
Abstractions for Fault-Tolerant Distributed Computing Idit Keidar MIT LCS.
41
Abstractions for Fault- Tolerant Distributed Computing Idit Keidar MIT LCS
-
date post
21-Dec-2015 -
Category
Documents
-
view
222 -
download
0
Transcript of Abstractions for Fault-Tolerant Distributed Computing Idit Keidar MIT LCS.

Abstractions for Fault-Tolerant Distributed Computing
Idit KeidarMIT LCS

?The Big Question
Q: How can we make it easier to build good* distributed systems?
*good = efficient; fault-tolerant; correct; flexible; extensible; …
A: We need good abstractions, implemented as generic services (building blocks)

In This Talk
Abstraction: Group Communication
Application: VoD
Algorithm: Moshe
Implementation, Performance
Other work, new directions

Abstraction: Group Communication (GC)
GC
Se
nd ( G
rp, M
sg )
Re
ceive ( M
sg )
Join / L
eave ( G
rp )
View
( Me
mbe
rs, Id)

Example: Highly Available Video-On-Demand (VoD)[Anker, Dolev, Keidar ICDCS 99]
• True VoD: clients make online requests
• Dynamic set of loosely-coupled servers– Fault-tolerance, dynamic load balancing– Clients talk to “abstract” service
VoD Service
MovieGroup
Chocolat
MovieGroup
Gladiator
MovieGroup
Spy Kids
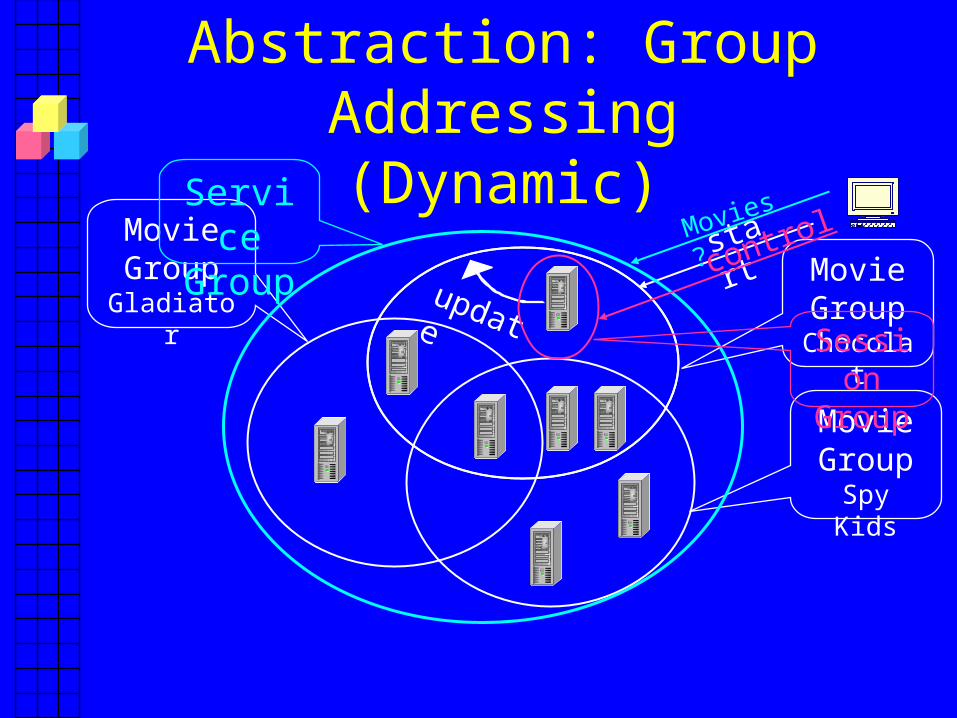
Abstraction: Group Addressing(Dynamic)
start
update
Movies?ServiceGroup control
SessionGroup

