
A. Moschitti, R. Basili · Naïve Bayes per la classificazione di documenti ... algoritmo (in...
39
1 Apprendimento Automatico e IR: introduzione al Machine Learning Apprendimento Automatico e IR: introduzione al Machine Learning MGRI a.a. 2007/8 MGRI a.a. 2007/8 A. Moschitti, R. Basili Dipartimento di Informatica Sistemi e produzione Università di Roma “Tor Vergata” Email: {moschitti,basili}@info.uniroma2.it
Transcript of A. Moschitti, R. Basili · Naïve Bayes per la classificazione di documenti ... algoritmo (in...

1
Apprendimento Automatico e IR: introduzione al Machine Learning
Apprendimento Automatico e IR: introduzione al Machine Learning
MGRI a.a. 2007/8MGRI a.a. 2007/8
A. Moschitti, R. Basili
Dipartimento di Informatica Sistemi e produzioneUniversità di Roma “Tor Vergata”
Email: moschitti,[email protected]

2
Sommario
• Apprendimento automatico (ML): motivazioni
• Definizione di ML– Supervised vs. unsupervised learning
• Algoritmi di Apprendmento Automatico– Alberi di Decisione– Naive Bayes
• Addestramento e Stima dei parametri in NB

3
Perché apprendere automaticamente delle funzioni
Perché apprendere automaticamente delle funzioni
• Le interazioni tra gli oggetti del mondo si possono esprimere con funzioni– Dal moto di pianeti (interazioni gravitazionali)– Alla relazione tra input/output negli algoritmi
• Apprendere tali funzioni automaticamente…

4
Perché apprendere automaticamente delle funzioni
• Le interazioni tra gli oggetti del mondo si possono esprimere con funzioni– Dal moto di pianeti (interazioni gravitazionali)– Alla relazione tra input/output negli algoritmi
• Apprendere tali funzioni automaticamente…risolverebbe molti problemi
– Progetto– Complessità– Accuracy

