
A Preliminary Noun Phrase Chunker for Polishiis.ipipan.waw.pl/2010/proceedings/iis10-18.pdf · ·...
12
Intelligent Information Systems ISBN 978-83-7051-580-5, pages 169–180 A Preliminary Noun Phrase Chunker for Polish * Adam Radziszewski and Maciej Piasecki Institute of Informatics, Wroclaw University of Technology Wybrzeże Wyspiańskiego 27, Wroclaw, Poland Abstract We present a chunker for Polish simple Noun Phrases. Some of its knowledge is provided by hand while the rest is acquired automatically from a manually annotated corpus using Machine Learning classifiers (currently Decision Trees). Knowledge acquisition is aided by hand-written patterns—expressions of a formal language (JOSKIPI) that transform local contexts into fixed-width feature vectors. Since Polish is an inflectional language, we rely on morpho-syntactic features of word forms to recognise chunks. Following similar works for Croatian, we focus on nominal chunks expressing morphological agreement on number, gender and case. Due to practical reasons, we also include simple adjective-based chunks. The chunk definitions are discussed and motivated in the paper. Keywords: chunking, morphological agreement, Machine Learning, Polish 1 Introduction Abney (1991) has proposed text chunking as a step towards full parsing. Later, the output of a chunker was found useful for many other practical purposes, e.g. Information Extraction tasks. Since then, most of the attention has been devoted to extracting “low-level noun groups” (Ramshaw and Marcus, 1995) and this is also our goal. We aim at construction of a language tool for processing Polish, henceforth called a chunker, which performs segmentation of Polish sentences into one and multi-word consecutive segments—i.e. chunks that represent phrases from a subset of Polish nominal phrases. The subset includes simple noun phrases (NPs) with a noun or pronoun as a head and is limited to the consecutive sequences of words expressing agreement on number, gender and case. Moreover, we have also taken into account simple phrases with an adjective as a head that fill positions of the nominal arguments. The exact extent of the subset is discussed in Sec. 2. Shallow parsing of Slavic languages is typically done with hand-written gram- mars (Przepiórkowski, 2007a; Radziszewski, 2009). There are several formalisms for description of grouping sequences of words together, according to some as- sumed criteria. Nenadić and Vitas (1998a) propose a formalism for capturing * Acknowledgement. This work was financed by Innovative Economy Programme project POIG.01.01.02-14-013/09 as well as the Fellowship co-financed by European Union within Eu- ropean Social Fund.
Transcript of A Preliminary Noun Phrase Chunker for Polishiis.ipipan.waw.pl/2010/proceedings/iis10-18.pdf · ·...

Intelligent Information SystemsISBN 978-83-7051-580-5, pages 169–180
A Preliminary Noun Phrase Chunker for Polish∗
Adam Radziszewski and Maciej PiaseckiInstitute of Informatics, Wrocław University of TechnologyWybrzeże Wyspiańskiego 27, Wrocław, Poland
AbstractWe present a chunker for Polish simple Noun Phrases. Some of its knowledgeis provided by hand while the rest is acquired automatically from a manuallyannotated corpus using Machine Learning classifiers (currently Decision Trees).Knowledge acquisition is aided by hand-written patterns—expressions of a formallanguage (JOSKIPI) that transform local contexts into fixed-width feature vectors.
Since Polish is an inflectional language, we rely on morpho-syntactic featuresof word forms to recognise chunks. Following similar works for Croatian, we focuson nominal chunks expressing morphological agreement on number, gender andcase. Due to practical reasons, we also include simple adjective-based chunks.The chunk definitions are discussed and motivated in the paper.Keywords: chunking, morphological agreement, Machine Learning, Polish
1 Introduction
Abney (1991) has proposed text chunking as a step towards full parsing. Later,the output of a chunker was found useful for many other practical purposes, e.g.Information Extraction tasks. Since then, most of the attention has been devotedto extracting “low-level noun groups” (Ramshaw and Marcus, 1995) and this isalso our goal.
We aim at construction of a language tool for processing Polish, henceforthcalled a chunker, which performs segmentation of Polish sentences into one andmulti-word consecutive segments—i.e. chunks that represent phrases from a subsetof Polish nominal phrases. The subset includes simple noun phrases (NPs) witha noun or pronoun as a head and is limited to the consecutive sequences of wordsexpressing agreement on number, gender and case. Moreover, we have also takeninto account simple phrases with an adjective as a head that fill positions of thenominal arguments. The exact extent of the subset is discussed in Sec. 2.