Abstraction: Virtual Synchrony
• Connected group members receive same sequence of events - messages, views
• Abstraction: state-machine replication– VoD servers in movie group share info about clients
using messages and views
• Make load-balancing decisions based on local copy– Upon start message– When view reports of server failure
• Joining servers get state transfer
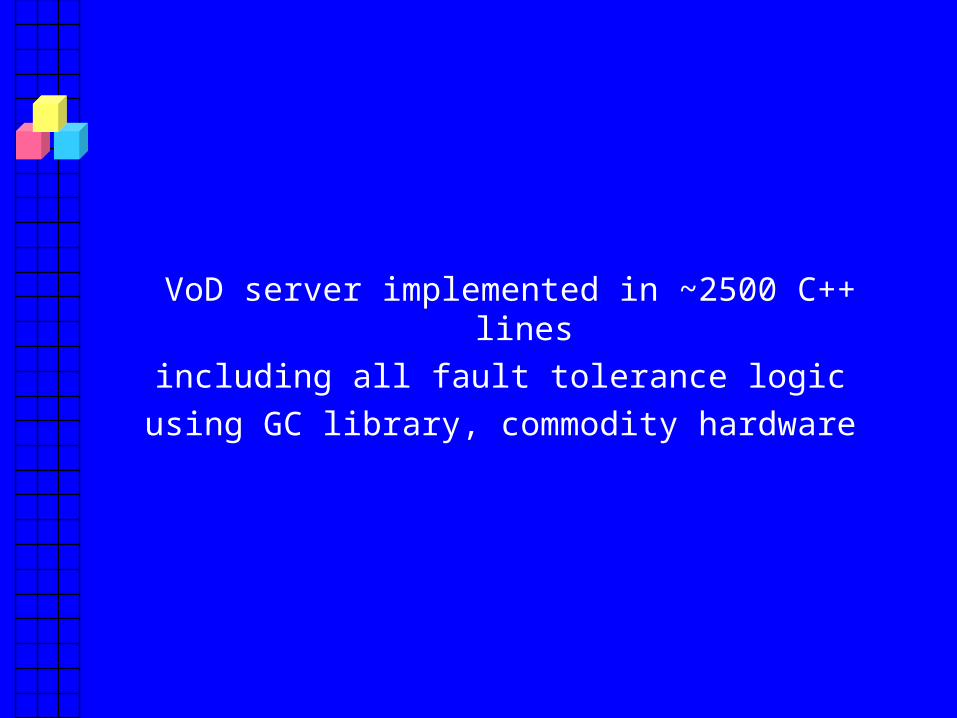
VoD server implemented in ~2500 C++ lines
including all fault tolerance logic
using GC library, commodity hardware

General Lessons Learned
• GC saves a lot of work– Especially for replication with dynamic groups
and “local” consistency – E.g., VoD servers, shared white-board,...
• Good performance but… only on LAN– Next generation will be on WANs (geoplexes)

WAN: the Challenge
• Message latency large and unpredictable
• Frequent message loss Time-out failure detection inaccurate Number of inter-LAN messages matters Algorithms may change views frequently,
view changes require communication e.g., state transfer, costly in WAN

GCMulticast & Membership
New Architecture“Divide and Conquer”
[Anker, Chockler, Dolev, Keidar DIMACS 98]
Virtual Synchrony
MembershipMoshe
Notification Service (NS)
Multicast
[Keidar, Khazan] [Keidar et al.]

New Architecture Benefits
• Less inter-LAN messages
• Less remote time-outs
• Membership out of way of regular multicast
• Two semantics:– Notification Service - “who is around”– Group membership view = <members, id>
for virtual synchrony

Moshe: A Group Membership Algorithm for WAN
[Keidar, Sussman, Marzullo, Dolev ICDCS 00]
• Designed for WAN from the ground up
• Avoids delivery of “obsolete” views– Views that are known to be changing
– Not always terminating
– Avoid excessive load at unstable periods
• Runs in 1 round, optimistically– All previous ran in 2

New Membership Spec
Conditional Liveness:If situation eventually stops changing
and NS_Set is eventually accurate,
then all NS_Set members have same last view
• Composable– Can prove application liveness
• Termination not required – no obsolete views• Temporary disagreement allowed – optimism

