Adaptive Filtering - Theory and Applicationssc.enseeiht.fr/doc/Seminar_Bermudez.pdf · Adaptive...
107
Adaptive Filtering - Theory and Applications Jos´ e C. M. Bermudez Department of Electrical Engineering Federal University of Santa Catarina Florian´ opolis – SC Brazil IRIT - INP-ENSEEIHT, Toulouse May 2011 Jos´ e Bermudez (UFSC) Adaptive Filtering IRIT - Toulouse, 2011 1 / 107
Transcript of Adaptive Filtering - Theory and Applicationssc.enseeiht.fr/doc/Seminar_Bermudez.pdf · Adaptive...

Adaptive Filtering - Theory and Applications
Jose C. M. Bermudez
Department of Electrical EngineeringFederal University of Santa Catarina
Florianopolis – SCBrazil
IRIT - INP-ENSEEIHT, ToulouseMay 2011
Jose Bermudez (UFSC) Adaptive Filtering IRIT - Toulouse, 2011 1 / 107

1 Introduction
2 Adaptive Filtering Applications
3 Adaptive Filtering Principles
4 Iterative Solutions for the Optimum Filtering Problem
5 Stochastic Gradient Algorithms
6 Deterministic Algorithms
7 Analysis
Jose Bermudez (UFSC) Adaptive Filtering IRIT - Toulouse, 2011 2 / 107

Introduction
Jose Bermudez (UFSC) Adaptive Filtering IRIT - Toulouse, 2011 3 / 107

Estimation Techniques
Several techniques to solve estimation problems.
Classical Estimation
Maximum Likelihood (ML), Least Squares (LS), Moments, etc.
Bayesian Estimation
Minimum MSE (MMSE), Maximum A Posteriori (MAP), etc.
Linear Estimation
Frequently used in practice when there is a limitation in computational
complexity – Real-time operation
Jose Bermudez (UFSC) Adaptive Filtering IRIT - Toulouse, 2011 4 / 107

Linear Estimators
Simpler to determine: depend on the first two moments of data
Statistical Approach – Optimal Linear Filters◮ Minimum Mean Square Error◮ Require second order statistics of signals
Deterministic Approach – Least Squares Estimators◮ Minimum Least Squares Error◮ Require handling of a data observation matrix
Jose Bermudez (UFSC) Adaptive Filtering IRIT - Toulouse, 2011 5 / 107

Limitations of Optimal Filters and LS Estimators
Statistics of signals may not be available or cannot be accuratelyestimated
There may not be available time for statistical estimation (real-time)
Signals and systems may be non-stationary
Memory required may be prohibitive
Computational load may be prohibitive
Jose Bermudez (UFSC) Adaptive Filtering IRIT - Toulouse, 2011 6 / 107

Iterative Solutions
Search the optimal solution starting from an initial guess
Iterative algorithms are based on classical optimization algorithms
Require reduced computational effort per iteration
Need several iterations to converge to the optimal solution
These methods form the basis for the development of adaptivealgorithms
Still require the knowledge of signal statistics
Jose Bermudez (UFSC) Adaptive Filtering IRIT - Toulouse, 2011 7 / 107

Adaptive Filters
Usually approximate iterative algorithms and:
Do not require previous knowledge of the signal statistics
Have a small computational complexity per iteration
Converge to a neighborhood of the optimal solution
Adaptive filters are good for:
Real-time applications, when there is no time for statistical estimation
Applications with nonstationary signals and/or systems
Jose Bermudez (UFSC) Adaptive Filtering IRIT - Toulouse, 2011 8 / 107

Properties of Adaptive Filters
They can operate satisfactorily in unknown and possibly time-varyingenvironments without user intervention
They improve their performance during operation by learningstatistical characteristics from current signal observations
They can track variations in the signal operating environment (SOE)
Jose Bermudez (UFSC) Adaptive Filtering IRIT - Toulouse, 2011 9 / 107

Adaptive Filtering Applications
Jose Bermudez (UFSC) Adaptive Filtering IRIT - Toulouse, 2011 10 / 107

Basic Classes of Adaptive Filtering Applications
System Identification
Inverse System Modeling
Signal Prediction
Interference Cancelation
Jose Bermudez (UFSC) Adaptive Filtering IRIT - Toulouse, 2011 11 / 107

System Identification
+ +
_
+x(n) d(n)
d(n)
y(n) e(n)
eo(n)
other signals
unknownsystem
adaptive
adaptive
algorithm
filter
Jose Bermudez (UFSC) Adaptive Filtering IRIT - Toulouse, 2011 12 / 107

Applications – System Identification
Channel Estimation
Communications systems
Objective: model the channel to design distortion compensation
x(n): training sequence
Plant Identification
Control systems
Objective: model the plant to design a compensator
x(n): training sequence
Jose Bermudez (UFSC) Adaptive Filtering IRIT - Toulouse, 2011 13 / 107

Echo Cancellation
Telephone systems and VoIP
Echo caused by network impedance mismatches or acousticenvironment
Objective: model the echo path impulse response
x(n): transmitted signal
d(n): echo + noise
H H
Tx
Rx
H H
Tx
Rx
EC
+
_
x(n)
d(n)e(n)
Figure: Network Echo Cancellation
Jose Bermudez (UFSC) Adaptive Filtering IRIT - Toulouse, 2011 14 / 107

Inverse System Modeling
Adaptive filter attempts to estimate unknown system’s inverse
Adaptive filter input usually corrupted by noise
Desired response d(n) may not be available
++ +
_UnknownSystem
Adaptive
AdaptiveFilter
Algorithm
Delay
othersignals
x(n)
s(n) e(n)
y(n)
d(n)z(n)
Jose Bermudez (UFSC) Adaptive Filtering IRIT - Toulouse, 2011 15 / 107

Applications – Inverse System ModelingChannel Equalization
++ +
_Channel
Adaptive
AdaptiveFilter
Algorithm
Local gen.
x(n)
x(n)
s(n) e(n)
y(n)
d(n)z(n)
Objective: reduce intersymbol interference
Initially – training sequence in d(n)
After training: d(n) generated from previous decisions
Jose Bermudez (UFSC) Adaptive Filtering IRIT - Toulouse, 2011 16 / 107

Signal Prediction
+_
Delay
Adaptive
AdaptiveFilter
Algorithmothersignals
x(n − no)
x(n) e(n)
y(n)
d(n)
most widely used case – forward prediction
signal x(n) to be predicted from samples{x(n − no), x(n − no − 1), . . . , x(n − no − L)}
Jose Bermudez (UFSC) Adaptive Filtering IRIT - Toulouse, 2011 17 / 107

Application – Signal Prediction
DPCM Speech Quantizer - Linear Predictive Coding
Objective: Reduce speech transmission bandwidth
Signal transmitted all the time: quantization error
Predictor coefficients are transmitted at low rate
+
_+
+
Speech
signalsignal DPCM
Quantizer
Predictor
prediction errorQ[e(n)]
e(n)
y(n) + Q[e(n)] ∼ d(n)
d(n)
y(n)
Jose Bermudez (UFSC) Adaptive Filtering IRIT - Toulouse, 2011 18 / 107