Shallow parsing of Slavic languages is typically done with hand-written gram-mars (Przepiórkowski, 2007a; Radziszewski, 2009). There are several formalismsfor description of grouping sequences of words together, according to some as-sumed criteria. Nenadić and Vitas (1998a) propose a formalism for capturing∗Acknowledgement. This work was financed by Innovative Economy Programme project
POIG.01.01.02-14-013/09 as well as the Fellowship co-financed by European Union within Eu-ropean Social Fund.

170 Adam Radziszewski, Maciej Piasecki
Serbo-Croatian NPs, based on so called regular morpho-syntactic expressions (reg-ular grammars operating on morpho-syntactic descriptions), later augmented withmeans of expressing morphological agreement (Nenadić and Vitas, 1998b). Agrammar has been written using the formalism: it is aimed at capturing simpleNPs agreed on number, gender and case, as well as coordinations of such phrases(Nenadić, 2000). Unfortunately no evaluation is discussed. A similar work is pre-sented by Vuc̆ković et al. (2008): hand-crafted regular grammars are employed tocapture Croatian NP chunks (simple NPs agreed on number, gender and case aswell as appositions and coordinations thereof), prepositional phrase chunks andverb chunks. The grammar for NP chunks is reported to achieve 94.50% precisionand 90.26% recall as tested on a corpus of 137 sentences. Osenova (2002) presentsa chunker for Bulgarian NPs, also based on hand-written regular grammars withsome extensions. With some exceptions, the chunks are assumed to agree on num-ber and gender (case is not considered as Bulgarian has no nominal declension).First experiments resulted in 90.1% precision and 87.7% recall.
A formalism for shallow constituency parsing of Polish intermingled with mor-pho-syntactic disambiguation is presented by Przepiórkowski (2008). Basically,it allows for writing grammars that perform disambiguation and group adjacentwords (or already grouped expressions) together. The matching rules are concep-tually similar to those of the morpho-syntactic regular expressions. The publishedgrammar is claimed to be rudimentary1 and no direct evaluation is presented;some results are reported for specific tasks, e.g. extraction of valence dictionary(Przepiórkowski, 2007b). There have been some more attempts at writing gram-mars for specific tasks concerning Polish, for instance Named Entity recognition(Piskorski, 2004), Information Extraction (e.g. Mykowiecka et al., 2005). To thebest of our knowledge, there is no publicly available shallow parser for Polishequipped with a wide coverage grammar.
We strive for such a wide coverage chunker, robust enough to be applied to textsof different genres and topic domains. Thus, contrary to the works presented above,we want to rely more on the knowledge acquired from corpora annotated withshallow syntactic information than on hand-written rules. The work presentedhere is the first step towards achieving this goal.
2 What Chunks?
The notion of a chunk is very difficult to be defined formally on the ground of syn-tax. NPs can be very complex and its syntactic description recursively refers tothe syntactic structures as complex as relative clauses. On the other hand, chunksare motivated rather from language engineering point of view than linguistic con-siderations. Guidelines for defining chunks in English have been proposed by theconcept-founder—Abney’s Chunk Stylebook, 1996. What is more, there are com-monly accepted chunked corpora, e.g. the corpus of the CoNLL-2000 shared task(Sang et al., 2000). In the case of the Slavic languages the situation is different:there are no popular datasets and no commonly accepted guidelines concerningnominal chunks. Direct adaptation of English chunk guidelines is barely feasible;
1Cf. the notes accompanying the grammar on http://nlp.ipipan.waw.pl/PPJP/.

A Preliminary Noun Phrase Chunker for Polish 171
for instance Sang et al. (2000) state that “besides the head, a chunk also containspremodifiers (. . . ) but not postmodifiers or arguments”, which seems unjustifiedfor freer word order languages (the position of many modifiers may be altered withonly subtle change in meaning). The chunk definitions referring to the prosodicstructure (Abney, 1995) are also not very helpful as such experiments have notbeen carried out for Polish. Thus, our starting point is the chunk definition pro-posed by Radziszewski (2009), which was inspired by the decisions made duringthe construction of the chunkers previously implemented for Croatian and Serbo-Croatian (Nenadić and Vitas, 1998a,b; Nenadić, 2000; Vuc̆ković et al., 2008) withsome extensions intended to better account for freer word order. The whole taskdefinition presented there consists of several stages of increasing difficulty. In thispaper we focus on the first stage, namely the recognition of simple NP chunks andadjective-based chunks. Both types are defined in the following way:
Noun phrases chunks (NP), whose elements are agreed on number, gender andcase. They must contain a nominal head, may contain adverbs and indeclinableforms. Coordination of adjectives and adjectivals should also be included butnot coordination of nouns (in principle, they may differ in gender). Some exam-ples: języka polskiego (Polish language, genitive case), trudne spojrzenie wstecz(a hard glance back), kontaktach społecznie i ideowo najbardziej pożytecznych(contacts socially and ideologically most useful, locative case).
