
7th Sem Cs&It CD Ct1 10 Solution
21
Silicon Institute of Technology Class Test – I (7 th Sem. B. Tech- CS & IT), 2010 Sub : Compiler Design Time – 60 mins. Max. Marks – 10 Date : 11.08.10 (Answer any Four including Q.1) Q.1. Short type (any Five) [0.5 x 5 = 2.5] a) What is a complier and how it is different from an interpreter? b) Define regular expression. c) Differentiate DFA & NFA. d) Differentiate left sentential form and right sentential form of a string. e) What is a cross compiler and its advantage? Q.2. Consider the following while statement : [2.5] While A > B && A <= 2 * B – 5 do A = A + B Identify the Tokens. Generate the Parse tree, intermediate code and optimized code. Q.3. Show that the following grammar is ambiguous. [2.5] E E+E | E*E | (E) | id Q.4. Using Thomson Construction Rule construct -NFA for the following regular expressions. [2.5] a) (a b)* b) ab (a b)* c) (a* b*)* a d) (a b)* a (a b) + e) (a b) + abb
Transcript of 7th Sem Cs&It CD Ct1 10 Solution

Silicon Institute of TechnologyClass Test – I (7th Sem. B. Tech- CS & IT), 2010
Sub : Compiler Design
Time – 60 mins. Max. Marks – 10 Date : 11.08.10
(Answer any Four including Q.1)
Q.1. Short type (any Five) [0.5 x 5 = 2.5]
a) What is a complier and how it is different from an interpreter?
b) Define regular expression.
c) Differentiate DFA & NFA.
d) Differentiate left sentential form and right sentential form of a string.
e) What is a cross compiler and its advantage?
Q.2. Consider the following while statement : [2.5]
While A > B && A <= 2 * B – 5 do
A = A + B
Identify the Tokens. Generate the Parse tree, intermediate code and optimized
code.
Q.3. Show that the following grammar is ambiguous. [2.5]
E E+E | E*E | (E) | id
Q.4. Using Thomson Construction Rule construct -NFA for the following regular
expressions. [2.5]
a) (a b)* b) ab (a b)* c) (a* b*)* a d) (a b)* a (a b)+
e) (a b)+ abb
Q5. Give an equivalent DFA for the regular expression (a|b)*abb.
[2.5]
Good Luck

Solutionto
Sub – Compiler DesignClass Test – I, 2010
1)a) Compiler and Interpreter both are translators for high level languages. But they
have differences which are given below.
Compiler
i. Compiler translates the whole source code at a time and produces a list of errors.
ii. After removal of all errors the compiler produces the object code for the given source code.
iii. Compiler is faster.iv. Compiler generates an object
code of the source code.v. The generated object code is
stored in permanent storage device
vi. The object code is used for execution of the program without any need of the source code.
Interpreter
i. Interpreter translates the source code line-by-line and halts when an error is found.
ii. After removal of the error the interpreter moves with the translation of the next line of the source code.
iii. Interpreter is slower.iv. Interpreter generates an
executable code of the source code.
v. The generated executable code is stored in temporary storage device i.e. primary memory.
vi. The source code is always needed for execution of the program as the executable code is lost after the execution.
b) Regular Expression: Regular expressions over can be defined recursively as follows:
1. Any terminal symbol (i.e. an element of ), and are regular expressions.
2. The union of two regular expressions R1 and R2, written as R1 + R2, is also a regular expression.
3. The concatenation of two regular expressions R1 and R2, written as R1 R2, is also a regular expression.
4. The iteration (or closure) of a regular expression R, written as R*, is also a regular expression.
5. If R is a regular expression, then (R) is also a regular expression.6. A recursive application of the rules 1-5 once or several times results into a
regular expression.

c) Non-deterministic Finite Automaton (NFA):
A non-deterministic finite automaton is a 5-tuple (Q, , , q0, F), wherei) Q is a finite nonempty set of states;
ii) is a finite nonempty set of inputs;iii) is the transition function mapping from Q x into 2Q which is the power set
of Q, the set of all subsets of Q;iv) q0 Q is the initial state; andv) F Q is the set of final states.
