236 IEEE TRANSACTIONS ON CIRCUITS AND SYSTEMS FOR...
8
236 IEEE TRANSACTIONS ON CIRCUITS AND SYSTEMS FOR VIDEO TECHNOLOGY, VOL. 23, NO. 2, FEBRUARY 2013 Silhouette Analysis-Based Action Recognition Via Exploiting Human Poses Di Wu, Student Member, IEEE, and Ling Shao, Senior Member, IEEE Abstract —In this paper, we propose a novel scheme for human action recognition that combines the advantages of both local and global representations. We explore human silhouettes for human action representation by taking into account the correlation between sequential poses in an action. A modified bag-of-words model, named bag of correlated poses, is introduced to encode temporally local features of actions. To utilize the property of visual word ambiguity, we adopt the soft assignment strategy to reduce the dimensionality of our model and circumvent the penalty of computational complexity and quantization error. To compensate for the loss of structural information, we propose an extended motion template, i.e., extensions of the motion history image, to capture the holistic structural features. The proposed scheme takes advantages of local and global features and, therefore, provides a discriminative representation for human actions. Experimental results prove the viability of the compli- mentary properties of two descriptors and the proposed approach outperforms the state-of-the-art methods on the IXMAS action recognition dataset. Index Terms—Action recognition, bag of correlated poses (BoCP), extended motion history image, soft assignment. I. Introduction I N RECENT years, human action recognition has drawn increasing attention of researchers, primarily due to its growing potential in areas, such as video surveillance, robotics, human–computer interaction, user interface design, and mul- timedia video retrieval. Spatiotemporal features [1], [2] have shown success for many recognition tasks when preprocessing methods such as foreground segmentation and tracking are not possible, e.g., in the Hollywood dataset [3] or the UCF sports dataset [4]. However, their computational complexity hinders their applicability in real-time applications. Wang et al. [5] showed that the average time for spatiotemporal feature ex- traction varies from 0.9 to 4.6 f/s, which makes the spatiotem- poral interest points (STIPs) features too time consuming in computation. Another major limitation of the local feature- based methods is that the sparse representation, such as bag of visual words (BoVWs), discards geometric relationship of the features and hence is less discriminative. Hard-assignment quantization during the codebook construction for BoVW, Manuscript received December 30, 2011; revised March 29, 2012; accepted April 28, 2012. Date of publication June 8, 2012; date of current version February 1, 2013. This paper was recommended by Associate Editor T. Zhang. The authors are with the Department of Electronic and Electrical En- gineering, the University of Sheffield, Sheffield S1 3JD, U.K. (e-mail: [email protected]; ling.shao@sheffield.ac.uk). Color versions of one or more of the figures in this paper are available online at http://ieeexplore.ieee.org. Digital Object Identifier 10.1109/TCSVT.2012.2203731 which is usually realized by the k-means clustering algorithm, also makes the sparse representation less informative. In this paper, we focus on the representation of actions using human poses, i.e., silhouettes, as our primitive descriptive units. We aim to address the above problem by incorporating additional information derived from temporally local features and holistic features. A. Related Works Recent research has focused on local feature. In their pio- neering work, Dollar et al. [1] introduced an efficient approach for detecting STIPs using a temporal Gabor filter and a spatial Gaussian filter. Later, a number of other STIP detectors and descriptors have been proposed. The mainstream STIP detec- tors include Harris3D by Laptev et al. [2], Cuboid by Dollar et al. [1], 3D-Hessian by Willems et al. [6], dense sampling by Fei-Fei and Perona [7], and spatiotemporal regularity-based feature by Goodhart et al. [8]. The mainstream STIP feature descriptors are HOG/HOF [2], HOG3D [9], extended SURF [6], and MoSIFT [10]. Researchers have shown that the human brain can easily recognize an action in a video simply by looking at a few key frames without examining the whole sequence [5]. From this observation, it can be deduced that human poses encapsulate useful information about the action being performed. Cao et al. [11] adopted a PageRank-based centrality measure to se- lect key poses according to the recovered geometric structure. A human action can be viewed as a set of sequential silhouettes over time. Each silhouette records a pose of this action at a particular instant. Davis and Bobick [12] found that a human action can be recognized even when it is projected onto a single frame. Gorelick et al. [13] regarded human actions as 3-D shapes induced by the silhouettes in the space-time volume and utilized properties of the solution to the Poisson equation to extract space-time features. Wang and Leckie [14] encoded human actions using the quantized vocabulary of av- eraged silhouettes that are derived from space-time-windowed shapes and implicitly capture local temporal motions as well as global body shapes. Shao and Chen [15] employed body poses sampled from silhouettes that are fed into a bag-of- features model. Similarly, Qu et al. [16] calculated the differ- ences between frames and used them as intermediate features. Incorporating the local and holistic features, Sun et al. [17] proposed a unified action recognition framework fusing local 3D-SIFT descriptors and holistic Zernike motion energy image (MEI) features. 1051-8215/$31.00 c 2012 IEEE
Transcript of 236 IEEE TRANSACTIONS ON CIRCUITS AND SYSTEMS FOR...

