
*2fflfllflflfnlflllf - apps.dtic.mil · ad-a.96 452 maryland univ college park dept of computer...
184
AD-A.96 452 MARYLAND UNIV COLLEGE PARK DEPT OF COMPUTER SCIENCE F/B 9/2 AN EXPERIMENTAL INVESTIGATION OF COMPUTER PROGRAM DEVELOPMENT A-ETC(U) DEC 79 R W REITER AFOSR-77-3181 UNCLASSIFIED TR-853 AFOSR-TR-81-0214 *2fflfllflflfnlflllf IIEIIIIEEIIIIE EIEEEIIEIIIII Ullllllllulll EIIIEEEIIIIIEE IIIIIIIIIIIIIE
Transcript of *2fflfllflflfnlflllf - apps.dtic.mil · ad-a.96 452 maryland univ college park dept of computer...

AD-A.96 452 MARYLAND UNIV COLLEGE PARK DEPT OF COMPUTER SCIENCE F/B 9/2AN EXPERIMENTAL INVESTIGATION OF COMPUTER PROGRAM DEVELOPMENT A-ETC(U)DEC 79 R W REITER AFOSR-77-3181
UNCLASSIFIED TR-853 AFOSR-TR-81-0214*2fflfllflflfnlflllfIIEIIIIEEIIIIEEIEEEIIEIIIIIUllllllllulllEIIIEEEIIIIIEEIIIIIIIIIIIIIE

AFosR-Th- 8 1-0214
LEV. .F.VE
V COMPUTER SCIENCE
TECHNICAL REPORT SERIES
RTICMAR 1 7181
E
UNIVERSITY OF MARYLANDCOLLEGE PARK, MARYLAND
20742
Approved for plbi elaSO;
81 1ibutio u0limit 03

/1
Technical Report TR-853 December 1979
An Experimental Investigation of
Computer Program Development Approaches
and Computer Programming Metrics*
by
Robert William Reiter, Jr.
AIR FCRCE C,'FVICE 0 S( [!-;T]FIC RESEARCH (AFSC)
Tz t . - ie.ed and is, , ' , ,,. A, AiR 190-12 (7b).
D .,t iL'. : :L ; :l '. e .
A. D.
Techoical infc.-ration Officer
Dissertation submitted to the Faculty of the Graduate School
of the University of Maryland in partial fulfillment
of the requirements for the degree of
Doctor of Philosophy
1979
*Research supported in part by the Air Force Office of ScientificResearch Grant AFOSR-77-3181. Computer time supported in partthrough the facilities of the Computer Science Center of theUniversity of Maryland.

* ~ SE uRITY SFICATIOI OF THIS IPArCF ( ' l. Itro ntHr,,)
Ri" L" D I,'I' R-) I[' Vi I (,NI .' M(J9 *PORT DOCUMENTATION PAGE )PA I, (-( :T~~.4' IR -- 2 GOVT ACCESI1ON NO. 3 -EI IPIEtT'S CATALGr, NUV~fiLRI _ ,1 : /)( /&L. ___/__
4 T1LE (1-d Sohrtil) 5 TYPE OF REPORT a tImYFc I" "1- FR
~N £XPE ITAL ;14VESTIGATION OF 4PUMER - / '" ROGRAM EVELMDIENT ,PPROACHES AND 4CXIPU''ER
RCOGRAMTING W7PCSaI-I____________
7. AUTHOR(.) 9 C'NT' A-T OR GRANT N JME'
( Robert William/Reiter, J r"-",FOSR-77-381
9. PERFORMING ORGANIZATION NAME AND ADC POK S ., A. A 4A , EL r -- j- .7 3
University of Maryland IDepartment of Mathematics r
College Park, Md. 20742 611 -- ,2304/ A211 CONTROLLING OFFICE NAME AND ADDRESS . L. Rt EPQ
# ' S A
Air Force Office of Scientific Research/NM , Dccec f7 /Bolling AFB, Washington, DC 20332 N'" - E -E .
150 __"74 MOJ'jT tRING AGENC NAME A ADDR SS(tI dtf~er om C',ntr, lrhf I-, T SE'uNIIy C_ -15.. "
UNC ASSIFIEDI -Ci .L-f.I
0,1 T I A - 2,7. .
-, ' SCHED LE
16. DISTRIRJTION STATEMENT (of this Report)
Approved for public release; distribution unlimited.
17. DISTRIBUTION STATEMENT (of rhe ah.tr.ct entled i f [31-k 20, ! dil(enot fo, ).R--j
IS SUPnLEMENTARY NOTES
19, KEY WOC)-S ''tn, nrv se,eI, it ars r d drl I-f/tv n, block or m- r - -
0L .A- - R AC T (('n-1r,' .. . r . idr If . . . .t ... f ," 17t - . r..
7here is a need in the emerging field Of software cngineerin: forempirical study of software development approaches and software mitrics.An experiment has been conducted to coimpare three programing envLromcntsindividual programming under an ad hoc approach, team programning under anad hoc approach, and team prograTming under a disciplined methodology. Thisdisciplined methodology integrates the use of top-down design, process designlanguage, structured programming, codQrading, and chief programer teamorganization. Data was obtained for 4.1A*ni,4iiber of automatable software
DD 1 N, 1473 UNCLASSIFIED
,- ,ECL.R.-Y CLASSII ,N C .
i.. . .

UNCLASSIFIEDSEC HITY CLASSIF ICA TION OF THIS PAGE(V471.I V~ata Fr.fterd)
", metrics characterizing the software development process and thedeveloped software product. The results reveal several statisticallysignificant differences among the progrrmling enviroments on the bais,of the metrics. These results are interpreted as demonstrating theadvantagcs of disciplined team progranming in reducing software dleveloup-ment costs relative to ad hoc approaches and improving software productquality relative to undisciplined team programiiing.
SECURITY CLASSIFICATION OF THIS PAGECW47ion Dora ErIeted)

ABSTRACT
Title of Dissertation: An Experimental Investigation of
Computer Program Development Approaches
and Computer Programming Metrics
Robert William Reiter, Jr., Doctor of Philosophy, 1979
Dissertation directed by: Dr. Victor R. Basili
Associate Professor
Department of Computer Science
There is a need in the emerging field of software engineering
for empirical study of software development approaches and software
metrics. An experiment has been conducted to compare three
programming environments: individual programming under an ad hoc
approach, team programming under an ad hoc approach, and team
programming under a disciplined methodology. This disciplined
methodology integrates the use of top-down design, process design
language, structured programming, code reading, and chief program-
mer team organization. Data was obtained for a large number of
automatable software metrics characterizing the software development
process and the developed software product. The results reveal
several statistically significant differences among the programming
environments on the basis of the metrics. These results are
interpreted as demonstrating the advantages of disciplined team
programming in reducing software development costs relative to ad
hoc approaches and improving software product quality relative to
undisciplined team programming. A~c o o
fii"c-io For
LTTS 7fk&
J/orDist K

DEDICATION
In honor of my mother and fatherv
"ary Edith Reiter
and
Rooert 4iLtiam Reiter, Sr.

ACKNOWLEDGMENTS
This work was supported in part by the Air Force Office
of Scientific Research through grant AFOSR-77-3l81A to the
University of Maryland. Computer time was provided in part
through the facilities of the Computer Science Center of the
University of Maryland.
This work couldi not have been accomplished without the
cooperation and assistance of others. To students who
participated in the experiment, colleagues who offered
helpful suggestions, and faculty who reviewed the work
critically, I am most grateful. Drs. Richard G. Hamlet and
Ben A. Shneiderman critiqued this manuscript thoroughly on
the basis of "programming sense," experimental procedure!
terminology, and writing style. Drs. Marvin V. Zelkowitz
and John D). Gannon imparted a healthy sense of reality and
provided an appropriate measure of stimulation/inspiration
throughout their lengthy service as members of my study
committee.
I am indebted beyond measure, however, to two people
whose professional contribution and personal sacrifice have
continually enriched my work as well as my life. I thank my
advisor, Dr. Victor R. Basili, for his expert guidance and
patient encouragement. I thank my wife, Lowrie Ebbert
Reiter, for her unselfish support and unfailing love.

FF"I.
TAPL6 OF CONTEN4TS
C ha &t e r
i. INTRODUCTION AND OVERVIEe * . . . . . . . . . . . 1
I. BACKGROUND AND RELATED RESEARCH . . . . . . . a . 9
Software evetopment Approaches . . * * . . . 9Software Metrics *. ..... .. 11EmoiricaIEpe rimenlai Study ......... 13
li*. INVESTIGATION SPECIFICS . . . . . . . . . . 17
Surroundins . ... , . ,.,. , 17Exoe rimental Des ian . . .. : 0 : 19ProQramminq Metho otoQies . . . . . . . . . . 24
Data Collection and Reduction . . . . . . . . ?6Programming Aspects and Metrics . . . . . . . 27
i-. GLOSSARY OF PROtRAMING ASPECTS * . . . .. t.. .
We DISCUSSION OF ELABORATIVE METQICS . . . . . . 51
rogram Chanoes . , * . : . . . : . . . . .Cew c Copext c !. 01 a I C . .' .) t e x5tData aindinqs . . . . . . . . . . .Software Science uni ..... . ..
VI. INVESTIGATIVE TECHNIQUE . . . . . . . . . . .. . 75
Step 1. Questions of Interest . , . . . . . . 76Step 2: Research Hyootheses ....... , . 77Step 3: Statistical Model 78Step 4: Statistical Hypotheses F : . : : .. 0Step r: Research Frdmeworiks • . . . . . . 92Stec 6: Experimental Desiqn e . . P . . . 4St~i;7: Collected Data. so ... 5Stepj 6: Statistical Test Procedurs .?.5...
* 9. Statistical Results . . . . . a . PSSteo 10: Statistical Conclusions . c . . ,
: 11: ese, rch Interpretations • • • 02
T f 7 j 1 T S . . . . . . . . . . . 0 0 a ¢q4
r. t a t ~i on . 9 5Imoact Evatuation • ....... 95; . '.ced Diff-rentiation View. . . . . . . . 08A Directionless Vie* 101:nbividual frijol iohts . . . . . . IC2
IN E P F TIv RESULTS . . . . . . . . . . . . . . 1 C7Accordinq to Lasic SuLpositions .. 7According to Proqramming-Aspect Cassif ication
M s e n . . . . . . . . . . . . . 113
IA. SUMMARY AND CONCLUSIONS 1 • . . • • • • . . . . , 129
Aovenai x
i. Statistical bescriotion of Raw Scores . . . . . . 11
keIerences . . . , . . . . o . . . . . . . . . . . . . . 17
iv

LIST OF TABLES
Table
1. Programming Aspects . . . . . . . . . . . a * . . . 30a
2. Statistical Conclusions . . . . . . . . . . . .. . oSa
3. Statistical Impact Evaluation . . . v . . . . 7
4.1 Non-Null Conclusions, for Location Comparisons.arranqed by outcome . . . . . . .98 . . . . . . . 98a
4.2 Non-Nutl Conclusions, for Dispersion Comparisons,arranced by outcome 9.8...... . . . . . .
5.1 Relaxed Differentiation for Location Comparisons 10a
5.2 Relaxed Differentiation for Dispersion Comparisons
6.1 Conclusions for Class I,Effort (Job Steps) . . . . . . . . . . . . . • . • 114a
6.2 Conclusions for Class 11,Errors (P'roqram Chanqes) . . . . . . . . . . . . 116a
6.3 Conclusions for Class III,Gross Size . . . . . . . . . . , . . . . . . . . 117a
6.4 Conclusions for Class IV,Control-Construct Structure * * * * e 9 e * . e * o 120a
6.5 Conclusions for Class V,Data Variable Organization . . . . . . . . . . . a 121a
6.6 Conclusions for Class VI,PackaainQ Structure . . . . . . . . . . . . . . . . 122a
6.7 Conclusions for las$ VII,invocation Organization . . . . . . . . . . . a . . 123a
6.8 Conclusions for Class VIII,Communication via Parameters . . . . . . . . a & . 124a
6.9 Conclusions for Class IX,Communication via Global Variables . . . . . . . . 125a
LIST OF FIGURES
F iQure
1. Frequency Distribution of Cyctomatic Complexity . . 58a
2. Investioative Methodoloqy Schematic * e a . . * * * 76a
3.1 Lattice of Possible Directional Outcomesfor Three-way Comoarisun . . a 0 . * . * a * * a * 83a
3.2 Lattice of Possible Nondirectional Outcomesfor Three-way Comoarison , . . . . a a . . * a 3a
4. Association Chart for Results and Conclusions . . . Q1a
V

CHAPTER I
n the evolution of a systematic body of knowLedte,
there are ceneraILy three phases of validation. The first
phase is the Logical aeveLopment of the theory based on a
set of sound principles. This is followed by the
3aplication of the theory and the gathering of evidence that
the tneory is applicable in practice. This usually involves
so-ie qualitative assessment in the form of case studies.
The final phase is the elpirical ano experimental analysis
of the applied theory in order to further unJerstand its
effects and better Oemonstrate its advantages in a
cotrolLed manner. This usually requires quantitative
measurement of the relevant phenomena.
.uch has been written about methodologies for
develooing computer softdare [Wirth 71; Dahl, Dijkstra
Hoare 72; Jackson 75; Myers 75; Linger, Mills v Witt 79).
Most of these methodologies are based on sound Logical
principles. Case studies have been conoucted to demonstrate
their effectiveness (Baker 75; 3asiLi & Turner 75). Their
a option within production ("real-world") environments has
generally ben successful, having practiced adaptations of
these methodologies, software designers and programmers have
asserteu that they got the job done fastert -ade fewer
errors, or produced a better product. Onfortunately, solid
quantitative evidence that comparatively assesses any
particular methodology is scarce [Shneiderman et al. 77;
"yers 76]. This is due oartialty to the cost and
imoracticality of a valiI experimental setup within a
oroauct ion environment.
Thus the question remains, are measurable benefits
derived from proarammin3 methodologies, with respect to
1l

CHAPTER I
-itner the software development Process or the developeosoftware Prodluct Even if the benefits are real, it is not
clear that they can be quantified and effectively monitored.
0 ft.are development is still too artistic, in the aesthetic
or spontaneous sense. In order to understand it more fully,
maiaoe it more effectively, and adapt it to particular
3polications or situations, software development must become
more scientific, in the engineering and calculateo sense.
vore empirical study, data collection, and experimental
-4nalysis re required to achieve this goal.
This dissertation strives to contribute to software
enlineering research in this vital thiri Phase of
validation. The dissertation reports on an original
research project dealing with three "dimensions" of software
enq ineering:
Software development approaches, i.e., programmingnethodologies and environments for developing software;
Software metrics, i.e., quantifiable aspects of
or,)Lrafing and measurements of software characteristics;-
Empipical/experimentat study, i.e., the collection and
,tistir-4l ,naiysis of empirical data about software
!henomena inrl, dinq controlled psychological
exoerimentation.
The immediate godis of the project were
(a) to investigate the effect of certain programming
methodoloqies ano environments upon software
aevelopment phenomena,
(o) to investigate the behavior of certain quantifiable
programming aspects and software measurements under
'jifferent approaches to software development, anu
(c) to devise and apply an investigative methodology,
founded on established crinciples of expcerimental
2

CHAPTEP I
research, but tailored for application to software
eniineering.
The oroject employed the investigative methodology to
conouct and analyze a controlled experiment with soft.are
development approaches as independent vdriables and software
metrics as dependent variables. In this way, both the
effect of the software aeveLopment approaches and the
behavior of the software metrics were investigated
In regara to software development approaches, the
croject focused on three distinct approaches, or programming
environments: single programmers using an ad hoc approach,
urDramminj teams using 3n ad hoc approacht and programming
teams using a disciplined methodology. These approacnes may
be cnaracterized according to two human-factors issues: the
size of the orogramming "team" deployed and the degree of
methodological discipline employed.
in terms of team size, individual programmers working
aIL:ne were compared to teams of three programmers worKing
tj .ether. In terms of methodological discipline, an ad hoc
.0oroach allowing programmers to develop software without
externally imposed methodological constraints was comparea
to a aisciolineo methodology obliging programmers to fotLow
certain modern programming practices and procedures. This
disciplined methodology consisted of an integrated set of
software development techniques and team organizations
including top-down design, process Cesign language,
structured programming, code reading, and chief programmer
tea1nS.
It snoula be noted that the terms 'methooology' and
,etnodoloyicalV (in reference to software development) are
uspo to connote an intejrated set of development techniques

CHAPTEP I
as .ell as team organizations, rather tnan a particular
technique or organization in isolation. Part of the
philosophy behind the project is the belief that. while
i rticuLar techniques or organizations may generate marginal
"e-efits individually, only a comprehensive ensemble can
ensure significant gains in software aevelopment
Pr3ouctivity and reliability.
in relard to software metrics, the project focused on
tte direct quantification of software development Dhenomena
Ji3 a host of nearly two hundred programming aspects ano
"teasurements. Attention was consciously restricted to
*,etrics exhibiting certain desirable characteristics; all of
tne software metrics examinea in the study are quantitative
(on it least an interval scale [Stevens 46)), objective
(free from inaccuracy due to human subjectivity),
unobtrusive (to those developing the software), and
autonatable (not dependent on human agency for computation).
This large set of programming aspects may be
C.Jcl timrizad on tne oasis of other criteria. Some of the
.::ects pertain to the software development Qro Iess; others,
c Lhe developed sottware po2dut. For example, the number
ct times that source code mooules are compiled during the
development period is a process measure, while the number of
IF statements in the deLivered program source code is a
craduct measure. Some of the aspects are rudimrnentarX, in
that they pertain to very si.mple surface features or lack
theoretical models to motivate intuitive appeal; others are
Ptc9ofaIive, in that they aim at more complicated underlying
features or possess provocative theoretical models. For
examole, the measurements mentioned above are both
rudimentary, while the program changes metric [Dunsmore &
cnnon 77) and the cyclomatic complexity metric [McCaoe 76)
are elaborative.
4

CHAPTEP I
in regard to emoirical/experimental study, the project
coitbined both emcirical data collection and controlleo
Psychological experiment3tion in a Laboratory-like setting.
The project involved extensive observation of forty-
ive programmers developing working software systems,
avera3ing twelve hundred Lines of code each, from scratch
lurin, a five week period. These programmers were divided
into three disjoint groups of "teams," each following one of
the three software development approaches mentioned above.
Vultiple raplications of a specific software oevelopment
task .ere cerformed indeoenuently and concurrently within
each group unuer conditions as otherwise identical as
coss ic I e.
In addition to some subjective qualitative observation
via Questionnaires, interviews, etc., objective quantitative
coserv3tion was achieved by automatically and unobtrusively
monitoring the computer activites of the programming
"ta'dS." For each replication, successive versions of the
softare oeing developed by that "team" were captured in an
historical data bank that recorcied details of the
levelocment process and oroouct. Raw scores for the
scft.are metrics mentioned above were extracted from the
Jata cank and summa.-ized via simple descriptive statistics.
S ecifically, the mean values and standard deviations
ocserved within each group on the various quantifiable
orP;rdmminV aspects constitute the i-emediate results of the
Droject as an emoirical data cotlection effort.
The project followed a rreptannd experimental oesign in
which extraneous factors were held .onstant wherever
possiole, to insure that differences in the software metrics
would be attributable to the aifferent software development
aporoaches. The metrics' raw scores were analyzed using

CHAPTEP I
noparametric inferential statistics to obtain an objective
conclusion for each measureo aspect. As precise statements
.of the statistically significant differences observed among
zhe three programming environments on the basis of the
-.easureu aspects, these objective conclusions constitute the
immiediate results of the project as a controlled experiment.
"-y testing for differences in either the location (expected
value) or the di1Qersion (variability) of the software
"etrics, the experiment adoressed both the expectancy and
-)reaictability of software development phenomena.
The experiment combined elements of both confirmatory
'=i exoloratory data analysis. Some so-called o2Ej.rMtIDr Z
"r~rammin.3 aspects had been earmarked as promising
indicators of important software characteristics in aovance
-f conducting the exoerivient. Hypotheses had been
'Sormulated, on the oasis of the programming environments'
,,.scected effects, regarding the expected objective
-onctusions for these confirmatory aspects. The projectr. cluoed other so-called exp2tga!t2rx programming aspects in
',r-er tO ir.A.stiqate the software development process and
.. . - m ore thnrouf hly.
The project ,as concerned with investigating an entire
rot.ere oevelop'nent project of nontrivial size in a Quasi-
-eatistic setting. The experiment was conducted within an
,c3upfmic environment in a laboratory or proving-grouna
4ashion so that an adequate experimental design could be
Ach.evea ohile simulating a production environment. In this
wdy. the project reached a reasonable compromise between
"toy" experiments, which facilitate etaoorate experimental
desi,.ns but often suffer from artificiality, and
production" experiments, which offer industrial realism but
inCrr orohibitively high costs.

CHAPTER I
The project's oasic premise was that distinctions among
these programming environments exist both in the process and
in tne product. With respect to the ueveLopea software
orZcuct, the oisciolined teac should approximate the
individual programnmer or at Least Lie somewhere between the
individual programmer and the ad hoc team, with regar to
oroauct characteristics (such as number of decisions coded
3nd global data accessibility). This is because the
disciplined methodoLogy should help the team act as a
mentaLLy cohesive unit during the design, coding, and
testing phases. .ith respect to the software development
orocess, the uiscipLined team should have advantages over
both indivicuats and ad hoc teams, displaying superior
oerformance on cost-reLated factors such as computer usage
and number of errors made. This is because of the
discipline itself and because of the ability to use team
menuers as resources for vaLidation.
The study's findings revealed several programming
ch3racteristics for which statisticalL, significant
differences do exist among the groups. The disciplined
te3ms used fewer computer runs and apparently made fewer
errors curing software deveLopment than either the
individual programmers or the ad hoc teams. The individual
programmers and the disciplined teams both produced software
with essentially the same nuMoer of decision statements, out
soltware produced by the ad hoc teams contained greater
numoers of decision statements* For no characteristic was
it concluded that the disciplined methodology impairea the
effectiveness of a programminy team or diminished the
au3Lity of the software orocuct.
The remainder of this oissertation is a comprehensive
reuort on the software engineering research project
introouced above. Chapter iI reviews appropriate background
7

CHAPTEP I
and retdted research tor' published literature. Chapter III
recounts specific details of the experiment itself. Chapter
V riefly describes all of the orogramming aspects and
neasurements, while Chapter V discusses the elaborative ones
in oepth. Chapter VlI depicts the investigative methodology
useJ to plan, execute, and analyze the experiment. Chapters
VII and VIII present the experiment's results, segregated
into objective findings and interpretative discussion,
respectively. Chacter IX summarizes the completed project,
"rqws generaL conclusions regarding its contribution to
software engineering, and mentions possible directions for
continued research in this area.
VI

CHAPTER II
This chapter reviews the general background for this
research project and surveys relateo work published in the
open Literature. For each of the three "dimensions" of
softwiare engineering outlined in Chapter I, specific
instances of research in that area will be mentioned and
loosely characterized, in order to show appropriate
similarities and constrasts with this work. As a catalog of
reLated research, the chapter is intended to be merely
reoresentative, not exhaustive.
There has been considerable concern regarding
orogramming methodologies over the past decade since the
advent of structured programming and the dawning of software
cost consciousness. Software "practitioners" (i.e.,
programmers, designers, systems analys t s, and managers) have
scght oetter ways to channel their energies toward
proJjcing cost-effective, reliable software. ALthougn a
braaj spectrum of concerns--spanning all phases of the
softdare life-cycle and covering the full range of system
size ana performance constraint--could be considered here,
attention has been restricted to methodology for
rogrdmming-in-the-smal1*: designing, implemertinG, and
testing computer programs to solve problems small enough to
be well-understood by a suitably trained individual. In
other worost the focus is on approaches for the kind of
software development that typical programmers/analysts in
tyoical software shops are accustomed to doing.
* 4s used here (and below), the meanings.of the terms;.roramming-in-the-small' and "provramming-in-the-large'
are clear from the context, but they differ slightly fromthe Teanings popularized by Dr. H.D. MiLLS.
9

CHAPTER It
A numher of good ideas on how to develop software,
covering techniques for how to proceed as weLt as
or dnizations for managing people and communicating
inform'tion, have been (or are being) devised, demonstrated,
cerfected, anc accepted into everday practice. Popular
exam;les include the following:
structured orogramming [Dahl, Dijkstra Hoare 7Z;
r'itLs 72; 93asiti & Baker 77; Linger, Mills a witt
79),
stepwise refinement [irth 713,
chief programmer teams (Baker 72; 8aker 75; arooKs 75),
process design language (DL) [Linger, vitts & Witt
793,
top-down design,
funct ional expansion,
oesign/code reading and walk-throughs [Fagan 76),
oata aostractionlencapsulation and information hiding,
iterative enhancement EBasiLi & Turner 75; Turner 76),
the Michael Jackson method [Jackson 75; Hughes 79J, and
composite design (yers 75].
These approaches and their highly touted benefits have
een the subject o' nuch written promotion and verbal
discussion. Indeed, several can boast of mathematical
foundations or format explication to support their
underlying principles or mechanisms; for others, there are
extensive tutorials on how to apply them in oractical
situations; and some have been embodied in programminj
languages or packaged into automated tools. AtL of this
attention, plus the favorable experiences of software
cractitioners, seems to indicate that these software
devetooment approaches do succeed in improving the
efficiency of the development Process or the Quality of the
devetoped product to some degree.

CHAPTER II
out there is Little empirical evidence to confirm the
aivantajes of these approaches or measure their benefits.
In several instances, case studies nave been performeu,
often in a pioneering spirit, to demonstrate particular
aparoaches; these case studies have usually involved
qu3litative assessment, with only limited or uncontrolled
forms of quantitative assessment. Comparative assessment of
software development approaches is even rarer: only a few
controlled experiments [Shneiderman et al. 77; Myers 78)
have oeen conducted, and they have generally focused on the
use of particular techniques in isolation. The difficulty
of investigating the effects of software development
aporoaches stems precisely from the fact that they pertain
to tne Least understood and most expensive elements in
software engineering: human beings.
So:tir& Metrics
There has ueen considerable interest in software
metrics over the past half decade in response to a growing
reaLliation of how "invisible," imponderable, and Iurcontrollaole software can be. Software "scientists" have
teen teeking ways to measure software phenomena. 9roadly
interpretea, tneir efforts may be characterized as
attempting to Quantify process efficiency and product
au3llty.* The software measurement domain extends from the
curicrete details of a program, including its fine structure
anJ the resource expenditure required to produce it, to its
aostract characteristics: reliabilityt cost-effectiveness,
t his concept of product quality is meant to includein:i.intaneous, as welt as evoLutionary, consioerations. Theformer considerations pertain to both static (at compile,iis) and dynamic (at execution time) features of a program,as it exists at a given point along its life-cycle. The6, tpr consideratigns pertain to issues of software
maintenance and software management throughout the life-,r I.. The suftware measures in this dissertation adaressproduct quality only in its instantaneous, static sense.
11

CHAPTER II
corplexity, modutarity, comprehensibity, modifiability, etc.
Because measurement is essential to most forms of
engineering, software metrics rightfully deserve a central
clacp within the emerging discipline of soft.dare
engineering. As in other technologies, the underlyiny
assunption is that approoriate measurement is the key to
Pffective control. It has Peen demonstrated [Gilb 77] that
the general concept of software measurement can be appliea
to a variety of programming issues: many interesting
suglestions were made regarding how and why to measure
software. But the metrics discussed by Gilb are vaguely
defined and superficial. The problem is that meaningful
Teisurement of software is extremely difficult, because of
software's intricate structure of concrete detail and
because of the tenuous relationship between its concrete
details and abstract characteristics. An additional problem
is the lack of well-understood and commonly accepted
terminology to describe the software phenomena to be
measured.
However, a numoer of well-defined and fairly credible
software metrics have been proposed and evaluated, usually
in conjunction with a motivating model or some intuitional
underpinnings. The program changes metric [Dunsmore a.
rainon 77; Dunsmore 761 extracts an error coant
algorithmicalLy from the textual revisions made to source
code during proyram development. The cyclomatic complexity
metric [vcCabe 76] counts the number of "basic" control-flow
paths in a program. The data bindings metric [Stevens,
-yers & Constantine 74; 3asili & Turner 75; Turner 76]
coints commmunication paths between code segments via data
variatles. The various metrics from software science theory
r .,lstead 771--program length, program volume, language
Level, effort, etc.--provide a unified syste- of

CHAPTER II
-e3surements for the size of a program, the amount of
information it contains, the level of abstraction it
exoressesv the amount of mental effort required to produce
or comorehend it, etc. The error-day metric [mills 76) is
an inoex of how early errors are detected and corrected
Jurin, software development. The span metric CElshoff 760]
is an inoex of the extent to dhich a program's data
variaules remain "live" (i.e., continue to affect control
flow and data value determination).
Each metric mentioneo above has been examined
emoiricalLy to one degree or another; but few software
metrics have oeen investigated in controlled experiments,
anJ there is Little research comparing metrics or examining
their interrelationships empirically. Further elaboration
and discussion of individual software metrics is deferred to
Chapters IV and V since many were examined in this reseach
oroject.
First-hand observation of software phenomena in the
",il'i," so to speakt has Long been regarded as a unique
source of information and the ultimate form of validation.
Ever since Knuth rummaged through wastebaskets at computer
centers for discarded listings of Fortran programs [Knuth
713, software "technicians" have been interested in watching
softiware be developed, to see how the Latest intuitive
opinions or theoretical modeLs fare against reality.
Ideally, it is useful to distinguish between data collection
efforts (with descriptive statistical analyses) and
controlled experimentation efforts (with inferential
statistical analyses); but, in practice, elements of both
are sometimes combined within the same empirical study.
1.3
LT

CHAPTER II
ueneralty streaking, the purpose of data collection
effurts has been to examine the behavior of software metrics
anj -odets under realistic conditions. A number of data
collection efforts have Deen aimed at progamming-in-the-
targe,* focusing on models of gross behavior (i.e., cost,
oroauctivity, resource estimation) during large- to medium-
sc3le software development. At IBM [walston & Felix 77)
ata was collected via project reporting forms in order to
Te3sure productivity on oroduction software developments.
At NASA/Goidard [3asili et aL. 77J data is being collected
vi3 information forms in order to evaluate cost or resource
sstimation models and to study software error phenomena.
Other data collection efforts, focusing on small- to
,nelium-scale sof tware development, have been aimed at
ouantitatively characterizing software's fine structure. In
stidies at G* [Elshoff 76b; ELshoff 76a], a large set of
commercial PL/1 programs was collected and measured
accoraing to a host of quantifiable programming aspects and
,,oftware metrics, including the span metric and the software
-cience metrics.
Generally speaking, the purpose of controlled
exoerimentation efforts has been to evaluate the effects of
rprogramming language features, human factors issues, and
:rro~ramming methodologies upon software phenomena and
aostract characteristics. Usually, the language features
exoeriments are done from a computer scientist's viewpoint,
while the human factors experiments are done from a
csychologist's viewpoint. However, because of areas of
natural overlap between these two concernst some
exoreriments fall into both categories. Together they
coRprise the bulk of controlled experimentation in software
* See earlier footnote.
14

CHAPTEk I
engineering.
There are several well-known examples of controlled
exDerinentation on programming language features. vieeissman
[weissman 74a; weissman 74b] conducted experiments on how
prorramming features affect the psychological complexity of
soft.ware; the -eatures included commenting, indentation,
mnemonic variable nam-eis, anu control structures. Gannon
[Gannon 75; Gannon & Horning 753 conducted an experiment on
how programming language features affect software
reliaoility and the presence/persistence of errors; the
features included statement vs. expression orientation, data
variaole scooe conventions, and expression evaluation order.
Later, Gannon [Gannon 771 ran experiments to examine how
data typing conventions affect software reliability. Using
the same empirical data, Dunsmore [Dunsmore 9 Gannon 77;
Dunsmore 7.9) examined how programming "complexity" is
affected by programmer-controllable variations in
orogramming features. "Complexity" was measured
algorithmically by the program changes metric; the features
included statement nesting oepth, frequency of data
references, and data communication mechanism preference.
There are several well-known examples of controlled
exoerimentation on human factors issues. Several
Pxoeriments [Sime, Green & Guest 73; Green 77) have been
conducted on the comorehensibility of different mechanisms
for imolementin4 conditional oranching. Several experiments
[She pard et at. 79J have been conducted on the effect of
moJern coding practices, such as structured coding, mnemonic
variaule names, and style of commenting upon the ease of
Performing comprehensiont modification, and debugging tasks.
Finally, there are a fe6 well-known examples of
controlled experimuentation on programming methodologies.
15