Deterministic Finite Automaton (DFA):
A deterministic finite automaton is a 5-tuple (Q, , , q0, F), where i) Q is a finite nonempty set of states;
ii) is a finite nonempty set of inputs;iii) is the transition function which maps Q x into Q;iv) q0 Q is the initial state; andv) F Q is the set of final states.
DFA:a) In DFA when an input is
given to a state it transits to a single state.
b) DFA can be implemented in a system.
NFA:a) In NFA when an input is
given to a state it may transit to multiple states.
b) NFA can not be implemented in a system.
d) If by a step in which the leftmost non-terminal in is replaced, we write . Every leftmost step, has the form wA w in which w consists of terminals only. If derives by a leftmost derivation, we write . If S , then we say is a left sentential form of the given grammar.
Similarly, If by a step in which the rightmost non-terminal in is replaced, we write . Every rightmost step, has the form Aw w in which w consists of terminals only. If derives by a rightmost derivation, we write . If S , then we say is a right sentential form of the given grammar.
For example: A given grammar is :S i C t SS i C t S e SS aC bAnd a string w = i b t i b t a e a can be derived using leftmost derivation as follows:S i C t S
lm lm
lm*
lm*
rm rm
rm*
rm*
lm

i b t S
i b t i C t S e S
i b t i b t S e S
i b t i b t a e S
i b t i b t a e a
It is in the form of S 1 2 n = w. Here all i, 1≤ i ≤ n, is a left-sentential
form of the given string.Similarly, the rightmost derivation of the string is as follows:
S i C t S
i C t i C t S e S
i C t i C t S e a
i C t i C t a e a
i C t i b t a e a
i b t i b t a e a
It is in the form of S 1 2 n = w. Here all i, 1≤ i ≤ n, is a right-sentential
form of the given string. The rightmost derivation is also known as canonical derivation.
e) A compiler is characterized by three languages: its source language, its object language, and the language in which it is written. These languages may all be quite different.
A compiler may run on one machine and produce object code for another machine. Such a compiler is often called a cross-compiler.
Suppose a new language L is made available to two different machines A
and B. As a first step we may write for machine A, a small compiler ,
that translates a subset S of language L into the machine or assembly code of A.
lm
lm
lm
lm
lm
lm
lm
lm
lm
rm
rm
rm
rm
rm
rm
rm rm rm rm

Then we write a compiler in the simple language S. This program,
when run through , becomes , the compiler for the complete
language L, running on machine A and producing object code for A.
Now suppose we want to have another compiler for L to run on machine B
and to produce code for B. If has been designed carefully and machine B
is not that different from machine A, then with little modification we can
convert into a compiler which produces object code for B.
So, using to produce , a compiler for L on B, is a two step
process which is given below. Here we first run through to produce
, a cross-compiler for L which runs on machine A but produces code for
machine B. Then we run through this cross-compiler to produce the
desired compiler for L that runs on machine B and produces object code for B.
Hence, we can see a cross-compiler helps us to create a compiler for another machine without starting from the scratch. It helps a lot in the form of reduction of amount of coding for a new compiler.
2) The given while statement is while A > B & A ≤ 2*B – 5 do
A := A + B;The list of tokens present in the given string are:
while [id, n1] > [id, n2] & [id, n1] ≤ [const, n3] * [id, n2] – [const, n4] do [id, n1] [id, n1] + [id, n2];
Here n1, n2, n3 and n4 stand for pointers to the symbol table entries for A, B, 2, and 5, respectively.
