grande entre una prueba y otra le llevara a que ocurran menos posibilidades de error, ya que la fase de limpieza de la cabina de almacenamiento es más probable que se haya completado. Si está utilizando el VSA Lefthand Networks, puede ver esta fase de limpieza en la pestaña de la Lista de Volumen en el Recovery Management Group
El efecto de esto no es inmediatamente evidente, pero usted encontrará que si navega por un DataStore que ha sido eliminado de la lista de esta manera, aunque la etiqueta del volumen/DataStore pueden estar presentes en el ESX, el contenido del datastore estará vacío, algo que es un poco desconcertante cuando lo descubre por primera vez. Realmente hay tres formas de evitar que esto ocurra.
• Aumentar el número de instantáneas que usted mantiene • Aumentar el tiempo entre una instantánea y la siguiente, así las instantáneas se conservan durante un período de tiempo más largo • Temporalmente pause el schedule de replicación y después reanúdelo de nuevo cuando haya finalizado la prueba del plan de recuperación.
Nota: Con el VSA Lefthand Networks usted puede detener el schedule muy fácilmente
En el ProtectedManagementGroup Seleccione su volumen Seleccione la pestaña de Schedules

164
Por supuesto, cuanto más tiempo tenga parado el scheduler, más cambios habrá que hacer en la capa de almacenamiento y usted debe recordar reanudar su schedule cuando haya terminado.
Conclusión En esta sección he intentado hacer que usted ponga en funcionamiento su plan de recuperación lo antes posible, de hecho esta ha sido mi intención desde el principio, lo crea o no, ya que ver un producto "en acción" es la forma más rápida de aprenderlo. Como ha visto, el hacer clic en el botón Test o Run genera una gran cantidad de actividad y de cambios. VMware SRM es un producto muy dinámico en ese sentido. Mi esperanza es que este siguiendo mi configuración mientras lee este libro. Sé que es un mucho pedir, por lo que si no lo ha hecho, le recomiendo ver el primer vídeo que he vinculado en este capítulo. No importa cuántas pantallas de ejemplo le adjunte, y como documente lo que pasa, nunca lo verá tan claro que como en un video. En segundo lugar, quise tratar de explicar algunas de las "extrañezas" que puede ver en el producto de SRM. No es extraño en absoluto, sino que es una característica de diseño del producto. Es la forma en que el ciclo de replicación de su capa de almacenamiento interactúa con el producto SRM. En el próximo capítulo usted pasara la mayor parte de su tiempo con el producto, creando planes de recuperación a medida, los cuales aprovecharan todas las características de SRM, para que usted pueda probar sus planes DR unos contra otros y para diferentes escenarios. Hasta ahora este libro se ha centrado en cómo hacer que SRM funcione. El próximo capítulo tratara acerca de lo que porque realmente su organización compro el producto.

165

166
Capítulo 6: Planes Personalizados de Recuperación

167
Hasta ahora siempre hemos aceptado la configuración por defecto de los planes de recuperación. Como sabe, es posible personalizar en gran medida los planes de recuperación. Los planes de recuperación personalizados, le permitirán controlar el flujo del proceso de recuperación. Junto con la personalización de las asignaciones de las máquinas virtuales, le permitirá automatizar completamente las tareas comunes cuando se ejecuta un plan DR. La creación de múltiples planes de recuperación, con diferentes opciones, nos permite hacer frente a diferentes situaciones que provocan el uso de nuestro sitio de recuperación y, además, nos permite poner a prueba los planes para medir su eficacia. Con los planes de recuperación personalizados y la personalización de la configuración de la máquina virtual, podemos controlar y automatizar una serie de ajustes como por ejemplo:
• Apagar las máquinas virtuales en el sitio protegido por orden de prioridad • Encendido de máquinas virtuales en el sitio recuperación mediante la configuración de la prioridad • Cambiar la configuración IP de las máquinas virtuales • Detener el plan y emitir un mensaje de operador • Detener el plan y ejecutar un comando
Además, en este capítulo quiero profundizar un poco más en SRM para discutir las consecuencias de las cuestiones siguientes:
• Crear/cambiar el nombre/cover objetos en el vCenter del sitio de protección y recuperación • Uso de las funciones de VMware RDM (Raw Device Mapping) • Escenarios de almacenamiento más complejos donde hay máquinas virtuales con múltiples discos virtuales, almacenados en varios datastores VMFS y usando VMFS extents • Creación de nuevas máquinas virtuales • Migración en frío con la reubicación de archivos con Storage VMotion
Vale la pena mencionar que algunos de estos valores sólo serán eficaces dependiendo de si usted solo está probando su plan de recuperación o si está realmente invocándolo. Así que algunos de estos valores sólo se aplicarán durante los pruebas y, lo que es más importante, algunos de estos valores sólo se aplicarán cuando evoca en realidad su plan de DR. Por ejemplo, la posibilidad de apagar las máquinas virtuales en el sitio protegido nunca es incluido en una prueba de un plan de recuperación, pero si es posible hacerlo cuando se invoca un plan de recuperación real. Puede ver si una configuración determinada llega a tal efecto, mirando la columna modo en la ventana de recovery plans recovery steps

168
Aquí podemos ver, que el apagado de las máquinas virtuales (paso 1) en el sitio de protección, sólo se produce cuando se ejecuta una recuperación, mientras que el proceso message, clean, resume y reset (pasos 8-9) solo se llevan a cabo cuando se ejecuta una prueba. Cuando un paso no está marcado ni como "Recovery Only" ni como "Test Only", significa que siempre se lleva a cabo independientemente del modo que se esté utilizando.
Configurar el apagado de las máquinas virtuales protegidas en el sitio protegido
Usted puede encontrar esta característica algo curiosa. Después de todo, si ha decidido invocar su plan DR - no es esto lo que se hace sólo cuando todo está perdido en el sitio protegido?. En cierto modo usted tiene razón, ya que si ocurre un gran incendio o un ataque terrorista, este puede eliminar totalmente su sitio principal. Para decirlo sin rodeos, puede haber nada que apagar en el sitio protegido y, de hecho, puede haber perdido todas las comunicaciones con su sitio de recuperación. Para muchos, esto parece ser una verdad innegable. Así que permítame ponerle un ejemplo de una situación en la que ocurrió un desastre, pero no dio lugar a la pérdida del sitio protección, de hecho, este desastre ni siguiera toco el sitio de protección, aunque terminamos invocando el plan DR de todos modos. En esta situación, la opción de apagado de las maquinas virtuales en el sitio de protección tiene un sentido lógico. En 1996 estaba trabajando para una empresa en el Reino Unido, la cual tiene su sede corporativa en el Centro Arndale, en Manchester. El Centro Arndale es un centro comercial muy grande, de empresas en el centro de Manchester y una bomba causo grandes daños. Los daños fueron valorados por las aseguradoras en el rango de £ 411m (GBP), con unos costos de reconstrucción en el rango de £ 1.2b (GBP). La bomba "camión bomba", estaba en un Ford mal aparcado y fue denotada por el IRA. La bomba pesaba 3.300 libras y ha sido, hasta la fecha, la bomba más grande puesta por el IRA. Usted puede leer informes de archivo en la BBC sobre ese día en este website: http://news.bbc.co.uk/onthisday/hi/dates/stories/june/15/newsid_2527000/2527009.stm

169
Si prefiere wiki, también hay una página wiki. http://en.wikipedia.org/wiki/1996_Manchester_City_Centre_bombing El edificio fue evacuado debido a advertencias anteriores de un inminente ataque, una táctica muy común utilizada por el IRA en esos momento. Desafortunadamente, cuando la bomba fue detonada, la gente que estaba detrás del cordón de seguridad de la policía, resultaron heridas. La empresa en la que estaba trabajando, tenía la sede corporativa en un piso tan alto del edificio que este no fue afectado. De hecho, el Centro Arndale sobrevivido a la explosión, mientras que otros edificios, cerca del epicentro, fueron demolidos y reconstruidos. Los sistemas que había en funcionamiento en el Centro Arndale no se vieron afectados, aunque no recuerdo ahora si había alguna comunicación con ese lugar. Yo era sólo un trabajador de nivel medio del personal de esta empresa y, estaba trabajando en Birmingham en ese momento, un largo camino de cualquier peligro real.

170
Es quizás aleccionador recordar que cuando estos terribles atentados tuvieron lugar, nuestra última preocupación fue el negocio y nuestro plan DR, sino la seguridad de los miembros del personal que viven y trabajan en la zona. El bomba exploto un sábado por la mañana con la intención de causar los máximos daños civiles, los cuales estaban haciendo sus compras semanales. Sin embargo, para ser sinceros, otra de las preocupaciones de una minoría del personal de la empresa fue, si la empresa podría sobrevivir a la situación y que si se iba a cobrar al final del mes. Después de todo, los sistemas de la nómina estaban centralizados en el Centro Arndale. No obstante, como se puede esperar, todo el lugar se convirtió en "escenario de un delito" muy rápidamente, después de que los servicios de emergencia hicieran su trabajo rescatando a todos los supervivientes. Por este motivo, incluso si nuestros sistemas hubiesen estado en Manchester, no hubiésemos podido acceder a ellos mientras que los organismos de investigación forense estaban realizando su trabajo explorando el sito donde la explosión tuvo lugar. En este contexto, la función "apagar maquinas virtuales en el sitio protegido" tiene sentido ya que no queremos encender los sistemas de recuperación que puedan tener el mismo nombre NetBIOS y la misma dirección IP al mismo tiempo que los sistemas del sitio de protección. Esto podría crear los conflictos suficientes como para poner fin a nuestro plan de recuperación o detener a nuestros usuarios finales de recibir los servicios requeridos. Usted podrá aplicar este ejemplo a cualquier invocación del plan DR "previsto", como por ejemplo, grandes inundaciones o un corte de energía que no cause daño directo en la zona protegida, pero que es lo suficientemente "intrusivo" para sus operaciones comerciales normales, que se considera necesario un plan de DR. En términos de SRM, el producto primero apagara las máquinas virtuales en el siguiente orden - Low, Normal, High. Esto es directamente contrario a la forma de recuperación que las máquinas virtuales son encendidas como se muestra en la pantalla siguiente
Por defecto, el apagado de las máquinas virtuales en el sitio de protección sólo sucede cuando usted activa su plan de recuperación real y todas las máquinas virtuales, por defecto, tienen un configuración de "Normal" por prioridad, tanto en el sitio protegido como en el sitio de recuperación.

171
A efectos de este capítulo, voy a crear un nuevo plan de recuperación
1. En la ventana SRM Manager del vCenter del sitio de recuperación, seleccione Recovery Plans y haga clic en el botón Create Recovery Plan
2. Escriba un nombre y una descripción para el plan, como por ejemplo Complete Loss of Site - Custom Plan y haga clic en Next 3. Seleccione sus grupos de protección(s) y haga clic en Next 4. Ajuste el tiempo de respuesta por defecto de la máquina virtual , y haga clic en Next 5. Seleccionar las opciones para Test Networks, y haga clic en Next 6. Seleccione cualquier máquina virtuale que desee suspender durante el plan de recuperación, y haga clic en Finish Nota: Esto debería crear un segundo plan como se ve a continuación
7. Seleccione su nuevo plan, haga clic en la pestaña Recovery Steps y amplié el signo + que aparece junto a 1. Shutdown Protected Virtual Machine at Protected Site

172
8. Seleccione una máquina virtual y utilizando el icono Step Up/Down de la barra de herramientas
re-ordene la ubicación de las máquinas virtuales para que estén en la ubicación correcta que precise. La pantalla de abajo muestra mi nuevo orden
Nota: Esto parece un proceso muy laborioso. Por supuesto, la decisión de parar a una máquina virtual antes que otra siempre tiene que ser configurado por máquina virtual y una a una. Nota: Usted podrá ver cómo pongo mis máquinas virtuales menos críticas con una prioridad baja, las cuales se ejecuta en primer lugar. La idea de esto podría ser quizás el querer realizar un plan de recuperación con una máquina virtual de menor importancia y comprobar con SRM que funciona

173
correctamente, antes de iniciar el plan de otras máquinas virtuales. Esto es más consistente con la invocación de un plan DR más "planeado". Quizás usted conoce que se van a realizar algunos trabajos en el área y sabe que le van a cortar la electricidad por unos días, mas días a los que su propio sistema de generación de energía o SAI puede hacer frente. Asumo que tiene algún tipo de generador diesel que permite alimentar a sus sistemas de 1-3 días. Esto podría provocar el uso del plan de recuperación a pesar de que no ha "perdido" el sitio protegido.
Configurar la prioridad/orden de las máquinas virtuales en el sitio de recuperación Por supuesto, es mucho más fácil de explicar y justificar este aspecto del plan de recuperación. Nuestras máquinas virtuales en el sitio de recuperación deben ser encendidas en el orden correcto para que aplicaciones muti-tier puedan funcionar correctamente. Sistemas de infraestructura básica tales como los controladores de dominio y DNS tendrán que entrar en funcionamiento en primer lugar, seguidos tal vez por sistemas de bases de datos. Estos servicios de sistemas de bases de datos, sin duda alguna, utilizaran cuentas de dominio para la puesta en marcha y sin el servicio de directorio en funcionamiento, esos servicios no pueden empezar. El caso es que para que funcione MV3, MV1 y MV2 deben ejecutarse primero y, para que funcione MV2, MV1 debe iniciarse primero. Por supuesto, el orden exacto que usted necesita para que su plan funcione va más allá del alcance de este libro ya que es algo muy específico para su organización. Sin esta función no se configura, las máquinas virtuales son más o menos encendidas aleatoriamente, aunque todas están contenidas en el marco de la prioridad "normal". La conclusión a esta lógica es que usted podría tener un plan de recuperación sólo para una determinada aplicación crítica de negocio. En este caso, usted no ha perdido el sitio protegido sino sólo una pieza crítica de la infraestructura del negocio. Esto requiere que usted gestione sus LUNs/volúmenes cuidadosamente. En este caso, la aplicación crítica de negocio estará en una LUN/Volumen dedicada sólo para él y habrá una asignación uno-a-uno entre las LUNs que contienen, digamos, su sitio Web de comercio electrónico, y sus "grupos de protección" en SRM. Esto permitiría tener "grupos de protección" para la web, Citrix, servidores de archivos, etc. Precisamente la interfaz de usuario para configurar el orden de prioridad de las máquinas virtuales en el sitio de recuperación, funciona de la misma forma que para el orden de apagado de las máquinas virtuales en el sitio de protección.
1. Seleccione su nuevo plan, haga clic en la pestaña Recovery Steps y amplié el signo + que aparece junto a 5. Recover Normal Priority Virtual Machines 2. Vuelva a seleccionar una máquina virtual y utilizando los iconos de Step Up/Down de la barra de herramientas
re-ubique y re-ordene las máquinas virtuales para que estén en la ubicación correcta. La pantalla de abajo muestra mi nuevo orden

174
Nota: Aquí he ampliado el símbolo + de la máquina virtual específica para destacar una característica útil de los planes de recuperación de SRM. Es posible bajar de nivel en eventos específicos mientras que una prueba se está ejecutando. Esto le permitirá seguir línea por línea cada acción. Como es posible que ya haya visto, la pestaña de Recovery Step también le da el valor, indicado en un porcentaje %, de cuánto tiempo tarda en cada paso.
Orden de puesta en marca paralelo y Normal/Baja Es importante que sepa que el orden de puesta en marcha en Normal/Bajo, funciona de forma muy diferente a la puesta en marcha en el orden alto. Con la prioridad alta, las máquinas virtuales se inician en serie. Así MV3 no se iniciará antes que MV2, y MV2 no se iniciará antes que MV1. Con prioridad Normal y Baja, las máquinas virtuales se inician en orden, pero si usted tiene más de un servidor ESX (como es el caso en la mayoría de los entornos) puede iniciar más de una al mismo tiempo. Así pues, si tengo seis máquinas virtuales (MV1, MV2, MV3, MV4, MV5, MV6) y tres servidores ESX, estas se iniciaran en este orden, pero si hay suficientes servidores ESX y suficientes recursos, entonces MV1, MV2 y MV3 se iniciarían en primer lugar, seguido por MV4, MV5, y MV6. SRM no encenderá MV4 hasta que MV1, MV2 y MV3 no se hayan iniciado correctamente.
Como consecuencia, el orden es menos estricto para la puesta en marcha de Normal/Baja. Después de todo si cada máquina virtual se puso en marcha en serie, en vez de simultáneamente, aquellas personas con un gran número de máquinas virtuales tendrán que esperar mucho tiempo para conseguir que sus máquinas virtuales arranquen.
Adición de Mensajes Es posible interrumpir el flujo de un plan de recuperación para enviar un mensaje al operador. Por defecto, cuando todos los planes de recuperación se crean y se prueban, hay un mensaje incorporado que para la prueba, para que se pueda proceder a realizar la fase de "limpieza" de la prueba. En este caso, el mensaje vale para dar al operador la oportunidad de examinar los resultados de la prueba y confirmar/diagnosticar la configuración.

175
Es posible añadir nuestros propios mensajes a nuestro plan de recuperación personalizado. En mi caso me gustaría que se produzca un mensaje, después de todas mis máquinas virtuales principales se hayan encendido. Estas máquinas virtuales son todas las etiquetadas con un número 1 como CC-1, CTX-1, y así sucesivamente. En mi caso quiero que aparezca un mensaje entre el High y Normal para poder pedir confirmación que las maquinas virtuales primarias están en funcionamiento, antes de permitir que las maquinas secundarias se enciendan. Nota: Los mensajes son siempre añadidos encima del paso seleccionado en el plan de recuperación 1. En el plan de recuperación, seleccione + 5. Recovery Normal Priority Virtual Machines 2. Haga click en el icono Add Message Step
Nota: También puede hacer clic con el botón derecho y seleccionar Add Menssage

176
3. En el cuadro de diálogo Add Message Step, escriba su mensaje y haga clic en OK
Nota: Este mensaje debe ser añadido a la lista de pasos y debe provocar una nueva numeración de todos los pasos en el plan de recuperación.

177
Nota: Es posible insertar mensajes y comandos en las propiedades de cada máquina virtual. En la pestaña de la máquina virtual del plan de recuperación, cada máquina virtual puede ser editada para agregar mensajes por máquina virtual.
Adición de comandos Al igual que ocurre con los mensajes, es posible añadir comandos en el plan de recuperación. Estos comandos pueden llamar a scripts en formato bat, cmd, vbs, wmi, Powershell o Perl, para automatizar otras tareas. Cuando se llaman a estos scripts, usted debe proporcionar la ruta completa de la secuencia de comandos del comando que se trate. Por ejemplo para ejecutar un archivo de Microsoft. BAT o archivo CMD usted debería escribir
C:\Windows\System32\cmd.exe /c c:\alarmscript.bat
Estos scripts se ejecutan en el servidor del sitio de recuperación de SRM y, en consecuencia, deberán almacenarse en este servidor. Usted debe saber que se ejecutan bajo el contexto de seguridad de la cuenta de administrador local del servidor SRM. Como prueba, he utilizado el comando NET SEND de Microsoft para enviar un mensaje a otro sistema. Esto requiere que el servicio de mensajería este habilitado en el sistema de destino. @ echo off
net send 192.168.2.198 Please contact [email protected] to inform him that the first recovery has completed
1. En el Recovery Plan seleccione, en mi caso, + 5. Message: WARNING: Please confirm that all the High Priority VMs have started and their services are functioning correctly 2. Haga clic en el icono Add Command Step

178
3. En el cuadro de diálogo Add Command Step, escriba la ruta de acceso al intérprete de comandos y el archivo de comandos y haga clic en OK
Nota: En mi caso este script se ejecuta justo antes de mi mensaje

179
Configure la dirección IP de configuración de las máquinas virtuales de recuperación
Una de las tareas que puede desear automatizar, es el cambio de una dirección IP dentro de la máquina virtual. Actualmente el método que tiene VMware para lograrlo es mediante sysprep de Microsoft, desde la parte de personalización de la configuración de usuario en vCenter. Lo importante a tener en cuenta es la función habitual de este componente para desplegar nuevas máquinas virtuales. En este caso los ajustes de personalización de los clientes son ignorados. Los únicos ajustes que se aplican son las IP. El inconveniente de este enfoque es que cada máquina virtual requerirá su propia personalización, lo cual es una tarea "administrativa" muy intensa. Por ello vale la pena considerar otros enfoques que no requieran un cambio en la configuración IP en todas y cada una de las máquinas virtuales. Estas otras alternativas podrían ser
• Mantener las direcciones IP actuales y redirigir los clientes por dirección IP • Usar stretched VLANs de forma que las máquinas virtuales siguen en la misma red • Asignar direcciones IP mediante un cliente DHCP y reservas
Si desea utilizar el método de VMware, empiece por la configuración personalizada de las máquinas virtuales afectadas en el vCenter del sitio de recuperación. A más largo plazo, no me sorprendería si VMware mejora este método, tal vez mediante la inclusión de un archivo separado por comas editado en Microsoft Excel, el cual podría permitir el cambio de las dirección IPs de forma conjunta, digamos, mediante la "inyección" de una secuencia de comandos VBS o WMI en el interior de la máquina virtual. Advertencia: Recuerde que para que este método funcione necesita copiar los archivos de sysprep en la ubicación C: \ Documents and Settings \ All Users \ Application Data \

180
VMware \ VMware VirtualCenter \ sysprep. Si no hace esto, vCenter no podrá encontrar la versión correcta de sysprep y usted recibirá este mensaje de error:
Creación de un IP personalizado
1. Sobre el vCenter del sitio de recuperación 2. En el menú, seleccione Edit y Customization Specification 3. En la ventana Customization Specification Manager, haga clic en el botón New
4. Escriba un nombre descriptivo, como SRM: CTX-1 IP y haga clic en Next
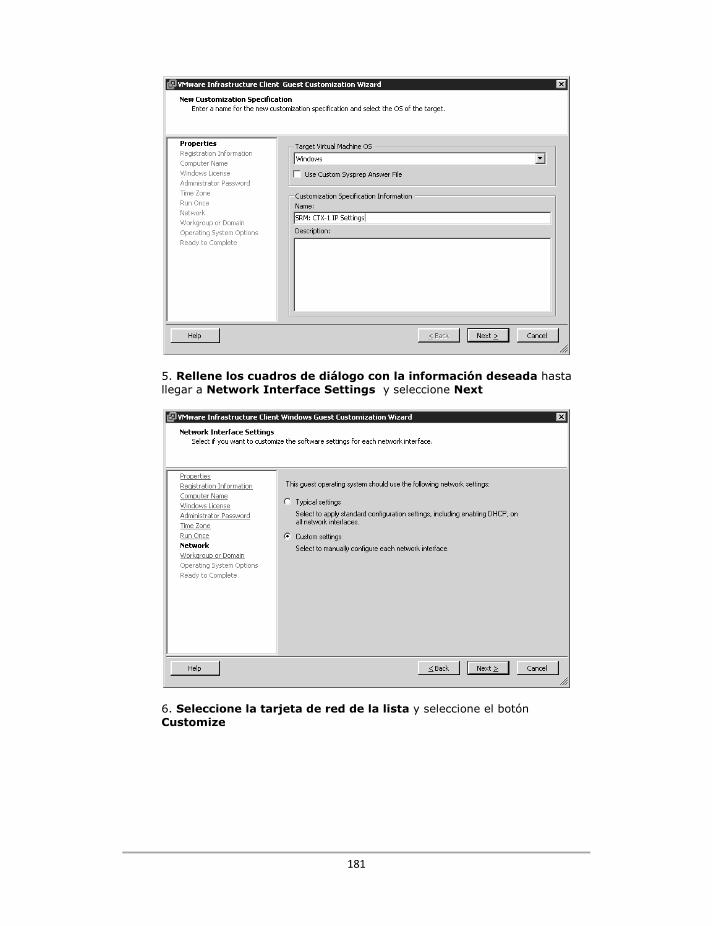
181
5. Rellene los cuadros de diálogo con la información deseada hasta llegar a Network Interface Settings y seleccione Next
6. Seleccione la tarjeta de red de la lista y seleccione el botón Customize