Satellite chunks (M), whose elements are agreed on number, gender and case butcontain no nominal elements. They may be “orphaned” NP modifiers (partsof a bigger NP separated from the NP head by some intervening material thatwould violate the agreement), although they can also fill argument positions(e.g. adjectives used nominally). Some examples: sprzyjającego i życzliwego(conducive and kind, genitive), tych ostatnich (those latter, genitive).
These definitions are heavily based on morphological agreement on number,gender and case; neither of the types allow presence of elements that would violatethe agreement (adverbs and other indeclinable elements are allowed). For thisreason, an NP containing a genitive modifier will be labelled at this stage astwo chunks, e.g. [NPTybetańska Księga] [MUmarłych] (Tibetan Book of the Dead),[NPdziewczyna] [NPratownika] (life guard’s girlfriend). The recognition of complexNPs, including genitive/dative modifiers and prepositional phrases, is planned asfurther work (the agreed chunks will constitute the building blocks to capture thecomplex NPs).
The satellite subclass was introduced as a compromise between simple taskdefinition (recognising sequences of agreed elements) and a wide range of capturedlinguistic structures. It allows to regain the information about closely associatedsequences of words that otherwise would be lost when some intervening materialviolates the agreement between NP head and its modifier and, this way, breaks acontinuous chunk into two parts—the second one being a satellite. For instance,the example modifier sprzyjającego i życzliwego occurs in the corpus as a part ofthe phrase mimo sprzyjającego i życzliwego do niej stosunku (despite the conduciveand kind attitude towards it), where the feminine pronoun niej (her) would violatethe agreement between the modifier and the noun head (stosunku, attitude) as

172 Adam Radziszewski, Maciej Piasecki
they both are masculine. According to the employed chunk definitions, the wholephrase is annotated mimo [Msprzyjającego i życzliwego] do [NPniej] [NPstosunku].Such cases are discussed in detail in Radziszewski (2009). There is also anotherbenefit of introducing M phrases: the adopted NP/M model is easier to acquire duringtraining, which directly translates into better precision of NP chunking (discussedin Sec. 4.3). Foreseen applications of our chunker provide some additional motiva-tion for focusing on phrases expressing morpho-syntactic agreement of the nominaltype: the extracted chunks are hoped to aid morpho-syntactic disambiguation ofindividual words.
3 System Architecture
The concept and architecture of the chunker have been inspired to a large extentby the architecture and ideas underlying TaKIPI—a morpho-syntactic tagger forPolish (Piasecki and Godlewski, 2006). The chunker works on sentences, which aresequences of morphologically analysed tokens. The morphological description is as-sumed to be compliant with the tagset of the IPI PAN Corpus (Przepiórkowski andWoliński, 2003; Przepiórkowski, 2004). Following the formalism of Przepiórkowski(2008), our chunker requires morphologically analysed but not necessarily disam-biguated input (partial disambiguation is performed during chunking).
