
7 Series DSP Resources Part 1. Objectives After completing this module, you will be able to:...
47
7 Series DSP Resources Part 1
-
Upload
gerald-rundall -
Category
Documents
-
view
217 -
download
0
Transcript of 7 Series DSP Resources Part 1. Objectives After completing this module, you will be able to:...

7 Series DSP Resources
Part 1

Objectives
After completing this module, you will be able to:
Describe the primary usage models of DSP slices
Describe the DSP slice in the 7 series FPGAs

DSP Overview
7 Series FPGA DSP Slice
Pre-Adder and Dynamic Pipeline Control Advantages
IP Support and Inference
Summary
Lessons

* Source: Jan Rabaey, BWRC
1960 1970 1980 1990 2000 2010
DSP/GPP*
Traditional Processor
Architectures
SD/HD VideoSD/HD Video
RadarRadarImagingImaging3G3G
4G4G
SDRSDR
Pe
rfo
rma
nc
e (A
lgo
rith
mic
& P
roce
sso
r F
ore
cast
)
Algorithm C
omplexity
Need a solution to fill the gap
Performance requirements are outpacing traditional
DSP solutions
Performance requirements are outpacing traditional
DSP solutions LTELTE
Growing DSP Performance Gap

Typical DSP Operation
Diagram of a typical FIR filter– Parallel computing process by nature– N number of taps– N multiplications should happen in parallel
i=N-1
i=0ki.X(n-i)
Y(n) =
Viewed as an Equation Viewed as a Diagram
MultiplyAccumulate N times
Z-1
k0
Z-1
k1
Z-1
k2 k3
Z-1
kN-1
X(n)
Y(n)
Multiply
Delay(Register)
Summation
Coefficients
Coefficient

Sequential vs. Parallel DSP Processing
Data Out
Single-MAC Unit
Coefficients
1.2 GHz1.2 GHz
3960 clock cycles 3960 clock cycles = 303 KSPS= 303 KSPS
3960 clock cycles needed
Data In
X
+Reg
600 MHz 600 MHz
1 clock cycle 1 clock cycle= 600 MSPS= 600 MSPS
Data Out
FPGA - Fully Parallel Implementation(7 Series FPGA)
3960 operations in 1 clock cycle
Data In
X
+
C0 C0XC1 XC2 XC3 XC2015…
Reg
Reg
Reg
Reg
Standard DSP Processor – Sequential
(Generic DSP)

DSP Slice Features
Z-1 MULT Z-1 ADD Z-1
Z-2
36
OpMode7
48A:B48
0
072
Y36
X
017-bit shift
17-bit shift
A
25
18
CE
M REG
D Q
CE
P REG
D Q
B48
D
ALUMode
CarryIn
48
Z
CE
C REG
D Q
1
4
=
C or MC
CE
A REG
D Q2-Deep
CE
B REG
D2-Deep
Q
P
PATTERN DETECT
C
Inpu
t C
ondi
tioni
ng
OPCTL
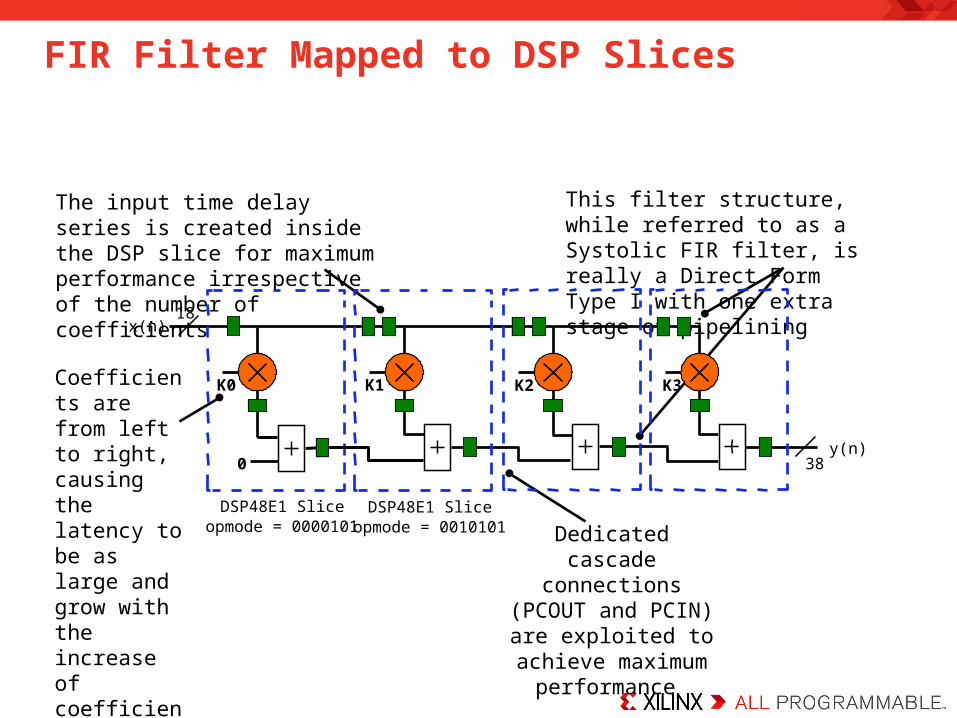
FIR Filter Mapped to DSP Slices
Coefficients are from left to right, causing the latency to be as large and grow with the increase of coefficients
The input time delay series is created inside the DSP slice for maximum performance irrespective of the number of coefficients
Dedicated cascade connections (PCOUT and
PCIN) are exploited to achieve maximum
performance
This filter structure, while referred to as a Systolic FIR filter, is really a Direct Form Type I with one extra stage of pipelining
K0 K1 K2 K3
0
DSP48E1 Sliceopmode = 0010101
DSP48E1 Sliceopmode = 0000101
x(n)
y(n)38
18

