
9-2.1 “Grid-enabling” applications Part 2 Using Multiple Grid Computers to Solve a Single...
71
9-2.1 “Grid-enabling” applications Part 2 Using Multiple Grid Computers to Solve a Single Problem MPI © 2010 B. Wilkinson/Clayton Ferner. Spring 2010 Grid computing course. slides9-2.ppt Modification date: Feb 26, 2010
-
Upload
herbert-stafford -
Category
Documents
-
view
229 -
download
0
Transcript of 9-2.1 “Grid-enabling” applications Part 2 Using Multiple Grid Computers to Solve a Single...

9-2.1
“Grid-enabling” applications
Part 2
Using Multiple Grid Computers to Solve a Single Problem
MPI
© 2010 B. Wilkinson/Clayton Ferner. Spring 2010 Grid computing course. slides9-2.ppt Modification date: Feb 26, 2010

9-2.2
Using Parallel Programming Techniques
Grid computing offers possibility of using multiple computers on a single problem to decrease execution time.
Potential of using multiple computers collectively well known (at least since 1950’s) and obvious.
Suppose a problem divided into p equal parts, with each part executing on a separate computer at same time. Overall time to execute problem using p computers simultaneously would be 1/p th of time on a single computer.
Ideal situation - problems cannot usually be divided into equal parts that can be executed simultaneously.

9-2.3
Message Passing ProgrammingComputers on a Grid connected through Internet or a high performance distributed network.
Suggests programming model similar to that often used in cluster computing.
In cluster computing, computers connected through a local network with computers physically nearby.
For such a structure, a convenient approach - have processes on different computers communicate through message passing.
Message passing generally done using library routines.
Programmer inserts message-passing routines into their code

9-2.4
Message passing concept using library routines
Fig 9.9

2.5
Multiple program, multiple data (MPMD) model
Sourcefile
Executable
Processor 0 Processor p - 1
Compile to suitprocessor
Sourcefile
• Different programs executed by each processor

2.6
Single Program Multiple Data (SPMD) model
Sourcefile
Executables
Processor 0 Processor p - 1
Compile to suitprocessor
• Same program executed by each processor• Control statements select different parts for each
processor to execute.

2.7
Message Passing Routines for Clusters
Late 1980’s Parallel Virtual Machine (PVM) - developed Became very popular.
Mid 1990’s - Message-Passing Interface (MPI) - standard defined.
Based upon Message Passing Parallel Programming model.
Both provide a set of user-level libraries for message passing. Use with sequential programming languages (C, C++, ...).

2.8
MPI(Message Passing Interface)
• Message passing library standard developed by group of academics and industrial partners to foster more widespread use and portability.
• Defines routines, not implementation.
• Several free implementations exist.

9-2.9
MPI version 1 finalized in 1994.
Version 2 of MPI introduced in 1997 with a greatly expanded scope.
MPI version 1 has about 126 routines
MPI version 2 has to about 156 routines.
MPI-2 standard daunting.
However, in most applications only a few MPI routines actually needed.
Suggested that many MPI programs can be written using only about six different routines.

9-2.10
Basic MPI Programming Model
Single program multiple data model (SPMD)
Each process executes same code User writes a single program compiled to suit processors and all processes started together.

9-2.11
MPI introduces concept of a communication domain or context it calls a communicator (a non-obvious name).
Defines scope of a communication and initially all processes enrolled in a communicator called MPI_COMM_WORLD.
Appears in all MPI message passing routines.
Enables one to constrain message-passing to be between agreed processes.
Also enables library routines written to be others to be incorporated into a program without conflicts by assigning different communicators in the library routines.
Many MPI programs, however, do not need additional communicators.
MPI communicator

In MPI, processes within a communicator given a number called a rank starting from zero onwards.
Program uses control constructs, typically IF statements, to direct processes to perform specific actions.
Example
if (rank == 0) ... /* rank 0 process does this */;
if (rank == 1) ... /* rank 1 process does this*/;...
2.12

Master-Slave approach
Usually computation constructed as a master-slave model .
Example
if (rank == 0) ... /* master does this */;
else ... /* slaves do this */;
2.13

