
Access Control for HTTP Operations on Linked Data - … · · 2018-05-03Access Control for HTTP...
16
HAL Id: hal-00815067 https://hal.inria.fr/hal-00815067 Submitted on 18 Apr 2013 HAL is a multi-disciplinary open access archive for the deposit and dissemination of sci- entific research documents, whether they are pub- lished or not. The documents may come from teaching and research institutions in France or abroad, or from public or private research centers. L’archive ouverte pluridisciplinaire HAL, est destinée au dépôt et à la diffusion de documents scientifiques de niveau recherche, publiés ou non, émanant des établissements d’enseignement et de recherche français ou étrangers, des laboratoires publics ou privés. Access Control for HTTP Operations on Linked Data Luca Costabello, Serena Villata, Oscar Rodriguez Rocha, Fabien Gandon To cite this version: Luca Costabello, Serena Villata, Oscar Rodriguez Rocha, Fabien Gandon. Access Control for HTTP Operations on Linked Data. ESWC - 10th Extended Semantic Web Conference - 2013, May 2013, Montpellier, France. 2013. <hal-00815067>
Transcript of Access Control for HTTP Operations on Linked Data - … · · 2018-05-03Access Control for HTTP...

HAL Id: hal-00815067https://hal.inria.fr/hal-00815067
Submitted on 18 Apr 2013
HAL is a multi-disciplinary open accessarchive for the deposit and dissemination of sci-entific research documents, whether they are pub-lished or not. The documents may come fromteaching and research institutions in France orabroad, or from public or private research centers.
L’archive ouverte pluridisciplinaire HAL, estdestinée au dépôt et à la diffusion de documentsscientifiques de niveau recherche, publiés ou non,émanant des établissements d’enseignement et derecherche français ou étrangers, des laboratoirespublics ou privés.
Access Control for HTTP Operations on Linked DataLuca Costabello, Serena Villata, Oscar Rodriguez Rocha, Fabien Gandon
To cite this version:Luca Costabello, Serena Villata, Oscar Rodriguez Rocha, Fabien Gandon. Access Control for HTTPOperations on Linked Data. ESWC - 10th Extended Semantic Web Conference - 2013, May 2013,Montpellier, France. 2013. <hal-00815067>

Access Control for HTTP Operations
on Linked Data
Luca Costabello1, Serena Villata1,Oscar Rodriguez Rocha2, and Fabien Gandon1
1 INRIA Sophia Antipolis, [email protected] Politecnico di Torino, Italy
Abstract. Access control is a recognized open issue when interactingwith RDF using HTTP methods. In literature, authentication and au-thorization mechanisms either introduce undesired complexity such asSPARQL and ad-hoc policy languages, or rely on basic access controllists, thus resulting in limited policy expressiveness. In this paper we showhow the Shi3ld attribute-based authorization framework for SPARQLendpoints has been progressively converted to protect HTTP operationson RDF. We proceed by steps: we start by supporting the SPARQL 1.1Graph Store Protocol, and we shift towards a SPARQL-less solution forthe Linked Data Platform. We demonstrate that the resulting authoriza-tion framework provides the same functionalities of its SPARQL-basedcounterpart, including the adoption of Semantic Web languages only.
1 Introduction
In scenarios such as Linked Enterprise Data, access control becomes crucial, asnot all triples are openly published on the Web. Solutions proposed in litera-ture protect either SPARQL endpoints or generic RDF documents and adoptRole-based (RBAC) [20] or Attribute-based (ABAC) [18] models. The SemanticWeb community is recently emphasizing the need for a substantially “Web-like”interaction paradigm with Linked Data. For instance, the W3C Linked DataPlatform3 initiative promotes the use of read/write HTTP operations on triples,thus providing a basic profile for Linked Data servers and clients. Another ex-ample is the SPARQL 1.1 Graph Store Protocol4, a set of guidelines to interactwith RDF graphs with HTTP operations. Defining an access control model forthese scenarios is still an open issue5. Frameworks targeting HTTP access toRDF resources rely on access control lists, thus offering limited policy expres-siveness [13,14,17,19] (e.g., no location-based authorization). On the other hand,
3http://www.w3.org/TR/ldp/4http://www.w3.org/TR/sparql11-http-rdf-update/5http://www.w3.org/2012/ldp/wiki/AccessControl

existing access control frameworks for SPARQL [1,4,10] add complexity rootedin the query language and in the SPARQL protocol, often introducing ad-hocpolicy languages, thus requiring adaptation to the HTTP-only scenario.
In this paper, we answer the research question: How to design an authoriza-tion framework for HTTP-based interaction with Linked Data? This researchquestion breaks down into the following sub-questions: (i) how to define an au-thorization model featuring expressive policies based on standard Web languagesonly and (ii) how to adopt this model in HTTP-based interaction with LinkedData scenarios like the Graph Store Protocol (GSP) and the Linked Data Plat-form (LDP).
We adapt the Shi3ld authorization framework for SPARQL [4] to a SPARQL-less scenario. We choose Shi3ld because its features satisfy our requirements: (i)it adopts attribute-based access policies ensuring expressiveness, and (ii) exclu-sively uses Semantic Web languages for policy definition and enforcement.
We illustrate Shi3ld-GSP, an intermediate version designed for the SPARQL1.1 Graph Store HTTP Protocol. We progressively shift to the Linked DataPlatform context, a scenario where SPARQL is no longer present. We have de-veloped two solutions for this scenario: (i) an authorization module embeddinga hidden SPARQL engine, and (ii) a framework where we completely get rid ofSPARQL. In the latter case, the Shi3ld framework adopts a SPARQL-less sub-graph matcher which grants access if client attributes correspond to the declaredpolicy graphs. For each framework, we evaluate the response time and we showhow the authorization procedure impacts on HTTP operations on RDF data.
The key features of our attribute-based authorization frameworks for HTTP-based interaction with Linked Data are (i) the use of Web languages only, i.e.,HTTP methods and RDF, without ad-hoc languages for policies definition, (ii)the adoption of attribute-based access conditions enabling highly expressive poli-cies, and (iii) the adaptation to the GSP and LDP scenarios as a result of aprogressive disengagement from SPARQL. Moreover, Shi3ld is compatible andcomplementary with the WebID authentication framework6.
In this paper, we focus on authorization only, without addressing the issuesrelated to authentication and identity on the Web. Although we discuss state-of-the-art anti-spoofing techniques for attribute data, the present work does notdirectly address the issue.
The remainder of this paper is organized as follows. Section 2 summarizesthe related work, and highlights the requirements of an authorization model forour scenario. Section 3 describes the main insights of Shi3ld, and presents thethree proposed solutions to adapt the framework to HTTP operations on RDF.An experimental evaluation of response time overhead is provided in Section 4.
6http://www.w3.org/2005/Incubator/webid/spec/