Interference Cancelation
One or more sensor signals are used to remove interference and noise
Reference signals correlated with the inteference should also beavailable
Applications:◮ array processing for radar and communications◮ biomedical sensing systems◮ active noise control systems
Jose Bermudez (UFSC) Adaptive Filtering IRIT - Toulouse, 2011 19 / 107
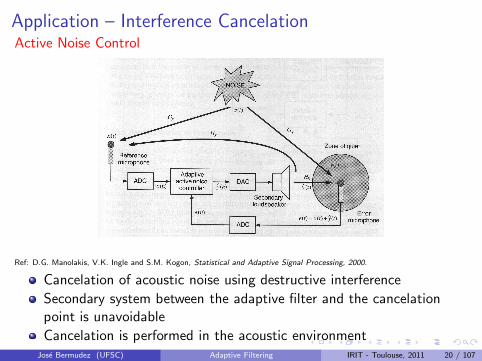
Application – Interference CancelationActive Noise Control
Ref: D.G. Manolakis, V.K. Ingle and S.M. Kogon, Statistical and Adaptive Signal Processing, 2000.
Cancelation of acoustic noise using destructive interference
Secondary system between the adaptive filter and the cancelationpoint is unavoidable
Cancelation is performed in the acoustic environmentJose Bermudez (UFSC) Adaptive Filtering IRIT - Toulouse, 2011 20 / 107

Active Noise Control – Block Diagram
s++
−
AdaptiveAlgorithm
wo
w(n)
x(n)
xf (n)
S
S
y(n) ys(n) yg(n)
d(n)
z(n)
e(n)
g(ys)
Jose Bermudez (UFSC) Adaptive Filtering IRIT - Toulouse, 2011 21 / 107

Adaptive Filtering Principles
Jose Bermudez (UFSC) Adaptive Filtering IRIT - Toulouse, 2011 22 / 107

Adaptive Filter Features
Adaptive filters are composed of three basic modules:
Filtering strucure◮ Determines the output of the filter given its input samples◮ Its weights are periodically adjusted by the adaptive algorithm◮ Can be linear or nonlinear, depending on the application◮ Linear filters can be FIR or IIR
Performance criterion◮ Defined according to application and mathematical tractability◮ Is used to derive the adaptive algorithm◮ Its value at each iteration affects the adaptive weight updates
Adaptive algorithm◮ Uses the performance criterion value and the current signals◮ Modifies the adaptive weights to improve performance◮ Its form and complexity are function of the structure and of the
performance criterion
Jose Bermudez (UFSC) Adaptive Filtering IRIT - Toulouse, 2011 23 / 107

Signal Operating Environment (SOE)
Comprises all informations regarding the properties of the signals andsystems
Input signals
Desired signal
Unknown systems
If the SOE is nonstationary
Aquisition or convergence mode: from start until close to bestperformance
Tracking mode: readjustment following SOE’s time variations
Adaptation can be
Supervised – desired signal is available ➪ e(n) can be evaluated
Unsupervised – desired signal is unavailable
Jose Bermudez (UFSC) Adaptive Filtering IRIT - Toulouse, 2011 24 / 107

Performance Evaluation
Convergence rate
Misadjustment
Tracking
Robustness (disturbances and numerical)
Computational requirements (operations and memory)
Structure◮ facility of implementation◮ performance surface◮ stability
Jose Bermudez (UFSC) Adaptive Filtering IRIT - Toulouse, 2011 25 / 107

Optimum versus Adaptive Filters in Linear Estimation
Conditions for this study
Stationary SOE
Filter structure is transversal FIR
All signals are real valued
Performance criterion: Mean-square error E[e2(n)]
The Linear Estimation Problem
+
−
Linear FIR Filter
w
x(n) y(n)
d(n)
e(n)
Jms = E[e2(n)]
Jose Bermudez (UFSC) Adaptive Filtering IRIT - Toulouse, 2011 26 / 107

The Linear Estimation Problem
+
−
Linear FIR Filter
w
x(n) y(n)
d(n)
e(n)
x(n) = [x(n), x(n − 1), · · · , x(n − N + 1)]T
y(n) = xT (n)w
e(n) = d(n) − y(n) = d(n) − xT (n)w
Jms = E[e2(n)] = σ2d − 2pT w + wT Rxxw
wherep = E[x(n)d(n)]; Rxx = E[x(n)xT (n)]
Normal Equations
Rxxwo = p ➪ wo = R−1xx p for Rxx > 0
Jmsmin= σ2
d − pT R−1xx p
Jose Bermudez (UFSC) Adaptive Filtering IRIT - Toulouse, 2011 27 / 107

What if d(n) is nonstationary?
+
−
Linear FIR Filter
wx(n) y(n)
d(n)
e(n)
x(n) = [x(n), x(n − 1), · · · , x(n − N + 1)]T
y(n) = xT (n)w(n)
e(n) = d(n) − y(n) = d(n) − xT (n)w(n)
Jms(n) = E[e2(n)] = σ2d(n) − 2p(n)T w(n) + wT (n)Rxxw(n)
wherep(n) = E[x(n)d(n)]; Rxx = E[x(n)xT (n)]
Normal Equations
Rxxwo(n) = p(n) ➪ wo(n) = R−1
xx p(n) for Rxx > 0
Jmsmin(n) = σ2
d(n) − pT (n)R−1xx p(n)
Jose Bermudez (UFSC) Adaptive Filtering IRIT - Toulouse, 2011 28 / 107

Optimum Filters versus Adaptive Filters
Optimum Filters
Computep(n) = E[x(n)d(n)]
Solve Rxxwo = p(n)
Filter with wo(n) ➪
y(n) = xT (n)wo(n)
Nonstationary SOE:Optimum filter determinedfor each value of n
Adaptive Filters
Filtering: y(n) = xT (n)w(n)
Evaluate error: e(n) = d(n) − y(n)
Adaptive algorithm:
w(n + 1) = w(n) + ∆w[x(n), e(n)]
∆w(n) is chosen so that w(n) is close towo(n) for n large
Jose Bermudez (UFSC) Adaptive Filtering IRIT - Toulouse, 2011 29 / 107

Characteristics of Adaptive Filters
Search for the optimum solution on the performance surface
Follow principles of optimization techniques
Implement a recursive optimization solution
Convergence speed may depend on initialization
Have stability regions
Steady-state solution fluctuates about the optimum
Can track time varying SOEs better than optimum filters
Performance depends on the performance surface
Jose Bermudez (UFSC) Adaptive Filtering IRIT - Toulouse, 2011 30 / 107

Iterative Solutions for the
Optimum Filtering Problem
Jose Bermudez (UFSC) Adaptive Filtering IRIT - Toulouse, 2011 31 / 107

Performance (Cost) Functions
Mean-square error ➪ E[e2(n)] (Most popular)Adaptive algorithms: Least-Mean Square (LMS), Normalized LMS(NLMS), Affine Projection (AP), Recursive Least Squares (RLS), etc.
Regularized MSE
Jrms = E[e2(n)] + α‖w(n)‖2
Adaptive algorithm: leaky least-mean square (leaky LMS)
ℓ1 norm criterionJℓ1 = E[|e(n)|]
Adaptive algorithm: Sign-Error
Jose Bermudez (UFSC) Adaptive Filtering IRIT - Toulouse, 2011 32 / 107

Performance (Cost) Functions – continued
Least-mean fourth (LMF) criterion
JLMF = E[e4(n)]
Adaptive algorithm: Least-Mean Fourth (LMF)
Least-mean-mixed-norm (LMMN) criterion
JLMMN = E[αe2(n) +1
2(1 − α)e4(n)]
Adaptive algorithm: Least-Mean-Mixed-Norm (LMMN)
Constant-modulus criterion
JCM = E[(γ − |xT (n)w(n)|2
)2]
Adaptive algorithm: Constant-Modulus (CM)
Jose Bermudez (UFSC) Adaptive Filtering IRIT - Toulouse, 2011 33 / 107

MSE Performance Surface – Small Input Correlation
−20 −10 0 10 20
−20
0
200
500
1000
1500
2000
2500
3000
3500
w1
w2
Jose Bermudez (UFSC) Adaptive Filtering IRIT - Toulouse, 2011 34 / 107

