
13 Rec Sys - SJTU
22
5/19/17 1 Mining of Massive Datasets Jure Leskovec, Anand Rajaraman, Jeff Ullman Stanford University http://www.mmds.org Note to other teachers and users of these slides: We would be delighted if you found this our material useful in giving your own lectures. Feel free to use these slides verbatim, or to modify them to fit your own needs. If you make use of a significant portion of these slides in your own lecture, please include this message, or a link to our web site: http://www.mmds.org High dim. data Locality sensitive hashing Clustering Dimensional ity reduction Graph data PageRank, SimRank Community Detection Spam Detection Infinite data Filtering data streams Web advertising Queries on streams Machine learning SVM Decision Trees Perceptron, kNN Apps Recommen der systems Association Rules Duplicate document detection J. Leskovec, A. Rajaraman, J. Ullman: Mining of Massive Datasets, http://www.mmds.org 2
Transcript of 13 Rec Sys - SJTU

5/19/17
1
Mining of Massive DatasetsJure Leskovec, Anand Rajaraman, Jeff Ullman Stanford University
http://www.mmds.org
Note to other teachers and users of these slides: We would be delighted if you found this our material useful in giving your own lectures. Feel free to use these slides verbatim, or to modify them to fit your own needs. If you make use of a significant portion of these slides in your own lecture, please include this message, or a link to our web site: http://www.mmds.org
High dim. data
Localitysensitivehashing
Clustering
Dimensionality
reduction
Graph data
PageRank,SimRank
CommunityDetection
SpamDetection
Infinite data
Filteringdata
streams
Webadvertising
Queriesonstreams
Machine learning
SVM
DecisionTrees
Perceptron,kNN
Apps
Recommendersystems
AssociationRules
Duplicatedocumentdetection
J.Leskovec,A.Rajaraman,J.Ullman:MiningofMassiveDatasets,http://www.mmds.org 2

5/19/17
2
¡ CustomerX§ BuysMetallicaCD§ BuysMegadeth CD
¡ CustomerY§ DoessearchonMetallica§ RecommendersystemsuggestsMegadeth fromdatacollectedaboutcustomerX
J.Leskovec,A.Rajaraman,J.Ullman:MiningofMassiveDatasets,http://www.mmds.org 3
Items
Search Recommendations
Products, web sites, blogs, news items, …
4J.Leskovec,A.Rajaraman,J.Ullman:MiningofMassiveDatasets,http://www.mmds.org
Examples:

5/19/17
3
¡ Shelfspaceisascarcecommodityfortraditionalretailers§ Also:TVnetworks,movietheaters,…
¡ Webenablesnear-zero-costdisseminationofinformationaboutproducts§ Fromscarcitytoabundance
¡ Morechoicenecessitatesbetterfilters§ Recommendationengines§ HowIntoThinAirmadeTouchingtheVoidabestseller:http://www.wired.com/wired/archive/12.10/tail.html
J.Leskovec,A.Rajaraman,J.Ullman:MiningofMassiveDatasets,http://www.mmds.org 5
Source: Chris Anderson (2004)
6J.Leskovec,A.Rajaraman,J.Ullman:MiningofMassiveDatasets,http://www.mmds.org

5/19/17
4
J.Leskovec,A.Rajaraman,J.Ullman:MiningofMassiveDatasets,http://www.mmds.org 7Read http://www.wired.com/wired/archive/12.10/tail.html to learn more!
¡ Editorialandhandcurated§ Listoffavorites§ Listsof“essential”items
¡ Simpleaggregates§ Top10,MostPopular,RecentUploads
¡ Tailoredtoindividualusers§ Amazon,Netflix,…
8J.Leskovec,A.Rajaraman,J.Ullman:MiningofMassiveDatasets,http://www.mmds.org