5
Avete già visto esempi di learning di funzioni
6
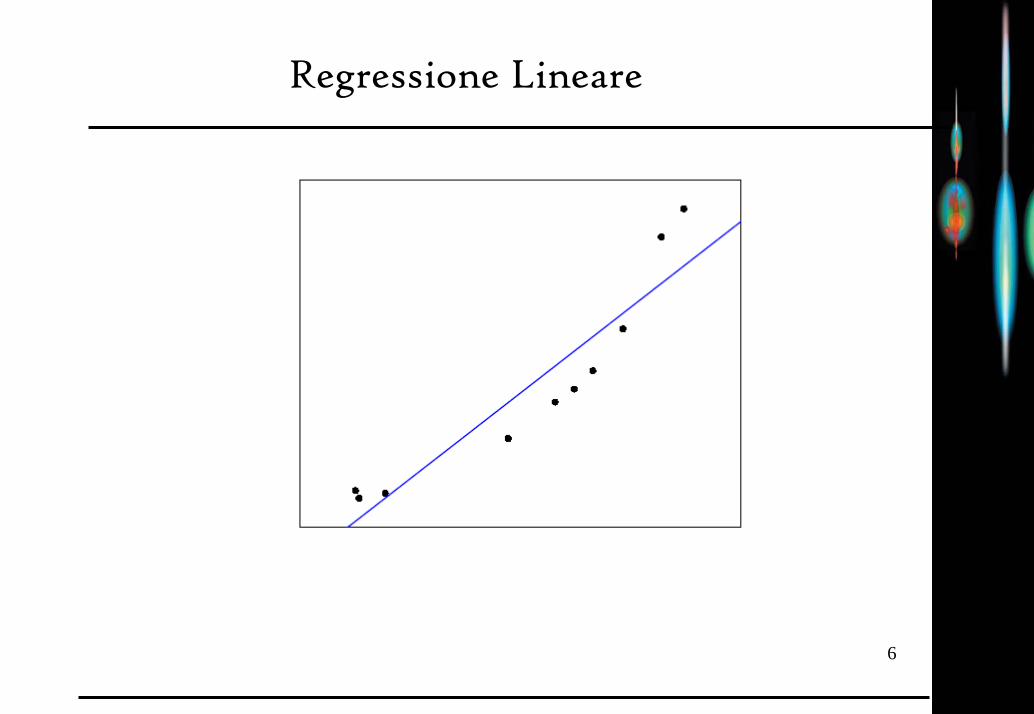
Regressione Lineare
7
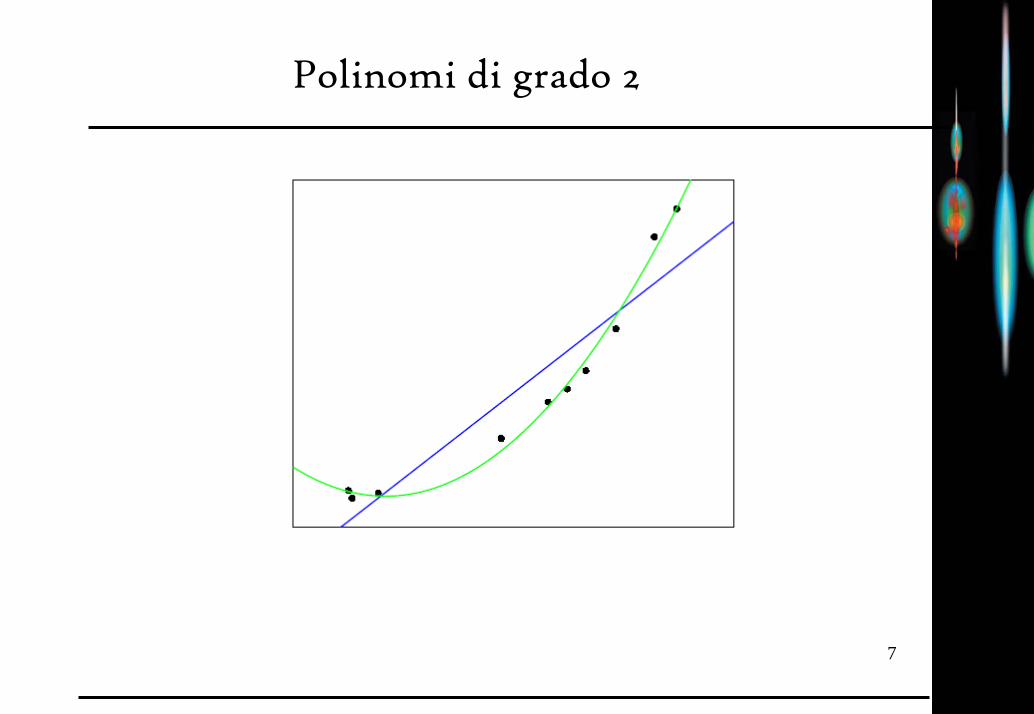
Polinomi di grado 2
8
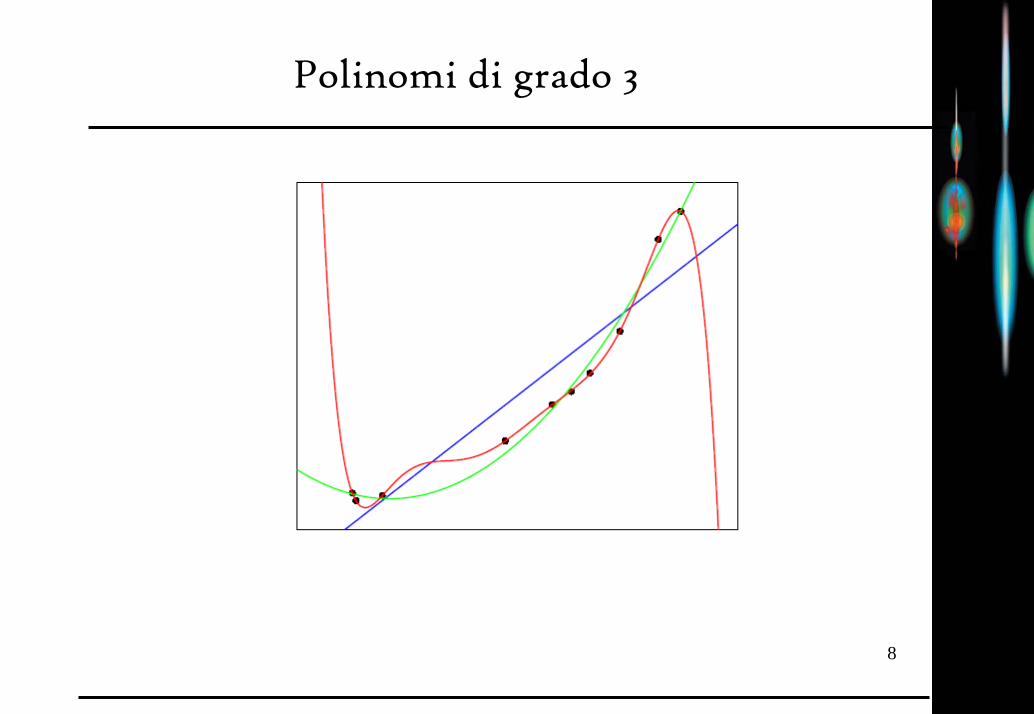
Polinomi di grado 3