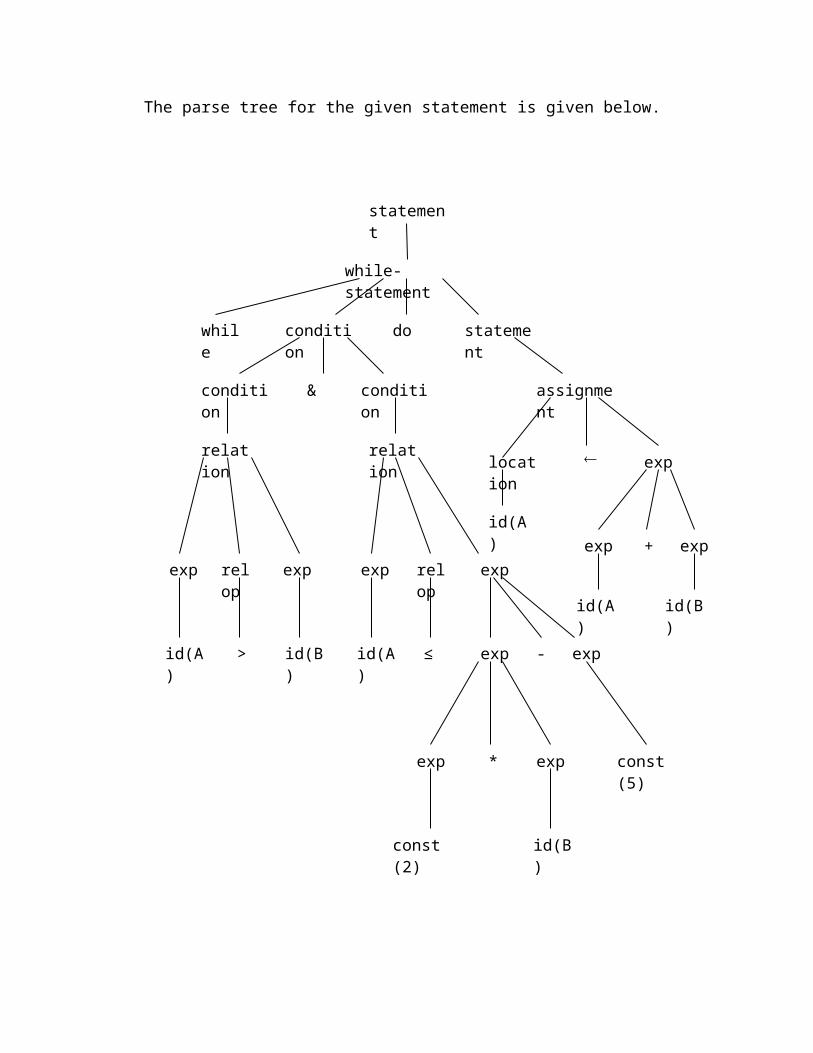
The parse tree for the given statement is given below.

statement
while-statement
while condition do statement
condition condition&
relation
exp relop exp
relation
exp exprelop
exp exp-
assignment
location exp
exp exp+
id(A) id(B) id(A)
id(B)
id(A)
exp exp*
const(2)
> ≤
const(5)
id(B)
id(A)

The intermediate code for the given string is as follows:
L1: if A > B goto L2goto L3
L2: T1 := 2 * BT2 := T1 – 5if A ≤ T2 goto L4goto L3
L4: A := A + Bgoto L1
L3:
