
Addressing Emerging Challenges in Designing HPC Runtimes
44
Addressing Emerging Challenges in Designing HPC Run5mes: Energy-Awareness, Accelerators and Virtualiza5on Dhabaleswar K. (DK) Panda The Ohio State University E-mail: [email protected] h<p://www.cse.ohio-state.edu/~panda Talk at HPCAC-Switzerland (Mar ‘16) by
-
Upload
inside-bigdatacom -
Category
Technology
-
view
294 -
download
0
Transcript of Addressing Emerging Challenges in Designing HPC Runtimes

AddressingEmergingChallengesinDesigningHPCRun5mes:Energy-Awareness,AcceleratorsandVirtualiza5on
DhabaleswarK.(DK)PandaTheOhioStateUniversity
E-mail:[email protected]
h<p://www.cse.ohio-state.edu/~panda
TalkatHPCAC-Switzerland(Mar‘16)
by

HPCAC-Switzerland(Mar‘16) 2NetworkBasedCompu5ngLaboratory
• Scalabilityformilliontobillionprocessors• CollecDvecommunicaDon• UnifiedRunDmeforHybridMPI+PGASprogramming(MPI+OpenSHMEM,MPI+
UPC,CAF,…)• InfiniBandNetworkAnalysisandMonitoring(INAM)• IntegratedSupportforGPGPUs• IntegratedSupportforMICs• VirtualizaDon(SR-IOVandContainers)• Energy-Awareness• BestPracDce:SetofTuningsforCommonApplicaDons
OverviewofAFewChallengesbeingAddressedbytheMVAPICH2ProjectforExascale

HPCAC-Switzerland(Mar‘16) 3NetworkBasedCompu5ngLaboratory
• IntegratedSupportforGPGPUs– CUDA-AwareMPI– GPUDirectRDMA(GDR)Support– CUDA-awareNon-blockingCollecDves– SupportforManagedMemory– EfficientdatatypeProcessing– SupporDngStreamingapplicaDonswithGDR– EfficientDeepLearningwithMVAPICH2-GDR
• IntegratedSupportforMICs• VirtualizaDon(SR-IOVandContainers)• Energy-Awareness• BestPracDce:SetofTuningsforCommonApplicaDons
OverviewofAFewChallengesbeingAddressedbytheMVAPICH2ProjectforExascale

HPCAC-Switzerland(Mar‘16) 4NetworkBasedCompu5ngLaboratory
PCIe
GPU
CPU
NIC
Switch
At Sender: cudaMemcpy(s_hostbuf, s_devbuf, . . .); MPI_Send(s_hostbuf, size, . . .);
At Receiver: MPI_Recv(r_hostbuf, size, . . .); cudaMemcpy(r_devbuf, r_hostbuf, . . .);
• DatamovementinapplicaDonswithstandardMPIandCUDAinterfaces
HighProduc,vityandLowPerformance
MPI+CUDA-Naive

HPCAC-Switzerland(Mar‘16) 5NetworkBasedCompu5ngLaboratory
PCIe
GPU
CPU
NIC
Switch
At Sender: for (j = 0; j < pipeline_len; j++) cudaMemcpyAsync(s_hostbuf + j * blk, s_devbuf + j * blksz, …); for (j = 0; j < pipeline_len; j++) { while (result != cudaSucess) { result = cudaStreamQuery(…); if(j > 0) MPI_Test(…); } MPI_Isend(s_hostbuf + j * block_sz, blksz . . .); } MPI_Waitall();
<<Similar at receiver>>
• Pipeliningatuserlevelwithnon-blockingMPIandCUDAinterfaces
LowProduc,vityandHighPerformance
MPI+CUDA-Advanced

HPCAC-Switzerland(Mar‘16) 6NetworkBasedCompu5ngLaboratory
At Sender: At Receiver: MPI_Recv(r_devbuf, size, …);
inside MVAPICH2
• StandardMPIinterfacesusedforunifieddatamovement
• TakesadvantageofUnifiedVirtualAddressing(>=CUDA4.0)
• OverlapsdatamovementfromGPUwithRDMAtransfers
HighPerformanceandHighProduc,vity
MPI_Send(s_devbuf, size, …);
GPU-AwareMPILibrary:MVAPICH2-GPU

HPCAC-Switzerland(Mar‘16) 7NetworkBasedCompu5ngLaboratory
• OFEDwithsupportforGPUDirectRDMAisdevelopedbyNVIDIAandMellanox
• OSUhasadesignofMVAPICH2using
GPUDirectRDMA– HybriddesignusingGPU-DirectRDMA
• GPUDirectRDMAandHost-basedpipelining
• AlleviatesP2Pbandwidthbo<lenecksonSandyBridgeandIvyBridge
– SupportforcommunicaDonusingmulD-rail
– SupportforMellanoxConnect-IBandConnectXVPIadapters
– SupportforRoCEwithMellanoxConnectXVPIadapters
GPU-DirectRDMA(GDR)withCUDA
IBAdapter
SystemMemory
GPUMemory
GPU
CPU
Chipset
P2P write: 5.2 GB/s P2P read: < 1.0 GB/s
SNBE5-2670
P2P write: 6.4 GB/s P2P read: 3.5 GB/s
IVBE5-2680V2
SNBE5-2670/
IVBE5-2680V2

