
Time Management SOS Workshop Presented by Guy Inaba February 2008.
Upload
zachery-oxtonCategory
view
226download
2
Access Map Pattern Matching Prefetch:
Optimization Friendly Method
Access Map Pattern Matching Prefetch:
Optimization Friendly Method
Yasuo Ishii1, Mary Inaba2, and Kei Hiraki2
1 NEC Corporation2 The University of Tokyo

BackgroundBackground
Speed gap between processor and memory has been increased
To hide long memory latency, many techniques have been proposed.Importance of HW data prefetch has been
increased
Many HW prefetchers have been proposed

Conventional MethodsConventional Methods
Prefetchers uses1. Instruction Address2. Memory Access Order3. Memory Address
Optimizations scrambles information Out-of-Order memory access Loop unrolling

Limitation of Stride Limitation of Stride Prefetch[Chen+95]Prefetch[Chen+95]Out-of-Order Memory AccessOut-of-Order Memory Access
Memory Address Space
・・・
・・・
0xAB04
0xAB03
0xAB05
0xAB06
0xABFF
0xAB04 2 steady
Cache Line
・・・
0xAB02
A Access 4
Access 3
Access 1
0xAB01
0xAB00
0xAAFF
Access 2
for (int i=0; i<N; i++) { load A[2*i]; ・・・・・ (A)}
Tag Address Stride State
Out of Order
Cannot detect strides

Weakness of Conventional Weakness of Conventional MethodsMethodsOut-of-Order Memory Access
Scrambles memory access order Prefetcher cannot detect address correlations
Loop-Unrolling Requires additional table entry Each entry trained slowly
Optimization friendly prefetcher is required

Access Map Pattern MatchingAccess Map Pattern Matching
Pattern MatchingOrder Free PrefetchingOptimization Friendly Prefetch
Access MapMap-base history2-bit state map
Each state is attached to cache block

State Diagram for Each Cache State Diagram for Each Cache BlockBlock
InitInitialized state
AccessAlready accessed
PrefetchIssued Pref.
RequestsSuccess
Accessed Pref. Data
Init Access
Access
Success
Access
Pre-fetch
Prefetch

Memory Access Pattern MapMemory Access Pattern Map
Corresponding to memory address spaceCache line granularity
I I
Memory Address Space
・・・
Cache Line
Zone Size
・・・
・・・
・・・
A
Memory Access Pattern Map
Pattern Match Logic
S PA

Pattern Matching LogicPattern Matching Logic
Access Map Shifter
Pattern Detector
Pipeline Register
Prefetch Selector
Addr
Memory Access Pattern Map
I AA AI AII I A
Access Map Shifter
10 1
I AA AI AA AII I
A
・・・
Addr
・・・
1
Priority Encoder & Adder
Prefetch Request
Feedback Path0
+1
+2
+3
・・・
(Addr+2)
Access Map Shifter
・・・
00・・・
Priority Encoder & Adder
II AI I AA AI A A

Parallel Pattern MatchingParallel Pattern Matching
Detects patterns from memory access mapDetects address correlations in parallelSearches candidates effectively
I SI AI AI AA II I I AA
Memory Access Pattern Map
・・・
・・・
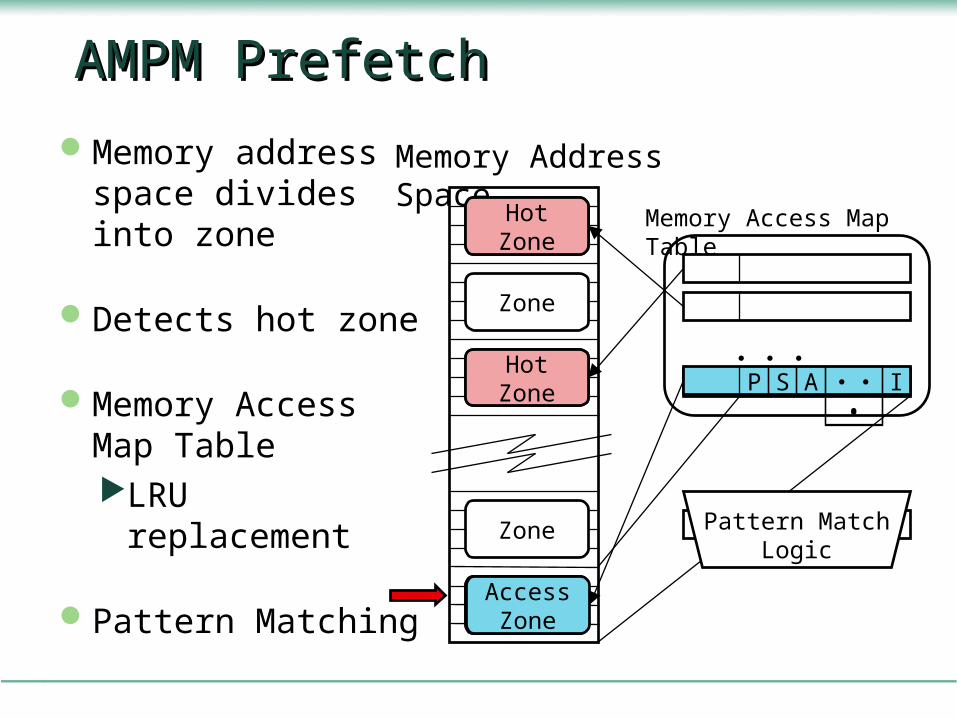
AMPM PrefetchAMPM Prefetch
Memory address space divides into zone
Detects hot zone
Memory Access Map TableLRU
replacement
Pattern Matching
Zone
Zone
Zone
Zone
Zone
Memory Address Space
HotZone
HotZone
HotZone
AccessZone
Prefetch Request
Memory Access Map Table
・・・
P S A I・・・
P S IA ・・・
Pattern MatchLogic