182
7. Configure su IP y haga clic en OK
8. Haga clic en Next y Finish en el cuadro de diálogo Nota: Una vez que haya creado la personalización de un sistema guest, es posible copiarlo utilizando el Guest Customization Manager. Una vez copiado, usted puede usarlo para editar y modificar la dirección IP aplicadas

183
Establezca la configuración personalizada de máquinas virtuales El siguiente paso es configurar cada máquina virtual con sus ajustes de personalización
1. En el vCenter del sitio de recuperación, seleccione Recovery Plan y haga clic en la pestaña de máquinas virtuales
2. Seleccione la máquina virtual en la lista, en mi caso ctx-1 y haga clic en botón Edit ... 3. En el cuadro de diálogo Configure Virtual Machine, haga clic en el botón Browse y seleccione Guest Customization/Specification Settings que creó anteriormente
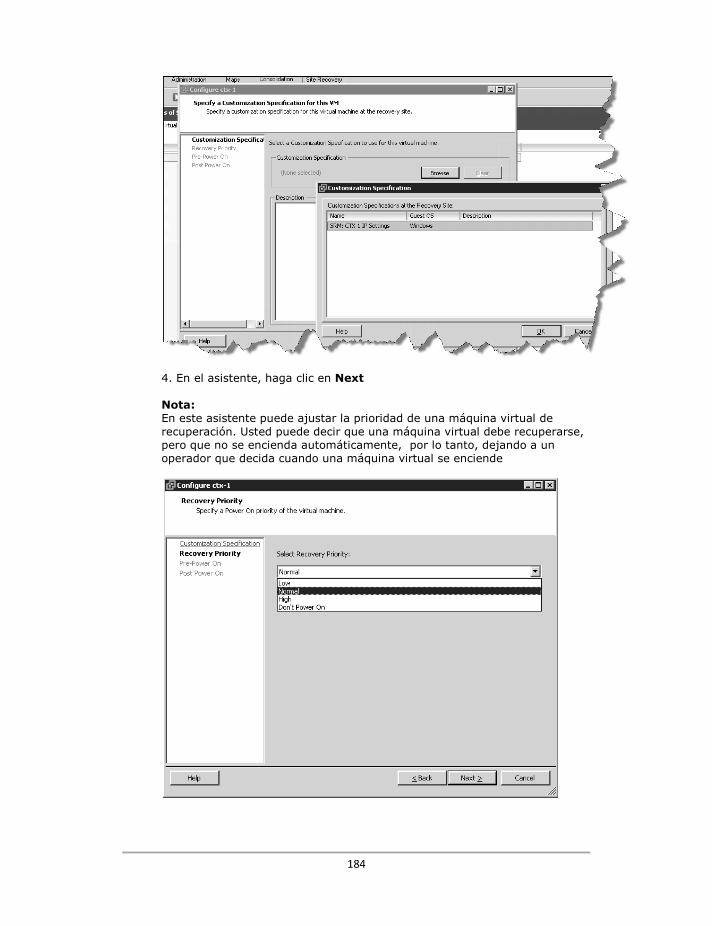
184
4. En el asistente, haga clic en Next Nota: En este asistente puede ajustar la prioridad de una máquina virtual de recuperación. Usted puede decir que una máquina virtual debe recuperarse, pero que no se encienda automáticamente, por lo tanto, dejando a un operador que decida cuando una máquina virtual se enciende

185
5. Además, podemos hacer que un comando/mensaje se ejecute antes o después de que una máquina virtual se haya encendido Nota: Si configura estas opciones, las verá en el plan de recuperación bajo las opciones de Pre-Power On y Post-Power On de la siguiente manera:
Asignaciones personalizadas de VM Como usted puede que recuerde, las "asignaciones de inventario" son opcionales, pero son muy útiles porque sin ellos, tendría que hacer mapeos de red, reserva de recursos y carpetas para cada máquina virtual. Puede que haya ocasiones en las que una máquina virtual no será añadida al sitio recuperación, porque SRM no pueda asignar dicha máquina virtual a una red válida, reserva de recursos o carpeta. Como alternativa, usted tendrá que decidir las asignaciones de la máquina virtual personalizada.
1. En SRM, seleccione el Grupo de Protección y haga clic en la pestaña de máquinas virtuales
2. Seleccione la máquina virtual afectada y haga clic en el botón Configuracion Protection 3. En el asistente Edit Virtual Machine, seleccione una ubicación de carpeta para la VM

186
Nota: Nota cómo puede sobrescribir la configuración de asignaciones de inventario por defecto, ya que esta máquina virtual se sitúa fuera del ámbito de los ajustes por defecto. Tal vez valga la pena dejar claro, que si la configuración de máquinas virtuales está cubierta en las "asignaciones de inventario", este cuadro de diálogo estaría desactivado. Recuerde que las "asignaciones de inventario", permiten "excepciones" a la norma general, lo mismo que ocurre con VMware HA y DRS. 4. En el asistente Edit Virtual Machines, seleccione un ESX para esta MV

187
Nota: En esta interfaz, si usted tiene la opción "Fully automated" DRS clúster, como yo tengo, no podrá especificar un servidor ESX. En lugar de eso sólo podrá seleccionar el clúster donde quiere que la máquina virtual se arranque y DRS decidirá que servidor ESX del clúster es usado para arrancar dicha maquina. Como sabe, esta funcionalidad es denominada "initial placement" en DRS. 5. En el asistente Edit Virtual Machines, seleccione una Resource Pool para esta máquina virtual
6. En el asistente Edit Virtual Machines, seleccione una red para esta máquina virtual

188
Nota: En este caso, la red de la columna de recuperación para la máquina virtual esta en blanco. Esto es una buena indicación de mi problema inicial, en donde el grupo de protección, no sabía asignar la red primaria (vlan10) de las máquinas virtuales a la red correcta en el sitio de recuperación, porque no se incluyó en las "asignaciones de inventario " Nota: La opción de prioridad de recuperación controla donde se colocara la máquina virtual en el plan de recuperación. Si elige "normal", por ejemplo, la máquina virtual se colocara en la categoría normal para apagar las máquinas virtuales en el sitio protegido, y en la categoría normal para el encendido de las máquinas virtuales en el sitio de recuperación.
Gestión de cambios en el sitio de protección Es posible que empiece a ver que SRM va a necesitar una gestión y un mantenimiento casi continuo. Como su sito protegido (producción) está en constante evolución y cambio diario, este mantenimiento es necesario para mantener el sitio de protección y el sitio de recuperación adecuadamente sincronizados. Una de las principales tareas de mantenimiento, es asegurarse que las nuevas máquinas virtuales que necesitan protección son debidamente incluidas por uno o más planes de recuperación. La simple creación de una máquina virtual y el almacenamiento de esta en un volumen VMFS replicado, no incluye automáticamente su máquina virtual en su plan de recuperación. Después de todo, no todas las máquinas virtuales puede que necesiten protección. Si sigue este hecho a una conclusión lógica, es posible que se haga esta pregunta - ¿por qué crear una nueva máquina virtual en un volumen VMFS que se replica si no lo necesito? Sin embargo, en la actualidad, en Vi3 es posible orientar o limitar a un usuario para que sólo pueda seleccionar un volumen VMFS determinados cuando se crea una nueva máquina virtual. Existe el riesgo de que un usuario involuntariamente pueda poner una MV en un volumen VMFS que se está

189
replicando cuando no debiera. Igualmente existe una clara posibilidad de que el usuario pueda almacenar su nueva máquina virtual en un volumen sin protección. Creación y protección de nuevas máquinas virtuales Usted puede asumir erróneamente que, como ha creado una nueva máquina virtual, esta será automáticamente "reconocida" por SRM y protegida por defecto. Sin embargo, este no es el caso. Si bien la creación de una nueva máquina virtual en un volumen VMFS replicado debe velar que los archivos de la máquina virtual, por lo menos son duplicados en el sitio de recuperación, una nueva máquina virtual no se "inscribe" automáticamente al grupo de protección definido en el sitio de protección. Usted puede ver esto si crea una nueva máquina virtual, como lo he hecho yo, con los mismos sitios cubiertos por la asignación de inventario.
Este comportamiento no es diferente de un error que vimos anteriormente, donde una máquina virtual o asignación de inventario falla al mapear las maquinas virtuales. Esto es muy fácil de solucionar.
1. En el sitio de protección, seleccione la máquina virtual de grupo de protección y seleccione la máquina virtual que actualmente no está protegida, en mi caso esta es la máquina virtual web-3 2. Haga clic en el botón Configure Protection

190
3. En el cuadro de diálogo Edit Virtual Machines Properties, seleccione una carpeta de destino para la máquina virtual situada en el sitio de recuperación
4. A continuación, seleccione un clúster donde poner la máquina virtual, o si no tiene un clúster, seleccione un servido ESX
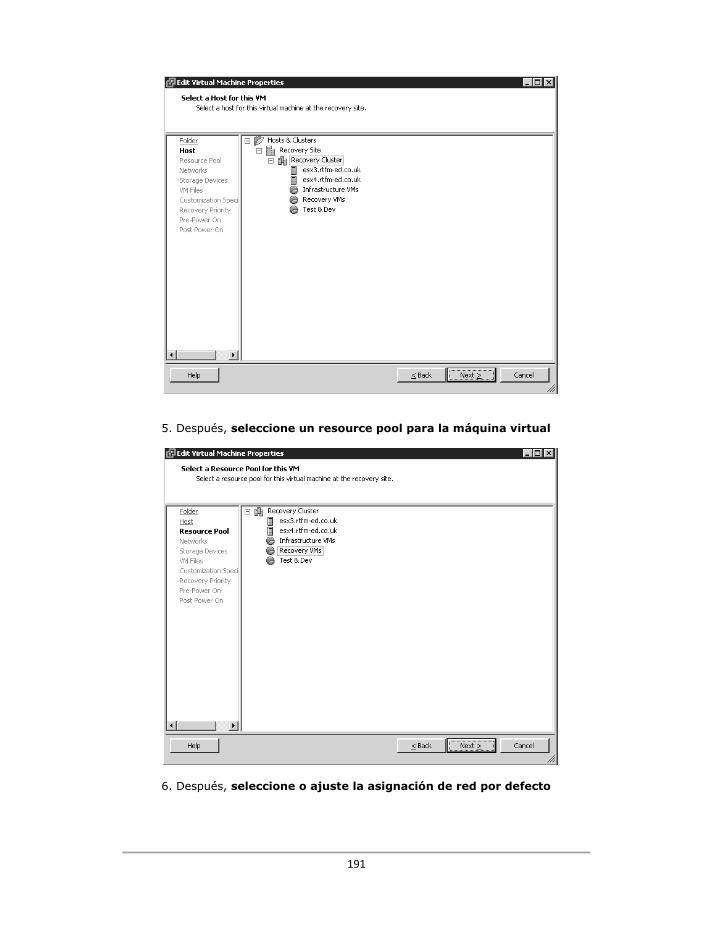
191
5. Después, seleccione un resource pool para la máquina virtual
6. Después, seleccione o ajuste la asignación de red por defecto
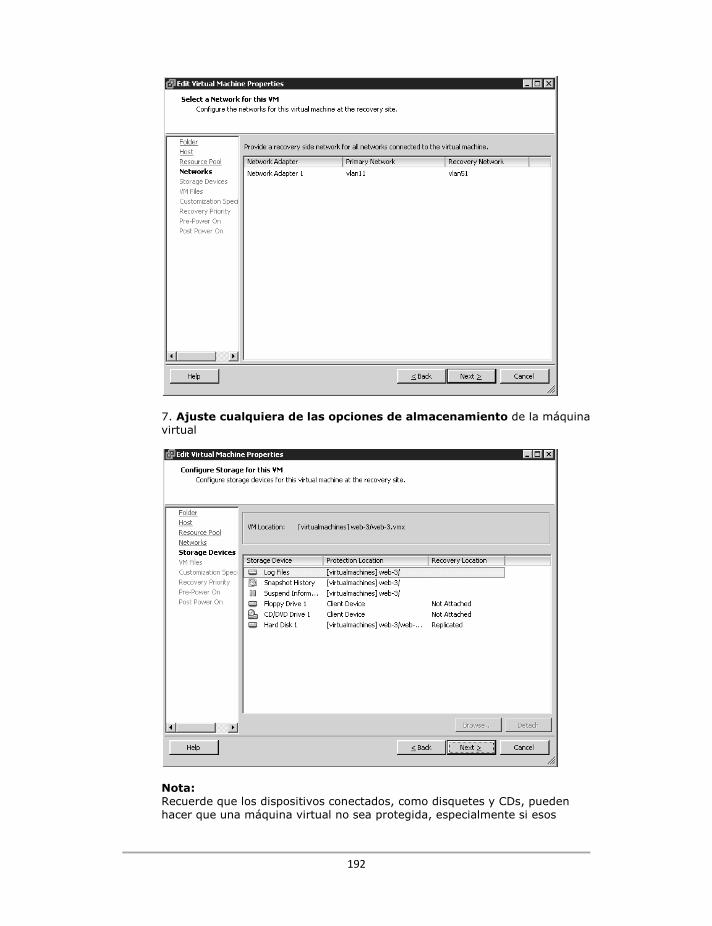
192
7. Ajuste cualquiera de las opciones de almacenamiento de la máquina virtual
Nota: Recuerde que los dispositivos conectados, como disquetes y CDs, pueden hacer que una máquina virtual no sea protegida, especialmente si esos

193
recursos no están disponibles en el sitio de recuperación. Esta es la razón por la cual usted tiene un botón de "detach" en el cuadro de diálogo anterior. 8. Seleccione, choose a storage location for the temporary placeholder/shadow files
Nota: Podría seguir de esta manera, con una pantalla de volcado por todos y cada uno de las partes del asistente. Pero esto podría llegar a ser algo tedioso y estoy seguro de que todo esto ya le "suena" bastante. Este proceso añadirá la máquina virtual a cada uno de los planes de recuperación, así como al inventario del sitio de recuperación. Como se puede ver debajo en la imagen adjunto, web-3 es una nueva máquina virtual que tiene ahora un archivo placeholder en el resource pool de las maquinas virtuales de recuperación. También esta listada en la categoría Normal de los planes de recuperación que utiliza el grupo de protección.

194
Cambiar y mover objetos de inventario del vCenter Como puede ver el producto SRM depende en gran medida de que el operador haya hecho el emparejamiento de las dos instancias de vCenter correctamente. Estos vCenters no comparten una base de datos en común. Así que puede estar legítimamente preocupado por lo que sucede cuando los objetos, ya sea en el sito de protección o de recuperación, son renombrados o reubicados. Existen algunas normas y regulaciones relativas al cambio de nombre de varios objetos en vCenter. En principio, el cambio de nombre o la creación de nuevos objetos no necesariamente "rompen" las asignaciones de inventario configuradas con anterioridad. Esto se debe a que las asignaciones, en realidad, apuntan a los números de referencia de objetos. Cada objeto en el inventario de vCenter es "sellado" con un valor MOREF (Managed Object Reference Numbers). Estos se pueden considerar como los SIDS en Active Directory, y cambiar el nombre de un objeto en vCenter no cambia el valor de los objetos MOREF. La única excepción a esto son los port groups, que no están asignados a un vCenter MOREF, de hecho, su configuración y los identificadores no están en el servidor de vCenter, sino en el servidor ESX. Si examinamos los escenarios siguientes, podremos ver el efecto del cambio de nombre de los objetos en vCenter:
• Cambiar el nombre de las máquinas virtuales
No es un problema grave. Los grupos de protección actualizan los nuevos nombres al igual que los planes de recuperación. Sin embargo, las referencias de la maquina virtual no son actualizadas automáticamente. Esperar al próximo ciclo de replicación o volver a ejecutar el plan de recuperación tampoco actualizara las referencias de la maquina virtual (placeholder/shadow). Afortunadamente, esto no hace parar a su plan de recuperación. Descubrí que la única forma de arreglar este problema era desproteger y volver a proteger la máquina virtual. Esto no es un método deseable, ya que significa que usted pierde las personalizaciones de su plan de recuperación.

195
• Cambiar el nombre del DataCenter, Clusters, Carpetas protegidas en el sitio de protección No es un problema. Las ventanas de asignaciones de inventario se actualizan automáticamente
• Cambiar el nombre de Resource Pools en el sito protegido
No es un problema. Las ventanas de asignaciones de inventario se actualizan automáticamente
Cambiar el nombre de los port grupos del Switch Virtual en el sitio protegido En este caso, una actualización de las asignaciones de inventario es requerido, y las asignaciones tendrán que ser re-creadas en el sitio de recuperación. Si no lo hace, las máquinas virtuales en el sitio de protección se convertirán en "huérfanas" (orphaned)
Nota: Este "orfandad" de la máquina virtual es una "característica" de Vi3, y no es específicamente un problema de SRM. Sin embargo, sí tiene un efecto significativo sobre SRM. Esto puede hacer que el proceso de grupo de protección (es el proceso que crea el marcador de posición/shadow o placeholder de las máquinas virtuales en el sito de recuperación) falle. Corregir esto para todos y cada una de las máquina virtual utilizando el cliente de Vi es trabajo muy laborioso. Puede automatizar este proceso con secuencias de comandos, por ejemplo con cmdlets de PowerShell para VMware y que proporciona el mismo VMware. Si desea obtener más información acerca de esto, escribí un libro sobre cómo empezar en PowerShell: http://www.rtfm-ed.co.uk/?p=543 Por ejemplo: get-vm | get-networkadapter | sort-object -property "NetworkName" | where {'vlan61' -contains $_.NetworkName} | Set-NetworkAdapter -NetworkName vlan21

196
En la pantalla de arriba, tuve que hacer clic en el botón Refresh para ver las redes. Cambiar el nombre del port group, de vlan10-12 a vlan20-23, provocó una pérdida de las asignaciones en el sitio de recuperación, indicado por el mensaje "None Selected Message". Los otros objetos están bien. Renombré:
o DataCenter y Cluster para tener referencias a la ubicación de Londres, o La carpeta a Server Room 1 o El resource pool a Production o El portgroup de vlan20, a vlan21

197
Gestión de cambios en el sitio de recuperación • Cambiar el nombre de DataCenters, Clusters y carpetas en el sitio de
recuperación No es un problema. Las ventanas de asignaciones de inventario se actualizan automáticamente. Yo renombre el DataCenter, Cluster y carpetas, a las referencias específicas de Londres y Reading.
• Cambiar el resource pools en el sitio de recuperación
No es un problema. Las ventanas de asignaciones de inventario se actualizan automáticamente. Yo renombre el resource pool, a las referencias específicas de Londres y Reading.
• Cambiar el nombre del port group del switch virtual en el sitio protegido Mi experiencia me dice que el cambio del nombre de los port groups en el sito de recuperación es mucho más intrusivo. Yo renombre mis port group de vlan50-52 a vlan60-62. Sin embargo, esto no se actualizo en la ventana de asignación de inventario. La ventana de inventario aún tenía los port groups en el vCenter del sitio de recuperación los cuales ya no existian en realidad. Incluso un reinicio del vCenter en el sitio de recuperación no corrige este problema. La única solución fue, manualmente asignar el port group
Antes ...
... después ....

198
Después de todo, el cambio de nombres de DataCenters, Cluster, carpetas, resource pools y redes en mis dos entornos en vCenter, parecen completamente distintos
Mis cambios aquí no son casuales. Utilizare esta estructura para demostrar un sitio de recuperación bidireccional, donde dos centros de datos actúan como sitios DR recíprocos, el uno del otro. Otros cambios en el Vi3 y el entrono de SRM Mi experiencia me dice, que hay otros cambios que pueden tener lugar en el Vi3 y SRM que pueden causar que las relaciones que configuramos en SRM se rompan. Por ejemplo, he descubierto que si se renombran los volúmenes VMFS en el sito de

199
protección antes de que este volumen haya sido tratado por un ciclo de replicación, puede causar problemas. Lo que puede suceder es que usted cambie el nombre de un volumen VMFS en el sitio de protección antes de que haya sido cubierto por el siguiente ciclo de replicación y, después ejecute una prueba. La prueba falla, porque el test espera ver el nombre antiguo, no el nombre nuevo y todavía se presentan con el nombre antiguo en el sitio de recuperación. El mensaje de error será "File not found", cuando el plan de prueba se ejecuta. Usted verá que su volumen VMFS replicado está vacío!. La solución que yo encontré fue simplemente esperar hasta que el volumen VMFS, al cual le cambiamos el nombre, llega al sitio de recuperación, en otras palabras, espere hasta el próximo ciclo de replicación y el problema se elimino. Para el cambio de nombre de volúmenes VMFS, vale la pena decir que las fases de la configuración de los SRM ocurren en un orden específico por una razón y, cada etapa tiene una dependencia de la etapa anterior. El orden de la configuración de SRM es la siguiente: 1. "Parear" los dos sitios 2. Array Manager 3. Asignaciones de inventario 4. Grupos de protección 5. Crear plan de recuperación Digamos por ejemplo que usted borra su grupo de protección. Lo que ocurre es que el plan de recuperación(s) tiene referencias a los grupos de protección que ya no existen. Si crea un nuevo plan de protección, entonces tiene que ir manualmente al plan de recuperación y configurar este para usar el grupo de protección correcto. Como, borrar las configuraciones y volverlas a crear, es una forma muy popular de "arreglar" los problemas de TI en general, usted debe tener mucho cuidado. Usted debe entender las consecuencias de la eliminación y la re-creación de los componentes. Por ejemplo, si decide borrar y recrear un grupo de protección y luego decide usar su plan de recuperación, lo que encontramos es que todas las prioridades de configuración en el plan se habrán perdido y se habrán establecido los valores por defecto. Por lo tanto, usted verá que todas las máquinas virtuales se re-alojan de nuevo en la categoría normal para el apagado y encendido de las máquinas virtuales. Esto es muy molesto, si después de todo se ha pasado mucho tiempo configurando que todas sus máquinas virtuales se enciendan en el momento adecuado y en el orden correcto. Por último, una palabra de advertencia. Como hemos visto, la mayoría de los cambios que se producen pueden ser hechos por SRM. Sin embargo, es importante destacar que las máquinas virtuales de producción no se propagan al sitio de recuperación. Si aumenta o disminuye la cantidad de memoria asignada a una máquina virtual, después de haberla incluido en un grupo de protección, la única manera de actualizar los cambios es eliminando el grupo de protección de la máquina virtual y volver a protegerla, lo que provoca la destrucción del placeholder VMX de la máquina virtual del sitio de recuperación. El desajuste entre el archivo real VMX y el placeholder no es técnicamente importante. Cuando se prueba el plan, la cantidad de memoria asignada a la máquina virtual en la zona protegida será utilizada. Moraleja de la historia: Mire a la eliminación eventual de las asignaciones de inventario y grupos de protección con extrema precaución. Lo que espero es que las futuras versiones de SRM, tendrán una función de importación y exportación que le permitirá una copia

200
de seguridad de sus planes de recuperación, separado de la base de datos SQL en el que están almacenados.
Creación de nuevas redes y nuevas máquinas virtuales en almacenamiento nuevo A medida que su organización crece y cambia el sitio protegido, una vez más será necesaria la actualización de SRM para que este sea consciente de estos cambios. Digamos, por ejemplo, que se crea una nueva red o VLAN en el sito de protección que usaran nuevas máquinas virtuales. En este caso, el SRM del sitio protegido deberá ser reconfigurado para actualizar estos cambios. Esto es particularmente "agudo" en la parte de asignaciones de inventario en SRM. Además, como el sitio de protección crece, también lo harán sus requisitos de almacenamiento y, la creación de nuevos LUNs/Volúmenes se tendrán que replicar al sitio de recuperación. Por consiguiente, la configuración de la cabina de almacenamiento tendrá que actualizarse para garantizar que el SRM es consciente de estas nuevas LUNs de almacenamiento.
En el siguiente ejemplo, he creado una nueva VLAN, llamada VLAN23 y toda una nueva serie de máquinas virtuales llamadas ctx-3, dc-3, fs-3, sql-3, y web-3. Estas maquinas virtuales fueron conectadas a la nueva VLAN. A los administradores de SRM del sitio protegido y de recuperación, se les asignó la tarea de asegurarse de que las maquinas virtuales están protegidas. Además, se identificó que el volumen VMFS llego a punto de saturación, tanto en términos de I/O como de espacio libre. Por lo tanto, una nueva LUN/volumen fue creada, y el equipo de almacenamiento se encargo de que esta nueva LUN fuera replicada al sito de recuperación.

