
2 WEB USAGE MINING CONTEXTUAL FACTOR HUMAN INFORMATION ... · WEB USAGE MINING CONTEXTUAL FACTOR:...
18
International Journal of Information Technology & Management Information System (IJITMIS), ISSN 0976 – 6405(Print), ISSN 0976 – 6413(Online), Volume 5, Issue 1, January - April (2014), © IAEME 12 WEB USAGE MINING CONTEXTUAL FACTOR: HUMAN INFORMATION BEHAVIOR Ms. Ravita Mishra Information Technology Dept, Ramrao Adik Institute of Technology, Nerul Navi Mumbai, India ABSTRACT With the rapid development of information technology, the World Wide Web has been widely used in various applications, such as search engines, online learning and electronic commerce. These applications are used by a diverse population of users with heterogeneous backgrounds, in terms of their knowledge, skills, and needs. Therefore, human factors are key issues for the development of web-based application and research. This paper first identifies reviews from different authorsand then examines the three important human factors: gender differences, prior knowledge, and cognitive styles. The review result is not significantly correct; a new model is proposed that will access the data (log data) and show the human access behavior. The proposed model has two stages: web intelligence and navigation pattern. Stage 1(web intelligence system) captures data from different server and converts in the form of table (data store). Stage 2 uses the N-gram algorithm which assumes that the last N-pages browsed affect the probability of the next page to be visited, and user navigation sessions are modelled as a hypertext probabilistic grammar whose higher probability strings correspond to the user’s preferred trails.In this paper web caching and pre- fetching are two important approaches used to reduce the noticeable response time perceived by users.The model improves the navigation pattern of users and find the users behavior ( gender difference and user type) that finding is used by site designer and researchers and also used for detecting and avoiding the terror threats caused by terrorists all over the world.The paper is organized into five different parts, first part contain introduction, second part contain different type of web mining third part contain usage mining on the web and forth part contain analysis of human factor and evaluation technique,fifth part contain propose methodology and last part contains application, limitation, conclusion and further work. Keywords: Pattern Discovery, Contextual factor, Information Retrieval, N-gram, Gender difference, Cognitive style and Prior experience. INTERNATIONAL JOURNAL OF INFORMATION TECHNOLOGY & MANAGEMENT INFORMATION SYSTEM (IJITMIS) ISSN 0976 – 6405(Print) ISSN 0976 – 6413(Online) Volume 5, Issue 1, January - April (2014), pp. 12-29 © IAEME: http://www.iaeme.com/IJITMIS.asp Journal Impact Factor (2013): 5.2372 (Calculated by GISI) www.jifactor.com IJITMIS © I A E M E
-
Upload
vuonghuong -
Category
Documents
-
view
223 -
download
0
Transcript of 2 WEB USAGE MINING CONTEXTUAL FACTOR HUMAN INFORMATION ... · WEB USAGE MINING CONTEXTUAL FACTOR:...

International Journal of Information Technology & Management Information System (IJITMIS),
ISSN 0976 – 6405(Print), ISSN 0976 – 6413(Online), Volume 5, Issue 1, January - April (2014), © IAEME
12
WEB USAGE MINING CONTEXTUAL FACTOR: HUMAN
INFORMATION BEHAVIOR
Ms. Ravita Mishra
Information Technology Dept, Ramrao Adik Institute of Technology, Nerul Navi Mumbai,
India
ABSTRACT
With the rapid development of information technology, the World Wide Web has
been widely used in various applications, such as search engines, online learning and
electronic commerce. These applications are used by a diverse population of users with
heterogeneous backgrounds, in terms of their knowledge, skills, and needs. Therefore, human
factors are key issues for the development of web-based application and research. This paper
first identifies reviews from different authorsand then examines the three important human
factors: gender differences, prior knowledge, and cognitive styles. The review result is not
significantly correct; a new model is proposed that will access the data (log data) and show
the human access behavior. The proposed model has two stages: web intelligence and
navigation pattern. Stage 1(web intelligence system) captures data from different server and
converts in the form of table (data store). Stage 2 uses the N-gram algorithm which assumes
that the last N-pages browsed affect the probability of the next page to be visited, and user
navigation sessions are modelled as a hypertext probabilistic grammar whose higher
probability strings correspond to the user’s preferred trails.In this paper web caching and pre-
fetching are two important approaches used to reduce the noticeable response time perceived
by users.The model improves the navigation pattern of users and find the users behavior (
gender difference and user type) that finding is used by site designer and researchers and also
used for detecting and avoiding the terror threats caused by terrorists all over the world.The
paper is organized into five different parts, first part contain introduction, second part contain
different type of web mining third part contain usage mining on the web and forth part
contain analysis of human factor and evaluation technique,fifth part contain propose
methodology and last part contains application, limitation, conclusion and further work.
Keywords: Pattern Discovery, Contextual factor, Information Retrieval, N-gram,
Gender difference, Cognitive style and Prior experience.
INTERNATIONAL JOURNAL OF INFORMATION TECHNOLOGY & MANAGEMENT INFORMATION SYSTEM (IJITMIS)
ISSN 0976 – 6405(Print) ISSN 0976 – 6413(Online)
Volume 5, Issue 1, January - April (2014), pp. 12-29 © IAEME: http://www.iaeme.com/IJITMIS.asp Journal Impact Factor (2013): 5.2372 (Calculated by GISI) www.jifactor.com
IJITMIS
© I A E M E

International Journal of Information Technology & Management Information System (IJITMIS),
ISSN 0976 – 6405(Print), ISSN 0976 – 6413(Online), Volume 5, Issue 1, January - April (2014), © IAEME
13
1.INTRODUCTION
Web mining is a very hot research topic which combines two of the activated research
areas: Data Mining and World Wide Web. The Web mining research relates to several
research communities such as Database, Information Retrieval and Artificial Intelligence.
Web mining is categorized in into three areas: Web content mining, Web structure mining
and Web usage mining. Web content mining focuses on the discovery/retrieval of the useful
information from the web contents/data/documents, while the Web structure mining
emphasizes to the discovery of how to model the underlying link structures of the web [14,
16]. Web usage mining is relative independent, but not isolated, category, which mainly
describes the techniques that discover the user's usage pattern and try to predict the user's
behaviors. Web mining is the term of applying data mining techniques to automatically
discover and extract useful information from the World Wide Web documents and services
[16]. Here, human factors are increasingly seen as important issues, as reflected in the
substantial number of existing studies in the area. Among various human factors, gender
differences (e.g., Roy, Taylor, & Chi, 2003), prior knowledge (e.g., Calisir&Gurel, 2003) and
cognitive styles (e.g., Chen &Macredie, 2004) have significant impacts on web-based
interaction. Furthermore, these three human factors have certain inter-relations. For example,
females tend to behave similarly to novices, in terms of the extent to which they experience
disorientation problems; males and experts seem to have similar preferences in their
interaction patterns, with studies reporting that they enjoy non-linear interaction (Ford &
Chen, 2000). Despite the growing number of studies looking at these three human factors,
there is a lack of an integrated review which synthesizes their effects.
2. WEB DATA MINING 2.1 Overview: Today, with the tremendous growth of the data sources available on the Web
and the dramatic popularity of e-commerce in the business community, Web mining has
become the focus of quite a few research projects and papers [13, 14, and 15]. In previous
research, they suggested a similar way to decompose web mining into the following subtasks:
Resource Discovery: The task of retrieving the intended information from web.
Information Extraction: Automatically selecting and pre-processing specific information
from the retrieved web resources. Generalization: Automatically discovers general patters at
the both individual web sites and across multiple sites. Analysis: Analyzing the mined
pattern. The authors of [10] claims the web involves three types of data: data on the web
(content), web log data (usage) and web structure data. The author classified the data type as
content data, structure data, usage data, and user profile data.
2.1.1 Web Content Mining: Web content mining describes the automatic search of
information resourceavailable online and involves mining web data contents. The web
document usually contains several types of data, such as text, image, audio, video, metadata
and hyperlinks. The technologies that are normally used in web content mining are NLP and
IR. Some of them are semi-structured such as HTML documents or a more structured data
like the data in the tables or database generated HTML pages, butmost of the data is
unstructured text data [14].