5/19/17
5
¡ X =setofCustomers¡ S =setofItems
¡ Utilityfunction u:X × Sà R§ R =setofratings§ R isatotallyorderedset§ e.g.,0-5 stars,realnumberin[0,1]
9J.Leskovec,A.Rajaraman,J.Ullman:MiningofMassiveDatasets,http://www.mmds.org
0.410.2
0.30.50.21
Avatar LOTR Matrix Pirates
Alice
Bob
Carol
David
10J.Leskovec,A.Rajaraman,J.Ullman:MiningofMassiveDatasets,http://www.mmds.org

5/19/17
6
¡ (1) Gathering“known”ratingsformatrix§ Howtocollectthedataintheutilitymatrix
¡ (2) Extrapolateunknownratingsfromtheknownones§ Mainlyinterestedinhighunknownratings
§ Wearenotinterestedinknowingwhatyoudon’tlikebutwhatyoulike
¡ (3) Evaluatingextrapolationmethods§ Howtomeasuresuccess/performanceofrecommendationmethods
11J.Leskovec,A.Rajaraman,J.Ullman:MiningofMassiveDatasets,http://www.mmds.org
¡ Explicit§ Askpeopletorateitems§ Doesn’tworkwellinpractice– peoplecan’tbebothered
¡ Implicit§ Learnratingsfromuseractions
§ E.g.,purchaseimplieshighrating
§ Whataboutlowratings?
12J.Leskovec,A.Rajaraman,J.Ullman:MiningofMassiveDatasets,http://www.mmds.org

5/19/17
7
¡ Keyproblem: UtilitymatrixU issparse§ Mostpeoplehavenotratedmostitems§ Coldstart:
§ Newitemshavenoratings§ Newusershavenohistory
¡ Threeapproachestorecommendersystems:§ 1) Content-based§ 2) Collaborative§ 3) Latentfactorbased
13J.Leskovec,A.Rajaraman,J.Ullman:MiningofMassiveDatasets,http://www.mmds.org
Today!

5/19/17
8
¡ Mainidea: Recommenditemstocustomerxsimilartopreviousitemsratedhighlybyx
Example:¡ Movierecommendations§ Recommendmovieswithsameactor(s),director,genre,…
¡ Websites,blogs,news§ Recommendothersiteswith“similar”content
J.Leskovec,A.Rajaraman,J.Ullman:MiningofMassiveDatasets,http://www.mmds.org 15
likes
Item profiles
RedCircles
Triangles
User profile
match
recommendbuild
16J.Leskovec,A.Rajaraman,J.Ullman:MiningofMassiveDatasets,http://www.mmds.org

5/19/17
9
¡ Foreachitem,createanitemprofile
¡ Profileisaset(vector)offeatures§ Movies: author,title,actor,director,…§ Text: Setof“important”wordsindocument
¡ Howtopickimportantfeatures?§ UsualheuristicfromtextminingisTF-IDF(Termfrequency*InverseDocFrequency)§ Term …Feature§ Document …Item
17J.Leskovec,A.Rajaraman,J.Ullman:MiningofMassiveDatasets,http://www.mmds.org
fij =frequencyofterm(feature)i indoc(item)j
ni =numberofdocsthatmentiontermiN =totalnumberofdocs
TF-IDFscore: wij =TFij × IDFiDocprofile= setofwordswithhighestTF-IDFscores,togetherwiththeirscores
18J.Leskovec,A.Rajaraman,J.Ullman:MiningofMassiveDatasets,http://www.mmds.org
Note: we normalize TFto discount for “longer” documents