CHAPTER II
Several experiments were conducted LShneiderrman et at. 77J
to evailuate the utility of detailed flowcharting (as a
Iesign tool and documentation aid) in program composition,
coiprehensiont oeougging, and modification tasks; novice
orogamming students were employed as subjects, with short
(i.e., less than 150 Lines) Fortran programs as test
materials. Some experiments were also conducted [4yers 76]
to evaluate the utility of code reading and walkthrou~hs in
deougging tasks; experienced professional orogrammers were
evoloyed as subjects, with a short PL/1 program as test
material. To date, however, controlled experimentation on
programmina methodologies has been limited in scope.
vxoerimentaL studies have not involved programming
activities spanning multiple phases of the software life-
cycle and requiring the natural integration of multiple
crogramming tasks. Nor have experimental studies useo
nontrivial test materials requiring sustained effort Lasting
severaL weeks and involving several hunored lines of code.
16

CHAPTER III
This chapter outlines the surroundings in which the
experiment was conducted, the experimental design that was
emalcyea, the programming methodologies that were compared,
the Jata coLtection and reduction that was performed, and
the rrogramming aspects that were measured.
L 2r rugn ijs
',overdl circumstances surrounding the experiment
D -'- ,tute significantly to the context in which its results
7,ust Le appraised. Tnes - 4nclude the setting in which the,
experiment was conducted, the people who participated as
subjects, the software development project that served as
the experimental task, the computer programming language in
which the software was written, and the computer system and
access mode that were used during development.
The experiment was conducted during the Spring 1976
setester, January through Mayt within regular academic
coirses given by the Department of Computer Science on the
CotLete Park campus of the university of Maryland. Two
cotparabte advanced elective courses were utilizeo, edch
with the same academic prerequisites. The experimental task
anJ treatments were built into the course material ana
assijnments. Everyone in the two classes participated in
the experiment; they cooperated willingly and were aware of
being monitored, out had no knowledge of what was being
observed or why.
rhe participants were advanced undergraduate and
orrduate students in the Department of Computer Science. On
tne wnole, they were reasonably competent computer
17

CHAPTER III
rD rammers, atL having completed at least four semesters of
programming course work and some having as much ds three
years' professional programming experience in government or
industry. Generally speaking, they were familiar with the
implementation Language and the host computer system, but
inexoerienced in team programming and the disciplined
net hodo logy.
The programming application was a simple compiler,
involving string processing and translation (via scanning,
narsing, code generation, ano symbol table management) from
an ALgo-like Language to zero-address code for a
hyoothetical stack machine. The total task was to design,
ivolement, test, and debug the complete computer software
system from given specifications. The scope of the project
excluded both extensive erro- handling and user
documentation. The project was of modest but nonnegtigibLe
difficulty, requiring between one and two man-months of
effort. The size of the resulting systems averaged over
12)0 Lines of high-level Language source code. ALL facets
of the project itself were fixed and uniform across all
development "teams." Given the same specifications,
conputer resource allocation, catenoar time allotment, host
machine, implementation language, debugging tools, etc.,
each "team" worked independently to build its own system.
The deLivered systems each ran (i.e., they worked) anu
passea an independent acceptance test.
The implementation language was the high-Level,
structured-programming language SIMPL-T [BasiLi g Turner
'6). This language was designed and developed at the
University of Maryland where it is taught and used
extensively in regular Department of Computer Science
coirses. SIMPL-T contains the following control constructs:
se:uence, ifthen, ifthenelse, whiLedo, case, exit from loop,
,' a

CHAPTER III
and return from routine (but no goto). SlmPL-T allows
essentially three levels of data declaration scope (i.e.,
local to an individual routine, global across the several
roitines of an individual module, or entry-global across the
routines of several modules), but routines may not be
nesteu. Adhering to a philosoohy of "strong typing," the
la ua'e supports integer, charactert and string oata types
and single dimension array data structures. It provices the
rrogrammer with automatic recursion and PL/1-like string-
orocessing capabilities. (Additional details regarding the
'71PL-T orogramming language are interspersedl among the
exolanatory notes in Chapter IV.)
The host computer system was the campus-wide computing
facility, a Univac 1100 machine with the usual Exec 8
operating system. This system supports, in its fashion,
both patch access (via punch cards) and interactive time-
sh3ring* access (via TTY or CRT terminals). The
participants were well acquainted with the system and
accustomed to either access mode. During the experiment,
the participants were allowed to choose whichever access
moJe they preferred and could switch freely between modes.
Almost everyone consistently preferred the interactive
access mode; only one person--in the Al group (see below),
by the way--usea the batch access mode extensively.
Exoerimental .ie ian
The major elements of an experimentaL design are its
units, treatment factors, treatment factor Levels, observed
variables, local control, and management of extraneous
factors. (Cf. JOstle and Mensing 75, chap. 0 for a general
treatment of these elements..)
* CatLed "demand" in Univac terminology.

CHAPTER III
An experimental unit s that object to which a single
treatment is apptied in one replication of the event Known
as the "basic experiment." In this study, the "basic
exoeriment" was the accomplishment of a specific software
development project (see above), ano the experimental unit
was tne software development team (ioe., a small group of
people working together to develop the software). A total
of 19 replications of this "basic experiment," each
performed concurrently and independently by a separateexoerimentaL unit, were involved in this experiment.
Most experiments are concerned with on one or more
indecendent variables and the behavior of a one or more
deoendent variables as the inaependent variables are
permitted to vary. These independent variables are known as
exoerimental treatment factors. This experiment focused on
the approach used to develop software, as the singleexperimental treatment factor.
Experiments usually involve some deliberate variwtionin the experimental treatment factor(s). Different values
or classifications of the factor(s) are known as the
exoerimentaL treatment factor levels. In this experiment,
three levels were selected for the software development
aporoach factor. Conceived as variations in two human-
factors-in-programming issues, size of oevelopment "team"
and degree of methodological discipline, the exoerimental
treatment factor Levels are denoted by the following
mnemonics:
Al -- individual programmers working alone, following
an ad hoc approach (see below);
AT -- teams of three programmers working together,
following an ad hoc approach (see below); and
DT-- teams of three programmers working together,
following a disciplined methodotogy (see below).
20

CHAPTER III
Durinq an experiment, observations of the dependent
variisle(s) are made for each experimental unit. An
exaeriment's immedidte objective is to ascertain the
relationship between the experimental treatment factor
levels and the experimental observed variables. In this
exoeriment, the observed variables were quantifiable
progr.nming aspects, or netrics (see below), of the software
development process or the developed software product. A
large set of such aspects were considered in the study.
Technically speaking, this amounted to conducting a series
of simultaneous univariate experiments, one for each
programning aspect, all sharing a common experimental design
and all based on the same empirical data sample.
Experimental local control addresses the configuration
by which (a) experimental units are obtained, (b) units are
La3cec into groups, and (c) groups are subjected to
different experimental treatments (i.e., specific
comt inations of experimental treatment factor levels).
Local control is employed in the design of an experiment in
order to increase its statistical efficiency or to improve
the sensitivity/oower of statistical test procedures.
Fxperimental local control usually incorporates some form of
ranoomization--a basic principle of experimental desitn--
since it is necessary for the validity of statistical test
orocedures.
For this experiment, subjects were obtained on the
basis of course enrollment: since the experiment was
emoedded aithin two academic courses, every student enrolled
in those courses automatically participated in the
exoeri-ment. Software development "teams" were formed among
these subjects. In the one course, the students were
allowed to choose between segregating themselves as
individual programmers or combining with two other
21

CHAPTER, III
ct, ssmates as three-person programming teams. In the other
cujrse9 the students were assigned (by the researcher) into
three-person team's. The two academic courses themselves
provided the variation in methodological discipline. The
atmosphere of the first course was conducive to an ad hoc
aporodch to programming, while the disciplined methodology
was stressed in the second course. In this manner, three
exoerimental treatments (corresponding to the three
exoerimentat treatment factor levels AI, AT, and DT) were
created, and three groups of 6, 6, and 7 units
(respectively) were exposed to them.
There are usually several extraneous factors, other
th3n the ones identified as experimental treatment factors,
that could influence the behavior being observed in an
exoeriment. many experivents (inctudings this one) follow a
reductionist paradigm, which seeks to control for alL
variaotes except a select few, so that the effect of the
inderendent variables upon the oependent variables can be
isolated and measured. in this experiment, a variety of
Drogramming factors which do affect software development
were given conscious consideration as extraneous variables:
- programming application and/or project
- project specifications
- implementation language
- calendar schedule
- avaitaoLe computer resources
- available automated tools
wherever possible, these variables were held constant by
exDlicitly treating all experimental units in the same
manner.
unfortunately, the ideal reductionist paradigm can only
he approximated, because of factors which arm suspected of
stron influence on the behavior of interest, but which
22

CHAPTFR Ill
cannot Cue exolicitly controlled within the experimental
desi ;n. In this experiment , there were two such factors:
the personal abi lity/experience of the participants and the
3mount of actual time/effort they (as students with other
cl3sses ano responsibilities) chose to devote to the
roject. However, information from a pretest questionnaire
was used to balance the Dersonal ability/experience of the
oarticipants in the disciplined teams (only), by first
c rtitioning the group DT students into three equal-sized
cate;>.ries (h gn, medium, low) oaseo on their grades in
zrevious computer courses and their extracurricular
progr.-ming experience, and then randomly selecting one
stjoent from each category to form each team.
For t Oe statistical mocel employed to analyze this
exoeriment, it was necessary to assume homogeneity among the
norticipants with respect to personal factors such as
aoility and/or experience, motivation, time and/or effort
devoted to the project, etc. As a reasonable measure of
individual programmer skill levels under the circumstances
of this study, the participants' grades from a particularly
pertinent prerequisite course provioed a post-experimental
co firmation of at least one facet of this assumed
honuloeneity: the distrioution of these grades among the
three experimental groups would have aisplayed the same
degree of homogeneity as was actually ooserved in over 9 out
of 17 ourety random assignments of the participants to the
groups. If anything, in the researcher's opinion, the
participants in group Al seemed to have a slight edge over
those in groups AT and DT with respect to native programming
aoility, while groups Al and AT seemed slightly favored over
croup ST with respect to formal training in the application
3rP a.
23

CHAPTER III
The discipLined methodoLogy imposed on teams in group
')T consisted of an integrated set of state-of-the-art
techniques, including too-down design, process design
tanguaqe (PDL), functional expansion, design and code
re3ding, walk-throughs, and chief programmer team
orjanization. These techniques and organizations were
taight as an integral oart of the course that the subjects
were taking, using [Linger, MiLs & Witt 79), [Basili &
"aker 75], and EBrooks 75] as textbooks. Since the subjects
were novices in the methodology, they executed it to varying
legrees of thoroughness and were not always as successful as
se3soned users of the methodology would be.
The discipLineo methodology prescribed the use of a PDL
+or exoressing the design of the problem solution. The
design was elaborated in a top-down manner, each Level
reoresenting a solution to the problem at a particular Level
ot abstraction and specifying the functions to be expanded
at the next level. The PDL consisted of a fixed set of
structured control and data structures, PLus an open-enoed
desiiner-defined set of operators and operands corresponding
to the Level of the solution and the particular application.
Vesign and code reading involved the critical review of each
team member's POL or code by at least one other member of
the team. walk-throughs representeo a more formalizeo
presentation of an individual's work to the other members of
the team in which the PDL or code was explained step oy
step. Under the chief programmer team organization, the
chief orogrammer defined the top-level solution to the
prooLem in POL, designed and implemented key portions of
cole himself, and assigned subtasks to the other two team
meroerse Each of these orogrammers, in turn, code-read for
the chief programmer, designed or coded their assigneu
24

CHAPTER III
sujcieces, anc performed liorarian activities (i.e.,
entering or revising code stored on-Line, making test runs,
etc*).
Two variants of chief programmer team organization,
lenoted CP and M, were employed. In both cases, one member
of the team (the chief programmer or the manager) was
responsible for designing and refining the top-level
solution to the proolem in PDL, identifying system
corponents to be implemented, and defining their interfaces.
rhe two other team members (the programmers) were each
responsibLe for designing or coding various system
corponents, as assigned by the chief programmer or manager.
In the CP case, the chief programmer maximized his cooing
duties oy implementing the key code himself, and the
programmers performed Librarian activities (i.e., entering
or revising code stored on-line, making test runs, etc.).
In the M case, the manater minimized his coding duties by
acting as Librarian and yielding greater responsibility for
ioementation to the programmers. Although there were
(sipposedly) four CP teams and three M teams in group DT,
this distinction between the CP and M variants of chief
pragrammer team organization is not utilized in the pre.ent
stidy, since it is believed that the impact of their common
*e3tures transcends any impact due to their differences.
• oreover, in actual practice, it was observed that the CP
anJ 11 variants are only identifiable extrema along a
continuum and that the group DT teams all gravitated toward
a romfortable compromise in this respect.
Each individual or team in groups Al or AT was allowed
to develop the software entirett in a manner of his or their
own choosing, which is herein referred to as an ad hoc
ap:roach. No methodology was taught in the course these
suojects were taking. Informal observation by the
25

CHAPTER III
researcher coni rmeo that approaches used by the individuals
and au hoc teams were indeeo Lacking in discipline anu aio
not utilize the key elements of the disciplined methouology
(e.,., an individual working alone cannot practice cooe
reading, and it was evident that the ad hoc teams did not
emotoy a PDL or a formal top-down design).
Due to the Partially exploratory nature of the
ex~eriment in terms of differences to be discovered in the
nroject and orocess, as much information was collecteo as
couli oe done in an efficient and unootrusive manner. A
variety of information sources was used. Individual
Questionnaires revealed the personal background and
programming experience of each participant. Private team
interviews and in-class team reports provided information
regarding individual performance on the project. "Run Logs"
and computer account bilting reports gave a record of the
computer activity during the project. Special module
compilation and program execution processors (invoked on-
line via very slight changes to the regular command
tngualie) created an historical data bank of source code and
test data accumulated throughout the project development.
The data bank provided the principal source of
information analyzea in the current investigation and other
information sources have been utilized only in an auxiliary
manner (if at all). Thus, data collection for the
exneriments themselves was automated on-line, with
essentially no interference to the programmer's normal
catt-rn of actions during computer (terminal) sessions. The
final products were isolated from the data bank and measured
for various syn-tactic and organizational aspects of the
fiiishea oruduct source code. Effort'and cost data were
k6

CHAPTER III
also extracted from the data bank. The inputs to the
analysis, in the form of scores for the various programming
asoects, reflect the quantitatively measured character of
the crouuct and the process. Much of the data reduction was
done automatically within a specially instrumented compiler.
Some was done manually (e.g., examining characteristics
across modules). Due to the underlying collection ana
reduction mechanism, which was uniformalty applied to all
exoerimental units, the data used in the analysis has the
characteristics of objectivity, uniformity, and
quantitativeness and is measured on an interval scale of
measurement [Stevens 46]. The raw scores for the measured
programming aspects are summarized in Apppenlix 1.
The dependent variaotes studiee in this experiment are
catleo programming aspects. They represent specific
isaLataute and observable features of programming phenomena.
rurthermore, they are measured in an objective ancd
automatable manner (i.e., they could be extracted or
couputea directly on-line from information readily
ootainabte from operating systems and compilers). For each
programming aspect there exists an associated metric, a
specitic algorithm which ultimately defines that aspect and
by which it is measured.
The programming aspects may be categorized as either
process- or product-related, on the basis of what they
measure. Process aspects represent characteristics of the
development process, in oarticuLart the cost and required
effort as reflected in the number of computer job steps (or
runs) and the amount of textual revision of source cooe
durir development. Product aspects represent
cn3racteristics of the final product that was developed, in
27

CHAPTER III
oarticular, the syntactic content and organization of the
symuoLic source code. Examples of product aspects are
numtber of lines, frequency of particular statement types,
average size of data variables' scope, etc.
The programming aspects may also be categorized as
either rudimentary or eLauorative, on the basis of their
conceptual nature. The rudimentary aspects are conceptually
quite simple, reflecting ordinary surface features of the
crocess or product. For example, the numbers of data
variatles and routines in a program are rudimentary aspects;
tney pertain to the sheer size of the software and are
somewhat uninteresting in themselves. The elaborative
,isoects are conceptually more subtle, reflecting deeper
ch3racteristics of the process or product. For example, the
numper of times Pairs of routines communicate via data
variables (see the data bindings metric below) is an
el3oorative aspect; it pertains to the software's modularity
and is intuitively appealing.
Finally, the programming aspects may be categorized as
either confirmatory or exploratory, on the basis of the
notivation for their inclusion in the study. The
confirmatory aspects had ueen consciously planned in ddvance
of colLecting and extracting the data, oecause intuition
su;gested that they would serve well as quantitative
inJicators of imoortant juatitative characteristics of
sofware development phenomena. It was predicted a priori
that these confirmatory aspects would verify the study's
basic premises regarding the programming environments being
investigated in the experiment. The exploratory aspects
were considered mainly because they could be collectea and
extracted cheaply (even as a natural by-product sometimes)
aLony with the confirmatory aspects. There was little
serious expectation that these exploratory aspects would be

CHAPTER III
useful indicators of differences among the groups; but they
were included in the study with the intent of observing as
many aspects as possible on the off chance of discovering
any unexpected tendency or difference. Thus, this study
conoines elements of both confirmatory and exploratory oata
analysis within one common experimental setting [Tukey 69].
The confirmatory programming aspects are identified in the
accompanying taoles by being flagged with asterisks; the
exoloratory rroiramming aspects are unflagged.
it should oe noted that a Large percentage of the
oroduct aspects fall into the rudimentary-exoloratory
category. On the whoLe, these product aspects represent a
fairly extensive taxonomy of the surface features of
software. The idea that important software qualities (e.g.,
"complexity") could be measured by counting Such surface
features has generally been disregarded by some researchers
as too simplistic (e.g., [Mills 73, p. 232)). A resclve to
study these surface features empirically, to see if
soretning might turn up, before rejecting the underlying
idea, was partially responsible for their inclusion in the
study.
The particular programming aspects examined in tnis
investigation are presented in Chapters IV and V. A
covplete list of aspects, together with explanatory notes,
is given in Chapter IV, with definitions for the nontrivial
or unfamiliar metrics. Chapter V contains a in-depth
discussion of the elaborative aspects.
29

CHAPTER IV
This chapter presents all of the programming aspects
examineo in the study. The goal of this chapter, in
conjunction with the next, is to describe each programming
asoect and, where appropriate, to motivate its intuitive
aDoeal as a software metric. 9ecause the brief explanatory
notes within this chapter do not adequately aescribe a
certain subset of the aspects (namely, the elaborative
a.ects)v they are further discussed within the next
(ia3 p t e r.
Table 1 Lists the programming aspects examined in this
investigation. They appear grouped according to
definitionaLLy related categories, with indented qualifying
phrases to specify variants of general aspects. When
referring to an individual aspect, a concatenation of the
major phrase with any qualifying phrases (separated by \
symbols) is used.* For example, the aspect Label
COMPUTER JOB STEPS\qODULE COMPILATION\UNIQUE
refers to a metric involving computer b steps that are
ncIuLe compilations in which the sourc code is unique from
.3Ll other compilea versions.
In oroer to avoid any misunderstanding, a reoundancy
issue must be statea and properly appreciated. Several
instances of duplicate programming aspects exist; that is,
sove Logically unique asoects reappear with another Label,
in oruer to provide alternative views of a given metric or
to round out a group of related aspects. For example, the
FUnCTION CALLS aspect and the STATEMENT TYPE COUNTS\
* Ascect Labels are always written compLeteLy in uppercaseletterst white references to general concepts appear inLCoerc4se Letters, with initial or defining occurrencesun ier Iined.

TA3LE 1
T+ab Le I. P rotram!inS S2.p t S
- Parenth'esized numbers refer to the explanatory notesin Cha:ter IV. Asterisks mark the confirmatory aspects; t'eeoLoratory asoects are unmarkeu.
rodimentary process aspects
* ICO PUTER JO STEPS(2) * I .1MODULE COCMPILATIONC ) * UNIQUE( ) IDENTICAL
(4) PROGRAM EXECUTION( 5) MISCELLANEOUS(6) * ESSENTIAL
(7) AVERAGE UNIQUE COIPILATIONS PER MODULE(_ ) 'AX. UNIOUE COMPILATIONS F.A.O. MODULE
"%. is an abbreviation for MAAIMUMF.A.O. is an aubreviat ion for FOR ANY OE
elaborative process aspects
(r)) * I ROGRAM CHANGES
rudimentary product aspects
(1 ) * ImODULE S
(11) * SEGMENTS
(i2) ISE(MENT TYPE COUNTS
(11) 1 FUNCTION'1, ) PROCEDURE
----------------------------------------------I(I1 ISEGMIENT TYPE PERCENTAGES
(1) ( FUNCTION1) PROCEDURE
(13) AVERAGE SEGMENTS PER MODULE
14i~) *LINES
15) * STTEMENTS
(1) STATEMENT TYPE COUNTS(lo) " Z
(! ) * CASE(jj) * wI'ILE(:I) * EXIT
(2 ,9) (PROC)CALL(23,90) NONINTRINSIC( , ) INTrRINSIC
(2'.)(E TURN
(1..).] • ISTA T E M EN T T Y P E P E R C E N T A G E S
11 ) " I CASE'.) * wHILE
30a

TAbLE 1
(.:1) EXIT(*:.) I (PROC)CALL(_2) INONINTRINSIC(2;) INTRINSIC(24) * RETURN
(?5) * AVERAGE STATEMENTS PER SEGMENT
(2o) * AVERAGE STATEMENT NESTING LEVEL
(27) * DECISIONS
(22,99) FUNCTION CALLS(23,99) NONINTRINSIC(23, 9) INTRINSIC(23) TOKENS(2) AVERAGE TOKENS PER STATEMENT
( ) INVOCATIONS( 11,9g) FUNCTION( 3, gO NON NTRINS IC(23,99) NTIN TRINSIC
(23,90) INTRINSIC(23,) NONINTRINSIC(23) INTRRINSIC
(30) aVG. INVOCATIONS PER (CALLING) SEGMENT(11) FUNCTION(23) NONINTAINSIC(2) INTRI NSIC(11) PPOCEDURE(23) NONINTRINS IC(23) I NTRI NSIC(2 99) NONINTRINSIC(23 INTRINSIC
('1 9Q) AVG. INVOCATIONS PER (CALLED) SEGMENT
(11) PROCEDURE
(32) DATA VARIAOLES
(37) DATA VARIABLE SCOPE COUNTS(33) GLOPAL(34) ENTRY(35) MODIFIED
(35) UNMODI F IED(34) NONENTRY(35) MODIFIED(35) UNMODIFIED
(35) MODIFIED'it c UNMOD IFIE0
("3) NONGLOBAL(33) PADM ETEP(36) VALUE(!o) REFERENCE
A33) A LOCAL
(37) DATA VARIABLE SCOPE PERCENTAGES('3) * GLOBAL(34) ENTRY(35) MOD!FIED(35) UNMODIFIED(34) NONENTRY(35) MODIFIED(35) UNMODIFIED(15) C DI F I ED(35) UNMODIFIED
30b

T ABL3 1
( . 3) NONGLOBAL(*5) PARAMETER
(30) VALUE(30) REFERENCE(33) LOCAL(3o) IAVERAGE GLOaAL vARIABLES PER MODULE I(34,) E TNTRY(34) NONENTRY(35) MODIFIED(35) UNMODIFIED
(7d) jVE-R-A-GEONGLOBAL VARIAaLES PER SEGMENT(33) PARAMETER(33) LOCAL
("9) PARA'.ETER PASSAGE TYPE PERCENTAGES(30) VALUE(36) REFERENCE(40) (SEGMENTGLOSAL) ACTUAL USAGE PAIRS(34) ENTRY
(35) M00IFIED(3z) UNMODIFIED(3Z) NONENTRY
(35) MODIFIED(35) UNMODIFIED
(35) NMODIFIED
(4) (SEGMENTGLOBAL) POSSIBLE USAGE PAIRS(34) ENTRY( 5) MODIFIED(35) UNMODIFIED(34) NONENTRY( 35) MODIFIED('5) UNMODIFIED(35) MODI FIED
5 UNMODIFIED II---------- -------------------- --------- I(4C) '(SEGMENT,GLOAL) USAGE PAIR ;EL.PERCENT.9
(34) ENTRY(7 5) MOD I F IED(3 5) UNMODIFIED(34) NONENTRY
7( r,) !ACD IF I FD
(35) U . %R0OD I F I(35) H 0OD FI E D(35) UNMODIFIED I
AVG. is in aobreviation for AVERAGEREL.PERCENT. is an abbreviation for RELATIVE PERCENTAGE
etaborative product aspects
(44) ICYCLOMATIC COMPLEXITY
(4j) SIMPPRED-NCASF VARIATION(46) TOTAL(47) #SEGS :CC>=10
(40) 0.5 QUANTILE POINT VALUE(4d) ,5 QUANTILE TAIL AVERAGE(4d) 0 .? QUANTILE POINT VALUE(4,) I 0.7 QUANTILE TAIL AVERAGE I(4) C. QUANTILE POINT VALUE(4*) . * 3.5 QUANTILE TAIL AVERAGE(46) C .9 QUANTILE POINT VALUE I(4C) I O. QUANTI LE TAIL AVERAGE
30Oc

TA6LE 1
(4) 1~ SIYPPPED-LUGCASE VARIATION :4:3) TOTAL(47) ISEGS:CC>=10
(4,-) '.5 QUAN'ILE POINT VALUE(4,) C.5 QUANTILE TAIL AVERAGE(4.1 I C.? QUANTILE POINT VALUE I(4.) 0.7 QUANTILE TAIL AVERAGE(4-,) I.0 QUANTILE POINT VALUE(4) 4F QUANTILE TAIL AVERAGE(4:) 0,, QUANTILE POINT VALUE(4.) 6,,9 QUANTILE TAIL AVERAGE
(45) COMPPRED-NCASE VARIATION(4o) TOTAL I(47) ,SFGS:CC>=1,(4;) 0.5 QUANTILE POINT VALUE(4:) 0.! QUANTILE TAIL AVERAGE(4c) 0.7 QUANTILE POINT VALUE(4.-) 0.7 QUANTILE TAIL AVERAGE I( ..) 0.q QUANTILE POINT VALUE I-. -°; C . QUANTILE TAIL AVERAGE
(4.) .9 QUANTILE POINT VALUE I(4. 0..9 QUANTILE TAIL AVERAGE
(45) COMPPCED-LOGCASE VARIATION(4) TOTAL(47) #ScGS :CC>=1 -J(4 -2) 0. QUA1NTILE POINT VALUE(4.) 0.5 QUANTILE TAIL AVERAGE I( 4) { 0.7 QUANTILE POINT VALUE(4o) . QUANTILE TAIL AVERAGE I(4 ,) 1 .3 QUANTILE POINT VALUE(43) C.S QUANTILE TAIL AVERAGE(4,,) 0. QUANTILE POINT VALUE(4.) 0.9 QUANTILE TAIL AVERAGE
(41) (SEGMENT,GLOJALSEGMENT) DATA BINDINGS :1(42) ACTUAL I(43) SU! FUNCTIONAL(4-.3) I INDEPENDENT(42) POSSI9LE(42) RELATIVE PERCENTAGE
(4i) SOFTWARE SCIENCE aUANTITIES( 7') I VOCABULARY(50) LENGTH(5) ESTIMATED LFNGT(S) /DIFFERENCE(N •(5 ) VOLUME1% 99) INTELLIGENCE CONTENT(C(" ESTIMATED BUGS
(51) 1ST CALCULATICN METHOD(% ) PROGRAM LEVEL(S 3) DIFFICULTY(50, 99) POTENTIAL VOLUME0( * U-) LANGUAGE LEVEL(s3) EFFORT I(5j) ES T IMATED TIME
(c1) 2ND CALCULATION METHOD(5,) PROGRAM LEVEL(50) DIFFICULTY(50) POTENTIAL VOLUME(in) %DI FFEtENCE(VI)(5u) LANGUAGE LEVEL( { ) IEFFORT
( J) IESTIMATED TIME
30d

CHAPTER IV
(PQOC)CALL aspect are each LaoeLpd and categorized from the
viewpoint of implementation Language construct frequencies.
nut the same metrics can also be considered from the
viewpoint of segment invocation frequencies, warranting the
inclusion of the two Ouplicate aspects INVOCATIONS\FUrvCTIONS
ani INVOCATIONS\PROCEDURES as variants of the general
I.%OCATIONS aspect. Among the 197 programming aspects
tisteu in Table 1t there are 8 pairs of duplicate aspects
(iientified in note 99 below), leaving 189 nonredundant
aspects examined in the study. Ry definitiont the data
scores obtained for any Pair of duplicate aspects will be
identical, and thus the same statistical conclusions will be
reached for both aspects. This redundancy must be kept in
mind when evaluating the results of the experiments.
Lrief explanatory notes about the programming aspects
are ':iven below, in the form of numbered paragraphs keyed to
the list in Table 1, with definitions for the nontrivial or
unfamiliar metrics. These notes usually supply Loose
exoLanations for the general concepts behind these
programming aspects, before mentioning any restrictions or
variations in how they were applied and measured in this
stJdy. Technical meanings for system- or language-dependent
terms (e.g.,t module segmwent, intrinsic, entry) also appear
here. Since computer Programming terminology is not
staniarcizedv the reader is cautioned against drawing
inferences not oasea on this dissertation's definitions.
.x:o1anator X g22 f2 It Pr2grI ADg !sIe~ts
(1) A con2uter Jo _ste2 is a conceptuatly indivisible
oroirammer-oriented activity that is performeo on a computer
at tme operating system command level, is inherent to the
software development effort, and involves a nontrivial
=oxenuiture of computer or human resources, IdeaLly
k ~~~31 .....