HPCAC-Switzerland(Mar‘16) 8NetworkBasedCompu5ngLaboratory
CUDA-AwareMPI:MVAPICH2-GDR1.8-2.2Releases• SupportforMPIcommunicaDonfromNVIDIAGPUdevicememory• HighperformanceRDMA-basedinter-nodepoint-to-point
communicaDon(GPU-GPU,GPU-HostandHost-GPU)• Highperformanceintra-nodepoint-to-pointcommunicaDonformulD-
GPUadapters/node(GPU-GPU,GPU-HostandHost-GPU)• TakingadvantageofCUDAIPC(availablesinceCUDA4.1)inintra-node
communicaDonformulDpleGPUadapters/node• OpDmizedandtunedcollecDvesforGPUdevicebuffers• MPIdatatypesupportforpoint-to-pointandcollecDvecommunicaDon
fromGPUdevicebuffers

HPCAC-Switzerland(Mar‘16) 9NetworkBasedCompu5ngLaboratory
9
MVAPICH2-GDR-2.2bIntelIvyBridge(E5-2680v2)node-20cores
NVIDIATeslaK40cGPUMellanoxConnect-IBDual-FDRHCA
CUDA7MellanoxOFED2.4withGPU-Direct-RDMA
10x2X
11x
2x
PerformanceofMVAPICH2-GPUwithGPU-DirectRDMA(GDR)
05
1015202530
0 2 8 32 128 512 2K
MV2-GDR2.2b MV2-GDR2.0bMV2w/oGDR
GPU-GPUinternodelatency
MessageSize(bytes)
Latency(us)
2.18us0
50010001500200025003000
1 4 16 64 256 1K 4K
MV2-GDR2.2bMV2-GDR2.0bMV2w/oGDR
GPU-GPUInternodeBandwidth
MessageSize(bytes)
Band
width(M
B/s)
11X
01000200030004000
1 4 16 64 256 1K 4K
MV2-GDR2.2bMV2-GDR2.0bMV2w/oGDR
GPU-GPUInternodeBi-Bandwidth
MessageSize(bytes)
Bi-Ban
dwidth(M
B/s)

HPCAC-Switzerland(Mar‘16) 10NetworkBasedCompu5ngLaboratory
LENS(Oct'15) 10
• Platform: Wilkes (Intel Ivy Bridge + NVIDIA Tesla K20c + Mellanox Connect-IB) • HoomdBlue Version 1.0.5
• GDRCOPY enabled: MV2_USE_CUDA=1 MV2_IBA_HCA=mlx5_0 MV2_IBA_EAGER_THRESHOLD=32768 MV2_VBUF_TOTAL_SIZE=32768 MV2_USE_GPUDIRECT_LOOPBACK_LIMIT=32768 MV2_USE_GPUDIRECT_GDRCOPY=1 MV2_USE_GPUDIRECT_GDRCOPY_LIMIT=16384
Applica5on-LevelEvalua5on(HOOMD-blue)
0
500
1000
1500
2000
2500
4 8 16 32
AverageTimeStep
sper
second
(TPS)
NumberofProcesses
MV2 MV2+GDR
0500100015002000250030003500
4 8 16 32AverageTimeStep
sper
second
(TPS)
NumberofProcesses
64KPar5cles 256KPar5cles
2X2X

HPCAC-Switzerland(Mar‘16) 11NetworkBasedCompu5ngLaboratory
0
20
40
60
80
100
120
4K 16K 64K 256K 1M
Overla
p(%
)
MessageSize(Bytes)
Medium/LargeMessageOverlap(64GPUnodes)
Ialltoall(1process/node)
Ialltoall(2process/node;1process/GPU)0
20
40
60
80
100
120
4K 16K 64K 256K 1M
Overla
p(%
)
MessageSize(Bytes)
Medium/LargeMessageOverlap(64GPUnodes)
Igather(1process/node)
Igather(2processes/node;1process/GPU)
Plagorm:Wilkes:IntelIvyBridgeNVIDIATeslaK20c+MellanoxConnect-IB
AvailablesinceMVAPICH2-GDR2.2a
CUDA-AwareNon-BlockingCollec5ves
A.Venkatesh,K.Hamidouche,H.Subramoni,andD.K.Panda,OffloadedGPUCollec5vesusingCORE-DirectandCUDACapabili5esonIBClusters,HIPC,2015

HPCAC-Switzerland(Mar‘16) 12NetworkBasedCompu5ngLaboratory
Communica5onRun5mewithGPUManagedMemory
● CUDA6.0NVIDIAintroducedCUDAManaged(orUnified)memoryallowingacommonmemoryallocaDonforGPUorCPUthroughcudaMallocManaged()call
● SignificantproducDvitybenefitsduetoabstracDonofexplicitallocaDonandcudaMemcpy()
● ExtendedMVAPICH2toperformcommunicaDonsdirectlyfrommanagedbuffers(AvailableinMVAPICH2-GDR2.2b)
● OSUMicro-benchmarksextendedtoevaluatetheperformanceofpoint-to-pointandcollecDvecommunicaDonsusingmanagedbuffers● AvailableinOMB5.2
DSBanerjee,KHamidouche,DKPanda,DesigningHighPerformanceCommunica,onRun,meforGPUManagedMemory:EarlyExperiencesatGPGPU-9Workshopheldinconjunc5onwithPPoPP2016.BarcelonaSpain
0
5
10
15
1 2 4 8 16
32
64
128
256
512
1024
2048
4096
8192
16384
Latency(us)
MessageSize(Bytes)
LatencyH-H MH-MH
0
2000
4000
6000
1 2 4 8 16
32
64
128
256
512
1024
2048
4096
8192
16384Band
width(M
B/s)
MessageSize(Bytes)
BandwidthD-D MD-MD

