
A Metadata Based Approach For Supporting Subsetting Queries Over Parallel HDF5 Datasets Vignesh...
34
A Metadata Based Approach For Supporting Subsetting Queries Over Parallel HDF5 Datasets Vignesh Santhanagopalan Graduate Student Department Of CSE
-
Upload
magnus-collins -
Category
Documents
-
view
216 -
download
1
Transcript of A Metadata Based Approach For Supporting Subsetting Queries Over Parallel HDF5 Datasets Vignesh...

A Metadata Based Approach For Supporting Subsetting Queries Over
Parallel HDF5 Datasets
Vignesh Santhanagopalan
Graduate StudentDepartment Of CSE

A Metadata Based Approach For Supporting Subsetting Queries Over Parallel HDF5 Datasets
2

A Metadata Based Approach For Supporting Subsetting Queries Over Parallel HDF5 Datasets
3

A Metadata Based Approach For Supporti ng Subsetti ng Queries Over Parallel HDF5 Datasets
4
Outline
Motivation Challenges Involved Contributions Background Overview of the System Design Metadata Extraction and Handling Pre-Processing and Post-Processing Modules Parallelization of our System Experiments Related Work Conclusion

A Metadata Based Approach For Supporti ng Subsetti ng Queries Over Parallel HDF5 Datasets
5
Motivation
Scientific Data Management• Extremely large datasets
Data Driven Applications• Scientific simulations• High precision data collection instruments • Sensors attached to a satellite

A Metadata Based Approach For Supporti ng Subsetti ng Queries Over Parallel HDF5 Datasets
6
Challenges Involved
Data exists in a variety of low-level formats • Hard for the user to extract the subset of data• Significant effort to understand the layout of
data More efficient access to scientific dataset is
needed• Parallel Computing

A Metadata Based Approach For Supporti ng Subsetti ng Queries Over Parallel HDF5 Datasets
7
Contributions
Providing a virtual relational table view over HDF5 dataset
Allows the users to specify the query using the powerful SQL statements
Supporting queries which are based on the dimensions of the dataset
Supporting queries which are based on the dimensions and attributes of the dataset

A Metadata Based Approach For Supporti ng Subsetti ng Queries Over Parallel HDF5 Datasets
8
Background-HDF5
Hierarchical Data Format is the name of a set of file formats and libraries designed to store and organize large amounts of numerical data
Stores the data in a tree like structureProvides organization by dividing the structure
into groups, datasets, attributes

A Metadata Based Approach For Supporti ng Subsetti ng Queries Over Parallel HDF5 Datasets
9
Structure of HDF5 file

A Metadata Based Approach For Supporti ng Subsetti ng Queries Over Parallel HDF5 Datasets
10
Parallel HDF5
Allows users to exploit parallelism to improve I/O performance
Provides standard parallel I/O interface and MPI programming
Opens a file in parallel using communicatorCollective parallel access to a file coordinated by
all processes

A Metadata Based Approach For Supporti ng Subsetti ng Queries Over Parallel HDF5 Datasets
11
Our System
Supports SQL-like data subsetting with a virtualized view of HDF5 datasets• Metadata Extraction and Handling• Pre-processing and Post-processing Modules
Parallel I/O optimizations with Data Virtualization• MPI• Query Partition

A Metadata Based Approach For Supporti ng Subsetti ng Queries Over Parallel HDF5 Datasets
12
Query Structure
Support SQL like abstraction with virtualized view of HDF5 datasets
SELECT <Dataset variables>FROM <Dataset name>
WHERE <Expression List>
Pre-Processing and Post-Processing Queries

SYSTEM DESIGN
SQL query input
Master Process
SQL parser
Metadata descriptor
Pre-Processing Module
Query Partition
Post-Processing Module
Slave Processes
Data Access Code
Data Access Code
Data Access Code
Parallel HDF5
HDF5 Dataset

A Metadata Based Approach For Supporti ng Subsetti ng Queries Over Parallel HDF5 Datasets
14
Main Steps of Our System(1/2)
Input: SQL queryOutput: Necessary subset of data to the userProcess:• For every HDF5 dataset, metadata descriptor is
generated• SQL parser is used to parse the SQL query to retrieve
the grammar information• Variables and dimensions from the WHERE expression
of the SQL query is retrieved

A Metadata Based Approach For Supporti ng Subsetti ng Queries Over Parallel HDF5 Datasets
15
Main Steps of Our System(2/2)
By evaluating the parse tree and the metadata information, a query request is generated
Based on the query request that was generated the data size is computed
Query-Partitioning module divides the query request into several sub-requests
The data results are obtained by each node based on the sub-request