Non-DSP Functions (Addition)
in
out
out
in
START: This is the typical adder tree found in many signal processing designs
in
out
1 2
3
Remove all pipelining from the tree. This makes it easier to understand and visualize the changes
Rearrange the tree. Notice that functionally has not changed. The diagram has just been redrawn
Pipelining is required for performance. Adding one in the chain requires one in the data path delay as well. Determining mapping to DSP48E is easy now
0
DSP48E Sliceopmode = 0010101
DSP48E Sliceopmode = 0000101
in
out

DSP Review
7 Series FPGA DSP Slice
Pre-Adder and Dynamic Pipeline Control Advantages
IP Support and Inference
Summary
Lessons

Summary
All 7 series FPGAs contain the same DSP48E1 cell– The DSP48E1 is identical to the one used in the Virtex-6 FPGA
The DSP48E1 cell has the following features– 25x18 signed multiplier– 48-bit add/subtract/accumulate– Pipeline registers for high speed– Pattern detector– SIMD operators– Cascade paths– 25 bit pre-adder– Dynamic pipeline control

Where Can I Learn More?
7 Series DSP48E1 Slice User Guide– Slice description– Design consideration
• How to design to optimize for power and performance• How to use advanced design techniques
– Design recommendations for XST• This guide has example inferences of many architectural resources
– XST User Guide• Refer to the Coding Techniques chapter
Xilinx Education Services courses– www.xilinx.com/training
• Xilinx tools and architecture courses and other Free videos!

Trademark Information
Xilinx is disclosing this Document and Intellectual Property (hereinafter “the Design”) to you for use in the development of designs to operate on, or interface with Xilinx FPGAs. Except as stated herein, none of the Design may be copied, reproduced, distributed, republished, downloaded, displayed, posted, or transmitted in any form or by any means including, but not limited to, electronic, mechanical, photocopying, recording, or otherwise, without the prior written consent of Xilinx. Any unauthorized use of the Design may violate copyright laws, trademark laws, the laws of privacy and publicity, and communications regulations and statutes.
Xilinx does not assume any liability arising out of the application or use of the Design; nor does Xilinx convey any license under its patents, copyrights, or any rights of others. You are responsible for obtaining any rights you may require for your use or implementation of the Design. Xilinx reserves the right to make changes, at any time, to the Design as deemed desirable in the sole discretion of Xilinx. Xilinx assumes no obligation to correct any errors contained herein or to advise you of any correction if such be made. Xilinx will not assume any liability for the accuracy or correctness of any engineering or technical support or assistance provided to you in connection with the Design.
THE DESIGN IS PROVIDED “AS IS" WITH ALL FAULTS, AND THE ENTIRE RISK AS TO ITS FUNCTION AND IMPLEMENTATION IS WITH YOU. YOU ACKNOWLEDGE AND AGREE THAT YOU HAVE NOT RELIED ON ANY ORAL OR WRITTEN INFORMATION OR ADVICE, WHETHER GIVEN BY XILINX, OR ITS AGENTS OR EMPLOYEES. XILINX MAKES NO OTHER WARRANTIES, WHETHER EXPRESS, IMPLIED, OR STATUTORY, REGARDING THE DESIGN, INCLUDING ANY WARRANTIES OF MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE, TITLE, AND NONINFRINGEMENT OF THIRD-PARTY RIGHTS.
IN NO EVENT WILL XILINX BE LIABLE FOR ANY CONSEQUENTIAL, INDIRECT, EXEMPLARY, SPECIAL, OR INCIDENTAL DAMAGES, INCLUDING ANY LOST DATA AND LOST PROFITS, ARISING FROM OR RELATING TO YOUR USE OF THE DESIGN, EVEN IF YOU HAVE BEEN ADVISED OF THE POSSIBILITY OF SUCH DAMAGES. THE TOTAL CUMULATIVE LIABILITY OF XILINX IN CONNECTION WITH YOUR USE OF THE DESIGN, WHETHER IN CONTRACT OR TORT OR OTHERWISE, WILL IN NO EVENT EXCEED THE AMOUNT OF FEES PAID BY YOU TO XILINX HEREUNDER FOR USE OF THE DESIGN. YOU ACKNOWLEDGE THAT THE FEES, IF ANY, REFLECT THE ALLOCATION OF RISK SET FORTH IN THIS AGREEMENT AND THAT XILINX WOULD NOT MAKE AVAILABLE THE DESIGN TO YOU WITHOUT THESE LIMITATIONS OF LIABILITY.
The Design is not designed or intended for use in the development of on-line control equipment in hazardous environments requiring fail-safe controls, such as in the operation of nuclear facilities, aircraft navigation or communications systems, air traffic control, life support, or weapons systems (“High-Risk Applications”). Xilinx specifically disclaims any express or implied warranties of fitness for such High-Risk Applications. You represent that use of the Design in such High-Risk Applications is fully at your risk.
© 2012 Xilinx, Inc. All rights reserved. XILINX, the Xilinx logo, and other designated brands included herein are trademarks of Xilinx, Inc. All other trademarks are the property of their respective owners.