In an attempt to code improvement we can have local transformations. Here we are having two instances of jumps over jumps in the intermediate code.
if A > B goto L2goto L3
L2:This sequence of code can be replaced by the single statement
if A ≤ B goto L3.
By applying such replacement the optimized code will be as follows
L1: if A ≤ B goto L2T1 := 2 * BT2 := T1 – 5if A > T2 goto L2A := A + Bgoto L1
L2:
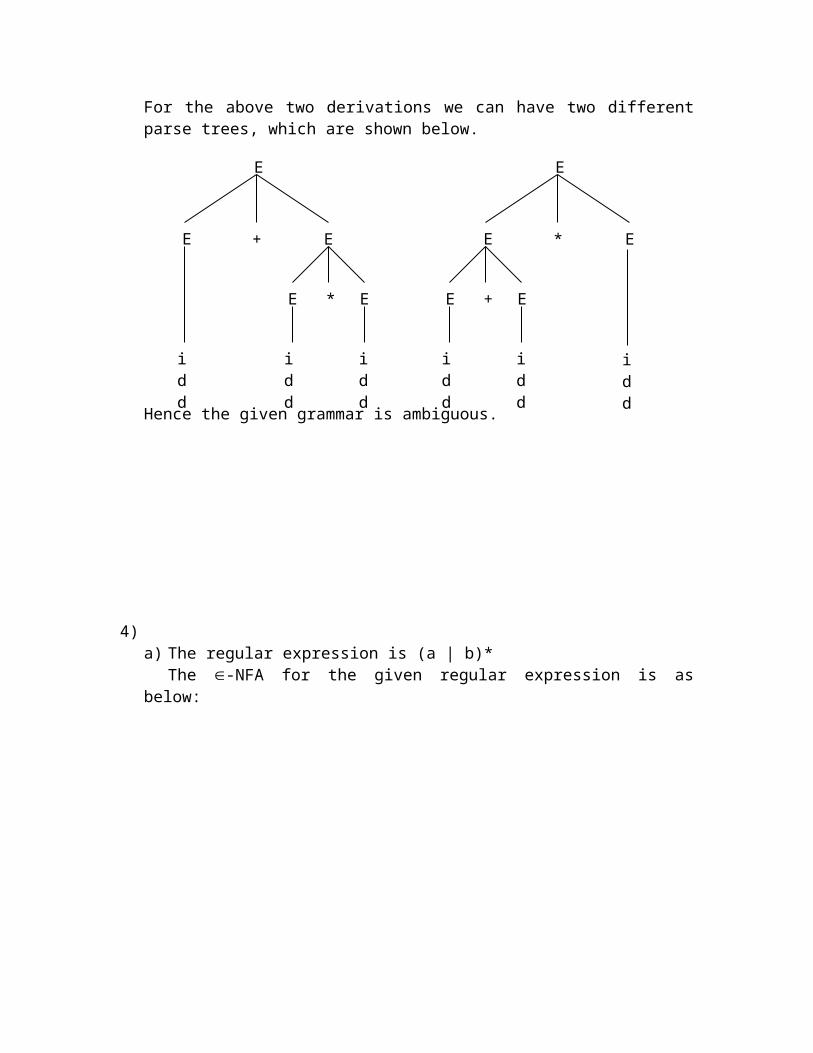
3) The given grammar is E E + E | E * E | (E) | id