HPCAC-Switzerland(Mar‘16) 13NetworkBasedCompu5ngLaboratory
CPU
Progress
GPU
Time
Initi
ate
Kern
el
Star
t Se
nd
Isend(1)
Initi
ate
Kern
el
Star
t Se
nd
Initi
ate
Kern
el
GPU
CPU
Initi
ate
Kern
el
Star
tSe
nd
Wait For Kernel(WFK)
Kernel on Stream
Isend(1)Existing Design
Proposed Design
Kernel on Stream
Kernel on Stream
Isend(2)Isend(3)
Kernel on Stream
Initi
ate
Kern
el
Star
t Se
nd
Wait For Kernel(WFK)
Kernel on Stream
Isend(1)
Initi
ate
Kern
el
Star
t Se
nd
Wait For Kernel(WFK)
Kernel on Stream
Isend(1) Wait
WFK
Star
t Se
nd
Wait
Progress
Start Finish Proposed Finish Existing
WFK
WFK
Expected Benefits
MPIDatatypeProcessing(Communica5onOp5miza5on)
Wasteofcompu5ngresourcesonCPUandGPUCommonScenario
*Buf1, Buf2…contain non-conDguousMPIDatatype
MPI_Isend(A,..Datatype,…)MPI_Isend(B,..Datatype,…)MPI_Isend(C,..Datatype,…)MPI_Isend(D,..Datatype,…)…MPI_Waitall(…);

HPCAC-Switzerland(Mar‘16) 14NetworkBasedCompu5ngLaboratory
Applica5on-LevelEvalua5on(HaloExchange-Cosmo)
0
0.5
1
1.5
16 32 64 96
Normalized
Execu5o
nTime
NumberofGPUs
CSCSGPUclusterDefault Callback-based Event-based
0
0.5
1
1.5
4 8 16 32
Normalized
Execu5o
nTime
NumberofGPUs
WilkesGPUClusterDefault Callback-based Event-based
• 2Ximprovementon32GPUsnodes• 30%improvementon96GPUnodes(8GPUs/node)
C.Chu,K.Hamidouche,A.Venkatesh,D.Banerjee,H.Subramoni,andD.K.Panda,Exploi5ngMaximalOverlapforNon-Con5guousDataMovementProcessingonModernGPU-enabledSystems,IPDPS’16
HPCAC-Switzerland(Mar‘16) 15NetworkBasedCompu5ngLaboratory
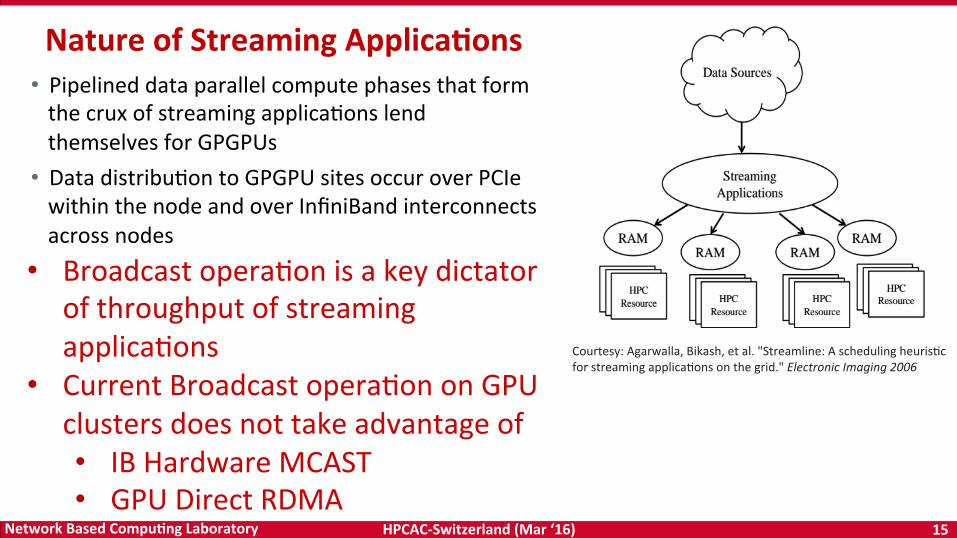
• PipelineddataparallelcomputephasesthatformthecruxofstreamingapplicaDonslendthemselvesforGPGPUs
• DatadistribuDontoGPGPUsitesoccuroverPCIewithinthenodeandoverInfiniBandinterconnectsacrossnodes
Courtesy:Agarwalla,Bikash,etal."Streamline:AschedulingheurisDcforstreamingapplicaDonsonthegrid."ElectronicImaging2006
• BroadcastoperaDonisakeydictatorofthroughputofstreamingapplicaDons
• CurrentBroadcastoperaDononGPUclustersdoesnottakeadvantageof• IBHardwareMCAST• GPUDirectRDMA
NatureofStreamingApplica5ons

HPCAC-Switzerland(Mar‘16) 16NetworkBasedCompu5ngLaboratory
SGL-baseddesignforEfficientBroadcastOpera5ononGPUSystems
• Currentdesignislimitedbytheexpensivecopiesfrom/toGPUs
• ProposedseveralalternaDvedesignstoavoidtheoverheadofthecopy
• Loopback,GDRCOPYandhybrid• Highperformanceandscalability• SDllusesPCIresourcesforHost-GPUcopies
• ProposedSGL-baseddesign• CombinesIBMCASTandGPUDirectRDMAfeatures• HighperformanceandscalabilityforD-Dbroadcast• DirectcodepathbetweenHCAandGPU• FreePCIresources
• 3Ximprovementinlatency
3X
A. Venkatesh,H.Subramoni,K.Hamidouche,andD.K.Panda,AHighPerformanceBroadcastDesignwithHardwareMul5castandGPUDirectRDMAforStreamingApplica5onsonInfiniBandClusters,IEEEInt’lConf.onHighPerformanceCompu5ng(HiPC’14)