MSE Performance Surface – Large Input Correlation
−20 −15 −10 −5 0 5 10 15 20
−20
−10
0
10
200
500
1000
1500
2000
2500
3000
3500
4000
4500
5000
w1
w2
Jose Bermudez (UFSC) Adaptive Filtering IRIT - Toulouse, 2011 35 / 107

The Steepest Descent Algorithm – Stationary SOE
Cost Function
Jms(n) = E[e2(n)] = σ2d − 2pT w(n) + wT (n)Rxxw(n)
Weight Update Equation
w(n + 1) = w(n) + µc(n)
µ: step-sizec(n): correction term (determines direction of ∆w(n))Steepest descent adjustment:
c(n) = −∇Jms(n) ➪ Jms(n + 1) ≤ Jms(n)
w(n + 1) = w(n) + µ[p − Rxxw(n)]
Jose Bermudez (UFSC) Adaptive Filtering IRIT - Toulouse, 2011 36 / 107

Weight Update Equation About the Optimum Weights
Weight Error Update Equation
w(n + 1) = w(n) + µ[p − Rxxw(n)]
Using p = Rxxwo
w(n + 1) = (I − µRxx)w(n) + µRxxwo
Weight error vector: v(n) = w(n) − wo
v(n + 1) = (I − µRxx)v(n)
Matrix I − µRxx must be stable for convergence (|λi| < 1)
Assuming convergence, limn→∞ v(n) = 0
Jose Bermudez (UFSC) Adaptive Filtering IRIT - Toulouse, 2011 37 / 107

Convergence Conditions
v(n + 1) = (I − µRxx)v(n); Rxx positive definite
Eigen-decomposition of Rxx
Rxx = QΛQT
v(n + 1) = (I − µQΛQT )v(n)
QT v(n + 1) = QT v(n) − µΛQT v(n)
Defining v(n + 1) = QT v(n + 1)
v(n + 1) = (I − µΛ)v(n)
Jose Bermudez (UFSC) Adaptive Filtering IRIT - Toulouse, 2011 38 / 107

Convergence Properties
v(n + 1) = (I − µΛ)v(n)
vk(n + 1) = (1 − µλk)vk(n), k = 1, . . . , N
vk(n) = (1 − µλk)nvk(0)
Convergence modes
◮ monotonic if 0 < 1 − µλk < 1
◮ oscillatory if −1 < 1 − µλk < 0
Convergence if |1 − µλk| < 1 ➪ 0 < µ < 2λmax
Jose Bermudez (UFSC) Adaptive Filtering IRIT - Toulouse, 2011 39 / 107

Optimal Step-Size
vk(n) = (1 − µλk)nvk(0); convergence modes: 1 − µλk
max |1 − µλk|: slowest mode
min |1 − µλk|: fastest mode
Jose Bermudez (UFSC) Adaptive Filtering IRIT - Toulouse, 2011 40 / 107

Optimal Step-Size – continued
1
0
|1−
µλ
k|
1/λmax 1/λminµo µ
minµ
max{|1 − µλk|}
1 − µoλmin = −(1 − µoλmax)
µo = 2λmax+λmin
Optimal slowest modes: ±ρ−1ρ+1 ; ρ = λmax
λmin
Jose Bermudez (UFSC) Adaptive Filtering IRIT - Toulouse, 2011 41 / 107

The Learning Curve – Jms(n)
Jms(n) = Jmsmin+
Excess MSE︷ ︸︸ ︷
vT (n)Λv(n)= Jmsmin+
N∑
k=1
λkv2k(n)
Since vk(n) = (1 − µλk)nvk(0),
Jms(n) = Jmsmin+
N∑
k=1
λk(1 − µλk)2nv2
k(0)
λk(1 − µλk)2 > 0 ➪ monotonic convergence
Stability limit is again 0 < µ < 2λmax
Jms(n) converges faster than w(n)
Algorithm converges faster as ρ = λmax/λmin → 1
Jose Bermudez (UFSC) Adaptive Filtering IRIT - Toulouse, 2011 42 / 107

Simulation Results
x(n) = α x(n − 1) + v(n)
0 20 40 60 80 100 120 140 160 180 200−70
−60
−50
−40
−30
−20
−10
0
iteration
MS
E (
dB)
Steepest Descent − Mean Square Error
Input: White noise (ρ = 1)
0 20 40 60 80 100 120 140 160 180 200−70
−60
−50
−40
−30
−20
−10
0
iteration
MS
E (
dB)
Steepest Descent − Mean Square Error
Input: AR(1), α = 0.7 (ρ = 5.7)
Linear system identification - FIR with 20 coefficients
Step-size µ = 0.3
Noise power σ2v = 10−6
Jose Bermudez (UFSC) Adaptive Filtering IRIT - Toulouse, 2011 43 / 107

The Newton Algorithm
Steepest descent: linear approx. of Jms about the operating point
Newton’s method: Quadratic approximation of Jms
Expanding Jms(w) in Taylor’s series about w(n),
Jms(w) ∼Jms[w(n)] + ∇T Jms[w − w(n)]
+1
2[w − w(n)]T H(n)[w − w(n)]
Diferentiating w.r.t. w and equating to zero at w = w(n + 1),
∇Jms[w(n + 1)] = ∇Jms[w(n)] + H [w(n)][w(n + 1) − w(n)] = 0
w(n + 1) = w(n) − H−1[w(n)]∇Jms[w(n)]
Jose Bermudez (UFSC) Adaptive Filtering IRIT - Toulouse, 2011 44 / 107

The Newton Algorithm – continued
∇Jms[w(n)] = −2p + 2Rxxw(n)
H(w(n)) = 2Rxx
Thus, adding a step-size control,
w(n + 1) = w(n) − µR−1xx [−p + Rxxw(n)]
Quadratic surface ➪ conv. in one iteration for µ = 1 ,
Requires the determination of R−1xx /
Can be used to derive simpler adaptive algorithms
When H(n) is close to singular ➪ regularization
H(n) = 2Rxx + 2εI
Jose Bermudez (UFSC) Adaptive Filtering IRIT - Toulouse, 2011 45 / 107

Basic Adaptive Algorithms
Jose Bermudez (UFSC) Adaptive Filtering IRIT - Toulouse, 2011 46 / 107

Least Mean Squares (LMS) Algorithm
Can be interpreted in different ways
Each interpretation helps understanding the algorithm behavior
Some of these interpretations are related to the steepest descentalgorithm
Jose Bermudez (UFSC) Adaptive Filtering IRIT - Toulouse, 2011 47 / 107

LMS as a Stochastic Gradient Algorithm
Suppose we use the estimate Jms(n) = E[e2(n)] ≃ e2(n)
The estimated gradient vector becomes
∇Jms(n) =∂e2(n)
∂w(n)= 2e(n)
∂e(n)
∂w(n)
Since e(n) = d(n) − xT (n)w(n),
∇Jms(n) = −2e(n)x(n) (stochastic gradient)
and, using the steepest descent weight update equation,
w(n + 1) = w(n) + µe(n)x(n) (LMS weight update)
Jose Bermudez (UFSC) Adaptive Filtering IRIT - Toulouse, 2011 48 / 107

LMS as a Stochastic Estimation Algorithm
∇Jms(n) = −2p + 2Rxxw(n)
Stochastic estimators
p = d(n)x(n) Rxx = x(n)xT (n)
Then,∇Jms(n) = −2d(n)x(n) + 2x(n)xT (n)w(n)
Using ∇Jms(n) is the steepest descent weight update,
w(n + 1) = w(n) + µe(n)x(n)
Jose Bermudez (UFSC) Adaptive Filtering IRIT - Toulouse, 2011 49 / 107