9
Distribuzioni di probabilità

10
Motivazioni
• Un programma è una funzione di riscrittura– La stringa di input è riscritta in quella di output
• Scrivere un programma per una ditta che:– data una gerarchia di livelli (organigramma)– dato un impiegato e le sue caratteristiche⇒ determini il suo livello nella gerarchia.
• Supponiamo che le caratteristiche siano migliaia, quanti if devo scrivere nel mio programma?– Esempio: Se è stato assunto prima del 2000, è laureato, ha
avuto esperienze all’estero … allora ha un livello x.

11
Motivazioni (cont)
• Per scrivere tale programma:– Dobbiamo studiare la gerarchia (spesso non documentata
esplicitamente)– Dobbiamo tenere conto di tutte le combinazioni:
• Caratteristiche/livello gerarchico
• Soluzione:– Apprendere tale funzione automaticamente da esempi.– Si accede al DB e si estraggono per ogni impiegato le
caratteristiche ed il suo livello.

12
Apprendimento Automatico
• (Langley, 2000): l’Apprendimento Automatico si occupa dei meccanismi attraverso i quali un agente intelligente migliora nel tempo le sue prestazioni Pnell’effettuare un compito C. La prova del successo dell’apprendimento è quindi nella capacità di misurare l’incremento ∆P delle prestazioni sulla base delle esperienze E che l’agente è in grado di raccogliere durante il suo ciclo di vita.
• La natura dell’apprendimento è quindi tutta nella caratterizzazione delle nozioni qui primitive di compito, prestazione ed esperienza.

13
Esperienza ed Apprendimento
• L'esperienza, per esempio, nel gioco degli scacchi può essere interpretata in diversi modi: – i dati sulle vittorie (e sconfitte) pregresse per valutare la
bontà (o la inadeguatezza) di strategie e mosse eseguite rispetto all'avversario.
– valutazione fornita sulle mosse da un docente esterno (oracolo, guida).
– Adeguatezza dei comportamenti derivata dalla auto-osservazione, cioè dalla capacità di analizzare partite dell'agente contro se stesso secondo un modello esplicito del processo (partita) e della sua evoluzione (comportamento, vantaggi, …).

14
Esperienza ed Apprendimento (2)
• Possiamo quindi parlare nei tre casi di:– apprendimento per esperienza, o induttivo, (partite
eseguite e valutate in base al loro successo finale), – apprendimento supervisionato (cioè partite, strategie
e mosse giudicate in base all'oracolo)– apprendimento basato sulla conoscenza relativa al
task, che guida la formazione di modelli del processo e modelli di comportamento adeguato.