2 Related Work
Many access control frameworks rely on access control lists (ACLs) that definewhich users can access the data. This is the case of the Web Access Controlvocabulary (WAC)7, that grants access to a whole RDF document. Hollenbach etal. [13] present a system where providers control access to RDF documents usingWAC. In our work, we look for more expressive policies that can be obtainedwithout leading to an increased complexity of the adopted language or model.
Similarly to ACLs, other approaches specify who can access the data, e.g.,to which roles access is granted. Among others, Giunchiglia et al. [12] proposea Relation Based Access Control model (RelBAC ) based on description logic,and Finin et al. [9] study the relationship between OWL and RBAC [20]. Theybriefly discuss possible ways of going beyond RBAC such as Attribute BasedAccess Control, a model that grants access according to client attributes, insteadof relying on AC lists.
The ABACmodel is adopted in the Privacy Preference Ontology (PPO)8 [19],built on top of WAC, where consumers require access to a given RDF file, e.g.,a FOAF profile, and the framework selects the part of the file the consumercan access, returning it. In our work, we go beyond the preference specificationbased on FOAF profiles. Our previous work [4] adopts ABAC for protecting theaccesses to SPARQL endpoints using Semantic Web languages only.
Other frameworks introduce a high level syntax for expressing policies. Abelet al. [1] present a context-dependent access control system for RDF stores,where policies are expressed using an ad-hoc syntax and mapped to existingpolicy languages. Flouris et al. [10] present an access control framework on topof RDF repositories using a high level specification language to be translatedinto a SPARQL/SerQL/SQL query to enforce the policy. Muhleisen et al. [17]present a policy-enabled server for Linked Data called PsSF, where policies areexpressed using a descriptive language based on SWRL9. Shen and Cheng [21]propose a Context-Based Access Control Model (SCBAC) where policies areexpressed using SWRL.
Access control models may consider not only the information about the con-sumer who is accessing the data, but also the context of the request, e.g., time,location. Covington et al. [5] present an approach where the notion of role pro-posed in RBAC is used to capture the environment in which the access requestsare made. Cuppens and Cuppens-Boulahia [6] propose an Organization BasedAccess Control model (OrBAC) that contains contextual conditions. Toninelliet al. [22] use context-awareness to control access to resources, and semantictechnologies for policy specification. Corradi et al. [3] present UbiCOSM, a se-curity middleware adopting context as a basic concept for policy specificationand enforcement.
7http://www.w3.org/wiki/WebAccessControl8http://vocab.deri.ie/ppo9http://www.w3.org/Submission/SWRL/

Table 1 summarizes the main characteristics of the related work describedabove10: none of the presented approaches satisfies all the features that we re-quire for protecting HTTP operations on Linked Data, i.e.: absence of ad hocpolicy languages, CRUD permission model, protection granularity at resource-level, and expressive access control model to go beyond basic access control lists.
Web-
basedAC model
Policy
language
Protection
granularity
Permission
model
Context
Awareness
Conflict
verificationEval.
WAC7 YES RBAC RDF RDF document R/W N/A N/A N/A
Abel et al. [1] YES ABAC Custom triples R YES N/A YESFinin et al. [9] YES RBAC OWL/RDF resources N/A N/A N/A N/ARelBAC [12] YES relation DL resources N/A N/A N/A N/AHollenbach[13] YES RBAC RDF RDF document R/W N/A N/A YESFlouris et al. [10] YES RBAC Custom triples R N/A YES YESPeLDS [17] YES RBAC SWRL RDF document R/W N/A N/A YESPPO [19] YES ABAC RDF, SPARQL RDF doc(part) R/W N/A N/A N/ASCBAC [21] YES context SWRL resources N/A YES YES N/AShi3ld-SPARQL[4] YES ABAC RDF, SPARQL named graphs CRUD YES N/A YESCovington [5] NO RBAC Custom resources R/W YES YES N/ACSAC [14] NO gen. RBAC XML resources R YES N/A N/AProteus[22] NO context DL Resources N/A YES YES YESOrBAC [6] NO organizationDatalog resources R/W YES YES N/AUbiCOSM [3] NO context RDF resources N/A YES YES YES
Table 1: A summarizing comparison of the related work.
3 Restricting HTTP operations on Linked Data
Before discussing how we modified the Shi3ld original proposition [4] to obtaina SPARQL-less access control framework for HTTP operations on Linked Data,we provide an overview of the original Shi3ld authorization model for SPARQLendpoints. Shi3ld [4] presents the following key features:
Attribute-based paradigm. Shi3ld is an attribute-based authorization frame-work, i.e., authorization check is performed against a set of attributes sentby the client along the query that targets the resource. Relying on attributesprovides broad access policy expressiveness, beyond the access condition listsadopted by RBAC frameworks. That means, among all, creating location-based and temporal-based access policies.
Semantic Web languages only. Shi3ld uses access policies defined with Se-mantic Web languages only, and no additional policy language needs tobe defined. In particular, the access conditions specified in the policies areSPARQL ASK queries.
CRUD permission model. Access policies are associated to specific permis-sions over the protected resource. It is therefore possible to specify rulessatisfied only when the access is in create, read, update and delete mode.
Granularity. The proposed degree of granularity is represented by named graphs,allowing protection from triples up to whole dataset.
10We use N/A when the feature is not considered in the work.