201
Como usted puede imaginar, la configuración actual que tengo de SRM, no hace nada para estas nuevas máquinas virtuales. Estas maquinas no están cubiertas ni por el Array Manager, ni por las asignaciones de inventario, ni por el grupo de protección y ni, en consecuencia, por los planes de recuperación. Actualización del Array Manager Simplemente creando una nueva LUN/Volumen de almacenamiento en una cabina que se replica a otro lugar, no es suficiente para que la parte del Array Manager de SRM lo actualice. Al parecer, los SRAs de los vendedores no son configurados para escanear la cabina de almacenamiento en intervalos determinados para ver nuevas LUNs o volúmenes. Esto tiene sentido ya que la mayoría de SRAs son sólo archivos de script. También, mi experiencia me dice, que a veces simplemente haciendo un re-escaneo de la cabina tampoco es suficiente.
1. En el SRM del sitio de protección 2. Haga clic en el enlace Configure junto al Array Manager
3. Seleccione la entrada para Protection Stie Array Manager y seleccione Edit

202
4. Escriba el nombre de usuario y la contraseña utilizada para autenticarse con la cabina de almacenamiento y haga clic en Connect. A continuación, y después de haber completado la conexión, haga clic en Next
Repita este proceso para la cabina en el sitio de recuperación 5. En el último cuadro de diálogo haga clic en el botón Refresh Array - esto debe actualizar la cabina de almacenamiento y mostrar las nuevas LUN/Volúmenes

203
Actualización de las asignaciones de inventario La actualización de las asignaciones de inventario, dependen de la configuración que usted tenía inicialmente y de cómo estas se han alterado. Por ejemplo, en mi caso, sólo ha cambiado la configuración de red. No he creado ningún resource pool o carpetas nuevas.
Crear un nuevo grupo de protección Por cada nuevo DataStore que usted crea, tendrá que crear un nuevo grupo de protección para cubrir las máquinas virtuales.
1. En el SRM del sitio de protección 2. Seleccione el contenedor del Protection Group, y haga clic en el botón Create Protection Group
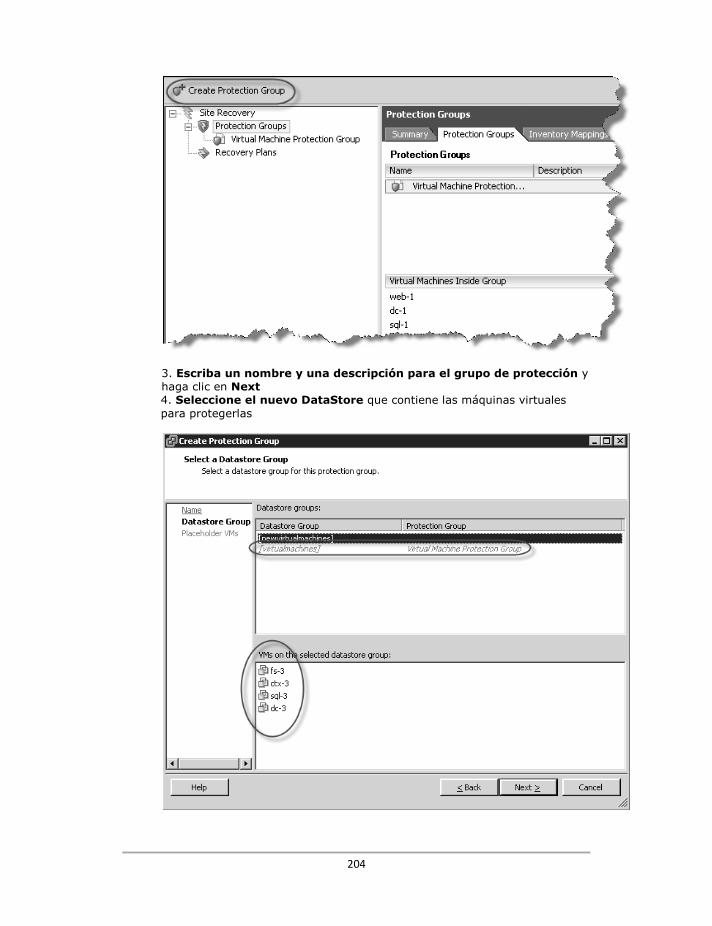
204
3. Escriba un nombre y una descripción para el grupo de protección y haga clic en Next 4. Seleccione el nuevo DataStore que contiene las máquinas virtuales para protegerlas

205
Nota: Note como el volumen VMFS existente está atenuado y en cursiva. Esto se debe a que este volumen ya está cubierto por un grupo de protección existente. Al seleccionar los otros volúmenes VMFS que convenientemente he llamado [newvirtualmachine] podemos ver las nuevas máquinas virtuales creadas en el nuevo almacenamiento. 5. Por último, seleccione una ubicación temporal para el almacenamiento del placeholder/shadow de las máquinas virtuales en el sitio de recuperación
Advertencia: La selección de una LUN local para la ubicación del archivo placeholder/shadow de la máquina virtual no es una gran idea. ¿Qué pasa si el servido ESX no está disponible? Es mucho mejor crear un pequeño volumen no replicado en el sitio de recuperación para almacenar estos archivos, al que puedan acceder todos los servidores ESX en el sitio de recuperación.
Actualización de planes de recuperación Ahora que hemos terminado con la actualización en la configuración del sitio de protección, es el momento de dirigir nuestra atención a los planes de recuperación. Nuestros planes actuales de recuperación sólo son conscientes de uno de nuestros grupos de protección, y los planes de recuperación requieren una actualización, o simplemente estos no tendrán ninguna referencia a las nuevas máquinas virtuales.

206
1. En el SRM en el sitio de recuperación 2. Elija su plan de recuperación 3. Seleccione la opción Edit Recovery Plan
4. Haga clic en Next para aceptar el nombre y descripción de plan de recuperación 5. Seleccione el nuevo grupo de protección para añadirlo a su plan de recuperación

207
6. Después de completar los requerimientos del plan de recuperación, usted debería ver que el nuevo DataStore/grupo de protección está incluido en el plan, y que las máquinas virtuales cubiertas por el grupo de protección son agregadas a la lista de prioridad "normal" para el apagado/encendido de las máquinas virtuales.
Nota: Esta configuración es cada vez más cerca a algo parecido al mundo real. En realidad es probable que tenga muchas máquinas virtuales almacenadas en muchos volúmenes VMFS. Después de todo, una de las recomendaciones de VMware es la de distribuir los discos virtuales a través de muchos Volúmenes LUN VMFS con el fin de distribuir los I/O del disco para evitar una saturación de las LUNs/Volúmenes con excesivas lecturas/escrituras. Por supuesto, habrá que tener mucho cuidado en la planificación y creación de la replicación y los grupos de protección, para garantizar que todos los archivos que componen una máquina virtual se estén replicando y estén incluidos en el plan de recuperación. Después de todo, una máquina virtual medio completa no va a ser de gran utilidad en el caso de un desastre.
Storage VMotion y grupos de protección VMware 3.5 ha liberado una nueva característica denominada "Storage VMotion". Esto le permite trasladar los archivos de una máquina virtual de un DataStore a otro, mientras que la máquina virtual está encendida, independientemente del tipo de almacenamiento (NFS, iSCSI, SAN) y del proveedor. Actualmente, Storage VMotion se lleva a cabo mediante el uso de secuencia de comandos con el RCLI que

208
se puede descargar desde la página web de VMware. Si bien la máquina virtual en el servidor ESX no es alterada, sus archivos serán movidos, y esto puede tener y, de hecho tiene consecuencias, para VMware SRM. Básicamente, hay tres escenarios:
• Escenario 1: La máquina virtual es movida desde una LUN no replicada a
otra LUN que se está replicando
• Escenario 2: La máquina virtual es movida desde una LUN que se está replicando a otra LUN que no se está replicando y por tanto ya no está cubierta por SRM
• Escenario 3: La máquina virtual es movida desde una LUN que se está replicando a otra LUN replicada por lo que la máquina virtual se mueve fuera del ámbito de aplicación de un grupo de protección a otro grupo de protección
Permítame explicarle y mostrare lo que ocurre en cada uno de los escenarios. El escenario 1 es muy sencillo, pues es una nueva máquina virtual de se acaba de crear. El grupo de protección tendrá un signo de exclamación amarillo que indica que la máquina virtual no tiene configurado su grupo de protección. En la pantalla siguiente, he creado una máquina virtual llamada web-3 y la he metido en una partición local de almacenamiento. Después, con Storage VMotion he movido la maquina virtual a un volumen VMFS llamado "virtualmachines2"
En el escenario 2, el resultado es algo desordenado. La eliminación de una máquina virtual en una LUN/volumen de almacenamiento replicada, producirá un mensaje de error en la pestaña de eventos y, la máquina virtual en el grupo de protección, se listara como "invalid"

209
Con el escenario 3, he visto mensajes de error similares. En este caso, la máquina virtual se traslada de un grupo de protección a otro pero hay que "eliminar" la maquina virtual del grupo de protección antiguo. En las pantallas siguientes se muestra el error:
En general, si el grupo de protección no re-configura correctamente el almacenamiento, seleccionando la máquina virtual "inválida" y haciendo clic en la opción "Remove Protection" arreglaría el error. En el caso del escenario 3, me he encontrado que primero he tenido que hacer clic en "Remove Protection" antes de seleccionar "Configure Protection" en el grupo de protección nuevo.

210
Máquinas virtuales almacenadas en múltiples Datastores VMFS Por supuesto, es posible almacenar archivos de máquinas virtuales en más de un DataStore VMFS. De hecho, si usted conoce bien Vi3, sabrá que en la realidad es una recomendación de VMware. Al almacenar nuestro disco de arranque, los logs, y los datos VMDK en diferentes LUNs, podremos mejorar la E/S del disco sustancialmente, reduciendo por consiguiente la contención en los discos. Incluso los discos de la máquina virtual más intensos, podrían ser almacenados en una LUN propia a tal efecto, y como tal, no tendría ningún tipo de contención de E/S a nivel de disco físico. Por tanto, le complacerá saber que SRM es compatible con una configuración de disco múltiple, siempre y cuando todos los datastores que la máquina virtual este utilizando, se repliquen en el sitio de recuperación. La ubicación del volumen VMFS del disco virtual es controlada por el asistente "Add" cuando se añaden discos a la máquina virtual.
Estos discos virtuales aparecen sin problemas en el sistema operativo invitado, por lo que desde Windows o cualquier otro sistema operativo invitado soportado, es imposible ver donde se encuentran físicamente los discos virtuales. En la situación anterior, he añadido otro volumen del VSA Lefthand Networks llamado "datavirtualmachines" para empezar a poner los discos de datos de las máquinas virtuales en el nuevo disco, como se muestra a continuación:

211
Todo lo que hice después, fue asegurarme de que el volumen VMFS "datavirtualmachines" se replicara exactamente en el mismo intervalo que mi volumen VMFS llamado virtual machines. Si usted tiene grupos de protección existentes, estos se actualizarán automáticamente para reflejar el hecho de que las máquinas virtuales están utilizando ahora múltiples datastores. Verá esto, si crea nuevos grupos de protección para cubrir los nuevos volúmenes VMFS. En la pantalla de abajo, usted puede ver como mi "grupo de protección de la máquina virtual", se ha actualizado para reflejar que hay máquinas virtuales en el volumen VMFS [virtualmachines], que también tienen archivos VDMK almacenados en [datavirtualmachines]:
Si usted está creando un grupo de protección nuevo, verá incluidos ambos volúmenes VMFS, si las máquinas virtuales están usando más de un DataStore VMFS:

212
Todo esto está muy bien. Sin embargo, pueden surgir problemas si estas relaciones entre el disco virtual y el DataStore cambian, después de haber creado los grupos de protección. Digamos que tiene dos volúmenes VMFS diferentes, en dos grupos de protección, y de momento no hay ninguna máquina virtual que use ambos grupos de almacenamiento. Usted se puede preguntar, ¿qué pasaría si después de que ha creado estos grupos de protección, modificó una máquina virtual de manera que abarcó los dos grupos de protección?
Eso es lo que he hecho en la situación siguiente. Tengo dos grupos de protección y, cada uno, está asignado a un solo DataStore. Uno se llama "grupo de protección de la máquina virtual" (que contiene un volumen VMFS llamado virtualmachines) y el otro se llama "segundo grupo de protección de la máquina virtual" (que contiene un volumen VMFS llamado secondvirtualmachines). Este tiene dos máquinas virtuales llamadas ctx-2 y web-3, como se muestra en la pantalla a continuación:
Después, he modificado las propiedades de ctx-2 añadiendo un segundo disco dentro del "grupo de protección de la máquina virtual". El efecto de esto es bastante notable. En primer lugar, el "segundo grupo de protección de la máquina virtual", se cambio a "invalid" y fue marcado con un signo de exclamación rojo a pesar de que la maquina virtual web-3 no se había modificado y seguía estando técnicamente en el mismo grupo. El segundo efecto, fue que web-3 y ctx-3 fueron

213
trasladados fuera de su grupo original de protección y añadidos a otro grupo de protección.
Aunque el efecto de esto no es bonito de ver, en cierta manera tiene sentido y es fácil de "corregir". Como ahora tenemos una máquina virtual que se extiende por más de un volumen VMFS, los dos volúmenes VMFS forman parte ahora del mismo grupo de protección (como hemos visto anteriormente en esta sección). Lo que es desagradable, no sólo la eliminación del grupo de protección invalido, si no que se dejan objetos huérfanos con un preocupante signo de exclamación rojo. La otra cuestión es que todas las máquinas virtuales, que una vez estuvieron protegidas, se quedan sin protección y estas tendrán que ser protegidas de nuevo y colocadas en el plan de recuperación correcto.
Para limpiar este escenario, usted debe borrar el grupo de protección no válido. Si usted no lo hace, recibirá un mensaje tipo "This virtual machine is already protected" cuando intente configurar la protección en las maquinas no configuradas.

214
Una vez que el grupo de protección antiguo se ha eliminado, puede configurar el grupo de protección para las máquinas virtuales que cambiaron de ubicación. Usted podría preguntarse sobre cuál es la lógica de marcar el grupo protección como no válido, y el desplazamiento de las máquinas virtuales a otros grupos de protección?. No he podido comprobar esto al 100%, pero creo que se basa en la creación del grupo de protección, el más antiguo es seleccionado en función de su valor MOREF (Managed Object Reference).
Máquinas virtuales con dispositivos en bruto/ asignaciones de disco En este libro, yo empecé con un único volumen VMFS y LUN en el sitio protegido. Es evidente que esta es una configuración muy simple, la cual fue elegida deliberadamente para mantener nuestro enfoque en el producto SRM. Quiero ahondar, en mayor detalle, en las configuraciones más avanzadas, como las características de VMware RDM (Raw Device Mappings) y configuraciones de disco múltiples, que reflejan más de cerca el mundo real y el uso de las tecnologías de VMware. En este momento, me enfrento un poco con un dilema. Mi dilema es el siguiente: ¿debería repetir la sección de almacenamiento de nuevo para demostrar el proceso de creación de una LUN/volumen en la cabina de almacenamiento?. También, debería documentar el proceso de agregar un disco RDM a una máquina virtual?. Al final pensé, que si usted como lector, ha llegado hasta aquí en la libro, usted debería ser capaz de volver a la sección de almacenamiento de esta libro y hacerlo por su cuenta. Por ejemplo, he añadido un disco RDM a mi máquina virtual ctx-1.

215
El tema importante a destacar aquí, en la segunda pantalla de la máquina virtual, es la sintaxis de la vmhba RDM en la MV protegida. Esto dice que el camino es vmhba32: 1:0:0. Quiero centrarme en las cuestiones específicas de cómo SRM maneja adiciones de nuevas instalaciones de almacenamiento en el sistema y la forma en la que se maneja la funcionalidad RDM. Después de crear el nuevo volumen/LUN, configurar

216
la replicación y añadir el disco RDM a la máquina virtual, el siguiente paso es asegurarse que el Array Manager ha descubierto el nuevo RDM.
Vale la pena comentar un hecho sobre RDMs y SRM. SRM resuelve dos "problemas" con RDM. Los archivos de asignación RDM tienen dos valores, uno es el LUN ID y otro es el SCSI ID. Estos valores almacenados con el propio archivo de mapeo, es más probable que sean totalmente diferentes en la cabina del sitio de recuperación. SRM fija estas referencias para que la máquina virtual pueda arrancar y usted pueda ver sus datos. Si usted no estuviera usando SRM y estuviera ejecutando su plan de recuperación de forma manual, tendría que eliminar el archivo de asignación RDM y añadirlo a la máquina virtual de recuperación. Si no hace esto, cuando la máquina virtual replicada fuese encendida, esta apuntaría al ID SCSI y LUN ID erróneos.
Note en esta pantalla de una máquina virtual de "recuperación", que el mapeo ha sido "corregido" por SRM y contiene la sintaxis vmhba correcta de vmhba32: 18.0.0. Si un nuevo volumen se crea, ya sea un volumen VMFS o volumen RDM, es importante re-escanear la configuración de la cabina en el sitio protegido para asegurarse de que esta es descubierta por SRM y SRA.
1. Inicie sesión con el cliente Vi en el vCenter del sitio protegido 2. Haga clic en el icono Site Recovery 3. En la pestaña Summary, en el panel Protection Setup - haga clic en Configure al lado de Array Managers Option 4. Haga clic en Next 5. Haga clic en Next otra vez 6. En el cuadro de diálogo Review Replicated Datastores, haga clic en el botón Rescan Arrays

217
Nota: En el asistente "Array Manager" de SRM, debería ver que el RDM replicado aparece en la lista:
Nota: Es posible que desee saber qué sucede si crea una nueva máquina virtual que contiene una mapeo RDM a una LUN que no se replica. Si usted trata de proteger dicha máquina virtual, SRM se dará cuenta de que usted está

218
tratando de proteger una máquina virtual que tiene acceso a una LUN/volumen que es inaccesible en el sitio de recuperación. Cuando intenta agregar esa máquina virtual al grupo de protección se encontrara con este mensaje de error:
He creado este error en CTX-1, cuando seleccione una LUN/volumen que no se estaba replicando a mi sitio de recuperación. Y he resuelto el problema seleccionando la LUN correcta. Este mismo error se puede producir si el Array Manager no puede encontrar el RDM replicado después de un "rescan" de la cabina". El error también puede ocurrir si tiene una VM con muchos archivos VMDK almacenados en LUNs que no se está replicando.
Múltiples grupos de protección y múltiples planes de recuperación Esta sección es bastante corta, pero puede ser la más importante para usted. Ahora que usted tiene una idea muy buena de todos los componentes de SRM, es el momento para mí de demostrarle lo que es una configuración muy popular en el mundo real. Es perfectamente posible, de hecho yo diría que es muy conveniente, disponer de muchos grupos de protección y planes de recuperación. Si recuerda, un grupo de protección está íntimamente relacionado con las LUNs/volúmenes que usted esta replicando. Un modelo de esto, que ya se sugirió anteriormente en el libro, es la agrupación de sus LUNs/volúmenes por el uso de aplicaciones para que estas puedan ser fácilmente seleccionadas por un grupo de protección en SRM. He creado esta situación en mi entorno de laboratorio para darle una idea de cómo son este tipo de configuraciones. No tengo la intención de que reproduzca esta configuración si ha seguido este libro paso a paso. Es solo para darle una idea de cómo es una configuración de SRM en "producción". Múltiples DataStores En el mundo real es muy probable que usted ponga sus máquinas virtuales en diferentes datastores para reflejar que esos LUNs/volúmenes representan un número de discos y niveles de RAID diferentes. Para reflejar este tipo de configuración, he creado cinco volúmenes llamados ad, Citrix, file, sql y web en el VSA Lefthand Networks.

219
Volúmenes con formato VMFS En vCenter, he re-escaneado cada unos de mis servidores ESX y, a continuación, he procedido a formatear estos volúmenes con formato VMFS, usando nombres de volumen y DataStore que reflejan su funcionalidad.
Además, he vuelto a ejecutar el asistente "Array Managers" en el sitio protegido para garantizar que SRM es consciente de que estas LUNs/volúmenes se replicaron y contienen las máquinas virtuales.

220
Actualización y reestructuración de la estructura de resource pools y carpetas En el sitio protegido y el sitio de recuperación, he reconfigurado mi carpeta y resource pools, a fin de reflejar el hecho de que estos sistemas diferentes requieren diferentes límites y reservas para garantizar que funcionan con un rendimiento aceptable. A su vez, esta estructura de carpetas y resource pools se duplicó en el sitio de recuperación. En el sitio de protección:

221
En el sitio de recuperación:
Como consecuencia, mi "asignaciones de inventario" necesitaron ser actualizadas para reflejar esta nueva estructura de carpetas y resource pool.
Múltiples grupos de protección Los cambios en el almacenamiento descritos en esta sección, se reflejaron en los grupos de protección que he creado. Ahora tendré cinco grupos de protección que reflejan los cinco tipos de máquinas virtuales. Cuando cree el grupo de protección de Citrix, seleccione el volumen VMFS de Citrix que cree para esa aplicación.
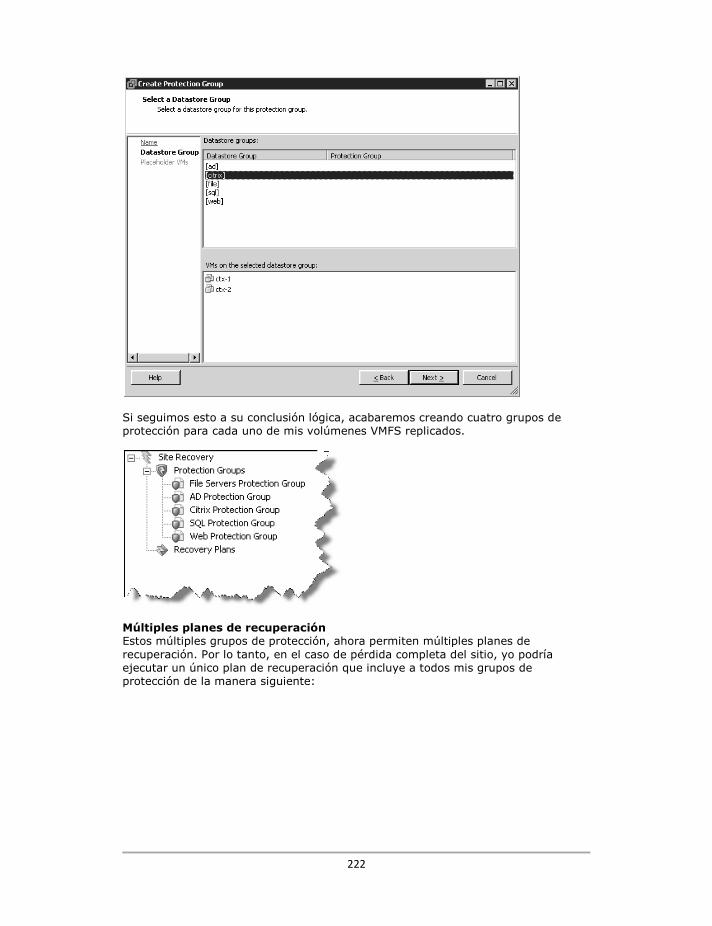
222
Si seguimos esto a su conclusión lógica, acabaremos creando cuatro grupos de protección para cada uno de mis volúmenes VMFS replicados.
Múltiples planes de recuperación Estos múltiples grupos de protección, ahora permiten múltiples planes de recuperación. Por lo tanto, en el caso de pérdida completa del sitio, yo podría ejecutar un único plan de recuperación que incluye a todos mis grupos de protección de la manera siguiente:

223
o, alternativamente, podría tener una serie de planes de recuperación que podría ejecutar en cualquier orden que quisiera, o simplemente utilizarlos para probar un failover de un conjunto de aplicaciones en particular.
Al final de este proceso, tendré una serie de planes de recuperación que se podría utilizar para cada una de las aplicaciones y también para poner a prueba un plan de recuperación completo. Sería muy probable que en este caso, cada plan de recuperación tuviera que ejecutar una recuperación de mis controladores de

224
dominio, pues tener el dominio de Windows disponible es un eje fundamental en la mayoría de las organizaciones.
Resumen Como puede ver, la forma más poderosa y sensata de utilizar SRM, es asegurarse de que diferentes máquinas virtuales, que reflejan los grandes componentes de la infraestructura en la empresa, están separadas a nivel de almacenamiento. Desde una perspectiva de SRM, esto significa que podemos separarlas lógicamente en distintos grupos de protección y, a continuación, utilizar los grupos de protección en nuestros planes de recuperación. Es infinitamente más funcional, que usar un solo volumen VMFS global y sólo uno o dos planes de recuperación. La intención en esta sección, no fue tratar de cambiar mi configuración, sino ilustrar lo que es una configuración de SRM en el "mundo real". Pude hacer todos estos cambios sin tener que recurrir a apagar las máquinas virtuales, mediante el uso de Storage VMotion, para reubicar a mis máquinas virtuales en la nueva LUNs/Volúmenes.
El botón reparación del Array Manager Si selecciona los planes de recuperación en el SRM del sitio de recuperación, verá que usted tiene un botón "Repair Array Managers":
Al igual que yo, usted podría encontrar este botón algo curioso, ya que la configuración Array Managers se fija en el sitio protegido y no en el sitio de recuperación. Puede que como yo, usted se pregunte en qué circunstancias la cabina tiene que estar para necesitar la "reparación" como tal. Me llevó algún tiempo averiguar un caso de uso de esta característica, porque esto no está especialmente incluido en la documentación de VMware, aunque esto es muy probable que cambie.