LMS – A Solution to a Local Optimization
Error expressionse(n) = d(n) − xT (n)w(n) (a priori error)ǫ(n) = d(n) − xT (n)w(n + 1) (a posteriori error)
We want to maximize |ǫ(n) − e(n)| with |ǫ(n)| < |e(n)|
ǫ(n) − e(n) = −xT (n)∆w(n)
∆w(n) = w(n + 1) − w(n)
Expressing ∆w(n) as ∆w(n) = ˜∆w(n)e(n)
ǫ(n) − e(n) = −xT (n) ˜∆w(n)e(n)
For max |ǫ(n) − e(n)| ➪ ˜∆w(n) in the direction of x(n)
Jose Bermudez (UFSC) Adaptive Filtering IRIT - Toulouse, 2011 50 / 107

➪ ˜∆w(n) = µx(n) and
∆w(n) = µx(n)e(n)
andw(n + 1) = w(n) + µe(n)x(n)
Asǫ(n) − e(n) = −xT (n)∆w(n) = −µxT (n)x(n)e(n)
|ǫ(n)| < |e(n)| requires |1 − µxT (n)x(n)| < 1, or
0 < µ < 2‖x(n)‖2 (stability region)
Jose Bermudez (UFSC) Adaptive Filtering IRIT - Toulouse, 2011 51 / 107

Observations - LMS Algorithm
LMS is a noisy approximation of the steepest descent algorithm
The gradient estimate is unbiased
The errors in the gradient estimate lead to Jmsex(∞) 6= 0
Vector w(n) is now random
Steepest descent properties are no longer guaranteed➪ LMS analysis required
The instantaneous estimates allow tracking without redesign
Jose Bermudez (UFSC) Adaptive Filtering IRIT - Toulouse, 2011 52 / 107

Some Research Results
J. C. M. Bermudez and N. J. Bershad, “A nonlinear analytical model for thequantized LMS algorithm - the arbitrary step size case,” IEEE Transactions onSignal Processing, vol.44, No. 5, pp. 1175-1183, May 1996.
J. C. M. Bermudez and N. J. Bershad, “Transient and tracking performanceanalysis of the quantized LMS algorithm for time-varying system identification,”IEEE Transactions on Signal Processing, vol.44, No. 8, pp. 1990-1997, August1996.
N. J. Bershad and J. C. M. Bermudez, “A nonlinear analytical model for thequantized LMS algorithm - the power-of-two step size case,” IEEE Transactions onSignal Processing, vol.44, No. 11, pp. 2895- 2900, November 1996.
N. J. Bershad and J. C. M. Bermudez, “Sinusoidal interference rejection analysisof an LMS adaptive feedforward controller with a noisy periodic reference,” IEEETransactions on Signal Processing, vol.46, No. 5, pp. 1298-1313, May 1998.
J. C. M. Bermudez and N. J. Bershad, “Non-Wiener behavior of the Filtered-XLMS algorithm,” IEEE Trans. on Circuits and Systems II - Analog and DigitalSignal Processing, vol.46, No. 8, pp. 1110-1114, Aug 1999.
Jose Bermudez (UFSC) Adaptive Filtering IRIT - Toulouse, 2011 53 / 107

Some Research Results – continued
O. J. Tobias, J. C. M. Bermudez and N. J. Bershad, “Mean weight behavior of theFiltered-X LMS algorithm,” IEEE Transactions on Signal Processing, vol. 48, No.4, pp. 1061-1075, April 2000.
M. H. Costa, J. C. M. Bermudez and N. J. Bershad, “Stochastic analysis of theLMS algorithm with a saturation nonlinearity following the adaptive filter output,”IEEE Transactions on Signal Processing, vol. 49, No. 7, pp. 1370-1387, July 2001.
M. H. Costa, J. C, M. Bermudez and N. J. Bershad, “Stochastic analysis of theFiltered-X LMS algorithm in systems with nonlinear secondary paths,” IEEETransactions on Signal Processing, vol. 50, No. 6, pp. 1327-1342, June 2002.
M. H. Costa, J. C. M. Bermudez and N. J. Bershad, “The performance surface infiltered nonlinear mean square estimation,” IEEE Transactions on Circuits andSystems I, vol. 50, No. 3, p. 445-447, March 2003.
G. Barrault, J. C. M. Bermudez and A. Lenzi, “New Analytical Model for theFiltered-x Least Mean Squares Algorithm Verified Through Active Noise ControlExperiment,” Mechanical Systems and Signal Processing, v. 21, p. 1839-1852,2007.
Jose Bermudez (UFSC) Adaptive Filtering IRIT - Toulouse, 2011 54 / 107

Some Research Results – continued
N. J. Bershad, J. C. M. Bermudez and J. Y. Tourneret, “Stochastic Analysis of theLMS Algorithm for System Identification with Subspace Inputs,” IEEE Trans. onSignal Process., v. 56, p. 1018-1027, 2008.
J. C. M. Bermudez, N. J. Bershad and J. Y. Tourneret, “An Affine Combination ofTwo LMS Adaptive Filters Transient Mean-Square Analysis,” IEEE Trans. onSignal Process., v. 56, p. 1853-1864, 2008.
M. H. Costa, L. R. Ximenes and J. C. M. Bermudez, “Statistical Analysis of theLMS Adaptive Algorithm Subjected to a Symmetric Dead-Zone Nonlinearity at theAdaptive Filter Output,” Signal Processing, v. 88, p. 1485-1495, 2008.
M. H. Costa and J. C. M. Bermudez, “A Noise Resilient Variable Step-Size LMSAlgorithm,” Signal Processing, v. 88, no. 3, p. 733-748, March 2008.
P. Honeine, C. Richard, J. C. M. Bermudez, J. Chen and H. Snoussi, “ADecentralized Approach for Nonlinear Prediction of Time Series Data in SensorNetworks,” EURASIP Journal on Wireless Communications and Networking, v.2010, p. 1-13, 2010. (KNLMS)
Jose Bermudez (UFSC) Adaptive Filtering IRIT - Toulouse, 2011 55 / 107

The Normalized LMS Algorithm – NLMS
Most Employed adaptive algorithm in real-time applications
Like LMS has different interpretations (even more)
Alleviates a drawback of the LMS algorithm
w(n + 1) = w(n) + µe(n)x(n)
◮ If amplitude of x(n) is large ➪ Gradient noise amplification◮ Sub-optimal performance when σ2
x varies with time (for instance,speech)
Jose Bermudez (UFSC) Adaptive Filtering IRIT - Toulouse, 2011 56 / 107

NLMS – A Solution to a Local Optimization Problem
Error expressionse(n) = d(n) − xT (n)w(n) (a priori error)ǫ(n) = d(n) − xT (n)w(n + 1) (a posteriori error)
We want to maximize |ǫ(n) − e(n)| with |ǫ(n)| < |e(n)|
ǫ(n) − e(n) = −xT (n)∆w(n) (A)
∆w(n) = w(n + 1) − w(n)
For |ǫ(n)| < |e(n)| we impose the restriction
ǫ(n) = (1 − µ)e(n), |1 − µ| < 1
➪ ǫ(n) − e(n) = −µe(n) (B)
For max |ǫ(n) − e(n)| ➪ ∆w(n) in the direction of x(n)
➪∆w(n) = kx(n) (C)
Jose Bermudez (UFSC) Adaptive Filtering IRIT - Toulouse, 2011 57 / 107