236 IEEE TRANSACTIONS ON CIRCUITS AND SYSTEMS FOR VIDEO TECHNOLOGY, VOL. 23, NO. 2, FEBRUARY 2013
Silhouette Analysis-Based Action Recognition ViaExploiting Human Poses
Di Wu, Student Member, IEEE, and Ling Shao, Senior Member, IEEE
Abstract—In this paper, we propose a novel scheme for humanaction recognition that combines the advantages of both local andglobal representations. We explore human silhouettes for humanaction representation by taking into account the correlationbetween sequential poses in an action. A modified bag-of-wordsmodel, named bag of correlated poses, is introduced to encodetemporally local features of actions. To utilize the property ofvisual word ambiguity, we adopt the soft assignment strategyto reduce the dimensionality of our model and circumvent thepenalty of computational complexity and quantization error. Tocompensate for the loss of structural information, we propose anextended motion template, i.e., extensions of the motion historyimage, to capture the holistic structural features. The proposedscheme takes advantages of local and global features and,therefore, provides a discriminative representation for humanactions. Experimental results prove the viability of the compli-mentary properties of two descriptors and the proposed approachoutperforms the state-of-the-art methods on the IXMAS actionrecognition dataset.
Index Terms—Action recognition, bag of correlated poses(BoCP), extended motion history image, soft assignment.
I. Introduction
IN RECENT years, human action recognition has drawnincreasing attention of researchers, primarily due to its
growing potential in areas, such as video surveillance, robotics,human–computer interaction, user interface design, and mul-timedia video retrieval. Spatiotemporal features [1], [2] haveshown success for many recognition tasks when preprocessingmethods such as foreground segmentation and tracking are notpossible, e.g., in the Hollywood dataset [3] or the UCF sportsdataset [4]. However, their computational complexity hinderstheir applicability in real-time applications. Wang et al. [5]showed that the average time for spatiotemporal feature ex-traction varies from 0.9 to 4.6 f/s, which makes the spatiotem-poral interest points (STIPs) features too time consuming incomputation. Another major limitation of the local feature-based methods is that the sparse representation, such as bagof visual words (BoVWs), discards geometric relationship ofthe features and hence is less discriminative. Hard-assignmentquantization during the codebook construction for BoVW,
Manuscript received December 30, 2011; revised March 29, 2012; acceptedApril 28, 2012. Date of publication June 8, 2012; date of current versionFebruary 1, 2013. This paper was recommended by Associate Editor T. Zhang.
The authors are with the Department of Electronic and Electrical En-gineering, the University of Sheffield, Sheffield S1 3JD, U.K. (e-mail:[email protected]; [email protected]).
Color versions of one or more of the figures in this paper are availableonline at http://ieeexplore.ieee.org.
Digital Object Identifier 10.1109/TCSVT.2012.2203731
which is usually realized by the k-means clustering algorithm,also makes the sparse representation less informative.
In this paper, we focus on the representation of actions usinghuman poses, i.e., silhouettes, as our primitive descriptiveunits. We aim to address the above problem by incorporatingadditional information derived from temporally local featuresand holistic features.
A. Related Works
Recent research has focused on local feature. In their pio-neering work, Dollar et al. [1] introduced an efficient approachfor detecting STIPs using a temporal Gabor filter and a spatialGaussian filter. Later, a number of other STIP detectors anddescriptors have been proposed. The mainstream STIP detec-tors include Harris3D by Laptev et al. [2], Cuboid by Dollaret al. [1], 3D-Hessian by Willems et al. [6], dense samplingby Fei-Fei and Perona [7], and spatiotemporal regularity-basedfeature by Goodhart et al. [8]. The mainstream STIP featuredescriptors are HOG/HOF [2], HOG3D [9], extended SURF[6], and MoSIFT [10].
Researchers have shown that the human brain can easilyrecognize an action in a video simply by looking at a few keyframes without examining the whole sequence [5]. From thisobservation, it can be deduced that human poses encapsulateuseful information about the action being performed. Caoet al. [11] adopted a PageRank-based centrality measure to se-lect key poses according to the recovered geometric structure.A human action can be viewed as a set of sequential silhouettesover time. Each silhouette records a pose of this action at aparticular instant. Davis and Bobick [12] found that a humanaction can be recognized even when it is projected onto asingle frame. Gorelick et al. [13] regarded human actions as3-D shapes induced by the silhouettes in the space-timevolume and utilized properties of the solution to the Poissonequation to extract space-time features. Wang and Leckie [14]encoded human actions using the quantized vocabulary of av-eraged silhouettes that are derived from space-time-windowedshapes and implicitly capture local temporal motions as wellas global body shapes. Shao and Chen [15] employed bodyposes sampled from silhouettes that are fed into a bag-of-features model. Similarly, Qu et al. [16] calculated the differ-ences between frames and used them as intermediate features.Incorporating the local and holistic features, Sun et al. [17]proposed a unified action recognition framework fusing local3D-SIFT descriptors and holistic Zernike motion energy image(MEI) features.
1051-8215/$31.00 c© 2012 IEEE

WU AND SHAO: SILHOUETTE ANALYSIS-BASED ACTION RECOGNITION 237
Fig. 1. Flow chart of the BoCP model. Note the two phases of dimensionality reduction and their corresponding methods explained in Section II-D.
B. Our Approach
The contributions of this paper lie in the following threeaspects.