2.1.2 Web Structure Mining: Technically, web content mining mainly focuses on the
structure of inner-document, while web structure mining tries to discover the link structure of

International Journal of Information Technology & Management Information System (IJITMIS),
ISSN 0976 – 6405(Print), ISSN 0976 – 6413(Online), Volume 5, Issue 1, January - April (2014), © IAEME
14
the hyperlinks at the inter-document level. Based on the topology of the hyperlinks, web
structure mining will categorize the web pages and generate the information, such as the
similarity and relationship between different web sites. Web structure mining can also have
another direction – discovering the structure of web document itself. This type of structure
mining can be used to reveal the structure (schema) of web pages; this would be good for
navigation purpose and make it possible to compare/integrate web page schemes. The
structural information generated from the web structure mining includes the following: the
information measuring the frequency of the local links in the web tuples in a web table; the
information measuring the frequency of web tuples in a web table containing links that are
interior and the links that are within the same document; the information measuring the
frequency of web tuples in a web table that contains links that are global and the links that
span different web sites; the information measuring the frequency of identical web tuples that
appear in a web table or among the web tables [15,20]. In general, if a web page is linked to
another web page directly, or the web pages are neighbors, we would like to discover the
relationships among those web pages. The relations maybe fall in one of the types, such as
they related by synonyms or ontology, they may have similar contents, and both of them may
sit in the same web server therefore created by the same person [13, 14].
2.1.3 Web Usage Mining: Analyzing the web access logs of different web sites can help
understand the user behaviour and the web structure, thereby improving the design of this
colossal collection of resources. There are two main tendencies in web usage mining driven
by the applications of the discoveries: General Access Pattern Tracking and Customized
Usage Tracking. The general access pattern tracking analyzes the web logs to understand
access patterns and trends. These analyses can be used for better structure and grouping of
resource providers. Applying data mining techniques on access logs unveils interesting access
patterns that can be used to restructure sites in a more efficient grouping, pinpoint effective
advertising locations, and target specific users for specific Selling ads. Customized usage
tracking analyzes individual trends. Its purpose is to customize web sites to users. The
information displayed the depth of the site structure and the format of the resources can all be
dynamically customized for each user over time based on their access patterns.
2.2. STEPS IN WEB MINING Web usage mining falls in three areas 1: Pre-processing 2: Pattern discovery 3:
Pattern analysis. Preprocessing further categorized into three parts.
2.2.1 Pre-processing: Pre-processing is categorized in three types they are: Content Pre-
processing, Structure Pre-processing and Usage Pre-processing. Content preprocessing is the
process of converting text, image, scripts and other files into the forms that can be used by
the usage mining. For the content of static page views, the preprocessing can be easily done
by parsing the HTML and reformatting the information or running additional algorithm as
desired [15].The structure preprocessing can be treated similar as the content preprocessing.
However, each server session may have to construct a different site structure than others [13,
15].The inputs of the preprocessing phase may include the Web server logs, referral logs,
registration files, index server logs, and optionally usage statistics from a previous analysis.
The outputs are the user session file, transaction file, site topology, and page classifications.
It’s always necessary to adopt a data cleaning techniques to eliminate the impact of the
irrelevant items to the analysis result. Without sufficient data, it is very difficult to identify
the users [14].The session identification is also a part of the usage preprocessing. The goal of

International Journal of Information Technology & Management Information System (IJITMIS),
ISSN 0976 – 6405(Print), ISSN 0976 – 6413(Online), Volume 5, Issue 1, January - April (2014), © IAEME
15
it is to divide the page accesses of each user, who is likely to visit the Web site more than
once, into individual sessions. The simplest way to do is to use a timeout to break a user’s
click-stream into session. Another problem is named as path completion, which indicates the
determining if there are any important accesses missed in the access log. The methods used
for the user identification can be used for path completion. The final procedure of the pre-
processing is formatting, which is a preparation module to properly format the sessions or
transactions.
2.2.2 Pattern Discovery
Pattern discovery converges the algorithms and techniques from several research
areas, such as data mining, machine learning, statistics, and pattern recognition. Pattern
discovery falls in following categories: Statistical Analysis, Association Rules, Clustering,
Classification, Sequential Pattern and Dependency Modeling. Statistical techniques are the
most powerful tools in extracting knowledge about visitors to a Web site. The analysts may
perform different kinds of descriptive statistical analyses based on different variables when
analyzing the session file [13]. By analyzing the statistical information contained in the
periodic web system report, the extracted report can be potentially useful for improving the
system performance, enhancing the security of the system.Association rule mining techniques
can be used to discover unordered correlation between items found in a database of
transactions [13]. The association rules refer to sets of pages that are accessed together with a
support value exceeding some specified threshold. The web designers can restructure their
web sites efficiently with the help of the presence or absence of the association rules.
Clustering analysis is a technique to group together users or data items with the similar
characteristics. Clustering of user information or pages can facilitate the development and
execution of future marketing strategies [13]. Clustering of users will help to discover the
group of users, who have similar navigation pattern. It’s very useful for inferring user
demographics to perform market segmentation in E-commerce applications or provide
personalized web content to the individual users. Classification is supervised inductive
learning technique that maps a data item into one of several predefined classes. In the web
domain, Web master or marketer will have to use this technique if he/she want to establish a
profile of users belonging to a particular class or category. This requires extraction and
selection of features that best describe the properties of a given class or category [13].
Sequential Patternfinds the inter-session pattern, such that a set of the items follows the
presence of another’s in a time-ordered set of sessions.It also includes other types of temporal
analysis such as trend analysis, change point detection, or similarity analysis. It’s very useful
for the web marketer to predict the future trend, which help to place advertisements aimed at
certain user groups [13]. Dependency Modelingrepresents significant dependencies among
the various variables in the web domain [13]. The modeling technique provides a theoretical
framework for analyzing the behavior of users, and is potentially useful for predicting future
web resource consumption.
2.3 PATTERN ANALYSIS The goal of this process is to eliminate the irrelative rules or patterns and to extract
the interesting rules or patterns from the output of the pattern discovery process. Output of
algorithms is not in the form suitable for direct human consumption, and thus need to be
transform to a format can be assimilate easily [13]. There are two most common approaches
for the pattern analysis. One is to use the knowledge query mechanism such as SQL, while
another is to construct multi-dimensional data cube before perform OLAP operations.

International Journal of Information Technology & Management Information System (IJITMIS),
ISSN 0976 – 6405(Print), ISSN 0976 – 6413(Online)
3. ANALYSIS OFCONTEXTUAL FACTOR
In the given framework
analysed and it includes: information exploration, seeking, filtering, use
Based on the framework, various contextual
credibility and browser dependence
economic, social, and political -
model, the user dimension is considered to be influenced by the particular task, information
need, knowledge state, cognitive style, affective state and so on. They measured users’
cognitive styles and affective states before a user study, applying a process
while users were conducting information
relationships among the elements of the dimensions
users judge cognitive authority and information quality by two types of judgment
judgment and evaluative judgment
the judgments through a user study.
Review process:Due to the massive growth of the
topic and attracts more and more attenti
extract information from data set for business needs, which determines its application is
highly customer-related. In business r
research area which demonstrates completes human information behavior based on
experimental dataset. Analysis of this factor is based on four points. 1. Gender difference 2.
Cognitive style 3. Prior experience
few commercial analysis applications available
efficient, flexible and powerful tools, lots of work needs to be done for
developer.
Figure 4.1 illustrates the review process, which consists of four stages
As shown in above Fig.
journals and search engines; here
include empirical studies related to gender differences, prior knowledge and cognitive styles.