A given grammar is said to be ambiguous if it produces more than one parse tree for some sentence. In other words, if a string is derivable in more than one ways using a given grammar, then the given grammar is said to be ambiguous.
Let’s have a sentence like id + id * id.We can derive the above string in two ways, which is given below:E E + E id + E id + E * E id + id * E id + id * id. And the other way is
E E * E E + E * E id + E * E id + id * E id + id * id.For the above two derivations we can have two different parse trees, which are shown below.
Hence the given grammar is ambiguous.
E
E + E
E * E
idd
idd
idd
E
E * E
idd
E + E
idd
idd

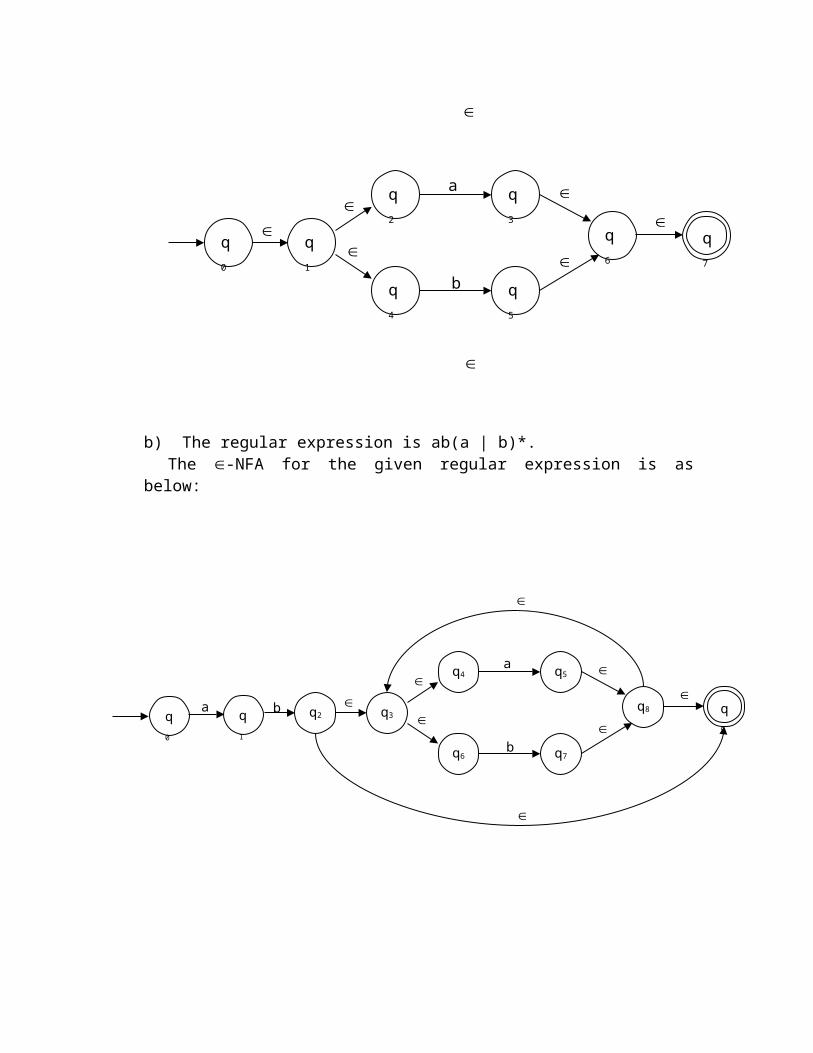
4)a) The regular expression is (a | b)*
The -NFA for the given regular expression is as below:
b) The regular expression is ab(a | b)*.The -NFA for the given regular expression is as below:
q1
q2
q4
q3
q5
q6q0q7
a
b
q1
q0
a b q3
q4
q6
q5
q7
q8q2q9
a
b

c) The regular expression is (a* | b*)*aThe -NFA for the given regular expression is as below:
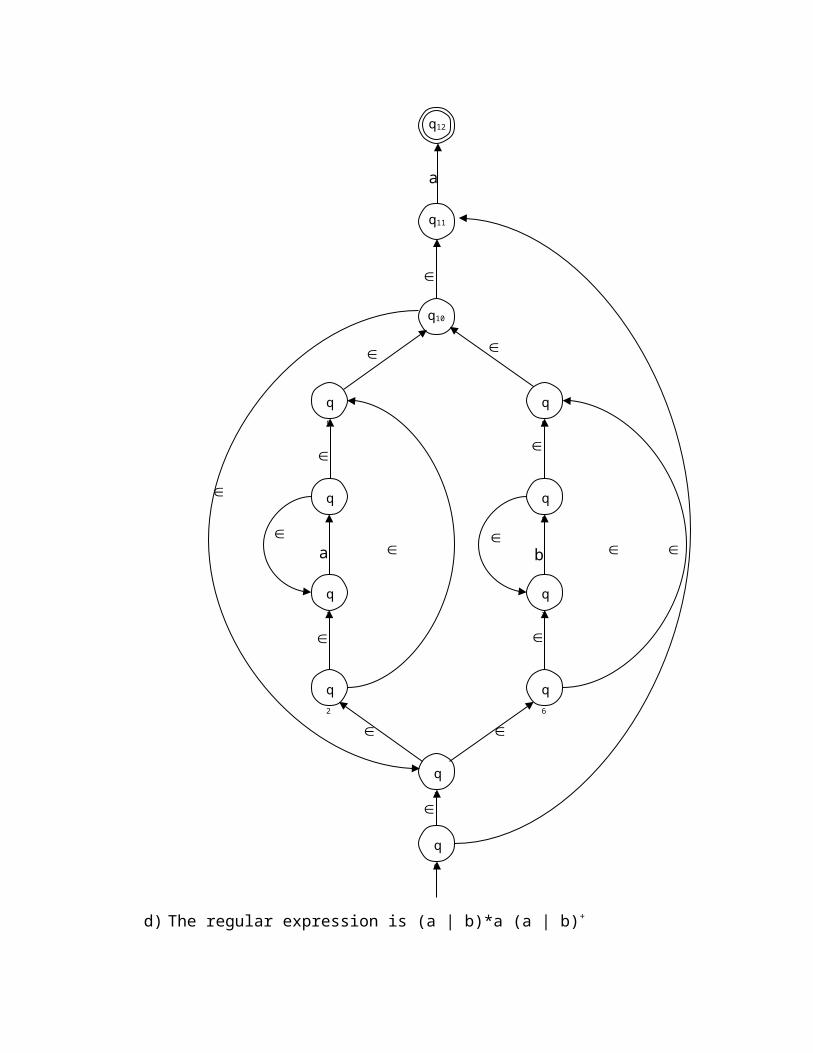
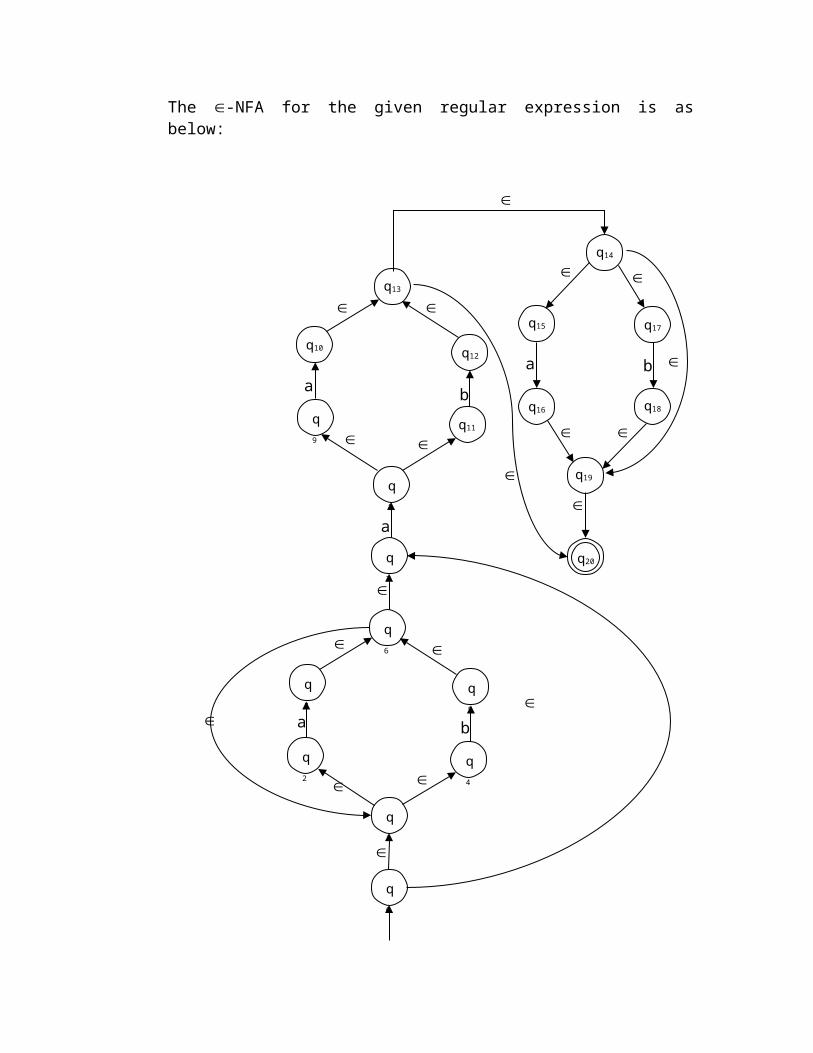
d) The regular expression is (a | b)*a (a | b)+
The -NFA for the given regular expression is as below:
q0
q2
q6
q1
q9
q8
q7
q5
q4
q3
q10
q11
q12
a
a
b
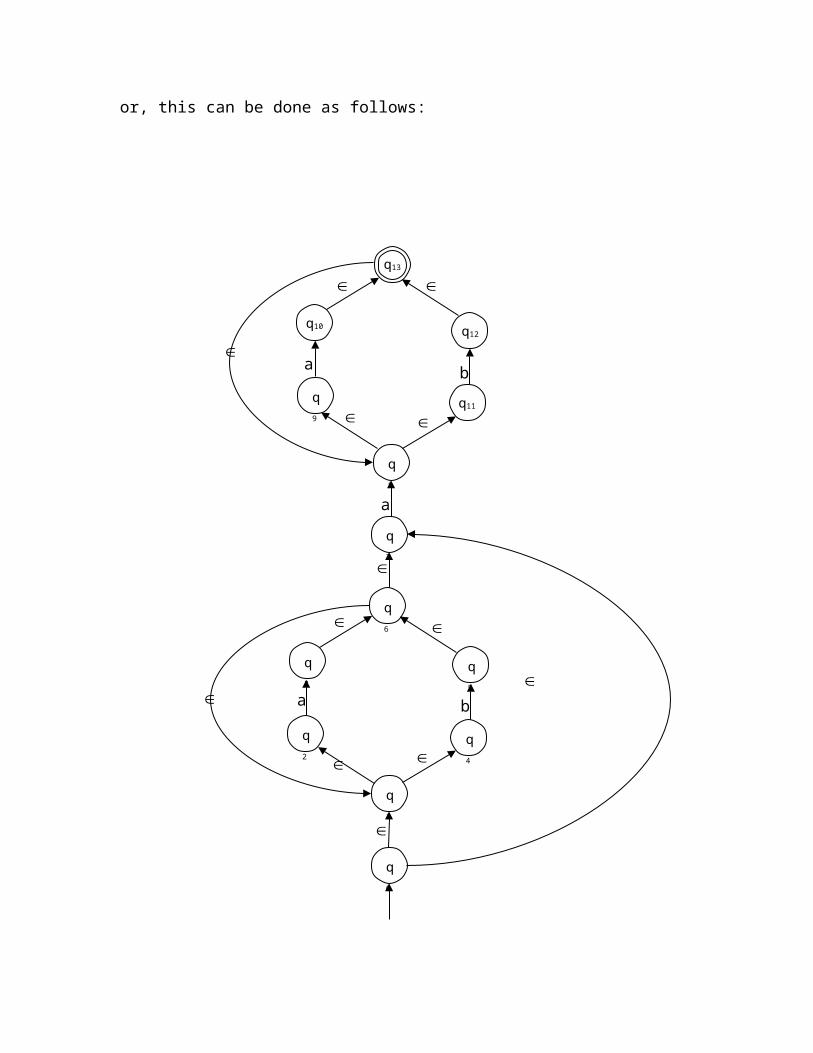
or, this can be done as follows:
q0
q2
q4
q1
q9
q7
q5
q6
q3
q8
q13
a
b
a
a
b
q10
q11
q12
q17
q16
q15
q14
a b
q19
q18
q20

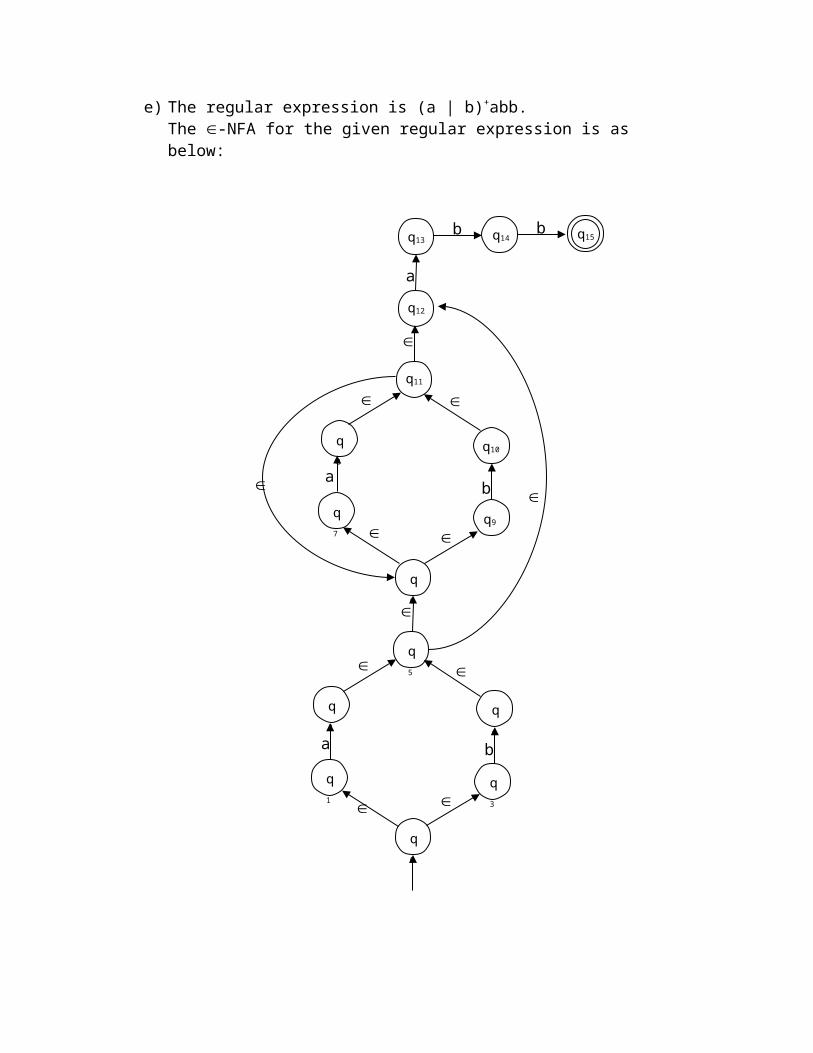
e) The regular expression is (a | b)+abb.