225
Este botón no repara la cabina de almacenamiento, sino que le permite reparar la configuración de la comunicación de la cabina con el sitio de recuperación. Supongamos que el sitio protegido ha desaparecido debido a una catástrofe. Usted entonces se mueve al sitio de recuperación para invocar su plan de recuperación, sólo para descubrir que hay un error en la configuración del SRM/SRA que se comunica con la cabina de almacenamiento en el sitio de recuperación. Ejemplos de esto incluye:
• La primera IP utilizada para comunicarse con la cabina es buena, pero la primera controlador no está disponible. Cuando el SRA va a utilizar la segunda controladora, falla porque el administrador SRM escribió mal el IP o, de hecho, falla en escribir la dirección IP especifica.
• Una persona en el sitio de recuperación ha cambiado la dirección IP utilizada
para comunicar con el almacenamiento en el sitio de recuperación, sin informar al administrador de SRM.
• Una persona en el sitio de recuperación ha cambiado el nombre de usuario o
la contraseña utilizada para autenticarse con la cabina. Al hacer clic en el botón Repair Array Managers, se abrirá un cuadro de diálogo estándar del "Array Managers" en el SRM del sitio de recuperación, el cual le permitirá corregir estos problemas. Usted no necesitara utilizar esta interfaz, si la cabina del sitio protegido esta dispone, como es el caso en una situación planificada de DR.
Conclusión Para mí este es uno de los capítulos más grandes porque realmente muestra lo que el SRM es capaz y, quizás también, donde se encuentran sus limitaciones. Una cosa que me pareció un poco molesto es que no hay opción de arrastrar y soltar para reordenar máquinas virtuales en una lista de prioridades y, el hacer clic en las flechas de arriba y abajo para cada máquina virtual llega a ser bastante molesto. Espero que haya cogido una buena idea sobre la gestión a largo plazo en SRM. Después de todo, las máquinas virtuales no son automáticamente protegidas por el simple hecho de ser almacenadas en volúmenes VMFS replicados. Además, vimos cómo otros cambios en el sitio de protección tienen un impacto en el servidor SRM, como cambiar el nombre del datacenter, clusters, carpetas, redes y datastores, y en la mayor parte, el SRM hace un buen trabajo mantenimiento los metadatos actualizados en el sitio de recuperación. Tal vez, merezca la pena destacar las dependencias dentro del producto SRM, especialmente entre los grupos de protección y planes de recuperación. Como ha podido ver, la eliminación de los grupos de protección es un poco peligrosa, a pesar de la relativa facilidad con que pueden ser re-creados. Esto desprotege todas las máquinas virtuales afectadas por el grupo de protección y elimina las maquinas virtuales de sus planes de recuperación. La recreación de todos los grupos de protección no pone las máquinas virtuales en su ubicación original, lo que obliga a recrear todos los ajustes asociados con sus planes de recuperación. Lo que se podría hacer con los planes de recuperación, es tener una forma de exportar e importar estos. De modo que, esas configuraciones no se perderían. De hecho, sería bueno tener una función de copia para los planes de recuperación para poder crear cualquier número de planes base y poder establecer todos los posibles enfoques para la creación de un plan de DR.

226
Espero que haya visto que hay una serie de eventos diferentes que pueden ocurrir, a los que SRM puede reaccionar con distintos grados de automatización. Como se verá en el próximo capítulo, es posible configurar alarmas que digan si hay una máquina virtual que necesita protección.

227
Capítulo 7: Alarmas, Exportando el Histórico y el Control de Acceso

228
Usted se pondrá muy contento de saber que, a diferencia de vCenter, SRM tiene un gran número de alarmas configurables y también una función de información muy útil. Las alarmas vienen bien definidas y con un montón de condiciones que podemos controlar y cambiar. Esta es una mejora muy esperada de los productos de VMware, que en el pasado han tenido, bastante limitada, la funcionalidad de presentación de informes de alarmas. La acción que podemos ejecutar en caso de una alarma que se activa, es todavía muy limitada; enviar un correo electrónico, enviar una trama SMNP o ejecutar un script. Quizás valga la pena destacar algo muy obvio; SMTP y SNMP son servicios de red. Estos servicios pueden no estar disponibles durante un desastre real y como tal es posible que no desee depender demasiado de ellos. Además, usted encontrará que SRM, no tiene una pestaña de "eventos" propia. En su lugar, SRM incluye los eventos en el log de eventos de diario. Si ha asignado roles y permisos utilizados para SRM, debería ser capaz de filtrar estas cuentas, por lo que debería mejorar su trazabilidad. Después de que haya explicado el "Control de acceso" (Access Control), incluiré algunas pantallas de filtrado/búsqueda para ilustrar lo que quiero decir.
Descripción alarmas Las alarmas abarcan una amplia gama de posibles acontecimientos, incluyendo, pero no limitado, a las condiciones siguientes:
• Recursos disponibles bajos o de disco o CPU o Memoria
• Situación del sitio de recuperación o el sitio de recuperación SRM esta encendido/apagado o No es posible hacerle un ping o Creado/Borrado
• Creación de grupos de protección y máquinas virtuales Shadow • Estado de los planes de recuperación
o Creado o Destruido o Modificado o a la espera de mensajes
• Estado de la licencia • Estado de los permisos • Conectividad SAN
Nota: Los umbrales de alarmas para el disco, CPU y memoria no se establecen dentro de la GUI, sino en el archivo vmwar-dr.xml. Como era de esperar, algunas de las alarmas son más útiles que otras y pueden, en algunos aspectos, facilitar la correcta utilización o la configuración del producto SRM. Existen algunos casos notables. Usted se dará cuenta de que tanto, el sitio de recuperación como el sitio de protección, tienen las mismas alarmas, con lo que la configuración de ambos sitios sería adecuada en una configuración bidireccional. He aquí algunos ejemplos
Ejemplo1: La creación de una nueva máquina virtual en un volumen VMFS que no se replica automáticamente, no añade la máquina virtual al grupo protección ni al

229
plan de recuperación. Un correo electrónico al administrador del SRM podría ser útil para que el administrador lleve a cabo las acciones apropiadas. Ejemplo 2: Aunque los planes de recuperación tienen una característica de notificación de mensajes, sólo verá el mensaje si tiene abierto el cliente Vi con el plug-in de "Site Recovery Manager". También sería conveniente enviar un correo electrónico a la persona. Ejemplo 3: El hecho de no recibir un ping o respuesta desde el sitio de recuperación, podría ser un indicio de una mala configuración del producto SRM Ejemplo 4: SRM requiere conectividad SAN, y ciclos de replicación fiable. El fallo en la capa de almacenamiento, puede provocar la uso del Plan DR o indicar un error de configuración. No tiene sentido tener SRM funcionando, cuando la cabina de almacenamiento ha fallado. Creación de una nueva máquina virtual que debe protegerse con una alarma (Script) Nota: A diferencia de los scripts ejecutados en el plan de recuperación, los scripts son ejecutados, bien por el vCenter del sitio protegido, o bien por el vCenter del sitio de recuperación. Como tales, los scripts deben ser creados y almacenados en el vCenter responsable del evento. Este puede ser identificado por el uso de la palabra "protegido" o "recuperación" en el nombre del evento.
1. En el sitio protegido, haga clic en el botón SRM 2. Seleccione la pestaña de alarma y haga doble clic en la alarma llamada VM Added
3. En el cuadro de diálogo Edit Alarm, seleccione la pestaña Actions 4. Haga clic en el botón Add 5. De la lista desplegable, seleccione Run a Script y escriba: C:\Windows\System32\cmd.exe /c c:\newvmscript.bat

230
Nota: Una condición puede tener muchas acciones, así que es posible crear una condición que envía un correo electrónico, una trama smnp y ejecutar un script. 6. En el sitio protegido, cree un script llamado newvmscript.bat, con este contenido: @ echo off net send 192.168.2.198 Una nueva máquina virtual se ha creado en el sitio de protección. Los grupos de protección necesitaran incluir la actualización de esta nueva máquina virtual en sus planes de recuperación. Nota: Este script sólo se diseñó a modo de ejemplo. Yo no recomiendo el uso del servicio Messenger en producción.
Creación de un mensaje de alarma (SNMP) 1. En el sitio de recuperación, haga clic en el botón SRM 2. Seleccione la pestaña de alarma y haga doble clic en la alarma llamada Recovery Profile Prompt Display
3. En el cuadro de diálogo Edit alarm, seleccione la pestaña de Actions 4. Haga clic en el botón Add 5. De la lista desplegable, seleccione Send notification trap Nota: Por defecto, si usted ejecuta una herramienta de administración SNMP en el vCenter en la comunidad "publica", recibirá las notificaciones. Para probar esta funcionalidad, he usado la utilidad gratuita llamada TrapReceiver.

231
VMware también usa esta utilidad en sus cursos de formación para probar/demostrar la funcionalidad SMNP sin necesidad de configurar algo más complicado como HP Openveiw. http://www.trapreceiver.com/ La imagen adjunta muestra el resultado de dicha alarma enviando tramas al Receptor.

232
Creación de un servicio de alarma SRM (SMTP) 1. En el sitio protegido, haga clic en el botón SRM 2. Seleccione la pestaña de alarma y haga doble clic en la alarma llamada Remote Site Down y Remote Site Ping Failed
3. En el cuadro de diálogo Edit Alarm, y seleccione la pestaña de Actions 4. Haga clic en el botón Add 5. De la lista desplegable, seleccione Send a notification email, y en el tipo seleccione destination/recipient email

233
Nota: En el cuadro de edición, escriba una dirección de correo electrónico de un individuo o un grupo que quiere que reciba el mensaje de correo electrónico. Una vez más, la configuración del servicio SMTP se encuentra en el menú Administración del vCenter, bajo la sección SMNP del cuadro de diálogo.

234
Nota: Los mensajes de correo electrónico serán enviados cuando el mensaje "Not Responding" aparece en la pestaña Summanry de SRM.
Nota:

235
Los mensajes de correo electrónico reales producidos con esta alarma puede ser un poco "crípticos", especialmente en la parte que dice "Old Status" y "New Status", pero hacen su función como se puede ver a continuación:
Exportando & Historia
Es posible exportar un plan de recuperación desde el SRM y, también exportar los resultados de un plan de recuperación. El proceso de exportación puede incluir los siguientes formatos:
• Word • Excel • Página Web • CSV • XML
Aunque los planes de recuperación pueden ser "exportados" fuera del SRM, estos no pueden ser importados en el SRM. La intención del proceso de exportación, está

236
en la posibilidad de darle una "copia" del plan de recuperación para que lo pueda compartir y distribuir sin que necesariamente estas personas necesiten acceso al SRM. Advertencia: Por defecto, SRM está tratando de abrir el archivo exportado en el lugar donde usted está ejecutando el cliente Vi. Si el sistema donde está ejecutando el cliente Vi Cliente, no dispone de Microsoft Word/Excel, este proceso de exportación fallara. No obstante el plan se exporta, pero el sistema no podrá a abrir el archivo. En mis experimentos con Microsoft Word Viewer 2007 funciono, pero con Microsoft Excel Viewer 2007 no fue así. Además, Microsoft Excel View no puede abrir el formato CSV de forma adecuada. Me pareció que necesitaba la versión completa de Excel para abrir estos archivos con éxito. El archivo XLS viene con el formato de excel, pero como era de esperar el fichero CSV no viene con ningún formato.
Exportación de planes de recuperación
1. En el SRM del sitio de recuperación, seleccione su plan de recuperación 2. Haga clic en el icono Export Recovery Plan
3. Desde el cuadro de diálogo Save As, seleccione el tipo de formato

237
Nota: El resultado del plan exportado se parece a esto:
Plan de Recuperación de Historia SRM tiene una pestaña de historia (history), la cual muestra el éxito, fallo, y resúmenes de error y, le permite ver ejecuciones anteriores del plan de recuperación en formato html, o exportarlos a otros formatos, como se indicó anteriormente.
1. En el SRM del sitio de recuperación, seleccione un plan de recuperación 2. Haga clic en la pestaña History, seleccione una ejecución previamente de un plan de recuperación y haga clic en View o Export
Nota: En la pantalla siguiente, he mostrado la historia de uno de mis resultados de error en formato html.

238
Control de Acceso Los permisos, control de acceso y gestión del cambio, son parte integrante de la mayoría de los entornos corporativos. Hasta ahora, y para todas las tareas, hemos estado utilizando la cuenta de "administrador" por defecto en la gestión de SRM. Esto no es sólo poco realista, sino que también es muy peligroso, especialmente en el ámbito de DR. El DR es una "empresa peligrosa" y no debe ser activado accidentalmente o a la ligera. Con los permisos correctamente configurados, debería permitir al producto ser configurado y probado por separado, de un proceso real de invocación de DR. Aunque se trata de una decisión ejecutiva de muy alto nivel, la gestión del proceso debe estar en manos de personal de TI muy competentes, capacitados y bien pagados. SRM introduce toda una serie de nuevos roles en vCenter y, como los derechos y privilegios del vCenter, el SRM muestra la misma naturaleza "jerárquica" que el vCenter. Una capa adicional de complejidad se añade al tener dos sistemas de vCenter (el vCenter del sitio protegido y en el sitio de recuperación), que se delegan por separado. Vale la pena decir que, en una configuración bidireccional, que estos permisos tienen que ser mutuamente recíprocos, para permitir a las personas adecuadas llevar a cabo sus tareas adecuadamente. Al igual que con las acciones de las alerta, el control de acceso se basa en la autenticación de los servicios. Para muchos esto significa Microsoft Active Directory y el DNS de Microsoft. Si estos servicios no están disponibles o no funcionan, no podrá ni siquiera ser capaz de acceder al vCenter para activar su plan de recuperación. Es necesario una adecuada planificación y preparación de estos servicios para evitar que esto ocurra y, puede quizás desear desarrollar un Plan B, donde un plan de recuperación podría ser activado incluso sin la necesidad de Active Directory de Microsoft. Dependiendo de sus políticas de empresa, esto podría incluir el uso de controladores de dominios físicos o virtuales, los cuales no están incluidos en el producto SRM. Los nuevos roles de Site Recover Manager(SRM) son:
• Protection Groups Administrator • Protection SRM Administrator

239
• Protection Virtual Machine Administrator • Recovery DataCenter Administrator • Recovery Host Administrator • Recovery Inventory Administrator • Recovery Plans Administrator • Recovery SRM Administrator • Recovery Virtual Machines Administrator
En el momento de escribir este libro, había poca información acerca de los privilegios asignados a estas funciones. No obstante, puede fácilmente averiguarlo, haciendo clic en cada role y comprobando los privilegios a mano, pero creo que hacer esto, con el fin de incorporarlos en este libro, sería bastante tedioso. En lugar de ello, pienso que podría ser más valioso para nosotros pensar sobre los cambios que se producen en el entorno de SRM para que nos ayude a reflexionar sobre los privilegios necesarios. En el caso que se produzcan nuevas instalaciones de almacenamiento, se debería crear un nuevo grupo de protección. Del mismo modo, al crear nuevas máquinas virtuales, estas deben estar correctamente configuradas para su protección. También queremos permitir a alguien, crear, modificar y poner a prueba los planes de recuperación, según cambien nuestras necesidades. En el siguiente escenario, voy a crear cuatro usuarios - Brian, Ken, Carla y Daniel - y asignarles a un grupo en Active Directory llamado Administradores SRM. Después, iniciare sesión como cada uno de estos usuarios para probar la configuración y validare que cada usuario puede llevar a cabo las tareas diarias que tienen que hacer.
La configuración permitirá que estos cuatro usuarios gestionen una configuración SRM unidireccional o activo/pasivo. En otras palabras, estos usuarios se limitarán simplemente a la creación y ejecución de planes de recuperación en el sitio de recuperación. En parte, lo que estoy reproduciendo en este libro, es un ejemplo de los permisos y derechos mencionados en la guía oficial de la administración de VMware SRM. A continuación, se muestra una tabla que resume los permisos necesarios para lograr esta configuración.
At the Protection Site Role Location in VirtualCenter Propagate? Read‐only VirtualCenter Hosts & Clusters NO Read-only Datacenters NO Protection Virtual Machine VirtualCenter host level1 YES

240
Administrator Protection SRM Administrator Site Recovery Root NO Protection Groups Administrator SRM Protection Groups Yes
At the Recovery Site Role Location in VirtualCenter Propagate? Recovery Inventory Administrator
VirtualCenter Hosts & Clusters NO
Recovery Datacenter Administrator
Datacenters NO
Recovery Host Administrator VirtualCenter host level NO Recovery Virtual Machine Administrator
Resource pools and VirtualCenter folders2
YES
Recovery SRM Administrator Site Recovery Root NO Recovery Plans Administrator SRM Recovery Plans level YES
1. Any object containing ESX hosts such as a cluster or folder. Use this method rather than setting the permission on per ESX host basis 2. I think much depends on how you structure your resource pools and folders. Do you create resource pools within resource pools; do you have a top-level folder from within which all other folders are created; are you using resource pools with DRS, as such perhaps you could set this privilege on the cluster (aka the “root resource pool”)
Como puede ver, hay un número significativo de los roles que hemos de utilizar (7 en total) en diferentes lugares (7 en total) y que algunos requieren la "herencia" o "propagación" (4), aunque la mayoría no lo necesitan (7). Sería muy interesante tener en SRM, una funcionalidad tipo "asistente de delegación", que permita establecer estos por nosotros! Advertencia: Como puede ver, los derechos de usuarios de SRM no son de por sí suficientes. Si usted sólo tiene derecho a parte del SRM en vCenter, ni siquiera será capaz de iniciar sesión a través del cliente Vi. Usted tendrá que conceder a sus usuarios y grupos, al menos, derechos de "Read Only" en alguna parte del inventario de vCenter para que el proceso de login tenga éxito. Configuración de un grupo Administrador SRM (sitio de protección)
1. Entrar en el vCenter del sitio protegido 2. Seleccione vCenter Host & Clusters nodo, y haga clic en la pestaña Permissions
3. Haga clic con el botón derecho debajo de los administradores y seleccione Add Permissions 4. A continuación, haga clic en Add button para añadir usuarios o grupos 5. Luego seleccione el role Read Only 6. IMPORTANTE: Desmarque la casilla de Propagate to Child

241
7. A continuación, seleccione su datacenter(s), y asigne el role Read Only 8. IMPORTANTE: Desmarque la casilla Propagate to child
Nota: Si usted tiene muchos datacenters, quizás quiera incluir estos en carpetas, por lo que podría controlar los permisos más eficientemente.

242
9. A continuación, seleccione su clúster DRS/HA, y asigne el role Protection Virtual Machine Administrator 10. PRECAUCIÓN: Deje seleccionada la opción Propagate to child objects
Nota: A falta de un clúster DRS/HA puede utilizar carpetas para agrupar los servidores ESX y evitar así el establecimiento de este permiso para cada servidor ESX. 11. Luego seleccione SRM View, seleccione Site Recovery nodo y seleccione el role Protection SRM Administrator 12. IMPORTANTE: Desmarque la casilla Progapate to child
13. Y por último, dentro del vCenter en el sitio protegido, seleccione el protección grupo y asigne el role Protection Groups Administrador 14. PRECAUCIÓN: Deje seleccionada la opción Propagate to child
MUY IMPORTANTE Espero que haya puesto los roles en la ubicación correcta, con la opción de fijar la herencia correcta! Lamentablemente, usted no ha terminado todavía. Recuerda las personas que trabajan en el sitio de protección?, necesitan derechos en el sitio de recuperación para crear y probar sus planes de recuperación.
Configuración de un grupo administrador SRM (sitio de recuperación) 1. Inicie sesión en el vCenter del sitio de recuperación

243
2. Seleccione VirtualCenter Host & Clusters nodo para asignar el role Recovery Inventory Administrator 3. IMPORTANTE: Desmarque la casilla Propagate to child
4. Seleccione datacenter(s) y asigne el role Recovery DataCenter Administrator 5. IMPORTANTE: Desmarque la casilla Propagate to child
6. Seleccione clúster(s) y asigne el role Recovery Host Administrator 7. IMPORTANTE: Desmarque la casilla Propagate to child
8. Seleccione resource pool(s) y folders para asignar el role Recovery Virtual Machine Administrator PRECAUCIÓN: Deje seleccionada la casilla Propagate to child objects

244
9. Luego seleccione SRM view, seleccione Site Recovery nodo y seleccione el role Recovery SRM Administrator 10. IMPORTANTE: Desmarque la casilla Propagate to child
11. Y finalmente, seleccione Recovery Plans nodo y asigne el role Recovery Plans Administrator 12. PRECAUCIÓN: Deje seleccionada la casilla Propagate to child objects
Nota: Eso es todo - ya esta! Ahora seguro que está probablemente deseando tener algún tipo de asistente de delegación. Estoy de acuerdo con usted!!!
Probando sus permisos Una cosa es configurar los permisos, y otra es verlos en acción. Personalmente, desde que empecé en el mundo de TI, en los años 90, siempre he creado una cuenta prueba con la que acceder para testear mis permisos. Es sólo para estar 100% seguro y para garantizar que no hay sorpresas desagradables. Si usted configuro los permisos como lo hicimos con anterioridad, encontrara lo siguiente en el sitio protegido:
• No hay posibilidad de crear máquinas virtuales

245
• No hay posibilidad de crear planes de recuperación
Y en el sitio de recuperación:
• Vistas restringidas sólo para la recuperación de máquinas virtuales

246
• No hay posibilidad de crear grupos de protección
Algunas limitaciones en los permisos Algo que puede querer hacer es, separar los privilegios de los planes de pruebas, de los planes de recuperación en funcionamiento. Lamentablemente, aun cuando usted crea un role personalizado con "Recovery Plans Administrator", el privilegio de poder "ejecutar" los planes de recuperación, incluyen tanto el proceso de prueba como el proceso de ejecutar. El único privilegio que puede establecer es, el derecho de crear, modificar y eliminar planes de recuperación, pero no incluye el privilegio de prueba o ejecución. Las dos pantallas que aparecen a continuación ilustran este punto:

247
Los archivos de registro de VMware SRM Al igual que con todo el software, VMware SRM tiene archivos de registro internos. Estos archivos se encuentran en esta ruta del directorio siguiente: C: \ Documents and Settings \ All Users \ Application Data \ VMware \ VMware Site Recovery Manager \ Logs La intención de estos registros o logs, no es para su uso diario, sino para usarlos como de soporte de VMware. Si usted tiene alguna vez, un problema grave con SRM que no puede resolver, a veces, buscar en estos archivos puede resultar ser muy útil.
El siguiente archivo de registro, muestra lo que sucede cuando dos máquinas virtuales que están protegidas, fallan a causa de una asignación de inventario no válida. En el archivo de registro no se muestran nombres "amigables" del vCenter, sino más bien los nombres menos "amigables" MOREF (Managed Object Reference ), los cuales se expresan en este formato - vm-275, network-288 y resgroup-895.