The search terms for these electronic resources included four group
International Journal of Information Technology & Management Information System (IJITMIS),
6413(Online), Volume 5, Issue 1, January - April (2014), © IAEME
16
ANALYSIS OFCONTEXTUAL FACTOR (HUMAN INFORMATION BEHAVIOR)
In the given framework, contextual parameter human information behaviour
information exploration, seeking, filtering, use and communication
e framework, various contextual factors –user interest, difficulty, time taken,
credibility and browser dependence and their influential factor physical, cognitive, affective,
- and their implications were investigated [12]. In
, the user dimension is considered to be influenced by the particular task, information
need, knowledge state, cognitive style, affective state and so on. They measured users’
states before a user study, applying a process-tracing technique
while users were conducting information-seeking tasks, and found various types of
relationships among the elements of the dimensions. In (Rieh 2002), the authors found that
ive authority and information quality by two types of judgment
judgment and evaluative judgment – and they also identified the main facets and keywords of
the judgments through a user study.
Due to the massive growth of the e-commerce, privacy becomes a sensitive
topic and attracts more and more attention recently. The basic goal of web mining is to
extract information from data set for business needs, which determines its application is
related. In business related customer data, Human factor is
which demonstrates completes human information behavior based on
experimental dataset. Analysis of this factor is based on four points. 1. Gender difference 2.
enceand 4. Web based interaction. Although there are quite a
few commercial analysis applications available and many more are free on to develop the
efficient, flexible and powerful tools, lots of work needs to be done for both researcher
4.1 illustrates the review process, which consists of four stages
Fig.there is four major stages. Stage one search
here resources were selected because they were known to
empirical studies related to gender differences, prior knowledge and cognitive styles.
The search terms for these electronic resources included four groups: (1) Internet and
International Journal of Information Technology & Management Information System (IJITMIS),
(2014), © IAEME
BEHAVIOR)
information behaviour is
and communication.
user interest, difficulty, time taken,
physical, cognitive, affective,
cations were investigated [12]. In previous
, the user dimension is considered to be influenced by the particular task, information
need, knowledge state, cognitive style, affective state and so on. They measured users’
tracing technique
seeking tasks, and found various types of
In (Rieh 2002), the authors found that
ive authority and information quality by two types of judgment - predictive
and they also identified the main facets and keywords of
commerce, privacy becomes a sensitive
eb mining is to
extract information from data set for business needs, which determines its application is
Human factor is a fertilized
which demonstrates completes human information behavior based on
experimental dataset. Analysis of this factor is based on four points. 1. Gender difference 2.
Although there are quite a
o develop the
both researcher and
4.1 illustrates the review process, which consists of four stages
searches electronic
resources were selected because they were known to
empirical studies related to gender differences, prior knowledge and cognitive styles.
s: (1) Internet and WWW;
International Journal of Information Technology & Management Information System (IJITMIS),
ISSN 0976 – 6405(Print), ISSN 0976 – 6413(Online), Volume 5, Issue 1, January - April (2014), © IAEME
17
(2) Gender, females/males; boys/girls, and men/women; (3) Prior knowledge, system
experience, novices/experts, domain expertise, domain knowledge, computer experience,
previous experience, Internet experience; and (4) Cognitive styles, learning styles, field
dependence.Stage two analyzes search based on timeline. Stage three selects the analysis
based on titles, elements and keywords. Stage four asses the behavior based on credibility.
3.1GENDER DIFFERENCES Gender difference is important variable that influences computing skills and find the
human information behavior and their emotions. As the web has become a popular platform
for various applications, such as search engines, online learning and electronic commerce, a
growing body of studies has been conducted to examine gender differences in the use of the
web, this literature suggests that major differences between males and females lie within
navigation patterns, attitudes and perceptions [8, 9].In the previous research number of
theoretical survey will be taken and the literature has suggested that males report lower levels
of computer anxiety than their female counterparts; in addition, it also seems that males
achieve much better outcomes than females in the use of computers (Karavidas, Lim,
&Katsikas, 2004). Gender difference will be analyzed by Navigation Pattern andAttitudes
and Perceptions.
Navigation pattern is defined as the way user access the webpages. Without good
navigation, a site becomes useless to visitors. They can’t find the information they need, and
then seek out competing sites instead. It’s vital that your sites be easy to navigate if you want
to be a successful designer. There are certain navigation patterns that work on virtually all
sites. The first pattern tabbed navigation, second pattern is header navigation and third pattern
is blog, informational and reference site, corporate site etc.Large et al. (2002) examined how
boys and girls behaved differently when retrieving information from the web. 53 students,
comprising 23 boys and 30 girls from two grade-six classes, were the subjects of their study.
Overall, the boys explored more hypertext links per minute, tended to perform more page
jumps per minute, entered more searches in search engines, and gathered and saved
information more often than the girls, while the boys spent less time viewing pages than the
girls [8, 9]. Furthermore, Ford, Miller and Moss (2001) investigated individual differences in
internet searching using a sample of 64 Master’s students with 20 males and 44 females. The
above mentioned studies suggest that females and males show different approaches to
navigation, reflected in the navigation patterns that they exhibit, but that there are
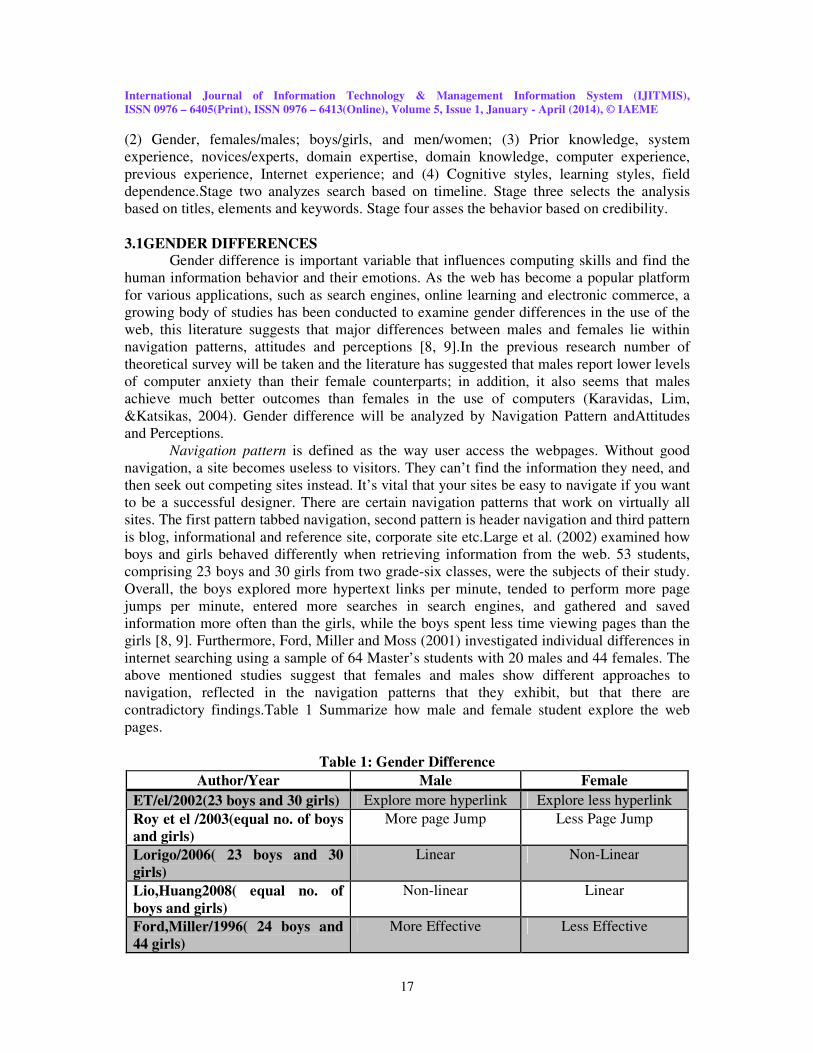
contradictory findings.Table 1 Summarize how male and female student explore the web
pages.