CHAPTFR IV
soeakirig, examPLes of jo!) Steps would include editing
syimooLic texts, compiLing source modules, Link-editing (or
cotlecting) object modules, and executing entire programs;
howeverv ocerat ions such as querying the operating system
for status informat ion or reouesting access to on-L ine fi Les
would not aualif y as job steps- In this study,
consicerat ion for the C014PUTER JOB STEPS aspect was Limitedexclusively to the activities of compiling source modlutes or
executing entire programs, but not all of the activities so
counted dealt with the finaL product (or logical
creaecessors thereof).
(2) A modyle r.miaiLctia is an invocation of the
itoLenientation Language orocessor on the source code of an
inlividual module. In this study, only compilations of
molules comprising the final software product (or logical
Predecessors thereof) are counted in the COM~PUTER JOB STEPS\v'VDULE CIMPILATION aspect.
(3) ALL module comoiLations are (suo)categorizeo as
either iclentiqil or uniggg dlepending on whether or not the
soirce code compiled is textuaLy identical to that of a
orevious compilation. During the development process, each
unique compilati on was necessary in some sense, whi Le an
identical compitation could conceivably have been avoided by
saving the (relocatable) object module from a previous
compi lation for Later reuse (except in the situat ion of
undoing source code revisions after they have been tested
and found to be erroneous or superf luous).
(4) A p gltgig is an invocation of a completePog~ramme r-deve Loped program (after the necessary
compiLation(s) and link-editing) upon some test data. In
this study, only executions of programs composed of modules
corprising the final product (or logical predecessors

CHAPTER IV
therpof) are counted in the COMPUTER JOt STEPS\PROGRAM
EXECUTIONj asoect.
(5) A _miii6ne2os i29 11Q1 is an auxiliary
conpilation or execution of something other than the final
software product. In this study, the COMPUTER JOB STEPS\
"ISCELLANEOUS aspect counts exactly those activities
inclucea in the COMPUTER JOB STEPS aspect but not incluaed
in the CO4PUTER JOB STEPS\MODULE COMPILATION or COMPUTER JOB
STEPS\PRnGRAm EXECUTION aspects.
(6) An essentiaj i2q ste is a computer job step that
involves the final software product (or Logical predecessors
thereof) and could not have been avoided (by off-Line
cotputation or by on-Line storage of previous compilations
or results). In this study, the COMPUTER JOB STEPS\
ESSENTIAL asoect is the sum of the COMPUTER JOB STEPS\MODULE
COmPILATION\UNIQUE aspect plus the COMPUTER JOB STEPS\PROGRA M
EXECUTION aspect.
(7) The AVERAGE UNIQUE COMPILATIONS PER MODULE aspect
is a way of normalizing the COMPUTER JO STEPS\MODULE
C04PILATION\UNIQUE aspect.
(3) The MAXIMUM UNIQUE COMPILATIONS FOR ANY ONE MODULE
asoect is another way of normalizing (by isolating the worst
c3se) the COMPUTER JOB STEPS\MODULE COMPILATION\UNIQUE
aspect.
(9) The 21:22La gbingl metric [Dunsmore & Gannon 77)
is a measure of the total amount of textual revision made to
croiram source code during the (postdesign) software
development period. The rules for counting program changes
are designed to identify individual conceptual changes
a;orithmicatLye .ach occurrence of the following revisions
33

CHAPTER IV
is counted as a single program change: modification of a
singLe statement, insertion of contiguous statements, or
modification of a single statement followed immediately by
insertion of contiguous statements. However, the following
revisions are not counteJ as program changes: deletion of
contigjuous statements, insertion of standard output
statements or special conpiler-provided debugging
directives, and instances of Lexical reformatting without
syntact ic/semantic alteration.
see Chapter v for further discussion of the program
changes metric.
(10) A rngdule is a separately compiled portion of the
covplete software system. In the implementation Language
SI4PL-T, a typical module is a collection of the
declarations of several global variables and the definitions
of several segments. In this study, only those modules
which comprise the final product are counted in the MODULES
asoect.
(11) A searnent is a collection of source code
statements, together with declarations for the formal
;.rameters and Local variables manipulated by those
statements, that may be invoked as an operational unit. In
the implementation language SIMPL-T, a segment is either a
value-returning fuD.12n (invoked via reference in an
expression) or else a non-value-returning roslFOI!re (invokeo
Via the CALL statement). The segment, function, and
orocedure of SIMPL-T correspond to the (sub)program,
function, and subroutine of Fortran, respectively.
(12) The group of aspects named SEGMENT TYPE COUNTS
gives the absolute number of programmer-defined segments of
each type. The group of aspects named SEGMENT TYPE
00CENTAGES gives the relative percentage of each type of
34,

CHAPTER IV
segment, comoared with the total number of proqrammer-
defined segments. The latter group of aspects is a way of
normaLizing the former groups of aspects.
(13) Since in the implementation Language SIMPL-T
segment definitions occur within the context of a moduLe, a
natural way to normalize (or average) the raw counts of
segments is provided. The AVERAGE SEGMENTS PER mODULL
asaect represents the average size, in segments, of modules
in the program.
(14) The LINES aspect counts every textual Line of
delivered source code in the final product, including
coi ments, compiler directives, variable declarations,
executable statements, etc.
(15) The STATEMENTS aspect counts only the executable
constructs in the source code of the final product. These
are high-levet, structured-programming statements, including
sivple statements--such as assignment and procedure catL--as
well ds compound statements--such as if-then-else and while-
do--which have other statements nested within them. The
i Lementation Language SIMPL-T allows exactly seven
different statement types (referred to Oy their
distinguishing keyword or symbol) covering assignment (.=),
alternation-selection (IF, CASE), iteration (wHILE, EAIT),
anj crocedure invocation (CALL, RETURN). Inout-output
operations are accomplished via calls to intrinsic
procedures.
(18) The group of aspects named STATEMENT TYPE COUNTS
gives the absolute number of 'executable statements of each
tyoe. The group of aspects named STATEMENT TYPE PERCENTAGES
gives the relative percentage of each type of statement,
cotpared with the total numoer of executable statements.

CHAPTER IV
The totter group of aspects is a way of normalizing the
former groups of aspects.
(17) AS mentioned abovet the := symbol aenotes the
issionment statement. It assigns the value of the
exoression on the right hand side to the variable on the
left hand side.
(1d) 3oth if-then and if-then-else constructs are
counted as IF statements. Each IF statement allows the
execution of either the then- or else-part statements,
deoenoing upon its boolean expression.
(19) The CASE statement provides for selection from
several alternatives, depending upon the value of an
exoression. In the implementation Language SIMPL-Tt exactly
one of the alternatives (or an optional eLse-part) is
selected per execution of a CASE, a list of constants is
exoLicitly given for each alternative, and spLection is
bdsed upon the equality of the expression value with one of
rhe constants. (These constants are referred to as 'case
laoers'; these alternatives, as "case branches.') A case
construct with n alternatives is Logically and
selmantically equivalent to a series of n nested if-then-
else constructs.
(20) The WHILE statement is the only iteration or
tooping construct provided by the implementation language
SIIPL-T. It allows the statements in the loop booy to be
executed repeatedly (zero or more times) depending upon a
0 ooLean expression which is reevaluated at every iteration;
the Loop may also be terminated via an EXIT statement. Each
wmILE statement may be ootionatLy labeled with a desi3nator
(referenced by EXIT statements) which uniquely identifies it
from other nested WHILE statements.
36

CHAPTER IV
(21) The EXIT statement allows the abnormal
termination of iteration Loops by unconditional transfer of
control to the statement immediately following the WHILE
statement. Thus it is avery restricted form of GOTO. This
exiting may take place from any depth of nested loops, since
the EXIT statement may optionaLly name a designator which
ioentifies the Loop to be exited; without such a oesi nator
only the immediatety enclosing loop is exited.
(22) Since there are two types of segments in the
imlementation Language SIMPL-T, there are two types of
"caLls" or segment invocations. Procedures are invoked via
the CALL statement, and functions are invoked via reference
in an expression. The counts for these separate constructs
are reported separately as the (PROC)CALL and FUNCTION CALL
aspects, and jointly as the INVOCATIONS aspect.
(23) Intrin1ij means provided and defined by the
imolementation Language; 2onintrinsi means provioed and
defined by the programmer. These terms are used to
distinguish built-in procedures or functions (which are
supported by the compiler and utilized as primitives) from
segments (which are written by the programmer). NearLy aLL
of the intrinsic procedures in the implementation language
SI'IPL-T perform input-output operations and external oata
file manipulations. ALl of the intrinsic functions in
SIPL-T perform data type coercions and character string
operations.
(24) The RETURN statement allows the abnormal
termination of the current segment by unconditional
resumption of the previously executing segment. Thus it is
another very restricted form of GOTO. within a functiont a
OETURJ statement must specify an expression, the value of
which becomes the value returned for the function
37

CWAPTER IV
invocdtion. within a procedure, a RETURN statement must not
specify such an expression. Additionally, a simple RETURN
st3tement is optional at the textual end of Procedures; it
will ue implicitly assumed if not explicitly coded. In this
stjoy, the total number of explicitly coded and implicitly
assumed RETURN statements, both from functions and
oroceoures combined, is counted.
(25) The AVERAGE STATEMENTS PER SEGMENT aspect
nrviaes a way of normalizing the number of statements
relative to their natural enclosure in a program, the
segment. The measure also represents the average length, in
Pxecutable statements, of segments in the program.
(26) In the implementation language SIMPL-T, both
simple (e.g., assignment) and compound (e.g., if-then-else)
statements may be nested inside other compound statements.
A oarticular nestin level is associated with each
-t3tement, starting at 1 for a statement at the outermost
leveL of each segment and increasing by 1 for successively
'ested statements. Nesting Level can be displayed visually
.,i3 proper and consistent indentation of the souce cooe
!isting.
(27) The DECISIONS aspect is the sum of the numoers of
'F, CASE, and WHILE statements within the program's source
:ole. Each of these statements represents a unique
(possihtly repeated) run-time aecision coded by the
nrogrammer. Because the implementation language SIMPL-T has
only structured control structures, this aspect is closely
related to the cyclomatic complexity metrics discussea
te t O.
(28) Tokens are the basic syntactic entities--such as
keywords, operators, parentheses, identifiers, etc.--that

CHAPTFR IV
occur in a program statement. The average number of tokens
cer statement may be viewed ds an indication of how mucn
"information" a typical statement contains, how "powerful" a
tyoicaL statement is, or how concisely the statements are
codeJ.
(p9) An iaQ Ilge is the syntactic occurrence of a
construct oy which either a programmer-defined segment or a
bjilt-in routine is invoked from within another segment;
both procedure calls and function references are counted as
!%VOCA T IONS. They are (sub)categorized by the type (i.e.,
+unction or procedure, nonintrinsic or intrinsic) of segment
or routine being invoked.
(30) The group of aspects named AVERAGE INVOCATIONS
PE? (CALLING) SEGMENT reoresents one way to normalize the
absolute number of invocations. These aspects reflect the
average number of calls to programmer-defined segments and
built-in routines from a programmer-defined segment. They
are (suo)categorized oy the type of segment or routine being
invoked.
(31) The group of aspects named AVERAGE INVOCATIONS
0 ER (CALLED) SEGMENT represents another way to normalize the
aosolute number of invocations. These aspects reflect the
avera~e numoer of calls to a programmer-defined segment from
other segments. They are (suo)categorized by the type
(i.e., function or procedure) of segment being invokeo.
(32) A gata 31rijab i is an individually named scalar
or structure. The implementation language SIMPL-T provides:
(a) three data tr2es for scalars--integer, character, and
(varying-Lengtn) string;
(o) -ne kind of data structure (besides scalar)--single
uimensional array, with zero-origin subscript range;
79

CHAPTER IV
a no
(c) several LeveLs of si212e (as explained in note 33 oeIow)
for data variables.
In aduition, all data variaoles in a SIMPL-T program must be
ex:Licitty declared, with attributes fully specified. The
DATA ARIASLES aspect counts each data variable declared in
the inal software product once, regardless of its type,
structure, or scope. Note that each array is counted as a
singLe data variable.
(!3) In the implementation Language SImPL-T, data
viriautes can have any one of essentially four Levels of
sco P--entry global, nonentry global, parameter, and Local--
-Oeoenaing on where and how they are declared in the program.
Note that the notion of scope deals only with static
accessibility by name; the effective accessibility of any
variaote can always be extended by passing it as a parameter
between segments. The scope Levels are explained here (and
presented in the aspect (sub)categorizations) via a
rierarchy of distinctions.
The primary distinction is between global anano-i Lobal. GLooaL variables are accessible by name to each
rlt. egmencs in the module in which they are declarea.
o~aj, variaoles are accessible oy name only to the
sinjle segment in which they are declared.
GLobal varaibtes are secondarily distinguished into
entry and nonentry categories. Entry a o is may be
aLcessioLe by na'-e to each of the segments in several
molules (as explained in note 34 below). Nann~r t b.iis
are accessiole by name only within the module in which they
are JecLared.
,4ongLobaL variaotes .re secondarily distinguished into
formal parameters and Locals. Formal plr1!tj srs are
accessible by name only within the enclosing (called)
s~e Tentq out their values are related to the calling segment
43J

CHAPTER IV
(as exolained in note 36 below). L2_IS are accessible by
navie only within the enclosing segment, and their values are
completely isolated from any other segment.
(34.) Entry means that the data variable (explicitly
declarea as ENTRY in one mooule) is accessible from within
other q eoarateLy compiled modules (in which it must be
exalicitly declared as EXTernal). UQnfn1ry means that the
d3ta variable is accessible only within the modute in which
it is declared. In this study, these terms are used only in
rpference to global variables, although the implementation
tan;uage SIMPL-T handles the accessibility of segments
across modules in the sane way.
Although the implementation Language SIMPL-T does allow
the ExTernal attribute to be declared Locally so that just
the enclosing segment has access to an identifier decLarea
as ENTRY in another module, this feature is seldom used; it
never occurred in any of the final software products
ex3mined in this study.
(35) ' _gified means referred to, at least once in the
vr +grom source code, in such a manner that the value of the
data variable miiht be (re)set when (and if) the appropriate
st3tements were to ue executed. Data variables can be
(re)set only oy (a) being the "target" of an assianment
statement, (b) being passed by reference to a programmer-
Jefired segment or built-in routine, or (c) being named in
an "input statement." (This third case is really covered by
the secona case since all the "input statements" in SIMPL-T
are actually calls to certain intrinsic procedures with
oasseu-oy-reference oaraveters.) Vn!22i1ieS means referred
to, throughout the program source code, in such a manner
that the value of the data variable could never be (re)set
r4Jrin,, execution. These terms refer only to global data
var i 3Dles.
41

CHAPTER IV
Any global variable is allowed to have an initial value
(constants only) specified in its declaration. Gtobaks
which are initiaLized but unmodified are especially useful
in SIMPL-T programs, serving as "named constants."
(36) The inplementation language SIMPL-T allows two
tyoes of parameter passage. Pass-by-vjtue means that the
value of the actual argument is copied (upon invocation)
into the corresponding format parameter (which thereafter
behaves like a local variable for all intents and purposes);
the effect is that the called routine cannot modify tne
value of the calling segment's actual argument. Pass-by-
referee means that the address of the actual argument
(,jhich must be a variable rather than an expression) is
passed (upon invocation) to the called routine; the effect
is that any changes made by the called routine to the
corresponding formal parameter wilt be reflected in the
value of the calling segment's actual argument (upon
return). In SIMPL-T, formal parameters that are scalars are
normalLY (default) passed by vatue, but they may be
A 4LicitLy declared to be passed by reference; formaL
..,rameters that a,-e arrays are always Passed by reference.
(37) The jroup of aspects named DATA VARIABLE SCOPE
COJNTS gives the absolute number of declared data variables
iccoroing to each level of scope* The group of aspects
ia-ed ATA VARIA8LF SCOPE PERCENTAGES gives the relative
percentage of variaotes 3t each scope level, compared with
the total number of declared variables. The latter group of
asoects is a way of normalizing the former groups of
a)Dects.
(30. A natural way to normalize (or average) the raw
counts of data variables is provided# since data variable
•JectLdrations in the implementation language SImPL-T may only
42

CHAPTER IV
ap~ear in certain contents within the program: gtobals in
the context of a module and nonglobats in the context of a
segment. The group of aspects named AVERAGE GLOgAL
VAQlAbLES PEq MODULE represents the average number of
glbaLs declared for a module. The group of aspects named
AVERAGE NONGLOBAL VARIABLES PER SEGMENT represents the
averaGe number of nonglobals declared for a segment.
(3*) Since there are two types of parameter passing
frecnanisms in the implementation Language SI*PL-T (as
exalained in note 36 above), it is desirable to normalize
their raw frequencies into relative percentages, indicating
the programmer's degree of "preference" for one type or the
other. The group of aspects named PARAMETER PASSAGE TYPE
0ECENTAGES gives the percentages of each type of parameter
relative to the total number of parameters declared in the
program.
(40) A segment-glooaL uSa dir (p,r) is an
instance of global variable r being used by a segment
(i.e., the global is either modified (set) or accessed
(fetched) at Least once within the statements of the
segment). Each usage pair represents a unique "use
connection" between a global and a segment. In this study,
segment-gtobal usage pairs were (suo)categarized by the type
(i.e., entry or nonentry, modified or unmodified) of global
jata variable involved and were counted in three different
ways.
First, the (SEGRENTGLOPAL) ACTUAL USAGE PAIRS aspects
count the absolute numbers of realized usage pairs (p,r)
the global variable r is actually used by segment p a
They represent the frequencies of use connections realized
within the program. Second, the (SEGMENTGLOBAL) POSSIBLE
!JSAGE PAIRS aspects count the absolute numbers of potential
usaue pairs (pr) , given the program's global variables
43

CHAPTER IV
.inJ tneir declared scoue: the scope of global variable r
-ereL/ contains segment p v so that p coul potentially
,4odify or access r * These counts of possible usage pairs
are computed as the Sum of the number of segments in each
qLooal's scooe. They represent a sort of "worst case"
frequencies of use connections. Third, the (SEGMENTGLLBAL)
USAGE PAIR RELATIVE PERCENTAGE aspects are a way of
normalizing the numoer of usage pairs since these measures
are ratios (expressed as Percentages) of actual usage pairs
to possible usage pairs. They represent the frequencies of
reaLi-ea use connections relative to potential use
cj'nections. These usage pair relative percentage metrics
are emoirical estimates of the likelihood that an arbitrary
segment uses (i.e. sets or fetches the value of) an
ar3i*rary global variable.
In some sense, all three types of aspects dealinu with
segment-global usage pairs (actual, possible, and relative
percentage) reflect quantifiable characteristics of "data
mouLarization" within a program, i.e., the static
organization of data definitions and references within
segments and modules. In particular, the possible usage
ojirs aspects reflect the general degree of encapsulation
-)forcea by the implementation Language for global
variaoles. "oreover? the usage Pair relative percentage
asoects retlect the general degree of "globality" for global
variables, i.e., the extent to which globals are actually
usea oy those segments that could possibly do so.
(41) A se.ment-globaL-segment d#t. Injnjc (Stevens,
Oy-brs & Constantine 74, op. 118-119] (prq) is defined as
an occurrence of the following arrangement in a program: a
selment p modifies (sets) a global variable r that is
also accessed (fetched) by a segment q , with p different
*r~m n - The (SEGMENTGLOBALSEGMENT) DATA BINDINGS
asoects count these unique communication paths between pairs
44

CHAPTER IV
of sewments via glooaL variables. These aspects thus
reflect the degree of one form of connectivity within a
progra .
See Chapter V for further discussion of the data
bindings metrics.
(42) In this study, segment-global-segment data
bindings were counted in three different ways: ACTUAL,
POSSIoLE, and RELATIVE PERCENTAGE. First, the DATA
PI4DINGS\ACTUAL aspect counts the total number of data
bindings actually coded in the program, reflecting the
degree of realized connectivity. Second, the DATA BIhDINGS\
POSSIOLE aspect counts the total number of data bindings
that could possibly be allowed, given the programs
organizational structure* It reflects the degree of
potential connectivity. Third, the DATA BINDINGS\RELATIVE
PERCENTAGE aspect is the ratio (expressed as a percentage)
of actual data bindings to possible data bindings,
reflecting the normalized degree of realized connectivity
relative to potential connectivity.
See Chapter V for further discussion of the data
bindings metrics.
(43) Actual data bindings are (sub)categorized
deoencing on the invocation relationship between the two
segments. A data bindin3 (orq) is su_9fun&ti2! if
either of the two segments o or q can invoke the other,
whether directly or indirectly, as a "subroutine." A data
binding (p,rtq) is intpEnqtE if neither of the two
segments p or q can invoke the other, whether directly
or indirectly.
See Chapter V for further discussion of the data
bindings metrics.
(44) j 2g1ilzzy [McCabe 76) is a graph-
45

CHAPTER IV
theoretic measure of control-flow complexity. For an
imoLementation Language with only structured control
structures (sucn as SIMPL-T), this measure is dependent only
on the number of predicates (i.e.,t aoolean expressions
governing flow of controL) in the source code. The
cyctomatic complexity v(p) of a program P with 11
oredicates strewn among s segments is computed as
v(P) = + s
the cycLomatic complexity v(S) of a segment S with iT
oredicates is computed as
v (S) = + I .
See Chapter V for further discussion of the cycLomatic
complexity metrics.
(45) Four definitional variations of the basic
cyclomatic complexity measure were examined in this study in
orler to explore alternatives for identifying predicates and
for handling case statement constructs. Under the SIMPPRED
alternative, simple 9oolean subexpressions joined by and or
gr connectives are each counted as predicates. Under the
COWPPRED alternative, only each complete Boolean expression
is counted as a preaicate. Under the NCASE alternative,
each case statement construct is counted as contributing n
predicates, where n is the number of "cases" involved.
Under the LOGCASE alternativet each case statement construct
is counted as contributing LLog 2( n )J* predicates, thus
giving a discount for case statement constructs relative to
series of nested ifthenetse constructs.
See Chapter V for further discussion of the cyclomatic
conpLexity metrics.
(46) For each of the definitional variations, tne
CYCLOMATIC COMPLEXITY%...\TOTAL asoect measures the
* The notation L x J signifies the greatest integer lessthan or equal to x
46

CHAPTFR IV
cycLomatic complexity of the entire program. It is simply
the sum of cycLomatic co-nplexity values for the individual
segments comprising the program.,ee Cnaoter V for further discussion of the cyclomatic
co-mplexity metrics.
(47) For each of the definitional variations, the
CYCLOMATIC COMPLEXITY\...\#SEGS:CC>=1O aspect counts the
nu-nDer of segments in the program whose cycLomatic
complexity values equal or exceed the threshold value 10.
See Chaoter V for further discussion of the cyclomatic
complexity metrics.
(46) For each of the aefinitional variations, a common
descriptive statistic of the empirical distribution of
cycLomatic complexity values from the individual segments
comprising an entire an entire program was used as a vehicle
for measuring the general level of cyclomatic complexity
within the relatively nontrivial segments of the program.
This descriptive statistic, known as a ggul [Conover 71,
P). 11-32, po. 72-73], can be Loosely described (in the
discrete case) as the value (of the random variable in
q-lestion) corresoonding to a Particular fixed probability
level on the cumulative relative frequency curve
(representing the distrioution of that random variable).
The CYCLOMATIC COMPLExITY\,,,\ f QUANTILE POINT VALUE
asoects are defined to measure the Largest integer x such
tr3t the fraction of cyclomatic complexity values which are
less than x is Less than or equal to the fixed fraction
f , The CyCLOMATIC 1OM0LEXITY\,.,\ f QUANTILE TAIL AVERAGE
asoects are defined to measure the average of cycLomatic
complexity values greater than or equal to the f quantile
point value. Several particular quantites were examined in
this study: the n.5 quantiLe is closely related to the
distribution's median, and the 3.7, 0.8, and 0.9 quantiles
47

CHAPTER IV
nrovide a series of increasingly smaller tails of the
di s t r ihut ion.
See Chapter V for further discussion of the cycLomatic
complexity metrics.
(4i) According to software science theory [Halstead
77], several interesting quantities can be computed from the
soirce code of a program anO uSed to measure characteristics
of both the aostract algorithm and its expression as
imoLemented. ALL of these software sienae gu o-itie E are
conputed in terms of the number of conceptuaLly unique
"ooerators" and "operands" and the total occurrences of such
"ocerators" and "ooerands" within a program. In this study,
these "operators" and "ooerands" were identified
syntacticaLLy according to a set of rules established for
the implementation Language SIMPL-T.
See Chapter V for further discussion of the software
science metrics.
(50) Given the basic parameters of software science:
total "operator" count N1
total "operand" count N 2
unique "ooerator" count n1
unique "ooerand" count T 2
unique potential "operand" count Ti
the following formulas define the software science
ouantities examined in this study;
VDCAEzULARY T1 = r) + T 2
LE4GTH N =N 1 N21 + N2 n ) T1 * t (l )
FSTIATED LENGTH n (n 1 og2 (n 1 + ( 2 tog2 2
%IFFEREN CE(NR) = - N (N)
V L u4E V = N Log 2 (n)
P3TENTIAL VOLU= 2 * Log2 ( 2 + 2*)
Pfk3GOAM LEVEL L V* / V
DIFFICULTY D= 1 P L

CHAPTER IV
INTELLIGENCE CONTENT I = (2 / /1 I (n2 N 2) V
*DIFFERENCE(V*#I) = (i - V*I) I (V*)
LANGUAGE LEVEL X = L * V*
EFFORT E = V *
ESTIMATED TI"E T = E / S
ESTIMATED BUGS = L • E / E0
wrere S and E are psychologically determined constants*
See Chapter V for further discussion of the software
science metrics.
(51) Two different calculation methods were emoLoyed
in the study to compute the subset of software science
quantities whose exact values cannot be obtained directly
(via the defining formulas) from a program's source code.
These cdculation methods each rely upon a different
estination technique to obtain approximate values for these
quantities. The 1ST CALCULATION METHOD relies upon the
commonly accepted theoretical estimate of the orogram Level
quantity; the 2ND CALCULATION METHOD relies upon an
internally applied empirical estimate of the Language level
quantity.
See Chapter V for further discussion of the software
science metrics.
(99) Several instances of duplicate programming
asoects exist in the Table 1 Listing. That is, some
logically unique aspects reappear with another label, for
reasons explained aoove. Listed below are the pairs of
-luolicate programming asoects that were considerea in this
study:
le FUNCTION CALLS <=> INVOCATIONS\FUNCTION
NONINTRINSIC • NONINTRINSIC
it INTRINSIC <=> INTRINSIC
4e STATEMENT TYPE COUNTS%(PROC)CALL <=> INVOCATION S\PROCEDUkE
NONINTRrustC <=> NONINTRINSIC

CHAPTER IV
114'TPINSIC (=> IN TR INSI C
'.AVERAGE INVOCATIONS DER(CALLING) SEGMENT\ < AVERAGE INVOCATIONS PERNONINTRINSIC (CALLED) SEGMENT
SO'LFTWARE SCIENCE SOFTWARE SCIENCEOUANrITIES\INTELLIGENCE <=> QUANTITIES \1ST CALCULATIONCONTENT mETHOD\POTENTIAL VOLUME
-?y definition, the data scores obtained for any pair of
du~ticate aspects will be identical, and thus the same
statisticaL conclusions will be reached for both aspects.

CHAPTER V
This chapter orovioes an in-depth discuSsion of the
elaoorative programming aspects examined in the study. The
material is presented, in a tutorial fashion, in order to
rotivate their aopeal as software metrics and to explain how
they might be interpreted. The reaoer who is acquainted
with one or nore of these measures might consider skimming
the corresponding sections.
_0 r_ r,* Changes
The program changes metric pertains to textual
revisions made to program source code during development?
fr3m the time a program is first presented to the computer
system, to the completion of the project. The metric's
definition is framed so that one program change approximates
one conceptual change to the program. The following rules
4or ioentifying program changes are reproduced from
[Dunsmore 78, pp. 19-20]:
"The following text changes to a program represent oneprogram change:
1. One or more changes to a single statement.(Even multiple character changes to astatement represent mental activity with onlya single aostract instruction.)
2. One or more statements inserted between existingstatements.
(The contiguous group of statements insertedprobably corresponds to the concretestatements that represent a single abstractinstruction*)
3. A change to a single statement followed by theinsertion of new statements.
IThis instancp probably represents adiscovery that an existing statement isinsufficient and that it must be altered andsupplemented by additional statements toimplement the abstract in;tructioninvolved.)
"however, the following text changes to a program arenot counted as pro;ram changes:

CHAPTER V
1. The deletion of one or more statements.(Deleted statements must usually be replacedby other statements elsewhere. The insertedstatements are counted; counting deletions aswell would give double weight to such achange. 3ccasionaLLy statements are deletedbut not replaced; these were probably beingused for debuiging purposes and theirdeletion requires Litte mental activity.)
2. The insertion of standard output statements orinsertion of soecial compiter-provioed Oebuigingstatements.
(These are occasionally inserted in awholesale fashion during debugging. when theproblem is found, these are then all removed,and the necessary program change takesplace.)
7. The insertion of blank lines, insertion ofcomments, revision of comments, and reformattingwithout alteration of existing statements.
(These are all judged to be cosmetic innature. )"
Fro~ram changes are counted aLgorithmically by comparing the
source code from each pair of consecutive compilations of a
module (or Logical predecessor thereof) and applying the
identification rules. Thus the total number of program
ch3nges is a measure of the amount of textual revision to
source code during (oostlesign) system development.
The program changes metric may be interpreted as a
Dr~ojrdming complexity measure, because textual revisions
7--p usuatly necessitated by errors encountered while
tuiLding, testing, and debugging software. Independent
research [Dunsmore & Gannon 77) has demonstrated a high
(r3nk order) correlation between total program changes (as
counted automatically according to a specific algorithm) and
total error occurrences (as tabulated manually from
exhaustive scrutiny of source code and test results) during
ssftware implementation in the SIMPL-T programming Language.
Thus empirical evidence justifies consideration ot the
DrOgram changes metric as a direct measure of the relative
nuioer of programming errors encountered outside of design
work. It is reasonable to assume that each textual revision
ert ;its some expenditure of the programmer's effort (e.g.,
nlinning the revision, editing source code on-line), In

FV
CHAPTER V
th t sense, this metric may also be considered an indirect
measure of the level of human effort devoted to
imo tement at ion.
Control-flow complexity may be measured in terms of
cyctomatic complexity ['cCabe 76), a graph-theoretic metric
that is independent ot physical size (i.e., insertion or
deletion of function statements Leaves the measure
unchanged) and dependent only on the decision structure of a
program. The cyctomatic number v(G) of a graph G having
n nodes, e edges, and p connected components is
defined as
v(G) z e - n * o
In a strongly connected graph, the cyctomatic number is
equal to the minimum number of basis paths from which all
other oaths may be constructed as linear combinations in an
edge-atgebraic fashion (see [M cCabe 76] for details). By
mojeLing the control flow of a program as a graph in the
traditional manner, the cyctomatic complexity measure is
defined to be the cycLomatic number of the graph
corresponding to the program's flow of control.
For a structured Language Like SIMPL-Tt it is not
necessary to construct a control-flow graph in order to
measure a program's cycLomatic complexity. The measure can
be computed directly from the source code simply by counting
the number of oredicates (i.e., Boolean expressions
governing control flow), since the predicates of the program
correspond exactly to the binary-branching decision points
of the controt-flow graph. It is easily shown, using a
temma proven in (ills 7Z , that for a segment S with It
credicates the segment's cyclomatic complexity is
53

CHAPTER V
v(S) Tr .1
and f(jr a royram P with II predicates strewn among s
segments the program's cyclomatic complexity is
v(P) = + s o
This measure originated as an absolute count of the
maximum number of Linearly independent execution paths
throuvh a segment, in the graph-theoretic edae-algebraic
sense alluded to above. Since each of these paths merits
individual testing, the measure was proposed to serve as a
auantitative indicator of the difficulty of testing a given
segment to a certain aegree of thoroughness. Testability is
clearly an issue closely related to software complexity in
-eneral, and a program's cycLomatic complexity may be viewed
as one quantitative measure of its control-structure
complexity.
Defin itiona I Variations
Several variations of the basic cycLomatic complexity
neasure were considered, because there are at least two
cefinitional issues for which intuitively motivated
alternatives lead to meaningful variations.
One of these issues is the weighting given to instances
of case statement constructs. The original definition of
cycLomatic complexity views a case statement as the
semanticatty equivalent series of nested ifthenelse
statements: each case statement contributes n units of
cyclomatic complexityg where n is the number of individual
@Icases" involved. It can be argued, however, that a case
st3tement deserves a smatler contribution to cyctomatic
coaplexity since its inherent uniformity and readability
have a moderating effect on programmer-perceived complexity
(relative to an explicit series of nested ifthenelse
54

CHAPTER V
statements). One reasonable alternative views each case
statement as contributing LLog 2 C n )J* units of cycLomatic
co-nptexity, where n is the number of inaiviouaL "cases"
involved. This logarithmic weighting is anpropriate since a
case statement's moderating effect seems to increase with
the number of "cases" involveo.
The other issue is the manner of counting predicates.The original definition counts simple (sub)predicates
iniividually, so that the compound predicate
(I < J) in ((A(I)= A(J)) 2r (ngl SORTED))
woull contribute three units of cyclomatic complexity, for
example. An alternative definition considers each complete
oredicate as an indivisible part of a program, contriouting
one unit of cyclomatic complexity. The motivation is that
the complete predicate represents a single abstract
coidition governing the flow of contro(. Note that this
issue is the basis for a proposed extension [Myers 77] to
the original cyctomatic complexity measure. This issue also
affects the way individual "cases" of a case statement
construct are identified and counted. The original
definition counts each case Label separately, since multiple
case laoels on the same case branch are semantically
ecuivatent to simple predicates joined by ors to form the
goalean expression governing the case branch. The
alternative defintion counts only the case branches
themselves, regardless of case label multiplicity. In
parallel with the motivation given above, multiple case
la:ets on a case branch represent a single abstract
condition governing that branch (e.g., the set of case
ta:eLs Q, I , ... , 2 may be abstracted to d .Lg).
This study examined the four variations of cyclomatic
* "ne notation L x-J signifies the greatest integer lessthan or eauat to x