The HTTP-based interaction with Linked Data requires some major modi-fications to the above features: although we keep the attribute-based paradigmand the CRUD permission model, the new versions of Shi3ld satisfy also thefollowing requirements:
Protection of HTTP access to resources. Protected resources are retrievedand modified by clients using HTTP methods only, without SPARQL query-ing11.
RDF-only Policies. In the SPARQL-less scenario, access conditions are RDFtriples with no embedded SPARQL.
Granularity. The atomic element protected by Shi3ld is a resource.
In this paper, we rely on the definition of resource provided by the W3CLinked Data Platform Working Group: LDP resources are HTTP resourcesqueried, created, modified and deleted via HTTP requests processed by LDPservers12. Linked Data server administrators adopting Shi3ld must define a num-ber of access policies and associate them to protected resources. Access policiesand their components are formally defined as follows:
Definition 1. (Access Policy) An Access Policy (P ) is a tuple of the form P =〈ACS,AP,R〉 where (i) ACS is a set of Access Conditions to satisfy, (ii) AP isan Access Privilege, and (iii) R is the resource protected by P .
Definition 2. (Access Condition) An Access Condition (AC) is a set of at-tributes that need to be satisfied to interact with a resource.
Definition 3. (Access Privilege) An Access Privilege (AP ) is the set of allowedoperations on the protected resource. AP = {Create,Read, Update,Delete}.
The lightweight vocabularies used by Shi3ld are s4ac13 for defining the pol-icy structure, and prissma14 for the client attributes15. Client attributes includeuser profile information, device features, environment data, or any given com-bination of these dimensions, in compliance with the widely-accepted definitionby Dey [7] and the work by Fonseca et al.16 (we delegate refinements and ex-tensions to domain specialists, in the light of the Web of Data philosophy). Themain classes and properties of these vocabularies are visualized in Figure 1.Shi3ld offers a double notation for defining access conditions: with embeddedSPARQL (Figure 2a) for SPARQL-equipped scenarios and in full RDF (Fig-ure 2b), adopted in SPARQL-less environments.
11This is in compliance with the LDP specifications.12An LDP server is an “application program that accepts connections in order to
service requests by sending back responses” as specified by HTTP 1.1 definition.13http://ns.inria.fr/s4ac14http://ns.inria.fr/prissma15Although this vocabulary provides classes and properties to model context-aware
attributes, it is not meant to deliver yet another contextual model: instead, well-knownWeb of Data vocabularies and recent W3C recommendations are reused. For moredetails, see Costabello et al. [4].
16http://www.w3.org/2005/Incubator/model-based-ui/XGR-mbui/

AccessConditionSet
AccessCondition
DisjunctiveACS
ConjunctiveACS
subClassOf
subClassOf
AccessPolicy
hasAccessCondition
AccessPrivilege
hasAccessPrivilege
appliesTo
UserDevice
Environment
Context
POI
Activity
foaf:Person
owl:equivalentClass
dcn:Device
geo:SpatialThing
owl:Thing geo:Point
environment
device user
hasAccessConditionSet
motion
nearbyEntity
poiLabel
poiCategory
ao:activity
subClassOf
foaf:based_near
s4ac:
prissma:
radius
subClassOf
hasContext
tl:start
tl:duration
hasQueryAsk
poi
Fig. 1: Interplay of s4ac and prissma vocabularies for Shi3ld access policies.
Example 1. Figure 2 presents two sample access policies, expressed with andwithout SPARQL. The policy visualized in Figure 2a allows read-only access tothe protected resource exclusively by a specific user and from a given location.The policy in Figure 2b authorizes the update of the resource by the given user,only if he is currently near Alice.
:policy1 a s4ac:AccessPolicy; s4ac:appliesTo :protected_res; s4ac:hasAccessPrivilege s4ac:Read; s4ac:hasAccessConditionSet :acs1.
:acs1 a s4ac:AccessConditionSet;
s4ac:ConjunctiveAccessConditionSet;
s4ac:hasAccessCondition :ac1.
:ac1 a s4ac:AccessCondition; s4ac:hasQueryAsk
"""ASK {?ctx a prissma:Context. ?ctx prissma:environment ?env.?ctx prissma:user <http://johndoe.org/foaf.rdf#me>. ?env prissma:currentPOI ?poi. ?poi prissma:based_near ?p.?p geo:lat ?lat; geo:lon ?lon.FILTER(((?lat-45.8483) > 0 && (?lat-45.8483) < 0.5|| (?lat-45.8483) < 0 && (?lat-45.8483) > -0.5)&& ((?lon-7.3263) > 0 && (?lon-7.3263) < 0.5 || (?lon-7.3263) < 0 && (?lon-7.3263) > -0.5 ))""".
PROTECTED
RESOURCE ACCESS
PRIVILEGE
ACCESS CONDITION
TO VERIFY
(a) SPARQL-based
:policy1 a s4ac:AccessPolicy; s4ac:appliesTo :protected_res; s4ac:hasAccessPrivilege s4ac:Update; s4ac:hasAccessConditionSet :acs1.
:acs1 a s4ac:AccessConditionSet;
s4ac:ConjunctiveAccessConditionSet;
s4ac:hasAccessCondition :ac1.
:ac1 a s4ac:AccessCondition; s4ac:hasContext :ctx1.
:ctx1 a prissma:Context;prissma:user <http://johndoe.org/foaf.rdf#me>.prissma:environment :env1
:env1 a prissma:Environment;
prissma:nearbyEntity <http://alice.org#me>.
PROTECTED
RESOURCE ACCESS
PRIVILEGE
ACCESS CONDITION
TO VERIFY
(b) SPARQL-less
Fig. 2: Shi3ld access policies, expressed with and without SPARQL.
Whenever an HTTP query is performed on a resource, Shi3ld runs the autho-rization algorithm to check if the policies that protect the resource are satisfiedor not. The procedure verifies the matching between the client attributes sentwith the query and the access policies that protect the resource.