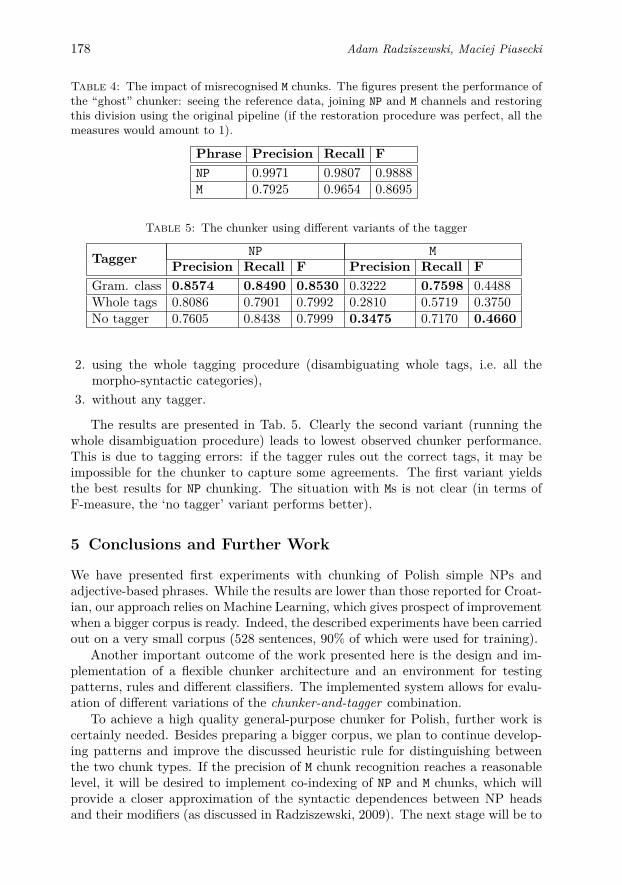
The overall architecture is depicted on Fig. 1. Each sentence is first disam-biguated with respect to grammatical class2 and some hand-written chunking rulesare fired. During training, both types of chunks are joined together and the re-sulting annotation is used as training material for the sequence labelling stage (i.e.the distinction between NP and M chunks is discarded). The joining procedure istrivial, since in principle those chunks may not overlap. During chunker perfor-mance, the sequence labelling stage produces chunking that needs post-processing:a simple rule is used to differentiate between headless chunks (M) and actual NPs(the decision is based on grammatical classes which by that time will have beendisambiguated). The underlying idea is that to decide whether a chunk containsa nominal head requires knowing its confines; thus it is easier first to recognisechunk boundaries and then to classify its type.
3.1 Grammatical Class Tagging
Grammatical class disambiguation is performed first. It is achieved by applyingthe re-implemented TaKIPI tagging algorithm3. According to the employed tagset,grammatical class defines the set of grammatical categories (such as case, gender,person etc.) whose values are given for a word form. For instance, nouns arespecified for number, gender and case while adverbs are not. Without knowing thegrammatical class, we would have to deal with an ambiguity between certain valuesof some categories and the situation when no values are applicable. For instance,
2Grammatical classes provide a more fine-grained division of words than Parts of Speech inthe IPI PAN Corpus tagset (Przepiórkowski and Woliński, 2003; Przepiórkowski, 2004). SeveralParts of Speech, especially the verb, are divided into several grammatical classes in this tagset.
3Technically speaking, we run the TaKIPI algorithm up to the first layer, which is responsiblefor disambiguation of grammatical class.

A Preliminary Noun Phrase Chunker for Polish 173
the word form otwarcie may be interpreted as a noun (opening) in the nominativecase, singular number and neuter gender; on the other hand it may be an adverb(openly), which does not have the grammatical categories of the number, genderand case. We have also experimented with running the complete morpho-syntacticdisambiguation of words as the first stage, however this configuration turns out toproduce worse chunking results (observed in lower precision and recall measures,see Sec. 4.4).
3.2 Labelling with IOB2 Tags
The main stage of the chunker is performed by the sequence labelling module,which is trained with a manually annotated corpus. This module is responsiblefor marking sequences of tokens with tags denoting chunk boundaries, namelyIOB2 tags (Sang and Veenstra (1999); B denotes chunk-initial token, I denotesother token belonging to a chunk, O tokens are outside chunks). Each sentenceis traversed left to right; for each token, its context is represented as a fixed-length vector of symbolic features. During training, such vectors labelled withthe correct IOB2 tag from the reference corpus constitute the training examples;during chunker performance they are fed trough a Machine Learning classifier andthis way the sought sequence of IOB2 tags is obtained4.
The context representation mechanism is directly adopted from TaKIPI. In-stead of feeding the classifier with a default set of features referring to tokenswithin a fixed-length window (as in Ramshaw and Marcus, 1995), we allow theuser (or an expert) to write more sophisticated patterns in a formal languagecalled JOSKIPI (Piasecki and Radziszewski, 2009). These patterns describe high-level features, for instance a heuristic test for possible coordination between thetoken currently being labelled and its left context. For the purpose of chunking,JOSKIPI has been extended with means of marking new phrases (used in rules)as well as referring to already marked chunks. The following example illustratesthe use of a pattern, named conju, which tests for a potential coordination withan adjectival:
!conju(and(
phrase(-1, NP),inter({pact, ppas, adj, adja}, flex[-1]),inter({pact, ppas, adj, adja}, flex[1]),or(
equal(flex[0], {conj}),equal(orth[0], {","})
),agrpp(-1, 1, {nmb,gnd,cas}, 3)
))
The expression will evaluate to true if:4The resulting sequence may be inconsistent if an I comes first or after an O; in such cases
these Is are reverted to Bs.