HPCAC-Switzerland(Mar‘16) 17NetworkBasedCompu5ngLaboratory
Accelera5ngDeepLearningwithMVAPICH2-GDR• Caffe:AflexibleandlayeredDeepLearning
framework.
• BenefitsandWeaknesses
– MulD-GPUTrainingwithinasinglenode
– PerformancedegradaDonforGPUsacrossdifferentsockets
• CanweenhanceCaffewithMVAPICH2-GDR?
– Caffe-Enhanced:ACUDA-AwareMPIversion
– EnablesScale-up(withinanode)andScale-out(acrossmulD-GPUnodes)
– IniDalEvaluaDonsuggestsupto8XreducDonintrainingDmeonCIFAR-10dataset
8ximprovement

HPCAC-Switzerland(Mar‘16) 18NetworkBasedCompu5ngLaboratory
• IntegratedSupportforGPGPUs• IntegratedSupportforMICs• VirtualizaDon(SR-IOVandContainers)• Energy-Awareness• BestPracDce:SetofTuningsforCommonApplicaDons
OverviewofAFewChallengesbeingAddressedbytheMVAPICH2ProjectforExascale
HPCAC-Switzerland(Mar‘16) 19NetworkBasedCompu5ngLaboratory
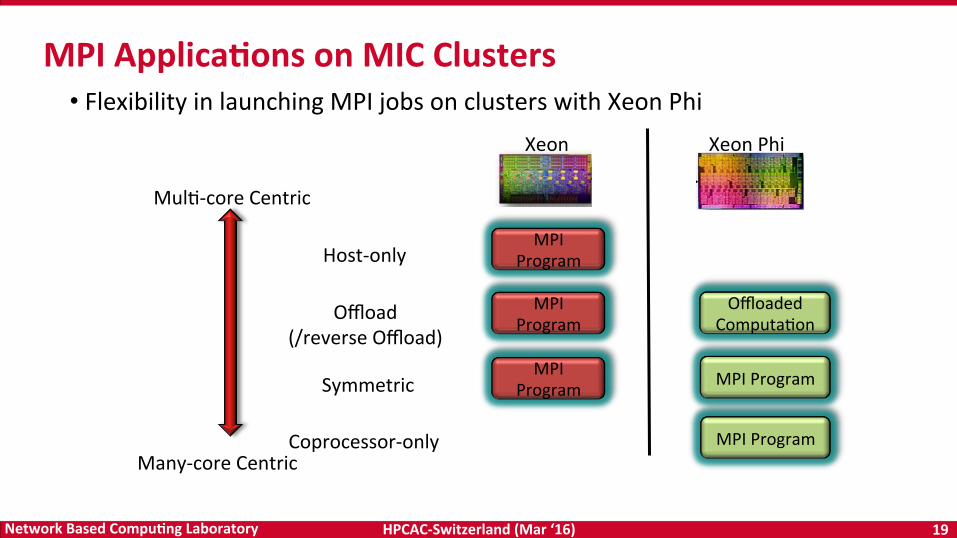
MPIApplica5onsonMICClusters
Xeon XeonPhi
MulD-coreCentric
Many-coreCentric
MPIProgram
MPIProgram
OffloadedComputaDon
MPIProgram MPIProgram
MPIProgram
Host-only
Offload(/reverseOffload)
Symmetric
Coprocessor-only
• FlexibilityinlaunchingMPIjobsonclusterswithXeonPhi

HPCAC-Switzerland(Mar‘16) 20NetworkBasedCompu5ngLaboratory
MVAPICH2-MIC2.0DesignforClusterswithIBandMIC
• OffloadMode
• IntranodeCommunicaDon
• Coprocessor-onlyandSymmetricMode
• InternodeCommunicaDon
• Coprocessors-onlyandSymmetricMode
• MulD-MICNodeConfiguraDons
• Runningonthreemajorsystems
• Stampede,Blueridge(VirginiaTech)andBeacon(UTK)
HPCAC-Switzerland(Mar‘16) 21NetworkBasedCompu5ngLaboratory
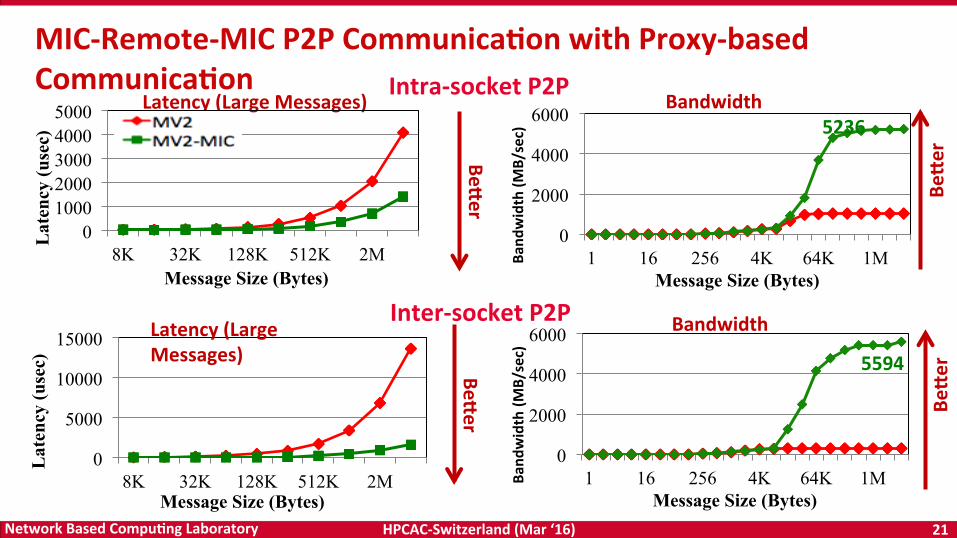
MIC-Remote-MICP2PCommunica5onwithProxy-basedCommunica5on
Bandwidth
Bemer
Bemer
Bemer
Latency(LargeMessages)
0 1000 2000 3000 4000 5000
8K 32K 128K 512K 2M
Lat
ency
(use
c)
Message Size (Bytes)
0
2000
4000
6000
1 16 256 4K 64K 1M Band
width(M
B/sec)
Message Size (Bytes)
5236
Intra-socketP2P
Inter-socketP2P
0
5000
10000
15000
8K 32K 128K 512K 2M
Lat
ency
(use
c)
Message Size (Bytes)
Latency(LargeMessages)
0
2000
4000
6000
1 16 256 4K 64K 1M Band
width(M
B/sec)
Message Size (Bytes) Bem
er
5594
Bandwidth