Shi3ld deals with authorization only. Nevertheless, authentication issues can-not be ignored as the trustworthiness of client attributes is critical for a reliableaccess control framework. Shi3ld supports heterogeneous authentication strate-gies, since the attributes attached to each client request include heterogeneousdata, ranging from user identity to environment information fetched by devicesensors (e.g. location). The trustworthiness of user identity is achieved thanks tothe WebID6 compatibility: in Shi3ld, user-related attributes are modelled withthe foaf vocabulary17, thus easing the adoption of WebID. Authenticating theattributes fetched by client sensors is crucial to prevent tampering. Hulseboschet al. [14] provide a survey of verification techniques, such as heuristics relying onlocation history and collaborative authenticity checks. A promising approach ismentioned in Kulkarni and Tripathi [16], where client sensors are authenticatedbeforehand by a trusted party. To date, no tamper-proof strategy is implementedin Shi3ld, and this is left for future work.
Moreover, sensible data, such as current location must be handled with aprivacy-preserving mechanism. Recent surveys describe strategies to introduceprivacy mainly in location-based services [8,15]. Shi3ld adopts an anonymity-based solution [8] and delegates attribute anonymisation to the client side, thussensitive information is not disclosed to the server. We rely on partially en-crypted RDF graphs, as proposed by Giereth [11]. Before building the RDFattribute graph and sending it to the Shi3ld-protected repository, a partial RDFencryption is performed, producing RDF-compliant results, i.e., the encryptedgraph is still RDF (we use SHA-1 cryptographic hash function to encrypt RDFliterals). On server-side, every time a new policy is added to the system, thesame operation is performed on attributes included in access policies. As longas literals included in access conditions are hashed with the same function usedon the client side, the Shi3ld authorization procedure still holds18.
We now describe the steps leading to a SPARQL-less authorization frame-work for HTTP operations on Linked Data. Our first proposal is a Shi3ld au-thorization framework for the SPARQL 1.1 Graph Store Protocol (Section 3.1).In Sections 3.2 and 3.3 we describe two scenarios tailored to the Linked DataPlatform specifications, the second being completely SPARQL-less. Our work isgrounded on the analogies between SPARQL 1.1 functions and the HTTP proto-col semantics, as suggested by the SPARQL Graph Store Protocol specification4.
3.1 Shi3ld for SPARQL Graph Store Protocol
The SPARQL 1.1 HTTP Graph Store Protocol4 (GSP) provides an alternativeinterface to access RDF stored in SPARQL-equipped triple stores. The recom-mendation describes a mapping between HTTP methods and SPARQL queries,
17http://xmlns.com/foaf/spec/18The adopted technique does not guarantee full anonymity [15]. Nevertheless, the
problem is mitigated by the short persistence of client-related data inside Shi3ld cache:client attributes are deleted after each authorization evaluation. Encryption is not ap-plied to location coordinates and timestamps, as this operation prevents geo-temporalfiltering.

thus enabling HTTP operations on triples. The Graph Store Protocol can beconsidered as an intermediate step towards an HTTP-only access to RDF data-stores, since it still needs a SPARQL endpoint.
Figure 3a shows the architecture of the authorization procedure of Shi3ld forGSP-compliant SPARQL endpoints (Shi3ld-GSP). Shi3ld-GSP acts as a moduleprotecting a stand-alone SPARQL 1.1 endpoint, equipped with a Graph StoreProtocol module. First, the client performs an HTTP operation on a resource.This means that an RDF attribute graph is built on the client, serialized and sentwith the request in the HTTP Authorization header19. Attributes are savedinto the triple store with a SPARQL 1.1 query. Second, Shi3ld selects the accesspolicies that protect the resource. The access conditions (SPARQL ASK queries,as in Figure 2a) included in the policies are then executed against the clientattribute graph. Finally, the results are logically combined according to the typeof access condition set (disjunctive or conjunctive) defined by each policy. If theresult returns true, the HTTP query is forwarded to the GSP SPARQL engine,which in turns translates it into a SPARQL query. If the access is not granted,a HTTP 401 message is delivered to the client.
3.2 Shi3ld-LDP with Internal SPARQL Engine
The Linked Data Platform Initiative (LDP) proposes a simplified configurationfor Linked Data servers and Web-like interaction with RDF resources. Comparedto the GSP case, authorization frameworks in this scenario must deal with acertain number of changes, notably the absence of SPARQL and potentially thelack of a graph store.
We adapt Shi3ld to work under these restrictions (Shi3ld-LDP). The frame-work architecture is shown in Figure 3b. Shi3ld-LDP protects HTTP operations,but it does not communicate with an external SPARQL endpoint, i.e. there areno intermediaries between the RDF repository (the filesystem or a triple store)and Shi3ld. To re-use the authorization procedure previously described, we in-tegrate an internal SPARQL engine into Shi3ld, along with an internal triplestore. Although SPARQL is still present, this is perfectly legitimate in a LinkedData Platform scenario, since the use of the query language is limited to Shi3ldinternals and is not exposed to the outside world20. Despite the architecturalchanges, the Shi3ld model remains unchanged. Few modifications occur to theauthorization procedure, as described in Figure 3a: clients send HTTP requeststo the desired resource. HTTP headers contain the attribute graph, serialized aspreviously described in Section 3.1. Instead of relying on an external SPARQLendpoint, attributes are now saved internally, using an INSERT DATA query. Theaccess policies selection and the access conditions execution remain substantiallyunchanged, but the whole process is transparent to the platform administrator,as the target SPARQL endpoint is embedded in Shi3ld.
19We extend the header with the ad-hoc Shi3ld option. Other well-known proposalson the web re-use this field, e.g. the OAuth authorization protocol.
20SPARQL is still visible in Access Policies (Figure 2a).