174 Adam Radziszewski, Maciej Piasecki
1. there is an already marked NP chunk intersecting with the previous token (i.e.one before the currently being labelled),
2. the previous (hence -1) as well as the following (hence 1) tokens may beinterpreted as adjectives or adjectival participles,
3. the current token is a conjunction or a comma,4. there holds a morphological agreement on number, gender and case between
the previous and the next token.
The formalism allows to divide the contexts into decision classes; for eachof them a different set of patterns may be supplied and a separate classifier istrained. The decision classes are defined as a decision list: a set of conditions pairedwith desired pattern names. The conditions, also being JOSKIPI operators, areevaluated sequentially and the first satisfied will define the chosen set of patterns.The last condition (true) is the fallback class. Currently there are seven classes.Below is a fragment of the definitions:
// pronouns: to, co@ inter(base[0], {"to", "co"}) (...pattern names...)@ inter(base[0], {"który", "jaki"}) (...) // relative pronouns@ in(flex[0], {ger, subst, depr}) (...) // nouns or gerunds@ in(flex[0], {ppron12, ppron3}) (...) // personal pronouns// containing number, gender and case but no nominal elements@ and(in(nmb[0], {nmb}), in(gnd[0], {gnd}), in(cas[0], {cas})) (...)
The module is parametrised with a classifier. We have tested Naive Bayes andDecision Tree and the latter has been chosen as giving better results.
3.3 Hand-written Rules and Lexicon Entries
Most of the employed hand-written rules are in fact context-free lexicon entries.These have been introduced to capture some lexicalised constructs that act asadverbs, particles or other indeclinable elements; for instance przede wszystkim(first of all), na przykład (for example), po kryjomu (secretly), w ogóle (generally).Some of these constructs contain nouns, although arguably such nouns shouldnot be captured as NPs (cf. example in for example). The constructs are markedas Qub chunks—with reference to the particle-adverb ‘qub’ class in the tagset(Przepiórkowski and Woliński, 2003). Currently there are 40 such entries. Thisruleset is fired before the main sequence labelling stage, providing the informationthat may be accessed by the labelling stage via appropriate JOSKIPI patterns.
The second ruleset, run as a post-processing stage, is a simple means of ensuringthat quotation marks are included where they belong5.
5For the sake of simplicity, we decided that left quotation marks should always be appendedto the following chunks, similarly with right quotation marks after chunks (it may happen thaton of the marks is included while the other is not). While such decisions seem not crucial for theuser, unexpected decision of the chunker could result in notable fall in performance measures.

A Preliminary Noun Phrase Chunker for Polish 175
Patterns
Classifier
Trained cr
Patterns
Patterns
Trained cr
Ruleset:
fixquotes
headlessto M
Ruleset:
indecl.phrases
Sequence
(training)
labelling
Sequence
labelling
(running)
Training Performance
Cond.:
Joining
Rule
Conditional
moving
chunk
application
NP+M
Wordclass tagging
Rule application
Figure 1: Overall architecture of the chunker
4 Evaluation
The chunker has been implemented in Python as a part of the Disaster6 system,using classifier implementations from the NLTK suite (Bird and Loper, 2004). Wehave employed NLTK’s Decision Tree algorithm with default parameters.
The evaluation has been carried out with the ten-fold cross-validation scheme.For each of the following experiments, we report the values of the standard mea-sures: precision, recall and F-measure (harmonic mean thereof).
4.1 Corpora
For the experiments, we have used two corpora. Both are based on subsets of thecorpus of the frequency dictionary (pol. korpus słownika frekwencyjnego; Ogrod-niczuk 20037), which is manually annotated with morpho-syntactic tags (each
6The system has been released under GNU GPL and may be obtained fromhttp://nlp.pwr.wroc.pl/trac/disaster. The site also hosts the chunked corpus and a current ver-sion of the chunk annotation guidelines. The name may be interpreted as DISAmbiguator andSTatistical chunkER (following the current trend in finding amusing acronyms for NLP software).