Using (A), (B) and (C),
k = µe(n)
xT (n)x(n)
and
w(n + 1) = w(n) + µe(n)x(n)
xT (n)x(n)(NLMS weight update)
Jose Bermudez (UFSC) Adaptive Filtering IRIT - Toulouse, 2011 58 / 107

NLMS – Solution to a Constrained
Optimization Problem
Error sequence
y(n) =xT (n)w(n) (estimate of d(n))
e(n) =d(n) − y(n) = d(n) − xT (n)w(n) (estimation error)
Optimization (principle of minimal disturbance)
Minimize ‖∆w(n)‖2 = ‖w(n + 1) − w(n)‖2
subject to: xT (n)w(n + 1) = d(n)
This problem can be solved using the method of Lagrange multipliers
Jose Bermudez (UFSC) Adaptive Filtering IRIT - Toulouse, 2011 59 / 107

Using Lagrange multipliers, we minimize
f [w(n + 1)] = ‖w(n + 1) − w(n)‖2 + λ[d(n) − xT (n)w(n + 1)]
Differentiating w.r.t. w(n + 1) and equating the result to zero,
w(n + 1) = w(n) +1
2λx(n) (*)
Using this result in xT (n)w(n + 1) = d(n) yields
λ =2e(n)
xT (n)x(n)
Using this result in (*) yields
w(n + 1) = w(n) + µe(n)x(n)
xT (n)x(n)
Jose Bermudez (UFSC) Adaptive Filtering IRIT - Toulouse, 2011 60 / 107

NLMS as an Orthogonalization Process
Conditions for the analysis◮ e(n) = d(n) − xT (n)w(n)◮ wo is the optimal solution (Wiener solution)◮ d(n) = xT (n)wo (no noise)◮ v(n) = w(n) − wo (weight error vector)
Error signal
e(n) = d(n) − xT (n)[v(n) + wo]
= xT (n)wo − xT (n)[v(n) + wo]
= −xT (n)v(n)
Jose Bermudez (UFSC) Adaptive Filtering IRIT - Toulouse, 2011 61 / 107

e(n) = −xT (n)v(n)
Interpretation: To minimize the error v(n) should be orthogonal to allinput vectorsRestriction: We have only one vector x(n)
Iterative solution:
We can subtract from v(n) its component in the direction of x(n) ateach iteration
If there are N adaptive coefficients, v(n) could be reduced to zeroafter N orthogonal input vectors
Iterative projection extraction➪ Gram-Schmidt orthogonalization
Jose Bermudez (UFSC) Adaptive Filtering IRIT - Toulouse, 2011 62 / 107

Recursive orthogonalization
n = 0 : v(1) = v(0) − proj. of v(0) onto x(0)
n = 1 : v(2) = v(1) − proj. of v(1) onto x(1)
... :...
n + 1 : v(n + 1) = v(n) − proj. of v(n) onto x(n)
Projection of v(n) onto x(n)
Px(n)[v(n)] ={x(n)[xT (n)x(n)]−1xT (n)
}v(n)
Weight update equation
v(n + 1) = v(n) − µ
scalar︷ ︸︸ ︷
[xT (n)x(n)]−1
−e(n)︷ ︸︸ ︷
xT (n)v(n) x(n)
= v(n) + µe(n)x(n)
xT (n)x(n)
Jose Bermudez (UFSC) Adaptive Filtering IRIT - Toulouse, 2011 63 / 107

NLMS has its owns problems!
NLMS solves the LMS gradient error amplification problem, but ...
What happens if ‖x(n)‖2 gets too small?
One needs to add some regularization
w(n + 1) = w(n) + µe(n)x(n)
xT (n)x(n)+ε(ε−NLMS)
Jose Bermudez (UFSC) Adaptive Filtering IRIT - Toulouse, 2011 64 / 107

ε-NLMS – Stochastic Approximation of
Regularized Newton
Regularized Newton Algorithm
w(n + 1) = w(n) + µ[εI + Rxx]−1[p − Rxxw(n)]
Instantaneous estimates
p = x(n)d(n)
Rxx = x(n)xT (n)
Using these estimates
w(n + 1) = w(n) + µ[εI + x(n)xT (n)]−1x(n)
e(n)︷ ︸︸ ︷
[d(n) − xT (n)w(n)]
w(n + 1) = w(n) + µ[εI + x(n)xT (n)]−1x(n)e(n)
Jose Bermudez (UFSC) Adaptive Filtering IRIT - Toulouse, 2011 65 / 107

w(n + 1) = w(n) + µ[εI + x(n)xT (n)]−1x(n)e(n)
Inversion of εI + x(n)xT (n) ?
Matrix Inversion Formula
[A + BCD]−1 = A−1 − A−1B[C−1 + DA−1B]−1DA−1
Thus,
[εI + x(n)xT (n)]−1 = ε−1I −ε−2
1 + ε−1xT (n)x(n)x(n)xT (n)
Post-multiplying both sides by x(n) and rearranging
[εI + x(n)xT (n)]−1x(n) =x(n)
ε + xT (n)x(n)
and
w(n + 1) = w(n) + µe(n)x(n)
xT (n)x(n) + ε
Jose Bermudez (UFSC) Adaptive Filtering IRIT - Toulouse, 2011 66 / 107

Some Research Results
M. H. Costa and J. C. M. Bermudez, “An improved model for the normalized LMSalgorithm with Gaussian inputs and large number of coefficients,” in Proc. of the2002 IEEE International Conference on Acoustics, Speech and Signal Processing(ICASSP-2002), Orlando, Florida, pp. II- 1385-1388, May 13-17, 2002.
J. C. M. Bermudez and M. H. Costa, “A Statistical Analysis of the ε-NLMS andNLMS Algorithms for Correlated Gaussian Signals,” Journal of the BrazilianTelecommunications Society, v. 20, n. 2, p. 7-13, 2005.
G. Barrault, M. H. Costa, J. C. M. Bermudez and A. Lenzi, “A new analyticalmodel for the NLMS algorithm,” in Proc. 2005 IEEE International Conference onAcoustics Speech and Signal Processing (ICASSP 2005) Pennsylvania, USA, vol.IV, p. 41-44, 2005.
J. C. M. Bermudez, N. J. Bershad and J.-Y. Tourneret, “An Affine Combination ofTwo NLMS Adaptive Filters - Transient Mean-Square Analysis,” In Proc.Forty-Second Asilomar Conference on Asilomar Conference on Signals, Systems &Computers, Pacific Grove, CA, USA, 2008.
P. Honeine, C. Richard, J. C. M. Bermudez and H. Snoussi, “Distributedprediction of time series data with kernels and adaptive filtering techniques insensor networks,” In Proc. Forty-Second Asilomar Conference on AsilomarConference on Signals, Systems & Computers, Pacific Grove, CA, USA, 2008.
Jose Bermudez (UFSC) Adaptive Filtering IRIT - Toulouse, 2011 67 / 107

The Affine Projection Algorithm
Consider the NLMS algorithm but using{x(n),x(n − 1), . . . ,x(n − P )}
Minimize ‖∆w(n)‖2 = ‖w(n + 1) − w(n)‖2
subject to:
xT (n)w(n + 1) = d(n)
xT (n − 1)w(n + 1) = d(n − 1)...
xT (n − P )w(n + 1) = d(n − P )
Jose Bermudez (UFSC) Adaptive Filtering IRIT - Toulouse, 2011 68 / 107

Observation matrix
X(n) = [x(n),x(n − 1), · · · ,x(n − P )]
Desired signal vector
d(n) = [d(n), d(n − 1), . . . , d(n − P )]
Error vector
e(n) = [e(n), e(n − 1), . . . , e(n − P )] = d(n) − XT (n)w(n)
Vector of the constraint errors
ec(n) = d(n) − XT (n)w(n + 1)
Jose Bermudez (UFSC) Adaptive Filtering IRIT - Toulouse, 2011 69 / 107