Static process creation
• All executables started together.
• Done when one starts the compiled programs.
• Normal MPI way.
2.14
2.15
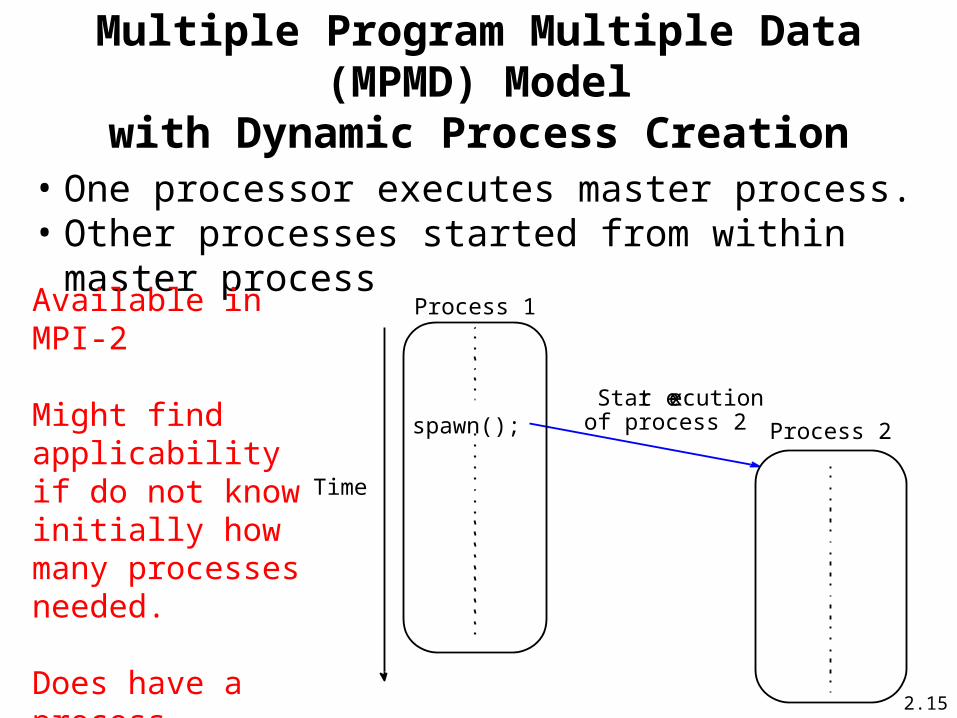
Multiple Program Multiple Data (MPMD) Modelwith Dynamic Process Creation
Process 1
Process 2spawn();
Time
Start executionof process 2
• One processor executes master process.• Other processes started from within master process
Available in MPI-2
Might find applicability if do not know initially how many processes needed.
Does have a process creation overhead.

9-2.16
#include <stddef.h> #include <stdlib.h> #include "mpi.h" main(int argc, char **argv ) { char message[20]; int i,rank, size, type=99; MPI_Status status; MPI_Init(&argc, &argv); MPI_Comm_size(MPI_COMM_WORLD,&size); MPI_Comm_rank(MPI_COMM_WORLD,&rank); if(rank == 0) { strcpy(message, "Hello, world"); for (i=1; i<size; i++) MPI_Send(message,13,MPI_CHAR,i,type,MPI_COMM_WORLD); } else MPI_Recv(message,20,MPI_CHAR,0,type,MPI_COMM_WORLD,&status); printf( "Message from process =%d : %.13s\n", rank,message); MPI_Finalize(); }
Sample MPI “Hello world” program
Will look at routines in more detail later
Fig 9.10

9-2.17
Message “Hello World” sent from master process (rank = 0) to the other processes (rank 0).
Then, all processes execute a println statement.
In MPI, standard output automatically redirected from remote computers to user’s console.
Final result:
Message from process =1 : Hello, worldMessage from process =0 : Hello, worldMessage from process =2 : Hello, worldMessage from process =3 : Hello, world...
except order of messages might be different—will depend upon how processes scheduled.