Shi3ld-GSPClientSPARQL 1.1
GSPTriple
Store
GET /data/resource HTTP/1.1
Host: example.org
Authorization: Shi3ld:base64(attributes)
INSERT/DATA(attributes)
SELECT(Access Policies)
ASK (AC1)
ASK (ACn)
.
.
.
GET /data/resource HTTP/1.1
Host: example.org
200 OK
HTTP HTTP
(a) Shi3ld-GSP
LDP Server
INSERT/DATA(attributes)
SELECT(Access Policies)
ASK (AC1)
ASK (ACn)
.
.
.
GET /data/resource HTTP/1.1
Host: example.org
Shi3ld-LDP Internal
Triple Store
Internal
SPARQL EngineShi3ld Frontend
Client
GET /data/resource HTTP/1.1
Host: example.org
Authorization: Shi3ld:base64(attributes)
200 OK
File
System/
Triple
Store
HTTP
getData()
Shi3ld Internal
(b) Shil3d-LDP (internal SPARQL engine)
File
System/
Triple
Store
Save attributes
Get Access Policies
attributes.contains(AC1)
attributes.contains(ACn)
.
.
.
Shi3ld-LDP
Subgraph
matcherShi3ld Frontend
Client
GET /data/resource HTTP/1.1
Host: example.org
Authorization: Shi3ld:base64(attributes)
LDP Server
HTTP Shi3ld Internal
GET /data/resource HTTP/1.1
Host: example.org
200 OK
getData()
(c) Shi3ld-LDP (SPARQL-less)
Fig. 3: Shi3ld Configurations
3.3 SPARQL-less Shi3ld-LDP
To completely fulfill the Linked Data Platform recommendations, thus achievinga full-fledged basic profile for authorization frameworks, we drop SPARQL fromthe Shi3ld-LDP framework described in Section 3.2. Ditching SPARQL allowsRDF-only access policies definition, and a leaner authorization procedure. To ob-tain a SPARQL-less framework, we re-use the access policy model and the logicalsteps of the previously described authorization procedure, although convenientlyadapted (Figure 3c). First, Shi3ld-LDP policies adopt RDF only, as shown inFigure 2b: attribute conditions previously expressed with SPARQL ASK queries(Figure 2a) are expressed now as RDF graphs. Second, the embedded SPARQLengine used in Section 3.2 has been replaced: its task was testing whether clientattributes verify the conditions defined in each access policy. This operation

boils down to a subgraph matching problem. In other words, we must check ifthe access conditions (expressed in RDF) are contained into the attribute graphsent along the HTTP client query. Such subgraph matching procedure can beperformed without introducing SPARQL in the loop. To steer clear of SPARQL,without re-inventing yet another subgraph matching procedure, we scrap theSPARQL interpreter from the SPARQL engine [2] used in Section 3.2, keepingonly the underlying subgraph matching algorithm21.
To understand how the SPARQL-less policy verification procedure works andcomprehend the complexity hidden by the SPARQL layer, we now provide a com-prehensive description of the adopted subgraph matching algorithm, along withan overview of the RDF indexes used by the procedure. The algorithm checkswhether a query graph Q (the access condition) is contained in the referencegraph R (the client attributes sent along the query).The reference graph R is stored in two key-value indexes (see example in Fig-ure 4): index Is stores the associations between property types and propertysubjects, and index Io stores the associations between property types and prop-erty objects. Each RDF property type of R is therefore associated to a list ofproperty subjects Sp and a list of property objects Op. Sp contains URIs orblank nodes, Op contains URIs, typed literals and blank nodes. Blank nodes arerepresented as anonymous elements, and their IDs are ignored.The query graph Q, i.e., the access condition attributes, is serialized in a list Lof subject-property-object elements {si, pi, oi}
22. Blank nodes are added to theserialization as anonymous si or oi elements.The matching algorithm works as follows: for each subject-property-object {si, pi,oi} in L, it looks up the indexes Is and Io using pi as key. It then retrieves thelist of property subjects Sp and the list of property objects Op associated topi. Then, it searches for a subject in Sp matching with si, and an object inOp matching with oi. If both matches are found, {si, pi, oi} is matched and theprocedure moves to the next elements in L. If no match is found in either Isor Io, the procedure stops. Subgraph matching is successful if all L items arematched in the R index. Blank nodes act as wildcards: if a blank node is foundin {si, pi, oi} as object oi or subject si, and Op or Sp contains one or more blanknodes, the algorithm continues the matching procedure recursively, backtrackingin case of mismatch and therefore testing all possible matchings.The example in Figure 4 shows a matching step of the algorithm, i.e., the suc-cessful matching of the triple “ :b2 p:nearbyEntity http://alice.org/me”against the client attributes indexes Is and Io. The highlighted triple is success-fully matched against the client attributes R.
Note that policies might contain location and temporal constraints: Shi3ld-GSP (Section 3.1) and Shi3ld-LDP with internal SPARQL endpoint (Section 3.2)handle these conditions by translating RDF attributes into SPARQL FILTER
21Third-party SPARQL-less Shi3ld-LDP implementations might adopt other off-the-shelf subgraph matching algorithms.
22A preliminary step replaces the query graph Q intermediate nodes into blanknodes. Blank nodes substitute SPARQL variables in the matching procedure.