Table 1: Gender Difference
Author/Year Male Female
ET/el/2002(23 boys and 30 girls) Explore more hyperlink Explore less hyperlink
Roy et el /2003(equal no. of boys and girls)
More page Jump Less Page Jump
Lorigo/2006( 23 boys and 30
girls)
Linear Non-Linear
Lio,Huang2008( equal no. of
boys and girls)
Non-linear Linear
Ford,Miller/1996( 24 boys and
44 girls)
More Effective Less Effective
International Journal of Information Technology & Management Information System (IJITMIS),
ISSN 0976 – 6405(Print), ISSN 0976 – 6413(Online), Volume 5, Issue 1, January - April (2014), © IAEME
18
Attitudes and Perceptions: Perceptioncan determine the attitude it defines how you perceive
the word.Attitude is what the individual thinks about the perception and perception is the
human subjective experience of information provided by the senses. A number of studies
suggest that there are gender differences in attitudes towards web-based interaction and
perceptions. The first survey result state that 630 Anglo-American undergraduates completed
the Student Computer and Internet Survey, the results of which indicated that females
reported more computer anxiety and less computer self-efficacy than males. Schumacher and
Morahan-Martin (2001) conducted a survey to identify gender differences in attitudes
towards computers and the Internet. The survey was completed by 619 students,the results of
which indicated that females reported more computer anxiety and less computer self-efficacy
than males. Similar results were also found in the study by Koohang(2004), which
investigated 154 students of undergraduate management program, and the results indicated
that males had significantly higher positive perceptions than the females toward using the
digital library [5].The studies reviewed so far in this section indicate that females tend to have
more negative attitudes towards the use of the web than males and that they feel less able
when using the web than their male peers.
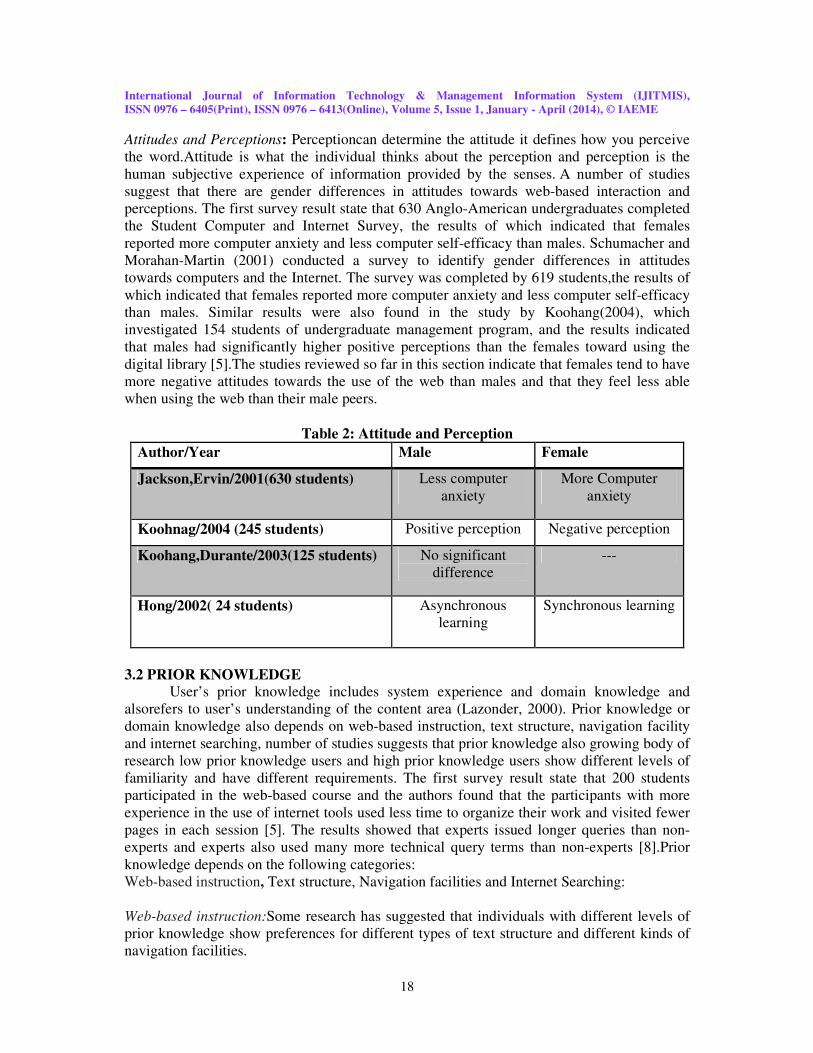
Table 2: Attitude and Perception
Author/Year Male Female
Jackson,Ervin/2001(630 students) Less computer
anxiety
More Computer
anxiety
Koohnag/2004 (245 students) Positive perception Negative perception
Koohang,Durante/2003(125 students) No significant
difference
---
Hong/2002( 24 students) Asynchronous
learning
Synchronous learning
3.2 PRIOR KNOWLEDGE
User’s prior knowledge includes system experience and domain knowledge and
alsorefers to user’s understanding of the content area (Lazonder, 2000). Prior knowledge or
domain knowledge also depends on web-based instruction, text structure, navigation facility
and internet searching, number of studies suggests that prior knowledge also growing body of
research low prior knowledge users and high prior knowledge users show different levels of
familiarity and have different requirements. The first survey result state that 200 students
participated in the web-based course and the authors found that the participants with more
experience in the use of internet tools used less time to organize their work and visited fewer
pages in each session [5]. The results showed that experts issued longer queries than non-
experts and experts also used many more technical query terms than non-experts [8].Prior
knowledge depends on the following categories:
Web-based instruction, Text structure, Navigation facilities and Internet Searching:
Web-based instruction:Some research has suggested that individuals with different levels of
prior knowledge show preferences for different types of text structure and different kinds of
navigation facilities.
International Journal of Information Technology & Management Information System (IJITMIS),
ISSN 0976 – 6405(Print), ISSN 0976 – 6413(Online), Volume 5, Issue 1, January - April (2014), © IAEME
19
Text structure: Three types of text structure – hierarchical, non-linear, and mixed
(hierarchical structure with cross referential links) has found and a number of studies have
examined how text structure interacts with user’s prior knowledge; the findings suggest that
experts and novices differ in their performance depending on the text structure used in Web-
based instruction. Survey 1, McDonald and Stevenson (1998) examined the effects of text
structure and prior knowledge on navigation performance [8, 9]. The results showed that the
performance of knowledgeable participants was better than that of non-knowledgeable
participants, as they had a better conception of the subject matter than non-knowledgeable
participants. Survey 2,Calisir and Gurel (2003) also investigated the interaction of three types
of text structure – linear, hierarchical and mixed in relation to the prior knowledge of users.