9-2.18
Very convenient model for many applications in which number of processes needed is fixed.
Typically, number of processes set to be same as number of available processor cores as generally less efficient to run multiple processes on a single processor core.
Possible to start processes dynamically from within a process in MPI version 2.
Single program multiple data model (SPMD)

9-2.19
Each process will have a copy of variables named in source program.
Can cause some confusion for the programmer.
For example, suppose source program has a variable i declared.
Variable i will appear in each process, although each is distinct and holds a value determined by the local process.
Single program multiple data model (SPMD)

9-2.20
Setting up Message Passing Environment
Usually computers to be used specified in a file, called a hostfile or machines file.
An example of a machines file is
coit-grid01.uncc.educoit-grid02.uncc.educoit-grid03.uncc.educoit-grid04.uncc.educoit-grid05.uncc.edu
If a machines file not specified, default machines file used or it may be that program will only run on a single computer.

9-2.21
Message routing between computers typically done by daemon processes installed on computers that form the “virtual machine”.
Application
daemon process
program
Workstation
Applicationprogram
Applicationprogram
Workstation
Workstation
Messagessent throughnetwork
(executable)
(executable)
(executable)
.
Can have more than one processrunning on each computer.
Depends upon MPI implementation. MPI daemon processes must be running before user submits programs

Process Creation and Execution
9-2.22
Compiling
Using SPMD model, single program written and compiled to include MPI libraries, typically using an MPI script mpicc, i.e.,
mpicc myProg.c -o myProg
mpicc typically uses cc compiler and cc options available.
.

9-2.23
Once compiled, program can be executed.
Executing program
MPI-1 does not specify implementation details at all. Common command to execute program is mpirun where -np option specifies number of processes.
Example
mpirun -np 4 myProg
Command line arguments for myProg can be added after myProg and could be accessed by the program.

2.24
Executing MPI program on multiple computers
Create a file called say “machines” containing the list of machines, say:
coit-grid01.uncc.educoit-grid02.uncc.educoit-grid03.uncc.educoit-grid04.uncc.educoit-grid05.uncc.edu

2.25
mpirun -machinefile machines -n 4 prog
would run prog with four processes.
Each processes would execute on one of machines in list. MPI would cycle through list of machines giving processes to machines.
Can also specify number of processes on a particular machine by adding that number after machine name.)

Initialization
MPI_Init()
Before any MPI routine can be called from within the program, the program must call MPI_Init() once (and only once) to initialize MPI environment.
MPI_Init() supplied with command line arguments that the implementation can use.
9-2.26

Termination
MPI_Finalize()
Program must call MPI_Finalize() to terminate the MPI environment.
One typically does not place anything after MPI_Finalize() including a return and certainly no MPI routine can be called.
9-2.27

Therefore, every MPI program has the structure:
main (int argc, char *argv[]) {
MPI_Init(&argc, &argv); /* initialize MPI */
.
.
.
MPI_Finalize(); /* terminate MPI */
}9-2.28

Finding process rankMPI_Comm_rank()
In most MPI programs, necessary to find the rank of a process within a communicator.
Can be found from routine MPI_Comm_rank().
MPI_Comm_rank(MPI_COMM_WORLD,&myid);
9-2.29

Finding number of processesMPI_Comm_size()
Often, also necessary to know how many processes there are in a communicator.
Can be found from the routine MPI_Comm_size().
MPI_Comm_size(MPI_COMM_WORLD,&numprocs);
9-2.30

A simple program using these routines is
main (int argc, char *argv[]) {
MPI_Init(&argc, &argv); /* initialize MPI */
MPI_Comm_rank(MPI_COMM_WORLD,&myid); /*rank */
MPI_Comm_size(MPI_COMM_WORLD,&numprocs); /*no of procs*/
printf(“I am %d of %d\n”, myid+1, numprocs);
MPI_Finalize(); /* terminate MPI */
}
9-2.31

All output redirected to console, so output at the console will be
I am 3 of 4
I am 1 of 4
I am 4 of 4
I am 2 of 4
but in any order, as the order of execution on different computers is indeterminate.
9-2.32

Note in previous slide, each process executes the same code. Typically though master-slave approach used.
Then one might have:
main (int argc, char *argv[]) {
MPI_Init(&argc, &argv);
MPI_Comm_rank(MPI_COMM_WORLD, &myrank); /* rank */
if (myrank == 0) master();
else slave();
MPI_Finalize();
}
where master() and slave() are executed by master process and slave process, respectively.
9-2.33