15
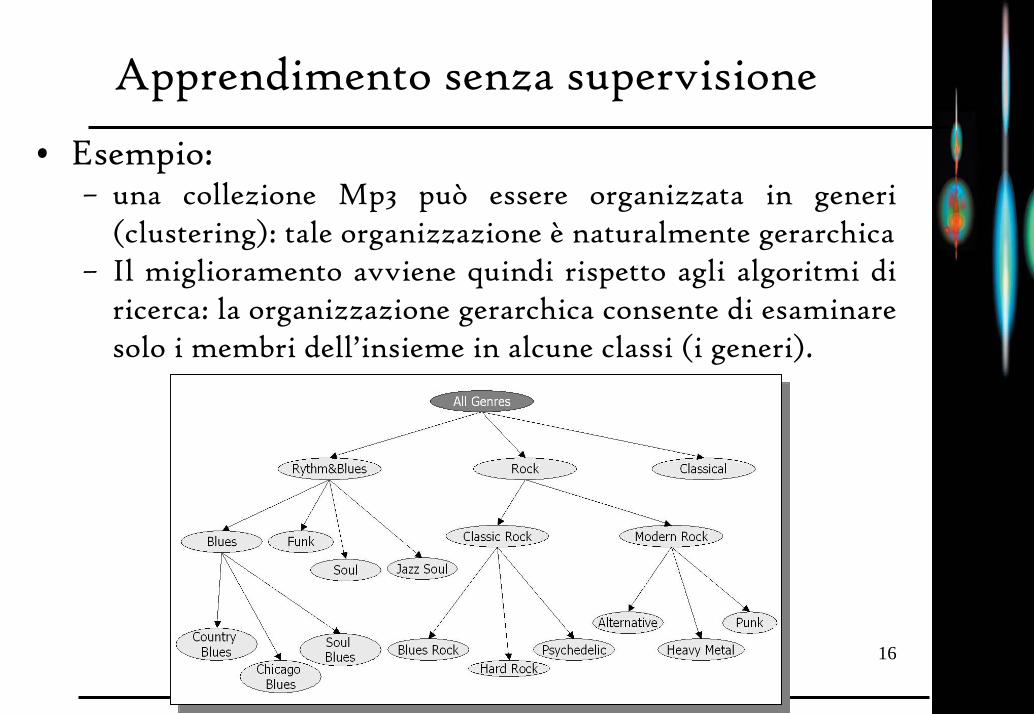
Apprendimento senza supervisione
• In assenza dell’oracolo e di conoscenza sul task esitono ancora molti modi di migliorare le proprie prestazioni, ad es.– Migliorando il proprio modello del mondo
(acquisizione di conoscenza)– Migliorando le proprie prestazioni computazionali
(ottimizzazione)
16
Apprendimento senza supervisione
• Esempio:– una collezione Mp3 può essere organizzata in generi
(clustering): tale organizzazione è naturalmente gerarchica – Il miglioramento avviene quindi rispetto agli algoritmi di
ricerca: la organizzazione gerarchica consente di esaminare solo i membri dell’insieme in alcune classi (i generi).

17
L’apprendimento automatico
• Apprendere la funzione da esempi:– a valori reali, regression– a valori interi finiti, classification
• Supponiamo di volere apprendere una funzione intera:– 2 classi, gatto e cane– f(x) gatto,cane
• Dato un insieme di esempi per le due classi– Si estraggono le features (altezza, baffi, tipo di
dentatura, numero di zampe).• Si applica l’algoritmo di learning per generare f

18
Algoritmi di Apprendimento
• Funzioni logiche booleane, (ad es., alberi di decisione).
• Funzione di Probabilità, (ad es., classificatore Bayesiano).
• Funzioni di separazione in spazi vettoriali– Non lineari: KNN, reti neurali multi-strato,…– Lineari, percettroni, Support Vector Machines,…

19
Alberi di decisione (tra le classi Gatti/Cani)
E’ alto + di 50 cm?
Ha il pelo corto?
No Si
Output: Cane
No
.Ha i baffi?
No
Output: Cane Output: Gatto
..Si

20
Selezione delle features con l’Entropia
• L’entropia di una distribuzione di classi P(Ci)è la seguente:
Misura quanto una distribuzione è uniforme (stato dell’entropia)per insiemi S1…Sn partizionati con gli attributi di una feature:

21
Definizione di Probabilità (1)
• Sia Ω uno spazio e sia β una famiglia di sottoinsiemi di Ω
• β rappresenta la famiglia degli eventi• Si definisce allora la probabilità P nel seguente
modo: [ ] 1,0: →βP

22
Definizione di Probabilità (2)
P è una funzione che associa ad ogni evento E un numero P(E)detto probabilità di E nel seguente modo:
1)(0 1) ≤≤ EP
1)( 2) =ΩP=∨∨∨∨ ...)...( )3 21 nEEEP
ji ,EE se EPi
jii ≠∀=∧= ∑∞
=1
0)(

23
Partizioni finite ed Equiprobabili
• Si consideri una partizione di Ω in n eventi equiprobabili Ei (con probabilità 1/n).
• Dato un evento generico E, la sua probabilità è data da :
Possibili Casi
Favorevoli Casi):(111
1)()(
))...(()()( 21
=⊂=
===∧
=∨∨∨∧=∧=
∑
∑∑ ∑
⊂
⊂⊂
EEinn
nEPEEP
EEEEPEEPEP
iEE
EEi
EEii
ntot
i
ii

24
Probabilità condizionata
• P(A | B) la probabilità di A dato B• B è l’informazione che conosciamo.• Si ha:
A BBA ∧)(
)()|(BP
BAPBAP ∧=

