
1 Planning under Uncertainty. Today’s Topics Sequential Decision Problems Markov Decision Process...
38
1 under Uncertaint y
-
Upload
solomon-welch -
Category
Documents
-
view
217 -
download
0
Transcript of 1 Planning under Uncertainty. Today’s Topics Sequential Decision Problems Markov Decision Process...

1
Planning under Uncertainty

Today’s Topics Sequential Decision Problems Markov Decision Process (MDP)
Value Iteration Policy Iteration Partially Observable MDPs (POMDPs)
Student Questions about the Midterm.
2

Big Assumption in Most of the Planning Techniques We’ve Seen so Far
What is it? NO UNCERTAINTY! Assumes the agent knows everything
about the world and what can happen in it. Sources of Uncertainty
Agent may not know all states of the world. Agent may not know what state of the
world it is in. Outcomes of actions may not be known
3

Sequential Decision ProblemExample
4
Problem• Beginning at the start
state, choose an action at each time step.
• Problem terminates when either goal state is reached.
• Possible actions are Up, Down, Left, and Right• Assume that the environment is fully observable, i.e., the agent
always knows where it is.

Sequential Decision ProblemExample
5
Deterministic Solution:
• If the environment is deterministic and the objective is get the maximum reward
The solution is easy: (Up, Up, Right, Right, Right)

Sequential Decision ProblemExample
6
What if actions are unreliable?• Suppose that there is a .8
probability to go to intended cell, but rest of the time it goes to cells at right angles of intended cell.
• If boundary or obstacle encountered, it does not move.
• The probability of reaching the goal state by executing (Up, Up, Right, Right, Right) is .85 + small probability of reaching the goal state the other path = .32776

Transition Model A transition model is a specification of the
outcome probabilities for each action in each possible state.
T(s,a,s¢) denotes the probability of reaching state s¢ if action a is done on state s.
Make Markov Assumption, i.e., the probability of reaching state s¢ from s depends only on s and not on the history of earlier states.
7

Rewards and Utilities A utility function must be specified for the agent in order
to determined the value of an action. Because the problem is sequential, the utility function
depends on a sequence of states (environment history). Rewards are assigned to states, i.e., R(s) returns the
reward of the state. For this example, assume the following:
The reward for all states, except for the goal states, is -0.04. The utility function is the sum of all the states visited.
E.g., if the agent reaches (4,3) in 10 steps, the total utility is 1 + (10 x -0.04) = 0.6.
The negative reward is an incentive to stop interacting as quickly as possible.
8

Markov Decision Process (MDP) Specification for a sequential decision
problem for a fully observable environment with a Markovian transition model and additive rewards.
Three components: Initial State: S0
Transition Model: T(s,a,s¢) Reward Function: R(s)
9

Solution for an MDP Since outcomes of actions are not
deterministic, a fixed set of actions cannot be a solution.
A solution must specify what an a agent should do for any state that the agent might reach.
A policy, denoted by π, recommends an action for a given state, i.e., π(s) is the action recommended by policy π for
state s.10

Quality of a Policy Since the environment is stochastic,
each time a given policy is executed starting from the initial state, there can be different environment histories.
Therefore, the quality of a policy is determined by the expected utility of the possible environment histories generated by that policy.
11

Optimal Policy An Optimal policy is a policy that yields
the highest expected utility. Optimal policy is denoted by π*. Once a π* is computed for a problem,
then the agent, once identifying the state (s) that it is in, consults π*(s) for the next action to execute.
12

Optimal Policy for Example
13
Note that at (3,1), the policy goes back towards the initial state. Why?

Balancing Risk and Reward The balance of risk and reward
depends on the value of R(s). Characteristic that appears often in the
real world. MDPs have been studied in many fields (AI, OR, economics, control theory, etc.).
The following four slides show π* for four different reward models.
14

R(s) < -1.6284
15
Get out of the environment as fast as possible.

-0.4278 < R(s) < -0.0850
16
Take the fastest route to (4,3) without concern for risk.

-0.0221 < R(s) < 0
17
Take no risks at all.
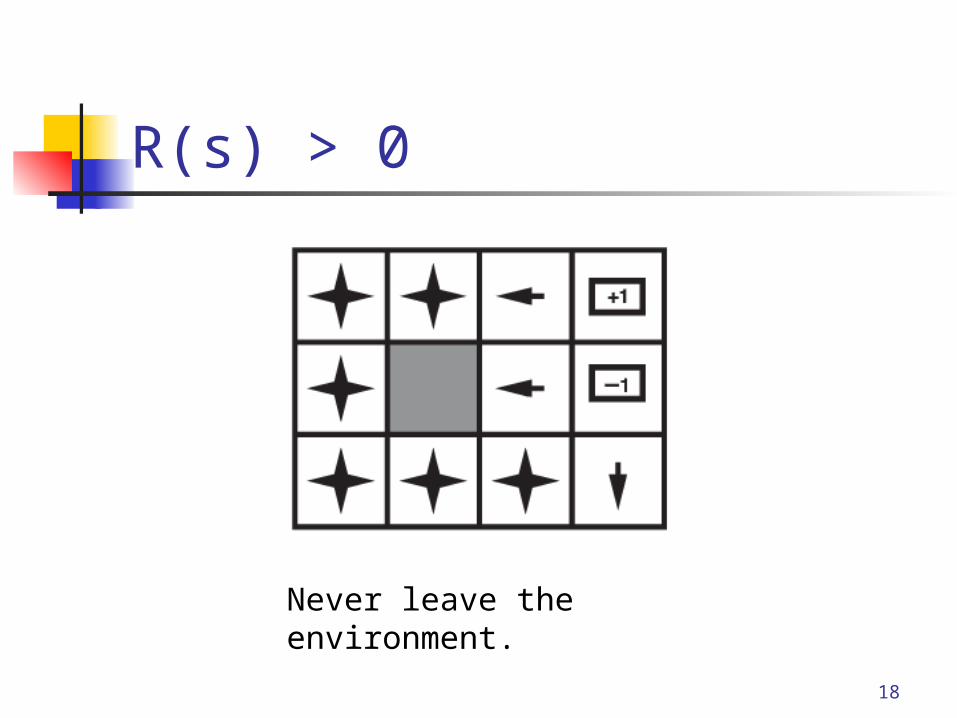
R(s) > 0
18
Never leave the environment.