MPI Message-Passing Routines
A brief overview
9-2.34

MPI point-to-point message passing using MPI_send() and MPI_recv() library calls
9-2.35Fig 9.11
Data TransferMPI_send() and MPI_recv()

9-2.36
Parameters of (blocking) send
MPI_Send(buf, count, datatype, dest, tag, comm)
Address of
Number of items
Datatype of
Rank of destination
Message tag
Communicator
send buffer
to send
each item
process

9-2.37
Parameters of (blocking) receive
MPI_Recv(buf, count, datatype, src, tag, comm, status)
Address of
Maximum number
Datatype of
Rank of source
Message tag
Communicator
receive buffer
of items to receive
each item
process
Statusafter operation

9-2.38
Example
To send an integer x from process 0 to process 1,
MPI_Comm_rank(MPI_COMM_WORLD,&myrank); /* find rank */
if (myrank == 0) {int x;MPI_Send(&x, 1, MPI_INT, 1, msgtag, MPI_COMM_WORLD);
} else if (myrank == 1) {int x;MPI_Recv(&x, 1, MPI_INT, 0,msgtag,MPI_COMM_WORLD,status);
}

Message TagsUsed to differentiate between messages being received at different times for different purposes.
An integer that is carried with the message.
Only messages with tags specified in MPI_Recv() accepted by receive routine.
Wild card for tag MPI_ANY_TAG -- receive will match with any message from the specified process in the communicator.
Wild card for source MPI_ANY SOURCE -- all messages in
communicator accepted.9-2.39

Semantics of MPI_Send() and MPI_Recv()
If process waits until message transmission is complete before moving on, this is called blocking.
MPI_Send() – Non-Blocking – Message may not reached its destination but process can continue in the knowledge that message safely on its way.
MPI_Recv() – Blocking – Returns when message received and data collected. Will cause process to stall until message received.
2.40

Semantics of MPI_Send() and MPI_Recv()
Data is buffered, meaning that after returning, any local variables used can be altered without affecting message transfer.
Other versions of MPI_Send() and MPI_Recv() have different semantics, i.e. blocking versus non-blocking, buffered versus non-buffered.
2.41

MPI broadcast operationMPI_Bcast()
9-2.42Fig 9.12

MPI_Bcast parameters
2a.43

Basic MPI scatter operationMPI_Scatter()
9-2.44Fig 9.13

MPI scatter parameters
2a.45
scount refers to number of items sent to each process.Normally, scount the same as rcount, and stype same as rtype.Somewhat strangely, send and receive types and count are specified separately and could be different.

Sending group of contiguous elements to each process
In following, 100 contiguous elements sent to each process:
main (int argc, char *argv[]) {int size, *sendbuf, recvbuf[100]; /* for each process */MPI_Init(&argc, &argv); /* initialize MPI */MPI_Comm_size(MPI_COMM_WORLD, &size);
sendbuf = (int *)malloc(size*100*sizeof(int));
MPI_Scatter(sendbuf,100,MPI_INT,recvbuf,100,MPI_INT,0,MPI_COMM_WORLD);
MPI_Finalize(); /* terminate MPI */}
9-2.46

Scattering contiguous groups of elements to each process
9-2.47Fig 9.14

Gather operationMPI_Gather()
9-2.48Fig 9.15

Gather parameters
2a.49

2a.50
Gather ExampleTo gather items from group of processes into process 0, using dynamically allocated memory in root process:
int data[10]; /*data to be gathered from processes*/
MPI_Comm_rank(MPI_COMM_WORLD, &myrank); /* find rank */
if (myrank == 0) {
MPI_Comm_size(MPI_COMM_WORLD, &grp_size); /*find group size*/
buf = (int *)malloc(grp_size*10*sizeof (int)); /*alloc. mem*/
}
MPI_Gather(data,10,MPI_INT,buf,grp_size*10,MPI_INT,0,MPI_COMM_WORLD) ;
…
MPI_Gather() gathers from all processes, including root.