Using Lagrange multipliers, we minimize
f [w(n + 1)] = ‖w(n + 1) − w(n)‖2 + λT [d(n) − XT (n)w(n + 1)]
Differentiating w.r.t. w(n + 1) and equating the result to zero,
w(n + 1) = w(n) +1
2X(n)λ (*)
Using this result in XT (n)w(n + 1) = d(n) yields
λ = 2[XT (n)X(n)]−1e(n)
Using this result in (*) yields
w(n + 1) = w(n) + µX(n)[XT (n)X(n)]−1e(n)
Jose Bermudez (UFSC) Adaptive Filtering IRIT - Toulouse, 2011 70 / 107

Affine Projection
Solution to the Underdetermined Least-Squares Problem
We want minimize
‖ec(n)‖2 = ‖d(n) − XT (n)w(n + 1)‖2
where XT (n) is (P + 1) × N with (P + 1) < N
Thus, we look for the least-squares solution of the underdeterminedsystem
XT (n)w(n + 1) = d(n)
The solution is
w(n + 1) =[XT (n)
]+d(n) = X(n)[XT (n)X(n)]−1d(n)
Using d(n) = e(n) + XT (n)w(n) yields
w(n + 1) = w(n) + µX(n)[XT (n)X(n)]−1e(n)
Jose Bermudez (UFSC) Adaptive Filtering IRIT - Toulouse, 2011 71 / 107

Observations:
Order of the AP algorithm: P + 1 (P = 0 → NLMS)
Convergence speed increases with P (but not linearly)
Computational complexity increases with P (not linearly)
If XT (n)X(n) is close to singular, use XT (n)X(n) + εI
The scalar error of NLMS becomes a vector error in AP (except forµ = 1)
Jose Bermudez (UFSC) Adaptive Filtering IRIT - Toulouse, 2011 72 / 107

Affine Projection – Stochastic Approximation of
Regularized NewtonRegularized Newton Algorithm
w(n + 1) = w(n) + µ[εI + Rxx]−1[p − Rxxw(n)]
Estimates using time window statistics
p =1
P + 1
n∑
k=n−P
X(k)d(k) =1
P + 1X(n)d(n)
Rxx =1
P + 1
n∑
k=n−P
X(k)XT (k) =1
P + 1X(n)XT (n)
Using these estimates with ε = ε/(P + 1),
w(n + 1) = w(n) + µ[εI + X(n)XT (n)]−1X(n)
e(n)︷ ︸︸ ︷
[d(n) − XT (n)w(n)]
w(n + 1) = w(n) + µ[εI + X(n)XT (n)]−1X(n)e(n)
Jose Bermudez (UFSC) Adaptive Filtering IRIT - Toulouse, 2011 73 / 107

w(n + 1) = w(n) + µ[εI + X(n)XT (n)]−1X(n)e(n)
Using the Matrix Inversion Formula
[εI + X(n)XT (n)]−1 = X(n)[εI + XT (n)X(n)]−1
and
w(n + 1) = w(n) + µX(n)[εI + XT (n)X(n)]−1e(n)
Jose Bermudez (UFSC) Adaptive Filtering IRIT - Toulouse, 2011 74 / 107

Affine Projection Algorithm as a
Projection onto an Affine Subspace
Conditions for the analysis◮ e(n) = d(n) − XT (n)w(n)◮ d(n) = XT (n)wo defines the optimal solution in the least-squares
sense◮ v(n) = w(n) − wo (weight error vector)
Error vector
e(n) = d(n) − XT (n)[v(n) + w(n + 1)]
= XT (n)w(n + 1) − XT (n)[v(n) + w(n + 1)]
= −XT (n)v(n)
Jose Bermudez (UFSC) Adaptive Filtering IRIT - Toulouse, 2011 75 / 107

e(n) = −XT (n)v(n)
Interpretation: To minimize the error v(n) should be orthogonal to allinput vectorsRestriction: We are going to use only {x(n),x(n− 1), . . . ,x(n−P )}
Iterative solution:
We can subtract from v(n) its projection onto the range of X(n) ateach iteration
v(n + 1) = v(n) − P X(n)v(n) (Proj. onto an affine subspace)
Using XT (n)v(n) = −e(n)
v(n + 1) = v(n) −{X(n)[XT (n)X(n)]−1XT (n)
}v(n)
= v(n) + µX(n)[XT (n)X(n)]−1e(n) (AP algorithm)
Jose Bermudez (UFSC) Adaptive Filtering IRIT - Toulouse, 2011 76 / 107

Pseudo Affine Projection Algorithm
Major problem with the AP algorithmFor µ 6= 1, e(n) → e(n) ➪ large computational complexity
The Pseudo-AP algorithm replaces the input x(n) with its P -th orderautoregressive prediction
x(n) =
P∑
k=1
akx(n − k)
Using the least-squares solution for a = [a1, a2, . . . , aP ]T ,
a = [XT
p (n)Xp(n)]−1XT
p (n)x(n), Xp(n) = [x(n − 1), . . . , x(n − P )]
Now, we subtract from x(n) its projections onto the last P inputvectors
φ(n) = x(n) − Xp(n)a(n)
= x(n) −{Xp(n)[XT
p (n)Xp(n)]−1XTp (n)
}x(n)
= (I − P P )x(n); (P P : projection matrix)
Jose Bermudez (UFSC) Adaptive Filtering IRIT - Toulouse, 2011 77 / 107

Example – Pseudo-AP versus AP
0 1000 2000 3000 4000 5000 6000−80
−70
−60
−50
−40
−30
−20
−10
0Mean Square Error
dB
Iterations
AR(8)=[−0.9 0.8 −0.7 0.6 −0.5 0.4 −0.3 0.2]N=64P=8SNR=80dBS=Null
AP(−72.82dB) PAP(−75.82)
α=0.7
Jose Bermudez (UFSC) Adaptive Filtering IRIT - Toulouse, 2011 78 / 107

Using φ as the new input vector for the NLMS algorithm,
w(n + 1) = w(n) + µφ(n)
φT (n)φ(n)e(n)
It can be shown that Pseudo-AP is identical to AP for an AR inputand µ = 1
Otherwise, Pseudo-AP is different from AP
Simpler to implement than AP for µ 6= 1
Can lead even to better steady-state results than AP for AR inputs
For AR inputs: NLMS with input “orthogonalization”
Jose Bermudez (UFSC) Adaptive Filtering IRIT - Toulouse, 2011 79 / 107

Some Research ResultsS. J. M. de Almeida, J. C. M. Bermudez, N. J. Bershad and M. H. Costa, “Astatistical analysis of the affine projection algorithm for unity step size andautoregressive inputs,” IEEE Transactions on Circuits and Systems - I, vol. 52, pp.1394-1405, July 2005.
S. J. M. Almeida, J. C. M. Bermudez and N. J. Bershad, “A Stochastic Model fora Pseudo Affine Projection Algorithm,” IEEE Transactions on Signal Processing, v.57, p. 107-118, 2009.
S. J. M. Almeida, M. H. Costa and J. C. M. Bermudez, “A Stochastic Model forthe Deficient Length Pseudo Affine Projection Adaptive Algorithm,” In Proc. 17thEuropean Signal Processing Conference (EUSIPCO), Aug. 24-28, Glasgow,Scotland, 2009.
S. J. M. Almeida, M. H. Costa and J. C. M. Bermudez, “A stochastic model forthe deficient order affine projection algorithm,” in Proc. ISSPA 2010, KualaLumpur, Malaysia, May 2010.
C. Richard, J. C. M. Bermudez and P. Honeine, “Online Prediction of Time SeriesData With Kernels,” IEEE Transactions on Signal Processing, v. 57, p.1058-1067, 2009.
P. Honeine, C. Richard, J. C. M. Bermudez, H. Snoussi, M. Essoloh and F.Vincent, “Functional estimation in Hilbert space for distributed learning in wirelesssensor networks,” In Proc. IEEE International Conference on Acoustics Speech andSignal Processing (ICASSP), Taipei, Taiwan, p. 2861-2864, 2009.
Jose Bermudez (UFSC) Adaptive Filtering IRIT - Toulouse, 2011 80 / 107