7 Series DSP Resources
Part 2

Objectives
After completing this module, you will be able to:
Describe the DSP slice in the 7 series FPGAs

DSP Overview
7 Series FPGA DSP Slice
Pre-Adder and Dynamic Pipeline Control Advantages
IP Support and Inference
Summary
Lessons
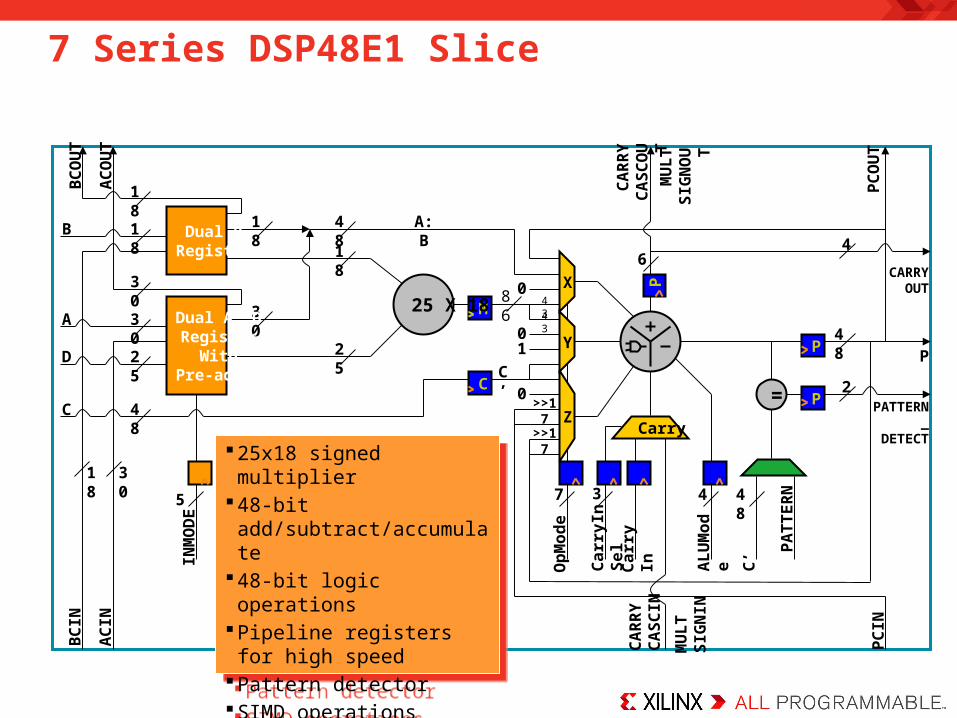
7 Series DSP48E1 Slice
PCIN
A:B
X
M
C
25 X 18
=
PY
Z>>17
>>170
0
0
1
CP
C’
C’
48
OpM
ode
7
Car
ryIn
ALU
Mod
e
4
P
Car
ryIn
Sel
3
PCO
UT
INM
OD
E
P
PATTERN_DETECT
AC
IN
BC
IN
A
B
48
48
18
D
CA
RRY
CA
SCO
UT
CARRYOUT
AC
OU
T
BC
OU
T
CA
RRY
CA
SCIN
30
18
30
18
MU
LTSI
GN
OU
T
6
MU
LTSI
GN
IN
25
PATT
ERN
Dual BRegister
Carry
5
Dual A, DRegister
WithPre-adder
30
18
48
4
4343
25
86
2
3018 25x18 signed multiplier 48-bit add/subtract/accumulate 48-bit logic operationsPipeline registers for high speedPattern detectorSIMD operations (12/24 bit)Cascade paths for wide functionsPre-adder
25x18 signed multiplier 48-bit add/subtract/accumulate 48-bit logic operationsPipeline registers for high speedPattern detectorSIMD operations (12/24 bit)Cascade paths for wide functionsPre-adder