CHAPTER V
coiplexity defined as follows for the SI4PL-T programming
(an jud ie :
SIMPPPED-NCASE -- Simple predicates contribute 1 unit;
case statements contribute 1 unit for each case
Label.
SI.4PPRED-LOGCASE -- Simple predicates contrioute 1
unit; case statements contribute LLog 2( n )J
units, where n is the number of case Labels.
COMPPRED-NCASE -- Compound predicates contribute 1
unit; case statements contribute 1 unit for each
case branch; multiple case Labels on the same case
branch are disregarded.
COMPPRED-LOGCASE -- Compound predicates contribute 1
unit; case statements contribute LLog 2 ( n )j
units, where n is the number of case branches;
multiple case labels on the same case branch are
disregarded.
Note that the SIMPPRED-NCASE variation of cyclomatic
complexity is McCabe's original measure.
There are several ways to apply the cyclomatic
complexity measure (or variations thereof) to an entire
orogram in order to obtain a metric for its overall control-
flow complexity. First of all, the metric is defined
directly for a program composed of individual segments: a
program's total cycLomatic complexity is simply the sum of
its segments' cyclomatic complexities. However, this total
cyclomatic complexity measure is not particularly useful as
a oasis for comparing entire programs because it is, in a
certain sense, insensitive to the program's modularization.
As a metric, the total cyctomatic complexity of a program is
(oy definition) a linear function in two variables, tne
nuioer of predicates ann the number of segments. A subtle
56
hi -

CHAPTER V
tr3de-off relationship exists between these two variaoLes,such that substantial fluctuation in the metricos value can
arise from simpleminded changes to a program'smoJuLarization atone.
A better comparison of entire programs is afforded by
focusing attention upon the cyclomatic complexity values ofindividual segments and upon instances of segments with high
values of the metric. MCCabe originally proposed the number
!' as a reasonaole thresholo value for a segment's
cycLomatic comolexity. Segments exceeding this threshold
need to be recoded or decomposed into smaller segments inorder to attain an acceptable Level of testability ano
co'ntrol-fLow complexity. Hence, a second way to apply the
CycLomatic complexity measure to an entire program is to
count the number of segments whose cycLomatic complexity
value exceeds this threshold. In this case, the basis for
covparing entire programs is the frequency of segments with
unacceptably high cyclomatic complexity.
Finally, it would be desirable to compare the fullspectrum of cyclomatic complexity values for the individual
segments of one program against that of another programt
since consideraote diversity often exists. Programs
typically contain several small segments with very LowcycLomatic complexity values (e.g., a function to compute
the dvera.ge of a vector) and a few large segments with high
cycLomatic complexity values. Being easily understood and
testea, the small segments are relatively inconsequential,
while the Large segments contain the substance of the
orogram and contribute most of the consequential control-
flow complexity. IdeaLly, one wishes to disregard the"svaLLer" cycLomatic comolexity values and summarize themagnitude and frequency of the "larger" cyclomatic
covplexity values via a single quantitative indicator, but
57

CHAPTER V
o so in a flexibLe, normalized fashion, where "smatter" and
"larger" are determined relative to one another within each
orogram.
This ideal can be aoproximated by means of the
quantiLes of the empirical distribution of cyclomatic
conplexity values across the segments comprising the program
(see Figure 1). QuantiLes are a standard tool from
descriotive statistics [Conover 71, pp. 31-32, pp. 72-73],
covmonly used to summarize the "shape" and "position" of a
listribution function, especialLy its upper tail region.
Both the quantile Point value (i.e., the largest integer x
such that the fraction of cycLomatic complexity values which
are Less than x is less than or equal to some fixed
fraction) and the quantile tail average (i.e., the average
of cycLomatic complexity values greater than or equal to the
nuantiLe point value) are normalized ways to quantify just
how high the cyclomatic complexity is for the relatively
nontriviaL segments of a program. Several different
Quantiles were examined: the 0.5 quantiLe is closeLy related
to the median of the distribution, and the 0.7, 0.8, and 0.9
ouantiles provide a series of increasingly smatler tails of
the distribution. Thus, the basis for this third comparison
of entire programs is a series of quantitative descriptors
of the empiricaL distribution of cycLomatic complexity
values within a Program.
The data bindings metrics [Stevens, Myers & Constantine
74; 7asili & Turner 75; Turner 76] originated as a way to
quantify a certain kind of connectivity (i.e., directed
cowmunication between segments via global variables) within
a orogram. Their motivation is based on the intuitive
58

FIGURE 1
figure 1. Fregumencx 2is1tW1-J2n 2f_ US12MI~o~Zif 12!!21Ei1y
6cth the absoLute and the relative-cumulative frequencydistribution of cycLomatic comoLexity values from 47seguents comprising an entire program are plotted. The tailregion associated with the 0.8 quantiLe is shaded on eachp tot.
---------------------- 0.5 quantite15 *
/\ :0.7 ouantite
a f a ----------------- 0.8 quantile
b r / \ V "
s e 10 / - -- - 0.9 quantiLe
l u /Iutn *e 5 *-*
y/
i ." " a S I I I
0 2 4 6 8 10 12 14
cyctomatic complexity per segment
0 2 4 6 8 10 12 14
1.0 I0.80.8 ------------ >
c f 0. 7 --------- '-"r u f
L U qa L U 0.5 - >t a ei t n 0.4v i ce v y 0.3
eC.2
0.1
G.0
0 2 4 6 8 10 12 14
cycLomatic complexity per segment
58a

CHAPTER V
orinciole that the Logical complexity of a composite system
is a function of the muttiolicity of connections amon its
component parts (cf. [Simon 693).
A segment-gLobal-segment dta tinding (p,r,q) is an
occurrence of the following arrangement in a program: a
segment p modifies a global variaole r that is also
accessed by a segment q , with segment p different from
segment q . The existence of a data binding (pvrvq)
suggests that the behavior of segment q is probably
deoenodent on the performance of segment p through the data
variaote r , wnose value is set by p and fetched by q
The binding (p,r,q) is different from the binding
(I,rp) which may also exist; occurrences such as
(Drp) are not counted as data bindings. Thus each data
binding represents a unique communication path between a
pair of segments via a gtobal variable. As a metric, the
total number of segment-gLobat-segment data bindings
reflects the aegree of that kind of connectivity within a
orogram.
Data bindings may be counted in three different ways:
actual, possible, and relative percentagee (iear in mind
that, since these measures are determined statically from
the source code, the terms 'actual' and 'possible' refer to
a orogram's syntactic form only.)
First, the A count is the absolute number of data
bindings (p,r,q) actually coded in the program: segment
p contains a statement modifying global variable r , and
segment q contains a statement accessing r . This count
of actual data oindings represents the degree of realized
connectivity in the program. Second, the Rq11ibjt count is
the absolute number of data bindings Cpr #) that could
possibly be allowed under the program's structure .)f segment
59

CHAPTER V
definitions and global variable declarations: the scope of
7L0oal variable r merely contains both segment P and
segment Q , So that segment o could potentially mooify
r and segment q could potentially access r . This
coint of possible data bindings represents the degree of
potential connectivity, in a "worst-case" sense. It is
computed as the sum of terms s* (s-1) for each global
variable, where s is the number of segments in that
IltoaL's scope; thus, it is heavily influenced (numerically
5.:eaking) by the sheer number of segments in a program.
',ir-z, the _re ative grCjC! e is a way of normatizin; the
aosotute numbers of data bindings, since it is simply the
Quotient (expressed as a percentage) of actual data bindings
divided by possible data bindings. It represents the degree
of realized connectivity relative to potential connectivity.
Actual data bindings may also be subcharacterizecd on
the basis of the invocation relationship between the two
segments. A data binding (p,rq) is l aflsncgntJ if
either of the two segments p or q can invoke the other,
whether directly or indirectly (via a chain of intermediate
invocations involving other segments). In this situation,
the functioning of the one segment may be viewed as
contributing to the overall functioning of the other
segment. A data binding (ptrq) is 1_n g..!2gCO.t if neither
of the two segments p or q can invoke the other, whether
directly or indirectly. The transitive closure of the call
graph among the segments of a program is employed to make
this distinction between suofunctionaL and independent data
bindings.
In some sense, all three measures dealing with segment-
globaL-segment data bindings--actual, possible, and relative
cercentage--reftect Quantifiable characteristics of a
orogram's "data modutarization" (i.e., the static
60

CHAPTER V
")r~dnizdtinn of Jatd detinitions anu references within
segments and modules).
In particular, the oossibte data bindings metric
reflects the yeneral degree of encapsulation enforced by the
imoLementation Language for global variables. One can
imagine two extremes of encapsulation for the same
collection of global variables and segments. On the one
hand, the program could be written (in the implementation
language SIr4PL-T) as a single module containing alL tne
segments, with each glooal potentially accessible from every
segment. This moduLarization would maximize (explosively
so, due to the squaring of the number of segments) the
number of possible data bindings. On the other handt the
Program could be written (in the implementation language
SIMPL-T) as several modules, one for each segment, with
appropriate ENTRY and EXTernal declarations to provide each
segment with potential access to exactly those gLobals it
actually uses. This modularization would minimize the
number of possible data bindings (to precisely the number of
actual data bindings).
Moreover, the data bindings relative percentage metric
also reflects the general degree of (operational)
"globality" for the global variables declared in a programt
i.e., the extent to which gLobals are actually modified
(set) and accessed (fetched) by those pairs of segments that
couLd possibly do so. One can imagine two different
situations in which the relative percentage of data bindings
for a small set of otherwise equivalent global variables
(say, an array and an integer) would be extremely high and
extremely low, respectively. On the one hand, this global
array and global integer could be serving as a stack, and
nearly every segment that refers to these glooals could be
botn popping the stack to examine its contents and pushing
61

CHAPTEP V
ned items onto it. Here the two global variables are quite
central to the overalL operation of that coLlection ot
segments; their data binding relative percentage woulu be
close to one. On the other hand, this global array and
global integer could be serving as a buffer for a varying-
length vector that is initially oroduced (set) by one
segment and nondestructively consumed (fetched only) oy
several Other segments. Here the twO globaL variables are
rather incidental to the overall operation of that
collection of segments, serving merely as a convenient
medium for disseminating information (which could also have
achieved via parameter passing); their data binding relative
vercentage would be close to zero.
The software science quantities are a set of metrics
based upon the tenets of software science (Halstead 77), as
Pioneered by Halstead and his colleagues. Billed as
a branch of experimental and theoretical science
dealing with the human preparation of computer programs
and other types of written material ... ,'
software science is concerned with measurable attributes of
algorithms or programs and with mathematical relationships
among those attrioutes. Software science is
characteristically actuarial in nature: its measures and
relationships may be inaccurate when applied to individual
proirams, but they become surprisingly more accurate when
apulied to Large numbers of orograms, such as are found in
large software development projects.
The software science quantities are all defined in
The blocked quotations throughout this section are taken4rorn (Halsteaa 77].

CHAPTER V
terms of certain frequencies of so-called "operators" and
"ooerands" aopearing within an atgorithm's functional
specification or a PrOgramos source code implementation.
Sove uf the nuantities (e.g., vocabulary, Length, volume)
are purely descriptive and provide the building-blocks of
the theory. A few (e.g.t estimated Length) are predictive
of other descriptive quantities within the theory. Several
(e.g., program Level, language Level, effort) claim to be
quantifications of fundamentally qualitative and intuitive
concepts. Stitl other Quantities (e.g.# estimated time,
estimated bugs) purport to measure--under ideal conditions--
externally observable and Quantifiable programming
Phenomena.
f!gntificati on Criteria
The criteria for identifying "operators" and "operands"
(and their uniqueness) are important since they are the
foindation for measuring the software science quantities.
Hodeyer, this identification is an area not clearly
aoressed by the theory. Except for the Fortran programming
tanguaje, in which most of the pioneering work was done,
exoLicit standards or guidelines for identification do not
exist. For another Language, a researcher can only attempt
to adapt and extend the principles that he personally judges
to oe behind the Fortran work. The following "operator/
operand" identification criteria were designed for the
SIMPL-T programming language:
1. In general, only the portion of source code pertaining
to executabte statements (after expansion of all
DEFINE-macros) is considered.
2. Constants and data variable identifiers are natural
"operands." Data structures (e.g., arrays, files) are
considered single o~jects and not decomposed into
c oioonen t s.
63

CHAPTER V
3. The input stream file and the output stream file are
counted as "ooerands," with implicit occurrences
recognized for each operation on these files.
4. The normal prefix unary and infix binary operator
symbols (i.e., for arithmetic, Logical, and character-
string operations) are natural "operators."
5. The intrinsic procedures (e.g., READ, WRITE, REWIND),
type-coercion functions, and input-output operation
keywords (e.g., EJECT, SKIP) are "operators."
6. Segment invocations (i.e., procedure calls and function
references) are "operators."
7. Different types of statements or constructs are
considered individual "operators," as follows:
(assignment)
IF...THEN.oEND
IFe.THEN...ELSE* .END
CASE. .OF...END
CASE. .OF..,ELSE. ..END
WHILE. ,.DO..,E4D
EXIT
RETURN
9. 0ther delimiter patterns are considered "operators," as
foLo. ws:
(caselabeL designation "operator")
coo *I (partword and substring "operators")
(..) (suoexpression, array subscript,
actual argument list, and function
return value "operators")
9 (List item separation "operator")
9. FinaLly, implicit statement List brackets (associated
with pairs of keywords such as THEN...ELSE and
ELSE...END) are considered "operators," as are implicit
statement separators between consecutive statements of
the same statement list.
(The quotation marks flagging "operator" and "operand" as
64

CHAPTER V
technical terms are suppresseu throughout the remainder of
this section for readability.)
The five basic parameters of software science are
determined in accordance with the criteria established for
iontfying operators and operands.
The theory defines four basic parameters pertaininy to
a orosram's implementation: the total operator count N 1 ,
the total operand count N, 9 the unique operator count
n 1 and the unique operand count n 2 * The total counts
include aLl occurrences of operators/operands, while the
unique counts disregard iultipte occurrences of the same
operator/operand. Although the issue of synonymy for
operators has already been dealt with in the identification
criteria, issues of synonymy for operands still remain. In
particular, formal parameters are considered to be
synonymous with corresponding actual arguments; therefore
occurrences of formal parameter identifiers contribute to
the total operand count but not to the unique operand count,
with respect to the entire program. This rule is not,
however, applied in the case of formal parameters passed by
value and modified by the segment; because these are
actually treated as special initialized-upon-entry Local
variaotes in the implementation language SIMPL-T, they are
not considered to be synonymous operands with respect to the
entire program.
The theory defines four additional basic parameters,
analoyous to those described above, but pertaining to an
algorithm's or program's "shortest possible or most succinct
form" (i.e., its "one-Liner" functional specification,
conceived as an assignment statement or procedure call
65

T
CHAPTER V
invoLving a single ouitt-in routine). These are the total
potential operator count N * , the total potential operand
count N 2 * , the unique potential operator count l * , and
the unique potential operano count 2* (The modifier
s*potential" and the superscripted asterisk distinguish
quantities pertaining to the functional specification from
analogous quantities pertaining to the implementation.) The
theory assumes, however, that the total potential operator/
operand counts must always equal the unique potential
perator/ooerana counts, because the most Succinct
;Qecification wouLd contain no redundant occurrences of
operators/operands. An assumption is also maoe that the
unique potential operator Count is always equal to the
coistant 2, because
"... the minimum possible number of operators .. must
consist of one distinct operator for the name of the
function or procedure and another to serve as an
assignment or grouping symbol."
Thus, all software science quantities pertaining to a
-)r-gram's specification are completely determined
Fnimerically speaking) by a single parameter# the unique
notentiat operand count n * It is the fifth basic2carameter of software science theory and is conceptually
equivalent to the number of "logically distinct input/output
narameters" for an algorithm or orogram. This count nolds
considerable significance in both the theory and its
apolication, but unfortunately it is rather intractable for
most nontrivial programs (i.e., those whose specifications
are not easily stated as "one-liners" without gross
oversimplification). For example, some logically distinct
innut parameters may appear as special constants embedded
within the code, ana the number of logically distinct output
rara-ieters represented within a printed report is often
unclear.
66

CmAPTEP V
An alternative and iore tractable conceptualization
defines this uninue potential operand count simply as the
numuer of distinct operands busy-on-entry (i.e., initially
containing a value that is utilized or accessed by the
algorithm or program) plus the number of distinct operands
busy-on-exit (i.e., finally containing a value that was
furnished by the algorithm or program to be utilized or
accessea suosequently). For an individual segment, 2
may be estimated from the implementation by counting all of
the global variables that are referenced, each of the formal
Darameters, one for both the input stream file and the
output stream file (if they are read or written), and one
for the function return value (if the segment is a
function). It shouLd be noted that this estimate is a lower
boind since it disregards the oossibility that a format
parameter which is passed by reference should be counted
twice because it is both busy-on-entry and busy-on-exit.
For an entire program, fl * may be estimated from the
imoLementation by counting ore for both the imput stream
file and the output stream file if the program reads or
writes them, plus one for the set of control bits or option
letters that might oe used to regulate the program's
execution.
Thus, for the programs examined in this study, the
esti-ated number of unique potential operands is always
either 2 or 3, depending on whetheroutput listing compileand~execute( inputdeck )
or
outputlisting
compileand execute( inputdeck, option letters )
states their functional specification. It is clear that
this kind of estimation of n 2* from the imolementation is
considerably more accurate for individual segments than for
entire programs; this fact is partial motivation for the
67

CHAPTER V
particular estimation techniaue employeL the second
methot! of calculation discussed below.
The derived properties of software science are defined
in terms of the five basic parameters.
The vocabulary fl is defined as
) = I 1 + T2
inI renresents the cardinatity of the set of Logically
distinct "symbols" used to implement the program. The
Length N is defined as
N = N N2
ani represents the abstract size of the program-s
implementation as measured in units of Logically distinct
"symbols." This property is closely associated with the
numoer of syntactic tokens in the source code of a program;
it can be considereo a refinement of the rudimentary TOKENS
isDect. The estimated Lenth R is defined as
q (1 * Log 2 ( 1 )) + (2 Log 2( 2 ))
-eflecting one of the fundamentaL conjectures of the theory;
namely, that the observed length of a program's
iDlementation is a function solely of the number of unique
operators/operands involved.
Considerable empirical evidence has supported the
vatidity of this "length prediction equation" on tht er
fi.e., major software studies have reported correlation
coefficients of between 3.95 and 0.99 for the relationship
het.een N and q [Fitzsimmons & Love 78)). HOwever, its
accuracy for tny livern E rr may be low; the theory
attrioutes this to the presence of so-called "impurities"
tnl.icating a Lack of polish in a program. These impurities
include instances of unnecessary redundancy and needless

CHAPTER V
constructions, such as inverse operations that cancel each
other, common subexpressions, or unreachable statements.
This has Led some researchers to view the discrepancy
between N and R as a possible software quality measure.
For these reasons, it was desirable to examine the
YDIFFEPENCE(N,n) aspect, calculated as
(IX - NI) / (N)which normalizes the degree of discrepancy.
The voJum V is defined as
V = N * Log 2 (n
and represents the abstract size of the program's
imolementation as measured in units of information-theoretic
bits. Specifically, it is the minimum number of bits
requirecl to encode the implementation as a sequence of
fixed-width binary strings (since it is the product of the
total number of "symbols" and the minimum bandwidth required
to distinguish each of the unique "symbols"). The 2210tiat
vYu_"e V* is defined analogously as
V* = N* * Log2 (*)
= (NI* + N2 *) * log 2 (n 1 * + T 2 )
= I + n 2*) * Lg 2 ( 1 * + n2(2 + n 2*) * Log2(2 + T2.) .
The potential volume of any algorithm or program is
theoretically indeoenOent of any Language in which it might
be implemented; thus,
"Orovided that r) * is evaluated as the number of2conceptually unique operands involved, V* appears to
be a most useful measure of an aLgorithm's content."
The Pro.ar tj v L is defined as
L Z V* / V
-vn, as a ratio of volumes, can only take on values between
iero ana one; it quantifies the intuitive concept of "level
datstraction" for an inplementation. Since the potential
69

CHAPTER V
volume of any given algorithm is constant, the formula
inlicdtes an inverse relationship (as desired intuitively)
bet.een Level of abstraction (measured by L ) and size
(measured by V ). The theory also attaches meaning to the
reciprocal of program level, defining diffiC Jty D as
which may alternatively be viewed a- the amount of
rejundancy within an impLementation.
unfortunately, this definition of program Level is not
OdrticuLarly useful since it is difficult (as discussed
aoave) to determine exactly a program's unique potential
operand count or its potential volume V* . Desiring
to be able to measure program Level even if these quantities
were unavailable, Halstead conjectured that an estimateg
2r2era j_ C , defined as
C (= * / nlI * / N2 )
= (2 / ) * ( I N ) ,
could be measured directly from an implementation alone,
without a specification or the unique potential operand
count l 2 * * With only limited evidence supporting the
validity of this estimate, the theory makes the qualified
claim that
,.. for many purposes L and C may be used
interchangeably to specify the level at which a program
has oeen implemented, at Least for smaller programs."
%Lthough most software science studies (e.g., CElshoft 76;
Love & Cowman 76; Curtis et al. 79)) have had no choice but
to rely upon this "program Level prediction equation" to
calculate the derived properties, the program level
estimator C has been criticized pubticaLLy COldehoeft 77]
for unsatisfactory behavior under certain conditions. The
ouestionable validity of this prediction equation is the
principal motivation for considering the two alternative
metnous of calculation discussed below.
70

CHAPTE.R V
In any event, the theory employs C internally,
defining in~j~jj2tD i IQDatOl 1 asI = C * V
and oroposing it as a measure of "how much is said" in an
aLgorithm or program (i.e., its information content). This
intelligence content quantity represents the amount of
detail expressed in an implementation but weiGhteo by its
level of expression. ey definition, I is determinaote
from an impLementaion aLone. If there is a strong
relationship between L and C , intelligence content I
would be approximately equat to potential volume V* * In
fact, Hatstead originally demonstrated that the removal of
program "impurities" (as described above) consistently
imoroved the numerical agreement between V* and I *
Normalizing the degree of discrepancy between these two
Quantities, the %DIFFERENCE(V*,I) aspect, calculated as
(II - V*|) / (v*)
may be interoreted as another possible software quality
measure, according to the theory.
The ta eL X is defined as
Lk = V*
X L L * V
V* V* I V
and claims to quantify the popular intuitive concept known
by the same name. The theory suggests that X should
raiain relatively constant for any particular implementation
Language white the implemented algorithm itself is allowed
to vary. Empirical evidence from a carefully constructed
set of programs, each implemented in several common
crogramming tanguages, indicated that the ordering of mean
values for X (which ranged from about 0.8 for assemoly
Language to about 1.6 for PL/1) concurred exactly with the
generally accepted intuitive ordering of the Languages
! hemse t yes.

CHAPTER V
The effort E is definea as
E =V *D
V L
= V * V I V(
but this Quantity does not purport to measure development
effort in the usual sense. Rather, the theory originally
restricted
S.g.. the concept of programming effort to be the mental
activity required to reduce a preconceived algorithm to
an actual implementation in a Language in which the
imptementor (writer) is fluent ...s
According to further elaooration of the theory [Gordon 793,
this property represents the effort required (under iueat
conditions) to comprehend an implementation rather than to
produce it; E may tnus be interpreted as a measure of
program clarity. The effort property is considered to have
the dimension either of bits or of "elementary mental
discriminations." Borrowing from research in psychology#
the theory converts this amount of mental effort into an
externally observable duration of time, defining the
estiated lime T asT" = E / S
where S is the so-called Stroud rate, i.e., the numoer of
"elementary mental discriminations" made by a programmer
(comprehender) per second. Psychologists had shown that
5 < S < 20 and Halstead determined empirically that S = 18
was a reasonable value.
Finally, the theory purports to quantify one other
Pxternally observable property, namely, the total number of
"oelivered" bugs in an implementation. The ttj1i*Sj. j
property is defined as
S=L E / E0
VIE0
where E is defined as "the mean number of elementaryo
72

CHAPTER V
mental discriminations between potential errors inprogramming." The theory argues that E 3000 is a
0reasonable value. This number of bugs may be interpreted as
either the expected number of errors remaining in a
delivered program or the number of errors observeo during
program testing; both interpretations have received some
empirical support.
3ecause the validity of the "program level prediction
equation" is suspect (as discussed above), this study
emoloyed two aifferent methods for calculating software
science quantities: one relies directly upon this estimate,
the other does not.
ooth methods calculate exact values for some derived
properties via their defining formulas directly from the
imolementation's basic parameters* The methods are
therefore identical with regard to the following measured
aspects: VOCABULARY, LENGTH, ESTIMATED LENGTH,
%DIFFERENCE(NdA), VOLUME9 INTELLIGENCE CONTENT* and
ESTJ'AATED BUGS. 3ut, because reasonable values for unique
cotential operand counts are generally unavailable (from
either the specification or the implementation) for programs
of the size considered in this studyt both methods of
calculation can only approximate the remaining derivea
properties by relying upon various estimates. Due to the
intrinsically high degree of interrelationship among the
softare science quantities, it generally suffices to
approximate just one additional derived property via some
estimdtion technique; the remaining derived properties can
then all be approximated in turn via their defining formulas
from the known exact values plus the estimated value. The
methods therefore differ in their choice of Quantity to be
737

CHAP T ER V
estiTated, in their estimation technique, and with rejard to
the following measured aspects: PROGRAm LEVEL, DIFFICULTY,
'DTEI!TIAL VOLUME, %DIFFERENCE(V*,l), LANGUAGE LEVEL, EFFORT,
and ESTIMATED TIME.
The first method relies upon a "theoretical" estimation
of the program Level quantity. The estimated program level
C is calculated directly from the program-s implementation
vi3 its delining formula and then substituted as an
aporoximation for the (true) program Level L . Under this
methoo the exact value for intelligence content I is, by
definition, always equal to the approximate value for
ootential volume V* ; hence it is pointless to examine the
'YDIFFEPENCE(V*,I) aspect under this method of calculation.
The second method relies upon an "empirical" estimation
of the language level quantity. A programos language level
is approximated as the mean value of estimates for tIe
language Levels of the segments comprising the program. An
estimate of each segment's Language level can be calculated
directly from the implementation (via the defining formulas
for X , , and V ), using an estimate of the segment's
unique potential operand count Tj 2 in addition to the
exact values of the segment's other basic parameters N1 ,
N 2 , T11 , an-d r 2 . The unique potential operand estimate
is obtained by counting operands that are busy-on-entry or
tusy-on-exit (as discussed above); this technique seems
Quite reasonaole when applied to segments, most of which are
smatt enough. Use of the mean estimate for X across the
individual segments of an entire program was inspired by the
exoerimental treatment of Language level given in Halstead's
book. Under this method of calculation, all of the derived
croperties defined above are distinct and nonredundantly
calculated.
74

CHAPTER VI
This chapter describes the Steps taken to guide the
olanning, execution, and analysis of the experimental
investigation reported in this dissertation. The
investi3ative methodology outlined here was devised as a
vehicle for research in software engineering. It relies
upon established principles and techniques for scientific
research: emoiricat study, controlled experimentation, and
statist ica ( analysis.
The central feature of the investigative methodology is
a "differentiation-among-groups-by-aspects" paradigm. The
research goal is to answer the question, what differences
exist among the treatment groups (which represent different
programming environments) as indicated by differences on
measureo aspects (which reflect quantitative characteristics
of soft.are phenomena)? This use of "difference
discrimination" as the analytical technique dictates a
statistical model of homogeneity hypothesis testing that
influences nearly every element of the investigative
met hoaoloqy.
Other analytical techniques could have been employed:
estimation of the magnitude of differences between
experimental treatments#
correlations between measured aspects across all
exaerimnental treatments,
multivariate analysis (rather than multiple univariate
analyses in DaralLeL, as is the case here), or
factor analysis (breakoown of variance in one aspect
among the other measured aspects),
to name a few examples. These are useful techniques and may
be used at a Later time to answer other research questions.
75

CHAPTER VI
For tne present investiojtion, difference discrimination was
Chosen as a reasonable "first-cut" probe of the empirical
data collected for the research project; by taking this
conservative approach, information may be obtained to help
guide more refined probes in the future.
ALthough the methodology is built around running an
exneriment, collecting data, and making Statistical tests,
these activities (i.e., the execution phase) Play a small
rote within the overall investigative methodology, in
comparison to the planning and analysis phases. This is
readily apparent from the schematic in Figure 2, which
charts some of the relationships among the various elements
(or steps) of the investigative methodology. Another
feature of the investigative met hodology is the careful
distinction made during the analysis phase between objective
results (the empirical scores for the metrics and the
statistical conclusions they infer) and subjective results
(interpretations of the objective results in Light of
intuition, research goals, etc.).
The remainder of this chapter outlines the overall
methoa by defining each step and discussing how it was
apolied. Further details of certain steps are given within
other chapters of the dissertation, as follows:-tep 5 Research Frameworks Chapter VIII
Step 6 Experimental Design Chapter III
Step 7 Collecteo Data Chapter III
Step 10 Statistical Conclusions Chapter VII
Step 11 Research Interpretations Chapter VIII
Step 1: 29fios 2f 1I1r1s
severaL questions of interest were initiated and
refined so that answers wight be given in the form of
76

,FIGURE 2
C3 .Z -
ua
Q. *
Ij,.4,o
- a
4'0
" I *.- ,, ;I I
I , , o
at
-.
. . . . . . . . . . . .
S76a
WON --

CHAPTER VI
statistical conclusions and research interpretations.
Cuestions were formulate on the basis of several concerns:
(1) software oeveLopment rather than software maintenance,
(2) a desire to assess the effectiveness of disciplined team
proiramming, in comparison to undisciplined team programming
and individual programming, (3) quantitatively measurable
asoects of the process and product, and (4) the analytical
tecnnique of difference discrimination. The questions of
interest took the final form, "During software development,
what comparisons between the effects of the three
programming environments,
(a) individual programming under an ad hoc approach,
(b) team programming under an ad hoc approach,
(c) team programming under a disciplined methodology,
appear as differences in quantitatively measurable aspects
of the software development process and product?
Furthermore, what kind of differences are exhibited and what
is the airection of these differences?"
Step 2: Research HYpothCs91
Since the investigative methodology involves hypothesis
testing, it is necessary to have fairly precise statements,
catled research hypotheses, which are to be either supported
or refuted by the evidence. The second step in the method
was to formulate these research hypotheses, disjoint pairs
designated null and alternative, from the questions of
interest.
A precise meaning was given to the notion of
°difference." The investigation considered both (a)
differences in central tendency or average value, and (b)
differences in variability around the central tendency, of
observed values of the quantifiable programming aspects. It
should be noted that this decision to examine both Location
7

CHAPTER VI
ani jiispersion comodrsons among the experimental groups
brought a pervasive duality to the entire investigation
(i.e., two sets of statistical tests, two sets of
statistical results, two sets of conclusions, etc.--always
in parallel and independent of each other), since it
addresses both the glctar~z and tne 2reidt1iJiitZ of
behavior under the experimental treatments.
Some vagueness was removed regarding the size of the
particular programming task bY making explicit the implicit
restriction that completion of the task not be beyond the
caoability of a single programmer working alone for a
reasonaole period of time. Additionally, a large set of
programming aspects were specified; they are discusseo in
Chapters IV and V. For each programming aspect there were
si-nilar questions of interest, similar research hypotheses
and similar experiments conducted in parallel.
The schema for the research hypotheses may be stated as
"In the context of a one-person-do-able software development
project, there < is not I is > a difference in the
< location I dispersion > of the measurements on programming
asoect < X > between individuals (AI), ad hoc teams (AT),
and disciplined teams (DT)." For each programming aspect
X' in the set under consideration, this schema generates
two pairs of nondirectional research hypotheses, aepending
upon the selection of 'is not' or 'is' corresponding to the
null and alternative hypothesis, anu the selection of
'Location' or 'disoersion' corresponding to the type of
dif ference.
Step 3: SItaitical Mode l
The choice of a statistical mooeL makes explicit
various assumptions regarding the experimental design, the
--. . . .-- .. .. . x .. . . . .: . . . i il~ l [ i iii ~ , ... .L . .-7. . . .. .=