1) Correlogram of human poses in an action sequence isintroduced to encode temporal structural information.We first extend the bag-of-features model to treat thesilhouette in each frame as a feature. In the originalbag-of-features representation, features are assigned totheir closest cluster centers, also called visual words,and an entire video sequence is represented as an occur-rence histogram of visual words. The traditional bag-of-features representation disregards structural informationamong the visual words. To encode the structural in-formation, Leibe et al. [18] proposed an implicit shapemodel using general Hough forest as a statistical method.We propose an explicit model to encode its temporal-structural information by constructing a correlogramthat is a structurally more informative version of thehistogram. The undesirable increase of dimension issuppressed by two stages of dimensionality reduction,i.e., unsupervised principal component analysis (PCA)and supervised linear discriminant analysis (LDA).
2) Soft-assignment scheme or kernel codebook is extendedfor circumventing the quantization error penalty. Tra-ditional bag-of-features model designates a feature bythe cluster number it belongs to; this hard assignmentscheme may incur penalty for its quantization error.Gemert et al. [19] investigated four types of soft-assignment schemes for visual words and demonstratedthat explicitly modeling visual word assignment ambi-guity improves classification performance compared tothe hard-assignment of the traditional codebook model.Boureau et al. [20] studied the relative importance ofeach step of mid-level feature extraction through a com-prehensive cross evaluation of several types of codingmodules for object and scene recognition. The adoptionof Mahalanobis distance achieved the state-of-the-artperformance for scene classification [21]. We extendtheir idea in our approach to maximize the preservationof information after the k-means clustering by assigninga feature proportionally according to its Mahalanobisdistance to different cluster centers, so that a feature isno longer a discrete addition to the histogram bin but acontinuous voting to multiple bins.
3) A holistic representation extension is proposed as acomplimentary descriptor for local representation. Asfound by Sun et al. [17], local descriptors and holisticfeatures emphasize different aspects of actions and sharecomplimentary properties. Motivated by their finding,we fuse the above temporally local descriptor with anextension of the holistic descriptor: motion history image
(MHI) by adding gait energy information (GEI) andinversed recording (INV). These two additional holisticdescriptors serve as the compensation for the loss ofinformation due to sequentially overlapping frames thatis discarded in the original MHI representation. Then, aunified framework is proposed to combine two distinctdescriptors by early fusion (feature vector concatena-tion) and achieve further improvement over the separatemethods.
The remainder of this paper is organized as follows. We firstdescribe the proposed temporally local descriptor called bag ofcorrelated poses (BoCPs) in Section II and the extended holis-tic descriptor (extended-MHI) is detailed in Section III. Weevaluate the performance of our methods on the Weizmann andInria Xmas motion acquisition sequences (IXMAS) datasets,and the experimental results on parameter sensitivity, visualword ambiguity effect, and viability of combining global andlocal features are reported in Section IV. Finally, conclusionsare drawn in Section V.
II. Bag of Correlated Poses
Fig. 1 shows the flow chart of the construction process forthe BoCPs representation. The initial idea of BoCP was pre-sented in [22], where it was called correlogram of body poses.An action sequence is a series of pictorial frames. Most currentapproaches [1], [2], [9], [13] bundle action frames together as amonocular 3-D volume representation. Unlike traditional 3-Dvolume representation, we treat each frame individually asan atomic input. The notion of body poses in our approachis represented by the silhouettes as in Fig. 2. A boundingbox, i.e., the smallest rectangle containing the human figure,is applied to each frame of the silhouette sequence and thenis normalized to a fixed size. The prepossessing steps reducethe original dimension and remove global scale and translationvariations. The interpolation during the normalization processsuppresses the noise as the morphological transformations(dilation and erosion) can isolate individual elements and joindisparate elements in an image. The rectangular region-of-interest mask serves as image unification in each action frame,making recognition invariant to body size as well as scale andtranslation variations resulting from perspective changes.
A. Codebook Creation
The extracted normalized silhouettes are used as inputfeatures for the BoCPs model. The traditional BoVW model[1], [2] in action recognition is based on the detection anddescription of STIPs as input while our approach is basedon holistic silhouettes. Due to the usage of pose silhouettes,the local feature detection and description steps in a tradi-tional BoVW method are not required. In the interest point-based action recognition method, each feature vector is a 3-D

238 IEEE TRANSACTIONS ON CIRCUITS AND SYSTEMS FOR VIDEO TECHNOLOGY, VOL. 23, NO. 2, FEBRUARY 2013
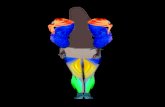
Fig. 2. (a) Illustration of the “cross arms” action. (b) Normalized silhouette.
descriptor calculated around a detected interest point in an ac-tion sequence. In our method, each feature vector is convertedfrom the 2-D silhouette mask to a 1-D vector by scanning themask from top-left to bottom-right pixel by pixel. Therefore,each frame at the time t in an action sequence is representedas a vector of binary elements Ft, the length of which isL = row ∗ column, where “row” and “column” are dimensionsof the normalized pose silhouette. Suppose the ith actionsequence consists of Si frames, then an action sequence canbe represented as a matrix Xi with Si rows and L columns.Each row of the matrix stands for a single frame. Therefore,for a training set with n action sequences, the whole trainingdataset can be represented as
X = [X1;X2; . . . ;Xn]. (1)
The total number of rows, which is also the total framenumber in the training dataset, is S = S1 + S2 + . . . + Sn .Because features are in high-dimensional space, we first usePCA for dimensionality reduction. Hence, each frame Ft isprojected into a lower dimension Ft. Then, visual vocabularycan be constructed by clustering feature vectors obtained fromall the training samples using the k-means algorithm. Thecenter of each cluster is defined as a codeword and the sizeof the visual vocabulary is the number of the clusters k.