Normal or 17-bit right shifted with MSB fill for multi-precision arithmetic
X, Y, and Z Multiplexers
Adder/subtractor operates on X, Y, Z and CIN operands– Table shows basic operations
X, Y, and Z multiplexers allow for dynamic OPMODEs
Multiplier output requires both X and Y multiplexers
ALUMODE Operation
0000 Z + X + Y + CIN
0001 -Z + (X + Y + CIN) – 1
0010 -Z – X – Y – CIN – 1
0011 Z – (X + Y + CIN)
Others Logic Operations
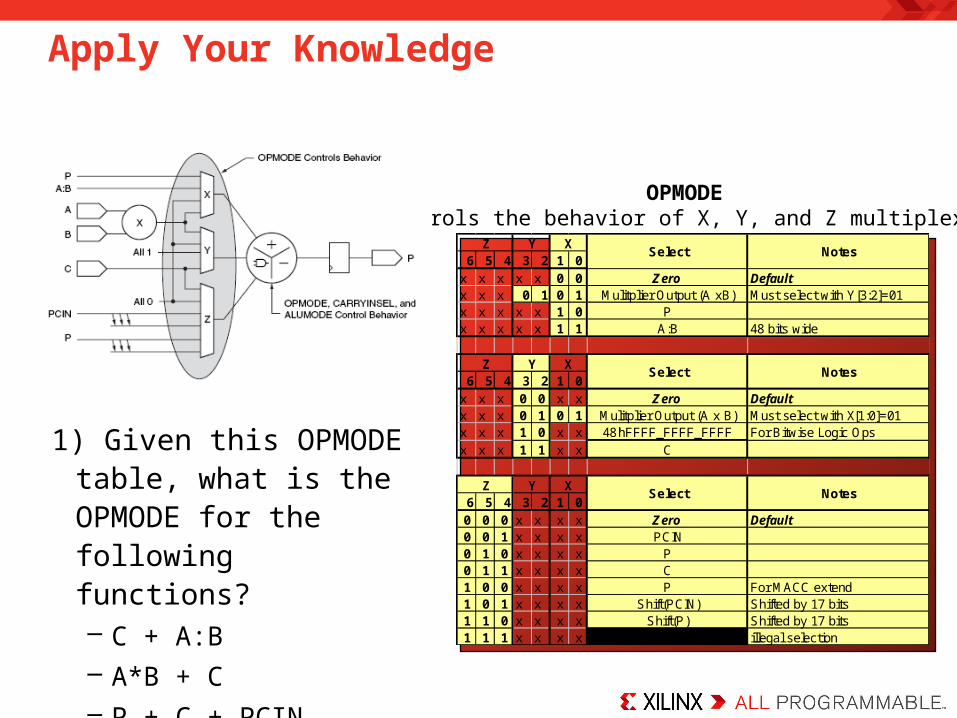
Apply Your Knowledge
1) Given this OPMODE table, what is the OPMODE for the following functions?– C + A:B– A*B + C– P + C + PCIN
6 5 4 3 2 1 0x x x x x 0 0 Zero Defaultx x x 0 1 0 1 Mulitplier Output (A xB) Must select with Y[3:2]=01x x x x x 1 0 Px x x x x 1 1 A:B 48 bits wide
6 5 4 3 2 1 0x x x 0 0 x x Zero Defaultx x x 0 1 0 1 Mulitplier Output (A x B) Must select with X[1:0]=01x x x 1 0 x x 48'hFFFF_FFFF_FFFF For Bitwise Logic Opsx x x 1 1 x x C
6 5 4 3 2 1 00 0 0 x x x x Zero Default0 0 1 x x x x PCIN0 1 0 x x x x P0 1 1 x x x x C1 0 0 x x x x P For MACC extend1 0 1 x x x x Shift(PCIN) Shifted by 17 bits1 1 0 x x x x Shift(P) Shifted by 17 bits1 1 1 x x x x illegal selection
Z Y X
Select
Select
Select
Z
Z Y X
XYNotes
Notes
Notes
OPMODE Controls the behavior of X, Y, and Z multiplexers

Dual B Register
B input to multiplier is controlled by INMODE[4]– Dynamically selects B1/B2 pipeline level
B input to X MUX and BCOUT cascade outputs are statically controlled by bitstream options
B1
B 18B2
BCINB MULT
BCOUT
X MUX
18
18
18
INMODE[4]
Bitstream Controlled
Dynamically Controlled

Dual A, D, Registers and Pre-Adder
A1
A 30A2
ACIN
A MULT
ACOUT
X MUX
D 25
30
30
DAD
INMODE[0]
INMODE[1]
INMODE[2]INMODE[3]25
25
25
A input to multiplier is controlled by INMODE[3:0]– Dynamically selects A1/A2 pipeline level– Dynamically selects add/subtract– Dynamically selects Zero for A or D
ACOUT and X MUX input are statically controlled
Bitstream Controlled
Dynamically Controlled

X
Y
Z
P0
PA:B
1
0
PPCIN
0
C
ALUMODE[3:0]
OPMODE[3:0]
Logic Unit Mode OPMODE[3:2] ALUMODE[3:0]
X XOR Z 00 0100
X XNOR Z 00 0101
X XNOR Z 00 0110
X XOR Z 00 0111
X AND Z 00 1100
X AND (NOT Z) 00 1101
X NAND Z 00 1110
(NOT X) OR Z 00 1111
X XNOR Z 10 0100
X XOR Z 10 0101
X XOR Z 10 0110
X XNOR Z 10 0111
X OR Z 10 1100
X OR (NOT Z) 10 1101
X NOR Z 10 1110
(NOT X) AND Z 10 1111
Two-Input Logic Functions
48-bit logic operations– XOR, XNOR, AND, NAND, OR,
NOR, NOT
ALUMODEs

Pattern Detect and SIMD
Pattern detection– Pattern and mask operation on output of adder
• Pattern can be constant (set by attribute) or C input– Enables
• Symmetric rounding for multi-precision operations• Convergent rounding• Saturation• Accumulator terminal count
SIMD operations– 48-bit adder broken into 2x24 bits or 4x12 bits
• Allows two or four independent additions to be done– Carry bits brought out independently and
disabled between sections• Carry bits can be cascaded between DSP48E1
slices
= P
C or MC

Cascade Paths
Cascade paths exist from each DSP48E1 slice to the slice above it– A input, B input, P output, and carry out
• P cascade path can be shifted by 17 bits by slice above
Enables common functions with little or no additional resources– Wider accumulators, wider multipliers, complex multipliers, and FIR filters– Example: 35-bit x 25-bit multiplier with two DSP48E1s
0,B[16:0]
A[24:0]
B[34:17]B P
25
18
B P
A 25
18
SHIFT 17
P[16:0] = OUT[16:0]
P[42:0] = OUT[59:17]
ACIN
DSP48_1OPMODE 0010101ALUMODE 0000
DSP48_0OPMODE 0000101ALUMODE 0000

DSP Review
7 Series FPGA DSP Slice
Pre-Adder and Dynamic Pipeline Control Advantages
IP Support and Inference
Summary
Lessons

Summary
All 7 series FPGAs contain the same DSP48E1 cell– The DSP48E1 is identical to the one used in the Virtex-6 FPGA
The DSP48E1 cell has the following features– 25x18 signed multiplier– 48-bit add/subtract/accumulate– Pipeline registers for high speed– Pattern detector– SIMD operators– Cascade paths– 25 bit pre-adder– Dynamic pipeline control

