
A Thousand Words in a Scene
13
A Thousand Words in a Scene A Thousand Words in a Scene P. Quelhas, F. Monay, J. Odobez, P. Quelhas, F. Monay, J. Odobez, D. Gatica-Perez and T. Tuytelaars D. Gatica-Perez and T. Tuytelaars PAMI, PAMI, Sept. 2006 Sept. 2006
-
Upload
camilla-todd -
Category
Documents
-
view
37 -
download
0
description
A Thousand Words in a Scene. P. Quelhas, F. Monay, J. Odobez, D. Gatica-Perez and T. Tuytelaars PAMI, Sept. 2006. Outline. Introduction Image Representation Bag-of-Visterms (BOV) Representation Probabilistic Latent Semantic Analysis (PLSA) Scene Classification Experiments - PowerPoint PPT Presentation
Transcript of A Thousand Words in a Scene

A Thousand Words in a SceneA Thousand Words in a Scene
P. Quelhas, F. Monay, J. Odobez, P. Quelhas, F. Monay, J. Odobez, D. Gatica-Perez and T. Tuytelaars D. Gatica-Perez and T. Tuytelaars
PAMI,PAMI, Sept. 2006 Sept. 2006

OutlineOutlineIntroductionIntroduction
Image RepresentationImage Representation– Bag-of-Visterms (BOV) RepresentationBag-of-Visterms (BOV) Representation– Probabilistic Latent Semantic Analysis (PLSA)Probabilistic Latent Semantic Analysis (PLSA)
Scene ClassificationScene Classification
ExperimentsExperiments– ClassificationClassification– Image RankingImage Ranking
ConclusionConclusion

Introduction Introduction Main workMain work– Scene modeling and classificationScene modeling and classification
What’s new?What’s new?– Combine text modeling methods and local Combine text modeling methods and local
invariant features to represent an image.invariant features to represent an image. A text-like bag-of-visterms representation A text-like bag-of-visterms representation (histogram of quantized local visual features)(histogram of quantized local visual features)
Probabilistic Latent Semantic Analysis (PLSA)Probabilistic Latent Semantic Analysis (PLSA)
– Scene classification is based on the image Scene classification is based on the image representationrepresentation
– Scenes can be ranked via PLSAScenes can be ranked via PLSA
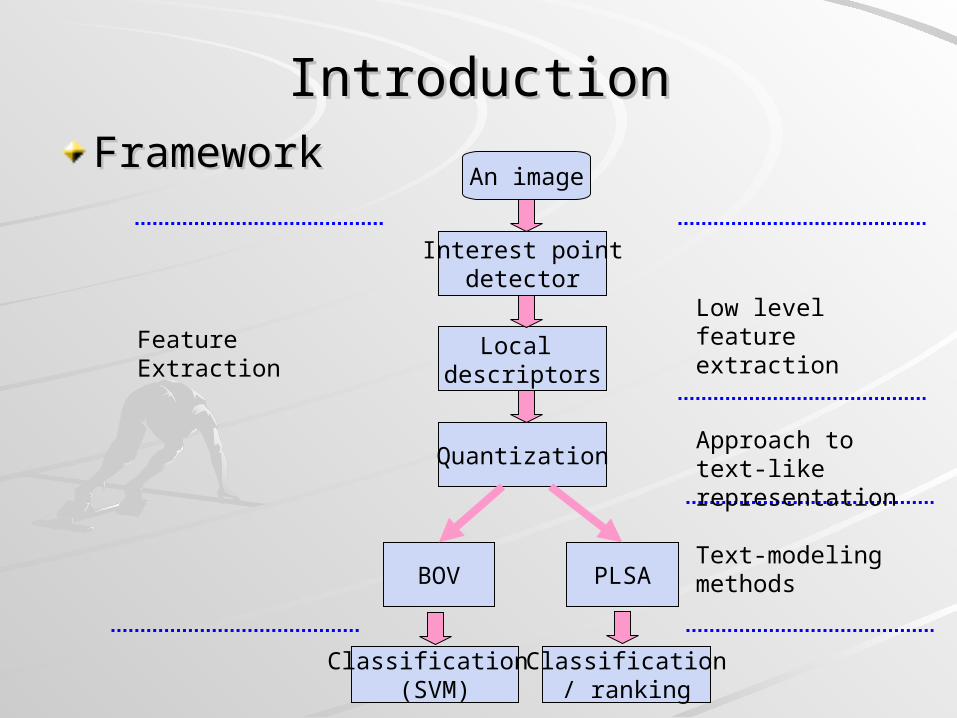
IntroductionIntroductionFrameworkFramework
An image
Interest pointdetector
Local descriptors
Quantization
BOV PLSA
Classification (SVM)
Classification/ ranking
Low level feature extraction
Approach to text-like representation
Text-modeling methods
Feature Extraction

Image Representation Image Representation Local invariant featuresLocal invariant features– Interest point detectionInterest point detection
Extract characteristic points and more generally regions Extract characteristic points and more generally regions from the images.from the images.
Invariant to geometric and photometric transformations, Invariant to geometric and photometric transformations, given an image and transformed versions, same points are given an image and transformed versions, same points are extracted.extracted.
Employ the Difference of Gaussians (DOG) point detector:Employ the Difference of Gaussians (DOG) point detector:–
– Compare a point with its eight neighbors to find Compare a point with its eight neighbors to find minimum/maximum.minimum/maximum.
– Invariant to translation, scale, rotation and illumination Invariant to translation, scale, rotation and illumination variations.variations.