A Metadata Based Approach For Supporti ng Subsetti ng Queries Over Parallel HDF5 Datasets
16
HDF5 File Organization
Organizes data as collection of various objects like groups, datasets and attributes
Groups provide logical structuring to dataDatasets contain multi-dimensional array of data
elements• Dataspace• Datatype
Attributes

A Metadata Based Approach For Supporti ng Subsetti ng Queries Over Parallel HDF5 Datasets
17
Metadata Extraction and Handling
For every HDF5 dataset, a metadata descriptor is generated
Metadata Information for each dataset:• Information to interpret data- Datatype• Information to describe the logical layout of data –
Dataspace• Information about Attributes attached to a dataset

A Metadata Based Approach For Supporti ng Subsetti ng Queries Over Parallel HDF5 Datasets
18
Metadata Extraction Example
Datatype- IntegerDataspace- Number of dimensions and size of each
dimension• Number of dimensions – 3• Size of dimension1 – 100• Size of dimension2 – 200• Size of dimension3 – 300
Attributes• Temperature• Velocity

19
Metadata Extraction and Handling
For each group – Information regarding datasets it contains must be extracted
Can be imagined as a table• Row- group• Columns- all the datasets it contains
Mapping between the dataset variables and groupInformation regarding attributes stored for each
dataset
A Metadata Based Approach For Supporti ng Subsetti ng Queries Over Parallel HDF5 Datasets

A Metadata Based Approach For Supporti ng Subsetti ng Queries Over Parallel HDF5 Datasets
20
Example HDF5 File
GROUP “/” { GROUP “HDFEOS”{ GROUP “GRIDS”{ GROUP “ColumnAmount03” { GROUP “Data Fields” { DATASET “SolarZenithAngle” { DATATYPE H5T_IEEE_F32LE DATASPACE SIMPLE { ( 720, 1440 ) / ( 720, 1440 ) } DATA { } ATTRIBUTE "_FillValue" {
DATATYPE H5T_IEEE_F32LEDATASPACE SIMPLE { ( 1 ) / ( 1 ) }DATA {}}

A Metadata Based Approach For Supporti ng Subsetti ng Queries Over Parallel HDF5 Datasets
21
Path Information
For Dataset SolarZenithAngle the path is /HDFEOS/GRIDS/ColumnAmount03/DataFields/SolarZenithAngleFor Attribute _FillValue the path is
/HDFEOS/GRIDS/ColumnAmount03/DataFields/SolarZenithAngle/_FillValue
Dataspace and Datatype for SolarZenithAngleDatatype: FloatNumber of Dimensions: 2Dimension Size: 720X1440Information about an attribute _Fillvalue:Datatype: FloatArray Size: 1

A Metadata Based Approach For Supporti ng Subsetti ng Queries Over Parallel HDF5 Datasets
22
Pre-Processing and Post-Processing Modules
Two different types of queries• Query based on dimensions• Query based on attributes also
First type query supported by HDF5 API• Complete understanding of the layout of data• Separate programs to retrieve each subset of data
Second type of query• No direct support • Detailed knowledge of the datasets, HDF5 API and complex
programming

A Metadata Based Approach For Supporti ng Subsetti ng Queries Over Parallel HDF5 Datasets
23
Pre-Processing and Post-Processing Modules
Pre-Processing Module:• Inputs:
– SQL grammar–Metadata
• Filtering is done based on dimensions of the dataset
Post-Processing Module:• Queried based on the attributes• Manually filter out to retrieve necessary subset of data

A Metadata Based Approach For Supporti ng Subsetti ng Queries Over Parallel HDF5 Datasets
24
Parallelization
Parallel HDF5 has MPI-I/O layer on top of HDF5API support for parallel access through message
passingCollective I/O call for shared access to a file

25
Parallelization
Master-Slave approach with Parallel HDF5 processingMaster Process:• Parses the SQL query given by the user• Generates data subsetting request• Partitions requests into several sub-requests• Also performs post-processing
Slave Processes:• Receives sub-requests from master process• queries a data chunk by accessing the HDF5 in parallel and
obtains the data results
A Metadata Based Approach For Supporti ng Subsetti ng Queries Over Parallel HDF5 Datasets