B. Soft Assignment Scheme
In the traditional BoVW model [1], [2], each feature vectorcan be assigned to its closet codeword based on the Euclideandistance. The visual word vocabulary in the codebook modelcan be constructed in various ways, e.g., Gaussian mixturemodel, spectral clustering, and others. Typically, a vocabularyis constructed by applying k-means clustering. Here, an impor-tant assumption is that a discrete visual word is a characteristicrepresentative of an image feature. The k-means algorithmminimizes the variance between the clusters and the data,placing clusters near the most frequently occurring features.However, the most frequent features are not necessarily themost discriminative [19] and the continuous nature of visualappearance complicates selecting a representative visual wordfor an image feature. Assigning a feature to its single clustergives rise to loss of information due to quantization errors,especially for features residing on boundaries of neighboringclusters. Thus, in our approach, we model our visual words bya kernel codebook to integrate the visual word ambiguity. Ker-nel density estimation is a robust alternative to histograms forestimating a probability density function. Because Gaussiankernel Kσ = exp(− 1
2x2
σ2 ) assumes that the variation between
Fig. 3. Illustration of the correlogram in our BoCP model. Inputs are a seriesof silhouettes. For every pair of two frames with time interval δt, each entryin the correlogram is the multiplication of two weights corresponding to thesetwo poses.
an image feature and a codeword is described by a normaldistribution with a smoothing parameter σ, we adopt thisstatistically viable kernel function. Our visual word can bedescribed as
Wi,t = exp
⎛⎜⎝−
∥∥∥Ft − Ci∥∥∥2
2σ2
⎞⎟⎠ , i = 1, 2, . . . , k (2)
where Ft is the projected low-dimension frame vector at timet, Ci is the ith cluster center, k is the number of clusters, andthe smoothing parameter σ determines the degree of similaritybetween data samples and is dependent on the dataset, thefeature dimensionality, and the range of the feature values.Note that we do not try to obtain the best fit of the data.In contrast, we aim to find the kernel size that discriminatesbest between classes. Therefore, we tune the kernel sizediscriminatively by cross-validation.
C. Correlogram of Poses
As the current BoVW model discards all geometric infor-mation and based on the 2-D picture correlogram, we extendthe original BoVW model to BoCP that takes advantage ofthe temporally local features while maintaining the holisticgeometric information. The concept of correlogram was firstintroduced by Huang et al. [23], where they used colorcorrelogram for image indexing. A color correlogram is a3-D matrix where each element indicates the co-occurrenceof two colors that are at a certain distance from each other.Therefore, a correlogram encodes more structural informationthan a flat histogram. Similarly, for action representation, eachelement in BoCP denotes the probabilistic co-occurrence oftwo body poses taking place at a certain time difference fromeach other. Note that we use the word “probabilistic” herebecause our visual word is not a discrete codebook number buta probabilistic distribution of multiple poses. Fig. 3 illustratesthe construction of a correlogram at a single temporal distancein our BoCP model. Since the poses are divided into k clusters,the dimensionality of the correlogram matrix at a fixed timeoffset �t is k ∗ k, where k represents the codeword number

WU AND SHAO: SILHOUETTE ANALYSIS-BASED ACTION RECOGNITION 239
Fig. 4. (a) Correlogram matrices of different actions, i.e., check watch, crossarms, scratch head, sit dow, get up, turn around, walk, wave punch, kick,pick up, performed by the same person. (b) Two rows of two actions: walkand cross arms performed by different people. (c) Correlogram matrices withdifferent time offsets.
of the constructed codebook. Each entry in the BoCP matrixcan be defined as
E(i, j; δt) =ST−δt∑t=1
Wi,t ∗Wi,t+δt (3)
where δt specifies the time offset,Wi,t is the frame Ft’s visualword probability to cluster i in (2), and ST is the number offrames in the action sequence. Note that the correlogram ma-trix in (3) can be obtained by assigning a number of differenttime offsets δt. Multiple time offsets scheme will accordinglyenhance distinctiveness of correlogram representation but atthe cost of the increase of dimensionality of the featuredescriptor and the computational time. In our implementation,four time offsets of 2, 4, 6, and 8 are employed. Fig. 4depicts examples of correlogram matrices. On the left side arecorrelogram matrices of different actions performed by thesame subject. It is even visually possible to distinguish thedifference in texture between different actions’ correlograms.On the top right, rows 1 and 2 are correlogram matrices oftwo actions performed by different people. We can observethat the correlogram matrices of the same action look muchmore similar than those of different actions, which makescorrelogram a discriminative representation for human actions.