CHAPTER VI
deoenaent variabtles, the underlying population
distributions, etc. because the study involves a
ho-nogeneity-of-populations problem with shift and spread
attern3tives, the multi-sample model used here requires the
fot lowing: independent populations, independent and random
sampling within each population, continuous underlying
distributions for each population, homoscedasticity (equal
variances) of underlying distributions, and interval scale
of measurement [Conover 71t pp. 65-0 7 1 for each programming
asoect. Although ranoom sampling was not explicitly
achieved in this study by rigorous sampling proceoures, it
was nonetheless assumed on the basis of the apparent
reoresentativeness of the subject pool and the Lack of
oovious reasons to doubt otherwise. Due to the small sample
sizes, the unknown shape of the underlying distrioutions,
anJ the partially exploratory nature of the study, a
nonparametric statistical model was used.
whenever statistics is emoloyed to "prove" that some
systematic effect--in this case, a difference among tne
groups--exists, it is imoortant to measure the risk of
error. This is usually done oy reporting a significance
level [Conover 71, p. 79), which represents the
prooability of deciding that a systematic effect exists when
in fact it does not. in the model, the hypothesis testing
for each programming aspect was regarded as a separate
iniepenoent experiment. Consequently, the significance
level is controlled and reported experimentwise (i.e., per
asoect). While the assunption of independence between such
exoeriments is not entirely supportable, this procedure is
valid as Long as statistical inferences that couple two or
more of the orogramming aspects are avoided or prooerly
qualified. In this study, statements regarding
interrelationships among aspects are made only within the
interpretations in Chapter VIII.
79

CHAPTER VI
Step ,.: IIIIJ1iiia _HY2ohese
The research hypotheses must be translated into
statistically tractable form, called statistical hypotheses.
A correspondence, governed oy the statistical model, exists
between application-oriented notions in the research
hyootheses (e.g., typical performance of a programming team
under the disciplined methodology) and mathematical notions
in the statistical hypotheses (e.g., expecteo value of a
raido:n variable defined Over the population from which the
disciplined teams are a representative samole). Generally
speaking, only certain mathematical statements involving
pairs of populations are statistically tractable, in the
sense that standard statistical procedures are applicable.
St3tements that are not directly tractatle may be decomposed
into tractable (sub)components whose results are properly
recomoined after having been decided individually.
In this study, the research hypotheses are concerneo
with ,irectionaL differences among three programming
environments. Since the corresponding mathematical
st3tements are not directly tractable, they were aecomposeo
into the set of seven statistical hypotheses pairs shown
below. As a shorthand notation for longer English
sentences, symbolic "equations" are useo to express these
statistical hypotneses. The - symbol denotes negation.
The + symbol oenotes pooling. The = , * , ano <
syvmbols indicate comparisons on the basis of either the
location or dispersion of the dependent variables.
The hypotheses Pair
null : p], rC oIiive:
Al = AT = DT -(tl = AT = DT)
adiresses the existence of an overall difference amon6 the
groups. However, due to the weak nondirectional
90

CHAPTER VI
alternative, it cannot indicate which groups are different
or in what uirection a difference ties. Standard
statistical practice prescrioes that a successful test for
overall difference among three or more groups be followed by
tests for pairwise differences. The hypotheses pairs
AI = AT AI $ AT or AI < AT or AT < AI
AT = DT AT t DT or AT < DT or DT < AT
Al = IT Al * DT or Al < DT or DT < Al
aaIress the existence and direction of pairwise differences
between groups. The results of these pairwise comparisions
were used to refine the overall comparison. Data collected
for a set of experiments may often De legitimately reused to
"simulate" other closely related experiments, by combining
certain samples together and ignoring the original
distinction(s) between them. It is meaningful, in the
context of this study's experimental design, to compare any
two groups pooled against the third since (1) Al and AT are
both undisciplined, while DT is disciplined; (2) AT and OT
are both teams, and Al is individuals; and (3) uncer the
assumption that disciplined teams behave like individuals--
which is part of the study's basic premise, DT and Al can be
pooLed and compared with AT acting as a control group. The
hyootneses pairs
null : allgrelalive:
AI+AT = DT AI+AT * DT or AI+AT < DT or DT < AI+AT
AT DT = Al AT*DT * Al or AT+DT < Al or AI < AT+DT
AI+DT = AT AI+DT 0 AT or AI*DT < AT or AT < AI+DT
adiress the existence and direction of such oocled
differences. The results of these pooled comparisons were
useo to corrooate the overall and pairwise comparisons.
Thus, for each orogramming aspect, the research
hyoutheses pair corresponds to seven different pairs (null
and alternative) of statistical hypotheses. The results of

AD-AO% 452 MARYLAND UkIV COLLEGE PARK DEPT OF COMPUTER SCIENCE F/6 9/2AN EXPERIMENTAL INVESTIGATION OF COMPUTER PROGRAM DEVELOPMENT A--ETCIU)DEC 79 R W REITER AFOSP-77-3181
UNCLASSIFIED TR-853 AFOSR-TR-81-0214 NL
22 Fl flUlllEEEEEEEEEEE-EEEEEniuEEE/hEEEEEEEIhEEEEEEEIIEEIIIIEEEEEEElllElllEEEEEI
I.E I

C-4APT F- V
*estin- each set of seven h ypotheses must be abstracted and
or ar"lzed into One %titisticak conctu% ion t sin the first
research framework discussei in the next steo.
The research frameworks provide the necessary
organizational basis for abstracting ano conceptualizing the
massive volume of statistical hypotheses (and statistical
results thdt follow) into a smaller and more intellectually
'ana eaole set of conclusions. Three separate research
fr3meworks have been chosen: (1) the framework of possitle
overall comparison outcomes for a given programming aspect,
(2) the framework of dependencies and intuitive
relationships among the various programming aspects
consiuered, and (3) the framework of basic suppositions
regarding expected effects of the exoerimental treatments on
the comparison outcomes for the entire set of programming
asoects° The first framework is employed in the statistical
conclusions step because it can be applied in a
statistically tractaole manner, while the remaining two
frameworks are reserved for employment in the research
interpretations step since they are not statistically
tr3ctable and involve subjective judgement.
Since a finite set of three different programminj
environments (Al, AT, and DT) are being compared, there
exists the following finite set of thirteen possible overall
comparison outcomes for each aspect considered:

CHAPTER VI
A I AT = DT
At < A T DT Al < AT < DTAl AT z DT
AT = DT < A J At < DT < AT
AT < DT = Ar AT < DT < AlAT $ DT = At Al # AT DT
DT = Al < AT AT < At < DT
DT < Al = AT' DT < At < ATDT A Al = AT
Ar = AT < DT DT < AT < AI
There is a hierarchical Lattice of increasing separation ano
directionality among these possible overall comparison
outcomes as shown in Figure 3. These thirteen possible
overall comparison outcomes comprise the first research
framework and may be viewed as providing a complete "answer
space" for the questions of interest. It is clear that any
consistent set of two-way comparisons (such as represented
in the statistical hypotheses or statistical results) may be
associated with a unique one of these three-way comparisons.
this framework is the basis for organizing and condensing
the seven statistical results into one statistical
conclusion for each programming aspect considered.
Since a large set of interrelated programming a3pects
are being examined, it would be desirable to summarize many
of the "per aspect" hypotheses and results into statements
which refer to several aspects simultaneously. For example,
average number of statements per segment is ore aspect
directly dependent on two other aspects: number of segments
ani number of statements. Other interrelationships are more
intuitive, Less tractable, or only suspected, for example,
the "trade-off" between global variables and formal
parameters. A simple classification of the programming
aspects into groups of intuitively related aspects at least
orovices a framework for jointly interpreting the
corresponding statistical conclusions in light of the
unierlying issues by which the aspects themselves are
related. The programming aspects considered in this study

FIGURE 3
figure 3. 1 Lattice 2f Possible ftjz~aSguj. Daim I=r Three-May QaQartn
I AX.AT*DT (null)
S&<AT-DT AT.iT(AI , -AI DT.AV(AT ' DT<AI.AT AI.AT(DT' (partially- - - - ,- ' differentiated)
AIk (&T(DY Al(bT[(AT &"T<!< AX T(AX<DCT D'Q1IAT OT<AT<AI (cm ~te.AUMVT HOUR MOTO MAI DUAVT IM AX Oosietely
" , differentiated)
M.S. The circles indicate which directional outcomes correspond to the same nondirectional outcome.
Figure 3.2 1-ttJlnn 2L Pgansble Handireaninati QWaC2h J= Thrueg-ay oanison
Al - AT - DT (null)
At d AT x DT AT d DT a AI DT i At a AT (partially
differentiated)
At J AT d OT (compLetely
differeptiated)
83a

CHAPTER VI
were classified according to a particular set of nine
higher-Level proqramming issues (such as data variabLe
organization, for example); details are given in Chapter
Viii. This second research framework is the oasis for
aostractinc and interpreting what the study's finoingi
inJicate about these higher-Level programming issues, as
well as explicitly mentioning several individual
relationships among the orogramming aspects and their
conclusions.
Since the design of the experiments, the choice of
treatments, etc., were at least partially motivated by
certain general beliefs regarding software development
(e.g., "disciplined methodology reduces software oevelopment
costs"), it should be possible to explicitly state what
comparison outcomes among the experimental treatments were
exoected a priori for which programming aspects. A list of
preplanned expectations (so-called "basic suppositions") for
thue outcomes of each asoect's experiment would provide a
frame.ork for evaluating how well the experimental findings
as a whole support the underlying general beliefs (oy
comparing the actual outcomes with the basic suppositions
across all the programming aspects). Such a list of oasic
suopositions was conceived prior to conducting the
exoeriments, and it constitutes the third research
framework; details are given in Chapter VIII. This
framework is the basis for interpreting the study's findings
as evidence in favor of the basic suppositions ano general
hetiefs.
step 6: r±xDnpi DeitQ
The experimental design is the plan according to which
the experiment is actually executed. It is based upon the
st3tistical model and deals with practical'issues such as

CHAPTFER VI
exoerimental units, treatments, local control, etc. The
e xerimentat design employed for this study has been
Jiscussed in considerable detail in Chapter Ill.
Step 7 : Co~~ LLF1. fl
The pertinent data to carry out the experimental design
was collected and orocessed to yield the information to
which the statistical test procedures were aoplied. Some
details of these activities have been given in Chapter III.
A statistical test oroceaure is a decision mechanism,
founded upon Oeneral principles of mathematical probaoility
and combinatorics and upon a specific statistical model
(i.e., requiring certain assumptions), which is used to
convert the statistical hypotheses together with the
calected data into the statistical results. As dictated by
the statistical model, the statistical tests used in the
study were nonparametric tests of homogeneity of populations
ag3inst shift alternatives for small samples. Nonparametric
tests are slightly ,more conservative (in rejecting the null
hyoothesis) than their parametric counterparts;
nonparametric tests generally use the ordinal ranks
associated with a Linear ordering of a set of scores, rather
tnan the scores themselves, in their computational formulas.
!n particular, the standard Kruskal-wallis H-test [Siegel
56, pp. 184-193] and Mann-Whitney U-test [Siegel 56, pp.
115-127) were employed in the statistical results step.
Ry3n's Method of Adjusted Significance Levels [Kirk 6d, p.
'7, pp. 495-497), a standard procedure for controlling the
exoeri'nentwise significance level when several tests are
verfornied on the same scores as one experiment, was also
emoloyed in the statistical conclusions step.
kR

CHAPTER VI
The Kruskal-wallis test is used in three-sample
situations to test an X = Y = Z null hypothesis; its test
St3tistic is comouted as
M = 12*[(Rx2 /nx)+(Ry2 /ny)+(Rz2 /nz)]/[n*(n+l)) - 3a(n+1)
where Rx , Ry , and Rz are the respective sums of the
ranks for scores from the x, Y, and Z samples; n equals
nx+ny+nz where nx , ny , ano nz are the respective
sample sizes. The Mann-,Whitney test is used in two-sample
situations to test an X = Y null hypothesis; its test
St3tiStic is computed a-
U = min[ nx*ny + nx*(nx+1)/2 - Pxny*nx + ny*(ny+1I/? - Ry
wnere Rx , Ry , nx , 3nd ny are defined as before.
For every statistical test, there exists a one-to-one
madding, usually given in statistical tables, between the
test statistic--a value completely determined by the sample
data scores--and the critical Level. The critical level
[Conover 71, p. 81) is defined as the minimum significance
level at which the statistical test procedure would allow
the nutL hypothesis to be rejected (in favor of the
alternative) for the given sample data. Thus critical level
reoresents a concise standarized way to state the full
resjlt of any statistical test procedure. Two-tailed
rejection regions are apolied for tests involving
n ondirectional alternative hypotheses, and one-tailed
rejection regions are apolied for tests involving
directiunal alternative hypotheses, so that the statea
critical level always pertains airectly to the stated
alternative hypothesis. A decision to reject the null
hypothesis and accept the alternative is mandated if the
critical level is low enough to be tolerated; otherwise a
decision to retain the null hypothesis is mane.
7he Ryan's procedure is used in situations involving
mattiple pairwise comparisons, in order to properly account

CHAPTER VI
for the fact that each pairwise test is made in conjunction
with the others, using the same sample data. The individual
critical Levels 6 obtained for each pairwise test in
isolation are adjusted to proper experimentwise critical
Levels & via the formula
6t = [(r*l)*k/2] *
where k is the total number of samples; and r is the
numner of (other) samples whose rank means fall between the
rank means of the particular pair of samples oeing compared.
A simple "minimax" step--taking the maximum of the several
aajusted pairwise critical levels, plus the overall
comparison critical level, which are all minimum
significance Levels--completes the procedure, yieldin a
sin;le critical level associated jointly with the overall
and pairwise comparisons.
These tests and procedures apply straightforwardly when
differences in location are considered. A slight
mojification makes them applicable for differences in
dispersion: prior to ranking, each score value is simply
reDLacea by its absolute deviation from the corresponding
within-group sample median [C'emenyi et al. 77, pp. 266-270).
It should be noted that this modification results in only an
aporoximate method for solving a tough statistical problem,
namely, testing whether one population is more variable than
another [Nemenyi et al. 77, op. 279-283J. The modification
is not statistically valid in the general case (it weakens
the power of the test procedures and can yield inaccurate
critical Levels when testiny for dispersion differences),
but every other available method also has serious
limitations. This method has been shown (empirically via
monte Carlo techniques) to possess reasonable accuracy, as
long as the underlying distributions are fairly symmetrical,
and is readily adapted to the study's three-way comparison
situation.
L=, a7,, ,

CHAPTER VI
Step C:' aijjjPu~
statistical result is essentially a decision reached
by aopLying a statistical test procedure to the set of
collected and refined data, regarding which one of the
corresponding pair (null, alternative) of statistical
hyootheses is indeed supoorted by that oata. For each pair
of statistical hypotheses, there is one statistical result
coisisting of four components: (1) the null hypothesis
itself; (2) the alternative hypothesis itself; (3) the
critical level, stated as a prouability value between 0 and
1; a-a (4) a decision either to retain the null hypothesis
or to reject it in favor of (i.e., accept) the alternative
hyoothesis.
y convention, the null hypothesis is that no
systematic difference apoears to exist, and the alternative
hypothesis purports that some systematic difference exists.
The critical levet is associated with erroneously acceoting
the alternative hypothesis (i.e., claiming a systematic
lifference when none in fact exits). The decision to retain
or reject is reached on the basis of some tolerable level of
significance, with which the critical level is compared to
see if it is Low enough. In cases where a null hypothesis
is relected, the appropriate directional alternative
hypothesis (if any) is used to indicate the direction of the
systematic difference, as determined by direct observation
from the sample medians in conjunction with a one-tailea
test.
Conventional practice is to fix an arbitrary
,i nificance level (e.g., 0.05 or 0.01) in advance, to be
used as the tolerable level; critical levels then serve only
as steoping-stonps towarl reaching decisions and are not
reoorted. For this partially exploratory study, it wiS
Q.

CHAPTER VI
,ltm,.j morv appropriate to fix a toleraole level only for
tfie rurpo-,v of d screening decision (simply to purnie those
results witn intolerably hivh critical levels) anu to
ex:)licitLy attach any surviving critical Level to each
st3tistical result. This unconventional practice yields
statisticaL results in a more meaningful and flexible form,
since the significance or error risk of each result may be
assessea individually, and results at other more stringent
significance levels may oe easily determined. Furthermore,
the necessary information is retained for properly
recomoining multiple related results on an experiment.,ise
basis in the statistical conclusions step.
The toleraole level of significance used throughout
this study to sceen critical levels was fixed at under 0.20.
, lthough fairly high for a confirmatory study, it is
re3sonabLe for a partially exploratory study, such as this
one, seeking to discover even slight trends in the data. A
critical level of 0.20 means that the odds of obtaining test
scores exhibiting the same degree of difference, due to
raiaom chance fluctuations alone, are one in five.
As an example, the seven statistical results for
location comoarisons on the programming aspect STATEM4ENT
TY3E COUNTS\IF are shown below. (N.9. The asterisks will be
exolained in Steo 10.)
null alternative critical (screening)
At = AT = DT -(AI = AT = DT) .06" rejectAl = AT AI < AT .046 rejectAl = DT Al * DT >.99Q ret ainAT = OT DT < AT .011 reject
AI+AT = DT DT < AI+AT 38 .3 reject *AI+DT = AT AI+DT < AT .009 rejectAT+DT = Al AT+DT I AI .335 retain *
"oserve that the stated decisions simply reflect the
aoolication of the 0.20 tolerable level to the stated
critical levels. Oesults under more stringent Levels of
,rignificance can be easily oetermined by simply aooLying a
L.o

CHAPTER VI
lo.er tolerabLe level to form the decisions; e.g., at the
?.]5 sijnificance ltvel, only the Al < AT, DT < AT, and
"1+ T < AT alternative hypotheses would be accepted; only
the AI+D T < AT hypothesis would be accepted at the 0.01
level
ste 1': tatistical Conclusions
The volume of statistical results are organized and
condensed into StatiStical conclusions according to tne
Drearranged researchi fraaework(s). A statistical conclusion
is an austraction of several statistical results, but it
retains the same statistical character, having been derived
via statistically tractanle methods and possessing an
associated critical level.
The first research framework mentioned aoove was
emoloyed to reduce the seven statistical results (with seven
individual critical levels) for each programming aspect to a
single statistical conclusion (with one overall critical
level) for that aspect. The statement portion of a
st3tistical conclusion is simply one of the thirteen
possible overall comparison outcomes. Each overall
comparison outcome is associatec with a particular set of
statistical results whose outcomes support the overall
comparison outcome in a natural way. For examole (reading
*r:m the fifth row of the chart in Figure 4), the
)T = AI < AT conclusion is associated with the following
results:
reject AI = AT DT in favor of -(AI = AT = OT),
reject Al = A7 in favor of AI < AT,
retain AI = DT,
reje.ct AT = DT in favor of DT < AT, and
reject AI D = AT in 4avor of AI+DT < AT.
Siice the other two comp3riscns (AI+AT versus AT, AT+L T

CHAPTER VI
versus AI) are in a sense orthogonal to the overall
comparison outcome (DT = AI < AT), their results are
considered irrelevant to this conclusion. The chart in
Figure 4 shows exactly which results are associated with
Pach concLusion: the relevant comparisons, the null
hyDotneses to be retained, and the alternative hypotheses to
te accepted. The other oortion of d statistical conclusion
is the critical Level associated with erroneously accepting
the statement portion. It is computed from the individual
critical Levels of certain germane results.
A simple algorithm based on the chart in Figure 4 was
useo to generate the statistical conclusions (and compute
the overall critical Level) automatically from the
st3tistical results. For each programming aspect, the
algorithm compared the set of actual results obtained for
t e seven statistical hyootheses pairs to the set of results
associated (in the chart) with each conclusion, searcning
for a match. Ryan's procedure was used to properly combine
the individual critical levels for the overall result and
the relevant pairwise results, by adjusting them via the
formula and then taking their maximum. The critical levels
for the relevant pooled results were then factoreu, by a
sivple formula based on the multiplicative rule for tne
joint probability of independent events.
Cnntinuing the examole startea in Steo 9, the
statistical results shown there for location comparisons on
the STATEMENT TYPE COUNTS\IF aspect are reduced to the
statistical conclusion DT = Al < AT with .07? critical level
overall. The five results not marked with an asterisK in
Step 9 match the five results associated above with the
DT = Al < AT outcome. (Note that the other two marked
results represent comparisons that are irrelevant to this
concl,,sion.) The .04b and .011 critical levels for tne two
?,I
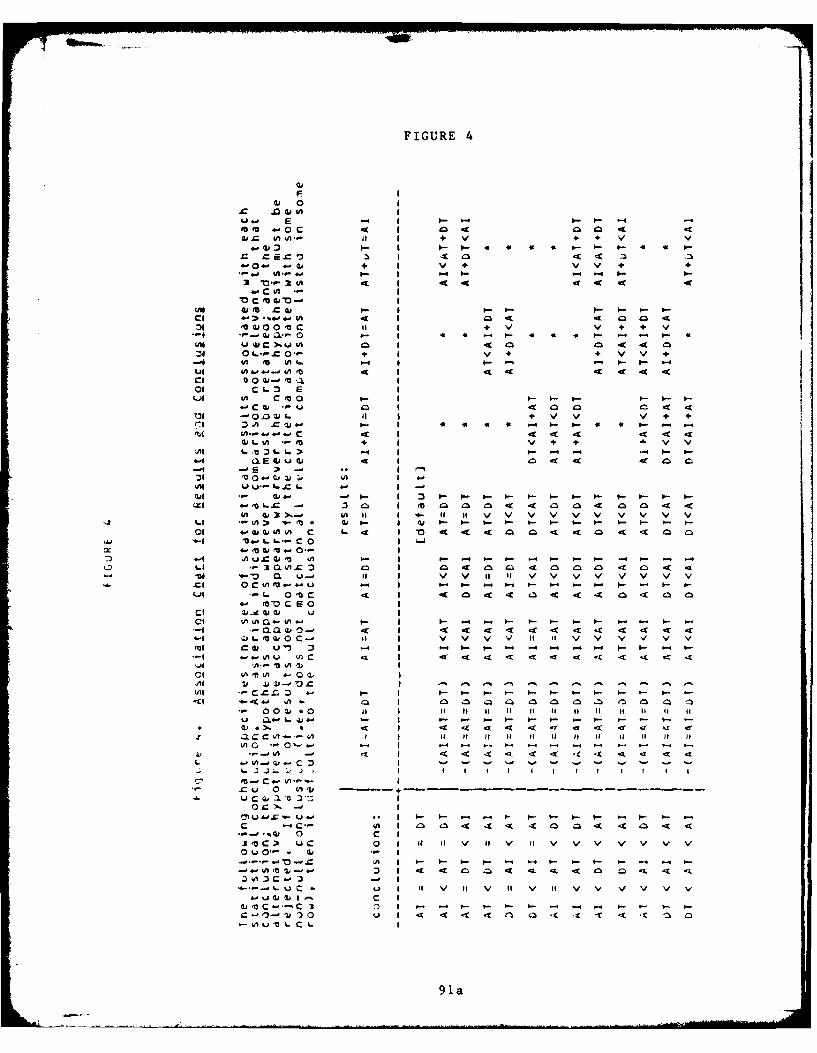
FIGURE 4
0.' 0I
0 ~ +nn I 4. V . 44-J1.- I b - 4 4 - I- 4 4 4
"CC 3 IAI 4 ' 4 4 3.
* C4 In ~-- - . 4 - .
cl > .4, . 4 I Q3 IC in --x321, Q0 0Mc If I 4. V + 4 . v
= t,- 0-+ Iv + + v v +
-'I In 'U IA'. -n m 4
Ul C -- 34IA'iI C M0 E-P .
4-CS -(U o3 C= 4 n < < 4I,f -~oz 0 LI. II I +. V V V + +(! A .CwJ4 I it It 4 4t - 4v-4-alt.-44- c I 4<
<u ~n *-'U + + + . 44m 3 16- .4 >4 "4
l .E 0 u-4 - I -X <- 9'r
-a >U.L.' 4- I _
jIl C.44 o. - - P.I 4 - I- - P- I.- o- I.- -CL -~..C .. <3 n ia -cc a3 n3 < 3 ' 4 3
Ia 03 - fin it I *- If If v V V V V V v V v VLI1 > 40 1.- 1 0 - 1.- l'- 4- P.- I.- I- l- l'- I..- P4-01 4-GJ iA#A 0 C ' 0 M4 -In a <4 -cc In4 4 < in 3
'* 'U4 ,6 - ~ C 0 I .
'-1 'A %jCG.w41 In 4 I p- .4 1- 4 -4 4 - 0.- -4 P.-L 30I C '3 Or '3 1 = 3 4r C 3 < 3 I= 9= 4 <4
- UI '-j CL u- I I V V it 11 V V v V V V V VOCo'-.-u -4 " -4 -- - - - I-- -
Lii L. 0'U 4 1 '3 4 Cl 4 '3 3
4- a- C~ In-10- -acti~.'G w -I <- < .
CIQ.in 4- I) C - - 4 - 4 4 - ~ -44
of I C.L 'DiC.= I V- I
(At4 C=. :3 I t- 0- 4 - 1.- P4-4-4- 4 0 .n 41 1 n "* a 43 a =k 4 -- 4. 47 Q 4
CI~~I It1IA .0O
(AI - %,Z - . I- I - i- - 9- - 4- 4- - - - P- -
6. . 000 .,. )l I I II I II II I I I I I
L~ ~ 4-c~ A-Cf IllI u I I v if v It v v I
I--. -- I-I
cImC-. " - 4- P. .- i - " - I- P.- 4
0CuOT.. Cs 6I
IA I 4- - - - '- 491a- 4 - ~ 4

CHAPTER VI
odiriise differences are adjusted to .070 and .033t
respectively, and the maximum among those aojusteo values
anJ the .063 overall difference critical level is .07.. The
relevant pooled comparison critical level of .008 is
factored in by taking the complement of the products of the
complement s:
S- (1- .06Q)*(1 - .008)] =072
Thus, the statistical conclusions are in one-to-one
correspondence with the research hypotheses and provide
concise answers on a "per aspect" basis to the questions of
interest. Further details and complete listing of the
statistical conclusions for this study are presented in
Chapter VII.
Ste p 11: R a LnIe1tr Ii 201
The final step in the method is to interpret the
statistical conclusions in view of any remaining research
framework(s), the researcher's intuitive understanding, and
the work of other researche rs. These research
interpretations provide the opportunity to augment the
o:jective findings of the study with the researcher's own
professional judgment and insight. The secono and thiro
research frameworks mentioned above--namely, the intuitive
relationships among the various programming aspects and the
basic suppositions governing their expected outcomes--were
consicered important for this purpose. However these
particular research frameworks can only be utilized for the
research interpretations, since they are not amenable to
rigorous manipulation. Nonetheless, within these frameworks
based upon intuitions about the software metrics and
programming environments unoer consideration, the study
hears some of its most interesting results and implications.
Complete details ano discussion of the research

CHAPTER VI
interpretations of this study appear in Chapter VIII.

CHAPTFR VII
This chapter reports the objective results of the
stidy , namely, the statistical conclusions for each
orogramming aspect considered. In keeping with the
emoiricat and statistical character of these conclusions,
the tone of discussion here is purposely somewhat
disinterested and analytical. ALL interpretive discussion
is deferred to Chapter VIII, in accordance with the
invest i gat ive methodology.
Each statistical conclusion is expressed in the concise
form of a three-way comparison outcome "equation." It
states any observed differencest ano the directions thereof,
among the programming environments represented by the three
groups examined in the study: ad hoc inoiyiduals (AI), ad
hoc teams (AT), and disciplined teams (DT). The equality
AI = AT = DT expresses the null outcome that there is no
systemat.c difference among the groups. An inequaLitY,
e.j., Al < AT = DT or DT < Al < AT, expresses a non-null (or
alternative) outcome that there are certain systematic
difference(s) among the groups in stateo direction(s). A
critical level value is also associated with each non-nutL
(or alternative) outcome, indicatinj its individual
retiarility. T his value is the oroDability of having
erroneously rejected the nult conclusion in favor of the
alternative; it also provides a relative index of how
pronounced the differences were in the sample data.
The remainder of this chapter consists of (a)
Presenting the full set of conclusions, (b) evaLuatin, their
imlact as a whote, (c) exposing a "relaxed differentiation"
view of the conclusions, (d) exposing a "directionless" view
of the conclusions, and (e) individually highlighting a few
94

CHAPTER VII
of the more noteworthy conclusions.
:r2sentation
The complete set of statistical conclusions for both
Location and dispersion comparisons appears in Table 2
arranged oy Programming 3spect. Instances of non-null (or
alternative) conclusions--those indicating some distinction
among the groups on the basis of a measured programming
asoect--are Listed by outcome in Taoles 4.1 (for Location
conparisons) and 4.2 (for dispersion comparisons).
Examination of Table 2 immediately demonstrates that a
large number of the programming aspects considereo in this
study, especially product aspects, failed to show any
distinction between the groups. This tow "yield" is not
surprising, especially amonq product aspects, and may be
attributed to the partially exploratory nature of the study,
the small sample sizes, and the general coarseness of many
of tI'e aspects considered. The issue of these null outcome
occurrences and their significance is treated more
thoroughly in the next subsection, Impact Evaluation.
It is worth notingt however, that several of the null
conclusions may indicate characteristics inherent to the
apotication itself. As one example, the basic symbol-table/
scanner/parser/code-generator nature of a compiler strongly
influences the way the system is modularized and thus
practically determines the number of modules in the final
croduct (give or take sove occasional slight variation due
to other design decisions).
The collective impact of these statistical conclusions
95

