
A really really fast introduction to PySpark - lightning fast cluster computing with python
48
PySpark Lightning fast cluster computing with Python
-
Upload
holden-karau -
Category
Data & Analytics
-
view
19.471 -
download
5
Transcript of A really really fast introduction to PySpark - lightning fast cluster computing with python

PySparkLightning fast cluster computing with Python

Who am I?
Holden● I prefer she/her for pronouns● Co-author of the Learning Spark book● @holdenkarau● http://www.slideshare.net/hkarau● https://www.linkedin.com/in/holdenkarau

What we are going to explore together!
● What is Spark?● Getting Spark setup locally OR getting access to cluster● Spark primary distributed collection● Word count● How PySpark works● Using libraries with Spark● Spark SQL / DataFrames

What is Spark?
● General purpose distributed system○ With a really nice API
● Apache project (one of the most active)● Must faster than Hadoop Map/Reduce

The different pieces of Spark
Apache Spark
SQL & DataFrames Streaming Language
APIs
Scala, Java, Python, & R
Graph Tools
Spark ML bagel & Grah X
MLLib Community Packages
Setup time!
Remote Azure HDI cluster:http://bit.ly/clusterSignup (thanks Microsoft!)We can use Jupyter :)
Local Machine:If you don’t have Spark installed you can get it from http:
//spark.apache.org/downloads.html (select 1.3.1, any hadoop version)

Some pages to keep open for the exercises
http://bit.ly/sparkDocs http://bit.ly/sparkPyDocs http://bit.ly/PySparkIntroExampleshttp://bit.ly/learningSparkExamples ORhttp://spark.apache.org/docs/latest/api/python/index.html http://spark.apache.org/docs/latest/ https://github.com/holdenk/intro-to-pyspark-demos

Starting the shell
./bin/pyspark[Lots of output]SparkContext available as sc, SQLContext available as sqlContext.
>>>

Reducing log level
cp ./conf/log4j.properties.template ./conf/log4j.properties
Then set
log4j.rootCategory=ERROR, console

Connecting to your Azure cluster
● Don’t screw up the password (gets cached)● Use the Jupyter link● Optionally you can configure your cluster to assign more
executor cores to Jupyter

Sparkcontext: entry to the world
● Can be used to create RDDs from many input sources○ Native collections, local & remote FS○ Any Hadoop Data Source
● Also create counters & accumulators● Automatically created in the shells (called sc)● Specify master & app name when creating
○ Master can be local[*], spark:// , yarn, etc.○ app name should be human readable and make sense
● etc.

Getting the Spark Context on Azure
from pyspark import SparkContextfrom pyspark.sql.types import *
sc = SparkContext( 'spark://headnodehost:7077', 'pyspark')

RDDs: Spark’s Primary abstraction
RDD (Resilient Distributed Dataset)● Recomputed on node failure● Distributed across the cluster● Lazily evaluated (transformations & actions)

Word count
lines = sc.textFile(src)words = lines.flatMap(lambda x: x.split(" "))word_count = (words.map(lambda x: (x, 1)) .reduceByKey(lambda x, y: x+y))word_count.saveAsTextFile(output)

Word count
lines = sc.textFile(src)words = lines.flatMap(lambda x: x.split(" "))word_count = (words.map(lambda x: (x, 1)) .reduceByKey(lambda x, y: x+y))word_count.saveAsTextFile(output)
No data is read or processed until after this line
This is an “action” which forces spark to evaluate the RDD

Some common transformations & actions
Transformations (lazy)● map● filter● flatMap● reduceByKey● join● cogroup
Actions (eager)● count● reduce● collect● take● saveAsTextFile● saveAsHadoop● countByValue
Photo by Steve
Photo by Dan G

Exercise time
Photo by recastle

Lets find the lines with the word “Spark”
import ossrc = "file:///"+os.environ['SPARK_HOME']+"/README.md"lines = sc.textFile(src)

What did you find?

A solution:
lines = sc.textFile(src)spark_lines = lines.filter(
lambda x: x.lower().find("spark") != -1)print spark_lines.count()

Combined with previous example
Do you notice anything funky?● We read the data in twice :(● cache/persist/checkpoint to the rescue!