D. Dimensionality Reduction
Both the original binary silhouette features and the finalcorrelogram representations are in very high dimensionality.Due to the “curse of dimensionality,” it is impractical to usethe original long feature vectors for classification. Therefore,the use of a dimensionality reduction method is necessary.There are two stages where dimensionality reduction is neededin our algorithm. The first stage is before feeding silhouettefeature vectors into the k-means clustering process and thesecond stage is for the reduction of the final correlogramrepresentations. We adopt the unsupervised PCA at the firststage and the combination of PCA and supervised LDA at thesecond stage. PCA seeks projection directions that maximizethe variance of the data and LDA maps the features to makethem more discriminative. Our argument for adopting differentdimensionality reduction methods is as follows. At the first
stage, a certain silhouette pose may appear in different actionclasses and the class label information is not very relevant.Therefore, an unsupervised method, i.e., PCA, is used. At thesecond stage, each correlogram matrix is at a high dimension(in a scale of 103-D); we first project the correlogram matrixinto a lower dimension of 100-D using PCA and because eachindividual correlogram matrix belongs to one unique actionclass, we further reduce the dimension to the number of actionclass-1 using LDA.
III. Extended-MHI
As found by Sun et al. [17], local descriptors and holisticfeatures emphasize different aspects of actions and sharecomplimentary properties. Motivated by their finding, we fusethe above temporally local descriptor BoCP with an extensionof the holistic descriptor: MHI by adding GEI and INV. Thesetwo additional holistic descriptors serve as the compensationfor the loss of information due to sequentially overlappingframes lost in the original MHI representation. We deduceour approach by first introducing motion templates.
A. Motion Templates
MEI and MHIs proposed by Davis and Bobick [12] areused to represent the motions of an object in video. Allframes in a video sequence are projected onto one image(MHI or MEI) across the temporal axis. As where and howmotion happens are recorded in the images, MHI captures thetemporal information of the motion in a sequence. AssumeI(x, y, t) is an image sequence and let B(x, y, t) be a binaryimage sequence indicating regions of motion, which can beobtained from image differencing. The binary MEI Eτ(x, y, t)with the temporal extent of duration τ is defined as
Eτ = ∪τ−1i=1 B(x, y, t − 1). (4)
The MHI Hτ(x, y, t) is used to represent how the motionimage is moving, and is obtained with a simple replacementand decay operator as follows:
Hτ(x, y, t) =
{τ, if B(x, y, t) = 1max(0, Hτ(x, y, t − 1) − 1), otherwise.
(5)It is stated in [17] that empirical observations show that a
single action cycle in two benchmark datasets, the KTH [24]and the Weizmann [13] datasets, can be as short as five frames.So, in their experiments, the duration is set to 5. However, fornonrepetitive actions, such as those in the IXMAS [25] dataset,choosing a τ is impractical. Notwithstanding, we observe thatlarger the τ, the more information is encoded. Therefore, weset τ as the duration of the whole action, and generally it is upto 100 frames in most action sequences. The redefined versionof MHI is
Hτ(x, y, t) =
{τ, if B(x, y, t) = 1Hτ(x, y, t − 1) − 1, otherwise.
(6)
Note that there is no maximum operator in front of Hτ ,see (5), because setting τ as the sequence duration will leadto nonnegativity of Hτ .

240 IEEE TRANSACTIONS ON CIRCUITS AND SYSTEMS FOR VIDEO TECHNOLOGY, VOL. 23, NO. 2, FEBRUARY 2013
Fig. 5. Setting τ as the whole action duration in MHI, the confusion matrixof the IXMAS dataset (Camera 3). Actions “wave” and “scratch head”are difficult to distinguish because they have similar motion patterns, i.e.,repetition of hand movement at similar spatial location.
We further extend motion templates that include two moreelements: GEI and INV.
GEI is to compensate for the nonmoving regions and themultiple motion instants regions of the action. The summationof all binary silhouette images and normalization of the pixelvalue define GEI as
G(x, y) =1
τ
τ∑t=1
B(x, y, t). (7)
INV is used to recover the loss of initial frames’ actioninformation, when setting τ as the whole action duration, andis defined as follows:
Iτ(x, y, t) =
{τ, if B(x, y, t) = 1Iτ(x, y, t + 1) − 1, otherwise.
(8)
Note that its subtle difference to (6) is the time variable thatbecomes t + 1 instead of t − 1 from which we get the nameINV.
We reason that MHI is poor at representing repetitive actionsfrom Figs. 5 and 6; the confusion matrix of the original MHIon the IXMAS dataset with τ as the whole action durationshows that “wave” and “scratch head” are the two mostdifficult actions to be distinguished, because they have similarmotion patterns, i.e., repetition of hand movement at similarspatial locations. INV provides complementary information byemphasizing (assigning larger value) at initial motion framesinstead of the last motion frames as in MHI. Fig. 6 illustratesthe similarities and differences between MHI, INV, and GEIof these two action sequences. The first columns are the MHIprojections, second are the INV projections, and the last are theGEI projections; the top row corresponds to the “wave” actionand the bottom “scratch head.” Again, the projection graphsshow that MHI emphasizes recent motion (ending frames)while INV the opposite. Hence, the combination of the two iscomplementary. Furthermore, GEI encodes the supplementaryinformation in repetitive actions, where both MHI and INV arepoor at representing. The experimental results in Section IVprove the viability of our conjecture.
Fig. 6. Illustration of the MHI, INV, and GEI. (a) Scratch head. (b) Wave.The projection graphs show that MHI emphasizes recent motion (endingframes) while INV emphasizes the opposite. GEI encodes the average gaitinformation and is supplementary in repetitive actions, whereas both MHIand INV are poor at representing.
Fig. 7. Parameters sensitivity test of BoCP. The choices of four parameters(from left to right). Cluster number: 10, 20, 30, 40; PCA (stage 1) dimension:10, 20, 30, 40; PCA (stage 2) dimension: 50, 100, 200, 400; δt (frames): 2,2–4, 2–4–6, 2–4–6–8.