However, in contrast to the study by McDonald and Stevenson (1998), they examined the
influence of text structure and prior knowledge on learning performance, rather than on
navigation performance. Survey 3,Amadieu, Tricot, and MarinéDo (2005) obtained similar
results. Three types of structure were provided: hierarchical; network; and linear. The results
indicated that low prior knowledge learners demonstrated better performance in the
hierarchical structure, whereas the hierarchical structure seemed to obstruct the domain
representation for high prior knowledge learners. The findings suggest that a hierarchical
structure is most appropriate for non-knowledgeable subjects. The summary of text structure
analysis is given below:
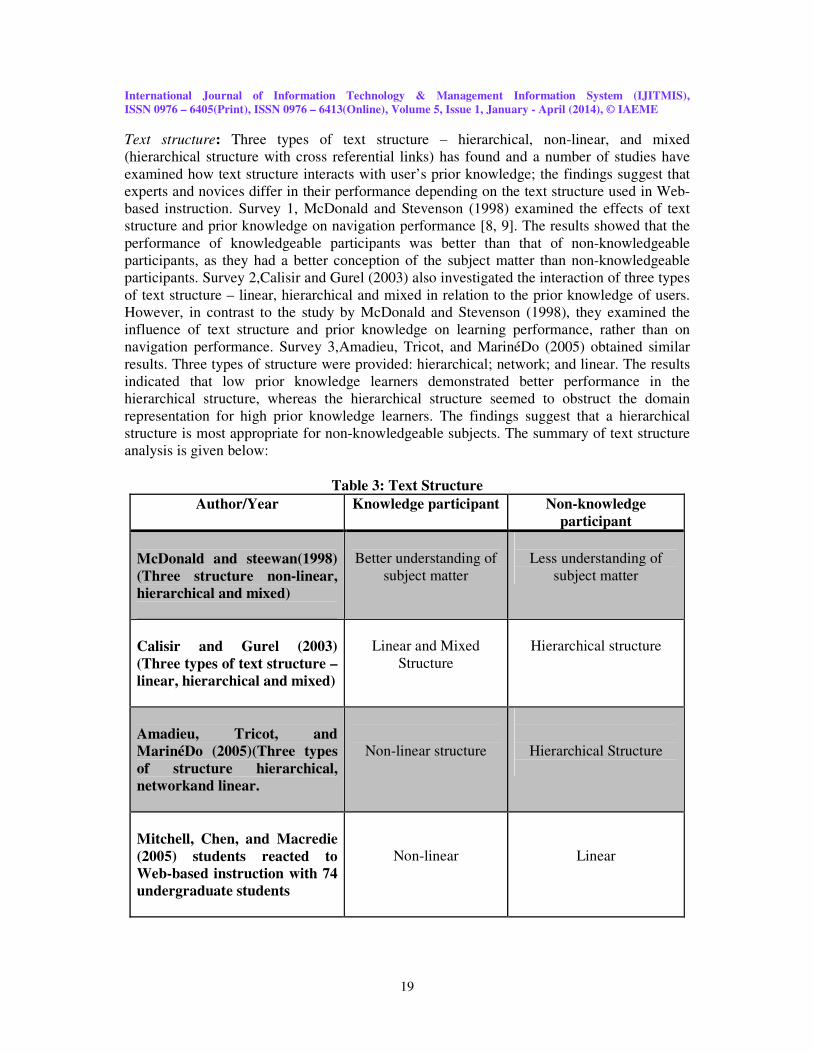
Table 3: Text Structure
Author/Year Knowledge participant Non-knowledge
participant
McDonald and steewan(1998)
(Three structure non-linear, hierarchical and mixed)
Better understanding of
subject matter
Less understanding of
subject matter
Calisir and Gurel (2003)
(Three types of text structure – linear, hierarchical and mixed)
Linear and Mixed
Structure
Hierarchical structure
Amadieu, Tricot, and MarinéDo (2005)(Three types
of structure hierarchical, networkand linear.
Non-linear structure
Hierarchical Structure
Mitchell, Chen, and Macredie
(2005) students reacted to Web-based instruction with 74 undergraduate students
Non-linear
Linear

International Journal of Information Technology & Management Information System (IJITMIS),
ISSN 0976 – 6405(Print), ISSN 0976 – 6413(Online), Volume 5, Issue 1, January - April (2014), © IAEME
20
Navigation facilities: When considering the relationships between learning strategies and
navigation facilities, student’s prior knowledge is an important factor in determining whether
a particular navigation facility is likely to be useful. Most current Web-based instruction
applications provide a range of navigation facilities to allow users to employ multiple
approaches to support their learning. Hierarchical maps and alphabetical indices are most
commonly used in Web-based instruction; each of them provides different functions in
relation to information access. The characteristics of the different navigation facilities may
influence how users develop their learning strategies, making navigation support a critical
issue. Farrell and Moore (2001) investigated with the use of different navigation facilities
(linear, main menu and search engine) influence user’s achievement and attitude [2, 3]. 200
students were placed into three groups based on their knowledge levels (low, middle, and
high) with the results indicating that high-knowledge users commonly tended to use search
engines to locate specific topics. Conversely, low-knowledge users seem to benefit from
hierarchical maps, which can facilitate the integration of individual topics [4].
Internet Searching: The goal of each fact-finding task was to find one specific answer to a
simple question while the broader tasks required the participants to find several documents
that would satisfy the task. The results indicated that no significant differences were noted
between experts and novices regarding the fact-finding, several studies also argue that prior
knowledge plays a substantial role in internet searching, which covers three aspects: search
strategies; search performance; and search perception. Regarding search strategies, Tabatabai
and Luconi(1998) investigated different strategies used by three experts and three novices.
The results showed that experts used more keywords while novices used the ‘Back’ key more
often; used fewer search engines; and missed some highly relevant sites [5].
Table 4: Internet searching
Author/Year Expert Novices
Tabatabi and Luconi/1998
More keywords
Back key
2006
One specific answer
Broader answer
Thatcher/2008
Web experience
Cognitive search
3.3 COGNITIVE STYLES
Cognitive style also plays an essential role in web-based instruction, learning
preference, learning performance and internet searching. Field Dependence is a user’s
perception or comprehension of information is influenced by the surrounding perceptual or
contextual field.
Web-based instruction:Web based instruction isthe relationships between the degree of Field
Dependence and student’s learning performance and learning preferences.
Learning performance: Students Cognitive styles are determined by using cognitive style
analysis (Riding, 1991) and their learning performance are in breadth first and depth first

International Journal of Information Technology & Management Information System (IJITMIS),
ISSN 0976 – 6405(Print), ISSN 0976 – 6413(Online), Volume 5, Issue 1, January - April (2014), © IAEME
21
versions. Ford and Chen (2000) found that Field Dependent learners in the breadth-first
version performed better than those in the depth-first version. Conversely, Field Independent
students performed better in the depth-first version than those in the breadth-first version [5].
Graff (2003) determine an individual’s cognitive style, and the relationship between cognitive
style and performance in two versions of the system – long-page and short-page versions [4].
The study’s findings indicated that Field Independent students achieved superior scores in the
long-page condition whereas Field Dependent students were superior in the short-page
condition [5]. Learning preferences: Learning preferences are the choices that learners show in certain
types of learning environments and activities such as the selection of certain navigation paths
or facilities. Studies state that field independent and field dependent students show different
learning preferences. Lee, Cheng, Rai, and Depickere (2005) investigated student’s learning
preferences in WebCT. The study’s findings indicate that field dependent students were
accustomed to linear learning whereas field independent students tended to have a preference
for non-linear learning.
Internet searching: In this analysis GEFT was used to identify the participant’s cognitive
styles and participants were asked to find answers from the Web for two search questions.
The results showed that there were a statistically significant correlation between GEFT scores
and the time spent for searching and the URLs visited. The participants with the higher GEFT
scores conducted the longer search sessions, and visited more URLs. In contrast, the
participants with the lower GEFT scores had the shorter search sessions.Kim, Yun, and Kim
(2004) compare search strategies of different cognitive style groups and the results showed
that the Field Dependent group demonstrated significantly more repeated search attempt and,
more use of search operators [4,5].