lets use toDebugString
un-cached:>>> print word_count.toDebugString()
(2) PythonRDD[17] at RDD at PythonRDD.scala:43 []
| MapPartitionsRDD[14] at mapPartitions at PythonRDD.scala:346 []
| ShuffledRDD[13] at partitionBy at NativeMethodAccessorImpl.java:-2 []
+-(2) PairwiseRDD[12] at reduceByKey at <stdin>:3 []
| PythonRDD[11] at reduceByKey at <stdin>:3 []
| MapPartitionsRDD[10] at textFile at NativeMethodAccessorImpl.java:-2 []
| file:////home/holden/repos/spark/README.md HadoopRDD[9] at textFile at NativeMethodAccessorImpl.java:-2 []

lets use toDebugString
cached:>>> print word_count.toDebugString()
(2) PythonRDD[8] at RDD at PythonRDD.scala:43 []
| MapPartitionsRDD[5] at mapPartitions at PythonRDD.scala:346 []
| ShuffledRDD[4] at partitionBy at NativeMethodAccessorImpl.java:-2 []
+-(2) PairwiseRDD[3] at reduceByKey at <stdin>:3 []
| PythonRDD[2] at reduceByKey at <stdin>:3 []
| MapPartitionsRDD[1] at textFile at NativeMethodAccessorImpl.java:-2 []
| CachedPartitions: 2; MemorySize: 2.7 KB; ExternalBlockStoreSize: 0.0 B; DiskSize: 0.0 B
| file:////home/holden/repos/spark/README.md HadoopRDD[0] at textFile at NativeMethodAccessorImpl.java:-2 []

A detour into the internals
Photo by Bill Ward

Why lazy evaluation?
● Allows pipelining procedures○ Less passes over our data, extra happiness
● Can skip materializing intermediate results which are really really big*
● Figuring out where our code fails becomes a little trickier

So what happens when we run this code?
Driver
Worker
Worker
Worker
HDFS / Cassandra/ etc

So what happens when we run this code?
Driver
Worker
Worker
Worker
HDFS / Cassandra/ etc
function
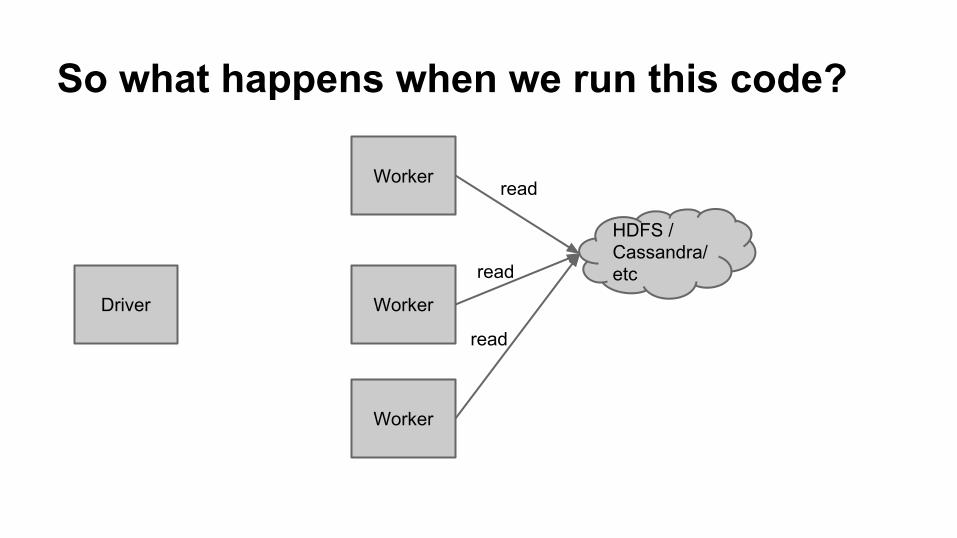
So what happens when we run this code?
Driver
Worker
Worker
Worker
HDFS / Cassandra/ etc
read
read
read

So what happens when we run this code?
Driver
Worker
Worker
Worker
HDFS / Cassandra/ etc
cached
cached
cached
counts

Spark in Scala, how does PySpark work?
● Py4J + pickling + magic○ This can be kind of slow sometimes
● RDDs are generally RDDs of pickled objects● Spark SQL (and DataFrames) avoid some of this

So what does that look like?
Driver
py4j
Worker 1
Worker K
pipe
pipe

Using other libraries
● built ins○ just import!*
■ Except for Hive, compile with -PHive & then import
● spark-packages○ --packages
● generic python○ pre-install on workers (pssh, puppet, etc.)○ add it with --zip-files○ sc.addPyFile

So lets take “DataFrames” out for a spin
● useful for structured data● support schema inference on JSON● Many operations done without* pickling● Integrated into ML!● Accessed through SQLContext● Not the same feature set as Panda’s or R DataFrames

Loading data
df = sqlContext.read.load("files/testweet.json", format="json")
# Built in json, parquet, etc.# More formats (csv, etc.) at http://spark-packages.org/