Reduce operationMPI_Reduce() with addition
9-2.51Fig 9.16

Reduce parameters
2a.52

Implementation of collective operations MPI_Bcast(), MPI_Scatter(), MPI_Gather(), and MPI_Reduce()
Not defined in MPI standard except that their effects equivalent to using a multitude of point-to-point sends and receives.
Same semantics of point-to-point blocking MPI_send()/MPI_recv() communications -- all processes return when locally complete and do not wait for each other.
Collective routines would be assumed to be much more efficient than MPI_send()/MPI_recv().
9-2.53

SynchronizationMPI_Barrier()
Related purpose for message passing is to synchronize processes so communication continues at a specific point.
MPI offers specific synchronization operation, MPI_Barrier(), which prevents any process calling routine returning until all have called it.
9-2.54Fig 9.17

Synchronous message-passing routines MPI_SSend()
9-2.55
MPI_SSend() does not continue until message received (Blocking).
Can be used with MPI_Recv() to effect a synchronous point-to-point message transfer.
Note, much better to avoid synchronization if possible as implies that processes waiting for other.

Grid-Enabled MPI
9-2.56
MPI uses networked computers with IP addresses so it would seem reasonable to extend MPI to include geographically distributed networked computers.
There have been several projects to implement MPI across geographically distributed computers connected on the Internet.
In fact, MPI alone could be used.

Message passing across geographically distributed computers
9-2.57Fig 9.18

MPICH abstract device interface
9-2.58Fig 9.19
MPICH-1 separates implementation of MPI routines from implementation of communication methods.

In MPICH, different implementations of abstract device interface provided for different systems, e.g. for workstation clusters, for shared memory systems.
MPICH-G
MPICH modified to operate across a Grid platform.
Includes abstract device for Globus version 2.
Perhaps first attempt at porting MPI to a Grid and
first projects that directly used Globus infrastructure and indeed proved utility of Globus toolkit.
9-2.59

(a) Using regular MPICH to run a remote job
9-2.60Fig 9.20 (a)
Comparing MPICH and MPICH-G

9-2.61
Comparing MPICH and MPICH-G(b) Using MPICH-G to run a remote job
Fig 9.20 (b)

9-2.62
Apart from early MPICH-G/MPICH-G2 project, other projects provided tools to run MPI programs across a geographically distributed Grid. Do not necessarily use Globus software.
Examples
PACX-MPI (Parallel Computer Extension - MPI• Can encrypt messages using SSL
GridMPI™ open source project•Avoided security layer altogether for performance. •Project investigators argue HPC Grid sites often use their own networks, so that security not an issue.•Found that MPI programs scale up to round-trip communication latencies of 20 mS, - about 500 miles for 1–10 Gbits/sec networks, the distance between major sites in Japan (where project developed) and then MPI programming feasible.

9-2.63
In both GridMPI and PACX-MPI, idea not to have to alter MPI programs at all and simply run MPI programs that would run on a local cluster.
That does not preclude modifying the programs to take into account the geographically distributed nature of the compute resources.
Grid Enabling MPI Programs

9-2.64
Most notable aspects for running MPI programs on a Grid are:
•Long and indeterminate communication latency
•Difficulty and effect of global synchronization
•Effect of failures (fault tolerance)
•Heterogeneous computers (usually)
•Need for communicating processes to be running simultaneously
Grid Enabling MPI Programs

9-2.65
Mostly, focus is to ameliorate effects of latency.
One basic concept - overlap communications with computations while waiting for communication to complete - comes directly from regular parallel programming

9-2.66
Overlapping communications with computations (send before receive)
Fig 9.21

9-2.67
Quiz(Multiple choice)

9-2.68
What is MPI?
(a) A standard for user-level message passing library routines
(b) An implementation of message passing routines
(c) A portal interface for message passing Grid applications
(d) A portlet interface for message passing Grid applications
SAQ 9-4

9-2.69
What is an MPI communicator?
(a) A talkative MPI program
(b) A process that sends messages
(c) An MPI compiler
(d) A way of defining a set of processes that can communicate between themselves
SAQ 9-5

9-2.70
What type of routine is the MPI_Recv() routine?
(a) Synchronous
(b) Blocking
(c) Non-blocking
(d) Asynchronous
SAQ 9-7

Questions
9-2.71


