TABLE 2
0c 411 Cc ~ 6
* ~~~~1 54 to ~4 4 4 6 I 6 6 6
0. IE ~ w 4 1- 60 * : . it 61
UC. 40 4. . . . . . . .-- 44fy 66- 4M 61 CO 4O *tlf it *
! ~ ~ ri ftkr 4 - 6 4* 4 i 6
- m 4 , 4 -9 64 4 4 6 6 6
c 6
6 4 o 06 of 11 1 "4 4, it'' i 4 66. I i it 6 1 6
01 4b -919- 4 - 6 4a w 6 6 6 6 6
16.4k* V V I V* I0 41 6v16 66V6 V6 V M66 466666 .666666 666666 1 VZ* I 0 4 14 1 6 6 6 6 6
_j6 to Uo a v I- - - 1 1-0- It - I 6 6C 4 4 4 1.6 0. 4 f 1-91 6 6 0
4 ~~ 4l I 6 6 6 6 6
05~t I44 4-166, 4D m I 6 6 6 6
546 cc 6. 6 6 6 6 6
U04 u5 4V6%60 VA.616~4 ~ 14 666~~6 6 6 66O'6 * ~ 066o~J 6.0. F ~ C4 666 6 *
.... 16.4~1 It5 0 06 .. 4 4 666 6 6 6In ~ ~ ~ ~ ~ ~ ~ ~ ~ I .1* 0 6*6 *66 44 4 66 6 6 6
C. U -c"0 0006 0 60 6O C 6* C U 4 4 4 4 4 66 4 66 6 6 6 1
- ~ ~ ~ ~ v _x_ z6 W. 4440 44 64 4 4 0 * 66 6 6 4U ~ ~ ~ ~ o wzi I605 4 , 6 6 6 6 6
C ~ ~ ~ ~ ~ ~ ~ ~ ~ i I4 4046 I6 C66166616 6666 4 V 1666 666 6666o a.. %Z04 ac 02 1 6
Cz jz & ac.64 ' 6 44'- : i 160 1 -- I I4S4 4 5=M 4L44z4 44 *1.4 U ,A -66I 6 ~ 1 .
0 - C 4 4 0 4000 004 .0 . .1 Q04 0. 4 64
- ~ ~ ~ ~ ~ ~ ~ ~ I IA. 11,.46 4 6 .4 66 6 66
S ~ ~ ~ ~ ~ ~ ~ 3 'A 4 4 4 4 6
- -6 4 - 4666664 6.6 4 - 4 6 95a 6

TABLE 2
IA A II iI II II II
AAU)A rMa 01 01 II II II Il O O 11 d.O~i - A ' I II N11. , :: *, I .. :1 I I I . *,l
N II n It of 0110 0i 0iol *. A1 :: I I V Ingo
Ac C; II o f It Iit IA
I 4A 4448 • II II II II 011 4 444 I 4 AII N II I A1
AMA AANA HIN iAAAii I i i ANI NIA1IV AAIA8HNNNAIAI NA II INViiVAiA iN A AiVN #l I INIINV A I N INNNNIAl I A A II IA II IIA
Ni -A, -- 8 -A t II II i a ' II IS -- I1 i N l # I 1 If v8 # I it if I 8 v i i 1 Is to so II II II II v I 4 0 I 4
11V I tlA Al It14 v sov I IAI 11 8 11 1 1 A1 it 1 IsAIIs IIt A:1 1:: I t ofAAIIto 41 111 I t fV V I s ifo Al IAN N IAIVN Is
N A II II II IIAISP-I-4- -t v-I It i I I AP- -
0 8i II II 0i i
N A2 0 i II It N A
AI Oc I I ;N 1 I. I A
SI I N it II IIP
IsII Ii If I .*1 sof II v 1 i
N A C OCA 0loss o N N Is00
N A 'l A A . .. .N .. ..I II A A
N A I A IA II IA II N I II{
i|N A Iy i I I I iV V I I I 1l A Al II V I lI IH I II tt Il II 88 N II II I U t II I I I
IN OH NV It N N f it toV IfVI I ft It It11H111 A f V ol :1 toV 11 IsIsN 11111111 1 11 Ittol I s V AN i 111.11111 to V. 1 IN A I i II N I I I
Nz i-i 11 0 it .. a 4 I.
141i I N i II II II A
liII A .P ~ .Al1 II l II II P - - II
AIA t 11 IA i 00 Z4II AAA II II II iI II A iI
II AII I N I IIIA II iI Ii IN II II A
il I A iI II II II II AZII AAA II II II il II I
I A II i II N I ItIA I Ii Il n I i ii Ii Il.IA I I I IAl il II ii II A .
liA I il 1l i II Al III
II I AAP IIAA II l II II I
iI A I 5 1 II lI II Ii II W I
4.1 Az 401 AU lI h. A 11 is . 12 I
II A U ICI l i I II ii l.JII A
II I A: I IJII I ii r- 3. il
i I- II II II Ii II m
iAl A~ APl,-l ~l ' AftI I lII l II I IO I l i Z i t 1i I i.. + , - I~
II I f A Z ,I , G. i- ,a i I iIU i I I I ,a -II itII I.1 AII + tl It. ,
o I, C Ik W I C Osll I" II U) II iZ I
it AI ) AC.- Q U) 0-I I 4m CI 1..1 U 9) A5b U )
II ~ ~ ~ ~ c 8141 cc of4 -- A.Ptz!1U1 If W. I-- -I - - -IA A C. .aftU) AC. ..Ifthfl A II 44111 II .a s) I 211 t) 3UU - fll CUU
N A P. ...JP-Z A P. .. AP.Z~~~~I A .Pl I. As, 2.1 l h l. ZIA -11.~.
N r Z-l IP. 42A I N11 14.N~ 41 )21.t.".I.. 4Z95bZ-...

TABLE 2
to0 0 00 00 0
- ~ ~ ~ ~ ~ ~ ~ I :!: A ?0~IU o~.N0 0S t 0-, ~ ~ ~ ~ ~ ~ 9 1 if .t . 0J N~ % 0 - 0 . 1:
o 0 tO C 0 0 0 00 0 00 cao of aCall
If 0 1 H i si ft fo 1I f1 fV 11 o fo fI t0 a 0 0 0 V 1 0 Itt 0 fII to V V I 0 .i
- of I - - : S $- -O - : - : o0
It I o t
St~~ O il0 tt S
00 0 0 -; -; -; 0 1 N 0 t
a a 01 a 0 St
OS I ot to- t 0 f 0 of -o -# U If N 0 lol 0 if I o $f l ~ l0 1 1 f0 I fI io f o t 0 tot. 1 . i li
: tot444 0 4 0 44 t St 4 t
to 0 0t V o to 0N t
I0 0 to t12 1e 1 i0 .
-- ~~~~ o0f -*. 0 0 ** * 0 * 00 of to
00~~~~o 10z 0 0C 0 0 0 0 t
to W 5 0 0 tO
tof 0 1 0 a - a I- 1 0
,A Wat a I wa wa a 0 0 .. toS. o c 0 o
o:; :: a I 0 0 0 0 I
'V 00 - - - 0f cc - 0 -- of tEI0io 440 0 4= 4 1 4 04 1 -co 0 4=Oa J: toow99 -MAzl
If 0 - 0 10 r 0 . KtO
0 0 0 z St St
to ~ 0 ON tOto
St 0 0 = to5t

TABLE 2
I C) O4O I I D
-C AK In CC A
4~~CC 4; 444 I A 0A
A 0 - ...A I A
A- C Ir C Ad le
A ~ ~ A C I
- A ~ A V AA -0
4 4 4 4 A 4 A 4 IAc a, -c =. m -cZ
I- a Cjk_ x-ac j
A A C A AA- w Ac I *w cA. EA A
AV% A 4 .* A L reAj' 2. *~
A. 7 I Co . . .A . A . *. IA C X 0I 0 4 4 A 00 A 00010 .
A aw wi A3 1 A
. . . . . .4 - 4. . . . . . . . . . .Az r A z4 C E A
A - to is * A6mA -
14 A 4 4 4 A 4 44 A 4 4 4
A C La * A AAAAIAAAAAAAAAAIAAAAVVIAAAAIII4 ~ 4C AAAVAVVAAIAAA AAAAUAAAIAorI
A A C 4 4 4 A9Ad

TABLE 2
If 5Iq to ai IO.
00uimi v If tov to0 it to 0 000 141M 11a.~pv v il N lo l
to1 ICa aM. of 16 0 " M t .I l 1 t w ti l1 6 H on v I f f IS It It.N If it it 1 11i i l o " H t
f- I 5 N 50 -9 -a: 440 za .. , 1ia 4 4
f O- '" 0 o' I wtoa s It a
- ~ ~ c 0*0 a -i m
4Z 7 5 z4i f 5 4 a4 44a.v f ~ v , 1~ :~ 4 v " t 0vo t n .I f1 t 4 I 11 if 55 I If ao .
Ia HS a
of' M ~ 0 of .0 v ofa a~ M It0 af t .t .It1 f I tI a w " ol l to 11 11 M o a. 1 i 11
o ~ ~ ~ ~ ~ ~ I %A to ao f m u aa------------ 0 ~ I 0 1s-..00 aa
N a N if. = f I f - - IIa
.4 144 of 444 1 a. -1 a. a a
ifZwo c W if ZI Ia.4 Q. a.-0 a for I aZ.-k
-Na - 1 is -1 if 5.
4z 04 a 4 4 a M: 4 I 4w ='C I 1a=
iio is a a I
a If -.1N - NN N i -. i1 w- - Z. a
w" It 5m5 a.K I 5
L tc8 0 *DI CL a. 0a00 0 zZ 1 M 'c - w COI wAl
if9 if a. I,. : a.- .0. a1c O s 19 5lml
95e5

CHAPTER VII
may be objectively evatuated according to the following
statistical principle [Tukey 69, pp. 34-953. Whenever a
series of statistical tests (or experiments) are made, all
at a fixed Level o4 significance (for exampLe, 0.10), a
corresoonding percentage (in the example, 10%) of the tests
are -xoected a priori to reject the null hypOtheSis in the
co-iplete absence of any true effect (i.e., due to chance
alDne). This expected rejection percentage provides j
conparative index of the true impact of the test results as
a ihole (in the example, a 25% actual rejection percentage
wojLJ indicate that a truel y significant effect, other than
chance alone, was operative).
The point here may be illustrated in terms of simple
coin-tossing experiments. The nature of statistics itself
dictates that, out of a series of 100 separate statistical
tests of a hypothetically fair coin at the 0.05 significance
level, roughly S of those tests would nonetheless indicate
that the coin was biased; if only 6 out of 110 tests of a
re3L coin indicate oias at the 0.05 level, those six results
have very little impact since the coin is behaving rather
unciaseoty over the full set of tests.
This same "multiplicity" prtnciole applies to the
st3tistic3L conclusions of the study, since they represent
the outcomes of a series of separate tests and were assumed
in the statistical model to be separate experiments. It is
aporoc.riate to evaluate the location ano dispersion results
seoarately, since they reflect two separate issues
(expectency and predictability) of software development
behavior. It is also aporopriate to evaluate the process
and product results separately. Finally, it is only fair to
evaluate the con'irmatory asoects as a distinct subset of
all :ispects examined, since they alone had been honestly
consiuered prior to collecting and analyzing the data.

CHAPTER VII
uetails of this impact evaluation for the study's
oojective results, oroken down into the appropriate
cateiories identified above# are presented in the following
ta:le. (This table is an excerpt from Table 3, which
orovides an extensive imoact evaluation, broken down
hierarchically according to all of the various dichotomies
ijentified for the programming aspects.) The evaluation was
oerformed at the OL = C.20 significance Level used for
screening purposes, hence the expected rejection percentage
for any category was 20%. For each category of aspects, the
taote gives the numoer of (nonredunoant) programming
asoects, the expected (roundea to whole numbers) and actual
numoers of rejections (of the null conclusion in favor of a
directional alternative), and the expected and actual
rejection oercentages. An asterisk marks those categories
demonstrating noticable statistical impact (i.e., actual
rejection oercentage welt above expected rejection
percentage).
----------..... 4.-----------. -------- -------------------------
category g 0 # ep ae:-I .. . ..rej. % I %
-- - -- - -- - - - - ------- --------- 4----------------- -----.lo cat ion 38C 51 1 0: j2: 1
oJrocess 109confir-natrry only 6 1 6 20.0 10.0
oroduct 1 179 1 36 I 44 1 20.0 1 .4.6 1confirmatory only 2 12 20.0 41.4
confirmatory only 35 1 18 1 200 14-- - -- - - -- - - -- - - ----- -- ---------------------
I o uonly 179 38 4 ;1 200 Z2 1confirmatory only 29 1 6 9 20.0 I 31.0 I'
confirmatory only 35 7200 25.7
----- 4-- -------------------------- ------------------
4: numoer of aspectsexp. I rej. : expected number of rejectionsact. I rej. : actual number of rejectionsexp. rej. : expected rejection percentageact. rej. : actual rejection percentage
The tadte shows that the location results, dealing with
the expectency of software aevelopment behavior, oo have
st3tistical impact in several subcategories. Process
aspects have mori i.pact than product aspects on the whoLe,

TABLE 3
Table 3. ttisti-CAt MRaQi [. uttiYi20
4 4o: . . 4e°.l" ' ' 4" .'o 4.' "number expect.Iactuatf expect. actuaL.category of num. o hum. of reject. reject.Iaspects reject. reject. oercent percentl
I location o189 1 38 53 1 20.0 1 z.O 1I process 1 10 I 2 1 9 1 20.0 1 90.0 1*
I rudimentary 9 I 2 I 8 I 20.0 I 88.9 1*confirmatory 5 1 1 5 20.0 100.0xploratory 4 I 3 28.0 75.0
etaborat ive 1 0 1 20.0 100.0confpratory 1 0 : 100.0eptoratory C' 0 ~
confirmatory 6 1 08.0 108:8exploratory 4 1 3 20.0 7
------ -- - -- -- -- -- -
ruoimentar 115 22 8I conf irmaforyl 26 5 11 288 2o3
elaborative 64 13 22 0.0 34,.4confirmatory 3 1 1 20.0 33.3 *exploratory 61 12 21 20.0 34.5
confirmatory 1 29 6 12 1 20.0 1 41.4 I*exploratory I 150 30 32 1 20.0 1 21.3 1
+.-----------------+----------------------4 --------------- -- 4
I rudimentary I 124 I 25 J 30 J 20.0 I 24.2 II confirmatory I 31 I 6 i 16 1 20.0 I 51.6 1*
elaborative 6 1 4 2 0
confirmatory 4 1 2 20.0 50.0 1*exploratory I 61 I 12 l 21 20.0 1 3..5 1*
confirmatory 31 7 18 2 0 1 51.4 J*xptora tory 154 31 35 0:- 22 .
Idisoersion 1 189 1 38 I 43 1 20.0 1 22.8 I--- ----- ------ ----------------- -----------------------io rocet 10 I 2 1 2 88 I 1 I:
rudimentary 4 1 2 2 5confirmatory 5 I 1 0 I 20.0 1 0.0 I
exploratory 9 I 0 0 20.0 0.0 1confirmatory 6 I 1 I 20.0 1 0.0 1exploratory 4 I 1 2 I 20.0 1 50.0 1*
------- --- ----------- .-- 4
I product 1 17Q 36 41 I 20.0 I 22.9 Irudimentary I115 I 23 I 28 20.0 2 24.:3confirmatory 26 5 I 20.0 30.8 *exploratory 89 i1 20 20.0 22.5 I
1 elaborative 64 13 13 20.0 I 20.3I confirmatory I 3 I 11I 11 20:0 I33:3I
expqoratory 61 12 12 20.0 19.7conf irmatory 29 6 9 20.0 31.0 1*
I exploratory 1 150 I 30 32 I 20.0 I 21.3 I
I rudimentary 124 25 °30 i20.01 24.2confirmatory 31 6 8 20 25.8exploratory 93 19 22 20.0 23.7
elaborative f 65 13 13- 20 Iconfirmatory 4 1 1 20.0 25:0
expLoratory 61 12 12 20.0 19.7confi rmatory 35 7 9 20.0 25.7 1exploratory 154 1 31 34 1 20.0 1 22.1 I
97a

CHAPTER VII
but when tempered by consideration of tne listinction
!-et.een confirmatory and exploratory aspects, the stucy's
location results Dear strong statistical impact for buth
orocess and product. They are better explained as the
consequence of some true effect related to the experimental
treatments, rather than as a random phenomenon.
It is also clear from the table that the dispersion
results, dealing with the oredictaoility of software
developmnent behavior, have little statistical impact in
_eneral. This is due primarily to the aiminished power of
statistical orocedures usea to test for dispersion
differences, compounded y the small sample sizes involved
anJ tne coarseness of many of the programming aspects
themselves. The lack of strong statistical impact in this
area of the study does not mean that the dispersion issue is
unimportant or undeserving of research attention, but rather
that it is "a tougher nut to crack" than the location issue.
The study's dispersion results are still worth pursuing,
however, as possible hints of where differences might exist,
provided this disclaimer regarding their impact is heeded.
A Relaxed 2iffe rentjajtioQn iew
As described in Chaoter VI, the research framework of
possiole three-way comparison outcomes provided the basis
for converting the statistical results into the statistical
concl.usions. This framework has two innerent structural
characteristics that may be exploited to make additional
observations regarding the statistical conclusions. These
structural characteristics and the supplemental views of the
conclusions that they afford are described here and in the
next subsection.
The first structural characteristic is that each

TABLE 4
0 I- - -44-Z
IG 11 Z.4 -'0.0
z 4-. C- w a
00 4*~~~~~ C2. O.,.4 a02 0 4
oa * 3- ao a .c a j a44...... 4 -
o I---- - - -- - - - -- Z2 0 cc
coo-----W---- - q-4
I .. co z 'L ... . .. 4....x...... ...
4 0 0 '0 0 0.20 2
- 0 ft 2.J rcrxx r 4 haL Ir thiI
C 4 I 4.4ft ~ 0 000 0=0000 00=2=
QM P -L 'Z=040004-= 04 0 - - - - -40..
m 2 --w- 00 --- != -o ==; 4-4.. 4 00
* 4 I oo =22 - - - - - ---- -- ----- - 44 ! 2f 444~~~ ...... 2tt~f~t ' t~t 4s.f
C ~ ~ ~ Z 4 . a - f4 4 4 f a.
O 4 I ~~C:7- In 23i4 44O.:. .. - ..... 4 24
- 4v =c cr 8I. K a- 20 8882. hi0 00-c hic. C. CI 0i 22 hahilh 0 'h' CD h0 4 0
4 c I 112 44 4.a4.44hh444444fh 0 2 f 4 4 4 L
4 -2a44a 022i1hiatIf~fhiia .. h4.4 0 .. O~hth98a 4 h

TABLE 4
1 1 06
a a -I oa 0 a-
* a a -a
-; - f. - -. aol
a~~Q aw .0
o~W- a a -240 53 -
o~~ =a I I ZiC 4wnai -0 .
= =aZ .4 00 c0u a- r a=
a ~ ~ o I t z - -o ,2 0 c 200 -I
a ~ ~ 2 a t_ OZ - - - - cc... - a ItI a a 4-~ O- 0-a .JC .. 2 5S' a
5 a-. azz Ixa0~ 040 2 - 0 - -
11.4~ 24 - 4 0 0 4 - -W ~~ c
- a 0a. >-a ~ 4 -c Ca o~ 2 a-a oo1a a
- a a 40- sa 25IO 0~ 001 O-D QOQ .M..00a
I lo ai 0I ~ 2aaC .W Wklltt
* r all13 l . 55t -3 O 2 a. tLloco o.uaZ 4 1 0 0 - .. a .CO acca 4
* ao -- c- - .an za-e~a- 2.5 aa34z98ba a-

CHAPTER VII
coipletely differentiated outcome is related to a specific
rair of partially differentiated outcomes, as shown in the
lattice of Figure !.1. For example, Al < AT < DTt a
completely differentiated outcome, naturally weakens to
either AI < AT = DT or Al = AT < DT, two partially
differentiated outcomes.
Eaci completely differentiated outcome consists of
three oairwise differences (AI < AT, AT < DT, AI < DT in the
ex3mole), while each partially differentiated outcome
consists of only two pairwise differences plus one pairwise
equality (Al < DT, AI < AT, AT = DT and AI < DT, AT < PT,
Al = AT in the example). The "outer" difference of the
completely differentiated outcome (Al < DT in the example)
is common to ooth partially differentiated outcomes, while
each partially differentiated outcome focuses attention on
one of the two "inner" differences (AI < AT and AT < DT in
the example) to the exclusion of the other "inner"
difference which is "relaxed" to an equality. Within a
statistical environment or model which places a premium on
cl3iming differences instead of equalities, a partially
differentiated outcome is a safer statement, containing less
error-prone information than a completely differentiated
outcome. Since these outcomes represent statistical
conclusions, the same data scores which support a completely
differentiated outcome at a certain critica.L Level also
s..pOort each of the two related partially differentiated
outcomes at tower critical Levels.
Thus, every completely differentiated conclusion may
also oe considered as two (more significant) partially
differentiated conclusions, each of these three conclusions
having equal ano complete statistical legitimacy. The
"outer" difference of a completely aifferentiated conclusion
is, of course, stronger than either of its two "inner"
99

CHAPTER VII
differences; but the strengths of the two "inner"
differences (relative to each other) will vary in accordance
with the data scores ano inoeed are reflected in the
significance Levels of the two corresponding partially
differentiated conclusions (relative to each other). Tables
5.1 and 5.2 give the details of this "relaxed
differentiation" analysis for each of the completely
differentiated conclusions found in the study, ana an
English paraphrase appears in the two paragraphs immediatetL
below. AlL of the partially differentiated conclusions
Listea in these tables shoulo be added to those presented in
Taoles 2 and 4; they deserve full consideration in any
analysis or interpretation of the study's findings.
Hooever, in the case that one of a partially differentiated
pair is noticeably stronger than the other, it is fair to
consider only the stronger one for the puroose of analysis
or interpretation dealing primarily with partially
differentiated outcomes, since the study is mainly concernzo
with the most pronounced difference affordea by each
asDect's data scores.
Un Location comparisons, four programming aspects
yielded completely differentiated conclusions. They are
"relaxed" to partially differentiated conclusions as
fol Lows:
1. From DT < AI < AT on the PROGRAM CHANGES aspect, the
DT < AI = AT conclusion dwarfs the DT = Al < AT
conclusion with respect to Level of significance.
2. The DT < AT difference is more pronounced than the
Al < DT difference from Ar < DT < AT on the LINES
aspect.
3. AT < DT < Al on the (SEGvENT,GLOBAL) USAGE PAIR RELATIVE
PERCE14T4GE\ENTRY asoect is more appropriately "relaxed"
to the AT < DT Al conclusion than to the AT = OT < Al
conclusion.

TABLE 5
4 I U64 11 4 V4
I -6 00 11 ~ 44ma I -- a9 9- a 0 I 6 0 10 --. 9
*-to:~ 00 00 00 00 * Mn 6 * cc 00; cc 00,a~ *4 V1 *4 . . .
aa ec. 1 0: --- - *. -C .9. NNZ ANC - o~ so40 4 4 44~I 4 4 4 4
4 I SO: 4N N60 064i 0o c VIlv o
* 4 00 604 C. NQ 4b C 490II. - a
04. W, ~ 4 4 I2
41 1 4 VI4 r4VI V I 4- 46 4 I I I I
40D 4 4 I
6 . 4 C4 0 04 4, 44 CC 0. 4 6 I 0 00 0 0
CL4 0.: U 4 I
V, Cc 1 0 go .6C s- o V 1
CO 1 COON C 4 as 4 16 0 a
61 1 so 64 4 4 I 4
10 4 1 4 '1 0 N I .6
OW or.I a a ~ ~ 4-I 40 a a4 4 OIU 4 46 462I 4
U~I 46 * f4............. j. -a.l 4. . . .
'AC~C 4L 0 0C C 4
c ~ ~ OU 00 44 I
-Z 6.. C04 -1 -. N N 1 N N -4 I *0 4 -4 464 I 0 4 4 JZ
AD %2. I - 4 I
64C 4 4 C z I..
4~~ 4 9
0~~~~ 4 zz 4 N "' 0 4 44
.I4 4p 4 44
64 .J ..J .. 5 4 1N00a

CHAPTER VII
4. The AT < DT and DT < AI differences from AT < DT < Al on
the (SEGMENT,GLOaAL) USAGE PAIR RELATIVE PERCENTAGE\
ENTRY\MODIFIED aspect are equally strong.
On dispersion comparisons, four programming aspects
yielded completely differentiated conclusions. They dre
"relaxed" to partially differentiated conclusions as
fotl Lows:
?. The DT < AI difference is much more pronounced than the
Al < AT aifference from DT < Al < AT on the MAXIMUM
UNIQUE COMPILATIONS FOR ANY ONE MODULE aspect.
2. From DT < Al < AT on the STATEMENT TYPE COUNTS\RETURN
aspect, the DT = Al < AT conclusion dwarfs the
DT < AI = AT conclusion with respect to Level of
si gni f icanc e.
!. AI < DT < AT on the (SEGMENTGLOBAL) POSSIBLE USAGE
PAIRS aspect is more appropriately "relaxed" to the
AI < AT = DT conclusion than to the DT = Al ( AT
conclusion.
4. The Al < DT difference is more pronounced than the
DT < AT difference from Al < DT < AT on the
(SEGMENTGLOBAL) POSSIBLE USAGE PAIRS\NONENTRY\
UNMODIFIED aspect.
A Direqtionis_ View
The second structural characteristic of the possible
outcome framework is that the outcomes may be classified
into another closely related set of directionless outcomes,
as shown in the lattice of Figure 3.2. For examole,
Al < AT = DT and AT = DT < AI, two directional partially
different iatea outcomes, both correspond to AI 0 AT = DT, a
nonairectional partially differentiated outcome. ALl six of
the directional completely differentiated outcomes
correspond to the single nondirectional completely
7~1

CHAPTER VII
lif fferent iated outCome Al A AT i DT.
iy emphasizing just the existence and not the direction
ot distinctions between the treatment groups, these
d1irectionless outcome categories focus attention on tne
original research issue of discovering which observaoke
programmina aspects differentiate among the three
prog,ramminq environments. In particular, there are three
nonairectional partially differentiated outcomes (each of
the form "one group different from the other two whicn are
similar"), and it is noteworthy to observe just what set of
orogra-ming aspects supports each of these basic
distinctions. (Table 4 is arranged so that the directional
distinctions listed there can be readily coalesced by eye
into airectionless categories.) It is revealing to note
that, with one exception, the directionLess distinctions on
location comparisons segregate cleanly along the process-
versus-product dichotomy Line: all of the product
distinctions fat into the Al A AT = DT or AT A DT = Al
categories, while the process distinctions consistently fall
into the DT * AI = AT category. Interestingly enough, the
one exception is that a number of the cyclomatic complexity
metric variations (which are product aspects) show the
DT $ AI = AT directionless outcome (which otherwise
ch3racterizes only process aspect distinctions).
The purpose of this concluding section is to point out
wh3t seem to be the "top ten" (well, eleven and nine) most
noteworthy conclusions from among the study's objective
results. These conclusions are interesting individually,
either because the programming aspect merits attention or
because the difference in its exvectency or predictability
is pronounced (as indicated by a Low critical siqnificance
102

!CHAPTER VII
level) in the experimental sample data.
Noteworthy jOrjtjg distinctions are mentioned below.
1. According to the DT ( AI = AT outcome on the COMPUTEP
JCB STEPS aspect, the ois:iplined teams used very
noticeably fewer computer job steps (i.e., module
compilations, program executions, and miscellaneous joo
steps) than either the ad hoc individuals or the ad hoc
teams .
2. This same difference was apparent in the total number of
module compilations, the number of unique (i.e., not
identical to a previous compilation) module
compilations, the number of program executions, and the
number of essential job steps (i.e., unique module
compilations plus program executions), accoroing to the
OT < Al = AT outcomes on the COMPUTER JOB STEPS\MODULE
COMPILATION, COMPUTER JOB STEPS\MODULE COMPILATION\
UNIQUE, COMPUTER J03 STEPS\PROGRAM EXECUTION, and
COMPUTER JO STEPS\ESSENTIAL aspects, respectively.
3. According to the DT < Al = AT outcome on the PROGRAM
CHANGES aspect, the disciplined teams required fewer
textual revisions to build and debug the software than
the ad hoc individuals and the ad hoc teams.
4. There was a definite trend for the ad hoc individuals to
hveeproduced fewer total symbolic lines (including
co entst compiler directivest statementst
declaNQations, etc.) than the disciplined teams who
produced fewer than the ad hoc teams, according to the
Al < DT < AT outcome on the LINES aspect.
5. According to the AI < AT = DT outcome on the SEGMENTS
aspect, the ad hoc individuals organized their software
into noticeably fewer routines (i.e., functions or
procedures) than either the ad hoc teams or the
uisciplinea teams.
6. The ad hoc individuals aisplayed a trend toward having a
103

CHAPTER VII
yreater number ot executable statements per routine
than did either the ad hoc teams or the disciptineo
teams, according to the AT = DT < AI outcome On the
AVERAGE STATEMENTS OER SEGMENT aspect.
7. ~According to the DT = Al < AT outcomes on the STATEMENT
TYPE COUNTS\IF and STATEMENT TYPE PERCETAGE\IF
dspects, both the ad hoc individuals and the
uisciplinej teams coded noticeably fewer IF statem.ents
than the ad hoc teams, in terms of both total number
ana percentage of total statements.
'. According to the DT = Al < AT outcome on the DECISIONS
aspect, both the ad hoc individuals and the disciplinea
teams tended to code fewer decisions (i.e., IF, wHILE,
or CASE statements) than the aa hoc teams.
Q. both the ad hoc teams and the disciplined teams declarec
i noticeably Larger number of data variables (i.e.,
scalars or arrays of scalars) than the ad hoc
individuals, according to the AI < AT = DT outcome on
the DATA VARIABLES aspect.
13. According to the AT = DT < AI outcome on the DATA
VARIABLE SCOPE PERCENTAGES\NONGLOBAL\LOCAL asoect, the
ad hoc individuals had a larger percentage of local
variables compared to the total number of declared data
variables than either the ad hoc teams or the
discip)lined teams.
11. There was a slight trend for ooth the ad hoc
individuals and the disciolineu teams to have fewer
potential data bindings (i.e., possible communication
paths between segments via global variables, as allowed
oy the software's modutarization) than the aa hoc
teams, according to the DT = Al < AT outcome on the
(SEG:4ENTGLOBAL,SEGMENT) DATA bINDINGS\POSSIBLE aspect.
Noteworthy d!-J2P}rp_2in distinctions are mentioned below.
l. There was a noticeable difference in variability, with
I34

CHAPTER VII
the disciplined teams Less than the ad hoc individuals
Less than the ad hoc teams, in the maximum number of
unique compilations for any one moaule, according to
the DT < Al < AT outcome on the MAXIMUM UNIQUE
COMPILATIONS FOR ANY ONE m ODULE aspect.
"he ad hoc individuals exhibited noticeably greater
variation than either the ad hoc teams or the
oisciplined teams in the number of miscellaneous job
steps (i.e., auxiliary compilations or executions of
something other than the final software project),
according to the AT = DT < Al outcome on the COMPUTER
JOB STEPS\MISCELLANEOUS aspect.
3. According to the DT = Al < AT outcome on the AVERAGE
SEGmENTS PER MODULE aspect, the a, hoc individuals and
the disciplined teavs both exhibited noticeably Less
variation in the average number of routines per modulethan the ad hoc teams.
4. According to the DT = Al < AT outcomes on the STATEMENT
TYPE COUNTS\RETURN and STATEMENT TYPE PERCENTAGES\
RETURN aspects, the ad hoc teams showed rather
noticeably greater variability in the number (both raw
count and normalized percentage) of RETURN statements
cooed than both the disciplined teams ana the ad hoc
individuals.
5. In the number of calls to orogrammer-defined routines,
the ad hoc individuals displayed noticeably greater
variation than both the ad hoc teams and the
disc ipLined teams, according to the AT = DT < AI
outcome on the INVOCATIONS\NONINTRINSIC aspect.
5. According to the DT < Al = AT outcome on the DATA
VARIABLES SCOPE PERCENTAGES\GLOSAL\NONENTRY\MODIFIED
aspect, the disciplined teams displayed noticeably
smaller variation than either the ad hoc individuals or
the ad hoc teams in the percentage of commonplace
(i.e., ordinary scooe and modified during execution)
105

CHAPTEK VII
IObd t variables compared to tne total number of data
variatles ajeclared.
7. Tnh ad noc individuals displayed noticeanly Less
v3riation in the number of formal parameters passed by
reference than botn the ad hoc teams and the
disciplined teams, 3ccoroing to the Al < AT = DT
outcome on the DATA VARIA 3LE SCOPE CCUNTS\NONGLD6AL\
PARAMETER\REFERENCE aspect.
Q. According to the Al < DT < AT outcome on the
(SEG-ENT,GLOBAL) POSSIbLE USAGE PAIRS aspect, there was
a noticeable difference in variability, with the ad hoc
individuals less than the disciplined teams Less than
the ad hoc teams, for the total numoer of possible
segment-global usage pairs (i.e., occurrences of the
situation where a global variaule coulo be modified or
accessed by a segment).
Q. According to the DT = AI < AT outcome on the
(SEGMENT,GLOBAL,SEGMENT) DATA BINDINGS\POSSI8LE aspect,
the ad hoc teams tended toward greater variaoility than
either the ad hoc individuals or the disciplined teams
in the number of potential data bindings.

CHAPTEQ VIII
VIII. INTERVRETI~. a_ SUL11
This chapter reports the interpretive results of the
stjdy, namely the research interpretations based on the
conclusions oresented in Chapter VII. The tone of
discussion here is purposely somewhat subjective and
opinionated, since the study's most important results are
derived from interpreting the experiment's immediate
finainas in view of the study's overall goals. These
interpretations also express the researcher's own estimation
of the study's implications and general import according to
his Drofessional intuitions about programming and software.
The interpretations presented here are neither
exhaustive nor unique. They only touch upon certain overall
issues and generally avoid attaching meaning to or giving
exolanation for individual aspects or outcomes. It is
anticipated that the reader and other researchers might
formulate additional or alternative interpretations of the
stidy's factual findings, using their own intuitive
juigments.
Tdo distinct sets of research interpretations are
discussed in the remainder of this chapter. The first set
states general trends in the conclusions according to the
basic suppositions of the study. The second set states
general trends in the conclusions according to a
classification of the programming aspects which reflects
certain abstract programming notions (e.g., cost,
modularity, data organizations, etc.).
The study's "basic suppositions" (or "hypotheses") are
107

CHAPTEP VIII
a set of simpleminned a priori expectations regaroing
dif ferences among the exoerimental programming environments
for location ano dispersion comparisons on process anc
prD,.uct aspects. These basic suppositions are stated in the
fol.owing table:
--------------------- ---------jasic Suppositions I for Location Ifor Dispersioni
I Comparisons I Comparisons I- ---- -- ----------------------- -----------------------------I on Process Aspects I DT < AI = AT I DT < AI = AT I---- --------------------------------------------
I I DT = At < ATe DT = AI < ATI on Product Aspects I Ar A or
I AT < DT = AII AT < DT = AI------------------------------------------------- -
The basic suppositions are founded upon "general
beliefs" regarding software phenomena, which had been
formulated oy the researcher prior to conducting the
experiment. These gener3L beliefs state that
(a) methodological discipline is the key influence on the
yeneral efficiency of the process;
(u) the disciplined methoaoLogy reduces the cost and
complexity of the process and enhances the
predictability of the process as well;
C) the preferred direction for both location and dispersion
jifferences on process aspects is clear and
undebatable, because of the familiarity of the process
aspects and the direct applicaoility of expected values
and varianc s in terms of average cost estimates and
tightness of cost estimates;
(a) "mental cohesiveness" (or conceptual integrity [3rooks
75, pp. 41-50]) is the key influence on the general
Quality of the product;
(e) a programming team is naturally burdened (relative to an
individual programmer) by the organizational overhead
and risk of error-prone misunderstanding inherent in
coordinating and interfacing the thoughts and efforts
o4 those on the tean;
(W) the disciplined methodoloy induces an effective mental
7 Q~h

CHAPTER VIII
cohesiveness, endbling a programming team to behave
more like an individual programmer with respect to
conceptual control over the program, its design, its
structure, etc., because of the disc ipLine's
antiregressive, comolexity-controlling FBelaay and
Lehman 76, o. 245] effect that compensates for the
inherent organizational overhead of a team; and
( ) the oreferred direction for both Location and dispersion
oifferences on oroduct aspects is not always clear,
c ecause of the unfamiliarity of many of the product
aspects anu a 3eneral lack of understanding regarding
the implication of dispersion for product aspects.
In view of the general beliefs and basic suppositions
stateo above, each possiole comparison outcome (Cf. Figure
3) may be ."egaraed as "voting" either for or against a given
basic supposition (or as "abstaining"), depending on whether
that outcome would substantiate or contravene the
corresponding general beliefs. For process aspects,
(1) outcome DT < AI = AT obviously affirms the
suppos it ion;
(2) outcomes DT < Al < AT or DT < AT < Al, which are
completely aifferentiated variations of the
supposition's main theme, indirectly affirm the
suPposition, especially when DT < AI = AT is the
stron; er of the corresponding partially
differentiated outcome pair;
(3) outcome Al = AT = DT may negative the supposition,
or it may be considered an abstention for any one
of several reasons
(it is possible that (a) the asoect's
critical level is not low enough, so it
defaults to the null outcome; (b) the aspect
reflects something characteristic of the
acplication/task or another factor common to
1,

ChAPTEP VIII
d L i the jroups in the exL)eriment; or (c) the
aspect measures somethin fundamentaL to
software development phenomena in general ano
would aldays result in the null outcome); and
(4) all other outcomes -- Al < AT < DT, AI < DT < AT,
C DT < , AT C AI <T, AI A AT = DT
(AI < AT = DT, AT = DT < AI), AT AI DT
(AT < DT = Al, DT = Al < AT), and Al AT < T --
neaative the supoostion.
For oroduct aspects,
(1) outcomes AT t DT = AI (AT < DT = Al, DT = Al < AT)
obviously affirm the suppostion;
(2) outcomes Al < DT < AT or AT < DT < Al, which may oe
considered approximations to the supposition (DT
is distinct from AT but falls short of AI, Jue to
lack of experience or maturity in the disciplined
methodology), indirectly affirm the supposition,
esoecially when DT = Al < AT or AT < D- = Al
(respectively) is the stronger of the
corresponding oartially differentiated outcome
pair;
(3) outcome AI = AT = DT may negative the supposition,
or it may be considered an abstention for any one
of several reasors
(it is possible that (a) the aspect's
critical level is not low enough, so it
aefaults to the null outcome; (b) the aspect
reflects something characteristic of the
arplication/task or anotner f3ctor common to
all the groups in the experiment; (c) the
aspect measures something fundamental to
software development phenomena in general and
would always result in the null outcome; or
(d) several of the study's hit-and-miss
collection of exploratory Proauct aspects are

CHAPTER VIII
Juds and vay be ignored as useless software
measures);
(4) outcomes AI < AT < DT, AT ( Al < DT, DT < Al < AT,
and DT < AT < Al negative the supposition;
(5) outcomes OT A AI = AT (DT < AI = AT, AI = AT < DT)
negative the suppostions, especially discreciting
the belief that "mental cohesiveness" is the key
influence on the product; and
(6) outcomes Al A AT = DT (AI < AT = PT, AT = DT < AI)
negative the Supposition, especially discrediting
the belief that discipline methodology effectively
molds a team into an individual.
Thus, interpreting the study's findings accordin to
the Dasic suppositions consists of assessing how well the
research conclusions have borne out the basic suppositions
and how well the experimental evidence substantiates the
cenerat beliefs. On the whole, the study's findings soundly
support the general beliefs ,resented aoove, although a few
conclusions exist that are inconsistent with the Dasic
suDpositions or difficult to allay individually.
Support for the general beliefs was relatively stronger
on process aspects than on product aspects, and in Location
conparisons rather than in dispersion comparisons.
Overwhelming support came in the category of Location
cotparisons on process aspects in which the research
conclusions are distinguished by extremely low critical
levels ano by near unanimity with the basic supposition. In
the category of dispersion comparisons on process aspects,
only two outcomes indicated any distinction among the
qroups: one aspect supported the study's general beliefs and
one aspect showed an explainable exception to them. Fairly
stronyj support also came in the category of location
co'mparisons on product aspects for which the only negative
111

CHAPTER VIIi
evidence (besides the neutrdl At = AT = DT conclusions)
a oearej in the form of several Al A AT = DT conclusions.
They inoicate some areas in .hich the disciplined
methodology was apparently ineffective in modifying a team's
behavior toward that of an individual, probably due to a
tack of fully developed training/experience with the
methocaology. Comparatively weaker support for the study's
beliefs was recordea in the category of dispersion
comparisons on product aspects. Although the basic
suopos-itions were borne out in a number of the conclusions,
tnere were also several distinctions of various forms whir."
contravene the basic suppositions.
Thus, according to this interpretation, the study's
findings strongly substantiate the claims that
(Cl) methodological discipline is the key influence on
the general efficiency of the software Oevelopment
process, and that
(CZ) the disciplined methodology significantly reduces
the material costs of software development.
The claims that
(C3) mental cohesiveness is the key influence on the
general quality of the software development
Proouctt that
(C4) relative to an individual, an ad hoc team is
mentally burdened by organizational overheau, and
that
(C S) the disciplined methodology offsets the mental
burden of organizational overhead and enables a
team to behave more Like an individual relative to
the software product,
are moderately substantiated by the study's findings, with
oarticularly mixed evidence for dispersion comparisons on
Pr3duct aspects.

CHAPTER VIII
It shouto ue noted that there is a simpler, better-
suoported interpretive model for the location results alone.
With the beliefs that a Jisciplined methooology provioes for
the minimum process cost and results in a proouct which in
sone aspects approximates the product of an individual and
at worst approximates the product developed by an ad hoc
tea.i, the suppositions are DT < AIAT with respect to
process and Al S DT < AT or AT S DT < AI with respect to
product. The study's findings support these suppositions
without exception.
l irgina: 12 2 rg!E{&m~inA=.ecp~t Edatsification
It is desirable to examine the study's findings in view
of the way that higher-Level programming issues are
reflected among the individual programming aspects. For
this purpose, the aspects considered in this study were
grouped into (so-called) programming aspect classes. Each
class consists of aspects which are related by some common
feature (for example, all aspects relating to the programos
statements, statement tyoes, statement nesting, etc.), and
the classes are not necessarily disjoint (i.e., a given
asoect may be included in two or more classes). A unioue
higher-teveL programming issue (in the example, control
structure organization) is associated with each class.
The programming aspects of this study were organized
into a hierarchy of nine aspect classes (with about 10%
overlap overall), outlined as follows:
11!

CHAPTER VIII
!iher-tevet Pro~rammi ng tW:£.s_
Development Process EfficiencyEffort (Job Steps) . . . . . . . IErrors (Program Chances) . . . . . . II
Final Product GualityC ross Size . . . . . . .Controt-Construct Structure . . • . . IVData Variable Organization . . .. . VModulari ty
Packaalng Structure . . . . . . VIInvocation Organization ... . . VI
Inter-Segment Communicationvia Parameters . . . . . . . VIIIVia Global Variables . . . . . . . IX
The individual aspects comprising each class, together with
the corresponding conclusions, are listed by classes in
Ta:les c.1 throuah 6.9. For each aspect class, it is
interesting to jointly interpret the inoividual outcomes in
an overall manner in order to see something of how these
higher-level issues are affected by team size and
-tetnodological discipline.
Class I: EffQCt (Joo Steos)
Within Class I (process aspects dealing with COMPUTER
J03 STEPS), there is strong evidence of an important
difference among the groups, in favor of the disciplined
methooology, with respect to average development costs. As
a class, these aspects directly reflect the frequency of
computer system activities (i.e., module compilations and
test program executions) during development. They are one
possible way of measuring machine costs, in units of oasic
activities rather than monetary charges. Assuming that each
cotputer system activity involves a certain expenditure of
the programmer's time and effort (e.g., effective terminal
coitact, test result evaluation), these aspects indirectly
reflect human costs of development (at least that portion
exclusive of design work).
The strength of the evidence supporting a difference
with respect to location comparisons within this class is
114

TABLE 6
* ~ . 1- - 44
0 - 1 #- 411,
*~~ ~ 0-4 0 a0 a0
*--* .9 *4 4**e
.4c 4... -KC I 4 .0
4C~~.1 21 *
o404 ~ v vl v - 40 - e
1 00- z C I t 44- 4 4
- ~~Z 4 C4I 4 cc4* 4 0411II 111.4II I .;:. 64 V6
O O x 4
- 4 4 - W I!!wv INC"~ a n 4-4 :c
o ~ N . 14I9 4 b4V9%~ Nt~'eh ' . 4 4
b 000 060
o eCU * i *14a

CHAPTER VIII
haser. on both (a) tne near unanimity CS out of 9 aspects] of
the T < AI = AT outcome ano (b) the very Low critical
Levels 1<.025 for 5 aspects] involved. Indeea, the single
exception among the Location comparisons (Al = AT = DT on
C34PUTER JOB STEPS\MODULE COMPILATIONS\IDENTICAL) is readily
exoLained as a direct consequence of the fact that all teams
made essentially similar usage (or nonuse, in this case,
since icenticaL compilations were not uncommon) of the on-
Line storage capability (for saving relocatabLe modules and
thus avoiding identical recompiLations). This was expected
since all teams had been provided with identical storage
ca:aoility. but without any training or urging to use it.
The conclusions on Location comparisons within this class
are interpreted as demonstratiny that
employment of the disciplined methodology by a
programming team reduces the average costs, ooth
machine and human, of software development, relative to
both individual programmers and programming teams not
employing the methodology.
Examination of the raw data scores themselves indicates the
m&gnitude of this reduction to be on the order of 2 to 1
(i.e., 50%) or better.
aith respect to disoersion comparisons within this
class, the evidence generally failed to make any
distinctions among the groups CAI = AT = DT on 7 out of 9
asoects], These null conclusions in dispersion comparisons
are interpreted as demonstrating that
variability of software development costs, especially
machine costst is relatively insensitive to programming
team size and degree of methodological discipline.T he two exceCtions on individual process aspects deserve
mention. The COM PUTER JOB STEPS\MISCELLANEOUS aspect showed
a AT = DT < Al dispersion distinction among the groups,
reflecting the variaoility (as expected) of individual
115

CHAP T EP VIII
programmers relative to orogramming teams in the area of
buiLding on-Line tools to indirectly support software
deveLoprment (e..g., stand-alone module drivers, one-shot
auxiliary computations, tabLe generators, unanticipated
debugging stubs, etc.). The MAX UNIQUE COMPILATIONS F.A.O.
"ODULE aspect showed a DT < Al = AT dispersion distinction
arong the groups at an extremely Low critical level [<.0O53,
reflecting the Lower variation (increased orecictabitity) of
th- isciptined teams relative to the ao hoc teams and
individuals in terms of "worst case" compilation costs for
any one module. The additional Al < AT distinction for this
comPparison is attributaote to the fact that several teams in
graup AT built monolithic single-module systems, yielaing
rather inflated raw scores for this aspect.
Class 11: Errorj (Progran Changes)
qithin Class I (the process aspect PROGRAM CHANGES),
there is strong evidence of an important difference among
the groups, again in favor of the disciplined methodology,
witn respect to average number of errors encountered during
imolementation. Chapter V contains a detailed explanation
of now program changes are counted. This aspect directly
reflects the amount of textual revision to the source code
during (postdesign) development. Claiming that textual
revisions are generally necessitated by errors encountered
while nuilding, testing, and debugging software, independent
research [Dunsmore and Gannon 77) has demonstrateo a high
(rank order) correlation between total program changes (as
counted automatically according to a specific algorithm) and
total error occurrences (as tabulated manually from
exhaustive scrutiny of source code and test results) during
software implementation. This aspect is thus a reasonable
measure of the relative number of programming errors
encountered outside of design work. Assuming that each
116

TABLE 6
* 464w C D. 4f 4" 4004 4 4 0 4
I * : .z: : . a,* . 0**C ace 4004
40W 4 4 40.04
4.1*me4 4
:%#: C 4eze44 0
400.4 4 4
0-4. 44 - 4 4
-%~ ~~~ ae~

CHAPTER VIII
textual revision involves an expenoiture of programmer
effort (e.g., planning the revision, on-Line editing of
soirce code), this aspect inoirectty reflects the Level of
huian effort devoteu to implementation.
with respect to location comparison, the strength of
the evidence supporting a difference among the groups is
based on the very low critical level [<.0051 for the
DT < Al = AT outcome. The additional trend toward AI < AT
is much less pronounced in the data. The interpretation is
that
the disciplined methodology effectively reduced the
average number of errors encountered during software
implementat ion.
This was expected since the methodology purposely emphasizes
the criticality of the design phase and subjects the
software design (code) to thorough reading and review prior
to coding (key-in or testing), enhancing error detection and
correction prior to implementation (testing).
with respect to disoersion comparison, no distinction
among the groups was apparent, with the interpretation that
variability in the number of errors encountered auring
implementation was essentially uniform across all three
programming environments considered.
Class III: Groql _Sz
within CLass III (product aspects dealing with the
qross size of the software at various hierarchical levels),
there is evidence of certain consistent differences among
the groups with respect to both average size and variability
of size. As a cLass, these aspects directly reflect thenumber of objects and the average number of component
(sub)objects per object, according to the hierarchical
117

TABLE 6
*cl -4 11a
c ~ lo- '0 1. 10 4 C
0; I C I OC I ca 0:. 0 a f if m Is of of
w a~ . I . * *I 4
.cu cc a CIO ac C' :CO:
c0 I a a 4 49 1
*mC '!1a a a 0 .
4~b4a i a a0 0. -
4--a. 1. I I I 4 4
* 0 I ow S * Cmi 10~I Vs~,0 1. *iaaaa Iav I: 4 4
* 04 I sel I I ~ ac-6 4
a Wi 1 0 . 1 a w 44 I 4 1
0 4 *4 I so 04 I 0
400 :,Ja -im 1 WA IP *
* a go 'Jaw 44 I I Ip- I-I. . I VIC I 0. 4Pb4
10,211 Z.cca 0 ~ .
I0 X-C.
C- -C I U la- --c - do I 4 I P-04 4 144 144 04 ~ 4 404
a- - 4 I a ~ 117a

CHAPTEP VIII
organization (imposed by the programming Language) of
sof tw re into objects such dS modules, segments, Jata
variautes, Lines, statements, and tokens.
,,ith respect to Location comparisons witnin this class,
the non-null conclusions [L7 out of 17 aspects] are nedrLy
unanimous C5 out of 7] in 'he AI < AT = DT outcome. The
interpretation is that individuals tend to produce software
which is smaLter (in certain ways) on the average than that
orDouceo by teams. It is unclear wnether such spareness of
exDression, primarily in segments, global variables, ano
formal parameters, is advantageous or not. The two non-null
exceptions to this Al < AT = DT trend deserve mention, since
the one is Only nominally eAceotional and actually
supportive of the tendency upon closer inspection, whiLe the
other indicates a size aspect in which the discipLineo
methooology enabled programming teams to break out of the
pattern of distinction from individual programmers. The
AT = DT < AI outcome on AVERAGE STATEMENTS PER SEGMENT is a
sirple conseduence of the outcome for the number of
STATEMENTS CAI = AT = DT] and the outcome for the numoer of
SESMENTS CAl < AT = DT) and it still fits the overall
oattern of At A AT = DT on location differences on size
asoects. On the LINES aspect, the DT = Al < AT distinction
breaks the pattern since DT is associated with AI and not
with AT. Since the number of statements was roughly the
sa-me for all three groups, this difference must be due
mainLy to the stylistic ianner of arranging the source code
(which was free-format with respect to Line boundaries), to
the amount o documentation comments within the source code,
and to the number of Lines taken up in data variable
declarations.
with respect to dispersion comparisons within this
class, the few aspects which do indicate any aistinction
11

CHAPTER VIII
aman4 the groups [5 out of 17 aspects] seem to concur on the
Al = AT < DT outcome. This pattern, which associates
increased variation in certain size aspects with the
disciplined methodology, is somewhat surprising and tacks an
intuitive exolanation in terms of the experimental
tr.atments. The exception DT = Al < AT on AVERAGE SEGMENTS
PE? ',ODULE is really an exaggeration due to the fact uf
several AT teams implementing monolithic single-module
systems, as mentioned above. The exception AT < DT = Al on
STAT.:_ENTS is only a very slight trend, reflecting the fact
th3t the AT products rather consistently contained the
largest numbers of statements.
Oje overall observation for Class ill is that while
certain distinctions did consistently appear (especially for
location out also for dispersion comparisons) at.the middle
levels of the hierarchical scale (segments, data variibles,
lines, ano statements), no distinctions appeared at either
the highest (modules) or lowest (tokens) Levels of size.The null conclusions for size in modules and average module
size seem attributaole to the fact that particular
programming tasks or application domains often have standard
designs at the topmost conceptual levels which strongly
influence the organization of software systems at this
highest level of gross size. In this case, the symOol-
ta le/scanning/parsing/code-generation design is extremely
cormon for language translation problems (i.e., compilers),
regaruless of the particular parsing technique or symrol
taoLe organization employed, and the moaules of nearly every
system in the study directly reflected this common design.
The null conclusions for size in tokens is interpretable in
vied of Halstead's software science concepts LHalsteaa 77),
accoroing to which the program length N is predictaole
from the number of basic input-output pdrameters T1 and
the language level X . Since the functional specification,
119

CHAP T EP VIII
3 lication area, and implementation Language were all fixed
in this study, uoth rl 2* and X shoulo be constant for
each of tne software systems, imolying virtually constant
crDrdm lengths N Since program length N can oe
re-:aroea as roughly equivalent to the numoer of tokens in a
proram, the study's oata seem to support the software
science concepts in this instance.
Ct3ss IV: coo!!rQ-SQI:ru_ ruIV!:t
aithin Class IV (proauct aspects dealinq with the
scft.ore's organization accoroing to statements, constructs,
and control structures), there are only a few distinctions
mnjJe oetween the groups.
with respect to location comparisons, the few [5 out of
24), aspects that Showed 3ny distinction at all were
unanimous in concluding DT = AI < AT. Essentially, three
particular issues were involved. The STATEMENT TYPE COUNTS\
IF, STATEMENT TYPE PERCENTAGES\IF, and DECISIONS aspects are
all related to the frequency of projrammer-coded decisions
in the software product. Their common outcome DT = Al < AT
is interpreted as demonstrating an important area in .hich
the cisciplined methodology causes a programming team to
behave like an individual programmer. The number of
decisions has been commonly accepted, and even formalized
[',cCaoe 76], as a measure of program complexity since more
decisions create more paths through the code. Thus, the
disci;LAined methodology effectively reduced the average
complexity from what it otherwise would have been. The
STATEMENT TYPE COUNTS\RETURN aspect indicates a difference
between the ad hoc teams and the other two groups. Since
the EXIT and RETUR% statements are restricted forms of
G&TOst this difference seems to hint at another area in
which the disciplined methodology improves conceptual
12-

TABLE 6
*I - : e
a c.a .N It aa a af n * o 1 1Nu001 f I tV
fill Ita ocVIV Ifa ia a at If N 1 1 1 4,c
.~ _ . : : . . .o. ~ ~ ~ ' 40-a1 a-- aa Q. C 4-
4CC ~ ~ ~ ~ 1 44 4 aa 0 4
"w 0N W li a 00 won 0a 41 of 5 to - *
- If 0 4 a a a a a 0 N ol 0 *,1 I
-~1 Cc- a a . 0- ~ ~ ~ ~ ~ ~ ~ ~ C . c .aCk ~ .
*~ ~ ~ ~ w 1 0p -a 0aaa 4 C
*~I a c Ca aa
C 00.. aZ
CIL aa a a I I-
- .OZ. a o :4 41 a &Z . .~~~~~t 4 : a a 4 0
ow at to a a0 a . Ua a 4 4 a a a-a-a a-1a42-a 4 4t
4 U 4 . a a aaa120a aa . e
a- U * 4 ra a a

CHAPTER VIII
control over projram structure. The STATEMENT TYPE COUNTS\
(P4OC)CALL\INTRIrNSIC aspect also indicates a slight trend in
the area of the frequency of input-outout operations, which
seems interpretable only as a result of stylistic
differences.
with respect to disoersion comparisons, only two
'articular issues were involved. The STATEMENT TYPE COUNTS\
;ETURI, ano STATEMENT TYPE PEPCENTAGE\RETURN aspects both
indicated a strong DT = AI < AT difference, suggestin that
tne frequency of these restricted GOTOs is an area in which
the disciplined methodology reduces variability, causing a
programming team to beha.ve more like an individual
crorammer. The STATEMENT TYPE COUNTS\(PROC)CALL and
STATEMENT TYPE COUNTS\(PROC)CALL\NONINTRINSIC aspects both
showed a DT < AI = AT distinction among the groups, which is
dealt with more appropriateLy within Class V11 below.
In summary of Class IV, the interpretation is that the
functional component of control-construct organization is
largely unaffected oy team size and methodological
discipline, probably due to the overriding effect of
croject/task uniformity/commonality. However, two facets of
the control component that were influenced were the
frequency of decisions (especially IF statements) and the
frequency of restricted GOTOs (especially RETURN
st3tements). For these aspects, the disciplined methodology
seems to have altered the size of the program's control
structure (and reduced its complexity) from that of a team's
product to that of an individual's product.
Class V: 2a1a arAaolj tjzCa±.&jU2o2
within Class V (product aspects dealing with data
variaoles and their organization within the software), there
121J

TABLE 6
S4w I66
c . - 4 Of V N v 16 0 H W V 1 0 1 V I 1 1 # o *4M i f V 1 4 1
18 *- . . 0 9. u 6 N u I'.I " uo it N I - 6
4 W .4 6.-' AI I C 0 009
C; 46 1' CO c0 # 0 06 C
4- I: a No 00a0 i N is N 0 0 1N a V i6 N M of
a. 0: V I' v N 00 6 a v 0000 N 0 4 N I I$I *
4~~0.4 L
IQU 4S VI 445.6I WIII Vh.416 NV MM6664465ro~i .-- 0 4
- 4~g4 6 N N I - N N I .
C 9 --- - N
oq a- at I
0 10 :;Peat W. N 4
-~~~~~w 4 ~ 0 J 6~0
020 400 0 0 ~ 6 afwa II 60.* ECU 4 6 66 3
*C0. Z0. **...Or-. ..... .... ....
~~~~1 1- a