5/19/17
10
¡ Userprofilepossibilities:§ Weightedaverageofrateditemprofiles§ Variation: weightbydifferencefromaverageratingforitem
§ …¡ Predictionheuristic:§ Givenuserprofilex anditemprofilei,estimate𝑢(𝒙, 𝒊) = cos(𝒙, 𝒊) = 𝒙·𝒊
| 𝒙 |⋅| 𝒊 |
J.Leskovec,A.Rajaraman,J.Ullman:MiningofMassiveDatasets,http://www.mmds.org 19
¡ +:Noneedfordataonotherusers§ Nocold-startorsparsity problems
¡ +:Abletorecommendtouserswithuniquetastes
¡ +:Abletorecommendnew&unpopularitems§ Nofirst-raterproblem
¡ +:Abletoprovideexplanations§ Canprovideexplanationsofrecommendeditemsbylistingcontent-featuresthatcausedanitemtoberecommended
J.Leskovec,A.Rajaraman,J.Ullman:MiningofMassiveDatasets,http://www.mmds.org 20

5/19/17
11
¡ –:Findingtheappropriatefeaturesishard§ E.g.,images,movies,music
¡ –:Recommendationsfornewusers§ Howtobuildauserprofile?
¡ –:Overspecialization§ Neverrecommendsitemsoutsideuser’scontentprofile
§ Peoplemighthavemultipleinterests§ Unabletoexploitqualityjudgmentsofotherusers
J.Leskovec,A.Rajaraman,J.Ullman:MiningofMassiveDatasets,http://www.mmds.org 21
Harnessingqualityjudgmentsofotherusers

5/19/17
12
¡ Consideruserx
¡ FindsetN ofotheruserswhoseratingsare“similar”tox’sratings
¡ Estimatex’sratingsbasedonratingsofusersinN
23J.Leskovec,A.Rajaraman,J.Ullman:MiningofMassiveDatasets,http://www.mmds.org
x
N
¡ Letrx bethevectorofuserx’sratings¡ Jaccard similaritymeasure§ Problem: Ignoresthevalueoftherating
¡ Cosinesimilaritymeasure§ sim(x,y)=cos(rx,ry)=
/0⋅/1||/0||⋅||/1||
§ Problem: Treatsmissingratingsas“negative”¡ Pearsoncorrelationcoefficient§ Sxy =itemsratedbybothusersx andy
J.Leskovec,A.Rajaraman,J.Ullman:MiningofMassiveDatasets,http://www.mmds.org 24
rx = [*, _, _, *, ***]ry = [*, _, **, **, _]
rx, ry as sets:rx = {1, 4, 5}ry = {1, 3, 4}
rx, ry as points:rx = {1, 0, 0, 1, 3}ry = {1, 0, 2, 2, 0}
rx, ry … avg.rating of x, y
𝒔𝒊𝒎 𝒙, 𝒚 =∑ 𝒓𝒙𝒔 − 𝒓𝒙 𝒓𝒚𝒔 − 𝒓𝒚�𝒔∈𝑺𝒙𝒚
∑ 𝒓𝒙𝒔 − 𝒓𝒙 𝟐�𝒔∈𝑺𝒙𝒚
� ∑ 𝒓𝒚𝒔 − 𝒓𝒚𝟐�
𝒔∈𝑺𝒙𝒚�

5/19/17
13
¡ Intuitivelywewant: sim(A,B)>sim(A,C)¡ Jaccard similarity: 1/5< 2/4¡ Cosinesimilarity: 0.380 > 0.322§ Considersmissingratingsas“negative”§ Solution:subtractthe(row)mean
J.Leskovec,A.Rajaraman,J.Ullman:MiningofMassiveDatasets,http://www.mmds.org 25
sim A,B vs. A,C:0.092 > -0.559Notice cosine sim. is correlation when data is centered at 0
𝒔𝒊𝒎(𝒙, 𝒚) = ∑ 𝒓𝒙𝒊 ⋅ 𝒓𝒚𝒊�𝒊
∑ 𝒓𝒙𝒊𝟐�𝒊
�⋅ ∑ 𝒓𝒚𝒊𝟐�
𝒊�
Cosine sim:
Fromsimilaritymetrictorecommendations:¡ Letrx bethevectorofuserx’sratings¡ LetN bethesetofk usersmostsimilartoxwhohaverateditemi
¡ Predictionforitemsof userx:§ 𝑟=> =
?@∑ 𝑟A>�
A∈B
§ 𝑟=> =∑ C01⋅/1D�1∈E∑ C01�1∈E
§ Otheroptions?¡ Manyothertrickspossible…
26J.Leskovec,A.Rajaraman,J.Ullman:MiningofMassiveDatasets,http://www.mmds.org
Shorthand:𝒔𝒙𝒚 = 𝒔𝒊𝒎 𝒙, 𝒚