248
[2008-09-30 17:36:04.464 'DrInventoryMapper: site-28' 2820 verbose] Recommendation for VM 'vm-725': (dr.primary.MappingRecommendation) { [#3] dynamicType = <unset>, [#3] vm = 'vim.VirtualMachine:vm-725', [#3] folder = <unset>, [#3] networkRecommendations = (dr.primary.MappingRecommendation.NetworkRecommendation) [ [#3] (dr.primary.MappingRecommendation.NetworkRecommendation) { [#3] dynamicType = <unset>, [#3] primaryNetwork = 'vim.Network:network-288', [#3] secondaryNetwork = 'vim.Network:network-215', [#3] } [#3] ], [#3] resourcePool = 'vim.ResourcePool:resgroup-895', [#3] conflict = false, [#3] } [2008-09-30 17:36:04.464 'DrInventoryMapper: site-28' 2820 verbose] Recommendation for VM 'vm-727': (dr.primary.MappingRecommendation) { [#3] dynamicType = <unset>, [#3] vm = 'vim.VirtualMachine:vm-727', [#3] folder = <unset>, [#3] networkRecommendations = (dr.primary.MappingRecommendation.NetworkRecommendation) [ [#3] (dr.primary.MappingRecommendation.NetworkRecommendation) { [#3] dynamicType = <unset>, [#3] primaryNetwork = 'vim.Network:network-289', [#3] secondaryNetwork = 'vim.Network:network-214', [#3] } [#3] ], [#3] resourcePool = 'vim.ResourcePool:resgroup-895', [#3] conflict = false, [#3] } [2008-09-30 17:36:04.464 'DrInventoryMapper: site-28' 2820 verbose] Made recommendations for 2 VMs in 0 seconds El error específico aquí, es que las dos máquinas virtuales están en una carpeta que no había sido asignada adecuadamente, y ello ha dado lugar a un signo de exclamación amarillo en el sitio de protección y, por lo tanto, en fallo al crear los ficheros placeholder en el sitio de recuperación.
Conclusiones
Como se ha podido ver, SRM extiende significativamente las alarmas del vCenter y las funcionalidades de informes y control de acceso. Y aunque las alarmas no pueden tener opciones configurables, usted puede ver en vCenter el gran número de alarmas o condiciones, lo que parece a veces un aspecto poco desarrollado en el producto de vCenter. Una vez más, simplemente la capacidad de generar informes en SRM, sería de gran utilidad. Por un lado, la inversión en el producto vCenter por VMware está pagando dividendos, permitiendo que la capacidad de sus propios desarrolladores puedan ampliar su funcionalidad con plug-ins. De manera similar, las ediciones recientes de las aplicaciones de VMware estables, como VDM (Virtual

249
Desktop Manager), necesitan también unirse a la "fiesta". En este sentido, VMware SRM ha encendido una antorcha para que otros puedan seguir el camino.
Llegamos más o menos a la conclusión de este tipo de configuración. Hasta ahora, este libro se ha adaptado a un escenario en el que su organización tiene un sitio dedicado exclusivamente para fines de recuperación, y ahora quiero cambiar esta situación en donde, dos centros de datos tienen CPU, memoria y capacidad de disco libre para que puedan corresponder a la recuperación de ambos centros de datos. Una situación en la que Chicago es el sitio de recuperación de Nueva York, y Nueva York es el sitio de recuperación de Chicago, o en donde Reading es el sitio de recuperación de Londres, y Londres es el sitio de recuperación para Reading. Para la gran empresa, esto ofrece la oportunidad de ahorrar mucho dinero, especialmente con las importantes y valiosas licencias de VMware.

250
Capítulo 8: Configuraciones Bi-direccionales

251
Hasta ahora este libro se ha centrado en una situación en la que la recuperación del sitio está dedicada a los efectos de la recuperación y se podría fácilmente contratar espacio en rack suministrado por un tercero. Esto es muy popular en organizaciones más pequeñas, donde quizás sólo tiene un centro de datos, o sus centros de datos son tan pequeños que no tienen los recursos necesarios para ser un centro de producción y recuperación al mismo tiempo. Al igual que ocurre con redundancias convencionales, este modelo de sitio de recuperación "dedicado" no es especialmente eficaz ya que estamos "perdiendo" valiosos recursos financieros para protegernos de un evento catastrófico, que quizás nunca suceda. Al igual que con todas las pólizas de seguros, el seguro del hogar y el seguro de su coche, esto es una pérdida de dinero. Hasta que usted tiene la mala suerte de que se encuentra un día con que han robado en su casa y un ladrón roba su coche y lo quema. Debido al coste de licencias y otros costes asociados, es mucho más eficiente "parear" dos o más centros de datos para ofrecer recursos DR entre sí. Esta configuración se denomina en la documentación oficial de VMware SRM, configuración bidireccional. He dejado este tipo de configuración para el final del libro, no porque pensara que la mayoría de la gente no estaría interesada, sino por tres razones principales. En primer lugar, quise aclarar al100% qué tareas se llevan a cabo en el sitio protegido (la vinculación o pareado, Array Manager, asignación de inventario), así como las tareas que se llevan a cabo en el sitio de recuperación. En segundo lugar, los permisos son más simples de explicar y probar en un sitio protegido convencional y en un sitio de recuperación dedicado. Por último, y a estas alturas, mi esperanza es que usted debería tener una muy buena comprensión de cómo funciona SRM y, por lo tanto, una configuración bi-direccional no debería ser tan difícil de añadir a una configuración unidireccional. Empecé este libro utilizando nombres FQDNs para mis servidores, como protectedvc.rtfm-ed.co.uk y recoveryvc.rtfm-ed.co.uk. Mis intenciones originales fueron eliminar esta configuración en favor de una convención de nombres que reflejaran dos lugares distintos en el Reino Unido, Londres y Reading. Al final he decidido que esto sería una pérdida de tiempo innecesaria. Así que, simplemente mediante el cambio del nombre de los objetos en el inventario y, algunas modificaciones tipo "alias" en el DNS, debería ser capaz de hacer esto con la configuración que ya tengo. Llámelo pereza, si usted quiere. También, pensé que si usted me había estado siguiendo al pie de la letra, le gustaría mantener su configuración para sólo convertir esta en una configuración bidireccional. Dicho esto, en posteriores versiones de este libro y en función de su recepción por los lectores de la Comunidad VMware, considerare la posibilidad de actualizar el contenido para hacer la captura de pantallas que reflejen más claramente dos lugares distintos de producción que ofrecen recursos DR entre sí. En cuanto a la configuración, es exactamente la misma que nuestra vinculación de protección a recuperación, pero invertida. En esta capitulo hice algunos cambios en el almacenamiento. Anteriormente, en el sitio de recuperación sólo tenía acceso a volúmenes replicados en el "ProtectedManagementGroup" y a una LUN "testvolume" para confirmar que el servidor ESX, en el sitio de recuperación, puede comunicarse con mi cabina. He creado una nueva LUN/volumen en el RecoveryManagementGroup. Esta nueva LUN/volumen fue configurada para ser replicada en el "ProtectedManagementGroup", una vez por hora y, para mantener las instantáneas

252
de tres ciclos. Para dejar esto claro, he llamado este volumen "bivirtualmachines" para indicar que se trata de un volumen que he configurado específicamente para una configuración bidireccional. Usted puede ver esta configuración en la captura de pantalla siguiente. Note que ahora la replicación se está produciendo en el sentido opuesto.
Además, he añadido este nuevo volumen a un volumen de la lista que configure anteriormente, llamado "testvolume", para asegurarme de que mi servidor ESX podía verlo. Usando mi cliente Vi, he re-escaneado mi servidor ESX y formateado este nuevo bloque de almacenamiento con VMFS. Después, he asignado algunas maquinas virtuales a este volumen VMFS en una carpeta y resource pool en el inventario de vCenter. En resumen, he hecho algunos cambios significativos a la configuración de vCenter. Quizás le gustaría ver ahora esos cambios en vCenter:

253
Resumen: Así se puede ver que estoy conectado al vCenter de London y Reading (LondonVC y ReadingVC). Esto no es más que un poco de alias en DNS. En el LondonVC he re-nombrado las máquinas virtuales de ctx-1 a london-ctx-1. Esto se debe, principalmente para evitar cualquier confusión acerca de donde esta las máquinas virtuales físicamente. También he creado un resource pool en Londres llamado Reading´s VMs. Aquí es donde se almacenara el placeholder/shadow de las máquinas virtuales. Además, en Reading, he creado un par de máquinas virtuales, reading-ctx1 como convención de nomenclatura, sobre el resource pool Producción. En esencia, el diseño y los nombres son los mismos en ambos vCenters. Usted podría notar que las máquinas virtuales en Londres llamadas ctx-3, web-3 han desaparecido. Básicamente lo que paso es que me estaba quedando sin espacio en la cabina de almacenamiento, por lo que he tenido que eliminarlas del inventario. Hice algo similar en la vista Virtual Machines and Templates. La razón principal de esto es que para cuando convierta a London, el sitio de recuperación de Reading, habrá un objeto que podre utilizar para las asignaciones de inventario.

254
Resumen: Así he creado una carpeta llamada "Reading's VMs" en el vCenter de London, como destino para el placeholder/shadow. En el vCenter de Reading, he creado un pequeño número de máquinas virtuales de prueba y las puse en una estructura de carpetas, similar a la configuración de Londres.
Configuración del Array Manager Nota: Como los dos sitios ya están vinculados, no hay necesidad de volverlos a vincular. Lo que debemos hacer es configurar la cabina de modo que, el SRA y el SRM en la localidad de Reading, sea consciente de los volúmenes disponibles y cuales están replicados.
1. Inicie sesión como administrador en el sitio de Reading 2. Haga clic en el icono SRM en la barra de herramientas 3. Junto a Array Managers, haga clic en el botón Configure
Nota: Note cómo no hay necesidad de vincular los sitios, ya que esto se ya ha hecho anteriormente en este libro. 4. En Protection Side Array Managers, haga clic en el botón Add

255
5. En el cuadro de diálogo Array Manager, escriba un nombre para este gestor, como Array Manager for Reading Site 6. Seleccione Lefthand Redes SAN / iQ como el tipo de administrador 7. Escriba la dirección IP de el VSA en el sitio protegido en el campo SAN/iQ Manager IP1, en mi caso este es mi sistema vsa2.rtfm-ed.co.uk con la dirección IP de 172.168.3.98
8. Escriba el nombre de usuario/contraseña 9. Haga clic en el botón Connect Nota: Esto debe conectar el servidor SRM con el VSA Manager y mostrar el nombre del grupo de gestión creado en el VSA
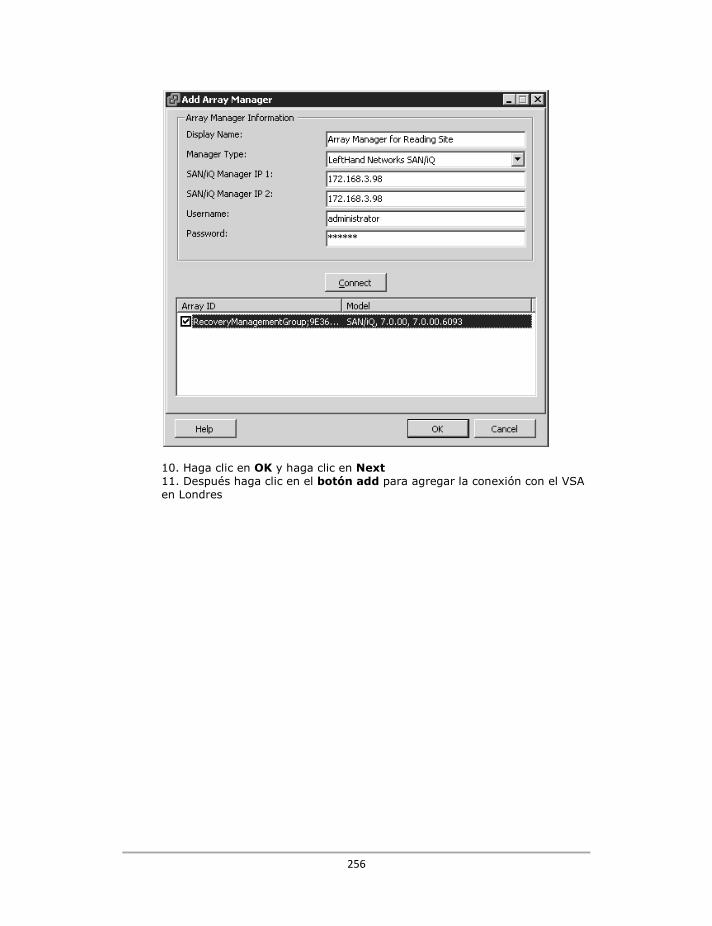
256
10. Haga clic en OK y haga clic en Next 11. Después haga clic en el botón add para agregar la conexión con el VSA en Londres
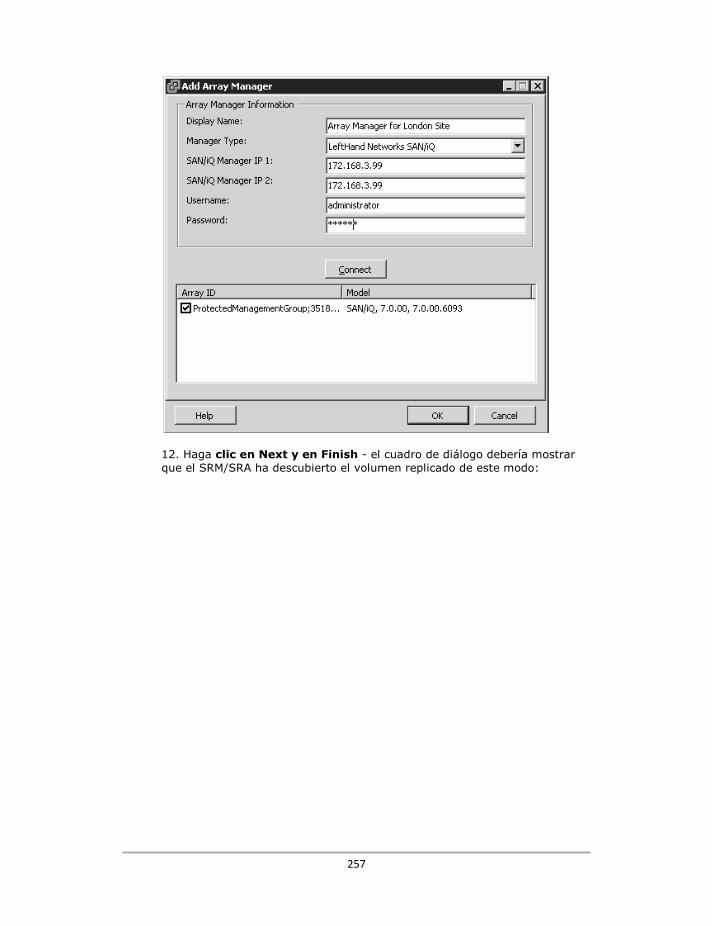
257
12. Haga clic en Next y en Finish - el cuadro de diálogo debería mostrar que el SRM/SRA ha descubierto el volumen replicado de este modo:

258
Configurando las asignaciones de inventario Como hicimos en la primera vinculación (pairing), la etapa siguiente es configurar las asignaciones de inventario. No voy a repetirme aquí, ya que podría ser bastante tedioso y también porque lo que usted quiere mapear va a variar de una implementación a otra. A continuación, se muestra una captura de pantalla de mis asignaciones de redes, resource pools y carpetas en Reading, con los objetos del vCenter en London.

259
Creación del grupo de protección Una vez más, la creación de un grupo de protección no difiere sustancialmente de una configuración bi-direccional.
Crear el plan de recuperación Una vez más, los planes de recuperación no difieren sustancialmente en una configuración bi-direccional. En este caso, tengo que iniciar sesión en el servidor vCenter de Londres para crear un plan de recuperación de las máquinas virtuales en Reading.

260
Mi configuración bidireccional ya esta completada. Lo único que hice fue hacer un cambio de nombre en los grupos de protección y planes existentes en el vCenter de Londres para hacer las cosas un poco más consistentes.
Como parte de esta limpieza general, también cambie el nombre del volumen VMFS en Londres, para que fuese un poco más significativo:
Conclusiones Una vez que entienda los principios y conceptos de SRM, una configuración bi-direccional es realmente una extensión de esos mismos principios contemplados en los capítulos anteriores. La única complejidad está en entender las relaciones. Quizás en ocasiones se haya detenido en este capítulo para aclarar las relaciones

261
entre los dos lugares, tanto en SRM como en la cabina de almacenamiento. Bien, usted no fue el único. Yo hice exactamente lo mismo. Estuve tan "envuelto" en la visión de un sitio protegido y un sitio de recuperación, que me llevo algún tiempo ajustar mi pensamiento para aceptar que cada sitio puede llegar a tener una doble funcionalidad. Por supuesto que siempre he sabido que podía hacer esto, pero la adaptación a ese cambio, una vez que tiene el concepto de que el sitioA es el sitio protegido y que el sitioB es el de recuperación, lleva un poco de tiempo. Lo que realmente me encantaría ver en versiones posteriores es un icono especial para el placeholder/shadow de las máquinas virtuales, ya que por el momento se usa exactamente el mismo icono, por lo que no es inmediatamente evidente cuál es cuál. Si su sitio de protección (Londres) y el sitio de recuperación (Reading) se configuran de una manera muy similar, a veces es difícil mantener las relaciones claras en la cabeza, y eso que sólo son dos sitios! A veces esta claro, ya que las máquinas virtuales "reales" están encendidas y las máquinas virtuales placeholder están apagadas. Esta distinción se hará menos clara una vez que haya activado su plan DR de una forma real, ya que algunos proveedores de almacenamiento requieren el apagado de las máquinas virtuales durante el proceso de recuperación o failback. Usted va a encontrar este inconveniente aun más, cuando nos ocupemos del failover y failback, especialmente con el failback. Yo tuve que concentrarme mucho cuando estaba haciendo mi primer failback y escribir el resultado para este libro, debido principalmente a que el failback es un proceso muy manual que requiere interactuar con la capa de almacenamiento de una forma aún más directa de lo que ya lo hemos hecho. En el próximo capítulo, failover y failback - ejecutando los planes de recuperación en una situación real, veremos lo que mucha gente denomina "Pulsar el gran botón rojo"

262
Capítulo 9: Failover and Failback

263
Lo único que todavía tenemos que discutir o cubrir, es exactamente que es SRM en realidad?. Cuando un desastre se produce, usted debe activar su plan de recuperación real. Es a veces llamado "presionar el gran botón rojo". La razón por la que este tema ha salido tan tarde es porque se trata de una decisión importante, con cambios permanentes en la configuración del entorno de su SRM y máquinas virtuales y por lo que no se debe ejecutar a la ligera. La segunda razón por la que cubro este tema ahora, es porque antes de iniciar este capítulo quise cambiar por completo el punto de vista del libro para cubrir la configuración bidireccional. De manera, que el cambio de nombre de todos los objetos del vCenter en el capítulo 6, fue el precursor para preparar la configuración bi-direccional. No quise ejecutar un plan real DR antes de hacer y entender una configuración bi-direccional. Mi última razón por la que deje este tema tan tarde en el libro, es que en esta versión no existe un "failback" después de poner en marcha el plan de recuperación. Por lo tanto, en esta versión de SRM, el proceso de failback es un proceso manual, tanto en la capa de almacenamiento, como en la capa de vCenter. Una ejecución real de su plan de recuperación es como una prueba, salvo que en este caso, la fase de la primera etapa del plan es realmente ejecutada. En otras palabras, si es posible, SRM apagará las máquinas virtuales en el sitio de protección (Londres), y si está disponible. Pero no ejecutara la parte final del plan, que es la de restablecer todas las máquinas virtuales del sitio de recuperación. SRM las dejara encendidas y en marcha. En el mundo real, el hacer clic en el "gran botón rojo", va a requerir la autorización de la dirección, por lo general a nivel de CEO, CTO, CIO, a menos que estos chicos están en el edificio que fue demolido por el desastre en sí. En ese caso, se delegara en alguien más abajo en la estructura de gestión la toma de la decisión. Usted puede considerar esta cuestión como parte del plan DR/BC. Si hemos perdido superiores encargados de adoptar decisiones, ya sea de forma temporal o permanente, alguien tendrá que asumir sus funciones y responsabilidades. Además, habrá importantes cambios en la cabina de almacenamiento. El SRA elegirá automáticamente la instantánea más reciente y luego se detendrá el ciclo normal de replicación entre el sitio protegido y el sitio de recuperación. Esto provocara, por lo general, un cambio de situación de las LUNs/Volúmenes y, pasaran de ser replicas secundarias a ser una replicas o LUNs/Volúmenes primarias. Todo esto se hace sin que tenga que avisar a los chicos del el equipo de almacenamiento. Si usted está usando VSA Lefthand Networks, vera que el volumen que normalmente estaba marcado como "remota" pasa a ser "primaria"

264
Activar el plan desde el SRM es muy fácil de hacer y, algunos podrían decir que es demasiado fácil. Solo tiene que pulsar el botón "Run", leer una advertencia, cambiar la opción de un botón para confirmar que entiende las consecuencias y hacer clic en OK.
Consideraciones antes de failover y recuperación Hay algunas consideraciones muy importantes que se deben considerar antes de presionar el botón rojo. De hecho, debería discutir estas cuestiones antes de abordar la implementación de la aplicación de SRM. En primer lugar y, dependiendo de cómo se haya licenciado SRM, es posible que tenga que transferir la licencia entre el SRM del sitio protegido al sitio de recuperación, para estar cubiertos por el acuerdo EULA de VMware. En segundo lugar, si usted está cambiando las direcciones IP de las máquinas virtuales, entonces sus sistemas de DNS deberán tener la correcta y correspondiente dirección IP y nombres de host en el DNS. Idealmente, esto será posible mediante el uso de su servidor DNS dinámico, pero tenga cuidado con los registros estáticos en la caché del DNS y los registros DNS en otros sistemas.
Failover previsto - El sitio protegido está disponible La principal diferencia obvia cuando se ejecuta el plan de recuperación y, el sitio protegido se encuentra disponible, es que las máquinas virtuales en el sitio protegido se apagarían basándose en un orden especificado en su plan. También, se efectúa un cambio, y es la suspensión de la replicación entre el sitio protegido y el sitio de recuperación. El siguiente diagrama, ilustra la suspensión del ciclo de replicación normal. Esto es necesario que ocurra para evitar conflictos de replicación y pérdida de datos, después de todo, las máquinas virtuales en el sitio de recuperación serán a las que los usuarios se conectaran y cambiaran los datos. A todos los efectos, son las máquinas virtuales principales, después de que un failover se ha producido.