C riA P TE P VI i
are several distinctions among the groups, with an overall
treni for both the Location and dispersion comparisons.
,ata variable organization was, however, not emphasized in
the disciplined methooology, nor in the academic course
which the participants in group DT , ere taking. with
re ,ect to location comparisusq all aSPectS Shoting anY
distinction at all were unanimous in concluding
AI * AT = DT. The trend for indiviouals to differ from
te3ms, regardless of the disciplined methodology, appears
not only for the total rumber of data variaoles declareo,
tut also for data variables at each scope level (global,
parameter, local) in one fashion or another. The difference
regaraing formal parameters is especially prominent, since
it Shows up for their raw count frequency, their normalized
Dercentage frequency, and their average frequency oer
natural enclosure (segment). With respect to dispersion
comparisons, the apparent overall trend for aspects which
show a distinction is toward the Al = AT < DT outcome. No
particular interpretation in view of the experimental
treatments seems appropriate. Exceptions to this trend
apoeareo for both the raw count and percentage of call-by-
reference paramenters (both Al < AT = DT), as well as two
other aspects.
Ct3ss VI: Packaing Structure
aithin Class VI (product aspects dealing with
moJularity in terms of the packaging structure), there are
essentially no distinctions among the groups, except for two
location comparison issues. Most of the aspects in this
class are also members of Class 1i1 , Gross Size, but are
(re)considered here to focus attention upon the packaiing
chiracteristics of modularity (i.e., how the source code is
livided into modules and segnents, what type of segments,
etc.). The disciplined 'nethooology did not explicitly

TABLE 6
'A Is V I NO N I Ist I
.c-s c;o404C I
40C* *. . . . . . .
soC 0 4 14 116 0 Is I 6 Is 6 4
* 1.1 64 II V III 1 1.0 II 1 UI Nh
owl4 S I -. MI :
- C C I -X 1 4V
, C 4 gO S I 4
6 4 I4 I I
99- 1- 3 I - I 4
469 1.4. I -- M I W 4
00 ; 4 . 0 O IOU "i'
*W161 46 5 60 I C
1 166 - 1 w m I I - $ 4
I. 4 I- I III W- C4* lc .. J As I c
-~~~~~1 COUNMNhW2 ggS.~ C -C e I I I
29 =wn GW W- I2 -
.0 6 4 *4 I 4122a

CHAPTER VIII
include (nor did group DT's course work cover) concepts of
modularization or criteria for evaluating good modularity;
hence, no particular distinctions among the groups were
expected in this area (Classes VI and VII).
with respect to Location comparisons, the Al < AT = DT
outcome for the SEGMENTS aspects, along with the companion
outcome AT = DT < AI for the AVERAGE STATEMENTS PER SEGMENT
asoect (as explained under Class IIl above), indicates one
area of packaging that is apparently sensitive to team size.
Individual programmers built the system with fewer, but
larger (on the average), segments than either the ad hoc
teams or the disciplined teams. The AI < AT = DT outcome
for the AVERAGE NONGLOBAL VARIABLES PER SEGMENT\PARAMETER
asoect indicates that average "calling sequence" Length,
curiously enough, is another area of packaging sensitive to
team size. With respect to dispersion comparisons, there
really were no differences, since the single non-null
outcome for AVERAGE SEGMENTS PER MODULE is actually a fluke
(raw scores for AT are exaggerated by the several monolithic
systems) as explained above. T he overall interpretation for
this class is that
modularity, in the sense of packaging code into
segments and modules, is essentially unaffected by team
size or methodological discipline, except for a
tendency by individual programmers towaro fewer, Longer
sejments than programming teams.
CL3ss VII: LnvoCat. n QrCaniati2n
Within Class VII (product aspects dealing with
modularity in terms of the invocation structure), there are
two distinction trends for location comparisons, but no
clear pattern for the dispersion comparison conclusions.
This class consists of raw counts and average-per-segment
1Z3

TABLE 6
C.: - • 1- 1* o- I e .
: Ic C n I a ; N *
. C cci Cc a0 0
c **. . . ....... .
'10 .9 1 a
on0. P.6a a * 4P
C 4w-C :0~C .8v.2-- I -; cc-
o .. .. . .. .. a. .. .. .. ..
- 42
' U @ mivm.ilmlui iii i
i..l~q i. m~uq Ous , i , l aw
- 9 . 5OZ -. l- 5- i .l l I- I a S 5 4
C 4 0 *k
c
*: 4 c 41aa
P. 00 C I
o o-. I.- a 4
* . !NZ** vivaz w ;0 10:
0 4 lZ I L = I OW
123a

CHAPTER VIII
frequencies for invocations (procedure CALL statementb or
function references in expressions) and is considered
separately from the previous class since modularity involves
not only the manner in which the system is packaged, out
also the frequency with which the pieces might be invoked.
For tne raw count frequencies of calls to intrinsic
prDceoures and intrinsic routines, the trend is for the
inJivi-luals and disciplined teams to exhibit fewer calls
th3n the ad hoc teams. These intrinsic proceoures are
alvost exclusively the input-output operations of the
language, while the intrinsic functions are mainly data type
conversion routines. The second trend for Location
co-"parisons occurs for two aspects (a third aspect is
actually redundant) related to the average frequency of
calls to programmer-defined routines, in which the
individuals display higher average frequency than either
tyoe of team. This seems coupled with group AI's preference
for fewer but larger routines, as noted above. With respect
to dispersion comparisons, several distinctions appear
within this class, but no overall interpretation is reaoily
apoarent (except for a consistent reflection of a DT < Al
difference, with AT falling in between, leaning one side or
the other).
Class VIII: Y -Sa eot f~mUoi~tion via Para:!ernfrs
within CLass VIII (orocuct aspects dealing with inter-
segment communication via format parameters), there are only
a few distinctions among the groups. With respect to
location comparisons, the total frequency of parameters and
the average frequency of parameters per segment both show a
difference. The interpretation is that
the individual programmers teno to incorporate Less
inter-segment communication via parameters, on tne
average, than either the ao hoc or the disciplined
124

TABLE 6
On or 0 0- S'00
Va= K I aK
b 0.0 0, "ON 1 on.0 : m. vu: VmS
- ; 40 1 S 4
O* I xm 4 v 4
4,~ " 2 I z
*3 4 0 * SI I
c 42 a 4-
OW CC.
-C : mm .5 -
- a , a- *1 oi*l0 . wo a
Ce- of .At I a
2a Im mi it 5- I 5-
o ~ 14 .0bm 122 m m .hD 4~0 S 5
4 bUC 5 5124a

CHAPTER VIII
programming teams.
witn respect to dispersion comparisons, in addition to the
difference in the raw count of parameters referred to in
Class V, there is a strong difference in the variability of
the number of caIl-oy-reference parameters, also apparent in
the percentages-by-type-of parameter aspects. The
interpretation is that
the individual programmers were more consistent as a
yroup in their use (in this case, avoidance) of
reference parameters than either type of programming
team.
CL3ss IA: 1n1L-feta Oten DIt £2uID2Q Iii 2 221k YitItI
within Class IX (product aspects dealing with inter-
segment communication via gLooal variables), there are
several differences among the groups, including two which
indicate the beneficial influence of the disciplined
methodology. This class is composed of aspects dealing with
absolute frequency of globals, average frequency of gLobaLs
Per module, segment-global usage pairs (frequency of access
paths from segments to gLobals), and segment-9lobal-segment
data bindings (frequency of communication oaths between
segments via global variables).
.ith respect to Location comparisons, there is the
Al < AT = DT distinction in sheer numbers of gLobats,
oarticularly gtobals which are modified during execution, as
noted in Class V. However, when averaged per module, there
apoears to be no distinction in the frequency of gLobats.
The Al < AT = DT difference in the number of possible
segment-gLobal access paths makes sense as the result of
group AI having both fewer segments and fewer gLobaLs. ALL
three groups had essentially similar average Levels of
actual segment-global access paths, but several differences
125

TABLE 6
o.~ ,e* ,i ** *** lac a, .Q ** °. **
* o* ,e6 * * I
U I I C! I Si so O
S 4 * " il. .... .* .U4VaUaaaa, aNle NUvSamaNuwuuaavu,.vumahaai ua a
a N 4 If 4 a 0 0 Is I I If If If H I
-4 a
* - I l 6
ID 4 -- a m
a 07a aa
IIO
: . s. .. . aq a1 al,. bJ aOII nm a1 . .
£ 4 • 0 Z OQ I* 0a€ lac a Z[ al
I~~~ OWLim
c12aa
W 0e 40a a 4
a a a0 a
0 0"*a a aW l W- a W- a I -
@ '0 4 a0-00 a a at aW,
~~m 4D4 Vivfoaaav a *Ub:aawo-amNzuvmmWMmIamwo- maw:,% a az c a aC a
*0 z 0*4d z4 a
4 U 4 44 4 a1a 5 a a4 4 a