5/19/17
14
¡ Sofar: User-usercollaborativefiltering¡ Anotherview:Item-item§ Foritemi,findothersimilaritems§ Estimateratingforitemi basedonratingsforsimilaritems
§ Canusesamesimilaritymetricsandpredictionfunctionsasinuser-usermodel
J.Leskovec,A.Rajaraman,J.Ullman:MiningofMassiveDatasets,http://www.mmds.org 27
åå
Î
Î×
=);(
);(
xiNj ij
xiNj xjijxi s
rsr
sij… similarity of items i and jrxj…rating of user x on item jN(i;x)… set items rated by x similar to i
121110987654321
455311
3124452
534321423
245424
5224345
423316
users
mov
ies
- unknown rating - rating between 1 to 5
28J.Leskovec,A.Rajaraman,J.Ullman:MiningofMassiveDatasets,http://www.mmds.org

5/19/17
15
121110987654321
455 ?311
3124452
534321423
245424
5224345
423316
users
- estimate rating of movie 1 by user 5
29J.Leskovec,A.Rajaraman,J.Ullman:MiningofMassiveDatasets,http://www.mmds.org
mov
ies
121110987654321
455 ?311
3124452
534321423
245424
5224345
423316
users
Neighbor selection:Identify movies similar to movie 1, rated by user 5
30J.Leskovec,A.Rajaraman,J.Ullman:MiningofMassiveDatasets,http://www.mmds.org
mov
ies
1.00
-0.18
0.41
-0.10
-0.31
0.59
sim(1,m)
Here we use Pearson correlation as similarity:1) Subtract mean rating mi from each movie i
m1 = (1+3+5+5+4)/5 = 3.6row 1: [-2.6, 0, -0.6, 0, 0, 1.4, 0, 0, 1.4, 0, 0.4, 0]
2) Compute cosine similarities between rows
5/19/17
16
121110987654321
455 ?311
3124452
534321423
245424
5224345
423316
users
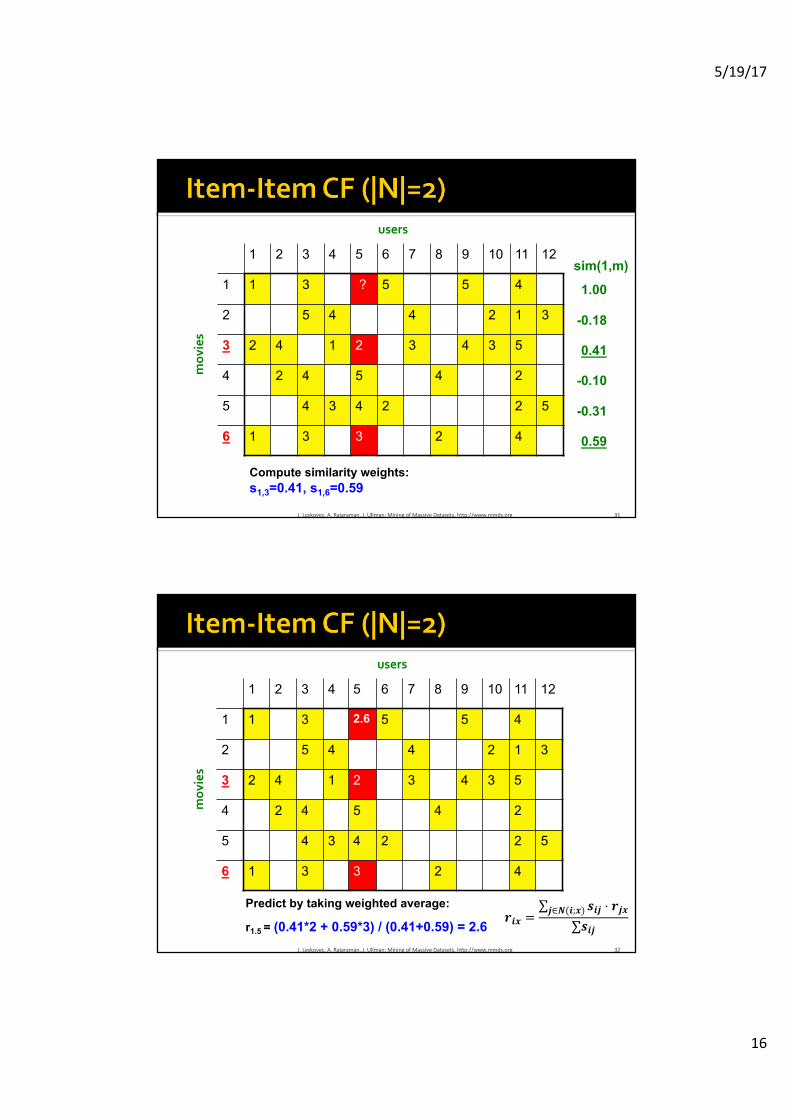
Compute similarity weights:s1,3=0.41, s1,6=0.59
31J.Leskovec,A.Rajaraman,J.Ullman:MiningofMassiveDatasets,http://www.mmds.org
mov
ies
1.00
-0.18
0.41
-0.10
-0.31
0.59
sim(1,m)
121110987654321
4552.6311
3124452
534321423
245424
5224345
423316
users
Predict by taking weighted average:
r1.5 = (0.41*2 + 0.59*3) / (0.41+0.59) = 2.632J.Leskovec,A.Rajaraman,J.Ullman:MiningofMassiveDatasets,http://www.mmds.org
mov
ies
𝒓𝒊𝒙 =∑ 𝒔𝒊𝒋 ⋅ 𝒓𝒋𝒙�𝒋∈𝑵(𝒊;𝒙)
∑𝒔𝒊𝒋