Trademark Information
Xilinx is disclosing this Document and Intellectual Property (hereinafter “the Design”) to you for use in the development of designs to operate on, or interface with Xilinx FPGAs. Except as stated herein, none of the Design may be copied, reproduced, distributed, republished, downloaded, displayed, posted, or transmitted in any form or by any means including, but not limited to, electronic, mechanical, photocopying, recording, or otherwise, without the prior written consent of Xilinx. Any unauthorized use of the Design may violate copyright laws, trademark laws, the laws of privacy and publicity, and communications regulations and statutes.
Xilinx does not assume any liability arising out of the application or use of the Design; nor does Xilinx convey any license under its patents, copyrights, or any rights of others. You are responsible for obtaining any rights you may require for your use or implementation of the Design. Xilinx reserves the right to make changes, at any time, to the Design as deemed desirable in the sole discretion of Xilinx. Xilinx assumes no obligation to correct any errors contained herein or to advise you of any correction if such be made. Xilinx will not assume any liability for the accuracy or correctness of any engineering or technical support or assistance provided to you in connection with the Design.
THE DESIGN IS PROVIDED “AS IS" WITH ALL FAULTS, AND THE ENTIRE RISK AS TO ITS FUNCTION AND IMPLEMENTATION IS WITH YOU. YOU ACKNOWLEDGE AND AGREE THAT YOU HAVE NOT RELIED ON ANY ORAL OR WRITTEN INFORMATION OR ADVICE, WHETHER GIVEN BY XILINX, OR ITS AGENTS OR EMPLOYEES. XILINX MAKES NO OTHER WARRANTIES, WHETHER EXPRESS, IMPLIED, OR STATUTORY, REGARDING THE DESIGN, INCLUDING ANY WARRANTIES OF MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE, TITLE, AND NONINFRINGEMENT OF THIRD-PARTY RIGHTS.
IN NO EVENT WILL XILINX BE LIABLE FOR ANY CONSEQUENTIAL, INDIRECT, EXEMPLARY, SPECIAL, OR INCIDENTAL DAMAGES, INCLUDING ANY LOST DATA AND LOST PROFITS, ARISING FROM OR RELATING TO YOUR USE OF THE DESIGN, EVEN IF YOU HAVE BEEN ADVISED OF THE POSSIBILITY OF SUCH DAMAGES. THE TOTAL CUMULATIVE LIABILITY OF XILINX IN CONNECTION WITH YOUR USE OF THE DESIGN, WHETHER IN CONTRACT OR TORT OR OTHERWISE, WILL IN NO EVENT EXCEED THE AMOUNT OF FEES PAID BY YOU TO XILINX HEREUNDER FOR USE OF THE DESIGN. YOU ACKNOWLEDGE THAT THE FEES, IF ANY, REFLECT THE ALLOCATION OF RISK SET FORTH IN THIS AGREEMENT AND THAT XILINX WOULD NOT MAKE AVAILABLE THE DESIGN TO YOU WITHOUT THESE LIMITATIONS OF LIABILITY.
The Design is not designed or intended for use in the development of on-line control equipment in hazardous environments requiring fail-safe controls, such as in the operation of nuclear facilities, aircraft navigation or communications systems, air traffic control, life support, or weapons systems (“High-Risk Applications”). Xilinx specifically disclaims any express or implied warranties of fitness for such High-Risk Applications. You represent that use of the Design in such High-Risk Applications is fully at your risk.
© 2012 Xilinx, Inc. All rights reserved. XILINX, the Xilinx logo, and other designated brands included herein are trademarks of Xilinx, Inc. All other trademarks are the property of their respective owners.

7 Series DSP Resources
Part 3

Objectives
After completing this module, you will be able to:
Describe the basic usage models of DSP slices
Describe the DSP slice in the 7 series FPGAs

DSP Overview
7 Series FPGA DSP Slice
Pre-Adder and Dynamic Pipeline Control Advantages
IP Support and Inference
Summary
Lessons

Pre-Adder
The pre-adder can add or subtract the two 25-bit operands on the A and the D inputs before the result drives the multiplier
Benefits– Perfect for operations using symmetrical coefficients– Doubles the efficiency of symmetric FIR and symmetric IIR and transpose
convolution filters– Half the power consumption compared to architectures without a pre-adder– Smaller total logic footprint– A small change with a big benefit

Symmetrical Filters
When the coefficients are symmetrical– The pre-adders either reduce the number of multiplications by 50% or
double the sample rate– Factorizing the taps replaces one multiplication by a pre-addition
(or pre-subtraction)
k13 k17 Non symmetrical filter (k13≠k17) :(tap13×k13) + (tap17×k17)
Symmetrical filter (k13=k17) :(tap13+tap17) × k13
2 mults and one post-add
1 pre-add
Symmetrical Filter Example
1 multDirect benefit: saves 50% of the DSP slices

Six-Tap Transpose FIR Filter Without Pre-Adder
Uses six legacy DSP slices (without pre-adder)
X X X Xk0 k1 k2 k1
+ + + +
y(n-4)
z-1 z-1 z-1 z-1
z-1 z-1 z-1 z-1
Xk0
+
z-1
z-10
Xk2
+
z-1
z-1
z-2 z-2 z-2 z-2 z-2 z-2
x(n-2)
x(n-3)x(n-4)x(n-5)x(n-6)x(n-7)
x(n)

Six-Tap Transpose FIR Filter Using the Pre-Adder
Optimized implementation supported by XST
using only three slices instead of six
x(n)
X Xk2 k1
+ +
y(n-4)
z-2
z-1
z-1 z-1
z-1 z-1
Xk0
+
z-1
z-1
z-10
z-2
z-1
+
z-2
+
z-1z-1
+
z-1
x(n-7)+x(n-2)x(n-6)+x(n-3)x(n-5)+x(n-4)