7Available at http://korpus.pl/index.php?lang=en&page=download. Our version contains asmall amount of corrections which have been made gradually over several years of usage in variousprojects.

176 Adam Radziszewski, Maciej Piasecki
Table 1: Employed corpora
Corpus Tokens Sentences NP chunks M chunksTagged 858784 52486 N/A N/AChunked 12136 528 3527 277
token is attached a set of possible tags among which some are marked as contex-tually appropriate). The bigger subset is used for training the tagger. The smallchunk-annotated corpus originates from SKIPI, a corpus with shallow syntacticannotations employed within a hand-writing recognition project8. SKIPI has beenautomatically converted and then manually corrected to meet our chunk annota-tion guidelines, resulting in the Chunked corpus, used for training and testing ofthe chunker. Figures are given in Tab. 1.
4.2 Comparison with Baseline Chunkers
The results of our chunker have been compared to those of a family of simple chun-kers based on Hidden Markov Models (HMM), implemented using NLTK’s HMMtagger with default parameter values. The baseline model attempts to discoverthe sequence of IOB2 tags underlying the observed sequence of contextually ap-propriate morpho-syntactic tags. Note that the chunker implementing this modelis somewhat favoured, since while our main chunker is provided with a set ofmorpho-syntactic tags per token (input ambiguity), the baseline implementationis trained and tested on manually disambiguated data.
To reproduce the conditions of the main chunker, the HMM module has beenplaced inside the whole pipeline instead of the sequence labelling module; theremaining stages of processing remain intact. We have run three versions of theHMM chunker:
1. working on full morpho-syntactic tags,2. working on tags reduced to grammatical class and the categories of number,
gender and case,3. working on grammatical class only.
The results are given in Tab. 2. The Main chunker clearly outperforms all ofthe baseline implementations. As far as attribute selection is concerned, it is notobvious which configuration gives better results.
Nevertheless, the results for NP chunking are considerably lower than those ofhand-written grammar for Croatian (94.50% precision and 90.26% recall, Vuc̆kovićet al., 2008). What is more, the precision of M chunk recognition is disappointinglylow. A possible reason is the use of over-simplified rule to classify chunks as M (i.e.containing no word tagged with a nominal grammatical class). Other possibilityis that the training corpus is too small (the whole reference corpus contains only277 M chunks).
8Ministry of Education and Science project no. 3 T11E 005 28.

A Preliminary Noun Phrase Chunker for Polish 177
Table 2: The results of our chunker in comparison with baseline HMM chunkers.
Chunker NP MPrec. Recall F Prec. Recall F
Main (DTs) 0.8574 0.8490 0.8530 0.3222 0.7598 0.4488Baseline: full tags 0.6185 0.4432 0.5161 0.2380 0.4039 0.2962Baseline: class+n,g,c 0.6133 0.4785 0.5374 0.2466 0.4542 0.3169Baseline: gram. class 0.5688 0.4400 0.4962 0.2743 0.4859 0.3478
Table 3: The performance of our NP chunker without seeing M chunks.
Precision Recall F0.8146 0.8537 0.8337
4.3 Impact of NP Satellites
To measure the impact of introducing M chunks on the performance of NP chunking,we have tested a simplified model: using the reference corpus without M chunks andthe chunker without special treatment of headless chunks (no joining, no relabellingto M). The obtained precision is lower with slightly higher recall, amounting to afall in F-measure (Tab. 3). This suggests that the proposed model is easier toacquire automatically than the simplified model with NP chunks only. This seemsintuitive: relying on the local context, it is easier to decide whether a word formbelongs to a chunk specified for number, gender and case (NP or M) than to decideon that matter as well as whether the chunk contains a nominal head (NP).
The mentioned rule to divide M from NP chunks is clearly very crude (for in-stance it does not solve the problem of unknown words, which do appear in thereference corpus). To measure its impact, we prepared a “ghost chunker”, com-prising the whole pipeline without the sequence labelling module. This way theprocess of joining and re-splitting of M and NP chunks is retained without theactual chunking. The experiment consisted in exposing this chunker to the refer-ence data and observing the amount of introduced errors (as the actual chunkingmodule has been removed, the only errors in the output may be introduced bymispredictions of the NP/M rule). The results are given in Tab. 4. While NP chunkshave almost remained unaffected, the fall in precision of M recognition is notable.This is a possible explanation of low precision M recognition by the main chunker(prev. section): perhaps a better heuristics for identifying M chunks could make asignificant improvement.