5/19/17
17
¡ Definesimilaritysij ofitemsi andj¡ Selectk nearestneighborsN(i;x)§ Itemsmostsimilartoi,thatwereratedbyx
¡ Estimateratingrxi astheweightedaverage:
J.Leskovec,A.Rajaraman,J.Ullman:MiningofMassiveDatasets,http://www.mmds.org 33
baseline estimate for rxi ¡ μ =overallmeanmovierating¡ bx =ratingdeviationofuserx
=(avg.ratingofuserx) – μ¡ bi =ratingdeviationofmoviei
åå
Î
Î=);(
);(
xiNj ij
xiNj xjijxi s
rsr
Before:
åå
Î
Î-×
+=);(
);()(
xiNj ij
xiNj xjxjijxixi s
brsbr
𝒃𝒙𝒊 = 𝝁 + 𝒃𝒙 + 𝒃𝒊
0.418.010.90.30.5
0.81Avatar LOTR Matrix Pirates
Alice
Bob
Carol
David
34J.Leskovec,A.Rajaraman,J.Ullman:MiningofMassiveDatasets,http://www.mmds.org
¡ Inpractice,ithasbeenobservedthatitem-itemoftenworksbetterthanuser-user
¡ Why?Itemsaresimpler,usershavemultipletastes