Dynamic Pipeline Control
The 7 series FPGA DSP slice has dynamic pipeline control on the A and B registers– User can select which of the two pipeline registers to use for calculations
on a clock-by-clock basis
Benefits– Allows an operation to reuse the same operand in subsequent cycles

Application: Sequential Complex Multiply
Complex Multiply• (A + ai) * (B + bi) = (AB-ab) + (Ab+aB)i• Use the two AB registers to locally store the real and imaginary parts of the operands– Read each component of the complex operands out of memory only once– Fewer memory reads because A, a, B, and b are then stored locally
Dynamic routing is controlled by an FSMupdating the INMODE register on the fly
Needs only four clocks for 18-bit datausing a single slice
A
a
A
CEA2
CEA1
INMODE
B
b
B
CEB2
CEB1
INMODE X m +
USE_DPORT=FALSEAA
aa
A
CEA2
CEA1
BB
bb
B
CEB2
CEB1
X mm +
USE_DPORT=FALSE

Application: Sequential Large Multiply
Four-step large multiplication42 bits * 34 bits = (A:a) * (B:b) =
A*B + sh17(A*0b + B*00000000a + sh17(0b*00000000a)
Needs only four clocks for 18-bit data using a single slice

DSP Review
7 Series FPGA DSP Slice
Pre-Adder and Dynamic Pipeline Control Advantages
IP Support and Inference
Summary
Lessons

IP Support and Inference
Some basic functions can be inferred– Example: Multiplier, Multiply-Accumulate, …
Other functions are supported through the CORE Generator™ interface– Examples: FFT, FIR Compiler, and DDS Compiler
New IP cores become available with each service pack– Visit the IP Center for information on the newest IP cores
• www.xilinx.com/ipcenter

--------------------------------------------------------------------- Example: 16x16 Multiplier, inputs registered once, -- outputs twice-- Matches 1 DSP48 slice-- OpMode(Z,Y,X):Subtract-- (xxx,01,01):0-------------------------------------------------------------------p1 <= a1*b1;
process (clk) is begin if clk'event and clk = '1' then if rst = '1' then a1 <= (others => '0'); b1 <= (others => '0'); p <= (others => '0'); elsif ce = '1' then a1 <= a; b1 <= b; p <= p1; end if; end if; end process;
--------------------------------------------------------------------- Example: 16x16 Multiplier, inputs registered once, -- outputs twice-- Matches 1 DSP48 slice-- OpMode(Z,Y,X):Subtract-- (xxx,01,01):0-------------------------------------------------------------------p1 <= a1*b1;
process (clk) is begin if clk'event and clk = '1' then if rst = '1' then a1 <= (others => '0'); b1 <= (others => '0'); p <= (others => '0'); elsif ce = '1' then a1 <= a; b1 <= b; p <= p1; end if; end if; end process;
///////////////////////////////////////////////////////////////////// Example: 16x16 Multiplier, inputs registered // once, outputs twice// Matches 1 DSP48 slice// OpMode(Z,Y,X):Subtract// (xxx,01,01):0///////////////////////////////////////////////////////////////////
assign p1 = a1*b1;
always @(posedge clk) if (rst == 1'b1) begin a1 <= 0; b1 <= 0; p <= 0; end else if (ce == 1'b1) begin a1 <= a; b1 <= b; p <= p1; end
///////////////////////////////////////////////////////////////////// Example: 16x16 Multiplier, inputs registered // once, outputs twice// Matches 1 DSP48 slice// OpMode(Z,Y,X):Subtract// (xxx,01,01):0///////////////////////////////////////////////////////////////////
assign p1 = a1*b1;
always @(posedge clk) if (rst == 1'b1) begin a1 <= 0; b1 <= 0; p <= 0; end else if (ce == 1'b1) begin a1 <= a; b1 <= b; p <= p1; end
Inferring a 16 x 16 Multiplier

-------------------------------------------------------------- Example: Multiply add function, single level of register-- Matches 1 DSP48 slice-- OpMode(Z,Y,X):Subtract-- (011,01,01):0------------------------------------------------------------
p1 <= a*b + c;
process (clk) is begin if clk'event and clk = '1' then if rst = '1' then p <= (others => '0'); elsif ce = '1' then p <= p1; end if; end if; end process;
-------------------------------------------------------------- Example: Multiply add function, single level of register-- Matches 1 DSP48 slice-- OpMode(Z,Y,X):Subtract-- (011,01,01):0------------------------------------------------------------
p1 <= a*b + c;
process (clk) is begin if clk'event and clk = '1' then if rst = '1' then p <= (others => '0'); elsif ce = '1' then p <= p1; end if; end if; end process;
////////////////////////////////////////////////////////////// Example: Multiply add function, single level of register// Matches 1 DSP48 slice// OpMode(Z,Y,X):Subtract// (011,01,01):0////////////////////////////////////////////////////////////
assign p1 = a*b + c;
always @(posedge clk) if (rst == 1'b1) p <= 0; else if (ce == 1'b1) begin p <= p1; end
////////////////////////////////////////////////////////////// Example: Multiply add function, single level of register// Matches 1 DSP48 slice// OpMode(Z,Y,X):Subtract// (011,01,01):0////////////////////////////////////////////////////////////
assign p1 = a*b + c;
always @(posedge clk) if (rst == 1'b1) p <= 0; else if (ce == 1'b1) begin p <= p1; end
Inferring a Multiply Accumulate (MACC)