Feedback Cycle: Breaking Conceptions
Application
Abstraction specs
Algorithms
Implementation
No obsolete views
Optimism Allowed

The Model
• Asynchronous – no bound on latency
• Local NS module at every server– Failure detection, join/leave propagation– Output: NS_Set
• Reliable communication– Message received or failure detected– E.g., TCP

Algorithm – Take 1
• Upon NS_Set, send prop to other servers with NS_Set, current view id
• Store incoming props
• When received props for NS_Set from all servers, deliver new view:– Members – NS_Set, – Id higher than all previous

Optimistic Case
• Once all servers get same last NS_Set:– All send props for this NS_Set – All props reach all servers– All servers use props to deliver same last view

• To avoid deadlock: A must respond• But how?
Out-of-Sync Case: Unexpected Proposal
X
prop +c
X-c
prop
A B C

Algorithm – Take 2
• Upon unexpected prop for NS_Set, join in:– Send prop to other servers with NS_Set, current
view id
viewview
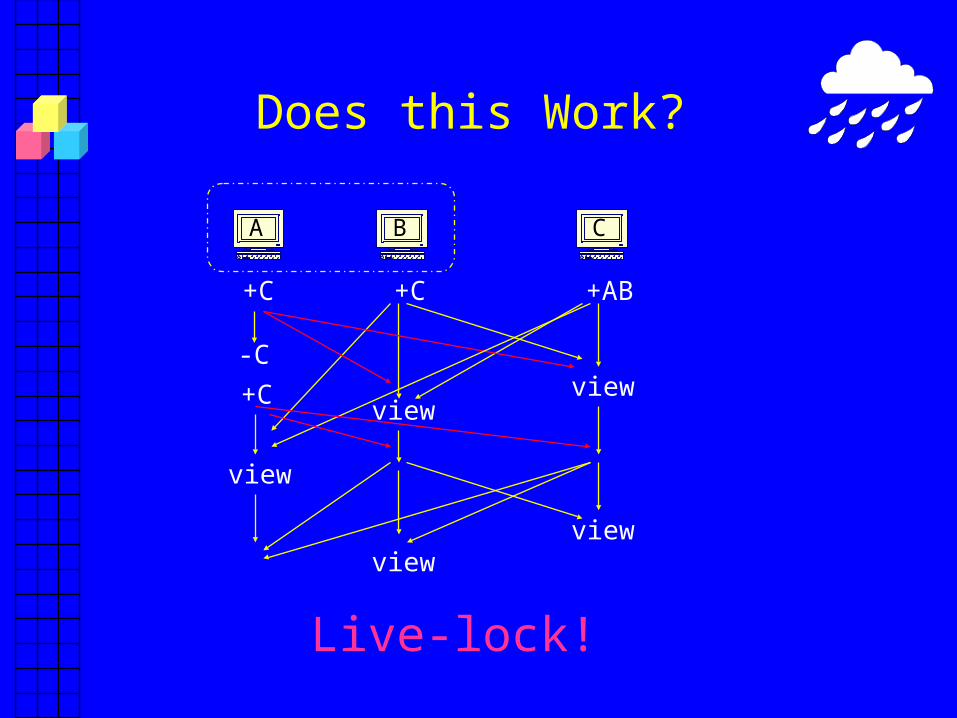
Does this Work?
+C +AB+C
A B C
-C
+C
view
viewview
Live-lock!
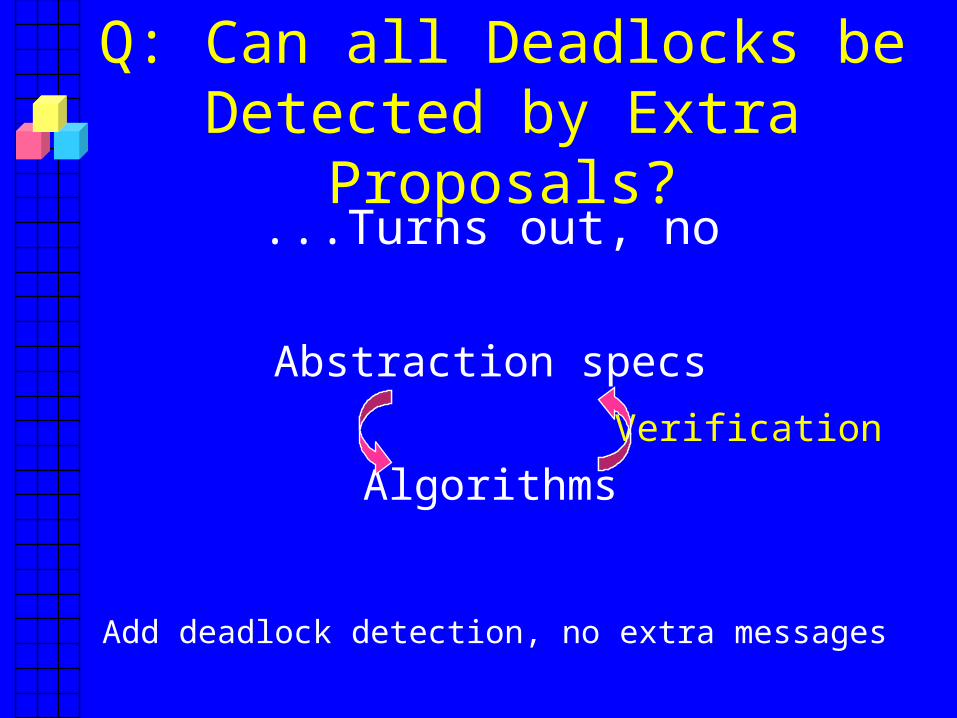
Q: Can all Deadlocks be Detected by Extra Proposals?
...Turns out, no
Abstraction specs
AlgorithmsVerification
Add deadlock detection, no extra messages
All C p
rops
C pro
ps
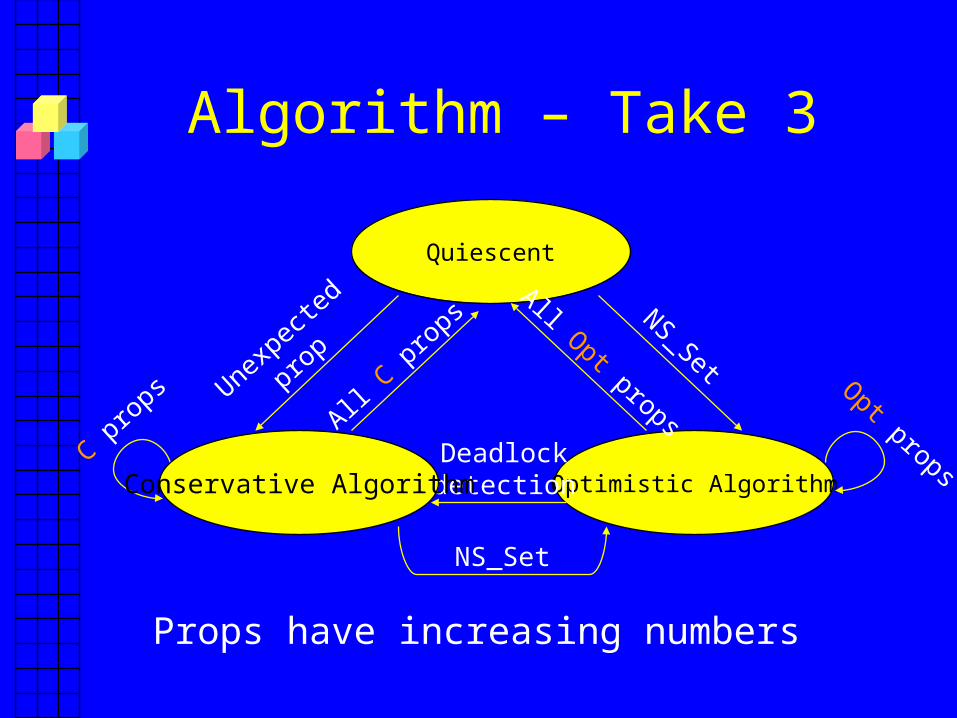
Algorithm – Take 3
Quiescent
Optimistic Algorithm
NS_Set
DeadlockdetectionConservative Algorithm
Unexp
ecte
d
prop
All Opt props Opt props
Props have increasing numbers
NS_Set

