
1.demystifying big data & hadoop
29
Demystifying Big Data Hadoop &
-
Upload
databloginfo -
Category
Data & Analytics
-
view
222 -
download
3
Transcript of 1.demystifying big data & hadoop

Demystifying
Big Data
Hadoop
&

What is Big Data Case Study – Retailer Why DFS What is Hadoop Brief history Core Components Limitations Ecosystem Why move to Hadoop Future of Data Oracle Big Data Appliance


Big Data refers to collection of
data sets so large and complex
that its difficult to store and process using traditional data
management systems

Huge data source
Social NetworkOnline Shopping (Clickstream data)Airlines, BankingCRM, Stock ExchangeHospital, HospitalityGeo Location dataSensors, CCcamsGovernment data

If we are living in 100% of data world then 90% of data is generated in last 3 years


Un-Structured Data is Exploding



Case Study : Retail

Limitation of Existing Architecture

Solution: A Combined Storage Layer

Why DFS ?

Why DFS ?
1000,000 MB/(100*4*60)41.67 min

Hadoop is a framework that
allows for distributed processing of large data sets across clusters of
commodity computers using a
simple programming model

Hadoop was designed to enable applications to make most out of cluster architecture by addressing two key points:1. Layout of data across the cluster ensuring data is evenly distributed2. Design of applications to benefit from data locality
It brings us two main mechanism of hadoop, hdfs and hadoop MapReduce

Hadoop Core Components
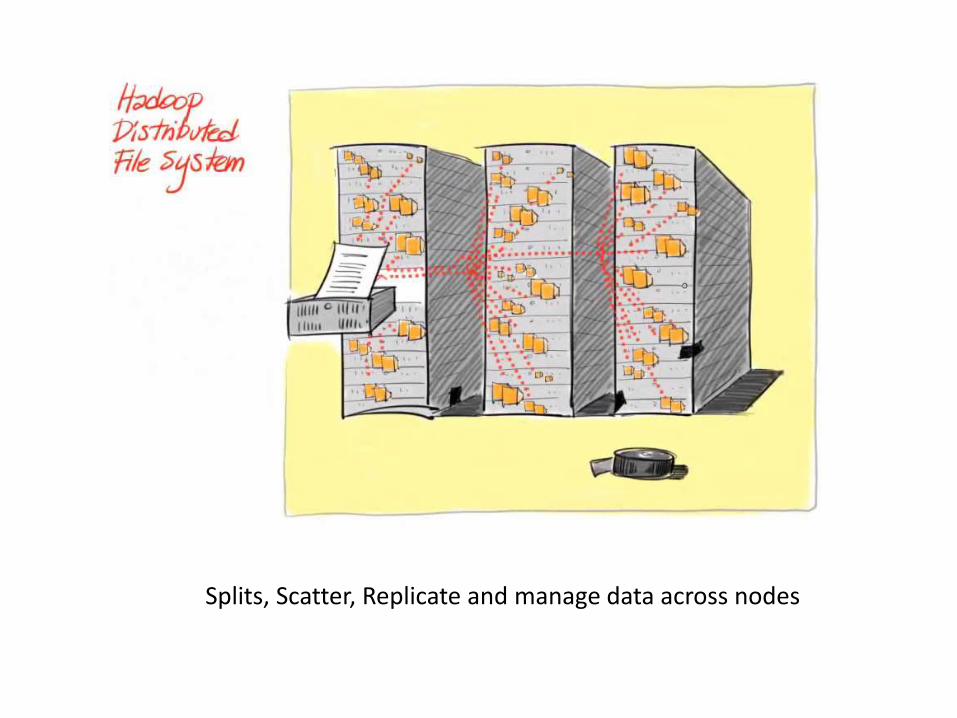
Splits, Scatter, Replicate and manage data across nodes

MapReduce is a mechanism to execute an application in parallel • by dividing it into tasks• collocating these task with part of the data• collecting and redistributing intermediate results• and managing failures in all nodes of the clusters

Hadoop Key Characteristics
• Open source (Apache License)• Large unstructured data sets (Petabytes)• Simple Programming model running on Linux• Scalable from single server to thousands of machines• Runs on commodity hardware and the cloud• Application level fault tolerance• Multiple tools and libraries

Hadoop History

Hadoop can handle small datasets but you can’t unleash the power of hadoop.There is overhead associated with each data distribution. If dataset is small you won’t get huge advantage in hadoop.
If dataset is small and unstructured, you will try to collate the data.
Areas where Hadoop is not good fit Today

Hadoop Ecosystem


Why move to Hadoop

future

Oracle Big Data Appliance



