-------------------------------------------------------------------------- Example: 16 bit adder 2 inputs, input and output -- registered once-- Mapping to DSP48 should be driven by timing as -- DSP48 are limited resources. The -use_dsp48 XST -- switch must be set to YES-- Matches 1 DSP48 slice-- OpMode(Z,Y,X):Subtract-- (000,11,11):0 or-- (011,00,11):0------------------------------------------------------------------------
p1 <= a1 + b1;
process (clk) is begin if clk'event and clk = '1' then if rst = '1' then p <= (others => '0'); a1 <= (others => '0'); b1 <= (others => '0'); elsif ce = '1' then a1 <= a; b1 <= b; p <= p1; end if; end if; end process;
-------------------------------------------------------------------------- Example: 16 bit adder 2 inputs, input and output -- registered once-- Mapping to DSP48 should be driven by timing as -- DSP48 are limited resources. The -use_dsp48 XST -- switch must be set to YES-- Matches 1 DSP48 slice-- OpMode(Z,Y,X):Subtract-- (000,11,11):0 or-- (011,00,11):0------------------------------------------------------------------------
p1 <= a1 + b1;
process (clk) is begin if clk'event and clk = '1' then if rst = '1' then p <= (others => '0'); a1 <= (others => '0'); b1 <= (others => '0'); elsif ce = '1' then a1 <= a; b1 <= b; p <= p1; end if; end if; end process;
////////////////////////////////////////////////////////////////////////// Example: 16 bit adder 2 inputs, input and output // registered once// Mapping to DSP48 should be driven by timing as // DSP48 are limited resources. The -use_dsp48 XST // switch must be set to YES// Matches 1 DSP48 slice// OpMode(Z,Y,X):Subtract// (000,11,11):0 or// (011,00,11):0////////////////////////////////////////////////////////////////////////
assign p1 = a1 + b1;
always @(posedge clk) if (rst == 1'b1) begin p <= 0; a1 <= 0; b1 <= 0; end else if (ce == 1'b1) begin a1 <= a; b1 <= b; p <= p1; end
////////////////////////////////////////////////////////////////////////// Example: 16 bit adder 2 inputs, input and output // registered once// Mapping to DSP48 should be driven by timing as // DSP48 are limited resources. The -use_dsp48 XST // switch must be set to YES// Matches 1 DSP48 slice// OpMode(Z,Y,X):Subtract// (000,11,11):0 or// (011,00,11):0////////////////////////////////////////////////////////////////////////
assign p1 = a1 + b1;
always @(posedge clk) if (rst == 1'b1) begin p <= 0; a1 <= 0; b1 <= 0; end else if (ce == 1'b1) begin a1 <= a; b1 <= b; p <= p1; end
Inferring a 2-Input Adder

--------------------------------------------------------------------------------- Example: Loadable Multiply Accumulate with one level -- of registers-- Map into 1 DSP48 slice-- Funtion: OpMode(Z,Y,X):Subtract-- - load (011,00,00):0-- - mult_acc (010,01,01):0-- Restriction: Since C input of DSP48 slice is used, then -- adjacent DSP cannot se a different c input (c input are -- shared between 2 adjacent DSP48 slices)-- Expected mapping:-- AREG: no, BREG: no, CREG: no, MREG: no, PREG: yes-------------------------------------------------------------------------------
with load select p_tmp <= signed(c) when '1' , p_reg + a1*b1 when others;
process(clk) begin if clk'event and clk = '1' then if p_rst = '1' then p_reg <= (others => '0'); a1 <= (others => '0'); b1 <= (others => '0'); elsif p_ce = '1' then p_reg <= p_tmp; a1 <= signed(a); b1 <= signed(b); end if; end if; end process;
p <= std_logic_vector(p_reg);
--------------------------------------------------------------------------------- Example: Loadable Multiply Accumulate with one level -- of registers-- Map into 1 DSP48 slice-- Funtion: OpMode(Z,Y,X):Subtract-- - load (011,00,00):0-- - mult_acc (010,01,01):0-- Restriction: Since C input of DSP48 slice is used, then -- adjacent DSP cannot se a different c input (c input are -- shared between 2 adjacent DSP48 slices)-- Expected mapping:-- AREG: no, BREG: no, CREG: no, MREG: no, PREG: yes-------------------------------------------------------------------------------
with load select p_tmp <= signed(c) when '1' , p_reg + a1*b1 when others;
process(clk) begin if clk'event and clk = '1' then if p_rst = '1' then p_reg <= (others => '0'); a1 <= (others => '0'); b1 <= (others => '0'); elsif p_ce = '1' then p_reg <= p_tmp; a1 <= signed(a); b1 <= signed(b); end if; end if; end process;
p <= std_logic_vector(p_reg);
///////////////////////////////////////////////////////////////////////////////// Example: Loadable Multiply Accumulate with one level // of registers// Map into 1 DSP48 slice// Funtion: OpMode(Z,Y,X):Subtract// - load (011,00,00):0// - mult_acc (010,01,01):0// Restriction: Since C input of DSP48 slice is used, then // adjacent DSP cannot use a different c input (c input are // shared between 2 adjacent DSP48 slices)// Expected mapping:// AREG: no, BREG: no, CREG: no, MREG: no, PREG: yes///////////////////////////////////////////////////////////////////////////////
assign p_tmp = load ? c:p + a1*b1;
always @(posedge clk) if (p_rst == 1'b1) begin p <= 0; a1 <=0; b1 <=0; end else if (p_ce == 1'b1) begin p <= p_tmp; a1 <=a; b1 <= b; end
///////////////////////////////////////////////////////////////////////////////// Example: Loadable Multiply Accumulate with one level // of registers// Map into 1 DSP48 slice// Funtion: OpMode(Z,Y,X):Subtract// - load (011,00,00):0// - mult_acc (010,01,01):0// Restriction: Since C input of DSP48 slice is used, then // adjacent DSP cannot use a different c input (c input are // shared between 2 adjacent DSP48 slices)// Expected mapping:// AREG: no, BREG: no, CREG: no, MREG: no, PREG: yes///////////////////////////////////////////////////////////////////////////////
assign p_tmp = load ? c:p + a1*b1;
always @(posedge clk) if (p_rst == 1'b1) begin p <= 0; a1 <=0; b1 <=0; end else if (p_ce == 1'b1) begin p <= p_tmp; a1 <=a; b1 <= b; end
Inferring a Loadable MACC