Deterministic Algorithms
Jose Bermudez (UFSC) Adaptive Filtering IRIT - Toulouse, 2011 81 / 107

Recursive Least Squares Algorithm (RLS)
Based on a deterministic philosophy
Designed for the present realization of the input signals
Least squares method adapted for real time processing of temporalseries
Convergence speed is not strongly dependent on the input statistics
Jose Bermudez (UFSC) Adaptive Filtering IRIT - Toulouse, 2011 82 / 107

RLS – Problem Definition
Define
xo(n) = [x(n), x(n − 1), . . . , x(0)]T
x(n) = [x(n), x(n − 1), . . . , x(n − N + 1)]T input to the N-tap filter
Desired signal d(n)
Estimator of d(n): y(n) = xT (n)w(n)
Cost function – Squared Error
Jls(n) =n∑
k=0
e2(k) =n∑
k=0
[d(k) − xT (k)w(n)]2
= eT (n)e(n), e(n) = [e(n), e(n − 1), . . . , e(0)]T
Jose Bermudez (UFSC) Adaptive Filtering IRIT - Toulouse, 2011 83 / 107

In vector form
d(n) = [d(n), d(n − 1), . . . , d(0)]T
y(n) = [y(n), y(n − 1), . . . , y(0)]T , y(k) = xT (k)w(n)
y(n) =
N−1∑
k=0
wk(n)xo(n − k) = Θ(n)w(n)
Θ(n) =
x(n) x(n − 1) · · · x(n − N + 1)x(n − 1) x(n − 2) · · · x(n − N)
......
......
x(0) x(−1) · · · x(−N + 1)
= [xo(n),xo(n − 1), . . . xo(n − N + 1)]
e(n) = d(n) − Θ(n)w(n)
Jose Bermudez (UFSC) Adaptive Filtering IRIT - Toulouse, 2011 84 / 107

e(n) = d(n) − Θ(n)w(n)
and we minimizeJls(n) = ‖e(n)‖2
Normal Equations
ΘT (n)Θ(n)w(n) = Θ
T (n)d(n)
R(n)w(n) = p(n)
Alternative representation for R and p
R(n) = ΘT (n)Θ(n) =
n∑
k=0
x(k)xT (k)
p(n) = ΘT (n)d(n) =
n∑
k=0
x(k)d(k)
Jose Bermudez (UFSC) Adaptive Filtering IRIT - Toulouse, 2011 85 / 107

RLS – Observations
w(n) remains fixed for 0 ≤ k ≤ n to determine Jls(n)
Optimum vector w(n) is wo(n) = R−1
(n)p
The algorithm has growing memory
In an adaptive implementation,
wo(n) = R−1
(n)p
must be solved for each iteration n
Problems for an adaptive implementation◮ Dificulties with nonstationary signals (infinite data window)◮ Computational complexity
Jose Bermudez (UFSC) Adaptive Filtering IRIT - Toulouse, 2011 86 / 107

RLS - Forgetting the Past
Modified cost function
Jls(n) =
n∑
k=0
λn−ke2(k) =
n∑
k=0
λn−k[d(k) − xT (k)w(n)]2
= eT (n)Λe(n), Λ = diag[1, λ, λ2, . . . , λn]
Modified Normal Equations
ΘT (n)ΛΘ(n)w(n) = Θ
T (n)Λd(n)
R(n)w(n) = p(n)
where
R(n) = ΘT (n)ΛΘ(n) =
n∑
k=0
λn−kx(k)xT (k)
p(n) = ΘT (n)Λd(n) =
n∑
k=0
λn−kx(k)d(k)
Jose Bermudez (UFSC) Adaptive Filtering IRIT - Toulouse, 2011 87 / 107

RLS – Recursive Updating
Correlation Matrix
R(n) =
n∑
k=0
λn−kx(k)xT (k)
=
n−1∑
k=0
λn−kx(k)xT (k) + x(n)xT (n)
= λR(n − 1) + x(n)xT (n)
Cross-correlation vector
p(n) =
n∑
k=0
λn−kx(k)d(k)
=
n−1∑
k=0
λn−kx(k)d(k) + x(n)d(n)
= λp(n − 1) + x(n)d(n)
Jose Bermudez (UFSC) Adaptive Filtering IRIT - Toulouse, 2011 88 / 107

We have recursive updating expressions for R(n) and p(n)
However, we need a recursive updating for R−1
(n), as
wo(n) = R−1
(n)p(n)
Applying the matrix inversion lemma to
R(n) = λR(n − 1) + x(n)xT (n)
and defining P (n) = R−1
(n) yields
P (n) = λ−1P (n − 1) −λ−2P (n − 1)x(n)xT (n)P (n − 1)
1 + λ−1xT (n)P (n − 1)x(n)
Jose Bermudez (UFSC) Adaptive Filtering IRIT - Toulouse, 2011 89 / 107

The Gain Vector
Definition
k(n) =λ−1P (n − 1)x(n)
1 + λ−1xT (n)P (n − 1)x(n)
Using this definition
P (n) = λ−1P (n − 1) − λ−1k(n)xT (n)P (n − 1)
k(n) can be written as
k(n) =
P(n)︷ ︸︸ ︷[λ−1P (n − 1) − λ−1k(n)xT (n)P (n − 1)
]x(n)
= R−1
(n)x(n)
➪ k(n) is the repres. of x(n) on the column space of R(n)
Jose Bermudez (UFSC) Adaptive Filtering IRIT - Toulouse, 2011 90 / 107

RLS – Recursive Weight Update
w(n + 1) = wo(n)
Using
w(n + 1) = R−1
(n)p(n) = P (n)p(n)
p(n) = λp(n − 1) + x(n)d(n)
P (n) = λ−1P (n − 1) − λ−1k(n)xT (n)P (n − 1)
k(n) = P (n)x(n)
e(n) = d(n) − xT (n)w(n)
yields
w(n + 1) = w(n) + k(n)e(n) RLS weight update
Jose Bermudez (UFSC) Adaptive Filtering IRIT - Toulouse, 2011 91 / 107

RLS – Observations
The RLS convergence speed is not affected by the eigenvalues ofR(n)
Initialization: p(0) = 0, R(0) = δI, δ ≃ (1 − λ)σ2x
This results in R(n) changed to λnδI + R(n)➪ Biased estimate of wo(n) for small n(No problem for λ < 1 and large n)
Numerical problems in finite precision◮ Unstable for λ = 1◮ Loss of symmetry in P (n)
⋆ Evaluate only upper (lower) part and diagonal of P (n)⋆ Replace P (n) with [P (n) + P T (n)]/2 after updating from P (n − 1)
Numerical problems when x(n) → 0 and λ < 1
Jose Bermudez (UFSC) Adaptive Filtering IRIT - Toulouse, 2011 92 / 107