Features of AMPM PrefetcherFeatures of AMPM Prefetcher
Pattern Matching Base PrefetchingMap base historyOptimization friendly prefetching
Parallel pattern matchingSearches candidates effectivelyComplexity-effective
implementation

Configuration for DPC Configuration for DPC CompetitionCompetitionAMPM Prefetcher
Full-assoc 52 maps, 256 states / map
Adaptive Stream Prefetcher [Hur+ 2006]16 Histograms, 8 Stream Length
MSHR Configuration16 entries for Demand Requests
(Default)32 entries for Prefetch Requests
(Additional)
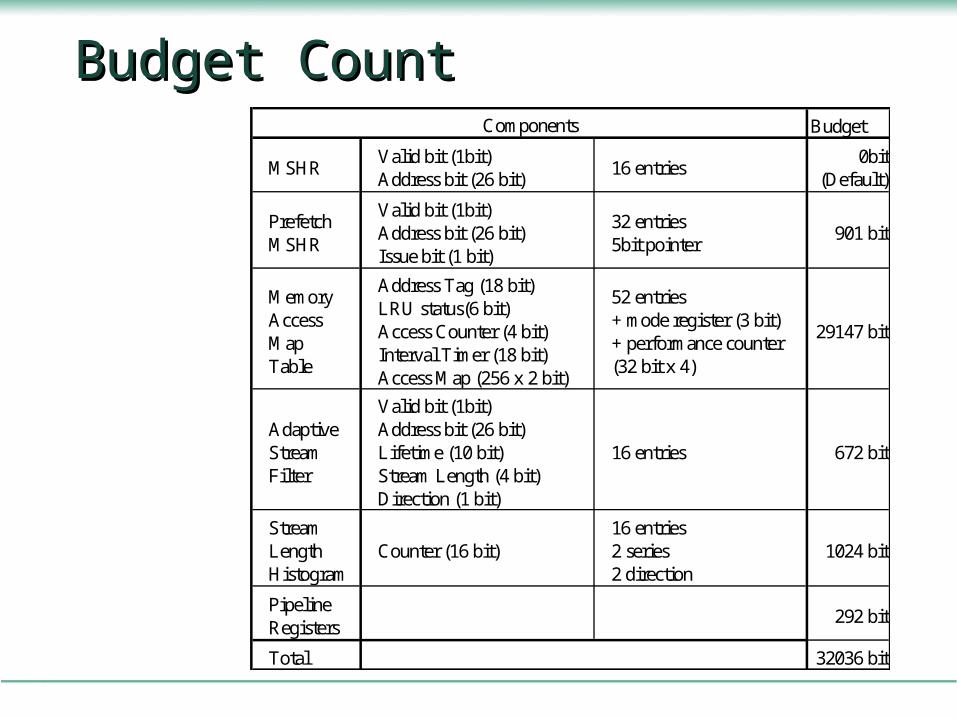
Budget CountBudget CountBudget
MSHRValid bit (1bit)Address bit (26 bit)
16 entries0bit
(Default)
PrefetchMSHR
Valid bit (1bit)Address bit (26 bit)Issue bit (1 bit)
32 entries5bit pointer
901 bit
MemoryAccessMapTable
Address Tag (18 bit)LRU status(6 bit)Access Counter (4 bit)Interval Timer (18 bit)Access Map (256 x 2 bit)
52 entries+ mode register (3 bit)+ performance counter(32 bit x 4)
29147 bit
AdaptiveStreamFilter
Valid bit (1bit)Address bit (26 bit)Lifetime (10 bit)Stream Length (4 bit)Direction (1 bit)
16 entries 672 bit
StreamLengthHistogram
Counter (16 bit)16 entries2 series2 direction
1024 bit
PipelineRegisters
292 bit
Total 32036 bit
Components