HPCAC-Switzerland(Mar‘16) 22NetworkBasedCompu5ngLaboratory
Op5mizedMPICollec5vesforMICClusters(Allgather&Alltoall)
A.Venkatesh,S.Potluri,R.Rajachandrasekar,M.Luo,K.HamidoucheandD.K.Panda-HighPerformanceAlltoallandAllgatherdesignsforInfiniBandMICClusters;IPDPS’14,May2014
0
10000
20000
30000
1 2 4 8 16 32 64 128256512 1K
Latency(usecs)
MessageSize(Bytes)
32-Node-Allgather(16H+16M)SmallMessageLatencyMV2-MIC
MV2-MIC-Opt
0
500
1000
1500
8K 16K 32K 64K 128K256K512K 1M
Latency(usecs)
MessageSize(Bytes)
32-Node-Allgather(8H+8M)LargeMessageLatencyMV2-MIC
MV2-MIC-Opt
0
500
1000
4K 8K 16K 32K 64K 128K256K512K
Latency(usecs)
MessageSize(Bytes)
32-Node-Alltoall(8H+8M)LargeMessageLatencyMV2-MIC
MV2-MIC-Opt
0
20
40
60
MV2-MIC-Opt MV2-MICExecu5
onTim
e(secs)
32Nodes(8H+8M),Size=2K*2K*1K
P3DFFTPerformanceCommunicaDonComputaDon
76%58%
55%

HPCAC-Switzerland(Mar‘16) 23NetworkBasedCompu5ngLaboratory
• IntegratedSupportforGPGPUs• IntegratedSupportforMICs• VirtualizaDon(SR-IOVandContainers)• Energy-Awareness• BestPracDce:SetofTuningsforCommonApplicaDons
OverviewofAFewChallengesbeingAddressedbytheMVAPICH2ProjectforExascale

HPCAC-Switzerland(Mar‘16) 24NetworkBasedCompu5ngLaboratory
• VirtualizaDonhasmanybenefits– Fault-tolerance– JobmigraDon– CompacDon
• HavenotbeenverypopularinHPCduetooverheadassociatedwithVirtualizaDon
• NewSR-IOV(SingleRoot–IOVirtualizaDon)supportavailablewithMellanoxInfiniBandadapterschangesthefield
• EnhancedMVAPICH2supportforSR-IOV• MVAPICH2-Virt2.1(withandwithoutOpenStack)ispubliclyavailable• HowabouttheContainerssupport?
CanHPCandVirtualiza5onbeCombined?
J.Zhang,X.Lu,J.Jose,R.ShiandD.K.Panda,CanInter-VMShmemBenefitMPIApplica5onsonSR-IOVbasedVirtualizedInfiniBandClusters?EuroPar'14
J.Zhang,X.Lu,J.Jose,M.Li,R.ShiandD.K.Panda,HighPerformanceMPILibrayoverSR-IOVenabledInfiniBandClusters,HiPC’14
J.Zhang,X.Lu,M.ArnoldandD.K.Panda,MVAPICH2OverOpenStackwithSR-IOV:anEfficientApproachtobuildHPCClouds,CCGrid’15

HPCAC-Switzerland(Mar‘16) 25NetworkBasedCompu5ngLaboratory
• RedesignMVAPICH2tomakeitvirtualmachineaware– SR-IOVshowsneartonaDve
performanceforinter-nodepointtopointcommunicaDon
– IVSHMEMofferszero-copyaccesstodataonsharedmemoryofco-residentVMs
– LocalityDetector:maintainsthelocalityinformaDonofco-residentvirtualmachines
– CommunicaDonCoordinator:selectsthecommunicaDonchannel(SR-IOV,IVSHMEM)adapDvely
OverviewofMVAPICH2-VirtwithSR-IOVandIVSHMEM
Host Environment
Guest 1
Hypervisor PF Driver
Infiniband Adapter
Physical Function
user space
kernel space
MPI proc
PCI Device
VF Driver
Guest 2user space
kernel space
MPI proc
PCI Device
VF Driver
Virtual Function
Virtual Function
/dev/shm/
IV-SHM
IV-Shmem Channel
SR-IOV Channel
J.Zhang,X.Lu,J.Jose,R.Shi,D.K.Panda.CanInter-VMShmemBenefitMPIApplicaDonsonSR-IOVbasedVirtualizedInfiniBandClusters?Euro-Par,2014.
J.Zhang,X.Lu,J.Jose,R.Shi,M.Li,D.K.Panda.HighPerformanceMPILibraryoverSR-IOVEnabledInfiniBandClusters.HiPC,2014.