q0
q2
q4
q1
q9
q7
q5
q6
q3
q8
q13
a
b
a
a
b
q10
q11
q12
The -NFA for the given regular expression is as below:
or, this can be done as follows:
q1
q3
q0
q8
q6
q4
q5
q2
q7
q12
a
b
a
a
b
q9
q10
q11
q14q13b
q15b
q3
q1
q2
q7
a
ba
q4
q5
q6
q9q8b
q10b
5) The given regular expression is (a | b)*abb. The -NFA for the given regular expression is given below:
Here the -closure of {q0}={q0, q1, q2, q4, q7}= A. Here all the states in A are equivalent. Now applying ‘a’ as the input to the states in A, we get {q3, q8}. Now to get all the equivalent states of {q3, q8}, we compute the -closure of {q3, q8}.-closure {q3, q8} = {q1, q2, q3, q4, q6, q7, q8} = B.Applying ‘b’ as the input to the states in A, we get {q5}.Now to get all the equivalent states of {q5}, we compute the -closure of {q5}.-closure {q5} = {q1, q2, q4, q5, q6, q7} = C.Similarly, applying ‘a’ to B, we get, {q3, q8}.-closure {q3, q8} = B.Applying ‘b’ to B, we get, {q5, q9}.-closure {q5, q9} = {q1, q2, q4, q5, q6, q7, q9} = D.Now applying ‘a’ to C, we get, {q3, q8}.-closure {q3, q8} = B.Applying ‘b’ to C, we get, {q5}.-closure {q5} = C.Now applying ‘a’ to D, we get, {q3, q8}.-closure {q3, q8} = B.Applying ‘b’ to D, we get, {q5, q10}.-closure {q5, q10} = {q1, q2, q4, q5, q6, q7, q10} = E.Now applying ‘a’ to E, we get, {q3, q8}.-closure {q3, q8} = B.Applying ‘b’ to E, we get, {q5}.-closure {q5} = C.Now the transition table for the DFA is shown belowState Input
q7
q1
q2
q4
q3
q5
q6q0
a
b
q8
q9
q10
a
b
b
a b A B C
B B DC B CD B EE* B C
Now let us minimize the above DFA to get an equivalent minimized DFA.Here the 0-equivalent classes will be given by Q1
0={E}, Q20={A, B, C, D}, which is a
set of all final states and a set of all non-final states. Hence the set of 0-equivalent classes is given by0={ Q1
0, Q20}.
Now for 1-equivalent classes we got,Q1
1={E}, Q21={A, B, C}, Q3
1={D}.Hence the set of 1-equivalent classes is given by1={ Q1
1, Q21, Q3
1}, where Q11, Q2
1, Q31 are given above.
Now for 2-equivalent classes we got,Q1
2={E}, Q22={A, C}, Q3
2={B}, Q42={D}.
Hence the set of 2-equivalent classes is given by2={ Q1
2, Q22, Q3
2, Q42}, where Q1
2, Q22, Q3
2, Q42 are given above.
Now for 3-equivalent classes we got,Q1
3={E}, Q23={A, C}, Q3
3={B}, Q43={D}.
Hence the set of 3-equivalent classes is given by3={ Q1
3, Q23, Q3
3, Q43}, where Q1
3, Q23, Q3
3, Q43 are given above.
We can see that 2=3. Hence 2 is the set of equivalence classes.
So, now the transition table for minimized DFA is given below.
State Input a b
A B AB B DD B EE* B A
The transition diagram for the DFA is shown below.
A B D
E
a
b
b
b
b
aa
a


