MethodologyMethodology
Simulation EnvironmentDPC FrameworkSkips first 4000M instructions and
evaluate following 100M instructions
BenchmarkSPEC CPU2006 benchmark suiteCompile Option: “-O3 -fomit-frame-pointer
-funroll-all-loops”

IPC MeasurementIPC Measurement
Improves performance by 53%Improves performance in all benchmarks
0.0
0.5
1.0
1.5
2.0
2.5
3.0
3.5
400.
perl
benc
h
401.
bzip
2
403.
gcc
410.
bwav
es
416.
gam
ess
429.
mcf
433.
mil
c
434.
zeus
mp
435.
grom
acs
436.
cact
usA
DM
437.
lesl
ie3d
444.
nam
d
445.
gobm
k
447.
deal
II
450.
sopl
ex
453.
povr
ay
454.
calc
ulix
456.
hmm
er
458.
sjen
g
459.
Gem
sFD
TD
462.
libq
uant
um
464.
h264
ref
465.
tont
o
470.
lbm
471.
omne
tpp
473.
asta
r
481.
wrf
482.
sphi
nx3
483.
xala
ncbm
k
Ari
th M
ean
Inst
ruct
ions
Per
Cyc
le
NOPREF PREFETCH

L2 Cache Miss CountL2 Cache Miss Count
Reduces L2 Cache Miss by 76%
0
500000
1000000
1500000
2000000
2500000
3000000
3500000
4000000
4500000
5000000
400.
perl
benc
h40
1.bz
ip2
403.
gcc
410.
bwav
es41
6.ga
mes
s42
9.m
cf43
3.m
ilc
434.
zeus
mp
435.
grom
acs
436.
cact
usA
DM
437.
lesl
ie3d
444.
nam
d44
5.go
bmk
447.
deal
II45
0.so
plex
453.
povr
ay45
4.ca
lcul
ix45
6.hm
mer
458.
sjen
g45
9.G
emsF
DT
D46
2.li
bqua
ntum
464.
h264
ref
465.
tont
o47
0.lb
m47
1.om
netp
p47
3.as
tar
481.
wrf
482.
sphi
nx3
483.
xala
ncbm
kA
rith
Mea
nL2
Mis
s C
ount
Per
100
M In
stru
ctio
ns L2 Miss Count / 100M Inst. (without Prefetch)L2 Miss Count / 100M Inst. (with Prefetch)

Related WorksRelated Works
Sequence-base PrefetchingSequential Prefetch [Smith+ 1978]Stride Prefetching Table [Fu+ 1992]Markov Predictor [Joseph+ 1997]Global History Buffer [Nesbit+ 2004]
Adaptive PrefetchingAC/DC [Nesbit+ 2004]Feedback Directed Prefetch [Srinath+ 2007]Focus Prefetching[Manikantan+ 2008]

ConclusionConclusion
Access Map Pattern Matching PrefetchOrder-Free Prefetch
Optimization friendly prefetchingParallel Pattern Matching
Complexity-effective implementation
Optimized AMPM realizes good performanceImproves IPC by 53%Reduces L2 cache miss by 76%

Spatial
Q & AQ & A
Stride PrefetchFu+ 1992
Markov PrefetchJoseph+ 1997
GHBNesbit+ 2004
Feedback basedHonjo 2009
HybridHsu+ 1998
Software SupportMowry+ 1992
AC/DCNesbit+ 2004
Adaptive StreamHur+ 2006
FDPSrinath+ 2007
Software
Sequence-Base(Order Sensitive)
Tag CorrelationHu+ 2003
Buffer Block Gindele1977
SMSSomogyi 2006
SequentialSmith+ 1978
RPTChen+ 1995
Locality DetectJohnson+, 1998
Spatial Pat. Chen+ 2004
Adaptive
Hybrid
Adaptive Seq.Dahlgren+ 1993
CommercialProcessors
SuperSPARC
R10000PA7200
Power4
Pentium 4
AMPM PrefetchIshii+ 2009
HW/SW IntegrateGornish+ 1994


