HPCAC-Switzerland(Mar‘16) 26NetworkBasedCompu5ngLaboratory
Nova
Glance
Neutron
Swift
Keystone
Cinder
Heat
Ceilometer
Horizon
VM
Backup volumes in
Stores images in
Provides images
Provides Network
Provisions
Provides Volumes
Monitors
Provides UI
Provides Auth for
Orchestrates cloud
• OpenStackisoneofthemostpopularopen-sourcesoluDonstobuildcloudsandmanagevirtualmachines
• DeploymentwithOpenStack– SupporDngSR-IOVconfiguraDon
– SupporDngIVSHMEMconfiguraDon
– VirtualMachineawaredesignofMVAPICH2withSR-IOV
• AnefficientapproachtobuildHPCCloudswithMVAPICH2-VirtandOpenStack
MVAPICH2-VirtwithSR-IOVandIVSHMEMoverOpenStack
J.Zhang,X.Lu,M.Arnold,D.K.Panda.MVAPICH2overOpenStackwithSR-IOV:AnEfficientApproachtoBuildHPCClouds.CCGrid,2015.

HPCAC-Switzerland(Mar‘16) 27NetworkBasedCompu5ngLaboratory
0
50
100
150
200
250
300
350
400
milc leslie3d pop2 GAPgeofem zeusmp2 lu
Execu5
onTim
e(s)
MV2-SR-IOV-Def
MV2-SR-IOV-Opt
MV2-NaDve
1% 9.5%
0
1000
2000
3000
4000
5000
6000
22,20 24,10 24,16 24,20 26,10 26,16
Execu5
onTim
e(m
s)
ProblemSize(Scale,Edgefactor)
MV2-SR-IOV-Def
MV2-SR-IOV-Opt
MV2-NaDve 2%
• 32VMs,6Core/VM
• ComparedtoNaDve,2-5%overheadforGraph500with128Procs
• ComparedtoNaDve,1-9.5%overheadforSPECMPI2007with128Procs
Applica5on-LevelPerformanceonChameleon
SPECMPI2007 Graph500
5%

HPCAC-Switzerland(Mar‘16) 28NetworkBasedCompu5ngLaboratory
NSFChameleonCloud:APowerfulandFlexibleExperimentalInstrument • Large-scaleinstrument
– TargeDngBigData,BigCompute,BigInstrumentresearch– ~650nodes(~14,500cores),5PBdiskovertwosites,2sitesconnectedwith100Gnetwork
• Reconfigurableinstrument– BaremetalreconfiguraDon,operatedassingleinstrument,graduatedapproachforease-of-use
• Connectedinstrument– WorkloadandTraceArchive– PartnershipswithproducDonclouds:CERN,OSDC,Rackspace,Google,andothers– Partnershipswithusers
• Complementaryinstrument– ComplemenDngGENI,Grid’5000,andothertestbeds
• Sustainableinstrument– IndustryconnecDons
h<p://www.chameleoncloud.org/

HPCAC-Switzerland(Mar‘16) 29NetworkBasedCompu5ngLaboratory
0
2
4
6
8
10
12
14
16
18
1 2 4 8 16 32 64 128256512 1k 2k 4k 8k 16k32k64k
Latency(us)
MessageSize(Bytes)
Container-Def
Container-Opt
NaDve
0
2000
4000
6000
8000
10000
12000
14000
16000
1 2 4 8 16 32 64 128256512 1k 2k 4k 8k 16k 32k 64k
Band
width(M
Bps)
MessageSize(Bytes)
Container-Def
Container-Opt
NaDve
• Intra-NodeInter-Container
• ComparedtoContainer-Def,upto81%and191%improvementonLatencyandBW
• ComparedtoNaDve,minoroverheadonLatencyandBW
ContainersSupport:MVAPICH2Intra-nodePoint-to-PointPerformanceonChameleon
81%
191%

HPCAC-Switzerland(Mar‘16) 30NetworkBasedCompu5ngLaboratory
0
500
1000
1500
2000
2500
3000
3500
4000
22,16 22,20 24,16 24,20 26,16 26,20
Execu5
onTim
e(m
s)
ProblemSize(Scale,Edgefactor)
Container-Def
Container-Opt
NaDve
0
10
20
30
40
50
60
70
80
90
100
MG.D FT.D EP.D LU.D CG.D
Execu5
onTim
e(s)
Container-Def
Container-Opt
NaDve
• 64Containersacross16nodes,pining4CoresperContainer
• ComparedtoContainer-Def,upto11%and16%ofexecuDonDmereducDonforNASandGraph500
• ComparedtoNaDve,lessthan9%and4%overheadforNASandGraph500
• Op5mizedContainersupportwillbeavailablewiththenextreleaseofMVAPICH2-Virt
ContainersSupport:Applica5on-LevelPerformanceonChameleon
Graph500 NAS
11%
16%

HPCAC-Switzerland(Mar‘16) 31NetworkBasedCompu5ngLaboratory
• IntegratedSupportforGPGPUs• IntegratedSupportforMICs• VirtualizaDon(SR-IOVandContainers)• Energy-Awareness• BestPracDce:SetofTuningsforCommonApplicaDons
OverviewofAFewChallengesbeingAddressedbytheMVAPICH2ProjectforExascale