TABLE 6
.O ~ C 4 a0 40:1 44 1~V
- 4 40 Z-
44 4 ... .4.
4 * 4 4
-4 way a0- &M v 444 4 6-0 4P. 4 v
a C
a 40 4 01
ab 0 .C won a a
'0 4w So %~ '
I. - 00 4 CQuo
4 4
- 4 .W- 4125b~

CHAPTER VIII
a;oear in the relative percentage (actual-to-possible ratio)
cateJory. These three instances of AT < DT = Al differences
indicate that the degree of "globaLity" for global variables
was higher for the individuals and the disciplined teams
than for the ad hoc teams. Finally, another AT 0 DT = Al
difference appears for the frequency of possible se~ment-
gl:oat-segment jata oindings, indicating a positive effect
of the aisciplined methodology in reducing the possiole data
coupling among segments. It may be noted that these Last
two categories of aspects, segment-global usage relative
percentages and segment-global-segment oata bindings, also
reflect upon the quality of modularization, since gooo
modularity should promote the decree of "gtobality" for
globaLs and minimize the data coupling among segments. The
interpretation here is that
certain aspects of inter-segment communication via
Llobals seems to be positively influenced, on the
average, by the disciplined methodology.
with respect to dispersion comparisons, there is a
diversity of differences in this class, without any unifying
interpretation in terms of the experimental treatments.
The cyclomatic complexity and software science metrics,
wM3se results have not been integrated into the two
interpretive frameworks discussed aoove, aefinitely mcrit
sove interpretation.
On location comparisons, the results for cyclomatic
complexity measures exhibited a common underlying trend,
namely, DT < AT < aI. In fact, the non-null outcomes were
usually either AT = DT < Al or else DT < Al = AT. This says
that either the teams were differentiated from the

CHAPTER VIII
inJivid.als or else the disciplined methodology was
differentiated from the ad hoc approach, depending on the
oarticular variation of cyclomatic complexity invotveu.
This corresponds well with the intuition that team
Droramming alone snoulo force a general reduction of
cyclomatic complexity for individual routines, and that use
of the disciplined methodology within team programminj
Sh~uld promote this effect even further. The observeo
results for the cycLoatic complexity metrics seem to
display this kind of behavior.
The generally weaker differentiation (i.e., larger
critical levels) observed for the cyclomatic complexity
asoects relative to other aspects considered in the study is
auite understandable in Light of the fact that all 19
systems were coded in a structured-programming Language
which greatly restricts ootentiat control flow patterns. We
wouli expect cyclomatic complexity metrics to be more useful
in the context of unrestrictive programming languages such
as Fortran.
The results for software science quantities are
safewhat disappointing: surprisingly few distinctions among
the 4roups were ootainea. On Location comparisons, only the
vocacutary and estimated length metrics (the latter is a
function solely of the former) yielded non-null conclusions.
Their Al < AT = DT outcome corresponds to that obtained for
the number of segments and data variables, both of which
c otribute heavily to the number of "operator/operands."
The overall interpretation here is that the software science
metrics appear to be insensitive to differences in how
so'tware is developed. "aybe these measures, with their
actuaridl nature, are sensitive only to gross factors in
software development (e.g.t project, application area,
imolementation Language), all of which were held constant in
127

CHAPTER VIII
th is e xper ime nt.
12~

CHAPTER IX
A practical methodology was designed and developed for
exoerimentally and quantitatively investigating software
develooment onenomena. It was employed to compare three
oarticuLar software development environments and to evaluate
the relative impact of a particular disciplined methodology
(maje up of so-called modern programming practices). The
exoeriments were successful in measuring differences among
orogrdmming environments ano the results support the claim
that disciplined methodology effectively improves botn the
orocess and product of software development.
One way to substantiate the claim for improved process
is to measure the effectiveness of the particular
programming methodology via the number of bugs initially in
the system (i.e., in the initial source code) and the amount
of effort required to re-nove them. (This criteria has been
suggested independently oy Professor M. Shooman of
Polytechnic Institute of New York [Shooman 7,3).) Altnough
neither of these measures was directly computed, they are
ea:n closely associated with one of the process asoects
considered in the study: PROGRAM CHANGES and COMPUTER JOB
STEPS\ESSENTIAL, resoectively. The location comparison
st3tistical conclusions for both these aspects affirmed
T < Al = AT outcomes at very low (<.01) significance
levels, indicating that on the average the disciptined teams
mehsurea Lower than either the ad hoc individuals or the ad
hoc teams which botn measured about the same. Thus, the
Pvidence collected in this study strongly confirms the
effectiveness of the disciplined methodology in building
retiaole software efficiently.
The second claims that the product of a disciplined

CHAPTER IX
te3m should closely reseflu e that of a single individual
since the aisciplined methodology assures a semblance of
conceptual inteyrity within a programming team, was
partially substantiateo. In many product aspects the
products developea using the jisciolineo methodology were
either similar to or tended toward the products developed by
the individuals. In no case did any of the measures show
the oiscipLined teams' products to ce worse than those
developed by the ad hoc teams. It is felt that the
suoerticiality of most of the product measures was chiefly
responsible for the Lack of stronger support for this second
cl3im. Tne need for product measures with increased
sensitivity to critical characteristics of sottware is very
clear.
The results of these experiments will be used to guide
further experiments and will act as a basis for analysis of
software development products and processes in the Software
En;ineering Laboratory at NASA's Goddaro Space Flight Center
[3asiLi et at. 77]. The intention is to pursue this type of
emoiricaL research, especially extending the study to more
soohisticated and Promising software metrics.
I 3C

APPENDIX I
C a aa S
4 QfI fka* I S v a a a P I S n I
00 0*a a .. n aaa- ~ ~ ~ ~ ~~0 4nag. AID .ee..vsm.raaa aaa
* aC2 a* a a S PM
-M V O.a a* *son 30 a4 =01Q0P-..,C .09 lwv' P*. 45 *Sl * a** *
A c b- ONW. waa~ vNSVS*~~1 19:4 aW.~N S.S9! a, %a56. ol a ~ aa~a a 5) 0
a C-a a 0 v, I ~IL~a a c . sa a S
CQ£ e& a a m
8:4c a-a a aa-. ~ ~~~~~~~~ a z.Ce-Oaa zme m'
-, I I . . . St .aa.em a a~a a~~a0~ ae *Q 5.cc.'o
C~~~~~~~~~i a e :~ l~ea~ ~SCA ae a
01 aa a a S
co a£ aC a a V mc.-s ae a a a a
C a aES a &"aSNa e aC ~56 a S a a aa ea a
a 0 2 S. a- a..........I aa ........
-Cb a 4 ~ 0 a~ V C ~ 0 a fae
.4 SIC a0a a a aaloz a0xaC. a- C 0 a: b 1 a 0 a. a a4 ut a a Zo I Ia~ cosoa a a.C 6 5 3 4 a aCo IV
CI -cc- a ww a a an 10 CW- aa - .e a 07~.e - aa SO 1.2 a Ca ~ ~ aCa a C a eo
i .a Sl a6 a a.a . 0 -A -0 U Oa j.ce. a Za a
~ s- s a a ~ a a a 5 a a13S1

APPENDIX 1
1.s-K .t. . n 't.OrnoK o IN N0~-K -O ~ --.N P.NK I I~tC OSwp u n W sofnn "PIC
IlQLr K_ 00. 0 IN M K0 f V 0 I0no w
' . . . . . .: IF 1. tio K; *n o *Kw 0;0 . .
AJ1r -SO K- " m -Wu"m I K K m ~ . Kw m o- C i
44 I~. . . .-tQ'O'c' 0 01 'OUo..........C)O
onQ 8PV~m WW no. 9 Wm~wj. I 4M 'tO K r~y *KmKwK KOKA .gl r--~o I
Ns I foK0 a K0 1S WW.o Kneu it podm0OK mK. K 4 K .G O
K. 0 I1 *KOKO m4o.*wN. .o_. . . .I-00 *KK.00
KP.*4*Vl4~,IK to I WOK Kn KP K
I K K I I I K K K K K
4L K 1 ,~ o-t .mI Oo ao.t~oIm KO .r7.IOK 4 N 4 . 0
~C IWI K K .. .. . .I ~ I411 '.. K KK .U . . . .
K KS.KmKOI .N~WC40~KI. . . . K4KU GO~W0 * V0C..0UC.1
m~ IK K 1 O~N WIWOWII 44 04WO IWNW: 0 trWN ~IKN ~ 0~o
IKNKWII ~ ~ ~ a N 0. Ito4~ IK K K K K
a No ~ 4 J~ g I bW4 P_ K N K KM _$WI %i N IIa K4a S IC K0 K'Z K W I
:: KK 49 a 0z K K 01 m K 4
at0 INK0 11- K 08& wilAQ OU. Ic Q' ~ 0.0 1' K CK MI KW QKAI QMI0 O- ~ ~ ~ 4 K doiv- KS *KIO I'OI.- . 1K... KWKK IIK -K IIrmda
I 9 5K I I Kp K K W Ke ma2
L~~~~C I II K K
4~~~~3 I II K K
O~~z K KZ: I K K K
I K K I I I K K K K1K2

APPENDIX I
~e00Aw* 0 1 V0*f%V I .. . 0 6 N0 000.V006~~ 6 1*00V*
00 0. a. O .. W . . . 0 .. ..... ~~ , 43.60,10. CoQ 010.4 0 6 0106! IN FI6 # M" V I vP.-w"C p 1. 09 0D .
40.P.N4 91Q .N . . .. .* .o . .C . .W ..40 u0*.W0PW v0 . . .0O.'. .
.6 0* 0 0 .£ F . 0.0 6 wt tv Of%* on0 I
,.oP~~~~cP.,-cw"I IV 0W1* -D40 6 6* -- 6 V*P00*.0 %0~ I 4NOI
* . . . . .- .P . .
i si WI M v- V- I
Z to 6 6 6 6m:
.*.. 1.110. .%p86. 6 :**00 .00 .00 o.N4* Add*A.* P n:70i*V.t0~00A6O04
0*omP.V~ - - 1 ve - . . . .* 0 4 . 2. 0. 4 . 6 . '-~ tm0* ~ ~ ~ ~ ~ 400om C. e0*0.04N-O60
(0*W.J ~ ~ ~ ~ ~ ~ ~ ~ ~ ~ ~ ~ ~ lop 0O qpvw 6 * 006 * A FnN0N0*%A%*J0 0CL* * 6 - 0 -4L6 *
z 00- 69
IL 16, CL_ 41 wo 0N Pu .
*, I,6
~O64.0**Pl6 *i~ * N 7a0i~#~w*00*m6*V6* iQ7.w w:-i* AV
~ :~ I *0* SA P6 ,0CZ 0*-! 1 69 6t WO
. .0* 6 6 6
A. - a- I 3Z IO-
7. 6L Z0* 6AL -g -g z 11 4 :
-1I' 0 oI I PA~~~~ ~ 6W 0 I6*16
-00 -* - - ~ -60 -------, 6n ~%* l 6n8 SE
a 0* *64163
ILs.

APPENDIX 1
w4 i fma P W avq r n arnan00PN9 C
* . .. .aa 0 0 1OIQ N-.V 9U~NW P~V~ ~'U.4I ~m'C C0 .SwqO 0wo00o.m
mmv w: mm H "I N COM- GOO. lot"ma~~C fma4 99
-4MM ml WI m .^ 0-U el W IE C aQ.u 0tm0WC% 9mm- r. uvmanD.y
. m m0.u ~ .. ~f0 .0 m m 0 e u " . .* .. ajWINN~~~~~~~~~m. M F.v#N0r~vm..0.~
ma evq~aaCo -.. 4a -0 o I I N Oa or_ aOUN01 4)a00. C W.V O .A.Cmtra OFWU9C Nv
N4rdN 01010 M ~4 WI f aNWI IC0.o 9So *m ~ jt MAR wamapw-l.oN I~w_ a C aCa.c9 I A.P
d o l 1 U aW & a 7 I G . -a: *
0.zuvo Na'aa *am lNw9 I.0
0:W qQ.QlA_0ry~A A I PI I 00.-VC .0 . .. . . . . . Wn1m NN0 a a, fuIP VlI Iam mak 0 1 a 0 r'a
N-m 0 al-. 00~4a-m..C., ~-.ov.cc a~m~.~91,Na.............. .IL . *a410WN C . N . 0 W . . ~ . . . . . .. . . 99 a .~ m * .
0n.Na v ~.O O~WN .0 Wa~F. 0 IV UN
- a m.NM *0A.D ~ fWO~I NN N NC9
.j a 0maa........................... OIL.
ma0 0 a--0: a 9 m'60c a
-1 no am l ! OKP - K_ Iu. '! amx a ad...-ftea.aama maV a 11 Clot
U,,"m NZ aavI0o ,.ea. a Cz Oal t.0w IN s.Or ,. ace -C .4 a l no F-0' jIC-*.O.Wla .4 00-tI.0anO a .0 ~ u O ' a........ .. mair ,a .9 1 a
mu ma g Ma a a cz Kz 0 0z K- aat so I 4a - .z a9 '" - S
a. ma ma a . c I ~ a-m- a ma am-9 mu ~ A.41 maW z9 aa~ Imu ma mamum amuC ~ -
if am ~ ma m ~ mmu C mu2-Ww ma man - a ~ c a. a..c
mu mu. a~ mm w 134

APPENDIX 1
m . 4: . .. . .a-. a:. .~.~ai .m . .- .- as~ .. f~lO . .fI on tv 5 I s Q@fa %ovs
* 5 I55 vsIN a run.
* a a a a................................................. ....................-~~odt-.a~~ 0i 00OC .mOWI4%la% ~ '.Q dcW amffe5 i~~.
........................... ............. 5 .. 54w55 *.-*~ue~.a rm-N.asw .mS V0.~fi.-5%JU 5,t0%O~~~N5Im s mt m sa0.@
55~e~, .. . .! . . . . . *a 11 .. ass -0-
5v~ Owev 5~ I e 5wo .0:AD 4*Df a 1EOV1It 01,
ma- f" 0 0 as as0-at~~~~~~~w~ a onvrkm0nSa A~..WN W~~a 0 , .r~~wO sN Om a as.
................ 5.........................................Rv5l ***O
h aW n J . O fa u AI L a w man as
- ~ ~ - 0-K co .4 Q coa m a .4E0asas 0.uo. CI foaf :G a. 21 as 9 .' as au.
aj- asJ j w N as Z 6 l11 ~ a .4ewz- -:: as uas1 0 v - " - w z " , , Z as w - a w m m~
.................... a...........a ... Z.as'"6 .. cw
cr ccaIl-I cl9a apI a AcpoppopI a as ej Z - as o a. 'ww
o ~ - a - - a i a v~ a . W v a ar woa a - a -a - as ~ as n'a~~~4 % a aCW
* - - Ma. a s as..oa
40a ovwmGom a or Go*asW"C a -
5 S a ss13a

APPENDIX 1
ItO I C~r@od 1 0 1
E%..I -O..- I Ad . QCaNCp WI 1N~~- 0evN.fJ
1 0 .0 S '
1 O . rvS * m I * c l ) -lem
.pr4... .. 4 6
*. W-9 ME*..0 0.aj .
fu*'0 *I 0 f_ U 4 c
C0 1 0I.5V 0 mI.*ee -
0.6 1 0 "- *N I UC 0 n w% w-I ~:'~' 1 C-0'r "'. : orn- *e6
... I 0.o.._I t-I ** Un%fv I~ %" . ' m I * - *
4L-
zI I z.03.t. Qj~w~ 21 ~ *
zD.Q ffWU %cw%" w S c a.I%0V 4
lo1 I N .I 0f.g C
- - - - - - - - .
...................

REFERENCES
ti33Ker 72) F.T. Baker. Chief programmer team management of
production Programming. H-T SY eMA !JVuAn, vol. 11,
no. 1 (1972), pp. 56-73.
[63ker 75) C.T. Baker. Structured programming in a
production programming environment. EE IrftA!c1tioQ1
oQ loftwari E n~teina, vol. 1, no. 2 (June 1975), pp.
Z41-252.
[33siLi baker 77] V.R. Basiti and F.T. Baker. Tutorial
of Structured Prg2rrmmin . IEEE Catalog No.
75CH1O49-6, Tutorial from the Eleventh IEEE Computer
Society Conference (COMPCON 75 Fall), revised 1977.
[!3sili 9 Reiter 7S] V.R. basili and R.W. Reiter, Jr.
Investigating software development approaches.
Technical Report TR-688, Department of Computer
Science, University of maryland, August, 197a.
C33sili 5 Peiter 79aJ V.R. assili and R.W. Reiter, Jr.
&valuating automatable measures of software
oevelopment. Proceedings of the IEEE/PoLy Workshop on
uantitative Software Models for Reliability,
Complexity, and Cost (October 1979), Kiameshia Lake,
New York.
lasili F, Reiter 79b] V.R. Basiti and R.W. Reiter, Jr. An
investigation of nuvan factors in software development.
-o2uMtI _ "agazine, vol. 12, no. 12 (December 1979), pp.
[dasiLi 9. Reiter 8C] V.R. 6asili and R.W. Reitert Jr, A
controlled experiment quantitatively comparing software
development approaches, to be published in [
ftra!3 1i-202 20 k29-t[r.- Enginjerin2, 1q60.
[33sili . Turner 75] V.P. basili and A.J. Turner.
Iterative enhancement: a practical technioue for
software developmento ILLE TIaD1a1ig 2oz gO e
E!i!nejin/, vol. 1, no. 4 (December 1975), po,
137

REFERENCES
[aasiLi ? Turner 76) V.R. Basili and A.J. Turner. SIMPL-I,
A Structured Prrammino Lafn uaae. Geneva, Illinois:
P3tain House, 1976.
[63sili K Zelkowitz 78] V.R. 9asili and M.V. Zelkowitz.
Analyzing medium-scale software development. IEEE
Catalog No. 7?CH1317-7C, Proceedings of the Thira
international Conference on Software Engineering (may
1975), AtLanta, Georgia, pp. 116-123.
[i3sili S. Zetkowitz 79] V.R. 9asili and M.V. Zelkowitz.
Measuring software develooment characteristics in the
Local environment. C p er _ tu r vol. 10
(1979), pp. 39-43.
(53sili et at. 77) v.R. Basili, M.v. Zelkowitz, F.E.
McGarry, R.W. Reiter, Jr., W.F. Truszkowski, and D.L.
weiss. The software engineering Laboratory. Technical
Report TR-535, Department of Computer Science,
University of maryland, r'-ay, 1977.
[Belady 9 Lehman 761 L.A. Belady and M.M. Lehman. A model
of large program development. IBM In J2murn
vol. 15, no. 3 (1975), Dp. 225-251.
( ery 73J C. Berge. Graphs and Ho2erra2hs. Amsterdam,
The Netherlands: North-Holland, 1973.
[arooks 75J F.P. 9 rooks, Jr. The MyIhicpi Tan-Aonth.
Reading, Massachusetts: Adoison-Wesley, 1975.
[Camooeli 1, Stanley 63) D.T. Campbell and J.C. Stanley.
x6xerimentat and Qujai-E xojr.Linta Desins fgr
rIearch. Reprintei from Handbook of Research on
I ifjbinS , edited by N.L. Gage. Chicago, Illinois: Rand
McNally, 1963.
[Conover 71) w.J. Conover. Prlctija_1 N2noaramtrik
jtttii. New York, %ew york: John wiley & Sons,
1 ?71
[Curtis et at. 79) 9. Curtis, S.3. Sheppard, P. MilLiman,
M.A. Borst, and T. Love. Measuring the psychological
138

RE FERENCES
complexity of software maintenance tasks with Halstead
and McCabe metrics. 1EL _r ania 2n o1.w £
fooqine.riog, voL. 5, no. 2 (March 1979), pp. 95-104.
[D3hlo Dijkstra S Hoare 72) 0.-J. Dahl, E.W. Dijkstra, and
C.A.R. Hoare. St. ruCuLrte Proi£aMming New York, New
York: Academic Press, 1972.
[D3Ley 77) E.B. Daley. Management of software development.
IEEE Trans ctlionj 20 S2tta:r Jniineerjnq, vol. 3, no.
3 ('ay 1977), pp. 229-242.
[Dinsmore 78) H.E. Duns1ore. The influence of programming
factors on programming complexity. Ph.D. Dissertation.
Department of Computer Science, University of Maryland,
July, 1078. available as Technical Report TR-679.
[Dunsmore & Gannon 77) H.E. Dunsmore and J.D. Gannon.
Lxperimental investigation of programming complexity.
Proceedings of the ACM/NBS Sixteenth Annual Technical
Symposium: Systems and Software (June 1q77),
washington, D.C., po. 117-125.
[Elshoff 70a) JL. ELshoff. Measuring commercial PL/I
programs using 4alstead's criteria. AC"M SIGPLAN
No1ice, vol. 11, no. 5 (M ay 1976), pp. 38-46.
[Elshoff 76b] JoL. Elshoff. An analysis of some commercial
FL/i programs. IEEE Transactions on Software
.njineerin., vol. 2, no. 2 (June 1 76), pp. 113-12C,
[F3gan 76) ".E. Fagan. Design and code inspections to
reauce errors in program development. W! S_1CeMs
J2oE01n , vol. 15, no. 3 (19'6), pp. 132-211.
[Fitzsimmons & Love 78) A. Fitzsimmons and T. Love, A
review and evaluation of software science. C2ePutin
.uryex: vol. 10, no. 1 (1arch 1978), pp. 3-18.
[Gannon 75) J.D. Gannon. Language design to enhance
programming reliability. Ph.D. Thesis. Department of
Computer Sciencet University of Toronto, January, 1975.
available as Technical Report CSRG-47.
[Gannon 77) J.D. Gannon. An experimental evaluation of
139

RE FERENCES
uata tyoe conv'.ntions. £QmnEi idLiO1 Q 2 h ILL Vol.
.. , no. 6 (August 1777), op. 5o4-595.
[Gannon ?. Horninq 75) J.D. Gannon and J.J. Homing.
Language design for programming reliability. 1on sf e Enineerin, vol. 1, no. 2
(June 1975), pp. 179-191.
[Gilo 772 T. Gilb. Sofkare Metrics. Cambridge,
Massachusetts: Winthrop, 1977.
[Gordon 79) R.D. Gordon. A qualitative justification for a
measure Of program clarity. UEE _rPQs1JQ!on on
2fiware EnQineerina, vol. 5, no. 2 (varch 1979), pp.
121-12A.
[Green 77] T.R.G. Green. Conditional program statf ments
and their comprehensibility to professional
programmers. Journal of Occupational PsYct21Q29, vol.
50 (1977), pp. 93-1)9.
[HaLstead 77) M. Halstead. ELt~ens 2 2ltare Sience.
New York, New York: ELsevier, 1977.
[Hughes 792 J.W. Hughes. A formalization and explication
of the "ichael Jackson method of program design.
Software--Pra ic Exerience, vol. 9, no. 3 (March
1 79) , op. 191-202.
CJackson 75] %'.A. Jackson. Principles of Program Desi2n.
New York, New York: Academic Press, 1075.
(Kirk 53) R.E. Kirk. Jx12r:inen.J!J Desiqn: Pro eLres 12r
th 3eta rat Sciienqej. Belmont, California:
4 aisworth, 1956 .
[Knutn 71) D.E. Knuth. An empirical study of FORTRANprograms. VofIware--PraCt _n _ ri n , vol. 1,
no. 2 (April-June 1971), pp. 105-133.
(Lin-ier, Mills , witt 79) R.C. Linger, H.D. Mills, and 9.I.
witto StrucJ~ureo Prog!rgmminZ: Ibrc2!r tog !rS-Jl
Reading, "assachusetts: Addison-wesley, 1979.
[Love ! nowman 76) L.T. Love and A.B. dowman. An
independent test of the theory of software physics.
140

REFERENCES
2M 1l No vol. 11, no. 11 (November 1976),
pp. 42-49.
[ ,cCdoe 76. T.J. McCabe. A complexity measure. IEEE
TaasA1.tigoi 20 glt.±.re En2i.nZering, vot 2, no. 4
(0ecember 1976), pp. 308-320.
rmilts 72) H.0. Mills. Mathematical foundations for
structured programming. FSC 72-6012, IBM Corporation,
Gaithersburg, Maryland, Feuruary, 1972.
[,MiLLs 73) H.D. Mills. The complexity of programs. in
_.rg.m I111 Methods, eoited by W.C. Hetzel, pp.
225-238. Englewood Cliffs, New Jersey: Prentice-Hall,
197 3.
Imills 76) H.D. Mills. Software development. IEjj
Irs1_o i 21ns 22 5S2oit wA__:e En)2i nee rin , vol. 2, no. 4
(December 1976), pp. 265-273.
Elyers 75) GeJ. Myers. alliabjS jofare through jgmpei
.tesin. New York, 4ew York: Petrocelli/Charter, 1975.
[,Myers 77) G.J. Myers. An extension to the cyclomatic
measure of program complexity. M SIGPLAN N2tics,
vot. 12, no. 10 (October 1977), pp. 61-64.
.tyers 7S ] Ge. Myers. A controlled experiment in program
testing and code walkthroughs/inspections.
Communications of the ACM, vol. 21, no. 9 (September
1978) , pp. 760-768.
['emenyi et al. 773 P. emenyi, S.K. Dixon, N.B. White,
Jre, and --L- Heastrom. 2__Iit±C fr2M Scratch. San
Francisco, California: Hotden-Day, 1977.
[31dehoeft 7?) P.R. Oldehoeft. A contrast between language
level measures* I§EE Transajtiofns 22 Sofwi~re
En2ine!rin5, vot. 3, no. 6 (November 1977), PO.
476-473.
J3stLe & Mensing 75) B OstLe and R.W. Mensing. S_1jistill
in Rstrch, Third Edition. Ames, Iowa: Iowa State
university Oress, 1775.
(Putnam 78) L.H. Putnam. A general empirical solution to
141

KEFERENCES
the macro software sizing and estimation problem. ILLL
TrCiaos.i2o. go 12jII FOttrq VOl. 4, no. 4
(July 1979), pp. 331-316.
[Reiter 79) R.,. Reiter, Jr. Empirical investigation of
computer program development approaches and computer
programming metrics. Ph.. Dissertation. Department
of Computer Science, University of Maryland, Decemoer,
1?79.
(Sheppard et at. 79) S.3. Sheppard, B. Curtis, P. Miltiman,
and T. Love. Modern coding practices ano programmer
performance. C2omoer 'agazine, voL. 12, no. 12
(December 1079), pp. 41-49.
[Shneiderman 76) 6. shneiderman. Exploratory experiments
in programmer behavior. IoIernati2n JouaLU 2f
M2uter and Information Iciences, vol. 5, no. 2 (June
1976), pp. 123-143.
[Shneiderman do] B. Shneiderman. Software Psqh22a:
HuMa Eators in C u~Ir i MUtJ2a 5X1tC21-Cambridge, Massachusetts: winthrop, 1980.
[Shneiderman et at. 77) B. Shneidermang R. Mayer, D. McKay,
and P. Heller. Experimental investigations of the
utility of detailed flowcharts in programming.Communications of the ACM, vol. 20, no. o tJvne 1977),
pp. 373-381.
[Shooman 78] M. Shooman. Private communication, in
conjunction with a colloquium (on Software Reliaoility
;mooels) given at the Department of Computer Science,
university of Maryland, October, 1978.
[Siele1 56) S. Siegel. on2EaraJrc Sttistils: for the
eir lj~rL litoce_. New York, New York: McGraw-Hill,
1956o
[Sime, Green & Guest 73) M.E. Sime, T.R.Go Green, and D.J.
Guest. Psychological evaluation of two conditional
constructs useo in computer languages. nIntrnodi2nai
2WJC01i 2! an-machine Studies, vol. 5, no. 1 (January
142

REFERENCES
1973), pp. 105-113.
(Simon 69 3 W.A. Simon. The architecture of complexity. in
U Sh 2_1D¢ of te liltizial, pp. 84-118. Camoridge,
M'assachusetts: MIT Press, 1969.
(Stevens 46) S.S. Stevens. On the theory of scales of
measurement. JrjearC vot. 103 (1946), pp. 677-6$0.
[Stevens, "yers Constantine 743 w.P. Stevens, G.J. Myers,
and L.L. Constantine. Structured design. lk_ 12sem
J2urna., vol. 13, no. 2 (1974), pp. 115-139.
[Tukey 69) J.W. Tukey. Analyzing data: sanctification or
uetective work? American P1Zlolot1ist, vol. 24, no. 2
(February 1969), pp. 83-91.
[Turner 76) A.J. Turner, Jr. Iterative enhancement: a
practical technique for software development. Ph.D.
Dissertation. Department of Computer Science,
university of Maryland, May, 1976.
EaLston & Felix 77] C.E. watston and C.P. Felix. A method
of programming measurement and estimation. IBM 1zstIlt
J2gr~ia_ vot. 16, no. 1 (1977), pp. 54-73.
[oeinberg 7.; G.M. Weinberg. The PsXcnj22oa 9. 2MI11
Pjr2grSA~m!inq. New York, New York: Van Nostrand
Reinhold, 1971.
Leissman 74a] L.m. weissman. Psychological complexity of
computer programs: an experimental methoaolo ;y. AL!
SIGPAN N2ticej, vol. 9, no. 6 (June 1974), po. 25-36.
C.eissman 74b] L.m. weissman. A methoaology for studying
the psychological complexity of computer programs.
Ph.D. Thesis. Department of Computer Science,
University of Toronto, August, 1974. available as
Technical Report CSRG-37.
%airtn 71] NY. Wirth. Program development by stepwise
refinement. 2oMuni~ain1 gf 2 he , vol. 14, no. 4
(Aorit 1971), pp. 221-227.
14

CURRICULUM VITAE
" e: kobert Williai Reiter, Jr.
Permanent address: 900 Jamieson Road,
Luthervitte, MaryLand 21043.
Degree and date to be conferred: Ph.D., December, 1979.
.t e of birth: June 7, 195C.
l'tce cf birth: aaltimore, Marytand.
Seconuary education: Loyola High School, Towson, Maryland,
June, 1963.
Collegiate Institutions Dates Degree Date of Degree
Uassachusetts Institute
of Technology 1968-72 S.8. June, 1972.
University of Mirytjna 1972-76 M.S. May, 1976.
UTniversity of Marytand 1976-79 Ph.D. December, 1979.
Major: Conputer Science.
Prifessional puctications:
V.R. F)asiti, -. V. Zetkowitz, F.E. McGarry, R.W. Reiter,Jr., .F. Truszkowski, and D.L. Weiss.
P'e software engineering Laboratory.Technical Report TR-535, Department of Computer
Science, University of Maryland, May, 1977.
V.t. Basiti and R.w. Reiter Jr.Investigating software development approaches.Technical Report TR-68b, Department of Computer
Science, University of Marytand, August, 19?8.
V.R. Basili and R.W. Reiter, Jr.Lvatuating automatabte neasures of software
deve Looment.Proceedings of the IEEE/Pol, yworkshop on Quantitative
Software. ModeLs for Re iaoility, Comptexity, anuCost (IEEE Catalog No. 9), Kiameshia Lake, NY(October 1979), pp. t-ft.
i!

V.R. Basili and R.W. Reiter, Jr.An investigation of human factors in software
development.Computer Magazine, vol. 12, no. 12 (December 1979), pp.
21-38.
V.R. Basili and R.W. Reiter, Jr.A controlled experiment quantitatively comparing
software development approaches.(to be published in IEEE Transactions on Software
Engineering, 1980)
Professional positions held:
1970-1973 (Summers only) -- Programmer/AnalystInformation Systems Department, Baltimore Gas &
Electric Company, Baltimore, Maryland 21203.
1972-1976 -- Graduate Teaching AssistantDepartment of Computer Science, University of Maryland,
College Park, Maryland 20742.
1976-1979 -- Graduate Research AssistantDepartment of Computer Science, University of Maryland,
College Park, Maryland 20742.
1979- -- Faculty Research AssistantDepartment of Computer Science, University of Maryland,
College Park, Maryland 20742.



