Como se puede ver, la X indilas LUNs que fueron marcadamarcado como R/W (read anrecuperación. En un DR manual, esto es noalmacenamiento por un operde los vendedores. Pero comalmacenamiento, esto puedecompletado con éxito, usted almacenamiento. Por ejempluna vez fue una copa remota
265
ica que la replicación de los datos se ha susas como R/O (read only) en nuestras prueband write) en la ejecución de nuestro plan de
ormalmente una tarea que se activa en la carador humano utilizando las opciones "failov
mo el SRA tiene derechos administrativos en e ser automatizado por SRM. Una vez que eldebe ser capaz de ver este cambio en su sio, en VSA Lefthand Networks verá que el voa secundaria, es ahora una copia primaria.
pendido y as, se han
abina de ver/ failback
el plan se ha stema de olumen que

266
Aquí puede ver que el volumen llamado replica_of_virtualmachine, está ahora marcada como "Primary", donde solía decir "Remote". Además, se puede ver que los números de las instantáneas están "fuera de sincronización". Ha pasado algún tiempo desde que he ejecutado un plan de verdad y, mientras que el ProtectedManagementGroup ha llevado a cabo el programa de instantáneas locales, estas instantáneas no han sido transmitidas a través del cable al RecoveryManagementGroup. El SRM/SRA ha detenido la copia remota automáticamente. Este es el comportamiento por defecto, cada vez que un plan de recuperación se ejecuta. En este ejemplo, voy a asumir que se ha perdido el acceso al sitio en Londres durante algunas horas o días.
1. En este caso necesito entrar en el vCenter del sitio de recuperación - en mi caso es Reading 2. Seleccione el plan de recuperación, y haga clic en el botón Run

267
3. Lea el texto de confirmación y selecciónelo. Luego haga clic en Run Recovery Plan
Nota: Tengo una grabación en vivo de la ejecución mi plan en el sitio web del Blog de Virtualización en Español. Si desea ver lo que sucedió cuando se ejecutó este plan lo puede ver aquí: http://www.josemariagonzalez.es/srm.html Si todo transcurre según el plan (perdonen el juego de palabras), no verá mucha diferencia con la ejecución del plan de prueba. Lo que usted verá, son eventos apagados en el sitio protegido.

268
Failback planeado - El sitio de protegido está disponible Como recordatorio, permítanme reiterar que SRM no fue diseñado para automatizar el failback al sitio primario o protegido. Dicho esto, SRM puede ser configurado para ayudar en ese proceso. En el estado actual, el sitio de recuperación (Reading) es el propietario de las máquinas virtuales de Londres. Estas se están ejecutando y están conectadas a los usuarios finales. Como tal, es posible crear un grupo de protección temporal en el sitio de recuperación y en el plan de recuperación en el sitio protegido y, por tanto, invertir el proceso para que se ejecute antes. Por supuesto, hay que tener cuidado y asegurarse de que cualquier cambio generado en el poco tiempo que hemos estado "corriendo" en el sitio de recuperación (para mí ha sido cerca de un día), se reproducen de nuevo a la zona protegida para evitar la pérdida de datos. Este procedimiento suena muy sencillo, sólo hay que darle "la vuelta" a la configuración. Usted puede pensar de esta situación, que es un poco como cuando va en su coche y se da cuenta que ha tomado la dirección equivocada y todo lo que necesita hacer es realizar es un cambio de sentido opuesto. Si desea ampliar aun más esta analogía del coche, es como que usted se equivoco de salida algunas horas atrás, y ahora la única manera de volver por el buen camino es cambiar de sentido y recorrer algunos sitios por los que ya había pasado. Ah, por cierto, sus hijos necesitan usar el baño, y se está quedando sin gasolina. Junto a todo esto, el pequeño acaba de decir, "Papi, ¿Hemos llegamos ya?" Desde una perspectiva de almacenamiento también significa invertir su ruta normal de replicación, desde el sitio protegida al sitio de recuperación. Esta es una tarea manual realizada con mucho cuidado y que se ha de hacer leyendo la documentación del proveedor de la cabina de almacenamiento para saber cómo llevar a cabo la reconfiguración. Si la cabina, en el sitio protegido, no ha sido destruida en el desastre, los datos contenidos en esta, estarán fuera de sincronización con el sitio de recuperación. ¿Cuánto?, dependerá enteramente de cuánto tiempo hemos estado usando el sitio de recuperación y cuando hayan cambiado los datos. Por otra parte, si la cabina de almacenamiento ha sido destruida o está altamente de sincronizada, quizás quiera traer la nueva cabina al sitio de recuperación y hacer la réplica a nivel local.

El proceso de failback se com"limpiar" manualmente la coconfiguración que teníamos aque el failback ha finalizado, facilito el failback en primer recuperación. Vamos a tratarinvertir el proceso de replica Paso 1: Limpieza de todosrecuperación (Reading) Durante la configuración de lfueron colocados en un almarecuperación, en mi caso ReaMientras que escribía este libdestrucción de máquinas virtnombre de algunas de mis mcreó una gran cantidad de "bficheros VMX placeholder. Esdedicado un lugar específico mantener estos totalmente iyo he utilizado "tontamente"VMX placeholder, usted puedencuentran en el mismo volu
269
mplica aún más por el hecho de que tenemosnfiguración original del SRM y volver a la mantes de que se produjera el error. Además,tenemos que "limpiar" la misma configurac
lugar, y recuperar nuestro proceso original dr este proceso de "limpieza", antes de preocción de almacenamiento.
s los archivos placeholder antiguos en e
los archivos VMX placeholder/shandow de Sacenamiento en un servidor ESX en el sitio dading. Estos deben ser borrados manualmenbro, he hecho muchos cambios, como la creatuales (ctx-3, fs-3 y otras) y también he cam
máquinas virtuales (london-ctx-2, london-fs-basura" en el lugar que escogí para almacensto me hizo darme cuenta de la necesidad depara el almacenamiento de estos ficheros, pndependientes de cualquier archivo VMX "re un lugar de almacenamiento local para mis
de ver que los archivos locales de mi VSA taumen VMFS.
s que isma , una vez ión que de cuparnos de
el sitio de
RM, estos de nte. ación y la mbiado el 2). Esto ar mis e haber para eal". Como s archivos mbién se

270
Utilizando [Shift] + clic en el panel de la derecha puede eliminar el archivo VMX placeholder muy rápidamente.

271
Nota: 99% de lo que he aprendido en la vida ha sido de los errores, esto no significa, sin embargo, que hago un 99% de errores todo el tiempo! Paso 2: Eliminar el grupo de protección en el sitio de protección (Londres) La próxima etapa será suprimir el grupo de protección en el sitio de protección, en mi caso Londres, el cual fue utilizado para poner en marcha el failover
1. Entre en el vCenter del sitio protegido (Londres) 2. Haga clic en el icono Site Recovery 3. Amplié + los grupos de protección y seleccione su grupo de protección 4. Haga clic en el botón Remove Protection Group
Paso 3: Borre del inventario todas las máquinas virtuales Protegidas "viejas" (Londres) El siguiente paso, es eliminar las antiguas y obsoletas máquinas virtuales que fueron ejecutadas una vez en el sitio protección (Londres). Aquí es donde una buena carpeta y una estructura de resource pools es muy útil para mantener la máquina virtual de protección fuera de las machinas locales o maquinas sin protección. Esta fase de limpieza es necesaria para que no tengamos conflictos en los nombres de las máquinas virtuales.
1. Entre en el vCenter del sitio protegido (Londres) 2. Seleccione todas las máquinas virtuales "out of date" 3. Haga clic con el botón derecho y seleccione Remove from Inventory

272
Paso 4: Apagado de las máquinas virtuales proteger en el sitio de recuperación (Reading) Para el siguiente paso, necesitara una ventana de mantenimiento. Tenemos que apagar de una forma controlada y limpia todas las máquinas virtuales en el sitio de recuperación. Esto asegurará que todas las maquinas virtuales son paradas de una forma limpia (quiesced) antes de invertir el camino de la replicación.
1. Inicie sesión en el vCenter del sitio de recuperación (Reading) 2. Utilice "Shutdown Guest Operating System" para apagar las máquinas virtuales

273
Paso 5: Detener la replicación/Snaphot e invierta el camino de replicación (cabina de almacenamiento) Muchos proveedores utilizan diferentes términos para esto. Algunos vendedores lo llaman "personality swap", otros vendedores lo llaman "failover y failback". Lo que realmente significa es que donde el camino de replicación solía ser: sitio protegido >> sitio de recuperación, tenemos que enviar los datos de vuelta al sitio protegido usando el camino: sitio de recuperación >> sitio protegido. Si no hacemos esto, podríamos tener una pérdida de datos. En primer lugar, tenemos que parar o detener cualquier proceso local de instantáneas que este teniendo lugar en el volumen original, antes de ejecutar un failback o "personality swap". Una vez que el proceso "invertir" se ha completado, tendremos que reanudar el programa de replicación o cualquier proceso de instantánea que tuviéramos en su lugar. En VSA Lefthand Networks, sería de la siguiente forma:
1. Entre como administrador en el Lefthand Networks CMC 2. Seleccione el volumen original y haga clic en la pestaña Schedules 3. Haga clic con el botón derecho sobre la instantánea y elija "Pause Snapshot Schedule"
Nota: Repita este proceso para todos los volúmenes VMFS afectados y también para cualquier volumen RDM.

274
Nota: Ahora que nuestro ciclo habitual de replicación se ha detenido, podemos replicar de vuelta una sola vez (no regular) los cambios que se han creado mientras que estábamos en funcionamiento en el sitio de recuperación. 4. En el RecoveryManagementGroup, haga clic derecho en el volumen replicado y elija New Schedule Remote Snapshot Nota: A pesar de que queremos hacer esta replica/instantánea sólo una vez, tenemos que seguir utilizando el Schedule remote snapshot para que SRM reconozca esta LUN/volumen replicada. 5. Para hacer de esta una única replica, elimine la opción en el cuadro de diálogo Recur Every option y seleccione bajo el Remote Shapshot Setup el destino como el volumen original que tenemos en el sitio de protección

275
ADVERTENCIA: NO SE EQUIVOQUE CON ESTO. Soy uno de esos tipos que tiene un cerebro hiperactivo y que no puede encontrar el interruptor de mi lóbulo frontal. Una vez a las 3:22am, jugando con esto y cuando no se requería "cerebro", hice mal este proceso. Era parte de la elaboración de este libro por lo que no fue el fin del mundo. Mi LUN RDM tenía tres archivos de un 1K llamados newfile.txt, afterfailover.txt y beforefailback.txt creados en diversos puntos en el proceso. De todos modos, y sin comprometer ningún lóbulo frontal, perdí mi archivo beforefailback. Esto es también una advertencia sobre los peligros del trabajo en solitario sin descanso por la noche, en lo que implica la manipulación de datos. 6. Haga clic en el botón Edit junto al Start At: y haga clic en OK. Esto fijará la fecha y la hora de inicio de la instantánea para que se ahora Nota: Esto va a sobrescribir el volumen original. Durante esta replica/instantánea, sólo la diferencia, ya que ejecutamos el plan de recuperación, será copiado de vuelta al sitio protegido, en mi caso Londres. El tiempo que tarde

276
depende en gran medida de la cantidad de cambios que hayan tenido lugar desde que se ejecuto el plan de recuperación. Es muy probable que aparezca un mensaje de advertencia ya que este proceso es en realidad, modificara nuestra LUN/volumen fuente.
Una vez que haga clic en OK, usted debe ver que la replicación sucede de inmediato. Con VSA Lefthand Networks, vera gráficos animados que muestran que la replicación está ocurriendo actualmente en la dirección opuesta.

277
Nota: Repita este proceso para los demás volúmenes, incluidos los RDMs.
Paso 6: Actualizar el almacenamiento en el sitio de recuperación (Reading) Como en el capítulo anterior, hemos configurado nuestro sistema para permitir un DR bidireccional, el sitio de recuperación (Reading) ya está configurado para comunicarse con las dos cabinas que componen nuestra configuración. Todo lo que tenemos que hacer es actualizar y volver a re-escanear la cabina, para asegurarse de que el sistema puede ver las nuevas LUNs/volúmenes que se han replicado. Si usted recuerda, en el anterior capítulo 6 del libro, ya hice un proceso muy similar cuando le mostré como actualizar su sitio protegido, para un nuevo escenario en el que las máquinas virtuales se ha creado sobre un volumen VMFS nuevo. He decidido repetir las instrucciones una vez más. La modificación de los gráficos refleja la nueva configuración.
1. En el sitio de recuperación del sitio de SRM (Reading) 2. Haga clic en el enlace Configure junto al Array Manager 3. Seleccione la entrada para el Protection Site Array Manager y seleccione Edit

278
4. Escriba el nombre de usuario y la contraseña utilizada para autentificarse con la cabina de almacenamiento y haga clic en Connect y después de que el proceso haya terminado, haga clic en Next

279
Nota: Repita esto para el Recovery Array Manager
5. En el último cuadro de diálogo haga clic en el botón Refrest Array. Esto deberá actualizar el sistema de almacenamiento y mostrar el nuevo LUN/Volumen

280
Nota: Usted podría notar que, a pesar del éxito de la replicación de mi LUN RDM al sitio protegido (Londres), este no aparece en esta lista. Esto es algo preocupante y sospecho que tendré que resolver manualmente cuando haga un failback, al igual que lo hice cuando hice un failover. Después de escribir este capítulo, volví hacer el mismo procedimiento de nuevo, esta vez simulando una caída del sitio protegido (Londres). En mi segundo intento, el cuadro de diálogo me dio una información mucho más tranquilizadora
Nota: Así que la moraleja es que si cuando usted está haciendo el procedimiento de failback y le faltan LUNs/volúmenes en esta lista, no se preocupe. No siga hasta que haya resuelto el problema, porque cuando usted participe en un

281
failback, y el almacenamiento simplemente no existe o es incompleto, sus máquinas virtuales también estarán incompletas.
Paso 7: Configurar las asignaciones de inventario en el sitio de recuperación (Reading) Como con todos los planes de recuperación, necesito configurar las asignaciones de inventario y los grupos de protección. Así que desde el sitio de recuperación (Reading), tengo que decirle a SRM cómo manejar la red, los resource pools y estructura de carpetas de Londres. Como tengo una configuración bidireccional para hacer failover de las máquinas virtuales de Reading a Londres, en mi caso no hay necesidad de mapear las VLANs en Reading (61,62,63) a Londres (21,22,23) . Todo lo que tiene que hacer es actualizar las asignaciones para incluir los resource pools y la localización de las carpetas. Puede que recuerde que no tenía un mapeo uno-a-uno de mis carpetas. En el sitio protegido (Londres) tenía esta estructura de carpetas:
En el sitio de recuperación fueron copias sin contemplaciones a una única estructura de carpetas como se muestra a continuación:
Pero he decidido que esto es indeseable. Cuando hago un failback quiero que todas mis máquinas virtuales se asignen a las carpetas correctas de "primaria" y "secundaria". Voy a corregir esto en el sitio de recuperación ahora. Después, configurare mis asignaciones. Creo que una recomendación, salida de esta experiencia, podría ser el crear una misma estructura "espejo" de carpetas/resource pools en el sitio de recuperación que "refleje" la misma estructura del sitio de protección (Londres), para que cualquier máquina virtual pueda ser trasladada a la carpeta correcta en todo momento.
1. Inicie sesión en el vCenter del sitio de recuperación (Reading) 2. Haga clic en el icono de SRM 3. Seleccione el + Protection Groups nodo, y haga clic en la pestaña de Inventory Mappings 4. Configure sus asignaciones adecuadamente
Advertencia: Si no ha configurado el DR bidireccional, tendrá que mapear los recursos de red también.

282
Paso 8: Crear un grupo de protección y recuperación (Reading) Ahora que tenemos el inventario de asignaciones, para decir al SRM donde debe poner nuestras maquinas virtuales protegidas (Londres), tenemos que configurar un grupo de protección para estas, en el servidor SRM del sitio de recuperación (Reading). Esto creará los archivos "placeholder" en el sitio protegido (Londres).
1. Inicie sesión en el vCenter del sitio de recuperación (Reading) 2. Seleccione el + Protection Group nodo, y haga clic en el botón Create Protection Group 3. En el cuadro de diálogo Protection Group, escriba un nombre como por ejemplo Failback London Virtual Machines 4. Seleccione el DataStore que tiene sus máquinas virtuales protegidas

283
Nota: Fíjese en cómo "reading_virtualmachines" está atenuado, ya que está cubierto por la protección de otro grupo llamado "Reading´s Virtual Machines" 5. Seleccione una ubicación temporal para el almacenamiento de los archivos VMS "placeholder" o "shadow" en el sitio protegido
Advertencia: Es en esta etapa recibirá advertencias, si la replicación no se ha configurado correctamente. En mis pruebas anteriores, como sospechaba que tenía problemas con uno de mis LUNs RDM, he recibido errores de la máquina virtual que tenía el RDM.

284
Esto causó que el placeholder de London-ctx1 no fuera creado y que no figurara en absoluto en el sitio de Londres.
Nota: Para corregir este problema en ese momento, decidí hacer clic derecho en la máquina virtual london-ctx-1 y eliminar su referencia al mapeo de la LUN RDM y después hice clic en el botón "Configure Protection". Pero la verdadera solución para arreglar el problema, fue arreglar el problema de replicación del almacenamiento subyacente. Más tarde me dio otro error, diciendo que había agotado el espacio para la creación de instantáneas. El problema no fue causado por SRM o Lefthand Networks, sino por mi incapacidad de monitorizar la utilización del almacenamiento real.
Paso 9: Crear un plan de recuperación y probarlo (Londres) Estamos ahora en condiciones de crear un plan de recuperación en el sitio protegido (Londres) para la recuperación de las máquinas virtuales de Londres. Evidentemente, es conveniente realizar, en este punto, una prueba para ver si el proceso de failback va a tener éxito y también, el plan de recuperación tendrá que ser tan sofisticado como el plan de recuperación que cubrimos en el Capítulo 6. No tengo la intención de repetirme aquí, pero tenga en cuenta que puede que tenga que utilizar propiedades "Low, Normal y High", órdenes de arranque, secuencias de comandos y mensajes, para automatizar el proceso en la forma deseada.
1. Inicie sesión en el vCenter del sitio protegido (Londres) 2. Haga clic en el icono de SRM 3. Seleccione + Recovery Plans y haga clic en el botón Create Recovery Plan 4. En el cuadro de diálogo del plan de recuperación, escriba un nombre como Failback London Virtual Machines y haga clic en Next 5. Seleccione el grupo de protección que contiene las máquinas virtuales con el que desee hacer failback al sitio de protección

285
Nota: Complete el plan de recuperación como hemos hecho anteriormente, recordando que hay que suspender las máquinas virtuales que no son necesarias en el lugar protegido. 6. Por último, ponga a prueba su plan de recuperación para ver si el failback tendrá éxito
Paso 10: Ejecute el plan de recuperación real (Londres) Una vez que he resuelto mi problema con la LUN RDM, pude continuar y ejecutar el plan de recuperación. No tengo nada más que añadir, más allá de lo que ya he dicho sobre este proceso.
Limpieza del plan de recuperación Espere!. No hemos terminado todavía!. Ahora que tenemos la máquina virtual de vuelta donde empezamos, tenemos que "limpiar" este proceso. Tenemos que asegurarnos de que nuestras máquinas virtuales que volvieron a nuestro sitio, se está replicando de nuevo a la cabina de almacenamiento del sitio de recuperación y también debemos asegurarnos de que están adecuadamente protegidas por un plan de recuperación.

286
Paso 1: Apagado de máquinas virtuales en el sitio protegido (Londres) Al igual que con el failover, es un procedimiento recomendado por Lefthand Networks, el apagar las máquinas virtuales para asegurar que se cierran correctamente (quiesced) antes de restablecer el ciclo regular de la replicación entre el sitio protegido (Londres) y el sitio de recuperación (Reading). Por favor consulte con su proveedor sobre documentación específica antes de comenzar este proceso. Antes de hacer un power down general, hice un cambio obvio en todas mis máquinas virtuales. Esto es necesario para que cuando se haya re-establecido el ciclo normal de replicación, entre el sitio protegido y el sitio de recuperación, pueda confirmar, cuando ejecute una prueba de mi plan de recuperación, que los dos lugares tienen las mismas máquinas virtuales. En mi caso, he cambiado el escritorio de color de rojo a negro. Paso 2: Limpieza de los archivos placeholders creados durante el failback (Londres) Durante el proceso de failback se creó un grupo de protección temporal en el sitio de recuperación (Reading), para facilitar el proceso de failback. Esto creó toda una serie de archivos de posición o placeholders en el sitio protegido (Londres), los cuales ya no son necesarios.
Tenga cuidado aquí, de no eliminar los archivos placeholder del sitio de recuperación (Reading), ya que siguen siendo válidos para la configuración bi-direccional. Nota: Note de nuevo que para los archivos placeholder, he seleccionado de manera ingenua un lugar de almacenamiento local. Recuerde que esto no es recomendable

287
en el mundo real. Yo recomendaría una LUN pequeña, no replicada y dedicada sólo al almacenamiento de estos archivos, lo cual le facilita la búsqueda y eliminación de estos archivos. Paso 3: Eliminar el grupo de protección (Reading) Lo siguiente fue borrar este grupo de protección en el sitio de recuperación (Reading), donde creamos un grupo de protección para facilitar el proceso de failback hacia el sitio de protección (Londres).
Paso 4: Eliminar las máquinas virtuales protegidas del sitio de recuperación Desde el sitio de recuperación (Reading), debemos eliminar las referencias antiguas de las maquinas virtuales del sitio protegido (Londres). Vamos a re-restablecer la protección para estas máquinas virtuales, que ahora están de vuelta en el sitio de protección (Londres), porque si los dejamos, se producirán conflictos entre los archivos placeholdres recién creados.

288
Paso 5: Eliminar el "Failback" plan de recuperación del sitio protegido (Londres) Ahora que el failback ha funcionado, no necesitamos este plan de failback.

289
Paso 5: Re-establecer el camino regular de replicación/replicación programada (Cabina de almacenamiento) Ahora que el sitio protegido (Londres) es propietario de las máquinas virtuales, hay que asegurarse de que se están replicando hacia el sitio de recuperación (Reading). Este proceso varía según el proveedor de almacenamiento. Con VSA Lefthand Networks, primero debemos cambiar el volumen que el sitio de recuperación (Reading) estaba utilizando y cambiarlo de un volumen "principal" o primario a que sea de nuevo un volumen remoto. Después de hacer esto, debemos hacer una "limpieza" de la vieja instantánea remota que fue tomada de este volumen para sincronizar los datos justo antes del failback. Por último, podremos reanudar el programa de copia remota de manera que el sitio de protección replique sus cambios al sitio de recuperación. En mi caso, tengo dos volúmenes que necesitan ser marcados como "remota" - mi replica_of_virtualmachines y mi replica_of_rdm_ctx1. Es muy fácil ver si un volumen es primario o remoto, por el color del icono del volumen en el interfaz de gestión. Volúmenes primarios
Volúmenes remotos
1. Entre en el Lefthand Networks SRM como Administrador 2. Amplie el + RecoveryManagementGroup (Reading), + RecoveryCluster y + Volúmenes 3. Haga clic derecho en replica_of_virtualmachines y del menú seleccione Edit Volume 4. Después, haga clic en la pestaña Advanced y cambie el tipo a Remote

290
Haga clic en OK en los dos cuadros de dialogo de advertencia
Nota: Esto debe de volver a poner en marcha el patrón regular de replicación/ instantánea entre el sitio protegido (Londres) y el sitio de recuperación

291
(Reading). Después de hacer clic en OK, el proceso de instantáneas debería comenzar de inmediato. En la captura de pantalla síguete se puede ver que la dirección de replicación es ahora de ProtectedManagementGroup (Londres) a RecoveryManagementGroup (Reading)
Nota: Una vez que esta sincronización inicial se ha llevado a cabo, podemos volver a habilitar el horario regular para la replicación en el ProtectedManagementGroup 5. Seleccione los volúmenes primarios hospedad en el ProtectedManagementGroup, en mi caso se trata de los volúmenes llamados virtualmachines y rdm_ctx1 6. Seleccione la pestaña de Schedules
Nota: Observe cómo el schedule de mi virtualmachines LUN/Volumen es pausado. También observará cómo el volumen rdm_ctx1 aun no se puede seleccionar.