4.4 Tagger Variants
To justify the usage of morpho-syntactic disambiguation, we have tested threevariants of the chunker:
1. using the tagger to disambiguate grammatical class only (as described in theprevious section),
178 Adam Radziszewski, Maciej Piasecki
Table 4: The impact of misrecognised M chunks. The figures present the performance ofthe “ghost” chunker: seeing the reference data, joining NP and M channels and restoringthis division using the original pipeline (if the restoration procedure was perfect, all themeasures would amount to 1).
Phrase Precision Recall FNP 0.9971 0.9807 0.9888M 0.7925 0.9654 0.8695
Table 5: The chunker using different variants of the tagger
Tagger NP MPrecision Recall F Precision Recall F
Gram. class 0.8574 0.8490 0.8530 0.3222 0.7598 0.4488Whole tags 0.8086 0.7901 0.7992 0.2810 0.5719 0.3750No tagger 0.7605 0.8438 0.7999 0.3475 0.7170 0.4660
2. using the whole tagging procedure (disambiguating whole tags, i.e. all themorpho-syntactic categories),
3. without any tagger.
The results are presented in Tab. 5. Clearly the second variant (running thewhole disambiguation procedure) leads to lowest observed chunker performance.This is due to tagging errors: if the tagger rules out the correct tags, it may beimpossible for the chunker to capture some agreements. The first variant yieldsthe best results for NP chunking. The situation with Ms is not clear (in terms ofF-measure, the ‘no tagger’ variant performs better).
5 Conclusions and Further Work
We have presented first experiments with chunking of Polish simple NPs andadjective-based phrases. While the results are lower than those reported for Croat-ian, our approach relies on Machine Learning, which gives prospect of improvementwhen a bigger corpus is ready. Indeed, the described experiments have been carriedout on a very small corpus (528 sentences, 90% of which were used for training).
Another important outcome of the work presented here is the design and im-plementation of a flexible chunker architecture and an environment for testingpatterns, rules and different classifiers. The implemented system allows for evalu-ation of different variations of the chunker-and-tagger combination.
To achieve a high quality general-purpose chunker for Polish, further work iscertainly needed. Besides preparing a bigger corpus, we plan to continue develop-ing patterns and improve the discussed heuristic rule for distinguishing betweenthe two chunk types. If the precision of M chunk recognition reaches a reasonablelevel, it will be desired to implement co-indexing of NP and M chunks, which willprovide a closer approximation of the syntactic dependences between NP headsand their modifiers (as discussed in Radziszewski, 2009). The next stage will be to

A Preliminary Noun Phrase Chunker for Polish 179
recognise complex NPs, including genitive/dative modifiers, prepositional phrases,coordination and apposition.
The chunker was implemented with additional aim in mind: to improve thequality of morpho-syntactic tagging. The influence of the proposed approach onthe accuracy of tagging has not been assessed yet and this is at the top of our tasklist.
References
Steven Abney (1991), Parsing By Chunks, in Principle-Based Parsing, pp. 257–278,Kluwer Academic Publishers.
Steven Abney (1995), Chunks and Dependencies: Bringing Processing Evidence to Bearon Syntax, in Computational Linguistics and the Foundations of Linguistic Theory,pp. 145–164, CSLI.
Steven Abney (1996), Chunk Stylebook, URL http://www.vinartus.net/spa/96i.pdf.Steven Bird and Edward Loper (2004), NLTK: The Natural Language Toolkit, in Pro-
ceedings of the ACL demonstration session, pp. 214–217, Association for Computa-tional Linguistics, Barcelona, URL http://www.nltk.org/.
Agnieszka Mykowiecka, Anna Kupść, and Małgorzata Marciniak (2005), Rule-BasedMedical Content Extraction and Classification, in Mieczysław A. Kłopotek, Sła-womir T. Wierzchoń, and Krzysztof Trojanowski, editors, Intelligent InformationSystems, Advances in Soft Computing, pp. 237–246, Springer.
Goran Nenadić (2000), Local Grammars and Parsing Coordination of Nouns in Serbo-Croatian, in Petr Sojka, Václav Matoušek, Karel Pala, and Ivan Kopeček, editors,Proceedings of TSD 2000, pp. 57–62, Springer, Brno, Czech Republic.
Goran Nenadić and Duško Vitas (1998a), Formal Model of Noun Phrases in Serbo-Croatian, BULAG, (23):297–311.