4. PROPOSED MODEL
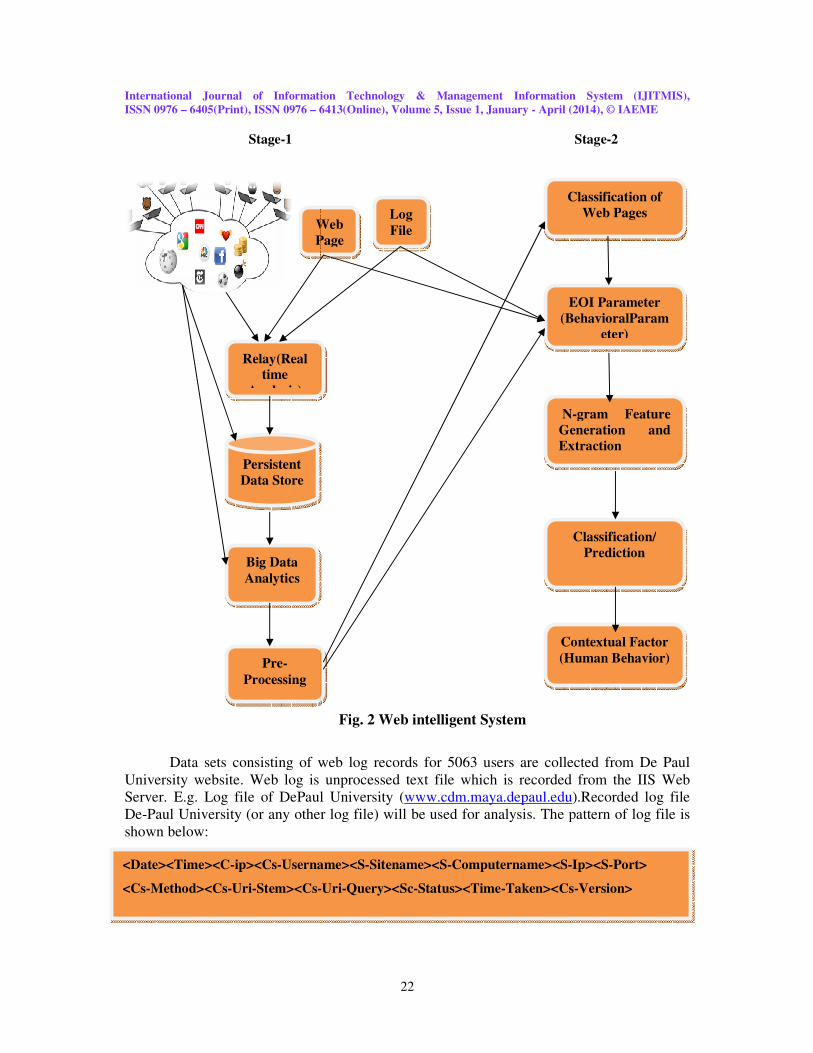
4.2 WEB INTELLIGENCE ARCHITECTURE The proposed model solves the problem discussed above and provides easier
technique to find behaviour and increased the reliability of the system. The model is divided
into two parts in first part web intelligent system is used to record the web logs from server or
client using ISP. Second part uses the N-gram technique to combine content and usage
mining. The framework should enable the collection of online data from various Internet
Service Providers (ISPs), optionally analyzing the data in real-time, andtransmitting the
relevant data cleaning purpose. Previous review results had some limitation like:Inconsistent
results:The results reported in existing studies are not fully consistent. There are
contradictory findings as to whether gender differences influence user’s attitudes and
perceptions towards Web-based interaction and whether cognitive styles affect user’s
learning performance. In the future, we are developing a standard template for the
questionnaires so that the accuracy of the results can be improved. Lack of mixed methods
and limited application:The survey suggests that quantitative methods are favoured when
seeking to find the overall effectiveness of the systems. It is clear that quantitative and
qualitative methods have different strengths and weaknesses. However, existing study mixes
quantitative and qualitative methods. Fig.2. Proposed Architecture. As illustrated in Fig. 1,
individual surfers' activities are managed by various ISP’s and are recorded by each ISP. The
data is cleaned and filtered according to requirements. Filtered data is transmitted to relay and
is further propagated to a persistent data store, where it can be further analyzed by Big-Data
analysis tools.
International Journal of Information Technology & Management Information System (IJITMIS),
ISSN 0976 – 6405(Print), ISSN 0976 – 6413(Online)
Stage-1
Data sets consisting of web log records for 5063 users are
University website. Web log is unprocessed text file which is recorded from t
Server. E.g. Log file of DePaul University (
De-Paul University (or any other log file) will be used for analysis. The pattern of log file is
shown below:
<Date><Time><C-ip><Cs-Username><S
<Cs-Method><Cs-Uri-Stem><Cs-
Web
Page
Persistent
Data Store
Big Data
Analytics
Pre-
Processing
Relay(Real time
Analysis)
International Journal of Information Technology & Management Information System (IJITMIS),
6413(Online), Volume 5, Issue 1, January - April (2014), © IAEME
22
1 Stage-
Fig. 2 Web intelligent System
Data sets consisting of web log records for 5063 users are collected from De Paul
University website. Web log is unprocessed text file which is recorded from t
Log file of DePaul University (www.cdm.maya.depaul.edu).Recorded log file
rsity (or any other log file) will be used for analysis. The pattern of log file is
Username><S-Sitename><S-Computername><S-Ip><S
-Uri-Query><Sc-Status><Time-Taken><Cs-Version>
Web
Page
EOI Parameter
(Behavioraleter)
N-gram
GenerationExtraction
Classification/
Prediction
Contextual F
(Human Behavior)
Classification of
Web PLog
File
International Journal of Information Technology & Management Information System (IJITMIS),
(2014), © IAEME
-2
collected from De Paul
University website. Web log is unprocessed text file which is recorded from the IIS Web
Recorded log file
rsity (or any other log file) will be used for analysis. The pattern of log file is
Ip><S-Port>
Version>
EOI Parameter
ehavioralParameter)
gram Feature
eneration and action
Classification/
Prediction
Contextual Factor
(Human Behavior)
Classification of
Web Pages

International Journal of Information Technology & Management Information System (IJITMIS),
ISSN 0976 – 6405(Print), ISSN 0976 – 6413(Online), Volume 5, Issue 1, January - April (2014), © IAEME
23
The structure of log file:
Here we are suggesting few parameters that indicate the active involvement of the
subject in an EOI. Where each parameter in itself may have a limited predictive value, the
combination of these parameters may yield an accurate prediction or evidence.
A. Intensity of surfing/accessing
It measures the intensity of the user's Internet surfing activities and measuringthe
browsing intensity value by the number of pages that the user visited in a given time. When a
user shows an increased interest in a given event, we can assume that he will visit related web
pages, more intensively than usual. Consequently, historical data of the user's surfing
intensity should be used when searching for anomalies. We are measuring browser intensity
of users by field CS-Uri-Stem and CS-Version of log file.
B. Frequency of revisiting/refreshing a given page
It measures the number of revisit/refresh operations performed by the user on each
page. Through this information the system may locate stressful behavior, where the user
strives for immediate updates regarding his topic of interest. He may repeatedly and
frequently revisit the same page, or simply push the 'refresh' button on the browser.
Significant peaks in this parameter may be observed at real-time and it is calculated by the
CS-Uri-Stem and Time-Taken field of log file.
C. Irregular/Unusual hours of activity It measures irregular surfing hours and irregular lengths of surfing sessions.
Examination of a user's historical data may reveal a regular pattern, concerning his surfing
hours. This parameter requires analyzing the user's historical data to learn the regular surfing
hours and session-lengths. The irregular hours are calculated by Time-Taken filed of log file
and deviations from such patterns can be found by anomaly detection methods.
D. Interaction level (Passive (high)/Active (low)) It measures the level of the user's interaction, ranging from 'low' (passive only), to
'high' (mostly active). In passive surfing the user suffices with reading pages, whereas in
active surfing he may chat, write email, commit responses or talkbacks, do Internet shopping,

International Journal of Information Technology & Management Information System (IJITMIS),
ISSN 0976 – 6405(Print), ISSN 0976 – 6413(Online), Volume 5, Issue 1, January - April (2014), © IAEME
24
and so on and it is calculated by S-code and Cs-Method filed of log file. Regarding our
'terrorist' scenario, we hypothesize that, as the deadline comes closer, the subject will lower
his or her active profile, and will focus on passive consumption of relevant information.
E. Diversity of interest topics/content topics
It measures user's range of interest topics, surfers are often attracted to diverse topics
such as news, sports, music, gaming or finances. When the subject is focused on an urgent
issue, we assume that it will affect his or her surfing pattern, restricting the range of visited
sites to a specific topic. The diversity measure can be learned from user’shistorical data,
using clustering methods and it is calculated by S-Sitename, CS-Uri-Stem and Cs-Uri-Query
field of log file. Significant deviations show up as anomalies or outliers.
F. Classification of webpage Web pages are index pages and content pages. An index page is a page used by the user
for navigation of the web site. It normally contains little information except links. A content
page is a page containing information the user would be interested in and its content offers
something other than links.
Algorithm step
• Two threshold count threshold and link threshold
• Set χ =1/(mean reference length of all pages)
• t= -ln(1-Ỵ)/χ
• For each page p
• If P’s file type is not HTML orP’s end of session count > count _threshold
• Mark P as a content page else
• P’s number of links > link _threshold
• Mark p as an index page else
• If P’s reference length < t
• Mark P as an index page else mark P as a content page
Correlation with EOI timing We assume that our five behavioral parameters are correlated with the timing of the
EOI. When the timing of the EOI is known to the investigator, as in forensic investigations,
such correlations can provide supportive evidence in a rather straightforward manner.