DataFrames aren’t quite as lazy...
● Keep track of schema information● Loading JSON data involves looking at the data● Before if we tried to load non-existent data wouldn’t fail
right away, now fails right away

Examining Schema Informationroot |-- contributorsIDs: array (nullable = true) | |-- element: string (containsNull = true) |-- createdAt: string (nullable = true) |-- currentUserRetweetId: long (nullable = true) |-- hashtagEntities: array (nullable = true) | |-- element: string (containsNull = true) |-- id: long (nullable = true) |-- inReplyToStatusId: long (nullable = true) |-- inReplyToUserId: long (nullable = true) |-- isFavorited: boolean (nullable = true) |-- isPossiblySensitive: boolean (nullable = true) |-- isTruncated: boolean (nullable = true) |-- mediaEntities: array (nullable = true) | |-- element: string (containsNull = true) |-- retweetCount: long (nullable = true) |-- source: string (nullable = true) |-- text: string (nullable = true) |-- urlEntities: array (nullable = true) | |-- element: string (containsNull = true) |-- user: struct (nullable = true) | |-- createdAt: string (nullable = true) | |-- description: string (nullable = true) | |-- descriptionURLEntities: array (nullable = true) | | |-- element: string (containsNull = true) | |-- favouritesCount: long (nullable = true) | |-- followersCount: long (nullable = true) | |-- friendsCount: long (nullable = true) | |-- id: long (nullable = true) | |-- isContributorsEnabled: boolean (nullable = true) | |-- isFollowRequestSent: boolean (nullable = true) | |-- isGeoEnabled: boolean (nullable = true) | |-- isProtected: boolean (nullable = true) | |-- isVerified: boolean (nullable = true) | |-- lang: string (nullable = true) | |-- listedCount: long (nullable = true) | |-- location: string (nullable = true) | |-- name: string (nullable = true) | |-- profileBackgroundColor: string (nullable = true) | |-- profileBackgroundImageUrl: string (nullable = true) | |-- profileBackgroundImageUrlHttps: string (nullable = true) | |-- profileBackgroundTiled: boolean (nullable = true) | |-- profileBannerImageUrl: string (nullable = true) | |-- profileImageUrl: string (nullable = true) | |-- profileImageUrlHttps: string (nullable = true) | |-- profileLinkColor: string (nullable = true) | |-- profileSidebarBorderColor: string (nullable = true) | |-- profileSidebarFillColor: string (nullable = true) | |-- profileTextColor: string (nullable = true) | |-- profileUseBackgroundImage: boolean (nullable = true) | |-- screenName: string (nullable = true) | |-- showAllInlineMedia: boolean (nullable = true) | |-- statusesCount: long (nullable = true) | |-- translator: boolean (nullable = true) | |-- utcOffset: long (nullable = true) |-- userMentionEntities: array (nullable = true) | |-- element: string (containsNull = true)

Manipulating DataFrames
SQLdf.registerTempTable("panda")sqlContext.sql("select * from panda where id = 529799371026485248")
APIdf.filter(df.id == 529799371026485248)

DataFrames to RDD’s & vice versa
● map lets us work per-rowdf.map(lambda row: row.text)
● Converting back○ infer_schema
○ specify the schema

Or we can make a UDF
def function(x):# Some magic
sqlContext.registerFunction(“name”, function, IntegerType())

More exercise funtimes :)
● Lets load a sample tweet● Write a UDF to compute the length of the tweet● Select the length of the tweet

Getting some tweets
● Could use Spark Streaming sample app if you have twitter keys handy
● Normally we would read data from HDFS or similar

import urllib2data = urllib2.urlopen('https://raw.githubusercontent.com/databricks/learning-spark/master/files/testweet.json').read()print datardd = sc.parallelize([data])path = "mytextFile.txt"rdd.saveAsTextFile(path)

Loading the tweets
df = sqlContext.jsonFile(path)df.printSchema()

MLLib / ML
● Example in the notebook :)

Additional Resources
● Programming guide (along with JavaDoc, PyDoc, ScalaDoc, etc.)○ http://spark.apache.org/docs/latest/
● Books● Videos● Training● My talk tomorrow

Learning Spark
Fast Data Processing with Spark(Out of Date)
Fast Data Processing with Spark
Advanced Analytics with Spark
Coming soon: Spark in Action

Conferences & Meetups
● Strata & Hadoop World (next one in NYC)● Spark summit (next one in Amsterdam)● Seattle Spark Meetup (next event on Aug 12th)
& more at http://spark.apache.org/community.html#events

Spark Videos
● Apache Spark Youtube Channel● Spark Summit 2014 training● Paco’s Introduction to Apache Spark


