A Metadata Based Approach For Supporti ng Subsetti ng Queries Over Parallel HDF5 Datasets
26
Experiments
Experimental Goals:• To evaluate our system with different types of queries
on Parallel HDF5• To show performance improvement of the parallel
version with sequential subsetting• To show our system’s capability on larger datasets• To show parallel scalability of our system
A Metadata Based Approach For Supporti ng Subsetti ng Queries Over Parallel HDF5 Datasets
27
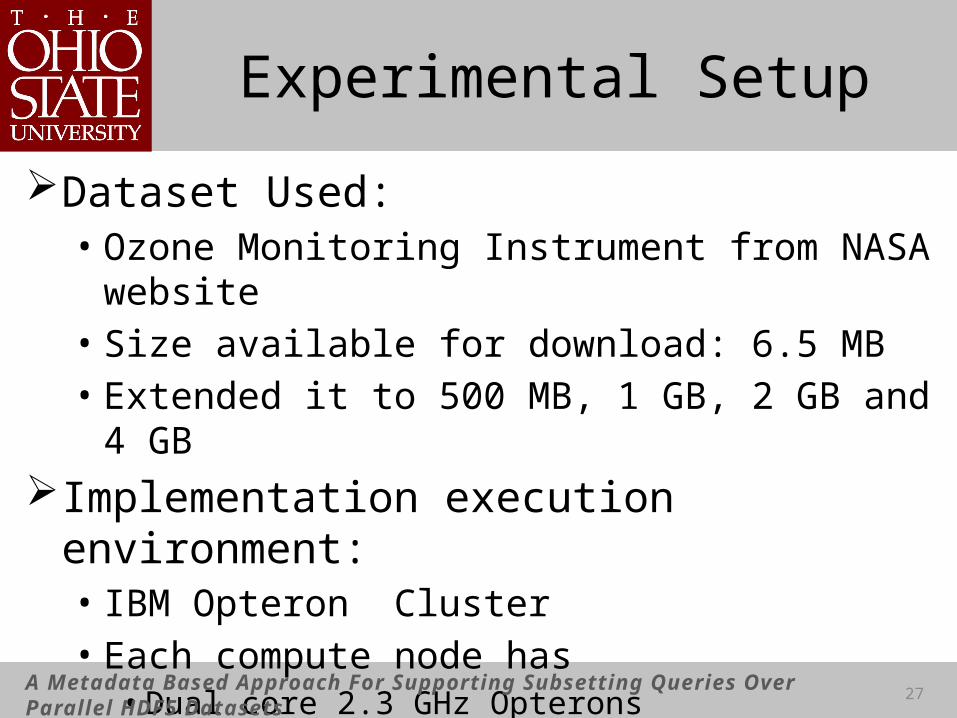
Experimental Setup
Dataset Used:• Ozone Monitoring Instrument from NASA website• Size available for download: 6.5 MB• Extended it to 500 MB, 1 GB, 2 GB and 4 GB
Implementation execution environment:• IBM Opteron Cluster• Each compute node has• Dual core 2.3 GHz Opterons• 8 GB memory

A Metadata Based Approach For Supporti ng Subsetti ng Queries Over Parallel HDF5 Datasets
28
Performance Comparison of sequential and parallel version (4 processors)
Dataset Size : 500 MB Dataset Size : 1 GB

A Metadata Based Approach For Supporti ng Subsetti ng Queries Over Parallel HDF5 Datasets
29
Performance Comparison of sequential and parallel version (4 processors)
Dataset Size : 2 GB Dataset Size : 4 GB

A Metadata Based Approach For Supporti ng Subsetti ng Queries Over Parallel HDF5 Datasets
30
Parallel Scalability of our System
Dataset Size : 500 MB Dataset Size : 1 GB

A Metadata Based Approach For Supporti ng Subsetti ng Queries Over Parallel HDF5 Datasets
31
Parallel Scalability of our System
Dataset Size : 2 GB Dataset Size : 4 GB

A Metadata Based Approach For Supporti ng Subsetti ng Queries Over Parallel HDF5 Datasets
32
Related Work
Li Weng et al provided the automatic data virtualization approach seven years back
SciDB provides a scientific database where natural way of storing data is Arrays
Beomseok Nam et al provide an indexing scheme for efficient retrieval of subset of data- No notion of data virtualization & use of parallel computing
Lot of work on extending relational database technology to support scientific data

A Metadata Based Approach For Supporti ng Subsetti ng Queries Over Parallel HDF5 Datasets
33
Conclusion
Provide a data management approach for scientific datasets stored in HDF5
Support for SQL queries over virtual view of dataParallelize queries based on dimensions and also
on attributesSignificant performance improvement over
Sequential subsetting System scales well with varying number of nodes
and different data sizes

A Metadata Based Approach For Supporti ng Subsetti ng Queries Over Parallel HDF5 Datasets
34
Thank You!


