Decision-Making Horizon Finite Horizon – Fixed time N after which
nothing matters. Optimal action could change over time.
E.g., in our example, suppose agent starts at (3,1) and N=3, then optimal action is to take the short cut. But, if N=100,…
Optimal policy is nonstationary. Infinite Horizon – no fixed time and optimal
action depends on the current state. Optimal policy is stationary.
19

Stationary Preferences between States
Assumption about preferences remaining the same independent of time.
If you prefer one future to another starting tomorrow, then you should still prefer that future if it were to start today.
Given stationary preferences, there are two ways to assign utilities to sequences.
20

Assignment of Utility to State Sequences
Utility function for environment histories (sequences of states) is denoted as Uh([S0,S1,…,Sn]).
Two methods: Additive rewards – Sum up rewards of states, i.e.,
Uh([S0,S1,…]) = R(s0) + R(s1) + R(s2) + … Discounted Rewards – Sum of progressively
discounted rewards of states, i.e., Uh([S0,S1,…]) = R(s0) + gR(s1) + g2R(s2) + …, where discount factor g is a number between 0 and 1.
Closer g to 0, the less future rewards count. When g is 1, the same as Additive Rewards.
21

Issue with Calculating Utilities on Infinite Horizons
If all environment histories are infinite (no terminal state reached), using additive rewards results in comparing +∞.
3 Solutions Discounted rewards – if rewards bounded by Rmax and g < 1, then Uh([S0,S1,…]) ≤ Rmax/(1 - g).
Ensure Proper policy, i.e., policy that is guaranteed to reach a terminal state.
Compare in terms of average reward (difficult to analyze).
22

Choosing between Policies The value of a policy is the expected
sum of discounted rewards obtained, where the expectation is taken over all possible state sequences that could occur, give that the policy is executed.
23

Value Iteration Value Iteration is an algorithm for
computing an optimal policy. Basic idea: Calculate the utility of each
state and then use the state utilities to select an optimal action in each state.
24

25
Utility of States Utility of a state is the expected utility of the state
sequences that might follow it, which are determined by a policy.
Let Uπ(s) be the utility of a state and st be the state the agent is in after executing π for t steps, then
Let U(s) be a shorthand for Uπ*(s)

Utilities for Example Problem
26
Note that utilities closer to (4,3) are higher because fewer steps are required to reach the exit.

Bellman Equation π* selects the action that maximizes the
expected utility of the subsequent state.
The Bellman equation defines U(s) as the utility of s plus the discounted utility of the next state, assuming the optimal action, i.e.,
27

Computing Bellman equation on Example Problem
28
The equation for state (1,1) is
When we plug in the numbers from slide 26, we find that Up is the best action.

Using Bellman equations for solving MDPs.
If there are n possible states, then there are n Bellman equations (one for each state).
To compute the n utilities, we would like to solve simultaneously the n Bellman equations. Problematic because max is not a linear operator.
Use iteration applying Bellman update:
Start with the utilities of all states initialized to 0. Guaranteed to converge.
29

Value-Iteration Algorithm
30

Value-Iteration Convergence
31
a. Evolution of selected states using value iteration. Note that some states have negative reward and until +1 goal state utility propagation reaches them
b. The number of iterations required to guarantee an error of at most = ec x Rmax, for different values of c,, as a function of the discount factor .g

Are True Utilities for States Required? What matters is that utilities are good
enough to recommend the optimal action in each state.
In practice πi often becomes optimal before Ui has converged.
For our example, the policy πi is optimal when i = 4 even though the maximum error in Ui is still 0.46
32

Policy Iteration Searches policy space. Basic idea:
Policy Evaluation: start with a random policy π0 and calculate utilities based on if that policy were executed.
Policy Improvement: Calculate a new MEU policy πi+1 based on computed utilities.
Iterate until the policy does not change.
33

Policy-Iteration Algorithm
34

Policy Evaluation Because policies are fixed, the max operator is
removed and standard linear algebra methods can applied to solve simultaneous equations. Complexity is O(n3)
For large state spaces, it may be prohibitive. Modified Policy Iteration - can do some
number of value iterations (simplified because policy is fixed) to get reasonable approximation of utilities.
35

Partially Observability What do you do if the system state
cannot always be determined? Action outcomes are not fully observable.
Use a Partially Observable MDP (POMDP). Must add: a set of observations O to the model an observation distribution U(s,o) for each
state. an initial state distribution.
36

POMDP Basic decision cycle:
Given the current belief state b, execute the action a = π*(b).
Receive the observation Update current belief state based on previous
belief state, the action taken, and the new observation.
Solve as an MDP by reasoning in belief space Requires calculating a probability distribution over
the possible states given previous observations.37

Big Problem with MDPs and Variants Does not scale. Too many states in real-world problems.
There are methods for focusing search only on significant states.
What if outcome is not in transition model? Have been attempts to have hybrid
approaches with MDP for short horizon and estimates through heuristic search for utilities for distant states.
38


