Some Research Results
C. Ludovico and J. C. M. Bermudez, “A recursive least squaresalgorithm robust to low- power excitation,” in. Proc. 2004 IEEEInternational Conference on Acoustics, Speech and Signal Processing(ICASSP-2004), Montreal, Canada, vol. II, p. 673-677, 2004.
C. Ludovico and J. C. M. Bermudez, “An improved recursive leastsquares algorithm robust to input power variation,” in Proc. IEEEStatistical Signal Processing Workshop, Bordeaux, France, 2005.
Jose Bermudez (UFSC) Adaptive Filtering IRIT - Toulouse, 2011 93 / 107

Performance Comparison
System identification, N=100
Input – AR(1) x(n) = 0.9x(n − 1) + v(n)
AP algorithm with P = 2
Step sizes designed for equal LMS and NLMS performances
Impulse response to be estimated
0 10 20 30 40 50 60 70 80 90 100−0.1
−0.05
0
0.05
0.1
0.15
0.2
0.25
0.3
0.35
0.4
sample
impu
lse
resp
onse
Jose Bermudez (UFSC) Adaptive Filtering IRIT - Toulouse, 2011 94 / 107

Excess Mean Square Error - LMS, NLMS and AP
0 1000 2000 3000 4000 5000 6000−80
−70
−60
−50
−40
−30
−20
−10
0
10
iteration
EM
SE
(dB
)
EMSE for LMS, NLMS and AP(2)
Jose Bermudez (UFSC) Adaptive Filtering IRIT - Toulouse, 2011 95 / 107

Excess Mean Square Error - LMS, NLMS, AP and RLS
0 1000 2000 3000 4000 5000 6000−80
−70
−60
−50
−40
−30
−20
−10
0
10
iteration
EM
SE
(dB
)
EMSE for LMS, NLMS, AP(2) and RLS
Jose Bermudez (UFSC) Adaptive Filtering IRIT - Toulouse, 2011 96 / 107

Performance Comparisons
Computational Complexity
Adaptive filter with N real coefficients and real signals
For the AP algorithm, K = P + 1
Algorithm × + /
LMS 2N + 1 2N
NLMS 3N + 1 3N 1
AP (K2 + 2K)N + K3 + K (K2 + 2K)N + K3 + K2
RLS N2 + 5N + 1 N2 + 3N 1
For N = 100, P = 2
Algorithm × + / ≃ factor
LMS 201 200 1
NLMS 301 300 1 1.5
AP 1, 530 1, 536 7.5
RLS 10, 501 10, 300 1 52.5
Jose Bermudez (UFSC) Adaptive Filtering IRIT - Toulouse, 2011 97 / 107

Typical values for acoustic echo cancellation (N = 1024, P = 2)
Algorithm × + / ≃ factor
LMS 2, 049 2, 048 1
NLMS 3, 073 3, 072 1 1.5
AP 15, 390 15, 396 7.5
RLS 1, 053, 697 1, 051, 648 1 514
Jose Bermudez (UFSC) Adaptive Filtering IRIT - Toulouse, 2011 98 / 107

How to Deal with Computational Complexity?
Not an easy task!!!
There are ”fast” versions for some algorithms (especially RLS)
What is usually not said is that ... speed can bring◮ Instability◮ Increased need for memory
➪ Most applications rely on simple solutions
Jose Bermudez (UFSC) Adaptive Filtering IRIT - Toulouse, 2011 99 / 107

Understanding the Adaptive Filter Behavior
Jose Bermudez (UFSC) Adaptive Filtering IRIT - Toulouse, 2011 100 / 107

What are Adaptive Filters?Adaptive filters are, by design, systems that are
Time-variant (w(n) is time-variant)
Nonlinear (y(n) is a nonlinear function of x(n))
Stochastic (w(n) is random)
LMS:
w(n + 1) = w(n) + µe(n)x(n)
=[I − µ x(n)xT (n)
]x(n) + µ d(n)x(n)
y(n) = xT (n)w(n)
They are difficult to understand
Different applications and signals require different analyses
Simplifying assumptions are necessary
➪ Good design requires good analytical models.Jose Bermudez (UFSC) Adaptive Filtering IRIT - Toulouse, 2011 101 / 107

LMS AnalysisBasic equations:
d(n) = xT (n)wo + z(n)
e(n) = d(n) − xT (n)w(n)
w(n + 1) = w(n) + µ e(n)x(n)
v(n) = w(n) − wo (study about the optimum weight vector)
Mean Weight Behavior:Neglecting dependence between v(n) and x(n)xT (n),
E[v(n + 1)] = (I − µRxx)E[v(n)]
Follows the steepest descent trajectory
Convergence condition: 0 < µ < 2/λmax
limn→∞
E[w(n)] = wo
However: w(n) is random➪ We need to study its fluctuations about E[w(n)] → MSE
Jose Bermudez (UFSC) Adaptive Filtering IRIT - Toulouse, 2011 102 / 107

The Mean-Square Estimation Error
e(n) = eo(n) − xT (n)v(n), eo(n) = d(n) − xT (n)wo
Square the error equation
Take the expected value
Neglect the statistical dep. between v(n) and x(n)xT (n)
Jms(n) = E[e2o(n)] + Tr{RxxK(n)}, K(n) = E[v(n)vT (n)]
This expression is independent of the adaptive algorithm
Effect of the alg. on Jms(n) is determined by K(n)
Jmsmin= E[e2
o(n)]
Jmsex = Tr{RxxK(n)}
Jose Bermudez (UFSC) Adaptive Filtering IRIT - Toulouse, 2011 103 / 107

The Behavior of K(n) for LMS
Using the basic equations
v(n + 1) =[I + µ x(n)xT (n)
]v(n) + µ eo(n)x(n)
Post-multiply by vT (n + 1)
Take the expected value assuming v(n) and x(n)xT (n) independent
Evaluate the expectations◮ Higher order moments of x(n) require input pdf
Assuming Gaussian inputs
K(n + 1) =K(n) − µ [RxxK(n) + K(n)Rxx]
+ µ2 {RxxTr[RxxK(n)] + 2RxxK(n)Rxx}
+ µ2 RxxJmsmin
Jose Bermudez (UFSC) Adaptive Filtering IRIT - Toulouse, 2011 104 / 107

Design Guidelines Extrated from the Model
Stability
0 < µ <m
Tr[Rxx]; m = 2 or m = 2/3
Jms(n) converges as a function of
[(1 − µλi)
2 + 2µ2λ2i
]n, i = 1, . . . , N
Steady-State
Jmsex(∞) ≃µ
2Tr[Rxx]Jmsmin
M(∞) =Jmsex(∞)
Jmsmin
(MSE Misadjustment)
Jose Bermudez (UFSC) Adaptive Filtering IRIT - Toulouse, 2011 105 / 107

Model Evaluation
x(n) = α x(n − 1) + v(n)
0 1000 2000 3000 4000 5000 6000−80
−70
−60
−50
−40
−30
−20
−10
0
10
EMSE. Blue: Simulation. Red: Analytical Model
EM
SE
LMS − Excess Mean Square Error
Input: White noise
0 1000 2000 3000 4000 5000 6000−80
−70
−60
−50
−40
−30
−20
−10
0
10
EMSE. Blue: Simulation. Red: Analytical Model
EM
SE
LMS − Excess Mean Square Error
Input: AR(1), α = 0.8
Linear system identification - FIR with 100 coefficients
Step-size µ = 0.05
Noise power σ2v = 10−6
Jose Bermudez (UFSC) Adaptive Filtering IRIT - Toulouse, 2011 106 / 107

Merci pour votre attention!!!
Jose Bermudez (UFSC) Adaptive Filtering IRIT - Toulouse, 2011 107 / 107