:policy1 a s4ac:AccessPolicy; s4ac:appliesTo :protected_res; s4ac:hasAccessPrivilege s4ac:Update; s4ac:hasAccessConditionSet :acs1.:acs1 a s4ac:AccessConditionSet; s4ac:ConjunctiveAccessConditionSet; s4ac:hasAccessCondition :ac1.:ac1 a s4ac:AccessCondition.:ac1 s4ac:hasContext _:b1.
_:b1 a prissma:Context._:b1 p:user <http://johndoe.org/foaf.rdf#me>._:b1 p:environment _:b2.
_:b2 p:nearbyEntity <http://alice.org#me>.
_:b1
<http://johndoe.org#me>
_:b2
<http://alice.org#me>
p:nearbyEntity
pr:user p:environment
<http://johndoe.org#me>:env_AC1
<http://alice.org#me>
p:nearbyEntity
p:user p:environment
p:nearbyEntity
:ctx_AC1
Reference Graph R(Client Attributes)
Query Graph Q (Access Condition)
L
p:user :ctx_AC1
p:environment :ctx_AC1
p:nearbyEntity :env_AC1
foaf:gender <blank>
Is
Sp:nearbyEntity
p:user <http://johndoe.org#me>
p:environment :env_AC1
p:nearbyEntity <http://jack.org#me>,
<http://alice.org#me>
foaf:gender "male"
Io
Op:nearbyEntity
Access Policy for SPARQL-less Shi3ld
foaf:gender
"male"
si = _:b2
pi = p:nearbyEntity
oi = <http://alice.org#me>
Fig. 4: Example of subgraph matching used in the SPARQL-less Shi3ld-LDP.
clauses. The subgraph matching algorithm adopted by SPARQL-less Shi3ld-LDPdoes not support geo-temporal authorization evaluation yet.
The three Shi3ld configurations described in this Section use theAuthorization header to send client attributes. Even if there is no limit tothe size of each header value, it is good practice to limit the size of HTTP re-quests, to minimize latency. Ideally, HTTP requests should not exceed the sizeof a TCP packet (1500 bytes), but in real world finding requests that exceed2KB is not uncommon, as a consequence of cookies, browser-set fields and URLwith long query strings23. To keep size as small as possible, before base-64 en-coding, client attributes are serialized in turtle (less verbose that N-triples andRDF/XML). We plan to test the effectiveness of common lossless compressiontechniques to reduce the size of client attributes as future work. Furthermore,instead of sending the complete attribute graph along all requests, a server-sidecaching mechanism would enable the transmission of attribute graph deltas (i.e.only newly updated attributes will be sent to the server). Sending differences ofRDF graphs is an open research topic24 and we do not address the issue in thispaper.
23https://developers.google.com/speed/docs/best-practices/request24http://www.w3.org/2001/sw/wiki/How_to_diff_RDF