5/19/17
18
¡ +Worksforanykindofitem§ Nofeatureselectionneeded
¡ - ColdStart:§ Needenoughusersinthesystemtofindamatch
¡ - Sparsity:§ Theuser/ratingsmatrixissparse§ Hardtofindusersthathaveratedthesameitems
¡ - Firstrater:§ Cannotrecommendanitemthathasnotbeenpreviouslyrated
§ Newitems,Esotericitems¡ - Popularitybias:
§ Cannotrecommenditemstosomeonewithuniquetaste
§ TendstorecommendpopularitemsJ.Leskovec,A.Rajaraman,J.Ullman:MiningofMassiveDatasets,http://www.mmds.org 35
¡ Implementtwoormoredifferentrecommendersandcombinepredictions§ Perhapsusingalinearmodel
¡ Addcontent-basedmethodstocollaborativefiltering§ Itemprofilesfornewitemproblem§ Demographicstodealwithnewuserproblem
36J.Leskovec,A.Rajaraman,J.Ullman:MiningofMassiveDatasets,http://www.mmds.org

5/19/17
19
- Evaluation- Errormetrics- Complexity/Speed
J.Leskovec,A.Rajaraman,J.Ullman:MiningofMassiveDatasets,http://www.mmds.org 37
1 3 4
3 5 5
4 5 5
3
3
2 2 2
5
2 1 1
3 3
1
movies
users
J.Leskovec,A.Rajaraman,J.Ullman:MiningofMassiveDatasets,http://www.mmds.org 38

5/19/17
20
1 3 4
3 5 5
4 5 5
3
3
2 ? ?
?
2 1 ?
3 ?
1
Test Data Set
users
movies
J.Leskovec,A.Rajaraman,J.Ullman:MiningofMassiveDatasets,http://www.mmds.org 39
¡ Comparepredictionswithknownratings§ Root-mean-squareerror (RMSE)
§ ∑ 𝑟=> − 𝑟=>∗M�
=>�
where𝒓𝒙𝒊 ispredicted,𝒓𝒙𝒊∗ isthetrueratingofx oni§ Precisionattop10:
§ %ofthoseintop10§ RankCorrelation:
§ Spearman’scorrelation betweensystem’sanduser’scompleterankings
¡ Anotherapproach:0/1model§ Coverage:
§ Numberofitems/usersforwhichsystemcanmakepredictions§ Precision:
§ Accuracyofpredictions§ Receiveroperatingcharacteristic (ROC)
§ Tradeoffcurvebetweenfalsepositivesandfalsenegatives
J.Leskovec,A.Rajaraman,J.Ullman:MiningofMassiveDatasets,http://www.mmds.org 40

5/19/17
21
¡ Narrowfocusonaccuracysometimesmissesthepoint§ PredictionDiversity§ PredictionContext§ Orderofpredictions
¡ Inpractice,wecareonlytopredicthighratings:§ RMSEmightpenalizeamethodthatdoeswellforhighratingsandbadlyforothers
41J.Leskovec,A.Rajaraman,J.Ullman:MiningofMassiveDatasets,http://www.mmds.org
¡ Expensivestepisfindingkmostsimilarcustomers:O(|X|)
¡ Tooexpensivetodoatruntime§ Couldpre-compute
¡ Naïvepre-computationtakestimeO(k·|X|)§ X…setofcustomers
¡ Wealreadyknowhowtodothis!§ Near-neighborsearchinhighdimensions(LSH)§ Clustering§ Dimensionalityreduction
42J.Leskovec,A.Rajaraman,J.Ullman:MiningofMassiveDatasets,http://www.mmds.org
5/19/17
22
¡ Leverageallthedata§ Don’ttrytoreducedatasizeinanefforttomakefancyalgorithmswork
§ Simplemethodsonlargedatadobest
¡ Addmoredata§ e.g.,addIMDBdataongenres
¡ Moredatabeatsbetteralgorithmshttp://anand.typepad.com/datawocky/2008/03/more-data-usual.html
J.Leskovec,A.Rajaraman,J.Ullman:MiningofMassiveDatasets,http://www.mmds.org 43


