25
Indipendenza
• A e B sono indipendenti iff:
• Se A e B sono indipendenti:
)()|( APBAP =)()|( BPABP =
)()()|()(
BPBAPBAPAP ∧
==
)()()( BPAPBAP =∧

26
Teorema di Bayes
Dimostrazione
)()()|(
EPEHPEHP ∧
=
)()()|(
HPEHPHEP ∧
=
)()|()( HPHEPEHP =∧
(Def. prob. Cond.)
(Def. prob. Cond.)
)()()|()|(
EPHPHEPEHP =

27
Categorizzatore Bayesiano
• Dato un insieme di categorie c1, c2,…cn• Sia E una descrizione di un esempio da classificare.• La categoria di E si calcola determinando per ogni ci
)()|()()|(
EPcEPcPEcP ii
i =
∑∑==
==n
i
iin
ii EP
cEPcPEcP11
1)(
)|()()|(
∑=
=n
iii cEPcPEP
1)|()()(

28
Categorizzatore Bayesiano (cont)
• Dobbiamo calcolare:– Le probabilità a posteriori: P(ci) – e le condizionate: P(E | ci)
• P(ci) si stimano dai dati di training D. – se ci sono ni esempi in D di tipo ci,allora
P(ci) = ni /|D|• Supponiamo che un esempio è rappresentato da m
features:
• Troppe rappresentazioni (esponenziale in m); dati di training non disponibili per stimare P(E |ci)
meeeE ∧∧∧= L21

29
Categorizzatore Naïve Bayes
• Assumiamo che le features siano indipendenti data la categoria (ci).
• Quindi dobbiamo stimare solo P(ej | ci) per ogni feature e categoria.
)|()|()|(1
21 ∏=
=∧∧∧=m
jijimi cePceeePcEP L
30
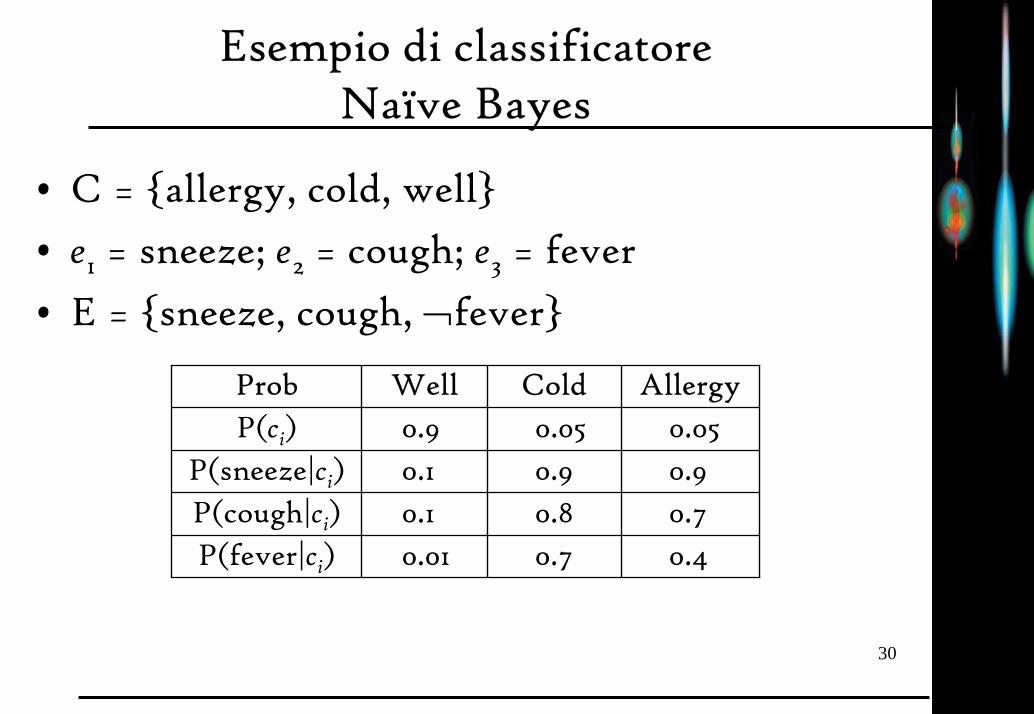
Esempio di classificatore Naïve Bayes
• C = allergy, cold, well• e1 = sneeze; e2 = cough; e3 = fever
• E = sneeze, cough, ¬fever
Prob Well Cold AllergyP(ci) 0.9 0.05 0.05
P(sneeze|ci) 0.1 0.9 0.9P(cough|ci) 0.1 0.8 0.7P(fever|ci) 0.01 0.7 0.4