4 Evaluation
We implemented the three scenarios presented in Section 3 as Java standaloneweb services25. The Shi3ld-GSP prototype works with the Fuseki GSP-compliantSPARQL endpoint26. The Shi3ld-LDP prototype with internal SPARQL end-point embeds the KGRAM/Corese27 engine [2]. Our test campaign assesses theimpact of Shi3ld on HTTP query response time25. We evaluate the prototypeson an Intel Xeon E5540, Quad Core 2.53 GHz machine with 48GB of memory.In our test configuration, Shi3ld-GSP protects a Fuseki SPARQL server, whileShil3d-LDP scenarios secure RDF resources saved on the filesystem. First, weinvestigate the relationship between response time and the number of access con-ditions to verify. Second, we test how access conditions complexity impacts onresponse time. Our third test studies the response time with regard to differentHTTP methods. We execute five independent runs of a test query batch consist-ing in 50 HTTP operations (tests are preceded by a warmup run). Each querycontains client attributes serialized in turtle (20 triples). The base-64 turtle se-rialization of the client attributes used in tests25 is 1855 bytes long (includingprefixes). Tests do not consider client-side literal anonymization (Section 3).
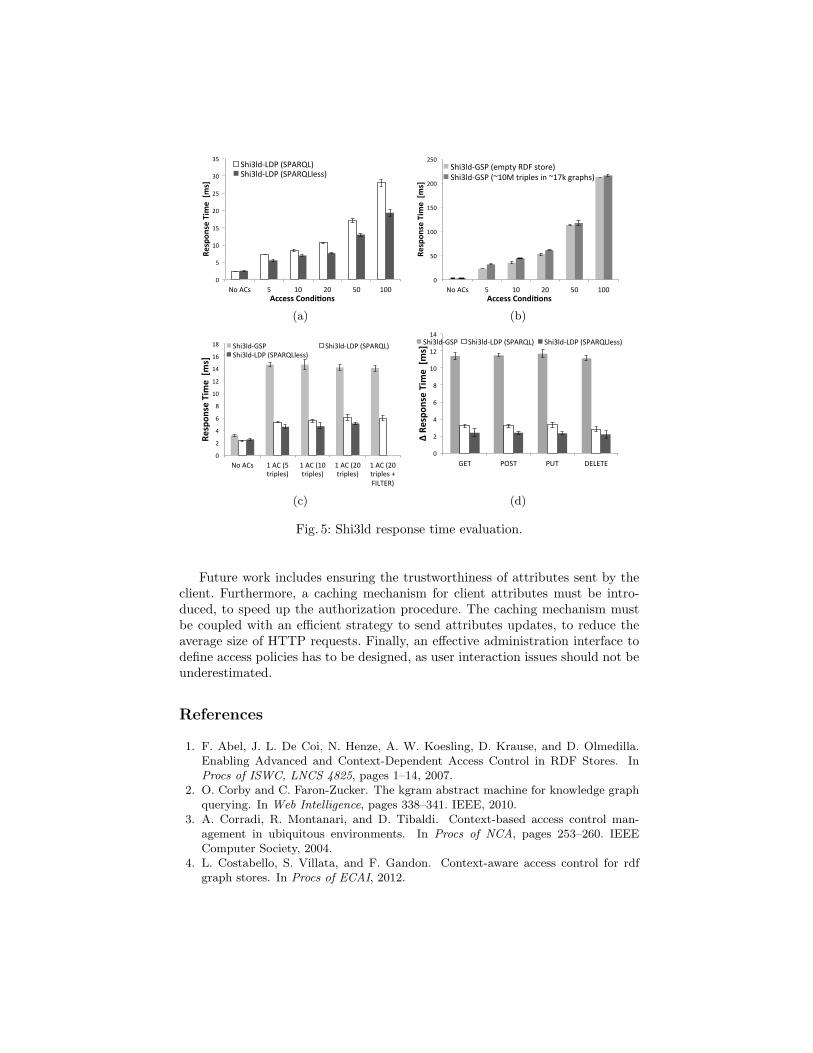
Our first test shows the impact of the access conditions number on HTTPGET response time (Figure 5a and 5b). Each policy contains one access condi-tion, each including 5 triples. We progressively increased the number of accessconditions protecting the target RDF resource. Not surprisingly, the number ofaccess conditions defined on the protected resource impacts on response time. InFigure 5a we show the results for Shi3ld-LDP scenarios: data show a linear rela-tionship between response time and access conditions number. We tested the sys-tem up to 100 access conditions, although common usage scenarios have a smallernumber of conditions defined for each resource. For example, the 5 access condi-tion case is approximately 3 times slower than unprotected access. Nevertheless,ditching SPARQL improved performance: Figure 5a shows that the SPARQL-less configuration is in average 25% faster than its SPARQL-based counterpart,due to the absence of the SPARQL interpreter. As predicted, the delay intro-duced by Shi3ld-GSP is higher, e.g., 7 times slower for resources protected by5 access policies (Figure 5b). This is mainly due to the HTTP communicationbetween the Shi3ld-GSP module and Fuseki. Further delay is introduced by theFuseki GSP module, that translates HTTP operations into SPARQL queries.Moreover, unlike Shi3ld-LDP scenarios, Shi3ld-GSP uses a shared RDF store forprotected resources and access control-related data (client attributes and accesspolicies). This increases the execution time of SPARQL queries, thus determininghigher response time: in Figure 5b, we show the behaviour of Shi3ld-GSP withtwo Fuseki server configurations: empty and with approximately 10M triples,stored in 17k graphs (we chose the “4-hop expansion Timbl crawl” part of the
25Binaries, code and complete evaluation results are available at:http://wimmics.inria.fr/projects/shi3ld-ldp
26http://jena.apache.org/documentation/serving_data27http://tinyurl.com/corese-engine