Image RepresentationImage Representation– Local descriptorsLocal descriptors
Compute the descriptor on the region around each Compute the descriptor on the region around each interest point.interest point.
Use Scale Invariant Feature Transform (SIFT) feature as Use Scale Invariant Feature Transform (SIFT) feature as local descriptor.local descriptor.
– Low level feature extraction exampleLow level feature extraction example
Each point has a feature vector of 128D

Image RepresentationImage RepresentationQuantizationQuantization– Quantize each local descriptor into a symbol via K-Quantize each local descriptor into a symbol via K-
meansmeans
Bag-of-visterms representationBag-of-visterms representation– Histogram of the vistermsHistogram of the visterms
– Cons: no spatial information between visterms.Cons: no spatial information between visterms.

Image RepresentationImage RepresentationProbabilistic Latent Semantic Analysis (PLSA)Probabilistic Latent Semantic Analysis (PLSA)– Introduce latent variables Introduce latent variables zzll, called aspect, and , called aspect, and
associate a associate a zzll with each observation (visterm), with each observation (visterm),
– Build a joint probability model over images and vistermsBuild a joint probability model over images and visterms
– Likelihood of the model parameters isLikelihood of the model parameters is
– Image representationImage representation

Image RepresentationImage RepresentationPolysemy and synonymy with vistermsPolysemy and synonymy with visterms– Polysemy: a single visterm may represent different Polysemy: a single visterm may represent different
scene content.scene content.– Synonymy: several visterms may characterized the Synonymy: several visterms may characterized the
same image content.same image content.– Example:Example:
samples from 3 randomly selected visterms from a vocabulary of size 1000. not all visterms have a clear semantic interpretation.
– Pros of PLSAPros of PLSAIntroduce aspect to capture visterm co-occurrence, thus can handle polysemy and synonymy issues.

ExperimentsExperimentsClassificationClassification– BOV classification (three-class)BOV classification (three-class)
Dataset: indoor, city, landscapeDataset: indoor, city, landscape
Training&testing: the whole dataset is slip into 10 parts, Training&testing: the whole dataset is slip into 10 parts, one for training, the other 9 for testing.one for training, the other 9 for testing.
Baseline methods: histograms on low-level features;Baseline methods: histograms on low-level features;
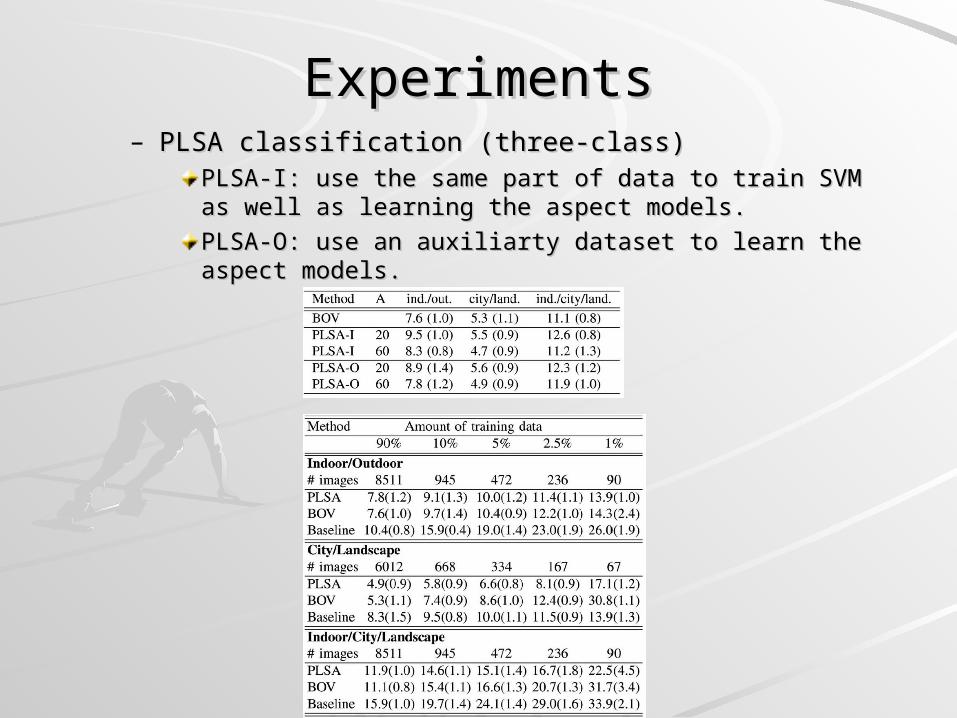
ExperimentsExperiments– PLSA classification (three-class)PLSA classification (three-class)
PLSA-I: use the same part of data to train SVM as well as PLSA-I: use the same part of data to train SVM as well as learning the aspect models.learning the aspect models.
PLSA-O: use an auxiliarty dataset to learn the aspect PLSA-O: use an auxiliarty dataset to learn the aspect models.models.

ExperimentsExperimentsAspect-based image rankingAspect-based image ranking– Given an aspect z, images can Given an aspect z, images can
be ranked according tobe ranked according to
– Dataset: landscape/cityDataset: landscape/city

ConclusionConclusionThe proposed scene modeling method is The proposed scene modeling method is effective for scene classificationeffective for scene classification
A visual scene is presented as a mixture of A visual scene is presented as a mixture of aspects in PLSA modeling.aspects in PLSA modeling.
















![One Thousand Words [about photography] 04](https://static.fdocuments.us/doc/165x107/579055d11a28ab900c968f50/one-thousand-words-about-photography-04.jpg)