HPCAC-Switzerland(Mar‘16) 32NetworkBasedCompu5ngLaboratory
DesigningEnergy-Aware(EA)MPIRun5me
EnergySpentinCommunicaDonRouDnes
EnergySpentinComputaDonRouDnes
OverallapplicaDonEnergyExpenditure
Point-to-pointRouDnes
CollecDveRouDnes
RMARouDnes
MVAPICH2-EADesigns
MPITwo-sidedandcollecDves(ex:MVAPICH2)
OtherPGASImplementaDons(ex:OSHMPI)One-sidedrunDmes(ex:ComEx)
Impact MPI-3RMAImplementaDons(ex:MVAPICH2)

HPCAC-Switzerland(Mar‘16) 33NetworkBasedCompu5ngLaboratory
• MVAPICH2-EA2.1(Energy-Aware)• Awhite-boxapproach• NewEnergy-EfficientcommunicaDonprotocolsforpt-ptandcollecDveoperaDons• IntelligentlyapplytheappropriateEnergysavingtechniques• ApplicaDonobliviousenergysaving
• OEMT• AlibraryuDlitytomeasureenergyconsumpDonforMPIapplicaDons• WorkswithallMPIrunDmes• PRELOADopDonforprecompiledapplicaDons• DoesnotrequireROOTpermission:
• AsafekernelmoduletoreadonlyasubsetofMSRs
Energy-AwareMVAPICH2&OSUEnergyManagementTool(OEMT)

HPCAC-Switzerland(Mar‘16) 34NetworkBasedCompu5ngLaboratory
• AnenergyefficientrunDmethatprovidesenergysavingswithoutapplicaDonknowledge
• UsesautomaDcallyandtransparentlythebestenergylever
• ProvidesguaranteesonmaximumdegradaDonwith5-41%savingsat<=5%degradaDon
• PessimisDcMPIappliesenergyreducDonlevertoeachMPIcall
MVAPICH2-EA:Applica5onObliviousEnergy-Aware-MPI(EAM)
ACaseforApplica5on-ObliviousEnergy-EfficientMPIRun5meA.Venkatesh,A.Vishnu,K.Hamidouche,N.Tallent,D.
K.Panda,D.Kerbyson,andA.Hoise,Supercompu5ng‘15,Nov2015[BestStudentPaperFinalist]
1

HPCAC-Switzerland(Mar‘16) 35NetworkBasedCompu5ngLaboratory
MPI-3RMAEnergySavingswithProxy-Applica5ons
0
10
20
30
40
50
60
512 256 128
Seco
nds
#Processes
Graph500 (Execution Time)
optimistic
pessimistic
EAM-RMA
0
50000
100000
150000
200000
250000
300000
350000
512 256 128
Joul
es
#Processes
Graph500 (Energy Usage)
optimistic pessimistic EAM-RMA
46%
• MPI_Win_fencedominatesapplicaDonexecuDonDmeingraph500
• Between128and512processes,EAM-RMAyieldsbetween31%and46%savingswithnodegradaDoninexecuDonDmeincomparisonwiththedefaultopDmisDcMPIrunDme

HPCAC-Switzerland(Mar‘16) 36NetworkBasedCompu5ngLaboratory
0
500000
1000000
1500000
2000000
2500000
3000000
512 256 128
Joul
es
#Processes
SCF (Energy Usage)
optimistic
pessimistic
EAM-RMA
0
100
200
300
400
500
600
512 256 128
Seco
nds
#Processes
SCF (Execution Time)
optimistic pessimistic EAM-RMA
MPI-3RMAEnergySavingswithProxy-Applica5ons
42%
• SCF(self-consistentfield)calculaDonspendsnearly75%totalDmeinMPI_Win_unlockcall
• With256and512processes,EAM-RMAyields42%and36%savingsat11%degradaDon(closetopermi<eddegradaDonρ=10%)
• 128processesisanexcepDondue2-sidedand1-sidedinteracDon
• MPI-3RMAEnergy-efficientsupportwillbeavailableinupcomingMVAPICH2-EArelease

HPCAC-Switzerland(Mar‘16) 37NetworkBasedCompu5ngLaboratory
• IntegratedSupportforGPGPUs• IntegratedSupportforMICs• VirtualizaDon(SR-IOVandContainers)• Energy-Awareness• BestPracDce:SetofTuningsforCommonApplicaDons
OverviewofAFewChallengesbeingAddressedbytheMVAPICH2ProjectforExascale

HPCAC-Switzerland(Mar‘16) 38NetworkBasedCompu5ngLaboratory
• MPIrunDmehasmanyparameters• Tuningasetofparameterscanhelpyoutoextracthigherperformance• CompiledalistofsuchcontribuDonsthroughtheMVAPICHWebsite
– h<p://mvapich.cse.ohio-state.edu/best_pracDces/
• IniDallistofapplicaDons– Amber– HoomdBlue– HPCG– Lulesh– MILC– MiniAMR– Neuron– SMG2000
• SoliciDngaddiDonalcontribuDons,sendyourresultstomvapich-helpatcse.ohio-state.edu.Wewilllinktheseresultswithcreditstoyou.
Applica5ons-LevelTuning:Compila5onofBestPrac5ces