IV. Experiments and Results
A. Datasets and Experimental Setup
We evaluate our approach on two public action recognitiondatasets: Weizmann [13] and IXMAS [25]. In the IXMASdataset, each action is performed three times by 10 differentsubjects and sequences are recorded from different viewpointswith multiple cameras. These actions include checking watch,crossing arms, scratching head, sitting down, getting up, turn-ing around, walking, waving, punching, kicking, and pickingup. This dataset is very challenging, because actors in thevideo sequences can freely choose their position and orienta-tion. There are also significant appearance changes, intraclassvariations, and self-occlusions. For the IXMAS dataset, weonly use single camera’s data for training or testing and followthe widely adopted leave-one-actor-out testing strategy. Forthe Weizmann dataset, we adopt the leave-one-sequence-outtesting strategy. We choose the following parameter settings:the bounding box of silhouettes is 30 ∗ 20 pixels and featurevectors are reduced to the dimension of 30 using PCA.During visual vocabulary construction, k = 30 is used forthe k-means clustering, which results in 30 codewords. Fourdifferent time offsets for δt: 2, 4, 6, 8 frames are used forthe construction of correlogram; hence, the dimensionality ofa BoCP representation is 30 ∗ 30 ∗ 4 = 3600-D. Each BoCPrepresentation is then reduced to the dimension of the number

WU AND SHAO: SILHOUETTE ANALYSIS-BASED ACTION RECOGNITION 241
TABLE I
Performance Comparison of Different Methods in Five Cameras on the IXMAS Dataset
Methods Camera 1 Camera 2 Camera 3 Camera 4 Camera 5BoCP + Extended-MHI 83.6 90.3 89.4 89.8 78.8
BoCP 81.4 87.6 84.9 88.5 71.3Shao and Chen [15] HBP 63.7 70.2 67.2 68.1 66.9
Weinland et al. [26] Local Product 85.8 86.4 88.0 88.2 74.7Varma and Babu [27] GMKL 76.4 74.5 73.6 71.8 60.4
Wu et al. [28] AFMKL 81.9 80.1 77.1 77.6 73.4Junejo et al. [29] PMK-NUP 76.4 77.6 73.6 68.8 66.1
Fig. 8. Algorithms for comparison. The first three columns of two datasets correspond to three values of τ in (5): five frames, half duration of the action,and the whole duration of the action. The following three columns correspond to MHI only, MHI+INV, and MHI+INV+GEI. The last two columns evaluateBoCP and the effect of combining two descriptors: BoCP and extended-MHI. (“All” stands for the combination of the two descriptors.)
of action class-1 using the combination of PCA (100-D) andLDA. Then, a unified framework is proposed to combinethe two distinctive descriptors, BoCP and extended-MHI, byearly fusion based on a very intuitive notion that the localdescriptor (BoCP) and the holistic descriptor (extended-MHI)are complementary to each other. For final classification, theGaussian kernel SVM classifier is adopted.
B. Parameter Sensitivity Test
There are a few parameters in the construction process ofour BoCP model and we demonstrate that our BoCP modelis insensitive to the choice of parameters in Fig. 7 using theIXMAS dataset. Four main parameters are tested: time offsetδt in (3), cluster number k during the k-means clustering, thereduced dimension after applying PCA at the first stage, andthe reduced dimension after applying PCA at the second stage.It can be seen that the BoCP model is rather robust to thechoice of different parameters as the overall accuracy variesin the range of 2%–7%. The most error-prone parameter is thesecond-stage dimension of PCA; excessively large dimensionmay lead to worsen performance.
C. Visual Word Ambiguity Effect
We examine the effect of the soft assignment strategy alsothrough Fig. 7. Note that the cross-validation-optimal numberof clusters in our model is quite small: 30 comparing with thetraditional BoVW model [1]–[3], [5], [6], [9], which usuallysurges up to 1000 and more. The graph also shows thata surprisingly small cluster number, i.e., a cluster numberof 10, still achieves comparable result but a larger clusternumber does not improve the overall recognition accuracy. Thereason behind the scene is that in our BoCP model, a visual
word is described by a vector whose elements are relatedto the distances to the cluster center, i.e., (2), instead of thequantized class membership. Moreover, we further utilize thisprobabilistic visual word descriptor for the entries in (3) sothat a frame spans over all the columns in the correlogrammatrix. Observe that our BoCP model is a matrix of dimensionk ∗ k, where k is the number of clusters. Again, a largercluster number increases the computational complexity duringk-means clustering O(k) and BoCP correlogram constructionO(k2) exponentially. By adopting the soft assignment scheme,we tactically circumvent the situation, where k can be easilyup to 1000 making the BoCP dimension up to what is simplyimpractical computationally and unnecessary for action rep-resentation. Thus, we gracefully achieve an action descriptorwith a dimension in the scale of thousands while encodingtemporal structural information.