Billion Triple Challenge 2012 Dataset28). Results show an average response timedifference of 14%, with a 27% variation for the 5 access condition case (Fig-ure 5b). The number and the distribution of triples in the RDF store influenceShi3ld-GSP response time. Results might vary when Shi3ld-GSP is coupled withSPARQL endpoints adopting different indexing strategies or with different triplenumber and graph partitioning.
In Figure 5c, we show the impact of access conditions complexity on HTTPGET response time. The requested resource is protected by a single access condi-tion, with growing complexity: we added up to 20 triples, and we assess an accesscondition containing a FILTER clause (for SPARQL-based scenarios only). Re-sults show no relevant impact on response time: this is because of the small sizeof the client attributes graph, over which access conditions are evaluated (inour tests, client attributes include 20 triples). Although attribute graph variesaccording to the application domain, it is reasonable that size will not exceedtens of triples.
The third test (Figure 5d) shows the delay introduced by Shi3ld for eachHTTP operation. The figure displays the difference between response timewith and without access control. We executed HTTP GET, POST, PUT andDELETE methods. Each HTTP method is associated to a 5-triple access con-dition. As predicted, the delay introduced by Shi3ld is independent from theHTTP method.
In Section 2, we addressed a qualitative comparison with respect to the re-lated work. On the other hand, addressing a quantitative evaluation is a trickypoint: among the list in Table 1, only few works explicitly designed for the Webcome with an evaluation campaign [1,4,10,13,17]. Moreover, although some ofthese works provide a response time evaluation, the experimental conditionsvary, making the comparison difficult.
5 Conclusions
We described an authorization framework for HTTP operations on LinkedData. The framework comes in three distinct configurations: Shi3ld-GSP (forthe SPARQL 1.1 Graph Store Protocol) and Shi3ld for the Linked Data Plat-form (with and without the internal SPARQL endpoint). Our solutions featureattribute-based access control policies expressed with Web languages only. Eval-uation confirms that Shi3ld-GSP is slower than the Shi3ld-LDP counterparts,due to the HTTP communication with the protected RDF store. Shi3ld-LDPwith internal SPARQL endpoint introduces a 3x delay in response time (whenresources are protected by 5 access conditions). Nevertheless, under the sameconditions, the SPARQL-less solution exhibits 25% faster response times. Weshow that response time grows linearly with the number of access conditions,and that the complexity of each access condition does not relevantly impact onthe delay.
28http://km.aifb.kit.edu/projects/btc-2012/
!"
#"
$!"
$#"
%!"
%#"
&!"
&#"
'(")*+" #" $!" %!" #!" $!!"
!"#$%&#"'()*
"''+*
#,'
-.."##'/%&0)1%&#'
,-.&/01234"5,4)6728"
,-.&/01234"5,4)672/9++8"
(a)
!"
#!"
$!!"
$#!"
%!!"
%#!"
&'"()*" #" $!" %!" #!" $!!"
!"#$%&#"'()*
"''+*
#,'
-.."##'/%&0)1%&#'
+,-./012+3"456789":;<"*8'=5>"
+,-./012+3"4?$!@"8=-7/5*"-A"?$BC"D=E7,*>"
(b)
!"
#"
$"
%"
&"
'!"
'#"
'$"
'%"
'&"
()"*+," '"*+"-."
/01234,5"
'"*+"-'!"
/01234,5"
'"*+"-#!"
/01234,5"
'"*+"-#!"
/01234,"6"
789:;<5"
!"#$%&#"'()*
"''+*
#,'
=>1?3@AB=C" =>1?3@A9DC"-=C*<E95"
=>1?3@A9DC"-=C*<E934,,5"
(c)
!"
#"
$"
%"
&"
'!"
'#"
'$"
()*" +,-*" +.*" /)0)*)"
!"#$%&'(%$")*+
$"",+
%-"-123456(-+" -1234560/+"7-+89:0;" -1234560/+"7-+89:04<==;"
(d)
Fig. 5: Shi3ld response time evaluation.
Future work includes ensuring the trustworthiness of attributes sent by theclient. Furthermore, a caching mechanism for client attributes must be intro-duced, to speed up the authorization procedure. The caching mechanism mustbe coupled with an efficient strategy to send attributes updates, to reduce theaverage size of HTTP requests. Finally, an effective administration interface todefine access policies has to be designed, as user interaction issues should not beunderestimated.
References
1. F. Abel, J. L. De Coi, N. Henze, A. W. Koesling, D. Krause, and D. Olmedilla.Enabling Advanced and Context-Dependent Access Control in RDF Stores. InProcs of ISWC, LNCS 4825, pages 1–14, 2007.
2. O. Corby and C. Faron-Zucker. The kgram abstract machine for knowledge graphquerying. In Web Intelligence, pages 338–341. IEEE, 2010.
3. A. Corradi, R. Montanari, and D. Tibaldi. Context-based access control man-agement in ubiquitous environments. In Procs of NCA, pages 253–260. IEEEComputer Society, 2004.
4. L. Costabello, S. Villata, and F. Gandon. Context-aware access control for rdfgraph stores. In Procs of ECAI, 2012.

5. M. J. Covington, W. Long, S. Srinivasan, A. K. Dey, M. Ahamad, and G. D.Abowd. Securing context-aware applications using environment roles. In Procs of
SACMAT, pages 10–20, 2001.6. F. Cuppens and N. Cuppens-Boulahia. Modeling contextual security policies. Int.
J. Inf. Sec., 7(4):285–305, 2008.7. A. K. Dey. Understanding and using context. Personal Ubiquitous Computing,
5:4–7, 2001.8. M. Duckham. Moving forward: location privacy and location awareness. In Procs
of SPRINGL, pages 1–3, 2010.9. T. W. Finin, A. Joshi, L. Kagal, J. Niu, R. S. Sandhu, W. H. Winsborough, and
B. M. Thuraisingham. ROWLBAC: representing role based access control in OWL.In Procs of SACMAT, pages 73–82. ACM, 2008.
10. G. Flouris, I. Fundulaki, M. Michou, and G. Antoniou. Controlling Access to RDFGraphs. In Procs of FIS, LNCS 6369, pages 107–117. Springer, 2010.
11. M. Giereth. On partial encryption of rdf-graphs. In Procs of ISWC, pages 308–322,2005.
12. F. Giunchiglia, R. Zhang, and B. Crispo. Ontology driven community access con-trol. In Procs of SPOT, 2009.
13. J. Hollenbach, J. Presbrey, and T. Berners-Lee. Using RDF Metadata To EnableAccess Control on the Social Semantic Web. In Procs of CK-2009, 2009.
14. R. J. Hulsebosch, A. H. Salden, M. S. Bargh, P. W. G. Ebben, and J. Reitsma.Context sensitive access control. In Procs of SACMAT, pages 111–119. ACM, 2005.
15. J. Krumm. A survey of computational location privacy. Personal Ubiquitous
Comput., 13(6):391–399, Aug. 2009.16. D. Kulkarni and A. Tripathi. Context-aware role-based access control in pervasive
computing systems. In Procs of SACMAT, pages 113–122, 2008.17. H. Muhleisen, M. Kost, and J.-C. Freytag. SWRL-based Access Policies for Linked
Data. In Procs of SPOT, 2010.18. T. Priebe, E. B. Fernandez, J. I. Mehlau, and G. Pernul. A pattern system for
access control. In Procs of DBSec, pages 235–249, 2004.19. O. Sacco, A. Passant, and S. Decker. An access control framework for the web of
data. In Proc. of TrustCom, IEEE, pages 456–463, 2011.20. R. S. Sandhu, E. J. Coyne, H. L. Feinstein, and C. E. Youman. Role-based access
control models. IEEE Computer, 29(2):38–47, 1996.21. H. Shen and Y. Cheng. A semantic context-based model for mobile web services
access control. I. J. Computer Network and Information Security, 1:18–25, 2011.22. A. Toninelli, R. Montanari, L. Kagal, and O. Lassila. A semantic context-aware
access control framework for secure collaborations in pervasive computing environ-ments. In Procs of ISWC, LNCS 4273, pages 473–486. Springer, 2006.


