292
Esto es debido a que es considerado todavía un volumen remoto. Este tiene que ser marcado como uno de los volúmenes principales antes de que su schedule sea reanudado. 7. Haga click derecho en Paused schedule, y elija Resume Snapshot Schedule
Paso 6: Limpieza única instantáneas/Schedule Durante el procedimiento de failback, hemos creado una instantánea desde el sitio de recuperación (Reading) al sitio protegido (Londres), para asegúranos de que las máquinas virtuales de Londres han estado corriendo por un número de días. Necesitamos asegurarnos de que Londres tenía la versión más reciente de los archivos de las máquinas virtuales. Para ello hemos creado una instantánea programada que sólo ha ocurrido una vez, y no se repitió. Ese fue el paso 5 en el proceso de failback. No necesitamos más estas instantáneas, ya que sólo sirvieron para facilitar el proceso de failback. Estas no crearán ningún error o problema, pero nos podría confundir más adelante, si nos olvidamos para que las utilicemos en el pasado. Aunque ahora parece que podríamos tener un número de instantáneas algo desconcertante, en realidad, son bastante fáciles de detectar, ya que normalmente apuntan en la dirección opuesta a nuestra dirección habitual de replicación/instantánea.

293
Nota: Cuando hace clic con el botón derecho y elimina la instantánea, VSA no borra las dos partes (Pri1 y Rmt1). Tampoco tenemos ninguna necesidad para las referencias a los schedules no recurrentes que crearon estas instantáneas en primer lugar. Una vez más, no están haciendo ningún daño, pero no son necesarias.
Paso 6: Re-crear el grupo de protección en el sitio de protección (Londres) Durante el proceso de failover hemos suprimido el grupo de protección que cubrió a nuestras máquinas virtuales en Londres. Ahora que hemos limpiado el sistema, estamos en la posición que re-establecer la protección.

294
1. Inicie sesión con el cliente Vi en el vCenter del sitio protegido (Londres) 2. Haga clic en el icono Site Recovery 3. En la pestaña Summary, en el panel de Protection Setup, haga clic en el enlace Create situado junto a la opción Protection Groups 4. En el cuadro de diálogo Create Protection Group - Name and Description, escriba un nombre y una descripción para el grupo de protección. En mi caso estoy creando un grupo de protección llamado London virtual Machines Protection Group 5. Al hacer clic en Next, el asistente de grupo de protección le mostrará los datastores descubiertos por el Array Manager 6. Después, seleccione un DataStore "placeholder" para sus máquinas virtuales. Puede utilizar el almacenamiento remoto, pero si lo hace debe usar un volumen VMFS stand-alone que no participe en ningún proceso de replicación.
Paso 7: Re-habilitar el grupo de protección en el plan de recuperación (Reading) Como hemos suprimido el grupo de protección en la fase anterior, simplemente con volver a crear el grupo de protección, no se reconectara automáticamente con nuestro viejo plan de recuperación. Tendremos que editar cada uno de ellos, y habilitar el grupo de protección. Lamentablemente, uno de los grandes efectos secundarios de la eliminación del grupo de protección y su re-creación, es que cuando las máquinas virtuales se añaden de nuevo en el plan de recuperación, todos los ajustes de prioridad se pierden y usted tendrá que volver a ordenar manualmente el orden de arranque de sus maquinas virtuales. Esto no es en absoluto nada agradable.
1. Inicie sesión con el cliente Vi en el vCenter del sitio de recuperación (Reading) 2. Haga clic en el icono Site Recovery 3. Seleccione el plan de Recuperación, en mi caso tengo dos, uno llamado de London's Customer Recovery Plan y el otro London's Simple Recovery Plan 4. Haga clic en Edit Recovery Plan y haga clic en Next en el cuadro de diálogo 5. Siguiente, re-habilítate el grupo de protección para el plan de recuperación
6. Haga clic en Next y en el cuadro de diálogo VM Response Times, seleccione un valor de tiempo que usted crea que es apropiado para el arrancado de sus maquinas virtuales de recuperación.

295
7. En el cuadro de diálogo Edit Recovery Plan - Configure Text Networks, establezca las opciones para manejar la creación de redes cuando usted ejecute una prueba. 8. Por último, usted puede suspender maquinas virtuales en el sitio de recuperación para liberar recursos de CPU y memoria en el cuadro de diálogo Create Recovery Plan - Suspend Local Virtual Machines. En mi caso he suspendido mi maquina virtual Test & Dev. 9. Haga clic en Finish. 10. IMPORTANTE: REVISE Y REAJUSTE TODAS LAS PRIORIDADES DE SU MAQUINA VIRTUAL Y ORDEN DE CONFIGURACION CONTENIDA EN EL PLAN DE RECUPERACIÓN Nota: Bueno, ahora estamos donde empezamos antes del failover y failback. Usted podría poder probar su plan de nuevo, para garantizar que funciona correctamente.
Errores de limpieza Como dije antes, el proceso de limpieza es un proceso que si no se sigue al pie de la letra podría causar problemas. Algunos de esos problemas, podrían estar en la capa de almacenamiento o en la capa de VMware. Este es un ejemplo de un proceso de limpieza mal ejecutado en la cabina de almacenamiento.

296
Ahora quiero ser honesto con usted. No soy un gurú de almacenamiento y he ido aprendiendo a lo largo de este libro con el VSA. He recibido un soporte fantástico de uno de sus técnicos llamado Adam Carter. Así que cuando hice mi limpieza había una serie de instantáneas de estos volúmenes y no sabía si los debía borrar o limpiar. Tengo otras instantáneas locales sobre la replica_of_virtualmachines y estos necesitan también ser eliminados.

297
La forma en la que "Remote Schedule Snapshot" funciona, es que cuando usted toma una instantánea, primero el sistema toma una instantánea local (SS_1, SS_2, SS_3); una vez que ha finalizado, la copia al volumen remoto. Así pues, estas instantáneas se crearon cuando hice una re-sincronización en el sitio de recuperación (Reading) con el sitio protegido (Londres), justo antes del proceso de failover. Así que esto es lo que muestra mi VSA Lefthand Networks después de haber hecho el proceso de limpieza correctamente.

298
Fíjese cómo la replica_of_virtualmachines sólo tiene instantáneas del tipo "RMT", y el volumen principal sólo tiene instantáneas de tipo "Pri".
Failover imprevisto - El sitio protegido está MUERTO Desde que hice la prueba de plan planeado, he vuelto a poner mi configuración inicial en su lugar, he incluso llegue a testear mi plan de recuperación de mis máquinas virtuales protegidas en Londres para asegurarme de que funcionaba correctamente. Ahora, lo que quiero hacer es, documentar el mismo proceso de failover y failback sobre la base de una pérdida total del sitio de protección (Londres). Para simular esta caída, hice un power off vía las tarjetas ILO de HP, de todos mis servidores ESX en el sitio protegido. En esencia, es como si quitáramos las fuentes de alimentación de los servidores ESX. Si recuerda, desde el principio estoy ejecutando todo sobre dos servidores ESX pequeños y un poco antiguos.

299
Esto incluye la protección del sitio SQL, vCenter, SRM y VSA Lefthand Networks. Esto simula un fallo catastrófico total en cuanto a que ya no hay nada funcionando en el sitio de protección (Londres). Hice un apagado no controlado para simular una pérdida inesperada del sistema total. La razón principal de ello, es por así podre documentar cómo se comporta y gestiona SRM, cuando esta situación ocurre. Usted puede que nunca llegue a probar esta situación hasta que llegue el día fatídico. Lo primero que usted notará cuando llegue al sitio de recuperación, aparte de un montón de rostros con caras preocupadas, es que sus herramientas de gestión de almacenamiento no será capaz de comunicar con el sitio protegido. Por ejemplo, en VSA Lefthand Networks usted verá que su VSA, en el sitio protegido, es eliminado de los sistemas de gestión.

300
La principal diferencia cuando el sitio protegido (Londres) no está disponible es que, cuando inicie sesión en el sitio de recuperación (Reading), el cliente Vi le pedirá que inicie la sesión en el vCenter del sitio protegido (Londres), porque recuerde, el vCenter del sitio protegido está muerto!.
Si usted trata de completar este registro tendrá un error:

301
Failback planeado - El sitio protegido ha vuelto! y está funcionando Por supuesto y por definición, el proceso de failback sólo puede proceder si el sitio protegido (Londres) está disponible de nuevo. A este respecto, no debe ser diferente del proceso de failback que hemos cubierto anteriormente en este capítulo. No obstante, para completar esta sección, quería cubrir otra vez esta parte. No tengo la intención de cortar y pegar toda la sección anterior, pero por brevedad sólo cubriré lo que es diferente en este caso de proceso de failback. Para simular esta situación encenderé de nuevo mis servidores ESX. Para generar toda una serie de errores y fracasos, quise hacer el encendido de los sistemas lo más difícil posible, por lo que me asegure de que mi cabina de almacenamiento, mi servidor SQL, y mi servidor de vCenter y SRM estaban todos de nuevo en línea pero con un orden de encendido equivocado. Pensé que repetiría este proceso de nuevo para ver si hay cualquier imprevisto o error sobre del que pudiera advertirle.
• Sitio de recuperación y sitio protegido no conectados En primer lugar, cuando volví a poner online el sitio protegido tuve algunos pequeños errores de servicio porque el SRM del sitio de protegidas arranco antes que mi SQL y el sistema de vCenter. El comando "net start vmware-dr" en el servidor SRM arreglo el problema. También tuve un par de problemas de conectividad por resolver y tuve que vincular los sitios de nuevo. Este error es similar al que cubrimos en el capítulo 5: Faiure to Connect to the SRM Server
• Problemas de acceso al almacenamiento "rompió" mi grupo de protección

302
Si usted se acuerda del failover, después de limpiar los archivos VMX viejos de placeholder/shadow, VMware recomienda eliminar el grupo de protección viejo. Vi que esto tenía un icono de exclamación rojo, lo cual no había visto antes.
Esto a su vez podría haber sido causado por un problema de almacenamiento. Recuerde, mis servidores ESX en el sitio de protección fueron encendidos antes que mi cabina de almacenamiento estuviera disponible.
Para ser honesto, este es un error sin importancia. Pensé que era un error relativo a alguna información desactualizada. Así que intente eliminar el grupo antiguo de protección utilizando "remover from inventory" sobre las máquinas virtuales "inaccesibles". SRM odio esto, tanto así que lanzo todo tipo de errores como este:

303
Nota: SRM odio tanto este hecho, que el servicio terminó inesperadamente y lo tuve que reiniciar manualmente con el comando net start vmware-dr. Lo extraño fue es que, pasara en el sitio de recuperación y no en el sitio protegido. Al final me vi obligado a volver a re-escanear mis servidores ESX para que pudieran ver la cabina de almacenamiento y, a continuación, borrar el grupo de protección.
A partir de ese momento, las cosas fueron según lo previsto. Pude eliminar del inventario las máquinas virtuales antiguas protegidas en el sitio protegido (Londres) y fui capaz de apagar las máquinas virtuales en el sitio de recuperación (Reading), antes de pausar los ciclos de replicación y de invertir la dirección de la replicación temporalmente desde el sitio de recuperación (Reading) al sitio protegido (Londres). La única pega fue que mi sistema de gestión de almacenamiento no era consciente de que mi cabina de almacenamiento, en el sitio protegido, volvió de nuevo en línea. En mi caso, simplemente cerré y volví a cargar la consola de administración de Lefthand Networks para arreglar este problema.
Resolviendo problemas con RDM - Failover Una vez, y al final de la ejecución del plan de recuperación, me di cuenta de que una de mis máquinas virtuales no se recuperó correctamente, a pesar de que previamente la prueba del plan tuvo éxito y no se reporto ningún problema. Decidí tratar de resolver este problema manualmente. Descubrí que la fuente del problema era mi máquina virtual ctx-1, la cual tenía incluido mapeos de LUNs RDM en el mismo archivo. La causa fundamental del problema fue un fallo en el ciclo de replicación, debido a que me había quedado sin espacio físico por no haber monitorizado la cabina como corresponde. Así que en realidad, esto no debería estar aquí, pero lo deje en el libro para darte una idea de los errores y cómo resolverlos. A veces puede aprender más sobre la tecnología cuando no funciona que cuando lo hace. Encontré esta máquina virtual en el inventario, y cuando la verifique me di cuenta que era un "marcador de posición" (placeholder) de máquina virtual.

304
Descubrí que si trataba de encender la máquina virtual mediante la opción "Add to Inventory", me daba este mensaje de error:
Cuando miré dentro de la máquina virtual, vi que lo que solía ser un RDM ahora se consideraba simplemente un disco virtual.
Esta pantalla compara la configuración de un RDM en funcionamiento.
Mis intentos iníciales de eliminar el RDM dañado, utilizando el cliente Vi, tuvieron como resultado de este error:

305
Tras un nuevo análisis, parece ser que el servidor ESX en Reading no tenía acceso a la réplica/instantánea del RDM que se añadió a la maquina ctx-1. Después de mirar más de cerca al VSA Lefthand Networks, me di cuenta que la réplica/instantánea de este LUN/volumen no se presentó a mi servidor ESX en Reading.
Como usted puede ver, rdm_ctx1 y ninguno de sus instantáneas se han asignado a mis servidores ESX. Después de identificar cual fue el problema raíz, pude arreglar a mano el error en la máquina virtual. Gestión Volumen Failover/Failback Para usar el sistema de gestión de la cabina como antes, tengo que decir al sistema que pare de replicar el volumen RDM, y marcar el volumen replicado como el volumen principal o primario. Antes de hacer esto, la mayoría de los vendedores de cabinas recomiendan desconectar los servidores ESX del volumen. La mayoría de los vendedores tienen instrucciones de cómo hacer esto con el iniciador iSCSI de Microsoft Windows, pero sorprendentemente muy pocos tienen documentación de cómo hacerlo con ESX. Desconectar un servidor ESX de la cabina o LUN, parece más simple de lo que es, sobre todo con el iniciador software iSCSI de VMware. Aunque no parece haber un procedimiento simple, fácil y efectivo de detener las comunicaciones de los servidores ESX, usando el iniciador software iSCSI. He probado muchos métodos, y todos ellos me han llevado a callejones sin salida. Las cosas que he intentado, para parar la comunicación iSCSI, han sido las siguientes:
• El bloqueo de los puertos iSCSI 3260 • Desactivación de la pila de software iSCSI • Eliminación de los volúmenes de las listas de volumen • Eliminar o modificar la autenticación de los grupos
Lo que siempre produce una desconexión es: • Modificación de las direcciones IP de la consola de servicios/VMKernel Port • Desactivación del interface vswif y vmkernel El modo en el que detuve temporalmente la comunicación iSCSI fue con los comandos del servicio de consola siguientes: esxcfg-vswif-s vswif1

306
esxcfg-D-vmknic iSCSI esxcfg-rescan vmhba32 esxcfg-vswif-e vswif1 esxcfg-vmknic-e iSCSI Adicionalmente, puede comprobar que las conexiones están paradas desde el software de gestión de la cabina, por ejemplo, en VSA Lefthand Networks se puede ver desde la pestaña de iSCSI Sessions:
1. Inicie sesión como administrador en la consola(CMC)de Lefthand Networks 2. Haga clic con el botón derecho sobre el volumen y seleccione el volumen Failover/Failback
3. En el asistente Failover/Failback Volume elija To Failover to the remote volume, replica_of_rdm_ctx1

307
4. En el cuadro de diálogo iSCSI Sessions, confirme que no hay hosts conectados al volumen
5. Por último, haga de la réplica o instantánea el volumen principal o primario. Esto detendrá cualquier replica que se haya programado anteriormente

308
6. Lea el cuadro de diálogo de resumen y recordatorio
Permitir acceso al volumen remoto al sitio de recuperación El siguiente paso es un proceso relativamente simple de concesión de acceso a los servidores ESX en el sitio de recuperación (en nuestro caso Reading), a la última instantánea buena del volumen remoto. En este caso, he usado la lista "testvolume" creada anteriormente en este libro para validar que los servidores ESX, en el sitio de recuperación, pueden comunicarse con el VSA Lefthand Networks.
1. Entre en el VSA Lefthand Networks como Administrador

309
2. Seleccione el RecoveryManagementGroup y seleccione la pestaña Volume List 3. Edite una lista de volumen existente 4. Haga clic en Add 5. Seleccione la instantánea más reciente del volumen RDM
Nota: Después de la asignación de esta instantánea a los servidores ESX, hice un re-escaneo para confirmar que podían ver el volumen replicado
Modificación y corrección del archivo VMX 1. En primer lugar, abrí una sesiones de PuTTY, y edite manualmente el archivo .VMX para suprimir las referencias antiguas al mapeo RDM scsi0:1.present = "true" scsi0:1.deviceType = "scsi-hardDisk"

310
scsi0:1.filename = "/vmfs/volumes/<UUID>/ctx-1/ctx-1_1.vmdk" scsi0:1.mode = "persistent" scsi0:1.redo = "" 2. Además, aproveche para corregir la configuración del port group editando la línea siguiente: ethernet0.networkName = "vlan21" pasa a ser ethernet0.networkName = "vlan61" 3. También opte por eliminar los archivos VMDK antiguos relacionados con el fallo del mapeo RDM: rm ctx-1_1 *. vmdk -f 4. Siguiente, busqué por el archivo VMX y añadí este en la ubicación correcta del inventario del vCenter utilizando la opción DataStore Browers "Add to Inventory"
5. Por último, hice clic derecho en la máquina virtual y volví a añadir en el archivo de mapeo RDM

311
Nota: Durante la preparación para el failback, permití que se produjeran algunos cambios en todas mis máquinas virtuales en Londres. Por lo tanto, en la maquina London-ctx1 cree un nuevo archivo RDM y cambie el fondo del escritorio.
Resolviendo problemas RDM - Failback
Una vez más, tuve una serie de errores cuando por primera vez probé mi plan de recuperación. Afortunadamente, fui capaz de resolver estos errores después de trabajar por un día entero en el problema. Particularmente, he encontrado este error muy interesante por lo que decidí mantenerlo en este libro. Una vez más el origen de este problema fueron los errores de replicación creados por mí personalmente, por no supervisar adecuada el almacenamiento. Fue un error de usuario!. El primer error que tuve en el failback se muestra a continuación:
Procedí a ver si podía encender mi máquina virtual de forma manual. Para mi sorpresa encontré que podía. Al encenderla, encontré algo extraño. Observe que algunas de estas máquinas virtuales (no todas, lo que indica un error del programa o un error de incoherencia),mostraron el mensaje "UUID.Moved", el cual puede ocurrir si usted elimina manualmente las máquinas virtuales del inventario y las añade a un nuevo servidor ESX. Opté por mantener el mismo UUID para asegurarme que mi dirección MAC y datos UUID seguirán siendo los mismos

312
Entonces, ¿Cual fue la causa del Error " Error: Virtual Disk ‘Hard Disk 2’ is not accessible on the host: Unable to access file "?. Al principio pensé que podría ser un número determinado de causa, las cuales todas resultaron ser falsas, pero podrían haber sido buenos candidatos.
• Instantánea incorrecta presentada • Volumen VMFS corrompido • Replicación incompleta de múltiples volúmenes VMFS • Mal UUID en el archivo VMX
Por un tiempo sospeche que realmente el problema era el último de ellos. Al final, la causa fue el problema con el RDM de mi máquina virtual. Y el motivo por el que me di cuenta fue por la referencia al "Hard Disk 2". Sólo una de mis máquinas virtuales tenía un segundo disco RDM y, esa era la máquina virtual london-ctx-1. Al final, el mejor arreglo fue eliminar la protección de esa máquina virtual del grupo de protección.
1. Entre en el vCenter del sitio de recuperación (Reading) 2. Seleccione el icono SRM 3. Seleccione el grupo de protección, en mi caso, Failback London Virtual Machines y haga clic en la máquina virtual con el problema, en mi caso, London-ctx-1, y seleccione el botón Remove Protection

313
Nota: Esto hará que el grupo de protección tenga una desagradable marca de exclamación sobre él, como si una nueva máquina virtual se haya añadido al sistema pero no haya sido configurada aún para su protección.
Tuve la oportunidad de añadir London-ctx-1 en el inventario a mano, pero tuve los mismos problemas experimentados durante el failover con el archivo de mapeo RDM. Arregle el problema utilizando el mismo procedimiento descrito anteriormente en este capítulo. Es decir, des-registrando la maquina, editando el archivo VMX para eliminar la entrada mala, añadiendo de nuevo la maquina en el vCenter y añadiendo el RDM de forma manual.
Conclusiones
Como usted ha visto el proceso de ejecución real de un plan no se diferencia mucho de la ejecución de una prueba. Las consecuencias de ejecución de un plan de recuperación son tan inmensas que no puedo encontrar las palabras para describirlo. Evidentemente, un plan de failover y failback es mucho más fácil de manejar que la causa de un evento catastrófico. Esto es principalmente por lo que usted comprara el producto, y tal vez, si tiene suerte, no tendrá que hacer uso de este. Como con todos los seguros contra desastres, SRM es una pérdida de dinero hasta que tienen que reclamar la póliza ante un desastre.

314
Si miramos hacia atrás en este capítulo, hay mucho más escrito acerca del failback que del failover. Y eso no es un erro. Esto es debido porque a pesar de ser capaz de utilizar las características de SRM para acelerar la recuperación, es en esencia, el failback es un proceso manual. Por supuesto, la salida a esta afirmación podría ser que SRM nunca tuvo la intención o nunca fue diseñado para automatizar la recuperación. Pero esto podría ser una limitación en la adopción de esta primera versión de SRM. Sé de algunos bancos, instituciones financieras y grandes empresas farmacéuticas, las cuales rigurosamente prueban sus estrategias de DR. Algunas tanto así que prueban sus estrategias DR una vez por trimestre, a pesar de no experimentar ningún desastre real. Hay una doble idea detrás de esto. En primer lugar, la única manera de saber si su plan DR funciona es si usted lo usa - véalo como un sistema SAI - no hay nada mejor para ver si funciona como quitar la fuente de alimentación del servidor. En segundo lugar, esto significa que el personal de TI está constantemente preparando, probando la estrategia y mejorando y actualizando esta, según se producen cambios en el sitio protegido. Para las grandes organizaciones la falta de un proceso automatizado de recuperación o failback en el producto SRM, puede ser un "punto de dolor" significativo. Algo que espero y deseo que se incluya en futuras versiones del producto según el producto madure. Quizás esta sea una buena oportunidad para pasar a otro capítulo. Soy un firme creyente de tener un plan B, para en el caso de que el plan A no funcione. Al menos usted podría dejar SRM y hacer todo lo que hemos hecho hasta ahora manualmente. Quizás el próximo capítulo, finalmente, le da la perspectiva de entender los beneficios del producto SRM.