The Conservative Algorithm
• Upon deadlock detection– Send C prop for latest NS_Set with number =
max(last_received, last_sent + 1)– Update last_sent
• Upon receipt of C prop for NS_Set with number higher than last_sent– Send C prop with this number; update last_sent
• Upon receipt of C props for NS_Set with same number from all, deliver new view

Rational for Termination
• All deadlock cases detected (see paper)
• Conservative algorithm invoked upon detection
• Once all servers in conservative algorithm (without exiting) number does not increase – Exit only upon NS_Set
• Servers match highest number received
• Eventually, all send props with max number

How Typical is the “typical” Case?
• Depends on the notification service (NS)– Classify NS good behaviors: symmetric and
transitive perception of failures
• Typical case should be very common
• Need to measure

Implementation
• Use CONGRESS [Anker et al.]
– Overlay Network and NS for WAN – Always symmetric, can be non-transitive– Logical topology can be configured

The Experiment
• Run over the Internet – US: MIT, Cornell (CU), UCSD– Taiwan: NTU– Israel: HUJI
• 10 clients at each location (50 total)– Continuously join/leave 10 groups
• Run 10 days in one configuration, 2.5 days in another
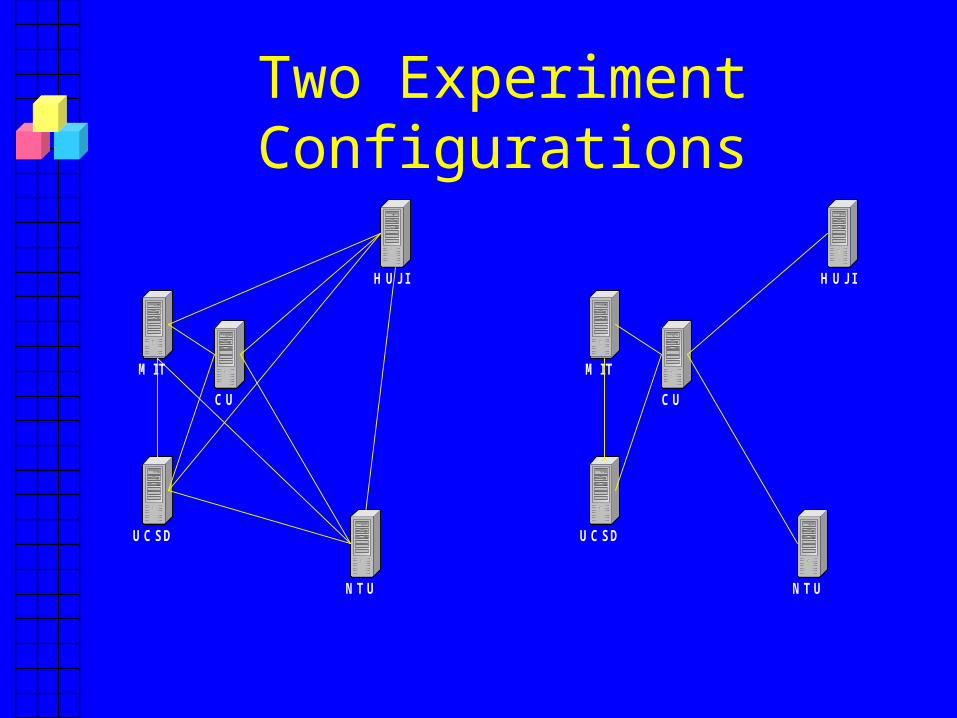
Two Experiment Configurations
M IT
U C S D
C U
N T U
H U J I
M IT
U C S D
C U
N T U
H U J I