HPCAC-Switzerland(Mar‘16) 39NetworkBasedCompu5ngLaboratory
MVAPICH2–PlansforExascale• PerformanceandMemoryscalabilitytoward1Mcores• Hybridprogramming(MPI+OpenSHMEM,MPI+UPC,MPI+CAF…)
• Supportfortask-basedparallelism(UPC++)*• EnhancedOpDmizaDonforGPUSupportandAccelerators• TakingadvantageofadvancedfeaturesofMellanoxInfiniBand
• On-DemandPaging(ODP)• Swith-IB2SHArP• GID-basedsupport
• EnhancedInter-nodeandIntra-nodecommunicaDonschemesforupcomingarchitectures• OpenPower*• OmniPath-PSM2*• KnightsLanding
• Extendedtopology-awarecollecDves• ExtendedEnergy-awaredesignsandVirtualizaDonSupport• ExtendedSupportforMPIToolsInterface(asinMPI3.0)• ExtendedCheckpoint-RestartandmigraDonsupportwithSCR• Supportfor*featureswillbeavailableinMVAPICH2-2.2RC1

HPCAC-Switzerland(Mar‘16) 40NetworkBasedCompu5ngLaboratory
• Exascalesystemswillbeconstrainedby– Power– Memorypercore– Datamovementcost– Faults
• ProgrammingModelsandRunDmesforHPCneedtobedesignedfor– Scalability– Performance– Fault-resilience– Energy-awareness– Programmability– ProducDvity
• Highlightedsomeoftheissuesandchallenges• NeedconDnuousinnovaDononallthesefronts
LookingintotheFuture….

HPCAC-Switzerland(Mar‘16) 41NetworkBasedCompu5ngLaboratory
FundingAcknowledgmentsFundingSupportby
EquipmentSupportby

HPCAC-Switzerland(Mar‘16) 42NetworkBasedCompu5ngLaboratory
PersonnelAcknowledgmentsCurrentStudents
– A.AugusDne(M.S.)
– A.Awan(Ph.D.)– S.Chakraborthy(Ph.D.)
– C.-H.Chu(Ph.D.)– N.Islam(Ph.D.)
– M.Li(Ph.D.)
PastStudents– P.Balaji(Ph.D.)
– S.Bhagvat(M.S.)
– A.Bhat(M.S.)
– D.BunDnas(Ph.D.)
– L.Chai(Ph.D.)
– B.Chandrasekharan(M.S.)
– N.Dandapanthula(M.S.)
– V.Dhanraj(M.S.)
– T.Gangadharappa(M.S.)– K.Gopalakrishnan(M.S.)
– G.Santhanaraman(Ph.D.)– A.Singh(Ph.D.)
– J.Sridhar(M.S.)
– S.Sur(Ph.D.)
– H.Subramoni(Ph.D.)
– K.Vaidyanathan(Ph.D.)
– A.Vishnu(Ph.D.)
– J.Wu(Ph.D.)
– W.Yu(Ph.D.)
PastResearchScien,st– S.Sur
CurrentPost-Doc– J.Lin
– D.Banerjee
CurrentProgrammer– J.Perkins
PastPost-Docs– H.Wang
– X.Besseron– H.-W.Jin
– M.Luo
– W.Huang(Ph.D.)– W.Jiang(M.S.)
– J.Jose(Ph.D.)
– S.Kini(M.S.)
– M.Koop(Ph.D.)
– R.Kumar(M.S.)
– S.Krishnamoorthy(M.S.)
– K.Kandalla(Ph.D.)
– P.Lai(M.S.)
– J.Liu(Ph.D.)
– M.Luo(Ph.D.)– A.Mamidala(Ph.D.)
– G.Marsh(M.S.)
– V.Meshram(M.S.)
– A.Moody(M.S.)
– S.Naravula(Ph.D.)
– R.Noronha(Ph.D.)
– X.Ouyang(Ph.D.)
– S.Pai(M.S.)
– S.Potluri(Ph.D.)
– R.Rajachandrasekar(Ph.D.)
– K.Kulkarni(M.S.)– M.Rahman(Ph.D.)
– D.Shankar(Ph.D.)– A.Venkatesh(Ph.D.)
– J.Zhang(Ph.D.)
– E.Mancini– S.Marcarelli
– J.Vienne
CurrentResearchScien,stsCurrentSeniorResearchAssociate– H.Subramoni
– X.Lu
PastProgrammers– D.Bureddy
-K.Hamidouche
CurrentResearchSpecialist– M.Arnold

HPCAC-Switzerland(Mar‘16) 43NetworkBasedCompu5ngLaboratory
Interna5onalWorkshoponCommunica5onArchitecturesatExtremeScale(Exacomm)
ExaComm2015washeldwithInt’lSupercompuDngConference(ISC‘15),atFrankfurt,Germany,onThursday,July16th,2015
OneKeynoteTalk:JohnM.Shalf,CTO,LBL/NERSC
FourInvitedTalks:DrorGoldenberg(Mellanox);MarDnSchulz(LLNL);CyrielMinkenberg(IBM-Zurich);Arthur(Barney)Maccabe(ORNL)
Panel:RonBrightwell(Sandia)TwoResearchPapers
ExaComm2016willbeheldinconjuncDonwithISC’16h<p://web.cse.ohio-state.edu/~subramon/ExaComm16/exacomm16.html
TechnicalPaperSubmissionDeadline:Friday,April15,2016

HPCAC-Switzerland(Mar‘16) 44NetworkBasedCompu5ngLaboratory
ThankYou!
TheHigh-PerformanceBigDataProjecth<p://hibd.cse.ohio-state.edu/
Network-BasedCompuDngLaboratoryh<p://nowlab.cse.ohio-state.edu/
TheMVAPICH2Projecth<p://mvapich.cse.ohio-state.edu/


