However, when the timing of the EOI is unknown to the investigator, as in pre-emptive
investigations, the behavioural parameters can still be used for prediction.
4.2 IMPROVED NAVIGATION PATTERN Here we are using the N gram model which assumes that the last N pages browsed
affect the probability of the next page to be visited. The model is based on the theory of
probabilistic grammars providing it with a sound theoretical foundation for future
enhancements. We propose a new model for handling the problem of mining log data which
directly captures the semantics of the user navigation sessions. We model the user navigation
records, inferred from log data, as a hypertext probabilistic grammar whose higher
probability generated strings correspond to the user’s preferred trails. There are two contexts
in which such model is potentially useful. On the one hand, it can help the service provider to
understand the user’s needs and as a result improve the quality of its service. The quality of

International Journal of Information Technology & Management Information System (IJITMIS),
ISSN 0976 – 6405(Print), ISSN 0976 – 6413(Online), Volume 5, Issue 1, January - April (2014), © IAEME
25
service can be improved by providing adaptive pages suited to the individual user, by
building dynamic pages in advance to reduce waiting time. On the other hand, such a model
can be useful to the individual web user by acting as a personal assistant integrated with
his/her web browser. Model has the advantage of being compact, self-contained, coherent,
and based on the well-established work probabilistic grammars. In fact the size of the model
depends only on the size of the web site being analysed and the amount of data collected.
Extensive experiments with both real and random data were conducted and the results show
that, in practice, the algorithm runs in linear time in the size of the grammar. Our model has
potential use both in helping the web site designer to understand the preferences of the
sitevisitor’s, and in helping individual users. To better understand their own navigation
patterns and increase their knowledge of the web’s content.Our approach has the following
characteristics: 1) Extracting search-focused information from web pages. 2) Taking key n-
grams as the representations of search-focused information. 3) Employing data mining for
extraction model using search log data. 4) Employing learning to search-focused key n-grams
as features.
4.2.1 KEY N-GRAMEXTRACTION
Extraction step requires data pre-processing, training data generation and N-gram
feature generation and N-gram extraction with task classification.
Pre-processing: We assume that the objects to be searched and ranked by the search engine
are web pages. During pre-processing, a web page in HTML format is parsed and represented
as a sequence of tags/words.
Algorithm step
• Read records in Logtable, For each record in Logtable
• Read fields (Sc_code, Sc_method)
• If Sc_code = ‘**’and Sc_ method = ‘**’ Then
• Get IP address and URL_link
• If suffix.URL_Link= {*.gif,*.jpg,*.css} Then
• Delete suffix.URL_link
• Save IP_sddress and URL_Link
• End if Else , Read next record End
Training Data Generation: We can consider automatically extracting queries from the page.
Head pages generally include a number of associated queries in the search log data. Such data
can naturally be used as training data for the automatic extraction of queries, particularly for
tail pages. We treat the n-grams in each of the document’s queries as its labelled key n-grams.
For example, when a document is “ABDC” associated with the query “ABC”, we consider
unigrams “A”, “B”, “C”, and bigrams “AB” are key n-grams with the assumption that they
should be ranked higher than unigram “D”, and bigrams “BD”and “DC”, by the extraction
model.
N-gram Features Generation: Web pages contain rich formatting information compared to
plain text. We utilize both textual and formatting information to create features in the
extraction model in order to accurately extract key n-grams. Feature generation based on two
parameter1. Frequency features 2. Appearance features.

International Journal of Information Technology & Management Information System (IJITMIS),
ISSN 0976 – 6405(Print), ISSN 0976 – 6413(Online), Volume 5, Issue 1, January - April (2014), © IAEME
26
1. Frequency Features The original/normalized term frequencies of an n-gram within several fields, tags and
attributes are utilized.
• Frequency in Fields: Frequency in fields is: URL, page title, meta- keyword and
meta-description.
• Frequency within Structure Tags: The frequencies of n-gram in texts within a header,
table or list indicated by HTML tags including <h1>, . . . ,<h6>, <table>, <li> and
<dd>.
• Frequency within Highlight Tags: Texts highlighted or emphasized by HTML tags
including <a>, <b>, <i>, <em> and <strong>.
• Frequency within Attributes of Tags: These are hidden texts which are not visible to
users. Specifically, title, alt, href and src tag attributes are used.
• Frequencies in other Contexts: It includes: page headers, page meta-data, page body
and HTML file.
2. Appearance Features The appearances of n-grams are also important for position, coverage and distribution
.indicators of their importance.Position indicates when it first appears in the title, paragraph
and document and Coverage indicate the coverage of an n-gram in the title or a header and
distribution are used to distribute across different parts of a page.
N-Gram Extraction and Task Classification: Features for each n-gram are then extracted, an
extraction model is trained.Key n-gram extraction is formalized as a learning to rank
problem.In learning, a ranking model is trained which rank n-grams and task user’s current
task will be finalized.The main aim task classification algorithm is to find the user’s task and
is classified into two main group’s casual user and careful user, in casual searching the user
wants to find the precise and credible information.
Algorithm step
• Frequently visited URLs as indicators for the task type classification (Cs-Uri-Stem)
field.
• Web task threshold (t=5ms).
• Storing all frequently visited URLs and counting the occurrence of the Frequently
Visited URLs.
• If frequently visited URLs are more than or equals to 5 then setting the user task is
careful user, otherwise the user task is casual user.
• If frequently visited URL have query (Cs-Uri-Query) and that query will be same then
setting the user task is casual otherwise the user task is careful user.
• Total no. of the URL in casual searching was higher than total no. of URL in careful
searching.
5. APPLICATION AND FUTURE TRENDS AND CONCLUSION 5.1 APPLICATION
Web-wide tracking – DoubleClick: ‘Web-wide tracking’, is tracking an individual across all
sites he visits is one of the most intriguing and controversial technologies, it provides an
understanding of an individual’s lifestyle and habits. The value of this technology in
applications such as cyber-threat analysis and homeland defense is quite clear, and it might

International Journal of Information Technology & Management Information System (IJITMIS),
ISSN 0976 – 6405(Print), ISSN 0976 – 6413(Online), Volume 5, Issue 1, January - April (2014), © IAEME
27
be only a matter of time before these organizations are asked to provide this information.
Understanding Web communities – AOL: Applying web mining to the data collected from
community interactions provides AOL with a very good understanding of its communities,
which it has used for targeted marketing through ads and e-mail solicitations. The idea is to
treat the community as a highly specialized focus group, understand its needs and opinions on
new and existing products; and also test strategies for influencing opinions. Web Catching:
The Web caching aims to improve the performance of web-based systems by storing and
reusing web objects that are likely to be used in the near future. It has proven to be an
effective technique in reducing network traffic, decreasing the access latency and lowering
the server load[18] .Web caching has focused on the use of historic information about web
objects to aid the cache replacement policies. Web Prefetching: Web prefetching is a
technique for reducing web latency based on predicting the next future web objects to be
accessed by the user and prefetching them during times. The prefetching technique has two
main components: The prediction engine and the prefetching engine. The prediction engine
runs a prediction algorithm to predict the next user’s request [18].
5.2 FUTURE DIRECTION Fraud and Threat analysis: The anonymity provided by the Web has led to a significant
increase in attempted fraud, from unauthorized use of individual credit cards to hacking into
credit card databases for blackmail purposes. Yet another example is auction fraud, which has
been increasing on popular sites like eBay. Since all these frauds are being perpetrated
through the Internet, Web mining is the perfect analysis technique for detecting and
preventing them. Web mining and Privacy: While there are many benefits to be gained from
Web mining, a clear drawback is the potential for severe violations of privacy. Public attitude
towards privacy seems to be almost schizophrenic – i.e. people say one thing and do quite the
opposite. The research issue generated by this attitude is the need to develop approaches,
methodologies and tools that can be used to verify and validate that a Web service is indeed
using an end-user’s information in a manner consistent with its stated policies.