Percentage of “Typical” Cases
• Configuration 1: – 10,786 views, 10,661 one round - 98.84%
• Configuration 2:– 2,559 views, 2,555 one round - 99.84%
• Overwhelming majority for one round!• Depends on topology, good for sparse
overlays
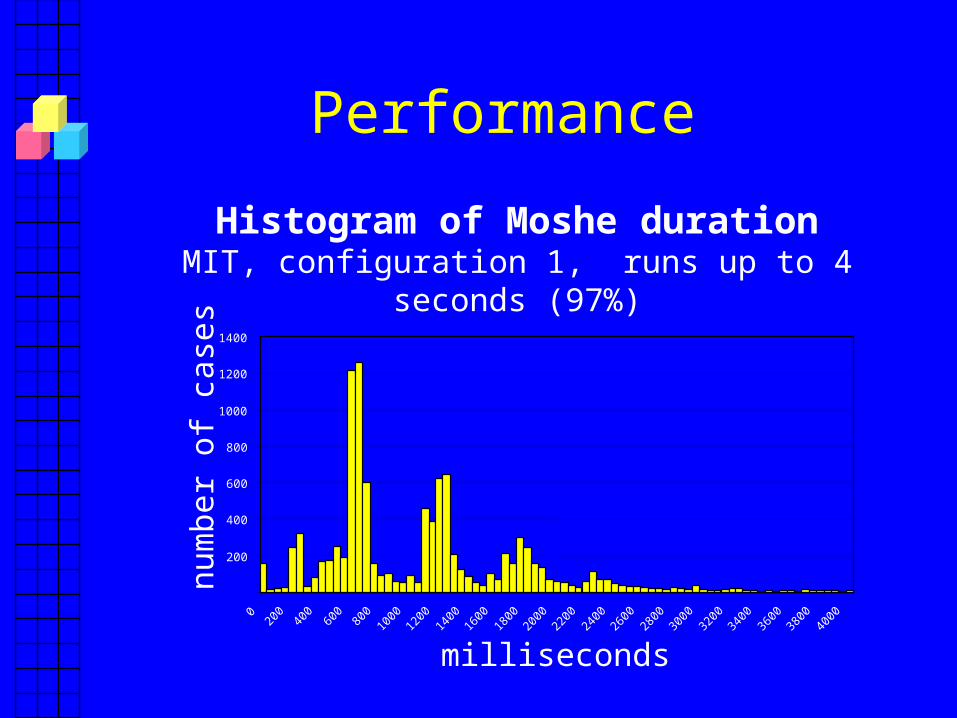
Performance
200
400
600
800
1000
1200
1400
020
040
060
080
010
0012
0014
0016
0018
0020
0022
0024
0026
0028
0030
0032
0034
0036
0038
0040
00
milliseconds
num
ber
of c
ases
Histogram of Moshe durationMIT, configuration 1, runs up to 4 seconds (97%)
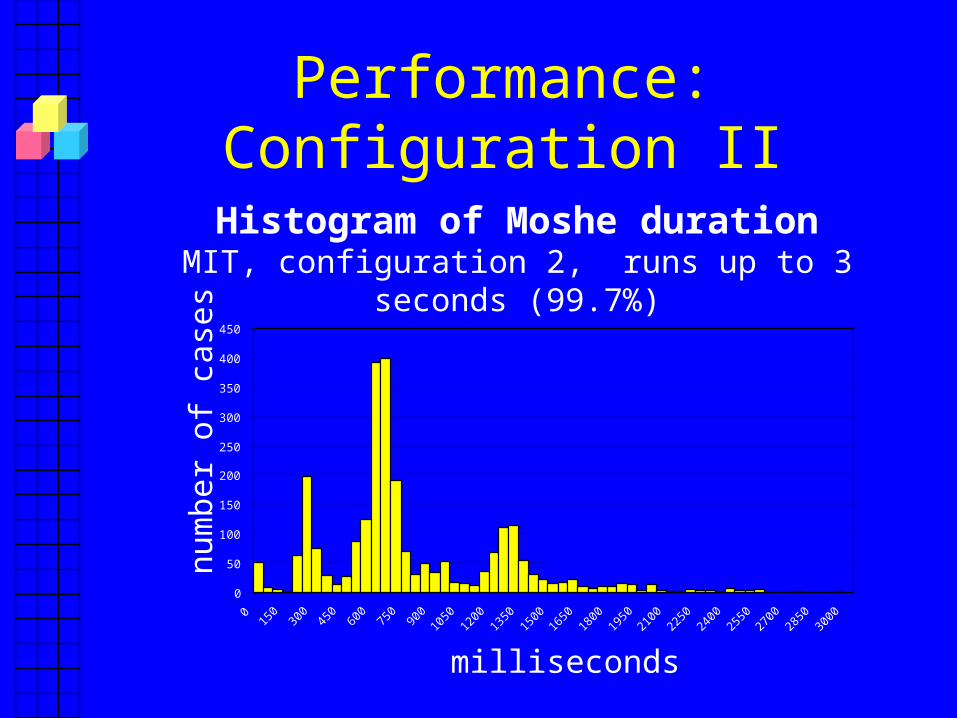
Performance: Configuration II
Histogram of Moshe durationMIT, configuration 2, runs up to 3 seconds (99.7%)
0
50
100
150
200
250
300
350
400
450
015
030
045
060
075
090
010
5012
0013
5015
0016
5018
0019
5021
0022
5024
0025
5027
0028
5030
00
milliseconds
num
ber
of c
ases