Goran Nenadić and Duško Vitas (1998b), Using Local Grammars for Agreement Mod-eling in Highly Inflective Languages, in Petr Sojka, Ivan Kopeček, and Karel Pala,editors, Proceedings of TSD 1998, pp. 91–96, Springer, Brno, Czech Republic.
Maciej Ogrodniczuk (2003), Nowa edycja wzbogaconego korpusu słownika frekwen-cyjnego, in Językoznawstwo w Polsce. Stan i perspektywy, pp. 181–190, Opole.
Petya Osenova (2002), Bulgarian Nominal Chunks and Mapping Strategies for DeeperSyntactic Analyses, in Proceedings of the Workshop on Treebanks and Linguistic The-ories, September 20-21 (TLT02), Sozopol, Bulgaria.
Maciej Piasecki and Grzegorz Godlewski (2006), Effective Architecture of the Pol-ish Tagger, in Text, Speech and Dialogue, 9th International Conference, TSD 2006,Brno, Czech Republic, September 11-15, 2006, Proceedings, volume 4188, pp. 213–220,Springer.
Maciej Piasecki and Adam Radziszewski (2009), Morphosyntactic Constraints in Ac-quisition of Linguistic Knowledge for Polish, in Aspects of Natural Language Processing(a festschrift for Professor Leonard Bolc), volume 5070, pp. 163–190, Springer, bolcFestschrift.
Jakub Piskorski (2004), Extraction of Polish Named-Entities, in Pro-ceedings of International Conference on Language Resources anEvaluation - LREC 2004, May 2004. Lissabon, Portugal, URLhttp://www.dfki.de/dfkibib/publications/docs/PiskorskiFinal_LREC2004.pdf.

180 Adam Radziszewski, Maciej Piasecki
Adam Przepiórkowski (2004), The IPI PAN Corpus: Preliminary version, Institute ofComputer Science, Polish Academy of Sciences, Warsaw.
Adam Przepiórkowski (2007a), Slavic Information Extraction and Partial Parsing,in Proceedings of the Workshop on Balto-Slavonic Natural Language Processing, pp.1–10, Association for Computational Linguistics, Prague, Czech Republic, URLhttp://www.aclweb.org/anthology/W/W07/W07-1701.
Adam Przepiórkowski (2007b), Towards a Partial Grammar of Polish for Valence Ex-traction, in Proceedings of Grammar and Corpora 2007, Liblice, Czech Republic.
Adam Przepiórkowski (2008), Powierzchniowe przetwarzanie języka polskiego, Aka-demicka Oficyna Wydawnicza EXIT, Warsaw.
Adam Przepiórkowski and Marcin Woliński (2003), A Flexemic Tagset for Polish, inProceedings of Morphological Processing of Slavic Languages, EACL 2003.
Adam Radziszewski (2009), Parsing with Agreement, in TSD ’09: Proceedings of the12th International Conference on Text, Speech and Dialogue, pp. 194–201, Springer-Verlag, Berlin, Heidelberg, ISBN 978-3-642-04207-2.
Lance A. Ramshaw and Mitchell P. Marcus (1995), Text Chunking usingTransformation-Based Learning, in Proceedings of the Third ACL Workshop on VeryLarge Corpora, pp. 82–94, Cambridge, MA, USA.
Erik F. Tjong Kim Sang, Sabine Buchholz, and Kim Sang (2000),Introduction to the CoNLL-2000 Shared Task: Chunking, URLhttp://www.cnts.ua.ac.be/conll2000/chunking/.
Erik F. Tjong Kim Sang and Jorn Veenstra (1999), Representing text chunks, inProceedings of the ninth conference on European chapter of the Association for Com-putational Linguistics, pp. 173–179, Association for Computational Linguistics, Mor-ristown, NJ, USA.
Kristina Vuc̆ković, Marko Tadić, and Zdravko Dovedan (2008), Rule-Based Chun-ker for Croatian, in European Language Resources Association (ELRA), editor, Pro-ceedings of the Sixth International Language Resources and Evaluation (LREC’08),Marrakech, Morocco.


















![chal·lenge [chal-inj] noun, verb, -lenged-leng·ing, adjective, noun](https://static.fdocuments.us/doc/165x107/56816500550346895dd76c8e/challenge-chal-inj-noun-verb-lenged-lenging-adjective-noun.jpg)