5.3 CONCLUSION
This paper will present a state-of-the art review of the current research associated with
these human factors. This review will be important for practitioners who want to develop a
sound understanding of the needs and preferences of users with various characteristics such
as intensity of surfing, interest, gender difference and topic similarity. Our model has
potential use both in helping the web site designer to understand the preferences of the site
visitor’s, and their behaviour and access pattern that will be used to decide the human
information behaviour. The model also analyzes the users’ web surfing patterns and traces the
terrorists and criminals activities. In this paper we are using the N-grams methods to search
log data, and the characteristics of key n-grams can be applied to the other data set. The
extracted key n-grams are used as features of the relevance ranking model for finding users
current task and their access behaviour. This approach also applicable to understand the
navigation patterns and increase their knowledge of the web’s content and it also applicable
in a posterior forensic investigation. The model will also help designers to develop web-based
personalized applications that can accommodate user’s individual differences and used for
detecting and avoiding the terror threats caused by terrorists all over the world.

International Journal of Information Technology & Management Information System (IJITMIS),
ISSN 0976 – 6405(Print), ISSN 0976 – 6413(Online), Volume 5, Issue 1, January - April (2014), © IAEME
28
REFERENCES
[1] Ford, N., Miller, D., & Moss, N, “ Web search strategies and human individual
differences: Cognitive and demographic factors, internet attitudes, and approaches” .
Journal of the American Society for Information Science and Technology, pp. 741–
756. 2005.
[2] Graff, M. (2003). “Learning from web-based instructional Systems and cognitive
style”. British Journal of Educational Technology, 34(4), 407–418.
[3] Chi E. H.; Pirolli P.; Chen K.; and Pitkow J. 2001. “Using information scent to model
user information needs and actions and the Web” . In Proceedings of the SIGCHI
conference on Human factors in computing systems,490- 497, Seattle, Washington,
United States: AC/M 22/11/2007).
[4] Kim K. and Allen B. 2002. Cognitive and task influences on web searching behavior.
Journal of the American Society forInformation Science and Technology, 53(2):109-
119: JohnWiley& Sons.
[5] Sherry y. chen, Robert Macradie,” web based interaction: A review of three important
human factors”, International journal of information management, journal homepage:
www.elsevier.com/locate/ijinfomgt pp. 1-9, 2010.
[6] G. Eason, B. Noble, and I. N. Sneddon, “On certain integrals of Lipschitz-Hankel
type involving products of Besselfunctions,” Phil. Trans. Roy. Soc. London, vol.
A247, pp. 529– 551, April 1955.
[7] White R. W. and Drucker S. M. 2007. Investigating behavioral variability in web
search. In Proceedings of the16th international conference on World Wide Web, 21-
30,Banff, Alberta, Canada: ACM.
[8] K.R.Suneetha, K.R.Krishnamoorthy,“Identifying User behavior by Analyzing Web
Server Access File” IJCSNA International Journal of Computer Science and Network
Security, Vol. 9 No.4 April 2009
[9] Alaa El-Halees “Mining Students Data to AnalyzingLearning Behavior: a Case
Study”, http://eref.uqu.edu.sa/files/eref2/folder6/f158.pdf
[10] R.Cooley, B.Mobasher, and J.Srivastav, “Web mining: Information and Pattern
Discovery on the World Wide Web”,Proc. IEEE Intl. Conf. Tools with Al, Newport
Beach, CA, pp.558-56, 1997
[11] Mahesh thyloreramkrishna, LathaKomalGowdar, LalatessSomashekarHavanur, “Web
mining: Key Accomplishments, Application, and Future Directions”, International
conference on Data Storage and Data Engineering, pp. 186-191, 2010
[12] Jinhyuk Choi, Jeongseok Seo, Geehyuk Lee “Analysis of web usage pattern using
various contextual factors” Association of advancement of artificial intelligence pp. 1-
9, 2009.
[13] R. Cooley, B. Mobasher, J. Srivastava, “Web Mining Information and Pattern
Discovery on the World Wide Web”, InProceedings of the 9th IEEE International
Conference on Tools With Artificial Intelligence, Newport Beach, CA, 1997.
[14] J.Srivastava, R. Cooley, M. Deshpande and P- N.Tan, “Web Usage Mining:
Discovery and Applications of usage pattern From Web Data”, SIGKDD
Explorations, Vol.1, Issue 2, 2000.
[15] Cooley, R., Mobasher, B.,&Srivastava, J. (1999). “Data preparation for mining world
wide web browsing patterns” Journal of Knowledge and Information Systems, 1 (1),
5-32.

International Journal of Information Technology & Management Information System (IJITMIS),
ISSN 0976 – 6405(Print), ISSN 0976 – 6413(Online), Volume 5, Issue 1, January - April (2014), © IAEME
29
[16] R. Kosala, H. Blockeel, “Web Mining Research: A Survey”,in SIGKDD Explorations
2(1), ACM, July 2000.
[17] JaideepSrivastava, Robert Cooleyz ,MukundDeshpande, Pang-Ning Tan, “Web
Usage Mining: Discovery and Applications of Usage Patterns from Web
Data”SIGKD Explorations. ACM SIGKDD, pp. 1-10, Jan 2000.
[18] Sandhaya Gawade , Hitesh Gupta, “Review of Algorithms for Web Pre-fetching
andCaching, International Journal of Advanced Research in Computer and
Communication Engineering Vol. 1, Issue 2, pp. 1-4, April 2012.
[19] RozitaJamiliOsfouei, “Behaviour mining of female students by analysing log files”, In
Proceeding of IEEE fifth international Conferences on Digital
InformationManagement ICDM 2010, Canada pp. 5-8. July 2010.
[20] T. Anand, S. Padmapriya, E. kirubakram, “Terror Tracking Using Advanced Web
Mining Perspective”, In Proceeding of IEEE Fourth international Conferences on
Intelligent agent and multimedia. pp. 1-4, 2009.
[21] Jos’eBorges and Mark Levene, “Data Mining of User Navigation Patterns”
Department of Computer Science, University College London, Gower Street, London,
pp. 1-19, April 2000.
[22] Chen Wan, KepingBi,Yunhua Hu, “Extracting Search-Focused Key N-Grams for
Relevance Ranking in Web Search” WSDM’12, February 8–12, 2012, Seattle,
Washington, USA, ACM. pp. 1-10.2012.
[23] Prof. Sindhu P Menon and Dr. Nagaratna P Hegde, “Research on Classification
Algorithms and its Impact on Web Mining”, International Journal of Computer
Engineering & Technology (IJCET), Volume 4, Issue 4, 2013, pp. 495 - 504,
ISSN Print: 0976 – 6367, ISSN Online: 0976 – 6375.
[24] Alamelu Mangai J, Santhosh Kumar V and Sugumaran V, “Recent Research in Web
Page Classification – A Review”, International Journal of Computer Engineering &
Technology (IJCET), Volume 1, Issue 1, 2010, pp. 112 - 122, ISSN Print: 0976 –
6367, ISSN Online: 0976 – 6375.
[25] Suresh Subramanian and Dr. Sivaprakasam, “Genetic Algorithm with a Ranking
Based Objective Function and Inverse Index Representation for Web Data Mining”,
International Journal of Computer Engineering & Technology (IJCET), Volume 4,
Issue 5, 2013, pp. 84 - 90, ISSN Print: 0976 – 6367, ISSN Online: 0976 – 6375.
[26] Purvi Dubey and Asst. Prof. Sourabh Dave, “Effective Web Mining Technique for
Retrieval Information on the World Wide Web”, International Journal of Computer
Engineering & Technology (IJCET), Volume 4, Issue 6, 2013, pp. 156 - 160, ISSN
Print: 0976 – 6367, ISSN Online: 0976 – 6375.
[27] Hemprasad Badgujar and Dr. R.C.Thool, “His: Human Identification Schemes on
Web”, International Journal of Computer Engineering & Technology (IJCET),
Volume 4, Issue 2, 2013, pp. 198 - 212, ISSN Print: 0976 – 6367, ISSN Online:
0976 – 6375.


