Performance over the Internet:What’s Going on?
• Without message loss, running time close to biggest round-trip-time, ~650 ms.– As expected
• Message loss has a big impact
• Configuration 2 has much less loss– More cases of good performance

Observation: Triangle Inequality does not Hold over the Internet
M IT
U C S D
C U
N T U
H U J I
M IT
U C S D
C U
N T U
H U J I
Concurrently observed by Detour, RON projects

Conclusion: Moshe Features
• Scalable divide and conquer architecture– Less WAN communication
• Avoids obsolete views – Less load at unstable times
• Usually one round (optimism) • Uses NS for WAN
– Good abstraction– Flexibility to configure multiple ways
Optimistic Sussman, Keidar,
Marzullo 00
SurveyChockler, Keidar,
Vitenberg 01
VS Algorithm,Formal Study
Keidar, Khazan 00
MosheKeidar, Sussman, Marzullo, Dolev 00
Replication Keidar, Dolev 96
CSCW Anker, Chockler,Dolev, Keidar 97
VoD Anker, Dolev,
Keidar 99
The Bigger Picture
Applications
Abstraction specs
Algorithms
Implementation

Other Abstractions
• Atomic Commit [Keidar, Dolev 98]
• Atomic Broadcast [Keidar, Dolev 96]
• Consensus [Keidar, Rajsbaum 01]
• Dynamic Voting [Yeger-Lotem, Keidar, Dolev 97], [Ingols, Keidar 01]
• Failure Detectors [Dolev, Friedman, Keidar, Malkhi 97], [Chockler, Keidar, Vitenberg 01]

New Directions
• Performance study: practice theory practice– Measure different parameters on WAN, etc. – Find good models & metrics for performance study– Find best solutions– Adapt to varying situations
• Other abstractions– User-centric: improve ease-of-use– Framework for policy adaptation, e.g., for collaborative
computing– Real-time, mobile, etc.

Bon Apetit

Group Communication in the Real World
• Isis used in NY Stock Market, Swiss stock exchange, French air traffic control, Navy radar system...
• Enabling technology for– Fault-tolerant cluster computing, e.g., IBM, Windows 2000 Cluster – SANs, e.g., IBM, North Folk Networks– Navy battleship DD-21
• OMG standard for fault-tolerant CORBA• Emerging: SUN Jini group-RMI• Freeware, e.g., mod_log_spread for Apache• Research projects at Nortel, BBN, military,...
* LAN only, WAN should come next



