DSP Review
7 Series FPGA DSP Slice
Pre-Adder and Dynamic Pipeline Control Advantages
IP Support and Inference
Summary
Lessons

Summary
All 7 series FPGAs contain the same DSP48E1 cell– The DSP48E1 is identical to the one used in the Virtex-6 FPGA
The DSP48E1 cell has the following features– 25x18 signed multiplier– 48-bit add/subtract/accumulate– Pipeline registers for high speed– Pattern detector– SIMD operators– Cascade paths– 25 bit pre-adder– Dynamic pipeline control
DSP48E1 slices can be inferred, instantiated or accessed using IP cores

Where Can I Learn More?
7 Series DSP48E1 Slice User Guide– Slice description– Design consideration
• How to design to optimize for power and performance• How to use advanced design techniques
– Design recommendations for XST• This guide has example inferences of many architectural resources
– XST User Guide• Refer to the Coding Techniques chapter
Xilinx Education Services courses– www.xilinx.com/training
• Xilinx tools and architecture courses and other Free videos!

Trademark Information
Xilinx is disclosing this Document and Intellectual Property (hereinafter “the Design”) to you for use in the development of designs to operate on, or interface with Xilinx FPGAs. Except as stated herein, none of the Design may be copied, reproduced, distributed, republished, downloaded, displayed, posted, or transmitted in any form or by any means including, but not limited to, electronic, mechanical, photocopying, recording, or otherwise, without the prior written consent of Xilinx. Any unauthorized use of the Design may violate copyright laws, trademark laws, the laws of privacy and publicity, and communications regulations and statutes.
Xilinx does not assume any liability arising out of the application or use of the Design; nor does Xilinx convey any license under its patents, copyrights, or any rights of others. You are responsible for obtaining any rights you may require for your use or implementation of the Design. Xilinx reserves the right to make changes, at any time, to the Design as deemed desirable in the sole discretion of Xilinx. Xilinx assumes no obligation to correct any errors contained herein or to advise you of any correction if such be made. Xilinx will not assume any liability for the accuracy or correctness of any engineering or technical support or assistance provided to you in connection with the Design.
THE DESIGN IS PROVIDED “AS IS" WITH ALL FAULTS, AND THE ENTIRE RISK AS TO ITS FUNCTION AND IMPLEMENTATION IS WITH YOU. YOU ACKNOWLEDGE AND AGREE THAT YOU HAVE NOT RELIED ON ANY ORAL OR WRITTEN INFORMATION OR ADVICE, WHETHER GIVEN BY XILINX, OR ITS AGENTS OR EMPLOYEES. XILINX MAKES NO OTHER WARRANTIES, WHETHER EXPRESS, IMPLIED, OR STATUTORY, REGARDING THE DESIGN, INCLUDING ANY WARRANTIES OF MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE, TITLE, AND NONINFRINGEMENT OF THIRD-PARTY RIGHTS.
IN NO EVENT WILL XILINX BE LIABLE FOR ANY CONSEQUENTIAL, INDIRECT, EXEMPLARY, SPECIAL, OR INCIDENTAL DAMAGES, INCLUDING ANY LOST DATA AND LOST PROFITS, ARISING FROM OR RELATING TO YOUR USE OF THE DESIGN, EVEN IF YOU HAVE BEEN ADVISED OF THE POSSIBILITY OF SUCH DAMAGES. THE TOTAL CUMULATIVE LIABILITY OF XILINX IN CONNECTION WITH YOUR USE OF THE DESIGN, WHETHER IN CONTRACT OR TORT OR OTHERWISE, WILL IN NO EVENT EXCEED THE AMOUNT OF FEES PAID BY YOU TO XILINX HEREUNDER FOR USE OF THE DESIGN. YOU ACKNOWLEDGE THAT THE FEES, IF ANY, REFLECT THE ALLOCATION OF RISK SET FORTH IN THIS AGREEMENT AND THAT XILINX WOULD NOT MAKE AVAILABLE THE DESIGN TO YOU WITHOUT THESE LIMITATIONS OF LIABILITY.
The Design is not designed or intended for use in the development of on-line control equipment in hazardous environments requiring fail-safe controls, such as in the operation of nuclear facilities, aircraft navigation or communications systems, air traffic control, life support, or weapons systems (“High-Risk Applications”). Xilinx specifically disclaims any express or implied warranties of fitness for such High-Risk Applications. You represent that use of the Design in such High-Risk Applications is fully at your risk.
© 2012 Xilinx, Inc. All rights reserved. XILINX, the Xilinx logo, and other designated brands included herein are trademarks of Xilinx, Inc. All other trademarks are the property of their respective owners.


