31
Esempio di classificatore –Naïve Bayes (cont.)
P(well | E) = (0.9)(0.1)(0.1)(0.99)/P(E)=0.0089/P(E)P(cold | E) = (0.05)(0.9)(0.8)(0.3)/P(E)=0.01/P(E)P(allergy | E) = (0.05)(0.9)(0.7)(0.6)/P(E)=0.019/P(E)
La categoria più probabile è allergy infatti:P(E) = 0.0089 + 0.01 + 0.019 = 0.0379P(well | E) = 0.23, P(cold | E) = 0.26, P(allergy | E) = 0.50
Probability Well Cold Allergy
P(ci) 0.9 0.05 0.05
P(sneeze | ci) 0.1 0.9 0.9
P(cough | ci) 0.1 0.8 0.7
P(fever | ci) 0.01 0.7 0.4
E=sneeze, cough, ¬fever

32
Stima delle probabilità
• Frequenze stimate dai dati di apprendimento.• Se D contiene ni esempi nella categoria ci, e nij di ni
contengono la feature ej, allora:
• Problemi: un corpus troppo piccolo.• Una feature rara, ek, ∀ci :P(ek | ci) ≈ 0.
i
ijij n
nceP =)|(

33
Smoothing
• Le probabilità debbono essere aggiustate perché il campione è insufficiente in modo da riflettere meglio la natura del problema.
• Laplace smoothing– ogni feature ha almeno una probabilità a priori,
p, – si assume che sia stata osservata in un esempio
virtuale di taglia m.
mnmpn
cePi
ijij +
+=)|(

34
Naïve Bayes per la classificazione di documenti
• Modello a “bag of words”– Generato per i documenti in una categoria
– Campionamento da un vocabolario V = w1, w2,…wm con probabilità P(wj | ci).
• Lo smoothing di Laplace– Si assume una distribuzione uniforme su tutte le
parole (p = 1/|V|) and m = |V|
– Equivalente a osservare ogni parola in una categoria esattamente una volta.

35
Training (version 1)
V è il vocabolario di tutte le parole dei documenti di training DPer ogni categoria ci ∈ C
Sia Di il sotto-insieme dei documenti di D in ci⇒ P(ci) = |Di| / |D|
ni è il numero totale di parole in Diper ogni wj ∈ V, nij è il numero di occorrenze di wj in ci
⇒ P(wj | ci) = (nij + 1) / (ni + |V|)

36
Training (version 2)
V è il vocabolario di tutte le parole dei documenti di training DPer ogni categoria ci ∈ C
Sia Di il sotto-insieme dei documenti di D in ci⇒ P(ci) = |Di| / |D|
ni è il numero totale di coppie <w,d>, d ∈ Di e w ∈ V.Per ogni parola wj ∈ V,
nij è il numero di documenti di ci che contengono wj cioè il numero delle coppie <wj,d> tale che d ∈ Di
⇒ P(wj | ci) = (nij + 1) / (ni + |V|)

37
Testing o Classificazione
Dato un documento di test XSia n il numero di parole che occorrono in XRestituisci la categoria:
dove aj è la parola che occorre nella j-esima posizione in X
)|()(argmax1
∏=∈
n
jiji
CiccaPcP

38
Sommario
• Apprendere Automaticamente significa sviluppare un algoritmo o una risorsa per milgiorare le proprie prestazioni
• Esistono diversi paradigmi di ML orientati alla soluzione di problemi e di domini diversi
• Nell’apprendimento induttivo l’agente deriva un algoritmo (in genere di classificazione) da un pool di esempi etichettati– Supervised vs. unsupervised learning
• Nell’apprendimento basato su conoscenza l’algoritmo apprende una nuova formulazione algoritmica usando un modello del task e del dominio

39
Sommario (2)
• Un tipo di apprendimento di base è quello probabilistico dove apprendere significa– Descrivere il problema mediante un modello generativo
che mette in relazione le variabili in input (e.g. sintomi) e quelle in output (e.g. diagnosi)
– Determinare i corretto parametri del problema (i.e. le distribuzioni analitiche o la stima delle probabilità discrete)
• Un esempio: clasificazione NB (caso discreto)• Nella stima dei parametri in NB un ruolo centrale è
svolto dalle tecniche di smoothing: a parità di modello infatti stimatori errati producono risultati insoddisfacenti


