D. Algorithms for Comparison
We first make a quantitative comparison between ourcorrelogram-based method (BoCP) and the histogram-basedmethod (HBP) [15] in Table I, and it can be seen that our pro-posed method BoCP consistently outperforms the histogram-based method. We then verify our choice of time duration in(6) over (5) through Fig. 8. The first three columns of twodatasets correspond to three values of τ in (5): five frames(suggested by [17]), half duration of the action, and the wholeduration of the action. Setting τ as the whole action durationachieves the best results among the three schemes. The fol-lowing three columns summarize the efficacy of concatenatingdifferent versions of motion templates described in Section III.The consistent improvement of accuracy validates that bothGEI and INV are complementary to the original MHI. Then,by early fusion (direct concatenation) of two descriptors, BoCP

242 IEEE TRANSACTIONS ON CIRCUITS AND SYSTEMS FOR VIDEO TECHNOLOGY, VOL. 23, NO. 2, FEBRUARY 2013
and extended-MHI, we show in the last two columns thatthe combination of temporal-local and holistic descriptorsfurther improve the overall accuracy by 1% for the Weizmanndataset (because the improvement for the Weizmann dataset’saccuracy is close to saturation: 97.78%, 88/90) and 3.6% forthe IXMAS dataset. Again, this explains the complementarycharacteristics between the BoCP model and the extended-MHI representation; BoCP is good at representing temporalpose correlations and the extended-MHI excels at holistic mo-tion representation. In addition, BoCP compensates for MHI’sineffectiveness in representing repetitive movements. Table Ishows the comparison to the state-of-the-art methods on theIXMAS dataset using a single camera view. Our algorithmoutperforms the state-of-the-art methods on the challengingfree viewpoint IXMAS dataset and this demonstrates that ourmodel is robust to large variations of viewpoint, position, andorientation. The experiments were done on an Intel 2-core3 GHz CPU and 4 GB memory PC in a single-thread runningMATLAB. The speed of our method is approximately 25 f/s(excluding the silhouette extraction process).
V. Conclusion
In this paper, we proposed two new representations, namely,BoCP and the extended-MHI for action recognition. BoCPwas a temporally local feature descriptor and the extended-MHI was a holistic motion descriptor. In the BoCP model,our unique way of considering temporal-structural correlationsbetween consecutive human poses encoded more informationthan the traditional bag-of-features model. Also, we utilizeda soft-assignment strategy to preserve the visual word am-biguity that was usually disregarded during the quantiza-tion process after k-means clustering. The extension of MHIcompensated for information loss in the original approachand later we verified the conjecture that local and holisticfeatures were complementary to each other. In this paper,our system showed promising performance and producedbetter results than any published paper on the IXMAS datasetusing only low-level features and a simple dimensionalityreduction method with the early fusion strategy. With moresophisticated feature descriptors and advanced dimensionalityreduction methods, we reckoned better performance. Futurework includes extending our BoCP framework to other bag-of-correlated-features frameworks to encode correlations ofaction descriptors. Also, we expect that a better multifeaturemerging algorithm can further improve our system’s effecti-veness.
References
[1] P. Dollar, V. Rabaud, G. Cottrell, and S. Belongie, “Behavior recognitionvia sparse spatio-temporal features,” in Proc. 2nd Joint IEEE Int.Workshop Vis. Surveillance Performance Eval. Tracking Surveillance ,Oct. 2005, pp. 65–72.
[2] I. Laptev and T. Lindeberg, “Space-time interest points,” in Proc. ICCV,2003, pp. 432–439.
[3] M. Marszalek, I. Laptev, and C. Schmid, “Actions in context,” in Proc.IEEE Conf. CVPR, Jun. 2009, pp. 2929–2936.
[4] M. Rodriguez, J. Ahmed, and M. Shah, “Action mach a spatio-temporalmaximum average correlation height filter for action recognition,” inProc. IEEE Conf. CVPR, Jun. 2008, pp. 1–8.
[5] H. Wang, M. Ullah, A. Klaser, I. Laptev, and C. Schmid, “Evaluation oflocal spatio-temporal features for action recognition,” in Proc. BMVC,2009, pp. 124.1–124.11.
[6] G. Willems, T. Tuytelaars, and L. Van Gool, “An efficient dense andscale-invariant spatio-temporal interest point detector,” in Proc. ECCV,2008, pp. 650–663.
[7] L. Fei-Fei and P. Perona, “A Bayesian hierarchical model for learningnatural scene categories,” in Proc. IEEE Comput. Soc. Conf. CVPR,vol. 2. Jun. 2005, pp. 524–531.
[8] T. Goodhart, P. Yan, and M. Shah, “Action recognition using spatio-temporal regularity based features,” in Proc. IEEE ICASSP, Mar.–Apr.2008, pp. 745–748.
[9] A. Klaser, M. Marszalek, and C. Schmid, “A spatio-temporal descriptorbased on 3d-gradients,” in Proc. British Mach. Vision Conf., 2008, pp.995—1004.
[10] M. Chen and A. Hauptmann, “MoSIFT: Recognizing human actions insurveillance videos,” Carnegie Mellon Univ., Tech. Rep. CMU-CS-09-161, 2009.
[11] X. Cao, B. Ning, P. Yan, and X. Li, “Selecting key poses on manifoldfor pairwise action recognition,” IEEE Trans. Indust. Inform., vol. 8,no. 1, pp. 168–177, Feb. 2012.
[12] J. Davis and A. Bobick, “The representation and recognition of humanmovement using temporal templates,” in Proc. IEEE Comput. Soc. Conf.Comput. Vision Patt. Recog., Jun. 1997, pp. 928–934.