315
Capítulo 10: La recuperación del sitio, sin VMware SRM

316
Reconocimiento especial Quisiera agradecer personalmente a tres personas que me ayudaron directamente en esta sección con referencias especiales en PowerShell. Me gustaría dar las gracias, en particular, a Carter Shanklin, Manager del producto VMware PowerShell Toolkit, quien siempre respondía felizmente a mis mensajes de correo electrónico. Además, quiero dar las gracias a Hal Rottenberg, a quien conocí por primera vez a través de la comunidad VMware. Hal es el autor de un nuevo libro llamado "Gestión de VMware Infrastructure con PowerShell". Si desea obtener más información acerca de la potencia de PowerShell, sin duda, le recomiendo chequear y unirse al foro de la comunidad VMware VMTN y comprar su libro. Por último, quiero dar las gracias a Luc Dekens, del foro de PowerShell, quien fue especialmente útil explicando cómo crear un switch virtual con PowerShell.
Introducción Una de las ironías o paradojas interesantes que descubrí a la hora de escribir este libro, fue ¿Que pasa si en el momento de ejecutar mi plan DR, VMware Recovery Manager falla o no está disponible?. Dicho de otro modo, ¿cuál es nuestro plan de recuperación para SRM!?. Bromas aparte, se trata de una pregunta que merece la pena considerar. No tiene mucho sentido el uso de cualquier tecnología sin un plan B, por si el plan A no funciona como esperábamos. Dado que la clave de cualquier plan de recuperación es la replicación de datos a un sitio de recuperación, el elemento más importante está a cargo de su cabina de almacenamiento y no por VMware SRM. Recuerde que todo lo que VMware SRM está haciendo es automatizar un proceso manual. Por lo que detrás de este capítulo, hay realmente dos grandes agendas. La primera es, como hacer manualmente todo lo que hace VMware SRM en el caso de que nuestro plan A no funcione. Y la segunda es, mostrarle que SRM es increíblemente útil para automatizar este proceso. Espero que pueda ver en este capítulo, lo difícil que es la vida sin VMware Site Recovery Manager. Como cualquier proceso de automatización o de secuencias de comandos, usted no ve realmente las ventajas hasta que sepa como es el proceso manual. Con esto en mente, podría haber empezado con este capítulo en el capítulo 1 o 2, pero pensé que usted desearía profundizar en SRM, que es el tema de este libro, y guardar este contenido para el final. Esto también le dará una idea de lo que SRM hace en el fondo, que es hacer su vida mucho más fácil. La gran ventaja de SRM, para mí, es que crece y reacciona a los cambios de su sitio protegido, algo a lo que un proceso manual tendría niveles mucho más altos de mantenimiento para lograrlo. Como parte de la preparación de este capítulo, he decidió suprimir la protección de los grupos y los planes de recuperación asociados a nuestra configuración bi-direccional de mi sitio de recuperación (Reading). La recuperación manual de máquinas virtuales exigirá alguna gestión de almacenamiento, como detener el actual ciclo de replicación y promover el "volumen remoto" en un volumen primario o principal de lectura-escritura. Mientras que SRM hace esto automáticamente por usted, a través del SRA de su proveedor de almacenamiento, en una recuperación manual, tendrá que hacerlo por sí mismo. Esto es asumiendo que todavía tienen acceso a la cabina en el sitio de protección,

317
como ocurre con una ejecución planeada de su plan DR. Además, una vez que la replicación se ha detenido, tendremos que conceder acceso a los servidores ESX del sitio de recuperación a la última instantánea buena que fue tomada. Por parte de los servidores ESX, una vez concedido el acceso a los volúmenes, estos tendrá que ser manualmente re-escaneados para asegurarse de que el volumen VMFS ha sido montando en los servidores ESX. Basándose en nuestras necesidades y la visibilidad de la LUN, tendremos la opción de no hacer el resignature o forzar una resignature del volumen VMFS. Después de haber "lidiado" con la parte de almacenamiento, tendremos que editar el archivo VMX de cada máquina virtual y mapear este a la red correcta. Después de hacer esto, estaríamos en condiciones de empezar a añadir cada máquina virtual en el sitio de recuperación y por cada máquina tenemos que decirle al cliente Vi que grupo, carpeta y resource pool va utilizar. En un mundo ideal, parte de la gestión de la máquina virtual podría ser hecha vía secuencia de comandos, utilizando diferentes kits de desarrollo de software de VMware como Perl Scripting ToolKit, el PowerShell Scripting Toolkit o el SDK de vCenter con el lenguaje de su elección - VB, C#, etc. Tengo la intención de utilizar el PowerShell Toolkit para VMware como un ejemplo. Como podrá ver, las secuencias de comandos, es un proceso muy laborioso y tedioso. Fundamentalmente, es un proceso muy lento por lo que impactara sobre la rapidez en su proceso de recuperación. Piense en todas las RTOs y RPOs.
Para una recuperación no planificada Para la recuperación no planificada, hay que apagar las máquinas virtuales que se están ejecutando en producción, antes de administrar el almacenamiento. Si recuerda, los primeros pasos de cualquier recuperación prevista, es apagar las máquinas virtuales en el sitio protegido.
Si usted está haciendo un failover manual con fines de prueba no es necesario.
Gestionar el almacenamiento Sin un SRA, tendremos que participar más con las herramientas del vendedor de almacenamiento para el control de las instantáneas y la replicación. Este área es muy específica de los proveedores, por lo que le aconsejo se lea la documentación. En el caso de VSA Lefthand Networks, serían los siguientes pasos. Actualmente, el grupo RecoveryManagementGroup (Reading) tiene la copia primera y el grupo ProtectedManagement (Londres) tiene la copia remota, mantenido por un ciclo de

318
instantáneas programado. Necesitaré dar acceso a los servidores ESX a la última instantánea o volumen replicado, añadiendo esta a una lista de volumen existente.
1. Entre en el VSA Lefthand Networks como administrador 2. Seleccione el ProtectedManagementGroup y, a continuación, seleccione la pestaña Volume Lists 3. Seleccione un volumen existente de la lista y añada la última instantánea a la lista
Nota: En el ejemplo anterior estoy dando acceso a mi servidor ESX en Londres a la última instantánea de mi volumen virtualmachines (776).
VMware PowerShell Toolkit Las siguientes secciones discuten el proceso manual de añadir las máquinas virtuales en vCenter y dejarlas listas para encenderlas. También he decidido mostrarle cómo hacer las mismas tareas con PowerShell. Lo que sigue es casi una guía de configuración para PowerShell. En primer lugar, descarge e instale, Windows PowerShell V2 Community Technology Preview 2 (CTP2). Pondría la URL en el libro, pero es demasiado larga y, en última instancia, es muy probable que cambie. En la actualidad, la versión oficial de Microsoft PowerShell es la versión 1. Habrá una versión 2 muy pronto aunque en la actualidad sólo está en fase de revisión.

319
Después, usted tendrá que descargar e instalar el VMware PowerShell Tookit (en realidad se llama Vi3 Toolkit): http://www.vmware.com/support/developer/windowstoolkit/beta/windowstoolkit-200803-releasenotes.html Luego usted tendrá que abrir sesión de PowerShell, y descargar VMware PowerShell Community Extensions. (new-object net.webclient).DownloadString("http://communities.vmware.com/servlet/JiveServlet/downloadBody/6051-102-1-3481/Extensions.psm1") > $env:temp/Extensions.psm1 add-module $env:temp/Extensions.psm1 Una vez descargado, usted podrá instalarlo con el siguiente comando: add-module $ env: temp/Extensions.psm1 PRECAUCIÓN: Descubrí que tenía que repetir este proceso cada vez que abría una nueva sesión de PowerShell. Para conectarse y acceder al vCenter, use el comando get-vc de este modo: get-vc londonvc.rtfm-ed.co.uk –user administrator –password vmware
ADVERTENCIA: Me imagino que esto cambie antes de que el libro sea publicado. Si usted tiene dificultades para encontrar los diferentes programas y enlaces, este es un buen lugar para empezar. Yo he usado esta web como punto de partida para descargar todos los archivos binarios que necesitaba. http://blogs.vmware.com/vipowershell/2008/06/fun-with-powers.html SUGERENCIA: Entiendo lo difícil que es escribir todos estos códigos a mano, y siendo este un libro en papel, no hay opciones de cortar y pegar. Por lo tanto, he cogido todos estos ejemplos de PowerShell y los he puesto en un archivo de texto. Puede descargar este archivo de texto desde el sitio web para

320
poder cortar y pegar, y cambiar las variables tales como los nombres de sus máquinas virtuales y recursos piscina nombres. http://www.josemariagonzalez.es/srm.html
Escanear las HBAs de cada servidor ESX Usted debe de saber, más que suficiente, cómo re-escanear un servidor ESX, bien desde la GUI o mediante el CLI. Lo que usted necesita es que aparezca un nuevo volumen VMFS.
Este re-escaneo tiene que ser hecho una vez por cada servidor ESX, y sería muy laborioso tener que hacerlo a través del cliente Vi. Por supuesto, usted podría entrar con PuTTy y usar el comando esxcfg-rescan. Personalmente, prefiero utilizar el Remote CLI para Windows, el cual puede ser instalado en el mismo sistema de gestión donde está instalado el PowerShell de VMware. Con el RCLI para Windows podemos utilizar el script esxcfg-rescan.pl esxcfg-rescan.pl --server esx1 --username root --password vmware vmhba32 El siguiente comando de PowerShell, rescanea todos los hosts ESX en vCenter, lo cual es mucho más eficiente desde una perspectiva de secuencias de comandos. get-vmhost | vmhoststorage-get-rescanallhba
Nota: La sintaxis del comando de PowerShell anterior es relativamente fácil de explicar. Get-vmhost recupera todos los nombres de los servidores ESX en el vCenter y esto es enviado al comando get-vmhoststorage para re-escanear todos los servidores ESX. Get-vmhoststorage soporta la opción -rescanALLhba que hace exactamente lo que usted piensa. Usted podría encontrar que el volumen VMFS no refleja el nombre original del DataStore. Esto depende en gran medida de si se ha hecho el resignatured, ya sea mediante SRM o manualmente utilizando la configuración avanzada del servidor

321
ESX. Si usted desea cambiar el nombre del volumen VMFS como lo hace SRM, después de una resignature, puede utilizar este comando de PowerShell. set-datastore -datastore (get-datastore *london_virtualmachines) –name london_virtualmachines
Nota: Set-datastore se puede utilizar para cambiar el nombre del volumen VMFS y el nombre del dataStore con la opción -name. Usado en conjunción con el comando get-datastore cmdlet, podemos buscar (usando un comodín *) por el volumen VMFS que incluya la cadena "london_virtualmachines", y cambiarle el nombre original al volumen VMFS y datastore.
Crear una red interna para las pruebas Es parte de mi configuración estándar crear en todos mis servidores ESX, un port group llamado "internal", el cual es un switch dedicado que no tiene mapeada ninguna tarjeta física.
Sin embargo, usted podría querer emular la forma en la que SRM hace sus pruebas para los planes de recuperación, creando una red de test llamada "testbubble".

322
La creación de los switches virtuales en la versión beta de VMware PowerShell es bastante complicado. Este hecho fue resaltado por el equipo de VMware PowerShell, y es probable que sea más fácil en la próxima versión. El comando PowerShell para crear esto es un poco largo: {noformat} $MyvSwitchName = "testBubble-1 vswitch" $MynumPorts = 64 $MyPortGroupName = "testBubble-1 group" $MyvlanID = 0 Get-VMHost | %{Get-View (Get-View $_.ID).configmanager.networkSystem} | %{ $vSwitchSpec = New-Object vmware.vim.HostVirtualSwitchSpec $vSwitchSpec.numPorts = $MynumPorts $_.AddVirtualSwitch($MyvSwitchName,$vSwitchSpec) $PortgroupSpec = New-Object vmware.vim.hostportgroupspec $PortgroupSpec.vswitchname = $MyvSwitchName $PortgroupSpec.Name = $MyPortGroupName $PortgroupSpec.vlanID = $MyvlanID $PortgroupSpec.policy = New-Object VMware.Vim.HostNetworkPolicy $_.AddPortGroup($PortgroupSpec) } {noformat} Nota: En este caso, en la parte superior de la secuencia de comandos de PowerShell, tenemos un número de variables que se definen como el nombre del switch virtual, número de puertos (16,32,64 hasta 1024) y, el primer nombre portgroup sin ajustes VLAN. Este script no crea ningún switch virtual. Para correr este script, usted tiene que abrir una sesión de PowerShell y guardar el contenido en un archivo de comandos PowerShell (. Ps1) con: notepad vswitch.ps1 y para ejecutar el script debería escribir: . \ vswitch.ps1
Añadir máquinas virtuales en el Inventario 1. En uno de los servidores ESX 2. Navegue por datastore que contiene las máquinas virtuales 3. Haga clic derecho en el archivo VMX y elija Add to Inventory

323
4. En el subsiguiente cuadro de diálogo, seleccione un DataCenter y una carpeta en donde almacenar su máquina virtual
Nota: Usted no tiene que especificar un nombre para su máquina virtual, lo que provoca que vCenter lea el archivo VMX por el campo displayName = "..." 5. Seleccione el Servidor ESX o Cluster

324
6. A continuación, seleccione un resource pool para la máquina virtual
Nota: Usted debería ser capaz de encender la máquina virtual. Usted tendrá que cambiar manualmente su dirección IP en el sistema operativo invitado. Es posible automatizar la adición de una máquina virtual al servidor ESX (no a un clúster), utilizando la línea de comandos del servidor ESX llamado vmware-cmd. Lamentablemente, este comando no puede manejar los metadatos de vCenter, tales como la ubicación de la carpeta y los resource pools. Recuerde que usted tendrá que repetir estos pasos por cada máquina virtual que debe ser recuperada. Quizás, una mejor forma de hacerlo es utilizando algunos PowerShell. Podemos usar el cmdlet get-datastorefile y get-datastore para proporcionar una lista de todas las máquinas virtuales en el DataStore.

325
get-datastorefiles (get-datastore london_virtualmachines) | where { $_.Path -match '.vmx$'} | select path
Nota: Este fragmento de PowerShell, listas todas las carpetas y archivos (get-datastorefiles) en un determinado volumen VMFS, el cual es recuperado por el get-datastore cmdlet. Esto es filtrado a través de una búsqueda (seleccione ruta) para mostrar únicamente la información sobre la ruta, donde la carpeta contiene un archivo VMX. Por último, la salida es filtrada de nuevo, sólo para mostrar rutas de archivos en este formato. [london_virtualmachines] / ctx1/ctx1.vmx Una vez que tenemos el camino, podemos pensar en tratar de registrar la máquina virtual. Hay un register-VM cmdlet, que podemos utilizar para manejar todo el proceso de registro, incluyendo el servidor esx, carpeta, y la ubicación resource pool en el inventario del vCenter inventario: register-VM "[london_virtualmachines] ctx-1/ctx-1.vmx" -vmhost (get-vmhost esx3.rtfm-ed.co.uk) -resourcepool (get-resourcepool London) -folder (get-folder "London VMs" | get-folder primary)
Nota: Espero que lo anterior tenga sentido para usted. La razón por la que he puesto -folder (get-folder "Reading VMs" | get-folder primary), es porque tengo dos carpetas, una en Londres y otra en Reading. La salida puede ser redireccionada al Register-VMs cmdlet, para registrar todas las máquinas virtuales que se encuentran en ese dataStore: $vmxpath = get-datastorefiles (get-datastore reading_virtualmachines) | where { $_.Path -match '.vmx$' } | select path | % { Register-VM $_.Path -vmhost (get-vmhost esx3.rtfm-ed.co.uk) -resourcepool (get-resourcepool “London VMs”) -folder (get-folder "London VMs" | get-folder primary) } Nota: La única diferencia aquí es la inclusión de $vmxpath y él %. En este caso estamos haciendo la ruta de acceso a los archivos de la VMX una variable y, a continuación, enviamos el resultado al comando Register-VM, a fin de que cada máquina virtual (VMX ruta de archivo) descubierta en reading_virtualmachines VMFS es registrada en el sistema.

326
Recuerde que este proceso de registro, tendría que ser repetido por todos y cada uno de los volúmenes VMFS y para cada máquina virtual que necesite un proceso de recuperación.
Arreglar los archivos VMX
Usando nano o vi, en el servicio de consola, edite el archivo VMX de cada máquina virtual, para arreglar el portgroup utilizado para la comunicación. ethernet0.networkName = "vlan61" tiene que ser ethernet0.networkName = "internal"
Por supuesto, tiene que repetir esto por cada máquina virtual. Si usted añade primero su máquina virtual en el vCenter (nuestra próxima tarea), puede automatizar el cambio de propiedad (como he mencionado anteriormente) con PowerShell para VMware. get-vm | get-networkadapter | sort-object -property "NetworkName" | where {'vlan21' -contains $_.NetworkName} | Set-NetworkAdapter -NetworkName “testBubble-1 group”
Usted podría utilizar, el comando de servicio de consola 'sed', para buscar y reemplazar la cadena del port group dentro del archivo VMX, pero creo que el

327
método de PowerShell es más limpio. Una vez más, esta secuencia de Powershell usa get-vm y get-network para encontrar la información de cada máquina virtual y la de configuración del portgroup. Después, es ordenado y luego se filtra para mostrar sólo las máquinas virtuales con portgroup vlan61. Una vez es filtrado y es enviado al comando set-networkadapter cmdlet, el cual ajusta todas las máquinas virtuales con vlan61, sustituye el contenido del portgroup con el valor "internal".
Conclusiones Como puede ver, el proceso manual es un proceso de "mano de obra" muy intensivo, lo cual es esperado por el uso de la palabra manual. Usted puede tener la impresión de que este problema puede ser arreglado por algún súper-script de PowerShell. Puede que incluso haya pensado, ¿por qué necesito SRM si tengo estas secuencias de comandos PowerShell?. Sin embargo, no es tan simple como parece por dos razones principales. Lo primero es que no hay realmente soporte para esta solución DR y, en segundo lugar, usted puede dedicar todo el tiempo que quiera probando sus scripts, pero luego su entorno cambiara y los scripts se quedarían obsoletos, lo que supondría un sinfín de re-ingeniería y re-análisis. De hecho, la verdadera razón por la que quise escribir este capítulo es para mostrar cómo de "doloroso" es el proceso manual y mostrarle así los verdaderos beneficios de SRM.
Fin - Conclusiones finales
Bueno este es el final del libro, y me gustaría aprovechar esta última parte hacer algunas observaciones y conclusiones finales acerca de VMware Site Recovery Manager y VMware en general. La primera vez que empezar a trabajar con productos VMware fue a finales del año 2003. De hecho, no fue hasta el año 2004 que me involucre seriamente con VMware ESX y VirtualCenter. Por lo tanto, veo que estamos todos ante una enorme curva de aprendizaje ya que incluso nuestros llamados expertos, gurús y evangelistas, son relativamente nuevos en la virtualización. Pero como siempre en nuestra industria, hay gente muy fuerte que trabaja en el campo que reaccionó de una forma más brillante al cambio radical que he visto venir cuando vi por primera vez una demostración de VMotion. Se ha hablado mucho de cómo los hipervisores se están convirtiendo en un commodity. Todavía creo que estamos un poco lejos de llegar a esto, como demuestra la concesión de licencias de VMware - todavía hay una prima que se cobra en la capa de virtualización. Pero las cosas están cambiando y los competidores de VMware se están poniendo al día, aunque no tan rápido como a veces pensamos. Esta situación es mala para todos los interesados, incluyendo VMware. Las empresas crecen cuando tienen un mercado para crear o defender. Desde la redacción de este libro, ESX3i se ha convertido en un producto libre, por lo que ahora podría argumentar que el hipervisor es un commodity. Sin embargo, esto significa que ahora el dinero se ha trasladado a la gestión y SRM está firmemente en ese campamento. Pero veo un cambio que igualmente es sísmico, en cuanto a que ha producido una verdadera revolución en nuestras herramientas de gestión, porque, sencillamente, las antiguas herramientas de gestión, simplemente no estaban a la altura. No son

328
conscientes de las maquinas virtuales. Es una pena que vmaware.com ya está registrado, sino fuera así, podría haber sido el nuevo nombre de RTFM! VMware está creando productos que tienen en cuenta las maquinas virtuales (Lab Manager, State Manager, Stie Recovery Manager, LifeCycle Manager y Virtual Desktop Manager). Así que si es usuario de VMware, no espere más y súbase a jugar con estas tecnologías, como lo he hecho yo, porque son "la próxima gran tecnología" que siempre ha estado buscando en su carrera. Por último, tengo una broma para usted. Estoy seguro de que en algún momento, en un curso de SRM, tendré este debate con un estudiante: Estudiante: SRM es un producto versión 1, verdad? Mike: Así es. Estudiante: Oooh, la versión 1, normalmente significa que no es bueno ¿verdad? Mike: Errrr, generalmente es así, si eres esa empresa de software grande en Seattle (risas generales del grupo ...). Por supuesto, lo que podrías hacer es liberar un producto que ya tiene un Service Pack en sí mismo - como Windows 2008, ya que esto ayuda a atraer clientes que no actualicen o adopten una versión 1, por lo menos hasta el primer Service Pack (más risas del grupo ...) Estudiante: Sí, Sí, muy gracioso, pero en serio, está listo para la producción? Mike: Bueno, piensa lo que estás diciendo aquí. ¿Qué quieres decir con "listo para la producción"?. Esto no es algo a lo que los usuarios finales se conectan como en Windows, ni es algo que permite que la infraestructura funcione como ESX. No está listo para la "producción" pero que está listo para su sitio DR. Y aquí hay otro pensamiento - en ausencia de cualquier otra cosa o hacer todas las cosas que SRM hace manualmente - ¿Que más haría usted, salvo tener que dedicar una gran cantidad de trabajo manual o de secuencias de comandos. Y lo que es peor - ¿cómo va a mantener todos de cosas que hasta la fecha se hacen manualmente?. Usted debe ver cómo es la vida sin SRM, quizás entonces la pregunta que me está haciendo le parecerá a usted tan extraña como a mí. Estudiante: Sí claro, (tengo un tipo inteligente por instructor de esta semana)

330
Index
A
Architecture, 46 Array Manager, 43, 47, 67, 80, 85, 86, 88, 90, 98, 105, 113, 137, 171, 172, 173, 174, 186, 187, 188, 190, 195, 196,
220, 223, 224, 245, 246, 260, 270
C Caution, 30 Configuring
Array Managers, 80 Lefthand Networks VSA, 28 Priority Orders, 147 Shutdown of VMs, 143 Software iSCSI, 36 SRM Administrators, 209
Creating Alarm - Script, 199 Alarms - Email, 202 Alarms - SNMP, 200 Basic Recovery Plan, 108 New Networks, 171 New Virtual Machines, 171 Protection Groups, 96 Volume Lists and Authentication Groups, 33
D Diagram, 8, 9, 10, 11, 46, 113, 233, 237
E Error, 55, 129, 130, 132, 133, 134, 277
F Failback, 51
Clean-up, 252 Clean-up Errors, 262
Failover Planned Failover, 233 Unplanned, 264
Failures, 70, 199, 266 File Level Consistency, 5
G Gotchas, 54
I Important, 30, 91, 111 Installing, 5, 45, 62, 67, 68, 75

331
Inventory Mappings, 71, 92, 93, 95, 104, 105, 158, 159, 161, 167, 171, 175, 192, 227, 248
L Licensing, 42, 56
P Parallel Host Start-Up Order, 148 Placeholder, 124, 198, 237, 253 Powershell, 150, 290
Add Virtual Machines, 286 Fix VM VLan Configuration, 289 Rescan HBAs, 283 Virtual Switches, 285
R RDMs, 43, 56, 91, 96, 142, 185, 186, 187, 188, 241, 243, 247, 250, 252, 268, 269, 270, 273, 274, 275, 276, 277, 278 Recovery Plans, 56, 103, 108, 112, 126, 127, 128, 139, 141, 145, 148, 166, 177, 189, 193, 195, 196, 198, 199, 205,
208, 209, 213, 215, 251 Renaming
DataCenters (Protection Site), 167 Datacenters (Recovery), 168 Resource Pools (Protection), 167 Resources Pools (Recovery), 142, 168, 169 Virtual Machines, 166 Virtual Switches (Protection), 167 Virtual Switches (Recovery), 169 VirtualCenter Objects, 166
Repair Array Manager Button, 195, 196
S SRM
Adding Commands, 150 Alarm - Script, 199 Alarms - Email, 202 Bidirectional Configuration, 219 Changes at the Protection Site, 161, 168 Changes at the Recovery Site, 168 Creating Protection Groups, 96 Custom Messages, 148 Customized VM Mappings, 158 Database, 58 Failback - RDM Errors, 268 Failback Clean-up, 252 Failback, after unplanned failover, 266 Failure to Protect VM, 104 Hardware Requirements, 51 Installation, 62 IP Address Reconfiguration, 152 Licensing, 56 Log Files, 216 Multiple Protection Groups and Recovery Plans, 189 Pairing, 74 Permissions and Access Control, 207 Permissions Limitations, 215 Planned Failover, 233 Plug-in, 68 RDMs, 185

332
Recovery Plan Events, 122 Recovery Plan History, 206 Release Notes, 54 Repair Array Managers, 195 Reports, 204 Service Failure, 70, 266, 267 Site Recovery Adapter, 66 SNMP, 200 Software Requirements, 48 Unplanned Failover, 264
Storage Multiple VMFS Volumes, 181 Principles & Caveats, 6 Replication Scenarios, 135 Storage VMotion, 179 Vendor Guides, 11
U URLs, 3, 4, 11, 12, 15, 21, 50, 112, 121, 143, 144, 167, 200, 235, 282, 283
V vmware-dr.xml, 54, 56, 59, 79, 124, 129, 137
W Warning, 36, 61, 65, 70, 76, 77, 85, 103, 125, 129, 153, 177, 205, 209, 248, 250


