[13] M. Blank, L. Gorelick, E. Shechtman, M. Irani, and R. Basri, “Actionsas space-time shapes,” in Proc. 10th IEEE ICCV, vol. 2. Oct. 2005, pp.1395–1402.
[14] L. Wang and C. Leckie, “Encoding actions via the quantized vocabularyof averaged silhouettes,” in Proc. Int. Conf. Patt. Recog., 2010, pp. 3657–3660.
[15] L. Shao and X. Chen, “Histogram of body poses and spectral regressiondiscriminant analysis for human action categorization,” in Proc. BMVC,2010, pp. 88.1–88.11.
[16] H. Qu, L. Wang, and C. Leckie, “Action recognition using space-timeshape difference images,” in Proc. 20th ICPR, 2010, pp. 3661–3664.
[17] X. Sun, M. Chen, and A. Hauptmann, “Action recognition via localdescriptors and holistic features,” in Proc. IEEE Comput. Soc. Conf.CVPR Workshops, Jun. 2009, pp. 58–65.
[18] B. Leibe, A. Leonardis, and B. Schiele, “Combined object categorizationand segmentation with an implicit shape model,” in Proc. WorkshopStatist. Learn. Comput. Vision (ECCV), 2004, pp. 17–32.
[19] J. van Gemert, C. Veenman, A. Smeulders, and J. Geusebroek, “Visualword ambiguity,” IEEE Trans. Patt. Anal. Mach. Intell., vol. 32, no. 7,pp. 1271–1283, Jul. 2010.
[20] Y. Boureau, F. Bach, Y. LeCun, and J. Ponce, “Learning mid-levelfeatures for recognition,” in Proc. IEEE Conf. CVPR, Jun. 2010, pp.2559–2566.
[21] X. Zhou, X. Zhuang, H. Tang, M. Hasegawa-Johnson, and T. Huang,“Novel Gaussianized vector representation for improved natural scenecategorization,” Pattern Recog. Lett., vol. 31, no. 8, pp. 702–708, 2010.
[22] L. Shao, D. Wu, and X. Chen, “Action recognition using correlogram ofbody poses and spectral regression,” in Proc. Int. Conf. Image Process.,2011, pp. 209–212.
[23] J. Huang, S. Kumar, M. Mitra, W. Zhu, and R. Zabih, “Image indexingusing color correlograms,” in Proc. IEEE Comput. Soc. Conf. Comput.Vision Patt. Recog., Jun. 1997, pp. 762–768.
[24] C. Schuldt, I. Laptev, and B. Caputo, “Recognizing human actions: Alocal SVM approach,” in Proc. 17th ICPR, vol. 3. 2004, pp. 32–36.
[25] D. Weinland, R. Ronfard, and E. Boyer, “Free viewpoint action recogni-tion using motion history volumes,” Comput. Vision Image Understand.,vol. 104, nos. 2–3, pp. 249–257, 2006.
[26] D. Weinland, M. Ozuysal, and P. Fua, “Making action recognition robustto occlusions and viewpoint changes,” in Proc. ECCV, 2010, pp. 635–648.
[27] M. Varma and B. Babu, “More generality in efficient multiple kernellearning,” in Proc. 26th Annu. Int. Conf. Mach. Learn., 2009, pp. 1065–1072.
[28] X. Wu, D. Xu, L. Duan, and J. Luo, “Action recognition using contextand appearance distribution features,” in Proc. IEEE Conf. CVPR, Jun.2011, pp. 489–496.
[29] I. Junejo, E. Dexter, I. Laptev, and P. Perez, “Cross-view action recogni-tion from temporal self-similarities,” in Proc. ECCV, 2008, pp. 293–306.

WU AND SHAO: SILHOUETTE ANALYSIS-BASED ACTION RECOGNITION 243
Di Wu (S’12) received the B.E. degree in electronicand electrical engineering from Zhejiang University,Zhejiang, China. He is currently pursuing the Ph.D.degree with the University of Sheffield, Sheffield,U.K., under the supervision of Dr. L. Shao.
His current research interests include human actionrecognition and gesture recognition.
Ling Shao (SM’10) received the B.E. degree in elec-tronic engineering from the University of Scienceand Technology of China, Hefei, Anhui, China, andthe M.S. degree in medical image analysis and thePh.D. (D.Phil.) degree in computer vision from theUniversity of Oxford, Oxford, U.K.
He is currently a Senior Lecturer (Associate Pro-fessor) with the Department of Electronic and Elec-trical Engineering, University of Sheffield, Sheffield,U.K. He was a Senior Scientist with Philips Re-search, Eindhoven, The Netherlands. He has pub-
lished over 70 academic papers in refereed journals and conference proceed-ings and has filed over 10 patent applications. His current research interestsinclude computer vision, pattern recognition, and video processing.
Dr. Shao is an Associate Editor of the IEEE Transactions on Systems,Man and Cybernetics, Part B: Cybernetics, the International Journal ofImage and Graphics, the EURASIP Journal on Advances in Signal Processing,and Neurocomputing. He has edited several special issues for journals ofIEEE, Elsevier, and Springer. He has organized several workshops with topconferences, such as ICCV, ECCV, and ACM Multimedia. He is a ProgramCommittee Member of many international conferences, including CVPR,ECCV, ICIP, ICASSP, ICME, ICMR, ACM MM, CIVR, and BMVC.


















